Lecture 8 - Page Faults
Page Fault 与虚拟内存功能
今天的课程主要讨论 Page Fault 及其相关的虚拟内存功能。这些功能在现代操作系统中非常重要,典型的功能包括:
- Lazy Allocation(惰性分配):下一个实验室的内容。
- Copy-On-Write Fork(写时复制的 Fork)。
- Demand Paging(按需分页)。
- Memory Mapped Files(内存映射文件)。
这些功能几乎在所有现代操作系统中都得到了实现,比如 Linux 就实现了所有这些功能。然而,在 XV6 中,出于简化的目的,这些功能并未实现。XV6 中的 Page Fault 处理方式非常保守:一旦用户空间进程触发 Page Fault,系统会直接杀掉该进程。
在今天的课程中,我们将探讨在 Page Fault 发生时,操作系统可以采取的一些更有趣的处理方式。虽然我们不会深入分析代码,但会重点讨论这些机制的设计理念,因为 XV6 并未实现这些功能。特别是,我们将看到如何利用 Page Fault 来实现一些复杂的虚拟内存管理功能,这也是后续实验的重点内容。下一个实验 Lazy Lab 将会发布,之后的实验中还会涉及 Copy-On-Write Fork 和 Memory Mapped Files 这些主题。它们都是操作系统中非常有趣和复杂的部分。
虚拟内存的基础
在深入探讨 Page Fault 的具体功能之前,我们首先回顾一下虚拟内存的基本概念。虚拟内存有两个主要的优点:
-
隔离性(Isolation):虚拟内存使得操作系统可以为每个应用程序提供独立的地址空间。这样,一个应用程序无论是有意还是无意,都无法修改另一个应用程序的内存数据。此外,虚拟内存还实现了用户空间与内核空间的隔离。我们在前面的课程中已经讨论过很多关于虚拟内存隔离的内容,并且通过之前的 Page Table 实验,大家也应该对虚拟内存的隔离性有了更深的理解。
-
抽象层(Level of Indirection):虚拟内存为处理器和所有的指令提供了一层抽象,使得这些指令只需处理虚拟地址,内核则负责将虚拟地址映射到物理地址。这种抽象使得许多高级的内存管理功能成为可能。在目前为止介绍的 XV6 中,内存地址映射基本上是静态的,一旦在初始化时设置好,无论是用户页表还是内核页表,通常都不会再发生变化。
动态内存映射与 Page Fault
Page Fault 的出现使得地址映射关系可以动态变化。通过 Page Fault,内核有机会在程序访问内存时动态更新 Page Table,从而实现灵活的内存管理。这一机制为操作系统提供了巨大的灵活性,并支持一些复杂且有趣的功能。
- 内核映射的示例:尽管 XV6 的内存映射通常是静态的,但它也包含了一些动态映射的例子。例如:
- Trampoline Page:内核可以将同一个物理内存页映射到多个用户地址空间中,实现内核代码的高效调用。
- Guard Page:在用户空间和内核空间中,Guard Page 保护栈免受溢出或错误访问的影响。
- Page Fault 的潜力:在传统的静态映射中,内核只需在启动时设定好页表即可,而 Page Fault 机制让内核能够在运行时动态调整这些映射。例如,当程序访问尚未映射的虚拟地址时,触发 Page Fault,内核可以选择在此时分配物理内存并更新页表。这种动态调整的能力使得实现 Lazy Allocation、Copy-On-Write Fork、Demand Paging 等高级功能成为可能。
通过这节课的内容,大家将对 Page Fault 及其带来的动态内存管理功能有更深的理解,这些内容也将为接下来的实验和实际操作打下坚实的基础。
Page Fault 处理所需的关键信息
在处理 Page Fault 之前,首先需要明确的是,当 Page Fault 发生时,操作系统需要掌握哪些关键信息才能做出正确的响应。
1. 出错的虚拟地址
最明显的一个信息是导致 Page Fault 的虚拟地址,即触发错误的内存地址。当一个用户进程访问了一个未被映射的虚拟地址时,会触发 Page Fault。这个出错的地址会被自动存储在 RISC-V 架构的 STVAL 寄存器中。因此,操作系统可以从 STVAL 寄存器中读取这个出错的地址,以确定哪个内存访问导致了错误。
- STVAL 寄存器:这是一个专门用于存储导致 Page Fault 的虚拟地址的寄存器。当 Page Fault 发生时,系统会将出错的地址存储在
STVAL中。这是处理 Page Fault 时首先需要获取的信息。
2. 出错的原因
了解触发 Page Fault 的原因也非常重要。Page Fault 可能是由于不同类型的内存操作引起的,例如:
- 加载操作(Load):例如,程序尝试从一个未映射的地址读取数据。
- 存储操作(Store):例如,程序尝试向一个未映射的地址写入数据。
- 指令取值操作(Instruction Fetch):例如,程序试图执行存储在一个未映射地址的指令。
RISC-V 的 SCAUSE 寄存器可以存储触发异常的具体原因。不同的异常原因会在 SCAUSE 中有不同的编码,例如:
- 13:表示是由于加载操作引起的 Page Fault。
- 15:表示是由于存储操作引起的 Page Fault。
-
12:表示是由于指令取值操作引起的 Page Fault。
- SCAUSE 寄存器:这个寄存器用于存储导致进入 supervisor mode 的原因。当出现 Page Fault 时,
SCAUSE寄存器会保存具体的错误类型,这对于操作系统决定如何处理这个 Page Fault 至关重要。
3. 触发 Page Fault 的指令地址
除了出错的地址和原因外,还需要知道引起 Page Fault 的指令的地址。RISC-V 架构通过 SEPC 寄存器来存储触发异常的指令的地址。这一点非常重要,因为在修复 Page Fault 后,系统需要重新执行这条指令。这个指令地址也会保存在 XV6 的 trapframe->epc 中,以便稍后恢复执行。
- SEPC 寄存器:
SEPC寄存器保存了发生异常的指令地址,这使得操作系统能够在处理完 Page Fault 后,从引发错误的地方继续执行程序。
Page Fault 处理的关键流程
通过以上三个关键信息,当发生 Page Fault 时,操作系统可以有效地处理错误,并在必要时更新 Page Table 以修复错误。
-
获取虚拟地址:从
STVAL寄存器中读取出错的虚拟地址。这是最基础的操作,操作系统需要知道具体哪个地址导致了错误。 -
确定出错原因:检查
SCAUSE寄存器,确定是由于加载、存储还是指令取值引发的 Page Fault。这一步有助于操作系统采取不同的策略进行处理。 -
获取触发指令的地址:通过
SEPC寄存器获取引发错误的指令地址。这使得在修复 Page Table 后,能够重新执行这条指令,确保程序继续正常运行。
理想情况下,当操作系统处理完 Page Fault 并修复 Page Table 后,可以恢复被中断的指令继续执行。这样,程序不会因为 Page Fault 而崩溃,而是能继续按预期运行。接下来,我们将深入探讨如何利用 Page Fault Handler 来动态修复 Page Table 并实现一些复杂的内存管理功能,例如惰性分配、写时复制等。
内存分配与 sbrk 系统调用
在操作系统中,内存的分配是一个关键的操作。sbrk 是 XV6 提供的一个系统调用,用于扩展用户程序的堆(heap)。当一个应用程序启动时,堆的初始位置由 p->sz 表示,即堆的底端,同时也是堆的起始位置。
1. sbrk 的工作机制
sbrk 接受一个整数参数,表示要扩展的字节数。调用 sbrk 后,堆的上边界将被扩大,即 p->sz 的值增加。
- 堆扩展:
sbrk通过调整p->sz的值来扩展堆。这意味着应用程序可以多次调用sbrk以获得更多的内存。 - 堆缩减:相反,传入负数参数时,
sbrk将缩小堆的边界。不过,本次讨论主要集中在内存的扩展上。
在 XV6 的默认实现中,sbrk 使用的是 eager allocation,即一旦调用 sbrk,内核就会立即分配相应的物理内存,并将其映射到用户程序的地址空间中。这种方式虽然简单直接,但会导致过度的内存分配,因为应用程序通常无法精确预估所需的内存量,往往会申请比实际需要更多的内存。
2. Lazy Allocation:更聪明的内存分配策略
为了优化内存的使用,可以采用 lazy allocation 策略。其核心思想是在 sbrk 调用时,仅调整 p->sz,而不立即分配物理内存。实际的内存分配推迟到应用程序真正访问这部分内存时才进行。
-
内存分配时机:当应用程序访问尚未实际分配的内存时(地址在
p->sz范围内,同时大于stack的合法地址中),会触发一个 Page Fault。在 Page Fault 处理程序中,内核通过kalloc分配物理内存,将其映射到用户的页表中,并将内容初始化为 0,然后重新执行导致 Page Fault 的指令。这种方式可以显著减少不必要的内存占用,特别是在程序申请了大量未使用的内存时。 -
例外处理:如果内核在分配物理内存时发现系统已经没有可用内存,则可以选择杀掉进程并返回错误,这种方式称为 OOM(Out Of Memory)处理。
在处理 Page Fault 时,内核需要根据触发 Page Fault 的虚拟地址判断其所属的内存区域,如果属于合法的堆区域,则分配物理内存,否则就认为是非法访问并杀掉进程。
3. 关于 OOM 处理的讨论
在采用 Lazy Allocation 策略时,如果系统内存不足,内核可以选择杀掉进程。这种方法虽然简单,但不够灵活。实际操作系统可能会采取更为智能的措施,例如尝试释放缓存或交换空间以获取更多内存,但如果最终无法满足需求,仍然可能会杀掉占用过多资源的进程。
一些学生可能会问,为什么操作系统不能简单地返回一个错误,而不是直接杀掉进程?这涉及到操作系统的设计哲学和复杂性管理。在实际系统中,有时杀掉进程是最直接和有效的处理方式,特别是在资源耗尽的极端情况下。尽管如此,实际操作系统通常会有更多的机制来延迟或避免 OOM 情况的发生。
通过 Lazy Allocation,我们可以实现更加智能的内存管理,减少不必要的内存浪费。这一机制虽然在 XV6 中没有直接实现,但它展示了如何通过 Page Fault 机制动态管理内存的可能性。这为后续的实验,如 Lazy Allocation Lab、Copy-On-Write Fork 和 Memory Mapped Files,奠定了基础,帮助我们理解操作系统如何更高效地管理资源。
以下是关于
sbrk和 Lazy Allocation 的简单框图,描述了它们的工作流程:+-----------------+ 调用 sbrk(n) +-----------------+ | User Process | -------------------> | Kernel | +-----------------+ +-----------------+ | | | | V V +-----------------+ 调整 p->sz +-----------------+ | p->sz += n | -------------------> | 不分配物理内存 | +-----------------+ +-----------------+ | | | | V V +-----------------+ +-----------------+ | 继续执行代码 | | 等待实际访问内存 | +-----------------+ +-----------------+ | | | | V V +-----------------+ 访问未分配内存 +-----------------+ | Page Fault 发生 | -------------------> |分配物理内存,并映射 | +-----------------+ 触发Page Fault +-----------------+ | | | | V V +-----------------+ +-----------------+ | 重新执行访问指令 | | 内存访问成功 | +-----------------+ +-----------------+在 Lazy Allocation 策略中,
sbrk调用时仅调整p->sz,而不立即分配物理内存。这个过程可以解释为以下几个关键点:
- 调整
p->sz是什么操作?
- 调整
p->sz的意思是修改进程控制块(PCB)中的一个字段p->sz,使其值增加指定的字节数n。p->sz代表当前进程的虚拟地址空间的顶部(即堆的末端)。- 这个操作只是更新 PCB 中的一个变量,而不是立即在内存中执行任何物理操作。因此,内核并不会立即为这个新增加的地址空间分配实际的物理内存。
- 内存分配的时机
- 实际的内存分配被推迟到应用程序访问新分配的地址空间时。这意味着当程序访问这些尚未分配物理内存的虚拟地址时,会触发一个 Page Fault。
- 在 Page Fault 发生时,内核会捕捉到这个异常,识别出该地址属于已分配的虚拟空间但尚未映射的部分,然后在这个时候内核才会实际分配物理内存,并更新页表。
p->sz是否可以超过实际堆的最大大小?
- 理论上,
p->sz可以调整到超过当前分配的实际物理内存的大小。因为 Lazy Allocation 的设计初衷就是允许这种“超前”分配,以便在未来需要时才实际分配物理资源。- 但是,
p->sz的增加必须在操作系统允许的虚拟地址空间范围内。如果超过了进程的最大虚拟地址空间,内核将会拒绝这种分配请求。- 这种机制与立即分配物理内存的区别在于,Lazy Allocation 不会占用过多的物理内存资源,直到程序实际使用这些内存。它在内存管理上提供了更高的效率和灵活性。
- 为什么 Lazy Allocation 更加高效?
- 在实际应用中,程序往往会预分配大量的内存以防万一,但这部分内存可能永远不会被实际使用。如果采用 eager allocation,这些内存就会被立即分配,从而浪费物理内存资源。
- Lazy Allocation 则允许程序在需要时动态分配内存,这不仅节省了物理内存资源,还降低了由于过度分配导致的内存碎片问题。
Lazy Allocation 实现探讨
接下来我们将通过修改 sys_sbrk 函数来实现 Lazy Allocation,并观察它在 XV6 中的效果。
原始代码分析
// kernel/sysproc.c
uint64 sys_sbrk(void)
{
int addr;
int n;
if(argint(0, &n) < 0)
return -1;
addr = myproc()->sz;
if(growproc(n) < 0)
return -1;
return addr;
}
在原始代码中:
- 参数解析:
argint(0, &n)从系统调用的参数中获取一个整数n,表示要扩展的内存大小(以字节为单位)。如果获取失败,则返回-1表示错误。 - 获取当前内存大小:
addr = myproc()->sz记录当前进程的内存大小sz。sz是进程的堆顶地址,表示进程当前已分配的内存大小。 - 内存扩展:调用
growproc(n)函数来扩展当前进程的内存空间。growproc(n)会实际分配物理内存,并将这部分内存映射到进程的地址空间。如果内存分配失败,返回-1表示错误。 - 返回值:如果内存扩展成功,则返回原始堆顶地址
addr,表示分配成功。
sys_sbrk 函数负责实际增加应用程序的地址空间,分配内存等相关操作。原本的实现中,它会立即分配所需的物理内存。但在 Lazy Allocation 的思想下,我们希望推迟这种内存分配,仅在进程真正访问这些内存时才进行分配。
修改后的代码分析
uint64 sys_sbrk(void)
{
int addr;
int n;
if(argint(0, &n) < 0)
return -1;
addr = myproc()->sz;
myproc()->sz = myproc()->sz + n;
// if(growproc(n) < 0)
// return -1;
return addr;
}
在修改后的代码中:
- 参数解析:与原始代码相同,通过
argint(0, &n)获取扩展的内存大小n。 - 获取当前内存大小:与原始代码相同,通过
addr = myproc()->sz获取当前进程的内存大小sz。 - 调整进程的内存大小:
myproc()->sz = myproc()->sz + n直接修改sz,增加n字节的空间。这一步只是在进程控制块(PCB)中记录了一个新的堆顶地址,但并没有实际分配物理内存。 - 注释掉内存扩展:原始代码中的
growproc(n)被注释掉了,也就是说,这里并没有进行实际的内存分配。 - 返回值:依然返回原始的堆顶地址
addr,与原始代码一致。
运行 XV6 并观察 Page Fault
在启动 XV6 并执行命令 echo hi 后,会引发一个 Page Fault。这发生在 Shell 中 fork 了一个子进程,然后该子进程通过 exec 执行 echo 程序。在这个过程中,Shell 试图申请一些内存,因此调用了我们修改过的 sys_sbrk 函数。然而,由于我们没有实际分配物理内存,当 Shell 尝试访问这块新“分配”的内存时,触发了 Page Fault。
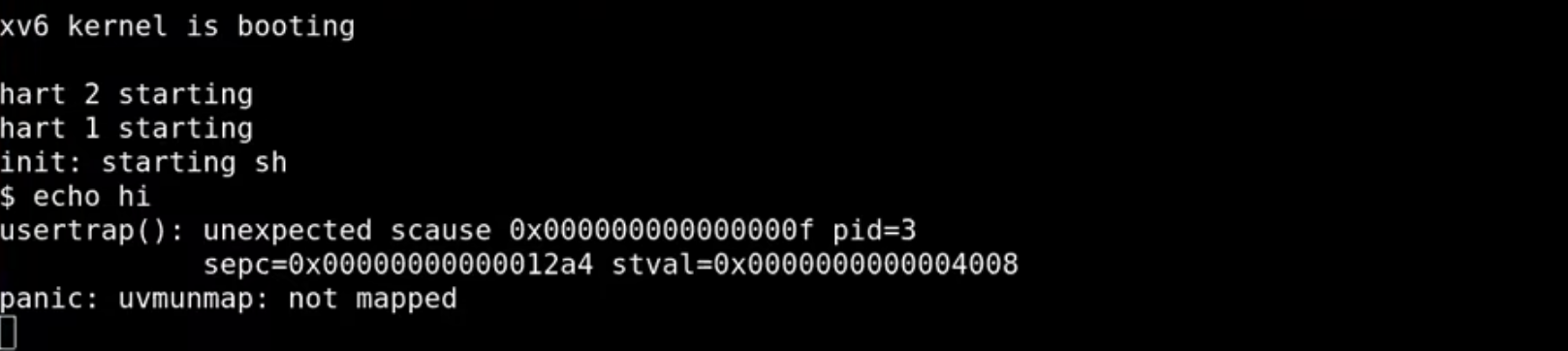
观察 XV6 输出的调试信息,可以帮助我们理解 Page Fault 的原因:
SCAUSE寄存器:其值为15,表示这是一个 Store Page Fault。- 进程的 PID:显示
3,可能是Shell的 PID。 SEPC寄存器:显示0x12a4,指向引发Page Fault的指令地址。- 出错的虚拟地址:
STVAL寄存器的值为0x4008,这是引发Page Fault的具体地址。
分析引发 Page Fault 的代码
通过查看 Shell 的汇编代码,我们可以定位到触发 Page Fault 的具体指令,并进一步分析原因。在这个例子中,Page Fault 发生在 malloc 的实现中,这是因为 malloc 函数试图向未被分配的内存写入数据。
void*
malloc(uint nbytes)
{
11f8: 7139 addi sp,sp,-64
11fa: fc06 sd ra,56(sp)
11fc: f822 sd s0,48(sp)
11fe: f426 sd s1,40(sp)
...
129e: 6398 ld a4,0(a5)
12a0: e118 sd a4,0(a0)
12a2: bff1 j 127e <malloc+0x86>
hp->s.size = nu;
12a4: 01652423 sw s6,8(a0)
free((void*)(hp + 1));
12a8: 0541 addi a0,a0,16
...
当执行 malloc 时,程序会调用 sbrk 来扩展堆空间。然而,修改后的 sys_sbrk 仅调整了 p->sz,而没有实际分配物理内存。当 malloc 尝试访问这块地址时,发现该地址并没有映射到物理内存,于是引发了 Page Fault。
另一个可以证明内存尚未被分配的地方是,在 xv6 中 Shell 程序的典型布局是由 4 个页(page)组成的,包括代码段(text)和数据段(data)。根据汇编代码,a0 寄存器持有的是 0x4000 地址,而偏移量为 8。这意味着程序试图访问的是 0x4000 + 0x8 = 0x4008 这个地址,而这个地址位于 Shell 程序的前 4 个页之外。因为这块区域尚未被 sbrk 真正映射到物理内存上,所以尝试访问该地址时会触发 page fault。
引发了 Page Fault 后,操作系统可以在 Page Fault 处理程序中为该地址分配物理内存,并将其映射到进程的地址空间中,然后重新执行导致 Page Fault 的指令。这样就可以实现 Lazy Allocation 的机制——内存的实际分配推迟到真正需要的时候,从而有效地利用系统资源。
12a4: sw s6,8(a0)这条指令的作用是将寄存器
s6中的值存储到内存地址a0 + 8处。这正是malloc函数中尝试将新分配的内存的大小写入到Header结构的size字段中。在此指令之前,
a0寄存器中存储的是p,即由sbrk函数返回的地址。如果sbrk调用返回了一个尚未实际分配的内存地址(由于我们修改了sys_sbrk,它不会立即分配物理内存),那么当malloc尝试在a0 + 8处写入数据时,就会导致Page Fault,因为这部分内存实际上还没有映射到任何物理内存。
Header
Header是在实现malloc(内存分配函数)时,用来管理已分配内存块的一种常见的数据结构。它通常包含了与内存块相关的元数据,如内存块的大小、下一个内存块的指针等。在动态内存分配中,Header结构体被用于链接已分配的内存块和空闲的内存块,形成一个链表,方便内存的管理和回收。
Header的作用
- 表示内存块的元数据:
Header结构体保存了内存块的大小信息,通常还包括一个指向下一个块的指针,以形成一个链表结构。- 管理空闲链表:
malloc函数在分配内存时,使用Header结构体来管理可用的空闲内存块。通过检查Header中的size字段,malloc可以找到合适大小的空闲块,进行分配。- 合并空闲块:在
free函数中,释放内存后,通过Header中的链表结构,可以尝试合并相邻的空闲内存块,以减少内存碎片。
Header的结构虽然不同的实现细节可能会有所不同,但典型的
Header结构体可能像这样:typedef struct Header { struct Header *next; // 指向下一个空闲块的指针 unsigned int size; // 当前块的大小(以字节或某种单位表示) } Header;
next:指向下一个空闲内存块的指针,形成一个链表。size:当前内存块的大小,用于判断是否能够满足分配请求。在
malloc的实现中,Header通常位于每个已分配或空闲的内存块的起始位置,这样malloc和free函数可以通过这个结构来管理内存。具体到
malloc的实现在本节内容中:
- 当
malloc调用sbrk请求内存时,它会返回一个指向新分配内存块的指针,通常这个指针指向新块的起始地址,而这个地址紧跟着的是一个Header结构。Header的size字段记录了这个内存块的大小。在你的代码中,指令sw s6, 8(a0)是试图在Header结构体中的size字段写入内存块的大小信息。通过使用
Header结构,malloc和free函数可以有效地管理堆内存,跟踪哪些内存已经分配,哪些内存可以再次分配。这也是为什么malloc中的12a4地址是sw指令的原因,因为它试图写入这个元数据。xv6 中的
Header
header是在 xv6 的内存分配器中使用的一个重要结构体。这个分配器的设计基于 Kernighan 和 Ritchie 在《The C Programming Language》第二版第 8.7 节中描述的内存分配器。// user/umalloc.c ... // Memory allocator by Kernighan and Ritchie, // The C programming Language, 2nd ed. Section 8.7. typedef long Align; union header { struct { union header *ptr; uint size; } s; Align x; }; typedef union header Header; static Header base; static Header *freep; void free(void *ap) ... void* malloc(uint nbytes) ...代码解释
1.
Align和Headertypedef long Align;
Align是用来强制header对齐的。内存块的开始位置通常需要对齐到某个特定的字节边界(比如 4 字节或 8 字节),以满足硬件架构对内存访问的要求。Align的大小一般和系统的最大对齐要求一致。2.
union headerunion header { struct { union header *ptr; uint size; } s; Align x; };
union header是一个联合体,包含两个成员:
s:这是一个结构体,包含两个字段:
ptr:指向下一个空闲块的指针。这使得空闲块形成一个链表,便于内存管理。size:当前内存块的大小,单位通常是Header的数量,而不是字节数。x:用于确保header的大小和对齐满足Align的要求。这个字段没有实际的功能,仅用于保证header的内存对齐。3.
typedef union header Headertypedef union header Header;将
union header定义为Header类型,以便在代码中更简洁地引用它。4.
static Header base和static Header *freepstatic Header base; static Header *freep;
base:这是一个静态的Header变量,通常用于初始化空闲块链表。它充当了链表的一个哨兵节点或起始节点。这个节点不会被实际使用,但它为空闲块链表提供了一个固定的起点。
freep:这是指向空闲链表中第一个块的指针。当程序首次调用malloc或free函数时,freep会指向base,然后在分配和释放内存时动态更新。这个内存分配器基于空闲链表管理内存。
Header结构体用来表示每个内存块的元数据(包括大小和下一个块的指针),通过将空闲块链接成链表,内存管理器可以高效地分配和释放内存。在释放内存时,通过合并相邻的空闲块,可以减少内存碎片,提高内存利用率。
处理 Page Fault
在操作系统的设计中,智能处理 Page Fault 可以显著提升内存管理的效率。下面我们简单分析如何通过 XV6 的代码来实现这一点,特别是在 usertrap 函数中进行的修改。在 lazy lab 中还需要完成更多的工作。
检查 Page Fault 的原因
// kernel/trap.c
...
// handle an interrupt, exception, or system call from user space.
// called from trampoline.S
//
void
usertrap(void)
{
int which_dev = 0;
if((r_sstatus() & SSTATUS_SPP) != 0)
panic("usertrap: not from user mode");
// send interrupts and exceptions to kerneltrap(),
// since we're now in the kernel.
w_stvec((uint64)kernelvec);
struct proc *p = myproc();
// save user program counter.
p->trapframe->epc = r_sepc();
if(r_scause() == 8){
// system call
if(killed(p))
exit(-1);
// sepc points to the ecall instruction,
// but we want to return to the next instruction.
p->trapframe->epc += 4;
// an interrupt will change sepc, scause, and sstatus,
// so enable only now that we're done with those registers.
intr_on();
syscall();
} else if((which_dev = devintr()) != 0){
// ok
} else {
printf("usertrap(): unexpected scause 0x%lx pid=%d\n", r_scause(), p->pid);
printf(" sepc=0x%lx stval=0x%lx\n", r_sepc(), r_stval());
setkilled(p);
}
if(killed(p))
exit(-1);
// give up the CPU if this is a timer interrupt.
if(which_dev == 2)
yield();
usertrapret();
}
...
在 usertrap 函数中,我们首先需要根据 SCAUSE 寄存器的值来判断触发 Page Fault 的原因。在 L06 中,我们遇到的情况有以下几种:
-
普通系统调用:
SCAUSE == 8时,表示这是一个系统调用触发的 Trap。 - 设备中断:如果不是系统调用,我们会检查是否是设备中断,通过
devintr()函数来处理。 - 两个条件都不满足,打印一些信息并杀掉进程。
现在我们需要增加一个情况:
- Page Fault:如果
SCAUSE == 15,表示这是由于 Store 操作引发的 Page Fault。
在处理 Page Fault 时,我们需要首先确认虚拟地址 STVAL 是否在进程的合法地址范围内。一种可能的处理方式是,我们可以检查 p->sz 是否大于 STVAL 中保存的虚拟地址。如果 p->sz 比虚拟地址大,说明这个虚拟地址是在进程的地址空间内,但尚未实际分配物理内存。
Page Fault 的处理流程
这里只以演示为目的简单的处理一下,在 lazy lab 中需要完成更多的工作。
如果确定这是一个合法的 Page Fault,我们需要进行如下操作:
- 调试信息输出:打印当前 Page Fault 的虚拟地址,以便调试和验证。
- 物理内存分配:调用
kalloc()为进程分配一个新的物理页面。如果分配失败(ka == 0),则说明系统内存耗尽,必须杀掉进程。 - 内存初始化:如果分配成功,将物理页面初始化为全零,以确保内存安全和一致性。
- 映射虚拟地址:将物理页面与引发 Page Fault 的虚拟地址关联。为了确保对齐,我们会使用
PGROUNDDOWN(va)将虚拟地址向下对齐到页面边界,然后使用mappages()函数将虚拟地址和物理页面映射到进程的页表中,并设置权限标志位(PTE_W | PTE_U | PTE_R)。
} else if (r_scause() == 15) {
uint64 va = r_stval();
printf("page fault %p\n", va);
uint64 ka = (uint64) kalloc();
if (ka == 0) {
p->killed = 1;
} else {
memset((void *) ka, 0, PGSIZE);
va = PGROUNDDOWN(va);
if (mappages(p->pagetable, va, PGSIZE, ka, PTE_W|PTE_U|PTE_R) != 0) {
kfree((void *)ka);
p->killed = 1;
}
}
}
在这个片段中,如果 r_scause() 为 15,表示这是一个 Page Fault(通常是由于访问未映射的内存地址引发的)。
r_stval()返回引发 Page Fault 的虚拟地址,并将其存储在va变量中。- 打印调试信息,输出引发 Page Fault 的虚拟地址。
- 尝试使用
kalloc()函数分配一个新的物理页面。如果分配失败(返回值为0),则标记当前进程为需要终止 (p->killed = 1)。 - 如果分配成功,将分配的页面初始化为全零 (
memset)。 - 使用
PGROUNDDOWN()函数将虚拟地址va向下取整到页面边界,确保其对齐。 - 尝试将新的物理页面映射到用户空间的虚拟地址。如果
mappages()函数调用失败,释放刚才分配的物理页面,并标记当前进程为需要终止。
出现双重 Page Fault 的问题

再次执行echo hi并没有正常工作。在处理完一个 Page Fault 后,我们遇到另一个 Page Fault。在图中,第二个 Page Fault 地址为 0x13f48,uvmunmap在报错。这是因为未分配的虚拟地址空间尝试被释放,即使这些地址空间还没有对应的物理内存。通常,uvmunmap 函数会尝试解除这些映射,这时会检测到没有物理页面对应的情况,而产生错误信息。
解决这一问题需要在代码中进行进一步的检查和验证,确保未分配的内存空间不会被误操作。
处理 uvmunmap 中的 Page
在继续深入讨论 usertrap 的 Page Fault 处理逻辑之前,我们首先需要分析 uvmunmap 函数的 Page Fault 。
// kernel/vm.c
...
// Remove npages of mappings starting from va. va must be
// page-aligned. The mappings must exist.
// Optionally free the physical memory.
void
uvmunmap(pagetable_t pagetable, uint64 va, uint64 npages, int do_free)
{
uint64 a;
pte_t *pte;
if((va % PGSIZE) != 0)
panic("uvmunmap: not aligned");
for(a = va; a < va + npages*PGSIZE; a += PGSIZE){
if((pte = walk(pagetable, a, 0)) == 0)
panic("uvmunmap: walk");
if((*pte & PTE_V) == 0)
panic("uvmunmap: not mapped");
if(PTE_FLAGS(*pte) == PTE_V)
panic("uvmunmap: not a leaf");
if(do_free){
uint64 pa = PTE2PA(*pte);
kfree((void*)pa);
}
*pte = 0;
}
}
...
uvmunmap 函数的修改分析
原始的 uvmunmap 函数在发现某个页表项(PTE)的 V 标志位(表示页面有效)为 0 时,会直接 panic,表示这是一个错误的状态。这样的设计在传统的 XV6 环境中是合理的,因为默认情况下,所有用户进程的内存都应该是映射过的。未映射的内存被访问到会引发错误,因此直接 panic 是一种防御性编程的策略。
if((*pte & PTE_V) == 0)
panic("uvmunmap: not mapped");
然而,随着我们引入 Lazy Allocation 的概念,情况发生了变化。
当启用了 Lazy Allocation 时,用户进程请求的某些内存区域可能已经被记录在进程的 sz(大小)字段中,但并没有实际分配物理内存。这就意味着,有些页表项在逻辑上是属于进程的地址空间的,但因为它们从未被访问过,所以它们没有映射到物理内存。此时,如果 uvmunmap 函数仍然坚持要求所有 PTE 都必须是有效的,那就会导致不必要的 panic。
解决方案是直接跳过这些未映射的页表项,因为这些页表项本来就没有物理内存与之关联,也就不存在实际的内存释放问题。在 Lazy Allocation 中,我们有意让一些内存页面在最初不进行映射,直到真正访问它们时才分配物理内存。因此,跳过这些未映射的页面是合乎逻辑的行为。这正是 continue 语句的作用。
if((*pte & PTE_V) == 0)
continue;
重编译和运行
在做了上述修改后,我们重新编译 XV6,并运行 echo hi 命令。尽管有两个 Page Fault 被触发,但由于我们已经在代码中处理了这些情况,最终程序成功执行了 echo hi,这标志着 Lazy Allocation 的基本框架已经搭建起来了。

随着 Lazy Allocation 的引入,XV6 的内存管理机制变得更加复杂,这对系统的其他部分也提出了更高的要求。特别是我们需要考虑如何在缩小用户进程的地址空间时,安全地处理这些未映射的页面,避免可能出现的内存泄露或其他问题。
通过这些改动,我们已经在 XV6 中实现了一个基础的 Lazy Allocation 机制。这不仅使得内存管理更加高效,而且为后续的实验打下了基础。
基于 Page Fault 和 Page Table 的其他优化
在操作系统设计中,除了之前讨论的 Lazy Allocation,还有其他一些依赖 Page Fault 和 Page Table 实现的有趣优化策略。其中一个简单但非常实用的技术就是按需填充零页(Zero-Fill-on-Demand)。
零填充按需分配(Zero-Fill-on-Demand)
在用户程序的地址空间中,通常会包含以下三个主要区域:
- Text 区域:包含程序的指令。
- Data 区域:存放已初始化的全局变量。
- BSS 区域:包含未被初始化或初始化为零的全局变量或静态变量。
BSS 区域的设计目的是节省内存。例如,如果一个程序声明了一个大数组,并且这个数组的初始值全为零,那么实际的物理内存中并不会预先为这个数组分配空间。相反,只需标记这些内存是零初始化的即可。
通过共享零页节省内存
当操作系统执行 exec 系统调用来加载一个程序时,它会为程序分配地址空间,包括 Text、Data 和 BSS 区域。在传统的物理内存管理中,BSS 区域需要分配大量内存以存储全零的初始值。然而,一个优化策略是将所有初始值为零的页都映射到同一个物理页,这个物理页的内容全部为零。
这种做法的优势在于:
- 节省物理内存:通过让多个虚拟页共享同一个零页,避免了为每个零初始化的页单独分配物理内存。
- 提高程序加载速度:在程序启动时,只需分配和映射一个物理页,其余的工作通过页表的共享机制完成。
写时复制(Copy-On-Write)
这种映射策略有一个前提:这些共享的零页必须是只读的。如果程序试图写入这些页,就会触发 Page Fault。这时,操作系统需要进行以下操作:
- 分配新的物理页:为要写入的页分配一个新的物理页,并将其内容初始化为全零。
- 更新页表:将该页的虚拟地址重新映射到新的物理页,并更新页表项中的权限,使其可读可写。
- 重新执行指令:重新执行引发 Page Fault 的指令,使其在新分配的物理页上完成写操作。
Page Fault 的代价与考虑
通过上述优化,可以显著减少内存使用和提升程序加载速度。但是,这种优化也带来了一个问题:Page Fault 的开销。
每当程序试图写入共享的零页时,都会触发一次 Page Fault。这涉及以下步骤:
- 陷入内核:程序从用户模式切换到内核模式,进入内核的 Trap 处理程序。
- 保存上下文:内核需要保存当前的寄存器状态,以便稍后恢复用户程序的执行。
- 分配内存并更新页表:内核为该页分配新的物理内存,并更新页表映射。
- 恢复执行:处理完成后,内核将控制权交还给用户程序。
与普通的内存访问(如一次简单的内存读取或写入)相比,Page Fault 的处理需要更多的时间。主要原因是:
- 上下文切换的开销:从用户态到内核态的切换需要额外的时间。
- 复杂的内核操作:在处理 Page Fault 时,内核需要执行多次内存操作、页表更新等复杂的工作。
因此,虽然通过共享零页可以显著节省内存,但在程序实际开始写入数据时,系统会因频繁的 Page Fault 而付出额外的开销。
零填充按需分配(Zero-Fill-on-Demand)前后内存分配和页表映射的变化:
1. 页面变化前:传统映射(无共享零页)
在传统映射下,每个虚拟页都被分配了一个独立的物理页。
+-----------------+ +-----------------+ | 虚拟页1 (BSS) | -> | 物理页1 (全0) | +-----------------+ +-----------------+ | 虚拟页2 (BSS) | -> | 物理页2 (全0) | +-----------------+ +-----------------+ | 虚拟页3 (BSS) | -> | 物理页3 (全0) | +-----------------+ +-----------------+每个 BSS 区域的虚拟页都有各自独立的物理页来存储初始化为 0 的数据。这样做虽然简单直观,但会浪费大量物理内存,尤其是当多个虚拟页都需要初始化为全 0 的数据时。
2. 页面变化后:零填充按需分配(Zero-Fill-on-Demand)
在启用了零填充按需分配的情况下,多个虚拟页可以共享一个物理页,直到其中一个虚拟页需要写入数据。
+-----------------+ | 虚拟页1 (BSS) | ------v +-----------------+ +---------------------+ | 虚拟页2 (BSS) | -> | 共享同一个物理页1 (全0)| +-----------------+ +---------------------+ | 虚拟页3 (BSS) | ------^ +-----------------+在这种情况下,所有 BSS 区域的虚拟页在初始时都映射到同一个物理页,这个物理页的内容是全 0。只有当某个虚拟页需要写入数据时,系统才会为它分配新的物理页,并更新页表映射。
写入操作后的变化
假设程序对虚拟页3执行了写操作,导致Page Fault。系统会为虚拟页3分配一个新的物理页,并将其映射到新的物理页上。
+-----------------+ | 虚拟页1 (BSS) | ------v +-----------------+ +---------------------+ | 虚拟页2 (BSS) | -> | 共享同一个物理页1 (全0)| +-----------------+ +---------------------+ | 虚拟页3 (BSS) | -> | 物理页2 (新分配) (全0)| +-----------------+ +---------------------+现在,虚拟页3被映射到一个新的物理页,这个页允许写操作,而其他未修改的虚拟页仍然共享原来的零页。
通过这个策略,系统有效地减少了物理内存的使用,并延迟了内存分配的开销,直到真正需要时才执行。这种机制能够提高内存利用率,特别是在程序刚启动时。
详解 Copy-On-Write Fork (COW Fork)
背景与问题
在类 Unix 系统中,fork() 是一种常用的方法,用于创建一个进程的副本。父进程调用 fork() 后,系统会创建一个几乎完全相同的子进程,子进程继承父进程的内存空间、文件描述符等资源。然而,在很多情况下,比如 Shell 处理一个指令时,它会通过 fork() 创建子进程,然后立即执行 exec() 来运行一个新的程序(如 echo)。这个过程中,fork() 会先复制父进程的整个内存空间,然后 exec() 立刻丢弃这些复制的内存空间,加载新程序的内容。这种操作显得非常浪费,因为复制的内存空间几乎立刻就被废弃了。
Copy-On-Write 优化的基本思想
为了解决上述问题,我们可以使用 Copy-On-Write (COW) 技术。COW 的核心思想是,在 fork() 时,父进程与子进程共享相同的物理内存页,而不是直接复制。这意味着,两个进程的虚拟内存页会指向相同的物理内存页,并且这些页被标记为只读。这种方式避免了不必要的内存复制,从而提高了性能和内存利用效率。
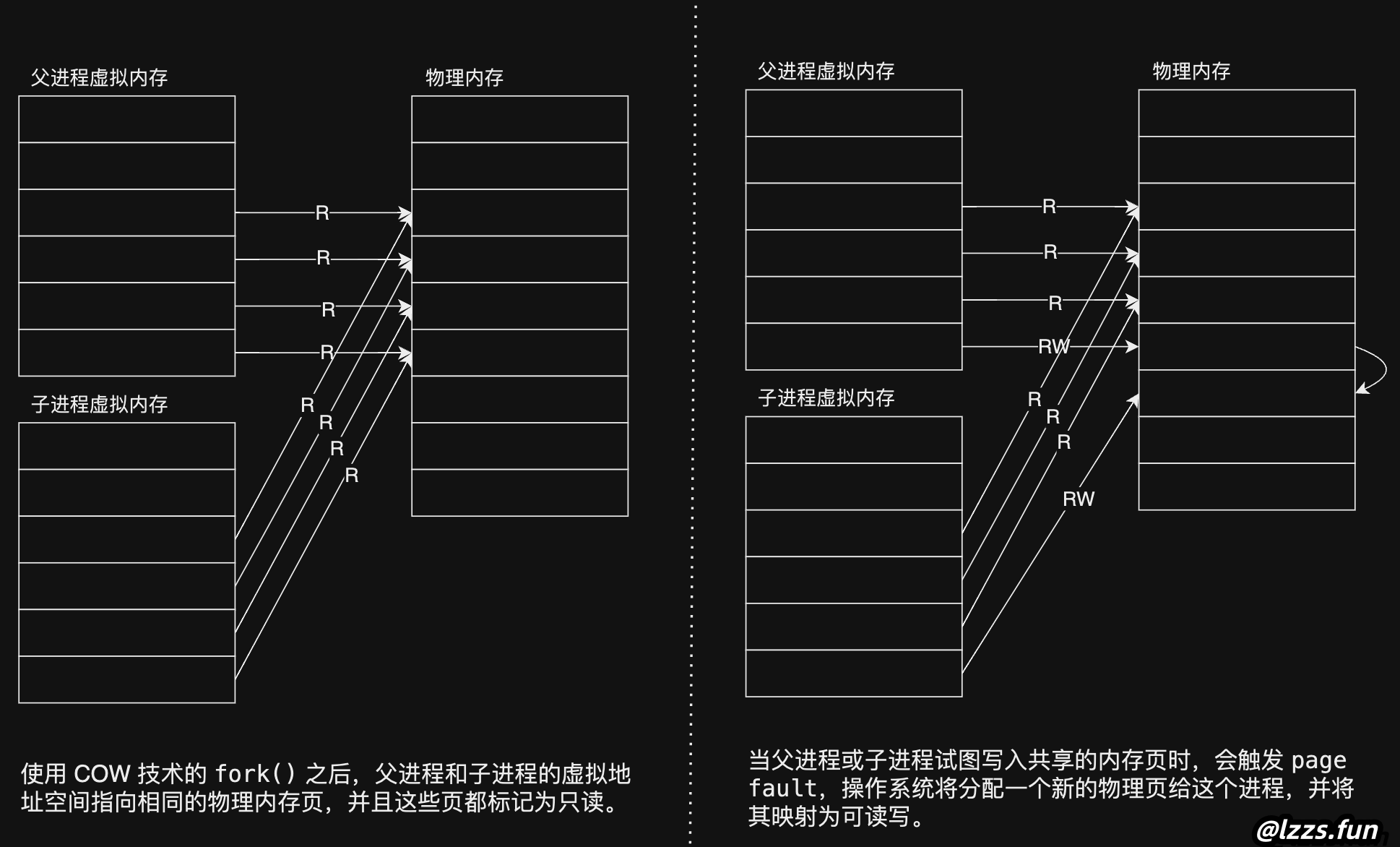
实现流程
-
共享物理页: 在
fork()时,父进程和子进程共享相同的物理内存页。操作系统会将这些页的页表条目 (PTE) 设置为只读模式(将PTE_W位清除)。子进程和父进程的 PTE 都指向同一个物理页,但这个页是只读的。 -
触发 Page Fault: 当子进程或父进程尝试修改这些共享页时,由于页表条目是只读的,因此会触发一个
page fault中断。这时,系统检测到进程试图写入一个只读的页面。 -
复制物理页: 在处理
page fault时,操作系统会执行以下操作:- 分配一个新的物理页。
- 将触发
page fault的共享物理页的内容复制到这个新的物理页中。 - 更新进程的页表条目,将其指向新的物理页,并将其标记为可读写(设置
PTE_W位)。
-
更新 PTE 并恢复执行: 在完成内存页的复制和映射后,系统会重新设置相应进程的页表,将新页标记为可读写。然后,进程会重新执行触发
page fault的指令,这次指令可以正常执行,因为它现在写入的是一个独立的、属于进程自己的物理页。触发刚刚 page fault 的物理页现在变为只对父进程可见,相应的PTE对于父进程也可以变成可读写的了。
优点
- 减少内存消耗: 在许多情况下(如
fork后立即exec),不需要为每个子进程立即复制父进程的所有内存页,极大地减少了内存消耗。 - 提高效率: 减少不必要的内存复制,提高了
fork操作的效率。
注意事项
虽然 COW 优化带来了明显的性能提升,但它也引入了一些复杂性,特别是在处理 page fault 时需要特别小心。例如,当子进程和父进程都需要修改同一个内存页时,如何确保它们的修改互不影响,这是 COW 机制需要特别处理的。
Copy-on-Write 的实现细节及优化
在讨论 Copy-on-Write(COW)机制时,理解内核如何管理和优化物理内存以及虚拟内存是非常重要的。下面,我们将进一步探讨这个过程中的关键概念和可能的实现方式,并结合上一节中的实验和理论进行更深入的讲解。
COW 的实现与优化
当 fork() 被调用时,内核会创建子进程,并为子进程分配一份父进程的虚拟地址空间的拷贝。此时,父进程和子进程的虚拟内存页面(PTE)都会指向相同的物理内存页面,但这些页面会被标记为只读。这样做的目的是为了节省内存并避免不必要的物理页面复制。
但是,标记为只读意味着一旦子进程或父进程尝试写入这些页面,就会触发 page fault。在这个 page fault 发生时,内核会识别出这是一个 Copy-on-Write 的情景,并执行以下操作:
- 分配新页面:内核为尝试写入的进程分配一个新的物理页面。
- 复制页面内容:将原页面的内容复制到新分配的物理页面中。
- 更新 PTE:将进程的 PTE 更新为指向新分配的物理页面,并将该 PTE 标记为可写。
- 重新执行指令:恢复并重新执行导致
page fault的写入指令。
通过这一机制,内核有效地推迟了物理页面的复制,直到确实需要修改页面内容时才进行。这减少了不必要的内存开销,并加快了 fork() 操作的速度。
进程退出时的内存释放
在实现 Copy-on-Write 机制后,一个物理页面可能同时被多个进程引用。当某个进程退出时,如果不小心释放了一个仍然被其他进程使用的物理页面,可能会导致数据损坏或系统崩溃。
为了解决这个问题,内核需要引入引用计数机制。对于每一个物理页面,内核维护一个引用计数器,用于记录当前有多少进程引用了这个页面。引用计数机制的工作流程如下:
- 引用计数的增加:当一个页面被共享时(例如在
fork()后),引用计数会增加。 - 引用计数的减少:当一个进程释放其虚拟页面时,引用计数会减少。
- 页面释放:当引用计数降为零时,内核才会实际释放这个物理页面,并将其返回到空闲内存池中。
使用 PTE 中的 RSW 位
在大多数硬件架构中,PTE(Page Table Entry)中保留了几个用于操作系统内部使用的位。在 RISC-V 架构中,RSW(Reserved for Supervisor Use)位可以由内核随意使用。在实现 Copy-on-Write 时,可以将这些位用于标记哪些页面属于 Copy-on-Write。这些标志可以在发生 page fault 时帮助内核迅速判断当前的页面是否属于 Copy-on-Write 类型,并执行相应的处理。
内核对不同场景的处理
在内核中,处理 Copy-on-Write 页面与处理普通的 page fault 需要有不同的逻辑分支。内核可以通过检查 PTE 中的标志位来区分这些场景。如果标志位指示页面为 Copy-on-Write,则内核会触发页面的复制操作;如果页面是由其他原因引发的 page fault,则可能执行例如 Lazy Allocation 或 Zero-fill-on-demand 之类的操作。
在实验中的实现自由度
在实验中,虽然存在多种实现方式,但核心思想都是确保页面的正确性与内存管理的高效性。例如,可以通过维护额外的元数据信息来管理和跟踪每个进程的内存使用情况,并判断哪些页面是可共享的,哪些页面需要复制。你还可以根据实验需求,自由选择在何处存储引用计数或标志位。
进一步的思考与实现
在实际的操作系统中,Copy-on-Write 只是内存管理优化的一部分。随着系统复杂性的增加,内核还需要考虑更多的优化与管理策略。例如,在多线程环境下如何确保内存一致性,在虚拟化环境中如何管理内存的共享与隔离等。通过这些实验,你将逐步理解操作系统在管理内存时所面临的挑战与解决方案,并为将来设计更复杂的系统奠定基础。
Demand Paging 的实现与优化
Demand Paging 是一种优化内存使用的技术,几乎所有现代操作系统都实现了这一功能。其核心思想是在程序执行过程中,根据实际需求逐步加载程序所需的内存,而不是在程序启动时一次性将整个程序加载到内存中。这不仅节省了物理内存,还提高了系统的整体性能,尤其是在处理大型程序时。
1. 什么是 Demand Paging?
在传统的内存管理策略中,当一个程序通过 exec 启动时,操作系统会立即将程序的 text 和 data 区域从磁盘加载到物理内存中,并将这些内存区域映射到进程的页表中。这种方式称为 eager allocation,即预先加载。但在实际操作中,程序可能并不需要立即访问这些数据,甚至在运行的过程中,也只会访问这些数据的一部分。因此,提前加载所有数据会导致内存资源的浪费。
Demand Paging 则采取了另一种策略:程序的 text 和 data 区域在虚拟地址空间中已经预留了地址,但它们的对应物理页面并未分配。因此,在初始阶段,这些区域的 PTE(页表项)的 valid 位都被设置为 0,即无效状态。当程序运行时,只有在实际访问这些页面时,才会触发 page fault,操作系统这时才会动态地分配物理页面并加载所需数据。
2. Demand Paging 的工作机制
在使用 Demand Paging 的场景下,当程序开始执行时,它最先尝试访问的是 text 区域中的代码,通常从地址 0 开始。由于此时这些地址尚未映射到物理页面,因此会触发 page fault。在 page fault 发生后,内核会执行以下操作:
-
确定页面类型:首先,内核会识别
page fault发生的位置——是text区域还是data区域。如果是text区域,说明程序尝试执行某条指令;如果是data区域,说明程序尝试访问某个变量。 -
从磁盘加载数据:内核从程序的二进制文件中读取相应的页面数据,并将其加载到一个新的物理页面中。
-
更新页表:将新分配的物理页面与触发
page fault的虚拟地址进行映射,并将该 PTE 的valid位设置为 1,同时根据需要设置读、写、执行权限。 -
重新执行指令:内核将控制权交还给用户进程,从
page fault发生时的指令处重新执行。
通过这种方式,程序所需的页面只会在真正使用时才被加载到内存中。这种按需加载的方式大大减少了内存的初始占用,同时也提高了系统响应速度。
3. 处理内存不足的问题
虽然 Demand Paging 能有效减少内存的初始使用量,但当系统内存不足时,仍然可能遇到问题。特别是在需要加载新页面而内存已耗尽的情况下,系统需要采取一些措施来解决这一问题。
一种常见的策略是 页面置换(page eviction)。当内存已满时,操作系统会选择某些页面从内存中移出,将其内容保存到磁盘上的交换区或对应的文件中,以腾出内存空间。之后,当需要访问这些被移出的页面时,可以再次触发 page fault,并将页面重新加载到内存中。
页面置换的选择策略通常涉及复杂的算法设计,例如 LRU(Least Recently Used,最近最少使用)算法。LRU 算法通过记录页面的访问时间,优先选择那些最长时间未被访问的页面进行置换。这种策略能有效地减少页面置换所带来的性能开销。
4. 优化的效果
Demand Paging 带来了两个主要的好处:
-
减少内存浪费:通过按需加载页面,系统只会为真正使用到的页面分配内存,减少了因预加载整个程序导致的内存浪费。这对于大规模程序尤其重要。
-
加快程序启动速度:由于程序的
text和data区域并不在程序启动时立即加载,exec操作的执行速度得以加快。程序启动后只需在实际需要时加载相应的页面,这种延迟加载的策略提升了系统的响应速度和用户体验。
Demand Paging 是一种高效的内存管理技术,通过延迟页面的加载和按需分配内存,有效地减少了内存使用和程序启动时间。然而,这种机制也带来了额外的 page fault 开销,如何平衡内存使用与 page fault 处理的开销是操作系统设计中的一个重要问题。通过适当的页面置换策略和内存管理优化,可以进一步提升系统的整体性能。
重新执行指令的复杂性
更新页表后内核将控制权交还给用户进程,从 page fault 发生时的指令处重新执行。重新执行用户指令实际上是一个复杂的过程,涉及到整个 userret 函数背后的机制,以及如何将程序的执行上下文从内核切换回用户空间。这不仅包括恢复用户寄存器和程序计数器(PC)的值,还涉及到设置正确的内存映射和处理可能的中断。总之,这个过程确保了用户程序在恢复执行时,能够在正确的上下文和状态下继续运行。
页面置换的策略
在执行 demand paging 或其他内存管理操作时,操作系统可能需要撤回某些页面以腾出内存。关键问题是,如何选择哪些页面可以被撤回,以及使用什么策略来决定这些页面的撤回顺序。
LRU(Least Recently Used)策略
最常用的策略是 LRU,即最久未使用页面优先撤回。这种策略基于一个简单的假设:最近使用的页面很可能在不久的将来再次被访问,因此应该优先保留在内存中,而长时间未被访问的页面则更有可能不再需要。
选择 Dirty 页还是 Non-Dirty 页?
在决定撤回哪一个页面时,内存管理系统通常会优先选择 non-dirty 页来撤回。以下是两者的定义:
- Dirty 页:曾经被写入过的页面。撤回一个 dirty 页意味着操作系统需要将其内容写回到磁盘,以便在未来需要时能够恢复。
- Non-Dirty 页:只被读取过但未被修改的页面。撤回 non-dirty 页相对简单,因为它可以直接被释放而无需将数据写回磁盘。
在大多数情况下,操作系统会优先选择 non-dirty 页来撤回,因为这样可以减少不必要的 I/O 操作。如果撤回了一个 dirty 页并且稍后又需要将其重新加载,操作系统可能会面临将数据写两次的开销(一次是撤回时写回磁盘,一次是重新加载时)。
判断 Dirty 页的方法
在内存管理中,判断一个页面是否为 dirty 的关键在于操作系统如何跟踪页面的使用情况。对于 memory-mapped 文件,操作系统会在页面被修改时设置页面为 dirty,以确保在页面被撤回时,文件的最新状态可以正确写回磁盘。
但对于一般的内存页面,如何判断它是否 dirty 呢?答案在于硬件支持的 PTE(页表项)标志位。常见的标志位包括:
- Dirty Bit(脏页标志位):当页面被写入时,硬件会自动设置这个标志位,指示该页面内容已经发生变化。
- Access Bit(访问标志位):当页面被访问(读取或写入)时,硬件会设置这个标志位,指示该页面已经被访问过。
Access Bit 和 Dirty Bit 的使用
- Access Bit:用于判断页面最近是否被访问。操作系统可以通过周期性地清除 Access Bit,并监控它是否在下一时间段内再次被设置,从而实现类似 LRU 的页面置换算法。
- Dirty Bit:用于判断页面是否已经被修改。如果 Dirty Bit 被设置,操作系统在撤回该页面之前需要将其内容写回磁盘。
扫描和清除标志位
为了有效地利用 Access Bit 和 Dirty Bit,操作系统通常会定期扫描所有页面,并根据这些标志位的状态决定页面的优先级。常见的做法是:
-
定时清除 Access Bit:操作系统定期清除每个页面的 Access Bit,这样在下一次访问时,硬件会重新设置它。通过这种方式,操作系统可以跟踪每个页面在特定时间段内是否被访问过。
-
基于 Access Bit 的页面置换:在执行页面置换时,操作系统优先选择那些 Access Bit 为 0 的页面,即最近未被访问过的页面。这些页面在 LRU 算法中排名较低,因此优先被撤回。
Memory Mapped Files
本节课的最后一个内容是 Memory Mapped Files(内存映射文件),这是操作系统中非常有用且常见的功能之一。在后续的实验中,你们将会实现这个功能。其核心思想是将文件的全部或部分内容映射到内存中,从而允许应用程序通过内存地址来直接访问和操作文件内容。
mmap 系统调用
现代操作系统通常通过 mmap 系统调用来实现内存映射文件功能。mmap 系统调用的参数包括虚拟内存地址(VA)、映射长度(len)、保护标志(protection)、文件描述符(fd)、和文件偏移量(offset)。
void* mmap(void* addr, size_t len, int prot, int flags, int fd, off_t offset);
- addr: 指定映射到的虚拟地址。
- len: 映射的字节长度。
- prot: 保护标志(例如只读、可读写等)。
- flags: 控制映射的行为,例如是否共享内存。
- fd: 打开的文件描述符。
- offset: 文件偏移量。
通过 mmap,文件的一部分或全部内容可以被映射到指定的虚拟内存地址空间。此后,应用程序可以像访问普通内存一样,通过读写内存地址来操作文件内容。
实现机制
在实现 mmap 时,操作系统可以选择 eager(即时) 方式或 lazy(懒惰) 方式:
-
Eager方式:文件内容立即被加载到内存中,并设置相应的页表项(PTE)。之后,应用程序可以直接访问这些内容。
-
Lazy方式:操作系统并不会立即将文件内容加载到内存中,而是记录相关信息(如文件描述符、偏移量等)。当应用程序实际访问映射区域时,会触发页面错误(page fault),操作系统在此时才从文件中加载数据到内存,并更新页表。
在大多数情况下,操作系统会采用 Lazy方式 来节省内存和加快映射速度。
虚拟内存区域(VMA)
为了管理映射的文件区域,操作系统使用了一个叫做 VMA(Virtual Memory Area) 的结构体。VMA 记录了映射的虚拟地址范围、对应的文件描述符、偏移量、保护标志等信息。当触发 page fault 时,操作系统根据 VMA 信息从磁盘读取文件内容,加载到内存并更新页表。
Page Fault 和 Dirty Bit
在执行 mmap 的过程中,dirty bit 是一个非常重要的标志。当应用程序修改了映射区域中的内容时,相应的物理页会被标记为 dirty。之后,在执行 munmap(解除映射)操作时,操作系统会检查 dirty bit 的状态。如果页面被标记为 dirty,那么操作系统需要将修改的内容写回到文件中。
共享文件和同步问题
一个常见的问题是,如果多个进程将同一个文件映射到内存中,那么它们的操作可能会导致数据同步问题。默认情况下,操作系统并不会自动处理这些冲突。例如,两个进程同时写入同一个文件的不同部分,其结果是不可预测的。
为了处理同步问题,一些操作系统提供了文件锁定机制,允许一个进程独占访问文件,确保数据一致性。但是,默认情况下,如果不使用锁定,数据同步问题将由应用程序自行处理。
总结
通过本节课的讲解,我们探讨了如何利用 page fault 处理机制来实现 memory mapped files 这一强大功能。结合前几节课对 page table 和 trap 机制的学习,你们应该能够理解内存管理和虚拟内存功能在现代操作系统中的重要性。通过实现和管理页表、处理页面错误,操作系统可以提供强大而灵活的内存管理功能,使得虚拟内存成为操作系统的重要组成部分。
你们将在接下来的实验中进一步实践这些概念,包括实现 mmap 和其他虚拟内存相关功能。理解这些原理不仅有助于你们完成实验任务,也能加深对操作系统内存管理机制的理解。