L03 Microcoding
Last Time in Lecture 2
在上次的讲座中,我们讨论了几项与计算机体系结构和存储器相关的重要技术,这些技术在计算机发展的早期阶段有着重要的应用,但随着时间推移,部分技术假设已被新的发展所取代。
首先,我们介绍了微代码(Microcoding),这是一种有效的技术,旨在管理控制单元的复杂性。微代码技术诞生于一个硬件技术百花齐放的时代,在那个时期,逻辑电路采用的是电子管(tubes),主存储器使用磁芯(magnetic core),而只读存储器(ROM)则采用了二极管(diodes)。这些不同的技术导致了控制单元设计和实现的复杂性增加,而微代码通过将复杂的操作逻辑转换为较为简单的指令序列,从而大大简化了控制单元的设计。
其次,讲座还讨论了ROM与RAM速度差异的影响。ROM(只读存储器)由于其相对较慢的访问速度,促使了在微指令系统中采用较为复杂的指令集。而RAM(随机存取存储器)访问速度较快,因此在需要高速数据处理的应用中,RAM成为了首选。然而,这种速度差异也导致了系统设计中需要权衡的部分增加,特别是在指令集设计和处理复杂指令时。
最后,随着技术的进步,特别是SRAM(静态随机存取存储器)的快速发展,之前基于不同存储器速度假设的技术设计逐渐失效。SRAM的高速性能使得许多早期关于存储器访问速度的技术假设变得不再适用,从而推动了计算机体系结构的进一步演进。
这些技术的历史背景和演变为我们理解现代计算机体系结构奠定了基础,同时也说明了随着硬件技术的发展,过去的设计假设可能会变得过时,需要通过新的技术和架构进行调整和改进。
Pure ROM Implementation
在纯 ROM 实现中,微程序控制器使用只读存储器 (ROM) 来存储微指令序列。该设计依赖于一个微程序计数器(μPC)来选择下一条需要执行的微指令。通过结合操作码(Opcode)、条件(Cond)和忙信号(Busy),微控制器可以灵活地控制微指令的执行顺序。每个 ROM 地址对应特定的微指令,通过微指令地址生成和数据读取来产生控制信号。这一部分描述了整个 ROM 控制的实现结构、地址位数的计算以及数据位数的分布。
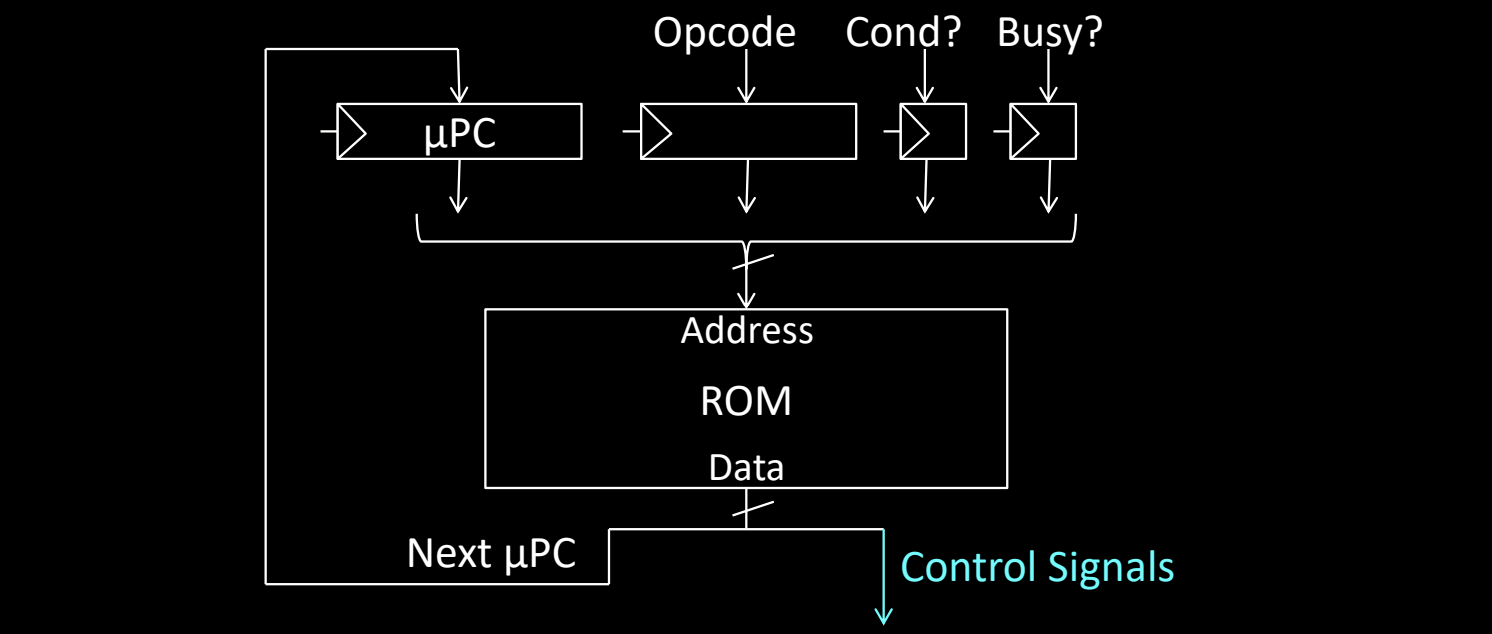
ROM 结构及数据流
- 微程序计数器(μPC):负责指向当前正在执行的微指令地址,并在每次微指令执行后更新到下一个微指令地址。
- 操作码(Opcode):指令集中的操作码,用于区分不同的指令类型,如算术操作、内存操作等。操作码被输入到微地址生成逻辑,用于进一步决定下一步要执行的微指令。
- 条件(Cond):根据某些操作的结果或状态条件决定是否继续当前操作或跳转到特定的微指令。例如,当某个条件满足时,可以跳转到其他微指令。
- 忙信号(Busy?):指示处理器当前是否忙碌或是否需要等待某些资源准备好。当忙信号为1时,处理器会暂停执行,直到信号变为0。
- ROM(只读存储器):存储所有的微指令,包含控制信号和下一条微指令的地址。ROM 接受地址输入并输出与该地址对应的控制信号和下一条微指令的地址。
地址位数计算
- 微地址(μAddress)位数计算: ROM 中的地址由微程序计数器、操作码、条件和忙信号共同决定。微地址位数的计算公式如下: \[ |\mu_{address}| = |\mu_{PC}| + |opcode| + 1 + 1 \] 这里,微地址的位数由 μPC 的位数、操作码的位数、条件位和忙信号位决定。条件和忙信号各占 1 位,总共需要 \( |\mu_{PC}| + |opcode| + 2\)位来生成唯一的 ROM 地址。
数据位数计算
- 微数据(μData)位数计算: ROM 中存储的每条数据包含微程序计数器的下一条指令地址以及控制信号。数据位数的计算公式为: \[ |\mu_{data}| = |\mu_{PC}| + |control signals| = |\mu_{PC}| + 18 \] 控制信号的宽度为18位,表示对每个功能单元的精确控制。因此,每个 ROM 地址输出的总数据位数为 μPC 的位数加上 18 位控制信号。
ROM 总大小
- ROM 大小: ROM 的总大小可以根据地址和数据的位数计算。公式为: \[ \text{Total ROM size} = 2^{|\mu_{address}|} \times |\mu_{data}| \] 通过计算得出 ROM 的总容量,这表明 ROM 需要足够的存储空间来保存所有微指令的控制信号和下一条指令地址。
微程序计数器(μPC)
微程序计数器(μPC)是控制器中用于跟踪当前正在执行的微指令位置的寄存器。它的主要作用是指示当前执行哪条微指令,并在每执行完一条微指令后更新其值,指向下一条要执行的微指令。因此,μPC 的值直接影响微指令的顺序,类似于普通程序中的程序计数器(PC),但μPC用于微指令层次。
可以说,μPC(微程序计数器)提供了微程序的基本控制流程,但并不能完全决定最终要执行的微指令。详见后面的表格。
微地址/微指令地址(μAddress)
微地址(μAddress) 是微程序控制器用来索引微指令存储器(通常是ROM)的地址。微地址由多个信息组合而成,不仅仅是μPC 的值。它实际上是一种复合地址,综合了多个决定因素,包括:
- 微程序计数器(μPC):指示当前微指令的编号。
- 操作码(Opcode):指示当前指令的类型,如加法、存储等。
- 条件位(Cond):判断是否满足某些特定条件(如状态寄存器的某个位)来决定执行流程。
- 忙信号(Busy?):指示是否有某些资源尚未准备好,需等待。
微地址(μAddress)不仅仅是一个单纯的微指令编号,而是通过结合微程序计数器(μPC)、操作码、条件位、忙信号等因素来精确定位ROM中的具体微指令。
可以把μPC理解为一个指向微程序执行流的主线索,它确保顺序执行或者条件跳转到不同的微指令位置,就像是程序中的主循环。而那些操作码、条件信号、忙信号等额外的控制位,就像是if-else条件判断,决定了在同一个μPC值下,具体执行哪条微指令。
微数据(μData)
微数据 是ROM中的每条微指令所存储的数据内容。这些数据通常包括两部分:
- 控制信号:直接用于控制处理器中的各个硬件模块的信号,如ALU操作、寄存器写入、内存访问等。这些信号确保处理器的硬件按照正确的步骤执行指令。
- 下一条微指令的地址:即下一条要执行的微指令的位置,通常是一个指向下一条微指令的地址。可以是微程序计数器(μPC)的更新值,或者是条件判断后可能的跳转地址。
因此,微数据(μData)是包含了当前微指令的所有控制信号以及下一条微指令的地址信息。
ROM中微地址和微数据的关系
微地址:
- 微地址是ROM的索引,用来定位存储在ROM中每条微指令的位置。
- 这个索引是由μPC(微程序计数器)与其他信息(如操作码、条件位、忙信号等)组合得到的。微地址的位数决定了ROM的地址空间大小,即ROM中可以容纳多少条不同的微指令。
微数据:
- 每条微地址对应的内容就是微数据,包含用于控制处理器操作的控制信号,以及下一条微指令的地址信息。
- 微数据的位数取决于控制信号的数量和每条微指令需要包含的其他信息(如下一条指令的地址)。
微地址和微数据位数不同的原因在于它们的功能不同:
- 微地址:是ROM的地址,用来索引ROM中的每一条微指令。微地址的位数取决于能索引的地址空间大小。比如,如果ROM中有1024条微指令,则微地址的位数为10位(\(2^{10} = 1024\))。
- 微数据:是ROM中存储的内容,包含控制信号和下一条微指令地址。微数据的位数取决于控制信号的宽度和需要存储的下一条微指令地址的位数。例如,假设控制信号需要18位,下一条指令地址需要10位,则每条微数据需要的位数为28位。
- 因此,微地址用于索引ROM中的位置,而微数据则是ROM中存储的每条微指令的具体内容,它们的位数根据需要各不相同。
- 微地址和微数据虽然都存在于ROM中,但它们的作用和位置是不同的区域。可以把它们想象成两个不同的部分:一个负责索引,另一个负责存储具体内容。
微地址和微数据如何协同工作
- 微地址生成:首先,根据当前的微程序计数器(μPC)、操作码、条件位和忙信号生成微地址。这个微地址就像是一个索引,通过它,处理器知道去ROM的哪个位置读取微指令。
- 读取微数据:处理器使用微地址从ROM中读取对应位置的微数据。微数据包含了具体的控制信号和下一条微指令的地址。
- 执行控制信号:微数据中的控制信号会直接用于控制处理器的硬件单元(如ALU、寄存器、内存等),让处理器完成当前微指令。
- 更新微程序计数器:根据微数据中的下一条微指令地址,更新μPC(微程序计数器),然后处理器再根据更新后的μPC生成下一个微地址,继续从ROM中读取下一条微指令。
例子
假设你当前有一个微程序计数器(μPC)值为
1010,操作码为1101101,条件位和忙信号各为1。则生成的微地址可能是:\[ \mu_{address} = \mu_{PC} + opcode + cond + busy = 1010 + 1101101 + 1 + 1 \]
这个微地址可能会映射到ROM中的一个位置,比如第256个地址。在这个地址处,ROM存储的微数据可能是:
- 控制信号:用于控制处理器内的操作,比如
ALU_op = add,Reg_write = 1。- 下一条微指令地址:指向下一个需要执行的微指令,比如
next_μPC = 1011。处理器根据当前微地址读取ROM中的微数据,执行相应的控制操作,并更新μPC,然后进入下一个微指令循环。
Pure ROM Contents (Truth Table)
微指令序列以真值表的形式展现,表中列出了不同微程序计数器(μPC)的地址输入和相应的控制信号输出。微指令控制处理器的每一个执行阶段,包括指令取值、ALU 操作、内存访问等。
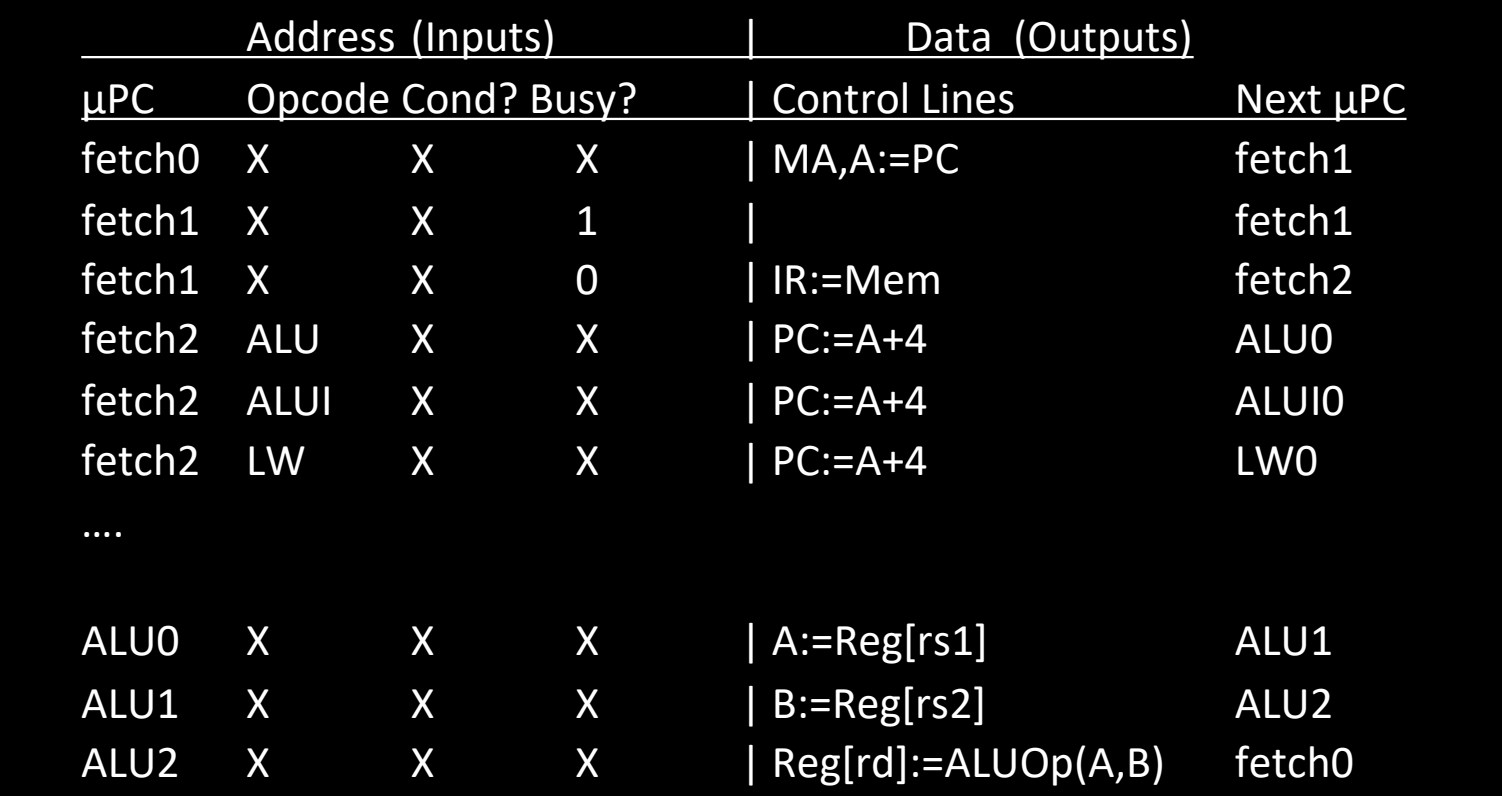
微地址和控制线示例
- Fetch0 (取指阶段 0):
- Address (Inputs):
μPC = fetch0,操作码、条件和忙信号均为任意值(X)。 - Control Lines (控制线输出):
MA, A := PC,将程序计数器的值加载到地址寄存器 (MA) 和 A 寄存器,用于下一条指令的取值。 - Next μPC:
fetch1,表示下一个微指令为取指阶段的第二步。
- Address (Inputs):
- Fetch1 (取指阶段 1):
- Address (Inputs):
μPC = fetch1,忙信号为 1 时,保持在 fetch1,忙信号为 0 时,继续执行下一条微指令。 - Control Lines (控制线输出):
IR := Mem,从内存中加载指令并存储在指令寄存器 (IR) 中。 - Next μPC:
fetch2,下一步进入取指阶段 2。
- Address (Inputs):
- Fetch2 (取指阶段 2):
- Address (Inputs):
μPC = fetch2,操作码为任意值。 - Control Lines (控制线输出):
PC := A + 4,将程序计数器的值加 4,准备取下一条指令。 - Next μPC: 根据操作码不同,分别进入不同的 ALU 操作阶段。例如,当操作码是ALU时,进入
ALU0阶段;当是加载指令(LW)时,进入LW0阶段。
- Address (Inputs):
ALU 操作
- ALU0:
- Address (Inputs):
μPC = ALU0,控制线指示从寄存器文件中读取rs1寄存器的值。 - Control Lines:
A := Reg[rs1],将rs1的值存储到 A 寄存器。 - Next μPC:
ALU1,进入下一步,继续从rs2读取数据。
- Address (Inputs):
- ALU1:
- Address (Inputs):
μPC = ALU1,从寄存器rs2中读取操作数。 - Control Lines:
B := Reg[rs2],将rs2的值存储到 B 寄存器。 - Next μPC:
ALU2,准备执行 ALU 运算。
- Address (Inputs):
- ALU2:
- Address (Inputs):
μPC = ALU2,执行 ALU 运算,将结果写入目标寄存器rd。 - Control Lines:
Reg[rd] := ALUOp(A, B),将 A 和 B 的值通过 ALU 运算,将结果存储到rd。 - Next μPC:
fetch0,回到取指阶段,准备执行下一条指令。
- Address (Inputs):
通过这种纯 ROM 实现的控制器,处理器能够灵活、精准地执行各种指令。ROM 的每一个地址对应特定的微指令,而每一条微指令控制着硬件的运作。
Single-Bus Microcode RISC-V ROM Size
在单总线微代码控制的 RISC-V 处理器中,控制逻辑是通过存储在只读存储器(ROM)中的微指令实现的。ROM 大小的计算涉及指令取值的步骤、指令组的数量、每组指令所需的执行步骤,以及控制信号的数量等要素。
Instruction Fetch 和 Instruction Groups
指令取值过程通常有三个通用步骤,而所有指令可以分为大约 12 个指令组(如算术运算、逻辑运算、内存操作、分支等)。每个指令组的执行大约需要 5 个步骤,其中一个步骤用于指令的分发或调度(dispatch)。
- 指令取值的 3 个通用步骤:每条指令都需要执行的基本操作,例如取指、解码和 PC 更新。
- 12 个指令组:根据操作码将指令分为不同组,每组有不同的微指令序列。
- 每组约 5 步骤:每个指令组的执行分为多个阶段,例如 ALU 操作、内存访问、写回寄存器等。
总的步骤计算为: \[ \text{Total steps} = 3 + 12 \times 5 = 63 \] 这意味着微程序计数器(μPC)需要 6 位来表示(因为 ( 2^6 = 64 ) 能够覆盖所有步骤)。
Opcode 和 Control Signals
- 操作码(Opcode):RISC-V 指令的操作码为 5 位,每条指令包含不同的操作码用于区分操作类型。
- 控制信号(Control Signals):处理器的各个功能单元由大约 18 个控制信号控制。这些信号决定了寄存器、ALU、内存和总线的操作。
ROM 大小计算
为了确定 ROM 的总大小,我们需要考虑地址和数据的位数。
-
地址位数计算: 地址由微程序计数器(μPC)、操作码和额外的条件位(如忙信号)共同决定。其位数为: \[ |\mu_{address}| = 6 + 5 + 2 = 13 \text{ bits} \] 其中,6 位用于 μPC,5 位用于操作码,另外 2 位用于条件信号和忙信号。
-
数据位数计算: 数据部分包含微程序计数器的下一步信息(μPC 的下一条指令地址)和 18 位控制信号。总数据位数为: \[ |\mu_{data}| = 6 + 18 = 24 \text{ bits} \]
-
ROM 总大小: 总大小为: \[ \text{Total size} = 2^{13} \times 24 = 8192 \times 24 \approx 25 \text{ KiB} \] 因此,ROM 的总大小约为 25 KiB,存储所有的微指令和控制信号。
Reducing Control Store Size
为了优化 ROM 的大小,可以从以下两个方面进行改进:减少地址位(ROM 高度)和减少数据位(ROM 宽度)。
减少 ROM 高度(地址位数)
- 使用外部逻辑来组合输入信号:可以使用额外的逻辑电路来优化地址生成,减少需要的地址空间。例如,通过外部逻辑合并操作码、条件信号和其他输入,减少直接存储在 ROM 中的状态数量。
- 通过分组操作码减少状态:将操作码分组处理,避免对每个操作码单独生成微指令,从而减少微程序的数量。
减少 ROM 宽度(数据位数)
- 限制 μPC 编码(如下一步、分发、等待内存等):通过优化微程序计数器的编码方式,减少控制信号的冗余信息。例如,不需要在每一条微指令中都存储完整的控制信号,只需存储对关键步骤的指示(如下一步、等待等)。
- 控制信号的编码(垂直微编码、纳米编码):可以采用更高效的编码方式,例如垂直微编码或纳米编码,将控制信号压缩成更小的位数。这样不仅能减少 ROM 的宽度,还能提高控制器的效率。
这些方法都能有效减少控制存储器(ROM)的大小,从而优化处理器的性能和成本。
Single-Bus RISC-V Microcode Engine
在单总线 RISC-V 微代码引擎中,微指令控制器通过 ROM 来存储微指令和相应的控制信号。每个指令执行由多个微指令组成,这些微指令的顺序由微程序计数器(μPC)控制,并通过微程序跳转逻辑(μPC Jump Logic)决定下一步的执行路径。
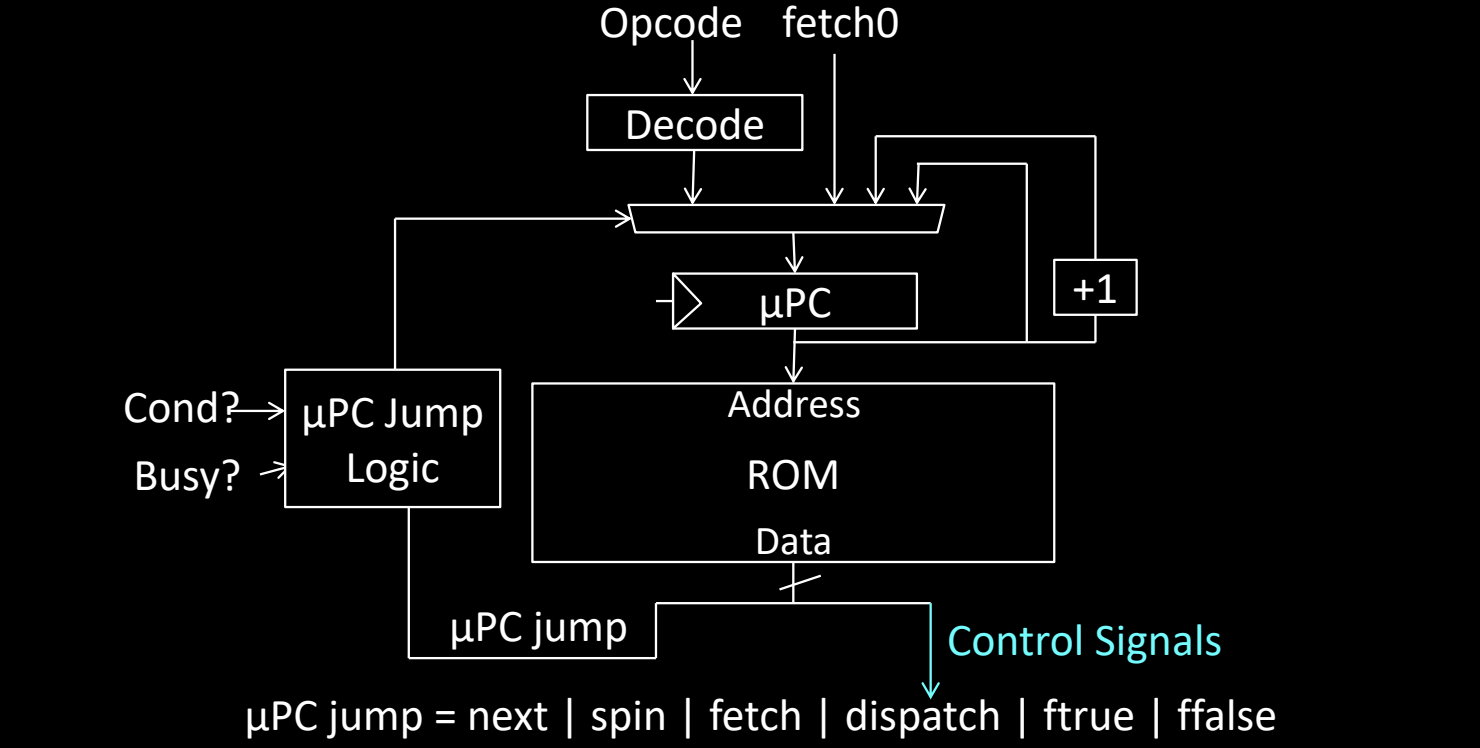
微程序控制逻辑
- Opcode:指令的操作码,用于区分不同的指令类型,并通过解码单元进行处理。
- μPC(Micro Program Counter):微程序计数器负责跟踪当前正在执行的微指令,并根据跳转逻辑确定下一条微指令的地址。
- Decode:解码单元从 Opcode 提取指令类型,并发送给 μPC,帮助生成下一条微指令地址。
- ROM:ROM 存储了所有的微指令,每条微指令包含控制信号和下一条微指令的地址。
- μPC Jump Logic:跳转逻辑决定如何更新 μPC,根据条件(如 Busy 和 Cond)以及当前的操作,选择是否跳转、继续执行、等待或重新取指。
μPC Jump 选项
μPC 的跳转选项包括:
- next:将 μPC 递增 1,进入下一条微指令。
- spin:处理器等待外部资源(如内存)的响应,μPC 暂时保持不变。
- fetch:跳转回取指阶段,开始执行下一条指令。
- dispatch:跳转到解码后的操作码组,开始执行具体的指令类型。
- ftrue/ffalse:根据条件跳转,若条件成立跳转到指定位置,否则返回取指阶段。
Encoded ROM Contents
在单总线 RISC-V 微代码引擎中,ROM 的内容以真值表的形式呈现,每个微程序计数器(μPC)对应特定的控制信号输出和下一步跳转信息。以下是真值表中的一些典型例子,展示了 RISC-V 指令执行的几个阶段的微指令控制。
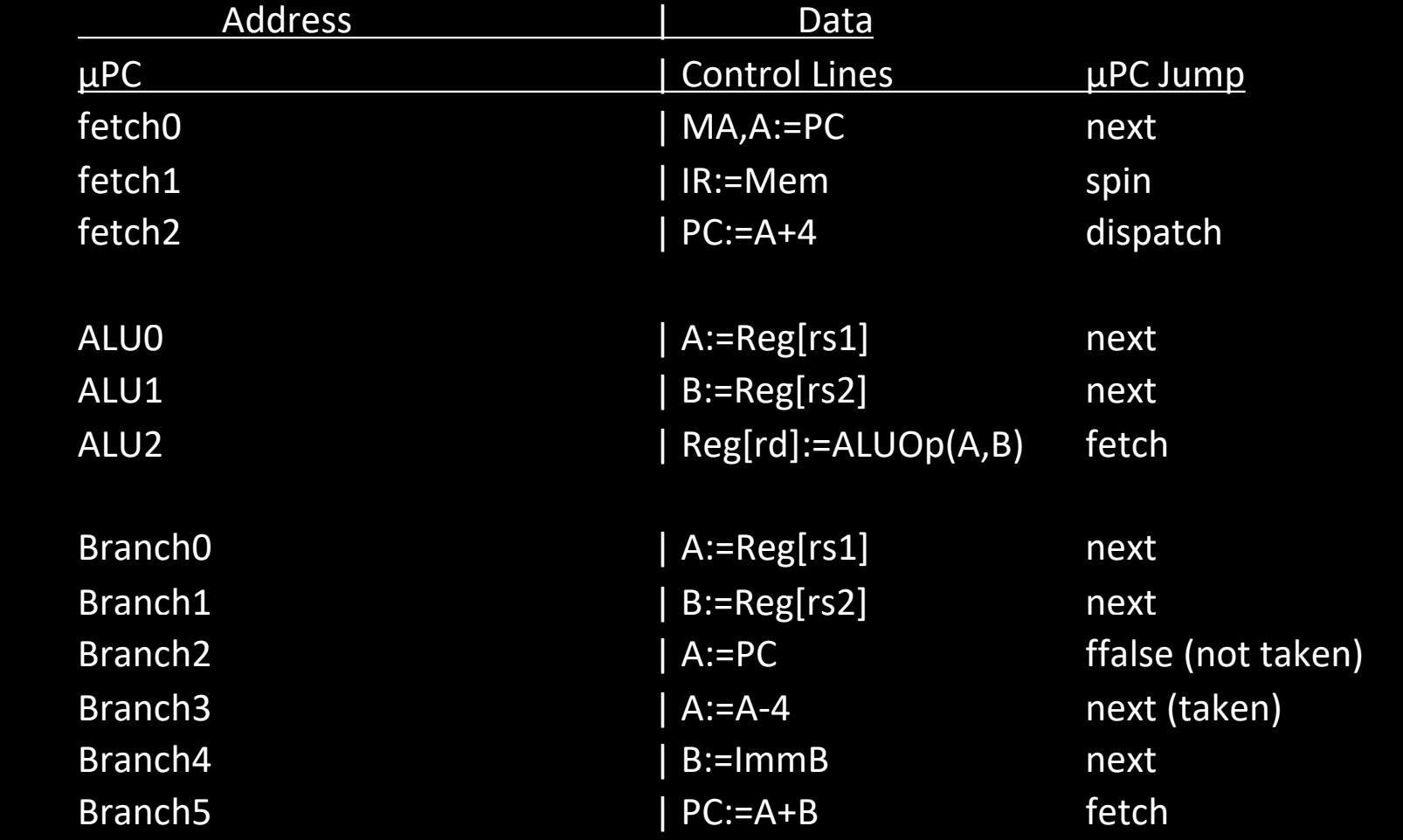
Fetch 阶段
- fetch0:
- Control Lines:
MA, A := PC,将程序计数器(PC)加载到地址寄存器(MA)和寄存器 A 中,准备取指。 - μPC Jump:
next,进入下一步微指令。
- Control Lines:
- fetch1:
- Control Lines:
IR := Mem,从内存中读取指令并加载到指令寄存器(IR)。 - μPC Jump:
spin,等待内存读取完成。
- Control Lines:
- fetch2:
- Control Lines:
PC := A + 4,将 PC 加 4,准备取下一条指令。 - μPC Jump:
dispatch,跳转到具体指令的操作码处理组。
- Control Lines:
ALU 操作
- ALU0:
- Control Lines:
A := Reg[rs1],从寄存器rs1读取数据,加载到寄存器 A 中。 - μPC Jump:
next,进入下一步微指令。
- Control Lines:
- ALU1:
- Control Lines:
B := Reg[rs2],从寄存器rs2读取数据,加载到寄存器 B 中。 - μPC Jump:
next,准备执行 ALU 运算。
- Control Lines:
- ALU2:
- Control Lines:
Reg[rd] := ALUOp(A, B),执行 ALU 运算,将结果写入目标寄存器rd。 - μPC Jump:
fetch,返回取指阶段,准备执行下一条指令。
- Control Lines:
Branch 指令
- Branch0:
- Control Lines:
A := Reg[rs1],从寄存器rs1读取数据,加载到 A 中。 - μPC Jump:
next,进入下一步微指令。
- Control Lines:
- Branch1:
- Control Lines:
B := Reg[rs2],从寄存器rs2读取数据,加载到 B 中。 - μPC Jump:
next,继续进行分支条件判断。
- Control Lines:
- Branch2:
- Control Lines:
A := PC,将当前 PC 值加载到 A 寄存器。 - μPC Jump:
ffalse (not taken),如果分支条件不成立,跳转回取指阶段执行下一条指令。
- Control Lines:
- Branch3:
- Control Lines:
A := A - 4,修正 PC 计数器,确保跳转正确。 - μPC Jump:
next (taken),如果分支条件成立,继续跳转。
- Control Lines:
- Branch4:
- Control Lines:
B := ImmB,将分支偏移量加载到 B 中。 - μPC Jump:
next,进入下一步计算跳转地址。
- Control Lines:
- Branch5:
- Control Lines:
PC := A + B,将当前 PC 值加上分支偏移量,得到跳转目标地址。 - μPC Jump:
fetch,跳转到新的地址后,进入取指阶段,准备执行新指令。
- Control Lines:
Implementing Complex Instructions
在微代码控制的 RISC-V 处理器中,实现复杂指令(如内存到内存的加法操作)并不需要对数据通路进行实质性的修改。相反,处理复杂指令的关键在于微指令的控制逻辑和程序。通过微代码的编排,复杂的指令可以通过多步骤执行,而无需重新设计硬件。
Memory-Memory Add: M[rd] = M[rs1] + M[rs2]
例如,对于内存到内存的加法指令,M[rd] = M[rs1] + M[rs2],该操作需要多个步骤完成,包括从内存读取数据、进行加法运算,并将结果写回内存。以下是该操作的微指令序列:

- MMA0:
- Control Lines:
MA := Reg[rs1],将寄存器rs1的值(第一个操作数的内存地址)加载到内存地址寄存器(MA)。 - μPC Jump:
next,进入下一步微指令。
- Control Lines:
- MMA1:
- Control Lines:
A := Mem,从内存中读取rs1地址的数据并存储到寄存器 A 中。 - μPC Jump:
spin,等待内存操作完成。
- Control Lines:
- MMA2:
- Control Lines:
MA := Reg[rs2],将寄存器rs2的值(第二个操作数的内存地址)加载到内存地址寄存器。 - μPC Jump:
next,进入下一步微指令。
- Control Lines:
- MMA3:
- Control Lines:
B := Mem,从内存中读取rs2地址的数据并存储到寄存器 B 中。 - μPC Jump:
spin,等待内存操作完成。
- Control Lines:
- MMA4:
- Control Lines:
MA := Reg[rd],将目标寄存器rd中的地址加载到内存地址寄存器,准备写入结果。 - μPC Jump:
next,进入下一步微指令。
- Control Lines:
- MMA5:
- Control Lines:
Mem := ALUOp(A, B),通过 ALU 执行加法操作,将 A 和 B 的结果写入到rd的内存地址。 - μPC Jump:
spin,等待内存写入操作完成。
- Control Lines:
- MMA6:
- 空微指令,标志该操作完成。
- μPC Jump:
fetch,跳转回取指阶段,准备执行下一条指令。
复杂指令的执行特点
- 复杂指令不需要修改数据通路:如上所示,实现复杂指令时,处理器的数据通路并不需要修改。处理器通过微指令序列执行多步骤操作,依次访问内存、执行运算、并写回结果。
- 控制程序需要额外的存储空间:复杂指令的实现通常需要更多的微指令,这意味着需要为控制程序分配更多的 ROM 空间,但硬件部分无需修改。
- 硬连线控制器实现复杂指令难度大:如果使用硬连线控制器,执行类似
M[rd] = M[rs1] + M[rs2]的复杂操作将需要大幅修改数据通路,并增加大量硬件控制逻辑。
Single-Bus Datapath for Microcoded RISC-V
在单总线微代码控制的 RISC-V 处理器中,所有复杂指令的执行均通过共享的总线实现,而不需要对数据通路进行任何修改。数据通路的设计在执行简单和复杂指令时保持一致。
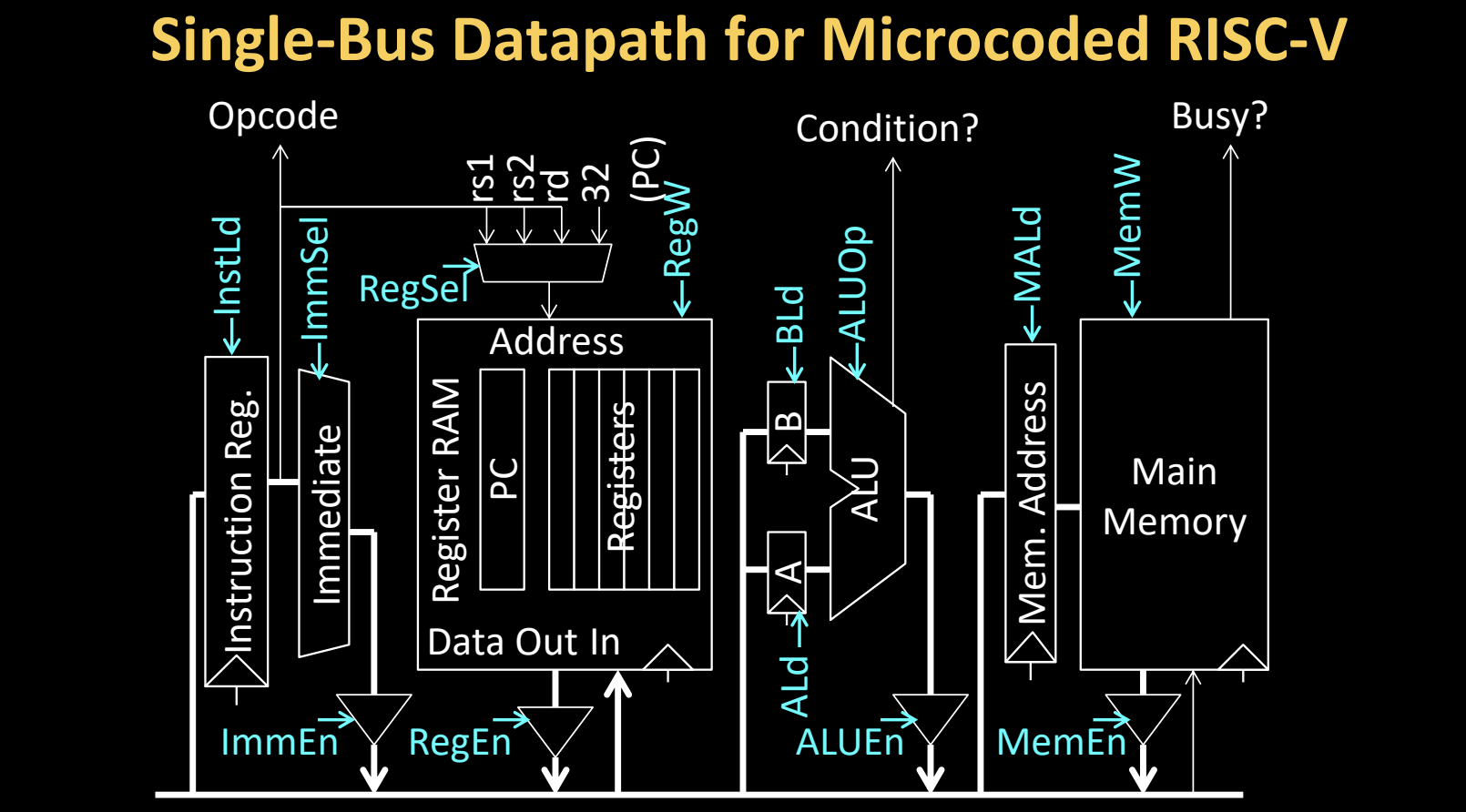
数据通路组成部分
- 指令寄存器(Instruction Register, IR):存储从内存中加载的当前指令。
- InstLd 信号:控制指令寄存器的加载。
- 立即数扩展器(Immediate Extension):处理指令中的立即数,生成用于 ALU 或内存操作的立即数。
- ImmSel:选择合适的立即数类型。
- ImmEn:使能立即数扩展。
- 寄存器文件(Register File):包含通用寄存器以及程序计数器(PC),用于存储和提供操作数。
- RegSel:控制从寄存器文件中读取的寄存器编号。
- RegEn:使能寄存器文件的读写操作。
- RegW:控制写回目标寄存器的时机。
- 算术逻辑单元(ALU):执行算术和逻辑运算。
- ALUOp:控制 ALU 的运算类型(如加法、减法等)。
- ALUEn:使能 ALU,启动运算。
- 主存储器(Main Memory):存储指令和数据,处理器通过地址总线和数据总线访问存储器。
- MALd:加载内存地址。
- MemEn:使能内存操作,决定何时从内存读取或写入数据。
- MemW:控制是否向内存写入数据。
复杂指令的无修改实现
- 数据通路的设计对于复杂指令和简单指令都保持不变。微代码程序通过控制信号来确保每一步都在适当的时机执行,例如内存地址的加载、ALU 运算的执行和内存的读写。
- 复杂指令如内存到内存的加法操作,通过多个微指令协调 ALU 和内存的访问,并通过控制信号保证操作顺序的正确性。
Horizontal vs Vertical Microcode
在微代码的设计中,水平微代码(Horizontal microcode)和垂直微代码(Vertical microcode)代表了两种不同的微指令编码方式。这两种方式在微指令的宽度(每条微指令的位数)、指令的数量、以及系统的复杂性上各有不同。
Horizontal Microcode
水平微代码具有更宽的微指令,每条微指令包含多个并行操作,允许处理器在一个时钟周期内执行多个数据通路操作。这种设计具有较高的执行效率,因为它减少了每条宏指令所需的微指令数量。
- 特点:
- 每条微指令包含多个并行操作。
- 每条宏指令所需的微指令步数更少,因此能更快执行宏指令。
- 由于多操作并行执行,编码相对稀疏,这意味着微指令占用更多的比特(位数更多)。
- 优点:
- 较高的并行性,能够在一个时钟周期内完成多项任务。
- 缺点:
- 需要更多的比特来表示控制信号,导致微代码存储空间更大。
Vertical Microcode
垂直微代码的微指令较窄,每条微指令通常只执行一个数据通路操作。这种设计的微指令更紧凑,但每条宏指令需要更多的微指令步数来完成。
- 特点:
- 每条微指令通常只执行一个操作。
- 每条宏指令所需的微指令步数更多。
- 更紧凑的编码,微指令需要更少的比特。
- 优点:
- 微指令编码更紧凑,存储空间需求较小。
- 缺点:
- 需要更多的微指令步数来完成一条宏指令,执行速度较慢。
Nanocoding
纳米编码是一种结合水平微代码和垂直微代码优势的技术。它试图通过利用微代码中经常重复的控制信号模式来减少微代码的宽度和复杂性。
- 特点:
- 利用微代码中经常重复的控制信号模式,将其分解为更小的“纳米指令”。
- 将微代码划分为两个层次:一个是常规的微指令集,另一个是用来解释这些微指令的纳米指令集。
Nanocoding in Detail
纳米编码利用微代码中的重复模式,将复杂的控制信号组合简化为更小的单元。通过这种方式,它减少了每条微指令的位数需求,同时保持了灵活的控制机制。
工作原理
- 微代码 ROM:处理器通过微程序计数器(μPC)从微代码 ROM 中读取微指令,这些指令包含了控制信号或指向纳米指令的指针。
- 纳米指令 ROM:当微代码指令指向纳米指令时,纳米指令 ROM 根据纳米指令地址生成更加详细的控制信号,进一步控制数据通路操作。
例子:Motorola 68000
- 17 位微指令:每条微指令包含 17 位,其中可能包括 10 位的微跳转(μjump)或 9 位的纳米指令指针。
- 68 位纳米指令:纳米指令宽度为 68 位,解码后能够生成 196 条控制信号。这种设计通过减少微指令的宽度节省了存储空间,但仍能提供足够的灵活性来控制复杂操作。
纳米编码通过精简微指令和利用更小的纳米指令来减小微代码的存储需求,同时保持处理器对复杂指令的控制能力。这种技术特别适合那些需要同时兼顾复杂指令支持和存储效率的处理器设计。
Microprogramming in IBM 360
在 IBM 360 系列计算机中,微程序设计在处理器控制和指令执行中起到了关键作用。不同型号的 IBM 360 系列计算机采用了不同的微程序实现方式,以适应各自的硬件和性能需求。
不同型号的比较
| Model | M30 | M40 | M50 | M65 |
|---|---|---|---|---|
| Datapath width (bits) | 8 | 16 | 32 | 64 |
| μinst width (bits) | 50 | 52 | 85 | 87 |
| μcode size (K μinsts) | 4 | 4 | 2.75 | 2.75 |
| μstore technology | CCR0S | TCR0S | BCR0S | BCR0S |
| μstore cycle (ns) | 750 | 625 | 500 | 200 |
| Memory cycle (ns) | 1500 | 2500 | 2000 | 750 |
| Rental fee ($K/month) | 4 | 7 | 15 | 35 |
- Datapath width (数据通路宽度):不同型号的处理器有不同的位宽,从 M30 的 8 位到 M65 的 64 位。随着位宽的增加,处理器每个时钟周期能够处理的数据量也相应增加。
- μinst width (微指令宽度):不同型号的微指令位宽也不同,M65 的微指令宽度最大,为 87 位。这反映了更多的并行控制信号和更复杂的操作。
- μcode size (微代码大小):各型号的微代码存储容量有所不同,M30 和 M40 具有 4K 条微指令,而 M50 和 M65 则较小,约为 2.75K。
- μstore technology (微存储技术):不同型号使用了不同的微存储技术,包括 CCR0S(Capacitor Read-Only Storage)、TCR0S(Transistor Capacitor Read-Only Storage)和 BCR0S(Binary Capacitor Read-Only Storage)。这些技术用于存储微指令。
- μstore cycle (微存储周期):反映了读取微存储中的一条微指令所需的时间。M65 的微存储周期最短,仅为 200 纳秒。
- Memory cycle (内存周期):内存访问时间,各型号差异较大,M65 的内存访问最快,为 750 纳秒,而 M40 的内存周期为 2500 纳秒。
-
Rental fee (租赁费用):每个月的租金从 M30 的 4000 美元到 M65 的 35000 美元不等,反映了性能和成本的差异。
- 微程序化设计:除了最快和最便宜的型号(如 M75 和 M95)使用了硬连线控制,其他型号的 IBM 360 计算机大多采用了微程序化设计。这使得控制器的设计更简单、灵活,并且便于支持复杂的指令集。
IBM Card-Capacitor Read-Only Storage (CCR0S)
IBM 在 1960 年代初期使用了一种创新的存储技术,称为 卡电容只读存储器(Card-Capacitor Read-Only Storage, CCR0S),如图所示。这种存储器通过打孔卡和金属膜的组合来存储数据。

- 工作原理:打孔卡上覆盖金属膜,作为电容的一部分。通过感应板读取电容变化来存取数据。
- 使用:这种技术主要用于存储微代码,因为其读取速度比当时的 DRAM 快得多,适合频繁访问的控制信号存储。
Microprogramming Thrived in the 1960s and 1970s
微程序设计在 1960 年代和 1970 年代得到了广泛应用,主要原因如下:
- 更快的 ROM 存储器:相比当时的 DRAM,ROM 提供了更高的访问速度,适合存储频繁调用的微指令。
- 支持复杂指令集:对于复杂的指令集,使用微程序化控制能够简化数据通路和控制器的设计,减少硬件的复杂性和成本。
- 扩展新指令:例如,浮点运算等新指令可以通过微代码支持,而不需要对数据通路进行修改。
- 便于修复控制器的错误:修复控制逻辑中的错误可以通过修改微代码实现,而不需要大规模更改硬件设计。
- ISA 兼容性:通过微代码,不同型号的处理器可以轻松实现指令集架构(ISA)的兼容性,从而节省设计和维护成本。
除了最快和最便宜的计算机,几乎所有的 IBM 360 型号都采用了微程序设计。这种设计在 20 世纪中期的计算机系统中占据了重要地位,不仅简化了复杂指令集的实现,还提高了系统的灵活性和可维护性。
Microprogramming: Early 1980s
在20世纪80年代初期,微程序控制技术面临着复杂性不断增加的挑战。随着计算机体系结构的演进和复杂指令集的广泛使用,微代码的复杂度也相应增加。以下是这一时期微程序设计的演变和面临的问题。
微机器的复杂化
- 复杂指令集:随着计算机指令集的复杂化,微代码需要支持更多的子程序调用(subroutine)和调用栈(call stack),从而进一步增加了微程序的复杂度。
- 修复控制程序中的错误:由于微存储器(μROM)是只读的,因此很难在不修改硬件的情况下修复微代码中的错误。这引发了对更灵活存储控制器的需求。
可写控制存储器(Writable Control Store, WCS)
- 为了解决上述问题,一些系统开始引入 可写控制存储器(WCS),允许控制存储器不再是只读的,用户可以对微代码进行修改。例如,B1700、QMachine 和 Intel i432 等系统都采用了 WCS 技术。
技术假设的失效
- VLSI 技术的进步:随着超大规模集成电路(VLSI)技术的发展,关于 ROM 和 RAM 速度的假设逐渐失效。ROM 与 RAM 之间的速度差距逐渐缩小,这使得系统的复杂性增加,因为可以选择使用 RAM 作为控制存储器。
- 编译器的进步:编译器技术的进步使得复杂指令集的重要性降低。通过更好的编译器优化,复杂指令可以通过较简单的指令组合来实现,从而减少对微代码的依赖。
- 微架构创新:新的微架构技术(如流水线、缓存和缓冲器)的引入,使得多周期的寄存器到寄存器指令不再具有吸引力,更多的指令能够在单周期内完成执行。
Writable Control Store (WCS)
WCS 是一种将控制存储器实现为 RAM 而不是 ROM 的技术。这种设计带来了灵活性,尤其是在修复微代码错误或实现更复杂的控制逻辑时具有优势。
WCS 的优势
- RAM 几乎和 ROM 一样快:到 1980 年代,MOS SRAM 的速度几乎接近控制存储器的速度。相比之下,早期的磁芯存储器或 DRAM 慢 2 到 10 倍,因此 SRAM 成为可行的替代方案。
- 修复错误的灵活性:由于微代码程序通常难以避免错误,使用可写控制存储器使得修复微程序错误更加容易。
用户可写控制存储器(User-WCS)
-
作为选项提供:一些微型计算机(minicomputer)提供了用户可写控制存储器(User-WCS)作为选项。用户可以根据需要修改每个处理器的微代码,从而实现更个性化的指令集支持。
-
User-WCS 失败的原因:
- 缺乏编程工具支持:用户缺乏合适的工具来编写和调试微代码,使得 User-WCS 在实际应用中难以推广。
- 难以将软件适配到有限的空间:微代码存储空间有限,用户编写的微代码难以适应这种小型存储。
- 微代码控制高度依赖于原有的指令集架构(ISA):微代码的设计是针对特定指令集架构的,其他用途下微代码的可用性和灵活性有限。
- 上下文切换开销高:WCS 成为了处理器状态的一部分,使得上下文切换成本很高。
- 安全和保护问题:允许用户修改微代码可能引发安全问题,特别是当虚拟内存系统要求可重启的微代码时,保护变得更加困难。
尽管 WCS 具有灵活性和修复错误的优势,但由于工具支持不足、性能开销和安全问题,User-WCS 在实际应用中并未得到广泛采用,尤其是对于普通用户来说,其复杂度过高。
Microprogramming is Far From Extinct
尽管微程序控制技术在现代处理器中的应用比以往有所减少,但它仍然在某些领域和应用中起着重要作用。以下是微程序在不同时间段和处理器中的应用情况。
1980年代微型计算机中的关键作用
- 微程序在1980年代的微型计算机中发挥了至关重要的作用。例如:
- DEC uVAX
- Motorola 68K系列
- Intel 286/386
在这些早期的微处理器中,微代码负责控制复杂指令集的执行,简化了处理器的设计。
现代处理器中的辅助作用
- 在大多数现代处理器中,微程序依然起着辅助作用。处理器的设计通常依赖硬连线控制来执行大多数常用指令,而微代码主要用于处理较少使用或复杂的指令。例子包括:
- AMD Zen
- Intel Sky Lake
- Intel Atom
- IBM PowerPC
特点:
- 大多数指令通过硬连线控制直接执行,效率较高。
- 不常用或复杂的指令通过微代码调用来完成。
可修补的微代码
- 在生产后的错误修复中,微代码修补已经成为常见的做法。例如,Intel 处理器在启动时加载微代码补丁,以修复在制造后发现的错误或安全漏洞。
- 一个显著的例子是 Intel 在应对 Meltdown 和 Spectre 安全漏洞时,必须紧急恢复使用微代码工具,并召回原来的微代码工程师,进行补丁开发和部署。
CS152 Administrivia
Homework 1
- HW1 已发布,提交截止日期为 2月2日。
实验室小组匹配
- 学生需填写表格进行实验室小组匹配:
成绩说明
- 学生需完成 5个实验中的至少3个,否则将自动获得 F 等级,无论其他分数如何。
宽限日政策
- 宽限日:每位学生有 7天宽限日,用于实验和问题集提交延迟。如果需要,请提前提交延长请求。
讨论和答疑时间
- 讨论和办公时间 本周开始,请查阅课程日历了解具体安排。
- 星期三上午10点至12点 的讨论已取消。
- 讨论会将被录制,供学生回看。
CS252 Administrivia
CS252 Readings on Website
- 请在 周三 前通过 hotcrp 上传文章的阅读评论:
- 写一段关于论文主要内容的总结,包含论文的优点和缺点。
- 同时回答或提出 1-3 个关于论文的问题,供讨论使用。
- 本周阅读的前两篇文章为:“360 Architecture” 和 “VAX11-780”。
- 讨论时间:周三下午 2-3 点,Soda 606 或通过 Zoom 在线。
CS252 Project Timeline
- 项目提案提交截止日期:2月22日周三。
- 提交要求:
- 提交一页 PDF 格式文件,内容包括:
- 项目标题
- 项目成员(每个项目 2 人)
- 需要解决的问题是什么?
- 你们的解决方案是什么?
- 需要使用的基础设施
- 时间线和关键里程碑
- 提交一页 PDF 格式文件,内容包括:
Analyzing Microcoded Machines
John Cocke and Group at IBM
- John Cocke 和 IBM 的团队致力于研究简单的流水线处理器 801,并在 IBM 内部开发了先进的编译器。
- 他们将实验性的 PL.8 编译器 移植到 IBM 370,并仅使用了简单的寄存器到寄存器的操作和类似于 801 的加载/存储指令。
- 该编译器生成的代码运行速度比当时其他使用所有 370 指令集的编译器要快很多(从 2 MIPS 提升到 6 MIPS,相比之下,2 MIPS 已被视为优良表现)。
Emer, Clark, at DEC
- Emer 和 Clark 使用外部硬件对 VAX-11/780 进行了测量。
- 他们发现,VAX-11/780 实际上是一台 0.5 MIPS 的机器,而此前人们普遍认为它是 1 MIPS 的机器。
- 进一步分析发现,只有 20% 的 VAX 指令占用了 60% 的微代码资源,而这些指令仅占执行时间的 0.2%。
VAX8800
- 控制存储器:VAX8800 使用了 16K*147b RAM。
- 统一缓存:64K*8b RAM。
- 存储器比例:微存储器的大小是缓存 RAM 的 4.5倍!
IC Technology Changes Tradeoffs
随着集成电路技术的进步,半导体设计和制造的权衡发生了显著变化。以下是这种变化的关键点:
- 逻辑、RAM、ROM 统一采用 MOS 晶体管实现:在过去,不同的存储器类型和逻辑门通常使用不同的技术实现。而在现代,MOS(Metal-Oxide-Semiconductor)晶体管被广泛用于逻辑电路、RAM 和 ROM 的制造,这统一了设计和生产工艺。
- 半导体 RAM 与 ROM 的速度接近:随着技术进步,半导体 RAM 的速度逐渐追上 ROM。这改变了系统设计中的存储器选择,允许使用更灵活的 RAM 而不牺牲性能。
Reconsidering Microcode Machine (Motorola 68000 Example)
在 1980 年代初期,微代码控制在一些处理器中仍然是主流设计。以 Motorola 68000 处理器为例,该处理器使用了微代码 ROM 来控制执行,但随着 RISC (精简指令集计算机)理念的兴起,处理器设计开始倾向于硬连线控制而非复杂的微代码。
- 68000 的微代码设计:
- 68000 的微代码宽度为 17 位,包含 10 位的微跳转指令(μjump)或 9 位的纳米指令指针。
- 纳米指令宽度为 68 位,可以解码生成多达 196 条控制信号。
- RISC 革命:由于 RISC 理念主张简化指令集和硬连线控制来提高效率,像 68000 这样的复杂微代码系统逐渐被取代,转向硬连线解码器和流水线设计,这减少了多周期指令的需求并提升了性能。
关键技术点:
- 硬连线解码:相比微代码,硬连线解码器可以更快地执行常用指令,简化控制逻辑并提高效率。
- 用户微代码(User PC):在早期一些系统中,允许用户自定义微代码,但这种灵活性很快因为复杂性和管理问题而被放弃。
- 指令缓存(Inst. Cache):现代处理器使用高速缓存来加速指令获取,减少对复杂微代码系统的依赖。
随着 RISC 架构的推广和半导体技术的发展,过去以微代码为核心的设计逐渐被简化的硬连线控制所取代。Motorola 68000 是这种转变的典型案例,它代表了微代码机器向现代处理器设计的过渡时期。
From CISC to RISC
在计算机架构的演变过程中,从 CISC(复杂指令集计算机)到 RISC(精简指令集计算机) 的转变带来了许多性能和效率上的提升。这一转变得益于技术进步和处理器设计理念的变化,特别是在简化指令集和利用快速存储器方面。
使用快速 RAM 构建高速指令缓存
- RISC 处理器使用快速的 RAM 来构建指令缓存,而不是像 CISC 一样依赖固定硬件微指令来实现复杂的指令。
- 这种缓存包含用户可见的指令,并根据应用的需求动态调整其内容。
- 通过这种方式,RISC 处理器能够更灵活地适应各种应用场景,提高指令执行速度。
使用简单的指令集架构(ISA)实现硬连线流水线
- 早期的研究发现,大多数编译后的代码实际上只使用了少数几条 CISC 指令。
- RISC 架构通过简化指令集设计,使处理器能够更容易地实现硬连线流水线,从而提高性能。
- RISC 的指令集结构与 垂直微代码 类似,简单且紧凑,允许每条指令都能快速解码并进入流水线。
集成化的进一步好处
- 到 1980 年代初,技术进步终于能够将32位数据通路和小型缓存整合到单个芯片上,这极大地减少了芯片之间的数据传输延迟。
- 没有芯片间数据传输的常见情况使得处理器运行速度进一步加快,增强了指令执行的效率。
Berkeley RISC Chips
RISC-I (1982)
- RISC-I 是最早的 VLSI RISC 处理器之一。
- 它包含 44,420 个晶体管,采用 5 µm NMOS 技术制造,芯片面积为 77 mm²,工作频率为 1 MHz。
- RISC-I 标志着 RISC 架构的诞生,推动了高效处理器设计的发展。
RISC-II (1983)
- RISC-II 是 RISC-I 的升级版本,包含 40,760 个晶体管,采用 3 µm NMOS 技术制造,芯片面积为 60 mm²,工作频率提高到 3 MHz。
- RISC-II 的设计更为紧凑,并且具有更高的时钟频率,进一步展示了 RISC 架构的性能潜力。
斯坦福大学的贡献
- 斯坦福 也在这段时间里开发了基于 RISC 架构的处理器,推动了 RISC 处理器的研究和实际应用。