L04 Pipelining I
“Iron Law” of Processor Performance
处理器性能的“铁律”公式表示为:
\[ \text{Time per program} = \frac{\text{Instructions per program} \times \text{Cycles per instruction (CPI)} \times \text{Time per cycle}}{\text{Program}} \]
影响处理器性能的三个关键因素:
- Instructions per program:
- 依赖于源代码、编译器技术和指令集架构(ISA)。编译器优化和程序设计可以影响每个程序中的指令数量。
- Cycles per instruction (CPI):
- 取决于指令集架构(ISA)和微架构设计。较低的 CPI 表示处理器可以在较少的时钟周期内执行完一条指令。RISC 设计通常通过硬连线控制和流水线技术来优化 CPI。
- Time per cycle:
- 受微架构和底层技术的影响。随着半导体工艺的进步,时钟周期缩短。RISC 架构的流水线设计可以通过更短的周期时间来提高性能。
不同微架构的 CPI 和周期时间
- Microcoded:CPI 大于 1,周期时间较短。这种架构使用微代码控制复杂指令,执行时间相对较长。
- Single-cycle unpipelined:CPI 为 1,但周期时间较长。所有操作都在一个周期内完成,导致单周期需要更多时间。
- Pipelined:CPI 为 1,周期时间较短。流水线架构通过分阶段处理指令,使多个指令可以同时执行不同的阶段,从而提高性能。
Classic 5-Stage RISC Pipeline
经典的 5 级 RISC 流水线通过分阶段执行指令来提高执行效率。流水线允许不同指令同时处于不同的执行阶段,最大化硬件利用率。
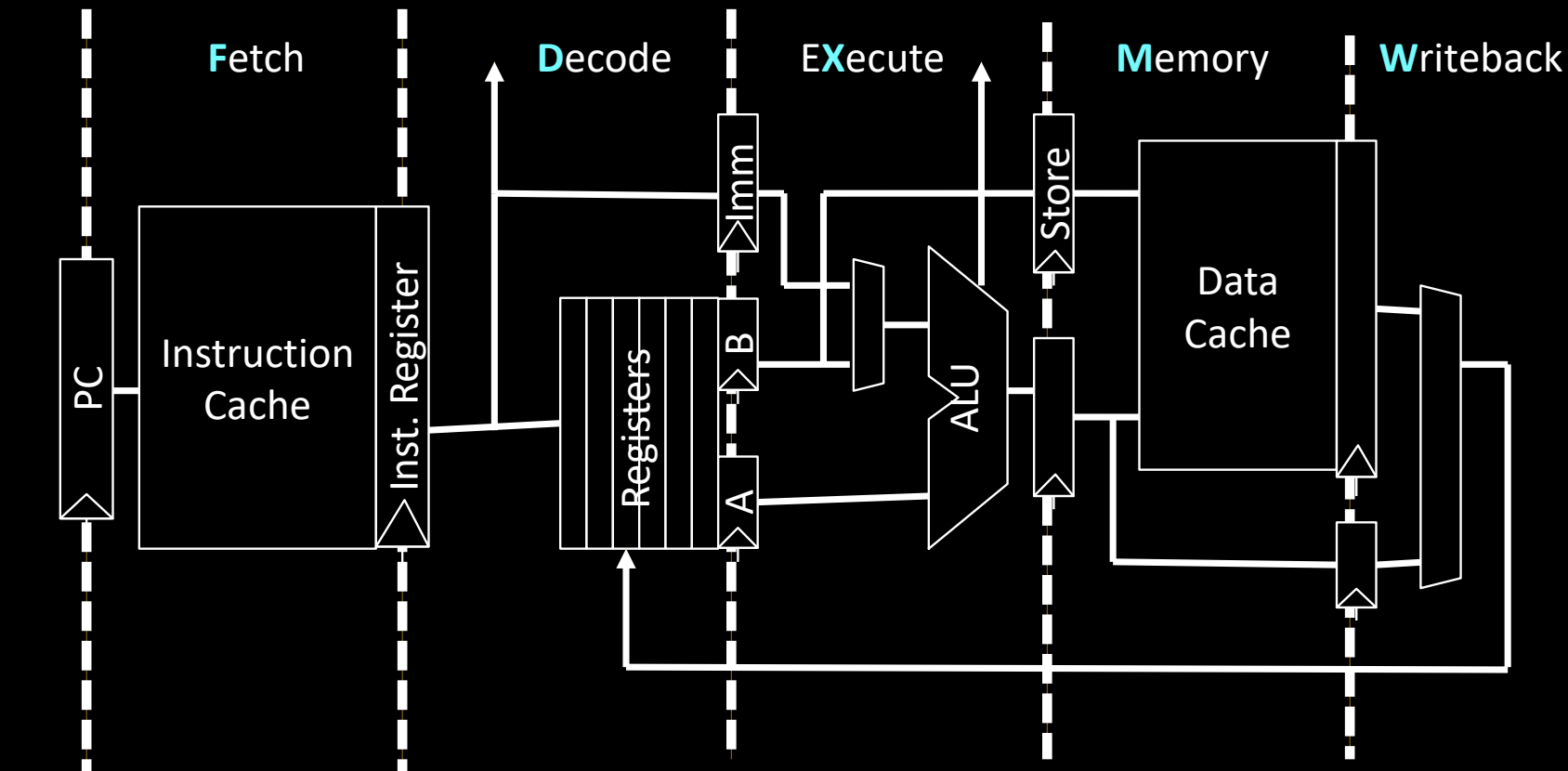
五个阶段:
- Fetch(取指):
- 从指令缓存中获取下一条指令,并将其加载到指令寄存器中。程序计数器(PC)用于追踪指令地址。
- Decode(解码):
- 解码指令,识别操作码,并读取需要的寄存器值。此阶段还涉及对立即数的扩展以及决定指令的类型。
- Execute(执行):
- 在此阶段,ALU(算术逻辑单元)对操作数进行算术或逻辑运算。对寄存器内容进行操作,或计算内存地址。
- Memory(内存访问):
- 如果是加载(load)或存储(store)指令,此阶段访问数据缓存。加载指令从内存中读取数据,存储指令将数据写入内存。
- Writeback(写回):
- 将计算或内存访问的结果写回寄存器,更新寄存器文件。
流水线特点
- 该流水线设计针对带有同步写入和异步读取功能的寄存器文件和内存进行了优化。
- 每个阶段在一个时钟周期内完成,流水线的并行性使得指令可以连续执行,提升了指令吞吐量。
CPI Examples
Microcoded Machine
在微代码控制的机器中,每条指令的执行可能需要多个时钟周期。这是因为微指令通常需要较长的执行时间,尤其是对于复杂的操作。
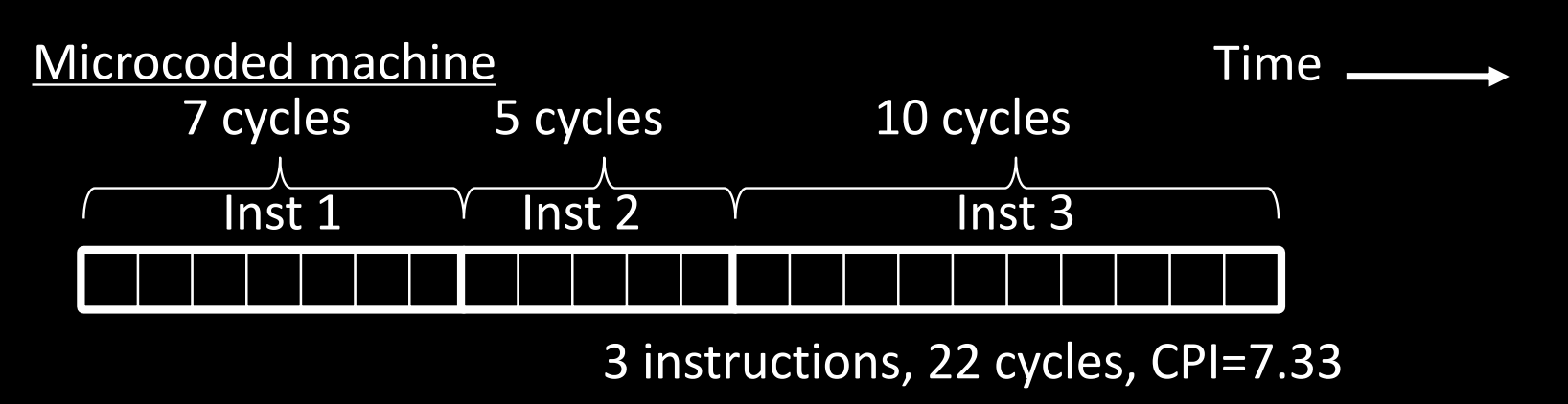
- 示例:
- 第一条指令执行需要 7 个周期。
- 第二条指令需要 5 个周期。
- 第三条指令需要 10 个周期。
- 总共执行了 3 条指令,用时 22 个周期。
- CPI = 7.33,远高于理想的 1。
Unpipelined Machine
在单周期、无流水线的处理器中,每条指令在一个时钟周期内完成,但所有指令必须顺序执行,因此一个指令完成后才能开始下一条指令。

- 示例:
- 每条指令执行时间为 1 个周期。
- 总共执行了 3 条指令,用时 3 个周期。
- CPI = 1,因为每条指令占用一个时钟周期。
Pipelined Machine
流水线处理器通过将指令执行拆分为多个阶段,实现了指令的并行处理。每条指令同时处于流水线的不同阶段,从而加速整体执行。
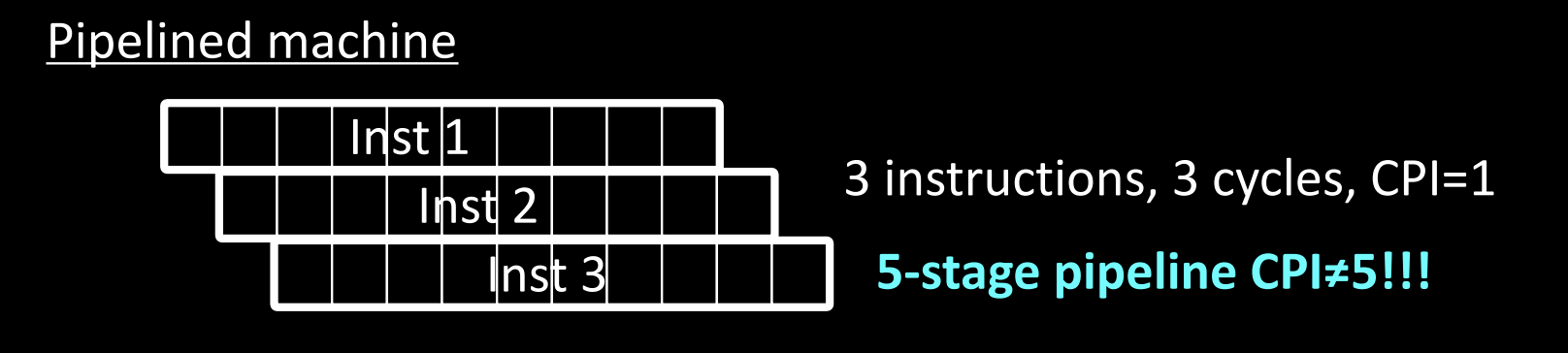
- 示例:
- 虽然执行了 3 条指令,但流水线允许每条指令占用不同的执行阶段,因此仅用了 3 个周期。
- CPI = 1,这是理想的结果,但实际上由于流水线冲突和延迟,CPI 通常高于 1。
指令在流水线中的交互
流水线中的指令交互
指令在流水线中并行执行,但有时会发生资源冲突或数据依赖,导致流水线效率降低。这些问题被称为流水线冒险(pipeline hazards)。
- 结构冒险(Structural Hazard):
- 当流水线中的两条指令需要同时使用相同的硬件资源时,会产生结构冒险。
- 例如,两条指令同时需要访问寄存器文件或内存,这会导致冲突,进而影响性能。
- 数据冒险(Data Hazard):
- 当一条指令依赖于前一条指令的执行结果时,产生数据冒险。
- 例如,如果一条指令需要读取前一条指令写入的寄存器值,但此时前一条指令尚未完成,流水线必须等待,这会导致流水线停顿。
- 控制冒险(Control Hazard):
- 控制冒险出现在跳转或分支指令时,因为接下来的指令取决于前一条指令是否发生跳转。
- 如果分支预测错误,可能会导致流水线必须清空,重新加载正确的指令,从而降低效率。
冒险的处理与 CPI 影响
处理这些冒险通常会引入气泡(bubbles)到流水线中,即延迟执行某些指令直到冒险被解决。这种延迟增加了实际的 CPI,导致它通常高于理想值 1。
Pipeline CPI Examples
流水线处理器的 CPI(每条指令的时钟周期数)取决于流水线中的指令交互和是否有冒险(如结构冒险)。以下是几个流水线 CPI 的例子:
理想情况(没有气泡)
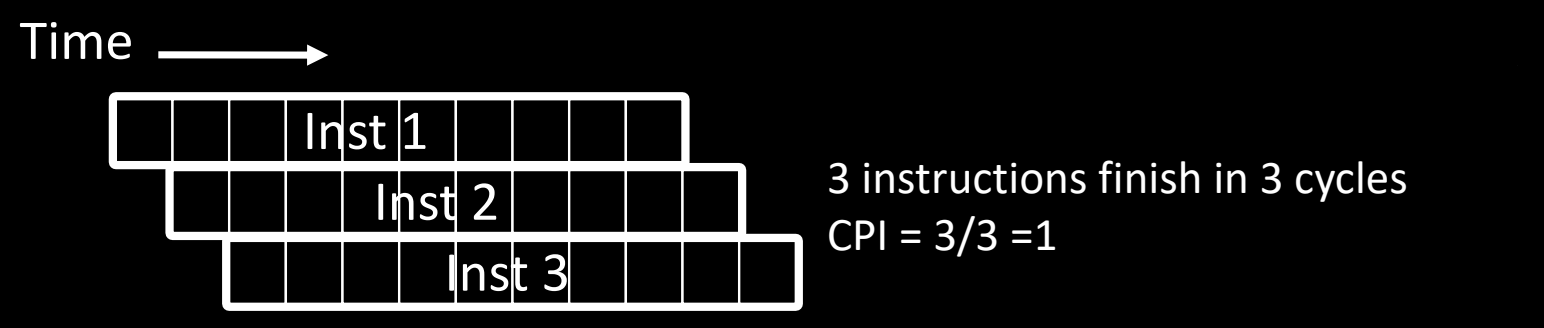
- 3 条指令在 3 个周期内完成。
- 没有冒险或气泡(bubble),每个时钟周期都有效执行。
- CPI = 3/3 = 1,这是理想的流水线 CPI。
有一个气泡的情况
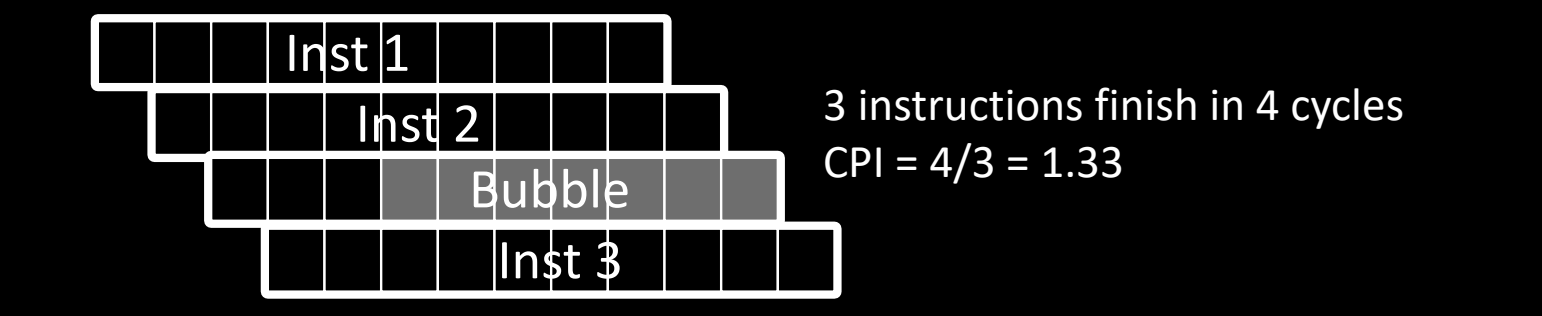
- 3 条指令在 4 个周期内完成。
- 流水线遇到一个冒险,导致产生一个气泡,延迟了流水线的执行。
- CPI = 4/3 ≈ 1.33,比理想的 CPI 略高。
有两个气泡的情况
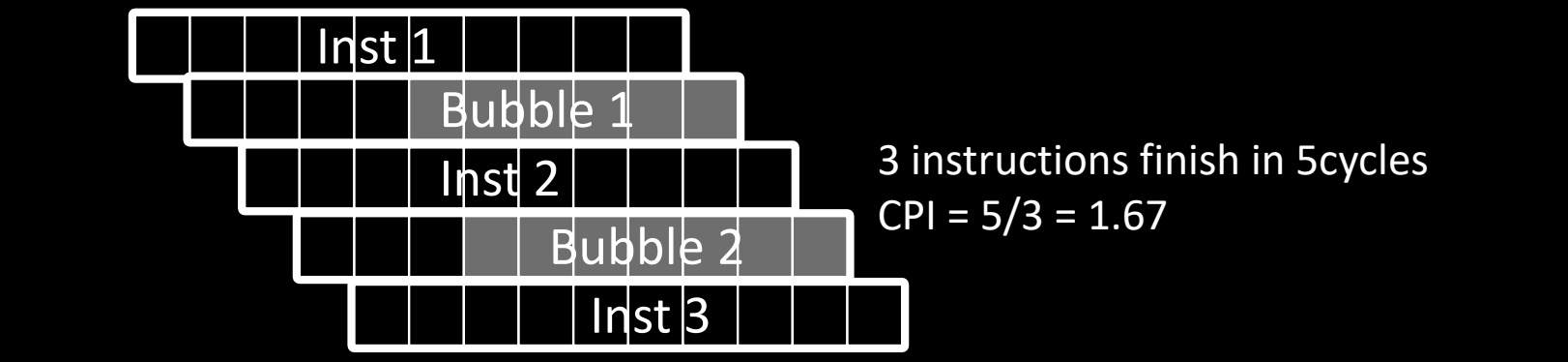
- 3 条指令在 5 个周期内完成。
- 流水线遇到两个冒险,产生了两个气泡,进一步延迟了指令执行。
- CPI = 5/3 ≈ 1.67,远高于理想的 CPI。
Structural Hazards
Resolving Structural Hazards
结构冒险 发生在流水线中两条指令同时需要相同的硬件资源时。这会导致资源冲突,进而影响性能。
解决结构冒险的方式
- 通过硬件阻塞解决:
- 可以在硬件中通过暂停(stall)新指令,直到前一条指令完成对资源的使用。
- 这种方法增加了流水线气泡,降低了效率,但能够确保正确性。
- 通过增加硬件资源避免冒险:
- 例如,如果有两条指令同时需要访问内存端口,可以通过增加第二个内存端口来避免结构冒险。
- 添加更多硬件资源虽然会增加设计成本,但能有效避免冒险。
- 经典的 RISC 5 级整数字流水线的设计避免了结构冒险:
- RISC 处理器的设计通过巧妙的硬件配置避免了常见的结构冒险。
- 但是,某些 RISC 实现中的多周期单元(如乘法器、除法器、浮点运算单元等)可能会出现结构冒险,特别是在寄存器写回阶段。
Data Hazards
Types of Data Hazards
在流水线处理器中,数据冒险 是指一条指令依赖于前一条指令的结果,导致流水线的执行顺序受阻。根据指令间依赖关系的不同,数据冒险可以分为以下几种类型:
数据依赖(Data Dependence)
- 读后写(RAW, Read-After-Write)冒险:
- 一条指令需要读取前一条指令写入的寄存器值。
- 如果写操作尚未完成而读操作已经开始,就会发生 RAW 冒险。
- 例如:
r3 ← r1 op r2r5 ← r3 op r4
- 这里,第二条指令需要读取寄存器
r3,但r3的值由第一条指令写入,必须等第一条指令写完才能继续。
反依赖(Anti-Dependence)
- 写后读(WAR, Write-After-Read)冒险:
- 一条指令需要写入一个寄存器,而该寄存器值在前一条指令中刚被读取。
- 如果写操作过早发生,就可能会覆盖正在读取的值,导致 WAR 冒险。
- 例如:
r3 ← r1 op r2r1 ← r4 op r5
- 第二条指令在第一条指令完成前写入
r1,可能导致数据冲突。
输出依赖(Output Dependence)
- 写后写(WAW, Write-After-Write)冒险:
- 两条指令需要写入同一个寄存器,如果后面的指令写入过早,可能会覆盖前面指令的写操作结果,导致 WAW 冒险。
- 例如:
r3 ← r1 op r2r3 ← r6 op r7
- 两条指令都要写入寄存器
r3,必须按顺序进行。
Three Strategies for Data Hazards
针对数据冒险,有三种常见的处理策略:
- 互锁(Interlock):
- 等待冒险消除,通过在发射阶段(issue stage)暂停依赖指令,直到前面的指令完成相应的操作。
- 这种方法通常会增加气泡,降低流水线的效率。
- 旁路(Bypass):
- 通过旁路转发机制,尽早解决冒险问题。旁路允许流水线直接从正在执行的指令中获取尚未写回寄存器的计算结果,而不是等待整个执行过程结束。
- 旁路技术能减少气泡的产生,提高流水线的并行执行效率。
- 推测执行(Speculate):
- 在值未完全计算出来之前,猜测可能的值并继续执行。如果猜测错误,则进行纠正。
- 推测执行有助于提高流水线效率,但可能导致误执行,并需要纠正的开销。
Interlocking Versus Bypassing
互锁(Interlocking)
当流水线中遇到数据冒险时,处理器可以通过暂停某些指令直到数据依赖消除。这种方法会在流水线中产生气泡(bubble),导致流水线停顿并降低效率。
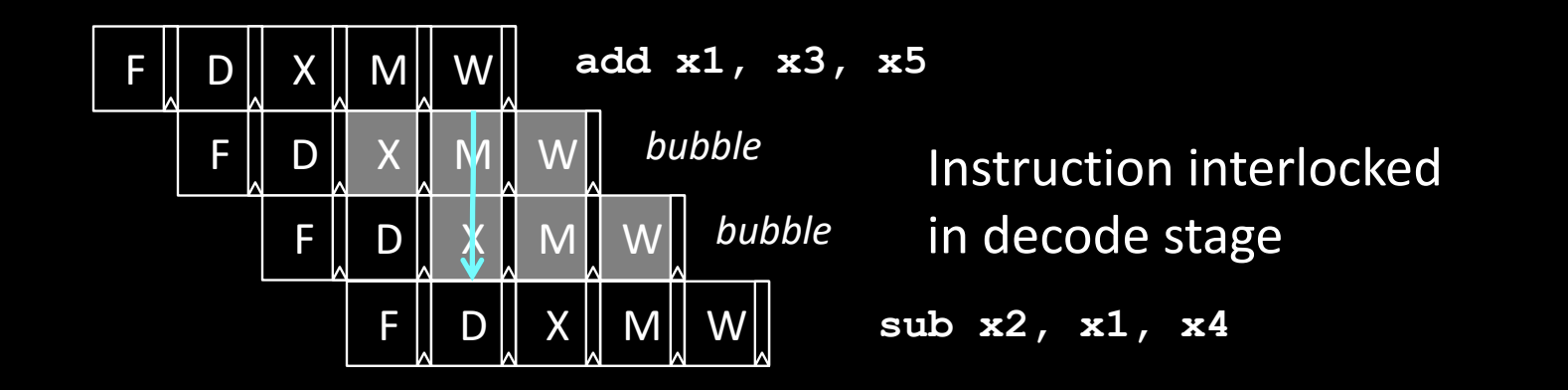
- 示例:
- 指令
add x1, x3, x5将结果写入寄存器x1。 - 紧接着的
sub x2, x1, x4需要读取寄存器x1。 - 因为
x1的值还没有被写回,处理器在解码阶段检测到数据冒险,插入了气泡,暂停sub指令直到add指令完成。 - 这种方法虽然解决了冒险问题,但由于气泡的存在,减少了流水线的执行效率。
- 指令
旁路(Bypassing)
旁路技术通过在流水线中直接从正在执行的指令(通常是执行阶段的 ALU)获取结果,而不是等待其写回寄存器,从而避免气泡的产生。

- 示例:
- 在
add x1, x3, x5执行完毕后,sub x2, x1, x4可以通过旁路从 ALU 中获取x1的值,而不是等待它被写回寄存器文件。 - 这种方法允许指令无气泡继续执行,从而提高流水线的效率。
- 在
Example Bypass Path
下图展示了一个典型的旁路路径。在经典的 5 级流水线架构中,旁路路径允许指令绕过写回阶段,直接从执行阶段(EX)获取数据。这种旁路路径帮助处理器减少数据冒险带来的延迟。
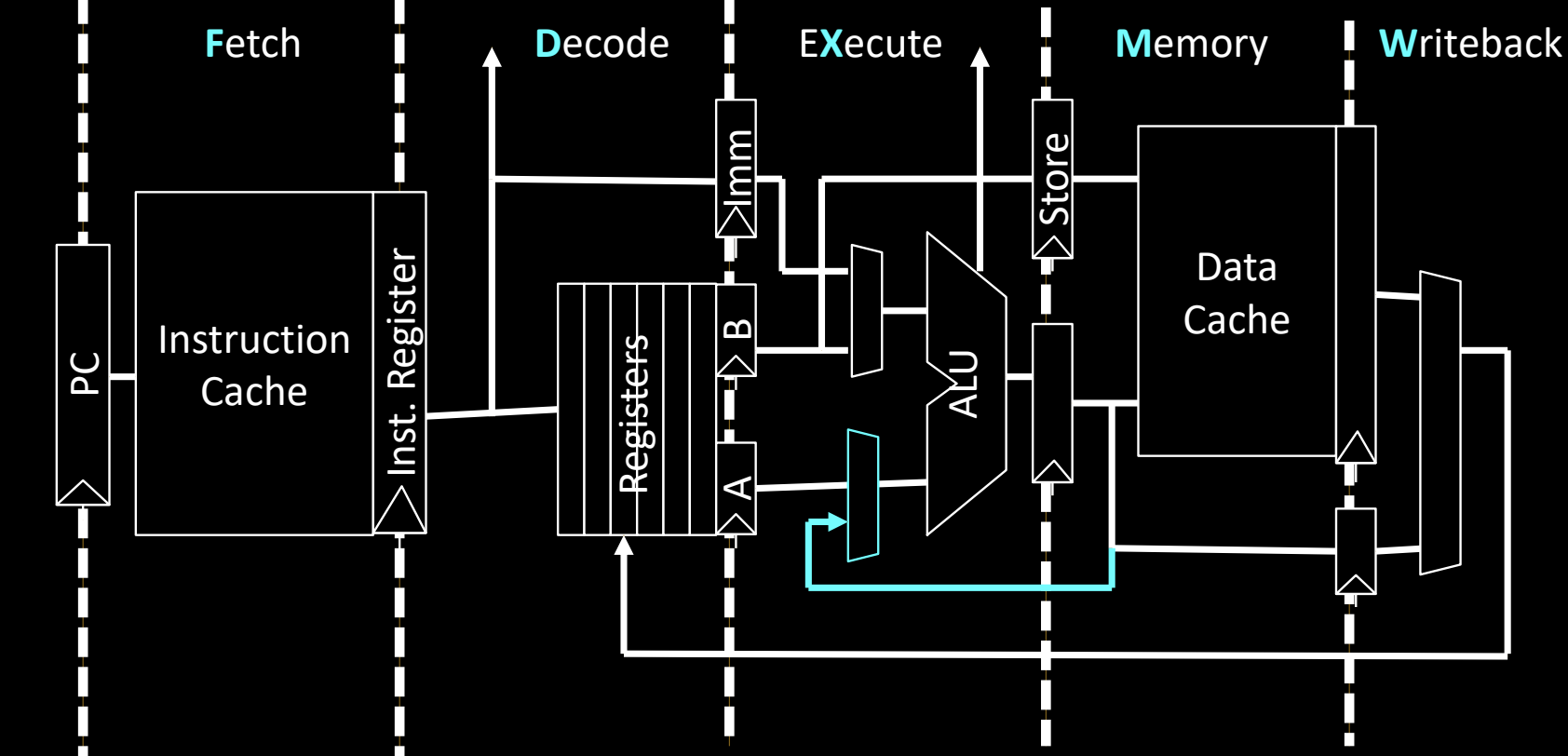
旁路路径说明:
- 例如,当
add指令的结果尚未写回寄存器文件时,旁路路径(蓝色箭头)可以将 ALU 的计算结果直接传递给下一条指令的输入端口(即寄存器A或B),使得sub指令无需等待写回阶段的完成即可使用该结果。
旁路技术是流水线设计中的一种重要优化手段,它能够有效减少流水线中的停顿和延迟,提高处理器的整体性能。
Fully Bypassed Data Path
在Fully Bypassed Data Path中,数据旁路(forwarding)技术的核心目标是减少流水线中的数据冒险,确保在指令执行过程中,不因等待前一条指令结果写回寄存器而造成停顿。该设计通过允许指令在执行阶段(EX阶段)计算结果后,立即将结果传递给下一个需要该数据的指令,实现流水线的高效运行。
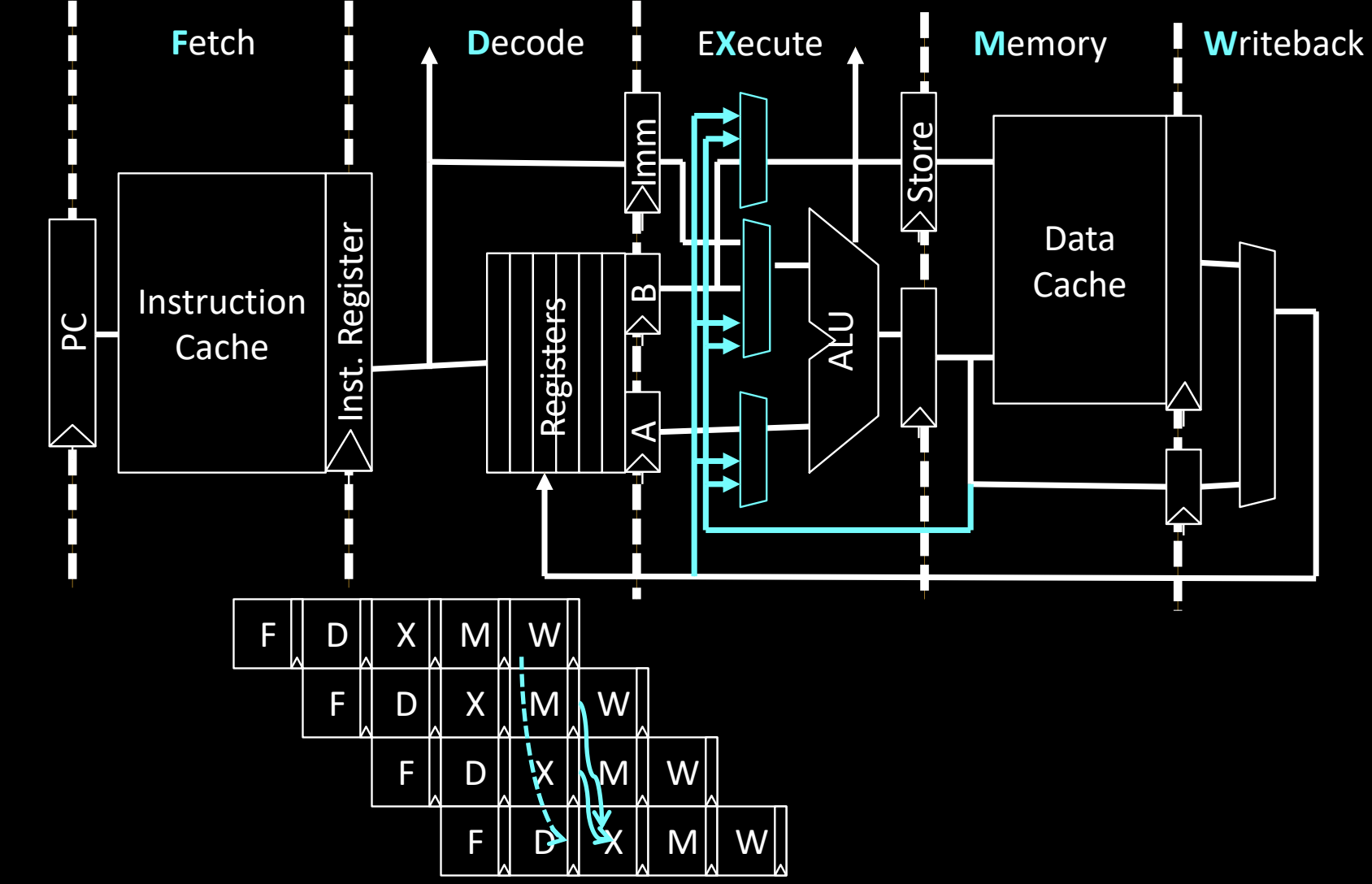
旁路路径的细节:
- 旁路路径(蓝色箭头):
- 当ALU计算出结果后,通常情况下,结果会被写回到寄存器(写回阶段)。然而,如果下一条指令依赖于该结果,而该指令已经进入流水线,则可以通过旁路路径直接将数据传递给后续指令的ALU输入,绕过寄存器文件,避免了数据冒险引发的流水线气泡。
- 这种旁路路径不仅包括执行阶段到ALU的输入,还可以在写回阶段和执行阶段之间实现旁路,即一条指令可以在写回前,通过旁路数据给其他指令提供输入。
- 写回阶段旁路:
- 旁路并不止限于从ALU直接转发到下一条指令。旁路路径可以跨越多个流水线阶段,例如从写回阶段(W阶段)直接旁路到执行阶段或存储阶段,避免在寄存器写回后再进行读取操作。
- 在图中,旁路还可能从内存存取阶段(M阶段)传递给执行阶段,这在某些复杂的流水线结构中也非常常见。
流水线中的旁路场景:
上图下方的流水线图显示了旁路机制如何在流水线中工作。蓝色箭头示意了旁路的数据流动:
- 第一条指令执行完ALU运算,结果通常应当写回寄存器,但由于后面的指令需要该结果,则通过旁路路径直接将数据传递给后续指令的ALU输入。
- 如果没有这个旁路机制,后面的指令必须等待第一条指令的结果写回,导致流水线出现气泡(bubble)并降低指令执行的效率。
完全旁路的优势:
- 提高指令执行效率:通过在不同阶段实现数据的旁路,后续指令可以更快获得所需的数据,减少不必要的停顿和等待时间。
- 减少气泡的产生:传统的流水线会因为数据冒险而停顿,产生气泡,但旁路机制极大地减少了这种停顿。
- 减少寄存器文件的频繁访问:旁路避免了每次都必须将数据写回寄存器并重新读取,这也减轻了寄存器文件的负担。
Value Speculation for RAW Data Hazards
值推测 是一种应对 读后写(RAW)冒险 的高级技术。与等待前一条指令执行完成后再读取其结果不同,值推测尝试通过猜测结果的方式,使流水线可以继续前进。
值推测的工作原理:
- 在一些特定的情况下,处理器可以猜测前一条指令的输出值,并继续执行依赖该值的后续指令。
- 如果猜测正确,则流水线不受影响。
- 如果猜测错误,则处理器需要纠正错误值并重新执行相关指令,但总体上可以提升性能。
值推测的适用场景:
- 分支预测:值推测经常用于分支预测技术中,处理器可以猜测分支条件的结果,并提前加载和执行可能的指令路径。
- 栈指针更新:在处理函数调用和返回时,值推测可用于栈指针的更新,以加速相关操作。
- 内存地址消除歧义:处理器可以推测某些内存地址是否有冲突,进而决定是否继续执行内存相关的指令。
尽管值推测技术在一些特定场景下有效,但其应用仍然有限,且当推测错误时,会产生一定的性能惩罚,因此需要权衡利弊。
Control Hazards
控制冒险 发生在程序中遇到分支、跳转或条件判断时,由于下一条指令的地址尚未确定,导致流水线的指令获取阶段必须等待正确的地址信息。为了正确计算下一条指令的程序计数器(PC),需要根据不同类型的指令确定相关信息。
计算下一个 PC 需要哪些信息?
- 对于无条件跳转(Unconditional Jumps):
- 需要:操作码(Opcode)、当前 PC 值和偏移量(Offset)。
- 对于寄存器跳转(Jump Register):
- 需要:操作码(Opcode)、寄存器的值(Jump 的目标地址),以及偏移量(Offset)。
- 对于条件分支(Conditional Branches):
- 需要:操作码(Opcode)、用于条件判断的寄存器值、当前 PC 值和偏移量。
- 对于其他指令:
- 需要:操作码(Opcode)和 PC 值,并且需要确定当前指令不是上述的跳转或分支指令。
Control Flow Information in Pipeline
流水线处理器需要在不同的阶段获取指令控制流的信息,以便正确预测和计算下一条指令的地址。
- 取指阶段(Fetch):
- 已知当前的 PC 值,用于从指令缓存中获取当前指令。
- 解码阶段(Decode):
- 此时解码出了操作码(Opcode)和偏移量(Offset),用于识别当前指令的类型和跳转信息。
- 执行阶段(Execute):
- 在该阶段,如果是分支指令,会根据条件寄存器的值判断是否跳转;对于寄存器跳转指令,此时也知道了寄存器中的目标跳转地址。
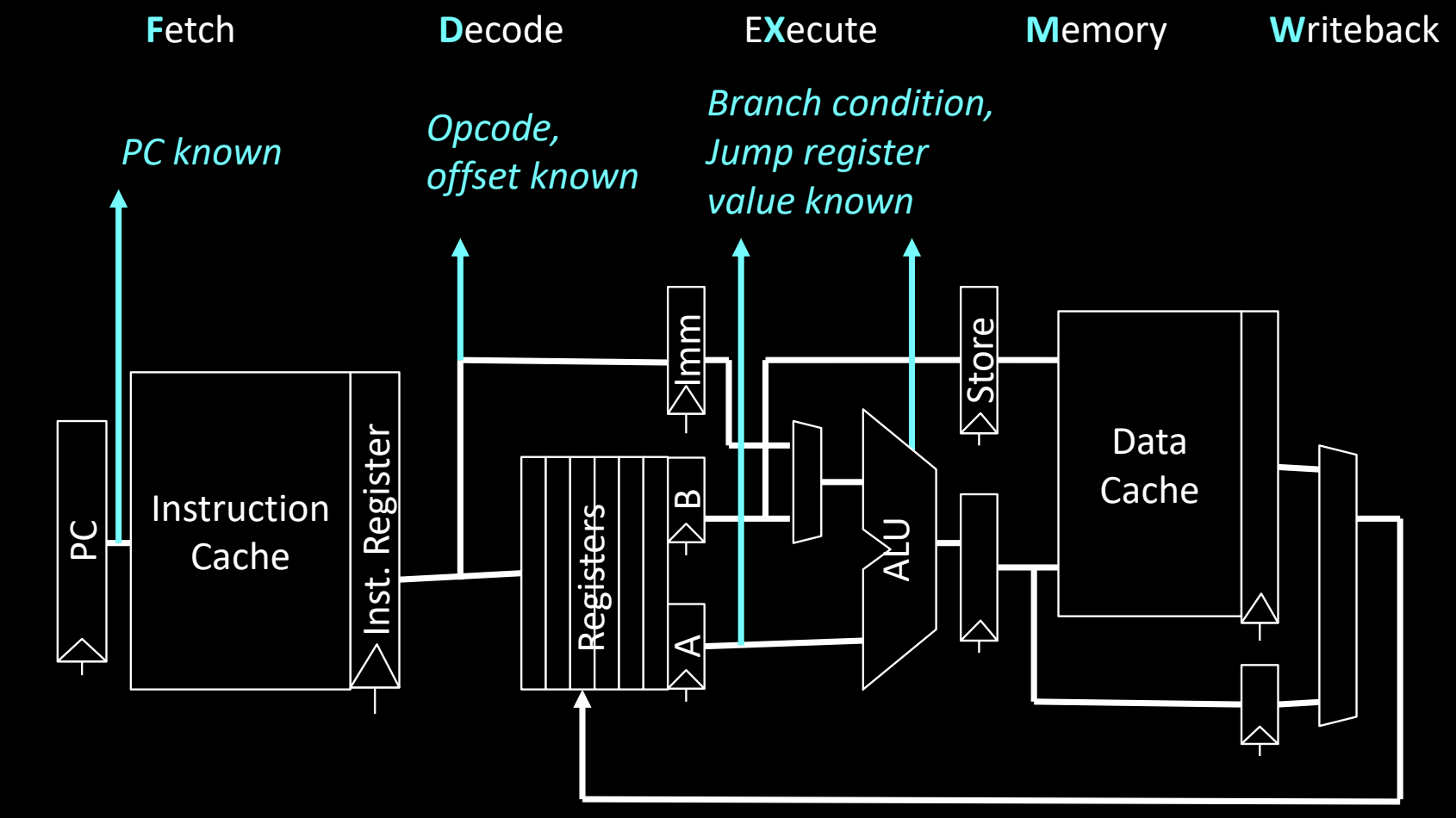
示例:流水线中的控制流信息
- 蓝色箭头 表示在每个阶段可用的控制流信息:
- 取指阶段已知 PC 值。
- 解码阶段已知操作码和偏移量。
- 执行阶段已知分支条件、寄存器跳转的目标值,从而可以决定下一条指令的地址。
控制冒险通过分支预测、推测执行等技术来减少流水线停顿,但错误的预测会导致流水线被清空(Flush),影响性能。
RISC-V Unconditional PC-Relative Jumps
在 RISC-V 架构中,无条件的 PC 相对跳转 是一种常见的控制流指令。通过使用当前的 PC 值和一个立即数偏移量来计算跳转目标地址,跳转指令可以快速改变程序的执行路径。
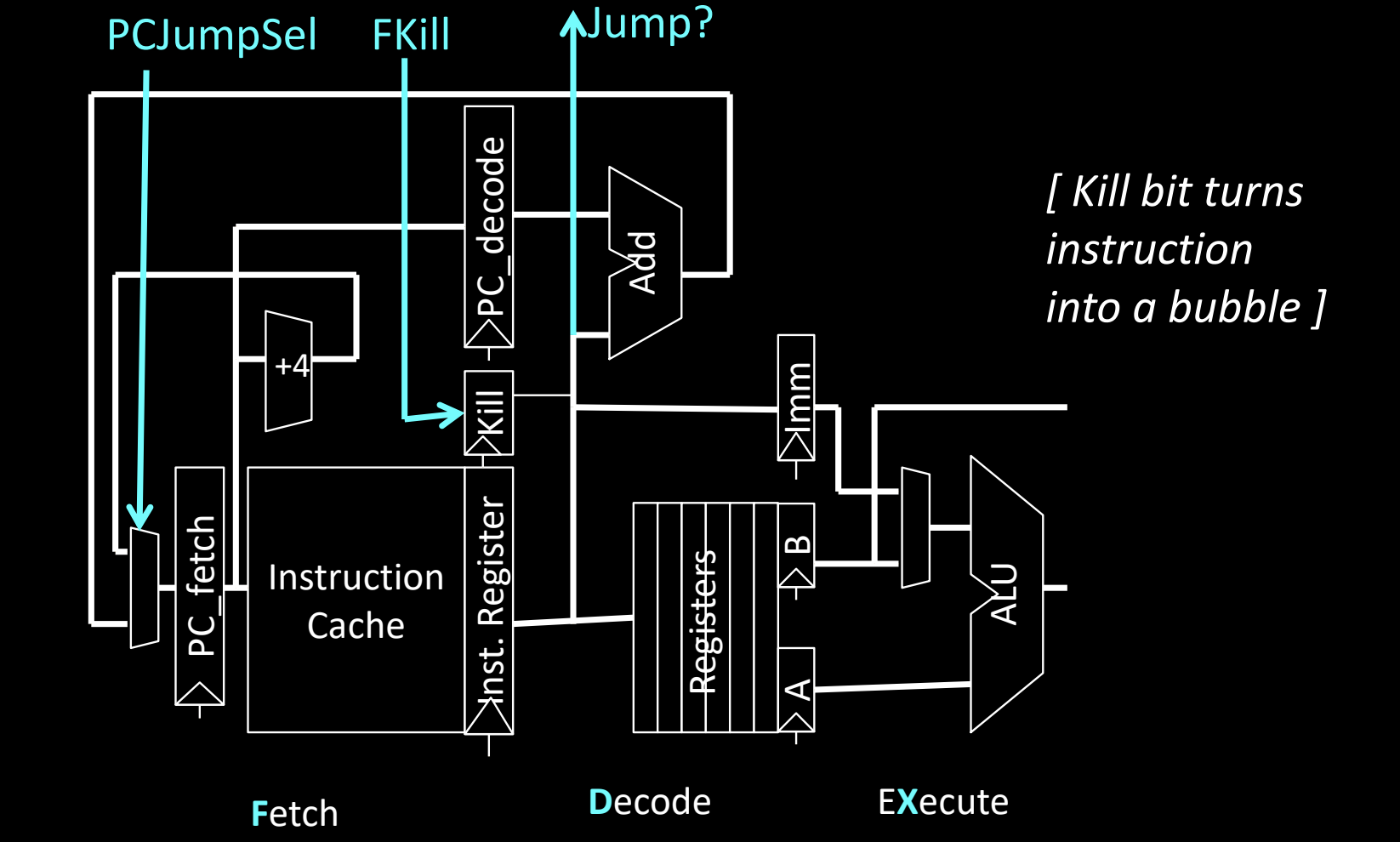
跳转的执行流程
-
PCJumpSel:用于选择跳转目标的控制信号。跳转目标地址是通过将当前 PC 值与立即数(offset)相加计算得出的。
-
FKill:这是一个Kill 信号,用于阻止错误获取的指令继续执行。当处理器决定跳转时,当前指令可能已经在流水线的后续阶段,这时
FKill信号将把错误的指令标记为气泡,防止其继续执行。- Kill Bit:在跳转后,跳转指令后面已经进入流水线的指令将被“杀死”,即转换为气泡,避免对系统状态产生影响。
-
Jump?:这是跳转条件的判断信号。在无条件跳转中,这个信号总是为真,意味着处理器会直接跳转到目标地址。
Pipelining for Unconditional PC-Relative Jumps
流水线设计中,当遇到无条件跳转指令时,处理器必须处理控制冒险,因为跳转目标指令和当前获取的指令不同步。即使是无条件跳转,处理器也可能会生成气泡以避免错误的指令继续执行。

流水线中的跳转处理
- 在图中,跳转指令
j target已经进入流水线的解码阶段(D)。此时,处理器判断需要跳转到新的目标指令。 - 跳转后,紧接着的指令已经进入了取指阶段(F),但这条指令被
Kill bit标记为无效,变为一个气泡,确保不会对处理器状态产生影响。 - 随后,目标指令
add x1, x2, x3正确进入流水线并继续执行。
这种设计确保了在处理跳转指令时,即使出现冒险,流水线的执行仍然可以保持正确的顺序,但为了避免错误指令执行,可能会引入气泡,从而暂时降低流水线的效率。
Branch Delay Slots
在早期的 RISC 架构中,为了适应流水线设计,采用了分支延迟槽(Branch Delay Slots) 的概念。这一机制允许在分支或跳转指令之后的指令总是被执行,即使跳转已发生。这使得流水线可以更高效地处理分支指令。
分支延迟槽的工作原理
- 在执行跳转指令后,紧跟在跳转指令后的指令会被执行,即便程序的控制流已经跳转到新地址。
- 例如:
0x100 j target 0x104 add x1, x2, x3 // 在跳转发生前执行 ... 0x205 target: xori x1, x1, 7在这个例子中,即使
j target指令将控制流跳转到0x205,位于跳转指令之后的add x1, x2, x3仍然会执行,称为延迟槽指令。
软件处理延迟槽
- 编译器或程序员需要确保分支延迟槽中的指令是有用的计算。否则,延迟槽可能会被填充为 NOP 指令(即空操作,No Operation)。
- 延迟槽可以帮助减少流水线停顿,但如果无法填充有效指令,则延迟槽可能浪费一个周期。

延迟槽的流水线示例
- 流水线图中展示了
j target指令后的一条add x1, x2, x3指令,它在目标指令xori x1, x1, 7执行前被运行。此add指令正好处在分支延迟槽中。
Post-1990 RISC ISAs Don’t Have Delay Slots
自 1990 年后,大多数 RISC 架构逐渐去除了分支延迟槽,这是因为随着硬件设计的进步和分支预测技术的改进,延迟槽不再必要,甚至会对性能产生负面影响。
延迟槽的缺点
- 引入微架构细节:
- 延迟槽将微架构的细节(如流水线的阶段设计)暴露给了 ISA(指令集架构)。这种设计增加了硬件与软件之间的紧耦合,使得未来的架构扩展变得更加复杂。
- 性能问题:
- 如果没有有效指令可填充延迟槽,编译器通常会插入 NOP,这会导致指令缓存(I-cache)命中率下降。
- 若在延迟槽中的指令发生了 I-cache 缺失,即使这个延迟槽只是一个 NOP,处理器仍然会因为等待该指令而停顿。
- 复杂的微架构设计:
- 延迟槽对现代复杂的微架构带来了额外的设计负担。例如,一个包含 30 级流水线并且每周期处理 4 条指令的处理器,需要处理多个分支延迟槽,这大大增加了设计难度。
- 更好的分支预测减少了延迟槽的需求:
- 随着分支预测技术的发展,处理器可以更加精准地预测跳转目标,从而大幅减少因分支跳转带来的性能损失,因此分支延迟槽的设计逐渐被淘汰。
在现代 RISC 处理器中,延迟槽已经不再常见,分支预测和推测执行等技术提供了更有效的解决方案。
RISC-V Conditional Branches
在 RISC-V 架构中,条件分支 指令会根据指定条件决定是否跳转到目标地址。如果条件满足,则跳转到目标地址;如果条件不满足,则继续顺序执行接下来的指令。由于条件的判断通常发生在流水线的执行阶段(Execute),因此条件分支容易引发控制冒险,特别是在预测错误时。
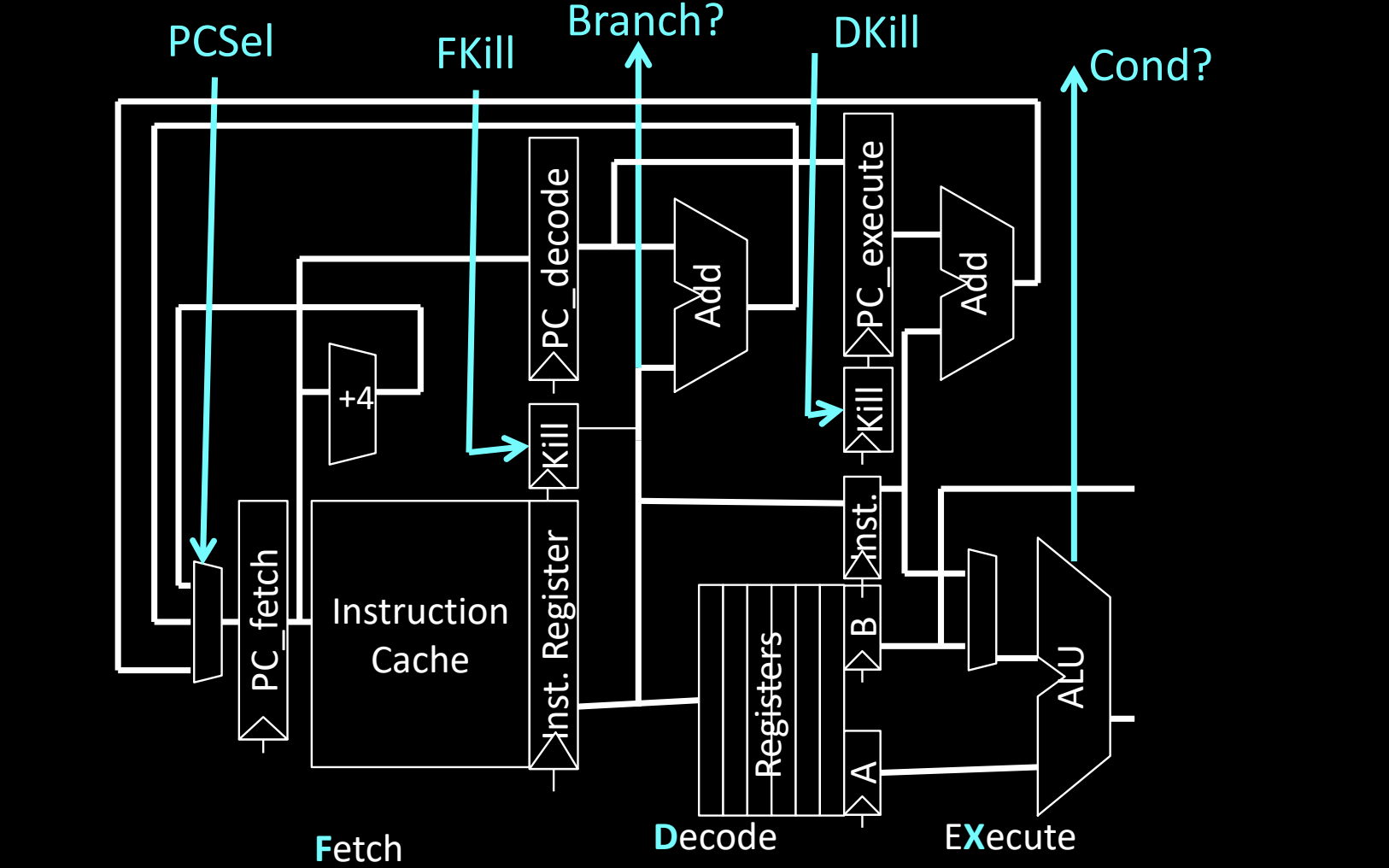
条件分支的流水线设计
- PCSel:这个控制信号决定下一个指令的取址来源。如果分支条件成立,
PCSel会选择跳转地址,否则选择顺序地址。 - FKill:这是一个用来杀死流水线中已经取到的错误指令的信号,如果分支发生了跳转,流水线中不应继续执行分支后的指令,
FKill会将这些指令标记为气泡。 - Branch?:用于判断是否满足分支条件的信号。如果条件成立,跳转到目标地址。
- DKill:解码阶段的杀死信号,用于防止在解码阶段错取的指令继续执行。
- Cond?:执行阶段的条件判断信号,用于判断跳转条件是否成立。
Pipelining for Conditional Branches
条件分支指令的执行过程会引入控制冒险,因为目标地址和是否跳转在执行阶段才能确定,这意味着流水线必须暂时等待条件的结果。
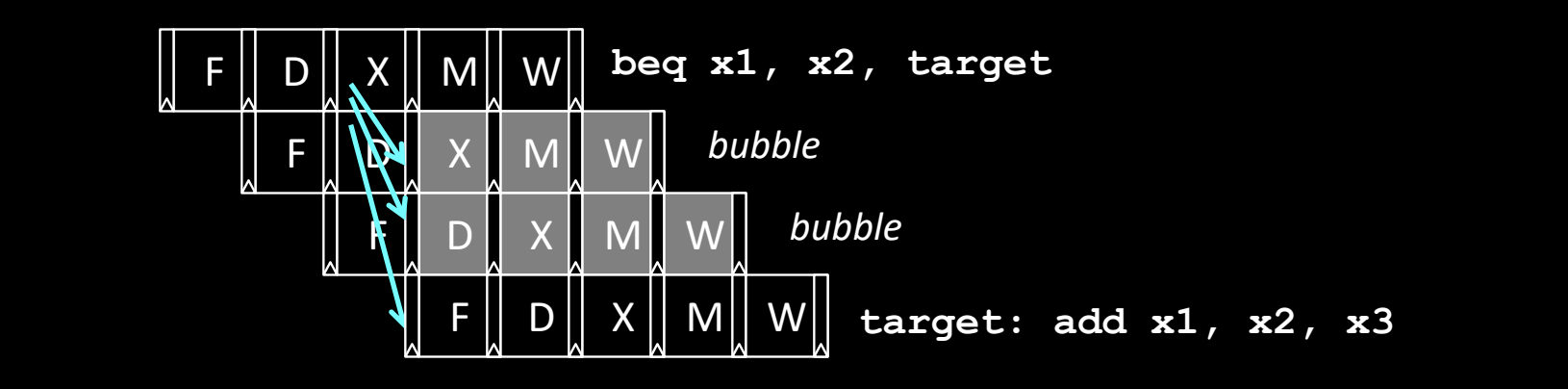
流水线中的条件分支处理
- 在
beq x1, x2, target(比较x1和x2,若相等则跳转)指令中,目标地址和跳转条件需要在执行阶段确认。因此,在确认是否跳转之前,流水线中已经取到的指令可能是错误的。 - 如图所示,
beq指令会产生气泡(bubble),直到条件结果计算完成并确定目标地址。这些气泡是因为需要等待条件分支的执行结果而暂时停止流水线的指令执行。
Pipelining for Jump Register
寄存器跳转(Jump Register,JR) 指令是根据寄存器中的值决定跳转地址。由于寄存器的值只有在执行阶段才能确定,因此跳转目标地址的计算会导致流水线停顿。
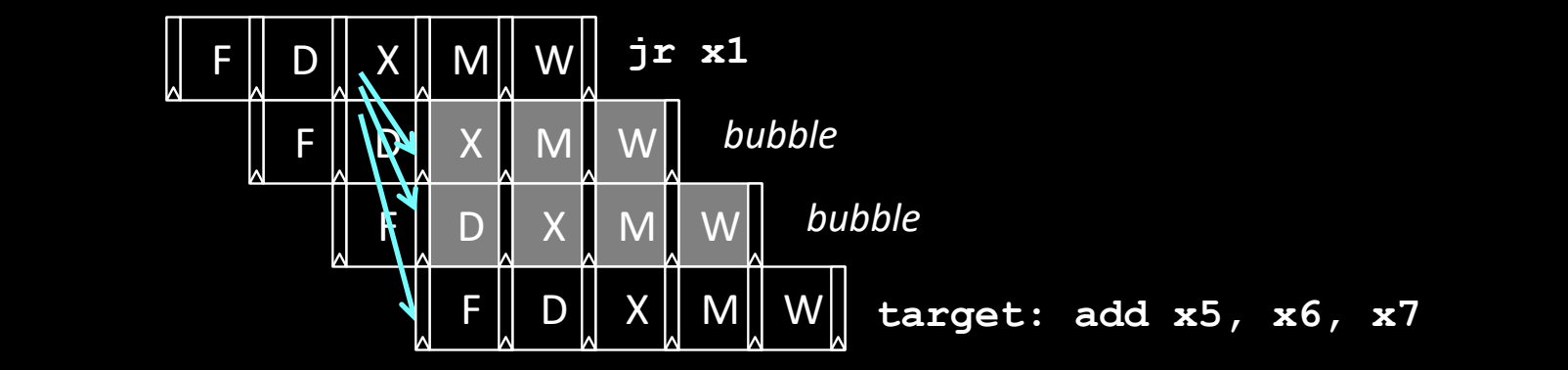
流水线中的寄存器跳转处理
- 对于
jr x1指令,跳转目标地址存储在寄存器x1中,而这个值是在执行阶段(EX)才能得到的。因此,在执行阶段之前,流水线无法确定下一条指令的地址。 - 在跳转完成之前,流水线已经进入的指令(如图中的气泡)可能会被丢弃,导致气泡的产生。
- 图中显示了
jr x1指令导致的气泡,直到目标跳转地址计算完成后,目标指令add x5, x6, x7才能正确进入流水线并开始执行。
寄存器跳转也会引发控制冒险,因此通常通过预测或推测执行来减少气泡的数量,提高流水线的效率。
Why Instruction May Not Be Dispatched Every Cycle in Classic 5-Stage Pipeline (CPI > 1)
在经典的五级流水线(如 RISC-V 和 MIPS 的设计)中,虽然理想情况下每个周期都能发射一条指令,但实际上有时会因为种种原因导致每个周期不能发射一条指令,导致 CPI(每条指令的周期数)大于 1。以下是造成这种情况的一些原因:
1. 完全旁路的代价过高
- 完全旁路(Full Bypassing):在流水线中,为了减少数据冒险,通常通过旁路将结果直接传递给后续指令,而不必等待写回寄存器文件。然而,实现完全旁路可能代价过高,因为要为每个可能的数据路径设计旁路。
- 常用路径旁路:处理器通常为一些常见的路径提供旁路,而较少使用的路径则可能不会提供旁路,从而可能导致周期延长。
2. Load 指令的双周期延迟
- 双周期延迟(Two-cycle Latency):Load 指令从内存中取数需要两周期,因此 Load 指令后面的指令如果立即使用 Load 结果,会造成流水线停顿。
- Load 延迟槽:MIPS-I 引入了Load 延迟槽来解决这个问题,要求编译器在 Load 指令后插入独立指令或 NOP(No Operation)以避免冒险。MIPS-II 则通过硬件插锁(Pipeline Interlocks)解决了这个问题。
3. 跳转和条件分支引发的气泡
- 跳转/条件分支:跳转指令或条件分支指令常常会引起控制冒险。因为分支的目标地址在执行阶段才能确定,因此在确定分支之前,流水线可能会错误取指并导致气泡。
- 无延迟槽时的处理:若没有延迟槽,分支指令可能会导致后续指令被杀死,形成气泡。
机器的延迟槽与 NOP 指令
- 如果处理器设计中有软件可见的延迟槽(如 MIPS-I 的设计),编译器可能会插入大量的 NOP 指令。虽然 NOP 可以避免冒险并降低 CPI,但它们会增加指令数量,进而影响程序的执行效率。
CS152 Administrivia
- HW1 发布:第一个作业(HW1)已经发布,截止日期为2月2日。
- Lab1 发布:第一个实验(Lab1)也已发布,截止日期为2月9日。
- 实验小组匹配:提供了一个链接,学生可以通过此表单进行实验小组的匹配。
- 讨论会和办公时间(OH):本周开始的讨论会和办公时间安排已发布。需要注意的是,周三10am-12pm的讨论会已经取消,讨论会将被录制以便回放。
CS252 Administrivia
- 阅读材料:CS252的阅读材料可以在特定链接上获取,学生需要在周三之前通过hotcrp平台提交阅读报告。报告要求:
- 写一个段落,概述文章的主要内容以及文章的优缺点。
- 回答或提出1-3个与文章相关的问题,便于课堂讨论。
- 第一批文章讨论的主题为“360 Architecture”和“VAX11-780”。
- 讨论会时间为每周三下午2-3点,地点为Soda 606或通过Zoom线上参与。
- 项目时间线:CS252的项目提案截止日期为2月22日,每个项目需要两名成员。提案内容包括:
- 项目标题
- 团队成员
- 要解决的问题
- 方法论
- 使用的基础设施
- 项目时间线和里程碑
Traps and Interrupts
在处理器的运行过程中,异常(Exception) 和 中断(Interrupt) 是两种不同的事件类型,处理器通过这些事件来管理意外情况和外部信号。下面是这些术语的定义:
Exception
- 异常 是指程序在执行过程中由于内部的异常情况导致的特殊事件。例如:
- 页错误(Page Fault)
- 算术下溢(Arithmetic Underflow)
Interrupt
- 中断 是指程序外部发生的事件。它们通常由外部设备或硬件引起,例如:
- 定时器中断
- 输入/输出设备的信号
Trap
- 陷阱(Trap) 是指当发生异常或中断时,处理器强制将控制转移到操作系统或监督程序进行处理的过程。
- 需要注意的是,并非所有的异常都会导致陷阱,例如根据 IEEE 754 浮点标准,一些浮点异常可能不会触发陷阱。
History of Exception Handling
Analytical Engine
- 分析机(Analytical Engine) 是最早具备异常处理的机器,它能够处理溢出异常。
Univac-I (1951)
- Univac-I 是第一个带有陷阱机制的系统。它能够在出现算术溢出时触发陷阱:
- 运行一个两条指令的修复程序(地址为 0 处),或者
- 在程序员的选择下,导致计算机停止。
- Univac 1103(1955):后来版本增加了外部中断功能,用于实时收集风洞数据。
DYSEAC (1954)
- DYSEAC 是第一个具有 I/O 中断的系统,配备两个程序计数器,当 I/O 信号出现时,可以在两个程序计数器之间切换。
- 这是首个支持直接内存访问(DMA)的系统,允许 I/O 设备直接与内存通信。
- 同时,DYSEAC 还是世界上第一个移动计算机,具备一定的移动性。

DYSEAC 是世界上第一台移动计算机,它是为美国陆军信号兵团(US Army Signal Corps)制造的,具有以下特点:
- 重量:总重量为 12 吨,再加上 8 吨的附加设备,它被装载在两辆拖车上,具备一定的移动性。
- 设计:这是一个创新的移动计算解决方案,能够在战场或其他需要移动计算能力的场景下工作。
Asynchronous Interrupts
异步中断 是指由外部设备(例如 I/O 设备)请求处理器的注意,以便在处理器完成当前指令后处理该中断。以下是异步中断的工作机制:
中断请求
- I/O 设备发出请求:I/O 设备通过发出优先级中断请求线来请求处理器的注意,要求处理当前的中断。
处理器处理中断的步骤
-
停止当前程序:处理器会在指令
I_i处暂停当前正在运行的程序,确保执行到I_i-1之前的所有指令都已完成(称为精确中断(Precise Interrupt))。 -
保存程序计数器(PC):处理器会将当前指令
I_i的程序计数器保存在一个特殊寄存器中,通常称为异常程序计数器(EPC),以便在中断处理结束后能够恢复程序执行。 -
转移控制:处理器会关闭其他中断并将控制权转交给运行在 supervisor mode 下的中断处理程序,负责处理此次中断。
Trap: Altering the Normal Flow of Control
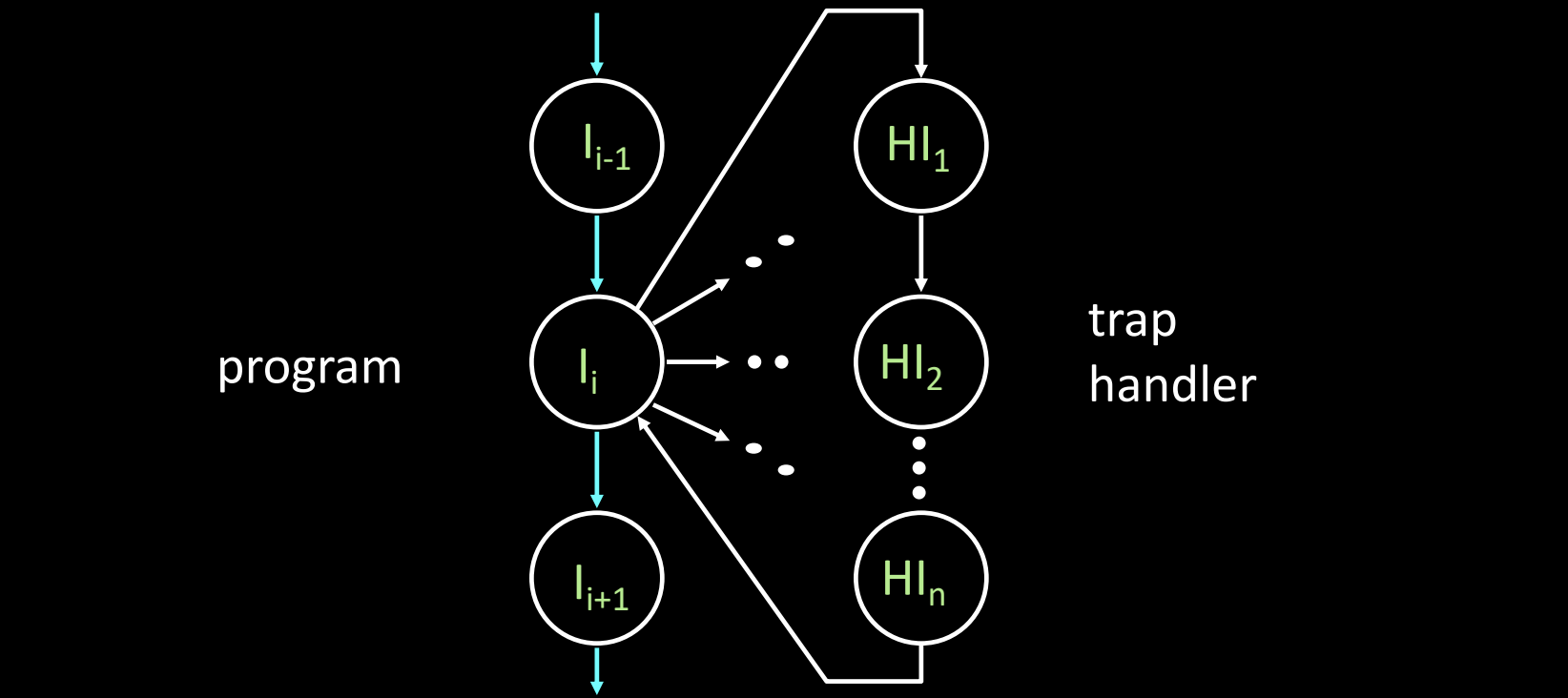
陷阱(Trap) 是指处理器因某种外部或内部事件而强制改变当前程序的控制流,从而跳转到特定的陷阱处理程序。陷阱通常是由程序无法预期或很少发生的事件引起的,典型例子包括异常或中断。如图中所示,在指令 I_i 处发生了异常或中断,控制流转移到相应的陷阱处理程序 H_i,在处理完陷阱后再返回继续执行程序中的 I_i+1。
Trap Handler
陷阱处理程序的职责是管理中断或异常事件,并确保在处理完事件后,处理器能够正常恢复执行原始程序。
1. 保存 EPC 并允许嵌套中断
- EPC(异常程序计数器) 保存了程序执行到发生陷阱时的指令地址。为了允许处理器处理嵌套中断,陷阱处理程序会在启用新中断之前保存 EPC。
- 需要通过指令将 EPC 移入通用寄存器文件(GPR)。
- 同时,必须提供一种屏蔽机制,防止在 EPC 保存之前处理新的中断。
2. 读取状态寄存器
- 陷阱处理程序还需要读取状态寄存器,该寄存器中记录了引发当前陷阱的原因,从而决定合适的处理方式。
3. 使用 ERET 恢复执行
- 陷阱处理程序在处理完成后,会使用一个特殊的间接跳转指令
ERET(从环境中返回)来恢复程序的执行。ERET的功能包括:- 启用中断:恢复处理中断期间禁止的中断。
- 恢复用户模式:将处理器从监督模式恢复到用户模式。
- 恢复硬件状态和控制状态:确保处理器恢复到陷阱发生前的硬件和控制状态,继续执行未完成的程序。
Synchronous Trap
同步陷阱(Synchronous Trap)是由特定指令导致的异常触发的。在同步陷阱中,异常的产生是与指令的执行紧密相关的。
特点:
- 异常由特定指令引发:同步陷阱通常由特定的指令引发,例如除零错误或内存访问越界。
- 指令需要重启:由于该指令无法正常完成执行,在处理完异常后通常需要重新执行这条指令。这就要求撤销或逆转部分已执行的操作,确保重启后的指令能够从头开始正常执行。
- 系统调用陷阱的特殊处理:对于系统调用导致的陷阱,指令被认为已经完成执行,因为系统调用通常意味着程序主动发起的上下文切换。此时的陷阱处理会涉及特权模式的转换和特殊的跳转指令。
Exception Handling in 5-Stage Pipeline
在经典的 5 级流水线中,异常处理尤为复杂,因为多个流水线阶段可能会同时发生不同的异常或中断事件。图中展示了一个典型的流水线中的异常处理流程,涉及到 PC 地址异常、非法操作码(Opcode)和数据地址异常等。
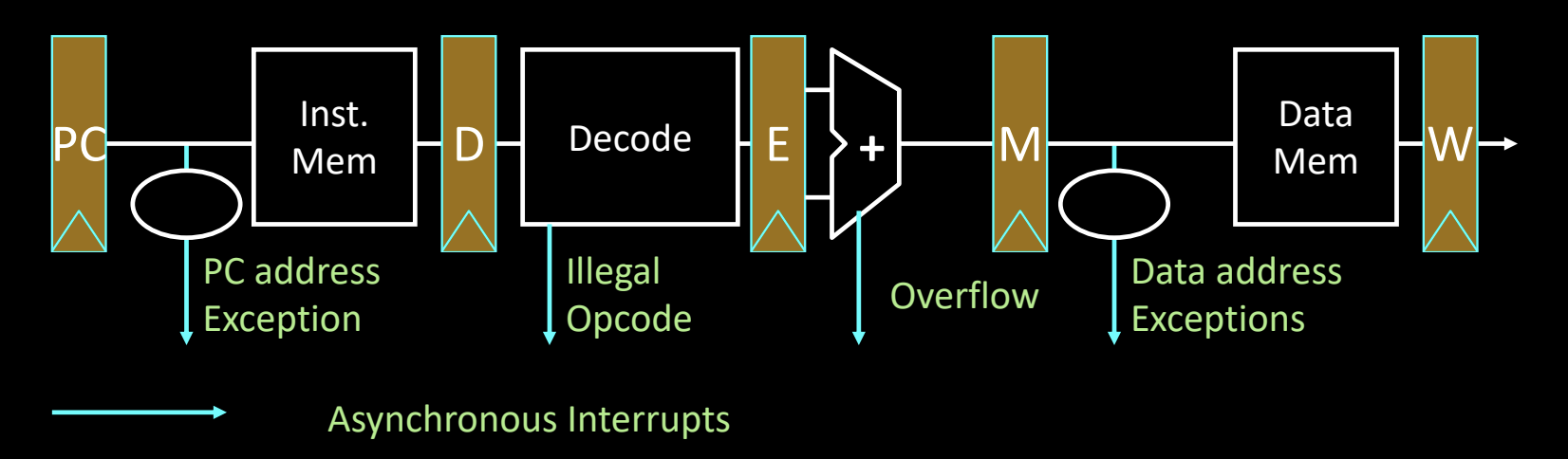
关键点:
- 流水线各阶段的异常来源:
- 取指阶段(Fetch):PC 地址可能导致异常,指令无法正确获取。
- 解码阶段(Decode):非法操作码导致异常。
- 执行阶段(Execute):例如算术溢出导致异常。
- 内存访问阶段(Memory):内存地址可能超出范围或无法访问。
- 异步中断的处理:异步中断与指令执行无关,可能在任何时间发生。因此,处理异步中断需要在流水线的任意阶段捕捉并处理这些中断。
需要解决的两个问题:
- 如何处理多个同时发生的异常:在不同的流水线阶段,可能会有多个异常同时发生,处理这些异常的顺序和优先级成为一个重要问题。
- 如何以及何处处理异步中断:异步中断不依赖于流水线内的指令执行,因此需要明确在哪里捕获和处理这些中断,并与同步异常的处理逻辑区分开来。
Exception Handling in 5-Stage Pipeline
在 5 级流水线架构中,异常处理是通过在流水线的不同阶段标记和处理异常事件来完成的。具体来说,流水线的每个阶段都可能会产生不同类型的异常,如 PC 地址异常、非法操作码、算术溢出以及数据地址异常。此外,异步中断也可能在任意时刻发生,需要在流水线中特定的提交点(M 阶段)来处理。
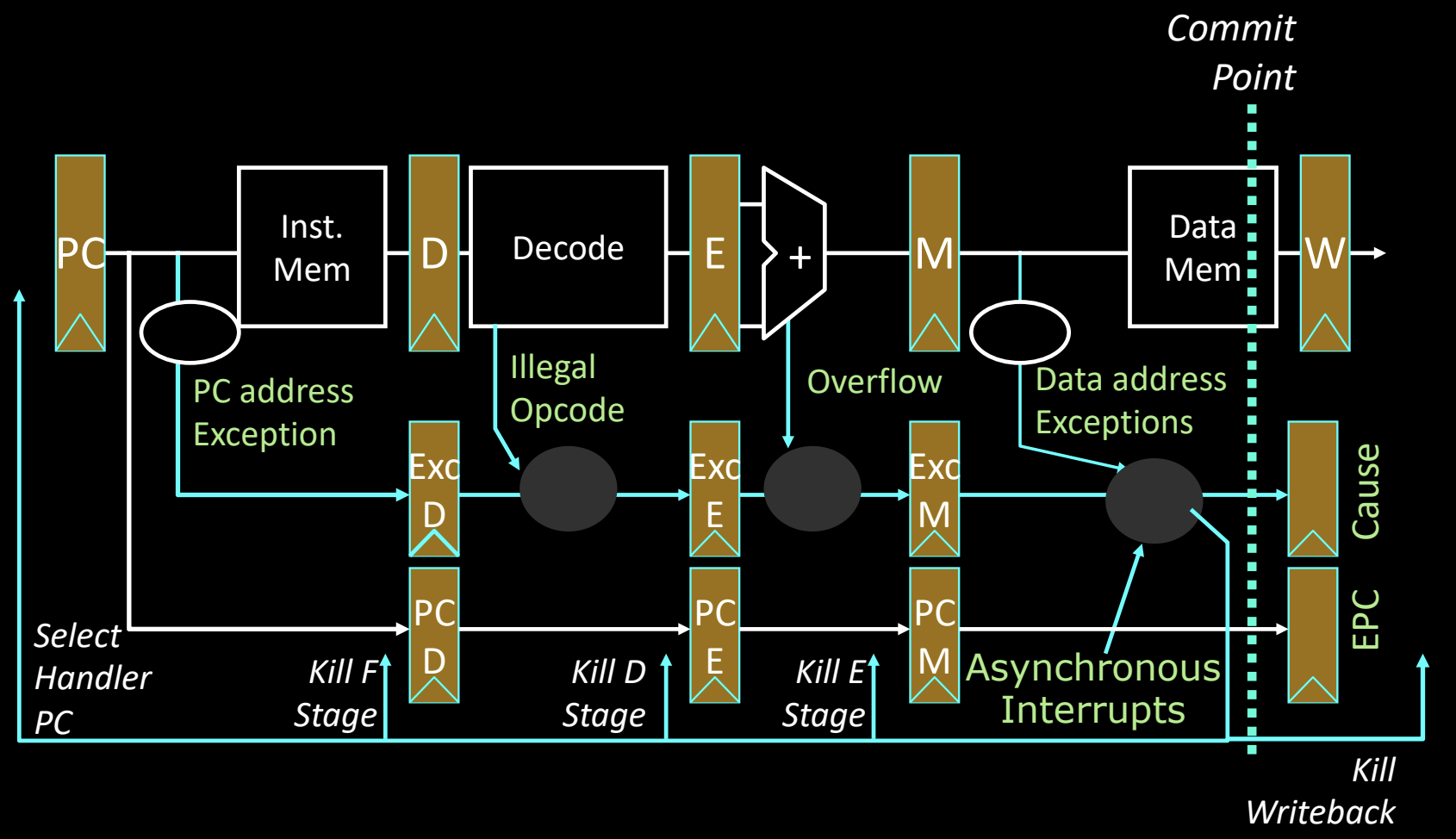
异常处理机制:
-
保持异常标志:当指令进入流水线时,任何阶段的异常标志都会保持到提交点(M 阶段),并在那里进行统一处理。
-
早期异常优先:对于同一条指令,如果早期的流水线阶段产生了异常,后续阶段的异常将会被忽略。例如,如果解码阶段产生了非法操作码异常,那么执行阶段或内存阶段的异常就不会再被处理。
-
异步中断的处理:异步中断的注入是在提交点进行的,这意味着它们将优先于其他异常。如果在提交点时检测到异步中断,流水线的所有阶段都会被终止,转而处理中断。
-
陷阱处理:当在提交点触发陷阱时,系统将会更新异常原因(Cause)寄存器和 EPC(异常程序计数器)寄存器,同时终止流水线的所有阶段。随后,处理器会将异常处理程序的地址注入到取指阶段,从而开始异常处理。
关键步骤:
- 在流水线中传递异常标志:每个阶段的异常标志会被传递并保持,直到 M 阶段进行统一处理。
- 各阶段异常处理的顺序:如果一个阶段的指令已经产生异常,则后续阶段的异常标志会被覆盖。
- 异步中断的优先级:异步中断在 M 阶段(提交点)注入,且具有最高优先级,会覆盖其他所有异常。
- 异常的清除与处理:一旦在提交点捕获异常,流水线的所有阶段都会被终止,处理器进入异常处理流程。
这种设计确保了流水线处理器在高效执行正常指令的同时,也能够可靠地处理多种同步和异步异常。
Speculating on Exceptions
在流水线处理器中,异常发生的频率较低,因此可以采用推测机制来简化异常处理的流程。这种机制旨在通过对异常的推测、检测以及恢复的结合,使得处理器能够以高效的方式应对稀有的异常事件。
推测机制:
-
预测机制:由于异常事件发生的概率很低,默认推测指令执行过程中不会发生异常是一个合理且高效的策略。这种方式可以避免对每条指令进行额外的异常检查,从而提高性能。
-
检查机制:指令的异常检测是在指令执行的最后阶段进行的,专门的硬件用于检测各类异常信号。如果在这个阶段检测到异常,处理器会进入异常处理流程。
恢复机制:
-
恢复状态:处理器只会在提交点(流水线的最后阶段)将指令的结果写入架构状态,这意味着在发生异常时,可以轻松丢弃那些已经部分执行但未提交的指令,从而恢复到异常发生之前的状态。
-
启动异常处理程序:当流水线被刷新后,处理器会启动异常处理程序来处理具体的异常类型。
此外,旁路机制允许跟随的指令使用未提交的指令结果,这样可以在一定程度上优化指令执行的效率,即使在处理异常的过程中,也能最大化利用已执行的部分操作结果。