Lecture 3 - OS Organization and System Calls
操作系统的组织结构
这节课我们将探讨操作系统的组织结构,并深入讨论以下四个关键话题:
-
Isolation(隔离性):隔离性是设计操作系统组织结构的核心驱动力。
隔离性指的是操作系统在管理计算机资源时,通过将不同的进程和用户空间隔离开来,防止它们互相干扰或访问未经授权的资源。
隔离性不仅增强了系统的安全性,还提高了系统的稳定性,使得单个进程的崩溃不会影响到其他进程或整个操作系统的运行。在现代操作系统中,隔离性通常通过虚拟内存、权限控制和进程管理等机制实现。
例如,虚拟内存为每个进程提供了一个独立的地址空间,确保它们只能访问自己的数据,而无法直接访问其他进程的数据。
-
Kernel 和 User Mode(内核模式和用户模式):这两种模式用于隔离操作系统内核和用户应用程序,确保系统的稳定性和安全性。
在内核模式下,操作系统可以访问所有的硬件资源和管理系统的各个部分;而在用户模式下,应用程序只能执行受限的操作,并且必须通过系统调用来请求内核服务。这种模式划分保证了即使用户程序出现错误,也不会直接影响到整个系统的安全和稳定性。
现代CPU提供了硬件支持,以在这两种模式之间进行切换,从而保证操作系统可以安全地控制硬件资源。例如,当应用程序试图执行一个不允许的操作时,CPU会触发一个异常,切换到内核模式,操作系统将决定如何处理这种情况。
-
System Calls(系统调用):系统调用是用户应用程序与内核交互的基本方式,使得应用程序可以访问操作系统的服务。
系统调用的作用类似于API,但它们更为底层,直接与操作系统内核交互。例如,当应用程序需要执行文件操作、创建进程或与硬件设备通信时,都会通过系统调用来完成。这些调用由操作系统提供的接口函数实现,通常涉及特权模式的切换以及内核代码的执行。
系统调用的设计不仅要考虑功能性,还要保证它们的执行效率和安全性,因为系统调用是操作系统提供的最为基础和关键的服务。
-
XV6中的实现:我们将看到这些概念在XV6中的简单实现。XV6是一个教学操作系统,它以其简洁的代码和结构化的设计著称,是理解操作系统内部工作原理的理想工具。
在XV6中,内核模式和用户模式的切换通过特定的中断和异常处理机制实现,而系统调用通过一组定义良好的接口函数实现。通过学习XV6,我们可以清楚地看到操作系统核心概念的具体实现方式,这将为进一步研究复杂的现代操作系统奠定坚实的基础。
复习与引入
首先,我们回顾一下上一节课的内容。在第一课结束后,你们应该已经对操作系统的结构有了初步的了解:
- 用户应用程序:例如Shell、echo、find等工具程序,它们运行在操作系统之上。这些应用程序通过操作系统提供的系统调用接口,与底层硬件进行交互,实现各自的功能。操作系统为这些程序提供了一个抽象层,使得它们不必直接处理硬件的复杂性。
- 操作系统的作用:操作系统通过抽象硬件资源(如磁盘和CPU)为应用程序提供服务。它不仅负责管理硬件资源的分配,还负责调度进程、处理系统调用、管理内存以及提供文件系统等基础服务。通过这些抽象和管理,操作系统使得应用程序能够在不同的硬件平台上运行,而无需关心底层硬件的具体实现细节。
- 系统调用接口:操作系统和应用程序之间的交互通常通过系统调用接口(System Call Interface)进行。在这门课程中,我们主要关注Unix风格的系统调用接口。Unix系统调用接口以其简洁和强大的功能著称,提供了一组通用的操作,如文件操作、进程管理、网络通信等。这些接口为应用程序开发者提供了强大的工具,使得他们能够开发出功能丰富且高效的软件。
在lab1中,你们通过编写代码体验了如何使用这些接口来完成不同的任务。这一实践经验不仅加深了你们对系统调用的理解,也为后续课程中更为复杂的操作系统概念打下了基础。
深入探讨操作系统内核
在这节课以及接下来的几节课中,我们将深入探讨操作系统内核内部的实现细节。特别是,我们会关注如何实现这些系统调用接口,这是理解操作系统运行机制的关键部分。内核的实现不仅涉及到代码的编写,还包括如何高效地管理系统资源、处理并发操作以及确保系统的安全性。内核代码通常以C语言编写,并结合汇编语言以实现与硬件的直接交互。通过学习内核的实现,我们可以了解到操作系统如何在底层高效地管理和调度资源,为上层应用程序提供可靠的服务。
尽管这是我们第一次深入讨论操作系统的实现细节,许多概念在后续的课程中会变得更加清晰。今天的讨论将为你们提供一个基础,帮助你们在接下来的实验和课程中更好地理解和实现操作系统的功能。我们将逐步解开操作系统内部的复杂性,帮助你们从底层理解这些系统是如何工作的。
问题引导与讨论
在进一步讨论之前,我想提出一个问题,作为今天课程的开始:你们在之前的utils lab(也就是lab1)中学到的最有意思的东西是什么?
作为一个引导,我可以分享一下我的体会。在实现lab1的过程中,我发现自己比以往更多地使用 exec 系统调用。之前,我主要使用其他方法来实现与 exec 类似的功能,但是在完成了 exec 实验后,我发现 exec 更加方便,因此我现在更加频繁地使用它。exec 系统调用是Unix系统中的一个关键功能,它允许一个进程用一个新的程序替换自身,这一功能在实现命令行解释器(如Shell)和其他应用程序时尤为重要。这个实验让我意识到,操作系统中很多工具和方法的选择直接影响了工作效率和代码的简洁性。
实验与课程内容的关系
希望你们都喜欢前一个实验,也希望你们在后面的实验中同样能够收获知识和乐趣。如果你们还没有完成前一个实验,今天的课程内容可能会帮助你们更好地理解和完成后续的System Call实验。
在今天的讨论中,我们会看到很多有关系统调用实现的内容。这些内容不仅能帮助你们理解操作系统的内部机制,还能为你们在实际开发和调试中提供指导。理解系统调用的实现不仅是学术研究的重要内容,也是实用技能,在现代软件开发中,系统调用是性能优化、安全分析和故障排查的关键工具。通过这次深入的学习,你们将能够在未来的编程中更好地利用操作系统的功能,实现更加高效和可靠的软件。
隔离性(Isolation)的重要性
隔离性(Isolation)是操作系统设计中一个至关重要的概念。它确保了多个应用程序在同一台计算机上运行时不会互相干扰,并且操作系统可以在处理用户应用程序时保持稳定性。以下是隔离性的重要原因及其应用场景:
- 应用程序之间的隔离:
- 当你在用户空间运行多个应用程序(例如Shell、echo、find等)时,任何一个应用程序的故障都不应影响其他应用程序的正常运行。例如,在运行你的Prime代码(来自lab1的一部分)时,即使代码出现问题,也不应该影响到Shell或其他正在运行的应用程序。
- 反例:如果Shell出现了问题,导致它错误地终止了其他进程,这将是非常糟糕的情况。这表明,必须在不同的应用程序之间实现强隔离性。
- 应用程序与操作系统之间的隔离:
- 操作系统作为所有应用程序的服务平台,必须保持高稳定性。当应用程序发生错误时,操作系统应该能够继续稳定运行。例如,应用程序可能传递了一些异常参数给操作系统,这时操作系统应该能够妥善处理,而不会崩溃。因此,应用程序和操作系统之间也需要强隔离性。
稻草人提案法:没有操作系统的情况
假设没有操作系统,或者操作系统只是一个库文件(例如在Python中通过 import os 加载),那么应用程序就会直接与硬件交互。
[应用程序]
|
[硬件资源:CPU, 内存, 磁盘]
应用程序直接与硬件交互的缺点
如果应用程序直接与硬件交互,会出现以下问题:
- 缺乏硬件资源的抽象:
- 应用程序将直接控制硬件资源,如CPU核、内存、磁盘等。这意味着不同的应用程序可能会争夺同一资源,导致资源冲突和不稳定性。
- 缺乏隔离性:
- 在这种架构下,不同的应用程序之间没有隔离性。这种设计非常容易导致一个应用程序的故障影响其他应用程序,甚至可能导致整个系统崩溃。
示例:CPU调度与隔离性
为了说明隔离性的重要性,我们可以考虑CPU调度的问题。假设在没有操作系统的情况下运行多个应用程序:
- CPU切换的困难:
- 如果没有操作系统,应用程序将直接负责管理CPU资源。这意味着当前运行的应用程序需要自己决定何时放弃CPU资源以便让其他应用程序运行。这个过程被称为协同调度(Cooperative Scheduling)。
- 隔离性问题:
- 假设当前运行的Shell应用程序占用了CPU资源,并且Shell中的某个函数陷入了死循环。这时,Shell将永远不会放弃CPU资源,导致其他应用程序无法获得运行机会。这破坏了隔离性,并且严重影响了系统的多任务处理能力。
- 在这种情况下,multiplexing(多路复用) 这一特性变得极其重要。Multiplexing确保无论某个应用程序在执行什么操作,它都必须时不时地释放CPU资源,让其他应用程序有机会运行。这是实现稳定多任务处理的关键。
+--------------------------------------------------+
| 操作系统内核 (Kernel) |
+--------------------------------------------------+
| | | |
v v v v
[应用程序1] [应用程序2] [应用程序3] [应用程序4]
- 操作系统内核位于系统的核心,它为上层的每个应用程序提供独立的执行环境。通过隔离,操作系统确保每个应用程序都在一个安全的空间内运行,互不干扰。
隔离性是操作系统设计中的基本原则,它通过限制应用程序之间以及应用程序与操作系统之间的交互,确保系统的稳定性和安全性。通过理解隔离性的重要性,我们可以更深入地理解操作系统如何在复杂环境中管理多任务处理,并为用户提供一个可靠的计算平台。我们将进一步探讨如何在操作系统内核中具体实现这些隔离性机制。
内存隔离的重要性
当应用程序直接运行在硬件资源之上时,内存隔离是一个重大问题。如果没有操作系统的介入,每个应用程序的文本、代码和数据都会直接保存在物理内存中,这样会导致应用程序之间的内存没有明确的边界。我们来看看这个场景可能会导致的后果:
-
内存冲突:
- 假设物理内存的一部分被Shell程序使用,另一部分被echo程序使用。如果echo程序错误地将数据存储在属于Shell的内存地址中(例如内存地址1000),这就会覆盖Shell程序的内容,导致Shell崩溃或者行为异常。这种内存冲突可能会非常难以调试和定位。
+--------------------------+ | Shell: 使用内存地址1000 | | echo: 同时使用内存地址1000 | +--------------------------+在这种设计中,如果echo程序写入了Shell的内存区域,便会破坏Shell的运行。
-
多进程管理的复杂性:
- 在这种设计下,应用程序彼此之间没有任何隔离,导致任何一个程序的错误都可能影响其他正在运行的程序。这种不稳定性和不可预测性是我们希望避免的。
操作系统的作用:实现内存隔离与多路复用
操作系统的引入解决了这些问题,确保了每个应用程序在运行时都有自己独立的内存空间,并且不会干扰其他应用程序。
-
内存隔离的实现:
- 操作系统通过管理每个进程的内存空间,确保不同进程的内存彼此隔离。这意味着一个进程不会访问或修改其他进程的内存区域,从而提高了系统的稳定性和安全性。
+---------------------------+ | 操作系统内核 | +---------------------------+ | | | v v v [进程1] [进程2] [进程3]每个进程都有自己的内存空间,不会相互干扰。
-
多路复用与进程抽象:
- 操作系统不仅实现了内存的隔离,还通过抽象出“进程”这一概念来管理CPU资源。每个进程代表一个独立的执行单元,它们并不直接与CPU交互,而是通过操作系统内核的调度在CPU上运行。
- 操作系统通过分时复用(Time-sharing)的方式来实现CPU的多路复用。即使系统只有一个CPU核,也可以通过在不同进程之间快速切换,实现多个进程的“并发”执行。
+---------------------------+ | CPU 核心 | +---------------------------+ | | | v v v [进程1] > [进程2] > [进程3]操作系统在多个进程之间切换CPU的使用,使得每个进程都获得了一定的CPU时间。
操作系统的关键角色
使用操作系统的核心原因在于其对内存隔离和多路复用的支持。如果没有操作系统,每个应用程序都直接与硬件交互,这不仅会导致内存冲突和系统不稳定,也使得多任务处理变得异常复杂。通过操作系统:
- 实现硬件资源的抽象:操作系统提供了进程这一抽象层,使得应用程序不用直接操作硬件。
- 保证资源的隔离与共享:在提供内存隔离的同时,操作系统通过调度机制确保多个进程能够共享CPU资源,而不会互相干扰。
示例:Unix接口的隔离性设计
在Unix系统中,接口的设计特别注重资源的隔离性。例如,通过 fork 创建进程时,每个进程都会有自己独立的内存空间,这个空间包括了代码段、数据段和堆栈。进程与进程之间无法直接访问彼此的内存,这就保证了各自的独立性与安全性。
- 进程抽象的核心:
- 进程并不是直接使用CPU,而是通过操作系统的调度在CPU上运行。这使得操作系统可以在多个应用程序之间有效地复用CPU资源,即使这些应用程序的数量远远超过了系统的CPU核心数量。
学生提问:进程抽象了CPU,这是否意味着一个进程只使用了部分CPU,而另一个进程使用了另一部分?CPU和进程之间的关系是什么?
教授的回答:进程抽象了CPU的使用,但并不意味着多个进程可以同时使用同一个CPU核。每个时刻,一个CPU核只能运行一个进程。操作系统通过分时复用,在多个进程之间快速切换,使得每个进程看起来都在同时运行。这样,即使系统只有一个CPU核,也可以支持多个进程的并发执行。
内存隔离和多路复用是操作系统设计的两个关键目标。通过这些机制,操作系统能够有效地管理硬件资源,确保系统的稳定性、安全性和高效性。在接下来的课程中,我们将继续探讨这些机制的实现细节,进一步理解操作系统如何在复杂环境中提供可靠的服务。
操作系统中的资源抽象与隔离
在操作系统中,资源抽象与隔离是核心概念,这些机制使得多个应用程序可以在同一台计算机上安全且高效地运行。接下来,我们通过几个关键的系统调用来探讨这些概念是如何实现的。
内存的抽象:exec 系统调用
exec 系统调用是一个重要的机制,它实现了对内存的抽象。具体来说,当我们执行 exec 系统调用时,我们传入一个文件名,这个文件名对应一个应用程序的内存镜像。这个内存镜像包含了应用程序所需的指令和全局数据。
- 内存镜像:内存镜像是应用程序在运行时所需的全部内存内容,包括代码段、数据段和堆栈。通过
exec,操作系统将这个内存镜像加载到一个独立的虚拟内存空间中。 - 内存隔离:尽管应用程序可以扩展自己的内存(例如通过动态分配内存),但它无法直接访问物理内存的特定地址范围(如物理地址1000-2000)。这是因为操作系统提供了内存隔离,防止应用程序直接操作物理内存,从而避免了潜在的冲突和安全问题。
+---------------------------+
| 操作系统内核 |
+---------------------------+
| | |
v v v
| [进程1] | [进程2] | [进程3] |
| 内存镜像 | 内存镜像 | 内存镜像 |
+---------+--------+---------+
操作系统内核为每个进程提供独立的内存镜像,确保内存隔离。
文件的抽象:files 和磁盘访问
在Unix系统中,磁盘的抽象通过文件系统(files)来实现。应用程序不会直接读写物理磁盘,而是通过文件系统进行交互。文件系统提供了对磁盘的高层次抽象,应用程序可以通过文件系统进行文件命名、读写等操作。
- 文件系统的隔离性:文件系统确保了磁盘资源的隔离。每个文件被分配到不同的磁盘块上,操作系统负责管理这些块的分配,以确保一个磁盘块只属于一个文件。同时,文件系统还提供了访问控制,确保用户A不能操作用户B的文件。
资源抽象与多路复用
通过对内存和磁盘的抽象,操作系统可以在多个应用程序之间安全地复用计算机硬件资源。这里的“抽象”不仅仅是提供了一个方便的接口,还确保了资源的隔离性,从而使得系统可以在多个应用程序同时运行时保持稳定和安全。
回顾与提问
通过上述的讨论,我们可以看到操作系统的设计是如何围绕资源的抽象和隔离来展开的。操作系统提供的这些抽象层,使得应用程序之间以及应用程序与硬件之间实现了强隔离性。
-
更复杂的内核优化:如同一位学生提问的那样,现代操作系统中会使用更复杂的调度策略,如缓存亲和性(Cache Affinity),来减少缓存未命中(Cache Miss)现象,并提升系统性能。这种优化在我们后续的课程中(尤其是在高性能网络相关的部分)会有更详细的介绍。
-
进程调度的实现:对于多进程复用CPU的实现,
proc.c文件是一个关键部分。我们将在接下来的几节课中深入探讨这一话题,具体介绍操作系统是如何在多个进程之间进行CPU资源的分配和调度的。
操作系统的防御性(Defensive)
防御性的重要性
在操作系统设计和开发中,防御性(Defensive)是一项至关重要的原则。操作系统需要具备防御能力,确保能够抵御来自应用程序的各种潜在威胁,包括无意的错误和恶意的攻击。如果操作系统因为应用程序的错误参数或恶意行为而崩溃,将会导致整个系统无法正常运行,影响所有正在运行的应用程序。因此,操作系统必须能够应对并抵御这些威胁。
- 抵御错误和攻击:
- 操作系统必须对传入的系统调用参数进行严格检查,以确保这些参数不会导致系统崩溃。操作系统的稳定性直接关系到整个系统的安全性和可靠性。
- 防御性的设计要求操作系统能够应对各种可能出现的异常情况,无论这些情况是由于编程错误还是恶意攻击所导致。
- 应用程序隔离:
- 另外一个需要关注的点是,应用程序不能打破其隔离性。应用程序可能是恶意的,由攻击者开发,以试图突破操作系统的防线,获取对内核的控制权。一旦攻击者能够控制内核,他们将能够访问和操控系统中的所有硬件资源,这将带来严重的安全风险。
防御性机制的挑战
在实际操作系统中,要实现这种防御性并不容易。例如,Linux系统中时常会出现内核漏洞,使得应用程序能够打破隔离并获得对内核的控制。这些漏洞提醒我们,在操作系统开发中,防御性设计必须是一个持续关注的焦点。
- 持续防御的必要性:
- 防御性设计要求操作系统在面对复杂的现实环境时,能够及时应对新出现的威胁。开发人员必须持续关注内核的安全性,并且尽量提供最好的防御措施。
- 强隔离墙的构建:
- 为了确保操作系统的防御性,必须在应用程序和操作系统之间建立起坚固的隔离墙。这道墙不仅要能够阻挡所有企图突破的攻击,还要能够执行操作系统所设定的各种安全策略。
硬件支持的必要性
要实现强隔离性,仅靠软件是不够的,必须借助硬件的支持。我们在这节课中将简单介绍一些与硬件隔离相关的内容,但在后续课程中,我们将对这些内容进行更深入的探讨。
- User/Kernel Mode(用户模式与内核模式):
- 硬件需要提供两种执行模式:用户模式(User Mode)和内核模式(Kernel Mode)。在RISC-V架构中,内核模式被称为监督模式(Supervisor Mode),但其基本概念与其他架构的内核模式一致。这两种模式确保了用户应用程序和操作系统之间的隔离。
- 虚拟内存与页表(Virtual Memory and Page Table):
- 虚拟内存和页表是操作系统实现内存隔离的关键机制。通过虚拟内存,操作系统可以将应用程序的内存地址映射到实际的物理内存地址,从而避免应用程序直接访问和操控物理内存。
防御性与硬件支持的关系
所有现代处理器,如果想要支持运行多个应用程序的操作系统,都必须提供用户模式与内核模式的切换,以及虚拟内存的支持。虽然不同架构的具体实现可能有所不同,但这些基本特性是必须具备的。
- RISC-V的支持:
- 在我们这门课程中使用的RISC-V处理器架构,提供了这些基本功能,使得我们可以探讨和实现操作系统中的防御性设计。
操作系统的防御性设计是确保系统安全性和稳定性的关键。通过结合软件和硬件层面的支持,操作系统能够有效地抵御来自应用程序的错误和攻击,维持系统的正常运行。在后续的课程中,我们将深入研究这些机制的具体实现,特别是用户模式与内核模式的切换,以及虚拟内存的运作原理。
硬件对强隔离的支持:User/Kernel Mode 和虚拟内存
在现代操作系统中,硬件对强隔离的支持至关重要。主要通过两种机制来实现:User/Kernel Mode 和 虚拟内存。这些机制确保了操作系统能够有效地隔离应用程序和内核操作,防止恶意程序或错误操作损害系统的安全性和稳定性。
User/Kernel Mode 的概述
处理器通过提供两种不同的操作模式来支持操作系统的隔离性:User Mode 和 Kernel Mode。
- User Mode(用户模式):
- 在用户模式下,CPU只能执行普通权限的指令(unprivileged instructions)。这些指令包括常见的基本操作指令,例如加法、减法、跳转等。这些指令可以在所有应用程序中执行,因为它们不会直接影响系统的安全性。
- 示例指令:
ADD:将两个寄存器的值相加。SUB:将两个寄存器的值相减。JMP:无条件跳转到指定的指令地址。
- Kernel Mode(内核模式):
- 在内核模式下,CPU不仅可以执行普通权限的指令,还可以执行特殊权限的指令(privileged instructions)。这些特殊权限指令能够直接操控硬件和系统的核心状态,例如设置页表寄存器或禁用时钟中断。这些指令对于操作系统的核心功能至关重要,普通应用程序无法直接访问。
- 示例指令:
SET_PG_REG:设置页表寄存器。DISABLE_INT:禁用时钟中断。
执行权限与模式切换
当一个应用程序在User Mode下尝试执行特殊权限指令时,处理器会拒绝执行该指令,并通常将控制权转移到Kernel Mode。这是为了防止未经授权的代码(例如应用程序中的恶意代码)直接操控系统的核心功能。
- 模式切换:
- 在处理器中有一个专门的标志位(flag bit),用于指示当前的操作模式。当这个标志位为1时,表示处理器处于User Mode;当标志位为0时,表示处于Kernel Mode。处理器会在执行每条指令时检查这个标志位,如果检测到用户模式下尝试执行特殊权限指令,处理器会拒绝执行并触发异常或进行模式切换。
硬件支持的强隔离机制
通过这种机制,处理器能够有效地隔离普通应用程序与操作系统核心功能。所有现代支持多任务操作系统的处理器都必须具备这种能力,不论是我们在课程中使用的RISC-V处理器还是其他架构的处理器,都有类似的机制。
学生提问:内核模式下允许执行某些指令,而用户模式下不允许执行。这些检查是如何完成的?
教授的回答:这些检查是通过处理器内部的标志位(flag bit)完成的。这个标志位记录了当前的模式,当它为1时,表示处于User Mode,处理器将拒绝执行特殊权限指令;当标志位为0时,表示处于Kernel Mode,处理器允许执行这些指令。标志位的设置本身只能通过特殊权限指令来完成,这样保证了普通应用程序无法自行切换到Kernel Mode,从而保证系统的安全性。
硬件的支持是实现操作系统强隔离性的重要基础。User/Kernel Mode 的设计确保了操作系统能够有效地隔离应用程序与内核操作,防止恶意程序或错误操作对系统的安全和稳定性造成威胁。在接下来的课程中,我们将进一步探讨这些机制的实际实现和应用,特别是在操作系统的虚拟内存管理和进程调度中的具体应用。
User/Kernel/Machine Mode
除了常见的User Mode和Kernel Mode之外,RISC-V架构还提供了第三种操作模式,即Machine Mode。尽管Machine Mode在操作系统开发中并不经常涉及,但它在硬件设计中起着至关重要的作用。在大多数情况下,我们可以忽略这种模式,专注于User Mode和Kernel Mode的区分和应用。
操作模式与安全性
多级权限系统
在RISC-V以及其他现代处理器架构中,系统的权限级别分为三种:
- User Mode(用户模式):应用程序在这一模式下运行,权限受限,只能执行非特权指令,无法直接访问硬件资源或执行敏感操作。
- Kernel Mode(内核模式):操作系统内核在这一模式下运行,具有最高权限,能够执行特权指令,如管理内存、控制硬件设备等。
- Machine Mode(机器模式):处理器的最高权限模式,通常由BIOS或硬件启动代码使用,负责系统的初始化和引导操作系统。
特权指令与安全机制
在Kernel Mode下,CPU可以执行特权指令,例如设置页表寄存器、启用或禁用中断等,这些操作对于系统的安全性和稳定性至关重要。然而,在User Mode下,CPU无法直接执行这些特权指令,这样可以防止普通应用程序对系统核心功能进行非法操作。
当用户程序需要执行特权操作时,通常会通过系统调用来实现。系统调用是用户程序与内核交互的主要方式,通过触发软中断,用户程序可以请求内核执行特定的操作,而内核在Kernel Mode下拥有执行这些操作的权限。
提问,用户程序如何能够请求内核执行特权指令。
当用户程序发出系统调用请求时,处理器通过执行ECALL指令触发软中断,将控制权交给内核。内核在接收到请求后,根据中断向量表中的指示,切换到Kernel Mode并执行相应的特权操作。这一机制确保了用户程序无法直接切换到Kernel Mode,从而保护系统免受恶意代码的威胁。
User/Kernel Mode是操作系统和CPU之间的一种约定,它通过硬件支持实现了不同模式下的指令集隔离。这个机制是现代操作系统安全性和稳定性的重要基础。
User/Kernel Mode 的基本概念
Kernel Mode(内核模式):也称为“超级用户模式”或“特权模式”,在这种模式下,CPU可以执行所有的指令,包括一些直接与硬件交互的特权指令(例如,管理内存、控制硬件设备等)。操作系统的内核代码运行在这种模式下,能够直接访问硬件资源和管理计算机的所有进程。
User Mode(用户模式):在这种模式下,CPU只能执行非特权指令,也就是普通的计算和控制流操作,而不能直接访问硬件资源或执行特权指令。用户空间的应用程序(例如,你的文字处理器、浏览器等)运行在这种模式下。
如何实现隔离
硬件通过以下方式实现了User Mode和Kernel Mode之间的隔离:
模式切换:CPU内部有一个模式位(通常称为一个状态寄存器中的标志位),它决定当前处理器运行在哪种模式下。当这个位被设置为User Mode时,CPU只能执行非特权指令;当设置为Kernel Mode时,CPU可以执行特权指令。
特权指令限制:在User Mode下,CPU不会允许执行特权指令。如果某个应用程序尝试执行这些指令,CPU会触发一个异常(通常是非法操作异常),这将导致操作系统介入,并采取适当的操作,例如终止程序。
系统调用(System Call):用户程序不能直接切换到Kernel Mode。相反,用户程序需要通过系统调用请求操作系统提供的服务。系统调用通常通过一个特殊的指令(如RISC-V中的
ECALL指令)触发,这个指令会将CPU模式从User Mode切换到Kernel Mode,使得内核可以执行请求的操作。在完成操作后,CPU会切换回User Mode并返回用户程序。虚拟内存:操作系统使用虚拟内存技术进一步加强隔离。每个进程在User Mode下都有自己独立的虚拟地址空间,即使多个进程使用相同的虚拟地址,它们实际访问的是不同的物理内存位置。只有在Kernel Mode下,操作系统才有权访问和管理所有的物理内存地址。
User/Kernel Mode 是由操作系统和CPU硬件协同实现的隔离机制。通过模式切换、特权指令限制、系统调用和虚拟内存等技术,CPU确保了用户空间程序不能直接访问和控制内核或硬件资源。这种隔离是操作系统安全性和稳定性的基石,防止了用户程序对系统的恶意操作或意外破坏。
虚拟内存与Page Table
虚拟内存的基本概念
虚拟内存是现代操作系统中一种关键的内存管理技术,通过将进程的虚拟地址空间映射到实际的物理内存,虚拟内存提供了一种逻辑上的内存连续性。每个进程都拥有独立的虚拟地址空间,这使得多个进程可以“共享”同一块物理内存,而不会互相干扰。
Page Table 的作用
Page Table(页表)是实现虚拟内存的核心数据结构,记录了虚拟地址到物理地址的映射关系。每个进程都有自己独立的页表,这确保了进程之间的内存隔离性。换句话说,进程A无法访问进程B的内存,因为进程A的页表中不包含指向进程B物理内存的映射。
- 内存隔离的实现:
- 当一个进程尝试访问某个虚拟地址时,处理器会根据该进程的页表,将虚拟地址转换为物理地址。若该虚拟地址在页表中不存在,进程将无法访问对应的物理内存,从而实现了内存隔离。
- 这种机制防止了进程间的内存访问冲突,确保了系统的稳定性和安全性。
系统内存结构的分离
进程内存空间的独立性
通过虚拟内存,每个进程都认为自己拥有完整的内存空间,通常从地址0开始,这使得开发人员可以方便地编写代码,而无需关心物理内存的实际布局。操作系统负责将这些虚拟地址映射到不同的物理内存地址,从而确保进程间的隔离性。
例如,ls进程的内存空间和echo进程的内存空间在逻辑上都是从地址0开始的,但它们在物理内存中却是映射到不同的区域,因此ls无法访问echo的内存。
内核与用户进程的隔离
不仅如此,操作系统内核本身也有独立的内存地址空间,这个空间与用户进程的空间完全分离。即便是操作系统的底层服务也不能随意访问用户进程的内存,除非通过合法的系统调用。这种设计进一步强化了系统的安全性,防止了意外或恶意代码影响操作系统的核心功能。
通过User/Kernel Mode和虚拟内存的硬件支持,现代操作系统能够有效地实现进程间的隔离与资源共享。User Mode和Kernel Mode的区分确保了用户程序无法直接控制系统核心功能,而虚拟内存和Page Table则提供了进程间内存隔离的机制。接下来的课程中,我们将更深入地探讨这些机制的具体实现,以及它们在操作系统设计中的应用。
User/Kernel Mode 和 系统调用
User/Kernel Mode 的边界与系统调用的进入点
我们可以将User Mode/Kernel Mode看作是用户空间和内核空间之间的分界线。所有用户空间的程序(如ls、echo等)运行在User Mode,而操作系统内核运行在Kernel Mode。这种设计确保了用户程序无法直接访问或修改内核中的数据和状态,从而实现了隔离性和系统的稳定性。
然而,用户程序需要访问内核提供的各种服务,例如文件操作、进程管理等,这就引出了系统调用的概念。系统调用是用户程序请求操作系统服务的唯一途径,通过系统调用,用户程序可以安全地从User Mode切换到Kernel Mode,以获得内核提供的服务。
ECALL指令:从用户空间到内核空间的桥梁
在RISC-V架构中,ECALL指令专门用于实现用户程序向内核请求服务。执行ECALL指令时,用户程序将控制权交给内核,并传递一个数字参数,该参数指示了具体的系统调用类型。
例如,当用户程序需要执行fork系统调用时,它实际上并不是直接调用内核中的fork函数,而是通过ECALL指令将控制权交给内核。内核接收到ECALL指令后,通过传递的参数确定要执行的具体系统调用,并调用相应的内核函数来处理该请求。
这种机制使得用户空间与内核空间之间的交互成为可能,同时确保了内核的安全性和稳定性,因为只有通过特定的ECALL指令,用户程序才能进入内核空间,而不能随意执行内核中的代码。
系统调用的具体实现流程
每次用户程序执行ECALL指令时,内核会通过一个统一的入口函数(如XV6中的syscall函数)处理所有的系统调用请求。这个入口函数会检查ECALL指令传递的参数,并根据参数确定具体需要调用的系统调用函数。
举例来说,当用户程序调用write系统调用时,实际的流程如下:
- 用户程序执行封装好的
write函数,该函数内部调用ECALL指令,并传递write系统调用对应的数字参数。 - ECALL指令将控制权转移到内核空间,并调用内核中的
syscall函数。 syscall函数根据传入的参数确定需要执行write系统调用,并调用内核中的write函数来处理请求。
以下是描述系统调用具体实现流程:
+-------------------------+ | 用户程序 (User Program) | +-------------------------+ | | 1. 调用封装好的 `write` 函数 (用户模式) v +-------------------------+ | ECALL 指令 | | (从用户模式切换到内核模式) | +-------------------------+ | | 2. ECALL 指令将控制权转移到内核空间 v +-------------------------+ | 内核入口点 | | (syscall.c) | +-------------------------+ | | 3. `syscall` 函数检查 ECALL 传递的参数 v +-------------------------+ | 确定系统调用类型 | | (如:write 调用) | +-------------------------+ | | 4. 调用内核中的 `write` 函数 v +-------------------------+ | 内核中的 Write 逻辑 | | (处理请求) | +-------------------------+ | | 5. 将结果返回给用户空间 v +-------------------------+ | 用户程序 (User Program) | +-------------------------+流程说明:
用户程序: 用户程序通过调用用户空间中的
write函数来发起一个写操作。这个函数是一个封装函数,最终会引发系统调用。ECALL 指令: 用户空间的
write函数调用ECALL指令。ECALL是一条特殊的机器级指令,用于从用户模式切换到内核模式。内核入口点 (syscall.c): 当
ECALL指令执行后,控制权被转移到内核,进入一个通用的入口函数(通常在syscall.c文件中实现)。这个入口函数负责处理所有的系统调用。确定系统调用类型:
syscall函数通过ECALL传递的参数来判断具体是哪种系统调用(如write、fork等)。内核中的 Write 逻辑: 如果系统调用被识别为
write,内核会执行相应的write逻辑,处理数据的写入操作。返回用户空间: 写操作完成后,控制权返回给用户程序,并将系统调用的结果(如写入的字节数或错误代码)返回给用户程序。
系统调用的权限检查与安全性
在系统调用的具体实现过程中,内核通常会执行各种检查以确保安全性。例如,在write系统调用中,内核会检查用户程序传递的内存地址是否合法,以防止用户程序试图通过非法的内存访问来破坏系统的稳定性或安全性。
内核通过这些检查来确保只有合法的系统调用请求才能被执行,恶意或错误的请求将被拒绝或处理为异常。这种设计增强了系统的防御性,确保操作系统能够抵御恶意程序的攻击或错误。
硬件定时器与内核的控制权
当用户程序陷入死循环或试图占用过多的CPU资源时,操作系统需要一种机制来强制收回控制权。为此,硬件定时器(Timer)可以帮助操作系统实现时间片轮转调度。
当定时器到期时,处理器会触发一个硬件中断,将控制权交回内核。内核接收到中断后,可以选择调度其他进程运行,从而确保系统的多任务处理能力和响应速度。这种机制有效地防止了单个用户进程独占CPU资源,确保了系统的公平性和稳定性。
C语言在操作系统开发中的优势
为什么大多数操作系统使用C语言进行开发,而不是C++。
C语言在操作系统开发中的主导地位可以追溯到其提供的直接硬件控制能力。C语言以其简洁性和高效性,使得它成为操作系统开发的理想选择,尤其是在底层系统需要与硬件紧密交互的场景中。
C语言的语法简洁,生成的代码执行效率高,非常适合操作系统这种需要处理大量底层操作、并且对性能要求极高的系统。它的历史地位以及在多代操作系统中的广泛应用,也为其在操作系统开发领域奠定了坚实的基础。
尽管C++提供了更高级的抽象和面向对象的特性,但这些特性在操作系统开发中并非必需,甚至在某些情况下会增加系统的复杂性。操作系统设计的核心是稳定性和效率,而C语言的简洁性和直观性帮助开发者减少了不必要的复杂性,避免了在关键任务中可能出现的性能开销。
近年来,Rust语言逐渐在操作系统开发中获得了一席之地。Rust在设计上强调内存安全和并发安全,这对于操作系统这样复杂且易出错的系统非常重要。Rust提供了现代化的编程工具和抽象,同时避免了C和C++中常见的内存管理问题(如缓冲区溢出、悬空指针等)。
尽管Rust的使用还没有达到C语言的普及程度,但它已经被用于一些新兴的操作系统项目,如Redox OS。这些项目展示了Rust在操作系统开发中的潜力,尤其是在需要更高安全性和并发处理能力的系统中。
随着时间的推移,Rust可能会在更多的操作系统开发项目中得到应用,特别是在那些需要更严格的内存安全性和并发控制的场景中。
内核与系统调用的关系
通过系统调用或ECALL指令,用户程序能够将控制权从用户空间转移到内核空间。在内核空间中,操作系统接管控制,执行相应的功能,并检查传递的参数,确保它们的合法性。这种机制确保了内核能够防止恶意应用程序试图通过传递不良参数来攻击或破坏系统。因此,内核通常被视为受信任的计算基础(Trusted Computing Base, TCB)。
TCB的安全性要求
作为TCB,内核必须是高度可靠的,尽可能地减少Bug的存在。任何一个Bug都有可能成为漏洞,允许攻击者利用这些漏洞打破操作系统的隔离性,进而接管整个系统。因此,内核代码的正确性和安全性至关重要。然而,由于内核需要直接操作硬件,并且执行各种复杂的检查,这使得完全消除Bug变得非常困难。几乎所有被广泛使用的操作系统都曾经发现并修复过安全漏洞,但新的漏洞可能会不断出现。
内核模式下运行的代码
内核代码需要在Kernel Mode下运行,以保证安全性。所有敏感的操作和数据处理都应该在Kernel Mode下进行,这是因为Kernel Mode具备最高的权限,能够直接操作硬件和管理系统资源。
宏内核设计 (Monolithic Kernel Design)
在许多Unix操作系统中,包括XV6,操作系统的所有代码都运行在Kernel Mode下,这种设计被称为宏内核设计(Monolithic Kernel Design)。
宏内核设计的特点与挑战:
- 高风险的安全性:
- 由于整个操作系统的代码都运行在Kernel Mode下,任何一个Bug都有可能带来安全漏洞。因为内核中的代码量庞大,Bug的数量也相对增加,从而提高了漏洞被利用的风险。
- 性能优势:
- 宏内核的一个显著优势在于其性能表现。由于所有的操作系统子模块(如文件系统、虚拟内存、进程管理等)都在同一内核空间内运行,它们可以更紧密地集成在一起,减少了模块之间的通信开销,从而提升了整体系统的性能。
- 复杂的错误管理:
- 由于内核内的代码量巨大,管理和调试这些代码变得非常复杂。一旦某个模块出现问题,可能会影响整个系统的稳定性。
宏内核设计在性能和集成性方面表现优越,但其庞大的代码量和复杂性也带来了更高的安全风险。操作系统设计者需要在安全性和性能之间找到平衡点,确保系统既高效运行又能防御潜在的攻击。
微内核设计 (Micro Kernel Design)
微内核设计的核心思想是将操作系统中尽可能多的功能移出内核空间,只保留最核心、最关键的部分在内核中运行。这种设计的目的是减少内核中的代码量,从而降低Bug的可能性。
微内核的特点
- 精简的内核功能:
- 在微内核设计中,内核仅包含最基本的功能,例如进程间通信(IPC),极少量的虚拟内存管理(如page table支持),以及CPU的分时复用等。其他功能,如文件系统、网络协议栈等,都会作为普通的用户空间程序运行。
这与宏内核设计形成鲜明对比,在宏内核中,这些功能通常直接嵌入到内核中。
- 用户模式下的系统服务:
- 在微内核设计中,文件系统、设备驱动程序、网络服务等操作系统的其他部分会运行在用户模式下,类似于普通的用户应用程序。这种做法减少了内核代码量,降低了内核中的Bug风险。
然而,系统服务运行在用户模式下也带来了性能方面的挑战。
微内核的性能挑战
- 频繁的上下文切换:
- 由于微内核设计要求应用程序与系统服务之间通过内核进行消息传递(IPC),这意味着每次交互都需要两次用户空间和内核空间之间的切换。与宏内核设计相比,这种频繁的上下文切换增加了系统的开销。
- 难以实现的资源共享:
- 在宏内核设计中,内核的各个模块可以紧密集成并共享资源,例如文件系统和虚拟内存系统可以共享page cache。而在微内核中,这些模块被隔离在不同的用户空间程序中,资源共享变得更加复杂,从而可能导致性能下降。
宏内核设计的优缺点
优点
- 高效的系统调用:
- 在宏内核中,所有的操作系统服务都在内核空间中运行,应用程序调用系统服务只需一次用户空间到内核空间的切换,效率较高。
- 紧密集成的系统组件:
- 由于所有模块都在内核中运行,资源共享和模块间的协作更加高效,这对于需要高性能的系统(如桌面操作系统和服务器操作系统)尤为重要。
缺点
- 安全性风险:
- 由于内核中的代码量巨大,任何一个模块中的Bug都有可能导致整个系统的崩溃或安全漏洞的出现。
- 复杂性增加:
- 宏内核的复杂性增加了调试和维护的难度。一旦系统出现问题,定位和修复Bug变得更加复杂。
微内核和宏内核的应用场景
宏内核应用:
- 大多数桌面操作系统(如Linux、Windows)和服务器操作系统使用宏内核设计,主要是因为它们需要高性能和紧密集成的系统组件。
微内核应用:
- 嵌入式系统和一些专用操作系统(如Minix、QNX)倾向于使用微内核设计,这些系统更关注内核的安全性和可靠性,代码量较小,便于在资源受限的环境中运行。
微内核和宏内核设计各有优劣。宏内核设计提供了高性能和紧密集成的系统,但也带来了更高的安全风险和复杂性。微内核设计虽然简化了内核,提高了系统的可靠性和安全性,但在性能方面面临更大的挑战。
XV6采用了宏内核设计,符合传统Unix系统的架构。而在本学期的后半部分课程中,我们将探讨更多有关微内核设计的内容,帮助大家更全面地理解操作系统的设计选择。
XV6 内核工作原理与代码结构
接下来我们将深入探讨XV6操作系统的代码结构及其工作原理,并通过对代码的分析,帮助大家更好地理解XV6是如何运作的。
XV6 代码结构概览
XV6代码结构主要由三个部分组成:

-
Kernel(内核):这是系统的核心部分,包含了所有在内核模式下运行的代码。XV6采用了宏内核结构,所有内核文件都会被编译成一个名为
kernel的二进制文件,并在内核模式下运行。$ ls kernel/这个目录下包含了XV6内核的所有源代码文件。
-
User(用户模式):这个部分包含了在用户模式下运行的程序。用户程序在该目录中编写,并且在系统运行时,这些程序将在用户模式下执行。
-
Mkfs(文件系统工具):这一部分用于创建一个空的文件系统镜像,将其存储在磁盘上,使得XV6能够在启动时使用一个预先准备好的文件系统。
内核编译过程
理解内核的编译过程有助于深入掌握XV6的工作原理。编译过程如下:
-
编译C文件:首先,
Makefile会读取一个C文件(例如proc.c),调用gcc编译器,将其编译成RISC-V汇编语言文件(proc.s)。 -
汇编解释:然后,汇编解释器将汇编语言文件
proc.s编译成二进制格式的proc.o文件。 -
链接文件:系统加载器(Loader)会将所有的
.o文件收集起来,并链接成一个完整的内核二进制文件。这个kernel文件就是最终在QEMU中运行的内核文件。 -
生成汇编语言输出:为了调试方便,
Makefile还会生成一个名为kernel.asm的文件,包含了内核的完整汇编语言代码。通过查看这个文件,开发者可以更容易地追踪和定位内核中的Bug。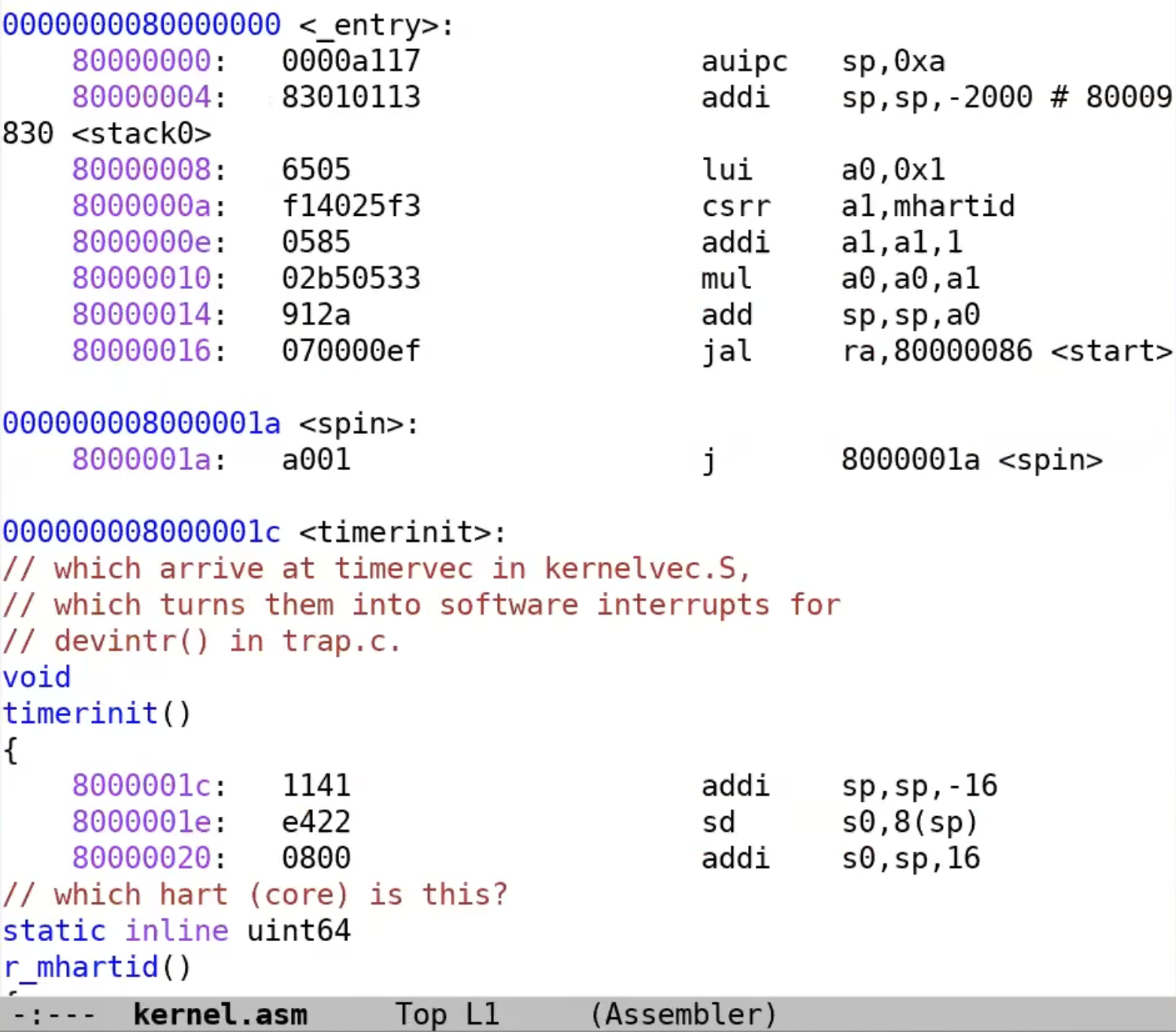
例如,
kernel.asm文件的起始指令位于地址0x80000000,第一个指令是RISC-V的auipc指令。每条汇编指令在文件中都有对应的十六进制编码(例如0x0000a117对应auipc指令)。这张图片展示了一个名为
kernel.asm的汇编语言文件,它是由XV6内核编译过程中生成的。我们可以看到,该文件展示了内核代码的反汇编结果,并且标注了各个指令的地址、十六进制编码、以及对应的汇编指令。具体内容解析:
- 地址和指令编码:
- 每行的开头是指令所在的内存地址,例如
0x80000000。 - 每个地址后面跟着的十六进制数字表示对应的机器指令编码,例如
0000a117。 - 机器指令编码之后是汇编指令,例如
auipc sp, 0xa表示将当前指令地址加上立即数0xa,并存入寄存器sp。
- 每行的开头是指令所在的内存地址,例如
- 指令:
auipc sp, 0xa:该指令的含义是加载当前PC值并加上立即数(这里是0xa)到寄存器sp。addi sp, sp, -2000:这是一个立即数加法指令,将sp寄存器的值减去2000。csrr a1, mhartid:这是一个控制状态寄存器读取指令,从mhartid寄存器中读取当前hart ID(硬件线程ID),并存入a1寄存器。
- 入口点:
- 地址
0x80000000是内核代码的入口点(),这是程序启动时加载并开始执行的第一个指令位置。
- 地址
- 定时器初始化(timerinit):
- 代码展示了
timerinit函数的汇编代码,该函数用于初始化系统定时器,这是操作系统启动过程中的关键部分。
- 代码展示了
这段
kernel.asm文件展示了XV6内核启动时的关键指令,包括入口点的初始化和定时器的设置。这些指令在操作系统启动的早期阶段执行,确保系统的各种功能模块能够正常运作。 - 地址和指令编码:
XV6 在 QEMU 中的运行
在完成编译后,我们可以通过QEMU模拟器运行XV6内核。以下是运行XV6时传递给QEMU的主要参数:
-
-kernel:指定将要在QEMU中运行的内核二进制文件,即kernel文件。 -
-m:指定RISC-V虚拟机的内存大小。 -
-smp:指定虚拟机可以使用的CPU核数。 -
-drive:指定虚拟机的磁盘驱动器,这里使用的是fs.img文件。
运行以下命令即可启动XV6系统:
$ make qemu
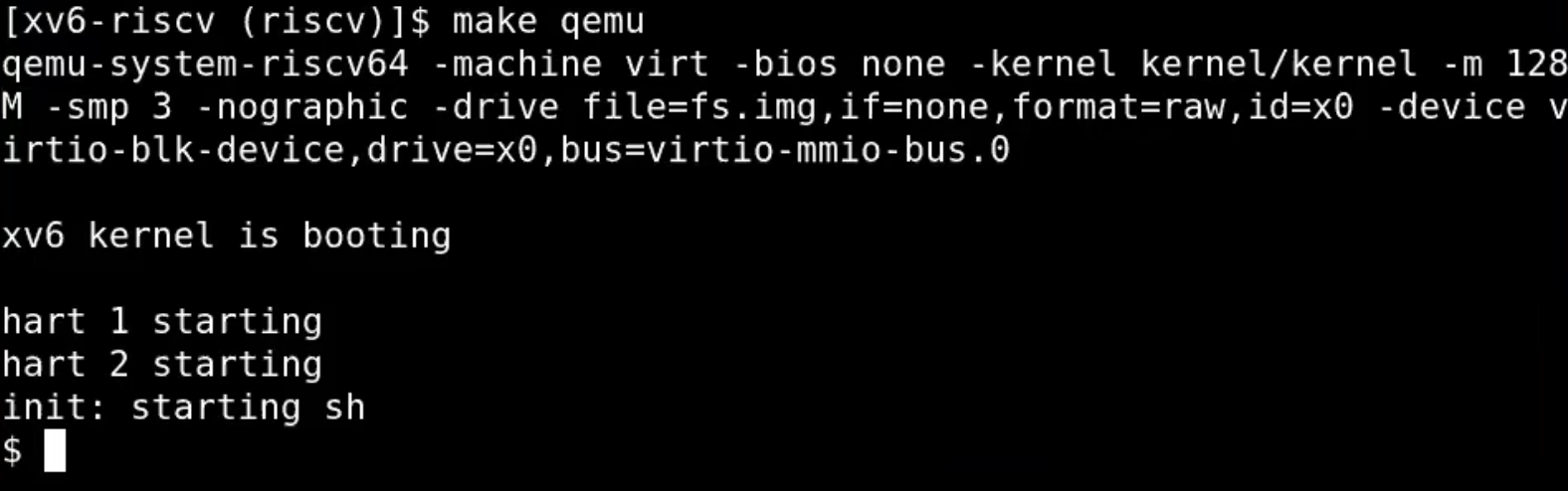
这将编译XV6并启动QEMU模拟器,在其中运行XV6操作系统。
通过对XV6的编译过程和运行机制的理解,我们可以更深入地了解操作系统的工作原理,以及如何通过代码和工具链来管理和调试操作系统。
QEMU的工作原理与操作
QEMU的本质与RISC-V硬件仿真
QEMU 是一个开源的硬件仿真器,模拟了一台完整的计算机。当你使用 QEMU 运行 XV6 内核时,你可以将其视为一台真实的 RISC-V 主板,如下图所示:

这个主板上包括了所有真实计算机所具有的硬件组件,如 CPU 核、内存、I/O 接口等。QEMU 通过软件模拟这些硬件组件,使得 XV6 操作系统可以在虚拟环境中运行,就像在真实硬件上一样。
RISC-V 处理器的硬件架构图如下:
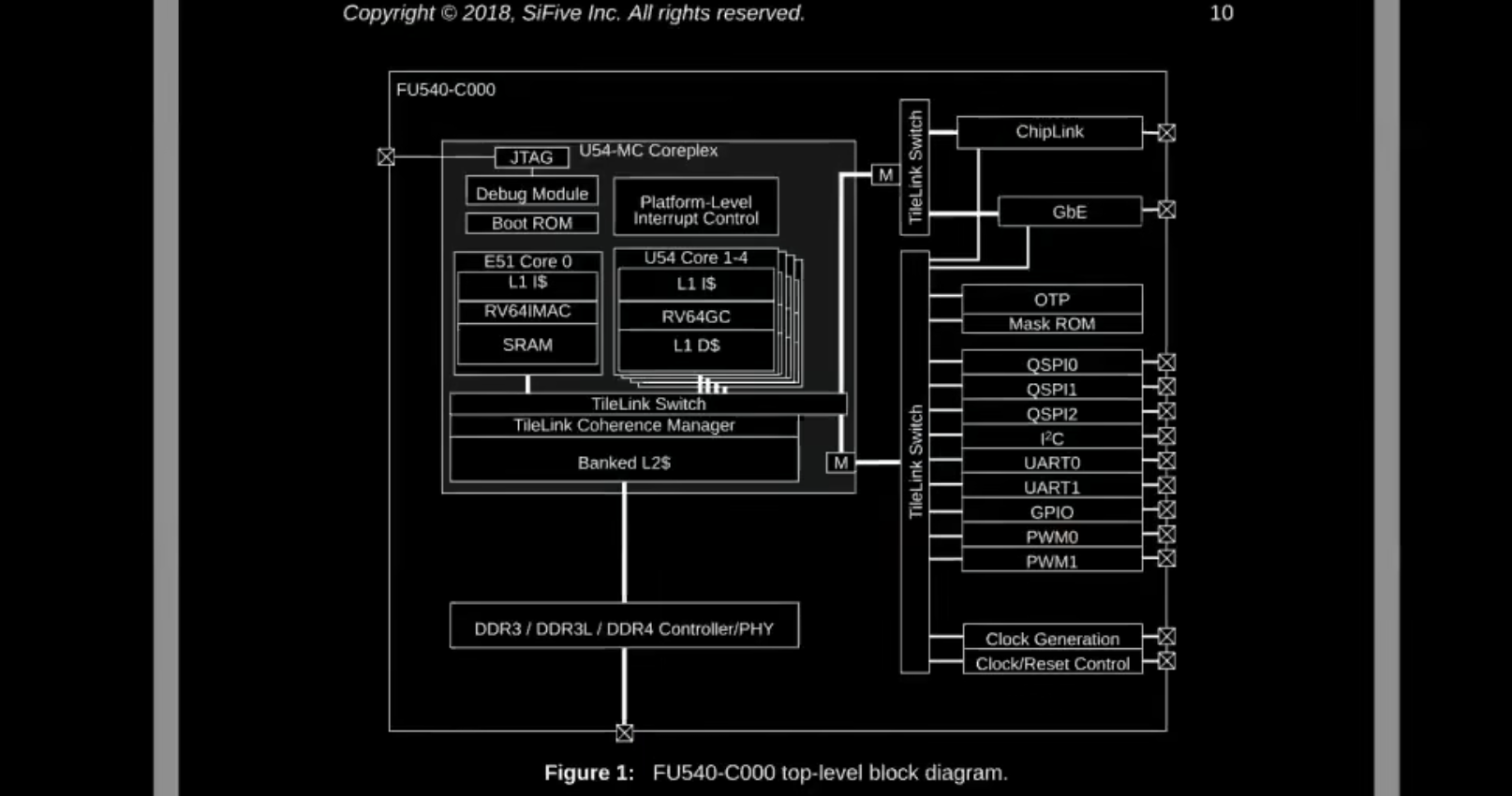
图中展示了 RISC-V 的主要组件:
- U54 Core 1-4:四个 CPU 核
- Banked L2:L2 缓存
- DDR Controller:连接 DRAM 的控制器
- UART0:用于键盘输入和终端通信的接口
- Clock Generation:时钟生成模块
这些组件通过 QEMU 仿真,使得操作系统能够与这些虚拟硬件交互。
QEMU 的仿真工作机制
QEMU 是一个复杂的 C 程序,其核心是一个主循环,负责模拟 RISC-V 处理器的行为。QEMU 的工作原理可以概括为以下几个步骤:
-
读取指令:QEMU 从仿真的内存中读取 4 字节或 8 字节的 RISC-V 指令。
-
解析指令:QEMU 解析指令,提取操作码(opcode),确定这是一个加法指令、减法指令还是其他类型的指令。
-
执行指令:QEMU 在软件中执行相应的指令,更新仿真 CPU 的寄存器状态和内存状态。
QEMU 在仿真 CPU 时,会维护所有寄存器的状态,例如寄存器 X0, X1 等等。当 QEMU 仿真执行一条指令(如 ADD a0, 7, 1),它会在 a0 寄存器中存储结果。然后 QEMU 继续读取并执行下一条指令,不断循环,直到所有指令执行完毕。
多线程支持与并行处理
QEMU 支持多线程仿真,能够并行仿真多个 CPU 核。例如,当 QEMU 仿真一台具有四个 CPU 核的 RISC-V 处理器时,它会在后台使用多个线程来并行处理这些 CPU 核的指令。这样,QEMU 就能够更真实地模拟多核处理器的行为,在多核环境下运行的程序也能够正确地并行执行。
在 QEMU 仿真环境中运行的代码与在真实的 RISC-V 处理器上运行的效果是相同的,这对于操作系统开发者来说,提供了一个理想的调试和测试平台。
QEMU 是一个强大的仿真器,能够通过软件模拟一整台计算机的硬件运行环境。它不仅可以让我们在不依赖真实硬件的情况下开发和测试操作系统,还能通过多线程实现并行仿真,为开发者提供接近真实硬件的体验。这种仿真能力使得 QEMU 成为操作系统开发和教学中不可或缺的工具。
XV6 启动与初始化的完整流程
在XV6的启动与初始化过程中,内核经历了一系列步骤,从最初的加载到最终启动用户空间的第一个进程。以下是整个流程的详细步骤,结合了前面各个回答中的内容。
1. 内核编译过程
首先,内核需要被编译为二进制文件,以便在QEMU中运行。编译过程如下:
- 编译C文件:
Makefile读取各个C文件(如proc.c),调用gcc编译器,将其编译为RISC-V汇编语言文件(proc.s)。 - 汇编解释:汇编解释器将汇编语言文件
proc.s编译为二进制格式的proc.o文件。 - 链接文件:系统加载器(Loader)将所有的
.o文件链接成一个完整的内核二进制文件,即kernel文件。 - 生成汇编语言输出:
Makefile生成一个kernel.asm文件,包含内核的完整汇编语言代码,方便开发者调试。
这个编译过程为内核的启动做了充分的准备。
2. QEMU 启动和调试
当内核编译完成后,我们通过QEMU来启动它,并使用gdb进行调试。
QEMU 是一个开源的仿真器和虚拟机,它能够模拟多种硬件架构,包括我们在这里使用的 RISC-V 架构。在本例中,我们使用 QEMU 来模拟运行 XV6 操作系统的环境。启动 QEMU 后,它仿真了一个完整的 RISC-V 计算机,包括 CPU、内存和 I/O 设备等。
GDB(GNU Debugger)是一个强大的调试工具,在本例中用于调试 XV6 操作系统。通过连接到 QEMU 内部的 GDB 服务器,我们可以在操作系统启动时设置断点、检查寄存器和内存的状态、单步执行代码等。通过这种方式,我们可以深入分析操作系统的行为并理解其工作机制。

以下是启动与调试的步骤:
-
启动QEMU:使用命令启动QEMU虚拟机,并加载编译好的
kernel文件,同时启动QEMU内部的gdb server。 -
连接gdb:在本地计算机上启动gdb客户端,并连接到QEMU的gdb server。
-
设置断点:在内核的入口地址(0x80000000)设置断点,这是QEMU将控制权交给内核的第一个指令地址。
-
通过命令
b _entry在_entry处设置了一个断点,然后执行c(continue)命令,程序在设置的断点处停止执行。(gdb) b _entry (gdb) c
-
-
调试内核启动过程:使用gdb调试内核启动过程,跟踪内核如何从
entry(入口)到main函数的执行。
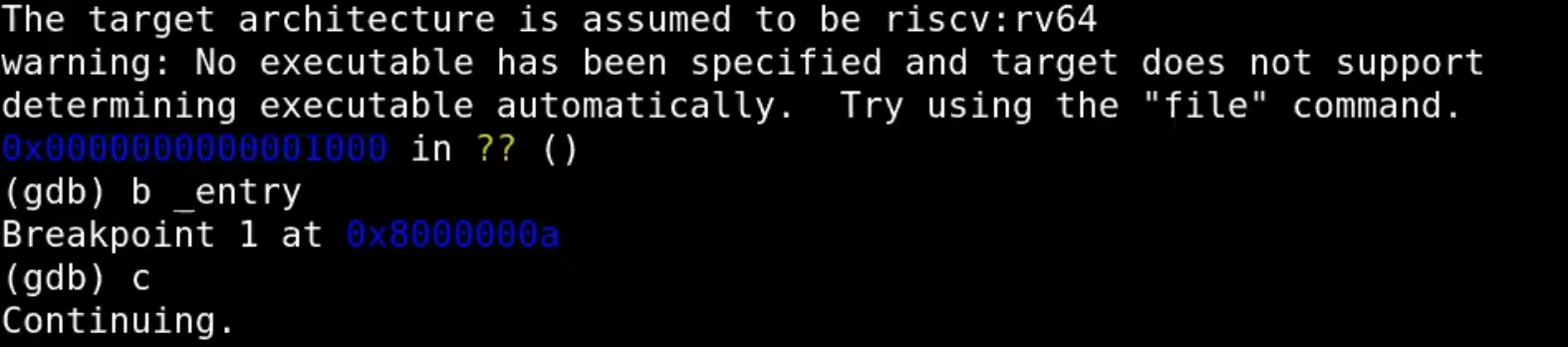
- 设置完断点之后,继续执行程序(使用
c命令),程序会在断点处停下来。此时,我们可以看到,程序的执行实际上并没有停在0x80000000,而是停在了0x8000000a。这表明QEMU将从这个地址开始加载和执行内核。 - 通过查看内核的汇编文件(
kernel.asm),我们可以理解每一条指令的作用。例如,在地址0x8000000a,程序读取了控制系统寄存器mhartid并将其结果加载到a1寄存器中。QEMU仿真执行这些指令,并逐步进入到内核的初始化过程。
3. 执行 main 函数的初始化代码
XV6的内核从entry.s开始启动,此时没有内存分页、没有隔离,系统处于Machine Mode(M-mode)。XV6会尽快切换到kernel mode(supervisor mode),我们在main函数设置断点以跟踪内核的初始化过程:
(gdb) b main
(gdb) c
此时,代码会在main函数的第一条指令处停下来。我们可以看到main函数的源代码和对应的汇编指令。
通过si(step into)命令逐步执行main函数内部的代码:
(gdb) si
main函数中的第一条执行的指令是一个条件判断:if(cpuid() == 0)。该函数用于检查当前CPU核的ID,只有ID为0的核才会执行接下来的初始化代码。这是因为在多核系统中,某些初始化操作只需要执行一次,通常由核ID为0的核心负责。
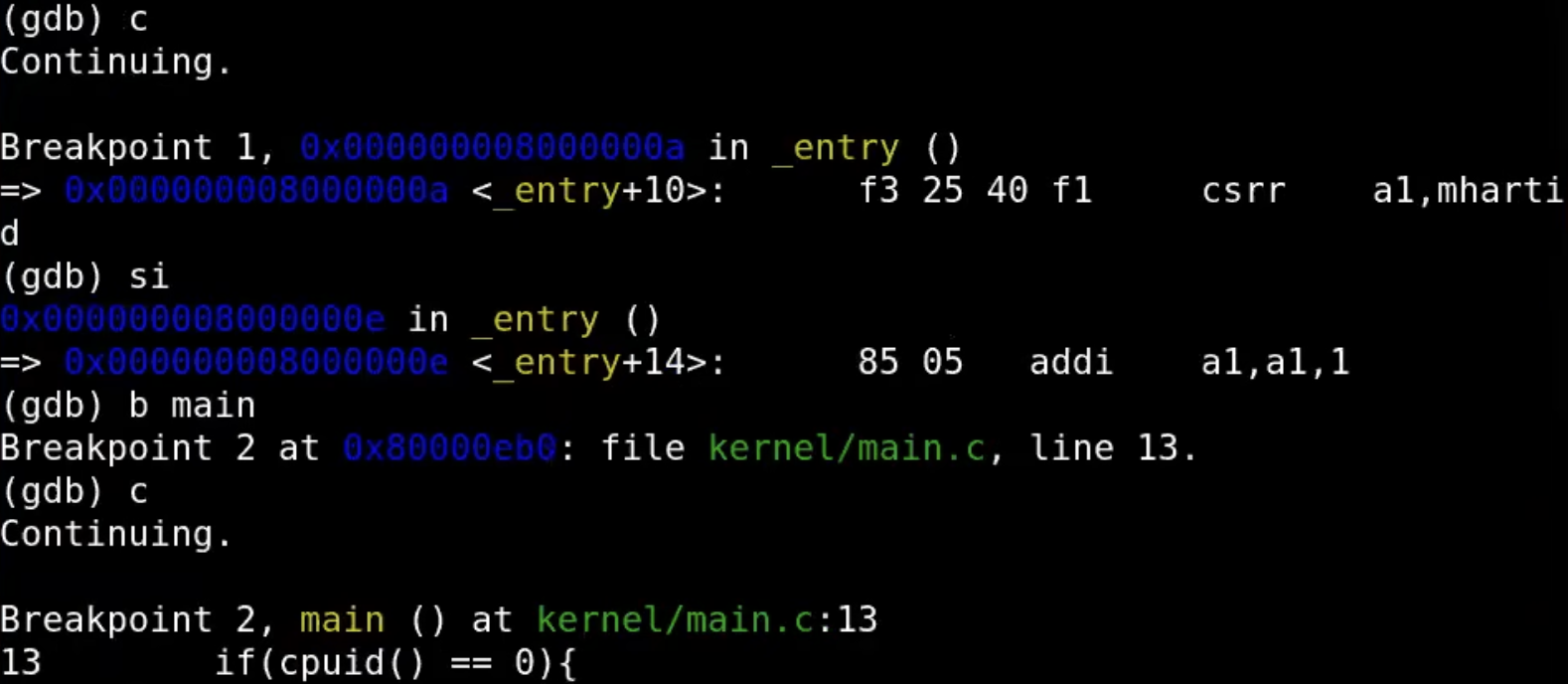
调用 consoleinit 函数
在使用gdb调试XV6内核时,可以使用
layout split模式,这种模式能够同时显示源代码和汇编代码,帮助你清楚地看到程序的执行流程。这有助于理解程序的执行顺序,并帮助我们准确设置和查看断点。(gdb) layout split在该模式下,我们可以清楚地看到gdb即将执行的下一条指令,并且可以确认当前断点的位置。在gdb中输入
n跳到下一条指令。
接着,consoleinit() 函数被调用,用于初始化内核的控制台(console)。这一步骤设置了控制台的输入输出,之后任何在内核中的打印操作都会输出到控制台。
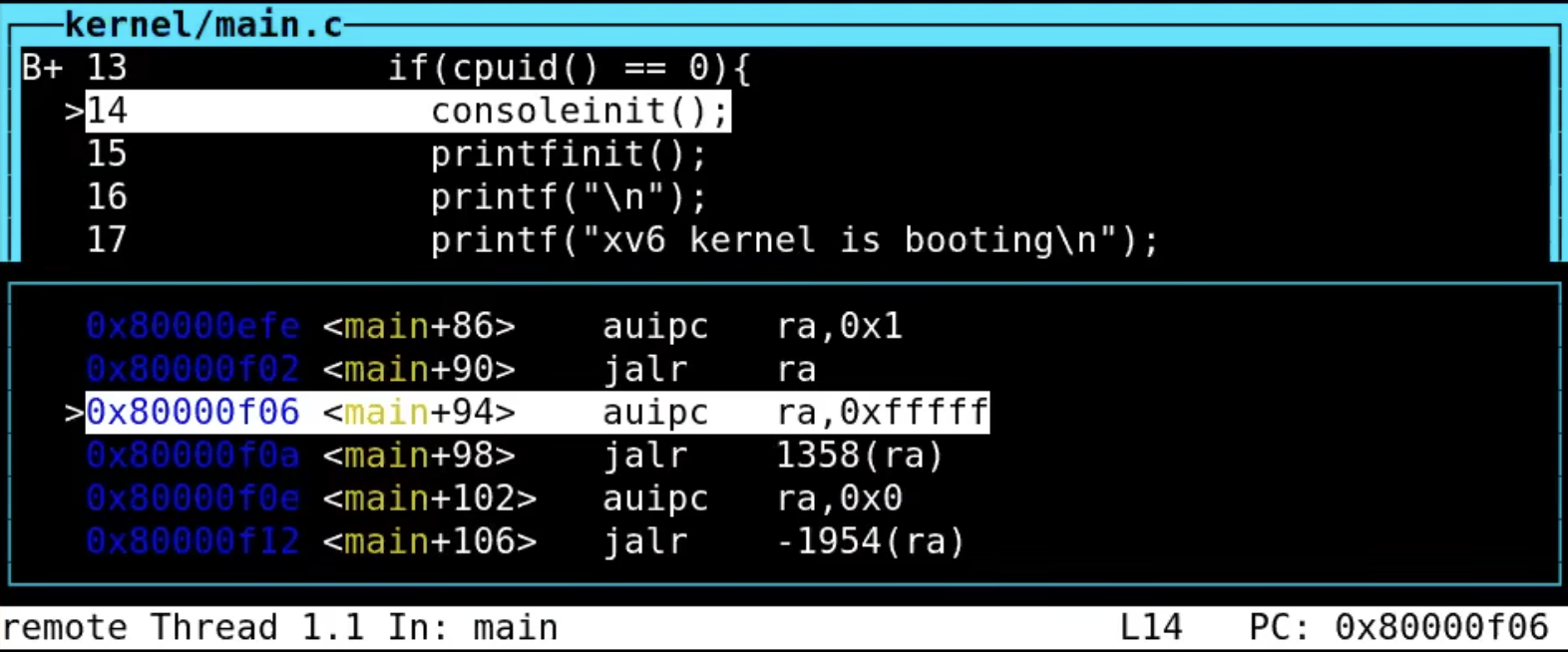
当consoleinit函数执行完毕并返回后,我们可以在QEMU中看到内核的启动信息,例如XV6 kernel is booting。这个输出确认了控制台的初始化是成功的,接下来内核会继续执行其他的初始化步骤。
继续进行内核初始化
#include "types.h"
#include "param.h"
#include "memlayout.h"
#include "riscv.h"
#include "defs.h"
volatile static int started = 0;
// start() jumps here in supervisor mode on all CPUs.
void
main()
{
if(cpuid() == 0){
consoleinit();
printfinit();
printf("\n");
printf("xv6 kernel is booting\n");
printf("\n");
kinit(); // physical page allocator
kvminit(); // create kernel page table
kvminithart(); // turn on paging
procinit(); // process table
trapinit(); // trap vectors
trapinithart(); // install kernel trap vector
plicinit(); // set up interrupt controller
plicinithart(); // ask PLIC for device interrupts
binit(); // buffer cache
iinit(); // inode table
fileinit(); // file table
virtio_disk_init(); // emulated hard disk
userinit(); // first user process
__sync_synchronize();
started = 1;
} else {
while(started == 0)
;
__sync_synchronize();
printf("hart %d starting\n", cpuid());
kvminithart(); // turn on paging
trapinithart(); // install kernel trap vector
plicinithart(); // ask PLIC for device interrupts
}
scheduler();
}
如代码所示,内核初始化还包括以下关键步骤:
-
kinit:初始化页表分配器。这一步骤为后续的内存管理设置了基本的结构,使得内核能够管理和分配物理内存页。 -
kvminit和kvminithart:分别初始化内核虚拟内存和启用页表。虚拟内存系统将物理内存抽象为一组虚拟地址空间,为进程提供隔离和保护。 -
processinit:初始化进程表单。这是内核管理进程的基础,记录所有正在运行或准备运行的进程。 -
trapinit和trapinithart:初始化用户模式和内核模式之间的陷阱向量(trap vector)。这些向量是从用户模式切换到内核模式的入口点,用于处理系统调用和中断。 -
plicinit和plicinithart:初始化平台级中断控制器(PLIC),用于管理硬件中断。例如,当磁盘准备好数据时,它会通过中断通知 CPU,这时 PLIC 就会发挥作用。 -
binit:初始化缓冲区缓存,用于文件系统的缓存管理。 -
iinit:初始化 inode 缓存,inode 是文件系统中用于表示文件和目录的结构。 -
fileinit:初始化文件系统,为文件的读写操作做好准备。 -
virtio_disk_init:初始化虚拟磁盘驱动,这是与 QEMU 虚拟硬盘交互的部分。
启动第一个用户进程
所有这些初始化步骤完成后,XV6 内核调用 userinit() 函数,创建并运行第一个用户进程。这通常是 init 进程,它会进一步启动 sh(shell)等系统服务。
4. userinit 函数的执行
userinit函数在XV6操作系统中具有至关重要的作用,它被设计为启动第一个用户进程的关键代码。userinit的设计不仅仅是初始化一个进程,而是将内核的初始化和第一个用户进程的启动联系在一起。这部分代码通常被称为“胶水代码(Glue code)”,因为它本身并不实现具体的功能,而是将不同部分的初始化工作和进程启动连接在一起,使操作系统的启动流程更加顺畅。
在操作系统启动时,我们需要有一个用户进程来提供与系统的交互,而userinit函数正是为了实现这个目的。它的主要任务是创建第一个用户进程并为其设置好运行环境。这个进程随后会执行内核中预先定义的一小段代码,这段代码被称为initcode,并且它会进一步启动更为复杂的用户进程。
下面是userinit函数及其对应的汇编代码的关键部分:
- 加载初始程序的地址到
a0寄存器。 - 加载参数的地址到
a1寄存器。 - 加载
exec系统调用对应的编号到a7寄存器。 - 执行
ECALL指令,将控制权交给内核,触发exec系统调用。
userinit通过这些步骤启动一个初始用户进程,而这个进程将进一步启动XV6的第一个真正的用户进程——init。
initcode是以二进制形式嵌入在内核中的一小段程序。它被加载到用户空间,并作为第一个用户进程执行。这段代码通过一系列的系统调用启动操作系统的第一个真正的用户进程,即/init。下面我们来详细解析initcode的内容。uchar initcode[] = { 0x17, 0x05, 0x00, 0x00, 0x13, 0x05, 0x45, 0x02, 0x97, 0x05, 0x00, 0x00, 0x93, 0x85, 0x35, 0x02, 0x93, 0x08, 0x70, 0x00, 0x73, 0x00, 0x00, 0x00, 0x93, 0x08, 0x20, 0x00, 0x73, 0x00, 0x00, 0x00, 0xef, 0xf0, 0x9f, 0xff, 0x2f, 0x69, 0x6e, 0x69, 0x74, 0x00, 0x00, 0x24, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00 };这段
initcode是一个由二进制字节数组组成的程序,它在XV6内核中被静态定义并链接。当userinit函数启动第一个用户进程时,这段代码会被加载到新进程的地址空间,并开始执行。
initcode.S- 汇编代码分析
initcode的内容实际上是由一段汇编代码生成的,下面是initcode.S文件的内容,这段代码被编译成二进制形式后嵌入内核中。# Initial process that execs /init. # This code runs in user space. #include "syscall.h" # exec(init, argv) .globl start start: la a0, init # 将字符串"/init"的地址加载到a0寄存器中,作为exec的第一个参数 la a1, argv # 将参数列表的地址加载到a1寄存器中,作为exec的第二个参数 li a7, SYS_exec # 将系统调用号SYS_exec加载到a7寄存器中,准备发起exec系统调用 ecall # 触发系统调用,将控制权交给内核 # for(;;) exit(); exit: li a7, SYS_exit # 将系统调用号SYS_exit加载到a7寄存器中,准备发起exit系统调用 ecall # 触发系统调用,将当前进程终止 jal exit # 进入一个无限循环,不断调用exit系统调用 # char init[] = "/init\0"; init: .string "/init\0" # 定义字符串"/init"作为exec系统调用要执行的文件路径 # char *argv[] = { init, 0 }; .p2align 2 argv: .quad init # 定义参数列表,包含字符串"/init"的指针 .quad 0 # 参数列表以NULL结尾详细分析
start标签:
start是程序的入口点,当用户进程启动时,从这里开始执行。la a0, init:将字符串/init的地址加载到a0寄存器,这个地址是exec系统调用的第一个参数,表示要执行的程序路径。la a1, argv:将参数列表的地址加载到a1寄存器,argv包含了指向/init字符串的指针以及一个NULL指针,作为exec系统调用的第二个参数。li a7, SYS_exec:将exec系统调用的编号加载到a7寄存器中。ecall:触发系统调用,将控制权交给内核。内核会根据a7寄存器中的值识别这是exec系统调用,并尝试执行指定的/init程序。exit标签:
- 这个部分是一个备用的退出逻辑,保证当
exec调用失败时,进程能够安全地退出。li a7, SYS_exit:将exit系统调用的编号加载到a7寄存器中。ecall:触发exit系统调用,终止进程。jal exit:进入一个无限循环,不断调用exit以防止进程错误地继续运行。init字符串和argv数组:
init是一个包含/init字符串的内存区域,表示要执行的程序。argv是一个参数列表,其中包含指向/init字符串的指针和一个NULL指针,作为exec系统调用的参数。
userinit的执行流程总结
userinit函数加载了initcode程序到第一个用户进程中,并启动该进程。initcode程序通过exec系统调用启动了/init,这是一段复杂的用户级代码,通常是一个初始化脚本或shell。- 如果
exec调用成功,init程序开始执行,整个XV6系统进入到用户空间与内核空间的交互阶段。如果exec失败,进程会被exit系统调用终止。通过深入理解
userinit和initcode的实现,可以看出XV6是如何通过一段简短的胶水代码启动整个操作系统的用户空间的。这些代码展示了操作系统在初始化阶段如何从内核空间无缝地过渡到用户空间,并为用户进程提供了基础设施和环境。
5. syscall 函数处理系统调用
系统调用(syscall)是用户空间与内核空间之间交互的主要机制。当用户程序需要操作系统提供的服务时,会通过ECALL指令向内核发出请求,而内核则通过syscall函数来处理这些请求。
当用户程序执行ECALL指令后,内核会通过syscall函数处理系统调用请求。我们可以通过设置gdb断点来观察这一过程。
(gdb) b syscall
(gdb) c
执行到syscall函数时,我们可以查看代码:
void
syscall(void)
{
int num;
struct proc *p = myproc();
num = p->trapframe->a7;
if(num > 0 && num < NELEM(syscalls) && syscalls[num]) {
// Use num to lookup the system call function for num, call it,
// and store its return value in p->trapframe->a0
p->trapframe->a0 = syscalls[num]();
} else {
printf("%d %s: unknown sys call %d\n",
p->pid, p->name, num);
p->trapframe->a0 = -1;
}
}
在syscall函数中,首先读取当前进程的陷阱帧(trapframe),从中获取用户程序传递的系统调用编号:
int num = p->trapframe->a7;
这行代码从trapframe中读取存储在a7寄存器中的值,该值表示具体的系统调用编号。通过在gdb中打印这个编号,我们可以确认它是7,这意味着用户程序请求执行的是exec系统调用。
(gdb) p num
$1 = 7
接下来,syscall函数使用系统调用编号作为索引,从系统调用表(一个函数指针数组)中找到对应的处理函数。这个函数指针数组定义在syscall.h文件中,在syscall.h文件中,我们可以看到编号7对应的系统调用是exec:
// System call numbers
#define SYS_fork 1
#define SYS_exit 2
#define SYS_wait 3
#define SYS_pipe 4
#define SYS_read 5
#define SYS_kill 6
#define SYS_exec 7
#define SYS_fstat 8
#define SYS_chdir 9
#define SYS_dup 10
#define SYS_getpid 11
#define SYS_sbrk 12
#define SYS_sleep 13
#define SYS_uptime 14
#define SYS_open 15
#define SYS_write 16
#define SYS_mknod 17
#define SYS_unlink 18
#define SYS_link 19
#define SYS_mkdir 20
#define SYS_close 21
这里本质上是告诉内核,某个用户应用程序执行了ECALL指令,并且想要调用exec系统调用。syscall函数通过索引操作将控制权交给了sys_exec函数,这是处理exec系统调用的具体函数。
在sys_exec函数中,内核首先从用户空间读取传递过来的参数,这通常是需要执行的程序的路径名:
char path[MAXPATH], *argv[MAXARG];
这个路径(使用(gdb) p path 打印path可以看到,在本例中为init程序)将作为exec系统调用的输入,用于加载并执行指定的用户程序。
接下来,内核为参数分配空间,并将这些参数从用户空间复制到内核空间。这个操作是关键的,因为它确保内核可以安全地操作这些数据而不会直接信任用户空间的数据。
最后,通过执行exec系统调用,init程序成功启动。
总结,当用户程序执行ECALL指令时,内核会通过syscall函数处理这个系统调用请求:
- 用户程序调用
exec:用户程序通过ECALL指令将系统调用编号(在这里是exec系统调用的编号7)传递给内核。 - 内核进入
syscall函数:内核通过p->trapframe->a7读取系统调用编号,并识别出这是一个exec调用。 - 调用系统调用处理函数:
syscall函数根据编号找到对应的处理函数,在这个例子中是sys_exec。 - 执行
sys_exec:内核在sys_exec中,从用户空间读取传递的参数(例如要执行的程序路径init),并在内核空间执行相应的exec逻辑,启动新的程序。
6. init 程序与 Shell 的启动
当exec系统调用成功执行后,XV6内核会加载并启动init程序。init程序的主要任务是设置好用户空间的环境,并启动第一个Shell进程。
// init.c
// init: The initial user-level program
#include "kernel/types.h" // 包含通用的类型定义,例如int, uint等
#include "kernel/stat.h" // 包含文件状态的相关定义和函数
#include "kernel/spinlock.h" // 包含自旋锁的定义,用于多核处理器上的同步
#include "kernel/sleeplock.h" // 包含睡眠锁的定义,用于进程间的同步
#include "kernel/fs.h" // 包含文件系统相关的定义
#include "kernel/file.h" // 包含文件操作相关的定义和函数
#include "user/user.h" // 包含用户空间程序使用的系统调用和库函数
#include "kernel/fcntl.h" // 包含文件控制相关的定义和函数
// 定义argv数组,用于存储传递给sh(shell)程序的参数
char *argv[] = { "sh", 0 };
int
main(void)
{
int pid, wpid;
// 尝试打开console设备,O_RDWR表示以读写模式打开
if(open("console", O_RDWR) < 0){
// 如果打开失败,可能是console设备文件不存在
// 使用mknod创建一个名为"console"的设备节点,类型为CONSOLE
mknod("console", CONSOLE, 0);
// 再次尝试打开console设备
open("console", O_RDWR);
}
// 将文件描述符0(stdin)复制到1(stdout)
dup(0); // 这样stdout也指向console
// 将文件描述符0(stdin)复制到2(stderr)
dup(0); // 这样stderr也指向console
for(;;){
// 输出提示信息,表示init即将启动shell
printf("init: starting sh\n");
// 创建一个子进程
pid = fork();
if(pid < 0){
// 如果fork失败,输出错误信息并退出
printf("init: fork failed\n");
exit(1);
}
if(pid == 0){
// 在子进程中执行sh(shell)程序
exec("sh", argv);
// 如果exec失败,输出错误信息并退出
printf("init: exec sh failed\n");
exit(1);
}
for(;;){
// 等待子进程结束,wait函数返回子进程的pid,或者在出现错误时返回-1
wpid = wait((int *) 0);
if(wpid == pid){
// 如果返回的pid与子进程的pid相同,说明shell退出了,重新启动它
break;
} else if(wp
- 头文件的包含:
init.c需要使用各种内核定义的结构和函数,包括类型定义、文件操作、同步机制等,因此它包含了多个内核头文件以及用户空间的系统调用定义。
- 文件描述符的设置:
- 代码首先尝试打开
console设备。如果console设备不存在,mknod会创建它。这是XV6确保控制台输入输出正确配置的步骤。 - 使用
dup函数将文件描述符0(标准输入)复制到文件描述符1(标准输出)和文件描述符2(标准错误输出),使得所有输入输出都通过控制台进行。这是用户空间程序与内核进行输入输出交互的基础。
- 代码首先尝试打开
- 创建子进程并启动Shell:
init程序进入一个无限循环,每次循环都会创建一个新的子进程,并在子进程中执行sh(XV6的Shell)。fork函数创建一个子进程,返回值pid表示子进程的PID。如果pid为0,表示当前进程是子进程,此时通过exec系统调用执行sh程序。- 如果
exec成功,子进程的内存空间会被sh程序替换,继续执行sh代码。如果exec失败,输出错误信息并退出子进程。
- 等待子进程结束:
- 父进程调用
wait函数等待子进程结束。如果Shell退出,wait返回的PID会与子进程的PID相同,表示需要重新启动Shell。 - 如果
wait返回-1,说明出现错误,init程序会输出错误信息并退出。
- 父进程调用
init.c是XV6中第一个用户空间程序,负责配置控制台、启动Shell,并确保Shell在退出时能够被重新启动。这个程序是XV6操作系统运行的基础,提供了与用户交互的接口。通过这个简单但重要的程序,XV6能够在用户空间中启动并管理其他进程,维持系统的正常运行。
总结,init程序的启动过程如下:
- 配置控制台:进一步为用户态的环境准备控制台(console),确保用户可以通过Shell与操作系统交互。
- 调用
fork:init程序创建一个子进程,这个子进程将用于运行Shell。 - 在子进程中调用
exec:子进程中通过exec系统调用启动Shell进程。
在XV6的Shell启动后,用户就可以通过Shell与操作系统交互了。这意味着操作系统从启动到可以接受用户命令的完整过程已经完成。
这个流程完整地展示了XV6操作系统从内核编译、启动,到第一个用户进程启动的全过程。通过理解这些步骤,我们可以深入掌握操作系统的工作原理,特别是XV6的架构和初始化过程。这一系列操作确保了操作系统能够成功启动,并为用户提供一个稳定的交互环境。
1. 关于“
init程序进入一个无限循环,每次循环都会创建一个新的子进程,并在子进程中执行sh(XV6的Shell)”
init程序进入一个无限循环的设计,是为了确保操作系统始终有一个Shell进程在运行。这是XV6操作系统在用户空间中管理和维护Shell进程的一种机制。无限循环的目的
在操作系统中,Shell是用户与系统交互的主要界面。用户通过Shell输入命令,Shell解释并执行这些命令。然而,Shell进程并不是永远不退出的。用户可以通过输入
exit命令或其他方式终止Shell进程。为了确保Shell总是可用,init程序采用了一种守护进程的角色,通过无限循环不断地监视Shell进程的状态,并在必要时重新启动它。无限循环的工作机制
- 创建子进程:
- 在每次循环中,
init程序会调用fork()函数创建一个新的子进程。fork()函数会复制当前进程(即init进程),生成一个新的进程。子进程的PID(进程标识符)在子进程中为0,在父进程中为子进程的PID。- 在子进程中执行Shell:
- 当
fork()成功创建子进程后,程序会判断pid的值。如果pid为0,说明当前是子进程。子进程继承了父进程的资源,但此时它需要执行一个新的任务,即启动Shell。- 子进程通过调用
exec("sh", argv)来替换自己当前的代码和数据,执行sh(Shell)程序。exec()函数会加载并执行Shell的二进制文件,从而将子进程变成一个Shell进程。- 监视子进程:
init程序(此时作为父进程)在创建子进程后,会调用wait()函数等待子进程的状态变化。wait()函数会阻塞父进程,直到有子进程结束。此时,wait()返回结束的子进程的PID。- 如果
wait()返回的PID与之前创建的子进程的PID相同,说明这个Shell进程已经退出(例如,用户输入了exit命令)。init程序会跳出内层的for循环,重新进入外层的无限循环,从而再次启动一个新的Shell进程。为什么需要重新启动Shell?
持续交互:Shell是用户与系统交互的主要工具。当Shell进程退出时,用户将无法再通过终端与系统交互。为了确保系统的可用性,
init必须在Shell退出后自动重新启动它。简化管理:通过这种方式,XV6不需要额外的机制来检测和处理Shell进程的退出。
init程序通过简单的无限循环和子进程管理逻辑,保证了Shell的持续可用性。这种设计既简洁又有效。
init程序的无限循环确保了Shell的持久性和系统的可用性。每当Shell进程退出时,init程序会立即创建一个新的子进程并执行Shell,使用户能够持续与操作系统交互。这种设计模式是操作系统中守护进程的一种常见实现方式,能够有效地维持关键服务的运行。2. 关于“允许用户退出Shell并自动启动新的Shell进程”
让用户能够退出Shell并不是操作系统设计中的缺陷,而是出于灵活性和用户体验的考虑。允许用户退出Shell再重新启动新的Shell进程,有几个重要的原因和设计考量:
1. 用户的自由和灵活性
操作系统的设计应该尽可能地赋予用户控制权,而不是强制用户保持在某个特定的状态中。允许用户退出Shell后再自动重启,给了用户一个退出当前Shell会话的选择,而不至于让他们感到被困在一个不可退出的环境中。
2. 释放资源
当用户退出Shell进程时,系统可以释放与该进程相关的所有资源(如内存、文件描述符等)。如果Shell无法退出,那么这些资源将一直被占用。允许退出并重新启动Shell,保证了资源的合理使用和释放,有助于保持系统的稳定性和高效性。
3. 清除环境
每次重新启动Shell,都可以提供一个全新的、干净的环境。用户可能在某个Shell会话中进行了各种操作,修改了环境变量、创建了临时文件等。当用户退出并重新启动Shell时,系统会回到默认状态,这样可以避免之前操作对新会话的影响。
4. 简化错误处理
如果Shell中发生了错误或者用户进入了某种不可恢复的状态(如进入了死循环或者Shell程序本身崩溃),退出Shell并重新启动是一个简单而有效的恢复手段。这样,系统不需要复杂的错误处理机制来应对各种可能的Shell错误或意外情况。
5. 保持系统的一致性
通过允许退出和重新启动Shell,可以保持系统的一致性。例如,在用户更改了某些系统配置后,重启Shell可以确保这些更改生效,而不需要手动重新加载配置或重新初始化环境。
6. 多用户和多任务的支持
在多用户系统中,不同用户可能会在同一台机器上启动不同的Shell会话。当一个用户退出自己的Shell时,系统并不会强制关闭其他用户的Shell。相反,系统会在该用户的环境中启动新的Shell,从而支持多用户并行操作。
允许用户退出Shell并不是为了增加复杂性,而是为了赋予用户更多的控制权,确保资源的合理管理,并提供一种简单有效的错误恢复机制。这种设计考虑到了用户体验、系统资源管理和错误处理的需求,是一个兼顾灵活性和稳定性的设计决策。