Lecture 4 - Page Tables
虚拟内存与页表
今天的主题是虚拟内存,特别是页表(page tables)的概念。我们将在本节课中详细讨论虚拟内存的工作机制,并且在后续课程中继续探讨虚拟内存的其他相关内容。
回顾与引入
为了开始今天的课程,我想先问问大家对虚拟内存的理解。在课程6.004和课程6.033中,我们已经接触过这个概念。当我第一次学习虚拟内存时,我觉得它很直观:只不过是一个将虚拟地址映射到物理地址的表单。但当我实际通过代码来管理虚拟内存时,才意识到它的复杂性和强大功能。希望你们在接下来的几节课和实验中,也能逐渐体会到这一点。
下面是一些同学对虚拟内存的理解:
学生1:虚拟内存是存放虚拟地址和物理地址映射关系的表。
学生2:它可以保护硬件设备,虚拟地址映射到物理地址时能提供一定的安全性。
学生3:虚拟内存让每个进程拥有独立的地址空间,通过内存管理单元(MMU)或其他技术将虚拟地址映射到物理内存地址。
学生4:它可以隐藏物理地址,让进程通过虚拟地址进行操作,实际影响的是物理地址。
学生5:虚拟内存对于实现进程间的隔离性至关重要,确保每个进程都有独立的内存空间。
从这些回答中,我们可以提炼出两个关键点:映射关系和隔离性。映射关系将虚拟地址转换为物理地址,而隔离性则确保每个进程的内存空间是独立的。
课程内容概述
在本节课中,我们将围绕三个核心主题展开讨论:
- 地址空间(Address Spaces):每个进程都拥有独立的地址空间,这是虚拟内存的核心概念。
- 支持虚拟内存的硬件:我们将探讨RISC-V架构中支持虚拟内存的硬件机制,包括页表和内存管理单元(MMU)。
- XV6中的虚拟内存实现:最后,我们会详细探讨XV6操作系统中如何实现虚拟内存,并了解内核地址空间和用户地址空间的结构。
地址空间(Address Spaces)
地址空间是虚拟内存的基础。每个进程都认为自己有一块完整、连续的内存空间可用,这就是它的虚拟地址空间。操作系统通过虚拟内存机制,将不同进程的虚拟地址空间映射到不同的物理内存区域。这种机制允许操作系统在物理内存有限的情况下,为每个进程提供一个独立的内存空间,从而实现进程间的隔离。
通过这种映射,操作系统可以保护进程的内存不被其他进程干扰,同时也能够灵活地管理内存资源。例如,当一个进程需要更多的内存时,操作系统可以为其分配新的物理内存,并更新相应的映射关系。
支持虚拟内存的硬件
现代处理器都设计了硬件来支持虚拟内存。RISC-V架构中,页表(page tables)和内存管理单元(MMU)是实现虚拟内存的关键组件。页表存储了虚拟地址到物理地址的映射关系,而MMU则负责在程序运行时,将虚拟地址实时转换为物理地址。
具体来说,当进程访问某个虚拟地址时,MMU会查找页表,找到对应的物理地址,然后进行实际的内存访问。这一过程对用户是透明的,用户只需操作虚拟地址,而硬件和操作系统共同完成实际的物理内存访问。
这种硬件支持使得虚拟内存的实现更加高效,同时也增强了系统的安全性和稳定性。
XV6中的虚拟内存实现
在XV6操作系统中,虚拟内存的实现主要体现在内核地址空间和用户地址空间的管理上。内核地址空间包含操作系统代码、数据结构和设备驱动程序等,而用户地址空间则包含用户程序的代码和数据。
通过页表,XV6能够将这些地址空间映射到物理内存中,并且可以根据需要动态调整映射关系。例如,当用户进程需要更多内存时,XV6可以为其分配新的物理内存,并更新页表,使得进程能够正确访问这些新分配的内存区域。
在具体实现中,XV6通过一系列函数来管理地址空间,并在进程切换时更新页表,从而保证每个进程都能独立运行,不受其他进程的干扰。
虚拟内存与隔离性
隔离性是操作系统设计中的一个核心目标,特别是在内存管理方面。如果我们能够正确设置页表(page tables)并通过代码进行有效管理,那么就能够利用虚拟内存实现强隔离。
隔离性的基本概念
隔离性意味着将每个用户程序“装进一个盒子”里,确保它们彼此独立、互不干扰。这不仅涉及用户程序之间的隔离,还包括用户程序与操作系统内核之间的隔离。这样,即使某个用户程序出现问题,也不会影响其他程序或操作系统的正常运行。
下图展示了这种隔离性的基本结构:
┌────────────┐ ┌────────────┐
│ Shell │ │ cat │
└────────────┘ └────────────┘
│ │
▼ ▼
┌───────────────────────────┐
│ 内核空间 │
└───────────────────────────┘
内存隔离性的需求
在讨论虚拟内存实现隔离性之前,让我们先了解一下操作系统中的典型系统结构。操作系统中有多个用户应用程序,如Shell、cat命令,以及其他用户开发的工具。这些应用程序运行在用户空间,而操作系统本身运行在内核空间。
理想情况下,每个用户程序都运行在独立的地址空间中,彼此之间没有任何干扰。同时,用户程序与内核之间也需要保持独立,以确保系统的安全性和稳定性。
内存共享的风险
如果没有引入任何隔离机制,内存的默认状态是共享的,这会带来严重的风险。所有程序的代码和数据都直接存储在物理内存中,没有任何隔离。
假设Shell程序的内存地址范围是1000-2000,而cat程序占用了其他的地址范围。由于没有隔离机制,cat程序可以访问Shell程序的内存地址。如果cat程序发生错误,将数据写入了Shell程序的内存区域,就会破坏Shell程序的正常运行。
物理内存:
┌────────────┬────────────┐
│ Shell cat │
│ 1000-2000 1000-3000 │
└────────────┴────────────┘
例如,如果cat程序由于编程错误,将内存地址1000(Shell的起始地址)加载到寄存器,并执行一条写入指令,那么它就会覆盖Shell程序的内存,导致Shell程序崩溃。这种内存冲突显然是我们不希望看到的。
地址空间的引入
为了解决上述问题,我们需要引入一种机制来实现不同程序之间的内存隔离。这种机制就是地址空间(Address Spaces)。
地址空间为每个进程提供了一个独立的虚拟内存视图,使得每个进程认为自己拥有一个完整的内存空间。实际上,操作系统和硬件通过页表将这些虚拟地址映射到不同的物理内存区域。这样,即使不同进程使用相同的虚拟地址,也不会相互干扰,因为它们背后的物理地址是不同的。
虚拟地址空间:
┌────────────┐ ┌────────────┐
│ Shell:0x0 │ │ cat:0x0 │
│ ▼ │ │ ▼ │
│ 物理:1000 │ │ 物理:2000 │
└────────────┘ └────────────┘
通过这种虚拟内存和地址空间的设计,我们能够确保每个进程的独立性,并为系统提供强有力的隔离机制。这不仅保障了程序之间的互不干扰,还保护了操作系统内核免受用户程序的影响。
地址空间的基本概念
虚拟内存的一个直观概念是:为每个程序(包括内核)提供一个专属的地址空间。在这个地址空间中,每个程序都可以从地址0开始使用内存,直至其所需的最高地址。这种设计使得每个程序的内存视图是独立的,不会与其他程序发生冲突。
┌─────────────┐ ┌─────────────┐ ┌───────────────┐
│ cat: 0x0000 │ │Shell: 0x0000│ │Kernel: 0x0000 │
│ ... │ │ ... │ │ ... │
│ 0xFFFF │ │ 0xFFFF │ │ 0xFFFF │
└─────────────┘ └─────────────┘ └───────────────┘
- 每个程序都有自己独立的地址空间,地址从0开始一直到某个较大的地址结束。重要的是,这些地址空间在程序之间是完全独立的。因此,当
cat程序尝试向地址1000写入数据时,它只能访问自己地址空间中的1000这个地址,而无法访问Shell或内核的地址空间。
虚拟内存与物理内存的关系
现在,我们的问题是如何在同一个物理内存上为不同的程序创建独立的地址空间。毕竟,物理内存本质上还是由一堆存储器芯片(如DRAM)组成的,所有程序的数据最终都必须存储在这些芯片中。
实现这种独立地址空间的关键是页表(page table)。页表是一个映射结构,它将每个虚拟地址转换为实际的物理地址。通过这个映射机制,不同程序可以在虚拟地址空间中使用相同的地址,而操作系统通过页表将这些虚拟地址映射到不同的物理地址,从而实现内存的隔离。
虚拟内存的大小与物理内存的限制
虚拟内存的一个强大之处在于,它并不受限于物理内存的实际大小。换句话说,虚拟内存可以比物理内存大得多。这样一来,即使系统中有多个程序同时运行,每个程序都可以认为自己拥有一个几乎无限大的地址空间,而不需要关心物理内存的实际容量。
这引出了一个关键问题:如果虚拟内存比物理内存大得多,会不会导致物理内存耗尽?答案是肯定的,尤其是在有多个大型程序同时运行时,物理内存可能会不够用。
为了应对这种情况,操作系统会通过内存管理单元(Memory Management Unit, MMU)和页表管理物理内存的分配。当物理内存耗尽时,操作系统可以采取一些措施,例如向应用程序返回错误消息,告知它没有足够的内存可用。此外,内核会使用某些机制来优雅地处理内存耗尽的情况,避免系统崩溃。
在XV6中,我们可以通过kalloc函数来查看内存的使用情况。kalloc维护了一个空闲页的列表,当列表为空时,kalloc会返回一个空指针,提示内存已经耗尽。内核则会将这个信息传递给用户程序,提醒它当前没有可用的内存。
通过引入虚拟内存和地址空间,我们能够在操作系统中实现至关重要的内存隔离性。虚拟内存不仅为每个程序提供了独立的内存视图,还帮助操作系统管理物理内存的分配,确保系统的稳定性和安全性。在接下来的课程中,我们将进一步探讨虚拟内存和页表的具体实现,以及它们如何在操作系统中发挥作用。
地址空间的实现:页表机制
在前面的讨论中,我们了解到地址空间隔离的重要性及其在现代操作系统中的关键作用。接下来,我们将深入探讨RISC-V架构下,如何通过页表(Page Tables)来实现多个独立的虚拟地址空间,并探讨其具体实现细节。
页表的设计与基本工作原理
为了有效管理虚拟内存地址空间,最常见的方法是使用页表。页表本质上是一个数据结构,它将虚拟内存地址映射到物理内存地址。为了高效管理,虚拟内存被分为多个固定大小的块,称为“页”(Page),而物理内存也被划分为相同大小的块,称为“页框”(Page Frame)。在RISC-V架构中,每个页的大小为4KB(4096字节)。
虚拟地址的分段
在RISC-V中,虚拟地址是64位的,但实际上目前使用的只有39位(其余的高25位尚未使用)。虚拟地址被分为两个部分:
- 页号(Page Number):27位,表示虚拟内存中的某个页。
- 页内偏移量(Offset):12位,表示页内的某个字节位置。
┌───────────────────┬──────────────────────┐
│ 页号 (27 bits) │ 页内偏移量 (12 bits) │
└───────────────────┴──────────────────────┘
在执行内存访问时,MMU会使用页号来查找页表,并获取对应的物理页号。页内偏移量保持不变,直接添加到物理页号中,得到最终的物理地址。
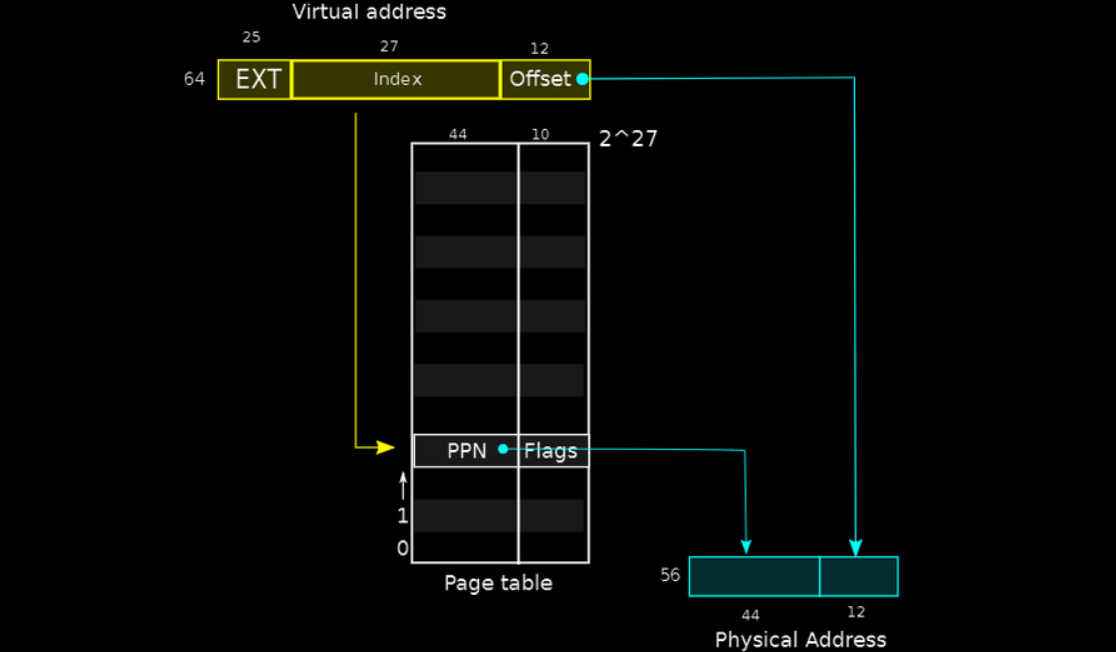
物理地址在 RISC-V 中为 56 位,物理页号占据其中的 44 位,剩余的 12 位直接从虚拟地址中的页内偏移量继承。因此,物理内存的最大地址空间为 2^56 字节。
页表的存储与MMU的角色
页表通常存储在物理内存中,而不是MMU内部。MMU通过处理器中的寄存器(如RISC-V中的SATP寄存器)来知道页表在内存中的位置。每个进程都有自己独立的页表,这使得不同进程的相同虚拟地址可以映射到不同的物理地址,从而实现进程间的内存隔离。
CPU (产生虚拟地址)
│
▼
MMU (通过SATP查找页表)
│
▼
页表 (映射虚拟地址到物理地址)
│
▼
物理内存 (访问物理地址)
页表项的存储与翻译
当CPU生成一个虚拟地址时,MMU首先根据虚拟地址的页号在页表中查找对应的物理页号。接着,物理页号与虚拟地址中的页内偏移量相加,形成完整的物理地址。
假设虚拟地址0x1000需要被翻译,MMU会查找页表中的相应条目,并找到与之对应的物理页号。接着,将虚拟地址的偏移量直接添加到物理页号中,得到最终的物理地址。
页表的层级设计与多级页表
尽管我们在前面的讨论中提到了页表的基本设计,但实际的页表结构更加复杂。对于每个虚拟地址创建一个独立的页表项会导致巨大的内存开销。因此,现代操作系统通常采用多级页表的设计,这种设计有效减少了页表的大小。
多级页表的优势
多级页表通过分级管理虚拟地址,将页表划分为多个级别。例如,RISC-V的页表可以被设计为三级结构,每一级页表都对应不同级别的虚拟地址。这样,只有实际使用到的虚拟地址才会占用页表空间,从而减少内存开销。
虚拟地址
├── 一级页表 -> 二级页表 -> 三级页表 -> 物理地址
多级页表不仅减少了页表的大小,也提高了地址转换的效率。通过这种设计,操作系统能够灵活地管理和分配内存资源,同时确保不同进程之间的内存隔离。
页表与虚拟内存的应用
通过页表,操作系统能够为每个进程创建一个独立的虚拟地址空间,使得每个进程都认为自己在独占整个内存。这种设计不仅提高了系统的安全性和稳定性,还简化了程序的编写和调试。
分级页表实现虚拟内存地址转换
为了高效管理虚拟内存,我们引入了分级页表(Multi-Level Page Tables)的概念。通过这种方式,我们不仅减少了内存的浪费,还能够灵活地应对不同进程的内存需求。接下来,我们将深入探讨如何通过分级页表实现虚拟内存地址到物理内存地址的转换,并解释其工作机制。
从单级到多级页表的演进
在传统的单级页表结构中,每个虚拟地址对应一个物理地址条目。然而,在实际操作中,这种方式并不高效。假设每个进程都有自己的页表,且每个页表包含2^27个条目(虚拟内存地址中的index为27位),那么这将消耗大量的内存空间(64位架构中,每个条目为 8 字节,每个页表大小 = \( 2^{27} \times 8 \text{ 字节} = 2^{30} \text{ 字节} = 1 \text{ GB} \)),迅速耗尽系统的物理内存资源。
为了解决这个问题,我们引入了分级页表的概念。通过将页表划分为多级结构,我们能够更有效地管理内存,并且只在需要的时候分配内存资源。
分级页表的结构
在RISC-V架构中,页表被划分为三级,每级页表负责管理虚拟内存地址的一部分。具体来说,虚拟内存地址中的27位index被分为三个9位部分:L2、L1、L0,分别对应三级页表。
- 最高级页表(L2):虚拟内存地址的高9位用于索引最高级页表,该页表负责指向中间级页表的物理页号(PPN,Physical Page Number)。
- 中间级页表(L1):虚拟内存地址的中间9位用于索引中间级页表,该页表负责指向最低级页表的物理页号。
- 最低级页表(L0):虚拟内存地址的低9位用于索引最低级页表,该页表最终指向实际的物理内存地址。
每个页表条目(PTE,Page Table Entry)都是64位长,其中包括物理页号(PPN)和一些标志位(Flags)用于控制地址权限。
下图展示了多级页表的结构:
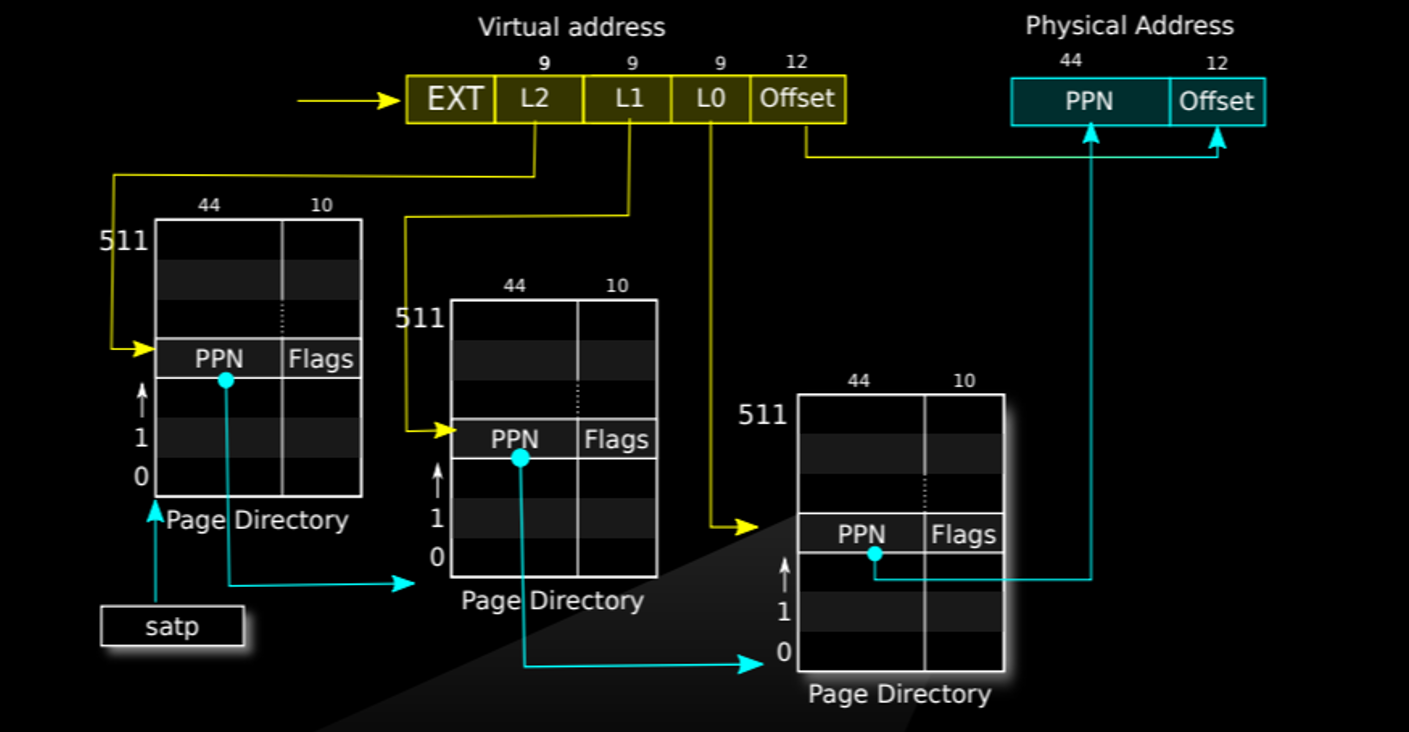
┌───────────────────┬──────────────────┬──────────────────┬──────────────────┐
│ L2 Index (9bit) │ L1 Index (9bit) │ L0 Index (9bit) │ Offset (12bit) │
└───────────────────┴──────────────────┴──────────────────┴──────────────────┘
▼
┌───────────────┐
│ L2 Page Table │
└───────────────┘
▼
┌───────────────┐
│ L1 Page Table │
└───────────────┘
▼
┌───────────────┐
│ L0 Page Table │
└───────────────┘
▼
┌───────────────┬───────────────┐
│ Physical Page │Offset (12bit) │
└───────────────┴───────────────┘
在这个结构中,SATP寄存器指向最高级页表的物理地址。CPU通过读取虚拟内存地址中的L2、L1、L0部分逐级索引各级页表,最终得到物理页号。然后,将虚拟内存地址中的Offset部分直接添加到物理页号上,得到最终的物理内存地址。
多级页表的优点
-
内存节省:在多级页表结构中,只有在需要的时候才分配页表。例如,如果进程只使用了一个4KB的页,那么只需分配少量的页表条目,而不必为整个虚拟地址空间分配条目。这大大减少了内存的浪费。
如果整个地址空间只使用了一个页,所需的内存量将大幅减少,仅需要3个页表,每个页表占用4KB,共计12KB内存。而在单级页表结构中,至少需要2^27个条目(约1GB内存)。
-
灵活性:通过分级页表,操作系统能够灵活地应对不同进程的内存需求,并在需要时动态扩展页表。这种机制确保了物理内存资源的高效利用,并减少了不必要的内存开销。
页表条目的结构
在RISC-V架构中,页表条目(PTE)包含了物理页号(PPN)和一些控制标志位(Flags)。每个PTE占用64位,其中44位用于存储物理页号,剩余的部分用于存储标志位和未来扩展。
┌───────────────────┬──────────────────────────────────────┬───────────────┐
│ Reserved (10bit) │ Physical Page Number (PPN) (44bit) │ Flags (10bit) │
└───────────────────┴──────────────────────────────────────┴───────────────┘
这些标志位用于控制访问权限、页是否在内存中等重要信息。此外,剩余的10位被保留以供未来扩展使用。这种设计确保了页表的灵活性和扩展性。
通过分级页表,操作系统能够高效地管理虚拟内存地址到物理内存地址的转换。分级结构不仅节省了内存,还提高了内存管理的灵活性。
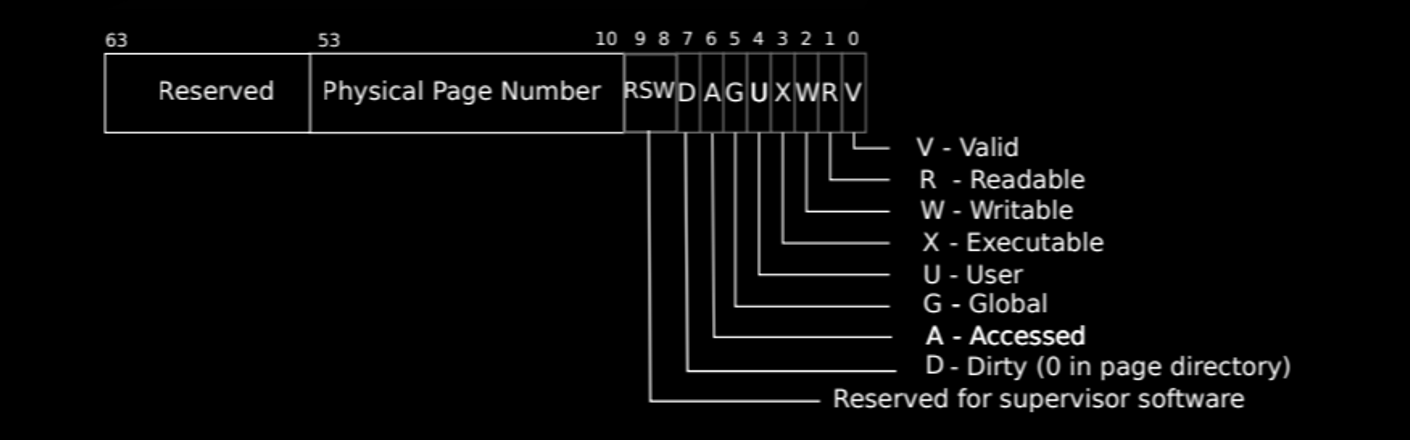
页表条目(PTE)中的标志位
在RISC-V架构中,每个页表条目(PTE)除了包含物理页号(PPN,Physical Page Number)外,还包含了10个标志位(Flags),用于控制内存访问权限和其他特性。这些标志位非常关键,因为它们直接影响操作系统和用户程序对内存的访问方式。下图展示了这些标志位的位置和作用:
让我们逐一解析这些标志位的含义、用途及其在具体场景中的应用:
- V - Valid:
- 位置:第0位(最低位)
- 功能:指示该PTE是否有效。如果此位为1,则表示该条目有效,MMU可以使用它进行地址翻译。如果为0,则表示该条目无效,试图访问该页面的任何操作都会触发一个页错误(Page Fault)。
- 应用场景:在操作系统初始化页表时,可能需要暂时禁用某些内存区域以防止意外访问。例如,在进程加载期间,某些内存区域可能尚未准备好,此时将这些区域的PTE的Valid位设置为0,以防止进程误访问这些区域而导致崩溃。
- R - Readable:
- 位置:第1位
- 功能:指示页面是否可读。如果此位为1,则表示该页面上的数据可以被读取。如果为0,则禁止读取。
- 应用场景:考虑一个存储加密密钥的内存区域,只有特定的内核进程需要读取这些密钥。通过将该内存区域的PTE的Readable位设置为1,同时将其他不需要访问的进程的PTE的Readable位设置为0,可以防止敏感数据泄露。
- W - Writable:
- 位置:第2位
- 功能:指示页面是否可写。如果此位为1,则表示可以向该页面写入数据。如果为0,则禁止写入。
- 应用场景:在许多应用程序中,代码段是只读的,以防止恶意或错误的代码修改。通过将代码段对应的PTE的Writable位设置为0,操作系统可以防止代码段被修改。例如,一个防病毒软件可能会设置其自身代码段为只读,以防止恶意软件修改其行为。
- X - Executable:
- 位置:第3位
- 功能:指示页面是否可执行。如果此位为1,则表示可以从该页面执行指令。如果为0,则禁止执行。
- 应用场景:为了防止代码注入攻击,操作系统通常会将数据段的PTE的Executable位设置为0。例如,在Web服务器中,防止输入的恶意代码被执行,可以通过将输入缓冲区对应的PTE设置为不可执行。
- U - User:
- 位置:第4位
- 功能:指示该页面是否可以由用户模式下的代码访问。如果此位为1,则表示用户模式下的代码可以访问该页面。如果为0,则只有内核模式下的代码才能访问。
- 应用场景:内核数据结构通常存储在只允许内核访问的内存区域中。通过将这些区域的PTE的User位设置为0,可以防止用户模式下的进程访问和修改内核数据。例如,文件系统的核心结构需要保护,避免用户进程直接访问以防止篡改。
- G - Global:
- 位置:第5位
- 功能:指示该PTE是否全局有效。如果此位为1,则表示该PTE在所有地址空间中都是有效的,不会被TLB刷新所影响。如果为0,则该PTE只对当前地址空间有效。
- 应用场景:在多进程系统中,某些系统库可能被多个进程共享。在这种情况下,可以将这些共享库的PTE的Global位设置为1,这样即使在进程切换时,也不需要刷新TLB,从而提升性能。
- A - Accessed:
- 位置:第6位
- 功能:指示该页面是否被访问过。如果此位为1,则表示页面已经被读取或写入。此位通常由硬件设置,用于支持内存管理中的页面替换算法(如LRU)。
- 应用场景:在内存管理中,操作系统需要跟踪哪些页面最近被使用过,以便在内存不足时选择合适的页面进行替换。通过检查PTE的Accessed位,操作系统可以确定哪些页面是“冷”的,可以安全地换出到磁盘。例如,在浏览器中,当内存不足时,操作系统可能会换出很久没有访问过的网页缓存。
- D - Dirty:
- 位置:第7位
- 功能:指示该页面是否被写入过。如果此位为1,则表示页面已经被修改。此位通常由硬件设置,用于确定哪些页面需要写回到磁盘。
- 应用场景:当一个页面的内容被修改后,操作系统需要在将其换出内存时将该页面的内容写回磁盘,以确保数据不会丢失。例如,在文字处理软件中,用户编辑的文档可能存储在内存中。当该页面的Dirty位为1时,操作系统在换出该页面前需要将其保存到磁盘。
- Reserved for Supervisor Software:
- 位置:第8-9位
- 功能:这些位通常保留给操作系统内核,用于特定的控制或扩展用途。在某些情况下,这些位可能被用来存储操作系统特定的状态信息或用于硬件扩展。
- 应用场景:操作系统可能会利用这些保留位来实现特定的功能,例如调试、内存跟踪或硬件扩展功能。例如,一个实时操作系统可能会利用这些位来存储任务的优先级信息,以便进行高效的任务调度。
这些标志位共同定义了每个页面的访问权限和状态,它们在操作系统的内存管理中发挥着重要作用。通过合理设置这些标志位,操作系统能够确保内存的安全性、稳定性和有效利用。这些标志位是操作系统实现进程隔离、权限控制和内存保护的核心工具。
分级页表的机制为操作系统提供了强大的内存管理功能,不仅提高了内存使用效率,还增强了系统的隔离性和安全性。在现代操作系统中,分级页表是实现虚拟内存管理的核心技术之一。
地址空间中的页表缓存与多级页表
在前面的讨论中,我们已经了解了RISC-V架构下的多级页表结构,以及如何通过页表(Page Table)将虚拟地址映射到物理地址。但是,这个过程中的效率问题引发了我们的关注。尤其是,当CPU需要访问一个虚拟地址时,通常要经过三级页表的查找,才能最终确定物理地址。这意味着每次内存访问都需要进行多次内存查找,代价相当高。因此,几乎所有的现代处理器都会使用一种机制来缓存这些翻译结果,以提高效率,这就是页表缓存或转换旁路缓存(Translation Lookaside Buffer,TLB)。
页表缓存(TLB)的工作机制
TLB 是一种专门用来存储虚拟地址到物理地址映射关系的缓存。当处理器第一次访问某个虚拟地址时,它需要通过多级页表查找来确定最终的物理地址。这个映射关系会被存储在TLB中,以便于将来访问相同的虚拟地址时,处理器可以直接从TLB中获取物理地址,而不必再进行多次查找。
例如:
-
第一次访问:假设CPU第一次访问虚拟地址
0x1000。CPU通过三级页表查找,确定其对应的物理地址为0xFFF0。此时,TLB会将0x1000到0xFFF0的映射关系缓存起来。 -
后续访问:当CPU再次访问虚拟地址
0x1000时,处理器会首先检查TLB是否已有这个地址的映射。如果有,TLB会直接返回0xFFF0作为物理地址,这样可以避免再次进行页表查找,从而提高访问效率。
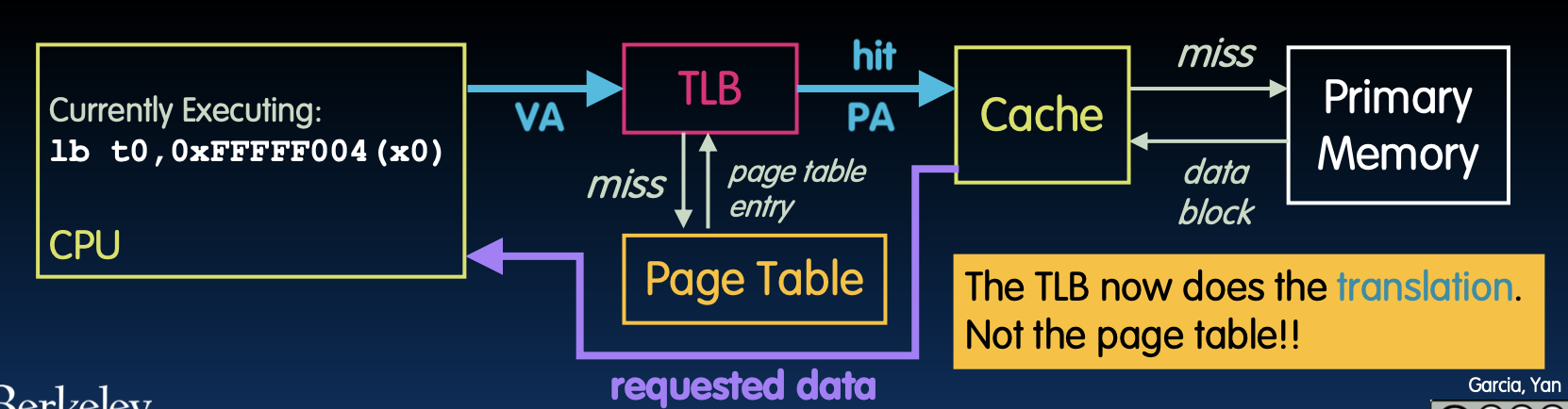
这种缓存机制大大减少了内存访问的延迟,因为多数情况下,最近访问过的地址会被频繁访问,因此TLB命中率通常较高。
页表切换与TLB失效
虽然TLB极大地提高了虚拟地址到物理地址翻译的效率,但它也带来了一个新的问题:当操作系统切换到不同的进程时,由于不同的进程有不同的页表,TLB中缓存的映射关系可能不再有效。为了避免错误的地址翻译,操作系统必须在切换页表时清空TLB。这一操作在RISC-V中通过sfence.vma指令实现。
例如,当操作系统从进程A切换到进程B时,必须执行sfence.vma指令清空TLB,以确保进程B使用自己的页表进行地址翻译。
硬件与软件的协同工作
在RISC-V中,三级页表的查找是由硬件完成的,即MMU(Memory Management Unit,内存管理单元)负责在硬件层面执行这一操作。而操作系统(例如XV6)则需要通过walk函数模拟MMU的行为,以完成某些软件级别的页表操作。
// kernel/vm.c
pte_t* walk(pagetable_t pagetable, uint64 va, int alloc);
walk函数的作用是通过遍历页表,找到与某个虚拟地址对应的物理地址。如果某个虚拟地址对应的页表条目无效(例如,PTE中的Valid位为0),walk函数可以在必要时动态创建新的页表条目。
这种机制使得操作系统能够灵活地管理内存,并且可以在运行时动态调整页表结构。例如,当内存不足时,操作系统可以通过page fault机制将某些页面从磁盘调入内存,并更新页表以反映这一变化。
页表中的抽象层次
页表不仅仅是虚拟地址到物理地址的映射,它实际上提供了一层抽象。这一抽象让操作系统能够实现复杂的内存管理策略,并为进程隔离、权限控制以及内存保护提供了基础。例如:
- 进程隔离:不同的进程拥有各自的页表,确保它们的地址空间彼此独立,避免了进程之间的内存冲突。
- 权限控制:通过设置PTE中的标志位(如Readable, Writable, Executable等),操作系统可以严格控制每个页面的访问权限,从而增强系统的安全性。
- 内存保护:当进程试图访问无效或无权限的页面时,硬件会触发
page fault,操作系统可以捕捉这个事件并采取相应的措施,如终止进程或将页面加载到内存中。
综上所述,页表不仅仅是虚拟内存管理的核心机制,它还为操作系统提供了丰富的控制手段,以实现更加灵活和安全的内存管理。
XV6 虚拟内存和物理内存映射
在XV6操作系统中,虚拟地址空间和物理地址空间之间的映射关系至关重要。这种映射关系决定了内核如何访问物理内存和I/O设备。物理地址的分布由硬件设计者决定,而操作系统负责管理虚拟地址和物理地址之间的映射关系。这使得操作系统不仅需要处理CPU指令,还需要管理与I/O设备的交互。例如,当操作系统需要与网卡交互时,它必须通过相应的物理地址与网卡设备通信。
虚拟地址空间与物理地址空间的映射关系
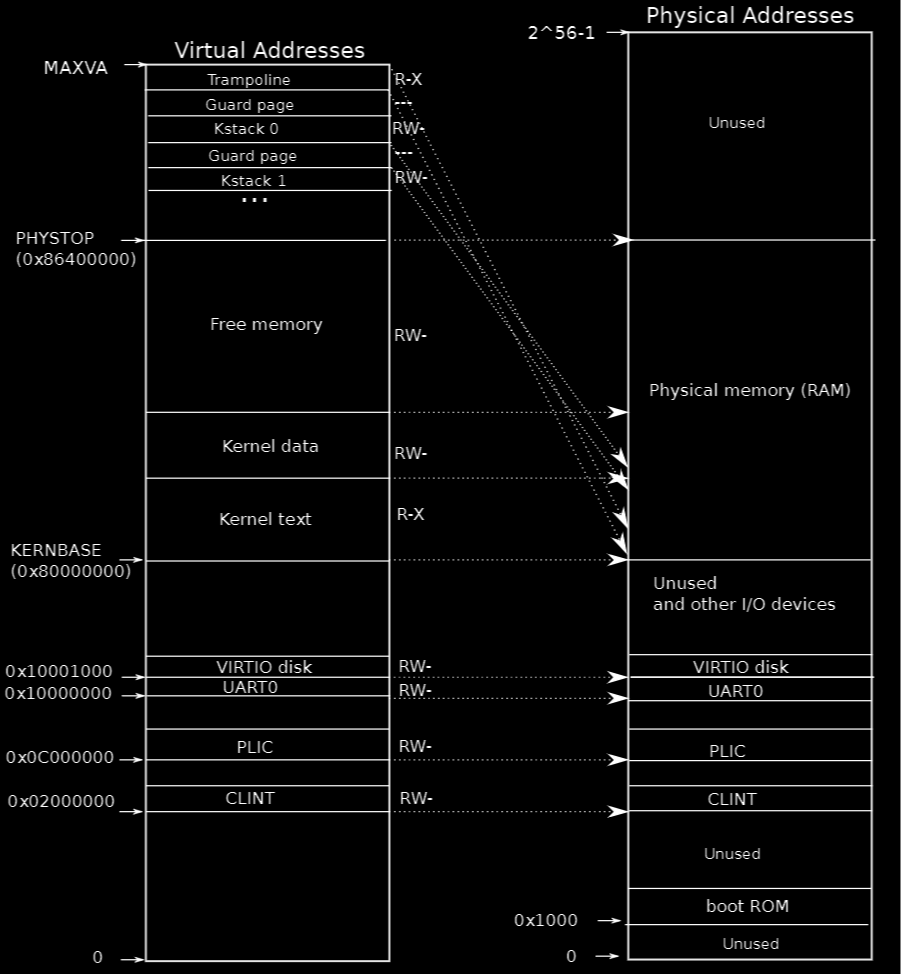
图片中的左侧表示虚拟地址空间(Virtual Addresses),右侧表示物理地址空间(Physical Addresses)。虚拟地址空间从KERNBASE(0x80000000)开始,一直延伸到MAXVA。物理地址空间的起点是0,一直延伸到2^56-1。在RISC-V架构中,物理地址空间的实际使用范围远小于其理论上限,这就是为什么大部分高位地址被标记为“未使用”。
物理地址空间(右侧)
- Physical memory (RAM):
- 地址0x80000000及以上的部分对应于主板上的DRAM(物理内存)。这是系统用来存储操作系统和应用程序数据的地方。
- 物理地址高于
PHYSTOP(0x86400000)的部分未被使用或保留用于将来的硬件扩展。
- Unused and other I/O devices:
- 物理地址低于0x80000000的部分通常用于I/O设备。例如,CLINT(0x02000000)和PLIC(0x0C000000)都是用于中断处理的设备。
- 还有一些地址用于映射VIRTIO磁盘和UART0设备。
- Boot ROM:
- 地址0x1000的物理内存通常用于系统启动时加载的Boot ROM。
虚拟地址空间(左侧)
- KERNBASE (0x80000000):
- 内核虚拟地址的起始点,所有的内核数据、代码和堆栈都在这个范围内。
- Kernel text (R-X):
- 内核代码部分(只读/可执行)。该部分直接映射到物理内存中对应的地址,并且是只读和可执行的。
- Kernel data (RW-):
- 内核数据部分(读写)。这部分映射到物理内存中,用于存储内核运行时的数据。
- Free memory (RW-):
- 映射到物理内存中未使用的区域,用于动态内存分配。
- I/O设备映射:
- 低于
KERNBASE的虚拟地址空间映射到不同的I/O设备。例如,VIRTIO磁盘(0x10001000)、UART0(0x10000000)、PLIC(0x0C000000)、CLINT(0x02000000)等。
- 低于
映射关系和内存管理
-
内核与物理内存的映射:
XV6中的内核直接映射到物理内存中的相应部分,虚拟地址与物理地址通常保持线性关系。这样,操作系统能够直接且高效地访问物理内存。 -
设备映射和内存映射I/O:
物理地址空间中的设备通过映射到特定的虚拟地址,使得操作系统能够通过简单的内存读写操作与这些设备交互。这种设计简化了硬件访问的复杂性。 -
内核栈的映射:
每个内核栈都映射到物理内存中不同的区域,确保了多个内核线程之间的隔离和独立性。
问题与解答
在介绍完这些内容后,有几个常见的问题需要澄清:
- I/O设备的物理地址如何与设备对应?
- 处理器内部有一个多路输出选择器(demultiplexer),可以根据不同的物理地址将指令路由到对应的I/O设备。例如,当物理地址低于0x80000000时,指令会被路由到特定的I/O设备,而不是DRAM。
- 为什么物理地址空间有一大块未使用?
- 物理地址空间总共可以达到2^56个地址,但实际使用的物理内存远远少于这个值。因此,许多物理地址在实际中并未使用。
内核虚拟地址与物理地址映射的细节
在之前的讨论中,我们了解到XV6操作系统通过页表(Page Table)来管理虚拟地址与物理地址之间的映射关系。接下来,我们深入探讨内核虚拟地址空间的两个关键点:Guard Page的使用和访问权限的设置,并通过示例来说明这些机制的作用。
虚拟地址和物理地址的映射
如图所示,内核的虚拟地址空间从KERNBASE(0x80000000)开始,一直到MAXVA。在这个范围内,大部分的虚拟地址与物理地址之间是线性映射的。这意味着虚拟地址与物理地址之间保持相等的关系。
这是一种简单且高效的映射方式,适合XV6这样设计简单的操作系统。
使用Guard Page保护内核栈
Guard Page是一种非常有用的技术,旨在防止栈溢出带来的潜在危害。在XV6中,内核栈(Kernel Stack)使用了一种特殊的映射方式:在每个内核栈的下方,都有一个未映射的Guard Page。这个Guard Page的PTE中的Valid标志位被设置为无效。
Guard Page的作用
- 栈溢出检测: 当内核栈增长并试图超出其分配的空间时,它将进入Guard Page。如果程序试图访问Guard Page的地址,由于该地址无效,系统将立即触发
Page Fault。这种设计可以防止栈溢出造成的不可预测的行为。 - 内存节省: Guard Page只占用虚拟地址空间,而不占用实际的物理内存。这意味着即使有多个Guard Page,也不会增加物理内存的使用。这是通过在页表中不为Guard Page分配物理页来实现的。
+------------------+ <- Virtual Address (Higher)
| Guard Page | (No Physical Mapping, Invalid PTE)
+------------------+
| Kernel Stack | (Mapped to Physical Memory)
+------------------+ <- Virtual Address (Lower)
内核栈的双重映射
在XV6中,内核栈有两个映射:一个在虚拟地址空间的上部,靠近MAXVA,另一个在内核数据段Kernel Data中。
- 上部映射:
- 这个映射利用了Guard Page提供的栈溢出保护,因此内核实际运行时更倾向于使用这个映射。
- Kernel Data中的映射:
- 这是内核栈的备用映射,确保在某些情况下能够安全访问内核栈。
设置内核段的访问权限
页表不仅仅是用来映射地址的,它还用来控制内存访问权限。在XV6中,内核的不同段具有不同的权限设置。
- Kernel Text (R-X):
- 只读和可执行。这是内核代码所在的部分,不能被修改,只能读取和执行。这种设计防止了恶意代码或错误代码对内核代码段的篡改,从而保护了系统的稳定性。
- Kernel Data (RW-):
- 读写但不可执行。这是内核的数据段,存储内核运行时的数据。内核数据可以被修改,但不能直接执行。这防止了数据段被恶意利用来执行任意代码。
+------------------+
| Kernel Text | R-X (Read and Execute Only)
+------------------+
| Kernel Data | RW- (Read and Write Only)
+------------------+
用户进程与内核的内存分配
在XV6中,每个用户进程都有其独立的虚拟地址空间和页表。内核为每个进程分配的页表通常位于虚拟地址空间的Free Memory部分,这部分内存会映射到实际的物理内存中。
- 用户进程的虚拟地址空间:
- 用户进程的虚拟地址空间理论上与内核地址空间一样大,但实际使用中通常会远远小于内核虚拟地址空间。
- 内核为用户进程分配内存:
- 内核从Free Memory中分配内存来存储用户进程的页表、代码和数据。如果内存耗尽,内核无法为新进程分配足够的内存资源,此时系统调用
fork或exec会失败。
- 内核从Free Memory中分配内存来存储用户进程的页表、代码和数据。如果内存耗尽,内核无法为新进程分配足够的内存资源,此时系统调用
通过这些设计,XV6操作系统在提供强大功能的同时保持了简单性。Guard Page机制、防止栈溢出和权限设置等策略,确保了操作系统在运行时的稳定性和安全性。对于初学者来说,理解这些机制能够帮助他们更好地掌握操作系统的设计理念和实现细节。
XV6内核地址空间的初始化与映射
接下来,我们将通过代码的具体实现,进一步加深对内核地址空间初始化和物理设备映射的理解。在这个过程中,我们会发现前面所讨论的概念如何通过代码来实现。
启动XV6并进入内核初始化
在这部分课程中,我们通过启动QEMU模拟的主板,并打开gdb进行调试,来一步步观察内核初始化的过程。
首先,启动XV6并进入到main函数,这是内核启动的主要入口。我们会在这里跟踪kvminit函数的执行,kvminit函数是用来初始化内核地址空间的。
/*
* the kernel's page table.
*/
pagetable_t kernel_pagetable;
extern char etext[]; // kernel.ld sets this to end of kernel code.
extern char trampoline[]; // trampoline.S
// Make a direct-map page table for the kernel.
pagetable_t
kvmmake(void)
{
pagetable_t kpgtbl;
kpgtbl = (pagetable_t) kalloc();
memset(kpgtbl, 0, PGSIZE);
// uart registers
kvmmap(kpgtbl, UART0, UART0, PGSIZE, PTE_R | PTE_W);
// virtio mmio disk interface
kvmmap(kpgtbl, VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W);
// PLIC
kvmmap(kpgtbl, PLIC, PLIC, 0x4000000, PTE_R | PTE_W);
// map kernel text executable and read-only.
kvmmap(kpgtbl, KERNBASE, KERNBASE, (uint64)etext-KERNBASE, PTE_R | PTE_X);
// map kernel data and the physical RAM we'll make use of.
kvmmap(kpgtbl, (uint64)etext, (uint64)etext, PHYSTOP-(uint64)etext, PTE_R | PTE_W);
// map the trampoline for trap entry/exit to
// the highest virtual address in the kernel.
kvmmap(kpgtbl, TRAMPOLINE, (uint64)trampoline, PGSIZE, PTE_R | PTE_X);
// allocate and map a kernel stack for each process.
proc_mapstacks(kpgtbl);
return kpgtbl;
}
// Initialize the one kernel_pagetable
void
kvminit(void)
{
kernel_pagetable = kvmmake();
}
kvminit(kvmmake)函数的代码解析
kvminit(kvmmake)函数是设置内核地址空间的关键代码。这个函数的主要任务是:
-
分配最高级的Page Directory:
- 通过调用
kalloc()函数为最高级的Page Directory分配物理页。这一页将用作内核页表的根,表示最高级的页目录。 - 通过调用
memset()初始化这段内存,将其内容清零,确保后续使用时的正确性。
在gdb中,我们可以设置断点并查看
kvminit函数的执行情况:(gdb) b kvminit (gdb) c通过
layout split命令,可以清楚地看到代码的执行过程,特别是在分配Page Directory时的操作。
- 通过调用
-
映射I/O设备:
kvminit(kvmmake)函数的另一项重要任务是通过调用kvmmap函数,将I/O设备映射到内核的地址空间。这些映射主要是将物理地址映射到相同的虚拟地址,以便内核可以直接访问这些I/O设备。
例如,UART0设备被映射到内核地址空间中的0x10000000。
-
代码片段:
kvmmap(UART0, UART0, PGSIZE, PTE_R | PTE_W); // void kvmmap(uint64 va, uint64 pa, uint64 sz, int perm)
kvmmap通常用于在内核的虚拟地址空间中创建一个映射,将虚拟地址映射到物理地址。这个函数的具体实现可能会根据操作系统的设计有所不同,但它通常用于设置页表项,以便将虚拟地址与物理地址关联起来。在修改后的版本中,
kvmmap函数增加了一个新的参数pagetable_t kpgtbl。我们来逐一解释每个参数及其意义,并分析这个新增参数的作用。函数签名及其参数
void kvmmap(pagetable_t kpgtbl, uint64 va, uint64 pa, uint64 sz, int perm)
pagetable_t kpgtbl:新增的参数,表示内核的页表(kernel page table)。在之前的版本中,可能隐含地使用了某个全局或默认的页表。现在这个参数明确传递了一个页表指针,使得调用者可以指定要操作的页表。这为页表管理提供了更多的灵活性,尤其是在初始化或处理多个页表时,调用者可以控制不同的页表。uint64 va:虚拟地址(virtual address),表示在虚拟地址空间中的起始地址。在此函数中,va是需要映射到物理地址空间的虚拟地址。
- 在这个上下文中,
UART0通常是一个宏或常量,定义了串口(UART)设备的物理地址。在许多操作系统(例如XV6)中,UART0指的是第一个串口设备的基地址。uint64 pa:物理地址(physical address),表示要映射到的物理地址。该参数决定了虚拟地址va将指向的实际物理内存地址pa。
- 在这个上下文中,
UART0是指要映射到的物理地址。在这个例子中,虚拟地址UART0被映射到同一个物理地址UART0。这种映射通常用于设备内存或I/O内存的访问,其中内核需要直接访问硬件设备。uint64 sz:映射的大小(size),表示需要映射的内存区域的大小。通常sz会以页大小为单位进行分配,kvmmap会根据sz的值设置从虚拟地址va到物理地址pa的映射。
- 在这个例子中,
PGSIZE通常是一个宏,定义了页的大小(通常是 4096 字节,也就是 4KB)。在这个调用中,它表示将从UART0开始的内存区域(大小为PGSIZE字节)映射到虚拟地址空间中。int perm:权限(permissions),控制页表项的读、写、执行权限。这通常包括读取权限(PTE_R)、写入权限(PTE_W)和执行权限(PTE_X)。这些标志控制了映射区域的访问权限。
- 在这个调用中,
PTE_R | PTE_W的组合表示这个映射的内存区域是可读和可写的。这意味着内核在访问这个虚拟地址时,可以读写对应的物理地址。函数行为
if(mappages(kpgtbl, va, sz, pa, perm) != 0) panic("kvmmap");
kvmmap函数调用了mappages函数,它负责实际在页表中设置从虚拟地址va到物理地址pa的映射,大小为sz,并应用权限perm。
mappages(kpgtbl, va, sz, pa, perm):mappages函数执行将va到pa的映射,并将其插入到指定的页表kpgtbl中。如果映射失败,它返回非零值。错误处理:如果
mappages返回非零值,意味着映射失败,kvmmap会触发panic("kvmmap"),导致系统崩溃。panic通常用于操作系统开发中的严重错误处理,它表示程序遇到了无法继续的错误。新增参数
pagetable_t kpgtbl的意义这个参数是对内核页表的一个显式引用。之前的版本可能是默认操作某个全局的或静态的页表,但这种方式缺少灵活性。在新的版本中,传递
kpgtbl作为参数,允许:
指定不同的页表:调用者可以传入不同的页表,以便将虚拟地址映射到不同的物理地址空间。这样可以支持多个页表的管理,比如在多进程、多核处理的操作系统中,可能需要为不同的内核或虚拟机创建单独的页表。
更灵活的页表管理:通过指定
kpgtbl,可以在不同场景下(如系统启动、进程切换)映射虚拟地址,而不局限于操作某个固定的内核页表。这在需要动态管理多个页表时非常有用。
kvmmap(kpgtbl, UART0, UART0, PGSIZE, PTE_R | PTE_W);这个调用在内核中创建了一个虚拟地址到物理地址的映射,将UART0地址映射到自身,并且设置为大小为PGSIZE字节的内存区域,并且该区域具有读写权限。这通常用于让内核能够访问串口设备或其他I/O设备。
查看memlayout.h文件
为了更好地理解kvminit中的kvmmap函数调用,我们需要查看memlayout.h文件。这是一个重要的头文件,定义了内核所需的内存布局和常量值。
// Physical memory layout
// qemu -machine virt is set up like this,
// based on qemu's hw/riscv/virt.c:
//
// 00001000 -- boot ROM, provided by qemu
// 02000000 -- CLINT
// 0C000000 -- PLIC
// 10000000 -- uart0
// 10001000 -- virtio disk
// 80000000 -- boot ROM jumps here in machine mode
// -kernel loads the kernel here
// unused RAM after 80000000.
// the kernel uses physical memory thus:
// 80000000 -- entry.S, then kernel text and data
// end -- start of kernel page allocation area
// PHYSTOP -- end RAM used by the kernel
// qemu puts UART registers here in physical memory.
#define UART0 0x10000000L
#define UART0_IRQ 10
// virtio mmio interface
#define VIRTIO0 0x10001000
#define VIRTIO0_IRQ 1
// qemu puts platform-level interrupt controller (PLIC) here.
#define PLIC 0x0c000000L
#define PLIC_PRIORITY (PLIC + 0x0)
#define PLIC_PENDING (PLIC + 0x1000)
#define PLIC_SENABLE(hart) (PLIC + 0x2080 + (hart)*0x100)
#define PLIC_SPRIORITY(hart) (PLIC + 0x201000 + (hart)*0x2000)
#define PLIC_SCLAIM(hart) (PLIC + 0x201004 + (hart)*0x2000)
// the kernel expects there to be RAM
// for use by the kernel and user pages
// from physical address 0x80000000 to PHYSTOP.
#define KERNBASE 0x80000000L
#define PHYSTOP (KERNBASE + 128*1024*1024)
...
在memlayout.h中,我们可以看到将文档中的物理地址(如UART0的地址0x10000000)翻译成了代码中的常量。
#define UART0 0x10000000
这个文件将所有关键的物理地址都定义为常量,这样在内核代码中,我们可以方便地引用这些设备的地址。
通过这部分的分析,我们清楚地了解了kvminit函数是如何初始化内核地址空间的,以及如何通过kvmmap函数将物理地址映射到虚拟地址。这些操作对于内核的正常运行至关重要,因为它们确保了内核能够正确地访问物理内存和I/O设备。
这种代码与硬件的紧密结合展示了操作系统设计的核心理念之一:操作系统需要在软件层面上对硬件资源进行有效的管理和抽象,而这些管理和抽象的实现往往通过如上所述的页表设置与内存映射等方式得以实现。
Page Table 实验与 Kernel Page Table 的验证
在XV6的Page Table实验中,第一个练习是实现vmprint函数,该函数的作用是打印当前的kernel page table。接下来,我们将跳过vmprint的具体实现,直接查看在执行完第一个kvmmap后的kernel page table的状态。
Kernel Page Table 的输出与验证
通过在代码中调用kvmmap函数,XV6会逐步完成对设备和内存的映射。此时,可以通过插入vmprint()打印kernel page table来观察内核地址空间的配置情况。

// uart registers
kvmmap(kpgtbl, UART0, UART0, PGSIZE, PTE_R | PTE_W);
vmprint(kpgtbl);
当我们查看kernel page table的输出时,可以看到以下信息:
-
Page Directory 层次结构:
- 第一行:打印的是最高一级page directory的物理地址,该地址会存储在SATP寄存器中,代表内核页表的根。
- 第二行:显示最高一级page directory的第一个PTE(序号为0),它指向了中间级page directory的物理地址。
- 第三行:显示中间级page directory中的一个PTE(序号为128),指向最低级page directory的物理地址。
- 第四行:最低级page directory中的PTE指向实际的物理内存地址,例如UART0的物理地址
0x10000000。
这段输出中的PTE结构验证了之前的解释,即三级页表结构如何分层管理虚拟地址到物理地址的映射。
-
虚拟地址到物理地址的验证:
- 我们可以通过位移操作将虚拟地址转换成用于索引page directory的索引值。具体而言,将虚拟地址
0x10000000右移12位,可以得到高27位的index部分,再将这部分右移9位,得到128,这对应于中间级page directory中的序号。
- 我们可以通过位移操作将虚拟地址转换成用于索引page directory的索引值。具体而言,将虚拟地址
在位移操作中,首先将虚拟地址右移12位,这样可以去掉页内偏移部分,剩下的就是用于索引页表的高27位(即3个9位)。
(gdb) p /x (0x10000000 >> 12) $1 = 0x10000上面命令的结果
0x10000是27位的高位部分,对应的是L2 + L1 + L0的组合。接下来,再右移9位,将L0部分去掉,得到的就是
L2 + L1索引部分。(gdb) p /x (0x10000 >> 9) $2 = 0x80在这个例子中,由于虚拟地址中的最高9位(即L2的索引)是0,所以当我们将地址右移9位后,L2部分就被移除了,剩下的就是L1的索引部分。因此,虽然我们在位移操作中处理的是L2和L1的组合,但因为L2是0,实际得到的就是L1的索引值,也就是128。
这种方式让我们能够准确地索引到中间级的页表条目 (PTE),进而找到下一步所需的物理页表地址。
如果L2索引不为0,那么我们在右移9位后,还会保留部分L2的值,因此需要进一步操作来提取L1的值。所以在你的例子中,因为L2索引为0,所以处理起来相对简单,直接得到了L1的索引。
从这些验证中,我们可以看到kernel page table的设置是符合预期的。
标志位的解析
在最低级page directory中的PTE标志位(fl部分)包含了读写标志位,并且Valid标志位也被设置。这表明此PTE可以被有效使用来翻译虚拟地址到物理地址。

- Valid 位:表示此条PTE有效,可以用来进行地址翻译。
- 读写标志位:表明该内存区域可以进行读写操作。
内核地址空间的进一步设置
内核会持续调用kvmmap函数来设置整个内核地址空间的映射。这包括了对多个关键设备和内存区域的映射,例如:
- VIRTIO0:用于磁盘访问。
- CLINT:用于定时器和软件中断。(新版本已删除)
- PLIC:用于外部中断。
- Kernel Text:只读的内核代码区域。
- Kernel Data:可读写的内核数据区域。
- TRAMPOLINE:用于在用户空间和内核空间之间切换。
最后,再次调用vmprint函数,我们可以看到完整的kernel page directory。此时,多个PTE已经设置好,它们构成了内核地址空间的映射关系。
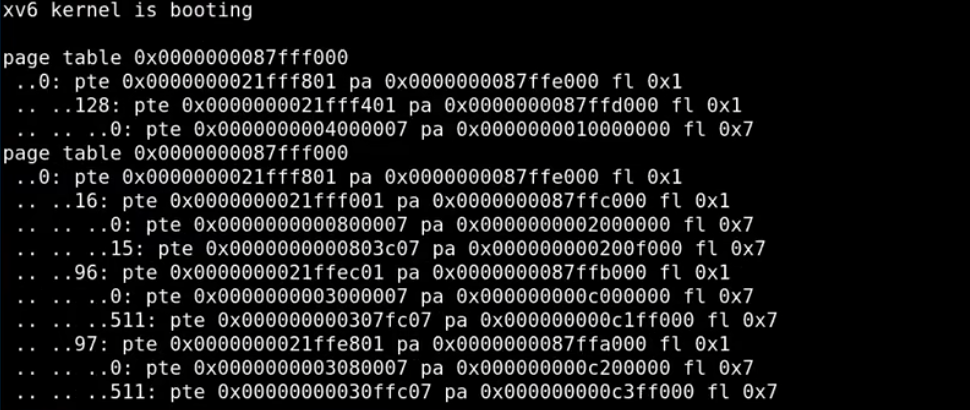
映射的正确性与安全性。这一过程不仅展示了XV6中的内存管理机制,也揭示了操作系统如何有效利用硬件提供的资源来确保系统的稳定与高效运行。
下面是本节内容相关额外补充:
补充1: 讲解kvminit
#include "param.h"
#include "types.h"
#include "memlayout.h"
#include "elf.h"
#include "riscv.h"
#include "defs.h"
#include "fs.h"
/*
* the kernel's page table.
*/
pagetable_t kernel_pagetable;
extern char etext[]; // kernel.ld sets this to end of kernel code.
extern char trampoline[]; // trampoline.S
// Make a direct-map page table for the kernel.
pagetable_t
kvmmake(void)
{
pagetable_t kpgtbl;
kpgtbl = (pagetable_t) kalloc();
memset(kpgtbl, 0, PGSIZE);
// uart registers
kvmmap(kpgtbl, UART0, UART0, PGSIZE, PTE_R | PTE_W);
// virtio mmio disk interface
kvmmap(kpgtbl, VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W);
// PLIC
kvmmap(kpgtbl, PLIC, PLIC, 0x4000000, PTE_R | PTE_W);
// map kernel text executable and read-only.
kvmmap(kpgtbl, KERNBASE, KERNBASE, (uint64)etext-KERNBASE, PTE_R | PTE_X);
// map kernel data and the physical RAM we'll make use of.
kvmmap(kpgtbl, (uint64)etext, (uint64)etext, PHYSTOP-(uint64)etext, PTE_R | PTE_W);
// map the trampoline for trap entry/exit to
// the highest virtual address in the kernel.
kvmmap(kpgtbl, TRAMPOLINE, (uint64)trampoline, PGSIZE, PTE_R | PTE_X);
// allocate and map a kernel stack for each process.
proc_mapstacks(kpgtbl);
return kpgtbl;
}
// Initialize the one kernel_pagetable
void
kvminit(void)
{
kernel_pagetable = kvmmake();
}
这个代码段展示了XV6内核如何设置和初始化内核页表 (kernel_pagetable)。它包括两个主要函数:kvmmake 和 kvminit。下面是对每一部分代码的详细讲解:
代码概述
-
kernel_pagetable:这是一个全局变量,表示内核的页表。所有内核空间的虚拟地址翻译都会使用这个页表。 -
etext[]和trampoline[]:这两个是外部声明的符号,分别表示内核代码的结束位置(由链接脚本kernel.ld设置)和用于处理陷阱(trap)的汇编代码段的起始位置。
kvmmake 函数
作用:kvmmake 函数用于创建并初始化一个直接映射(Direct-map)的内核页表。
1. 分配和清零页表
kpgtbl = (pagetable_t) kalloc();
memset(kpgtbl, 0, PGSIZE);
kalloc():这是一个内存分配函数,返回一个物理页面的地址。这里它分配了一个新的页表。memset:将分配的内存清零,为后续的映射初始化一个空的页表。
2. 映射硬件设备的物理地址
// uart registers
kvmmap(kpgtbl, UART0, UART0, PGSIZE, PTE_R | PTE_W);
// virtio mmio disk interface
kvmmap(kpgtbl, VIRTIO0, VIRTIO0, PGSIZE, PTE_R | PTE_W);
// PLIC
kvmmap(kpgtbl, PLIC, PLIC, 0x4000000, PTE_R | PTE_W);
kvmmap:这个函数将物理地址映射到虚拟地址空间。- UART0: 映射UART0的寄存器,大小为一个页面,权限为读写。
- VIRTIO0: 映射VirtIO磁盘的MMIO接口,大小为一个页面,权限为读写。
- PLIC: 映射PLIC(平台级中断控制器),大小为
0x4000000字节,权限为读写。
3. 映射内核代码和数据
// map kernel text executable and read-only.
kvmmap(kpgtbl, KERNBASE, KERNBASE, (uint64)etext-KERNBASE, PTE_R | PTE_X);
// map kernel data and the physical RAM we'll make use of.
kvmmap(kpgtbl, (uint64)etext, (uint64)etext, PHYSTOP-(uint64)etext, PTE_R | PTE_W);
- 内核代码(text):
- 映射从
KERNBASE(内核基地址)开始,到etext结束的地址区间。这个区域存储的是内核代码,设置为只读且可执行(PTE_R | PTE_X)。
- 映射从
- 内核数据:
- 映射
etext之后的内存区域到PHYSTOP,这是内核数据和可用物理内存的部分,设置为可读写(PTE_R | PTE_W)。
- 映射
4. 映射陷阱处理代码(Trampoline)
// map the trampoline for trap entry/exit to the highest virtual address in the kernel.
kvmmap(kpgtbl, TRAMPOLINE, (uint64)trampoline, PGSIZE, PTE_R | PTE_X);
- Trampoline: 映射一个用于处理陷阱(trap entry/exit)的小段代码,设置为只读和可执行。这个区域映射到了内核的最高虚拟地址。
5. 为每个进程分配和映射内核栈
proc_mapstacks(kpgtbl);
proc_mapstacks:这个函数为每个进程分配并映射一个内核栈。栈的映射对于每个进程来说是独立的,以防止进程之间的干扰。
6. 返回内核页表
return kpgtbl;
kvmmake函数最终返回构建完成的内核页表。
kvminit 函数
void
kvminit(void)
{
kernel_pagetable = kvmmake();
}
kvminit是一个简单的初始化函数,用来创建内核页表。它调用了kvmmake函数来生成内核页表,并将结果存储在全局变量kernel_pagetable中,供内核后续使用。
这个代码段通过kvmmake函数构建了一个完整的内核页表,确保了内核能够正确映射设备和内存地址,同时也为每个进程创建了独立的内核栈。kvminit 函数只是简单地调用kvmmake来初始化内核页表。
补充2: XV6 内核地址空间的初始化与映射流程详解
XV6操作系统的内核地址空间初始化与映射是操作系统启动过程中至关重要的环节。这个过程涉及多个核心组件的协同工作,包括虚拟地址、页表(Page Table)、TLB(Translation Lookaside Buffer),以及关键的内核函数,如kvminit和kvmmap。以下是对这一流程的完整结构化表述,涵盖了所有相关的知识点。
虚拟地址与物理地址映射
在现代操作系统中,内存管理通过虚拟内存机制实现。虚拟内存允许每个进程拥有独立的地址空间,使得多个进程可以在同一物理内存中独立运行而不会互相干扰。XV6通过页表实现虚拟地址到物理地址的映射。
- 虚拟地址:
- 虚拟地址是操作系统为每个进程分配的逻辑地址,进程通过这些地址访问内存中的数据。
- 虚拟地址并不直接对应物理内存位置,而是通过页表转换成物理地址。
- 物理地址:
- 物理地址是内存中的实际位置,由硬件决定。
- 在XV6中,物理地址大于0x80000000的部分对应DRAM,低于0x80000000的部分则对应各种I/O设备,如UART、PLIC、CLINT等。
页表(Page Table)结构
页表是实现虚拟内存的关键数据结构,它保存了虚拟地址与物理地址之间的映射关系。在RISC-V架构中,页表采用三级结构,即L2、L1、L0级。
- 三级页表:
- L2页表:最高级的页表目录,保存L1页表的物理地址。
- L1页表:中间级的页表目录,保存L0页表的物理地址。
- L0页表:最低级的页表目录,保存实际的物理页号(PPN)。
每一级页表的索引都是从虚拟地址中提取出来的,虚拟地址的高27位被分为三部分,每部分9位分别作为L2、L1、L0页表的索引。
- 页表项(PTE):
- 页表项(PTE)保存了每一页的物理地址和访问权限。
- PTE中低10位是标志位(如Valid、Readable、Writable等),用于控制内存访问的权限。
- TLB(Translation Lookaside Buffer):
- TLB是一个缓存,用于加速地址转换过程。
- 当处理器第一次查找一个虚拟地址时,硬件通过三级页表得到最终的物理地址,并将这个映射关系缓存到TLB中。下次访问相同虚拟地址时,可以直接从TLB中获取物理地址,而不必再次查找页表。
XV6 内核页表的初始化过程
在XV6中,内核的页表初始化和虚拟地址空间的设置是通过kvminit和kvmmap函数实现的。这个过程包括将内核的不同部分(如内核文本段、数据段、I/O设备等)映射到合适的虚拟地址空间。
kvminit函数:kvminit是内核页表初始化的起点。它调用kvmmake函数来创建内核的页表,并将这个页表保存到全局变量kernel_pagetable中。kvminit完成后,内核的页表结构已经建立,所有的虚拟地址都已正确映射到物理地址。
kvmmake函数:kvmmake函数负责分配最高级的页表目录(L2页表),并初始化为0。- 该函数随后调用
kvmmap函数,将内核的各个部分映射到相应的虚拟地址。 - 最后,
kvmmake返回构建好的页表给kvminit函数。
kvmmap函数:kvmmap用于将物理地址范围映射到虚拟地址空间,并设置相应的权限标志位。- 它逐一映射了UART、PLIC、CLINT、内核文本段、内核数据段等到合适的虚拟地址空间。
- 例如,内核文本段被映射为只读可执行(R-X),内核数据段被映射为可读可写(RW-)。
XV6 内核地址空间的布局
内核地址空间的布局如下:
- 内核文本段(Kernel Text):
- 包含内核的代码,被映射为只读且可执行(R-X)。
- 内核数据段(Kernel Data):
- 包含内核的全局变量和动态分配的内存,被映射为可读可写(RW-)。
- 内核栈(Kernel Stack):
- 为每个内核线程分配,通常在虚拟地址空间中有多个映射。
- Guard Page:
- 在内核栈之后,设置一个Guard Page,防止栈溢出导致的内存破坏。Guard Page没有映射到任何物理内存,如果访问会导致Page Fault。
- I/O设备映射:
- UART、PLIC、CLINT等设备被映射到指定的虚拟地址,通常与物理地址相同。
- Trampoline:
- Trampoline用于内核到用户空间的切换,映射到最高的虚拟地址空间。
过程总结
在整个XV6内核初始化过程中,通过kvminit和kvmmap函数,内核成功创建并配置了一个完整的页表,管理虚拟地址到物理地址的映射。这个页表保证了内核的各个部分可以正常运行,并通过不同的标志位确保内核的安全性和稳定性。
- Page Table的结构提供了高度的灵活性,允许复杂的地址映射和权限管理。
- TLB作为缓存机制,显著提高了地址转换的效率。
- Guard Page的使用和权限标志位的设置进一步提升了内核的安全性。