rCore Series Notebook
建设中
清华大学操作系统2022-课程笔记,以及以一些相关资源工具的学习补充。
关于 rCore 和清华大学操作系统课程
rCore 是清华大学计算机系开发的一个开源操作系统内核学习项目,基于 Rust 语言,旨在让学生从底层理解操作系统的结构与设计。该项目伴随清华大学的操作系统课程,内容覆盖了从基本操作系统理论到实践的各个方面。
课程目录
-
第零章:实验环境配置
-
第一章:应用程序与基本执行环境
-
第三章:多道程序与分时多任务
-
第四章:地址空间
-
第五章:进程及进程管理
-
第六章:文件系统与 I/O 重定向
-
第七章:进程间通信
-
第八章:并发
更多资源
在学习过程中,我将分享一些翻译的资料与额外的资源,帮助你更好地理解 rCore 和操作系统课程中的内容。如果你对某些部分有疑问或者需要更详细的补充,可以随时在下面评论。
0. 开始前的阅读
An Introduction to RISC-V Boot Flow
本讲座由Atish Patra和Anup Patel主讲,主要讲解了RISC-V体系结构的启动流程。RISC-V是一种开源指令集架构,其灵活性和模块化设计使其在嵌入式系统和高性能计算领域日益受到关注。此文档针对RISC-V启动流程,介绍了它在嵌入式系统中的应用、与传统体系的对比、当前发展状态,以及未来可能的工作方向。
原始内容来源:
幻灯片标题:An Introduction to RISC-V Boot Flow
原作者:Atish Patra, Anup Patel
出处:Western Digital
原始发布日期:2019年12月19日
版权声明:该幻灯片及其内容的版权归Western Digital公司所有。翻译与讲解仅供学习和参考,更多详细信息请参见原文链接。
本文是2019年12月的一个讲座内容,虽然其中的部分技术进展和版本信息已经有些过时,但本文的学习重点在于了解RISC-V启动流程(RISC-V Boot Flow)的基本原理和结构。随着RISC-V生态系统的快速发展,某些工具和固件可能已经更新,因此不必对具体的版本和实现细节深究。阅读本文的目的在于掌握启动流程的整体框架和概念,了解RISC-V如何从上电到操作系统启动的过程,这对未来进一步研究和开发仍然有重要的参考价值。
简单看看即可,重点在于理解基本原理。
Outline
本次介绍的内容包括以下几个方面:
- Common embedded boot flow:介绍常见的嵌入式系统启动流程,帮助读者了解嵌入式系统在启动过程中涉及的关键步骤和组件。
- Current RISC-V boot flow:对RISC-V目前的启动流程进行详细解释,特别是在RISC-V架构上如何实现启动流程,区别于其他常见架构的启动过程。
- OpenSBI Project:深入讲解OpenSBI项目,作为RISC-V系统启动的一个关键组件,它的工作原理及如何在RISC-V启动过程中发挥作用。
- Tutorials:为读者提供关于RISC-V启动的实际操作教程,帮助其在真实环境中应用所学内容。
- Current Status:讲述RISC-V启动流程的当前状态,包括目前的进展、已解决的问题和仍存在的挑战。
- Future work:展望RISC-V启动流程未来的发展方向,探讨可能的改进和新的技术发展。
- Tutorials:再次提供相关的教程链接,帮助用户更深入理解和实践。
Prerequisite
在进行本次学习之前,需要做一些准备工作:
-
下载演示文稿:用户可以通过提供的短链接(shorturl.at/clITU)下载完整的演示文档。
-
操作系统要求:需要一台运行Linux操作系统的设备,任何发行版均可接受。这是因为RISC-V相关的开发环境多基于Linux。
-
可选的内核源代码构建环境:可以选择设置Linux内核源代码的构建环境,这对深入研究和开发RISC-V启动流程非常有帮助。
-
Ubuntu用户的具体指令:对于使用Ubuntu操作系统的用户,提供了安装相关开发环境的软件包命令:
sudo apt-get install git build-essential kernel-package fakeroot libncurses5-dev libssl-dev bison flex这条命令会安装一系列工具,包括构建工具链、内核打包工具、SSL库开发包等,这些都是在构建、调试和运行RISC-V启动流程时可能需要的依赖项。
Getting started
开始RISC-V的启动流程实验,需要完成以下几步准备工作:
-
创建工作目录
使用以下命令创建一个新的目录,并进入该目录:mkdir summit_demo; cd summit_demo -
下载交叉编译工具链
RISC-V的开发通常需要使用交叉编译工具链来编译代码,工具链可从以下链接下载: -
下载预构建的镜像
预先构建好的RISC-V镜像文件可以从以下链接获取: -
克隆OpenSBI项目
使用Git将OpenSBI项目克隆到本地,OpenSBI是RISC-V启动流程中重要的部分:git clone https://github.com/riscv/opensbi.git -
克隆U-Boot项目
同样,使用Git克隆U-Boot项目并切换到指定版本(v2019.10)。U-Boot是一个通用的引导加载程序,广泛用于嵌入式系统中:git clone https://github.com/u-boot/u-boot.git; git checkout v2019.10
这些步骤将为RISC-V启动实验设置好基础的开发环境和工具链,确保可以顺利运行后续的启动过程。
Common boot flow
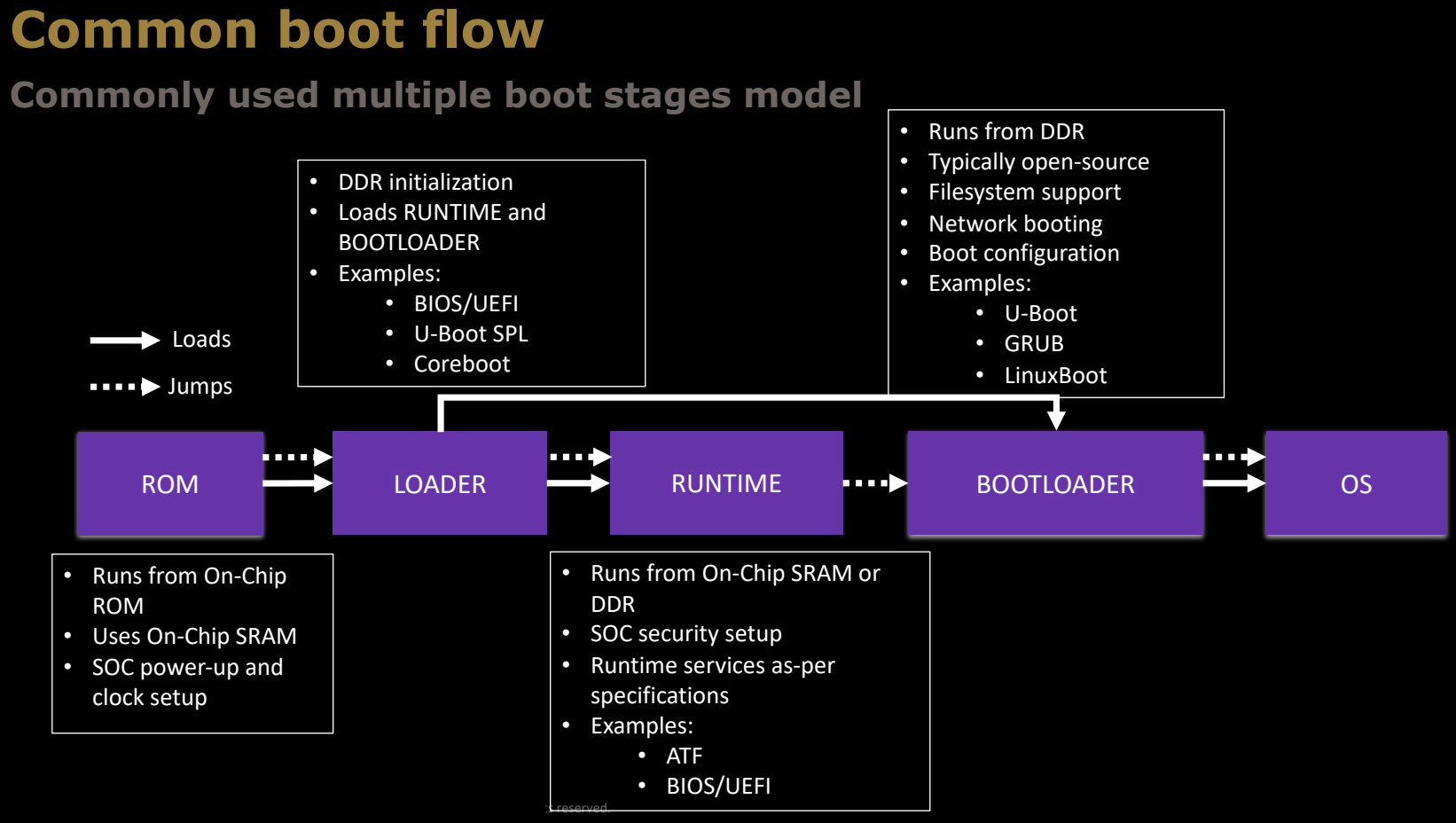
在嵌入式系统中,启动过程通常分为多个阶段,每个阶段的功能和执行环境不同。常见的启动流程包括以下几个阶段:
-
ROM阶段
- 运行环境:从片上ROM(Read-Only Memory)中执行。
- 功能:负责系统上电和时钟设置,SOC(系统级芯片)的启动。
- 该阶段的软件直接存储在芯片中,执行非常基础的启动任务,为后续阶段的运行做准备。
-
LOADER阶段
- 运行环境:通常从片上SRAM(Static RAM)中运行,有时也会初始化DDR内存。
- 功能:加载运行时环境(RUNTIME)和引导加载程序(BOOTLOADER)。
- 示例:BIOS/UEFI、U-Boot SPL、Coreboot。
在这一阶段,系统开始对内存进行初始化,加载更复杂的启动代码,准备进入运行时阶段。
-
RUNTIME阶段
- 运行环境:可以从片上SRAM或已初始化的DDR内存中执行。
- 功能:处理SOC的安全设置,提供符合规格的运行时服务。
- 示例:ATF(Arm Trusted Firmware)、BIOS/UEFI。
该阶段开始执行系统的安全设置,并确保系统的关键资源按照设计规格被正确管理。
-
BOOTLOADER阶段
- 运行环境:从DDR内存中运行,通常为开源软件。
- 功能:文件系统支持、网络启动、引导配置等。
- 示例:U-Boot、GRUB、LinuxBoot。
引导加载程序负责加载操作系统内核,提供网络启动等功能,并引导进入最终的操作系统。
-
OS阶段
在引导加载程序的引导下,操作系统(OS)被加载并开始执行,系统正式进入工作状态。
整个流程通过不同阶段的加载和跳转,逐步引导系统从最初的硬件上电状态进入功能完善的操作系统,确保了启动过程的安全性和稳定性。
Common boot flow in ARM64
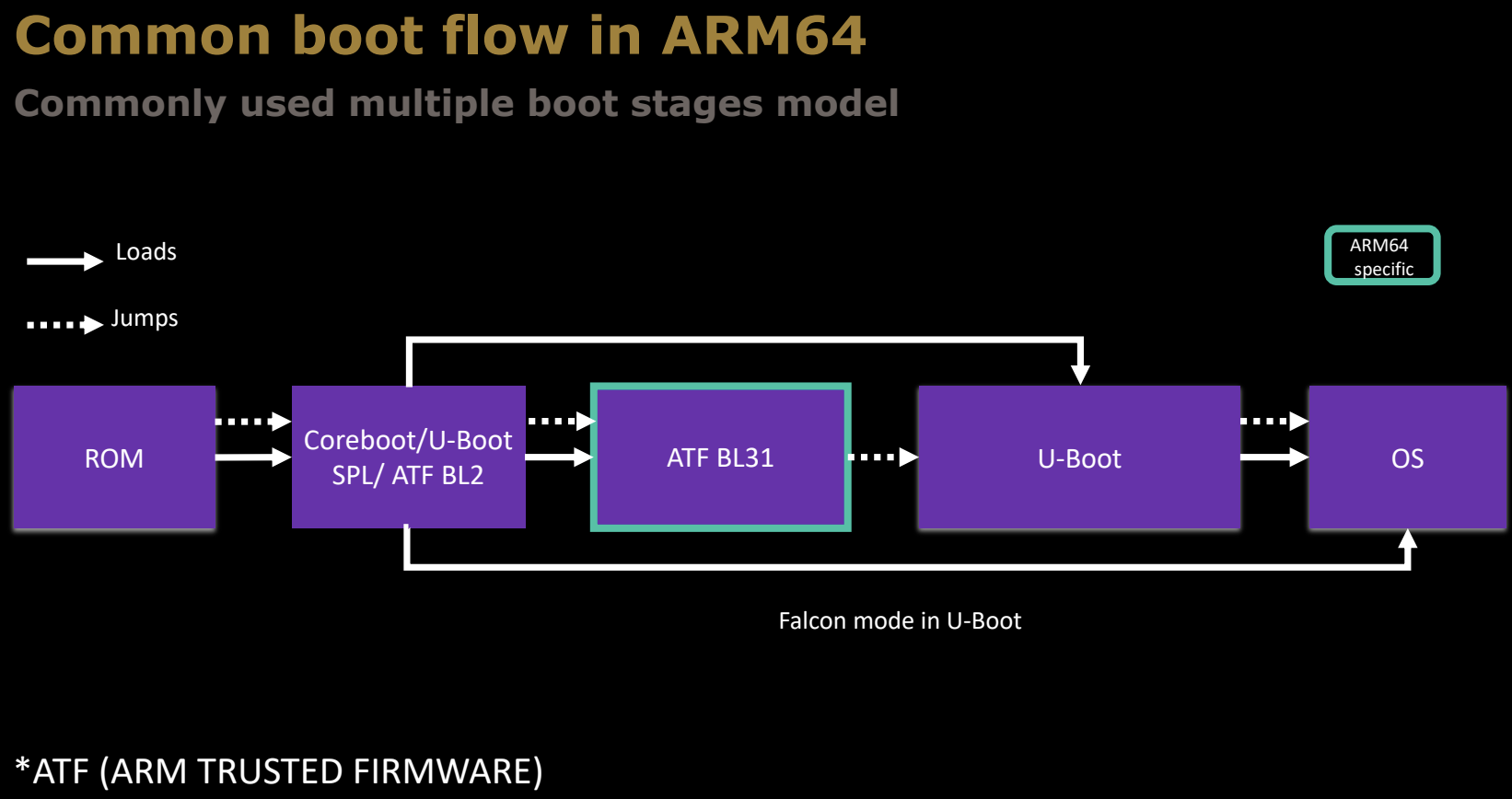
在ARM64架构中,启动流程也分为多个阶段,常见的启动模型如下:
-
ROM阶段
- 功能:从片上ROM中运行,负责启动系统最初的硬件初始化。通常,它会加载下一个阶段的启动加载程序,例如Coreboot或U-Boot SPL(Secondary Program Loader)。
-
Coreboot/U-Boot SPL / ATF BL2阶段
- 功能:从ROM加载,负责初始化系统内存(如DDR)和其他关键硬件资源。对于某些系统,还会加载ATF(Arm Trusted Firmware)BL2,它处理一些系统安全和电源管理任务。
-
ATF BL31阶段
- 功能:这是ATF的一个关键部分,负责处理安全性问题,例如设置安全世界与非安全世界之间的隔离。它在系统进入U-Boot或操作系统之前,确保所有的安全配置和硬件初始化已经完成。
-
U-Boot阶段
- 功能:U-Boot作为引导加载程序,负责加载操作系统内核。它可能会使用"Falcon模式"来直接加载操作系统,跳过某些额外的初始化步骤,以加快启动速度。
-
OS阶段
- 功能:操作系统加载并开始运行。ARM64平台通常使用Linux等操作系统。
这个启动流程中,ATF(Arm Trusted Firmware)是ARM64平台的一个重要部分,负责处理安全模式的切换和运行时的硬件管理。整个流程从硬件初始化开始,经过多次加载和跳转,最终将系统引导至操作系统。
RISC-V Upstream Boot Flow
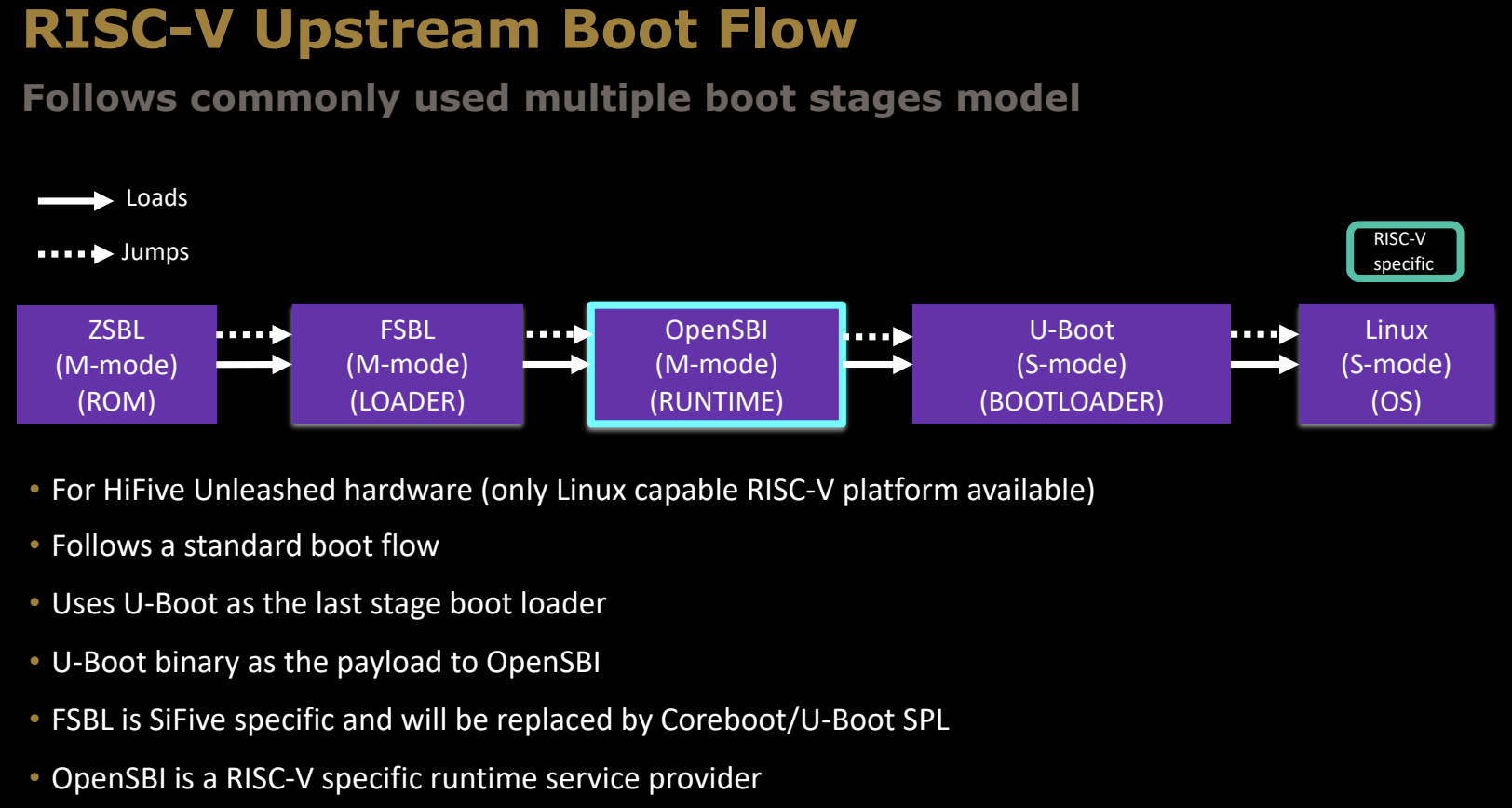
与ARM64相似,RISC-V的启动流程也遵循多个阶段的模型,以下是RISC-V的启动流程:
-
ZSBL阶段 (M-mode, ROM)
- 功能:ZSBL(Zero Stage Boot Loader)是启动的第一个阶段,从片上ROM运行,负责最基础的硬件初始化任务。它会加载FSBL(First Stage Boot Loader)。
-
FSBL阶段 (M-mode, LOADER)
- 功能:FSBL从ZSBL加载,进一步初始化内存和其他外设资源。对于SiFive开发的RISC-V平台,FSBL是特定的加载程序,不过在其他平台上可能会被Coreboot或U-Boot SPL取代。
-
OpenSBI阶段 (M-mode, RUNTIME)
- 功能:OpenSBI(Open Source Supervisor Binary Interface)是RISC-V架构中的一个关键组件,它为上层软件提供RISC-V特定的运行时服务。OpenSBI运行在机器模式(M-mode)下,直接控制硬件,并提供标准化的接口给下一阶段的引导加载程序或操作系统。
-
U-Boot阶段 (S-mode, BOOTLOADER)
- 功能:U-Boot在S-mode(Supervisor Mode)下运行,作为引导加载程序,负责加载操作系统内核。U-Boot在此阶段的作用与其他架构相似,处理网络启动、存储设备管理和文件系统加载。
-
Linux阶段 (S-mode, OS)
- 功能:最终操作系统被加载并进入运行。RISC-V目前主要支持Linux等开源操作系统。
关键说明
- 适用平台:这个流程主要适用于HiFive Unleashed硬件平台,这是目前 (2019.12) 唯一支持Linux的RISC-V开发板。
- 使用U-Boot作为最后阶段的引导加载程序:U-Boot是一个通用的引导加载程序,处理操作系统的加载。
- OpenSBI:这是RISC-V的特定组件,负责为引导加载程序和操作系统提供运行时服务。
与ARM64的启动流程相比,RISC-V的启动流程同样分为多个阶段,但其中的OpenSBI是RISC-V独有的一个关键部分。它提供了机器模式(M-mode)下的关键服务,使得引导加载程序和操作系统可以在RISC-V平台上顺利运行。
RISC-V boot flow development timeline
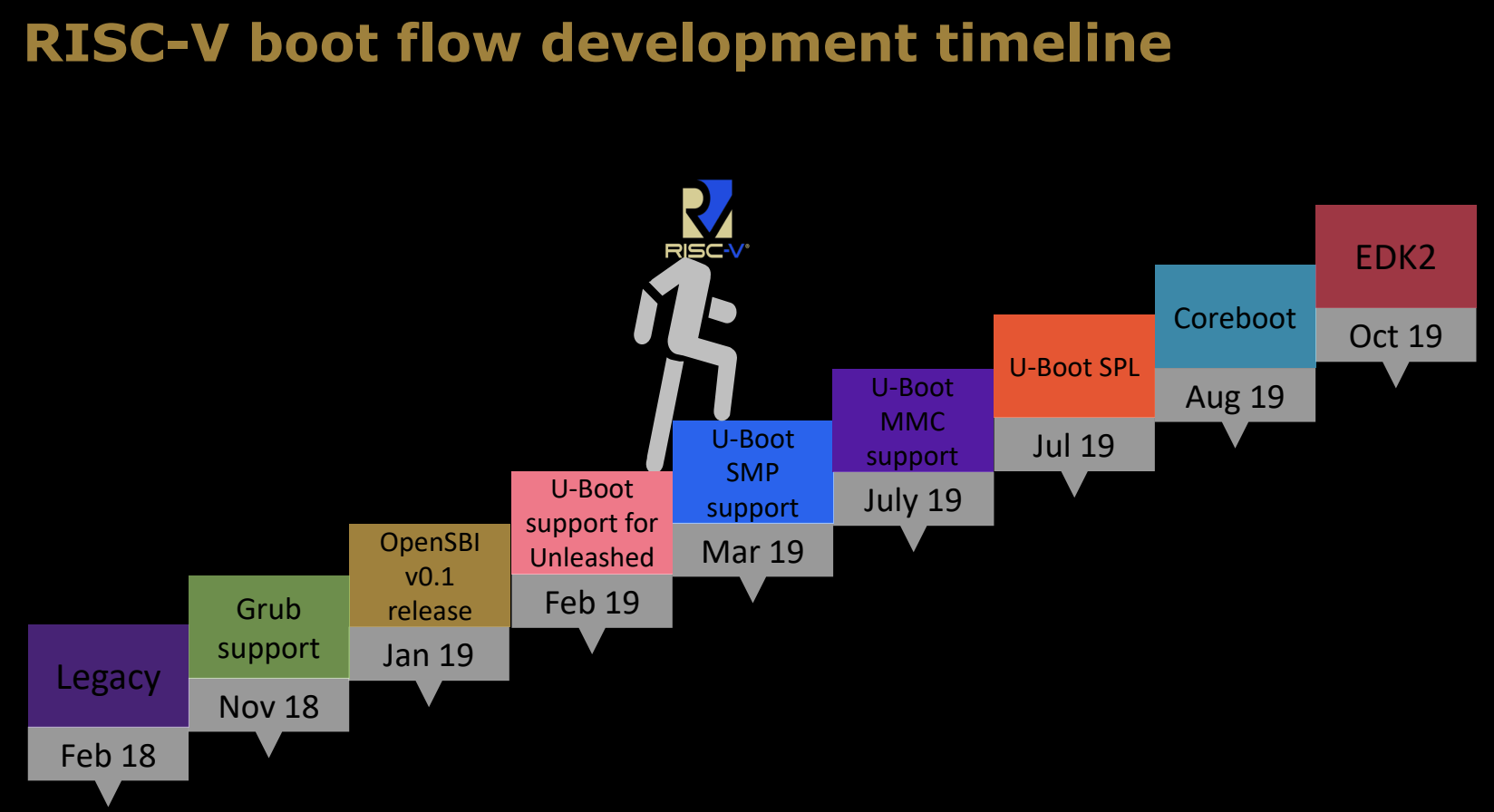
RISC-V启动流程的发展历程 (-2019.12) 展现了该架构的逐步成熟和演变。每个重要的里程碑标志着RISC-V启动流程支持的新功能和特性:
-
Legacy(Feb 18)
在2018年2月之前,RISC-V启动流程仍处于早期阶段,很多现代启动组件尚未完善。 -
Grub support(Nov 18)
2018年11月,RISC-V得到了Grub(Grand Unified Bootloader)的支持。Grub是一个常用的开源引导加载程序,它为RISC-V引入了更通用的启动加载选项,支持多种操作系统。 -
OpenSBI v0.1 release(Jan 19)
2019年1月,OpenSBI v0.1版本发布。OpenSBI是RISC-V启动流程中的关键组件,为操作系统提供运行时服务并管理硬件资源。 -
U-Boot support for Unleashed(Feb 19)
2019年2月,U-Boot引入了对HiFive Unleashed开发板的支持。这是RISC-V平台上首个支持Linux的开发板,U-Boot的支持使得该平台能够顺利引导操作系统。 -
U-Boot SMP support(Mar 19)
2019年3月,U-Boot增加了SMP(对称多处理)支持,允许多核处理器在RISC-V平台上进行并行处理,提升系统的性能和灵活性。 -
U-Boot MMC support(July 19)
2019年7月,U-Boot引入了对MMC(多媒体卡)的支持,允许RISC-V设备通过MMC卡存储和加载操作系统。 -
U-Boot SPL(July 19)
同样在2019年7月,U-Boot SPL(Secondary Program Loader)支持引入。SPL是一种轻量级引导程序,专门用于初始化内存和加载完整的引导程序。 -
Coreboot(Aug 19)
2019年8月,Coreboot支持被引入RISC-V启动流程。Coreboot是一个快速、灵活的开源固件平台,旨在替代传统的BIOS/UEFI。 -
EDK2(Oct 19)
2019年10月,EDK2的支持被加入。EDK2是UEFI固件的开源实现,它为RISC-V提供了标准化的固件接口,使其能够与更广泛的软件生态系统兼容。
这条时间线展示了RISC-V启动流程逐步从基础的启动支持走向复杂的多处理器支持、高级存储设备支持和开源固件的集成,最终形成一个功能完善、模块化的启动系统。
What is SBI?
SBI(Supervisor Binary Interface)是RISC-V架构中的管理模式二进制接口,其作用类似于系统调用接口,允许超级模式(S-mode)的操作系统与机器模式(M-mode)的执行环境(SEE, Supervisor Execution Environment)进行通信。它定义了一组标准化的接口,使得不同的操作系统和平台可以在不重复编写硬件相关代码的情况下,访问底层硬件资源。
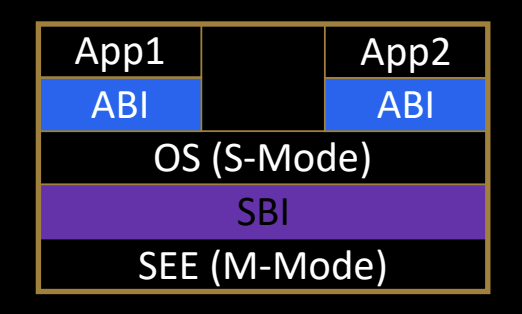
SEE的定义
- M-mode下的运行时固件:为运行在HS-mode(Hypervisor Supervisor Mode)的操作系统或虚拟机管理器提供运行时服务。
- HS-mode下的虚拟机管理器:为运行在VS-mode(Virtual Supervisor Mode)的客户操作系统提供管理功能。
SBI的作用
- 减少平台代码的重复:通过统一的接口,减少Linux、FreeBSD等操作系统中的平台特定代码,简化操作系统在不同硬件平台上的移植和维护工作。
- 提供共享驱动程序:使多个平台可以共享驱动程序,避免为每个平台单独编写。
- 提供硬件资源访问接口:SBI允许操作系统直接访问机器模式下(M-mode)的硬件资源。
规范和开发进展
SBI的规范由Unix平台规范工作组制定,当前的版本包括:
- SBI v0.1:目前 (2019.12) 广泛使用。
- SBI v0.2:正在草案阶段,旨在提供更多功能和更好的性能。
SBI的详细文档和规范可以通过RISC-V的SBI GitHub项目获取。
What is OpenSBI?
OpenSBI是RISC-V体系结构中Supervisor Binary Interface (SBI) 规范的开源实现。它为机器模式(M-mode)提供运行时服务,是RISC-V启动流程中的关键组件,通常在ROM/LOADER阶段之后使用。OpenSBI通过提供标准化接口,使得上层操作系统可以与硬件进行交互,从而避免了SBI实现的碎片化。
OpenSBI的主要特性
- 开源实现:OpenSBI遵循BSD-2条款许可证,由社区维护和开发。它确保SBI的实现一致性,并避免不同平台上SBI实现的差异。
- 提供运行时服务:OpenSBI在机器模式(M-mode)下运行,负责为操作系统(通常是在超级模式S-mode下运行)提供必要的服务。
- 支持参考平台:OpenSBI为不同平台提供了参考驱动程序,包括PLIC(平台级中断控制器)、CLINT(核心本地中断器)和UART 8250驱动程序等。其他平台可以基于这些通用代码添加自己的平台驱动程序。
- 社区维护的开源项目:用户可以通过OpenSBI的GitHub获取源代码、文档以及最新的更新。
OpenSBI的作用
OpenSBI主要为RISC-V平台提供一个标准化的接口,使操作系统可以高效、安全地与硬件交互。它被设计为可移植和模块化的,使得不同硬件平台可以复用它的核心功能,同时添加各自平台特定的驱动程序。
Key Features
OpenSBI具备以下几个重要的功能特性,确保其能够在广泛的硬件环境中高效运行,并适应不同的使用场景:
分层结构以适应多种用例
-
通用SBI库与平台抽象层:
通用的SBI库实现了平台抽象,通常与外部固件和引导加载程序(如EDK2、Secure Boot工作组实现的UEFI)一起使用。它提供了标准的SBI接口,使得外部引导加载程序可以在不同的平台上稳定运行。 -
平台特定的库:
与核心库类似,但包含特定平台的驱动程序。它允许硬件厂商根据自身硬件的特点进行定制,而不影响SBI核心功能的通用性。 -
平台特定的参考固件:
提供三种不同类型的运行时固件,供开发人员参考和使用。它们涵盖了从最基本的引导流程到高级的硬件初始化需求。

广泛支持的硬件特性
OpenSBI支持多种硬件特性,确保它能够在各种不同的RISC-V系统中运行,包括:
- 支持RV32和RV64:既支持32位的RISC-V架构,也支持64位架构,使其在不同的硬件平台上都可以使用。
- 虚拟化支持:支持Hypervisor模式,允许虚拟机管理程序在硬件上运行多个操作系统实例。
- 未对齐的加载/存储处理:处理未对齐的内存访问操作,确保在所有情况下都能正确处理数据。
- CSR(控制状态寄存器)仿真:为某些平台提供CSR仿真,确保它们能够顺利运行RISC-V的通用指令集。
- 使用PMP(物理内存保护)保护固件:通过PMP确保固件在运行时免受非法内存访问的威胁,增强系统的安全性。
OpenSBI的层次结构设计和其支持的硬件特性使其能够适应从简单到复杂的各种RISC-V平台,成为RISC-V生态系统中不可或缺的一部分。通过提供标准化的接口和驱动支持,OpenSBI确保了RISC-V平台的可移植性和扩展性。
Platform support
OpenSBI支持多种RISC-V平台,包括以下几种:
- SiFive HiFive Unleashed:这是RISC-V开发板中最为著名的硬件平台之一,支持Linux操作系统运行。
- Andes AE350:由Andes Technology开发的RISC-V处理器平台,适用于嵌入式系统和IoT应用。
- Ariane FPGA SoC:基于Ariane RISC-V内核的可编程逻辑器件(FPGA)系统芯片,适合硬件验证和研究。
- Kendryte K210:一个专为物联网和AI应用设计的RISC-V芯片,内置AI加速器和神经网络处理器。
- QEMU虚拟机(32位/64位):QEMU是一款开源虚拟机仿真器,可以通过模拟RISC-V架构的虚拟机进行开发和测试,支持32位和64位系统。
- OmniXtend:一个支持RISC-V的开源互连协议,用于高性能计算和数据中心应用。
这些平台覆盖了从硬件开发板到虚拟机环境的广泛应用场景,能够帮助开发者在不同的硬件和虚拟化环境中进行RISC-V软件开发和测试。
Tutorial
Setup details
为了成功设置RISC-V开发环境,以下步骤详细说明了如何配置工具链、QEMU仿真器以及环境变量。
-
查看当前工作目录的设置
运行以下命令查看当前目录下的文件和设置:ls -l
输出结果展示了几个关键文件:
linux_Image:Linux内核镜像文件。linux_rootfs.img:根文件系统镜像,用于仿真系统的文件结构和内容。opensbi:OpenSBI的二进制文件,提供运行时服务。qemu-system-riscv64:QEMU的RISC-V 64位二进制文件,用于虚拟机仿真。riscv64--glibc--bleeding-edge-2018.11-1:RISC-V的交叉编译工具链。u-boot:U-Boot引导加载程序,用于启动系统。
-
解压工具链并将其添加到环境路径
下载并解压RISC-V工具链后,需要将其路径添加到系统环境变量中:tar -xvf riscv64--glibc--bleeding-edge-2018.11-1.tar.bz2 export PATH=$PATH:riscv64--glibc--bleeding-edge-2018.11-1/bin/这将确保可以在命令行中直接调用交叉编译工具链进行开发和构建。
-
更改QEMU二进制文件的权限
为了能够运行QEMU仿真器,需要为其二进制文件设置执行权限:chmod a+x qemu-system-riscv64这一步确保QEMU仿真器可以被正确执行,用于模拟RISC-V系统。
-
设置环境变量CROSS_COMPILE和ARCH
设置交叉编译工具链的相关环境变量,以确保编译过程中可以正确识别目标架构:export ARCH=riscv export CROSS_COMPILE=riscv64-linux-这里的
ARCH变量指定了目标架构为RISC-V,而CROSS_COMPILE则设置了用于交叉编译的前缀,使得编译器知道要为RISC-V平台生成代码。
通过上述步骤,可以成功配置一个完整的RISC-V开发和仿真环境。这些步骤尤其适合那些希望在虚拟化环境中运行RISC-V操作系统或开发软件的开发者。
Tutorial-I: Boot Linux in Qemu as a payload to OpenSBI
这部分指导如何通过OpenSBI在Qemu中启动Linux系统。Qemu是一个强大的虚拟化工具,支持RISC-V等多种架构,允许用户在虚拟环境中运行完整的操作系统。本教程将详细介绍如何将Linux内核作为OpenSBI的payload,在Qemu中运行RISC-V Linux系统。
1. 编译OpenSBI
首先,进入OpenSBI的源代码目录,并编译适用于Qemu虚拟机的OpenSBI固件。这里的PLATFORM参数指定了编译目标为Qemu的虚拟机平台,FW_PAYLOAD_PATH参数指定了将Linux内核作为OpenSBI的payload(负载)。
cd opensbi; make PLATFORM=qemu/virt FW_PAYLOAD_PATH=../linux_Image; cd ..
这一过程会生成适用于Qemu虚拟机的OpenSBI镜像,之后可以用作引导加载程序,将Linux内核作为payload。
2. 在Qemu中运行OpenSBI和Linux
接下来,通过Qemu运行OpenSBI,并将Linux根文件系统和内核加载到虚拟机中。以下是用于启动Qemu的命令,其中包括各个参数的具体含义:
qemu-system-riscv64 -M virt -m 256M -nographic \
-kernel opensbi/build/platform/qemu/virt/firmware/fw_payload.elf \
-drive file=linux_rootfs.img,format=raw,id=hd0 \
-device virtio-blk-device,drive=hd0 \
-append "root=/dev/vda rw console=ttyS0"
-M virt:指定Qemu使用的虚拟硬件平台,这里选择的是虚拟机平台。-m 256M:分配给虚拟机的内存大小,设定为256MB。-nographic:以无图形界面的方式运行虚拟机,所有输出将通过命令行显示。-kernel:指定OpenSBI固件的路径,OpenSBI的固件负责引导系统并加载Linux内核。-drive:指定根文件系统镜像的路径,这里使用的是linux_rootfs.img,格式为原始镜像。-device virtio-blk-device:使用virtio块设备驱动,为Qemu虚拟机提供存储设备支持。-append:向Linux内核传递命令行参数,指定根文件系统位于/dev/vda,并设置控制台为ttyS0。
通过上述命令,Qemu将启动虚拟的RISC-V系统,加载OpenSBI并运行Linux内核。
Adding Support for New Platforms
在开发过程中,可能需要为OpenSBI添加对新平台的支持。以下是为新平台添加支持的步骤:
-
在
/platform目录下创建新的平台目录
为新平台创建一个名为<xyz>的目录,用于存放与该平台相关的配置文件和源码。 -
创建平台配置文件
<xyz>/config.mk
该文件将包含平台的配置选项、常用驱动程序的标志以及固件选项。可以参考模板platform/template/config.mk创建该文件。 -
创建平台对象文件
<xyz>/objects.mk
在此文件中列出需要编译的与平台相关的特定对象文件。可以参考platform/template/objects.mk创建该文件。 -
创建平台源码文件
<xyz>/platform.c
该文件实现与平台相关的具体功能,并提供struct sbi_platform实例。可以参考platform/template/platform.c创建该文件。
额外说明
- 新平台的支持目录
<xyz>可以放置在OpenSBI源代码外部,但需要确保其路径在编译时正确指定。
通过这些步骤,开发者可以为OpenSBI添加对新硬件平台的支持,确保其能够在不同的硬件环境中正常运行。
Reference Firmwares
OpenSBI提供了几种类型的参考固件,每种固件都针对特定的平台需求。不同类型的固件适用于RISC-V启动流程中的不同阶段和使用场景。
1. FW_PAYLOAD
- 功能:该固件将下一阶段的引导程序作为负载(payload)进行加载。这是适用于Linux等操作系统的RISC-V硬件上最常用的固件类型。
- 默认使用:在可运行Linux的RISC-V硬件中,FW_PAYLOAD是最常用的参考固件。
2. FW_JUMP
- 功能:该固件带有一个固定的跳转地址,用于跳转到下一个引导阶段。这种方式适用于需要手动指定引导地址的场景。
- 默认使用:这是QEMU仿真环境中的默认引导方法。
3. FW_DYNAMIC
- 功能:该固件通过动态信息来确定下一个引导阶段。这种方式通常用于U-Boot SPL或Coreboot等加载程序,能够根据运行时信息灵活调整引导流程。
- 使用场景:U-Boot SPL和Coreboot等平台使用FW_DYNAMIC来管理引导流程。
SOC厂商的选择
SOC厂商可以根据自身需求选择适合的固件类型:
- 使用OpenSBI的参考固件作为M-mode的运行时固件。
- 使用OpenSBI作为库,完全从头构建M-mode运行时固件。
- 扩展现有的M-mode固件(如U-Boot_M_mode或EDK2),并将OpenSBI作为库来增强功能。
通过这些选项,硬件厂商能够根据平台的实际需求,灵活地选择和定制适合的固件解决方案。
U-Boot: An universal boot loader
U-Boot(Universal Boot Loader)是嵌入式系统中最常用的通用引导加载程序,广泛用于多个架构和平台。它作为最后阶段的引导加载器,负责加载操作系统并管理底层硬件资源。
U-Boot的支持范围
- 支持多种指令集架构(ISA):包括x86、ARM、AARCH64、RISC-V、ARC等,使其在不同架构的硬件上都能使用。
- 支持多种外设接口:如UART、SPI、I2C、以太网、SD卡、USB等,涵盖了几乎所有常见的嵌入式外设。
- 支持多种文件系统:能够从不同的文件系统中加载镜像,包括常见的文件系统格式。
- 支持多种网络协议:如TFTP等网络协议,允许从网络中加载操作系统镜像或数据。
U-Boot的功能
- 加载镜像:可以从网络、文件系统、可移动设备等多种介质中加载操作系统镜像。
- 命令行管理界面:U-Boot提供了一个简便的命令行接口,用于执行引导命令、配置启动参数以及调试系统。
高度的可定制性
U-Boot具备丰富的定制选项,能够根据实际需求进行裁剪和优化:
- U-Boot SPL:这是U-Boot的精简版本,通常作为启动的第一级引导加载器,用于最小化引导时间并加载完整的U-Boot程序。
- Falcon模式:该模式用于加速启动流程,直接加载操作系统,跳过某些不必要的初始化步骤。
U-Boot凭借其广泛的支持、灵活的定制性以及强大的功能,成为嵌入式系统中几乎标准的引导解决方案。它可以适应从开发板到生产环境的多种场景,使得系统启动流程更加高效和灵活。
Tutorial-II: Boot Linux in Qemu using U-Boot proper
这部分介绍如何在Qemu中通过完整的U-Boot(U-Boot proper)引导Linux系统。与之前的教程不同,这里使用的是U-Boot作为最后阶段的引导加载程序,而不是直接将Linux作为OpenSBI的payload。通过此方法,用户可以充分利用U-Boot的灵活性和强大的引导功能。
1. 编译U-Boot
首先,进入U-Boot的源代码目录,并为RISC-V平台的Qemu环境进行配置和编译。这里使用了qemu-riscv64_smode_defconfig配置文件,它为RISC-V 64位的Qemu虚拟机环境生成适合的U-Boot配置。
cd u-boot; make qemu-riscv64_smode_defconfig; make; cd ..
2. 编译OpenSBI
接下来,进入OpenSBI的源代码目录,并编译适用于Qemu的OpenSBI固件。与之前不同,这次没有指定payload,意味着OpenSBI的职责仅仅是作为U-Boot的引导器。
cd opensbi; make PLATFORM=qemu/virt; cd ..
这里使用fw_jump固件类型,允许U-Boot来加载Linux内核。
3. 在Qemu中运行U-Boot和OpenSBI
编译完成后,可以通过Qemu运行U-Boot和OpenSBI,同时加载Linux内核和根文件系统。运行以下命令:
./qemu-system-riscv64 -M virt -smp 4 -m 256M -nographic \
-bios opensbi/build/platform/qemu/virt/firmware/fw_jump.elf \
-kernel u-boot/u-boot.bin -device loader,file=linux_Image,addr=0x84000000 \
-drive file=linux_rootfs.img,format=raw,id=hd0 \
-device virtio-blk-device,drive=hd0
-M virt:指定使用Qemu的虚拟机平台。-smp 4:为虚拟机分配4个CPU核心,模拟多核环境。-m 256M:分配256MB内存。-nographic:以无图形界面的方式运行。-bios:指定OpenSBI固件路径,此处使用的是fw_jump.elf。-kernel:指定U-Boot二进制文件作为引导加载程序。-device loader:加载Linux内核,并指定其地址为0x84000000,这是U-Boot期望的内核加载地址。-drive:指定根文件系统镜像,格式为原始格式。-device virtio-blk-device:使用virtio块设备模拟存储设备。
通过该命令,Qemu将启动虚拟机,加载OpenSBI和U-Boot,并进入U-Boot的命令行界面。
4. 在U-Boot命令行引导Linux
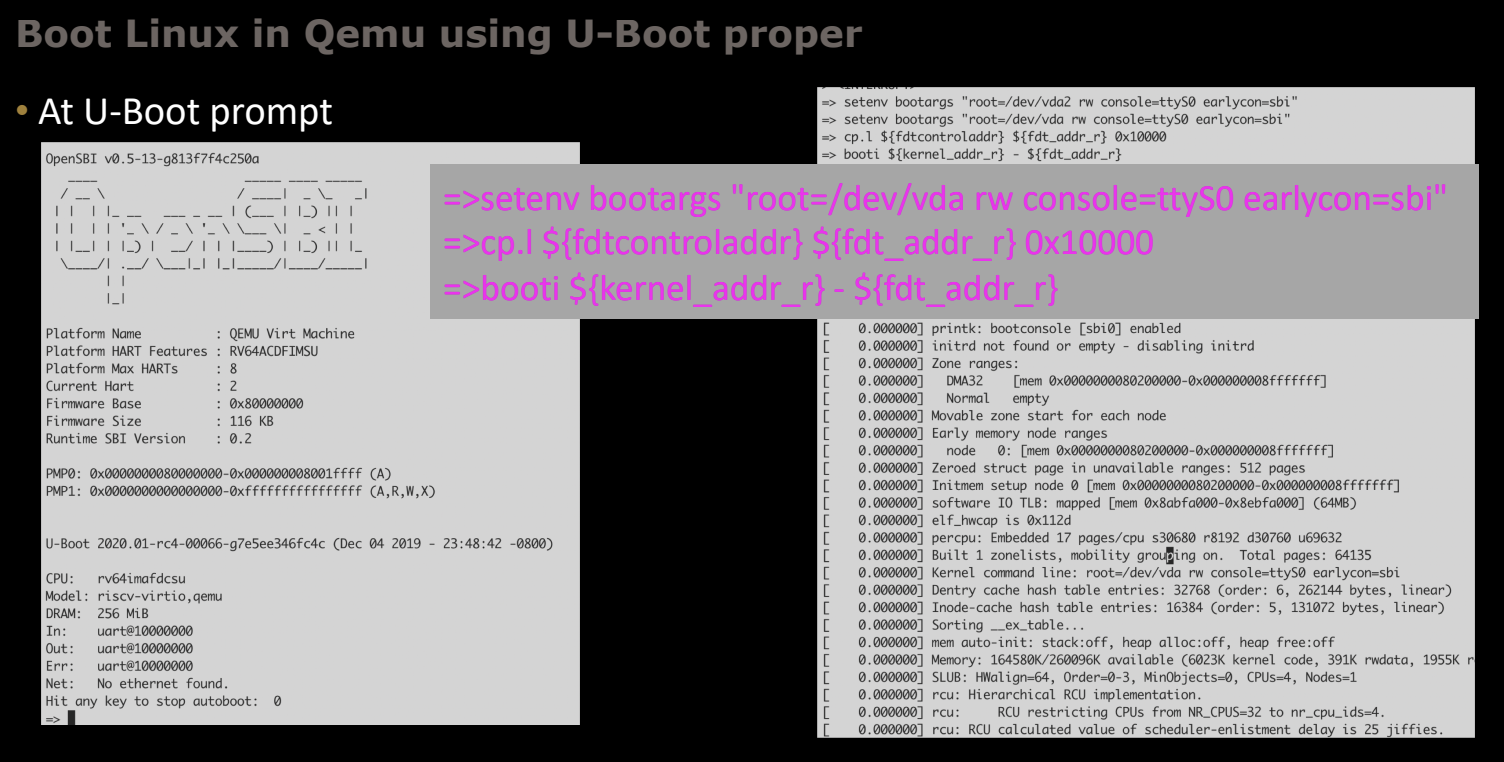
启动后,你将进入U-Boot的命令行提示符。在这里,可以通过以下命令引导Linux内核:
=> setenv bootargs "root=/dev/vda rw console=ttyS0 earlycon=sbi"
=> cp.l ${fdtcontroladdr} ${fdt_addr_r} 0x10000
=> booti ${kernel_addr_r} - ${fdt_addr_r}
setenv bootargs:设置内核引导参数,这里指定根文件系统为/dev/vda,并配置控制台输出。cp.l:复制设备树控制块(fdtcontroladdr)到设备树地址寄存器(fdt_addr_r)。booti:引导Linux内核,kernel_addr_r是内核的加载地址,fdt_addr_r是设备树的地址。
执行这些命令后,U-Boot将加载Linux内核并启动系统。
Boot flow using OpenSBI dynamic firmware
在使用OpenSBI动态固件的启动流程中,固件通过动态信息来确定下一个引导阶段。这种方式比固定地址跳转更加灵活,适用于复杂的启动场景。以下是使用OpenSBI动态固件的典型启动流程:
-
ZSBL (M-mode, ROM)
第一个阶段是从机器模式(M-mode)执行的片上ROM固件,负责最基本的硬件初始化。 -
U-Boot SPL/Coreboot (M-mode)
第二阶段使用U-Boot SPL或Coreboot,它们在M-mode下运行,并负责加载下一阶段的启动固件。 -
OpenSBI (M-mode, RUNTIME)
OpenSBI在M-mode下提供运行时服务,使用动态固件(fw_dynamic),通过寄存器a2传递关于下一引导阶段的信息。 -
U-Boot (S-mode, BOOTLOADER)
OpenSBI引导进入U-Boot,U-Boot运行在超级模式(S-mode)下,负责加载Linux内核。 -
Linux (S-mode, OS)
最终,U-Boot加载并引导Linux操作系统,进入正式的工作环境。
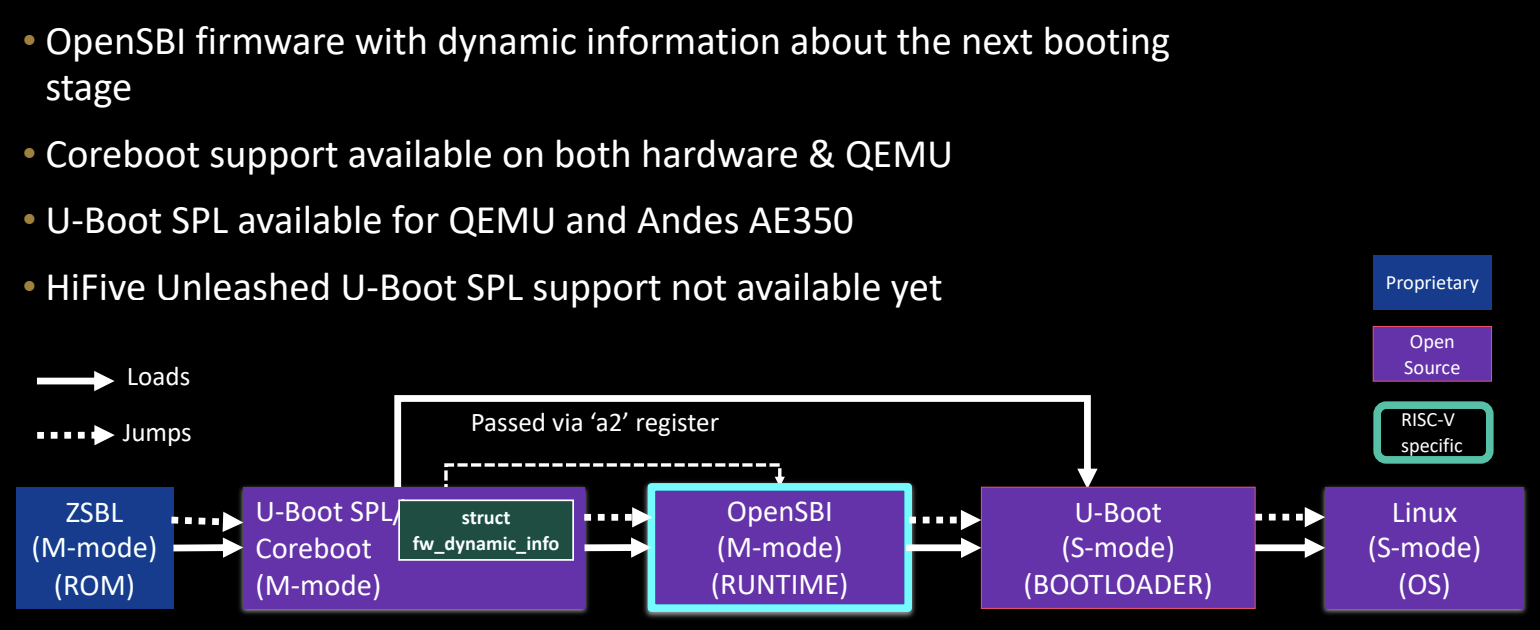
核心要点
- OpenSBI动态固件通过
a2寄存器传递下一引导阶段的地址。 - 支持Coreboot和U-Boot SPL在硬件和QEMU中运行。
- 目前HiFive Unleashed板上尚不支持U-Boot SPL。
Tutorial-III: Boot Linux in Qemu using U-Boot SPL
这部分介绍如何在Qemu中使用U-Boot SPL作为第一阶段的引导加载程序来引导Linux操作系统。U-Boot SPL是U-Boot的简化版本,通常用于初始化系统硬件并加载完整的U-Boot或操作系统。
1. 编译OpenSBI
首先,编译OpenSBI固件,生成适用于Qemu虚拟机的动态固件。与之前不同,这次不指定payload,OpenSBI的职责是加载U-Boot SPL。
cd opensbi; make PLATFORM=qemu/virt; cd ..
这里生成的fw_dynamic.bin固件将用于引导U-Boot SPL。
2. 编译U-Boot SPL
接下来,编译U-Boot SPL。在这个过程中,需要设置CROSS_COMPILE环境变量并指定OpenSBI动态固件的路径。
cd u-boot; export OPENSBI=../opensbi/build/platform/qemu/virt/firmware/fw_dynamic.bin; \
ARCH=riscv CROSS_COMPILE=riscv64-linux- make qemu-riscv64_spl_defconfig; \
ARCH=riscv CROSS_COMPILE=riscv64-linux- make; cd ..
这里使用qemu-riscv64_spl_defconfig配置文件为Qemu生成U-Boot SPL的配置。
3. 在Qemu中运行U-Boot SPL和Linux
使用以下命令在Qemu中运行U-Boot SPL和Linux镜像:
./qemu-system-riscv64 -nographic -machine virt -m 2G -bios u-boot/spl/u-boot-spl \
-kernel u-boot/u-boot.itb -device loader,file=linux_Image,addr=0x86000000 \
-drive file=linux_rootfs.img,format=raw,id=hd0 \
-device virtio-blk-device,drive=hd0
-machine virt:指定Qemu虚拟机硬件平台。-m 2G:为虚拟机分配2GB内存。-bios u-boot/spl/u-boot-spl:指定U-Boot SPL的二进制文件路径。-kernel u-boot/u-boot.itb:使用FIT镜像(包含U-Boot和设备树)。-device loader:加载Linux内核,并指定其地址为0x86000000。-drive:指定根文件系统镜像。-device virtio-blk-device:使用virtio块设备模拟存储。
通过该命令,Qemu将启动U-Boot SPL,加载U-Boot并引导Linux内核。
4. 在U-Boot命令行引导Linux
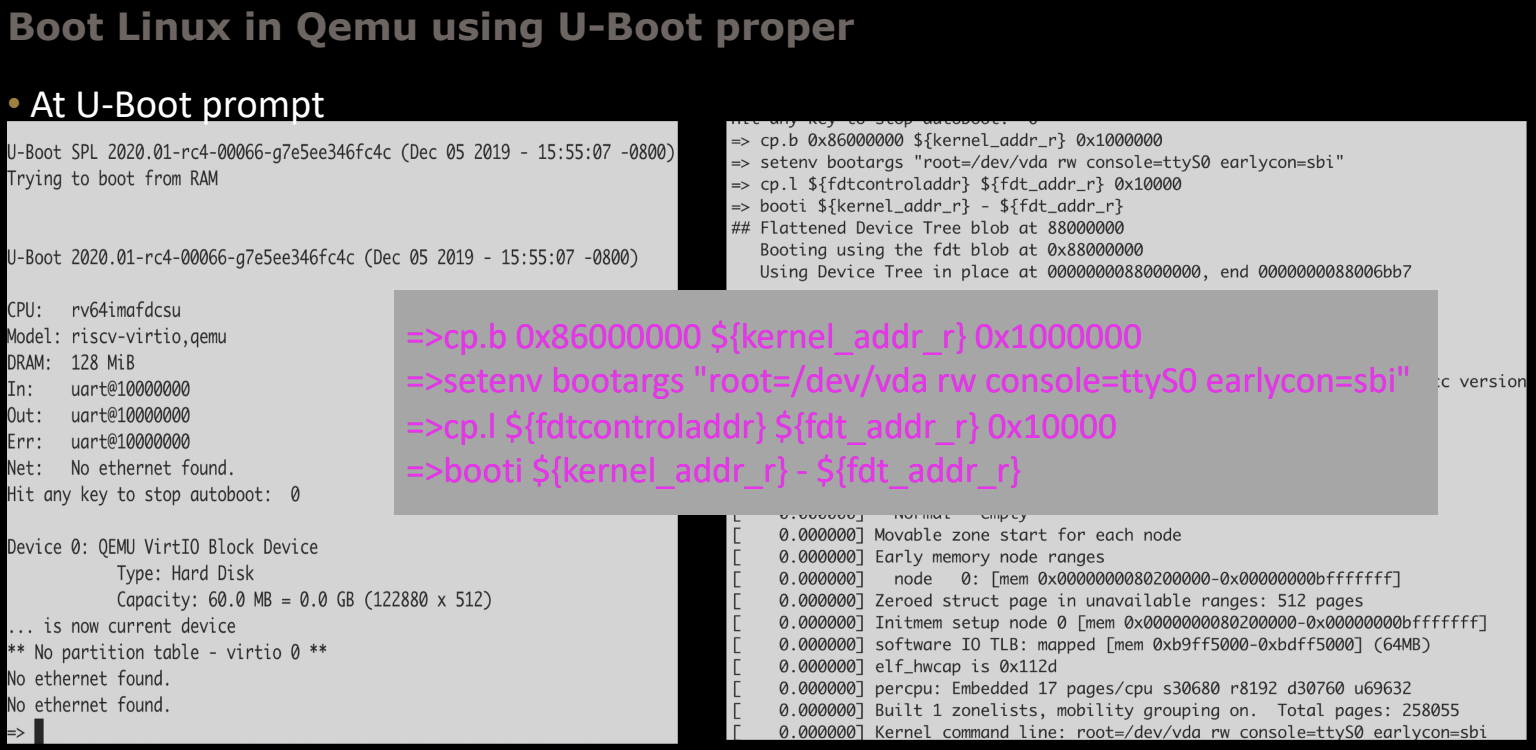
当Qemu成功运行后,您将进入U-Boot的命令行界面。在这里,您需要设置引导参数并引导Linux内核:
=> cp.l 0x86000000 ${kernel_addr_r} 0x100000
=> setenv bootargs "root=/dev/vda rw console=ttyS0 earlycon=sbi"
=> cp.l ${fdtcontroladdr} ${fdt_addr_r} 0x10000
=> booti ${kernel_addr_r} - ${fdt_addr_r}
cp.l 0x86000000 ${kernel_addr_r} 0x100000:将Linux内核从加载地址0x86000000复制到内存中的U-Boot地址空间。setenv bootargs:设置内核引导参数,这里指定根文件系统为/dev/vda,并配置控制台输出为ttyS0。cp.l ${fdtcontroladdr} ${fdt_addr_r} 0x10000:复制设备树控制块到设备树地址寄存器。booti:引导Linux内核,指定内核地址和设备树地址。
执行这些命令后,U-Boot将加载Linux内核并启动系统。
Boot flow using OpenSBI as a library
当OpenSBI作为库使用时,它被集成到外部固件的源代码中。通过这种方式,外部固件可以调用OpenSBI的功能,并作为其启动流程的一部分来执行。在这种模式下,必须确保正确的配置和编译环境,使得OpenSBI能够与外部固件无缝集成。
核心要点
- OpenSBI作为外部固件源代码的一部分:OpenSBI与外部固件紧密集成,外部固件需要调用OpenSBI的API。
- 必须配置程序堆栈和scratch空间:为了确保每个HART(硬件线程)的独立运行,外部固件必须为每个HART配置专属的堆栈和scratch空间。
- 相同的GCC目标选项:外部固件和OpenSBI的源代码必须使用相同的GCC编译选项,例如
-march、-mabi和-mcmodel,以保证兼容性。 - EDK2与OpenSBI的集成:目前 (2019.12),HPE公司正在推动OpenSBI与EDK2的集成。该集成已经适用于U540和Xilinx VC707 FPGA平台,OpenSBI在EDK2的Pre-EFI Initialization (PEI)阶段作为库来使用。
EDK2集成的详细说明
- EDK2 mailing list上已有集成的OpenSBI内容可供参考。
- OpenSBI与EDK2构建环境兼容,并作为PEI阶段的一部分使用。这种集成极大增强了OpenSBI与EDK2固件的合作,尤其在高性能嵌入式系统中使用RISC-V的环境下。
Constraints on using OpenSBI as a Library
当OpenSBI作为外部固件的库使用时,存在一些必须遵守的限制条件和技术要求,以确保正确的运行。
编译选项要求
- 相同的GCC目标选项:必须为外部固件和OpenSBI使用相同的GCC目标编译选项,包括:
-march:指定RISC-V指令集架构的版本和扩展。-mabi:定义应用二进制接口(ABI),确保外部固件与OpenSBI之间的函数调用兼容。-mcmodel:指定内存模型,控制生成代码时的内存寻址方式。
外部固件必须为每个HART创建独立的堆栈和scratch空间
- 程序堆栈(Program Stack):外部固件需要为每个HART配置一个独立的堆栈,避免不同HART之间的堆栈冲突。
- OpenSBI scratch空间:外部固件必须为每个HART设置OpenSBI的scratch空间,通常是通过
struct sbi_scratch结构体来实现。
使用OpenSBI函数的约束
调用OpenSBI的函数时,外部固件需要遵守以下限制:
- MSCRATCH寄存器:必须为每个调用HART将其MSCRATCH寄存器设置为其专属的OpenSBI scratch空间。
- SP寄存器:调用HART的栈指针(SP)必须设置为该HART的独立堆栈空间,确保各HART之间不会干扰彼此的堆栈。
其他要求
外部固件还必须确保以下条件:
- 中断状态:在调用
SBI函数时,必须禁用MSTATUS和MIE寄存器中的中断位,以避免中断干扰函数执行。 - sbi_init()的调用:必须为每个HART在系统启动时或HART热插拔事件中调用
sbi_init(),以正确初始化。 - sbi_trap_handler()的调用:当发生机器模式(M-mode)中断或陷阱时,必须调用
sbi_trap_handler(),以确保能够正确处理这些异常情况。
Current Status
RISC-V启动生态系统正在快速发展,预计在 (2019) 年末之前将实现完整的传统启动流程支持。以下是当前的进展情况:
OpenSBI
- 积极开发与维护:OpenSBI作为RISC-V架构的关键组件之一,正在被持续开发和维护。
- 版本 0.5 已发布:最新版本具备更完善的功能和优化。
- 默认使用:在多种构建工具中,OpenSBI已经成为默认的BIOS接口,例如Buildroot、Yocto、OpenEmbedded和QEMU BIOS。
- 镜像可用:Fedora和Debian的RISC-V系统镜像已经包含了OpenSBI的二进制文件。
U-Boot
- U-Boot-2019.10 发布:该版本已经完全支持HiFive Unleashed S模式。
- 支持网络和MMC引导:该版本支持通过网络和MMC卡引导操作系统。
- FIT镜像支持:U-Boot支持FIT镜像加载,它包含了内核、设备树、RAM盘等多个组件。
- EFI支持:为RISC-V架构提供了EFI支持,进一步增强了启动灵活性。
Grub
- 上游支持RISC-V:Grub已经在上游版本中提供了对RISC-V的支持,能够加载Linux内核。
Linux Kernel
- 内核主线支持QEMU引导:上游Linux内核可以在QEMU中正常启动。
- 设备树集成:RISC-V的设备树已经集成在Linux内核中,支持多种硬件配置。
- v5.3内核:Linux 5.3版本可以与OpenSBI和U-Boot配合,在HiFive Unleashed板上正常工作。
Future Boot Support
未来,RISC-V的启动支持将进一步扩展,目标是构建一个稳定、易用的启动生态系统。以下是未来的启动支持方向:
EFI Stub支持
- Linux内核中的EFI Stub支持:正在开发中,目标是提供完整的UEFI支持。这将为RISC-V带来企业级的启动环境,确保兼容更多高级功能。
U-Boot SPL 支持 HiFive Unleashed
- HiFive Unleashed的U-Boot SPL支持:正在开发中,未来可以通过SPL引导HiFive Unleashed板的操作系统。
Coreboot中的SMP支持
- 多处理器支持:Coreboot正在开发对SMP(对称多处理)支持,以便在多核系统中更好地管理硬件资源。
EDK2项目上游集成
- 持续进行的EDK2集成:OpenSBI与EDK2的集成正在逐步上游化,进一步扩展RISC-V的固件支持。
Oreboot
- 基于Rust的Coreboot:Oreboot项目是用Rust编写的Coreboot版本,目标是为RISC-V提供更加安全和可靠的固件解决方案。
LinuxBoot和其他引导加载程序
- LinuxBoot?:未来可能会为RISC-V提供LinuxBoot的支持,使启动流程更加简化和灵活。
- 其他引导加载程序?:随着RISC-V的生态系统不断发展,未来可能会出现更多的引导加载程序,进一步丰富启动选项。
通过这些即将到来的支持,RISC-V的启动流程将变得更加多样化和稳定,为开发者提供更灵活的工具链和启动选项,适应从嵌入式系统到高性能计算的广泛应用场景。
Ongoing Work
为了构建一个稳定且易于使用的RISC-V启动生态系统,当前有多个方面的工作正在进行中。这些工作涵盖了SBI规范的更新、OpenSBI的改进、以及Linux内核的持续开发。
SBI Specifications
- SBI v0.2 规范:新版SBI v0.2规范正在制定中,将带来更多改进和扩展。
- Hart状态管理扩展:在SBI v0.2中,将引入对Hart(硬件线程)状态管理的扩展,以便更好地控制和管理系统中的各个Hart。
- 替换旧版SBI扩展:SBI的遗留扩展将被更现代的功能替代,进一步优化性能和兼容性。
OpenSBI
- 通过CPU热插拔实现顺序CPU启动:改进OpenSBI以支持CPU热插拔,允许系统在运行时动态启动或关闭CPU。
- 支持其他M-mode引导加载程序:OpenSBI正在扩展以支持其他机器模式(M-mode)的引导加载程序,例如Coreboot和U-Boot SPL。
- 虚拟化支持:当SBI规范发生变化时,OpenSBI将增加对虚拟机管理程序(Hypervisor)的支持。
- 更多平台支持:OpenSBI计划扩展支持更多硬件平台,但这些扩展需要额外的硬件支持。
Linux Kernel
- SBI v0.2实现:SBI v0.2规范的实现正在进行中,补丁正在审查过程中。
- EFI stub的支持:EFI stub正在内核中开发,旨在提供完整的UEFI支持,这对企业级应用至关重要。
- 替换旧版SBI扩展:与OpenSBI一样,Linux内核也在逐步替换SBI的遗留扩展。
- 顺序启动:内核将支持顺序启动功能,确保系统能够按需有序地启动。
- CPU热插拔支持:内核正在开发对CPU热插拔的支持,以实现更灵活的系统资源管理。
Acknowledgements
在RISC-V启动生态系统的开发过程中,多个团队和个人做出了重要贡献。以下是对这些贡献者的感谢:
U-Boot
- Lukas Auler
- Bin Meng
- Anup Patel
Coreboot
- Ron Minnich
- Jonathan Neuschäfer
- Patrick Rudolph
- Philip Hug
EDK2
- Abner Chang
其他贡献者
- 感谢所有为RISC-V启动流程做出贡献的开发者和社区成员,他们的努力推动了整个生态系统的前进。
这些开发者和团队通过持续的贡献,使得RISC-V启动流程更加成熟,进一步推动了开源硬件平台的普及和发展。
Reference
© 2019 Western Digital Corporation or its affiliates. All rights reserved. 12/19/19
More
The future of RISC-V Supervisor Binary Interface(SBI) - Atish Patra - Western Digital
OpenSBI Deep Dive - Anup Patel - Western Digital
【翻译】RISC-V SBI and the full boot process
原文作者: @popovicu
原文链接: RISC-V SBI and the full boot process
版权声明: 本文为 @popovicu 的原创作品。本文的翻译仅供学习参考,更多详细信息请访问原文链接。
RISC-V SBI 和完整的启动过程
发表于:2023年9月9日 | 晚上09:00
在上一篇文章中,我们讨论了RISC-V上的裸机编程。在继续阅读本文之前,请先熟悉之前的内容,因为本文是对前述文章的直接延续。
这次我们将讨论 RISC-V 的 SBI(Supervisor Binary Interface,监督者二进制接口),并以 OpenSBI 作为示例。我们将探讨 SBI 如何帮助我们实现操作系统内核的基本功能,并以 riscv64 virt 机器为例结束本文。
RISC-V 和“BIOS”
在前文中,我们详细讨论了 RISC-V 启动过程的最初阶段。我们提到,首先运行的是 ZSBL(零阶段引导加载程序),它初始化一些寄存器并跳转到 ZSBL 硬编码的地址。在 QEMU 的 riscv64 virt 虚拟机中,这个硬编码的地址是 0x80000000。这就是用户提供的代码首次运行的地方,默认情况下,QEMU 会在这里加载 OpenSBI。
机器模式
到目前为止,我们避免讨论不同的机器模式,现在是引入它们的最佳时机。机器模式的概念在于,并不是每个软件都应该能够访问机器上的任意内存地址,甚至不是所有的指令都应该被 CPU 执行。传统的教科书示例中,通常有两种主要的权限划分:
- 特权模式
- 非特权模式
特权模式 是机器在启动时的模式。此时允许执行任何指令,且没有地址访问违规的概念。一旦操作系统接管系统控制并开始执行用户代码(即用户空间代码),模式就会开始切换。当用户代码在 CPU 核心上运行时,它是在 非特权模式 下运行,此时并不能访问所有资源。返回内核模式意味着切换回特权模式。
这是操作权限的一种非常教科书化的简化视角,但问题来了:为什么只有两种模式?
在系统中,通常有超过两种模式,形成多个访问模式的保护环。RISC-V 规范并没有明确规定一个核心必须实现哪些模式,除了 M(机器)模式,这是最具特权的模式。
通常,只有 M 模式的处理器是简单的嵌入式系统,而更安全的系统会支持 M 和 S 模式,直到可以运行类似 Unix 操作系统的完整系统(支持 M、S 和 U 模式)。
SBI
官方文档 提供了正式定义,我将在此对其进行简化解释,以帮助更直观地理解。
RISC-V 的 SBI 规范定义了 RISC-V 软件栈底层的软件层。这非常类似于 BIOS,后者通常是机器上运行的第一段软件。你可能看到过一些从零开始开发简单内核的指南,它们通常涉及与我们在RISC-V裸机编程指南中所做的类似操作,带有一点不同——它们往往依赖于一些预先存在的软件来完成某些 I/O 操作。与我们之前的指南相似之处在于,它们也仔细对齐了第一条指令的地址,以确保处理器的执行流程按预期进行,并且简单的内核能够在正确的时间接管。然而,我通常在这些简短的指南中观察到,目标通常是向VGA屏幕打印类似‘Hello world’的东西。最后这一点看起来相当复杂,事实上确实如此。
那么,如何轻松地向 VGA 打印内容呢?答案是 BIOS 在这里帮助我们完成最基本的 I/O 操作,例如向屏幕上打印字符,因此它被称为 Basic Input Output System(基本输入输出系统)!请注意裸机编程指南的开头部分:我们是在没有依赖于机器上任何现有软件的情况下与用户交互的(严格来说,这并不完全正确,我们仍然通过了零阶段引导加载程序,但我们并不依赖于它的任何结果,也无法真正控制它;它是系统中硬编码的)。如果我们要在 VGA 屏幕上打印内容,而不是通过 UART 发送字符,我们将需要做的不仅仅是向某个地址发送 ASCII 码。VGA 需要通过发送多个值来设置显示设备,配置不同的参数等。这是一个相当复杂的操作。
那么 BIOS 通常如何帮助处理这些任务?主要的概念是,无论最终在机器上安装了什么操作系统,它都需要一些基本功能,比如向 VGA 屏幕打印信息。因此,机器可以将这些标准操作预先集成到系统中,供任何操作系统使用。从概念上讲,我们可以将这些过程视为我们应用程序编写时所依赖的日常库。
此外,如果操作系统是针对这样的“库”编写的,它将自动变得更加可移植。“库”应该包含所有底层细节,例如“输出到 UART 意味着写入 0x10000000”(在 QEMU 的 riscv64 virt 虚拟机中),与“输出到 UART 意味着写入 0x12345678”相比,操作系统只需要调用“输出到 UART”的过程,而这个“库”将知道如何与硬件进行交互。
精妙的抽象
这些讨论归根结底是编程中从第一天就开始使用的一个非常简单的概念:我们在编程中应用了抽象层。想象一下,一个 Python 函数执行类似“将本地文件发送到电子邮件地址”的操作。从高层视角看,我们只是简单地调用一个函数 send_file_to_email(file, email),然后底层的库会打开网络连接并开始传输字节。这可能是另一个 Python 库。在某个时刻,这个操作可能会下移到软件栈的底层,Python 库将依赖于用 C 语言编写的 Python 运行时,后者通过系统调用操作系统来执行核心操作(例如打开网络套接字)。操作系统的深处有一个网络驱动程序,它知道应该将字节发送到地址空间中的哪个地址,以便将字节通过网络传输出去。这里的主要概念是,我们已经建立了一种隐藏操作复杂性的方式,通过将它们委托给软件栈的底层来处理。我们并不是从原子部分构建更大的系统,而是从“分子”构建。
如果我们将复杂性委托给底层库,这可能只是一个函数调用。然而,一旦需要将复杂性委托给操作系统及以下层次,这就会通过一个二进制接口来实现。
二进制接口
自从计算机开始广泛使用以来,x86 架构一直是我们使用的台式机或笔记本电脑的主导架构。近年来,情况发生了很大变化,其他架构开始进入我们的视野,但让我们暂时集中于 x86。那么,是什么使为 Linux 构建的应用程序与 Windows 的应用程序不兼容呢?如果它是为 x86 编写的,并且 Linux 和 Windows 都运行在 x86 上,那么差异究竟在哪里?CPU 指令并没有因平台不同而改变,那么原因是什么呢?答案是应用程序和操作系统之间的接口。用户软件与操作系统之间的这个特定链接称为应用二进制接口(ABI)。ABI 只是一个定义,规定了如何从用户应用程序调用操作系统的服务。
因此,当我们说“这个软件是为平台 X 编写的”时,仅仅说 X 是 x86 或 RISC-V 还不够,我们必须明确说 x86/Linux 或 x86/Windows 或 RISC-V Linux 等。如果涉及动态链接,平台定义甚至可能更加复杂,但我们暂且不讨论这个问题。
让我们来看一个用汇编语言为 x86/Linux 编写的程序的简单例子,该程序只是将‘Hello’字符串打印到标准输出。
.global _start
.section .text
_start: mov $4, %eax ; 4 是 'write' 系统调用的代码
mov $1, %ebx ; 我们正在写入文件 1,即 '标准输出'
mov $message, %ecx ; 我们要打印的数据位于 message 符号定义的地址
mov $5, %edx ; 我们要打印的数据长度是 5
int $0x80 ; 调用系统调用,即请求内核将数据打印到标准输出
mov $1, %eax ; 1 是 'exit' 系统调用的代码
mov $0, %ebx ; 0 是进程的返回码
int $0x80 ; 调用系统调用,即请求内核关闭该进程
.section .data
message: .ascii "Hello"
用以下命令汇编该程序:
as -o syscall.o syscall.s
链接:
ld -o syscall syscall.o
运行:
./syscall
你应该会看到输出“Hello”。如果你使用的是 Bash,并且想要检查进程的返回码,可以运行:
echo $?
你应该会看到 0。
提示:如果你没有 x86/Linux 机器,但想尝试上面的例子,可以通过一个模拟 x86 系统的 JavaScript 虚拟机来实现这里;这是一个非常酷的网站!
这样我们就得到了一个在 x86 机器上运行并在 Linux 内核下打印消息的程序。没有使用 C 标准库。最终生成的 ELF 二进制文件应该能够在 Linux 上运行,唯一的依赖条件是它运行在正确的平台上。
现在回到问题本身,是什么可能使这个二进制文件与 Windows 不兼容?不同的操作系统以不同的方式编码系统调用(例如,写入操作的代码在 Linux 是 4,而在 Windows 可能是 123,或者参数通过不同的 CPU 寄存器传递)。 现在你对如何直接与内核交互有了更好的理解,而不依赖标准库(尽管你几乎不会想这么做)。这意味着你已经揭示了软件执行诸如打开文件、分配内存、发送信号等操作的那一层。C 标准库可以看作是一个封装器,它隐藏了通过 int 指令调用软件中断与内核通信的复杂性,而是使其看起来像一个正常的 C 函数调用,但实际上它的底层机制就是这样。公平地说,库做的远不止这些,但对于本文的目的,可以简单地将其视为一个封装器。
现在在 RISC-V 的世界里,情况也是类似的:用户应用程序通过软件中断的 CPU 指令与内核交互,并通过 CPU 寄存器传递参数。而内核则通过 SBI 来调用它的服务,执行的方式完全相同!不同之处在于,这一层的逻辑调用被称为 SBI,而不是 ABI。可以把它理解为,这不是应用程序在工作,而是应用程序的监督者在工作。名称不同,概念却是完全一致的。
使用 OpenSBI 的实际示例
到此为止,我们已经明确了,SBI 和 ABI 类似,都是调用软件栈底层功能的一种方式。同时我们也明确了,SBI 处于 RISC-V 机器的软件栈的最底层,并在最具特权的 M 模式下运行。现在让我们进一步补充一些细节。
现在应该可以理解为什么 QEMU 开发者选择使用 -bios 标志来接受 SBI 软件镜像(因为其功能与 BIOS 基本相同)。需要提醒的是,-bios 标志应该指向一个 ELF 文件,该文件将从地址 0x80000000 开始布局 SBI 软件。
让我们在仅加载 OpenSBI 的情况下启动 QEMU 的虚拟机,看看会发生什么。我们不需要传递任何参数给 QEMU,因为默认情况下它会将 OpenSBI 加载到 0x80000000。
qemu-system-riscv64 -machine virt
这是输出(在串行端口上,不是 VGA):
OpenSBI v0.8
____ _____ ____ _____
/ __ \ / ____| _ \_ _|
| | | |_ __ ___ _ __ | (___ | |_) || |
| | | | '_ \ / _ \ '_ \ \___ \| _ < | |
| |__| | |_) | __/ | | |____) | |_) || |_
\____/| .__/ \___|_| |_|_____/|____/_____|
| |
|_|
Platform Name : riscv-virtio,qemu
Platform Features : timer,mfdeleg
Platform HART Count : 1
Boot HART ID : 0
Boot HART ISA : rv64imafdcsu
BOOT HART Features : pmp,scounteren,mcounteren,time
BOOT HART PMP Count : 16
Firmware Base : 0x80000000
Firmware Size : 96 KB
Runtime SBI Version : 0.2
MIDELEG : 0x0000000000000222
MEDELEG : 0x000000000000b109
PMP0 : 0x0000000080000000-0x000000008001ffff (A)
PMP1 : 0x0000000000000000-0xffffffffffffffff (A,R,W,X)
虚拟机就这样一直运行下去,可能是因为默认情况下它被设置为这样运行,因为没有其他软件传递给 QEMU 来在 OpenSBI 之后接管控制。此时看来一切正常,OpenSBI 已经成功设置(其输出也确认它位于 0x80000000)。
接下来我们如何继续扩展软件栈呢?新的一层可以是操作系统内核,因此类似于我们之前构建的包含指令的 ELF 文件,它被放置在 0x80000000,我们将构建另一个 ELF 文件,供 QEMU 加载到内存中,但这次指令将加载到另一个地址,因为从 0x80000000 开始的部分已经被 OpenSBI 占用。
那么,我们应该将这个“虚拟内核”加载到哪个地址呢?
在 SBI 之后启动操作系统内核并调用 OpenSBI
当我们加载 BIOS/SBI/无论你想怎么称呼它时,这个地址基本上是“写死”在机器逻辑中的。最初的几条指令是零阶段引导加载程序(ZSBL),它的最后一条指令跳转到硬编码的地址 0x80000000。正如我们之前提到的,这是我们所使用的平台的不可更改的事实,它就是这样工作的。然而,这就是它目前所硬编码的全部内容:它只是硬编码了你必须从 0x80000000 开始,而我们现在已经在这里放置了 OpenSBI,那么 OpenSBI 接下来将带我们到哪里呢?
这时,ZSBL 的重要性再次出现了,现在它如何在执行跳转到 0x80000000 之前初始化这些寄存器真的很关键。ZSBL 实际上做了两件事:
- 确保在 OpenSBI 初始化后运行的软件可以运行,这基本上是操作系统内核的引导加载程序,或者直接是内核本身(这就是你在 QEMU 指南中启动 Linux 时通常看到的,跳过引导加载程序,内存中直接加载内核)。
- 跳转到 OpenSBI。
我们已经详细讨论了第二点,现在让我们深入探讨它如何完成第1点。
ZSBL 中究竟发生了什么?
我们之前提到 ZSBL 的执行从地址 0x1000 开始。让我们通过 QEMU 跟踪执行情况,看看发生了什么。为此,我们将在 QEMU 命令行中添加两个标志:-s 和 -S。这些标志确保 QEMU 暴露一个 gdb 调试端口,并且虚拟机在创建时立即暂停,等待我们通过 gdb 手动驱动它。
我们现在开始这个逆向工程的过程。我们首先启动 QEMU:
qemu-system-riscv64 -machine virt -s -S
在另一个终端中,我们连接到嵌入在 QEMU 中的 gdb 服务器,以便控制虚拟机的执行。我是在 x86 机器上执行的,所以我会使用 gdb-multiarch 来进行跨平台的 riscv 调试。在这个新的终端中,我运行以下命令:
gdb-multiarch
在连接到虚拟机之前,我想先设置几件事:
set architecture riscv:rv64
这行命令的作用显而易见。接下来,我希望每次执行一条指令时都能在终端中打印出实际的运行指令:
set disassemble-next-line on
现在是时候连接到 QEMU 的 gdb 服务器了(端口 1234 基本上是 QEMU 的默认设置,虽然可能可以通过 -s 标志进行某种方式的配置;不过我从未尝试过,也认为你不需要改变这个行为)。
target remote :1234
此时,gdb 正在等待我们,它停在了地址 0x1000,这是系统上电后执行的第一条指令的地址。我们将使用 si 多次单步执行指令,直到我们跳转到位于 0x80000000 的 SBI。
(gdb) target remote:1234
Remote debugging using :1234
warning: No executable has been specified and target does not support
determining executable automatically. Try using the "file" command.
0x0000000000001000 in ?? ()
=> 0x0000000000001000: 97 02 00 00 auipc t0,0x0
(gdb) si
0x0000000000001004 in ?? ()
=> 0x0000000000001004: 13 86 82 02 addi a2,t0,40
(gdb) si
0x0000000000001008 in ?? ()
=> 0x0000000000001008: 73 25 40 f1 csrr a0,mhartid
(gdb) si
0x000000000000100c in ?? ()
=> 0x000000000000100c: 83 b5 02 02 ld a1,32(t0)
(gdb) si
0x0000000000001010 in ?? ()
=> 0x0000000000001010: 83 b2 82 01 ld t0,24(t0)
(gdb) si
0x0000000000001014 in ?? ()
=> 0x0000000000001014: 67 80 02 00 jr t0
(gdb) si
0x0000000080000000 in ?? ()
=> 0x0000000080000000: 33 04 05 00 add s0,a0,zero
在 ZSBL 中只有 6 条指令,之后控制权就交给了 OpenSBI,包含跳转指令。然而,这几条指令的意义是什么呢?
事实证明,这也是 SBI 规范的一部分,它是启动序列的一部分。然而,对于 OpenSBI,有三种不同的实现方式,在我们深入讨论 ZSBL 之后发生的事情之前,先来看看这些不同的实现方式。
OpenSBI 的三种实现方式
你可以通过三种不同的方式构建 OpenSBI:
FW_PAYLOAD
这个方式概念上最容易理解。构建这个版本的 OpenSBI 时,你会将 make 工具指向你的内核或“你希望在 OpenSBI 之后运行的任何软件”镜像,然后你将获得一个可以直接加载的单一二进制文件。在 QEMU 的虚拟机中,地址为 0x80000000。据我了解,可以调整你的软件在内存中与 OpenSBI blob 相关的位置,但为了简化起见,我们可以认为 OpenSBI 和你的软件被组合在一起成一个单一的 blob,一旦 OpenSBI 初始化完成,下一条指令就是你的软件(基本上 OpenSBI 之后直接过渡到你的软件)。
实现这个的方式是:
- 确保在
make过程中设置FW_PAYLOAD=y,这将确保生成一个名为fw_payload的文件。 - 在
make过程中设置FW_PAYLOAD_PATH,指向你希望在 OpenSBI 之后运行的软件。
根据上面链接的文档,如果你省略了第二个标志,OpenSBI 会与一个非常简单的无限循环软件一起拼接。这就解释了为什么当我们只启动 QEMU 而不加任何标志时,机器基本上只是原地打转——OpenSBI 很可能就是这样构建的(因为你不能继续执行随机的内存内容),它只是忙于原地等待。
这种方式的优点在于,现在你有了一个单一的、拼接的、整体的软件镜像,可以加载到你的机器中。你不需要处理多个独立的软件块,只需处理一个整体。如果你的软件构建过程比较简单,你甚至可能最终找到一种非常简单的方式来管理目标机器上的所有软件,同时还能享受 OpenSBI 为你提供的一些工作便利。
缺点是,现在你需要负责将所有东西拼接在一起,包括 OpenSBI。更糟的是,如果机器已经有了 OpenSBI,例如,烧录在某个 ROM 中,它已经有了启动 OpenSBI 的能力,重复加载 OpenSBI 可能会导致问题。
FW_JUMP
这种方式也相对简单:你基本上将 OpenSBI 之后的软件地址硬编码。类似于上述情况,也需要两步。
- 确保在
make过程中设置FW_JUMP=y,这将生成一个名为fw_jump的文件。 - 在
make过程中设置FW_JUMP_ADDR,指向 OpenSBI 完成后跳转的地址。
这与前一种情况非常相似,只是跳转地址是硬编码的。在这种情况下,你仍然需要负责构建 OpenSBI 镜像,但它易于重建,并且可以针对不同的机器指向不同的地址(例如,具有不同内存布局的机器)。
FW_DYNAMIC
这是最通用的方式,因此我们最后讨论这一种。在这种方式中,ZSBL 中寄存器设置的重要性开始显现出来。
在这种模式下,OpenSBI 之前的启动阶段负责向 OpenSBI 传递一些指针。在这个例子中,当然是 ZSBL。如果我们仔细观察,会看到它修改了寄存器 a2。
在这里,我鼓励读者阅读这篇文章中的 ZSBL 部分。整篇文章都很棒,只是我一开始觉得它有点难以理解,所以可以把本文看作是理解那篇文章的预备知识,值得花时间去阅读。
简单来说,ZSBL 设置 a2 寄存器的意义是什么?它指向一个 struct fw_dynamic_info 结构,这为动态 OpenSBI 提供了继续启动过程的方式!实际上,这个结构中的一项数据是 OpenSBI 之后运行的软件的地址。一个很好的问题是:在真实机器上,谁来填充这个结构?根据我们将看到的内容,显然 QEMU 会将该内容硬编码到内存中,这一逻辑并不是 ZSBL 的一部分,但我可以想象,在某些设备上 ZSBL 实际上会填充这个结构并传递给 OpenSBI。
来自西部数据的一名工程师的演讲的第17页(他可能是 OpenSBI 的核心贡献者)概述了这个 struct 的内容:
- 魔术数
- 版本号
- 下一个地址
- 下一个模式
- 选项
所有这些都是无符号长整型(我猜是 64 位,8 字节?)。
探索 fw_dynamic_info 结构
到此为止,我们来一个快速的绕道,确保我们在讨论相同的版本。我们检查一下 OpenSBI 的版本,因为不同系统的 QEMU 可能带有不同版本的 OpenSBI。构建 OpenSBI 源码非常简单,让我们快速进行。首先,我们需要克隆 Git 仓库(本文写作时是 2023 年 9 月 10 日;如果你想要完全可重复的构建,可以使用这一天的提交版本):
git clone https://github.com/riscv-software-src/opensbi.git
cd opensbi
make ARCH=riscv CROSS_COMPILE=riscv64-linux-gnu- PLATFORM=generic
构建速度应该非常快,且占用资源较少。我们感兴趣的输出文件是 build/platform/generic/firmware/fw_dynamic.bin。我们将通过 QEMU 的 -bios 标志来传递这个文件。从刚刚克隆的 opensbi 文件夹中启动 QEMU:
qemu-system-riscv64 -machine virt -s -S -bios build/platform/generic/firmware/fw_dynamic.bin
在 gdb 中执行几次 si 之后,我们回到之前的状态。让我们通过 gdb 查看 QEMU 的内存,以了解 ZSBL 结束时的情况。在 ZSBL 的最后一条指令处,我们查看寄存器转储(使用 i r 来查看):
=> 0x0000000080000000: 33 04 05 00 add s0,a0,zero
(gdb) i r
结果显示 a2 指向 0x1028。正如我们所说的,让我们通过 gdb 检查该内存。我们让它读取从 0x1028 开始的 10 个连续的 8 字节值,并以十六进制格式显示。
(gdb) x/10xg 0x1028
g 标志用于以 8 字节的“巨大”块打印内存内容。
(gdb) x/10xg 0x1028
0x1028: 0x000000004942534f 0x0000000000000002
0x1038: 0x0000000000000000 0x0000000000000001
0x1048: 0x0000000000000000 0x0000000000000000
0x1058: 0x0000000000000000 0x0000000000000000
0x1068: 0x0000000000000000 0x0000000000000000
这大致符合Vysakh的文章中的描述。我们确实看到了文章中提到的魔术数,后面跟着的是 0x02 版本信息。接下来应该是下一个跳转的地址,但这里全是零……这有点奇怪,不过我们继续看。下一个值是 0x01,根据文章,它应该对应于执行的下一个模式,也就是 S 模式。这是正确的,我们从运行 SBI 的 M 模式切换到运行操作系统内核引导程序(或直接是内核)的 S 模式。为什么下一个跳转地址全是零呢?在这个时候,我决定让 QEMU 不再受 gdb 干扰而继续运行。我在 gdb 中运行以下命令:
continue
现在一切都停止了,但由于我正在运行更新版本的 OpenSBI,所以 UART 上输出了更新的内容:
OpenSBI v1.3-54-g901d3d7
____ _____ ____ _____
/ __ \ / ____| _ \_ _|
| | | |_ __ ___ _ __ | (___ | |_) || |
| | | | '_ \ / _ \ '_ \ \___ \| _ < | |
| |__| | |_) | __/ | | |____) | |_) || |_
\____/| .__/ \___|_| |_|_____/|____/_____|
| |
|_|
Platform Name : riscv-virtio,qemu
Platform Features : medeleg
Platform HART Count : 1
Platform IPI Device : aclint-mswi
Platform Timer Device : aclint-mtimer @ 10000000Hz
Platform Console Device : uart8250
Platform HSM Device : ---
Platform PMU Device : ---
Platform Reboot Device : syscon-reboot
Platform Shutdown Device : syscon-poweroff
Platform Suspend Device : ---
Platform CPPC Device : ---
Firmware Base : 0x80000000
Firmware Size : 322 KB
Firmware RW Offset : 0x40000
Firmware RW Size : 66 KB
Firmware Heap Offset : 0x48000
Firmware Heap Size : 34 KB (total), 2 KB (reserved), 9 KB (used), 22 KB (free)
Firmware Scratch Size : 4096 B (total), 768 B (used), 3328 B (free)
Runtime SBI Version : 1.0
Domain0 Name : root
Domain0 Boot HART : 0
Domain0 HARTs : 0*
Domain0 Region00 : 0x0000000002000000-0x000000000200ffff M: (I,R,W) S/U: ()
Domain0 Region01 : 0x0000000080040000-0x000000008005ffff M: (R,W) S/U: ()
Domain0 Region02 : 0x0000000080000000-0x000000008003ffff M: (R,X) S/U: ()
Domain0 Region03 : 0x0000000000000000-0xffffffffffffffff M: () S/U: (R,W,X)
Domain0 Next Address : 0x0000000000000000
Domain0 Next Arg1 : 0x0000000087e00000
Domain0 Next Mode : S-mode
Domain0 SysReset : yes
Domain0 SysSuspend : yes
Boot HART ID : 0
Boot HART Domain : root
Boot HART Priv Version : v1.10
Boot HART Base ISA : rv64imafdc
Boot HART ISA Extensions : zicntr
Boot HART PMP Count : 16
Boot HART PMP Granularity : 4
Boot HART PMP Address Bits: 54
Boot HART MHPM Info : 0 (0x00000000)
Boot HART MIDELEG : 0x0000000000000222
Boot HART MEDELEG : 0x000000000000b109
这与我们之前看到的相符,接下来的地址全是零……这很奇怪,不可能是对的。我现在运行 QEMU 时没有让它暂停,而是让它直接运行,并异步连接 gdb。我就不详细说明了,但在这种“实时运行”中检查寄存器时,确实显示没有任何指令在 0x0000000000000000 区域执行。CPU 似乎在某个其他地址上循环。
这可能与我实际上没有向 QEMU 传递除了 OpenSBI 以外的其他软件有关,所以这可能导致了问题。QEMU 可能将该结构填充为全零,OpenSBI 识别到这是一个非法的边缘情况,因此它一直在 OpenSBI 中无休止地循环——这是我的推测。
我们如何传递一些除 OpenSBI 以外的软件呢?**与传递 OpenSBI 的方式相同,只是使用不同的标志!**这次我们使用 -kernel QEMU 标志。我们将如何构建这个软件?与之前的“伪 BIOS”构建方式相同,只是将其映射到不同的内存位置。让我们试着把它加载到 0x80200000。
构建一个“无限循环的伪内核”
我们的操作系统内核将无限循环。它将在 0x80200000 处包含一条跳转指令,永远保持在那里。以下是汇编源代码:
.global _start
.section .text.kernel
_start: j _start
链接脚本如下:
MEMORY {
kernel_space (rwx) : ORIGIN = 0x80200000, LENGTH = 128
}
SECTIONS {
.text : {
infinite_loop.o(.text.kernel)
} > kernel_space
}
有关如何使用这些文件构建可加载到 QEMU 的 ELF 映像的详细信息,请参阅原始的裸机编程文章。
一旦我们构建完成,我们会得到一个名为 infinite_loop 的 ELF 文件,可以作为我们的伪内核。现在我们运行 QEMU:
qemu-system-riscv64 -machine virt -s -S -bios build/platform/generic/firmware/fw_dynamic.bin -kernel ~/work/github_demo/risc-v-bare-metal-fake-kernel/infinite_loop
再次,我连接 gdb 并用 si 一步步执行到 ZSBL 结束。现在,当我查看臭名昭著的 0x1028 结构时,情况好多了,这证实了 QEMU 之前奇怪地填充了那个结构的理论。
=> 0x0000000080000000: 33 04 05 00 add s0,a0,zero
(gdb) x/10xg 0x1028
0x1028: 0x000000004942534f 0x0000000000000002
0x1038: 0x0000000080200000 0x0000000000000001
0x1048: 0x0000000000000000 0x0000000000000000
0x1058: 0x0000000000000000 0x0000000000000000
0x1068: 0x0000000000000000 0x0000000000000000
我们现在看到该结构中的新地址已经填充,正如预期的那样。这也反映在 UART 上的 OpenSBI 输出中。让我们通过 gdb 继续进入我们的伪内核,看看那里一切是否正常。
(gdb) break *0x080200000
Breakpoint 1 at 0x80200000
(gdb) continue
Continuing.
Breakpoint 1, 0x0000000080200000 in ?? ()
=> 0x0000000080200000: 6f 00 00 00 j 0x80200000
一切看起来都很正常。让我们总结一下:
- ZSBL 是上电后运行的第一段代码。它初始化了一些寄存器,关键的寄存器是
a2,它指向一个fw_dynamic_info结构,该结构包含 OpenSBI 动态模式操作的关键信息。在 QEMU 的情况下,这个结构在上电时被虚拟化引擎神奇地填充,但在现实中,这很可能是 ZSBL 的工作。不管怎样,OpenSBI 现在知道完成后要做什么。 - OpenSBI 提供了一个基于中断的接口,供上层软件(大概是操作系统内核引导程序或内核本身)调用。这个接口称为 SBI,它在概念上与操作系统之上的应用程序软件的 ABI 相同。
- 我们将内核映像作为另一个 ELF 文件传递给 QEMU,加载到内存的另一个区域。QEMU 填充该结构,使得 OpenSBI 能够将控制权传递到那里,并且在切换到那里之前,它会进入
S模式。
有意略过的细节
ZSBL 还修改了 a0 和 a1 寄存器。
a0 与 RISC-V 的 hart 有关,但我们不深入探讨这些细节,因为它们对本文的其余部分没有太大相关性。此外,这个引导过程中的这一步似乎并不重要,参见Github评论。
a1 是一个有趣的指针,它指向内存中的设备树数据结构。对于本文的其余部分,这个数据结构并不相关,因此我们可以忽略它。然而,对于像 Linux 这样的真实内核,设备树非常有用。Linux 能够从内存中扫描设备树,并了解它运行的机器的结构,而不是针对每种硬件组合编写大量的 if/else 分支。你可以从维基百科文章中了解它在 Linux 中的使用情况。不过,正如所提到的,我们不会在本文中讨论设备树的细节。
Hello World 伪内核
现在我们已经掌握了足够的知识,可以编写一个伪操作系统内核,它只是在 UART 设备上打印“Hello world”。这个功能与我们在前一篇文章中看到的裸机程序没有太大区别,但我们到达目标的方式有显著不同。这次,我们将通过 SBI 调用来打印到 UART,而不是直接与 UART 设备交互(我们将这项工作委托给一个更底层的特权软件层)。即使在像“Hello world”这样简单的例子中,这也可能带来重大影响:我们将与 UART 硬件交互的责任委托给 SBI 层,从而实现跨不同符合 SBI 接口的机器的可移植性。
如何调用 RISC-V 的 SBI 层?概念上,这与在 x86 Linux 上调用标准输出打印非常相似——我们需要填充一些寄存器并触发软件中断/陷阱,将控制传递到软件栈的底层 OpenSBI。OpenSBI 在 SBI 层提供了许多服务,其中许多服务对于开发可移植的操作系统内核非常有用,例如与定时器的交互(这与时间切片和使多个线程共享同一 CPU 核心相关)。有关 SBI 层暴露的全部功能列表,请查看这里。
在本指南中,我们将专注于调试控制台功能,即通过 SBI 向 UART 写入内容。让我们开始编写代码吧!
首先,我们需要知道如何通过寄存器编码我们希望 OpenSBI 执行的功能。这在这里有详细记录。简而言之,SBI 功能被分组到“扩展”中。寄存器 a7 包含扩展 ID (EID),而 a6 编码该扩展中的功能 ID (FID)。然后通过 a0、a1、a2 等寄存器传递参数。
要打印到控制台,我们需要的 EID 是 0x4442434E(一个相当有趣的值),而 FID 则是 0x00。
这次,和之前裸机编程指南中的逐字打印不同,我们将一次性调用打印功能。毕竟,我们应该从 SBI 层提供的高级功能中受益。因此,我们的二进制文件应该将输出字符串存储在内存中的某个地方,理想情况下,我们希望通过调用 SBI 从该地址开始打印。我们将这样做:
.global _start
.section .text.kernel
_start: li a7, 0x4442434E
li a6, 0x00
li a0, 12
lla a1, debug_string
li a2, 0
ecall
loop: j loop
.section .rodata
debug_string:
.string "Hello world\n"
这里有几个需要注意的地方:
- 我们在这里使用了 PC 相对寻址来处理输出字符串。需要提醒的是,内核存储在一个非常大的无符号整数表示的地址上。这个值太大,无法用任何 RISC-V 32 位指令字编码。这不是问题,我们只需使用一小段
AUIPC和ADDI指令即可到达那里(有关更多信息,请查看这篇文章)。如果你不理解这一点,请务必复习不同的内存寻址模式及其差异:这是任何裸机编程的关键。由于这是一个常见的模式,RISC-V 汇编器提供了一个伪指令LLA,我们在这里使用了它。 - SBI 需要将要打印的字符串指针分为两部分传递。可以看到其中一部分是 0。我不太确定为什么需要这样,但这是 API 设计的要求。
SBI 调用涉及的寄存器
a7标识 SBI 扩展。a6标识扩展中的功能(在本例中是调试控制台扩展)。a0包含需要发送到调试控制台输出的字符串长度。a1和a2结合在一起,形成指向需要打印的字符串地址的 64 位指针。
SBI 调用通过 ecall 指令触发,它会激活 CPU 陷阱。此时,OpenSBI 接管并通过 UART 输出数据,方式与我们在最初的裸机编程指南中所做的完全相同。如果你想知道为什么简单的 ecall 调用会将控制权交给 OpenSBI,这是因为 OpenSBI 设置了陷阱处理机制,当我们的内核进入陷阱时,程序计数器会跳转到 OpenSBI 的软件部分。这些细节超出了本文的范围,但我们可能会在其他文章中详细讨论。
现在,只需查看 QEMU 的串行端口,确认“Hello world”已正确打印:
qemu-system-riscv64 -machine virt -s -S -bios build/platform/generic/firmware/fw_dynamic.bin -kernel ~/work/github_demo/risc-v-bare-metal-fake-kernel/hello_world_kernel
输出应该如下所示:
OpenSBI v1.3-54-g901d3d7
____ _____ ____ _____
/ __ \ / ____| _ \_ _|
| | | |_ __ ___ _ __ | (___ | |_) || |
| | | | '_ \ / _ \ '_ \ \___ \| _ < | |
| |__| | |_) | __/ | | |____) | |_) || |_
\____/| .__/ \___|_| |_|_____/|____/_____|
| |
|_|
Platform Name : riscv-virtio,qemu
Hello world
作为练习,我建议通过 gdb 探索基础扩展(0x10),以调查你构建的 QEMU 机器和 OpenSBI 能提供哪些功能。
结论
最终,我们得到了一个完全可移植的伪内核,它能够通过 UART 打印“Hello world”!虽然看起来不特别,但其背后的概念非常强大。你可以在支持调试控制台扩展的不同 RISC-V 64 位机器上直接使用相同的内核映像,无需重新构建。
事实上,我在这里玩了个小技巧 :) 让我建议你从源代码构建 OpenSBI 的原因之一是,某些 Linux 发行版包管理器提供的 QEMU 版本不支持调试控制台扩展(它们的版本较旧)。这正是我在 Debian 的 QEMU 中默认使用的 OpenSBI 遇到的情况。
最后,提醒大家我们主要关注的是带有 RISC-V 核心的 QEMU virt 机器,本文的所有细节都与此相关。不过,我希望读者已经了解了足够的启动顺序和裸机编程概念,以便将这些知识轻松应用到现实中的特定场景。
在接下来的文章中,我们将讨论如何进一步引导完整的 Linux 内核,并逐步扩展,直到我们实现一个能够处理键盘、鼠标、屏幕和以太网网络的 Linux 部署。
希望你喜欢这篇长篇文章!
代码指引
如果你不想复制粘贴代码,它可以在这个 GitHub 仓库中找到。
【翻译】Bare metal programming with RISC-V guide
原文作者: @popovicu
原文链接: Bare metal programming with RISC-V guide
版权声明: 本文为 @popovicu 的原创作品。本文的翻译仅供学习参考,更多详细信息请访问原文链接。
RISC-V 裸机编程指南
发表于:2023年9月9日 | 上午12:05
今天我们将探讨如何为 RISC-V 机器编写一个裸机程序。为了确保可重复性,我们将目标设定为 QEMU 的 riscv64 virt 虚拟机。
我们将简要介绍 RISC-V 机器启动的初始阶段,以及如何插入你自己的定制软件来进行裸机编程!
在本文的结尾,我们将为我们的 RISC-V 机器编写一个裸机程序,并向用户发送字符串“hello”,而不依赖于运行机器上的任何支持软件(操作系统内核、库等)。
机器启动和初始软件运行
一般概念
如果你熟悉计算机如何启动,可以跳过这一部分。
当一台真实的机器启动时,硬件首先运行健康检查,然后将要运行的第一批指令加载到内存中。一旦指令加载完成,处理器核心初始化其寄存器,程序计数器指向第一条指令。从那时起,软件便可以运行。
在像小型微控制器这样的简单系统中,所有的软件都包含在一个单一的二进制指令块中。处理器接下来将只执行这些指令。在像笔记本电脑或手机这样的更复杂的系统中,启动有更多阶段。
在这些复杂系统中,传统上,第一批指令是 BIOS,它的任务是将引导加载程序加载到内存中并将控制权移交给它。引导加载程序通常很小,便于加载到运行内存中,处理器可以轻松开始执行它的代码。然后它将操作系统内核加载到内存中(实现引导加载程序本身就是一门学问)。
每台机器以自己的方式加载初始软件。例如,BIOS 可以存储在一个独立的存储芯片上,通电后,存储的内容将被加载到内存中的固定地址,然后处理器从该地址开始执行。
QEMU 启动
即使 riscv64 virt 机器是虚拟的,它仍然有自己的启动顺序。它会经历多个阶段,目前我们不会探索所有细节。请关注后续文章中的更多详细介绍。
理解这个虚拟机的关键在于,显然它没有连接读取软件的芯片(它是虚拟的),所以 QEMU 通过某种方式模拟这一过程。你可能在之前的 QEMU 示例中见过 -bios 标志,现在你应该能对它有一个强烈的直觉。如果你猜测这是传递你的虚拟 RISC-V 核心在启动时执行的第一批指令,你是几乎正确的*。
零阶段引导加载程序 (ZSBL)
一旦你启动了这个虚拟机,QEMU 就会在 0x1000 地址填充一些指令,并将程序计数器设置为该地址。这相当于一台真实的机器在板上有一些硬编码的 ROM 固件(存放在某个芯片中),并在启动时将其内容转储到 RAM 中。你无法控制这些指令,它们不是你软件镜像的一部分,通常来说,我认为你没有理由想要覆盖这些指令,而且它们实际上对于更复杂的设置非常有用(我保证我们会在后续文章中讨论它们)。对于好奇的人来说,这几条指令就是零阶段引导加载程序(ZSBL)。ZSBL 设置了一些寄存器,具体原因我们将在未来探索(现在,你可以基本忽略这些寄存器的设置),并跳转到 0x80000000 地址,这才是真正的“战斗”开始的地方!
QEMU 的 -bios 标志
0x80000000 是 QEMU 开始运行用户提供的第一条指令的地址,这些指令在虚拟机启动时立即加载。如果你不传递任何东西,QEMU 将使用默认设置,并加载一个名为 OpenSBI 的软件。下一篇文章将详细介绍 RISC-V 中 SBI 的概念,以及 OpenSBI 究竟是什么。需要注意的是,RISC-V 中的 SBI 并不是真正的 BIOS,而是非常类似的东西。我的个人猜测是,QEMU 作者简单地复用了在其他架构(如 x86)上代表 BIOS 的标志。不过需要记住的是,SBI 在功能上与 BIOS 非常相似,更重要的是,它是可以定制的。
-bios 标志接受一个 ELF 二进制文件,包含指令和其他数据,按段组织。ELF 是 Linux 的标准二进制格式,虽然 ELF 文件格式的详细内容超出了本文的讨论范围,但我们可以简化理解为它是一个键值对映射,其中键是段的起始地址,值是需要加载到该地址的字节序列。因此,传递给 -bios 标志的 ELF 文件会填充从 0x80000000 开始的内存(这正是 QEMU 默认的 OpenSBI 镜像所做的事情)。
关于 -kernel 标志的说明
如果你之前用 QEMU 启动过操作系统(例如 Linux),你可能用过 -kernel 标志。它的作用基本与 -bios 标志相同:你可以传递一个 ELF 映像,覆盖其他内存区域,从概念上讲,它只是将字节转储到内存中。我们今天不会使用这个标志,但会在后续文章中详细介绍它的用法。
ELF 文件如何在启动过程中使用?
虽然概念上 ELF 文件只是一种填充内存的方法,但它们绝对不简单,你无法在一个下午编写一个简单的解析器。细心的读者可能会想:机器如何知道从 ELF 文件中解析出映射到某个地址(如 0x12345678)的内容并将其加载到内存中?这是个很好的问题——在我们的案例中,我们使用的是虚拟机,基本上是在模拟一台拥有智能数字电路或极其复杂的初始软件引导程序的机器,而这些内容在机器上电时已经准备好存储在内存中。当然,这不是在真实机器中发生的事情。真实机器上电时加载的软件是存储在机器存储器中的平坦二进制块,上电时它会直接被转储到内存中,实际上并没有任何解析过程。但由于我们在这里处理的是虚拟机器,几乎没有限制,我们无需受到制造硬件复杂性的约束。
为 RISC-V 编写自定义 “BIOS”
我们已经确定 0x80000000 是机器执行的第一条用户提供指令的位置。我只是将其作为一个事实给出,如果你想了解更多背景,可以从这里开始。基本上,我们看到的是,DRAM 在地址空间中映射为从 0x80000000 开始(如果你不理解这是什么意思,不用担心,本文接下来的内容对这个概念的依赖不大)。
让我们开始构建一个 ELF 文件,它将在地址 0x80000000 处布置一些处理器指令,以向用户显示消息“hello”!
通过 UART 与用户交互
曾经做过嵌入式系统编程的人肯定熟悉 UART 的概念。UART 是一种非常简单的设备,用于最基本的输入/输出形式:它有一根输入线(接收,称为 RX)和一根输出线(发送,称为 TX),每次传输一位。如果你要连接两台设备通过 UART 通信,一台设备的 TX 连接到另一台设备的 RX,反之亦然。如果你阅读本文时从未接触过 UART,我强烈建议你至少购买最便宜的 Arduino,并通过 USB 转 UART 电缆与计算机通信。这个概念与我们在这里做的完全相同,但你将真正动手操作,理解会更加深刻,因为这里的场景是完全虚拟化的。
QEMU 虚拟化了虚拟机上的 UART 设备,我们的软件可以访问它。当你打开 QEMU 的串行端口(UART)部分时,基本上当你按下键盘上的按钮时,按键的代码会从主机的 TX 发送到虚拟机的 RX,而当虚拟机在其 TX 上输出某些内容时,它会在终端中图形化显示给你(因此你不必解码来自模拟板的电信号 :)),例如,如果虚拟机发送 8 位代表 65 的数据,你的 QEMU 将显示字符 a,因为这是它的 ASCII 代码。
我们知道 QEMU 将 UART 映射到地址 0x10000000(可以在 QEMU 的源代码中查看),这里虚拟化的设备是 NS16550A。具体细节不重要:对于本文的目的来说,这意味着如果你从软件中向该地址发送一个 8 位值,它将通过虚拟化的 UART 设备的 TX 线路发送出去。实际上,这意味着如果你打开 QEMU 的串行端口,你写入 0x10000000 的字符将显示在你的控制台中。
将代码整合在一起
了解了所有这些知识后,我们现在可以编写代码。我们即将构建的 ELF 文件会在地址 0x80000000 上布局一些指令,这些指令依次将字符 ‘h’、‘e’、‘l’、‘l’ 和 ‘o’ 发送到地址 0x10000000。最后,代码会进入一个无限循环(这样 QEMU 不会由于某些奇怪的原因崩溃,并且我们可以检查输出)。
.global _start
.section .text.bios
_start: addi a0, x0, 0x68
li a1, 0x10000000
sb a0, (a1) # 'h'
addi a0, x0, 0x65
sb a0, (a1) # 'e'
addi a0, x0, 0x6C
sb a0, (a1) # 'l'
addi a0, x0, 0x6C
sb a0, (a1) # 'l'
addi a0, x0, 0x6F
sb a0, (a1) # 'o'
loop: j loop
将此文件保存为 hello.s。让我们将这个文件汇编为机器码。在我的情况下(可能也是你的情况),我使用了跨平台的工具链,这意味着我在与目标平台不同的平台上进行开发。具体来说,我在 x86 机器上开发此软件,并为 riscv64 机器构建。
要汇编此文件,我运行以下命令:
riscv64-linux-gnu-as -march=rv64i -mabi=lp64 -o hello.o -c hello.s
具体命令可能会根据你使用的 riscv64 汇编器有所不同,这是我通过 Debian 系统的包管理器获得的工具。我建议你通过互联网获取构建 riscv64 软件的正确工具链,通常只需获取正确的软件包。
现在,代码只是被汇编了,这意味着我们已经将软件指令转换为机器码格式,但这个二进制文件还不能作为我们的伪 BIOS 使用。我们需要使用 链接器 并通过 链接脚本 来确保生成的指令按预期布局在 0x80000000 地址。让我们编写链接脚本。
MEMORY {
dram_space (rwx) : ORIGIN = 0x80000000, LENGTH = 128
}
SECTIONS {
.text : {
hello.o(.text.bios)
} > dram_space
}
我们不会深入解释这些内容的含义,但简而言之,现在我们有一种方法可以将这些指令准确地放置在我们想要的位置。让我们用 objdump 验证一下。
riscv64-linux-gnu-objdump -D hello
输出应该类似如下:
Disassembly of section .text:
0000000080000000 <.text>:
80000000: 06800513 li a0,104
80000004: 100005b7 lui a1,0x10000
80000008: 00a58023 sb a0,0(a1) # 0x10000000
8000000c: 06500513 li a0,101
80000010: 00a58023 sb a0,0(a1)
80000014: 06c00513 li a0,108
80000018: 00a58023 sb a0,0(a1)
8000001c: 06c00513 li a0,108
80000020: 00a58023 sb a0,0(a1)
80000024: 06f00513 li a0,111
80000028: 00a58023 sb a0,0(a1)
8000002c: 0000006f j 0x8000002c
在 QEMU 上运行“伪 BIOS”
现在可以通过运行以下命令启动 QEMU:
qemu-system-riscv64 -machine virt -bios hello
要查看 UART 上发生的情况,请点击顶部菜单中的 View 按钮并切换到串行端口视图。输出应该如下图所示:
我只想运行代码
访问本文的 GitHub 仓库,运行 make 命令,它将执行我们上述的所有步骤。然后你可以启动 QEMU。
RISC-V Privileged Architecture
本讲座是由Allen Baum在第八届RISC-V研讨会上,于2018年5月7日在西班牙巴塞罗那进行的,讲述了RISC-V特权架构的内容。该架构是RISC-V处理器设计中的关键部分,决定了系统不同操作模式下的安全性、隔离性和性能。此幻灯片的内容重点阐述了特权架构的基本组成部分及其在处理器功能中的作用。
原始内容来源:
幻灯片标题:RISC-V Privileged Architecture
原作者:Allen Baum Esperanto Technologies.
出处:8 th RISC-V Workshop Barcelona, Spain
原始发布日期:2018年5月7日
版权声明:该幻灯片及其内容的版权归 Allen Baum 所有。翻译与讲解仅供学习和参考,更多详细信息请参见原文链接。
这是2018年发布的RISC-V特权架构资料,其中的大部分内容仍然与当前的RISC-V架构相关和有效,特别是在架构的基础概念、特权模式、控制状态寄存器(CSRs)和特权指令方面。然而,随着RISC-V的持续发展和标准的更新,部分技术细节可能已经有所改进或扩展。
如果你希望深入了解RISC-V在某些特定领域的最新进展,建议参考最新的RISC-V规范,或者查阅RISC-V基金会的最新文档和技术报告。
目录
为什么需要特权架构?
在处理器架构中,引入特权级别的目的是为了提供更高的系统安全性和资源控制。特权架构确保操作系统和用户程序运行在不同的权限级别,防止普通应用程序访问或修改关键的系统资源。例如,操作系统需要完全访问硬件资源和内存管理功能,而用户程序则只应在受限的环境下运行,以避免误操作或恶意行为影响整个系统的稳定性。特权架构通过分离不同的权限模式,帮助实现系统的可靠性和安全性。
配置文件(Profiles)
RISC-V特权架构根据不同的应用场景设置了不同的配置文件(Profiles),以适应多样化的需求。这些配置文件的存在使得RISC-V架构能够在嵌入式系统、服务器、移动设备等不同领域中灵活应用。每个Profile可以包括不同的功能和特权级别,从而满足特定应用的需求。
权限级别和模式(Privileges and Modes)
RISC-V特权架构划分了几种不同的权限模式,这些模式对应处理器在不同上下文中的操作需求。常见的模式包括:
- 机器模式(M模式):这是RISC-V系统中最高的权限模式,通常由系统固件或低级别管理程序使用,直接控制硬件。
- 监督模式(S模式):用于操作系统内核,允许访问部分硬件资源,但受到比机器模式更多的限制。
- 用户模式(U模式):最低权限的模式,用户应用程序在此模式下运行,无法直接访问硬件或特权指令。
不同的模式通过硬件层级来隔离,确保每个级别的程序只能访问其权限范围内的资源。
特权功能(Privileged Features)
控制和状态寄存器(CSRs)
控制和状态寄存器是RISC-V特权架构中的重要部分,用于管理处理器的操作模式和状态。在特权模式下,CSRs控制包括中断、内存管理、性能计数等各种功能。不同的模式可以访问不同的CSRs,确保系统安全性。例如,用户模式无法修改系统级别的CSRs。
特权指令
RISC-V定义了一系列特权指令,这些指令只能在特定模式下运行,主要用于管理硬件资源和处理系统级别的操作,如中断处理和内存保护。
内存寻址(Memory Addressing)
内存寻址机制包括地址翻译和保护功能。RISC-V采用了一种分页机制来实现虚拟内存管理,允许操作系统将物理内存抽象为更灵活的虚拟地址空间。内存保护则确保不同模式下的程序只能访问特定范围的内存,避免越权访问。
地址翻译(Translation)
地址翻译通过页表将虚拟地址映射到物理地址,支持多级页表结构以提高寻址灵活性和效率。这一机制使得RISC-V处理器能够支持大规模内存应用和多任务处理。
内存保护(Protection)
内存保护的核心是防止低权限程序访问或修改高权限内存区域。通过在页表中设置访问权限位,RISC-V能够有效地隔离不同权限模式下的内存访问。
异常处理(Trap Handling)
异常处理机制用于处理运行过程中出现的各种异常情况,包括硬件中断和软件异常。RISC-V特权架构对这些异常的处理进行了细致的定义,确保系统能够在发生异常时迅速恢复或进行适当的操作。
异常(Exceptions)
当发生例如非法指令、访问未授权内存等异常情况时,处理器会捕获这些异常并转入相应的处理程序。这些异常处理程序通常运行在高权限模式下,以确保能够正确恢复系统。
中断(Interrupts)
RISC-V支持硬件和软件中断处理。硬件中断通常由外部设备引发,而软件中断则由处理器内部指令触发。中断处理需要快速响应并恢复正常执行,这也是操作系统设计中的一个关键部分。
计数器(Counters)
RISC-V架构中的计数器用于记录处理器的时间和性能信息。通过这些计数器,操作系统可以监控系统的运行状态,执行诸如时间片轮转、性能调优等任务。
时间(Time)
时间计数器记录系统运行的时间戳,用于系统时钟、定时器和其他时间相关功能。
性能(Performance)
性能计数器用于测量处理器的性能参数,如指令执行数、缓存命中率等。这些数据有助于优化系统性能,并为开发者提供性能调试信息。
Why a Privileged Architecture?
RISC-V特权架构的设计背后有着明确的目的,主要是为了更好地管理共享资源、保护系统的核心功能,并隔离具体实现的细节。共享资源的管理和保护对于现代计算系统至关重要,尤其是在多核、多任务环境中,特权架构的存在能够确保不同任务之间的安全隔离和资源分配。同时,它还提供了软件与硬件层的通信机制,尤其是在虚拟化支持方面,RISC-V架构通过引入一系列执行环境(Execution Environments)实现不同层次的任务隔离和资源共享。
管理共享资源
共享资源包括内存、I/O设备以及处理器核心。在多任务操作系统中,不同任务会争夺这些资源,而没有特权架构的管理会导致系统冲突和崩溃。通过特权架构,系统能够高效地分配这些资源,并在不同任务之间进行适当的隔离与协调。
关键资源管理包括
- 内存:虚拟内存映射使得各个任务能够使用独立的地址空间,从而避免直接访问物理内存。
- I/O设备:通过虚拟内存映射,系统能够保护设备接口,防止低权限任务直接访问关键I/O资源。
- 处理器核心:特权架构可以管理处理器核心的分配,确保高权限任务优先运行。
保护共享资源
资源保护是特权架构的另一个重要目的。通过使用虚拟内存映射以及访问权限控制,RISC-V能够有效防止任务间的越权访问和资源冲突。
具体的保护手段包括
- 内存保护:通过虚拟内存,系统可以为每个任务分配独立的内存空间,防止任务间的非法访问。
- I/O保护:与内存一样,I/O访问也被映射到虚拟地址空间,通过特权级别控制,防止低权限模式直接操作硬件设备。
- 访问权限控制:权限位可以设置在内存映射中,以确保只有特定权限模式能够访问相应的资源。
隔离实现细节
在多任务、多用户环境中,隔离不同实现的细节非常重要。特权架构通过捕获未实现的操作并通过软件仿真进行处理,从而能够兼容不同的实现。此外,处理异步事件(如I/O事件、计时器事件、软件中断)也是特权架构的重要任务,确保外部事件能够被及时响应并处理。
具体措施包括
- 未实现操作的捕获和仿真:当任务执行一个硬件不支持的操作时,特权架构能够捕获该操作并交由软件进行仿真。
- 外部异步事件处理:如I/O设备事件、计时器中断、线程间的中断等,特权架构能够管理这些事件的优先级和处理流程。
- 两级地址转换:为了支持虚拟化,RISC-V引入了两级地址转换机制,特别是在虚拟机管理程序(Hypervisor)模式下,这一机制至关重要。
RISC-V Privileged Architecture Layers
RISC-V特权架构分为多个层次,每个层次负责不同的执行环境,并通过特定的接口进行通信。这些层次清晰地划分了应用程序、操作系统、虚拟机管理程序之间的权限和功能,确保系统的可扩展性和安全性。
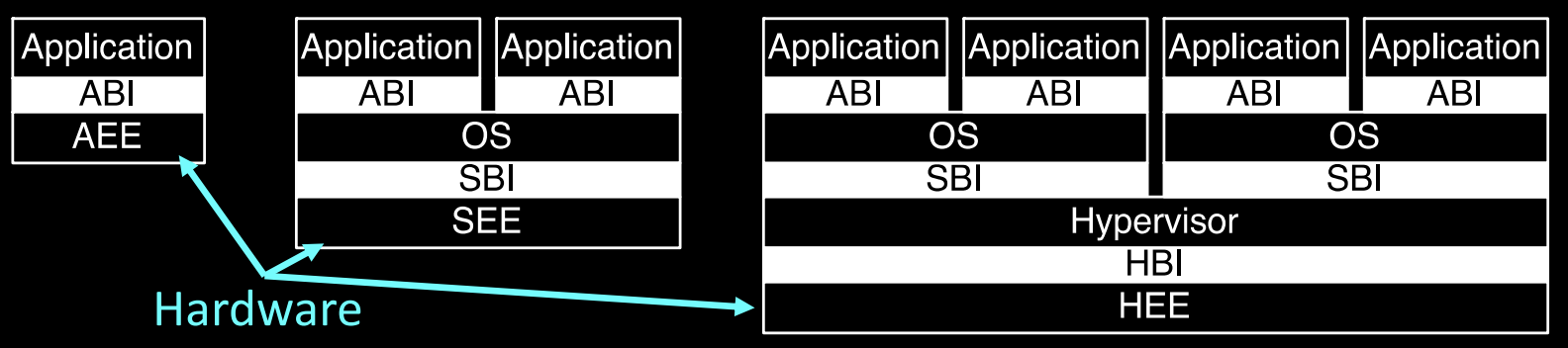
主要层次
-
应用层(Application):
- 应用执行环境(AEE):为应用程序提供一个运行环境,通过**应用二进制接口(ABI)**与底层系统进行交互。
-
操作系统层(Operating System):
- 监督执行环境(SEE):操作系统运行在监督模式下,管理系统资源,并通过**系统二进制接口(SBI)**与硬件进行通信。
-
虚拟机管理程序层(Hypervisor):
- 虚拟机管理程序执行环境(HEE):支持虚拟化,虚拟机管理程序能够通过虚拟机管理程序二进制接口(HBI)与操作系统层进行交互,管理虚拟机的执行。
层次间的通信
每一层都有其特定的二进制接口,通过这些接口,应用程序、操作系统和虚拟机管理程序能够顺利地进行通信和资源管理。例如,应用程序通过ABI接口调用操作系统的服务,而操作系统通过SBI接口管理底层硬件资源。
通信接口包括
- ABI(Application Binary Interface):应用程序通过ABI与操作系统交互。
- SBI(System Binary Interface):操作系统通过SBI直接与硬件进行通信。
- HBI(Hypervisor Binary Interface):虚拟机管理程序通过HBI接口管理虚拟化环境中的资源和操作系统。
特权层次间的指令通信:ECALL指令
RISC-V引入了ECALL指令来实现不同权限层次之间的通信。当应用程序需要访问高权限功能时,它可以发出ECALL指令,这一指令会触发进入监督模式或虚拟机管理模式进行相应处理。这样,系统能够在保护低权限程序不直接访问高权限功能的同时,提供必要的功能调用接口。
支持虚拟化
RISC-V的所有ISA层次都设计为支持虚拟化。通过虚拟化,操作系统和应用程序可以在不同的虚拟机中运行,彼此隔离而不会影响底层硬件的安全性和资源分配。虚拟化的实现依赖于特权架构中的多级地址翻译机制和特定的二进制接口。
Profiles
在RISC-V特权架构中,"Profiles"定义了处理器可以支持的不同配置和特性集,以适应从简单嵌入式系统到复杂的云计算环境不等的应用需求。每个Profile描述了特定的操作模式、信任级别、内存保护方式以及其他特性,这些都是为了优化特定的使用场景而设计的。
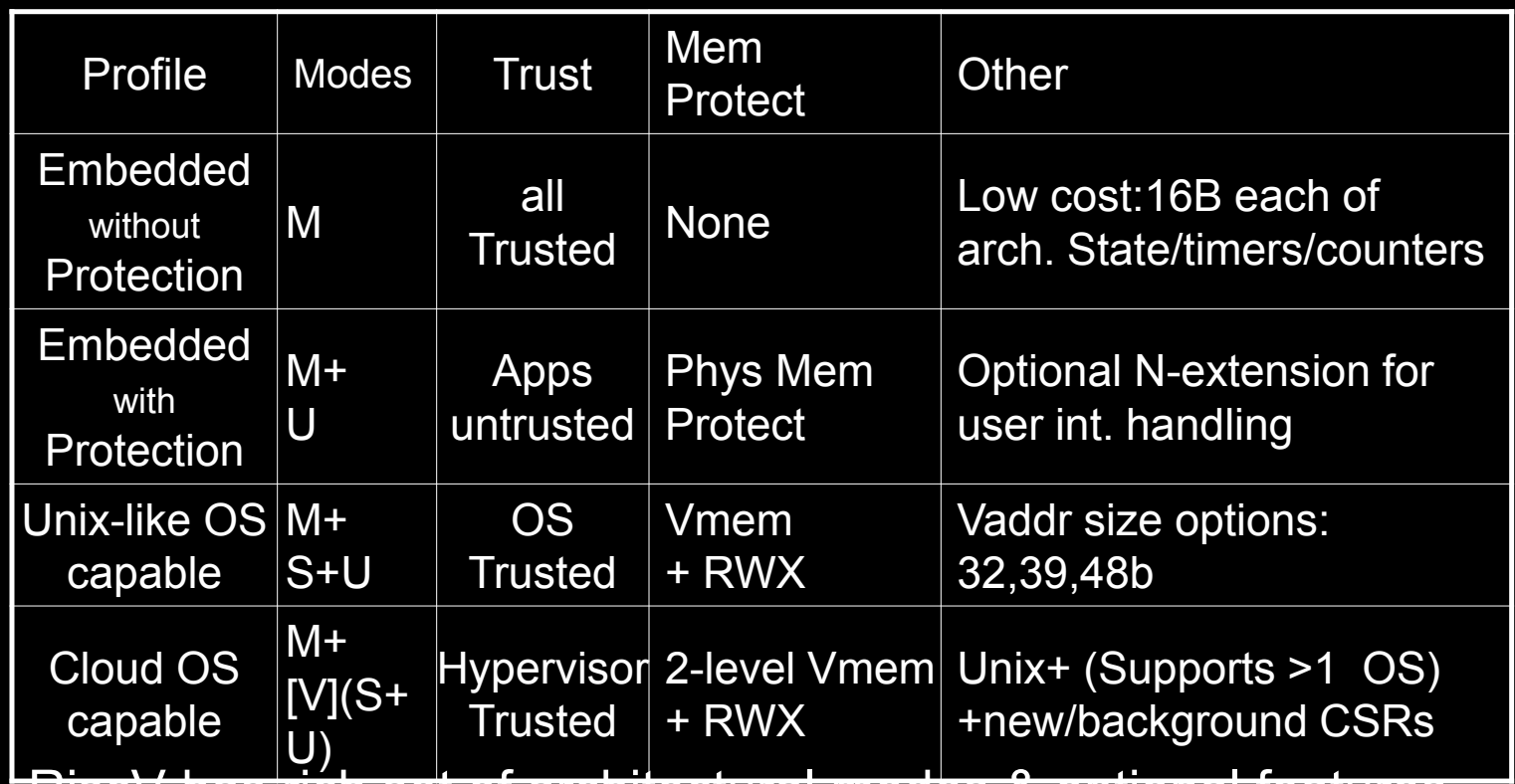
主要的RISC-V Profiles
- Embedded without Protection:
- 模式(Modes):M(机器模式)
- 信任(Trust):所有代码均可信
- 内存保护(Mem Protect):无
- 其他特性(Other):成本低廉,拥有16B的架构状态、计时器和计数器
这个Profile适用于需要极低成本和资源使用的简单嵌入式设备,如简单的传感器或控制器。不支持内存保护,意味着所有代码都运行在机器模式下,具有完全的硬件访问权限。
- Embedded with Protection:
- 模式(Modes):M+U(机器模式和用户模式)
- 信任(Trust):应用不可信
- 内存保护(Mem Protect):物理内存保护
- 其他特性(Other):可选的N扩展,用于用户中断处理
这个Profile适用于需要隔离应用程序的更复杂嵌入式系统。通过引入用户模式,提高了系统的安全性,避免了不可信应用直接访问关键硬件资源。
- Unix-like OS Capable:
- 模式(Modes):M+S+U(机器模式、监督模式和用户模式)
- 信任(Trust):操作系统可信
- 内存保护(Mem Protect):虚拟内存和读写执行(RWX)保护
- 其他特性(Other):支持不同的虚拟地址大小(32位、39位、48位)
此Profile旨在支持类Unix的操作系统,提供完整的内存虚拟化支持和多用户环境。操作系统运行在监督模式下,管理用户模式下运行的应用程序。
- Cloud OS Capable:
- 模式(Modes):M+V(机器模式和可选的Hypervisor模式)
- 信任(Trust):Hypervisor可信
- 内存保护(Mem Protect):两级虚拟内存和RWX保护
- 其他特性(Other):支持Unix+,支持多操作系统,新的后台CSR
专为云计算环境设计,支持虚拟化技术,允许在同一硬件上运行多个虚拟机和操作系统。Hypervisor模式提供硬件级别的隔离和资源管理,优化了多租户环境的安全性和性能。
Profiles的应用
通过这些不同的Profiles,RISC-V能够为广泛的市场和应用提供灵活的解决方案。无论是低成本的嵌入式设备还是高性能的云服务器,RISC-V架构都能通过选择合适的Profile来最大化硬件的效能和适应性。这种灵活性是RISC-V在现代计算领域中逐渐成为一个重要选项的关键因素。
Privileges and Modes
RISC-V特权架构通过设置多种权限级别和操作模式来确保系统的安全性和功能完整性。这些权限模式为不同类型的任务分配了不同的权限,以确保高权限任务能够安全地管理硬件资源,而低权限任务则受到适当的限制。这种设计不仅提升了系统的安全性,还支持虚拟化、多任务处理等复杂应用。
RISC-V权限模式(Privilege Modes)
RISC-V定义了一个分层的权限模式结构,分为用户模式、监督模式和机器模式,它们以等级结构从低到高排列:
-
用户模式(User Mode,U-mode):
- 最低权限,通常用于运行用户应用程序。程序在该模式下无法直接访问硬件资源,只能通过操作系统提供的系统调用接口进行有限的操作。
- 虚拟化支持:也可在虚拟化环境下运行,虚拟机管理程序可以限制用户模式下的虚拟机行为。
-
监督模式(Supervisor Mode,S-mode):
- 中级权限,通常由操作系统内核使用。监督模式允许对硬件资源和内存管理进行更直接的控制,如页表管理和中断处理。
- 虚拟化支持:可以在虚拟化环境下运行,支持在Hypervisor管理下的操作系统执行。
-
机器模式(Machine Mode,M-mode):
- 最高权限,通常由固件或低级系统管理程序使用。该模式具有对所有硬件资源的完全访问权限,负责处理最低级别的系统初始化和管理任务,如启动、异常处理和中断控制。
- 特殊模式:还有更高的调试模式,但此处不做讨论。调试模式类似于机器模式,但用于硬件调试。
支持的模式组合
RISC-V根据应用场景支持以下几种常见的权限模式组合:
- M模式(仅机器模式):适用于简单的嵌入式系统,所有任务都在最高权限下运行,不需要复杂的内存保护。
- M + U模式:嵌入式系统中常见的组合,机器模式用于底层管理,而用户模式用于运行普通应用程序,提供了基本的内存保护。
- M + S + U模式:适用于类Unix操作系统(如Linux),在这种组合下,操作系统内核运行在监督模式,用户程序运行在用户模式,实现了虚拟内存管理和多用户隔离。
- M + [V(S + U)]模式:适用于支持多个操作系统和虚拟化的复杂系统,允许多个操作系统在虚拟机管理程序的监督下并行运行。
控制和状态寄存器(Control and Status Registers, CSRs)
每个特权模式都可以访问专门的控制和状态寄存器(CSRs),用于管理模式下的操作。CSRs的访问权限根据运行模式而不同,低权限模式无法访问高权限模式的寄存器,以确保系统的安全性和完整性。
- CSRs的作用:这些寄存器控制处理器的关键操作,如中断使能、内存管理以及时间计数器等。每个特权模式可以有其专属的CSR集合,以保证隔离。
- 多副本CSRs:通常,每个模式都有多个CSR副本或视图,确保不同模式下的操作隔离和安全。
通过这种分层的特权模式和CSR访问机制,RISC-V确保了系统从上电到应用程序执行的每个阶段都受到严格的权限控制,同时支持灵活的虚拟化和多操作系统环境。
Privileged Features: Instructions and CSRs
在RISC-V架构中,特权指令和控制状态寄存器(CSRs)是特权模式下的核心功能。它们允许操作系统和固件有效地管理硬件资源,同时提供安全的多用户和多任务环境。特权指令只能在相应的特权模式(如机器模式或监督模式)下执行,确保系统的控制权不会被低权限的用户模式所滥用。
模式专属指令(Mode Specific Instructions)
RISC-V为机器模式(M-mode)和监督模式(S-mode)定义了一系列特权指令,这些指令扩展了基本的用户模式(U-mode)操作,以便在不同的权限模式下更好地控制系统。
- 特权指令只能在适当的特权模式下执行,低权限模式(如U-mode)无法访问高权限模式的指令。这些指令是为了保证不同模式间的隔离和安全。

所有模式下的指令(All Modes)
-
ECALL:
- 生成环境调用异常,触发从当前模式到更高特权模式的系统调用。
- 例如,当用户模式的应用程序需要操作系统的服务时,它会通过ECALL指令请求监督模式处理系统调用。
-
EBREAK:
- 生成断点异常,通常用于调试。
- 当程序执行到某个断点时,处理器会捕获断点并进入调试模式。
-
FENCE.I:
- 同步对内存的更新,确保指令的修改在所有后续指令中可见。
- 这一指令在多核或并发系统中尤为重要,用于确保不同处理器核心之间的内存一致性。
-
RET :- 从指定模式的异常中返回。
- SRET:用于从监督模式的陷阱或异常中返回。
- URET:用于从用户模式的异常中返回,通常在N扩展(用户模式异常)被支持时使用。
监督模式(S-mode)和机器模式(M-mode)下的特定指令
S-mode(及M-mode)新增指令
- SFENCE.VMA:
- 用于同步虚拟内存的更新。
- 此指令确保对内存页表的更改在所有处理器核心中都被正确识别,防止出现页面翻译错误。
M-mode新增指令
- WFI(Wait For Interrupt):
- 当前hart进入等待状态,直到有中断需要服务时再恢复运行。
- 该指令用于节省功耗,通常在低功耗模式下使用,是一个提示性指令,可能被实现为空操作(noop)。
特权指令的作用
特权指令的引入是为了增强RISC-V在特权模式下的控制能力。通过ECALL和EBREAK等指令,用户模式的程序可以请求高权限的服务或在调试时打断程序的执行。而诸如SFENCE.VMA和FENCE.I这样的指令则确保了内存管理和同步操作的安全性和一致性。
特权指令确保了不同模式下的隔离和安全性,同时也增强了处理器对多任务、虚拟化和并发场景的支持,使得RISC-V能够灵活适应各种复杂的系统需求。
Mode Specific CSRs
控制和状态寄存器(Control and Status Registers, CSRs)是RISC-V特权架构中的重要组成部分,它们用于管理处理器的操作模式、硬件资源和系统状态。每个权限模式(用户模式、监督模式、机器模式)都有其特定的CSRs,确保不同权限模式下的任务只能访问与其权限相关的寄存器。
CSR的地址空间和访问机制
-
独立的地址空间:CSRs有自己专用的地址空间,直接通过地址访问。这意味着不同的寄存器集在各模式下有不同的编码和访问方式。
-
每个硬件线程(hart)都有自己的CSRs:每个hart(硬件线程)拥有独立的一组CSRs,通常每个模式拥有多达1000个寄存器,总共4K个CSRs(即1000个寄存器乘以4个模式)。
-
专用操作:CSRs通过特定的操作访问,例如支持原子交换或位设置/清除的指令。这些操作确保了对CSRs的高效读写。
-
模式敏感:CSRs只能被运行在相应或更高权限模式下的代码访问。低权限模式(如用户模式)尝试访问高权限模式(如机器模式)的寄存器时,会触发陷阱(trap),从而保护系统安全。
可选和只读CSRs
许多CSRs是可选的,或者具有可选字段,其行为依赖于具体实现:
- 访问不存在的CSRs会触发陷阱:如果某一特权模式的代码尝试访问一个不存在的CSR,处理器会产生异常。
- 只读寄存器的写操作会触发陷阱:尝试写入只读寄存器时,也会产生异常。不过,如果是只读/读写寄存器中的只读字段,写入操作将被忽略,不会触发异常。
- 可选寄存器的访问:可选寄存器在没有实现时,会读取为零,并且(如果是读写寄存器)忽略写入操作。
这使得系统的实现具有高度灵活性,不同的处理器可以根据需要实现不同的CSRs集,依赖于具体的架构和应用需求。
CSR Address Space
在RISC-V架构中,控制和状态寄存器(Control and Status Registers,CSRs)是用来管理处理器的操作模式、硬件资源和系统状态的核心组件。不同的特权模式下,处理器会使用不同的CSR集,确保权限隔离。CSR地址空间由多层结构组成,遵循特定的编码规则,用于区分不同的模式和寄存器。
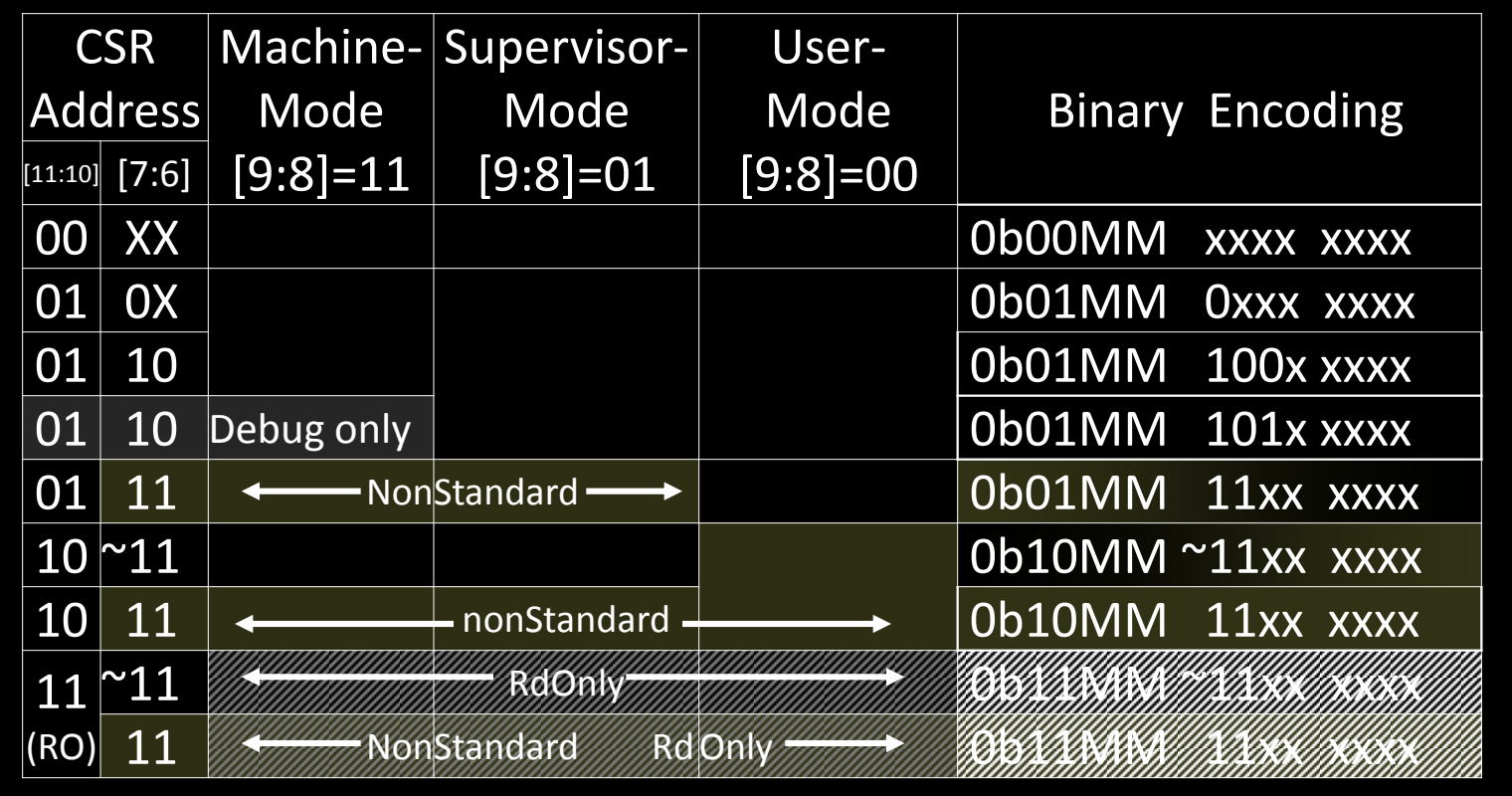
CSR地址的编码结构
CSR地址是12位的二进制值,用来标识不同的寄存器。具体的编码结构如下:
- 高两位[11:10]:用于定义CSR的类型。
- 中两位[9:8]:用于区分不同的特权模式:
00:用户模式(U-mode)专用的CSRs01:监督模式(S-mode)专用的CSRs11:机器模式(M-mode)专用的CSRs10:为虚拟机管理程序(Hypervisor,V-mode)保留,当前版本尚未实现。
- 其余位[7:6]:用于标识CSR的具体种类和用途。
通过这种结构,RISC-V的CSR地址可以灵活地支持不同的模式、权限级别和操作需求。
CSR地址空间划分
CSR地址空间分为多个区域,每个区域对应不同的特权模式。根据特定的二进制编码,CSR地址的用途如下表所示:
| CSR地址 | 机器模式(M-mode) | 监督模式(S-mode) | 用户模式(U-mode) | 二进制编码说明 |
|---|---|---|---|---|
00 XX | - | - | 可访问 | 0b00MM xxxx xxxx 用户模式专用寄存器 |
01 0X | - | 可访问 | - | 0b01MM 0xxx xxxx 监督模式下的常规寄存器 |
01 10 | 可访问 | - | - | 0b01MM 100x xxxx 调试模式专用寄存器 |
01 11 | 非标准(NonStandard) | - | - | 0b01MM 11xx xxxx 非标准寄存器 |
10 ~11 | - | - | - | 0b10MM ~11xx xxxx 保留给虚拟化支持的CSR |
11 ~11 | 只读(ReadOnly) | 非标准(NonStandard) | 只读(ReadOnly) | 0b11MM 11xx xxxx 机器模式的只读寄存器 |
关键编码细节
-
0b00MM xxxx xxxx:这些CSR主要供用户模式使用,最低权限,通常用于用户程序的控制状态信息,如性能计数器或用户态的软中断控制等。 -
0b01MM xxxx xxxx:这些CSR供监督模式和调试模式使用,权限较高,典型的应用是页表管理、内存访问控制和中断处理等。监督模式的操作系统内核可以使用这些CSR来管理用户进程。 -
0b11MM xxxx xxxx:这些CSR为机器模式(M-mode)专用,权限最高。通常,这些寄存器用于系统初始化、硬件配置以及固件层面的管理。 -
0b10MM xxxx xxxx:这一段目前保留给虚拟化支持(Hypervisor mode)。虽然当前版本的RISC-V规范尚未全面实现虚拟化,但这一编码区域为将来虚拟机管理程序的功能预留了空间。将来,虚拟机管理程序会通过这些CSR来管理多虚拟机的操作。
特殊类型的CSR
-
只读寄存器(ReadOnly):某些寄存器是只读的,用于存储系统状态或硬件信息,这类寄存器在低权限模式下也可以读取,但无法被写入。
-
非标准寄存器(NonStandard CSRs):有些CSR的地址编码不属于RISC-V标准,通常由处理器厂商或特定实现提供。这类CSR通常是硬件优化或扩展功能的一部分,处理器厂商可以根据需要定义。
-
调试模式专用CSR:
01 10开头的CSR是调试模式下专用的,用于在调试环境中保存系统的状态信息并控制调试操作。这些寄存器只有在调试端口连接时才能访问。
错误处理与陷阱机制
-
访问不存在的CSR:如果代码试图访问不存在的CSR,处理器会触发一个陷阱(trap),即系统会捕获这个错误并执行相应的异常处理程序。
-
写入只读CSR:同样,试图写入只读CSR也会触发陷阱,这种机制确保了系统的稳定性,防止低权限模式中的错误操作破坏关键数据。
-
可选CSR:某些CSR是可选的,具体实现时可以有选择地支持这些寄存器。如果某个CSR在实现中不存在,处理器在读取时将返回零,并且在写入时忽略操作。
CSR地址空间通过严格的编码规范,确保了不同特权模式下的CSR访问权限划分。机器模式(M-mode)拥有最高权限,能够访问最广泛的CSR集合,而监督模式(S-mode)和用户模式(U-mode)的权限则逐步递减。这种设计保障了系统的安全性和稳定性,同时为未来的扩展(如虚拟化支持)预留了足够的灵活性。
CSRs and Categories
RISC-V架构中的控制和状态寄存器(CSRs)根据其功能被划分为不同的类别,每个类别负责管理处理器的某一方面操作。CSRs为处理器提供了对硬件资源的精细控制和状态监控,涵盖了从异常处理、内存保护到计时器、调试等多个领域。部分CSR在不同的模式(如M-mode、S-mode、U-mode)下会有各自的副本或复制,这样可以保证不同权限级别的隔离性。
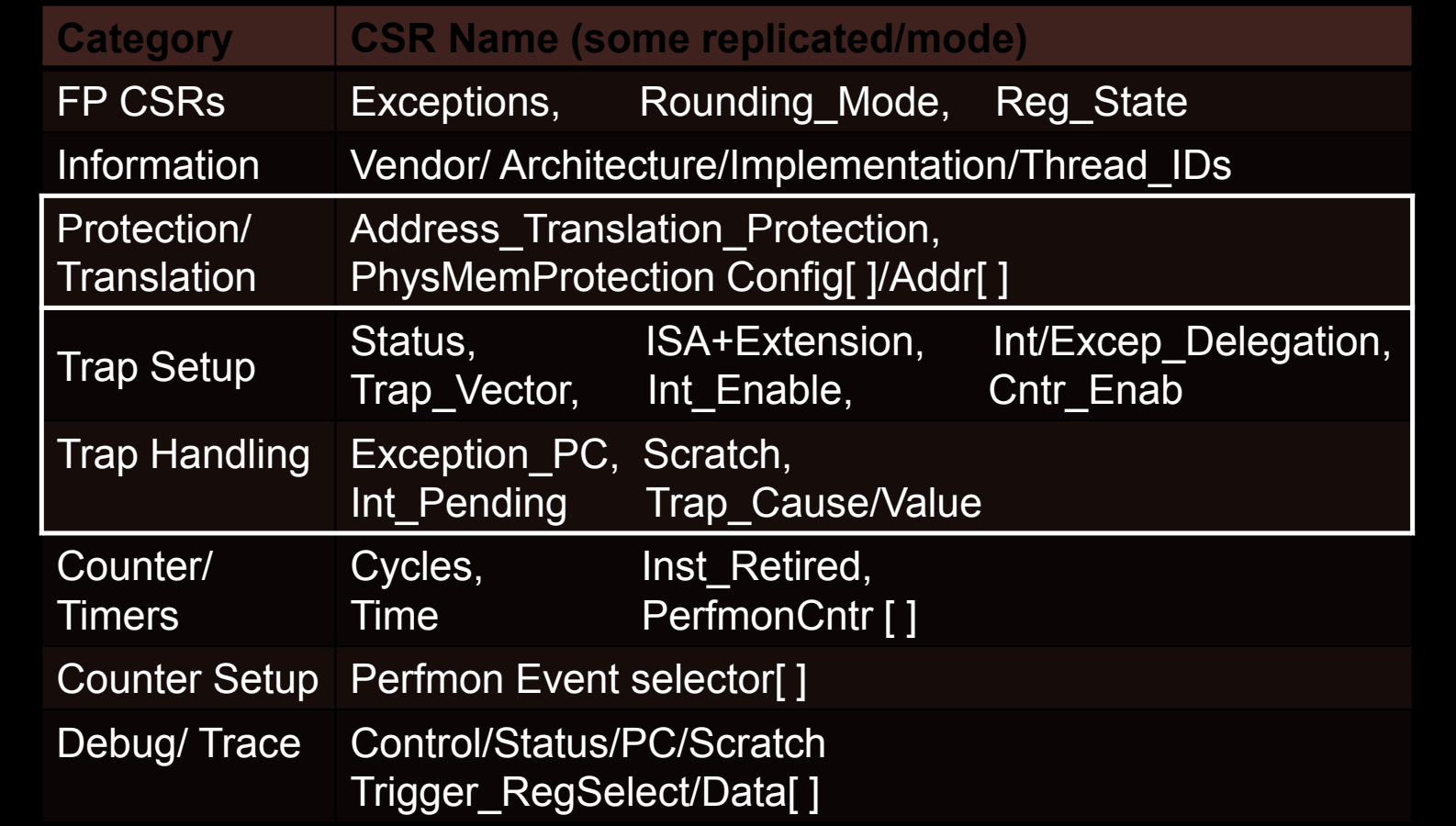
主要CSR类别
-
FP CSRs(浮点运算相关)
- 这些寄存器主要用于管理浮点操作和状态。它们负责处理浮点运算的异常、舍入模式以及浮点寄存器的状态。
- 关键CSR名称:
- Exceptions:用于浮点异常的处理。
- Rounding_Mode:控制浮点运算的舍入模式。
- Reg_State:浮点寄存器的状态保存。
-
Information(信息寄存器)
- 这些CSR保存处理器的厂商信息、架构标识、实现细节以及当前硬件线程的ID。
- 关键CSR名称:
- Vendor/Architecture/Implementation:用于识别处理器的厂商、架构版本和实现方式。
- Thread_IDs:管理多线程或多核心系统中每个hart(硬件线程)的标识符。
-
Protection/Translation(保护和地址翻译)
- 这些CSR用于虚拟内存的地址翻译和物理内存的保护,特别是在多任务操作系统中,保证不同任务之间的内存隔离。
- 关键CSR名称:
- Address_Translation_Protection:控制虚拟地址到物理地址的翻译,并应用内存保护。
- PhysMemProtection Config[]/Addr[]:管理物理内存保护的配置和地址。
-
Trap Setup(陷阱设置)
- 这些寄存器用于设置和配置异常(trap)的行为,例如指定异常向量地址或启用特定类型的异常处理。
- 关键CSR名称:
- Status:保存处理器的当前状态,如当前运行模式、全局中断使能等。
- Trap_Vector:指定异常处理程序的入口地址。
- Int_Enable:启用或禁用中断。
- Cntr_Enab:启用或禁用特定的计数器功能。
-
Trap Handling(陷阱处理)
- 这些CSR用于处理异常事件,包括保存异常发生时的处理器状态和异常的原因。
- 关键CSR名称:
- Exception_PC:保存异常发生时的程序计数器(PC)值,以便在异常处理完成后返回。
- Scratch:用于异常处理中的临时数据存储。
- Int_Pending:记录当前待处理的中断。
- Trap_Cause/Value:保存异常的原因和相关数据。
-
Counter/Timers(计数器和计时器)
- 这些寄存器用于记录处理器的周期数、时间以及指令执行情况,通常用于性能监控和系统调度。
- 关键CSR名称:
- Cycles:记录处理器执行的时钟周期数。
- Time:用于记录处理器的运行时间。
- Inst_Retired:记录处理器已执行的指令数。
- PerfmonCntr[]:性能监控计数器,用于跟踪性能指标。
-
Counter Setup(计数器设置)
- 用于配置性能监控事件,选择哪些事件需要计数。
- 关键CSR名称:
- Perfmon Event selector[]:性能监控事件的选择器。
-
Debug/Trace(调试与跟踪)
- 这些寄存器用于系统的调试和跟踪功能,帮助开发者分析程序执行情况和定位问题。
- 关键CSR名称:
- Control/Status/PC/Scratch:调试模式下的控制与状态寄存器,用于保存调试过程中的状态。
- Trigger_RegSelect/Data[]:调试触发器寄存器,用于调试时设置条件断点或数据监控。
Memory Addressing: Translation
在RISC-V架构中,虚拟内存是监督模式(S-mode)下的重要功能,它通过页表机制将虚拟地址映射到物理地址,为多进程操作系统提供内存隔离和保护。虚拟内存的引入允许用户模式下的程序拥有各自独立的地址空间,避免直接访问物理内存,从而提升系统的安全性和稳定性。
S-mode中的虚拟内存页映射
- 最小保护/映射单位是4 KB的页面:
- RISC-V的虚拟内存使用固定大小的页面来进行地址映射,通常情况下每个页面大小为4 KB。4 KB是虚拟内存映射的最小单位,也是分页机制的基本单位。
多用户进程支持
- 支持多个用户模式进程,分别拥有独立的地址空间:
- 通过使用SATP(Supervisor Address Translation and Protection)CSR中的Addr_Space_ID字段,RISC-V能够为每个用户模式进程分配独立的地址空间。这使得多个进程可以安全并行运行,而不会互相干扰或影响彼此的数据。
页表(Page Tables)的多级结构
RISC-V采用了多级页表机制来实现虚拟地址到物理地址的映射。这种分层结构的页表能够有效管理大量内存,同时支持不同的虚拟地址长度和物理地址长度。
- 页表级数:
- Sv32(32位架构):使用2级页表,适用于RISC-V的32位架构(RV32)。
- Sv39、Sv48(64位架构):分别使用3级或4级页表,适用于RISC-V的64位架构(RV64)。这些页表机制允许处理更大的内存空间。
- Sv57、Sv64(保留机制):这两个机制保留用于未来可能的更大虚拟地址或物理地址空间(如57位或64位地址空间的处理器)。
超大页面(Superpages)
- 页表遍历可以在任意级别停止以创建超级页:
- 在RISC-V中,超级页是比4 KB常规页更大的内存页块。通过在不同层级的页表遍历中提前停止,可以实现超级页的映射。
- 例如:
- 在Sv39架构下,如果页表遍历在第2级停止,可以映射2 MB的超级页。
- 如果遍历在第1级停止,则可以映射1 GB的超级页。
- 超级页的存在显著减少了页表项的数量,优化了大数据集或大内存应用的内存管理。
硬件页表遍历机制
- 硬件页表遍历语义由特权模式规范(Privileged Mode Spec)定义:
- RISC-V硬件负责自动遍历页表以进行地址转换。硬件会按照特权模式规范中定义的方式,逐级遍历页表项来完成虚拟地址到物理地址的映射。
- 如果硬件无法完成页表遍历,可能会触发陷阱(trap),并进入机器模式(M-mode)以进行软件方式的TLB(Translation Lookaside Buffer)重填。
RISC-V Page Table Entries (PTEs)
可参见 Lzzs 6.S081 Notebook: Page Tables
在RISC-V虚拟内存机制中,页表条目(Page Table Entries, PTEs)负责将虚拟地址映射到物理地址,并定义了每个内存页面的权限和状态。每个PTE包含多个字段,这些字段共同决定内存访问的规则、状态和权限。根据虚拟地址的格式(如Sv32、Sv39、Sv48或Sv64),PTE的结构可能有所不同。

页表条目的结构
以下是以Sv32格式为例的页表条目(PTE)结构,其字段解释如下:
-
PPN(物理页面号,Physical Page Number):用于指定映射的物理页面地址。
- PPN[1] 和 PPN[0] 是物理地址的一部分。PPN字段可以根据虚拟地址空间的大小有不同的长度,比如Sv32、Sv39、Sv48和Sv64的长度各不相同。
- PPN字段在最终的物理地址形成中起关键作用,它决定虚拟地址指向的物理内存块。
-
RSW(保留位,Reserved for Supervisor):这些位由操作系统内核自行使用,不会被硬件直接处理。通常用于页表管理和内存分配的额外元数据。
-
D位(Dirty):标识页面是否被写入过。
- 如果页面被修改过,D位会被设置为1,表示该页面已经“脏”,需要同步回主存。
- 如果没有设置,可能需要陷阱(trap)到软件层进行处理。
-
A位(Accessed):标识页面是否被访问过。
- 当该页面被读取或写入时,A位会被设置为1,用于管理页面的生命周期或优化内存交换策略(如LRU)。
- 如果A位未设置,也可能触发陷阱处理。
-
G位(Global):指示该映射是否在所有地址空间中全局可见。
- 如果该位设置为1,则此映射对于所有进程都是全局有效的(如Unix系统中的内核页面),在进程切换时不需要刷新TLB。
-
U位(User):控制页面是否可被用户模式访问。
- 如果设置为1,用户模式代码可以访问该页面。
- 如果为0,则该页面只能被更高权限的模式(如S-mode或M-mode)访问。
-
X位(Execute):控制页面是否可被执行。
- 设置为1时,页面上的内容可以作为指令执行。
- 如果为0,则不允许执行,防止代码注入或其他安全风险。
-
W位(Write):控制页面是否可写。
- 设置为1时,允许对页面进行写操作;否则,写操作将被禁止。
-
R位(Read):控制页面是否可读。
- 设置为1时,允许读取页面内容;否则,读取操作将被禁止。
-
V位(Valid):指示该页表项是否有效。
- 如果V位为0,则该页表项无效,访问该页面时会触发异常。
页粒度的权限设置
- 权限(User/Read/Write/eXecute):RISC-V PTE支持按粒度设置页面的用户权限,包括读、写和执行权限。如果某个页表条目未设置任何权限位(即000),则该页表项表示为非叶子节点,指向下一层页表。
多地址空间的支持
- Addr_Space_ID(地址空间ID,ASID):用于支持多进程系统。每个进程的地址空间都有独立的ASID字段,存储在SATP(Supervisor Address Translation and Protection)CSR中。SATP管理当前虚拟地址的宽度、当前进程的ASID以及页表根地址。
多级页表的遍历
根据不同的虚拟地址长度,RISC-V支持不同级数的页表。以Sv64为例,PTE的格式适配64位虚拟地址,在SATP中包括44位的页表根物理地址、16位的ASID和4位的模式字段。
Memory Fences: More Control
内存屏障(Memory Fences)在多处理器系统中确保不同处理器核之间的内存访问顺序一致性。RISC-V引入了SFENCE.VMA指令,用于同步内存结构的更新,特别是页表。
SFENCE.VMA 指令
- S-mode下的SFENCE.VMA:这条指令用于同步虚拟内存数据结构的更新,特别是在修改页表之后,确保新的页表项能够被处理器正确使用。
- 作用范围:
- 可以作用于所有页表级别,或者只影响与特定地址相关的级别。
- 可以作用于所有地址空间,或者仅影响当前地址空间。
- 作用范围:
页表同步与TLB刷新
- 类似于其他架构的TLB刷新:在许多处理器架构中,当页表发生变化时,需要刷新TLB(Translation Lookaside Buffer,翻译后备缓冲区),以避免旧的映射被继续使用。RISC-V通过SFENCE.VMA实现这一功能。
确保指令顺序
- 确保存储操作有序:SFENCE.VMA可以确保所有先前的存储操作在后续的隐式内存访问前完成,防止出现内存顺序紊乱的情况。
影响范围
- 仅影响本地hart(硬件线程):SFENCE.VMA指令只影响发出指令的当前hart。如果需要与其他hart同步,通常通过IPI(Inter-Processor Interrupt)进行通知。
SFENCE.VMA 和 FENCE.I 都是RISC-V架构中用于处理内存同步和一致性的指令,但它们的作用和使用场景有所不同。让我们详细对比它们的功能与用途,并解释为什么在操作系统(如xv6)中会用到FENCE.I作为内存屏障。
1. SFENCE.VMA:虚拟内存的同步
全称:Supervisor Fence Virtual Memory Address
作用:用于同步虚拟内存的页表更新。具体来说,当修改页表(例如创建新的页面映射或释放旧页面)后,需要通过SFENCE.VMA指令来确保这些修改对处理器的地址翻译单元(如TLB,Translation Lookaside Buffer)可见。
使用场景:
- 当操作系统更新页表或修改虚拟内存结构时,必须确保这些更新被所有内存操作正确识别。在不执行SFENCE.VMA的情况下,TLB可能仍然保留旧的虚拟地址到物理地址的映射,导致系统使用过时的数据。
- SFENCE.VMA通常由内核代码调用,用于清除当前硬件线程(hart)中与虚拟地址相关的TLB条目,确保地址翻译映射的正确性。
示例:如果操作系统为进程分配了新的内存页面或者进行了页表的切换(例如,切换到一个新的进程地址空间),SFENCE.VMA指令会确保处理器清除缓存的旧地址映射,并使用新的页表。
2. FENCE.I:指令缓存的同步
全称:Fence Instruction
作用:FENCE.I用于同步指令缓存(I-cache)与内存。当在内存中修改了代码(例如动态加载新代码或自修改代码的场景),FENCE.I指令确保指令缓存中的旧指令被清除,并强制处理器从内存中重新加载最新的指令。
使用场景:
- 当内存中存储的指令被修改后,指令缓存和内存之间可能会不一致。为了确保处理器执行最新修改的指令,必须使用FENCE.I,清除缓存并刷新指令流。
- FENCE.I 通常用于内存中的代码被动态修改的场景。例如,操作系统在某个位置加载了一段新的代码,这时就需要使用FENCE.I来保证处理器看到的是最新的代码。
示例:在操作系统xv6中,使用FENCE.I指令作为内存屏障,确保处理器在加载新指令后执行正确的指令流。特别是当进程从用户模式切换到内核模式,或者当处理器加载新的用户态代码后,使用FENCE.I可以避免执行缓存中的旧指令。
两者的主要区别
功能/特性 SFENCE.VMA FENCE.I 目的 用于同步页表更新,清除TLB中的旧虚拟地址到物理地址映射 用于同步指令缓存,确保指令缓存与内存的一致性 影响范围 虚拟内存(页表和TLB) 指令缓存 使用场景 当页表更新或地址空间切换时使用 当内存中的指令被修改或动态加载代码时使用 触发对象 内存地址映射的变化(如进程切换、页表修改) 内存中代码修改或动态生成代码的场景 影响对象 影响当前hart的虚拟地址空间翻译 影响当前hart的指令缓存 为什么xv6使用FENCE.I?
在操作系统(如xv6)中,通常有一些场景需要动态修改内存中的指令,或者加载新的程序代码到内存中。此时,为了确保处理器执行的是内存中的最新代码,而不是已经缓存的旧指令,必须使用FENCE.I来刷新指令缓存,保证代码的正确性。例如,当xv6从内核模式切换到用户模式,或者从磁盘加载新的程序时,FENCE.I确保处理器执行的指令是最新加载的。
SFENCE.VMA 则更多用于处理虚拟地址映射的变化。如果xv6进行页面映射的更改,或切换到新的地址空间,它则会用到SFENCE.VMA。
Memory Addressing: Protection
RISC-V特权架构中的虚拟内存保护机制通过设置每个页面的权限来保证系统的安全性和稳定性。虚拟内存的保护不仅包括传统的读、写、执行(RWX)权限,还引入了针对不同特权模式的访问控制,从而确保内核与用户进程之间的隔离。
页面权限(RWX)
- 标准的RWX权限:每个虚拟内存页面可以配置读(R)、写(W)、执行(X)权限组合。这样做确保了特定页面的访问权限明确,可以精细控制哪些页面可以被读取、写入或执行。
- 支持执行权限单独设置(X-only pages):可以将页面设为只允许执行(X-only),这对于一些存储代码但不需要写入的页面很有用。
- 写和非读(W和非R)的组合被保留:在当前架构中,不允许页面被设置为可写但不可读。这种组合通常没有实际应用,并且可能导致安全漏洞,因此在设计中被保留未使用。
监督模式(S-mode)的内存访问限制
- 默认情况下,S-mode不能访问用户模式(U-mode)的页面:
- 这种设计有助于检测操作系统或驱动程序中的潜在错误,并确保用户进程与内核的隔离。
- 如果S-mode需要读取用户内存(例如处理系统调用时),可以通过设置sStatus寄存器中的"Supervisor Access to User Memory"(SUM)位来暂时允许S-mode访问用户内存。
- SUM位的设置过程是暂时的,S-mode读取用户内存后,应立即关闭此权限,确保安全性。
- S-mode无法从U-mode页面执行代码,即使SUM位被设置为1。这种设计防止了潜在的权限升级攻击。
执行页面的保护
- S-mode默认不能读取只执行(execute-only)页面:
- 执行权限和读取权限是独立设置的,S-mode无法读取仅设置了执行权限的页面。这样可以防止未经授权的内核代码试图读取用户模式中的代码页面内容。
- 如果必须读取执行页面(例如非法指令陷阱处理程序需要读取指令内容),可以通过设置sStatus寄存器中的“Make eXecutable Readable”(MXR)位来覆盖默认行为。
虚拟内存的启用与禁用
- S-mode可以启用或禁用虚拟内存(VM):通过控制SATP(Supervisor Address Translation and Protection)寄存器中的模式字段,S-mode可以选择启用或禁用虚拟内存管理(例如在嵌入式系统或裸机环境中可能不需要虚拟内存)。
- 选择页表的深度:S-mode还可以通过SATP寄存器选择页表的深度,以适应不同的地址空间需求。例如,使用Sv32、Sv39或Sv48的多级页表结构来管理不同大小的虚拟地址空间。
RISC-V Physical Memory Protection Unit (PMP)
物理内存保护单元(PMP)是RISC-V架构中的一个可选特性,用于在硬件级别对物理内存进行访问控制,特别是在处理器的监督模式(S-mode)或用户模式(U-mode)下,这对于未受信任的操作系统和进程至关重要。PMP的主要作用是通过定义物理内存的权限,来限制访问,并防止未经授权的代码操作敏感的内存区域。
PMP的功能和特性
-
可选的新特性(v1.10):
- PMP是从RISC-V的v1.10版本引入的,作为一个可选的特性,允许系统在硬件层面上控制对物理内存的访问。
-
默认无权限:
- 在启用PMP的情况下,默认情况下,监督模式(S-mode)和用户模式(U-mode)对物理内存没有任何权限。PMP通过明确授予读、写、执行(RWX)权限来决定哪些内存区域可以被访问。
-
R/W/X权限配置:
- PMP允许为多达16个PMP区域设置读、写、执行权限,每个区域可以设置不同的权限组合。
- 这些区域是以自然对齐的2^N字节(N>=2)为单位的连续内存块,PMP使用这些内存块来定义特定的内存访问规则。
- 也可以通过相邻的PMP寄存器组合来形成基址/边界(base/bounds)的区域,以灵活设置更复杂的内存访问规则。
-
PMP可以被锁定:
- PMP区域一旦被配置,可以通过设置为“锁定”,即使是机器模式(M-mode)也无法更改,除非系统进行复位(reset)。
- 锁定机制确保了在某些关键应用场景下,重要的内存访问权限不会被意外或恶意修改。
-
虚拟内存与PMP的优先级:
- 当虚拟内存(VM)启用时,虚拟内存的页表和缺页处理会在PMP检查之前发生。这意味着如果虚拟地址映射失败或者发生缺页错误,PMP检查不会继续。
- 这种机制对于不受信任的监督模式(S-mode)特别有用,PMP可以作为额外的保护层。
使用场景
- 未受信任的S-mode:在安全敏感的场景下,PMP可以防止不受信任的操作系统(或S-mode应用)访问物理内存中的关键资源,例如固件、特权数据等。
- 嵌入式系统和安全关键系统:PMP在没有复杂虚拟内存机制的情况下,仍然提供了对物理内存的保护,特别适用于嵌入式系统、物联网设备等。
Physical Memory Attributes (PMA)
物理内存属性(PMA)是RISC-V体系结构中用于管理物理地址空间的访问属性的硬件特性。这些属性是平台和实现特定的,这意味着它们由具体的硬件平台决定,而不是RISC-V架构标准中的固定部分。PMA定义了内存访问的各种行为,如访问宽度、对齐限制、可缓存性等。
PMA的功能和特性
-
平台和实现相关:
- PMA的配置因具体平台而异。不同平台可能有不同的总线事务类型和内存访问限制。例如,在某些嵌入式系统中,特定的内存地址可能映射到外设,而在另一些平台上则可能是系统内存。
-
映射到总线事务类型或错误:
- PMA会将内存访问映射到特定的总线事务类型(例如内存读取、内存写入、设备访问等),或者返回一个错误,指示该访问是不被允许的。
-
专用硬件控制:
- PMA由专用硬件单元管理,该硬件负责将特定的物理地址范围映射到相应的访问属性。以下是一些常见的物理内存属性:
- 访问宽度:支持的访问宽度可以是1/2/4/8/16/64字节等,决定每次内存访问的最小/最大数据块大小。
- 对齐限制:可能要求内存访问不能跨越特定字节边界(例如2^N字节对齐)。
- 幂等性(Idempotency):指在启用推测执行时,允许对某些地址进行重复访问,而不会改变其结果。
- 内存访问顺序:强顺序或弱顺序控制(Strong/Weak Ordering),用于确保不同通道的内存操作顺序一致性。
- 缓存行为(Cacheability):决定特定的内存区域是否可以被缓存(包括写穿、写合并等缓存策略)。
- 优先级:当多个请求同时访问内存时,可以根据优先级控制冲突时的处理顺序。
- 原子性:定义是否允许特定类型的原子操作,如交换、逻辑操作、加法等。
- 允许的访问模式:定义不同的访问模式,如M-mode、S-mode、U-mode、调试模式等是否可以访问特定内存区域。
- PMA由专用硬件单元管理,该硬件负责将特定的物理地址范围映射到相应的访问属性。以下是一些常见的物理内存属性:
-
部分属性可配置:
- 虽然PMA的部分行为是由硬件固定的,但有些属性可以通过软件配置。这使得系统在运行时可以根据需求调整内存的访问行为。
使用场景
- 内存映射设备:PMA非常适用于嵌入式系统和SoC架构,其中一部分内存空间被映射为外设的寄存器,通过PMA可以为这些地址设置不同的访问权限和行为。
- 缓存控制:PMA允许为不同的内存区域指定缓存策略,特别是在多核处理器或需要处理外部设备的情况下,决定哪些数据应该缓存以及缓存的策略(如写回、写穿等)是非常重要的。
- 系统优化与安全:通过设置访问顺序、优先级和对齐要求,PMA可以提升系统性能,并且通过严格的访问控制可以增强安全性。
Trap Handling: Exceptions and Interrupts
可参见 Lzzs 6.S081 Notebook: Page Faults、Interrupts
在RISC-V架构中,陷阱(Trap)机制用于处理两类重要的事件:异常(Exceptions) 和 中断(Interrupts)。这两类事件的发生方式和处理机制稍有不同,但它们的处理流程在硬件层面是相似的。
异常(Exceptions)与中断(Interrupts)的区别
-
异常(Exceptions):
- 异常是同步事件,它们由具体指令的执行引发。通常,异常是在指令执行过程中检测到错误(如非法操作码、除零错误、内存访问违规等)时触发的。
- 示例:当程序试图执行一条未定义的指令时,处理器会触发一个异常并进入异常处理程序。
-
中断(Interrupts):
- 中断是异步事件,它们与当前执行的指令无关。中断通常由外部设备(如I/O设备、定时器)或者来自其他处理器核心的信号引发。
- 示例:当定时器超时时,系统会触发一个中断,处理器暂停当前执行的指令并处理定时器中断。

统一的陷阱处理流程
尽管异常和中断的触发机制不同,它们在RISC-V中通过类似的陷阱机制来处理。
- 陷阱处理的基本流程:
-
xTVEC CSR:保存陷阱处理程序的入口地址。无论是异常还是中断,处理器都会根据xTVEC的值跳转到相应的处理程序。
- 中断可以根据xCause的值选择一个可选的偏移量,通过
xTVEC + 4 * xCause来跳转到不同的处理程序。
- 中断可以根据xCause的值选择一个可选的偏移量,通过
-
xI/DELEG CSR:用于选择陷阱处理的模式。这个寄存器决定了发生的异常或中断应该陷入哪个特权模式。例如,操作系统可以配置某些中断直接由用户模式处理,而无需进入内核模式。
-
xCause CSR:保存引发陷阱的原因。
- 高位(MSB)用于区分这是中断还是异常。
- 低位(LSB)保存具体的中断或异常编号,标识是什么原因引发的陷阱。
-
xTVAL CSR:保存额外的关于陷阱的信息,例如非法地址或非法操作码的值。对于某些异常(如非法内存访问),xTVAL可以保存发生错误的虚拟地址。
-
xEPC CSR:保存导致陷阱的指令的程序计数器(PC)值。陷阱处理程序完成后,处理器将从xEPC中存储的PC地址继续执行,可能是中断处理后的下一条指令,或者重试之前的指令(异常处理)。
-
xSTATUS CSR:保存处理器的当前状态,包括当前模式(用户、监督或机器模式)以及中断使能位。处理器在进入陷阱处理程序时会自动保存这些状态,以便在处理完成后正确返回。
- 当陷阱处理完成时,
xSTATUS[IntEn]位会被清除,确保处理器在恢复时不会发生竞态条件。
- 当陷阱处理完成时,
-
更详细的陷阱处理机制
-
陷阱处理的位置(Where to trap):
- 处理器会根据xTVEC CSR的值找到陷阱处理程序的入口地址。处理器可能跳转到一个固定的处理程序地址,也可能根据不同的原因(xCause)偏移跳转到不同的处理程序。
-
陷阱的处理模式(Mode to trap into):
- 不同的中断或异常可以配置为陷入不同的特权模式(如U-mode、S-mode、M-mode)。这些模式的选择由xI/DELEG寄存器决定,操作系统可以根据需要配置哪些陷阱直接进入用户模式处理,哪些需要更高权限的模式来处理。
-
陷阱原因(Reason for trap):
- 处理器会在xCause CSR中保存引发陷阱的具体原因。这一原因可能是中断(如外部设备中断)或者异常(如非法指令)。xCause还用于区分不同的中断或异常源,以便跳转到不同的处理程序。
-
返回机制(How to return from trap):
- 在陷阱处理完成后,处理器会从xEPC CSR保存的程序计数器继续执行之前被中断的程序。xEPC保存的是引发陷阱的指令地址,而处理器可以通过恢复xSTATUS CSR的状态确保正确的执行模式和中断状态恢复。
异常与中断的处理细节
-
异常的处理:通常是由于指令执行过程中产生的同步错误。处理器会将异常处理程序的入口保存在xTVEC中,并在处理完后根据xEPC返回到同一指令或执行下一条指令。
-
中断的处理:由于中断是异步事件,处理器可以在处理完中断后从xEPC中保存的地址继续执行后续指令。常见的中断包括定时器中断、外设中断或多处理器间的中断(如IPI)。
Trap Setup: Interrupt/Exception Handler Delegation
在RISC-V架构中,陷阱(Trap)通常默认发送到机器模式(M-mode),但为了提高处理效率,某些中断和异常可以被委派到较低的特权模式(如S-mode或U-mode)进行处理。陷阱委派机制允许操作系统根据需求减少开销,同时确保系统的安全性和特权隔离。
委派机制(Delegation Mechanism)
-
默认发送到M-mode:
- 在RISC-V架构中,所有的中断和异常默认都会被处理器发送到最高权限的M-mode。这是因为M-mode拥有对系统的完全控制,负责处理所有的低级硬件事件。
-
委派到低权限模式:
- 虽然陷阱默认被发送到M-mode,但可以通过设置委派寄存器将某些中断和异常委派到较低的特权模式(如S-mode或U-mode)。
- 不能将陷阱委派到比触发陷阱的模式权限更低的模式。例如,M-mode的异常可以委派到S-mode,但不能委派到U-mode(除非没有S-mode)。
-
委派寄存器:
- mideleg 和 medeleg:这些寄存器控制从M-mode到S-mode的中断和异常的委派。如果没有S-mode(如在嵌入式系统中),可以将陷阱直接委派到U-mode。
- sideleg 和 sedeleg:在存在S-mode的情况下,这些寄存器用于将中断和异常委派给U-mode,前提是系统启用了N扩展。
-
中断的启用:
- 中断的委派只有在对应的启用位(如mie或sie)被设置时才会发生。启用位用于控制中断是否允许处理。
- 注意:异常总是被启用并处理,无需像中断那样设置启用位。
-
陷入模式的选择:
- 委派发生时,中断或异常将被发送到下一级权限模式(M→S,或者S→U)。这可以减轻M-mode的负担,允许低权限模式处理与其相关的事件,例如用户程序引发的异常可以直接在U-mode处理,而不需要进入S-mode。
-
中断设置CSR位:
- 当中断或异常发生时,相应的位会在xE/IP CSR(如mip、sip)中被设置,指示当前的中断/异常状态。
Trap Handling: Interrupt/Exception Causes
在RISC-V中,每个中断和异常的原因都存储在xCause CSR中,该寄存器会指示当前发生的中断或异常的类型,便于操作系统采取相应的处理。
xCause CSR 及其功能
-
原因指示:
- xCause CSR 保存了中断或异常发生的具体原因。通过该寄存器,操作系统可以知道是哪种类型的事件引发了陷阱,并根据事件类型选择合适的处理方式。
- 最高位(MSB)用于区分是中断(1)还是异常(0),而低位(LSB)则保存了具体的中断或异常代码。
-
xE/IP CSR 中的位设置:
- 当一个中断或异常被触发时,对应的位会在xE/IP CSR(如mip、sip)中设置。这个寄存器记录了当前系统中待处理的中断或异常事件,并为系统提供了事件的优先级队列。
-
同时发生的中断/异常的优先级:
- RISC-V为同时发生的多个中断和异常设置了优先级规则:
- 中断优先于异常:当中断和异常同时发生时,处理器优先处理中断。
- M-mode > S-mode > U-mode:机器模式的中断和异常优先级最高,其次是监督模式,最后是用户模式。
- Pending[N] > Pending[M] if N > M:较高优先级的中断(如外部中断)优先于较低优先级的中断。
- RISC-V为同时发生的多个中断和异常设置了优先级规则:
-
特殊情况:定时器和软件中断:
- 在某些特定情况下(如定时器中断和软件中断),优先级可能会被交换,以确保系统的定时和内部同步机制不被外部设备的中断打断。
中断与异常的原因代码(Trap Code)
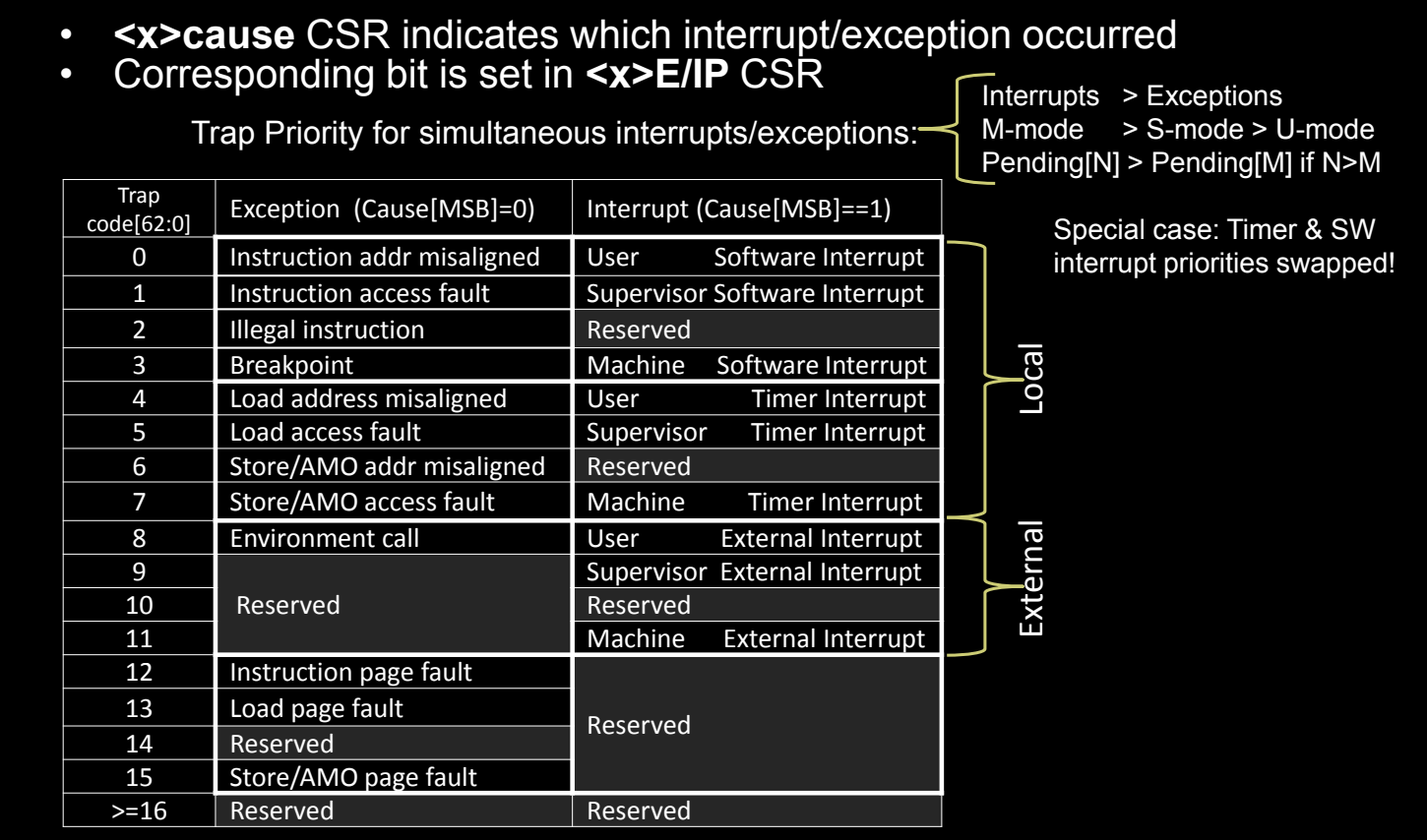
| Trap Code | 异常(Cause[MSB] == 0) | 中断(Cause[MSB] == 1) |
|---|---|---|
| 0 | 指令地址未对齐 | 用户软件中断 |
| 1 | 指令访问故障 | 监督软件中断 |
| 2 | 非法指令 | 保留 |
| 3 | 断点 | 机器软件中断 |
| 4 | 加载地址未对齐 | 用户定时器中断 |
| 5 | 加载访问故障 | 监督定时器中断 |
| 6 | 存储/AMO地址未对齐 | 保留 |
| 7 | 存储/AMO访问故障 | 机器定时器中断 |
| 8 | 环境调用(用户模式) | 用户外部中断 |
| 9 | 保留 | 监督外部中断 |
| 10 | 保留 | 保留 |
| 11 | 环境调用(机器模式) | 机器外部中断 |
| 12 | 指令页错误 | 保留 |
| 13 | 加载页错误 | 保留 |
| 14 | 存储/AMO页错误 | 保留 |
| >= 16 | 保留 | 保留 |
Interrupt
Platform-Level Interrupt Overview
在RISC-V架构中,中断系统分为全局中断(Global Interrupts)和本地中断(Local Interrupts)。这些中断管理的核心是平台级中断控制器(PLIC),它负责处理和调度外部设备发出的中断信号,并将其分发给系统中的各个硬件线程(harts)。本地中断则直接在每个hart内处理,与定时器和软件中断紧密相关。
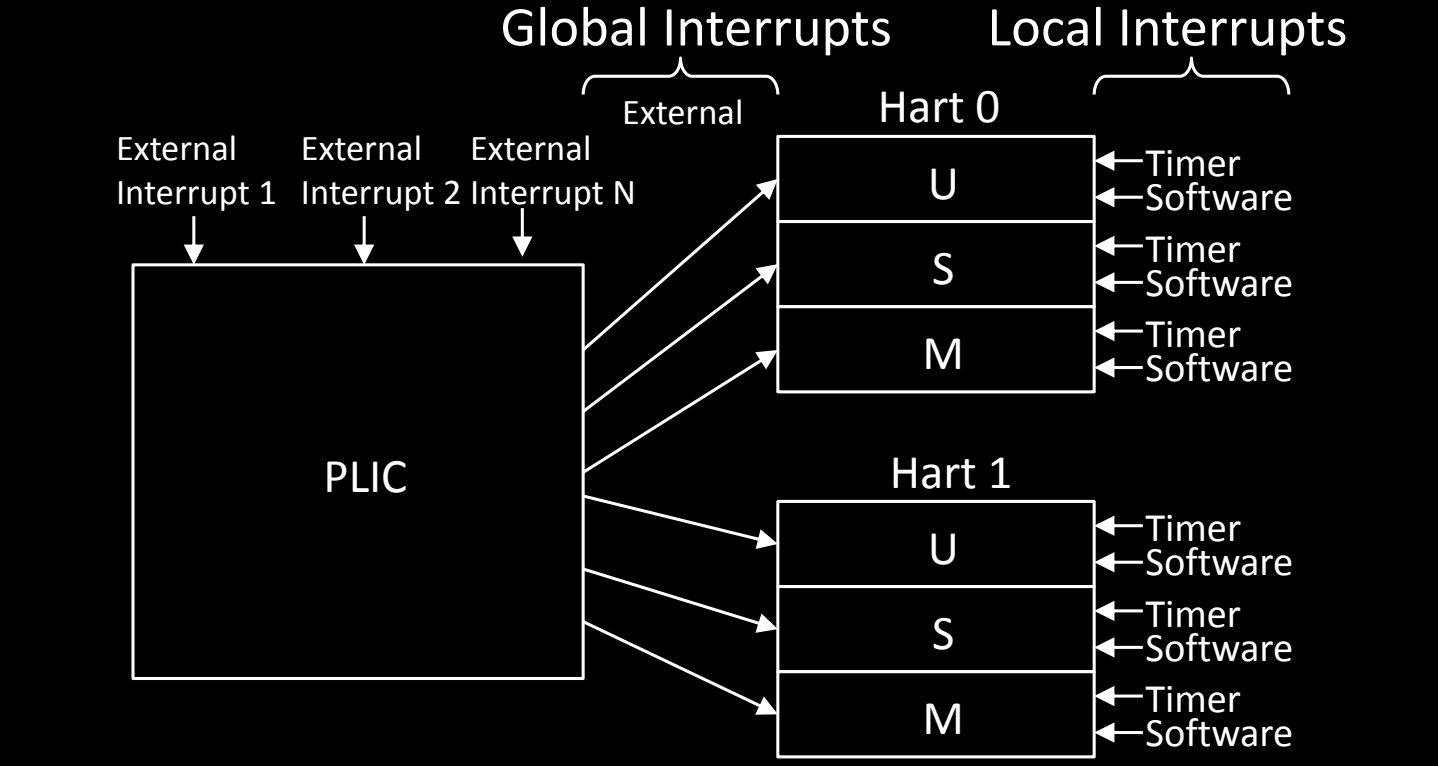
全局中断(Global Interrupts)
-
外部中断(External Interrupts):
- 全局中断由平台上的外部设备发起,例如外部I/O设备、网络接口或存储设备。这些中断通过PLIC传递给每个hart。
- PLIC(Platform-Level Interrupt Controller)是RISC-V系统中处理外部中断的核心模块。它接收来自多个外部设备的中断请求,根据中断的优先级和配置决定哪个hart来处理中断。
- 通过PLIC,每个外部中断被分配给不同的hart(硬件线程),这些中断可以在不同的特权模式(U-mode、S-mode、M-mode)下进行处理。
-
PLIC的工作机制:
- 中断分发:PLIC接收到外部设备的中断信号后,根据中断的优先级和目标hart,将中断传递到合适的hart。
- 优先级处理:每个外部中断可以被分配不同的优先级,PLIC会根据优先级的高低决定哪个中断优先处理。
- 中断路由:PLIC负责将外部中断路由到指定的hart和特权模式(U、S、M)。
本地中断(Local Interrupts)
本地中断是与每个hart直接相关的中断,通常涉及到定时器和软件中断。这类中断只影响对应的hart,并不需要通过PLIC进行分发。
-
定时器中断(Timer Interrupts):
- 定时器中断是由处理器内部的定时器触发的,用于操作系统的时钟管理或任务调度。这些定时器中断直接分发到对应的hart,不经过PLIC。
- 每个hart都有自己独立的定时器,这意味着多个hart可以同时处理各自的定时器中断。
-
软件中断(Software Interrupts):
- 软件中断通常用于多hart(多核)系统中,hart之间的通信。操作系统可以触发软件中断来通知其他hart执行特定的任务(如任务切换、进程调度等)。
- 软件中断通过操作系统触发,作用于指定的hart,并由其直接处理。
每个hart的中断处理
每个hart(硬件线程)有自己独立的中断处理机制,并且可以根据特权模式(M-mode、S-mode、U-mode)处理不同级别的中断。每个模式都有自己对应的定时器中断和软件中断。
- M-mode中断处理:M-mode拥有最高优先级的中断处理权力,负责管理最底层的硬件和外部设备的中断。
- S-mode中断处理:S-mode通常用于操作系统内核,用来处理用户进程的调度、虚拟内存管理和设备管理。
- U-mode中断处理:U-mode的中断通常由用户态程序触发,用于软件中断或用户应用程序的定时器管理。
RISC-V Interrupt Source Categories
RISC-V的中断源分为两大类:全局(外部)中断和本地中断。每种中断类型在处理方式和目标硬件上有所不同,并通过特定的机制来分发和处理。
全局(外部)中断
- 路由到hart:全局中断通常来自平台上的外部设备,这些中断由**平台级中断控制器(PLIC)**负责管理。PLIC根据每个hart的中断阈值和优先级,决定将中断路由到哪个hart进行处理。
- 确定中断源:中断源可以通过读取PLIC的MMIO(内存映射I/O)CSR来确定。PLIC负责接收多个外部设备的中断,并根据配置的优先级处理它们。
本地中断
-
本地中断与单个hart相关:本地中断直接连接到每个hart,独立于其他harts。它们不通过PLIC,而是由每个hart自己处理。RISC-V定义了两种标准的本地中断类型:
- 软件中断:通常用于hart之间的通信,或由操作系统触发,用于多核系统中的任务调度。
- 定时器中断:由定时器触发,用于时间管理或操作系统的时钟调度。
-
通过xCause CSR确定中断原因:本地中断的原因可以直接从xCause CSR中读取。每个hart在接收到本地中断后,可以通过这个寄存器查看具体的中断类型,并进行相应的处理。
任意中断可用于任意模式(M/S/U)
- 中断可指向任何特权模式:无论是全局中断还是本地中断,都可以根据需要分发到任何特权模式(M-mode、S-mode、U-mode)。例如,某些中断可以直接由用户态程序处理,而不需要进入内核模式。
- 同时发生中断时优先级决定处理顺序:当同时发生多个中断时,系统会根据特权模式和中断优先级来决定处理顺序。处理器会首先处理优先级更高的中断。
External Interrupts
外部中断是由系统中的外部设备触发的中断,例如I/O设备、外设或其他硬件模块。这些中断通过PLIC进行管理和分发。
外部中断的工作机制
-
PLIC管理外部中断输入:
- **平台级中断控制器(PLIC)**接收外部设备的中断请求,并将这些中断分发到合适的hart。PLIC根据hart的中断阈值、中断启用状态以及中断优先级来决定哪些hart处理中断。
-
多hart的中断目标:
- PLIC可以将同一个外部中断同时发送到多个hart。在这种情况下,多个hart需要通过仲裁机制来决定哪个hart处理该中断。
- 仲裁机制:例如,多个hart可以竞争读取映射到PLIC的MMIO寄存器,第一个读取到中断源的hart将负责处理该中断。
-
PLIC的特权模式标签:
- PLIC可以根据中断的来源和配置,为每个中断输出标记一个特权模式(M/S/U),这允许不同的特权模式处理不同的中断。例如,某些低优先级的外部设备中断可以由用户模式(U-mode)处理,而高优先级中断则交由机器模式(M-mode)处理。
-
清除外部中断:
- 外部中断通过MMIO映射的LD(加载)/ST(存储)操作发送到PLIC后,可以通过写入相应的寄存器来清除中断。处理完中断后,操作系统或硬件会通过这种方式通知PLIC,表示中断已完成处理。
-
软件注入中断:
- 软件可以直接通过设置SEIP和UEIP中断位来支持PLIC虚拟化。这允许通过软件控制来模拟外部中断,通常用于操作系统的虚拟化环境中,在这种情况下,软件层面可以直接注入中断信号而无需实际硬件设备的中断触发。
Software Interrupts
软件中断是RISC-V架构中hart之间相互中断的机制,通常用于多核处理器中的核间中断(IPI,Inter-Processor Interrupts)。这种机制允许一个hart触发另一个hart的中断,以实现核间的同步或调度。
软件中断的工作机制
-
hart间通信:
- 软件中断用于hart之间的相互通信。例如,一个hart可以通过发送软件中断来通知另一个hart执行任务或处理事件。这种中断不依赖于外部设备,而是纯粹在处理器内部进行的通信机制。
-
设置SIP位:
- 设置某个hart的SIP(Supervisor Interrupt Pending)寄存器位来触发软件中断。这通常通过MMIO写操作实现,即通过内存映射I/O写入来设置目标hart的SIP位,通知它有软件中断需要处理。
- 如果当前模式(current mode)权限足够(如S-mode或M-mode),hart也可以自行设置其SIP位。
-
操作系统中的应用:
- 操作系统或应用程序通常通过ABI/SBI调用来触发hart之间的中断。这些调用可以确保中断请求在虚拟化环境下能够正确传递到目标虚拟hart。
- 当目标hart处于非活动状态(例如未调度或暂停),中断请求可能会被推迟,直到目标hart再次被调度运行。
- 在虚拟化环境中,M-mode软件(如监控器或虚拟机管理程序)负责使用**MSIP(Machine Software Interrupt Pending)**寄存器来虚拟化软件中断,确保中断能够在虚拟hart中正确传播。
Timer Interrupts
定时器中断是RISC-V系统中的关键机制,用于管理实时任务调度、操作系统时钟和其他基于时间的操作。定时器中断由硬件定时器触发,并通过MMIO(内存映射I/O)进行管理。
定时器中断的工作机制
-
单个M-mode 64位硬件定时器:
- RISC-V系统中通常有一个64位的实时硬件定时器,该定时器为整个系统提供统一的时间基准。这个定时器是所有hart共享的,并不属于特定的hart。
- 该定时器以固定的速率计数,独立于处理器的时钟速率和功耗管理。
-
每个hart的时间比较器:
- 每个hart都有自己的时间比较器(Time Comparator),即mtimecmp寄存器。该寄存器存储一个时间阈值,当定时器的值(mtime寄存器)达到该阈值时,触发hart的定时器中断。
- 当mtime ≥ mtimecmp时,目标hart的**MTIP(Machine Timer Interrupt Pending)**位被设置,表示该hart的定时器中断需要处理。
-
定时器和比较器通过MMIO管理:
- 定时器和时间比较器并不是通过CSR(控制状态寄存器)来控制的,而是通过MMIO地址空间进行读写操作。这意味着操作系统可以通过内存映射的方式与定时器和比较器交互。
-
M-mode负责虚拟化定时器中断:
- M-mode(机器模式)负责将硬件定时器虚拟化,以支持S-mode和U-mode下的定时器中断。
- 当较低权限的模式(如U-mode)读取定时器相关的CSR时,操作系统会捕获并通过M-mode进行处理。这样可以确保系统中所有hart能够共享同一个硬件定时器,并且在虚拟化环境中,虚拟机能够使用独立的虚拟定时器。
-
STIP和UTIP的处理:
- **STIP(Supervisor Timer Interrupt Pending)和UTIP(User Timer Interrupt Pending)**是CSR中的定时器中断位,分别用于监督模式和用户模式下的定时器中断管理。
- 这些定时器中断通过操作系统(SBI/ABI调用)进行设置,M-mode负责写入和清除这些中断位,确保定时器中断能够及时处理。
Counters: Time and Performance
RISC-V体系结构支持多种计时器和计数器,这些工具主要用于性能监控、调试和时间管理。大多数计时器和计数器在RISC-V中都作为控制和状态寄存器(CSRs)来实现,主要通过特权模式下的访问进行管理。
Timers and Counters
RISC-V架构提供了多个计时器和计数器,用于不同场景的时间管理和性能监控。这些计数器大多数是64位的,在RV32架构下被分成两个32位的寄存器来读取。
-
实时时钟(Real-Time Clock, Time):
- 实时时钟通过特定的CSR记录系统当前的时间。这个计时器的行为在定时器中断部分已经解释过了。
- 当U-mode(用户模式)或S-mode(监督模式)读取这个CSR时,系统会发生陷阱(trap)进入M-mode,M-mode通过MMIO进行相应的读操作。
-
指令退休计数器(Instructions Retired, InstRet Counter):
- InstRet 计数器记录处理器执行的指令数,通常用于性能分析和调试。U-mode可以只读(RO),M-mode则可以读写(RW)。
- 操作系统或监控器可以通过伪指令
RDINSTRET读取该计数器,用于测量执行的指令数量。
-
周期计数器(Cycles, Cycle Counter):
- Cycle 计数器用于记录处理器自启动以来经过的时钟周期数。和InstRet一样,U-mode可以只读,M-mode可以读写。
- 伪指令
RDCYCLE允许操作系统或应用程序读取该计数器,以测量程序执行所消耗的时钟周期。
-
硬件性能监视器(Hardware Performance Monitors, HPMCounters):
- RISC-V提供了多达30个硬件性能监视器(mhpmcounters),用于监控各种硬件事件,如缓存命中、分支预测失败等。
- 每个硬件性能监视器都有一个对应的事件选择寄存器(HPMEvent),用来选择该计数器需要监控的硬件事件。用户或系统可以根据需要,设置这些计数器来分析不同的硬件行为。
Timer/Counter Protections
由于计时器和计数器可以用于性能分析和测量,未经限制的访问可能会导致安全性问题,例如侧信道攻击。因此,RISC-V架构提供了对计时器和计数器的保护机制,防止不必要或不安全的访问。
-
计时器的安全隐患:
- 可访问的计时器和计数器可能导致问题,包括:
- 可重复性不足:如果计时器或计数器的访问不可控,可能导致调试结果的不一致性。
- 侧信道攻击:例如Meltdown和Spectre等攻击可以利用计时器和计数器信息来推断系统内部的状态。因此,限制这些工具的访问权限至关重要。
- 可访问的计时器和计数器可能导致问题,包括:
-
CounterEn寄存器(xCounterEn CSRs):
- 通过CounterEn寄存器,RISC-V系统可以控制不同模式下对计时器和计数器的访问权限。
- 每个计数器有一个对应的控制位:该控制位决定了是否允许某个模式(如M-mode、S-mode或U-mode)访问特定的计时器或计数器。
- 计时器(Time)、周期计数器(Cycle)、指令退休计数器(InstRet)以及硬件性能监视器(HPMCounters)都受到此机制的保护。
- 如果在某个模式下访问了被禁止的计时器或计数器,处理器将触发陷阱,以确保非法访问不会发生。
-
可硬连线为0的控制位:
- 某些计数器的控制位可以在硬件上被设置为永远为0,确保在任何模式下都无法访问这些计数器。这为系统提供了一个额外的安全保护层,防止计数器被恶意使用。
Some Additions
<x>Status CSR 寄存器详解
RISC-V架构中的<x>Status CSR(控制和状态寄存器)是一个关键的寄存器,用于管理处理器的运行状态。不同的特权模式(如M-mode、S-mode、U-mode)都有各自的<x>Status寄存器,例如M-mode使用mstatus,S-mode使用sstatus,U-mode使用ustatus。这个寄存器的不同位控制着处理器的特权模式切换、异常处理、中断启用等行为。
寄存器位定义
该寄存器的每个位都有特定的功能,从低位到高位的主要字段如下:
1. 中断控制位(Bits 0-3, 7-11)
- IE(Interrupt Enable,位0):控制当前模式下的全局中断使能。如果该位被设置为1,则当前模式允许中断;否则,当前模式下中断被禁用。
- PIE(Previous Interrupt Enable,位4):在中断发生前记录的中断使能状态。当中断返回时,这个位的值会恢复到
IE位中,确保处理器在中断返回时能够恢复中断前的中断使能状态。 - SIE、UIE:分别为监督模式和用户模式的中断启用控制位,类似于M-mode的
IE位功能。 - SPIE、UPIE:记录S-mode和U-mode下的上一次中断使能状态,处理机制类似于M-mode。
2. 特权模式切换字段(Bits 11-12, 13-14)
- MPP(位11-12):记录M-mode之前的特权模式,用于异常处理返回时恢复正确的模式。可能的值包括:
- 00: U-mode
- 01: S-mode
- 11: M-mode
- SPP(位8):在S-mode下,记录之前的特权模式。当从S-mode返回时,根据该位的值决定返回U-mode还是S-mode。
3. 特权模式中断相关字段(Bits 15-16)
-
XS(位15-16):表示扩展状态的清洁度,主要用于浮点扩展或其他处理器扩展:
- 00: 无状态
- 01: 有扩展,但初始状态
- 10: 清洁状态
- 11: 脏状态(已被使用)
-
FS(位13-14):表示浮点寄存器的状态和是否被使用:
- 00: 浮点单元未启用
- 01: 浮点单元被初始化,但未使用
- 10: 浮点单元已清洁,但可能使用过
- 11: 浮点单元已脏,正在使用
4. Supervisor模式控制位(Bits 18-21)
- SUM(位18):当此位被设置为1时,S-mode允许访问U-mode的页面。当设置为0时,S-mode无法访问U-mode页面。这有助于保护用户态的内存不被内核意外访问。
- MXR(位19):允许S-mode加载执行权限为只读的页面。这个位为某些加载代码段提供了灵活性。
- TVM(位20):当设置为1时,S-mode无法修改虚拟内存页表(如
SFENCE.VMA指令将陷阱到M-mode)。该位用于限制S-mode对虚拟内存的直接访问。 - TW(位21):当设置为1时,S-mode的
WFI指令会触发陷阱,避免内核等待可能导致的延迟。
5. S-mode扩展位(Bits 32-35, 63)
- SXL、UXL(位32-35):控制S-mode和U-mode的XLEN(操作位宽,如32位、64位)。这允许处理器在S-mode或U-mode下选择适当的位宽。
- SD(位63):表示扩展状态是否被修改,如果设置为1,说明浮点、扩展状态寄存器(如FS、XS等)已经被使用并且是“脏”的。
6. 其他字段
- TSR(位22):如果设置为1,
SRET指令在S-mode执行时会陷阱到M-mode。此字段用于控制S-mode返回机制。 - TW(位21):当设置为1时,
WFI指令在S-mode下会触发陷阱,防止S-mode中执行WFI导致的长时间等待。 - MPRV(位17):当设置为1时,处理器在M-mode下使用当前的特权模式进行加载/存储操作。
特别注意
- 清除/设置位:一些寄存器位在不同模式下读回0值。例如,当在U-mode下读取特定的S-mode或M-mode相关字段时,这些位会被读取为0。
- 高位的SD字段:此字段会标记浮点或其他扩展状态是否已被使用("脏"),并且影响处理器对这些扩展状态的保存与恢复操作。
RISC-V的控制和状态寄存器(CSRs)、特权模式和选项
RISC-V架构通过**控制和状态寄存器(CSRs)**来管理处理器的运行状态、特权模式之间的切换,以及各种硬件资源的使用。不同的CSRs有特定的访问权限,只有在适当的特权模式下才能读写。以下是常见的CSRs分类及其在各特权模式(M-mode、S-mode、U-mode)中的可用性和作用。
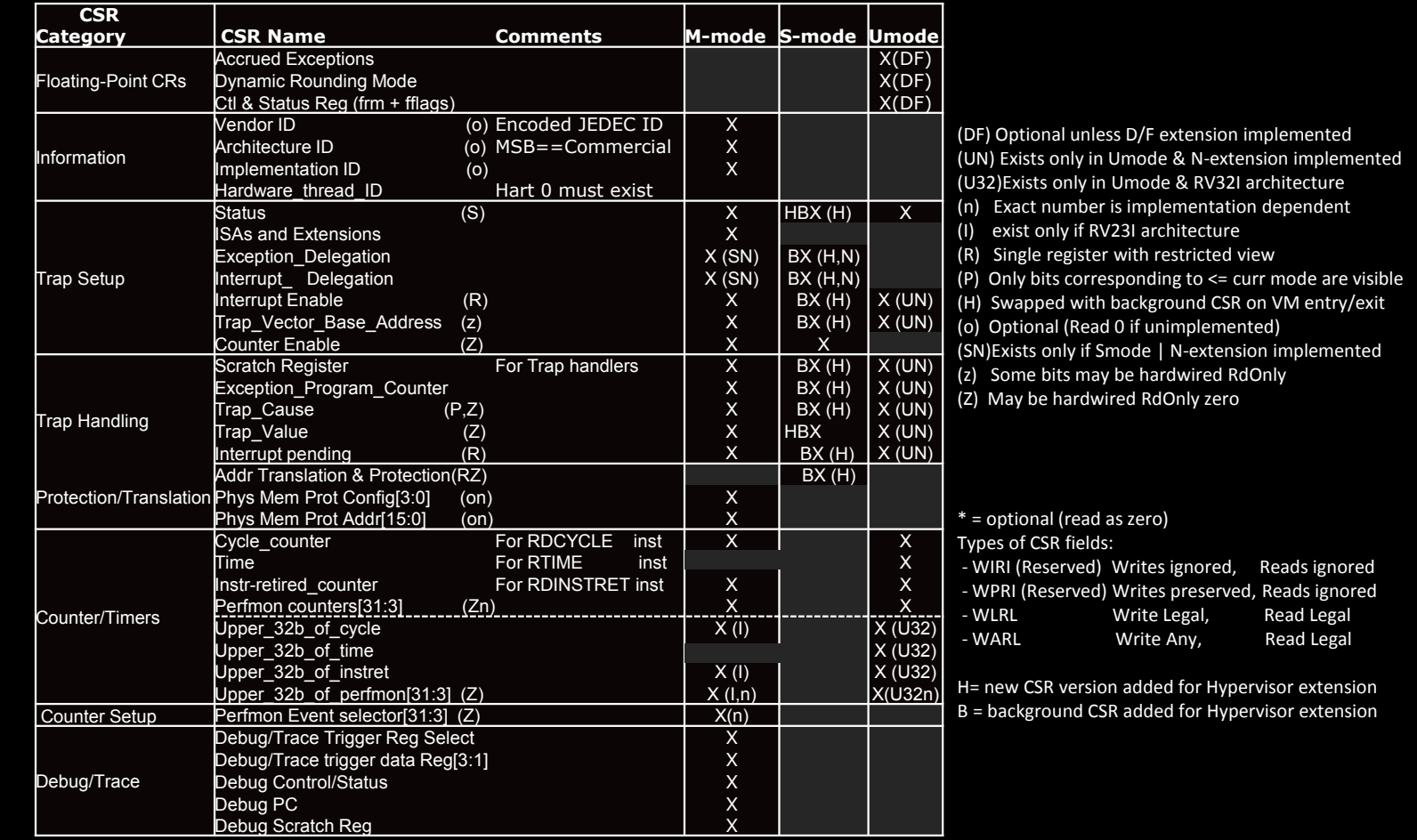
1. 浮点控制寄存器(Floating-Point CRs)
- 这些寄存器用于浮点单元(FPU)的控制和状态存储,适用于实现了浮点扩展的系统。
- Accrued Exceptions、Dynamic Rounding Mode 和 Control & Status寄存器均在M-mode、S-mode和U-mode中可用,默认(DF)情况下可以访问。
- 这些寄存器通常与浮点运算密切相关,控制浮点计算时的舍入模式、异常等。
2. 信息类寄存器(Information)
- 包含处理器的供应商、架构ID、硬件实现信息、以及硬件线程ID等。
- Vendor ID、Architecture ID、Implementation ID、Hardware Thread ID 等信息寄存器通常只能在M-mode中读取。它们提供了有关处理器的硬件规格信息,帮助操作系统识别平台。
- Hardware Thread ID 对于hart 0 是必须存在的,其他harts可能根据实现而定。
3. 陷阱设置寄存器(Trap Setup)
- 这些寄存器用于设置和管理异常或中断的处理。
- Status CSR:记录当前处理器状态,可在所有特权模式下访问,但访问权限和可见字段根据特权模式有所不同。
- Exception Delegation、Interrupt Delegation:用于将异常和中断委派给较低权限的模式(例如,将M-mode的陷阱委派给S-mode),这些寄存器通常仅在M-mode下使用。
- Interrupt Enable 和 Trap Vector Base Address:分别控制中断使能和陷阱向量的基地址。在M-mode、S-mode中都可访问,但某些位可能是只读的。
- Counter Enable:决定是否允许较低模式访问计数器(如时间计数器、周期计数器)。
4. 陷阱处理寄存器(Trap Handling)
- 用于处理异常和中断,保存相关信息,以便在陷阱发生时进行正确的处理。
- Scratch Register:用于存储处理器在陷阱处理过程中的临时信息,各模式均可访问,但访问权限不同。
- Exception Program Counter(EPC):存储触发异常或中断的指令地址。
- Trap Cause:标识异常或中断的原因。
- Trap Value 和 Interrupt Pending:存储陷阱相关的其他信息,包括中断挂起状态。
- 这些寄存器在M-mode和S-mode下可用,在U-mode下通常只读(RO)。
5. 内存保护和地址翻译(Protection/Translation)
- 包括物理内存保护(PMP)和虚拟内存地址翻译功能,主要用于管理处理器访问内存时的权限和映射。
- Physical Memory Protection Config 和 Physical Memory Protection Address:用于配置物理内存的保护策略,防止未经授权的访问。主要在M-mode中配置。
- 这些寄存器通常在虚拟内存启用时启用,并允许对特定内存区域进行保护设置。
6. 计数器/定时器(Counters/Timers)
- 这些寄存器用于记录处理器的周期、指令计数和时间,主要用于性能分析和系统调度。
- Cycle Counter 和 Time Counter:分别记录处理器运行的时钟周期和系统时间,M-mode可读写,U-mode通常只读。
- Instruction Retired Counter:记录处理器执行的指令数,伪指令
RDINSTRET可用来读取。 - Performance Counters(HPM Counters):用于监控特定的硬件性能事件,具体的性能事件通过对应的HPMEvent寄存器进行选择。M-mode可访问多个性能计数器,而U-mode的访问可能受限。
7. 调试/追踪寄存器(Debug/Trace)
- 这些寄存器主要用于调试目的,帮助开发者捕获处理器的运行状态并追踪问题。
- 包括Debug Trigger Register、Debug Control/Status Register、Debug Program Counter等,用于配置和记录调试器的触发条件和状态。
- 这些寄存器大多只能在M-mode中访问,因为它们与硬件的调试功能紧密相关。
CSR字段类型
不同的CSR字段有不同的访问权限和使用规则,常见的字段类型包括:
- WIRI(Write-Ignored, Read-Ignored):写入和读取都被忽略。
- WPRI(Write-Preserved, Read-Ignored):写入后值保留,但读取时忽略。
- WLRL(Write Legal, Read Legal):合法的读写操作。
- WARL(Write Any, Read Legal):写入任意值,但读取时返回合法值。
访问模式和选项总结
- M-mode:拥有最高权限,能够访问和修改所有CSRs。
- S-mode:可以访问许多与异常处理、内存管理和计时器相关的寄存器,但某些功能受限于M-mode的设置。
- U-mode:权限最少,通常只能读取特定寄存器,用于应用程序级别的性能监控或时间管理。
这张表提供了一个全面的概览,帮助理解哪些寄存器在不同的特权模式下可用,以及它们的访问权限如何受到限制。这种设计确保了RISC-V在不同特权模式下的安全性,同时提供了灵活的系统配置选项。
Interrupt/Exception Handler Delegation
在RISC-V架构中,中断和异常的处理通常默认在最高特权级别的M-mode(机器模式)进行。但为了提升系统的效率,部分中断和异常可以委派到较低特权模式,如S-mode(监督模式)或U-mode(用户模式),这就是中断/异常处理委派的机制。委派的机制通过特定的控制和状态寄存器(CSRs)来实现,如mideleg和medeleg等。
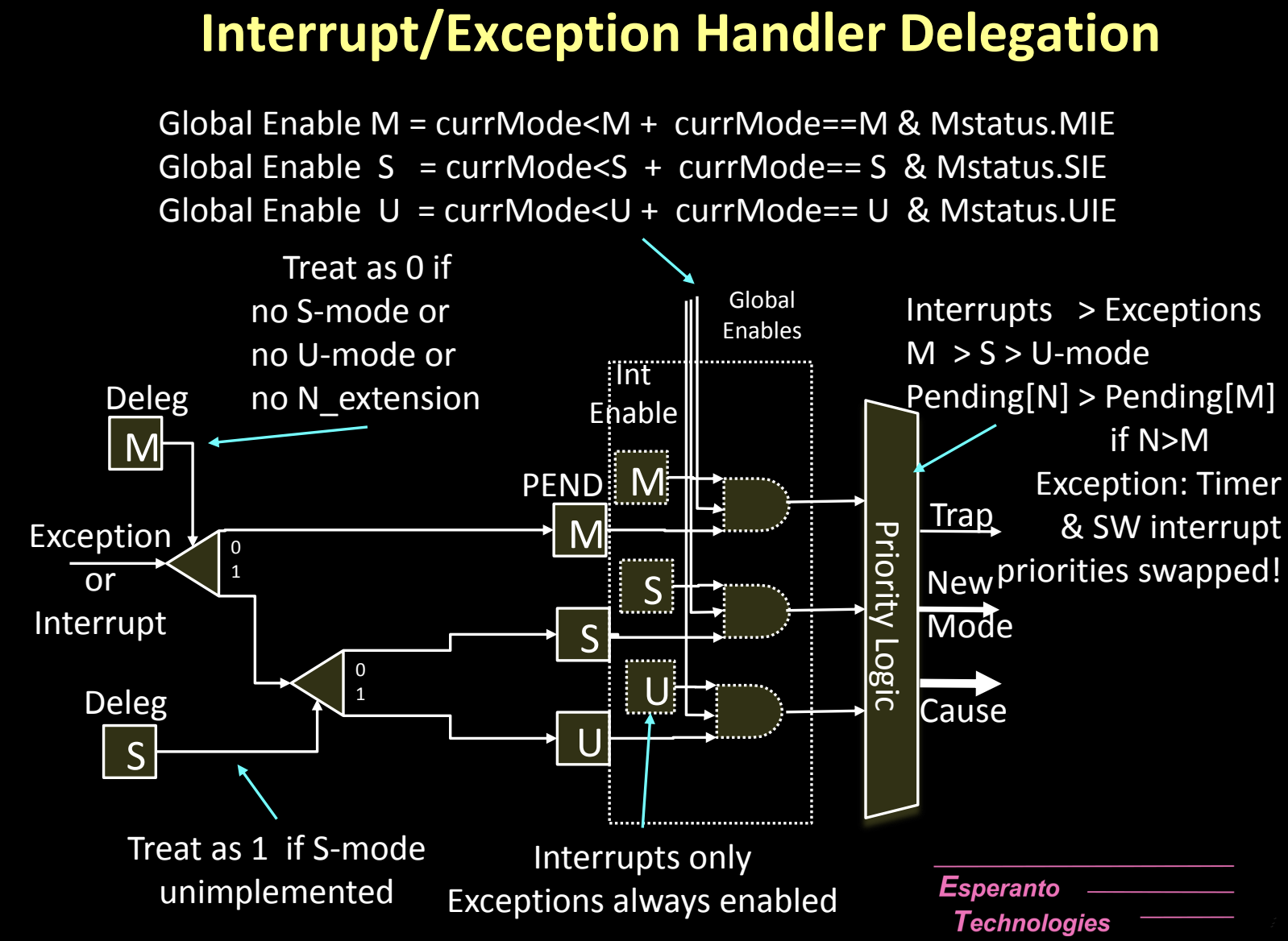
1. 全局中断使能(Global Interrupt Enable)
全局中断使能位根据当前的特权模式(M-mode、S-mode、U-mode)启用或禁用相应模式的中断处理。
-
M-mode中断使能:
- 全局中断使能条件为
currMode < M,即当前模式的权限低于M-mode。 - 当前模式为M-mode时,
Mstatus.MIE位决定是否启用M-mode的中断处理。如果MIE被设置为1,则允许M-mode中断;否则,M-mode中断被禁用。
- 全局中断使能条件为
-
S-mode中断使能:
- 全局中断使能条件为
currMode < S,即当前模式的权限低于S-mode。 - 当前模式为S-mode时,
Mstatus.SIE位决定是否启用S-mode的中断处理。同样,如果SIE被设置为1,则S-mode中断被启用。
- 全局中断使能条件为
-
U-mode中断使能:
- 全局中断使能条件为
currMode < U,即当前模式的权限低于U-mode。 - 在U-mode下,
Mstatus.UIE控制是否启用U-mode的中断处理。U-mode是权限最低的模式,通常用于用户应用程序的中断处理。
- 全局中断使能条件为
2. 委派机制
委派机制允许将某些中断和异常委派给较低特权的模式处理,减少高特权模式(如M-mode)的处理负担。
-
mideleg和medeleg寄存器:用于将M-mode的中断和异常分别委派给S-mode。
- mideleg:决定哪些中断可以委派给S-mode处理。如果对应位被设置为1,则该中断由S-mode处理;否则由M-mode处理。
- medeleg:决定哪些异常可以委派给S-mode处理。如果对应位被设置为1,则该异常由S-mode处理;否则由M-mode处理。
-
sideleg寄存器:如果S-mode被实现并启用,S-mode也可以进一步将中断委派给U-mode处理。
3. 中断与异常的优先级
RISC-V通过优先级逻辑决定当多个中断或异常同时发生时的处理顺序。优先级从高到低依次为:
- 中断 > 异常:中断的优先级高于异常,系统会优先处理中断。
- M-mode > S-mode > U-mode:高特权模式的中断和异常优先处理。例如,M-mode的中断优先级高于S-mode和U-mode的中断。
- Pending[N] > Pending[M] 如果 N > M:如果中断优先级N大于M,则优先处理中断N。这种机制确保了重要的中断能够优先被响应。
4. 特殊优先级情况
对于定时器和软件中断,在某些特殊情况下,优先级可能会被交换。例如:
- 定时器中断和软件中断的优先级被交换:通常情况下,硬件会根据系统需求调整定时器中断和软件中断的优先级,以确保系统的定时和同步机制不被其他中断影响。
5. Trap处理流程
- 当一个中断或异常发生时,系统首先判断是否启用了中断(由
Int Enable位决定)。 - 系统根据优先级逻辑确定处理的模式,并生成相应的Trap,将控制权交给指定模式的中断或异常处理程序。
- 处理器将陷入新的模式(M-mode、S-mode或U-mode),并在Cause寄存器中记录引发Trap的原因。
Interrupt Pending/Enable CSRs (<x>ip, <x>ie)
在RISC-V架构中,中断挂起(Pending)寄存器和中断使能(Enable)寄存器管理着每个硬件线程(hart)的中断状态和中断启用情况。这些寄存器分别是<x>ip和<x>ie,其中<x>代表特定的特权模式,例如m(M-mode,机器模式)、s(S-mode,监督模式)和u(U-mode,用户模式)。这些寄存器与每个hart关联,用于管理不同来源的中断,包括外部中断、定时器中断和软件中断。
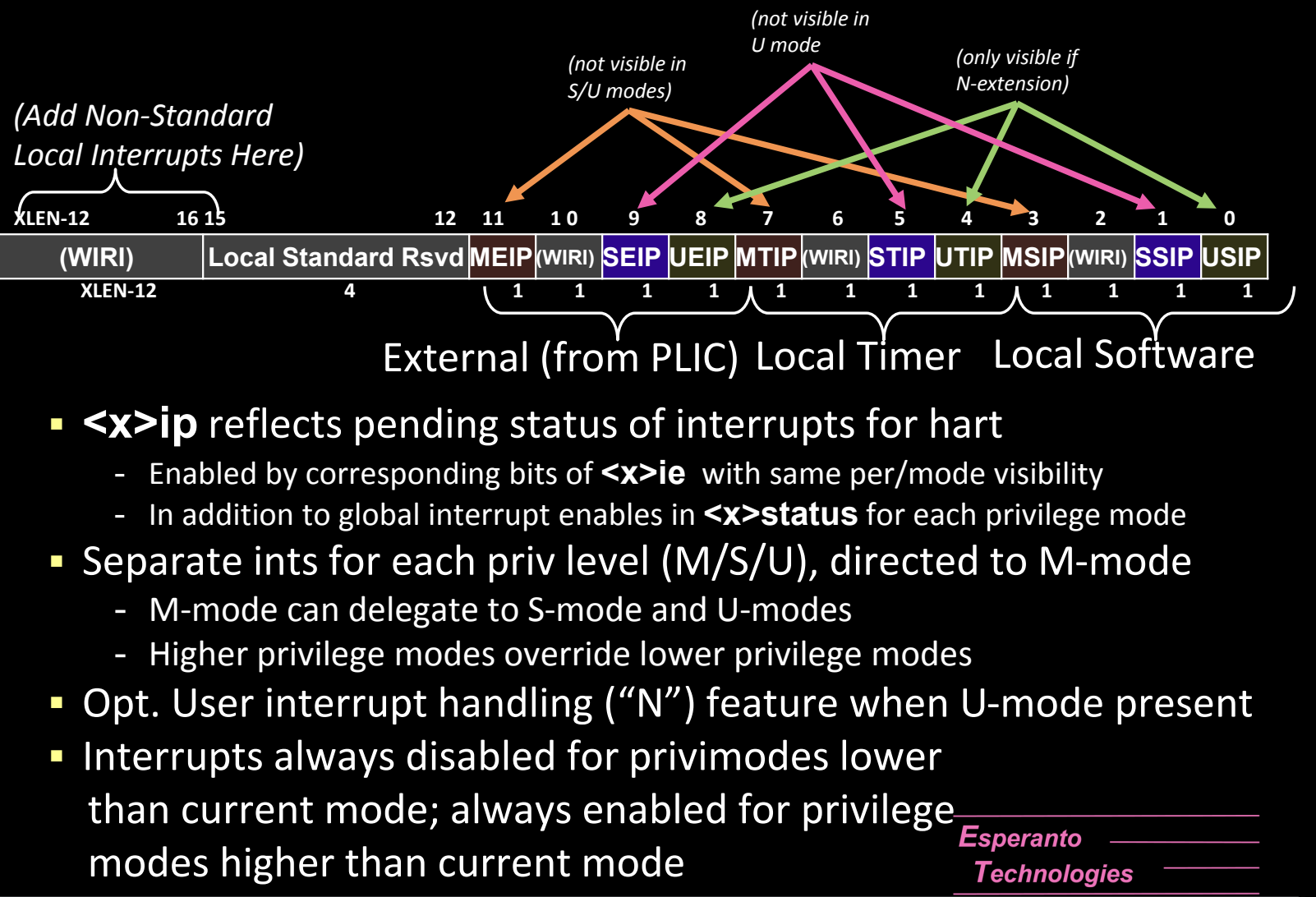
1. <x>ip寄存器
- 功能:
<x>ip寄存器反映了当前hart的中断挂起状态(Pending)。该寄存器的每一位对应不同类型的中断来源,当中断发生且尚未被处理时,相关位将被置为1。 - 中断源:
- MEIP(位11):外部中断,来自PLIC(Platform-Level Interrupt Controller),通过PLIC路由到相应的hart。
- SEIP(位9):监督模式的外部中断。
- UEIP(位8):用户模式的外部中断。
- MTIP(位7):机器模式定时器中断,表示定时器中断挂起。
- STIP(位5):监督模式定时器中断。
- UTIP(位4):用户模式定时器中断。
- MSIP(位3):机器模式软件中断,通常用于hart间通信。
- SSIP(位1):监督模式软件中断。
- USIP(位0):用户模式软件中断。
- 可见性:特定的中断源可能在某些特权模式下不可见。例如,U-mode中无法看到
MEIP和MTIP位。
2. <x>ie寄存器
- 功能:
<x>ie寄存器用于启用或禁用各类中断。与<x>ip对应,<x>ie的每一位控制是否允许相关类型的中断被处理。当相应的<x>ie位为1时,中断被允许;为0时,中断被屏蔽。 - 中断使能:
<x>ie寄存器控制每个特权模式下中断的启用状态,类似于<x>status中的全局中断使能位,但<x>ie的作用更为精细化,允许为特定类型的中断单独启用或禁用。 - 多级中断管理:M-mode可以管理和启用S-mode和U-mode的中断,S-mode则可以管理U-mode的中断。这种层级化的中断使能机制保证了中断的处理优先级。
3. 中断的处理和委派
- 中断的特权级别区分:RISC-V为每个特权级别提供独立的中断挂起和使能寄存器。例如,M-mode处理与机器模式相关的中断,而S-mode和U-mode处理各自的中断。M-mode可以选择将部分中断委派给S-mode或U-mode进行处理。
- 委派机制:M-mode可以通过
mideleg寄存器将某些中断委派给S-mode处理,S-mode也可以进一步将中断委派给U-mode。通常,较高优先级的模式可以控制较低优先级模式的中断处理。
4. 用户模式中断处理(N扩展)
- 如果实现了N扩展(用户模式中断处理功能),则U-mode可以直接处理某些类型的中断,而无需通过S-mode或M-mode。这种情况下,用户模式的中断处理更加高效,减少了特权模式切换带来的开销。
5. 中断优先级与处理顺序
- 中断优先级:RISC-V体系结构规定了中断的优先级,高优先级的中断将优先于低优先级中断。通常,M-mode的中断优先级最高,其次是S-mode和U-mode。
- 优先处理的中断类型:定时器中断、外部中断和软件中断的优先级可以根据系统需求进行调整。例如,定时器中断和软件中断在某些情况下可能交换优先级。
6. 挂起中断的全局管理
- 全局使能条件:中断的处理依赖于多个条件,首先需要通过
<x>status中的全局中断使能位(如MIE、SIE、UIE)启用,然后通过<x>ie启用具体类型的中断。只有在全局使能和具体中断类型使能均为1的情况下,中断才会被处理。 - 中断禁用:当当前特权模式低于中断的优先级时,中断将自动禁用。例如,U-mode无法处理M-mode的中断;中断优先级较高的模式将优先处理中断。
PLIC (Platform-Level Interrupt Controller) Block Diagram 详解
RISC-V架构中的平台级中断控制器(PLIC)是用于处理外部中断的关键组件,它负责将来自多个外部设备的中断请求路由到适当的hart(硬件线程)。PLIC可以管理大量的外部中断,并根据中断的优先级、使能状态以及目标hart的配置,选择合适的中断处理顺序。
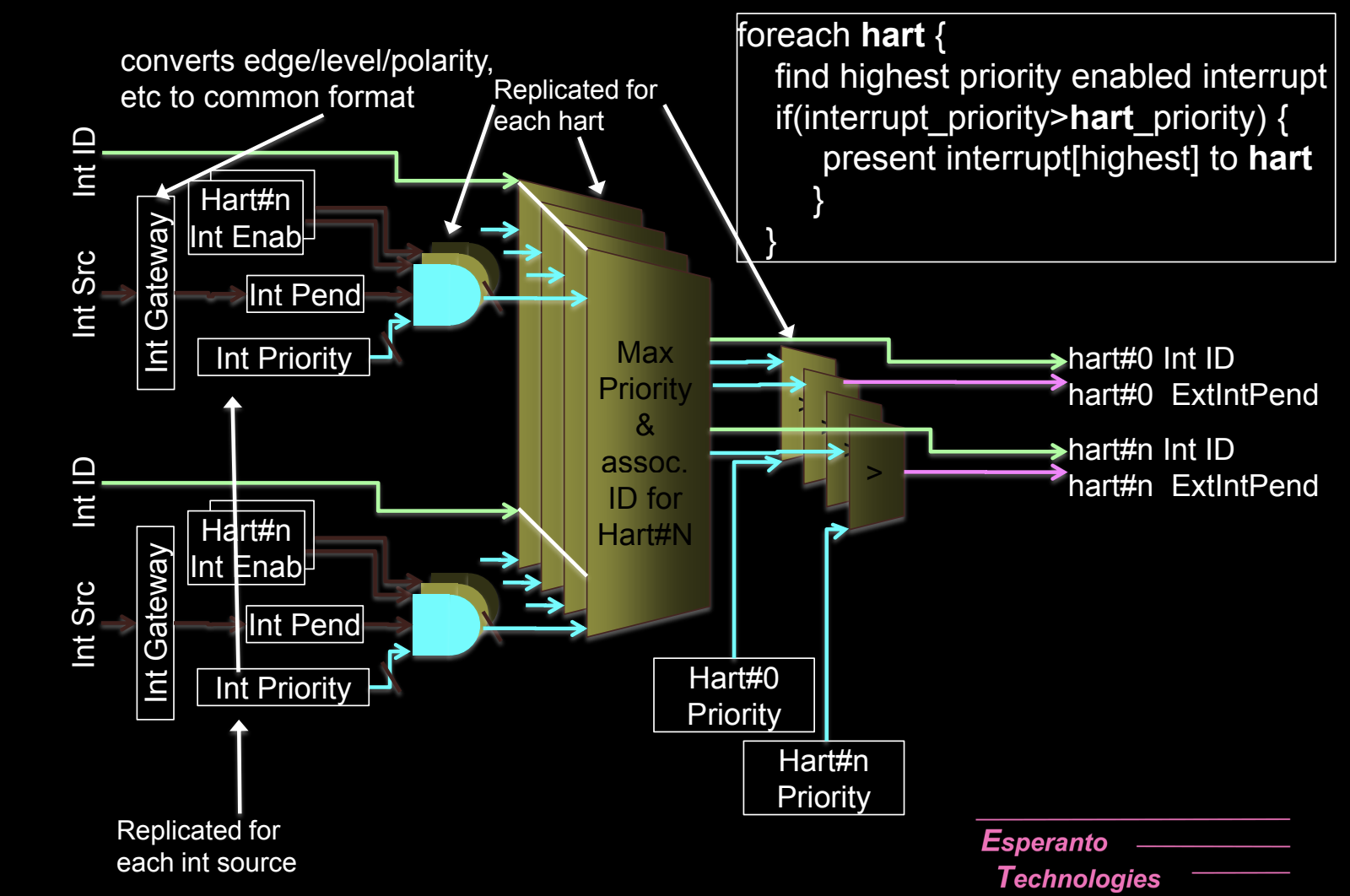
1. PLIC的主要功能
PLIC的主要功能是根据每个hart的配置,确定最高优先级的挂起中断,并将其传递给目标hart进行处理。每个hart可以通过PLIC控制其中断的处理优先级和使能状态。
2. 中断输入转换(Int Gateway)
每个外部中断源都会通过Int Gateway模块,进行边沿触发、极性和电平的标准化处理。此模块将不同外设设备发出的中断信号转换成一个标准格式,以便PLIC进行后续处理。
3. 中断挂起和优先级管理
- 中断挂起寄存器(Int Pend):每个中断源都有一个挂起寄存器,用来记录该中断是否处于挂起状态。挂起状态意味着该中断请求已经被发出但尚未被处理。
- 中断优先级寄存器(Int Priority):每个中断源还有一个优先级寄存器,用来设置该中断的优先级。优先级数值越大,表示该中断的重要性越高。PLIC根据这些优先级来决定哪些中断应该优先处理。
4. 中断使能寄存器(Int Enable)
每个hart可以为各自相关的外部中断配置其中断使能寄存器(Int Enab)。如果某个中断源的使能位被设置为1,则该中断被允许触发处理;否则,即使中断请求挂起,PLIC也不会将其发送到hart进行处理。
5. 优先级比较与中断分配
PLIC为每个hart维护一个当前优先级,并且会根据该hart的最大优先级设置决定处理哪一个中断:
- Max Priority & Associated ID:PLIC会为每个hart查找最高优先级的挂起中断。如果某个挂起中断的优先级高于当前hart正在处理的中断优先级,则PLIC将此中断信息传递给hart。
- 比较过程:在每个hart的中断队列中,PLIC通过优先级比较器(
>符号表示)查找最高优先级的中断请求,并根据优先级分配给hart处理。
6. 中断处理流程(for each hart)
PLIC为每个hart执行以下操作:
- 查找最高优先级的已启用中断:遍历每个外部中断源,找到其优先级高于当前hart中断优先级的中断源。
- 将最高优先级的中断发送到hart:如果找到的中断优先级比hart当前处理的中断高,则PLIC将该中断的ID和挂起状态发送到目标hart,hart将开始处理该中断。
7. 每个hart的独立配置
PLIC的结构针对每个hart独立复制一套中断管理逻辑,确保多个hart能够并行处理不同的中断请求。每个hart都有自己的优先级和中断挂起状态,PLIC会根据每个hart的配置进行中断分配。
8. Hart Priority 和中断处理
- 每个hart都有自己的当前处理中断的优先级,如果有新的中断请求且其优先级高于当前优先级,PLIC将会中断当前处理中断,将新的更高优先级的中断传递给hart进行处理。
Hypervisor Mode
RISC-V引入了虚拟机管理程序模式(Hypervisor Mode),以支持虚拟化功能,允许多个操作系统或“客户机”在同一个物理硬件上独立运行。RISC-V的Hypervisor模式主要运行在S-mode(监督模式)下,并通过一系列控制和状态寄存器(CSRs)来管理客户机操作系统的虚拟化资源和权限。
1. 硬件支持虚拟化
- Type-2 Hypervisor:RISC-V的虚拟化功能类似于Type-2虚拟机管理程序,如KVM(Kernel-based Virtual Machine)。Type-2虚拟机管理程序运行在S-mode之上,由操作系统控制,管理多个客户机的虚拟机。
- Type-1 Hypervisor:RISC-V也可以支持Type-1虚拟化,这种类型的虚拟机管理程序直接运行在硬件上,不依赖于操作系统。
2. Hypervisor运行于S-mode
- 虚拟机管理程序(Hypervisor)通常运行在S-mode下,它负责分配物理资源给虚拟机,并管理虚拟机的生命周期和状态。客户机操作系统(Guest OS)则运行在虚拟化后的V-mode下,分别对应虚拟化的S-mode和U-mode。
3. 客户机运行在虚拟化的S-mode和U-mode
- 虚拟化模式(V-mode):客户机操作系统可以运行在虚拟化的V-S-mode和V-U-mode,这些模式与真实的S-mode和U-mode类似,但由Hypervisor管理。
- 两级页表遍历(2-level Page Table Walk):客户机操作系统的虚拟内存管理使用两级页表。第一层页表由Hypervisor管理,第二层由客户机管理。这种设计确保了客户机的内存管理受到Hypervisor的严格控制,防止客户机直接访问未经授权的内存区域。
4. 操作的限制与陷阱
某些操作在虚拟化环境中可以被限制或引发陷阱,以便由Hypervisor来处理:
WFI指令:当客户机运行的WFI(等待中断)指令等待时间超过设定的阈值时,该指令可能会触发陷阱,由Hypervisor处理。SRET、SFENCE.VMA、SATP和计数器访问:这些指令和寄存器的访问可以被Hypervisor禁止或设置为陷阱。当客户机试图访问这些资源时,Hypervisor会介入并进行适当的处理。- 强制使用监督模式的特权级别进行地址转换:Hypervisor可以强制使用S-mode的权限级别进行地址转换,确保客户机无法超越其权限范围访问内存。
5. STATUS CSR中的附加位
- 在虚拟化模式下,STATUS CSR(控制和状态寄存器)添加了额外的位以支持虚拟化功能:
- Previous Virtualization Mode:用于记录之前的虚拟化模式,便于异常处理时的状态恢复。
- Translation Fault Level:用于标识地址转换过程中出现的错误级别,帮助Hypervisor诊断虚拟内存管理问题。
6. 控制位的解释变化
在虚拟化模式下,一些控制位的解释方式发生了变化:
- SPRV、SPV和SPP:这些控制位用于指示当前的特权模式和状态,虚拟化模式下的解释可能与非虚拟化模式有所不同。
7. 虚拟化模式(Vmode)的CSR切换与选择
在虚拟化环境中,特权模式的切换可能会引发CSR(控制和状态寄存器)的切换和选择,RISC-V提供了一套专门用于虚拟化的CSR,包括:
hstatus:用于管理虚拟化状态。hedeleg和hideleg:用于委派异常和中断给虚拟化的S-mode或U-mode处理。htval:记录虚拟机相关的地址转换错误信息。
同时,以下CSR会在虚拟化模式切换时交换:
sstatus、sie、sip:监督模式的状态、中断使能和中断挂起寄存器。stvec、sscratch、scause:分别为陷阱向量、临时存储和异常原因寄存器。sepc、stval、satp:分别为异常程序计数器、异常值寄存器和地址转换寄存器。
内核与应用程序的接口
应用程序与操作系统内核之间的交互接口通常被称为内核的 API(Application Programming Interface)。这一 API 是操作系统为用户空间的应用程序提供的一组服务,它定义了应用程序如何请求内核执行某些任务或获取系统资源。在实际操作中,最常见的这种交互方式是通过 系统调用(System Call)。虽然系统调用表面上与普通函数调用类似,但它本质上更为复杂,因为它不仅涉及到跨越不同权限的边界,还要保证整个系统的安全性和稳定性。
系统调用 是用户空间程序访问内核服务的唯一合法途径。当一个应用程序希望执行诸如文件读写、进程管理或内存分配等操作时,它必须通过系统调用来实现。这是因为用户空间的应用程序被限制在较低权限的用户模式(User Mode)中,无法直接访问硬件资源或修改系统的核心数据。为了确保对系统资源的访问是在受控环境下进行,操作系统通过系统调用将这些敏感操作委托给内核态(Kernel Mode)来完成。
在系统调用执行时,应用程序首先发出请求,处理器随后从用户模式切换到内核模式。此时,操作系统接管控制权,开始执行内核中的代码。内核会检查请求是否合法并根据内核 API 提供相应的服务,比如读取磁盘文件、分配内存、或与外部设备进行通信。完成操作后,处理器会再次切换回用户模式,将控制权交还给应用程序,并返回操作结果。这一过程确保了应用程序只能通过规范的接口访问硬件资源和系统数据,从而防止应用程序直接操作硬件或破坏系统的稳定性。
系统调用的设计目的不仅是为了实现应用程序和内核之间的功能交互,更重要的是为了提供一种安全性机制。通过将用户态与内核态分隔,操作系统可以有效地防止用户程序直接访问或篡改内核数据,避免意外或恶意操作导致系统崩溃。此外,系统调用的这种模式也为系统提供了更高的灵活性,操作系统可以对系统调用的实现进行优化或扩展,而无需改变应用程序的代码。
在本节的后续内容中,我们将深入探讨系统调用的具体实现方式,尤其是在现代操作系统中的工作原理。通过对系统调用的源代码和执行过程的详细分析,我们可以逐步理解操作系统如何为应用程序提供底层支持。同时,我们也会通过实际编程实践,展示如何编写和调用系统调用,进一步了解它们在操作系统中的关键作用。
系统调用的实际例子
在操作系统中,系统调用是用户空间程序与内核交互的关键机制。尽管系统调用在代码中看起来像普通的函数调用,但实际上它们触发了从用户模式到内核模式的切换,从而执行内核中的特定操作。
1. open 系统调用
#![allow(unused)] fn main() { // user/src/file.rs pub fn open(path: &str, flags: OpenFlags) -> isize { sys_open(path, flags.bits) } // user/src/syscall.rs pub fn sys_open(path: &str, flags: u32) -> isize { syscall(SYSCALL_OPEN, [path.as_ptr() as usize, flags as usize, 0]) } // os/src/syscall/fs.rs pub fn sys_open(path: *const u8, flags: u32) -> isize {...} }
当应用程序需要打开一个文件时,调用 open 系统调用,并将文件名作为参数传递给系统。假设我们需要打开一个名为 “out” 的文件,同时希望对文件进行写操作,可以使用类似以下代码的方式进行调用:
#![allow(unused)] fn main() { let fd = open("out", OpenFlags::WRONLY); }
"out"是文件的路径。OpenFlags::WRONLY表示我们希望以只写模式打开文件。
在rCore中,文件的打开过程也是通过系统调用与内核进行交互的,但由于 rCore 使用 Rust 编写,系统调用的接口和内部处理与传统的 C 语言操作系统(如 xv6)有所不同。
系统调用实现(sys_open)
在 rCore 的用户态代码中,sys_open 函数用于封装用户程序与内核的交互。该函数负责向内核发起 open 系统调用,请求内核打开文件并返回文件描述符。
#![allow(unused)] fn main() { pub fn sys_open(path: &str, flags: u32) -> isize { syscall(SYSCALL_OPEN, [path.as_ptr() as usize, flags as usize, 0]) } }
path:文件路径,通过传递字符串引用。flags:打开文件的标志位,表示文件的操作模式,例如只读、只写等。syscall:这是系统调用的通用接口,它负责通过SYSCALL_OPEN系统调用号与内核通信。syscall函数将path和flags等参数转换为整数形式传递给内核。path.as_ptr() as usize:将文件路径的指针转换为usize类型,以便传递给内核。
调用 syscall 后,系统会切换到内核模式,内核接收这些参数,并查找文件的磁盘位置,然后为文件分配一个文件描述符(File Descriptor, fd)。
用户态接口 (open 函数)
在用户程序中,open 函数进一步封装了 sys_open 系统调用,提供了更高层次的抽象,让用户更方便地使用 open 系统调用。
#![allow(unused)] fn main() { pub fn open(path: &str, flags: OpenFlags) -> isize { sys_open(path, flags.bits) } }
path:文件路径,表示需要打开的文件名。flags:这是OpenFlags枚举类型,用来指定文件的打开模式,例如只读、只写等。通过flags.bits获取具体的标志位值。sys_open:调用封装好的sys_open,将文件路径和标志位传递给系统,实际执行系统调用并返回文件描述符。
内核的处理
当 sys_open 被调用时,rCore 内核会处理来自用户态的系统调用,执行文件的查找、权限检查等操作,并最终返回文件描述符。文件描述符是一个整数,用于标识已打开的文件,它为后续的文件操作(例如读写)提供了句柄,简化了文件的操作流程。
OpenFlags 枚举
在 rCore 中,文件操作模式是通过 OpenFlags 枚举类型来定义的。这些标志位与传统操作系统中的文件操作模式类似:
#![allow(unused)] fn main() { bitflags! { pub struct OpenFlags: u32 { const RDONLY = 0; const WRONLY = 1 << 0; const RDWR = 1 << 1; const CREATE = 1 << 9; const TRUNC = 1 << 10; } } }
RDONLY:只读模式。WRONLY:只写模式。RDWR:读写模式。CREATE:如果文件不存在,则创建该文件。TRUNC:如果文件存在,打开时清空文件内容。
2. write 系统调用
在 rCore 中,write 系统调用的实现与传统的 xv6 逻辑类似。它负责将数据从用户空间缓冲区写入到指定的文件中。在 Rust 中,由于其所有权模型和安全检查机制,这一过程变得更加复杂和安全。
#![allow(unused)] fn main() { // user/src/file.rs pub fn write(fd: usize, buf: &[u8]) -> isize { sys_write(fd, buf) } // user/src/syscall.rs pub fn sys_write(fd: usize, buffer: &[u8]) -> isize { syscall(SYSCALL_WRITE, [fd, buffer.as_ptr() as usize, buffer.len()]) } // os/src/syscall/fs.rs pub fn sys_write(fd: usize, buf: *const u8, len: usize) -> isize { let token = current_user_token(); let process = current_process(); let inner = process.inner_exclusive_access(); if fd >= inner.fd_table.len() { return -1; } if let Some(file) = &inner.fd_table[fd] { if !file.writable() { return -1; } let file = file.clone(); // release current task TCB manually to avoid multi-borrow drop(inner); file.write(UserBuffer::new(translated_byte_buffer(token, buf, len))) as isize } else { -1 } } }
当用户想要向一个已打开的文件写入数据时,会调用 write 系统调用,并传递以下参数:
- 文件描述符(
fd),表示要写入的文件,由open返回。 - 数据缓冲区(
buffer),这是一个字节数组,包含要写入的数据。 - 要写入的数据长度(
len),指定需要写入的字节数。
在 rCore 中,用户态和内核态的 write 调用分别由 user/src/syscall.rs 和 os/src/syscall/fs.rs 中的代码实现。
用户态的 write 实现
#![allow(unused)] fn main() { // user/src/syscall.rs pub fn sys_write(fd: usize, buffer: &[u8]) -> isize { syscall(SYSCALL_WRITE, [fd, buffer.as_ptr() as usize, buffer.len()]) } }
-
sys_write函数:fd: usize:文件描述符,表示已经打开的文件。buffer: &[u8]:这是一个字节数组切片,表示要写入的数据缓冲区。- 返回值类型是
isize,用于指示系统调用的结果,成功时返回写入的字节数,失败时返回负数(通常为 -1)。
-
syscall函数:syscall是一个通用的系统调用接口,负责将系统调用号和参数传递给内核,并等待内核返回结果。这里传递的参数包括:SYSCALL_WRITE:表示write系统调用的系统调用号。[fd, buffer.as_ptr() as usize, buffer.len()]:参数列表,其中:buffer.as_ptr():获取缓冲区的指针,指向数据在内存中的起始地址。buffer.len():获取缓冲区的长度,即要写入的字节数。
用户态通过 sys_write 调用,向内核发送系统调用请求,请求内核将 buffer 中的数据写入到文件。
内核态的 write 实现
#![allow(unused)] fn main() { // os/src/syscall/fs.rs pub fn sys_write(fd: usize, buf: *const u8, len: usize) -> isize { let token = current_user_token(); let process = current_process(); let inner = process.inner_exclusive_access(); if fd >= inner.fd_table.len() { return -1; } if let Some(file) = &inner.fd_table[fd] { if !file.writable() { return -1; } let file = file.clone(); // release current task TCB manually to avoid multi-borrow drop(inner); file.write(UserBuffer::new(translated_byte_buffer(token, buf, len))) as isize } else { -1 } } }
内核态函数暂时不做要求
sys_write函数:fd: usize:文件描述符,用来标识要写入的文件。buf: *const u8:指向用户空间缓冲区的指针,表示要写入的数据。len: usize:要写入的字节数。步骤:
- 获取当前用户进程信息:
current_user_token():获取当前用户进程的令牌(token),用于用户态与内核态之间的内存转换。current_process():获取当前执行的进程信息。process.inner_exclusive_access():通过独占访问锁(inner_exclusive_access)获取进程的内部信息(例如文件描述符表)。
- 检查文件描述符的有效性:
if fd >= inner.fd_table.len() { return -1; }:检查传入的文件描述符fd是否超出当前进程的文件描述符表长度。如果文件描述符无效,则返回 -1。
- 检查文件是否可写:
if !file.writable() { return -1; }:检查文件是否具有可写权限。如果文件不可写,也返回 -1。
- 克隆文件句柄并释放锁:
let file = file.clone();:克隆文件句柄,避免出现多次借用问题。drop(inner):手动释放对进程内核对象的独占访问锁,确保在后续操作中不会重复借用。
- 写入数据到文件:
file.write(UserBuffer::new(translated_byte_buffer(token, buf, len))):
- 首先,通过
translated_byte_buffer(token, buf, len)将用户空间的缓冲区地址翻译为内核可访问的地址。- 然后,构造一个新的
UserBuffer,用于表示用户态的字节缓冲区。- 最后,调用
file.write()函数,将UserBuffer中的数据写入文件。
- 返回写入字节数:
file.write()的返回值是写入的字节数,返回给用户态程序。如果写入失败,返回 -1。
用户态调用接口
#![allow(unused)] fn main() { // user/src/file.rs pub fn write(fd: usize, buf: &[u8]) -> isize { sys_write(fd, buf) } }
这个函数封装了对 sys_write 的调用,进一步简化了用户程序的使用接口。用户只需传递文件描述符和缓冲区,调用 write 函数即可完成数据写入操作。
内核态与用户态和系统调用
在操作系统中,内核态 和 用户态 是两种运行模式。它们提供了不同的权限级别,来保障系统安全性和稳定性。在讨论 系统调用 时,用户态和内核态有各自的作用和层次,这两者的协同工作是系统正常运行的基础。
内核态和用户态
- 用户态(User Mode):运行普通应用程序的模式,权限有限,不能直接访问硬件或执行某些敏感操作(如 I/O 操作、内存管理等)。所有与硬件、资源管理相关的操作都必须通过系统调用请求内核来执行。
- 内核态(Kernel Mode):运行操作系统内核和核心服务的模式,拥有最高权限,可以直接访问硬件资源,管理系统资源并执行重要的低级操作。系统调用会从用户态切换到内核态,让内核代替应用程序完成这些操作。
系统调用的概念
系统调用(System Call)是用户态程序与内核通信的机制。用户态程序需要通过系统调用来请求内核执行某些操作,例如文件读写、内存分配、进程管理等。
在用户态,系统调用看起来像是普通函数调用,但实际上,系统调用会触发 特权指令,将程序从用户态切换到内核态,内核负责处理请求后返回结果。
用户态和内核态在系统调用中的视角与作用
系统调用在不同的层次中有不同的表现,从用户态到内核态,每个层次都有其特定的工作。我们用一个 文件写操作(write 系统调用) 为例,展示其在不同层次的实现和视角。
(1) 用户态的视角:系统调用封装
在用户态,开发者看不到内核的细节,只能调用高层次的系统调用接口。以 rCore 用户态的 write 系统调用为例:
#![allow(unused)] fn main() { // 用户态:user/src/syscall.rs pub fn sys_write(fd: usize, buffer: &[u8]) -> isize { syscall(SYSCALL_WRITE, [fd, buffer.as_ptr() as usize, buffer.len()]) } }
用户态执行过程:
- 封装系统调用:
sys_write是一个封装好的系统调用函数。用户态程序调用sys_write,传递文件描述符fd和写入数据buffer。 - 参数准备:将参数打包成标准的形式(如将缓冲区指针转换为整数,准备文件描述符和长度)。
- 发起系统调用:
syscall(SYSCALL_WRITE, ...)触发系统调用,通过硬件机制(如中断或陷入指令)将程序从用户态切换到内核态,并将请求传递给内核。
(2) 内核态的视角:处理系统调用
在内核态,操作系统接收到系统调用请求后,会处理这些用户态程序无法完成的任务。在 rCore 中,write 系统调用在内核的实现如下:
#![allow(unused)] fn main() { // 内核态:os/src/syscall/fs.rs pub fn sys_write(fd: usize, buf: *const u8, len: usize) -> isize { let token = current_user_token(); let process = current_process(); let inner = process.inner_exclusive_access(); // 检查文件描述符是否有效 if fd >= inner.fd_table.len() { return -1; } // 查找文件并判断是否可写 if let Some(file) = &inner.fd_table[fd] { if !file.writable() { return -1; } let file = file.clone(); // 释放锁以防止重复借用 drop(inner); // 将用户态缓冲区中的数据写入文件 file.write(UserBuffer::new(translated_byte_buffer(token, buf, len))) as isize } else { -1 } } }
内核态执行过程:
- 参数接收:内核接收到用户态传递的参数,例如文件描述符
fd和数据缓冲区指针buf。 - 用户态到内核态的缓冲区转换:由于用户态和内核态处于不同的地址空间,内核需要通过
translated_byte_buffer函数将用户态缓冲区地址转换为内核态可访问的地址。 - 权限检查:内核检查文件描述符是否有效,并确保该文件具有写权限。如果检查失败,则返回错误码。
- 实际操作:内核调用内部的文件写入函数,将数据写入到对应的文件系统或设备中。
- 返回结果:操作完成后,内核返回写入的字节数或错误码,并切换回用户态。
(3) 硬件的视角:用户态到内核态的切换
用户态程序通过系统调用进入内核态的过程涉及硬件机制:
-
触发系统调用:系统调用通常是通过一条特殊的指令触发的,例如
syscall(在 x86-64 架构上)或ecall(在 RISC-V 上)。这条指令会产生一个陷入(trap)或中断,导致处理器从用户态切换到内核态。 -
进入内核态:处理器根据陷入向量跳转到内核的系统调用处理函数。陷入后,处理器会切换到内核态运行,并保护当前的用户态上下文。
在 RISC-V 架构中,处理系统调用或异常的机制使用 陷入向量。关键寄存器:
stvec(Supervisor Trap Vector Base Address Register):用于存储系统调用或异常处理函数的基地址。当发生系统调用或异常时,处理器会根据stvec的值跳转到对应的地址执行陷入处理函数。- 参见 lzzs xv6 notebook: usertrap
-
保存上下文:内核会保存当前的用户态寄存器状态,以便在系统调用结束后能恢复用户态程序的执行。
系统调用流程总结
从系统调用的全过程来看,用户态和内核态的工作是密切相关的。用户态和内核态的系统调用处理过程可以分为几个关键步骤:
-
用户态:
- 发起系统调用,提供需要的参数(如文件描述符、缓冲区、数据长度等)。
- 用户态程序并不知道内核的具体实现细节,它只关心系统调用的接口和结果。
-
内核态:
- 接收并处理系统调用,进行一系列操作,如权限检查、资源管理、硬件访问等。
- 内核负责实际的操作,如与文件系统交互、与设备交互等。
- 返回处理结果(如写入的字节数或错误码)并切换回用户态。
-
硬件层:
- 实现用户态与内核态的隔离,通过硬件机制确保用户态程序不能直接访问内核权限级别的资源。
- 提供特权指令或陷入机制,允许用户态程序通过系统调用进入内核。
示例流程:文件写操作的系统调用
举例来说,用户态程序调用 write(fd, buffer) 的全过程如下:
-
用户态:
- 程序调用
sys_write(fd, buffer),封装参数并通过syscall函数使用 **ecall**指令触发系统调用。
- 程序调用
-
陷入内核:
ecall触发处理器切换到内核态,内核接管执行。
-
内核态:
- 内核的系统调用处理函数
sys_write(fd, buf, len)接收参数。 - 内核检查文件描述符的有效性、权限,确保写入操作合法。
- 内核将数据从用户态缓冲区拷贝到内核缓冲区(必要时进行地址转换)。
- 内核调用文件系统接口,将数据写入文件。
- 完成写入操作后,返回结果(如写入的字节数),并切换回用户态。
- 内核的系统调用处理函数
-
用户态继续执行:
- 系统调用结束,程序继续执行,处理返回的结果。
总结
- 用户态 的视角:系统调用像普通函数一样,但其实底层涉及内核操作。
- 内核态 的视角:接收用户的系统调用请求,进行底层的资源管理和硬件交互操作。
- 硬件层 提供用户态和内核态的隔离机制,并通过陷入机制实现状态切换。
这层次化的设计保证了系统的安全性和稳定性,同时也为程序提供了强大的操作能力。
系统调用与syscall() 函数
系统调用(System Call)是操作系统提供给用户态程序与内核进行交互的一种机制。用户态程序无法直接访问硬件资源或者执行某些敏感的操作(如进程管理、文件操作等),因此需要通过系统调用向内核发出请求,执行这些操作。在用户态程序中,系统调用的接口通常封装成类似函数的调用形式,但其本质是通过硬件机制将执行权限从用户态切换到内核态。
在 rCore 操作系统中,系统调用通过 syscall() 函数来封装,这个函数根据不同的系统调用 ID 和参数,执行相应的操作。
syscall() 函数
#![allow(unused)] fn main() { // user/src/syscall.rs fn syscall(id: usize, args: [usize; 3]) -> isize { let mut ret: isize; unsafe { core::arch::asm!( "ecall", // 触发系统调用 inlateout("x10") args[0] => ret, // 参数 1 传递给 x10 寄存器,返回值也通过 x10 返回 in("x11") args[1], // 参数 2 传递给 x11 in("x12") args[2], // 参数 3 传递给 x12 in("x17") id // 系统调用号传递给 x17 ); } ret } }
syscall() 是系统调用的核心,它封装了系统调用的执行流程。这个函数的执行步骤如下:
-
传递系统调用号:系统调用号(
id)被传递给寄存器x17,用于告诉内核应该执行哪种系统调用。 -
传递参数:系统调用的三个参数存储在
x10,x11,x12寄存器中,这些寄存器会传递到内核中的系统调用处理程序。 -
触发系统调用:使用
ecall指令触发系统调用,中断当前的用户态执行,进入内核态。 -
返回结果:系统调用的返回值通过
x10寄存器返回给用户程序,存储在ret变量中。RISC-V 处理器有 32 个通用寄存器(
x0到x31),其中某些寄存器被预先规定用于特定的目的,比如存储函数参数、返回值、临时值和保存调用者的上下文等。在 RISC-V 架构中,函数调用(包括系统调用)的参数传递和返回值处理是由 RISC-V ABI 和指令集规范定义的。具体来说,不论是普通函数还是系统调用,参数和返回值都通过指定的寄存器进行传递。这些寄存器的使用规则在 RISC-V Calling Convention 中有明确的定义。
典型系统调用的实现
1. sys_open() 系统调用
sys_open() 是用于打开文件的系统调用。在用户态,sys_open() 封装了文件打开操作,它将文件路径和打开模式传递给内核,通过 syscall() 来执行。
#![allow(unused)] fn main() { pub fn sys_open(path: &str, flags: u32) -> isize { syscall(SYSCALL_OPEN, [path.as_ptr() as usize, flags as usize, 0]) } }
- 系统调用号:
SYSCALL_OPEN指定了这是一个文件打开操作。 - 参数:
path.as_ptr() as usize:文件路径的指针地址被传递给内核。flags as usize:指定文件的打开模式(如只读、只写等)。
内核处理文件打开请求后,返回一个文件描述符,该描述符用于后续的文件操作(如读写)。
2. sys_write() 系统调用
sys_write() 是用于向文件或标准输出写入数据的系统调用。该系统调用将文件描述符、写入的缓冲区和缓冲区的长度作为参数传递给内核。
#![allow(unused)] fn main() { pub fn sys_write(fd: usize, buffer: &[u8]) -> isize { syscall(SYSCALL_WRITE, [fd, buffer.as_ptr() as usize, buffer.len()]) } }
- 系统调用号:
SYSCALL_WRITE指定了这是一个写操作。 - 参数:
fd:文件描述符,指定要写入的文件或输出流。buffer.as_ptr() as usize:数据缓冲区的指针。buffer.len():要写入的数据长度。
内核会根据文件描述符,将缓冲区中的数据写入到指定的文件或设备中。
其他系统调用
sys_open 和 sys_write 的系统调用模式适用于大多数其他系统调用,流程基本相同:
- 将系统调用号和参数传递给
syscall()函数。 - 通过
ecall触发内核执行操作。 - 获取结果并返回给用户态程序。
类似的系统调用有:
sys_read():读取文件内容。sys_close():关闭打开的文件描述符。sys_fork():创建一个新的进程。sys_exit():退出当前进程。
每个系统调用根据不同的操作会传递不同的参数,但它们的工作机制都是类似的,通过 syscall() 函数向内核发起请求,执行系统级的操作。更多 rCore 系统调用参见user/src/syscall.rs
总的来说,系统调用是用户态程序与内核进行交互的桥梁。在 rCore 中,syscall() 函数封装了系统调用的执行流程,用户态程序通过调用相应的系统调用函数(如 sys_open、sys_write 等),间接调用内核提供的服务。系统调用的机制保证了用户态和内核态的隔离,确保了系统的安全性和稳定性。
接下来的章节将开始深入探讨如何通过这些系统调用实现更复杂的系统操作,如进程管理、文件操作以及设备交互。
hello_world.rs
在操作系统开发的过程中,用户态程序是与内核交互的关键桥梁。一个简单的用户态程序可以通过调用系统调用,与操作系统内核进行通讯、执行文件操作、管理进程和输入输出等任务。在本章中,我们将以一个经典的 "Hello, World!" 程序作为切入点,探讨用户态程序的结构与实现方式,并逐步分析它如何通过系统调用与内核进行交互。
这个 hello_world.rs 程序展示了一个用户态应用如何在不依赖标准库的环境下,使用 Rust 的基本功能输出到控制台。通过深入分析这个简单的程序,我们将揭示从 println! 宏到底层的输出实现,了解 用户态 和 内核态 的交互原理。
接下来,我们将首先讲解 hello_world.rs 程序的基本结构,然后逐步深入分析控制台输出的实现方式,并探索 rCore 中如何使用 Rust 的特性来实现安全、高效的系统调用机制。
"Hello, World!"
// user/src/bin/hello_world.rs #![no_std] #![no_main] #[macro_use] extern crate user_lib; #[no_mangle] pub fn main() -> i32 { println!("Hello world from user mode program!"); 0 } // user/src/console.rs impl Write for Stdout { fn write_str(&mut self, s: &str) -> fmt::Result { write(STDOUT, s.as_bytes()); Ok(()) } } // user/src/console.rs use core::fmt::{self, Write}; const STDIN: usize = 0; const STDOUT: usize = 1; use super::{read, write}; struct Stdout; impl Write for Stdout { fn write_str(&mut self, s: &str) -> fmt::Result { write(STDOUT, s.as_bytes()); Ok(()) } } pub fn print(args: fmt::Arguments) { Stdout.write_fmt(args).unwrap(); } #[macro_export] macro_rules! print { ($fmt: literal $(, $($arg: tt)+)?) => { $crate::console::print(format_args!($fmt $(, $($arg)+)?)); } } #[macro_export] macro_rules! println { ($fmt: literal $(, $($arg: tt)+)?) => { $crate::console::print(format_args!(concat!($fmt, "\n") $(, $($arg)+)?)); } } pub fn getchar() -> u8 { let mut c = [0u8; 1]; read(STDIN, &mut c); c[0] }
用户程序:hello_world.rs
#![no_std] #![no_main] #[macro_use] extern crate user_lib; #[no_mangle] pub fn main() -> i32 { println!("Hello world from user mode program!"); 0 }
-
#![no_std]:- 这个指令告诉编译器不使用标准库 (
std)。在 rCore 中,由于这是一个操作系统运行在裸机上,没有完整的标准库支持,因此需要使用no_std环境。 - 取而代之的是
core库,它提供了语言本身的基础功能(例如基础类型、内存操作等),但没有诸如文件系统或 I/O 等高级功能。
- 这个指令告诉编译器不使用标准库 (
-
#![no_main]:- 由于操作系统的用户程序不需要
std库中的标准main函数签名,使用#![no_main]来禁用标准的入口点。相反,用户自己定义一个main函数作为入口。
- 由于操作系统的用户程序不需要
-
#[macro_use]:- 这指令引入了
user_lib中的宏定义,允许在当前文件中使用该库定义的宏(如println!)。
- 这指令引入了
-
extern crate user_lib;:- 明确导入外部库
user_lib,这是 rCore 的用户态库,提供了与系统交互的基础设施,包括系统调用、打印等操作。
- 明确导入外部库
-
#[no_mangle]:- 这是一个属性,防止编译器对函数名进行名称混淆(mangling)。
main函数作为入口函数必须保持原始名称,以便系统能正确调用。
- 这是一个属性,防止编译器对函数名进行名称混淆(mangling)。
-
println!宏:- 这是用户态打印宏,用于打印 "Hello world from user mode program!"。
println!是宏,它将字符串打印到标准输出 (stdout)。
控制台输入输出:console.rs
#![allow(unused)] fn main() { use core::fmt::{self, Write}; const STDIN: usize = 0; const STDOUT: usize = 1; use super::{read, write}; struct Stdout; ... }
-
core::fmt::Write:Write是一个core::fmt模块中的 trait,用于处理格式化输出。通过实现Writetrait,可以自定义如何将数据写入输出(例如标准输出)。
-
STDIN和STDOUT:- 这是两个常量,
STDIN和STDOUT分别对应标准输入和标准输出的文件描述符编号。它们用于系统调用中的读写操作。
- 这是两个常量,
-
struct Stdout:Stdout是一个空结构体,用于表示标准输出设备。
实现 Write trait
#![allow(unused)] fn main() { impl Write for Stdout { fn write_str(&mut self, s: &str) -> fmt::Result { write(STDOUT, s.as_bytes()); Ok(()) } } }
-
impl Write for Stdout:- 这里实现了
Writetrait 的write_str方法,用于将字符串输出到标准输出。 - 通过实现
Writetrait,Stdout结构体可以用于格式化输出,类似于 C 语言中的printf。
- 这里实现了
-
write_str方法:- 接收一个字符串
s: &str,将其转化为字节数组(as_bytes())后,通过write(STDOUT, s.as_bytes())系统调用将数据写入标准输出。 fmt::Result是返回类型,表示格式化操作是否成功。在这里,总是返回Ok(())表示成功。
- 接收一个字符串
打印函数与宏:print! 和 println!
#![allow(unused)] fn main() { pub fn print(args: fmt::Arguments) { Stdout.write_fmt(args).unwrap(); } #[macro_export] macro_rules! print { ($fmt: literal $(, $($arg: tt)+)?) => { $crate::console::print(format_args!($fmt $(, $($arg)+)?)); } } #[macro_export] macro_rules! println { ($fmt: literal $(, $($arg: tt)+)?) => { $crate::console::print(format_args!(concat!($fmt, "\n") $(, $($arg)+)?)); } } }
-
print(args: fmt::Arguments):- 这是一个接收
fmt::Arguments的函数,fmt::Arguments是用于格式化输出的数据结构,通常通过format_args!宏生成。函数调用Stdout.write_fmt(args)执行格式化输出,将数据写入Stdout。
- 这是一个接收
-
print!和println!宏:- 这两个宏分别对应打印和带换行符的打印(类似于
printf和puts)。 println!使用了concat!宏将字符串内容与换行符\n拼接,确保打印后自动换行。format_args!宏会生成fmt::Arguments类型的对象,用于格式化输出。它将字符串和任何附加的参数转换成一种可以用于输出的可变参数类型,支持Writetrait 的实现。- 这些宏的作用是简化格式化输出,用户可以像在常规环境中那样使用
print!和println!。
- 这两个宏分别对应打印和带换行符的打印(类似于
宏展开示例
#![allow(unused)] fn main() { println!("Hello, world!"); }
展开后:
#![allow(unused)] fn main() { $crate::console::print(format_args!(concat!("Hello, world!", "\n"))); }
这会将 "Hello, world!\n" 作为参数传递给 console::print 函数。
系统调用的封装
在用户态程序中,write 和 read 函数都是系统调用,它们负责与内核通信,将数据写入或从标准输入读取数据。在这里,通过调用这些封装的系统调用函数实现输入输出功能。
write 系统调用回顾
write() 函数定义在用户态库中,负责将数据通过系统调用发送到内核:
#![allow(unused)] fn main() { pub fn write(fd: usize, buf: &[u8]) -> isize { sys_write(fd, buf) } }
sys_write 封装了对内核的系统调用,实际上发起了将数据从用户态发送到内核态的请求:
#![allow(unused)] fn main() { pub fn sys_write(fd: usize, buffer: &[u8]) -> isize { syscall(SYSCALL_WRITE, [fd, buffer.as_ptr() as usize, buffer.len()]) } }
当 sys_write 被调用时,操作系统的内核会处理这个系统调用,并将数据写入到对应的设备(在本例中是标准输出)。
简化的内核流程如下:
- 内核接收系统调用
SYSCALL_WRITE及其参数。 - 内核检查文件描述符
fd是否有效(例如1对应STDOUT)。 - 内核将用户传入的缓冲区地址和长度转换为内核可访问的地址空间。
- 内核将字节数据写入标准输出设备(例如屏幕、终端等)。
- 如果写入成功,内核返回写入的字节数;如果失败,返回负数表示错误。
流程总结
- 用户调用
println!("Hello, world!"),该宏展开后生成对print()函数的调用,并将格式化的fmt::Arguments传递给print。 print函数调用Stdout.write_fmt(args),将格式化的数据传递给标准输出。Stdout.write_fmt(args)调用write_str(),将字符串转换为字节数组并通过write(STDOUT, s.as_bytes())系统调用发起写请求。write(fd, buf)通过sys_write(fd, buf)将数据发送给内核,内核将数据写入标准输出设备(如终端、屏幕等)。- 数据成功输出后,内核返回写入的字节数,用户态函数处理该返回值。
整个流程的核心在于:
println!宏展开 ->print调用 ->Stdout.write_fmt()处理格式化输出 ->sys_write()系统调用 ->- 内核处理标准输出。
通过这种方式,rCore 用户态程序实现了将数据从用户态打印到标准输出的完整流程。
Write trait
Stdout 结构体实现了 Write trait,并且 write_fmt() 依赖 write_str() 来实际执行写操作。
write_str
#![allow(unused)] fn main() { impl Write for Stdout { fn write_str(&mut self, s: &str) -> fmt::Result { write(STDOUT, s.as_bytes()); Ok(()) } } }
Writetrait:Writetrait 定义了如何将格式化后的数据写入某种输出设备。write_str()是Writetrait 的方法之一,专门用于写入字符串。write_str(&mut self, s: &str):- 这个函数接收一个不可变的字符串切片
&str,然后将字符串内容转换为字节数组s.as_bytes(),再通过write函数将字节数组写入标准输出。 STDOUT是标准输出文件描述符,通常为1。调用write(STDOUT, s.as_bytes()),这实际发起了对系统调用write的请求,将数据发送到标准输出设备。
- 这个函数接收一个不可变的字符串切片
Required Methods: write_str, Provided Methods: write_fmt
在 Rust 中,write_fmt 和 write_str 是通过实现 Write trait 关联起来的。write_fmt 是一个定义在 core::fmt::Write trait 中的高层次方法,用于格式化输出,而 write_str 是 Write trait 的一个低层方法,专门用来处理字符串的写入。
要了解它们之间的关系,我们需要理解 core::fmt::Write trait 是如何工作的。让我们详细说明这两个函数是如何通过 Write trait 关联起来的。
Rust 的官方文档会列出所有方法,并在描述中明确说明哪些是必须实现(Required Methods)的,哪些是有默认实现(Provided Methods)的。例如,搜索 core::fmt::Write ,
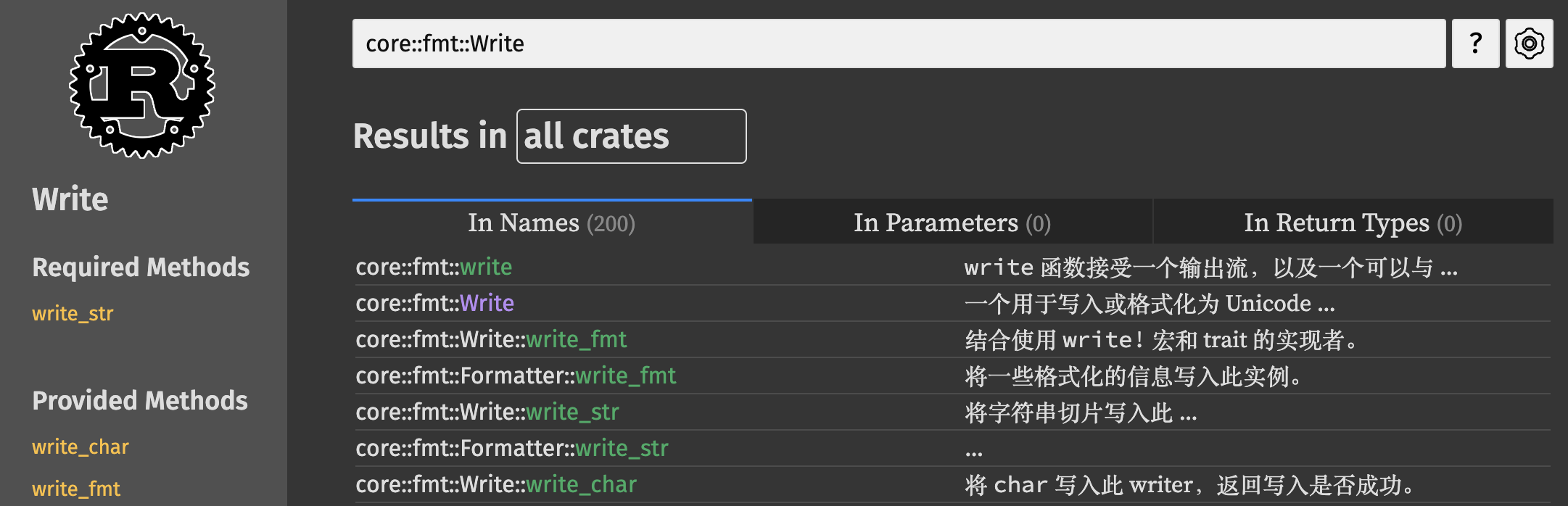
查看它的说明部分。
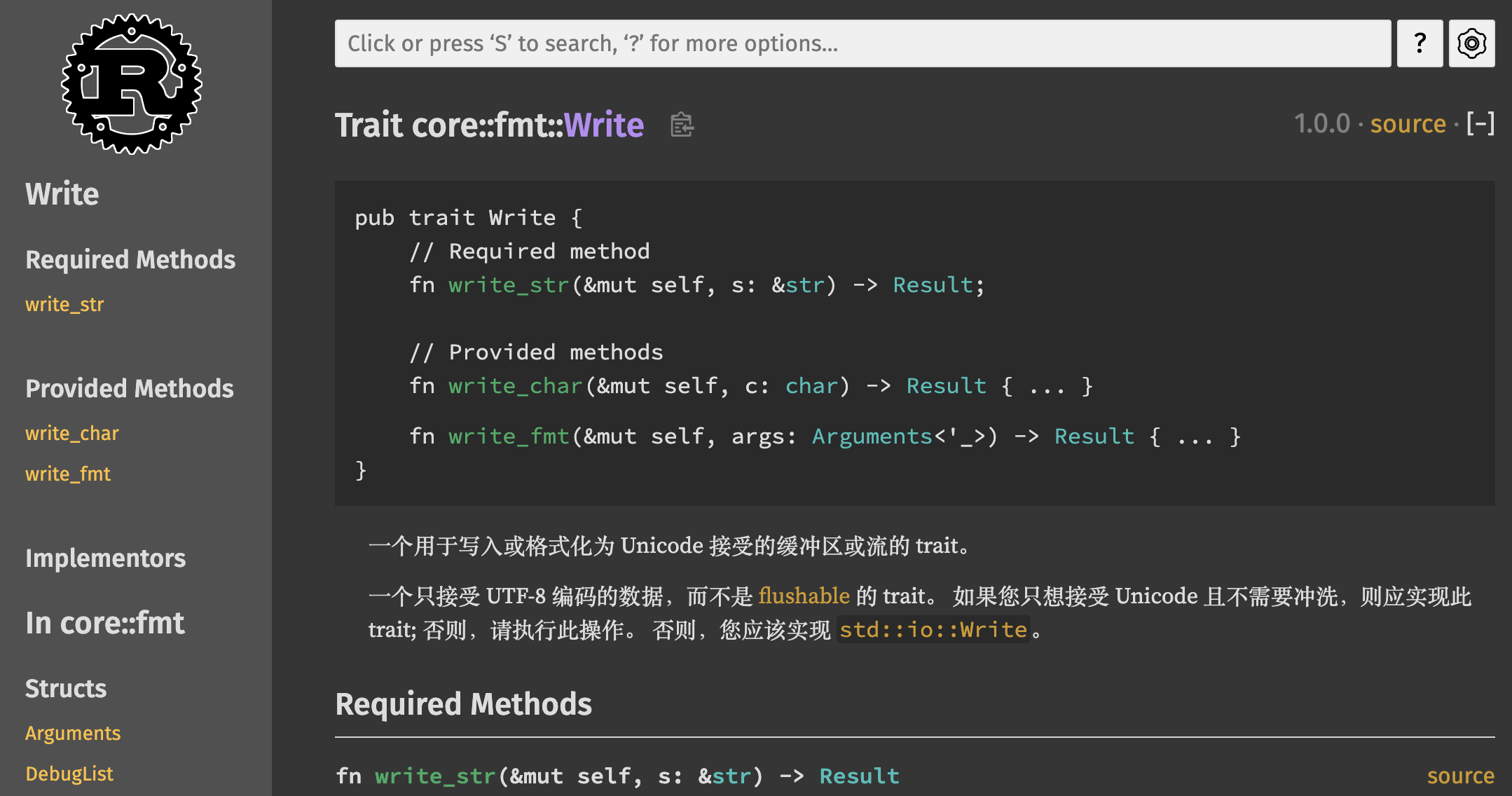
#![allow(unused)] fn main() { pub trait Write { // Required method fn write_str(&mut self, s: &str) -> Result; // Provided methods fn write_char(&mut self, c: char) -> Result { ... } fn write_fmt(&mut self, args: Arguments<'_>) -> Result { ... } } }
文档明确区分了 "Required method"(必需实现的方法)和 "Provided methods"(有默认实现的方法)。在 Rust 的文档中,这种方式非常有用,帮助我们快速了解哪些方法是必须要实现的,哪些可以依赖于默认实现。
这里隐藏了默认实现的代码,你可以点击右侧的 source 按钮查看源代码。
#![allow(unused)] fn main() { pub trait Write { ... fn write_str(&mut self, s: &str) -> Result; ... fn write_char(&mut self, c: char) -> Result { self.write_str(c.encode_utf8(&mut [0; 4])) } ... fn write_fmt(mut self: &mut Self, args: Arguments<'_>) -> Result { write(&mut self, args) } } }
这是 Write trait 的一部分,它定义了在 Rust 中处理格式化输出的行为。我们会逐步分析这个代码片段中每个方法的作用和工作原理。
write_str 方法
#![allow(unused)] fn main() { fn write_str(&mut self, s: &str) -> Result; }
write_str是Writetrait 中唯一的必须实现的方法。它的任务是将传入的字符串s写入输出设备(如文件、标准输出、缓冲区等)。&mut self:表示该方法会对实现Writetrait 的目标进行可变引用。目标可能是一个缓冲区或其他输出流。s: &str:这是传入的字符串,它是一个不可变的字符串切片(&str)。Result:返回值是一个标准的Result类型,通常用于表示操作是否成功。Ok(())表示成功,Err表示发生错误。
任何实现了 Write trait 的类型,都需要提供 write_str 的具体实现,它是输出行为的基础。
write_char 方法
#![allow(unused)] fn main() { fn write_char(&mut self, c: char) -> Result { self.write_str(c.encode_utf8(&mut [0; 4])) } }
write_char是Writetrait 的一个默认实现,它的任务是将单个字符c写入目标。- 字符编码:由于在计算机系统中,字符(
char)通常需要编码为字节序列才能被写入,因此write_char方法使用c.encode_utf8()将字符c编码为 UTF-8 字符串。c.encode_utf8(&mut [0; 4]):这是将字符c编码为 UTF-8 的方法。由于 UTF-8 编码一个字符最多需要 4 个字节,因此这里使用一个长度为 4 的数组作为缓冲区,来存储编码后的字节。
self.write_str:将编码后的字符串通过write_str方法写入输出目标。- 默认实现:如果类型没有显式实现
write_char,它会使用这个默认的实现。
write_fmt 方法
#![allow(unused)] fn main() { fn write_fmt(mut self: &mut Self, args: Arguments<'_>) -> Result { write(&mut self, args) } }
write_fmt是Writetrait 的另一个默认实现,用于处理格式化输出。它接受一个fmt::Arguments类型的参数args,这是由format_args!宏生成的格式化数据。Arguments<'_>:这是一个专门用于格式化输出的类型,封装了格式化字符串和格式化参数(如println!或format!)。write_fmt的工作:write函数:实际完成输出工作的函数是fmt::write,它会将args中的格式化内容解析并通过self.write_str写入输出目标。mut self: &mut Self:表示write_fmt方法会对目标进行可变引用。
write_fmt 提供了一个高层次的接口,用于处理复杂的格式化输出,如 println! 或 format!。如果类型实现了 write_str,write_fmt 可以通过这个默认实现直接使用。
write 函数: fmt::write
#![allow(unused)] fn main() { pub fn write(output: &mut dyn Write, args: Arguments<'_>) -> Result { let mut formatter = Formatter::new(output); let mut idx = 0; match args.fmt { None => { // 我们可以对所有参数使用默认格式设置参数。 for (i, arg) in args.args.iter().enumerate() { // SAFETY: args.args 和 args.pieces 来自同一个参数,保证索引总是在限定范围内。 // let piece = unsafe { args.pieces.get_unchecked(i) }; if !piece.is_empty() { formatter.buf.write_str(*piece)?; } arg.fmt(&mut formatter)?; idx += 1; } } Some(fmt) => { // 每个规范都有一个对应的参数,该参数后有一个字符串。 // for (i, arg) in fmt.iter().enumerate() { // SAFETY: fmt 和 args.pieces 来自同一个 参数,保证索引总是在限定范围内。 // let piece = unsafe { args.pieces.get_unchecked(i) }; if !piece.is_empty() { formatter.buf.write_str(*piece)?; } // SAFETY: arg 和 args.args 来自相同的参数,从而确保索引始终在范围之内。 // unsafe { run(&mut formatter, arg, args.args) }?; idx += 1; } } } // 只能剩下一个尾随的字符串切片。 if let Some(piece) = args.pieces.get(idx) { formatter.buf.write_str(*piece)?; } Ok(()) } }
刚才的源码中也包含write 函数,你也可以在 Module core::fmt 看到 Functions 中包含 write,即fmt::write。
这个 write 函数是 Rust 中 core::fmt 模块的重要部分,它用于将格式化的输出写入到实现了 Write trait 的目标。该函数是格式化输出(如 println! 或 format!)的底层实现之一,依赖于 Arguments 结构体,Arguments 由宏如 format_args! 预编译生成,包含了格式化输出所需的信息。
`write` 函数暂不做要求
1. 核心功能
write 函数接受两个参数:
output: &mut dyn Write:一个实现了Writetrait 的动态输出流。例如,它可以是一个String、文件或者标准输出。args: Arguments:包含格式化的参数,由宏format_args!生成,描述了需要格式化的字符串和插值的变量。
write 函数的工作是:
- 遍历
args,获取格式化的字符串片段和相应的参数。 - 对每个片段应用相应的格式规则,将结果写入到
output中。 - 最后,将剩余的字符串部分(如果有)写入输出流。
2. 结构和工作原理
以下是 write 函数的结构和具体功能的分解。
2.1 Arguments 结构体
Arguments 是 fmt 模块中的核心结构体,它包含了:
pieces:这是字符串片段数组,表示格式化字符串的静态部分。例如"Hello {}!"中的"Hello "和"!"都属于pieces。args:这是插值参数数组,表示{}中需要插入的参数(例如"world")。它存储每个被格式化的数据项。fmt:可选的格式化规则,用于指定每个参数如何格式化(例如是否使用十进制、是否填充空格等)。
2.2 formatter
write 函数创建了一个 Formatter 实例来处理实际的输出写入:
#![allow(unused)] fn main() { let mut formatter = Formatter::new(output); }
Formatter 是 Rust 的一个内部结构,用于封装 Write 对象并提供与格式化相关的各种功能。它会根据传递的 Arguments 和对应的格式规则,调用 Write 实现的 write_str 方法。
2.3 遍历格式化片段和参数
函数会遍历 args.pieces(静态字符串部分)和 args.args(插值参数),并依次将它们写入 formatter。
-
格式化无自定义规则的情况: 如果没有自定义格式规则(
args.fmt == None),它直接遍历每个字符串片段和插值参数,并调用参数的fmt方法来格式化它们:#![allow(unused)] fn main() { for (i, arg) in args.args.iter().enumerate() { let piece = unsafe { args.pieces.get_unchecked(i) }; if !piece.is_empty() { formatter.buf.write_str(*piece)?; } arg.fmt(&mut formatter)?; idx += 1; } }这个代码块执行的步骤:
- 使用
get_unchecked(不安全地)访问pieces数组中的字符串片段。 - 如果片段非空,调用
write_str方法将其写入formatter。 - 对每个参数调用
fmt方法,这会格式化参数并将其写入到输出中。
- 使用
-
格式化带有自定义规则的情况: 如果存在格式化规则(
args.fmt),则使用这些规则对插值参数进行格式化:#![allow(unused)] fn main() { for (i, arg) in fmt.iter().enumerate() { let piece = unsafe { args.pieces.get_unchecked(i) }; if !piece.is_empty() { formatter.buf.write_str(*piece)?; } unsafe { run(&mut formatter, arg, args.args) }?; idx += 1; } }这部分逻辑基本与上面类似,但在对参数进行格式化时,调用了
run函数来执行格式化规则。
2.4 处理尾随字符串片段
在遍历完 args.args 后,可能还有一个尾随的字符串片段没有写入,例如:
#![allow(unused)] fn main() { Hello {}! }
在处理完 {} 的参数后,剩余的 ! 需要被写入输出。write 函数会检查是否还有剩余片段,并调用 write_str 将其写入:
#![allow(unused)] fn main() { if let Some(piece) = args.pieces.get(idx) { formatter.buf.write_str(*piece)?; } }
2.5 错误处理
整个过程中的每个写入操作都使用 ? 操作符进行错误传播。如果写入过程中发生错误(例如缓冲区满或输出设备出现问题),write 会提前返回一个 Err(fmt::Error),并终止输出。
3. write! 宏
文档中还提到,使用 write! 宏可能更加方便。write! 是 Rust 中的另一个宏,提供了简化的语法来进行格式化输出:
#![allow(unused)] fn main() { use std::fmt::Write; let mut output = String::new(); write!(&mut output, "Hello {}!", "world") .expect("Error occurred while trying to write in String"); assert_eq!(output, "Hello world!"); }
- 区别:
write!宏是对fmt::write的进一步封装,它使得使用更加简洁,尤其在用户编写输出代码时。它内部会自动处理format_args!生成Arguments结构体,并调用fmt::write函数。
4. 总结
fmt::write 函数的作用是将格式化的字符串与参数写入一个实现了 Write trait 的输出流。它通过遍历格式化的字符串片段与参数,调用 write_str 将每个部分写入输出。最终,它可以完成诸如 println!、write! 等宏背后的核心工作。在这种设计下,fmt::write 实现了高度的灵活性,能够支持多种格式化输出的目标,如 String、文件或标准输出。
示例代码解读
文档中的示例展示了如何使用 fmt::write 将格式化内容写入到 String 中:
#![allow(unused)] fn main() { use std::fmt; let mut output = String::new(); fmt::write(&mut output, format_args!("Hello {}!", "world")) .expect("Error occurred while trying to write in String"); assert_eq!(output, "Hello world!"); }
工作流程
format_args!宏:- 宏
format_args!("Hello {}!", "world")会生成一个Arguments结构体,包含"Hello "和"!"作为静态字符串片段,以及"world"作为参数。
- 宏
write_fmt- 如果调用
write_fmt(如通过println!或write!宏间接调用)实际调用的是fmt::write函数。 fmt::write遍历fmt::Arguments,其中的格式化片段最终都通过调用write_str写入输出流。
- 如果调用
fmt::write函数:fmt::write(&mut output, format_args!(...))将格式化内容写入output,其中output是一个String。这个String实现了Writetrait,所以可以作为输出流。
- 最终输出:
- 最终,
output中包含"Hello world!",这个值被断言验证。
- 最终,
println! 宏
标准库中的 println! 宏
在使用 标准库(即没有使用 #![no_std] 的项目)时,println! 宏是由标准库自动提供的。它依赖于标准库中已经实现的输入/输出系统和格式化输出机制。
在标准环境下:
println!是由std::fmt模块提供的宏,用户可以直接使用它来向标准输出打印格式化的文本。println!会自动将输出定向到标准输出(如终端),并且它使用了标准库的Writetrait 和相关的 I/O 设施。
fn main() { println!("Hello, world!"); // 使用标准库中的 println! 宏 }
这个例子中,println! 宏自动可用,因为 标准库 提供了它的实现。
no_std 环境下的 println! 宏
当你在一个 no_std 项目中工作时,标准库是不可用的,因为它依赖于高级的操作系统功能(如文件系统、标准 I/O 等),这些功能在裸机或嵌入式开发中是不可用的。
- 在
no_std环境中,标准库中的println!宏不可用,因此如果需要类似的功能,你必须自己实现。 - 在
no_std环境中,通常需要自己定义如何处理 I/O,比如打印到串口、内存映射的 I/O 设备,或者像 rCore 这样的操作系统中的设备驱动程序。 - 为了实现类似的
println!功能,你需要手动实现输入输出的逻辑(如write函数)以及相应的 宏 来实现格式化打印功能。
在本节开始的代码中,println! 宏就是手动实现的,适配了相应的输入输出系统,而不是使用标准库中的版本。
对比:标准库 vs no_std 环境下的 println!
| 环境 | println! 宏的来源 | 实现方式 | 输出设备 |
|---|---|---|---|
| 标准库 | 标准库自动提供 | 使用标准库的 I/O 系统(std::io 等) | 默认输出到标准输出(如终端) |
no_std | 需要自己实现 | 使用自定义的宏和 Write trait | 自定义输出(如串口、屏幕、缓冲区等) |
为什么 no_std 需要自己实现 println!?
no_std 环境下没有标准库,意味着:
- 没有标准的 I/O 库,因此没有默认的标准输出设备。
- 没有标准库中的宏,如
println!,所以需要自己定义类似的功能来适应具体的运行环境。
在 rCore 代码中手动实现的 println! 宏通过调用自定义的 console::print 函数来实现输出功能。这是因为在 no_std 环境下,我们不能依赖标准库的输入输出设施。
#![allow(unused)] fn main() { #[macro_export] macro_rules! println { ($fmt: literal $(, $($arg: tt)+)?) => { $crate::console::print(format_args!(concat!($fmt, "\n") $(, $($arg)+)?)); } } }
这个自定义的 println! 宏定义了如何将格式化字符串打印到设备上,而不依赖标准库。
从 hello_world.rs 到sys_write
让我们从头到尾回顾一下整个流程,从 hello_world.rs 程序开始,一直到系统调用触发内核处理输出的过程。这一过程涵盖了 Rust 宏的展开、Write trait 的实现、格式化字符串处理、系统调用 以及 内核态与用户态的切换。
1. 用户态程序 hello_world.rs
#![no_std] #![no_main] #[macro_use] extern crate user_lib; #[no_mangle] pub fn main() -> i32 { println!("Hello world from user mode program!"); 0 }
这个简单的用户态程序使用 println! 宏来打印 "Hello world from user mode program!"。由于这是一个 no_std 项目,它不依赖标准库,而是使用 rCore 定义的自定义宏和库。
关键点
#![no_std]:表示禁用了标准库,不能使用如println!等标准库宏,必须自己实现。#![no_main]:没有使用标准的main函数,而是自定义程序入口。println!:使用println!宏进行格式化字符串输出。
2. println! 宏展开
println! 是在 user_lib 中自定义的一个宏,定义在 console.rs 文件中:
#![allow(unused)] fn main() { #[macro_export] macro_rules! println { ($fmt: literal $(, $($arg: tt)+)?) => { $crate::console::print(format_args!(concat!($fmt, "\n") $(, $($arg)+)?)); } } }
宏展开解释
println!宏接收一个格式化字符串$fmt,并将它和换行符\n连接在一起,形成"Hello world from user mode program!\n"。format_args!:将字符串和任何格式化参数打包成fmt::Arguments,这是 Rust 标准格式化输出的基础。$crate::console::print():最终宏会调用console::print函数,将生成的fmt::Arguments传递给它。
3. print() 函数
println! 宏展开后,调用了 console.rs 中的 print 函数:
#![allow(unused)] fn main() { pub fn print(args: fmt::Arguments) { Stdout.write_fmt(args).unwrap(); } }
print()接收格式化后的fmt::Arguments参数,并调用Stdout结构体的write_fmt方法。write_fmt是Writetrait 提供的默认实现,用于处理格式化输出,它依赖于write_str来完成输出。
4. Write trait 的实现
Stdout 结构体实现了 Write trait 的核心方法 write_str,这允许 Stdout 处理字符串并输出。
#![allow(unused)] fn main() { impl Write for Stdout { fn write_str(&mut self, s: &str) -> fmt::Result { write(STDOUT, s.as_bytes()); // 调用底层的 write 函数,将字符串转换为字节并写入标准输出 Ok(()) } } }
Write trait 工作原理
write_str:将传入的字符串s转换为字节数组(as_bytes),并调用底层的write函数,将这些字节传递给输出设备。write_fmt:通过write_str完成格式化数据的写入,它会逐步将格式化字符串中的每个部分(如 "Hello world" 和\n)输出。
5. write 函数与系统调用
write 函数负责将字符串数据写入到标准输出设备(如屏幕或文件),它最终触发一个 系统调用(sys_write):
#![allow(unused)] fn main() { pub fn write(fd: usize, buf: &[u8]) -> isize { sys_write(fd, buf) // 通过系统调用将数据写入标准输出 } }
fd:文件描述符,表示要写入的输出设备(STDOUT通常是 1)。buf:要写入的数据缓冲区,这里是字节数组形式的字符串。sys_write:执行实际的系统调用,将数据从用户态传递到内核态。
6. sys_write 系统调用
sys_write 是用户态程序与内核通信的方式,它通过系统调用号 SYSCALL_WRITE 来告知内核要执行写操作。
#![allow(unused)] fn main() { pub fn sys_write(fd: usize, buffer: &[u8]) -> isize { syscall(SYSCALL_WRITE, [fd, buffer.as_ptr() as usize, buffer.len()]) } }
syscall:这是系统调用的封装函数,它负责通过ecall指令将控制权从用户态切换到内核态,并传递必要的参数。
7. syscall 函数与 RISC-V ecall 指令
#![allow(unused)] fn main() { fn syscall(id: usize, args: [usize; 3]) -> isize { let mut ret: isize; unsafe { core::arch::asm!( "ecall", // 触发系统调用 inlateout("x10") args[0] => ret, // 参数 1 -> x10, 返回值从 x10 获取 in("x11") args[1], // 参数 2 -> x11 in("x12") args[2], // 参数 3 -> x12 in("x17") id // 系统调用号 -> x17 ); } ret } }
x10到x12:用于传递系统调用的参数(如文件描述符、缓冲区指针和长度)。x17:存储系统调用号,这里是SYSCALL_WRITE,表示这是一个写操作。ecall:触发系统调用,将 CPU 从用户模式切换到内核模式,进入内核处理程序。
8. 内核态处理 sys_write 系统调用
在内核态,系统调用 sys_write 的处理函数位于 syscall/fs.rs 中:
#![allow(unused)] fn main() { pub fn sys_write(fd: usize, buf: *const u8, len: usize) -> isize { let token = current_user_token(); let process = current_process(); let inner = process.inner_exclusive_access(); if fd >= inner.fd_table.len() { return -1; } if let Some(file) = &inner.fd_table[fd] { if !file.writable() { return -1; } let file = file.clone(); drop(inner); file.write(UserBuffer::new(translated_byte_buffer(token, buf, len))) as isize } else { -1 } } }
内核态处理流程
- 参数解析:从用户态接收传递的参数(文件描述符
fd、缓冲区指针buf、数据长度len)。 - 权限检查:检查文件描述符是否有效、文件是否可写。
- 数据写入:将缓冲区中的数据通过内核的文件系统接口写入到对应的输出设备。
- 返回结果:系统调用完成后,将写入的字节数返回到用户态。
9. 从内核返回用户态
系统调用执行完毕后,内核通过寄存器将返回值传回用户态。用户程序从 sys_write 函数中接收返回值,表示写操作成功写入的字节数。
全流程总结
hello_world.rs程序调用println!宏,开始格式化输出。println!宏展开 后调用了print()函数,传递格式化后的字符串。print()函数通过Stdout.write_fmt()输出格式化数据,实际调用了write_str()方法处理字符串。write()函数 通过sys_write发起系统调用,将数据传递给内核。syscall()函数 使用 RISC-V 的ecall指令触发系统调用,切换到内核态。- 内核态的
sys_write处理 将数据写入标准输出设备,并将结果返回给用户态。 - 最终,用户程序完成了 "Hello world from user mode program!" 的输出。
这个全流程展示了从用户态程序中的格式化字符串输出到内核处理系统调用,再到最终完成输出的整个
0. GDB章节
GDB安装
安装 GDB 流程来自【笔记】rCore (RISC-V):GDB 使用记录 - 2024/04/25 - 苦瓜小仔。
以下是对整个流程的详细描述和讲解:
1. 安装依赖项
首先,我们需要为编译 GDB 安装一些必要的依赖项。libncurses5-dev 是为终端用户界面 (TUI) 提供支持的库,其他依赖项包括 texinfo 和 libreadline-dev,它们用于支持命令行输入以及生成文档。
sudo apt-get install libncurses5-dev texinfo libreadline-dev
在这里,Python 和 Python 开发库(python-dev)并不严格要求是 Python 2,也可以是 Python 3。只要你的系统中有 Python 3,它可以正常编译和运行。
使用 Python 3 进行配置
由于 Python 2 逐步被淘汰,建议你使用 Python 3。请确保系统中已经安装了 Python 3,并且有对应的开发库
python3-dev。你可以通过以下命令安装这些包:sudo apt-get install python3 python3-dev
2. 检查本地 Python 路径
在编译 GDB 时,需要确保 Python 的路径正确。你可以通过以下命令来检查 Python3 的路径:
which python3
也可以通过以下命令查看详细的 Python 路径信息,确认是否链接到 Python 3:
ll $(which python3)
例如,输出可能是:
/usr/bin/python3 -> python3.8
3. 下载最新的 GDB 源码
从清华大学的开源镜像站下载 GDB 源码。确保下载的是最新版本,比如 gdb-14.2.tar.xz:
wget https://mirrors.tuna.tsinghua.edu.cn/gnu/gdb/gdb-14.2.tar.xz
4. 解压源码文件
解压下载好的压缩文件。你可以使用标准的 tar 命令,或者使用其他工具(如 ouch)来解压文件。
tar -xvf gdb-14.2.tar.xz
或
ouch d gdb-14.2.tar.xz
解压后,源码文件将位于当前目录的 gdb-14.2 文件夹中。
5. 创建构建目录
进入 gdb-14.2 目录,并在该目录下创建一个新的目录来存放构建结果和生成的二进制文件:
cd gdb-14.2
mkdir build-riscv64
6. 配置编译参数
进入创建的构建目录 build-riscv64,并通过 configure 脚本配置编译参数。指定安装路径、Python 路径、目标架构(RISC-V),并启用 TUI(终端用户界面)支持:
cd build-riscv64
../configure --prefix=/root/qemu/gdb-14.2/build-riscv64 --with-python=/usr/bin/python3 --target=riscv64-unknown-elf --enable-tui=yes
../configure:configure在gdb-14.2目录。--prefix=/root/qemu/gdb-14.2/build-riscv64:指定安装路径。--with-python=/usr/bin/python3:指定 Python 路径。--target=riscv64-unknown-elf:指定目标平台(RISC-V 架构)。--enable-tui=yes:启用 TUI 支持。
在编译 GDB(GNU 调试器)时,
configure脚本可以使用多种选项来指定编译过程中的配置和行为。这些选项可以用于指定编译目标、启用或禁用某些功能、配置依赖项路径等。下面详细介绍一些常见的configure配置参数及其作用。1.
--prefix=PREFIX
作用: 指定安装的根目录。编译后的 GDB 文件会被安装到该目录中。
示例:
--prefix=/usr/local/gdb这将会把 GDB 安装到
/usr/local/gdb,其中可执行文件会放在bin/目录,库文件会放在lib/目录等。2.
--target=TARGET
作用: 指定要调试的目标架构。这是交叉编译的情况下非常重要的选项,定义你希望调试的架构类型。
示例:
--target=riscv64-unknown-elf这指定了要生成支持 RISC-V 架构的 GDB。
3.
--with-python[=PYTHON]
作用: 启用 Python 支持并可选择性地指定 Python 解释器的路径。GDB 支持 Python 插件,因此 Python 支持对于扩展 GDB 功能非常重要。
默认: 如果没有提供路径,GDB 会自动查找系统中的 Python。
示例:
--with-python=/usr/bin/python3如果你不指定路径,你可以使用:
--with-python=yes这会让
configure脚本自动找到可用的 Python 解释器。4.
--enable-tui
作用: 启用 TUI(Text User Interface,文本用户界面)模式,这使得 GDB 提供类似于
vi和emacs的命令行界面。示例:
--enable-tui启用 TUI 模式后,GDB 会有分屏窗口用于显示源代码和寄存器内容等,非常适合调试时查看复杂的程序状态。
5.
--disable-nls
作用: 禁用 NLS(Native Language Support,本地语言支持),即禁用国际化功能。如果你不需要在调试器中显示非英语的本地化内容,可以选择禁用此选项。
示例:
--disable-nls6.
--with-gmp=DIR和--with-mpfr=DIR
作用: 指定 GMP 和 MPFR 的安装路径,GDB 需要这两个库来进行高精度数学计算。GMP 和 MPFR 是很多编译器和调试器的数学库依赖项。
示例:
--with-gmp=/usr/local --with-mpfr=/usr/local7.
--disable-werror
作用: 在编译过程中,GDB 默认会将所有警告视为错误。启用这个选项可以避免警告被视为错误,从而使编译能够继续,即使出现了非致命性警告。
示例:
--disable-werror8.
--enable-targets=TARGETS
作用: 启用对多个目标架构的支持。GDB 可以在一个实例中支持多个不同的架构,因此可以同时调试不同平台的程序。
示例:
--enable-targets=all这将启用所有支持的目标架构,但你也可以指定特定架构:
--enable-targets=riscv64-unknown-elf,x86_64-pc-linux-gnu...
7. 编译并安装
使用 make 编译 GDB,并指定使用多核编译以提高编译速度:
make -j$(nproc)
接下来,运行 make install 安装编译好的二进制文件到指定的安装目录中:
make install
遇到权限问题使用:
sudo make install如果你不希望使用
root权限或者不想将文件安装到/root目录,可以在配置时指定一个你有写权限的路径(例如:你的home目录)。你需要在configure阶段指定一个新的--prefix目录,如下所示:../configure --prefix=$HOME/apps/gdb-14.2/build-riscv64 --with-python=/usr/bin/python3 --target=riscv64-unknown-elf --enable-tui=yes
8. 确认 GDB 二进制文件
生成的 GDB 二进制文件位于 build-riscv64/bin/ 目录下。通过 --version 来检查 GDB 二进制文件(相对build-riscv64目录):
./bin/riscv64-unknown-elf-gdb --version
9. 配置环境变量
你可以将该目录( build-riscv64/bin/)添加到系统的 PATH 环境变量中,以便在终端中全局使用 GDB:
export PATH="/root/qemu/gdb-14.2/build-riscv64/bin:$PATH"
根据你选择的安装路径修改。
为了在每次登录时自动生效,可以将该行代码添加到你的 ~/.bashrc 文件中,并执行以下命令使其立即生效:
source ~/.bashrc
确认环境变量,检查版本号:
riscv64-unknown-elf-gdb --version
10. 安装 GDB Dashboard 扩展
为了增强 GDB 的使用体验,可以安装 GDB Dashboard,它是一个用 Python 编写的启动扩展,提供了更多调试功能和用户界面。你可以使用以下命令将 GDB Dashboard 下载到 ~/.gdbinit 文件中:
wget -P ~ https://github.com/cyrus-and/gdb-dashboard/raw/master/.gdbinit
安装完成后,每次启动 GDB 时,GDB Dashboard 都会自动加载并提供更加友好的调试界面。
通过以上步骤,你就成功编译并安装了 GDB,并且安装了 GDB Dashboard 扩展工具。你现在可以使用这个定制的 GDB 来调试 RISC-V 架构的项目。
等一下,安装好了,怎么用?
GDB使用
在安装完 GDB 之后,如果你想开始使用 GDB 进行调试,了解 Makefile 是一个很好的起点。Makefile 是在构建项目时控制编译和链接过程的重要工具,它定义了如何将源代码编译为可执行文件。通过 Makefile,你可以快速完成复杂的编译工作,而不用手动输入一长串编译命令。
1. 了解 Makefile 和 GDB 调试
Makefile 是一个脚本文件,通常用于控制 C、C++ 或其他编译型语言的构建过程。它能够自动化编译、链接、清理等任务。GDB 可以用于调试你编译出来的可执行文件,因此理解 Makefile 的工作流程可以帮助你正确生成可调试的目标文件。
基本的 Makefile 结构
target: dependencies
command
- target:目标文件(通常是编译生成的可执行文件)。
- dependencies:生成该目标文件所依赖的源文件或其他目标文件。
- command:为生成目标文件执行的命令。
基本示例
假设我们有一个简单的 C 程序 hello.c,它的内容如下:
#include <stdio.h>
int main() {
printf("Hello, world!\n");
return 0;
}
我们可以写一个最基本的 Makefile 来编译这个程序:
hello: hello.c
gcc -g -o hello hello.c
- hello:这是目标文件,即生成的可执行文件。
- hello.c:这是依赖文件,指明生成
hello需要依赖hello.c源代码文件。 - gcc -g -o hello hello.c:这是生成
hello的命令,其中-g选项表示生成带有调试信息的可执行文件,方便后续的 GDB 调试。
请确保你在
Makefile中使用 Tab 而不是空格来缩进命令行。
编译命令
在终端中输入以下命令执行 Makefile 以编译程序:
make
这会生成一个名为 hello 的可执行文件。
最基础的 GDB 调试例子
现在,我们有了一个带有调试信息的 hello 可执行文件,可以使用 GDB 进行调试。下面是最基础的调试步骤:
-
启动 GDB:
gdb ./hello -
运行程序:
run(或简写r)在 GDB 中运行可执行文件:
run -
设置断点:
break(或简写b)设置断点的位置,例如在
main函数处设置断点:break main -
单步执行:
step(或简写s)单步执行代码,进入函数:
step -
下一步:
next(或简写n)单步执行代码,但不进入函数:
next -
查看变量:
print打印变量的值:
print var_name -
继续执行:
continue(或简写c)继续执行程序,直到下一个断点或程序结束:
continue -
退出 GDB:
quit(或简写q)退出 GDB 调试器:
quit
riscv64-unknown-elf-gdb和gdb的区别
riscv64-unknown-elf-gdb:
- 专门用于调试 RISC-V 架构的裸机程序(即不依赖操作系统的嵌入式系统开发,或类似环境)。
- 这个工具通常与嵌入式开发的交叉编译工具链配合使用,调试的是目标平台上的代码(比如 RISC-V 处理器上的代码)。
- 调试的程序通常是裸机(
bare-metal)或者没有完整的操作系统(如实时操作系统 RTOS),通常生成的程序格式为ELF文件。普通的 gdb:
- 用于调试本地的、标准操作系统(如 Linux、macOS 等)上运行的程序。
- 这种
gdb调试的是本地平台上的程序,比如在 x86 或 ARM 架构的机器上编译并运行的程序。- 它主要用于调试操作系统下运行的用户态程序,如 C/C++、Go 等编译后的可执行文件。
使用场景
riscv64-unknown-elf-gdb:如果你在做 RISC-V 平台的开发,尤其是开发裸机程序、操作系统内核、固件或者嵌入式系统,那么这个是你要用的调试工具。
标准 gdb:如果你在调试本地计算机上的应用程序,或者使用标准的桌面或服务器环境来开发 C/C++ 程序,那么你应该使用普通的
gdb。它们可以共存。两者是不同的工具链,分别服务于不同的架构和开发场景。在同一个系统上同时安装它们是完全可以的。你只需要根据当前调试的目标来选择合适的
gdb版本。总结:如果你是做嵌入式开发或者 RISC-V 开发,使用
riscv64-unknown-elf-gdb;如果是一般的桌面应用程序开发,使用本地的gdb。
2. Hello, world!\n✖️10
下面是一个简单的 C 语言程序,它会打印 "Hello, world!" 10 次:
代码:hello.c
#include <stdio.h>
int main() {
for (int i = 0; i < 10; i++) {
printf("Hello, world!\n");
}
return 0;
}
使用 Makefile 编译
创建一个 Makefile,如下所示:
hello: hello.c
gcc -o hello hello.c
编译和运行步骤
-
将代码保存到文件
hello.c。 -
创建
Makefile,并确保使用 Tab 缩进命令行。 -
在终端运行
make命令:make -
编译完成后,运行生成的可执行文件:
./hello
输出结果
Hello, world!
Hello, world!
Hello, world!
Hello, world!
Hello, world!
Hello, world!
Hello, world!
Hello, world!
Hello, world!
Hello, world!
这个程序会通过一个简单的 for 循环,打印 "Hello, world!" 10 次。
3. GDB 调试界面
下面我们来使用 GDB 调试Hello, world!✖️10:
启动 GDB
gdb ./hello
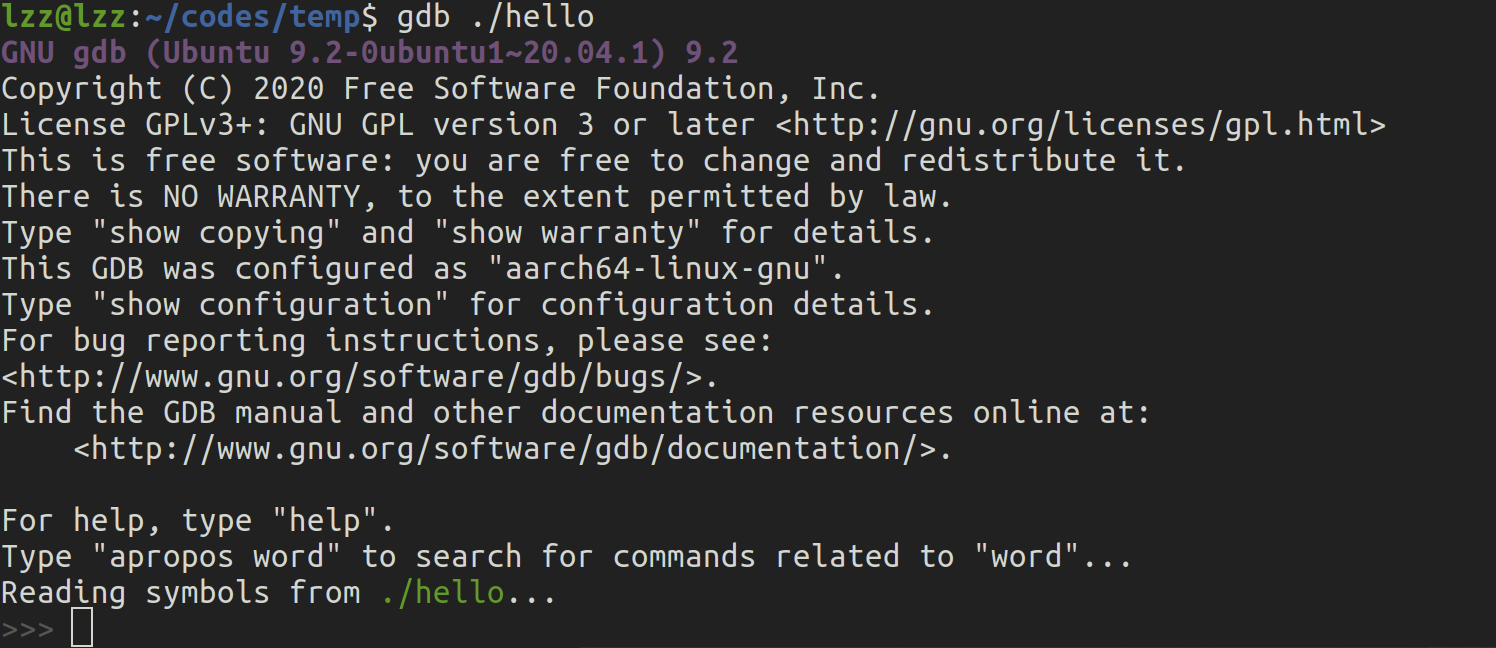
设置断点:break(或简写 b)
设置断点的位置,例如在 main 函数处设置断点:
break main

4. 运行程序:run(或简写 r)
在 GDB 中运行可执行文件:
run
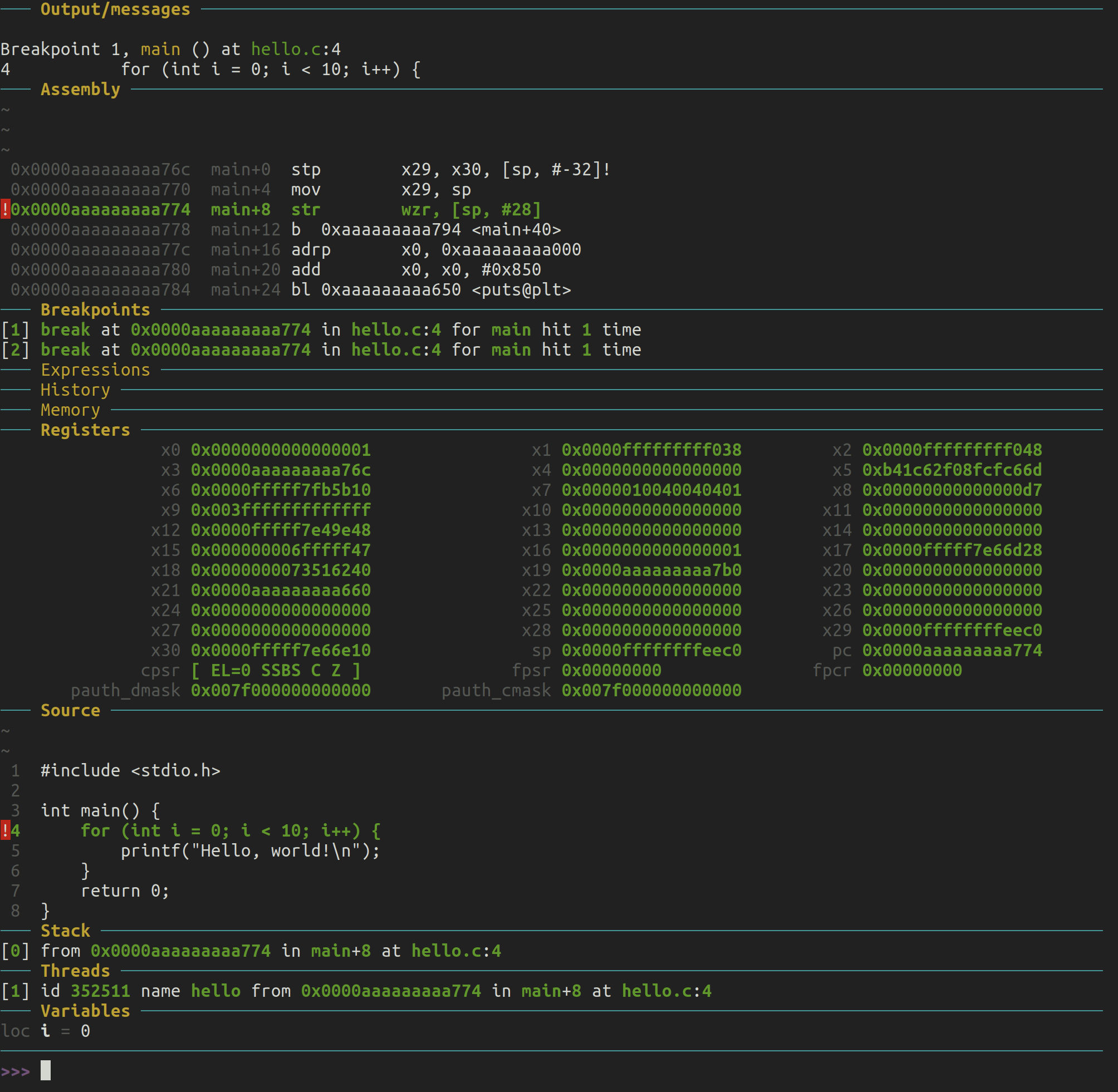
1. Output/messages (输出/消息)
在这一部分,我们可以看到调试器捕获到的断点信息和程序状态:
Breakpoint 1, main () at hello.c:4
4 for (int i = 0; i < 10; i++) {
调试器在文件 hello.c 的第4行命中了断点,这是 main 函数开始的地方。通过命令 break main,调试器在进入 main() 函数的第一行代码前暂停程序执行。这个命令非常常见,尤其在调试阶段,它允许开发者从程序的主入口函数开始检查并控制执行流程。
第4行包含一个 for 循环,循环条件为 i < 10,即这个循环会执行10次。调试器在这里暂停,等待用户的进一步指令。
2. Assembly (汇编指令)
这一部分展示了与 main 函数相关的汇编代码,说明了程序在底层机器语言中的执行方式。
汇编部分展示了程序在 ARM 架构下的指令。这里的汇编指令是根据 ARM64 指令集生成的,如果这个程序运行在 x86 或其他架构下,汇编代码将会有所不同。
0xaaaaaaaaa774 <+0>: stp x29, x30, [sp, #-32]!
0xaaaaaaaaa778 <+4>: mov x29, sp
0xaaaaaaaaa77c <+8>: str wzr, [sp, #28]
0xaaaaaaaaa780 <+12>: bl 0xaaaaaaaaa794 <main+40>
0xaaaaaaaaa784 <+16>: adrp x0, 0xaaaaaaaaa000
0xaaaaaaaaa788 <+20>: bl 0xaaaaaaaaa650 <puts@plt>
这里的汇编代码是编译器将C代码翻译为机器可执行指令的结果。每一行表示一条指令,其中包括:
stp指令:保存寄存器的值,通常在进入函数时保存调用者的寄存器状态(x29和x30)。mov指令:将sp(栈指针)的值移动到x29,用以设置帧指针。str指令:将wzr(零寄存器)的值存储到内存中,可能用于初始化变量。bl指令:调用位于main+40的子函数。adrp指令:将地址加载到寄存器中,这里是x0。bl指令:调用puts函数,它通常用于输出字符串。
这些指令显示了函数调用时的常见序列:保存调用者寄存器、设置栈指针、调用其他函数以及返回。
3. Breakpoints (断点)
[1] break at 0xaaaaaaaaa774 in hello.c:4 for main hit 1 time
这段信息显示在文件 hello.c 的第4行(通过命令 break main在进入 main() 函数的第一行代码前)设置了一个断点,程序已经命中这个断点1次。这表明程序执行到这个位置后暂停下来。
4. Registers (寄存器)
x0 0xaaaaaaaaa76c x1 0xfffffffffffb1b10 x2 0xfffffffffffb1b08 x3 0x0000000000000000
x4 0x0000000140404041 x5 0xb41c62f08fcf6c6d x6 0x0000000000000007 x7 0x0000000000000000
x8 0xaaaaaaaaa7b0 x9 0x0000000000000001 x10 0x0000000000000000 x11 0x0000000000000000
...
x29 0xfffffffffffeec0 x30 0xaaaaaaaaa774 sp 0xfffffffffffeec0 pc 0xaaaaaaaaa774
这里列出了当前的寄存器值(在 ARM 架构下),包括通用寄存器(x0 到 x30)和栈指针(sp)、程序计数器(pc)。这些寄存器是处理器用来存储数据和指令执行的核心组件:
x0至x7:常用来存储函数参数或局部变量。x29和x30:分别是帧指针(fp)和返回地址(lr)。sp:栈指针,指向当前栈顶位置。pc:程序计数器,指向当前执行的指令地址。
5. Source (源代码)
#include <stdio.h>
int main() {
for (int i = 0; i < 10; i++) {
printf("Hello, world!\n");
}
return 0;
}
这是源代码部分,展示了一个简单的C语言程序。程序在 main() 函数中使用了一个 for 循环,循环条件是 i < 10,每次循环执行 printf("Hello, world!\n"); 打印 "Hello, world!"。执行完循环后,函数返回 0,表示程序正常结束。
这段代码的主要功能是打印10次 "Hello, world!"。通过调试器的输出,我们可以看到程序在循环开始处暂停,因为我们在第4行设置了断点。
6. Stack (栈)
from 0x0000aaaaaaaaa774 in main+8 at hello.c:4
这一部分展示了调用栈,当前函数是 main,位于地址 0xaaaaaaaaa774,并且在执行第4行代码时中断。栈帧的信息可以帮助我们理解程序的执行顺序和函数调用层次。
7. Threads (线程)
id 352511 name hello from 0x0000aaaaaaaaa774 in main+8 at hello.c:4
此部分显示了当前正在运行的线程信息:
id:线程ID,表示正在执行的线程。name:线程的名称,这里是hello,与程序相关。from:表示线程暂停的位置,即main函数中的第4行代码。
8. Variables (变量)
i = 0
这一部分显示当前循环中的变量 i 的值为0。这表明 for 循环尚未执行,程序刚刚在循环开始时暂停。通过观察变量的值,开发者可以验证程序的逻辑是否按预期运行。
5. 运行后的选择
在使用 GDB 调试程序时,当我们在断点处暂停程序后,可以使用不同的命令来控制程序的执行。以下是几种常见的调试命令,它们提供了不同的执行控制方式:
1. s(step) - 逐步执行代码
step 命令用于逐行执行代码。如果当前行是一个函数调用,step 会进入该函数,并继续逐行调试函数内部的代码。这个命令特别适用于你想要深入了解函数内部逻辑的情况。
2. si(stepi) - 逐步执行汇编指令
stepi 命令用于逐条执行汇编指令,而不是按源码逐行执行。它非常适合用于低层次调试,尤其是在检查汇编代码或理解底层执行逻辑时有帮助。
3. n(next) - 下一行代码
next 命令与 step 类似,但是它不会进入函数内部。如果当前行包含一个函数调用,next 会执行整个函数,直到返回到当前函数的下一行。这个命令适用于不关心函数内部细节,而是想要快速跳过函数的情况。
4. c(continue) - 继续运行
continue 命令告诉程序继续运行,直到遇到下一个断点或程序正常结束。如果你想暂时跳过调试的细节,并观察程序是否能够完整执行,这是一个常用的命令。
5. finish - 跳出当前函数
finish 命令用于让程序继续运行,直到当前函数执行完毕并返回到调用该函数的地方。这可以帮助你快速退出正在调试的函数,而不需要逐行跟踪其余的代码。
6. 使用si 逐步执行汇编指令

这段汇编代码对应的是 main 函数的开始部分,尤其是在处理 for 循环中变量 i 的初始化和条件判断。ARM 汇编指令 str wzr, [sp, #28] 对应的就是 int i = 0 的初始化,而后续的 ldr w0, [sp, #28] 和 cmp w0, #0x9 则是对 i 进行的条件判断与循环控制。如果使用的是其他架构(如 x86),这些汇编代码会有所不同,但逻辑仍然是相同的,即通过栈帧管理和寄存器操作来处理局部变量和循环条件。
1. stp x29, x30, [sp, #-32]!
这条指令首先做了两件事:
- 保存帧指针(x29)和链接寄存器(x30)到栈中:
x29是帧指针寄存器,x30是链接寄存器(用于存储返回地址)。这一步是为了保存调用者的上下文,以便稍后函数返回时可以恢复。 - 调整栈指针(sp)分配32字节空间:栈指针
sp向下移动32字节,用于当前函数的局部变量和其他信息的存储。这通常是进入一个新栈帧的标准操作。
2. mov x29, sp
- 将当前栈指针
sp的值复制到帧指针x29:这一步的作用是更新x29,标记当前栈帧的起始位置。x29将作为新的帧指针,在整个函数执行期间,帮助管理局部变量和调用者栈帧的访问。
3. str wzr, [sp, #28](当前位置,si后发生)
- 将
wzr(零寄存器)的值存储到栈上的某个偏移位置:在 ARM 中,wzr是一个常量寄存器,总是等于零。这里将 0 存储在栈指针偏移28字节的位置。这很可能是初始化局部变量int i,因为在 C 代码的for (int i = 0; i < 10; i++)中,i初始化为 0。
根据标准 C 代码编译后的行为,i 很可能被分配到栈上偏移量 28 的位置,这条指令是在初始化 i 为 0。
si
接下来发生的事情
4. bl 0xaaaaaaaaa794 <main+40>
- 分支并链接:
bl指令将跳转到main+40处,保存当前的返回地址到x30。在main+40,你给出的代码展示了下一组与for循环控制有关的汇编指令。
继续si,跳转到 main+40 处
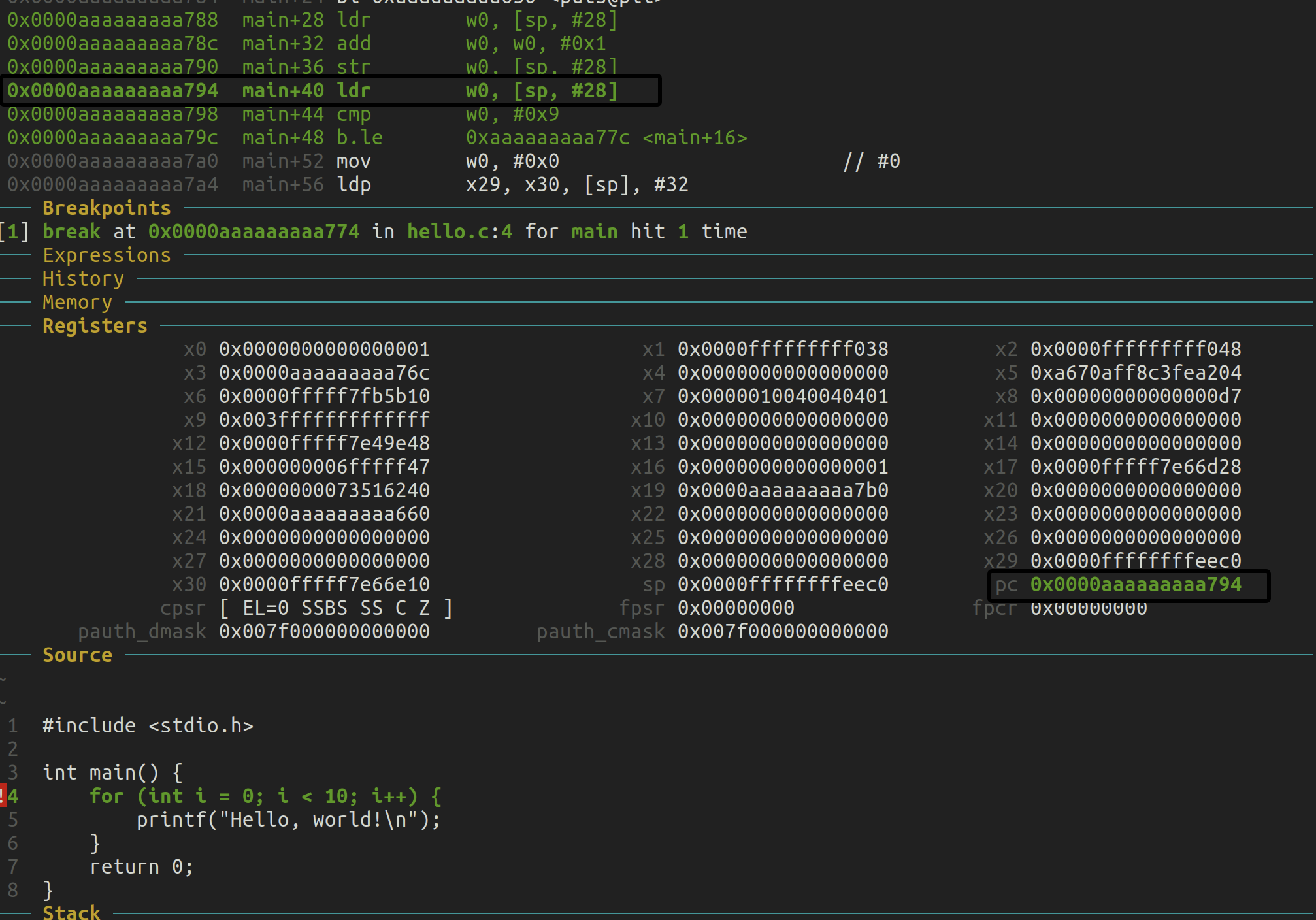
5. ldr w0, [sp, #28]
- 从栈中加载
i的值:这里从栈的28字节偏移处(也就是之前存储i的位置)加载值到寄存器w0。此时w0的值是 0,因为之前将 0 存入了栈中的该位置。
在 ARM64 架构中,
w0是一个 32 位的通用寄存器,它经常用于存储函数的返回值或者函数参数。在调试过程中,特别是在使用 GDB 的时候,我们可以直接查看寄存器的值,包括w0。
查看寄存器: 在 GDB 中,可以使用以下命令来查看所有寄存器的值,
info registers:(gdb) info registers输出将包含所有通用寄存器的值,包括
w0。例如,你可能会看到如下输出:x0 0x0000000000000001 w0 0x00000001 x1 0x0000000000000000 w1 0x00000000 x2 0x0000000000000000 w2 0x00000000其中,
x0是 64 位寄存器,而w0是它的低 32 位部分。w0的值就是寄存器w0当前存储的 32 位数据。单独查看
w0: 如果你只想单独查看w0的值,可以使用以下命令:(gdb) print $w0GDB 会输出寄存器
w0的当前值,例如:$1 = 1单步执行并查看: 如果你想在单步执行指令时查看
w0的值,可以使用step或next命令进行单步调试,每执行一步都可以使用info registers或print $w0来查看w0的更新情况。
si
6. cmp w0, #0x9
- 比较寄存器
w0(i的值)和 9:这是for (int i = 0; i < 10; i++)循环的条件部分。这里i被比较是否小于等于 9(即i < 10)。
si
7. b.le 0xaaaaaaaaa77c <main+16>
- 条件跳转:如果
w0(i的值)小于等于9,则跳转到main+16,也就是循环体部分。如果条件为真,这会跳回到之前执行的部分,循环继续。
关联到 C 代码中的 for (int i = 0; i < 10; i++)
结合汇编代码与 C 代码,流程如下:
- 在进入
main函数时,栈帧被设置,局部变量i被分配到栈的偏移28字节的位置。 str wzr, [sp, #28]将i初始化为 0。- 程序执行循环条件检查,
ldr w0, [sp, #28]从栈中加载i的值,cmp w0, #0x9与 9 进行比较。 - 如果
i <= 9,则通过b.le跳转回循环体,执行printf("Hello, world!\n")语句,之后再递增i,继续下一次循环。 - 当
i超过 9,循环结束,程序跳出for循环。
7. 进入循环
s(或者3个si)
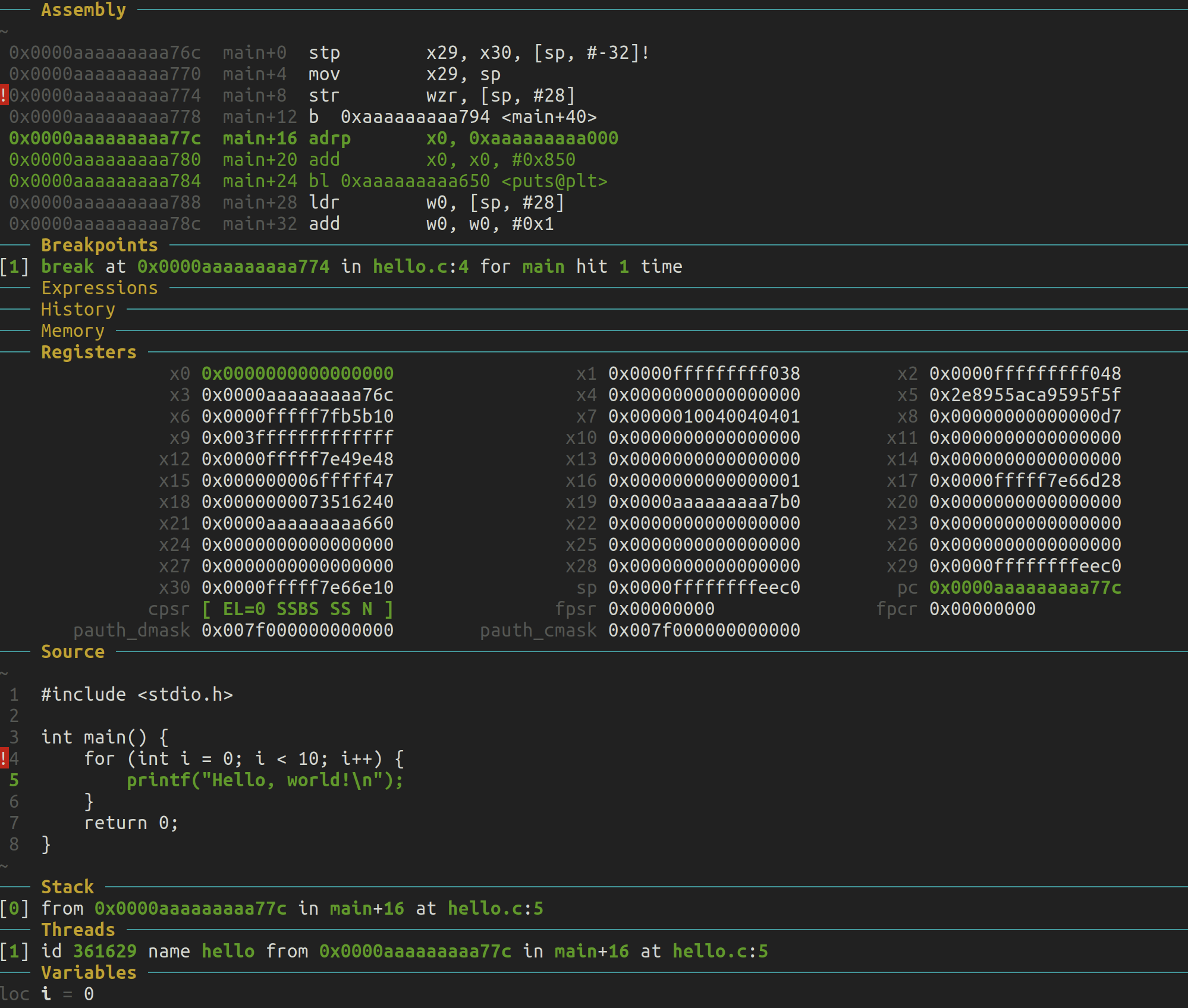
这段代码表示调用了 puts 函数,并且在调用 puts 之前对寄存器 x0 进行了修改:
0x0000aaaaaaaaa77c main+16 adrp x0, 0xaaaaaaaaa000
0x0000aaaaaaaaa780 main+20 add x0, x0, #0x850
0x0000aaaaaaaaa784 main+24 bl 0xaaaaaaaaa650 <puts@plt>
-
adrp x0, 0xaaaaaaaaa000(0x0000aaaaaaaaa77c):- 这是 ARM64 中的“Page-relative address”指令,用来加载一个基址(page address)到寄存器
x0。在这里,它将地址0xaaaaaaaaa000的页基址加载到x0。
- 这是 ARM64 中的“Page-relative address”指令,用来加载一个基址(page address)到寄存器
-
add x0, x0, #0x850(0x0000aaaaaaaaa780):- 将
x0(基址)加上偏移量0x850。这个操作的目的是构建一个完整的地址,用于后续操作。这种模式在调用外部函数时很常见,比如准备puts函数的参数。
- 将
-
bl 0xaaaaaaaaa650 <puts@plt>(0x0000aaaaaaaaa784):bl(Branch with Link)是 ARM64 中的函数调用指令。在这里,它调用了puts@plt,这是一个外部函数puts的地址。x0中的值通常会被用来作为函数参数传递给puts。- 在这个调用中,
x0存储了puts的参数(通常是一个指向要打印的字符串的地址)。
这里即将进入printf函数。
8. 函数调用规则
printf 或者 puts 这样的函数调用会使用 w0 寄存器(或者更广泛的 x0 寄存器)来传递函数参数。在 ARM64 架构中,函数参数通常通过寄存器传递,w0 或者 x0(根据参数的大小,使用 32 位的 w0 或 64 位的 x0)是第一个用于传递参数的寄存器。
在 ARM64 架构中,w0 和 x0 寄存器(分别为 32 位和 64 位寄存器)是第一个用于函数参数传递的寄存器,通常函数调用过程中会修改这些寄存器。实际上,函数调用的过程中,寄存器 w0 或 x0 不仅仅是 printf 或 puts 会修改,几乎所有的函数调用,只要它需要传递参数或者返回值,都会对这些寄存器进行使用和修改。
ARM64 函数调用规则(AArch64 ABI)
ARM64 的调用约定(ABI, Application Binary Interface)定义了函数如何传递参数和接收返回值。根据这个约定:
-
参数传递:
- 函数的前 8 个参数通过寄存器
x0到x7传递。如果是 32 位参数,会用到寄存器的低 32 位,也就是w0到w7。 w0和x0是第一个用于传递参数的寄存器,因此任何需要第一个参数的函数都会使用w0或x0。
- 函数的前 8 个参数通过寄存器
-
返回值传递:
- 函数返回值也是通过
x0或w0传递的。如果函数有返回值(无论是整数、指针等),该值会存储在x0或w0中。所以,当一个函数返回时,你可以在x0或w0中找到返回值。
- 函数返回值也是通过
-
函数调用后,
w0和x0的值变化:- 如果函数有返回值,调用完函数后
x0或w0中会包含返回值。 - 如果函数没有返回值,
x0或w0的值可能没有明确规定,因此在调用之后可能会被修改,不能再依赖它保存之前的值。
- 如果函数有返回值,调用完函数后
更广泛的修改 w0 或 x0 的情景
以下是一些更常见的情景,展示了在函数调用过程中如何修改 w0 或 x0:
-
参数传递时:
- 任何需要传递第一个参数的函数调用都会使用
w0或x0。无论是标准库函数、用户定义的函数还是系统调用,它们都会将第一个参数存储在w0或x0中。
示例:
mov w0, #10 // 将整数 10 存储到 w0,作为第一个参数传递 bl my_function // 调用函数 my_function(w0=10) - 任何需要传递第一个参数的函数调用都会使用
-
函数返回值:
- 如果函数有返回值,返回值通常会放在
w0或x0中。如果函数调用后你检查w0,看到的值通常是函数的返回结果,而不再是之前的循环变量或其他值。
示例:
bl my_function // 调用函数 my_function mov x1, x0 // 将返回值(保存在 x0 中)存储到 x1 - 如果函数有返回值,返回值通常会放在
-
系统调用:
- 在 ARM64 架构下,系统调用也是通过寄存器传递参数。
x0是传递给系统调用的第一个参数的寄存器,同时系统调用的返回值也通过x0传递。
示例:
mov x8, #93 // 系统调用号(例如 exit) mov x0, #0 // 将 0 作为系统调用的第一个参数 svc #0 // 发出系统调用 - 在 ARM64 架构下,系统调用也是通过寄存器传递参数。
-
库函数调用:
- 类似
printf、malloc等库函数也会使用x0或w0来传递参数。对于这些函数来说,它们会读取w0中的值,并在其完成时修改w0,以传递返回值。
- 类似
当前我们依旧处于即将进入printf函数的位置。
在函数调用之前查看 w0 的值:
info registers w0
或
print $w0

可以看到当前i的值为0。
接下来如果使用si,你将进入printf函数的实现,这里我们选择忽略内部的实现,使用next跳转到直接执行完printf函数的位置,你也可以尝试si和finish执行完printf函数。
n
在函数返回后查看返回值:

如果函数返回一个值,w0 或 x0 中将存储这个值。对于 32 位返回值,使用 w0,对于 64 位返回值,使用 x0。
9. printf 函数
printf 是 C 标准库中的一个非常常用的函数,它用于格式化输出。它的功能可以概括为:接受一系列参数,根据指定的格式化字符串,将这些参数转换为对应的字符串,然后输出到标准输出(通常是控制台)上,并返回成功输出的字符数量。
printf 函数的工作原理概述
-
函数声明:
int printf(const char *format, ...);const char *format:格式化字符串,定义了输出内容的结构、顺序和格式。...:可变参数,这些是根据format字符串指定的类型,传递给printf的数据。- 返回值:
printf的返回值是成功打印的字符总数。
-
参数的解释:
- 格式化字符串:
printf第一个参数是格式化字符串,其中可以包括文字和格式说明符(如%d,%s,%f等)。这些说明符告诉printf如何处理后面的参数。 - 可变参数:
printf函数是一个“可变参数”函数(variadic function),它可以接受任意数量和类型的参数,但这些参数的数量和类型必须与格式化字符串中的说明符相匹配。
- 格式化字符串:
-
返回值:
printf成功执行后,会返回它实际输出的字符数(包括空格和换行符等)。如果发生错误,printf返回一个负值。
printf 内部工作流程
printf 的内部工作可以概括为以下步骤:
-
解析格式化字符串:
printf首先解析它接收到的第一个参数,即格式化字符串。它会从左到右扫描字符串,直到遇到格式说明符(如%d,%s,%f)。这些格式说明符指示printf如何格式化后续的参数。 -
处理可变参数: 对于每一个格式说明符,
printf会依次从剩余的可变参数列表中获取对应类型的参数。然后,它将这个参数格式化为对应的字符串表示。- 如果遇到
%d,printf会从参数中获取一个int类型的值,并将其格式化为十进制数字。 - 如果遇到
%s,printf会从参数中获取一个char*类型的字符串,并将其直接打印。 - 如果遇到
%f,printf会从参数中获取一个float或double类型的浮点数,并将其格式化输出。
- 如果遇到
-
格式化输出:
printf将解析的内容和从参数中提取的值组合在一起,然后输出到标准输出(通常是控制台)。 -
返回输出字符数:
printf在成功输出所有内容后,会返回打印到标准输出的字符数。这包括所有输出的字符,但不包括最终的\0终止符。
printf 函数的示例
以下是一个简单的例子,展示 printf 的参数如何与格式化字符串结合使用:
int main() {
printf("Hello, world!\n");
return 0;
}
在这个例子中,printf 输出的字符串是 "Hello, world!\n"。如果你数一数,这个字符串包含 14 个字符:
Hello, world!是 13 个字符。\n是换行符,算作一个字符。
因此,printf 返回的值是 14,表示总共输出了 14 个字符。
10. 继续循环
si

这段汇编代码回到了 ARM64 架构下的for循环执行过程,具体是在一个循环体中对变量 i 进行加载、加1、比较的操作。对应的 C 代码中的循环部分:
for (int i = 0; i < 10; i++) {
// do something
}
1. ldr w0, [sp, #28] (地址:0x0000aaaaaaaaa788)
- ldr(Load Register):从内存中加载数据到寄存器。
w0:表示 ARM64 的 32 位通用寄存器w0,存储的是变量i的值。[sp, #28]:表示从栈指针(sp)加上偏移量 28 个字节的位置读取数据,加载到寄存器w0中。
解释:
这里的指令从内存中读取变量 i(存储在栈中 sp + 28 的位置),并将其加载到 w0 寄存器中,供后续操作使用。
2. add w0, w0, #0x1 (地址:0x0000aaaaaaaaa78c)
- add:加法运算。
w0, w0, #0x1:将寄存器w0的值加 1,并将结果保存在w0中。
解释:
这里的指令对 w0(也就是变量 i)的值加 1,更新后的值存储回 w0。
3. str w0, [sp, #28] (地址:0x0000aaaaaaaaa790)
- str(Store Register):将寄存器中的值存储到内存中。
w0:这是存储i变量的新值的寄存器。[sp, #28]:表示将寄存器w0中的值存储到栈指针sp偏移量为 28 的位置。
解释:
将更新后的变量 i(即 w0 中的值)存回栈中的 sp + 28 位置。
4. ldr w0, [sp, #28] (地址:0x0000aaaaaaaaa794)(与 main 函数开始时重复)
- ldr(Load Register):从内存中加载数据到寄存器。
[sp, #28]:表示从sp偏移 28 个字节的位置加载数据到w0。
解释:
再次将变量 i(存储在 sp + 28 的位置)的值加载到寄存器 w0 中,准备进行比较。
5. cmp w0, #0x9 (地址:0x0000aaaaaaaaa798)
- cmp(Compare):比较两个值,常用于控制流中的分支判断。
w0, #0x9:比较w0中的值(即变量i的值)与 9。
解释:
这里进行比较,判断变量 i 的值是否小于 10(i < 10),为后续控制流做准备。如果 i 小于 10,则继续循环;否则跳出循环。
6. b.le 0xaaaaaaaaa77c <main+16>
- 条件跳转:如果
w0(i的值)小于等于9,则跳转到main+16,也就是循环体部分。如果条件为真,这会跳回到之前执行的部分,循环继续。
汇总解释
这段代码展示了一个典型的 for 循环核心操作:
- 从内存中加载循环变量
i的当前值。 - 将
i加 1。 - 更新内存中的
i值。 - 再次加载
i,并与 9 进行比较,决定是否继续执行循环。
这些指令就是实现 for (int i = 0; i < 10; i++) 的循环控制逻辑。
11. 继续运行到退出
接下来你可以尝试多次n,同时观察i和寄存器x0的值,大概变化像这样0 14 1 14 2 14 3 14...,直到循环结束退出。
Makefile似乎没怎么用上?我们可以开头的
Makefile中添加 GDB 的调试目标,这样可以方便你使用 GDB 进行调试。基本的Makefile将生成一个可执行文件hello,并且支持使用 GDB 进行调试。在原来的
Makefile基础上,我们添加一个名为debug的目标来启动 GDB。具体操作如下:修改后的
Makefile# 定义目标文件 hello: hello.c gcc -g -o hello hello.c # 运行程序 run: hello ./hello # 定义调试目标 debug: hello gdb ./hello # 定义清理目标,删除生成的文件 clean: rm -f hello解释
hello: hello.c:
- 这表示生成目标文件
hello需要依赖源文件hello.c。gcc -g -o hello hello.c: 使用 GCC 编译生成hello,并且通过-g选项生成带有调试信息的可执行文件,方便后续调试。运行程序目标
run:
run: hello:这个目标依赖于hello,确保可执行文件已经生成。./hello:执行生成的hello程序。gdb: hello:
- 这是一个新的目标,名字是
gdb,它依赖于目标hello。也就是说,执行make gdb会首先确保生成可执行文件hello,然后运行 GDB。gdb ./hello: 通过 GDB 启动hello可执行文件,方便进行调试。clean:
- 这是一个清理目标,用于删除生成的
hello文件,保持工作目录整洁。rm -f hello: 强制删除hello,不会提示错误。使用方法
运行
make或make hello来编译程序。make输入
make run来运行编译生成的hello程序。make run运行
make gdb来启动 GDB 并调试hello。make gdb运行
make clean来清理生成的可执行文件。make clean现在这个
Makefile可以完成编译hello.c并生成可执行文件hello。当你需要使用 GDB 进行调试时,只需要运行make gdb,它会自动启动 GDB 并加载可执行文件hello,方便调试工作。
通俗地说,
Makefile是一种用于自动化编译和管理项目中文件依赖的工具。它的主要作用是通过定义规则告诉计算机如何编译和链接项目中的源代码文件,省去你每次手动输入命令的麻烦。下面是一个更加直观的解释:1.
Makefile是什么?
Makefile就像一张“说明书”,告诉编译器和开发工具应该怎么去处理你的代码。想象一下,你有一个项目,有很多源代码文件,比如.c文件或者.cpp文件。这些文件需要被编译成一个最终的可执行文件,而Makefile就是用来组织、管理和自动执行这些步骤的工具。
- 为什么要用
Makefile?
- 如果项目有很多文件,你不需要每次手动输入命令来编译、链接这些文件。
Makefile能追踪文件的变化,只编译那些发生了变化的文件,节省时间。- 它让编译的步骤更有条理,一次输入命令就可以自动完成很多操作。
2.
Makefile的基本构造一个简单的
Makefile包含两部分内容:
- 目标文件(想生成的文件,通常是可执行文件)。
- 规则(告诉你如何生成目标文件)。
举个例子
假设你有一个源代码文件叫
hello.c,它是用 C 编写的程序。你希望生成一个叫hello的可执行文件。你平常需要手动输入这样的命令来编译它:gcc -o hello hello.c这次,我们可以写一个最简单的
Makefile:hello: hello.c gcc -o hello hello.c3. 如何理解这个
Makefile?
hello: hello.c:这里hello是目标,表示我们想生成的文件是hello。hello.c是依赖文件,表示hello的生成依赖于hello.c这个源代码文件。gcc -o hello hello.c:这一行就是生成hello可执行文件的具体指令。它告诉make:当你看到hello.c发生变化时,使用gcc来编译它,并生成可执行文件hello。4.
Makefile的工作原理当你在终端输入
make时,make会去找当前目录中的Makefile,然后按照里面的指令执行编译。
- 如果源代码没有变动,
make会判断出不需要重新编译,跳过这一步。- 如果源代码文件改变了,
make会重新编译生成新的可执行文件。5. 更多功能:自动化和清理
你可以让
Makefile做的不仅仅是编译程序,还可以让它帮助你自动化一些工作,比如清理不需要的文件(比如编译生成的中间文件)。添加一个清理规则
hello: hello.c gcc -o hello hello.c clean: rm hello
clean:这是一个新添加的规则,用于删除生成的hello文件。rm hello:这个命令会删除hello可执行文件。现在,如果你输入
make clean,它就会执行rm hello命令,帮你清理掉生成的文件。6. 完整示例:添加调试和运行规则
假设你还想要运行程序、用 GDB 调试或者清理文件,那么
Makefile可以做更多的事:hello: hello.c gcc -g -o hello hello.c # 生成带调试信息的可执行文件 run: hello ./hello # 运行程序 gdb: hello gdb ./hello # 用 GDB 调试程序 clean: rm -f hello # 清理生成的文件
run:编译好后运行程序。gdb:用 GDB 调试程序。clean:清理生成的可执行文件。7. 为什么
Makefile有用?
- 简化复杂的编译流程:如果你有很多源代码文件,它们相互依赖,
Makefile能够根据这些依赖来确定如何自动编译所有文件,而不需要你一个个去编译。- 节省时间:如果某个文件已经编译好了,没有修改,
Makefile不会重新编译它,只会编译发生了变化的文件。- 自动化项目管理:不仅仅可以用来编译,还可以用来运行程序、清理临时文件,甚至自动化测试。
明白了,让我们开始调试操作系统吧!
riscv64-unknown-elf-gdb和QEMU
接下来我们将结合使用 riscv64-unknown-elf-gdb 和 QEMU 来调试 RISC-V 的程序。QEMU 是一个开源的模拟器,它可以用来模拟不同架构的硬件环境,而 riscv64-unknown-elf-gdb 则是专门为 RISC-V 目标编译的 GDB 调试器。回顾riscv64-unknown-elf-gdb 和 gdb的区别。
一、尝试 Hello, world!\n✖️10
将上节的hello.c复制到一个新的文件夹,我们来尝试使用 riscv64-unknown-elf-gdb 和 QEMU 在 RISC-V 架构下调试它。
1. 编译 RISC-V 程序
首先将hello.c程序为 RISC-V 架构编译。可以使用如下的 gcc 命令来编译你的程序:
riscv64-unknown-elf-gcc -g -o hello hello.c
-g选项会确保编译后的程序包含调试信息,方便 GDB 使用。hello.c是你的源代码文件,hello是编译生成的目标文件(RISC-V 架构的可执行文件)。
2. 使用 QEMU 运行 RISC-V 程序
接下来,我们使用 QEMU 来模拟 RISC-V 环境并运行刚刚编译的 hello 程序。命令如下:
qemu-system-riscv64 -machine virt -nographic -kernel hello.elf -s -S
-machine virt:选择 QEMU 中的虚拟 RISC-V 机器。-nographic:表示不使用图形界面,所有输出通过当前终端处理。-kernel hello:指定要加载并运行的 RISC-V 程序。-s:启用调试模式,会在端口 1234 上开启一个 GDB 服务器。-S:告诉 QEMU 在启动后暂停 CPU,这样我们可以连接 GDB 进行调试,而不会立即运行程序。
此时,QEMU 会启动,但它会处于暂停状态,等待 GDB 连接。
3. 使用 riscv64-unknown-elf-gdb 连接 QEMU
现在,我们使用 GDB 连接到 QEMU 并调试程序。首先启动 riscv64-unknown-elf-gdb:
riscv64-unknown-elf-gdb hello.elf
hello.elf是之前编译的可执行文件,GDB 会加载它的调试信息。
然后在 GDB 中输入以下命令,连接到 QEMU 的调试服务器:
(gdb) target remote localhost:1234
- 这里的
localhost:1234是 QEMU 默认开启的调试端口。
4. 设置断点和调试
现在,你已经成功连接到了 QEMU 模拟的 RISC-V 环境,可以开始调试了。
报错1:等一下?我的第一步编译就出错了

二、RISC-V 裸机编程
在RISC-V裸机编程(bare-metal programming)中,将无法再使用 stdio.h 这样的标准C库头文件,主要原因是裸机编程与操作系统环境的差异。以下是详细的解释:
1. 裸机编程与操作系统的区别
在操作系统(如 Linux、Windows 等)上,C 标准库(包括 stdio.h)依赖操作系统提供的功能和服务来执行输入输出等操作。例如,printf 函数依赖于操作系统提供的系统调用(system call),将数据发送到标准输出设备(如屏幕或终端)。操作系统会管理这些资源和设备,提供文件系统、内存管理、硬件抽象等功能。
而裸机编程中,程序直接运行在硬件上,没有操作系统的帮助,也没有提供类似的系统调用接口。因此,诸如 stdio.h 头文件中定义的标准输入输出函数(如 printf、scanf)都无法工作,因为它们依赖于操作系统来管理硬件资源。
2. stdio.h 的功能依赖
stdio.h 提供的功能主要用于标准输入输出流的操作,包括文件的读取写入和格式化输出。这些功能在操作系统环境下是通过一系列系统调用(例如 POSIX 标准中的 write()、read())实现的。而在裸机环境中:
- 没有文件系统:裸机程序没有操作系统提供的文件系统来管理文件,因此标准输入输出流无法找到目标文件或设备。
- 没有设备驱动程序:操作系统负责管理设备(如显示器、键盘、网络接口等)并提供驱动程序。裸机程序则必须直接操作硬件寄存器与外设通信,而标准库无法提供这样的功能。
例如,在操作系统上使用 printf 输出信息时,实际执行的是系统调用,操作系统会将格式化的字符串写入标准输出设备。而在裸机程序中,没有系统调用,因此 printf 无法正常工作。
3. 替代方案:SBI 调用或直接访问硬件
在裸机环境中,可以通过以下方式来实现与外界的交互:
1) SBI(Supervisor Binary Interface)调用
在 RISC-V 裸机编程中,通常依赖 SBI(Supervisor Binary Interface)提供的接口来执行某些基本的硬件操作。SBI 是 RISC-V 中一个运行在特权模式下的小型运行环境,提供了裸机程序和硬件之间的抽象接口。例如,使用 ecall 指令与 SBI 通信,可以执行控制台输出、关机、时间中断等操作。
类似下面的 sbi_call() 函数,通过 SBI_CONSOLE_PUTCHAR 实现字符输出,而不是使用 stdio.h 的 printf。
#define SBI_CONSOLE_PUTCHAR 0x1
static inline void sbi_call(uint64_t sbi_num, uint64_t arg0) {
register uint64_t a0 asm ("a0") = arg0;
register uint64_t a7 asm ("a7") = sbi_num;
asm volatile ("ecall" : "+r"(a0) : "r"(a7) : "memory");
}
void print_char(char c) {
sbi_call(SBI_CONSOLE_PUTCHAR, c);
}
2) 直接访问硬件
在裸机环境中,常常需要直接操作硬件设备,比如直接写入硬件寄存器来控制串口输出。以 UART(通用异步收发传输器)为例,裸机程序可以通过直接访问串口的寄存器,实现字符的输出和输入,而不需要依赖 stdio.h。
4. RISC-V 裸机编程中的常见输入输出方式
-
UART 串口输出:裸机程序可以通过访问 UART 寄存器,发送数据到终端设备。对于很多裸机程序来说,UART 是最常见的调试输出手段。
-
SBI 调用:RISC-V 提供了 SBI 规范,在裸机程序中,可以通过
ecall指令与 SBI 交互,完成输出字符到控制台的功能,如上面的代码中通过SBI_CONSOLE_PUTCHAR实现字符输出。
5. 在裸机环境中使用 Rust 和 core 库
在 Rust 裸机编程 中,由于没有操作系统的支持,标准库 (std) 同样是不能使用的。因为标准库依赖操作系统提供的功能(如文件系统、网络等)。但是,core 库 是可以使用的,因为它是 no_std 环境中的基础库,不依赖操作系统的功能。
core 库提供了许多基础功能,比如基础的数据类型、数学运算、内存操作等,但不包括 I/O、线程、文件操作等。这样就允许在没有操作系统的裸机环境下编写 Rust 代码。更多内容见下一节。
三、不使用标准库的 Hello World C 代码
现在我们需要将 Hello, world!\n✖️10 替换为一个不使用标准库的 Hello World C 代码。
下面是一个不带标准库的 "Hello, World" C 程序,适用于 riscv64-unknown-elf-gdb 和 QEMU 模拟的 RISC-V 环境。我们将使用 RISC-V 的 SBI(Supervisor Binary Interface)来进行字符输出。
不使用标准库的 Hello World C 代码(适用于 RISC-V 裸机编程)
// hello.c
// 定义标准整数类型(手动定义)
typedef unsigned long long uint64_t;
typedef unsigned int uint32_t;
typedef unsigned char uint8_t;
#define SBI_CONSOLE_PUTCHAR 0x1
static inline void sbi_call(uint64_t sbi_num, uint64_t arg0, uint64_t arg1, uint64_t arg2) {
register uint64_t a0 asm ("a0") = arg0;
register uint64_t a1 asm ("a1") = arg1;
register uint64_t a2 asm ("a2") = arg2;
register uint64_t a7 asm ("a7") = sbi_num;
asm volatile ("ecall"
: "+r"(a0)
: "r"(a1), "r"(a2), "r"(a7)
: "memory");
}
void print_char(char c) {
sbi_call(SBI_CONSOLE_PUTCHAR, c, 0, 0);
}
void print_string(const char* str) {
while (*str) {
print_char(*str++);
}
}
int main() {
print_string("Hello, World! x10 (fake)\n");
while (1) {} // 无限循环,防止程序退出
return 0;
}
代码说明
- 手动定义固定宽度整数类型:由于
stdint.h无法使用,我们手动定义了常见的固定宽度整数类型,比如uint64_t、uint32_t和uint8_t。typedef unsigned long long uint64_t;:定义 64 位无符号整数。typedef unsigned int uint32_t;:定义 32 位无符号整数。typedef unsigned char uint8_t;:定义 8 位无符号整数。
- SBI 调用:我们使用 RISC-V 的 SBI(Supervisor Binary Interface)来向控制台输出字符。SBI 是一种操作系统与底层硬件通信的接口,类似于 x86 架构的 BIOS 中断。
SBI_CONSOLE_PUTCHAR:SBI 提供了控制台输出字符的接口,这个接口编号是 0x1。
sbi_call函数:使用内联汇编指令ecall实现的 SBI 调用,用于与硬件交互。print_char函数:调用sbi_call向控制台输出单个字符。print_string函数:循环调用print_char来输出字符串。main函数:程序的入口,调用print_string输出 "Hello, World! x10 (fake)",之后进入无限循环,防止程序退出。
详细代码说明
1. 定义标准整数类型
typedef unsigned long long uint64_t; typedef unsigned int uint32_t; typedef unsigned char uint8_t;这三行代码定义了标准的无符号整数类型:
uint64_t是无符号 64 位整数(unsigned long long)。uint32_t是无符号 32 位整数(unsigned int)。uint8_t是无符号 8 位整数(unsigned char)。这些类型通常在裸机编程中用于确保明确的位宽,因为不同平台上
int和long的位宽可能有所不同。代码内容只使用了
uint64_t,为了增加代码的健壮性和可移植性,手动定义了额外的整数类型(32 位和 8 位),即便它们在这段代码中没有直接用到。2. SBI Console Putchar 定义
#define SBI_CONSOLE_PUTCHAR 0x1这是一个宏定义,用于指定
SBI调用的编号。SBI_CONSOLE_PUTCHAR的值为0x1,它是 RISC-VSBI调用接口中的一个标识符,用于向控制台输出一个字符。
SBI(Supervisor Binary Interface)是 RISC-V 的一个标准接口,允许裸机程序(运行在机器模式或超级模式的程序)通过ecall指令与底层固件(如 OpenSBI)交互。SBI_CONSOLE_PUTCHAR是SBI的一部分,专门用于字符输出。3. SBI 调用实现
static inline void sbi_call(uint64_t sbi_num, uint64_t arg0, uint64_t arg1, uint64_t arg2) { register uint64_t a0 asm ("a0") = arg0; register uint64_t a1 asm ("a1") = arg1; register uint64_t a2 asm ("a2") = arg2; register uint64_t a7 asm ("a7") = sbi_num; asm volatile ("ecall" : "+r"(a0) : "r"(a1), "r"(a2), "r"(a7) : "memory"); }解释:
函数定义:
sbi_call是一个内联函数(inline函数),表示编译器在调用该函数时不会产生实际的函数调用,而是将函数体嵌入到调用该函数的位置,从而避免函数调用的开销。该函数通过汇编指令ecall来执行SBI调用。寄存器绑定:
register uint64_t a0 asm ("a0") = arg0;通过asm ("a0")将 C 语言中的变量arg0绑定到 RISC-V 的a0寄存器。- 同理,
a1、a2分别绑定到 RISC-V 的a1和a2寄存器,a7寄存器绑定到sbi_num,即SBI调用编号。汇编指令
ecall:
ecall是 RISC-V 中的一个特权指令,用于在机器模式(M-mode)或超级模式(S-mode)下执行系统调用(类似于 x86 架构中的syscall指令)。此指令触发陷入系统的特权模式,通过SBI与底层固件交互。asm volatile声明告诉编译器不要优化掉这个汇编块,并且要确保其副作用会被执行。输入输出约束:
"+r"(a0)表示a0寄存器会在调用前后都被使用,并且在调用过程中可能被修改("read-write")。"r"(a1), "r"(a2), "r"(a7)表示a1、a2和a7作为输入寄存器,指令只会读取这些寄存器的值。"memory"表示该汇编指令会对内存有影响,防止编译器对内存操作进行重排。在 RISC-V 的
SBI调用中,有时可能需要传递多个参数。在这里可以只传递一个字符数据,即arg1和arg2是不必要的,直接使用两个参数即可。提供额外的
arg1和arg2参数,是为了更通用的用途。尽管在print_char中不需要这些参数,但这使得sbi_call更加通用,可以在其他场景中使用更多的寄存器传递额外信息。使用两个参数的版本
static inline void sbi_call(uint64_t sbi_num, uint64_t arg0) { register uint64_t a0 asm ("a0") = arg0; register uint64_t a7 asm ("a7") = sbi_num; asm volatile ("ecall" : "+r"(a0) : "r"(a7) : "memory"); }总结:
该函数通过
ecall发起系统调用,并使用a0到a7寄存器传递参数。a0是返回值寄存器,而a7用于传递SBI编号,a1和a2用于传递额外的参数。4. 输出字符
void print_char(char c) { sbi_call(SBI_CONSOLE_PUTCHAR, c, 0, 0); }解释:
print_char函数用于输出一个字符。它调用了sbi_call函数,将SBI_CONSOLE_PUTCHAR作为sbi_num,并将字符c作为第一个参数(通过a0寄存器传递)。arg1和arg2被设置为 0,因为字符输出不需要额外的参数。5. 输出字符串
void print_string(const char* str) { while (*str) { print_char(*str++); } }解释:
print_string函数用于输出一个字符串。它通过指针str遍历字符串的每个字符,调用print_char输出每个字符,直到遇到字符串末尾的空字符('\0')。每次输出一个字符后,str++使指针指向下一个字符。6. 主函数
int main() { print_string("Hello, World! x10 (fake)\n"); while (1) {} // 无限循环,防止程序退出 return 0; }解释:
字符串输出:
main函数中调用了print_string,输出字符串"Hello, World! x10 (fake)\n"到控制台。无限循环:
while (1) {}是一个空的无限循环,用于防止程序在输出完成后退出。这是因为在裸机环境中,没有操作系统管理程序的退出行为。如果没有这个循环,程序会继续执行到未定义的内存区域,可能导致未定义行为甚至崩溃。
将hello.c内容替换为以上不使用标准库的 Hello World C 代码,再次尝试编译:
riscv64-unknown-elf-gcc -g -o hello hello.c
报错2:还是报错:找不到
crt0.o、-lc和-lgcc

四、不使用默认的启动代码
crt0.o、-lc 和 -lgcc 是编译和链接过程中的重要组成部分,通常在操作系统环境下使用。在裸机编程环境中,编译器报错找不到这些文件或库,原因还是裸机编程的环境与操作系统支持的环境截然不同。
1. crt0.o(C Runtime Object File)
crt0.o 是 C 语言运行时库(C runtime)的启动代码(C runtime startup code)。它是一个对象文件,通常在链接阶段被包含进程序,用于为 C 语言程序的运行做准备。它的主要职责是:
- 设置程序的入口点(通常是
_start)。 - 初始化全局和静态变量。
- 调用
main函数。 - 程序退出时执行清理操作。
在操作系统中的角色
在操作系统(如 Linux)上,crt0.o 会做如下工作:
- 设置栈指针。
- 初始化
.bss和.data段。 - 调用操作系统提供的动态链接器,加载共享库。
- 最后调用
main函数。
在裸机编程中的问题
在裸机编程中,没有操作系统和动态链接器,也不需要操作系统提供的初始化工作。因此,裸机程序通常自行编写启动代码,手动设置栈指针、初始化 .bss 和 .data 段等工作。这就是为什么在裸机环境下不需要 crt0.o,并且会报错找不到它。你需要**提供自己专门的启动文件(通常是汇编代码)**来替代 crt0.o 的功能,比如一个 start.s 文件。
2. -lc(C Standard Library)
-lc 是指链接标准 C 库(libc)。C 标准库提供了许多基本的功能,比如:
- 输入输出(
printf、scanf等)。 - 字符串处理(
strlen、strcpy等)。 - 数学运算(
sin、cos等)。
在操作系统中的角色
在有操作系统支持的环境中,C 标准库依赖操作系统提供的系统调用来实现许多功能。例如,printf 函数通过系统调用将字符串输出到控制台,而文件操作、内存分配等功能也都依赖操作系统的支持。
在裸机编程中的问题
裸机编程没有操作系统,因此也没有文件系统、终端或控制台等资源供标准 C 库调用。例如,裸机程序无法调用 printf,因为没有操作系统提供的输入输出设备支持。所以在裸机编程中,标准 C 库是无用的,链接 -lc 会导致错误。
为了解决这个问题,裸机编程通常需要自己编写或者使用特定的库来替代部分 libc 的功能,比如通过访问硬件寄存器或使用 SBI 来实现字符输出。你不能直接使用操作系统依赖的 libc,而是需要为裸机环境定制输出、内存管理等基本功能。
3. -lgcc(GCC Low-Level Runtime Library)
-lgcc 是 GCC 编译器的运行时支持库。它包含了一些 GCC 编译器生成代码时所需要的底层函数。例如,它提供了整数除法、浮点运算等基本功能,这些功能在硬件没有直接支持时需要通过软件实现。
在操作系统中的角色
在操作系统环境下,-lgcc 负责提供一些基本的低级函数,但通常与标准 C 库和操作系统密切结合。例如,如果编译器生成的代码需要除法操作而目标处理器不支持直接的硬件除法指令,-lgcc 中的函数将为其提供支持。
在裸机编程中的问题
在裸机编程环境中,如果尝试链接 -lgcc 而没有提供必要的底层支持库或编译器的完整配置,可能会遇到链接器错误。虽然 -lgcc 作为底层库通常可以用于裸机环境,但其功能必须与裸机的需求相匹配。如果编译器配置不完整或者工具链不支持裸机环境,可能导致找不到 -lgcc,从而报错。
裸机程序通常不依赖于完整的 GCC 运行时支持库,尤其是在编译器已经生成适合裸机的代码时。你可以手动实现一些关键的低级功能,例如通过直接使用硬件指令来进行除法或者浮点数运算,而不是依赖 -lgcc 提供的这些函数。
总的来说
- 裸机程序必须手动提供启动代码和运行时支持。这意味着程序员需要实现类似
crt0.o的功能(如栈指针设置、全局变量初始化等),而不是依赖 C 运行时环境。 - 裸机程序通常不会使用完整的 C 标准库,而是使用特定的库或者直接操作硬件来实现必要的功能。
启动代码(Startup Code)的作用
- 硬件初始化:在没有操作系统的情况下,必须手动初始化硬件资源,例如设置堆栈指针(
sp),初始化.bss段(存储未初始化的全局和静态变量),设置时钟等硬件外设。 - 程序入口设置:启动代码提供了程序的入口点,通常是
_start,它是裸机程序的执行起点。启动代码会调用main函数,使 C 代码能够开始执行。 - 防止程序异常返回:在裸机程序中,没有操作系统来接管程序退出后的行为。启动代码通常在
main函数结束后进入无限循环,避免程序运行到未定义区域。
下面,为了在裸机环境下成功编译,必须告诉链接器不要使用默认的 C 运行时启动文件(crt0.o)和标准库(libc)。你可以通过以下步骤解决这个问题:
修改编译命令
你需要通过 -nostartfiles 和 -nostdlib 告诉编译器不要链接标准启动文件和库。
使用如下的命令编译:
riscv64-unknown-elf-gcc -g -nostartfiles -nostdlib -o hello.elf hello.c
-nostartfiles:不使用默认的 C 运行时启动文件(如crt0.o)。-nostdlib:不链接标准库(如libc和libgloss)。
手动指定启动文件
在裸机编程中,你需要手动提供启动代码(startup),通常这被称为启动汇编文件 crt0.s 或类似文件,负责设置堆栈指针、清理 bss 段等。你可以编写一个简单的启动代码来解决这个问题。
这里是一个简单的裸机 RISC-V 启动文件 start.s:
# start.s
.globl _start
_start:
# 设置堆栈指针 (sp)
la sp, _stack_top
# 跳转到 main 函数
call main
# 无限循环,防止返回
1: j 1b
这个文件设置了堆栈指针并跳转到 main 函数。
这个汇编代码(
start.s)讲解1.
.globl _start.globl _start
作用:这是一个汇编伪指令,定义符号
_start为全局符号,使其可以在链接器阶段被其他文件(如链接器脚本或编译器)引用。全局符号的作用是告诉链接器,程序的入口点在这个标签_start。程序入口:在裸机编程中,程序不会像在操作系统环境中那样自动找到
main函数作为入口。取而代之的是程序从_start标签开始执行。链接器脚本中的ENTRY(_start)就指定程序从这个标签开始执行。2.
_start:_start:
- 标签:这是一个汇编标签,表示代码执行的起始位置。这里的
_start就是程序的入口点,程序执行从这里开始。通过链接器脚本将_start设置为程序入口,机器在复位后或上电启动后会从这里开始执行指令。3. 设置堆栈指针(
la sp, _stack_top)la sp, _stack_top
解释:
la是load address的缩写,它的作用是将_stack_top的地址加载到sp寄存器中。sp寄存器是 RISC-V 架构中存放堆栈指针(stack pointer)的寄存器。作用:程序运行时,堆栈(stack)用于存储函数调用时的返回地址、局部变量、保存寄存器状态等。
sp寄存器指向堆栈的栈顶。这里将_stack_top的地址设置为栈顶地址,表示从该地址开始向下增长存储数据。堆栈通常向低地址方向增长,因此
_stack_top设置为某个高地址位置,以确保堆栈有足够的空间来存储数据。裸机编程中的作用:在操作系统中,堆栈指针通常由操作系统设置,但在裸机编程中,开发者必须手动设置堆栈指针。在没有操作系统的环境中,这一行代码确保函数调用和局部变量可以正常使用堆栈。
4. 跳转到
main函数call main
解释:
call是 RISC-V 的调用指令,它的作用是跳转到指定函数的地址并保存当前的返回地址。作用:这里通过
call main跳转到 C 语言中定义的main函数。此时,C 语言代码的执行开始,main函数通常包含程序的主要逻辑。
call指令细节:
- 跳转到
main函数。- 将当前指令地址(即
_start位置)保存到ra寄存器(返回地址寄存器),以便main函数执行完成后能够返回。裸机编程中的返回问题:在操作系统环境中,
main函数返回后,系统会自动清理程序并退出。但在裸机编程中,没有操作系统管理返回点。如果main函数执行完毕,裸机程序无法返回到有效的地址(因为没有操作系统接管程序),这会导致未定义的行为。因此,通常在启动代码中会防止程序返回。5. 无限循环(
1: j 1b)1: j 1b
解释:
1:是一个标签,用于标识代码中的位置。j 1b是一个跳转指令,1b表示向上跳转到标签1,即再次跳转到1:的位置,形成一个无限循环。作用:这一行代码确保程序在
main函数返回后不会继续执行到未知区域。如果没有这行代码,程序可能会继续运行到未定义的内存区域,引发错误或系统崩溃。裸机程序中的必要性:裸机程序通常没有明确的退出机制。为了防止程序返回到没有定义的地址区域,常常使用一个无限循环来保证程序停留在安全的已知位置,而不会继续执行未定义的指令。通过这个无限循环,程序会保持执行状态,直到硬件系统被复位或重启。
重新编译
在当前目录下添加start.s启动文件后,将启动文件与程序一起编译:
riscv64-unknown-elf-gcc -g -nostartfiles -nostdlib -o hello.elf start.s hello.c
报错3:又报错了 你是不是故意的 😠

五、使用链接脚本
上面的错误提示说明了一个很明显的问题,我们之前在启动文件 start.s中使用的 _stack_top 这个符号没有定义。_stack_top 通常是用来表示堆栈顶的地址,而这个地址需要在链接脚本中定义或在程序中指定。
链接脚本(Linker Script)的作用
- 内存布局控制:链接脚本负责将程序的各个部分(代码段、数据段、堆栈等)分配到正确的内存地址。裸机程序无法依赖操作系统分配内存,所以必须通过链接脚本手动指定程序的内存布局。
- 定义程序入口:链接脚本告诉编译器和链接器程序的入口点,例如
_start。这样编译器能够正确识别启动代码的位置。 - 控制段的布局:链接脚本控制
.text(代码段)、.data(初始化数据段)、.bss(未初始化数据段)等段在内存中的位置,确保它们不互相重叠并且正确对齐,以便裸机程序正常运行。
启动代码、链接脚本与编译器和链接器
启动代码、链接脚本与编译器和链接器紧密关联,它们在程序的编译、链接以及执行过程中各自承担不同的职责,共同确保裸机程序可以正确运行。
1. 编译器的角色
编译器(如
gcc、clang)的主要任务是将高级语言(如 C、C++)代码编译成汇编代码或机器码。这个过程中,编译器只负责将单个源文件翻译成目标文件(.o文件),但编译器并不知道程序的入口点、内存布局等系统级信息。编译器的作用可以分为以下几步:
- 编译 C 代码:将 C 文件(如
main.c)转换成目标文件(.o文件),这个文件只包含机器码,并未包含程序如何加载和执行的信息。- 引入汇编代码:编译器也可以将汇编文件(如
start.s)编译为目标文件,这个文件通常包含程序的启动逻辑,如设置堆栈指针、调用main函数等。2. 启动代码与编译器的关系
启动代码(通常是汇编文件,如
start.s)告诉编译器程序从哪里开始执行,如何初始化环境。它作为一个源文件由编译器处理,将其转换为目标文件。启动代码与编译器的关系:
- 启动代码提供程序的入口点,例如
_start。这个入口点是编译器需要知道的,用于将机器指令汇编成目标文件。- 启动代码中设置的堆栈指针(
sp)、全局变量初始化等都是程序开始执行时的必要步骤,编译器生成的目标文件依赖于这些初始化操作。3. 链接器的角色
链接器(如
ld)的任务是将多个目标文件(编译器生成的.o文件)合并成一个最终的可执行文件(如.elf文件),并解决所有符号引用。链接器的职责包括:
- 符号解析:链接器将不同目标文件中的符号(如函数名、变量名)进行解析和匹配,确保函数调用和数据访问都指向正确的地址。
- 内存布局控制:链接器根据链接脚本提供的指令,将代码段、数据段等放置到正确的内存地址。
4. 链接脚本与链接器的关系
链接脚本(如
linker.ld)为链接器提供程序的内存布局信息,它指定了程序各个段(.text、.data、.bss等)在内存中的具体位置,以及程序入口点。链接脚本与链接器的关系:
- 内存布局控制:链接脚本告诉链接器如何将程序的各个部分(如代码段、数据段)映射到目标机器的物理内存地址。例如,指定
.text段从内存的0x10000开始。- 入口点设置:链接脚本通常指定程序的入口点,例如
ENTRY(_start),告诉链接器在生成最终的可执行文件时,将程序从_start开始执行。- 符号定义:链接脚本可以定义一些特殊符号,如栈顶(
_stack_top)的位置,供启动代码和链接器使用,确保正确的运行时环境。5. 启动代码、链接脚本与编译器和链接器的整体关系
编译器阶段:
- 编译器将 C 代码和汇编代码分别编译成目标文件(
.o文件),其中启动代码的汇编文件提供了程序的入口点(_start)以及堆栈指针的初始化。- 编译器生成的目标文件中并没有绝对的地址,它只包含相对地址和未解析的符号(如
main函数的地址)。链接器阶段:
- 链接器接收多个目标文件(如
start.o和main.o),根据链接脚本中的指令,将代码段、数据段等放置到合适的内存位置,并解析所有未定义的符号。- 链接脚本告诉链接器程序的入口点、各个段的布局(如
.text、.data、.bss等),并设置堆栈位置等特殊符号。- 链接器最后生成一个可执行文件(如
hello.elf),这个文件包含了裸机程序的完整布局和所有已解析的符号。程序运行时:
- 程序从启动代码(
_start)开始执行,启动代码根据链接脚本定义的堆栈顶地址(_stack_top)设置堆栈指针,然后跳转到main函数。- 在没有操作系统的环境下,启动代码还负责初始化全局变量(如
.data段)、清零.bss段等。
使用链接脚本
在裸机环境下,堆栈和其他内存区域的地址通常是在链接脚本(linker script)中定义的。为了解决错误,你可以编写一个简单的链接脚本,手动定义堆栈顶的地址。
- 编写一个简单的链接脚本,如
linker.ld:
/* linker.ld */
OUTPUT_ARCH(riscv)
ENTRY(_start) /* 设置入口点为 _start */
SECTIONS
{
. = 0x80000000; /* 指定代码起始地址,假设放在 0x80000000 处 */
.text : {
*(.text) /* 将所有 .text 段放在 .text 区 */
}
.rodata : {
*(.rodata) /* 将只读数据段放在 .rodata 区 */
}
.data : {
*(.data) /* 将 .data 段放在 .data 区 */
}
.bss : {
*(.bss) /* 将 .bss 段放在 .bss 区 */
}
_stack_top = 0x80010000; /* 定义堆栈顶的地址 */
}
这里将堆栈顶定义为 0x80010000(这个地址可以根据你的需求调整)。
在汇编文件中定义 _stack_top
我们需要在启动代码中,添加 _stack_top的地址:
s
添加链接脚本linker.ld和修改启动代码start.s后,重新编译:
riscv64-unknown-elf-gcc -g -nostartfiles -nostdlib -T linker.ld -o hello.elf start.s hello.c
不用说肯定还得报错😊,甚至紧跟着两个报错
另外提前说一下,如果 QEMU 卡住了,你可以通过【 Ctrl + A,然后按 X 】退出。
六、修复报错,启动QEMU
报错4

这个问题通过添加使用 -mcmodel=medany选项解决。
这个问题不用深究,未来的 rust 裸机编程没有这个问题。
如果你想了解更多,参见The RISC-V Code Models / RISC-V Options。
简单来说,RISC-V 有不同的代码模型(Code Model)来决定如何处理内存地址的范围:
medlow(默认):
- 假设所有全局数据和代码的地址都在低于 2GB 的范围内,通常是从基地址 0 开始。
- 这种模型只适用于小型程序,因为它限制了可访问的内存范围。
medany:
- 允许全局数据和代码放置在内存中的任意位置(中高位置),不局限于低 2GB 地址空间。
- 这个模型使用了更多的指令来确保数据和代码的地址可以被访问,而不受限制。
重新编译:
riscv64-unknown-elf-gcc -g -nostartfiles -nostdlib -T linker.ld -mcmodel=medany -o hello.elf start.s hello.c
成功了!

接下来是,使用 QEMU 来模拟 RISC-V 环境并运行刚刚编译的 hello 程序。命令如下:
qemu-system-riscv64 -machine virt -nographic -kernel hello.elf -s -S
-machine virt:选择 QEMU 中的虚拟 RISC-V 机器。-nographic:表示不使用图形界面,所有输出通过当前终端处理。-kernel hello:指定要加载并运行的 RISC-V 程序。-s:启用调试模式,会在端口 1234 上开启一个 GDB 服务器。-S:告诉 QEMU 在启动后暂停 CPU,这样我们可以连接 GDB 进行调试,而不会立即运行程序。
不出意外的话,QEMU 会启动,但处于暂停状态,等待 GDB 连接。
出意外的话。。
报错5
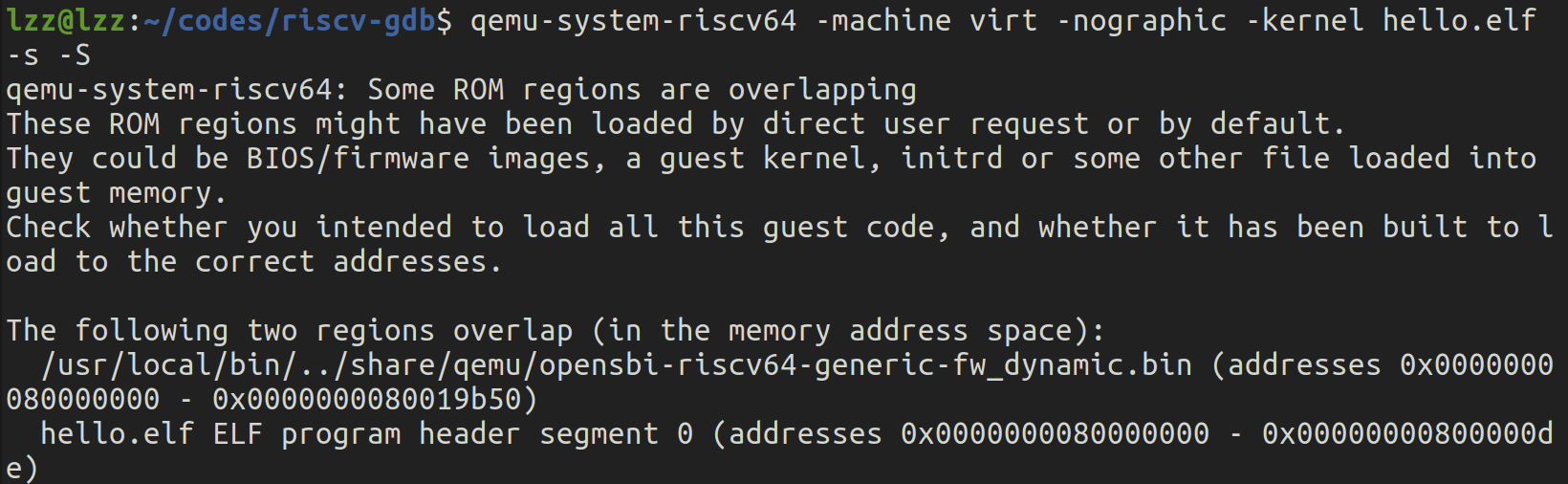
从错误信息来看, hello.elf 程序和 QEMU 默认加载的 OpenSBI 固件的地址发生了冲突。OpenSBI 固件被加载到 0x80000000 地址空间,而 hello.elf 程序的代码段也从 0x80000000 开始,这导致了地址重叠问题。
解决方案
1. 使用 -bios none 禁用 OpenSBI 固件
如果当前的程序不需要依赖 OpenSBI 提供的服务(例如打印字符等),可以通过-bios none禁用 QEMU 默认加载的 OpenSBI 固件来避免冲突:
qemu-system-riscv64 -machine virt -nographic -bios none -kernel hello.elf -s -S
这个命令会让 QEMU 不加载任何 BIOS 或 OpenSBI 固件,而直接运行你自己的 hello.elf 程序。
2. 更改程序加载地址
显然我们还需要 OpenSBI 的功能,那么可以将 hello.elf 程序加载到不同的内存地址,避免和 OpenSBI 地址重叠。默认情况下,OpenSBI 固件从 0x80000000 地址加载,我们可以在 linker.ld 文件中设置不同的加载地址。例如,你可以把加载地址设置为 0x80200000 或者更高:
/* linker.ld */
OUTPUT_ARCH(riscv)
ENTRY(_start)
SECTIONS
{
. = 0x80200000; /* 将代码段起始地址设置为 0x80200000,避免和 OpenSBI 地址冲突 */
.text : {
*(.text) /* 将所有的 .text 段放在 .text 区 */
}
.rodata : {
*(.rodata) /* 将只读数据放在 .rodata 区 */
}
.data : {
*(.data) /* 将 .data 段放在 .data 区 */
}
.bss : {
*(.bss) /* 将 .bss 段放在 .bss 区 */
}
_stack_top = 0x80400000; /* 定义堆栈顶的地址为更高的地址 */
}
这样,程序就会被加载到 0x80200000 以避免与 OpenSBI 地址重叠。
3. 指定 OpenSBI 固件
你也可以使用 -bios 选项指定一个 OpenSBI 固件,并让 QEMU加载你的程序和 OpenSBI。比如你下载了一个 OpenSBI 固件 opensbi.elf,可以使用以下命令运行:
qemu-system-riscv64 -machine virt -nographic -bios /path/to/opensbi.elf -kernel hello.elf -s -S
这个以后再说。
总之我们选择了让程序为 OpenSBI 让路,把加载地址设置为 0x80200000,同时start.s 文件中的栈指针设置也应该根据新的加载地址进行调整。
更新后的 start.s 文件
.globl _start
_start:
# 设置堆栈指针 (sp),将其设置在 0x80400000 位置(比代码地址更高)
la sp, _stack_top
# 跳转到 main 函数
call main
# 无限循环,避免程序退出
1: j 1b
.globl _stack_top
_stack_top:
.word 0x80400000 # 将栈顶设置在 0x80400000 位置(高于代码加载区域)
更新完文件后再次运行QEMU:
qemu-system-riscv64 -machine virt -nographic -kernel hello.elf -s -S
怎么没反应啊,不会还有bug吧?
当你看到只剩下闪动的光标,别担心,恭喜你已经完成了QEMU的启动🎉,正如前面参数介绍的那样:
-machine virt:选择 QEMU 中的虚拟 RISC-V 机器。-nographic:表示不使用图形界面,所有输出通过当前终端处理。-kernel hello:指定要加载并运行的 RISC-V 程序。-s:启用调试模式,会在端口 1234 上开启一个 GDB 服务器。-S:告诉 QEMU 在启动后暂停 CPU,这样我们可以连接 GDB 进行调试,而不会立即运行程序。
QEMU 已经启动,但处于暂停状态,正在等待 GDB 连接。
七、连接 GDB 进行调试
接下来的步骤是连接 GDB 进行调试。
简要步骤
-
打开一个新的终端:在新终端中,确保你的程序已经编译并准备好运行。
-
启动 GDB:使用 GDB 加载你的程序。例如,如果你的程序名为
hello,输入以下命令:riscv64-unknown-elf-gdb hello.elf
-
连接到 QEMU:在 GDB 提示符下,输入以下命令连接到 QEMU 的 GDB 服务器(连接成功后就和上一节类似啦):
target remote :1234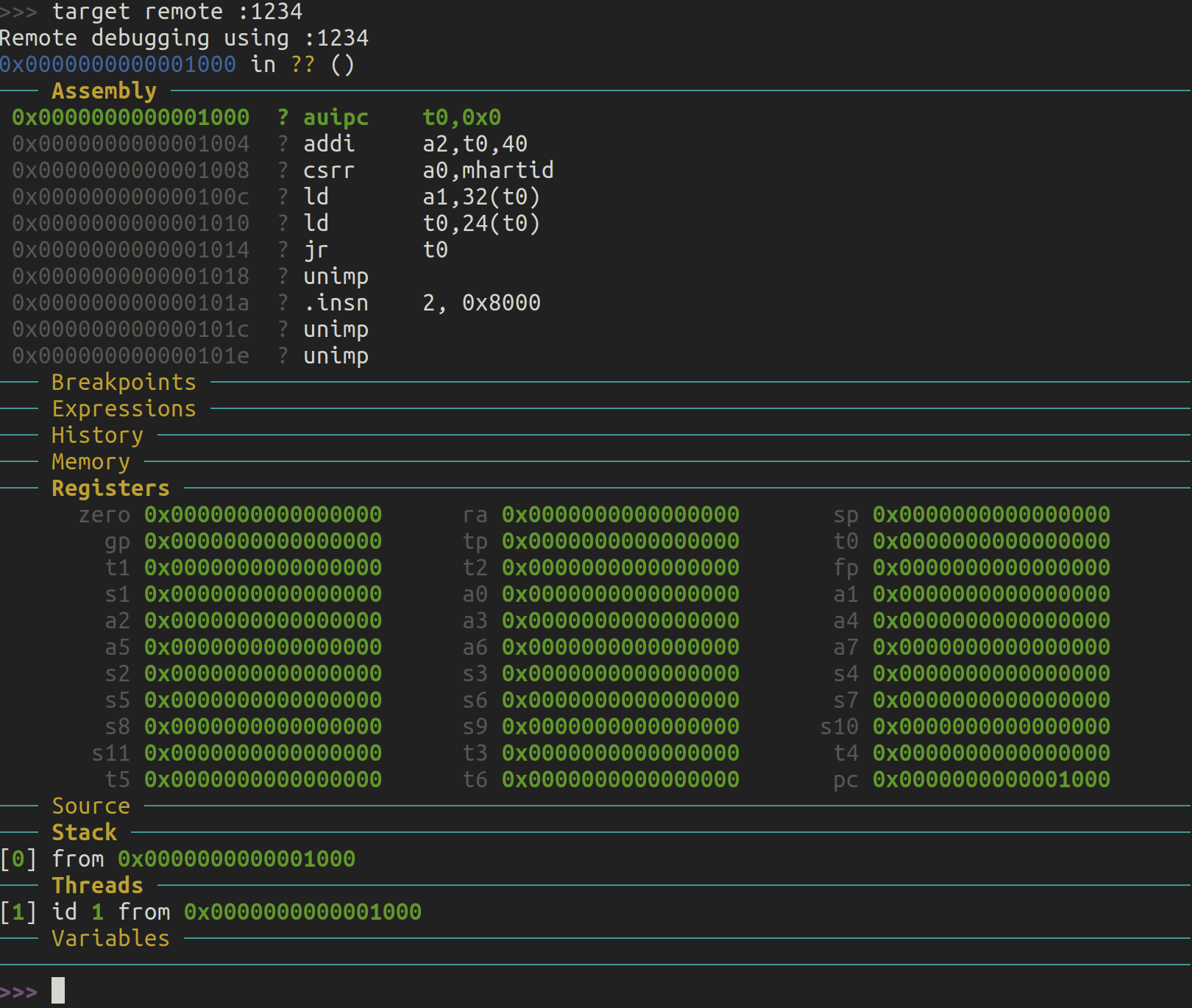
-
设置断点(可选):如果你想在程序的某个位置停止执行,可以设置断点,例如:
break main -
开始执行程序:输入以下命令开始程序的执行(到断点):
continue -
调试程序:在程序运行时,你可以使用 GDB 的各种命令来查看寄存器状态、内存内容等。
-
退出 GDB:完成调试后,可以使用以下命令退出 GDB:
quit
调试细节步骤
连接成功后break main在 main 函数入口处设置断点,

c开始程序执行到断点。
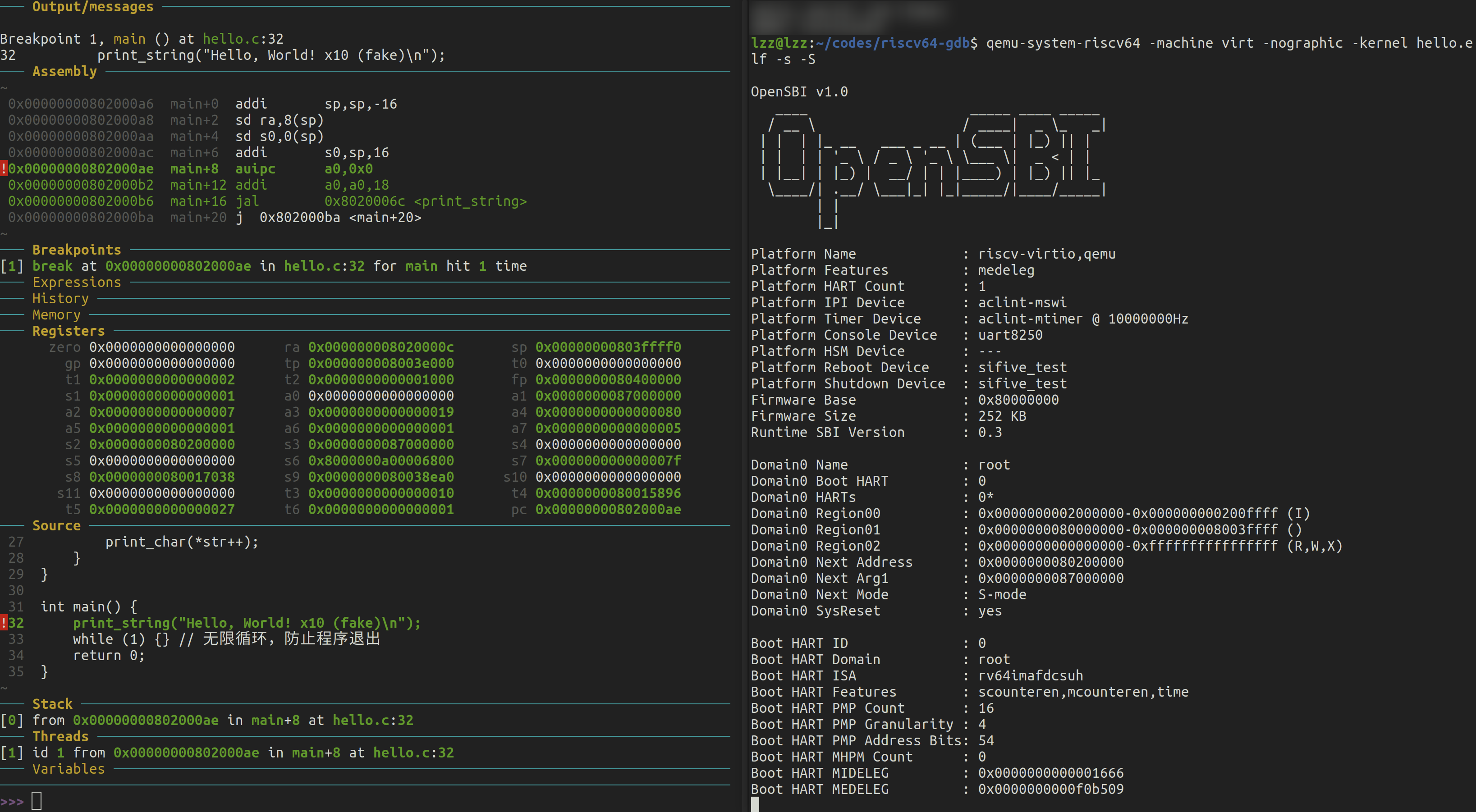
当前屏幕展示了两个窗口,分别是调试窗口(左侧)和 QEMU 界面(右侧)。
左侧 - GDB 调试界面
- 调试工具:这是你使用
riscv64-unknown-elf-gdb启动的调试会话。你已成功连接到运行在 QEMU 上的 RISC-V 模拟器。 - 断点信息:
- 在 main 函数入口处设置了一个断点,这一行调用了
print_string("Hello, World! x10 (fake)\n");。 - 当前 GDB 已经在这个断点停住,命中了一次,即程序执行到这一行时被暂停。
- 在 main 函数入口处设置了一个断点,这一行调用了
- 汇编指令窗口:
- 显示了当前程序执行位置周围的 RISC-V 汇编指令。
- 可以看到 GDB 解释的指令,如
addi、auipc、jal等,这些是编译后的程序的实际指令,正在被 QEMU 模拟器执行。
- 寄存器信息:
- 当前寄存器的状态已经显示在调试界面的左下角部分。
- 可以看到
sp、ra、a0等寄存器的当前值,表明程序的执行状态。
- 源码窗口:
- 可以看到 C 源码的当前执行位置,
print_string("Hello, World! x10 (fake)\n");正在等待被执行。 - 下方有一个无限循环
while(1),目的是防止程序退出,让程序一直运行。
- 可以看到 C 源码的当前执行位置,
右侧 - QEMU 界面
- QEMU 启动输出:
- QEMU 模拟器已经启动,并加载了 OpenSBI(Supervisor Binary Interface),用于在 QEMU 虚拟机上管理硬件抽象。
- 右侧窗口显示的是 OpenSBI 启动时的输出信息:
- OpenSBI 的版本为
0.3。 - 平台名称为
riscv-virtio,qemu,即 QEMU 使用的 RISC-V 虚拟平台。 - 列出了平台的各种设备信息,例如定时器、IPT(中断控制)设备和 UART 控制台设备。
- OpenSBI 的版本为
- 暂停状态:
- 由于 QEMU 启动时使用了
-S参数,模拟器启动后暂停了 CPU 的执行。当前,QEMU 处于等待状态,没有执行加载的程序。 - 一旦你在 GDB 中发出
continue(或c)命令,QEMU 会继续执行程序。
- 由于 QEMU 启动时使用了
s进入print_string
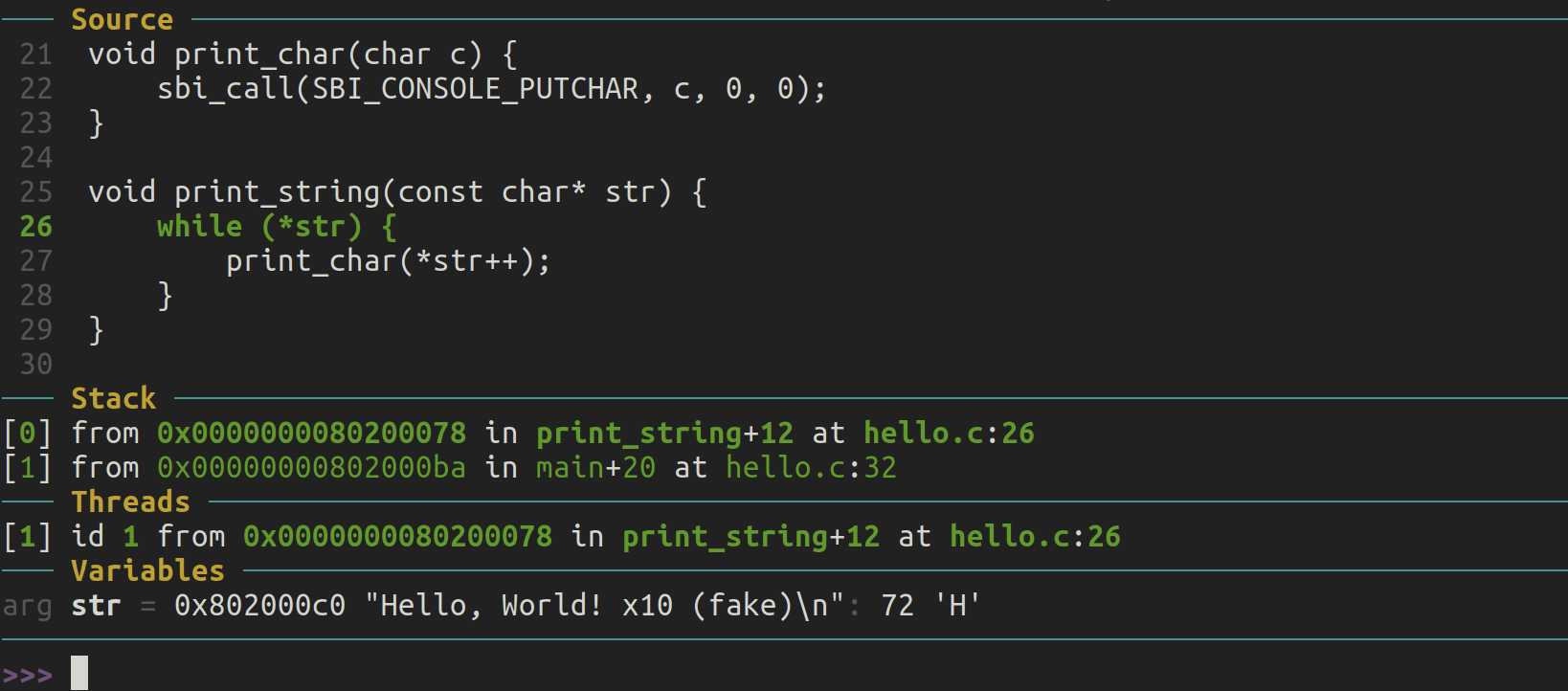
n运行下一条代码,这里我们依旧忽略print_char调用sbi_call以及后续一系列的内部的实现,继续n跳转到第一次执行完print_char函数的位置。
观察QEMU发生了什么:

继续:
{
n进入下一个循环(或者回车自动继续执行上一条指令)
n完成下一次打印
}
直到:

下一步是进入无限循环。
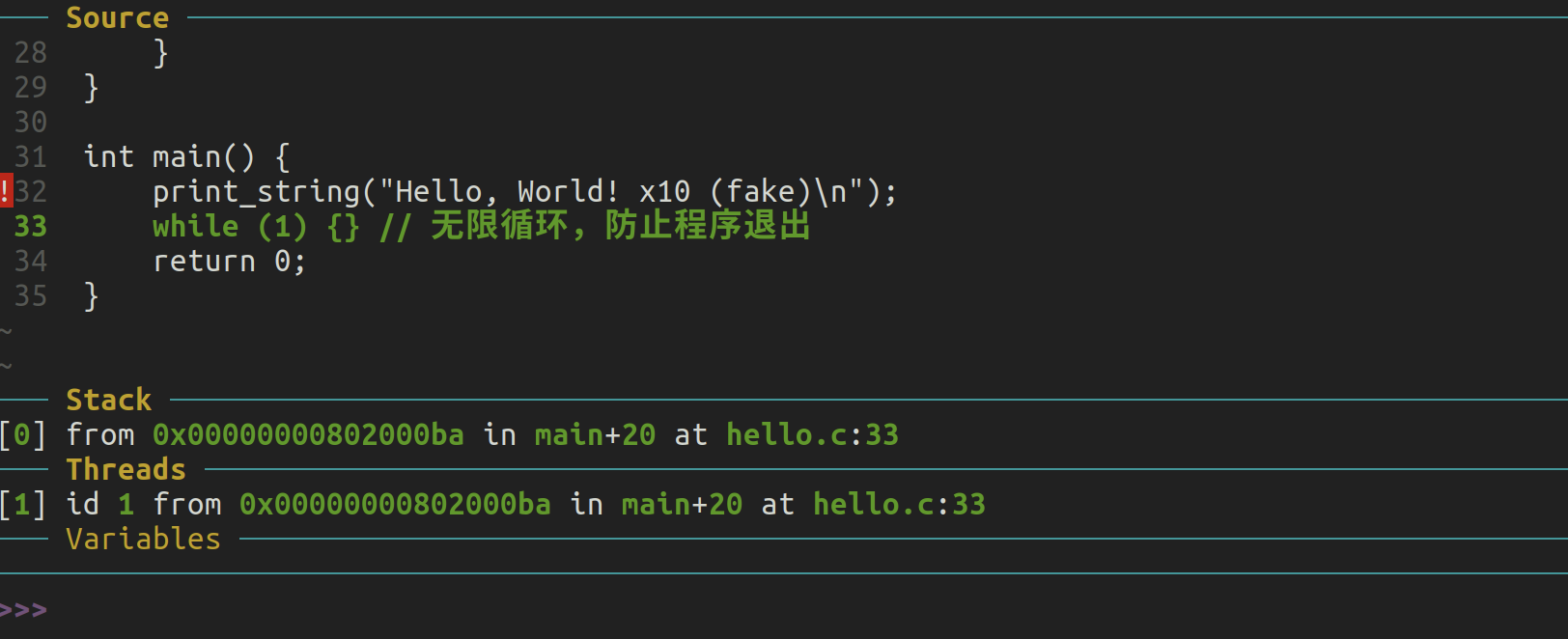
结束。通过【 Ctrl + A,然后按 X 】退出QEMU,通过q退出QEMU。
终于算是暂时结束了 [/躺平]
下一节开始转向 RUST!
等等等等,好像把 Makefile 忘了?
使用rust-gdb调试Rust/标准库println!的实现
一、调试基础 Rust 程序:使用 GDB 调试 Hello, World!
A. 安装和设置 GDB 调试环境
在 Rust 中,调试器 rust-gdb 是基于 GNU 调试器 (GDB) 的一个增强版,专门为 Rust 提供了语言特定的支持,比如对 Rust 类型的更好解析、语法和格式化信息显示。使用 rust-gdb,可以轻松调试 Rust 程序,并查看代码的实际运行过程,包括变量状态和函数调用链等。
安装 rust-gdb:
Rust 工具链中的调试器 rust-gdb 作为一个可选组件,需要通过 rustup 工具安装:
rustup component add rust-gdb
这个命令会将 rust-gdb 安装到当前的 Rust 工具链中。成功安装后,可以直接在终端中运行 rust-gdb 命令来启动调试会话。
系统要求:
rust-gdb 依赖于你系统中已经安装的 GDB,因此请确保系统中有 GDB 并且版本与当前 Rust 工具链兼容。你可以通过以下命令检查 GDB 的版本:
gdb --version
Rust 的调试信息生成是通过 DWARF 格式,因此在调试器中需要确保 GDB 能够识别并使用这些调试信息。
B. 编写并编译简单的 Hello, World! 程序
现在,我们编写一个非常简单的 Rust 程序,并使用 cargo 进行编译。
新建 Rust 项目:
可以使用 cargo 命令创建一个新的项目:
cargo new hello_world_gdb --bin
该命令会在当前目录下创建一个新的二进制项目,项目名为 hello_world_gdb。目录结构如下:
hello_world_gdb/
├── Cargo.toml
└── src/
└── main.rs
编写 Hello, World! 代码:
进入 src/main.rs 文件,已经包含基础的 Hello, World! 程序:
fn main() { println!("Hello, World!"); }
这个程序会在运行时输出 "Hello, World!"。println! 是一个宏,它会打印文本并自动在文本末尾加上换行符。
编译程序:
使用以下命令编译程序:
cargo build
这个命令会生成调试版本的可执行文件,编译后的二进制文件通常位于 target/debug 目录下:
target/debug/hello_world_gdb
默认情况下,cargo build 会启用调试信息生成,这是非常重要的,因为调试器需要这些信息来解析源代码中的变量和函数调用。Rust 编译器会生成 DWARF 格式的调试信息,并嵌入到编译出的可执行文件中。
你可以使用 cargo build --release 来生成优化后的可执行文件,但在调试时应尽量避免使用这种模式,因为优化后的代码可能会使调试信息不完整。
C. 用 rust-gdb 调试程序
接下来,我们使用 rust-gdb 调试 Hello, World! 程序。
启动 rust-gdb:
在项目目录中,执行以下命令启动 rust-gdb,并加载生成的可执行文件:
rust-gdb target/debug/hello_world_gdb
这会启动 GDB 调试器,并加载 Rust 生成的二进制文件 hello_world_gdb。进入 GDB 后,你会看到 GDB 的命令行界面,显示出调试器的启动信息。
设置断点并运行程序:
在 GDB 的命令行界面中,我们首先设置一个断点,让程序在执行 main 函数时暂停:
(gdb) break main
这条命令会在 main 函数的入口处设置一个断点。当程序执行到 main 函数时,会暂停并让我们进行调试。然后,使用以下命令运行程序:
(gdb) run
运行命令后,程序会启动并在 main 函数的入口处暂停。此时,GDB 会输出类似如下的内容:
Breakpoint 1, hello_world_gdb::main () at src/main.rs:2
2 println!("Hello, World!");
查看调用栈和变量:
此时,程序已经暂停在 main 函数的开头。对于复杂的 Rust 程序你可以通过 GDB 的各种命令查看程序状态,比如查看调用栈和局部变量。
-
查看调用栈: 使用
backtrace或bt命令可以查看调用栈:(gdb) backtrace这会显示当前函数的调用路径,帮助你理解程序执行到当前位置时的函数调用链。
-
查看局部变量: 使用
info locals可以查看当前作用域中的所有局部变量:(gdb) info locals
更多调试步骤与前两节调试C语言相同。
通过使用 rust-gdb,你可以轻松调试 Rust 程序,查看函数调用、变量状态,并逐步执行代码。结合 Rust 生成的丰富调试信息,GDB 允许你深入了解程序的运行过程。这对于分析和解决程序中的问题、理解代码的执行流程非常有帮助。
二、通过标准库查看 println! 的内部实现
2A. 通过标准库文档查看 println! 的实现
在开始调试前,我们可以通过 Rust 官方的 标准库文档 来了解 println! 宏的实现。Rust 提供了全面的在线文档,涵盖标准库的每个模块和函数,实现细节透明。
使用在线标准库文档
-
访问标准库文档: 你可以通过访问 Rust 标准库文档(中文) 来查看宏、模块、类型和函数的定义和说明。
-
查找
println!宏: 在文档的搜索栏中搜索println!,你会看到它是一个用于打印格式化字符串到标准输出并添加换行符的宏。 -
宏的定义: 在文档中,
println!被定义为:#![allow(unused)] fn main() { macro_rules! println { () => { $crate::print!("\n") }; ($($arg:tt)*) => {{ $crate::io::_print($crate::format_args_nl!($($arg)*)); }}; } }println!可以处理两种情况:- 无参数时,直接输出一个换行符。
- 带参数时,将参数传递给
_print函数来处理格式化字符串。
2B. 安装标准库源码
如果你想进一步研究 println! 宏的底层实现,可以安装 Rust 标准库的源码并深入查看,这也可以让 rust-gdb 在调试时可以查看标准库源码。Rust 的标准库源码是开源的,并且可以通过 rustup 工具下载。
安装标准库源码
为了安装标准库的源码,你可以运行以下命令:
rustup component add rust-src
这个命令会将标准库的源码下载到你的 Rust 工具链目录下,通常路径为:
~/.rustup/toolchains/<your-toolchain>/lib/rustlib/src/rust/
其中,<your-toolchain> 表示你正在使用的工具链(如 stable-x86_64-unknown-linux-gnu)。
查看 println! 宏的源代码
你可以在标准库源码的以下位置找到 println! 宏的定义:
~/.rustup/toolchains/<your-toolchain>/lib/rustlib/src/rust/library/std/src/macros.rs
在该文件中,println! 宏的定义与文档中的一致。
2C. 解释 println! 的实现
println! 宏是 Rust 标准库中最常用的宏之一。它允许我们将格式化字符串输出到标准输出,并在结尾添加一个换行符。其实现虽然看起来简单,但背后涉及了多个函数和抽象层。
1. println! 宏的两种模式
-
无参数模式:当你调用
println!()而不传递任何参数时,宏会简化为调用print!("\n"),也就是直接打印一个换行符。#![allow(unused)] fn main() { println!(); }这相当于调用:
#![allow(unused)] fn main() { print!("\n"); } -
带参数模式:当
println!接收参数时,它会使用format_args_nl!宏进行格式化处理,并将生成的格式化参数传递给内部的_print函数。#![allow(unused)] fn main() { println!("Hello, {}!", "World"); }这会展开为:
#![allow(unused)] fn main() { _print(format_args_nl!("Hello, {}!", "World")); }
2. format_args_nl!:处理格式化参数并添加换行符
format_args_nl! 宏是 format_args! 的扩展版本,它专门用于处理带换行符的输出。这个宏会将传递的格式化字符串和参数转换成一个 fmt::Arguments 结构体,并自动在末尾添加换行符。
#![allow(unused)] fn main() { macro_rules! format_args_nl { ($fmt:expr) => (format_args!(concat!($fmt, "\n"))); ($fmt:expr, $($arg:tt)*) => (format_args!(concat!($fmt, "\n"), $($arg)*)); } }
-
无参数时:
format_args_nl!会将传入的格式化字符串拼接上一个"\n",生成一个带换行符的字符串。例如,
println!("Hello")会通过format_args_nl!变为"Hello\n"。 -
有参数时:当传入多个参数时,
format_args_nl!会通过format_args!进行格式化,并在末尾自动添加换行符。
3. _print:println! 背后的核心函数
#![allow(unused)] fn main() { #[doc(hidden)] #[cfg(not(test))] pub fn _print(args: fmt::Arguments<'_>) { print_to(args, stdout, "stdout"); } }
功能简介:
-
_print函数 是println!宏的最终调用目标,它将格式化后的字符串输出到标准输出。此函数被标记为#[doc(hidden)],因为它是标准库的内部实现,不在标准文档中显示。 -
args参数 是一个fmt::Arguments类型,用于封装所有格式化的内容。它是 Rust 的格式化系统核心类型,能够高效地存储和传递多个格式化参数。 -
调用
print_to:_print实际上调用了print_to函数,后者负责处理输出的具体逻辑。
3.1. print_to 函数:输出逻辑的封装
#![allow(unused)] fn main() { fn print_to<T>(args: fmt::Arguments<'_>, global_s: fn() -> T, label: &str) where T: Write, { if print_to_buffer_if_capture_used(args) { // Successfully wrote to capture buffer. return; } if let Err(e) = global_s().write_fmt(args) { panic!("failed printing to {label}: {e}"); } } }
功能简介:
-
泛型函数
print_to:这个函数用于将格式化后的字符串输出到目标设备。它接受三个参数:args:格式化的内容(通过fmt::Arguments表示)。global_s:一个函数指针,返回实现了Write特性的目标(例如标准输出stdout)。label:一个标签,用于在错误信息中标识输出目标,通常是"stdout"。
-
捕获输出(
print_to_buffer_if_capture_used):首先检查是否有输出捕获机制启用,例如在测试环境中,输出可能会被捕获到某个缓冲区,而不是直接输出到终端。如果启用了捕获,并成功写入了缓冲区,则函数会提前返回,避免直接输出到终端。 -
global_s().write_fmt(args):如果没有捕获输出,程序会调用global_s()函数来获取目标输出设备,并使用write_fmt方法将格式化内容写入目标设备。对于标准输出,global_s()返回的是stdout()。 -
错误处理:如果输出失败(
write_fmt返回Err),程序会调用panic!,并输出相关错误信息。
3.2. write_fmt 的实现:核心输出操作
#![allow(unused)] fn main() { impl Write for &Stdout { fn write_fmt(&mut self, args: fmt::Arguments<'_>) -> io::Result<()> { self.lock().write_fmt(args) } } }
功能简介:
-
这里实现了
Write特性,用于标准输出的引用&Stdout。Write特性是 Rust 标准库中的一个重要接口,它定义了向输出流中写入数据的方法。write_fmt是该接口的一个方法,用于处理格式化输出。 -
write_fmt实现:write_fmt接受fmt::Arguments作为输入,表示要格式化输出的内容。- 锁定标准输出:
self.lock()会锁定标准输出(stdout()),这一步非常关键,它确保了在多线程环境下,标准输出不会被多个线程同时访问,从而避免输出的竞态条件。 - 调用
write_fmt:锁定后调用StdoutLock的write_fmt方法,将格式化内容写入到标准输出设备中。
3.3. 深入分析:流程解析
println! 宏背后的完整流程:
-
宏展开:当你调用
println!时,例如println!("Hello, World!");,它会被展开为类似下面的代码:#![allow(unused)] fn main() { _print(format_args_nl!("Hello, World!")); } -
调用
_print:_print接收通过format_args_nl!生成的fmt::Arguments,然后调用print_to函数。 -
print_to逻辑:- 首先,
print_to检查是否有捕获输出的情况,例如在单元测试中,如果启用了输出捕获,数据将写入捕获缓冲区。 - 如果没有输出捕获,
print_to会调用stdout().write_fmt(args),将内容输出到标准输出。
- 首先,
-
线程安全的输出:
- 当
write_fmt被调用时,stdout()返回的输出流被锁定,防止其他线程干扰输出。 - 锁定的
StdoutLock确保在当前线程输出完成之前,其他线程不能访问标准输出。
- 当
-
错误处理:
- 如果写入输出失败,Rust 通过
panic!触发错误并终止程序。这种设计确保了输出的可靠性。
- 如果写入输出失败,Rust 通过
3.4. 扩展:捕获输出的机制
在 print_to 函数中,调用了 print_to_buffer_if_capture_used(args) 来检查是否有输出捕获的情况。这通常用于测试场景下,当你在单元测试中使用 cargo test 运行测试时,测试框架可能会捕获 println! 的输出,以便在测试失败时提供调试信息。
- 捕获输出的情况:如果输出被捕获,程序会将输出内容写入到捕获缓冲区中,而不是直接打印到标准输出。这样在运行测试时,测试框架可以收集所有输出信息,并根据测试结果选择是否展示这些输出。
3.5. 总结
通过解析 Rust 标准库中 println! 宏的实现,我们可以看到整个输出流程的复杂性以及多个函数之间的协作。以下是一些关键点:
println!背后的多层抽象:虽然println!表面上是一个简单的宏,但它背后依赖多个底层函数(如_print和write_fmt)来处理格式化输出。- 线程安全:通过
stdout().lock(),Rust 保证了在多线程环境下的输出安全性,避免了并发输出时的混乱。 - 灵活的输出捕获机制:
print_to_buffer_if_capture_used为测试框架提供了捕获输出的能力,使得println!不仅可以在终端输出,还可以被重定向到缓冲区进行分析。
这种设计展示了 Rust 标准库如何在提供简洁的 API 接口(如 println! 宏)的同时,处理复杂的并发、安全性以及多层抽象,使得开发者可以在更高层次上编写安全且高效的代码。
4. 隐藏的 _print 函数
在调试过程中,Rust 标准库的一些内部函数(如 _print)被标记为 #[doc(hidden)],这些函数虽然是 println! 宏的重要组成部分,但不会在标准文档中展示。通过调试器或者阅读源码,我们可以查看这些隐藏的实现,并深入理解 println! 宏的工作机制。
5. 锁的实现机制
stdout().lock() 的内部实现依赖于标准库中的 锁机制(通常是 Mutex 或 RwLock)。Rust 通过锁来保证多线程下的共享资源访问安全。
锁的核心原理是:
- 当一个线程调用
lock()时,它会阻塞其他线程对该资源的访问,直到锁被释放。这样可以避免多个线程同时修改或读取相同的数据,确保数据一致性。
通过调试器,你可以逐步查看 stdout().lock() 的具体执行过程。在 GDB 中,执行以下命令单步进入 lock() 的实现:
(gdb) step
这会进入标准库中锁的实现代码,帮助你更好地理解 stdout().lock() 是如何确保线程安全的。
2D. 通过 GDB 查看 println! 的执行
安装了标准库源码后,在 rust-gdb 调试环境中,你可以通过设置断点和单步执行来查看 println! 宏的具体执行过程,深入了解每个步骤的内部实现。
1. 设置断点在 _print 函数
为了观察 println! 的执行过程,我们可以在 _print 函数上设置一个断点:
(gdb) break _print
当 println! 被调用时,程序会暂停在 _print 函数,GDB 会显示调用栈和当前的源代码。
三、标准库中的复杂性与隐藏函数
3A. 为什么要隐藏某些实现?
在 Rust 标准库中,某些内部实现(如 _print 函数)被标记为 #[doc(hidden)],这意味着它们在生成的标准库文档中不会显示。这种设计理念背后有几个重要的原因:
-
简化 API 接口:
- Rust 标准库的设计目标之一是提供简洁易用的 API 接口,屏蔽掉不必要的复杂实现细节,让开发者专注于应用逻辑而不是底层细节。通过隐藏这些内部实现,用户可以通过宏(如
println!)进行格式化输出,而不用担心底层 I/O 的复杂性。
- Rust 标准库的设计目标之一是提供简洁易用的 API 接口,屏蔽掉不必要的复杂实现细节,让开发者专注于应用逻辑而不是底层细节。通过隐藏这些内部实现,用户可以通过宏(如
-
隐藏实现细节:
println!宏背后的函数如_print和write_fmt是标准库中专门用于处理输出的低层函数,但对于大多数用户来说,这些函数的具体实现并不重要。标准库通过封装这些细节,减少了 API 的暴露面积,使得 API 更加稳定。如果未来要对这些内部实现进行优化或更改,开发者无需担心 API 会发生重大变化。
-
保持代码库灵活性:
- 将内部实现隐藏起来允许标准库的开发者在不影响外部 API 的情况下优化或调整实现。Rust 标准库可以在不影响开发者代码的情况下对这些内部函数进行性能优化或修复潜在的 bug。
解释 #[doc(hidden)]
#[doc(hidden)] 是 Rust 中一个常用的属性,它可以用于标记那些希望在文档中隐藏的符号(函数、结构体、模块等)。这些符号仍然可以在代码中被访问和调用,但不会显示在标准库的公开文档中。标记为 #[doc(hidden)] 的函数如 _print,实际上是为了简化公共 API,而不向开发者暴露不必要的细节。
3B. API 封装与标准库设计
Rust 标准库是一个为开发者设计的高层次抽象 API,通过对底层实现的封装,使开发者能够轻松使用功能强大的工具,而无需了解具体实现。这种封装设计体现了以下几个关键点:
-
安全性与简洁性:
- Rust 标准库 API 的设计优先考虑安全性和简洁性。像
println!这样简单的宏其实是多层抽象的结果,内部通过一系列安全的函数调用来确保正确的 I/O 操作。开发者只需调用高层次的println!宏,而不需要直接管理格式化、线程安全和输出锁等细节。
- Rust 标准库 API 的设计优先考虑安全性和简洁性。像
-
隔离复杂实现:
- 标准库通过对复杂功能的封装,如格式化字符串、锁定标准输出(
stdout().lock()),确保了多线程环境下的安全性。开发者在使用时无需关心这些复杂的实现逻辑,只需调用标准库提供的 API。
- 标准库通过对复杂功能的封装,如格式化字符串、锁定标准输出(
-
稳定性和灵活性:
- Rust 的 API 设计隔离了内部实现与用户接口,使得标准库可以在保持接口不变的情况下对内部进行优化或修改。例如,
println!的底层实现可以更换,而用户代码不受影响。
- Rust 的 API 设计隔离了内部实现与用户接口,使得标准库可以在保持接口不变的情况下对内部进行优化或修改。例如,
通过这种设计,Rust 提供了强大的工具,开发者可以用简单的接口解决复杂的问题。这种封装和隐藏机制确保了标准库的灵活性、稳定性和安全性。
四、与裸机编程的对比:用 core 实现 `println!
4A. 裸机编程的环境
在裸机编程(bare-metal programming)环境下,没有操作系统来管理硬件资源,也没有类似于 std 这样的标准库。程序必须直接与硬件交互,管理 I/O、内存、定时器等资源。
在这种环境下,实现类似 println! 的功能需要通过硬件接口(例如 UART 串口)直接发送字符数据。裸机环境没有多线程调度机制,因此无需考虑标准库中使用的线程安全和锁定机制。
裸机编程下,输出通常会通过 UART 串口完成,而不需要处理像文件系统或多任务调度这样的高级系统功能。因此,实现 println! 的复杂度大大降低。
4B. 使用 core 实现简化的 println!
由于裸机编程环境不依赖操作系统,不能使用 std 库,但可以使用 Rust 的 core 库。core 是 std 的精简版,它不依赖于操作系统,提供了一些基础的特性,如格式化、基本类型等。
在裸机编程中,我们可以通过实现 core::fmt::Write 特性来创建一个println! 宏。以下是一个简化版的实现。
示例代码
// user/src/bin/hello_world.rs #![no_std] // 禁用标准库 #![no_main] // 禁用标准的入口点 #[macro_use] extern crate user_lib; // 使用自定义的宏库 #[no_mangle] pub fn main() -> i32 { println!("Hello world from user mode program!"); 0 } // user/src/console.rs use core::fmt::{self, Write}; // 通过串口或其他设备直接输出 const STDIN: usize = 0; const STDOUT: usize = 1; // 假设这是一个底层的硬件接口,可以将数据写入设备 fn write(fd: usize, buffer: &[u8]) { // 在这里实现硬件写入的逻辑,通常是向某个内存映射寄存器写入数据 // 例如 UART 的数据寄存器 } // 定义一个结构体用于输出 struct Stdout; impl Write for Stdout { fn write_str(&mut self, s: &str) -> fmt::Result { write(STDOUT, s.as_bytes()); Ok(()) } } // 用于格式化输出的 `print` 函数 pub fn print(args: fmt::Arguments) { Stdout.write_fmt(args).unwrap(); } // 定义 `print!` 宏 #[macro_export] macro_rules! print { ($fmt: literal $(, $($arg: tt)+)?) => { $crate::console::print(format_args!($fmt $(, $($arg)+)?)); } } // 定义 `println!` 宏 #[macro_export] macro_rules! println { ($fmt: literal $(, $($arg: tt)+)?) => { $crate::console::print(format_args!(concat!($fmt, "\n") $(, $($arg)+)?)); } }
代码解析:
-
#![no_std]与#![no_main]:#![no_std]:告诉编译器不使用 Rust 标准库。裸机编程环境中没有操作系统,因此不能使用标准库的功能。#![no_main]:禁用标准的程序入口(main函数),以便自定义程序入口。
-
core::fmt::Write特性:- 我们实现了
core::fmt::Write特性中的write_str方法,用于将字符串输出到硬件设备(如 UART)。在这个例子中,write函数会将数据发送到STDOUT,这是裸机编程中实现打印输出的关键。
- 我们实现了
-
print!和println!宏:print!宏使用format_args!进行格式化,将格式化后的数据通过print函数输出。println!宏是在print!的基础上添加了一个换行符。concat!宏会将用户提供的字符串与\n拼接在一起。
4C. 对比标准库与裸机编程的 println! 实现
1. 标准库版本 println! 的复杂性
在操作系统环境下,Rust 标准库的 println! 宏功能强大,但其实现也更加复杂。这是因为它必须在多任务、多线程的环境中保证输出的正确性和安全性。下面是标准库版本的 println! 关键特性:
-
多层次抽象:
println!的实现涉及多个抽象层。宏本身会展开为format_args_nl!,负责对参数进行格式化,然后调用内部的_print函数。_print通过write_fmt方法将格式化后的内容写入标准输出流(stdout)。- 这种多层抽象允许标准库灵活地处理各种 I/O 设备和环境,同时确保代码的可扩展性。
-
线程安全性:
- 标准库中的
println!必须处理多线程环境。为此,stdout()返回一个可写流,而stdout().lock()会在进行输出时锁定标准输出,确保同一时刻只有一个线程能够写入数据。这样可以避免并发写入时数据混乱。 - 锁的使用增加了实现的复杂性,但保证了在复杂的操作系统环境中输出操作的正确性。
- 标准库中的
-
系统调用:
- 标准库最终依赖于操作系统的 I/O 系统调用,将数据写入到标准输出设备。操作系统管理着诸如终端、文件或网络等 I/O 设备。每次调用
println!,都会经过系统调用层,这也是为什么标准库版本的实现更加复杂。 - 这些系统调用通过内核来管理底层设备,确保数据能够正确、安全地输出到目标设备。
- 标准库最终依赖于操作系统的 I/O 系统调用,将数据写入到标准输出设备。操作系统管理着诸如终端、文件或网络等 I/O 设备。每次调用
2. 裸机编程版本 println! 的简单性
在裸机编程(bare-metal programming)环境下,没有操作系统作为中间层,开发者必须直接与硬件交互。这使得 println! 的实现相对简单,因为不需要处理多线程或系统调用等复杂问题。
-
直接硬件交互:
- 在裸机环境下,
println!直接与硬件设备(如 UART 串口)交互,通常通过寄存器或内存映射的方式将数据发送到外设。 - 这里没有像标准库那样的多层抽象。开发者会自己实现一个
write函数,这个函数直接负责将字符通过硬件接口输出。因此,println!的底层实现只需调用这个write函数,向外设发送数据即可。
- 在裸机环境下,
-
不涉及线程安全:
- 裸机编程通常运行在单任务或简单任务环境中,意味着程序只有一个执行线程或没有复杂的调度机制,因此不需要像标准库那样处理线程安全问题。
- 没有多线程,也就不需要对输出流进行锁定。在裸机环境下,
println!的实现可以非常简单,直接输出数据,而不必考虑多个线程同时访问同一输出设备。
-
没有系统调用:
- 裸机编程中没有操作系统提供的系统调用,因此所有的 I/O 操作都是通过直接访问硬件完成的。开发者需要自己编写与硬件交互的代码,如通过 UART 将数据发送到串口设备,或者通过直接访问内存映射寄存器来进行输出操作。
- 没有操作系统的调度或管理,所有 I/O 直接由开发者控制,这使得
println!的实现更加轻量,也更贴近底层硬件。
3. 在裸机环境中自己实现相关功能
当在裸机编程环境下构建一个操作系统时,你需要自己实现与硬件的交互。这包括编写诸如 println! 的 I/O 操作函数,而这些功能在标准库中则由操作系统和标准库管理。
-
实现
write函数:-
在裸机环境下,你需要编写
write函数直接与硬件设备通信。例如,若使用 UART 进行串口通信,你可能会通过访问特定的硬件寄存器来发送字符。你可以实现类似下面的代码:#![allow(unused)] fn main() { fn write(uart_address: usize, buffer: &[u8]) { for &byte in buffer { unsafe { // 向硬件的 UART 寄存器写入数据 core::ptr::write_volatile(uart_address as *mut u8, byte); } } } }
-
-
实现
print!和println!宏:-
与标准库类似,你可以定义自己的
print!和println!宏,并使用core::fmt::Write特性进行格式化。不同的是,裸机环境下的println!直接输出到硬件设备,而不是通过系统调用:#![allow(unused)] fn main() { pub fn print(args: fmt::Arguments) { write_to_uart(args); } #[macro_export] macro_rules! print { ($fmt:literal $(, $($arg:tt)+)?) => { $crate::console::print(format_args!($fmt $(, $($arg)+)?)); } } #[macro_export] macro_rules! println { ($fmt:literal $(, $($arg:tt)+)?) => { $crate::console::print(format_args!(concat!($fmt, "\n") $(, $($arg)+)?)); } } }
-
-
硬件层次的管理:
- 在操作系统中,尤其是裸机编程的操作系统,你需要自己编写对硬件的管理代码,比如串口初始化、内存管理、中断处理等。而标准库中的这些功能通常依赖操作系统,因此在裸机环境下,开发者需要手动实现所有相关功能。
-
调度与多任务处理:
- 如果你需要支持多任务或简单的调度,可能需要设计一个自己的输出锁机制,类似于标准库中的
stdout().lock(),以防止多个任务同时输出时的冲突。但在简单的裸机应用中,多数情况下不需要这种复杂性。
- 如果你需要支持多任务或简单的调度,可能需要设计一个自己的输出锁机制,类似于标准库中的
4. 总结:标准库与裸机实现的差异
-
标准库版本的
println!:功能强大,适合复杂的多线程、多任务环境,具有线程安全、系统调用支持等特性,但其实现更加复杂,需要依赖操作系统。 -
裸机版本的
println!:实现更简单,直接与硬件交互,适用于单任务、单线程环境。裸机编程没有操作系统和系统调用的支持,开发者需要手动实现 I/O 和其他底层硬件交互逻辑。
在构建操作系统时,开发者不仅要实现基本的 println! 功能,还要处理与硬件的直接通信、系统资源的管理以及可能的多任务支持。这使得裸机编程既简单又复杂——简单在于直接访问硬件,但复杂在于没有操作系统时,所有细节都由开发者自行管理。
4. RISC-V: 使用 GDB 和 QEMU 调试 (Rust 语言)
Makefile 章节
1. Makefile 入门
Makefile 基本示例:逐步构建
在构建 C 项目的过程中,Makefile 是一种非常重要的工具,它可以自动化管理项目中的编译、链接等操作。通过 Makefile,我们可以简化构建过程,提高工作效率,尤其是在项目规模增大时,能够避免重复编译全部文件。
假设你正在开发一个简单的 C 项目,项目有一个主文件 main.c 和一个工具模块 utils.c,以及可能的头文件 utils.h。这两个 .c 文件将被编译成对象文件 .o,然后链接成一个可执行文件 my_program。项目目录结构如下:
my_project/
├── Makefile
├── main.c
├── utils.c
└── utils.h
项目文件介绍:
main.c:主程序,包含程序的主要逻辑。utils.c:工具模块,包含辅助功能代码。utils.h:utils.c的头文件,定义函数声明和常量。
接下来,我们将逐步构建一个 Makefile,逐渐引入常见的编译、链接和清理功能。
第一步:最简单的 Makefile
在最简单的情况下,你只需告诉 Makefile 如何从源文件生成目标文件。这是最基础的 Makefile,它直接定义了编译和生成可执行文件的方式。
# 定义目标
my_program: main.c utils.c
gcc main.c utils.c -o my_program
Makefile 解析:
- 目标文件:
my_program是最终生成的可执行文件。 - 依赖文件:
my_program依赖于两个源文件main.c和utils.c,它们将被编译。 - 编译命令:
gcc main.c utils.c -o my_program是编译和链接的命令,gcc是使用的编译器,将main.c和utils.c编译并链接成my_program。
这个 Makefile 非常简洁,但它没有分离编译和链接步骤,也没有处理头文件的依赖问题。每次运行 make,都会重新编译所有源文件,即使只有一个文件发生了变化。
使用:
-
创建 Makefile:将上述内容保存到项目目录下的
Makefile文件中。 -
编译项目:在终端中运行以下命令,Make 会自动执行:
makeMake 会调用 GCC,将
main.c和utils.c一起编译,并生成可执行文件my_program。 -
执行程序:生成的可执行文件
my_program可以直接运行:./my_program -
清理文件:由于这个 Makefile 没有定义清理规则,因此你需要手动删除生成的文件:
rm my_program
第二步:分离编译与链接
在稍微复杂的项目中,通常会将 .c 文件先编译为中间目标文件 .o(对象文件),然后再将这些对象文件链接为可执行文件。这种做法的好处是,当某个源文件发生变化时,Make 只会重新编译该文件,其他未修改的文件无需重新编译,从而提高了编译效率。
更新的 Makefile:
# 定义编译器和编译选项
CC = gcc
CFLAGS = -Wall
# 定义目标文件
my_program: main.o utils.o
$(CC) $(CFLAGS) -o my_program main.o utils.o
# 定义编译规则
main.o: main.c
$(CC) $(CFLAGS) -c main.c -o main.o
utils.o: utils.c
$(CC) $(CFLAGS) -c utils.c -o utils.o
解析:
-
分离编译与链接:
- 首先,
main.c和utils.c分别被编译为对象文件main.o和utils.o。 - 然后,使用
gcc将这两个对象文件链接成最终的可执行文件my_program。
- 首先,
-
变量使用:
CC:指定使用的编译器(GCC)。CFLAGS:定义编译选项。-Wall表示启用所有警告,以帮助开发者发现潜在的问题。$@和$<等自动化变量将在后续步骤详细介绍。
使用步骤:
-
编译项目:运行
make,Make 会按照规则依次编译源文件并链接生成可执行文件:make输出结果类似于:
gcc -Wall -c main.c -o main.o gcc -Wall -c utils.c -o utils.o gcc -Wall -o my_program main.o utils.o -
运行程序:可执行文件
my_program生成后,可以直接运行:./my_program -
查看中间文件:这时,你会看到生成了
main.o、utils.o和my_program。 -
清理文件:手动删除生成的中间文件和可执行文件:
rm *.o my_program
第三步:引入伪目标(Phony Targets)
在大型项目中,除了生成目标文件(如可执行文件或库)之外,通常还需要执行其他与生成文件无关的辅助任务,例如清理构建过程中生成的中间文件或最终的目标文件。这时,伪目标(Phony Targets)就派上用场了。伪目标是一类特殊的目标,它们不生成任何文件,而是作为执行特定任务的触发点。
在 Makefile 中,我们可以使用 .PHONY 标记某些目标为伪目标。比如,clean 伪目标用于删除生成的对象文件(.o 文件)和最终的可执行文件。
完整的 Makefile:
# 定义编译器和编译选项
CC = gcc
CFLAGS = -Wall
# 定义目标文件
my_program: main.o utils.o
$(CC) $(CFLAGS) -o my_program main.o utils.o
# 定义编译规则
main.o: main.c
$(CC) $(CFLAGS) -c main.c -o main.o
utils.o: utils.c
$(CC) $(CFLAGS) -c utils.c -o utils.o
# 伪目标 clean,用于清理生成的文件
.PHONY: clean
clean:
rm -f *.o my_program
解析:
-
伪目标
clean:clean是一个伪目标,通过.PHONY声明不会生成与clean同名的文件。它的作用是删除项目编译生成的中间文件(如.o文件)和可执行文件(my_program)。 -
.PHONY:明确指定clean作为伪目标,防止如果目录中不小心有一个名为clean的文件时产生冲突。 -
rm -f:执行删除命令,-f选项用于避免文件不存在时报错。
使用:
-
编译项目:
make这会生成
main.o、utils.o和my_program。 -
清理项目:
make clean运行
make clean时,Make 会删除所有.o文件和生成的可执行文件my_program,确保项目目录回到清洁状态。
通过这种方式,每次你需要重新编译或清理项目时,都可以使用 make clean 删除所有中间文件和最终的可执行文件,而不需要手动去删除它们。
第四步:使用自动化变量简化规则
Makefile 提供了一些自动化变量,可以减少重复代码的书写,提高 Makefile 的简洁性和可维护性。使用这些变量,可以让 Makefile 自动根据文件名和依赖关系生成相应的编译命令,避免手动为每个文件单独编写编译规则。
常见的自动化变量有:
$@:表示当前目标文件的名字。$^:表示所有依赖文件的列表。$<:表示第一个依赖文件。
完整的 Makefile(使用自动化变量):
# 定义编译器和编译选项
CC = gcc
CFLAGS = -Wall
# 定义目标文件
my_program: main.o utils.o
$(CC) $(CFLAGS) -o $@ $^
# 定义编译规则,使用自动化变量
%.o: %.c
$(CC) $(CFLAGS) -c $< -o $@
# 伪目标 clean,用于清理生成的文件
.PHONY: clean
clean:
rm -f *.o my_program
解析:
-
自动化变量:
$@:表示目标文件的名称。在my_program: main.o utils.o规则中,$@等价于my_program。$^:表示所有依赖文件的列表。在my_program: main.o utils.o中,$^等价于main.o utils.o。$<:表示第一个依赖文件。在%.o: %.c规则中,$<表示对应的.c文件(即main.c或utils.c)。
-
模式规则(Pattern Rule):
%.o: %.c是一个模式规则,表示所有的.c文件都可以使用相同的规则编译为.o文件。%是通配符,可以匹配文件名的任意部分。因此,main.c会被编译为main.o,utils.c会被编译为utils.o。
使用:
-
编译项目:
make运行时 Make 会自动编译
main.c和utils.c为对象文件main.o和utils.o,然后将它们链接成my_program可执行文件。 -
清理项目:
make clean清理所有生成的中间文件和可执行文件,保持项目目录的整洁。
为什么使用自动化变量?
-
简化规则:自动化变量可以让规则更加简洁,减少重复代码。例如,在没有自动化变量的情况下,你可能需要为每个
.c文件分别编写编译规则。使用自动化变量和模式规则后,所有的.c文件都可以通过一条通用规则编译为.o文件。 -
提高可维护性:当项目规模增大时,手动为每个文件编写编译规则变得不可行。自动化变量让 Makefile 变得更加灵活,可以自动处理不同文件之间的依赖关系。
第五步:自动生成依赖文件
在大型 C 项目中,源文件(.c 文件)往往依赖于头文件(.h 文件)。当头文件发生变化时,相关联的源文件也需要重新编译。为了避免手动管理这种依赖关系,Makefile 可以通过编译器选项自动生成包含依赖信息的 .d 文件(依赖文件)。
在这一步中,我们将使用 GCC 的 -MMD 选项自动生成这些依赖文件,以确保当头文件发生变化时,Makefile 能够自动重新编译相关的源文件。
更新的 Makefile:
# 定义编译器和编译选项
CC = gcc
CFLAGS = -Wall -MMD
# 定义目标文件
my_program: main.o utils.o
$(CC) $(CFLAGS) -o $@ $^
# 定义编译规则,使用自动化变量
%.o: %.c
$(CC) $(CFLAGS) -c $< -o $@
# 包含自动生成的依赖文件
-include *.d
# 伪目标 clean,用于清理生成的文件
.PHONY: clean
clean:
rm -f *.o my_program *.d
解析:
-
-MMD选项:这个选项告诉gcc编译器在编译.c文件时生成对应的.d文件。.d文件中包含了源文件(.c文件)对头文件(.h文件)的依赖关系。例如,main.c编译时会生成main.d,它记录了main.c对utils.h的依赖关系。 -
-include *.d:通过-include命令,Makefile 会自动加载所有.d文件。如果这些文件不存在(例如首次构建时),-include不会报错。这确保当头文件发生变化时,相关.c文件能够自动重新编译。 -
clean目标:clean目标现在也删除自动生成的.d文件,以确保清理工作彻底。
使用步骤:
-
构建项目:
make在编译过程中,Makefile 不仅会生成目标文件(如
main.o、utils.o),还会生成相应的依赖文件(如main.d和utils.d)。这些.d文件会被自动加载,以跟踪源文件对头文件的依赖关系。 -
修改头文件:假设你修改了
utils.h,下次运行make时,Makefile 会自动重新编译依赖utils.h的源文件(如main.c或utils.c)。 -
清理生成文件:
make clean这个命令会删除
.o文件、可执行文件my_program和生成的.d文件。
第六步:引入并行构建
在现代计算机上,多核处理器的普及为加速编译过程提供了可能。GNU Make 支持并行构建,可以同时执行多个任务,从而充分利用 CPU 资源。这对于有大量源文件的大型项目特别有效。
使用并行构建:
为了使用并行构建,我们不需要对 Makefile 做额外的改动,直接在命令行中使用 make 的 -j 选项即可。
并行构建命令:
make -j4
-j4:这个命令告诉 Make 同时执行 4 个任务。这意味着 Make 会同时编译最多 4 个文件,如果项目中有足够的独立文件,这将显著提升构建速度。
依赖关系注意事项:
确保 Makefile 中的依赖关系定义正确非常重要。通过之前引入的 .d 文件自动管理头文件依赖,以及 Makefile 本身的分离编译与链接结构,可以确保并行构建时各个文件之间的依赖关系能够被正确处理,不会产生编译顺序错误。
使用步骤:
-
并行编译项目:
make -j4在多核处理器上,这会显著加快编译过程,特别是当项目中有多个源文件时。
-
查看编译速度:你会发现 Make 同时编译多个
.c文件,而不是依次逐个编译。这样做能够更高效地利用 CPU 资源。
最终的综合示例 Makefile
通过逐步引入新特性,我们构建了一个完整且高效的 Makefile,涵盖了变量使用、通用规则、自动化变量、伪目标、自动生成依赖文件以及并行构建等功能。这是一个适用于中小型 C 项目的基础 Makefile,也为更复杂的项目提供了一个很好的起点。
完整的 Makefile:
# 定义编译器和编译选项
CC = gcc
CFLAGS = -Wall -MMD
# 定义目标文件
my_program: main.o utils.o
$(CC) $(CFLAGS) -o $@ $^
# 定义编译规则,使用自动化变量
%.o: %.c
$(CC) $(CFLAGS) -c $< -o $@
# 包含自动生成的依赖文件
-include *.d
# 伪目标 clean,用于清理生成的文件
.PHONY: clean
clean:
rm -f *.o my_program *.d
-
编译和链接规则:我们使用自动化变量和模式规则,实现了更简洁的编译和链接过程。
%.o: %.c表示每个.c文件都可以自动生成相应的.o文件。 -
自动生成依赖:通过
-MMD选项,编译时会自动生成.d文件,这些文件记录了源文件和头文件之间的依赖关系。Makefile 会自动包含这些依赖文件,确保当头文件发生变化时,相关源文件会重新编译。 -
清理规则:
clean伪目标会删除所有中间文件(.o和.d)以及最终生成的可执行文件,确保项目目录干净整洁。 -
并行构建支持:通过
make -j命令,可以利用并行编译加速构建,特别适合多核处理器环境。
使用总结:
-
生成文件:
make这将编译所有源文件并生成可执行文件
my_program,同时生成.d文件管理头文件依赖。 -
清理项目:
make clean这会删除所有生成的文件,包括中间的
.o文件和.d文件。 -
并行编译:
make -j4这会同时运行 4 个编译任务,加快多文件项目的编译速度。
通过这个 Makefile,构建过程得到了全面优化,涵盖了从基础编译到自动依赖管理和并行构建等各个方面。这个 Makefile 不仅适用于小型项目,还可以随着项目的扩展进一步调整和优化,是一个灵活且高效的解决方案。
RISC-V: Makefile 与 GDB/QEMU 调试 (C 语言)
本节为 RISC-V 裸机编程提供了一个逐步构建的 Makefile 教程,帮助你使用 riscv64-unknown-elf-gcc 进行编译和链接,同时通过 QEMU 启动虚拟机,并利用 GDB 进行调试。该教程适用于裸机编程环境,并逐步引入编译、链接、启动和调试的各个步骤。
项目结构
假设你的项目目录如下:
riscv-baremetal/
├── Makefile
├── hello.c
├── start.s
├── linker.ld
hello.c:C 语言编写的主程序。start.s:汇编启动文件,负责启动 CPU 并跳转到 C 代码。linker.ld:链接器脚本,控制程序的内存布局。
通过这些文件,我们将使用 riscv64-unknown-elf-gcc 编译和链接,并使用 QEMU 进行模拟调试。
第一步:编译和链接
首先,我们使用 riscv64-unknown-elf-gcc 交叉编译工具链来编译项目中的源文件,并将它们链接为一个可执行的裸机程序 hello.elf。在这个步骤中,我们将构建最基础的编译规则。
编译命令说明
为了编译和链接 hello.c 和 start.s,我们需要在命令行中使用以下命令:
riscv64-unknown-elf-gcc -g -nostartfiles -nostdlib -T linker.ld -mcmodel=medany -o hello.elf start.s hello.c
参数解释:
-g:生成调试信息,使得我们可以在 GDB 中查看源代码级的调试信息。-nostartfiles:告诉编译器不要链接标准的启动文件。标准启动文件通常用于初始化环境(如 C 库),但裸机编程中我们通常自己编写启动代码,所以禁用它。-nostdlib:禁用标准库(如libc),因为在裸机环境中,标准库并不可用,我们必须自己管理所有内存和 I/O 操作。-T linker.ld:指定链接器脚本,控制程序在内存中的布局。这个脚本将告诉编译器如何将各个段(如代码段.text和数据段.data)布局到内存的正确位置。-mcmodel=medany:这是 RISC-V 的内存模型,用于裸机编程。它允许指令和数据在较大范围的内存地址中进行操作。-o hello.elf:指定输出文件的名称为hello.elf,这是最终生成的可执行文件。start.s和hello.c:这两个文件分别为启动汇编代码和主程序。
使用 Makefile 管理编译和链接
为了简化编译过程并避免每次手动输入复杂的编译命令,我们可以使用 Makefile 来自动管理编译和链接过程。Makefile 可以帮助我们定义规则,自动化整个构建过程。
Makefile 第一步:基础编译规则
以下是一个基础的 Makefile,用于编译和链接 start.s 和 hello.c 生成 hello.elf:
# 定义工具链和编译器选项
CC = riscv64-unknown-elf-gcc
CFLAGS = -g -nostartfiles -nostdlib -mcmodel=medany
LDFLAGS = -T linker.ld
# 目标文件
TARGET = hello.elf
# 源文件
SRCS = start.s hello.c
# 编译规则
$(TARGET): $(SRCS)
$(CC) $(CFLAGS) $(LDFLAGS) -o $(TARGET) $(SRCS)
# 伪目标 clean,用于清理生成的文件
.PHONY: clean
clean:
rm -f $(TARGET)
CC:定义了我们使用的编译器,这里是riscv64-unknown-elf-gcc,适用于 RISC-V 架构的交叉编译器。CFLAGS:编译选项,包括调试信息(-g)、禁用标准启动文件(-nostartfiles和-nostdlib),以及指定 RISC-V 的内存模型(-mcmodel=medany)。LDFLAGS:链接选项,指定链接器脚本linker.ld。TARGET:目标文件,即最终生成的可执行文件hello.elf。SRCS:源文件列表,包括汇编启动文件start.s和主程序hello.c。- 编译规则:当 Makefile 检测到目标
hello.elf需要更新时,它会调用riscv64-unknown-elf-gcc进行编译和链接。 clean伪目标:定义一个伪目标clean,用于清理生成的文件。每当运行make clean时,它会删除hello.elf,保持目录的整洁。
使用步骤:
-
创建 Makefile:
- 在项目的根目录下(与
hello.c、start.s、linker.ld同级)创建一个名为Makefile的文件,并将上面的内容粘贴进去。
- 在项目的根目录下(与
-
编译项目:
- 打开终端,导航到项目根目录,运行以下命令:
make - 这会调用
riscv64-unknown-elf-gcc,并使用指定的编译选项和链接器脚本生成hello.elf。
- 打开终端,导航到项目根目录,运行以下命令:
-
查看生成的文件:
- 编译完成后,项目目录下会生成
hello.elf。你可以运行以下命令查看生成的文件:ls -l hello.elf
- 编译完成后,项目目录下会生成
-
清理生成文件:
- 为了保持项目目录整洁,您可以使用
make clean来删除生成的hello.elf文件:make clean
- 为了保持项目目录整洁,您可以使用
-
调试信息:
hello.elf文件中包含调试信息(由于使用了-g选项)。这在后续使用 GDB 进行调试时非常重要,因为它允许我们在调试时查看源代码、设置断点等。
第二步:使用 QEMU 启动裸机程序
在编译并生成了 RISC-V 裸机程序 hello.elf 之后,接下来我们将使用 QEMU 启动该程序。QEMU 是一个强大的虚拟化和仿真工具,支持多种架构,包括 RISC-V。它能够模拟裸机环境,帮助我们运行和调试 hello.elf,无需在物理硬件上执行。
我们将通过 QEMU 启动 hello.elf 程序,并使用 GDB 进行调试。QEMU 将模拟 RISC-V CPU,加载并运行该裸机程序,并提供调试接口供 GDB 使用。
QEMU 启动命令详解
为了启动 hello.elf 裸机程序,我们需要执行以下命令:
qemu-system-riscv64 -machine virt -nographic -kernel hello.elf -s -S
参数说明:
qemu-system-riscv64:启动 QEMU,模拟 RISC-V 64 位架构的系统。-machine virt:虚拟化环境下的 RISC-V 机器类型。这个选项告诉 QEMU 使用“virt”虚拟平台,它是 RISC-V 模拟中常用的一个虚拟开发平台。-nographic:不使用图形界面,将所有输入输出重定向到终端。这使得输出可以直接在终端中显示,适合裸机环境的开发。-kernel hello.elf:加载hello.elf作为裸机程序。这是我们使用riscv64-unknown-elf-gcc编译生成的可执行文件,它将被 QEMU 模拟器加载并执行。-s:开启 GDB 服务器,默认监听端口1234,允许 GDB 通过远程调试接口连接到 QEMU 上运行的程序。-S:启动 QEMU 后立即暂停程序执行。QEMU 将在启动时等待 GDB 连接,直到我们在 GDB 中下达continue命令后才开始执行程序。这使得我们能够在程序执行之前设置断点或查看初始状态。
QEMU 启动过程
- 加载和启动裸机程序:
hello.elf被 QEMU 作为内核程序加载。这与操作系统环境不同,因为裸机程序并没有任何操作系统提供的服务或库。QEMU 将模拟硬件平台,为程序提供执行环境。 - 暂停并等待 GDB 调试:通过
-S选项,QEMU 在启动后暂停程序的执行,这为我们调试提供了准备时间。我们可以连接 GDB 并设置断点、检查寄存器或执行其他调试操作。 - 无图形输出:由于裸机程序一般不涉及 GUI 操作,我们通过
-nographic将输出直接映射到终端。这有助于捕获程序的标准输出、日志或其他调试信息。
Makefile 第二步:添加 QEMU 启动规则
为了简化启动过程,我们可以将 QEMU 启动命令添加到 Makefile 中。这样可以通过运行 make qemu 来自动启动 QEMU 并加载我们的程序。
以下是更新后的 Makefile,增加了 QEMU 启动的规则:
# 定义工具链和编译器选项
CC = riscv64-unknown-elf-gcc
CFLAGS = -g -nostartfiles -nostdlib -mcmodel=medany
LDFLAGS = -T linker.ld
# 目标文件
TARGET = hello.elf
# 源文件
SRCS = start.s hello.c
# QEMU 启动命令
QEMU = qemu-system-riscv64
QEMU_FLAGS = -machine virt -nographic -kernel $(TARGET) -s -S
# 编译规则
$(TARGET): $(SRCS)
$(CC) $(CFLAGS) $(LDFLAGS) -o $(TARGET) $(SRCS)
# 启动 QEMU 进行调试
.PHONY: qemu
qemu: $(TARGET)
$(QEMU) $(QEMU_FLAGS)
# 伪目标 clean,用于清理生成的文件
.PHONY: clean
clean:
rm -f $(TARGET)
QEMU:定义了 QEMU 模拟器的名称,这里是qemu-system-riscv64,用于模拟 RISC-V 64 位架构。QEMU_FLAGS:QEMU 启动时所需的参数,包含虚拟平台配置、无图形输出模式、内核加载、调试支持等选项。qemu伪目标:这是一个伪目标,用于启动 QEMU。当我们执行make qemu时,它会检查是否已经生成了目标文件hello.elf,然后执行 QEMU 启动命令。
使用步骤:
-
编译程序: 首先,确保程序已经成功编译并生成
hello.elf文件。你可以通过运行以下命令来构建项目:make这将会调用
riscv64-unknown-elf-gcc生成hello.elf,并准备好用于 QEMU 启动。 -
启动 QEMU: 一旦程序编译完成,你可以通过以下命令启动 QEMU:
make qemuQEMU 将加载
hello.elf,并根据-s和-S参数暂停在程序的起始位置,等待 GDB 调试器的连接。 -
连接 GDB(下一步): 启动 QEMU 后,它会暂停程序的执行,并在端口
1234上开启一个 GDB 服务器。在下一步中,我们将使用 GDB 连接到这个服务器,并调试hello.elf程序。 -
清理项目: 如果你想清理生成的文件,可以运行以下命令:
make clean这会删除编译生成的
hello.elf文件,使目录保持干净。
第三步:使用 GDB 调试
在第二步中,我们使用 QEMU 启动了 hello.elf 裸机程序,并让程序处于暂停状态,等待调试器的连接。现在我们将使用 riscv64-unknown-elf-gdb 连接到 QEMU,进行程序的调试。GDB 是一个强大的调试工具,它支持设置断点、单步执行、检查寄存器、查看内存内容等功能,非常适合用于调试裸机程序。
通过 GDB,我们可以在程序运行的不同阶段插入断点、跟踪变量和内存状态,或者单步执行代码,深入了解程序的执行流程。
使用 GDB 连接 QEMU
QEMU 启动时使用了 -s 和 -S 选项,分别开启了 GDB 服务器并让程序在启动时暂停。现在我们可以通过 GDB 连接到 QEMU 提供的调试接口,开始调试 hello.elf。
启动 GDB 的命令
首先,在终端中启动 GDB,并加载 hello.elf 文件以获取调试信息:
riscv64-unknown-elf-gdb hello.elf
这将启动 GDB,并加载 hello.elf 中的调试符号表(因为在编译时使用了 -g 选项)。接下来,我们需要让 GDB 连接到 QEMU 服务器。
连接到 QEMU 服务器
QEMU 在启动时通过 -s 选项开启了 GDB 服务器,默认监听在 localhost:1234 端口。我们需要在 GDB 中执行以下命令,连接到 QEMU 的 GDB 服务器:
(gdb) target remote localhost:1234
一旦连接成功,GDB 将能够控制程序的执行。由于 QEMU 使用了 -S 选项,程序已经在启动时暂停,等待进一步的指令。
Makefile 第三步:添加 GDB 调试规则
为了进一步简化调试流程,我们可以将 GDB 调试命令整合到 Makefile 中。通过添加 GDB 调试的伪目标,可以直接通过 make gdb 启动 GDB 并自动连接到 QEMU。
以下是更新后的 Makefile,增加了 GDB 调试的规则:
# 定义工具链和编译器选项
CC = riscv64-unknown-elf-gcc
CFLAGS = -g -nostartfiles -nostdlib -mcmodel=medany
LDFLAGS = -T linker.ld
# 目标文件
TARGET = hello.elf
# 源文件
SRCS = start.s hello.c
# QEMU 启动命令
QEMU = qemu-system-riscv64
QEMU_FLAGS = -machine virt -nographic -kernel $(TARGET) -s -S
# GDB 命令
GDB = riscv64-unknown-elf-gdb
# 编译规则
$(TARGET): $(SRCS)
$(CC) $(CFLAGS) $(LDFLAGS) -o $(TARGET) $(SRCS)
# 启动 QEMU 进行调试
.PHONY: qemu
qemu: $(TARGET)
$(QEMU) $(QEMU_FLAGS)
# 启动 GDB 并连接到 QEMU
.PHONY: gdb
gdb: $(TARGET)
$(GDB) $(TARGET) -ex "target remote localhost:1234"
# 伪目标 clean,用于清理生成的文件
.PHONY: clean
clean:
rm -f $(TARGET)
GDB:我们定义了riscv64-unknown-elf-gdb作为 GDB 的命令。gdb伪目标:这个伪目标将自动启动 GDB,并使用-ex "target remote localhost:1234"命令连接到 QEMU 提供的 GDB 服务器,简化了调试过程。- QEMU 和 GDB 的独立目标:
qemu目标启动 QEMU,而gdb目标启动 GDB,并连接到正在运行的 QEMU 实例。
使用步骤:
-
构建程序: 首先,确保程序已经成功编译并生成
hello.elf文件。你可以通过以下命令编译项目:make -
启动 QEMU: 运行以下命令启动 QEMU,并让程序处于暂停状态,等待调试器连接:
make qemu -
启动 GDB 并连接到 QEMU: 在另一个终端中,运行以下命令启动 GDB 并自动连接到 QEMU:
make gdb这将会打开 GDB 并连接到 QEMU 的 GDB 服务器,准备调试。
-
开始调试: 你现在可以在 GDB 中执行各种调试操作,例如设置断点、查看寄存器、单步执行等。例如:
-
继续执行程序:
使用
continue命令让程序从当前暂停的状态继续执行,直到遇到断点或程序结束。(gdb) continue -
设置断点:
在特定的函数或代码行处设置断点,程序执行到此处时会暂停。例如,设置一个断点在
main函数:(gdb) break mainGDB 会在程序执行到
main函数的第一行时暂停,等待进一步指令。 -
单步执行:
单步执行可以逐行检查程序的运行情况,适合调试复杂的逻辑。
step命令会执行当前代码行,并进入函数调用。(gdb) step使用
next命令可以跳过函数调用,不进入函数内部。(gdb) next -
查看寄存器状态:
裸机程序需要密切关注寄存器的状态。通过 GDB,你可以查看 CPU 寄存器的值,例如:
(gdb) info registers这将显示当前所有 CPU 寄存器的内容。
-
查看内存:
你还可以检查特定内存地址的内容。例如,查看地址
0x80000000处的 16 个字节:(gdb) x/16xb 0x80000000其中,
x表示检查内存,16xb表示以 16 个字节为单位查看。 -
退出调试:
调试完成后,可以使用
quit命令退出 GDB。(gdb) quit
-
包含多个源文件
最后我们可以结合上一节的内容,创建一个包含多个源文件(main.c、utils.c、utils.h)的 Makefile,使用 GDB 调试和 QEMU 启动,并加入自动依赖生成的功能。这个 Makefile 适合用于裸机开发,并且可以自动管理编译、链接、清理、调试等任务。
项目结构
假设项目的目录结构如下:
riscv-baremetal/
├── Makefile
├── hello.c
├── start.s
├── utils.c
├── utils.h
├── linker.ld
hello.c:主程序文件。start.s:启动汇编代码。utils.c:工具模块,包含辅助函数。utils.h:工具模块的头文件,声明utils.c中的函数。linker.ld:链接器脚本,定义程序的内存布局。
Makefile 各部分功能
编译与链接
为了编译 hello.c 和 utils.c,并将它们与启动代码 start.s 链接在一起,我们需要定义一个包含多文件的 Makefile。在这里,我们还会自动生成头文件的依赖关系,确保当 utils.h 发生变化时,相关的 .c 文件会自动重新编译。
启动 QEMU 并连接 GDB
Makefile 中会有两个独立的目标:
qemu:用于启动 QEMU 虚拟机并加载hello.elf,虚拟机启动后处于暂停状态,等待 GDB 连接。gdb:用于启动 GDB 并自动连接到 QEMU 的调试接口。
最终 Makefile
以下是完整的 Makefile,它将编译多文件项目、生成依赖文件、清理生成的目标文件、并提供通过 QEMU 和 GDB 进行调试的功能。
# 定义工具链和编译器选项
CC = riscv64-unknown-elf-gcc
CFLAGS = -g -nostartfiles -nostdlib -mcmodel=medany -Wall -MMD
LDFLAGS = -T linker.ld
# 定义目标文件
TARGET = hello.elf
# 源文件
SRCS = start.s hello.c utils.c
# 对象文件 (将所有 .c 文件和 .s 文件编译为 .o 文件)
OBJS = $(SRCS:.c=.o)
OBJS := $(OBJS:.s=.o)
# QEMU 启动命令
QEMU = qemu-system-riscv64
QEMU_FLAGS = -machine virt -nographic -kernel $(TARGET) -s -S
# GDB 命令
GDB = riscv64-unknown-elf-gdb
# 编译规则
$(TARGET): $(OBJS)
$(CC) $(CFLAGS) $(LDFLAGS) -o $@ $^
# 定义编译规则,使用自动化变量,适用于 .c 和 .s 文件
%.o: %.c
$(CC) $(CFLAGS) -c $< -o $@
%.o: %.s
$(CC) $(CFLAGS) -c $< -o $@
# 包含自动生成的依赖文件
-include $(SRCS:.c=.d)
# 启动 QEMU 进行调试
.PHONY: qemu
qemu: $(TARGET)
$(QEMU) $(QEMU_FLAGS)
# 启动 GDB 并连接到 QEMU
.PHONY: gdb
gdb: $(TARGET)
$(GDB) $(TARGET) -ex "target remote localhost:1234"
# 伪目标 clean,用于清理生成的文件
.PHONY: clean
clean:
rm -f $(OBJS) $(TARGET) *.d
-
自动化编译规则:
%通配符规则让.c文件和.s文件都可以自动编译为.o文件,避免手动为每个文件编写规则。$@代表当前目标,$^代表所有依赖文件。每个.o文件都会根据其依赖的.c或.s文件自动生成。
-
自动生成依赖文件:
-MMD选项告诉编译器在编译.c文件时自动生成.d文件,记录头文件的依赖关系。-include包含所有生成的.d文件,以确保在头文件修改时,Make 会自动重新编译相关源文件。
-
QEMU 与 GDB 调试:
qemu伪目标:启动 QEMU,加载hello.elf,并暂停等待调试。gdb伪目标:启动 GDB 并连接到 QEMU 提供的 GDB 服务器。
-
清理规则:
clean伪目标用于删除所有生成的.o文件、hello.elf可执行文件,以及自动生成的.d依赖文件。
使用步骤
-
编译项目:
首先运行
make命令,Makefile 会自动编译所有源文件并生成hello.elf:make如果一切正常,你将会看到
hello.elf文件生成。 -
启动 QEMU:
使用
make qemu启动 QEMU,并让程序暂停等待 GDB 连接:make qemuQEMU 将加载
hello.elf,并根据-s和-S参数启动调试服务器并暂停程序。 -
启动 GDB 并连接 QEMU:
在另一个终端中,运行
make gdb,这将自动启动 GDB 并连接到 QEMU:make gdb你可以在 GDB 中使用常用的调试命令,例如设置断点、单步执行、查看寄存器和内存等。
-
清理项目:
完成调试后,你可以使用
make clean清理生成的文件,保持项目目录整洁:make clean
总结
通过这个综合的 Makefile,我们实现了:
- 多文件编译与链接:编译多个
.c和.s文件,生成裸机可执行文件hello.elf。 - 自动生成依赖文件:通过
-MMD自动生成.d文件,确保源文件和头文件之间的依赖关系被正确管理。 - QEMU 启动与 GDB 调试:通过
make qemu启动虚拟机并加载程序,通过make gdb启动调试器并自动连接 QEMU。 - 清理规则:提供了
clean目标,快速清理生成的中间文件和目标文件。
这个 Makefile 是裸机开发的基础,可以根据项目的复杂性进一步扩展。例如,你可以添加更多的源文件或头文件,或者调整编译选项以适应特定的硬件平台和应用需求。
4. RISC-V: Makefile 与 GDB/QEMU 调试 (Rust 语言)
L02 操作系统概述2
回顾
上一堂课的内容主要回顾了操作系统的基本概念、抽象和历史演变。操作系统的抽象主要包括以下几个重要的方面:
- CPU 与进程:操作系统将 CPU 抽象为进程,通过进程的调度和管理来协调 CPU 资源的使用。
- 存储设备与文件系统:磁盘和其他存储设备被抽象为文件,操作系统通过文件系统来管理数据的存取。
- 内存与地址空间:操作系统将内存抽象为地址空间,进程通过地址空间访问内存,从而保证了进程间的独立性和安全性。
这些抽象的概念在后续的实验和实践中将会更深入理解,特别是涉及到操作系统的并发、共享、虚拟化和异步等核心特征。
操作系统的发展演变
操作系统并不是一开始就具有现代的特征。它随着硬件技术和应用需求的变化不断演变,经历了多个阶段的发展。
- 硬件驱动的演变:操作系统的功能和结构随着硬件的发展而变化。例如,早期的个人电脑操作系统功能较弱,但满足了当时的需求。
- 应用需求的变化:随着应用的多样化,操作系统也逐步增加了新的特性,例如多任务、多用户支持等。
历史上,操作系统的发展经历了螺旋上升的过程,有时甚至出现短暂的回退。例如,早期的个人电脑操作系统功能相对简化,是对大型计算机操作系统的功能性“退步”,但它适应了个人电脑有限的硬件资源和应用场景。
操作系统的定义和作用
操作系统的定义并不是一个严格的数学定义,而是一个随着需求变化的动态定义。基本上,操作系统有两个主要功能:
- 向上为应用提供服务:操作系统通过提供抽象层来简化应用程序对硬件资源的使用。
- 向下管理硬件资源:操作系统负责协调和管理底层硬件资源,使得多个应用能够高效地共享和使用这些资源。
操作系统的具体特性可能在不同阶段、不同场景中发生变化。例如,在早期实验中,某些特性可能没有被实现,而随着课程进展,这些特性会逐步被引入。
面向服务器与面向手机的操作系统
面向服务器的操作系统和面向手机的操作系统在功能上有所不同,主要体现在以下几个方面:
- 用户体验:手机操作系统更加注重用户的交互体验,强调流畅度和易用性。相比之下,服务器操作系统更注重性能和稳定性,通常通过命令行进行操作,缺少图形界面的需求。
- 硬件管理:服务器操作系统需要处理更强大的硬件资源,例如多核处理器、大量内存和存储设备,而手机操作系统则需要在有限的资源下优化功耗和性能。
- 应用场景:手机操作系统主要面向个人用户,强调人机交互,而服务器操作系统主要处理后台服务,面向大规模并发请求。
尽管存在这些差异,操作系统的核心任务,即管理硬件资源和为应用提供抽象服务,仍然是相同的。
网络浏览器与操作系统的整合
随着技术的发展,网络浏览器已经逐渐成为现代通用操作系统的一部分。在过去的 30 年中,操作系统的组成发生了显著的变化。早期,浏览器并不是操作系统的核心组件,但随着互联网的普及和应用需求的增长,浏览器已成为现代操作系统中的标配功能,尤其是在桌面和移动设备中。现代操作系统,特别是通用操作系统,如桌面操作系统和手机操作系统,已经默认集成了网络浏览器。这反映了操作系统随着需求和技术发展的动态变化。
理解操作系统的这种演变,要求我们从不同历史阶段和需求背景下理解其组成部分的变化。早期操作系统的功能相对简单,但随着时间的推移,越来越多的功能被纳入其中,网络浏览器便是其中之一。
关于操作系统是否应当包含网络浏览器的问题,答案取决于应用场景。现代操作系统在设计时,往往会包含支持网络通信的基本功能,如 TCP/IP 协议栈和 HTTP 协议库等。这些功能为网络浏览器的运行提供了基础支持。随着网络应用的普及,网络浏览器已经成为操作系统中不可或缺的一部分,尤其是在桌面和移动设备中。
然而,在服务器操作系统中,图形用户界面和网络浏览器通常并不是核心需求,因为服务器通常通过命令行和远程控制进行管理。
实验进展和实践要求
关于实验部分,助教已经在平台上发布了实验的初步文档和代码,后续还会有测试的更新。实验任务的安排将根据课程进度进行同步,学生可以根据需要提前进行实验。通过实验的实践,学生能够更深入理解操作系统的概念和特性,特别是操作系统的并发、共享、虚拟化和异步特性。
操作系统的核心抽象
操作系统的核心抽象概念可以总结为三个关键部分:
- 进程(Process):管理 CPU 资源,通过进程调度来确保多任务处理。
- 文件(File):抽象存储设备,操作系统通过文件系统管理存储数据的存取。
- 地址空间(Address Space):内存的抽象,确保每个进程拥有独立的内存空间,防止进程间的相互干扰。
尽管这些抽象概念表面上看起来简单,背后涉及大量复杂的设计与实现细节。课程的主要目标之一是帮助学生理解这些抽象,并掌握它们在操作系统中的具体实现方式。
操作系统与应用程序的交互
操作系统与应用程序之间的交互,主要通过系统调用实现。应用程序通过系统调用请求操作系统提供的服务,这种请求通常是单向的,即应用程序请求操作系统执行某些操作,而操作系统并不会主动请求应用程序执行任务。
然而,在数据层面,交互是双向的。应用程序可能将数据从用户空间传递给操作系统内核进行处理,内核在处理后也可能将结果数据返回给应用程序。理解这一点对于掌握操作系统的互操作性非常重要。
操作系统的并发、共享、虚拟化与异步特征
操作系统的四个核心特征包括:
- 并发(Concurrency):多个程序可以同时运行,体现为多任务并行的能力。
- 共享(Sharing):多个进程可以共享同一个资源,如同一文件的读写。
- 虚拟化(Virtualization):操作系统通过虚拟化技术,使每个进程感觉自己独占整个计算机资源,即使实际情况并非如此。
- 异步(Asynchrony):程序的执行不一定按照预期的顺序完成,存在不确定性。
通过实际编写小程序来体现这些特征,可以加深对操作系统设计和实现的理解。例如:
- 并发可以通过让两个程序同时运行来体现。
- 共享可以通过两个程序同时对同一文件进行读写操作来展示。
- 虚拟化可以通过申请比实际物理内存更多的内存空间进行测试。
- 异步特征可以通过测量程序的实际执行时间,发现其存在不确定性。
这些特征不仅仅体现在应用层面,也体现在操作系统设计的深层次逻辑中。
基于 C 和 Java 应用的执行环境差异
C 和 Java 应用程序的执行环境存在显著差异:
- C 程序的执行环境:C 程序直接运行在操作系统提供的环境中,操作系统负责为其管理资源,如内存、文件系统和 CPU。
- Java 程序的执行环境:Java 程序运行在 Java 虚拟机(JVM)中,JVM 是 Java 的抽象执行环境,负责跨平台兼容性和资源管理。JVM 自身运行在操作系统之上,提供了额外的抽象层。
这一区别意味着 C 程序直接依赖操作系统的服务,而 Java 程序则通过 JVM 间接与操作系统交互。这是两者在执行环境上的根本不同点。
操作系统的系统结构
操作系统(OS)是一种非常复杂的软件系统。以我们在实验中编写的操作系统为例,它至少包含几千行代码。而像 Linux、Windows 这样的现代操作系统,往往包含数千万行代码,甚至更多。如此庞大的软件系统需要借助软件架构的设计来支撑,这类复杂软件的设计属于软件工程的范畴。
简单结构
简单结构的操作系统,像早期的 MS-DOS,其设计理念非常简单,应用程序与操作系统的关系类似于库函数调用。应用程序可以直接调用操作系统提供的服务,且两者之间没有严格的隔离或保护机制。这种架构虽然简单,但也因此容易出现安全隐患。
然而,简单结构并非完全过时。在某些应用需求非常简单的场景下,简单结构依然有其价值。例如,某些工业控制领域,系统复杂度较低,使用简单结构可以降低开发成本和复杂度。
单体分层结构
单体分层结构是目前主流操作系统(如 UNIX、Linux、BSD、MacOS、Windows 等)采用的架构。这种结构通过分层的方式将操作系统划分为多个模块,从最底层的硬件抽象层,到上层的文件系统、进程管理和内存管理等。
这种分层设计的优点是每一层只依赖于下一层的服务,从而在开发过程中只需关注与下一层的交互,不需要了解整个系统的全貌。然而,随着操作系统规模的不断增加,实际开发中不同层次之间的耦合关系变得更加复杂,理想中的分层结构逐渐被打破,导致开发和维护变得更加困难。
尽管如此,单体内核结构仍然是大多数通用操作系统的首选,因为它能够在性能与复杂度之间取得较好的平衡。
微内核结构
微内核架构主要来自学术界,最早由卡内基梅隆大学(CMU)的研究者提出。他们认为,操作系统的复杂性随着功能的增加而膨胀,为了应对这一问题,微内核架构将内核的功能缩减到最小,只保留最基础的硬件控制功能和进程间通信机制。
在微内核架构中,传统操作系统中的大部分功能(如文件系统、内存管理和设备驱动等)被移到用户态运行,以减少内核的复杂度。微内核通过消息传递机制(如本地过程调用 LPC(Local Procedure Call))来实现进程间的通信。这种设计理论上可以降低系统复杂性,增强安全性。
然而,微内核架构的一个主要问题是性能。由于大量功能从内核移到了用户态,数据传递和控制流变得更加间接,导致性能显著下降。与单体内核相比,微内核架构在相同的硬件上运行同样的应用程序时,性能可能会降低数倍。因此,尽管微内核在安全性上有所优势,但在性能需求较高的领域,仍然难以得到广泛应用。
不过,在某些对安全性有极高要求的场景,如核电站、医疗设备等,微内核架构依然有其存在的价值。
外核架构
外核架构是由 MIT 的教授 Frans Kaashoek 和他的学生提出的。与传统的内核架构不同,外核架构(Exokernel)旨在将操作系统的许多传统功能下放到应用层。通常情况下,内核负责管理硬件资源,例如文件系统、网络协议栈和设备驱动。然而,外核架构认为这些功能应该与应用程序紧密耦合,使应用程序能够直接控制硬件资源。
外核的设计理念
外核的核心理念是将内核的功能最小化,只保留硬件的直接管理,例如中断处理和进程通信。而文件系统、网络协议等高级服务则作为库提供,直接绑定到应用程序中。这样,应用程序可以根据自身需求直接访问硬件,而无需通过系统调用进入内核,从而减少性能开销。
例如,TCP/IP 协议栈和文件系统可以被设计成应用程序库,通过直接访问硬件提供更高效的操作。这种设计在性能上有一定优势,因为它避免了传统内核中频繁的上下文切换和内核空间与用户空间之间的数据传递。然而,它的缺点在于安全性,因为应用程序拥有更多直接访问硬件的权限,一旦发生错误,可能影响系统的稳定性。
外核架构的实际应用与局限
虽然外核架构在理论上具有很高的灵活性和性能,但它在实际中很少被广泛应用。外核架构的一个局限性是,它要求每个应用程序都为其功能定制操作系统库,这在开发和维护上增加了复杂性。虽然外核架构曾被广泛讨论,并且在学术界引起了很大的兴趣,但并未在主流操作系统中得到广泛应用。
与外核架构相似的思想在云计算的虚拟化技术中得到了扩展和实际应用。现代虚拟化技术利用类似的概念,将硬件资源进行虚拟化,多个虚拟机(VM)可以同时运行在同一台物理机器上,每个虚拟机都有独立的操作系统和应用程序。
虚拟机与云计算
虚拟机的思想是将一台物理计算机虚拟化成多个虚拟计算机,每个虚拟机运行自己的操作系统和应用程序。这种方式能够最大化硬件资源的利用率,尤其是在云计算的数据中心中。通过在一台物理服务器上运行多个虚拟机,服务提供商可以为多个用户同时提供云服务。
虚拟化技术的核心思想是与外核架构类似的硬件虚拟化,不同的是,虚拟化技术更侧重于提供完整的虚拟硬件环境,使操作系统和应用程序可以不加修改地运行在虚拟机中。而外核架构的重点是为每个应用定制轻量级的操作系统服务,减少系统开销,提升性能。
虚拟化与外核架构的联系与区别
外核架构的目标是通过直接将硬件资源暴露给应用程序,减少系统开销。而现代虚拟化技术则是通过抽象出多个虚拟的物理机,实现对硬件资源的高效利用。两者的主要区别在于:
- 外核架构旨在为每个应用程序定制一个“轻量级内核”,减少系统的中间层,提高性能。
- 虚拟机架构则是通过在一台物理机上运行多个完整的虚拟机,最大化硬件资源的使用率。
尽管外核架构并未在实际中广泛应用,但它的思想对现代操作系统设计,尤其是虚拟化技术,产生了深远的影响。
现今的虚拟化技术应用
虚拟化技术已经成为现代云计算基础设施的核心。像阿里云、腾讯云等大型云服务提供商,通过虚拟化技术,将闲置的硬件资源进行虚拟化处理,然后以低成本的形式提供给用户。这不仅提高了服务器的资源利用率,还降低了用户的使用成本。用户可以根据需求购买不同性能的虚拟机,无需关心底层硬件的实际配置。
这种技术的广泛应用使得云计算成为现代计算领域的重要组成部分。无论是个人开发者还是企业,都可以通过云服务轻松部署和扩展自己的应用程序,从而实现高效的资源利用。
UNIX / Linux
首先,我们讨论 UNIX 和 Linux 的渊源及其发行版之间的关系。
UNIX 与 Linux 的历史背景
UNIX 是一种早期的操作系统,起源于 20 世纪 60 年代,由 AT&T 的贝尔实验室开发。它的设计哲学强调简洁和模块化,使其成为后续众多操作系统的蓝本。Linux 则是基于 UNIX 思想开发的开源操作系统,最初由林纳斯·托瓦兹(Linus Torvalds)在 1991 年发布。Linux 内核是一个完全从零开始编写的操作系统内核,但它与 UNIX 共享很多相同的设计理念。
Linux 的发行版
Linux 内核只是一个操作系统的核心部分,基于该内核的操作系统通常会打包大量的应用程序、库和工具,这些被称为发行版(distributions)。各类 Linux 发行版,例如 Ubuntu、Fedora、SUSE、国内的麒麟、欧拉等,都是在 Linux 内核的基础上进行的定制开发,差异主要体现在系统工具、包管理器、桌面环境等方面。这些发行版虽然名字不同,但它们的核心——Linux 内核——是相同的。
因此,尽管 Linux 发行版种类繁多,但它们在系统核心上是统一的,即所有发行版都是基于 Linux 内核进行开发的。差别主要体现在用户体验、工具链和针对不同应用场景的优化。
虚拟机与 Linux 的应用
在虚拟机环境中,Linux 也被广泛应用。以 Windows 上的 WSL(Windows Subsystem for Linux)为例,WSL 允许用户在 Windows 上运行一个完整的 Linux 子系统。WSL 实际上是在 Windows 操作系统上运行的虚拟机环境,用户可以在 WSL 中安装诸如 Ubuntu 或者 Fedora 等 Linux 发行版。
例如,在 WSL 中,你可以运行 Ubuntu 20.04,尽管它是作为虚拟环境存在,但其核心仍然是基于 Linux 的完整操作系统。
MacOS 与 UNIX 的渊源
MacOS 是苹果公司的操作系统,它实际上也是基于 UNIX 发展而来的。具体来说,MacOS 是基于 BSD(Berkeley Software Distribution),这是 UNIX 的一个分支。虽然 MacOS 在图形用户界面(GUI)方面做了大量改进,但其底层仍然遵循 UNIX 的设计原则。
为什么选择 Linux?
Linux 的最大优势在于其开源性、丰富的文档以及广泛的社区支持。Linux 操作系统被广泛应用于从超级计算机到服务器,再到移动设备的各个领域。尤其在服务器和超级计算机领域,Linux 占据了主导地位,得益于其高度的可定制性和稳定性。
在桌面操作系统市场上,Linux 的影响力相对较小,Windows 和 MacOS 占据了主要市场份额。然而,Linux 依然是许多开发者和技术人员的首选,特别是在软件开发和服务器管理领域。Linux 的命令行界面(CLI)和强大的脚本支持,使其成为开发和自动化任务的理想选择。
Linux 系统的服务与抽象
Linux 提供了多种服务来支持应用程序的运行。主要包括以下几个抽象层次:
- 进程管理:操作系统负责管理应用程序的运行,将每个运行的程序作为一个进程管理,并进行进程调度。
- 内存管理:Linux 提供地址空间的抽象,分配内存给进程,并提供虚拟内存机制,以确保进程之间的隔离。
- 文件系统:数据以文件的形式存储在磁盘上,文件系统负责管理文件的存储、访问权限等。
- 多用户支持:Linux 提供多用户环境,用户可以根据权限进行不同操作。
- 网络支持:Linux 内核支持 TCP/IP 等网络协议,允许程序通过网络进行通信。
这些服务通过系统调用(Syscalls)实现,程序通过系统调用与内核交互。例如,open() 函数用于打开文件,write() 用于写入数据,这些函数调用在底层实际上是系统调用的封装。
系统调用的数量与复杂性
尽管 Linux 操作系统的代码量高达数千万行,但它提供的系统调用(Syscall)数量相对较少,约为 400 个左右。操作系统提供的系统调用数量有限,但每个调用背后可能包含大量复杂的代码和功能支持。
举个例子,简单的文件操作可能涉及多个系统调用,如 open()、write()、fork() 等。这些看似简单的函数调用实际上会涉及到内核的复杂操作,但 Linux 通过 C 库将这些系统调用封装成用户友好的接口,使得应用程序开发者不必直接处理复杂的系统级细节。
操作系统(OS)的核心系统调用
下面讨论操作系统(OS)的核心系统调用,特别是进程管理、内存管理以及文件系统的相关功能。以 UNIX 和 Linux 系统为例探讨这些系统调用的实现及其抽象背后的原理。
1. 系统调用与进程管理
操作系统的系统调用是用户程序与内核交互的主要方式。在操作系统中,进程管理是核心任务之一,下面是与进程相关的几个重要系统调用:
-
fork():用于创建一个新进程。调用
fork()后,系统会复制一个与父进程几乎完全相同的子进程。子进程会继承父进程的大部分资源。xv6:fork() -
exit() 和 wait():进程在完成任务后会调用
exit()退出,父进程可以通过wait()等待子进程的结束,并获取子进程的退出状态。exit()和wait()形成了一对,用于进程生命周期的管理。xv6:exit()/wait() -
kill():用于强制终止进程,传入的参数是进程的 PID(进程标识符),即需要被终止的进程号。xv6:
kill() -
getpid():获取当前进程的 PID,以便在需要时可以识别进程。
-
sleep():让当前进程暂停执行一段时间,相当于让进程“睡眠”,在指定的时钟周期后再恢复运行。xv6: Sleep & Wakeup
-
exec():将当前进程的执行内容替换为一个新的程序。这是
fork()后通常会调用的函数,通过exec()加载并运行新的程序代码。xv6:fork&exec
这些系统调用主要围绕进程的创建、调度和终止进行,构成了进程管理的基础。
2. 内存管理
内存管理是操作系统的重要功能,操作系统负责为进程分配、回收内存:
-
sbrk():调整进程的数据段的大小,用于增加或减少进程的内存空间。
sbrk()的参数可以是正数也可以是负数,正数表示增加内存,负数表示减少内存。尽管直接使用sbrk()的场景不多,但它是底层内存分配的基础。xv6:sbrk -
malloc() 和 free():高层次的内存管理函数。
malloc()从堆中分配一块内存,而free()用于释放内存。这些库函数实际上调用了sbrk()来进行内存的底层操作。操作系统和库(如 C 标准库)共同管理内存,库函数一般通过内存池的机制来减少频繁的系统调用,从而提高效率。
3. 文件系统管理
文件系统的操作是应用程序与持久存储设备交互的方式。常见的文件操作包括打开、读取、写入和关闭文件:
-
open():用于打开一个文件,返回一个文件描述符(FD),后续对文件的操作都通过文件描述符来进行。
-
write():向打开的文件中写入数据。需要提供文件描述符、内存中的数据缓冲区以及要写入的字节数。
-
read():从文件中读取数据到内存缓冲区,同样需要提供文件描述符和缓冲区,以及读取的字节数。
-
close():关闭文件描述符,释放与文件相关的资源。
这些文件操作通过系统调用实现,它们使得程序可以与底层存储设备交互,完成数据持久化。
文件描述符的管理
- dup(): 创建一个新的文件描述符,指向与现有文件描述符相同的文件。这样,两个文件描述符(FD1 和 FD2)可以同时访问同一个文件。
dup() 的主要作用在于进程间通信和资源共享,通过为同一个文件创建多个文件描述符,进程可以通过不同的描述符进行并行操作。这在需要同时读写同一文件的场景下非常有用。
4. 目录操作
- chdir(): 用于改变当前工作目录。
- mkdir(): 创建一个新的目录。
这些操作扩展了文件系统的功能,允许操作系统对目录进行管理。在 UNIX 和 Linux 中,目录是文件系统的核心组成部分,通过这些系统调用,程序可以创建、删除或导航目录。
5. 特殊的文件和设备文件
- mknod(): 用于创建一个特殊文件,通常是设备文件。设备文件是操作系统中对硬件设备的一种抽象,UNIX 系统中“所有东西都是文件”(Everything is a File)的设计哲学意味着设备也可以通过文件系统进行访问。
例如,操作系统可以通过 mknod() 创建一个表示磁盘或网络设备的文件,这个文件可以像普通文件一样被打开、读写。这个抽象使得操作系统能够简化对硬件设备的访问,将所有设备视为文件来统一处理。
6. 文件状态与信息获取
- fstat() 和 stat(): 获取文件的状态信息,如文件大小、创建时间、权限等。
这些系统调用让用户可以获取有关文件的详细信息,以便于进一步处理。通过这些调用,用户可以判断文件是普通文件、目录还是设备文件。
7. 链接与解除链接
link():用于创建文件的硬链接。硬链接是指在文件系统中为同一个文件创建多个名称。这意味着一个文件可以通过不同的路径和名称被访问,但它们指向的是同一个底层文件数据。当一个进程对其中一个文件名进行操作时,实际上是在操作同一个物理文件。unlink():用于删除文件的一个链接。重要的是,它并不立即删除文件,而是删除文件的一个名称。当文件所有的硬链接都被删除后,操作系统才会真正删除文件的内容。
例如,用户可以在一个目录下创建文件 file1,然后在另一个目录下通过 link() 创建 file2,它们都指向同一个文件。当 unlink() 删除 file2 后,file1 依然存在,文件的内容并不会被删除,只有当 file1 也被 unlink() 后,文件才会真正消失。
关于 link() 和 unlink() 的设计
- 灵活性:硬链接的设计极大增强了文件管理的灵活性,允许同一个文件在不同的目录下有多个名称,这为复杂的文件组织和共享提供了便利。
- 安全性:通过多个文件名的映射机制,即使一个用户或进程删除了一个文件名,其他使用相同文件的进程仍可以继续操作该文件,直到所有硬链接都被删除。
系统调用的特点与效率
C 语言在系统调用的参数设计上非常简洁,大部分参数都是整数类型(如 PID、文件描述符等)。这反映了 C 语言的灵活性,但也带来了一定的风险,因为类型系统较为弱化,容易出现类型不匹配或参数误用的问题。
现代操作系统如 Linux 的系统调用数量大约在 400 个左右,尽管操作系统的代码量可能达到数千万行,但提供给用户的接口相对精简。系统调用的实现细节由操作系统内核处理,而用户程序通过调用封装在 C 库中的系统调用接口与内核通信。
C 语言与系统调用的封装
在 UNIX 系统中,系统调用并不是直接通过汇编语言调用内核,而是通过 C 库的函数封装实现的。这些封装函数为开发者提供了简洁的接口。例如,malloc() 和 free() 是对 sbrk() 的进一步封装,提供了更高层次的内存管理机制。通过这种封装,操作系统可以屏蔽底层细节,简化应用程序的开发流程。
文件系统的抽象
UNIX 操作系统的设计哲学之一是将所有资源抽象为文件,不仅普通文件、目录是文件,设备、管道、网络套接字等也被视为文件。通过这种抽象,操作系统可以为不同类型的资源提供统一的访问接口,使得应用程序开发更加简洁和一致。
这种设计的一个优点是,它允许不同类型的设备通过同样的系统调用(如 open()、read()、write())进行操作,降低了系统和应用程序的复杂性。虽然文件系统本质上处理的是磁盘上的数据,但它扩展了功能,能够管理各种硬件和系统资源。
copy.c 示例程序
copy.c是一个非常简单的 C 程序,用来演示文件的读取和写入过程。该程序使用标准的 read() 和 write() 系统调用从标准输入(键盘)读取数据,并将其输出到标准输出(屏幕)。
// copy.c: copy input to output.
#include "kernel/types.h"
#include "user/user.h"
int
main()
{
char buf[64];
while(1){
int n = read(0, buf, sizeof(buf));
if(n <= 0)
break;
write(1, buf, n);
}
exit(0);
}
程序结构
buffer:程序首先定义了一个缓冲区,用来存储从标准输入读取的字节数据。read():从标准输入读取buffer中的内容,这里FD 0是标准输入的文件描述符,即键盘输入。write():将读取到的字节数据写入到标准输出,FD 1是标准输出的文件描述符,即屏幕。exit():程序结束时,调用exit(0),表示程序成功结束。
这个程序的实际效果是:
- 从键盘输入字符串;
- 然后程序将字符串原样显示在屏幕上。
文件描述符的角色
FD 0 和 FD 1 分别对应标准输入和标准输出,这是 UNIX 和 Linux 系统中的常见约定。在进程创建时,系统默认会为每个进程打开标准输入、标准输出和标准错误(FD 2)这三个文件描述符,因此程序无需手动调用 open() 来打开这些描述符。
Xv6 实验环境
copy.c 这个程序是在 MIT 的 Xv6 操作系统上运行的。Xv6 是一个基于 UNIX 的简化版操作系统,常用于操作系统课程的教学。Xv6 的设计遵循 UNIX 的核心思想,但代码量和复杂度大大降低,便于学习和理解。
- QEMU:在实验中使用了 QEMU 模拟器运行 Xv6,这是一种模拟硬件的方式,可以让学生在虚拟机中运行自己的操作系统。
- Shell:Xv6 提供了一个简单的 Shell 作为用户接口,学生可以在其中输入命令、执行程序。
在执行 copy.c 时,程序运行在 Xv6 的 Shell 中,通过键盘输入数据,程序将数据读取并回显到屏幕上。
操作系统复杂性与用户应用便利性
通过这个简单的 copy.c 示例,展示了操作系统如何通过一系列底层的系统调用来为应用程序提供服务。尽管 copy.c 程序只有几十行代码,但操作系统需要支持的功能却非常复杂,涉及到文件管理、进程调度、内存管理等诸多内容。这也是操作系统设计的挑战所在——为用户提供简洁、直观的接口,同时在底层实现复杂的功能。
文件操作与 open()
open() 系统调用用于打开文件,并返回一个文件描述符,随后可以通过 read() 或 write() 对该文件进行读写操作。在讨论中,解释了如何通过 open() 创建或打开文件,然后使用 write() 将数据写入文件。
以下是一个简单的示例流程:
open():打开一个文件,指定读写权限(如O_WRONLY表示只写)。write():将数据写入打开的文件。close():关闭文件,释放文件描述符。
这是一套常见的文件操作流程,通过 open() 获取文件描述符后,可以对文件执行一系列读写操作。
fork() 和 exec() 的结合
在 UNIX 和 Linux 系统中,进程管理是通过 fork() 和 exec() 系统调用来实现的。fork() 创建一个新的进程(称为子进程),子进程几乎完全复制了父进程的所有资源。而 exec() 则用于在子进程中执行一个新的程序代码,替换掉子进程原有的代码。
-
fork():用于创建一个新的进程,称为子进程。子进程几乎复制了父进程的所有资源,除了它们的进程 ID(PID)不同。fork()返回两次:一次在父进程中,返回子进程的 PID;一次在子进程中,返回 0。 -
exec():用于在子进程中执行新的程序。通过exec(),子进程的地址空间被新程序替换,因此子进程的执行逻辑发生变化。exec()不返回到调用点,因为一旦执行新程序,旧的进程内容就被新程序覆盖了。
xv6:fork & exec例子中,程序演示了如何通过 fork() 创建子进程,并用 exec() 加载新的程序逻辑,这两个调用的结合是 UNIX 系统中多任务处理的基础。
父子进程通信和退出机制
wait():父进程通过wait()等待子进程的结束。当子进程结束时,操作系统会将子进程的退出状态(status)传递给父进程,这样父进程就知道子进程已经完成了任务。exit():子进程完成任务后调用exit(),并传递一个退出状态(例如 0 表示成功)。操作系统捕获这个状态并通知父进程。
这种父子进程间的通信和同步机制是通过系统调用实现的,确保父进程可以获取到子进程的执行结果。
fork() 的返回值解释
fork() 的返回值决定了当前是在父进程还是子进程中执行:
- 子进程:
fork()返回 0,表示这是子进程。此时子进程可以执行新的任务,通常会调用exec()来加载并运行新的程序。 - 父进程:
fork()返回子进程的 PID,表示这是父进程。父进程可以选择继续执行自己的任务,也可以通过wait()等待子进程完成。
通过这样的设计,父子进程可以执行不同的代码逻辑,父进程通常等待子进程完成,而子进程可以执行不同的程序。
示例程序中的 fork() 和 exec()
forkexec.c 程序使用 fork() 创建子进程,然后子进程通过 exec() 执行新程序,父进程则通过 wait() 等待子进程的退出。这是一种常见的编程模式,尤其是在实现多任务处理时:
fork()创建子进程:父进程调用fork(),此时操作系统复制父进程,创建一个几乎相同的子进程。- 子进程调用
exec():子进程用exec()执行新程序,替换自身的地址空间为新程序。 - 父进程调用
wait():父进程通过wait()等待子进程结束,并获取子进程的退出状态。
例如,Shell 程序(命令行解释器)通常通过 fork() 创建子进程,然后子进程通过 exec() 来执行用户输入的命令。父进程(Shell)则等待子进程执行完成后,再继续处理其他用户命令。
进程退出和 status
子进程结束时,通过 exit() 将退出状态传递给父进程。父进程通过 wait() 获取子进程的退出状态:
exit(status):子进程调用exit(),并将状态码status传递给操作系统。wait():父进程通过wait()获取子进程的退出状态,并可以对其进行处理。例如,status == 0表示子进程成功结束。
I/O 重定向
I/O 重定向是 UNIX 系统中的一个关键功能,它允许将程序的标准输入、输出重定向到文件或其他程序。redirect.c
- 标准输入 (
stdin):通常是键盘输入,文件描述符为FD 0。 - 标准输出 (
stdout):通常是屏幕输出,文件描述符为FD 1。 - 标准错误 (
stderr):用于输出错误信息,文件描述符为FD 2。
在示例中,copy.c 程序通过 read() 从标准输入读取数据,通过 write() 将数据写入标准输出。这种方式可以轻松地将用户输入通过程序处理,并输出结果到屏幕上。
I/O 重定向与管道机制
UNIX 系统设计哲学之一是“小而美”,即通过小型、专注的程序组合来完成复杂任务。管道(|)和 I/O 重定向是实现这种组合的关键机制。
- 管道 (
|):将一个程序的输出作为另一个程序的输入。例如,cat file.txt | grep "pattern"将cat的输出通过管道传递给grep,grep再对其进行处理。 - I/O 重定向 (
>,<):将程序的输出重定向到文件,或从文件读取输入。例如,ls > output.txt会将ls命令的输出保存到output.txt文件中。
通过这种方式,多个小程序可以组合起来执行复杂任务,而每个程序本身都只专注于某一特定功能。这种设计不仅提高了程序的复用性,还使得系统更加灵活。
fd 的概念
文件描述符(fd)是操作系统中用于表示打开文件的抽象概念。每个进程在运行时都有一个文件描述符表,记录着当前进程所打开的所有文件。常见的 fd 包括:
0: 标准输入(stdin)1: 标准输出(stdout)2: 标准错误(stderr)
在应用程序中,open() 返回的文件描述符用于后续的读写操作。当文件被关闭后,文件描述符也会被释放。
UNIX 系统中的进程管理哲学
UNIX 系统中的进程管理非常简洁,通过简单的系统调用如 fork() 和 exec(),操作系统可以创建和管理多个进程。每个进程都有独立的地址空间,并且可以通过文件描述符与外部系统(如文件、设备、其他进程)进行交互。进程之间的通信则可以通过管道和共享内存等机制实现。
这种设计哲学保证了系统的灵活性和可扩展性,应用程序可以通过简单的调用组合,构建出复杂的功能,而操作系统则负责底层的资源管理。
第二讲 实践与实验介绍
第一节 实践与实验简要分析
操作系统的调试与调试工具
当编写操作系统时,调试过程比在应用程序中复杂得多。因为操作系统运行在底层,缺乏现成的调试工具和环境。通常开发者使用硬件模拟器(如 QEMU)或集成的调试器(如 GDB)来调试内核代码。
- GDB(GNU 调试器):可以通过模拟器(如 QEMU)调试操作系统。通过 GDB,开发者可以设置断点、单步执行代码以及检查寄存器和内存状态。
- 物理硬件调试的困难:在真实硬件上调试操作系统更加复杂,因为缺乏模拟环境中的便利工具。这时,通常依赖串口输出、内核日志等简单方式调试代码。
循续渐进的操作系统实验
批处理系统
批处理系统是最早期的操作系统模型之一,其核心目的是提高计算机的利用率,通过在一段时间内执行多个程序。批处理系统的关键点在于:
- 多程序执行:批处理系统允许多个程序依次执行,但同时内存中通常只有一个程序在运行。虽然这种方式提高了计算效率,但仍有一些局限。
- 特权级与隔离机制:为了确保批处理系统中的应用程序不会破坏操作系统,现代操作系统使用硬件的特权级机制(Privilege Levels)来实现隔离。应用程序运行在用户态,而操作系统运行在内核态,这种特权级的划分确保了系统的安全性和稳定性。
特权级与系统调用
在批处理系统中,为了实现应用程序与操作系统之间的安全交互,依赖于硬件支持的特权级机制。特权级机制通过不同的权限划分,确保应用程序无法直接访问或破坏操作系统的资源:
- 特权级切换:通过系统调用、异常或中断机制,应用程序可以请求操作系统执行某些受限操作。在这个过程中,CPU 切换到内核态(特权级更高),以执行操作系统代码。
- 状态保存与恢复:当从用户态切换到内核态时,操作系统需要保存当前程序的状态(如寄存器内容),以便在任务切换完成后恢复程序的执行。
多道程序设计
多道程序设计(Multiprogramming)是批处理系统的改进,它允许多个程序同时驻留在内存中,以提高 CPU 利用率和系统响应速度。多道程序设计的关键挑战是:
- 内存共享:多个程序共享一个内存空间,操作系统必须确保每个程序只能访问自己的内存区域,防止相互干扰。
- 内存地址空间问题:在多道程序设计中,程序必须知道自己在内存中的起始地址,这导致程序编写复杂。随着虚拟内存技术的发展,这个问题得到了有效解决。
分时多任务系统
分时多任务操作系统的最大特点是支持多个程序的并发执行,并且能够通过抢占式调度提高系统的交互性和响应速度:
- 抢占式调度:当一个程序占用 CPU 时间过长,操作系统可以强制中断其执行,切换到另一个程序运行。这避免了某个应用程序垄断 CPU,保证了系统的公平性和响应速度。
- 上下文切换:当系统从一个程序切换到另一个程序时,必须保存当前程序的状态,并恢复目标程序的状态。这个过程称为上下文切换,它涉及到保存和恢复 CPU 的寄存器内容、堆栈信息等。
地址空间与虚拟内存
地址空间是操作系统为每个程序分配的内存区域,它可以是物理内存的一部分或通过虚拟内存技术实现。虚拟内存通过将物理内存抽象为连续的虚拟地址空间,简化了程序编写和内存管理:
- 虚拟内存的优势:虚拟内存使得每个程序都可以使用从地址 0 开始的虚拟地址空间,而无需关心物理内存的实际布局。操作系统通过页表机制将虚拟地址映射到物理地址。
- 隔离性与安全性:通过虚拟内存,操作系统可以为每个程序分配独立的地址空间,从而防止程序相互干扰。每个程序只能访问自己的内存区域,增强了系统的安全性和稳定性。
内存管理与虚拟存储
内存管理是操作系统中的一个关键任务,它包括:
- 静态和动态内存分配:静态内存分配在编译时完成,而动态内存分配则在程序运行时根据需求动态分配内存。
- 分页与页表:操作系统通过分页机制管理内存,页表用于维护虚拟地址与物理地址的映射关系。页表的高效管理对系统性能至关重要。
- TLB(Translation Lookaside Buffer):TLB 是一种缓存机制,用于加速虚拟地址到物理地址的转换。操作系统必须管理好 TLB 以确保内存访问的效率。
- 虚拟存储:虚拟存储允许应用程序申请比物理内存更大的地址空间,通过将不常用的数据存储在硬盘上。当需要时,操作系统将数据从磁盘加载到内存。这种机制大大提升了系统的灵活性。 例如,常用的数据存放在内存中,不常用的数据则存储在硬盘上。通过置换算法(如 LRU, Least Recently Used),操作系统决定哪些数据留在内存中,哪些数据需要被交换到硬盘上。这种机制优化了内存的利用效率,减少了数据交换的频率,提高了系统性能。
进程管理与进程调度
进程是操作系统管理程序执行的基本单位,操作系统不仅负责进程的创建和销毁,还需要对进程的执行进行有效的调度:
- 进程抽象:进程是操作系统用来管理程序执行的抽象。操作系统为每个进程分配资源(如内存、CPU 时间等)并对进程进行调度。
- 进程的创建和销毁:通过
fork()创建新进程,使用exit()销毁进程。子进程可以创建新的子进程,形成进程树。 - 进程调度:操作系统使用不同的调度算法(如先来先服务,短作业优先,时间片轮转等)来决定哪个进程获得 CPU 资源。对于单处理器系统,进程调度是一个关键问题,而在多处理器系统中,调度变得更加复杂。
多处理器调度
随着多核处理器的普及,操作系统必须考虑如何在多个处理器上有效调度任务,以提高系统的并行性能:
- 多处理器调度:操作系统需要管理多个处理器或处理器核的调度,确保任务能够有效地分配到不同的核上执行。不同的任务可以同时运行在不同的处理器上,从而提高系统的并行度和效率。
- 并行编程:在多核系统中,应用程序可以使用并行编程技术,充分利用多核处理器的优势。OS 需要支持多线程和进程的并行调度,并处理线程之间的同步与通信问题。
文件系统与文件抽象
文件系统是操作系统用于管理持久存储数据的核心模块,提供了一种层次化的存储结构:
- 文件系统的实现:操作系统通过文件系统来组织和管理磁盘上的数据,文件系统的核心功能包括文件的创建、删除、读取、写入等操作,以及目录结构的管理。
- 文件抽象:在操作系统中,文件不仅代表磁盘上的数据块,还可以代表其他资源,如管道、设备等。文件描述符(FD)是操作系统提供的一种抽象,允许程序以统一的方式操作各种资源。
- 虚拟文件系统:通过文件系统的抽象,操作系统能够将不同类型的资源(如网络连接、进程间通信)都视为文件,统一接口,简化了程序员对资源的操作。
进程间通信(IPC)
进程间通信(IPC)是操作系统提供的一系列机制,允许不同进程之间交换数据或协调工作:
- 管道(Pipe):管道是最简单的进程间通信机制,允许一个进程的输出作为另一个进程的输入。
- 消息队列、共享内存:消息队列允许进程发送和接收结构化的数据,而共享内存则允许进程共享同一个内存空间,从而实现高效的通信。
- 信号量与锁:用于处理进程或线程之间的同步问题,确保多个进程或线程在访问共享资源时不会产生冲突。
线程与同步机制
线程是进程的子集,允许进程内部并行执行多个任务。线程共享进程的地址空间,这带来了高效的资源使用,但也引发了并发控制的问题:
- 线程的抽象:一个进程可以包含多个线程,多个线程可以并行执行并共享进程的资源(如内存、文件描述符等)。线程的切换比进程切换开销小,适合并发任务。
- 线程同步与互斥:由于线程共享地址空间,需要通过同步机制(如锁、信号量、条件变量等)来控制多个线程对共享数据的访问,防止竞争条件(race condition)和数据不一致问题。
协程与并发模型
- 协程(Coroutine):协程是比线程更轻量级的并发单位,通常不依赖于操作系统的线程调度,而是在应用层通过特定的协程库管理。协程的切换开销比线程更小,适合处理大量 I/O 密集型任务。
- 协程与线程的关系:协程通常运行在线程之上,一个线程可以包含多个协程。协程的切换在用户态完成,而不需要操作系统的介入,因此效率更高。
进程、线程与协程的区别与联系
- 进程:进程是操作系统分配资源的基本单位,一个进程拥有独立的内存空间,彼此隔离。进程切换时,操作系统需要保存并恢复其上下文,包括寄存器、内存映射等。
- 线程:线程是进程内的执行单位,多个线程共享同一个进程的资源(如内存和文件描述符)。相比于进程,线程的创建和切换开销较小,因为它们不需要切换整个内存空间。
- 协程:协程是一种比线程更轻量级的并发单元。协程在用户态调度,不依赖操作系统的线程调度机制,因此切换开销比线程更小。多个协程可以在同一个线程内执行,适合处理 I/O 密集型任务。
随着粒度逐渐减小,进程、线程、协程的管理开销依次降低。协程的优势在于它们的调度是用户态完成的,因此对性能的影响较小,更适合处理大量并发任务。
并发问题与死锁
并发编程中,多个控制流(如线程或协程)可能同时访问共享资源,导致数据竞争、死锁等问题。以下是关键概念:
- 同步与互斥:为了防止多个线程或进程同时访问共享资源,操作系统提供了同步和互斥机制。常见的同步机制包括锁(Lock)、信号量(Semaphore)和条件变量(Condition Variable)。这些机制确保在访问共享资源时,多个线程能够按顺序进行,不会产生冲突。
- 死锁(Deadlock):死锁是一种特殊的并发问题,指多个进程或线程因相互等待资源而进入永久阻塞状态。解决死锁问题的方法包括资源分配图、死锁检测算法、避免循环等待等。
设备管理与 I/O 操作
设备管理是操作系统的重要任务之一,尤其是在现代操作系统中,外设的种类繁多(如网络设备、显示设备、存储设备等)。设备的管理和交互涉及多个层次:
- 设备交互模型:操作系统通过轮询、中断和 DMA(直接内存访问)与外设进行交互。中断是一种高效的机制,允许设备在完成任务时通知 CPU,从而避免 CPU 的忙等待。
- 同步与异步 I/O:I/O 操作可以是同步的或异步的。在同步 I/O 中,程序必须等待 I/O 操作完成后才能继续执行;而在异步 I/O 中,程序在发出 I/O 请求后无需等待操作完成,而是可以继续执行,等到 I/O 操作完成时再处理结果。
课程实验设计
为了帮助学生深入理解操作系统的原理与实现,课程安排了五个实验,每个实验都涵盖了操作系统的不同关键功能:
- 实验一:任务切换与系统调用。该实验重点是实现任务切换和系统调用,理解操作系统如何在不同的任务间进行切换,以及如何通过系统调用与用户程序交互。
- 实验二:地址空间管理。该实验涉及虚拟地址空间和异常处理,学生将学习如何实现地址空间的映射、页面置换以及处理内存缺页等问题。
- 实验三:进程管理与调度。学生将在该实验中实现进程的创建、销毁、调度等功能,理解进程的生命周期管理。
- 实验四:文件系统。学生将扩展现有的文件系统,增加目录结构等功能,学习如何组织和管理存储设备上的数据。
- 实验五:同步与并发控制。该实验将引导学生实现线程同步机制,如锁、信号量等,并解决可能出现的并发问题,如死锁。
扩展实验与项目
课程提供了一些扩展实验的机会,学生可以根据兴趣选择扩展项目,深入探索操作系统的某个方面,甚至设计新的特性。扩展实验可能包括:
- 开发游戏或图形界面:比如在操作系统中实现一个简单的图形化游戏,如贪吃蛇,通过学习显示设备的管理和显存的操作,增强对设备管理的理解。
- 实现新特性:学生还可以通过扩展操作系统,增加如多线程支持、设备驱动程序、网络协议栈等功能,从而对操作系统的设计与实现有更深入的理解。
本课程通过理论讲解与实践结合,涵盖了操作系统的核心概念与实现技术。从进程、线程、协程到并发控制,从内存管理到文件系统,学生将学习操作系统的设计原理和实现技巧。通过一系列的实验,学生不仅能加深对操作系统各个模块的理解,还能掌握操作系统开发中的实际技能。同时,扩展实验为学生提供了进一步探索和创新的机会。
操作系统作为计算机系统的核心,为应用程序提供基础服务,因此理解其设计与实现是计算机科学中至关重要的技能。通过本课程,学生将具备深入理解操作系统的理论知识,并能够通过实践应用这些知识。
第二节 Compiler与OS
编译器与操作系统的关系
编译器和操作系统是紧密相关的两部分,尽管它们的任务不同:
- 编译器的任务是将高级编程语言(如C或Rust)编写的源代码转换为可以在特定硬件上运行的机器码。
- 操作系统的任务是管理计算机资源,并加载和执行编译后的程序。
这两者的关系可以总结为:编译器负责生成可执行的二进制文件,而操作系统负责加载这些文件并让它们在硬件上运行。
编译过程与执行流程
编译过程通常分为以下几个步骤:
- 编译(Compilation):将源代码转换为汇编代码(或中间代码)。
- 汇编(Assembly):将汇编代码转换为机器码,生成目标文件(Object File)。
- 链接(Linking):将多个目标文件链接在一起,生成一个可执行文件(Executable File)。
- 链接器会处理外部依赖,确保所有的函数调用和变量引用都能被解析。
操作系统需要读取这个可执行文件的结构,然后根据它的格式将相应的代码和数据加载到内存中执行。
交叉编译与工具链
交叉编译(Cross Compilation)是指在一种平台上编译出在另一种平台上运行的程序。例如:
- 你可以在x86平台上编译一个适用于RISC-V架构的程序。
- 这需要使用针对目标架构的编译器工具链,比如 RISC-V 的 GCC 工具链。
编译器工具链的基本组成包括:
- 编译器(Compiler):如 GCC 或 Rust 编译器,负责将源代码转换为目标代码。
- 汇编器(Assembler):将汇编代码转换为机器码。
- 链接器(Linker):将多个目标文件链接为一个可执行文件。
可执行文件格式
操作系统必须能够理解编译器生成的可执行文件格式。常见的文件格式有:
- ELF (Executable and Linkable Format):Linux 等类 Unix 操作系统使用的一种标准可执行文件格式。它包含了程序的代码段、数据段、符号表等信息。
- PE (Portable Executable):Windows 操作系统使用的可执行文件格式。
以 ELF 为例,操作系统在加载程序时需要理解其内部结构,包括哪些部分是代码,哪些部分是数据,以及程序的入口点在哪里。
加载与执行
当操作系统加载一个可执行文件时,它需要完成以下任务:
- 解析可执行文件:操作系统读取文件头,了解文件的结构和内容。
- 加载到内存:根据文件的描述,将代码段、数据段等加载到合适的内存区域。
- 设置程序入口:操作系统将控制权转交给程序的入口地址,使程序开始执行。
这一过程不仅适用于普通的用户程序,操作系统本身也是通过类似的过程启动的。
Bootloader 与操作系统加载
当一台计算机启动时,操作系统本身需要被加载并运行,这个任务通常由 Bootloader 完成。Bootloader 是操作系统加载的第一步:
- Bootloader 是一个小型的程序,负责将操作系统加载到内存中。它通常被嵌入到计算机的固件或硬盘的引导扇区中。
- 启动时,计算机硬件首先加载 Bootloader,Bootloader 再将操作系统的内核加载并启动。
这是一个递归的过程,从硬件加载 Bootloader,再从 Bootloader 加载操作系统,最终操作系统加载并运行用户程序。
操作系统的自举问题(Bootstrapping)
操作系统自身也是一个可执行文件,最初也是通过编译器生成的。因为操作系统需要管理整个系统的资源,操作系统的启动过程尤为复杂。通常操作系统的启动依赖于 Bootloader 完成初始加载工作。
Bootloader 本质上也是一个编译后的程序,它的任务是将操作系统内核从存储设备加载到内存,并启动内核。
编译器与操作系统之间的协议
操作系统和编译器之间有一些隐式的协议,这些协议规定了如何生成可以由操作系统正确加载和执行的程序。这些协议包括:
- 文件格式协议:如 ELF 或 PE 格式,规定了可执行文件的结构。
- 系统调用协议:编译器生成的代码可能需要调用操作系统提供的服务(例如 I/O 操作、进程管理等),这通过系统调用接口实现。
ELF 文件格式简介
ELF(Executable and Linkable Format)是一种常见的可执行文件格式,广泛用于 Linux 和其他类 Unix 操作系统。它的作用是定义了程序的结构,包括代码段、数据段和文件头信息,便于操作系统识别和加载。ELF 文件格式将程序的不同部分(如代码和数据)分割成不同的段,并提供了这些段的位置信息,让操作系统能够将它们正确加载到内存中。
ELF 文件的基本结构:
- 文件头:描述整个文件的布局,包含元数据信息,如程序入口点、段表的偏移等。
- 段(Sections):包括代码段、数据段等,分别保存程序的指令和数据。
- 符号表(Symbol Table):用于解析全局变量和函数调用的符号信息。
编译器与生成 ELF 格式
编译器在处理 C 或 Rust 代码时,会通过编译(Compile)、汇编(Assemble)和链接(Link)步骤,将源代码转换为 ELF 格式的可执行文件。
- 编译:将源代码转换为中间汇编代码。
- 汇编:将汇编代码转换为机器码,生成目标文件(Object File)。
- 链接:将多个目标文件链接成一个完整的可执行文件,形成 ELF 格式的程序。
在 Rust 和 C 编译中,编译器会生成 ELF 文件,通过标准工具链(如 GCC、LLVM 等)完成这些步骤。
裸机程序(Bare-metal programming)
裸机编程是在没有操作系统支持的环境下,直接与硬件交互的编程方式。因为没有操作系统,程序必须直接处理硬件资源和异常。因此,裸机编程的代码通常非常简单,主要关注初始化硬件和运行关键功能。
在使用 Rust 或 C 语言进行裸机编程时,程序不依赖于任何操作系统提供的库(如标准库 libc 或 Rust 的标准库 std)。这使得程序需要更直接地与硬件交互,并且通常需要提供特殊的错误处理机制。
Rust 裸机程序中的 Panic 处理
Rust 是一种相对新兴的系统编程语言,提供了强大的内存安全和并发支持。在裸机编程中,Rust 语言由于其严格的安全检查机制,要求程序必须定义一些关键的处理方法,比如当程序崩溃时的 panic 处理。
#![allow(unused)] fn main() { #[panic_handler] fn panic(_info: &PanicInfo) -> ! { loop {} } }
Panic handler 是 Rust 程序中的一个强制性部分,它用于定义当程序出现未处理的错误时应该执行的操作。在上例裸机编程中,这个函数会进入一个死循环,防止程序崩溃时不受控地运行。
Bare-metal 程序的构建
为了构建裸机程序,无论是 C 还是 Rust,都需要确保以下几点:
- 不依赖标准库:裸机程序不能使用诸如 std 这样的标准库,因为这些库依赖操作系统。
- 自定义入口点:裸机程序需要自行定义程序的入口点,而不是使用操作系统提供的默认入口。
- 硬件初始化:程序需要自行初始化硬件,如设置堆栈指针、配置中断等。
在 Rust 中,构建裸机程序时可以通过禁用标准库并启用核心库 core:
#![allow(unused)] #![no_std] #![no_main] fn main() { }
no_std:禁用标准库。no_main:禁用 Rust 默认的 main 函数。
如何加载和执行裸机程序
操作系统通过解析 ELF 文件格式,将可执行程序加载到内存中并开始执行。裸机程序的加载过程不同于一般应用程序,因为它没有操作系统的帮助。以下是两种典型的加载方式:
-
通过 Bootloader 加载:
- 裸机程序通常通过一个简化的引导加载程序(Bootloader)来启动。Bootloader 是嵌入在硬件中的一段代码,负责加载操作系统或裸机程序到内存中并运行。
-
直接加载到内存:
- 在一些情况下(如嵌入式系统开发),程序可能被直接加载到特定的内存位置,并且 CPU 会从预定的地址开始执行。
Binary Image 格式与 ELF 格式的区别
ELF(Executable and Linkable Format)是现代操作系统中常用的可执行文件格式,它包含了程序代码、数据段和元数据,如程序的入口点、各段的位置等,方便操作系统加载和管理程序。然而,在某些情况下,ELF 格式解析可能过于复杂,例如在较为简单的 BOOTLOADER 或嵌入式系统中。
Binary Image 格式 是一种更为简化的可执行文件格式,它去掉了所有的元数据(如 ELF 的头部信息),只保留程序的实际代码段和数据段。这种格式通常用于直接将程序加载到内存的某个特定位置,简化了加载过程。
- ELF 格式:包含丰富的元数据,适用于复杂的 OS 和应用程序。
- Binary Image 格式:没有元数据,只包含纯代码和数据,适用于简单的系统或直接内存加载。
BOOTLOADER 的作用
BOOTLOADER 是系统启动时负责加载操作系统的关键组件。在复杂的系统中,BOOTLOADER 可能会解析 ELF 格式,将代码和数据段加载到内存的适当位置。但对于简化的系统,BOOTLOADER 可能无法解析 ELF 格式,只能将 Binary Image 格式的程序加载到指定的内存地址。这种情况下,开发者需要预先约定好程序的加载地址,如 0x80000000,确保 BOOTLOADER 能将程序加载到正确的位置。
步骤:
- BOOTLOADER 启动,负责从存储设备(如闪存)加载程序。
- 根据预先约定的内存地址,将程序的代码和数据段加载到内存中。
- 跳转到指定的程序入口地址,开始执行程序。
OS 对应用程序的加载
当 OS 加载应用程序时,通常是通过读取 ELF 文件格式并解析其中的代码段、数据段等部分。解析 ELF 文件头可以帮助 OS 知道哪些段需要加载到内存的哪个位置,程序的入口点在哪里等。
然而,在实验环境或简单系统中,OS 也可以加载 Binary Image 格式的应用程序。这时,OS 不需要解析复杂的 ELF 结构,只需要将二进制代码直接加载到内存的某个位置,然后跳转执行即可。
内存管理——栈 (Stack) 和堆 (Heap)
内存管理是操作系统的核心职责之一。在应用程序运行时,OS 需要为其分配内存空间,特别是栈(用于函数调用和局部变量)和堆(用于动态内存分配)。
-
栈 (Stack):主要用于管理函数调用和局部变量。编译器生成的代码依赖栈来保存函数的返回地址、局部变量和参数。OS 在加载应用程序时会为栈分配特定的内存空间,并在执行过程中动态管理栈的增长和收缩。
-
堆 (Heap):堆空间主要用于动态内存分配,应用程序可以通过调用
malloc(在 C 语言中)或其他类似函数申请动态内存。堆的管理通常由操作系统与标准库(如libc或 Rust 的alloc库)共同完成。
当编写操作系统时,开发者必须手动为 OS 本身管理栈空间,因为 OS 需要为自身以及所有应用程序维护多个栈。在应用程序层面,栈和堆的管理则是通过 OS 提供的机制和库函数完成的。
OS 初始化中的栈管理
操作系统不仅需要为应用程序管理内存,它在自身初始化时也需要分配栈空间,以便执行函数调用和管理局部变量。通常情况下,OS 会在启动时自行选择一块内存作为栈区域。OS 初始化时的栈管理与应用程序类似,但由于 OS 本身需要管理整个系统的内存,它可以直接访问并配置物理内存中的栈区域。
栈与堆的区别
栈是为函数调用准备的,具有固定的大小和生命周期,通常由编译器生成代码管理;堆则用于动态分配内存,大小和生命周期不固定,由程序员通过函数(如 malloc 和 free)控制。栈的内存管理效率较高,但灵活性较低;堆的灵活性高,但管理复杂,容易出现内存泄漏。
编译器与 OS 的协作
操作系统和编译器在处理程序时有紧密的合作关系。编译器负责生成符合 ELF 或 Binary Image 格式的可执行文件,OS 负责将这些程序加载到内存并执行。为了实现这种协作,编译器和 OS 之间必须有一致的约定,如内存地址的分配、栈的初始化等。
编译器生成的代码不仅包含程序的逻辑,还包含了 OS 如何调用和管理它的指令。OS 则通过系统调用接口和底层硬件管理程序的执行。
第三节 硬件启动与软件启动
QEMU 模拟器与虚拟机
QEMU 是一个开源的虚拟化工具,能够模拟各种硬件平台。在这次课程中,使用 QEMU 模拟 RISC-V 架构的处理器和系统,包括虚拟的 CPU、内存、存储设备和串口等基本硬件。
- QEMU的模拟配置:典型的配置包括 128 MB 的内存,基础的存储和串口设备,并且可以通过命令行参数
-nographic禁用图形界面,使得所有输出都通过命令行窗口显示。
操作系统启动流程
操作系统的启动需要经过多个阶段,主要包括:
- 硬件启动:在模拟的环境中,QEMU 会启动并首先执行一段固化在 ROM 中的代码。这个代码一般放在固定的内存地址,称为固件代码(如 0x1000 处)。
- BOOTLOADER 加载:固件代码会启动 BOOTLOADER(启动加载器),它负责加载操作系统的核心部分。BOOTLOADER 通常位于某个指定的内存地址(如 0x80000000)。
- 操作系统加载:BOOTLOADER 将操作系统的核心代码加载到内存并跳转到相应的入口点开始执行操作系统的初始化过程。
- OS 初始化:操作系统完成一系列初始化任务后,最终启动应用程序(如 init 进程)。
BIOS 和 BOOTLOADER 的作用
- BIOS(基本输入输出系统):在这里,BIOS 是一段固化在内存中的代码,它的主要任务是初始化硬件,并启动 BOOTLOADER。
- BOOTLOADER:负责加载操作系统到内存。它从 ROM 读取硬件信息,包括 CPU 和外设配置,并将操作系统的核心部分加载到指定的内存地址。
操作系统的内存布局
QEMU 模拟的虚拟机中,内存布局相对简单。ROM 固件一般位于较低的地址(如 0x1000),而操作系统被加载到 0x80000000 的地址。BIOS 的功能是识别系统的外设、处理器信息,并将这些信息传递给 BOOTLOADER。
RISC-V 汇编代码分析
在固件中,有一段 RISC-V 汇编代码,它的功能是将控制权交给 BOOTLOADER。这段代码的关键部分包括:
- 初始化寄存器:通过 RISC-V 指令
AUIPC和ADD等指令来设置跳转目标地址,最终跳转到 BOOTLOADER 的入口。 - 传递参数:通过寄存器 A0 和 A1 传递两个关键参数,A0 表示当前的 CPU 核心 ID,A1 则是系统的外设信息。
这段汇编代码的执行逻辑较为简单,主要是完成对 BOOTLOADER 的跳转和基础参数传递。
Lab0
OS 环境配置教程
支持的操作系统
本实验主要支持 Ubuntu 18.04/20.04 操作系统。这是因为Ubuntu提供了稳定的更新和广泛的软件库,适合教学和开发使用。对于使用 Windows 和 macOS 的读者,建议安装Ubuntu 18.04/20.04虚拟机或使用Docker进行实验。
本站作者尝试了 Windows 下使用 Ubuntu 20.04 虚拟机和 Mac 下使用 macOS 以及 Arm 版 Ubuntu 20.04 虚拟机。Lab 0 ✅
Windows 用户的配置
安装虚拟机软件如 VMware Workstation 或 Oracle VirtualBox,并在其中安装Ubuntu操作系统。这为用户提供了一个接近真实Linux系统的环境,有助于更好地模拟生产环境。
- 虚拟机安装Ubuntu:虚拟机提供了一个隔离的环境来运行其他操作系统,对系统配置或主操作系统影响较小。网络上有大量关于如何在VMware或VirtualBox中安装Ubuntu的教程,用户可以根据这些详细的指南进行操作。
通过系统内置的 Windows Subsystem for Linux 2 (WSL2) 来安装Ubuntu 18.04/20.04。WSL2提供了一个完整的Linux内核,与WSL1相比,它支持更多Linux特性和更好的性能。用户可以在微软的官方文档中找到安装和配置WSL2的详细指南。
- WSL2使用真实的Linux内核,而WSL1则是一个兼容层,WSL2在文件系统性能和系统调用支持方面有显著改进。
Docker 开发环境
略
macOS 用户的配置
macOS用户可以在本地直接配置所需的开发环境。具体的配置步骤和教程可以参考以下文章:在 macOS 14 (M1 Pro) 编译 QEMU 7.0.0 - Nelson's Note。
- M系列芯片的Mac用户:如果是使用Apple的M系列芯片的Mac用户,并希望通过虚拟机安装Ubuntu,需要特别注意选择ARM架构的Ubuntu版本。官网主要提供的是ARM架构的Server版本 ubuntu-20.04.4-live-server-arm64.iso,用户如果有需求可以在此基础上安装桌面环境。具体的安装桌面环境步骤,可以参考下面的文章:mac pro M1(ARM)安装:ubuntu虚拟机(四)。
QEMU 系统仿真(System Mode)
xxx-softmmu:编译生成qemu-system-xxx,用于 xxx 架构的系统仿真。- 功能:模拟一个完整的基于不同 CPU 的硬件系统,包括处理器、内存及其他外部设备,支持运行完整的操作系统。
- 应用场景:适用于需要模拟整个操作系统的场景,例如开发和测试嵌入式系统、操作系统内核等。
- Mac中
QEMU 用户模式仿真(User Mode)
xxx-linux-user:编译生成qemu-xxx,用于在 xxx 架构中运行用户应用程序。- 功能:在开发主机上运行为目标架构编译的用户态应用程序,而不需要模拟整个操作系统。
- 应用场景:适用于需要在不同架构上运行用户态程序的场景,例如测试跨平台应用程序。
- Linux中
关联和独立性
- 独立性:
qemu-system-xxx和qemu-xxx是独立的二进制文件,分别用于系统仿真和用户模式仿真。你可以独立地使用它们中的任何一个,具体取决于你的需求。- 关联性:两者都源自同一个 QEMU 项目,因此在某些情况下,二者可能共享部分内部代码和机制。但是,系统仿真和用户模式仿真有着不同的用途和实现细节,它们各自处理的环境和需求也不同。
适用场景
- 系统仿真(
qemu-system-xxx):
- 需要模拟完整操作系统的功能。
- 适用于内核开发、操作系统调试、嵌入式系统仿真等。
- 用户模式仿真(
qemu-xxx):
- 仅需要在不同架构上运行用户态程序,不需要模拟完整操作系统。
- 适用于跨平台应用程序开发和测试。
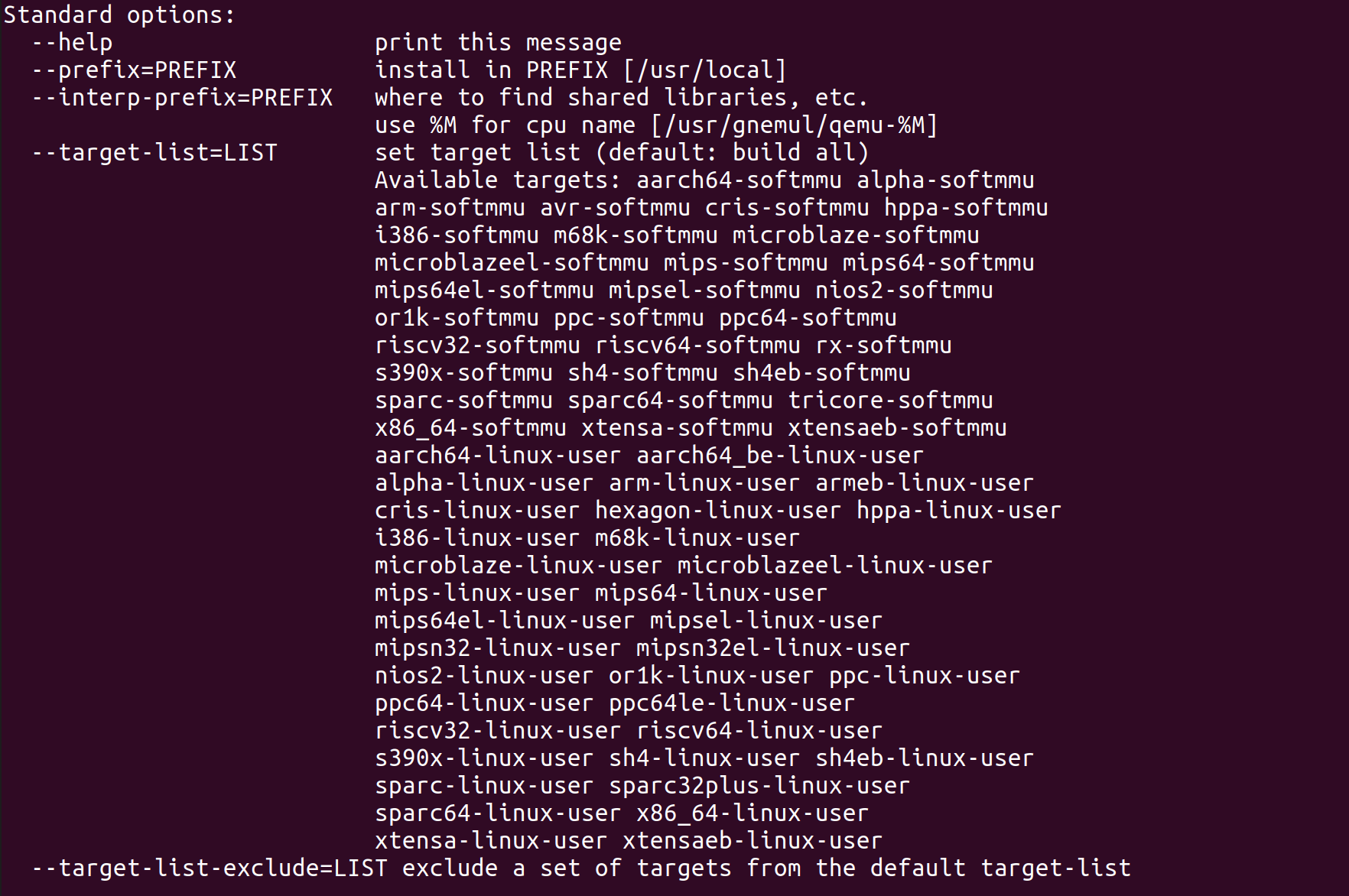
Rust 开发环境配置
Rust是一种注重安全和性能的编程语言,广泛用于系统编程和应用开发。为了在本实验中使用Rust,需要安装Rust语言的版本管理器 rustup 和包管理器 cargo。
安装Rust和Cargo
-
安装命令:
curl https://sh.rustup.rs -sSf | sh这个命令使用
curl下载rustup的安装脚本,并通过管道|将其传递给sh(shell) 执行。这种安装方式简单且跨平台,但要确保在可信的网络环境下操作以避免安全风险。 -
rustup允许用户管理不同的Rust版本和相关工具链,这在处理不同项目或不同Rust版本的实验时非常有用。
-
安装后步骤: 安装完成后,您需要重启终端或运行
source $HOME/.cargo/env来更新当前会话的环境变量,确保rustc和cargo命令可用。 -
推荐 Visual Studio Code 搭配 rust-analyzer 和 RISC-V Support 插件 进行代码阅读和开发。
- ...
- 当然,采用 VIM,Emacs 等传统的编辑器也是没有问题的。
优化下载速度
1. 参考官方文档配置Rust镜像源
2. 使用代理TUN模式
为了有效解决网络连接问题并加速Rust及其依赖的下载,推荐使用代理并开启TUN模式(在Mac上通常称为增强模式)。这种方式可以为整个系统提供透明代理,从而简化配置并提高效率。
QEMU模拟器安装教程
1. 安装编译所需的依赖包
首先,你需要确保所有必要的依赖包都已安装。这些包是编译QEMU所必需的。在Ubuntu系统上,可以通过以下命令安装(Mac还是参考之前提到的文章):
sudo apt install autoconf automake autotools-dev curl libmpc-dev libmpfr-dev libgmp-dev \
gawk build-essential bison flex texinfo gperf libtool patchutils bc \
zlib1g-dev libexpat-dev pkg-config libglib2.0-dev libpixman-1-dev git tmux python3
2. 下载源码包
下载QEMU 7.0.0的源码包。如果你位于中国大陆,由于网络问题,可以使用提供的百度网盘链接下载:
链接:https://pan.baidu.com/s/1z-iWIPjxjxbdFS2Qf-NKxQ
提取码:8woe
或者使用标准的wget命令从官方源下载:
wget https://download.qemu.org/qemu-7.0.0.tar.xz
3. 解压源码包
使用tar命令解压下载的源码包:
tar xvJf qemu-7.0.0.tar.xz
4. 编译安装并配置RISC-V支持
切换到解压后的目录,配置QEMU以支持RISC-V架构:
cd qemu-7.0.0
./configure --target-list=riscv64-softmmu,riscv64-linux-user
make -j$(nproc)
这里$(nproc)会利用所有可用的处理器核心来加速编译过程。
5. 安装QEMU
一般推荐使用sudo make install安装QEMU,但这可能会与系统中已有的其他版本产生冲突。因此,一个更好的做法是将编译后的执行文件添加到你的用户路径中:
编辑你的~/.bashrc文件,添加以下行:
export PATH="$HOME/os-env/qemu-7.0.0/build/:$PATH"
export PATH="$HOME/os-env/qemu-7.0.0/build/riscv64-softmmu:$PATH"
export PATH="$HOME/os-env/qemu-7.0.0/build/riscv64-linux-user:$PATH"
这样做的好处是避免全局安装可能带来的问题,同时便于管理多个版本的QEMU。
6. 使环境变量生效
更新环境变量以使改动生效:
source ~/.bashrc
或者,你可以重新启动终端。
7. 确认QEMU版本
最后,验证安装的QEMU版本是否正确:
qemu-system-riscv64 --version
qemu-riscv64 --version
这一步骤确保你安装的是预期的版本,并且所有组件都已正确安装。
注意
- 如果在安装过程中遇到特定依赖包缺失的错误,应根据错误信息安装相应的包。
- 对于想使用QEMU 8或QEMU 6的用户,需要注意不同版本可能需要的额外步骤和潜在的不兼容问题。
将编译出来的程序添加到你的PATH环境变量中,意味着你可以在任何位置的终端里直接运行这些程序,无需指定完整路径。这样做提高了命令行工具的易用性。下面是在MacOS终端中添加路径到PATH的步骤:
1. 找到编译后的可执行文件位置
首先,确保你知道编译后的文件存放的具体路径。根据你的说明,文件位于
./build文件夹下,你需要具体的绝对路径。在qemu-7.0.0目录下,你可以运行以下命令来获取当前目录的绝对路径:pwd这将显示类似于
/Users/yourusername/path/to/qemu-7.0.0的路径。因此,编译后的程序可能位于/Users/yourusername/path/to/qemu-7.0.0/build。2. 编辑你的shell配置文件
在MacOS上,根据你使用的shell,通常是bash或zsh,你需要编辑相应的配置文件(
.bash_profile,.bashrc,.zshrc等)来永久添加路径到PATH环境变量。假设你使用的是zsh(MacOS的默认shell),你可以使用nano或任何其他文本编辑器打开配置文件:
nano ~/.zshrc3. 添加路径到PATH变量
在打开的文件中,添加以下行:
export PATH=$PATH:/Users/yourusername/path/to/qemu-7.0.0/build确保替换
/Users/yourusername/path/to/qemu-7.0.0/build为实际的路径。这行命令的意思是将build目录添加到现有的PATH变量中。4. 保存并关闭编辑器
如果你使用nano,可以通过按
Ctrl+O保存修改,然后按Ctrl+X退出编辑器。5. 使更改生效
更改保存后,你需要加载你刚才编辑的配置文件,使PATH变量的更改立即生效:
source ~/.zshrc或者,你可以简单地关闭并重新打开你的终端窗口。
6. 验证PATH变量
为了确认新路径已经被添加,你可以打印出PATH变量看看:
echo $PATH你应该能在输出中看到你添加的路径。
通过这些步骤,你就可以在任何位置通过终端运行QEMU了,无需指定完整的程序路径。
试运行 rCore-Tutorial
git clone https://github.com/LearningOS/rCore-Tutorial-Code-2024S
cd rCore-Tutorial-Code-2024S
我们先运行不需要处理用户代码的 ch1 分支:
git checkout ch1
cd os
LOG=DEBUG make run
如果你的环境配置正确,你应当会看到如下输出:
通常 rCore 会自动关闭 Qemu 。如果在某些情况下需要强制结束,可以先按下 Ctrl+A ,再按下 X 来退出 Qemu。
Lab0
OS 环境配置教程
支持的操作系统
本实验主要支持 Ubuntu 18.04/20.04 操作系统。这是因为Ubuntu提供了稳定的更新和广泛的软件库,适合教学和开发使用。对于使用 Windows 和 macOS 的读者,建议安装Ubuntu 18.04/20.04虚拟机或使用Docker进行实验。
本站作者尝试了 Windows 下使用 Ubuntu 20.04 虚拟机和 Mac 下使用 macOS 以及 Arm 版 Ubuntu 20.04 虚拟机。Lab 0 ✅
Windows 用户的配置
安装虚拟机软件如 VMware Workstation 或 Oracle VirtualBox,并在其中安装Ubuntu操作系统。这为用户提供了一个接近真实Linux系统的环境,有助于更好地模拟生产环境。
- 虚拟机安装Ubuntu:虚拟机提供了一个隔离的环境来运行其他操作系统,对系统配置或主操作系统影响较小。网络上有大量关于如何在VMware或VirtualBox中安装Ubuntu的教程,用户可以根据这些详细的指南进行操作。
通过系统内置的 Windows Subsystem for Linux 2 (WSL2) 来安装Ubuntu 18.04/20.04。WSL2提供了一个完整的Linux内核,与WSL1相比,它支持更多Linux特性和更好的性能。用户可以在微软的官方文档中找到安装和配置WSL2的详细指南。
- WSL2使用真实的Linux内核,而WSL1则是一个兼容层,WSL2在文件系统性能和系统调用支持方面有显著改进。
Docker 开发环境
略
macOS 用户的配置
macOS用户可以在本地直接配置所需的开发环境。具体的配置步骤和教程可以参考以下文章:在 macOS 14 (M1 Pro) 编译 QEMU 7.0.0 - Nelson's Note。
- M系列芯片的Mac用户:如果是使用Apple的M系列芯片的Mac用户,并希望通过虚拟机安装Ubuntu,需要特别注意选择ARM架构的Ubuntu版本。官网主要提供的是ARM架构的Server版本 ubuntu-20.04.4-live-server-arm64.iso,用户如果有需求可以在此基础上安装桌面环境。具体的安装桌面环境步骤,可以参考下面的文章:mac pro M1(ARM)安装:ubuntu虚拟机(四)。
QEMU 系统仿真(System Mode)
xxx-softmmu:编译生成qemu-system-xxx,用于 xxx 架构的系统仿真。- 功能:模拟一个完整的基于不同 CPU 的硬件系统,包括处理器、内存及其他外部设备,支持运行完整的操作系统。
- 应用场景:适用于需要模拟整个操作系统的场景,例如开发和测试嵌入式系统、操作系统内核等。
- Mac中
QEMU 用户模式仿真(User Mode)
xxx-linux-user:编译生成qemu-xxx,用于在 xxx 架构中运行用户应用程序。- 功能:在开发主机上运行为目标架构编译的用户态应用程序,而不需要模拟整个操作系统。
- 应用场景:适用于需要在不同架构上运行用户态程序的场景,例如测试跨平台应用程序。
- Linux中
关联和独立性
- 独立性:
qemu-system-xxx和qemu-xxx是独立的二进制文件,分别用于系统仿真和用户模式仿真。你可以独立地使用它们中的任何一个,具体取决于你的需求。- 关联性:两者都源自同一个 QEMU 项目,因此在某些情况下,二者可能共享部分内部代码和机制。但是,系统仿真和用户模式仿真有着不同的用途和实现细节,它们各自处理的环境和需求也不同。
适用场景
- 系统仿真(
qemu-system-xxx):
- 需要模拟完整操作系统的功能。
- 适用于内核开发、操作系统调试、嵌入式系统仿真等。
- 用户模式仿真(
qemu-xxx):
- 仅需要在不同架构上运行用户态程序,不需要模拟完整操作系统。
- 适用于跨平台应用程序开发和测试。
Rust 开发环境配置
Rust是一种注重安全和性能的编程语言,广泛用于系统编程和应用开发。为了在本实验中使用Rust,需要安装Rust语言的版本管理器 rustup 和包管理器 cargo。
安装Rust和Cargo
-
安装命令:
curl https://sh.rustup.rs -sSf | sh这个命令使用
curl下载rustup的安装脚本,并通过管道|将其传递给sh(shell) 执行。这种安装方式简单且跨平台,但要确保在可信的网络环境下操作以避免安全风险。 -
rustup允许用户管理不同的Rust版本和相关工具链,这在处理不同项目或不同Rust版本的实验时非常有用。
-
安装后步骤: 安装完成后,您需要重启终端或运行
source $HOME/.cargo/env来更新当前会话的环境变量,确保rustc和cargo命令可用。 -
推荐 Visual Studio Code 搭配 rust-analyzer 和 RISC-V Support 插件 进行代码阅读和开发。
- ...
- 当然,采用 VIM,Emacs 等传统的编辑器也是没有问题的。
优化下载速度
1. 参考官方文档配置Rust镜像源
2. 使用代理TUN模式
为了有效解决网络连接问题并加速Rust及其依赖的下载,推荐使用代理并开启TUN模式(在Mac上通常称为增强模式)。这种方式可以为整个系统提供透明代理,从而简化配置并提高效率。
QEMU模拟器安装教程
1. 安装编译所需的依赖包
首先,你需要确保所有必要的依赖包都已安装。这些包是编译QEMU所必需的。在Ubuntu系统上,可以通过以下命令安装(Mac还是参考之前提到的文章):
sudo apt install autoconf automake autotools-dev curl libmpc-dev libmpfr-dev libgmp-dev \
gawk build-essential bison flex texinfo gperf libtool patchutils bc \
zlib1g-dev libexpat-dev pkg-config libglib2.0-dev libpixman-1-dev git tmux python3
2. 下载源码包
下载QEMU 7.0.0的源码包。如果你位于中国大陆,由于网络问题,可以使用提供的百度网盘链接下载:
链接:https://pan.baidu.com/s/1z-iWIPjxjxbdFS2Qf-NKxQ
提取码:8woe
或者使用标准的wget命令从官方源下载:
wget https://download.qemu.org/qemu-7.0.0.tar.xz
3. 解压源码包
使用tar命令解压下载的源码包:
tar xvJf qemu-7.0.0.tar.xz
4. 编译安装并配置RISC-V支持
切换到解压后的目录,配置QEMU以支持RISC-V架构:
cd qemu-7.0.0
./configure --target-list=riscv64-softmmu,riscv64-linux-user
make -j$(nproc)
这里$(nproc)会利用所有可用的处理器核心来加速编译过程。
5. 安装QEMU
一般推荐使用sudo make install安装QEMU,但这可能会与系统中已有的其他版本产生冲突。因此,一个更好的做法是将编译后的执行文件添加到你的用户路径中:
编辑你的~/.bashrc文件,添加以下行:
export PATH="$HOME/os-env/qemu-7.0.0/build/:$PATH"
export PATH="$HOME/os-env/qemu-7.0.0/build/riscv64-softmmu:$PATH"
export PATH="$HOME/os-env/qemu-7.0.0/build/riscv64-linux-user:$PATH"
这样做的好处是避免全局安装可能带来的问题,同时便于管理多个版本的QEMU。
6. 使环境变量生效
更新环境变量以使改动生效:
source ~/.bashrc
或者,你可以重新启动终端。
7. 确认QEMU版本
最后,验证安装的QEMU版本是否正确:
qemu-system-riscv64 --version
qemu-riscv64 --version
这一步骤确保你安装的是预期的版本,并且所有组件都已正确安装。
注意
- 如果在安装过程中遇到特定依赖包缺失的错误,应根据错误信息安装相应的包。
- 对于想使用QEMU 8或QEMU 6的用户,需要注意不同版本可能需要的额外步骤和潜在的不兼容问题。
将编译出来的程序添加到你的PATH环境变量中,意味着你可以在任何位置的终端里直接运行这些程序,无需指定完整路径。这样做提高了命令行工具的易用性。下面是在MacOS终端中添加路径到PATH的步骤:
1. 找到编译后的可执行文件位置
首先,确保你知道编译后的文件存放的具体路径。根据你的说明,文件位于
./build文件夹下,你需要具体的绝对路径。在qemu-7.0.0目录下,你可以运行以下命令来获取当前目录的绝对路径:pwd这将显示类似于
/Users/yourusername/path/to/qemu-7.0.0的路径。因此,编译后的程序可能位于/Users/yourusername/path/to/qemu-7.0.0/build。2. 编辑你的shell配置文件
在MacOS上,根据你使用的shell,通常是bash或zsh,你需要编辑相应的配置文件(
.bash_profile,.bashrc,.zshrc等)来永久添加路径到PATH环境变量。假设你使用的是zsh(MacOS的默认shell),你可以使用nano或任何其他文本编辑器打开配置文件:
nano ~/.zshrc3. 添加路径到PATH变量
在打开的文件中,添加以下行:
export PATH=$PATH:/Users/yourusername/path/to/qemu-7.0.0/build确保替换
/Users/yourusername/path/to/qemu-7.0.0/build为实际的路径。这行命令的意思是将build目录添加到现有的PATH变量中。4. 保存并关闭编辑器
如果你使用nano,可以通过按
Ctrl+O保存修改,然后按Ctrl+X退出编辑器。5. 使更改生效
更改保存后,你需要加载你刚才编辑的配置文件,使PATH变量的更改立即生效:
source ~/.zshrc或者,你可以简单地关闭并重新打开你的终端窗口。
6. 验证PATH变量
为了确认新路径已经被添加,你可以打印出PATH变量看看:
echo $PATH你应该能在输出中看到你添加的路径。
通过这些步骤,你就可以在任何位置通过终端运行QEMU了,无需指定完整的程序路径。
试运行 rCore-Tutorial
git clone https://github.com/LearningOS/rCore-Tutorial-Code-2024S
cd rCore-Tutorial-Code-2024S
我们先运行不需要处理用户代码的 ch1 分支:
git checkout ch1
cd os
LOG=DEBUG make run
如果你的环境配置正确,你应当会看到如下输出:
通常 rCore 会自动关闭 Qemu 。如果在某些情况下需要强制结束,可以先按下 Ctrl+A ,再按下 X 来退出 Qemu。
第二讲 实践与实验介绍
实践:裸机程序 -- LibOS
- Ⅰ. 实验目标和思路
- Ⅱ. 实验要求
- Ⅱ½. 总体思路/历史背景
- Ⅲ. 实践步骤
- Ⅳ. 代码结构
- Ⅴ. 内存布局
- Ⅵ. 基于 GDB 验证启动流程
- Ⅶ. 函数调用
- Ⅷ. LibOS 初始化
- Ⅸ. SBI调用
操作系统的演化
操作系统并不是一成不变的,而是随着历史的发展不断演变。随着新技术的引入、硬件的提升、用户需求的改变,操作系统也在相应调整。因此,学习操作系统需要理解其发展变化,并掌握相关知识。
复杂的软件架构
操作系统作为一个庞大的软件系统,涉及到软件架构的设计问题。不同于单一的算法,操作系统需要考虑如何组织结构、协调各个组件,从而保证整个系统的稳定和高效运行。
UNIX/Linux 的实践
通过学习 UNIX/Linux 系统的基本程序和应用程序,可以让学生从用户的角度理解操作系统的功能。这些程序体现了操作系统的核心任务,并帮助学生形成对操作系统的基本概念。
理论联系实践
操作系统的学习应当将理论与实践结合,在实际操作中巩固所学理论。学生应了解如何编写各种不同的操作系统,从而深刻理解其中的原理。虽然各操作系统看似多样,但它们往往是在现有系统上进行渐进式叠加发展而来,并非彼此完全独立。
操作系统与编译器
操作系统与编译器密不可分。操作系统离不开编译生成的程序,而编译器也需要操作系统来支持其运行。因此,理解编译器的工作原理和目标对于使用和开发操作系统至关重要。
操作系统与硬件
操作系统与硬件之间有着紧密的联系。作为系统软件,操作系统需要配合硬件启动和运行。它通过管理硬件资源,为应用程序提供运行环境。
实践写作 OS
在操作系统课程中,学生不仅要学习理论知识,还需通过实践掌握编写 OS 的能力。虽然编写 OS 看起来困难,但通过课程讲授与实践练习,学生能够逐步理解并掌握其中的知识,具备编写基本 OS 的能力。操作系统并非难以理解的庞然大物,而是为满足应用需求而存在的系统软件。
Compiler 和操作系统的共识
编译器和操作系统共享的共识是关于地址空间的理解。当编译器生成目标代码时,它会指定每条指令和数据的地址。而操作系统必须确保这些代码在加载并执行时,被放置到指定的地址空间。只有这样,程序才能正确运行。
编译器和操作系统之间的共识不仅限于这点,还涉及到内存管理和访问权限的设定。这种共识确保操作系统能为程序提供可靠的执行环境,同时能有效管理和保护系统资源。
硬件和软件的共识
硬件和软件之间的共识主要体现在引导启动过程上。硬件通常在只读存储器(ROM)中加载一段初始代码,即所谓的引导程序。这个引导程序会执行基本的硬件初始化,并最终跳转到操作系统的入口地址。
在这个过程中,硬件和引导程序(通常称为 Bootloader)共享起始地址的共识,Bootloader 和操作系统则共享入口地址的共识。这种共识确保硬件知道如何启动 Bootloader,而 Bootloader 知道如何正确加载和启动操作系统。
Bootloader 的作用
Bootloader 是硬件和操作系统之间的桥梁。它在启动时执行一系列任务,包括硬件检测、初始化和基本的系统配置。最终,它将跳转到操作系统的入口地址,完成操作系统的加载。
Bootloader 与硬件共享固定的起始地址,并与操作系统共享已知的入口地址,这种共识确保操作系统能顺利启动并进入正常运行状态。
系统调用和编译器
尽管系统调用(Syscall)是操作系统提供的功能,但编译器在生成代码时通常并不直接处理系统调用。因此,系统调用并不是编译器和操作系统之间的共识。
对计算机体系结构的理解
学习操作系统需要对计算机的整体体系结构有深刻理解,包括编译器、操作系统、CPU 和硬件之间的关系。系统的启动、加载和运行都依赖于它们之间的合作和协调。掌握这些知识有助于学生更全面地理解计算机系统的工作原理。
第四节:实践与实验目标
在第四节中,通过实际实验,更好地理解一个简单操作系统的工作原理和功能。主要内容包括:
- 目标与问题:了解 LibOS系统的目标和它需要解决的问题。
- 设计思路:明确 LibOS的总体设计思路,参考历史背景进行设计和改进。
- 具体操作步骤:掌握 LibOS系统的具体操作步骤和软件设计流程。
Ⅰ实验目标和思路
进化目标
设计一个简化的 LibOS系统,为应用程序提供更方便的执行环境。执行环境的概念首次提出,强调为软件提供资源的多层次软硬件系统。LibOS的进化目标包括:
- 应用与硬件的隔离:确保应用程序可以在硬件抽象层上运行,而无需直接与硬件交互。
- 简化硬件访问:通过 LibOS屏蔽底层硬件的复杂度,简化应用程序访问硬件资源的难度。
- 执行环境的定义:执行环境是为其上层软件提供功能和资源的系统。它包含硬件、操作系统、应用程序和相关组件。
设计思路
LibOS的设计需要综合考虑应用程序的需求和硬件资源的约束,整体上遵循以下思路:
- 多层次设计:从硬件层到应用层进行分层,确保各层模块职责分明。
- 资源管理:操作系统作为中间层,负责管理内存、CPU 和 I/O 设备,为应用程序提供稳定的资源访问接口。
- 隔离与安全:操作系统应该尽量隔离应用程序与硬件的直接交互,防止安全隐患。
实现与反馈
LibOS系统的实现需要具体的步骤和设计细节,这需要深入掌握每个模块的功能和相互作用。通过课堂反馈机制,学生可以及时向教师反映不清晰或困惑的概念,帮助改进课程内容并加强理解。

Ⅱ实验要求
学习目标与实践要求
学习操作系统时的目标和实践要求需要明确,以便学生在学习过程中知道要掌握什么内容:
-
编写和运行裸机程序:学习在无操作系统的环境下直接编写和运行程序,深入理解如何构建操作系统的基础设施。
-
理解裸机程序的函数调用:熟悉裸机程序的函数调用机制,深入理解函数在汇编和机器码层面的实现。了解汇编代码与机器码的对应关系以及伪汇编代码。
-
掌握混合编程:学会将高级语言和低级语言混合编程,以应对编写操作系统时经常遇到的需求。了解如何将汇编和其他高级语言有机结合。
-
初步理解 SBI 调用:理解 SBI(Supervisor Binary Interface)调用,了解其在支持操作系统运行方面的重要性。它是 ABI(Application Binary Interface)的一种扩展,为操作系统提供了更多的功能接口。
进阶知识与深层理解
通过对高级概念的理解,学生需要具备以下深入知识:
-
函数调用与计算机体系结构:深入理解在机器级别的函数调用过程,以及汇编级别的函数组织与执行方式,从更底层的角度理解计算机的结构与工作原理。
-
软件与硬件的层次关系:认识到操作系统并不总是软件的最底层,它有时依赖于 SBI 或 Bootloader 等底层组件来实现与硬件的交互和管理。
-
SBI 与操作系统:SBI 是 ABI 的扩展,为操作系统提供了底层函数接口,使其能够与硬件有效协作。掌握这一概念有助于深入了解计算机系统的组织结构。
-
在机器级层面理解函数:
- 寄存器(registers)
- 函数调用/返回(call/return)
- 函数进入/离开(enter/exit)
- 函数序言/尾声(prologue/epilogue)
学习后的综合认识
在学习这门课后,学生将具备对计算机系统的整体认识,能够以系统级视角来理解硬件与软件之间的关系。通过深入实践和理论学习,掌握从编写到执行操作系统的完整过程。
Ⅱ½总体思路/历史背景
总体设计思路
在明确课程目标与学生的目标后,总体设计思路变得更加清晰:
-
代码编写与运行:与编写一般应用程序类似,需要编写代码通过编译并成功运行。然而,这些代码属于裸机程序(Bare-metal Program),即在没有操作系统的帮助下运行。这就要求在编写过程中必须解决编译器不足的问题,自行实现所需功能。
-
栈的使用:在编写裸机程序时,需要自己编写与栈相关的功能。包括栈空间的大小、位置、申请和释放等细节,都需自行管理和优化。
-
地址空间与初始化:编写程序时需要与编译器和操作系统(或 Bootloader)之间达成地址空间的共识,确定程序在哪个地址执行。此外,在运行前需要考虑程序的初始化流程,确保正确分配资源。
历史背景
第一代操作系统的背景和设计思路为现代操作系统奠定了基础:
-
第一代 OS:最早的操作系统被认为是在欧洲由英国的一家餐饮业公司和剑桥大学联合设计的一台计算机上运行的。这一代的系统没有正式的 OS 名称,但本质上体现了 OS 的基本功能。
-
硬件约束与函数调用:由于当时硬件条件较差,寄存器和指令设计都未完善,函数调用非常困难。于是项目中的研究人员提出了子程序的概念,使得可以在相对低级的系统中实现函数调用。这一理念为操作系统的函数库和子程序奠定了基础。
-
现今的嵌入式 OS:现代的许多简单 RTOS(实时操作系统)或嵌入式操作系统仍然保持着这种设计思路,通过函数库提供基础功能。
现代应用与价值
尽管这些设计属于历史范畴,但现代很多领域仍然延续了这种设计思路:
- 实时与嵌入式系统:实时和嵌入式操作系统仍在使用函数库的理念来提供核心功能,使得它们能在资源受限的硬件上正常运行。
- 持续改进与创新:现代 OS 不断在这些基础概念上改进,并通过抽象层来实现与硬件的解耦,使得开发者能更加专注于上层应用的实现。
Ⅲ实践步骤
-
搭建开发环境:
- 首先需要在自己的计算机上搭建开发环境,以确保可以顺利进行开发和测试。
- 如果硬件条件有限,也可以利用树莓派等小型开发板,但这会影响性能。
-
按照教程操作:
- 建立基本开发环境后,学生需要按照教程中的步骤逐步操作。
- 教程可以选择
aco tutorial book或其他类似教程,重点是了解如何脱离标准库实现基本操作系统功能。
-
移除标准库依赖:
- 学生需要移除标准库的依赖,直接操作硬件资源。
- 使用 Rust 或 C 语言都可以,但 C 语言的安全性问题需要格外注意。
-
函数与接口的实现:
- 理解和实现与系统相关的函数,确保能够支持基本的输入输出操作和系统功能,如打印字符串和关机。
-
内存空间与布局:
- 学生需要在开发过程中理解运行程序的内存空间和布局。
- 包括代码段、数据段、栈和 BSS 段的位置与作用。
-
系统信息输出:
- 运行
libOS的示例代码时,系统会打印应用程序的相关信息,如代码段、数据段、栈段的位置。 - 系统还会执行关机操作以模拟完整的操作流程。
- 运行
操作步骤
git clone https://github.com/rcore-os/rCore-Tutorial-v3.git
cd rCore-Tutorial-v3
git checkout ch1
cd os
make run
实践结果与反馈
-
执行效果:运行后,可以看到
libOS成功启动,并打印出Hello World等字符串,以及系统的内存布局信息和关机操作。这表明系统在正确运行。 -
学生反馈:老师可以询问学生在实际操作中是否遇到问题,以调整教学节奏,确保每个学生都能跟上进度,掌握相关知识。
执行结果
[RustSBI output]
Hello, world!
.text [0x80200000, 0x80202000)
.rodata [0x80202000, 0x80203000)
.data [0x80203000, 0x80203000)
boot_stack [0x80203000, 0x80213000)
.bss [0x80213000, 0x80213000)
Panicked at src/main.rs:46 Shutdown machine!
除了显示 Hello, world! 之外还有一些额外的信息,最后关机。
Ⅳ代码结构
操作系统设计与实现
代码结构设计
虽然完整的操作系统代码只有 100 多行,但仍比一般算法复杂一些,因此需要合理设计结构。代码主要由两部分组成:
- Bootloader
- Bootloader 负责加载和启动操作系统,通常是由其他程序员编写的基础工具。
- 在本案例中,Bootloader 是由一名本科生编写的
rustsbi,它主要作用是为操作系统的启动提供基本的硬件初始化。 - 虽然学习者无需深入了解它的实现细节,但需要知道它的存在及其作用。
./os/src
Rust 4 Files 119 Lines
Assembly 1 Files 11 Lines
├── bootloader(内核依赖的运行在 M 特权级的 SBI 实现,本项目中我们使用 RustSBI)
│ ├── rustsbi-k210.bin(可运行在 k210 真实硬件平台上的预编译二进制版本)
│ └── rustsbi-qemu.bin(可运行在 qemu 虚拟机上的预编译二进制版本)
- 操作系统代码
- 操作系统的主体代码使用 Rust 语言编写,但其设计思路与 C 语言类似。
- 主程序位于
main函数中,该函数是整个操作系统的核心。 - 为支持该应用程序的运行,代码中实现了两个主要功能模块:输出库和启动入口。
├── os(我们的内核实现放在 os 目录下)
│ ├── Cargo.toml(内核实现的一些配置文件)
│ ├── Makefile
│ └── src(所有内核的源代码放在 os/src 目录下)
│ ├── console.rs(将打印字符的 SBI 接口进一步封装实现更加强大的格式化输出)
│ ├── entry.asm(设置内核执行环境的的一段汇编代码)
│ ├── lang_items.rs(提供给 Rust 编译器的一些语义项,目前包含内核 panic 时的处理逻辑)
│ ├── linker-qemu.ld(控制内核内存布局的链接脚本以使内核运行在 qemu 虚拟机上)
│ ├── main.rs(内核主函数)
│ └── sbi.rs(调用底层 SBI 实现提供的 SBI 接口)
输出库与启动入口
-
输出库
- 为应用程序提供字符串输出的功能。
- 包含类似于
printf的功能,可以将数字转化为字符串,然后通过 SBI(Supervisor Binary Interface)向 Bootloader 发起显示请求。 - 这个请求最终会显示在串口中,供用户查看。
-
启动入口
- 启动入口是系统启动的第一段代码,负责为
main函数准备执行环境。 - 在
main函数执行之前,初始化代码需要设置栈、初始化数据段等资源,以确保程序能够正确运行。 - 启动入口的代码通常是用汇编语言编写,以确保能够直接与硬件进行交互。
- 启动入口是系统启动的第一段代码,负责为
架构概览
- 应用程序:
main函数是整个操作系统的核心,包含应用程序的主要逻辑。 - 输出与服务:输出库通过与底层 SBI 接口通信,为应用程序提供输出字符串的功能。
- 启动部分:启动入口代码初始化执行环境,使
main函数在执行时能够获得合适的资源配置。
这个架构的设计使得操作系统代码得以保持简洁,同时能够通过良好的模块化提供完善的系统功能。
Ⅴ内存布局
内存布局的定制
应用程序内存布局概览
- 程序内存布局在编译器课和程序设计课中有所涉及,但很多高级语言如 Python 或 Java 不会展示这种细节。
- 使用 C 或 Rust 编写的程序通常由代码段和数据段构成,这些段的起始地址由编译器设定,并与操作系统达成共识,确保在内存中正确加载和执行。

-
堆和栈的动态管理
- 堆(Heap)与栈(Stack)通常在程序执行时动态管理:
- 堆:编译器不会直接处理堆空间的管理,而是由系统库或操作系统负责动态分配与释放。
- 栈:由编译器或操作系统设置栈底,函数调用导致栈顶向下移动,具有动态属性。
- 堆(Heap)与栈(Stack)通常在程序执行时动态管理:
-
BSS 段的特殊性
-
BSS(Block Started by Symbol)段是存放未初始化的全局变量的区域。
-
BSS 段属于静态内存分配,因为编译时已经确定了它的大小和位置。
-
C 语言允许声明未初始化的全局变量,将它们置于 BSS 段;Rust 则要求所有变量初始化以确保安全。
-
.bss : {
*(.bss.stack)
sbss = .;
*(.bss .bss.*)
*(.sbss .sbss.*)
-
段的静态与动态属性
- 静态段:
- 代码段(Text):保存程序的指令,不随程序运行扩展或缩小。
- 数据段(Data):保存已初始化的全局变量。
- 动态段:
- 堆段:在运行时动态分配。
- 栈段:在函数调用时动态调整。
- BSS 段是静态段的一部分,因为它在编译时确定了大小和位置。
- 静态段:
-
操作系统的灵活性与动态调整
- 操作系统的定义和属性具有灵活性,因其是人设计和实现的产物。
- 虽然代码段通常不会改变大小,但恶意程序可能通过修改代码段达到扩展目的。
- 操作系统也可以调整内存段以提供更多功能,但这需要确保安全与稳定。
Data 段和 Text 段的特性
-
Data 段
- Data 段专门存放已初始化的全局变量,属于静态内存分配。
- 在编译阶段,编译器将该段的起始地址设置好。
- 在程序运行时,操作系统会将其加载到内存中。
-
Text 段
- Text 段存放程序的代码部分,是只读的。
- 编译器生成时会标记此区域为不可修改,属于只读区域。
- 在程序加载过程中,操作系统需要将该段从源文件复制到目标内存位置,在设定为只读前进行写入操作。
堆和栈的区别与使用
-
堆(Heap)
- 堆是用于动态分配内存的区域,可以随着程序运行扩展和收缩。
- 使用
malloc和free(在 C 中)或Box(在 Rust 中)来动态管理堆内存。 - 堆适用于存放大小不确定的数据结构或需要长时间存储的数据。
-
栈(Stack)
- 栈主要用于存储局部变量和函数调用帧,遵循先进后出的原则。
- 进入函数时分配栈空间,退出函数时释放对应空间,栈指针简单调整即可。
- 栈的效率很高,但只能存放大小确定的变量。
数据存储与性能
-
栈与性能
- 栈具有很高的性能,因为它的分配和释放操作非常简单,适合处理局部变量和临时数据。
- 但栈只能存储在编译时已知大小的数据结构,无法灵活扩展。
-
堆与灵活性
- 堆提供了更大的灵活性,可以动态分配和释放内存。
- 适用于大小在运行时才确定的数据结构,但其管理机制较为复杂。
OS 编程与应用编程的区别
-
操作系统编程:操作系统编程要求深入理解堆和栈的底层原理,包括寄存器和指令级别的实现。这种编程需要掌握操作系统如何组织和维护堆与栈。
-
应用编程:应用程序编写一般无需了解这些底层细节,因为编译器和操作系统已经为开发者做好了堆与栈的分配与管理。了解底层机制有助于优化代码,但对普通应用程序开发者不是必需的。
静态变量的存储
- 静态变量区域
- 静态变量存储位置取决于其初始化状态。
- 已初始化的静态变量:放置于
data段中。 - 未初始化的静态变量:放置于
BSS段中。 data和BSS段都属于静态分配的区域,在编译时由编译器决定。
自定义内存布局
-
定制内存布局的必要性
- 编写应用程序时,编译器通常负责预设内存布局,无需开发者干预。
- 但编写操作系统时,编译器的默认布局不足以满足需求,必须自行定制布局。
-
链接脚本(Linker Script)
- 为了为链接器提供指导,需要编写专门的链接脚本(Linker Script)。
- 脚本明确指出 OS 应被放置的地址和各个段的布局。
- 在此示例中,OS 被放置在地址
0x80200000,链接器确保代码、data、BSS等段按照脚本布局。 - 参见,链接脚本 linker.ld
-
Bootloader、QEMU 与地址共识
- Bootloader 需根据指定地址加载 OS,并在执行时跳转到该地址。
- QEMU 模拟器也需知道该地址,以正确模拟 OS 的加载与执行。
生成二进制镜像
-
ELF 格式与二进制镜像
- 操作系统代码最初生成的是 ELF(Executable and Linkable Format)文件。
- Bootloader 在加载时不解析 ELF 格式,因此需要将其转换为纯二进制镜像。
-
工具与转换流程
- 使用
objcopy工具(或类似工具)可以将 ELF 文件转换为二进制镜像,剔除无关的元数据。 - 二进制镜像仅包含代码和数据段,以供 Bootloader 直接加载。
- 通过文件检查工具
file可以查看文件属性,验证其是否成功转换为二进制格式。
- 使用
-
文件结构检查
- 使用
file工具查看 OS 文件格式,确认是否成功转换为纯二进制格式。 - 如果转换正确,则会显示文件包含代码段和数据段信息。
- 使用
rust-objcopy --strip-all \
target/riscv64gc-unknown-none-elf/release/os \
-O binary target/riscv64gc-unknown-none-elf/release/os.bin
参见,Makefile - 变量定义/内核入口地址和Binutils工具/构建规则
Ⅵ基于 GDB 验证启动流程
启动过程验证
-
QEMU 与 GDB 的配合
- 使用 QEMU 模拟计算机运行环境,GDB 用于调试程序。
- QEMU 与 GDB 需要通过特定协议进行通信,以配合调试目标程序。
- 两个特殊参数
-s和-S用于 QEMU,指示模拟计算机在启动时暂停,等待 GDB 接管。
-
QEMU 调试启动步骤
- 配置参数:设置 QEMU 使用
-s和-S参数,确保计算机从 ROM 执行第一条指令时暂停。 - 启动 GDB:使用
riscv64-unknown-elf-gdb启动调试工具。 - 加载文件:在 GDB 中,通过
file命令加载 OS 的 ELF 文件,获取符号信息并关联到 C 或 Rust 代码。 - 连接 QEMU:通过
target remote localhost:1234与 QEMU 建立连接。 - 调试开始:连接后,GDB 获取 QEMU 当前暂停的地址位置,可查看汇编或源代码。
- 配置参数:设置 QEMU 使用
qemu-system-riscv64 \
-machine virt \
-nographic \
-bios ../bootloader/rustsbi-qemu.bin \
-device loader,file=target/riscv64gc-unknown-none-elf/release/os.bin,addr=0x80200000 \
-s -S
riscv64-unknown-elf-gdb \
-ex 'file target/riscv64gc-unknown-none-elf/release/os' \
-ex 'set arch riscv:rv64' \
-ex 'target remote localhost:1234'
[GDB output]
0x0000000000001000 in ?? ()
Ⅶ函数调用
函数调用的支持
-
概述与重要性
- 函数调用是程序设计的核心,需要在汇编和机器码层次确保调用的正确性和规范性。
- 操作系统在支持函数调用时需考虑参数传递、返回地址和调用规范等细节。
-
指令:CALL 与 RETURN
- 函数调用和返回在汇编中分别由
call和ret指令实现。 call指令保存返回地址,并跳转到目标函数;ret指令使用堆栈恢复调用者的执行位置。
- 函数调用和返回在汇编中分别由
-
函数调用规范
- 编译器生成的汇编代码需符合系统的 ABI(Application Binary Interface)规范。
- 函数调用规范包括参数的传递方式、返回值位置、寄存器的保存策略等。
-
操作系统初始化与函数调用支持
- 在操作系统启动时,需要初始化栈和其他内存区域,以确保函数调用正常运行。
- 这包括设置堆栈指针、保存返回地址等,使系统和应用程序能够有效使用函数调用。
编译器与汇编代码
-
中间代码生成
- 编译器首先生成中间代码,表示函数调用的逻辑结构。
-
汇编代码生成
- 编译器将中间代码转换为汇编代码,确保
call和ret指令正确生成。
- 编译器将中间代码转换为汇编代码,确保
-
机器码生成
- 汇编代码最终转化为机器码,以在目标硬件上执行函数调用逻辑。
-
理解函数调用的构造
- 学习函数调用的构造,理解参数和返回值的存储、栈的操作、寄存器的使用等。、
- 编译原理课 -- 实现函数调用编译支持
- 快速入门RISC-V汇编的文档
保存与恢复函数上下文
- 保存与恢复机制
- 编译器负责在函数调用时保存和恢复上下文(寄存器和参数)。
- 简化的方法是将所有需要保存和恢复的寄存器存储到内存中,并通过内存传递参数。
- 工业级编译器的优化
- 工业级编译器如 Rustc 和 GCC,不仅注重正确性,还需优化性能。
- 这些编译器通常通过寄存器直接传递参数,而不依赖内存。
- 调用与返回指令
call和ret只是汇编伪指令,最终转换为底层机器指令。

CALL 与 RETURN 指令的底层实现
- CALL 指令
call实际上是两条机器指令的组合:AUIPC和JALR。- AUIPC:
Add Upper Immediate to PC,将立即数的上半部分添加到程序计数器(PC)以计算相对偏移量。 - JALR:
Jump and Link Register,将计算出的返回地址存储在X1(RA)寄存器中,并跳转到目标函数的地址。
- RETURN 指令
ret指令映射到机器指令JALR,即基于 RA 寄存器中的地址跳转回调用点。JALR执行从寄存器中读取目标地址并跳转。
| 伪指令 | 基本指令 | 含义 |
|---|---|---|
| ret | jalr x0, x1, 0 | 函数返回 |
| call offset | auipc x6, offset[31:12]; jalr x1, x6, offset[11:0] | 函数调用 |
函数调用的规范
- 保存返回地址
- 函数调用时,返回地址会通过
call指令存储在 RA 寄存器中。 - 通过
return指令从 RA 读取地址,确保正确跳转。
- 函数调用时,返回地址会通过
- 多层函数调用的上下文保存
- 在多次嵌套调用中,需将 RA 保存到内存或栈中,以防止后续调用覆盖它。
- 编译器会在调用前将 RA 存储到栈中,并在返回时恢复。
- 调用约定与规范
- 函数调用的规范包括参数传递方式、返回值位置、寄存器保存策略等。
- 虽然这些规范不是强制标准,但开发者遵循约定,可以确保程序的可移植性和一致性。
- 函数调用跳转指令
| 指令 | 指令功能 |
|---|---|
| jal rd, imm[20 : 1] | rd ← pc+4; pc < pc+imm |
| jalr rd, (imm[11 :0])rs | rd ← pc+4; pc < rs+imm |
插入补充:
jal和jalr
jal和jalr都是 RISC-V 中的跳转指令,用于函数调用和控制流程跳转。它们的主要区别在于目标地址的确定方式。
jal指令
- 语法:
jal rd, imm[20:1]- 描述:
rd寄存器存储当前 PC 加 4 的值,这样调用函数返回时可以跳回。- PC 跳转到
PC + imm所计算出的目标地址,imm是一个相对偏移量,允许的偏移范围相对较大(±1 MiB)。- 主要特点:
- 适用于在当前程序计数器(PC)位置基础上跳转的情况。
- 可以用于直接跳转到固定偏移的地址,比如调用子程序。
jalr指令
- 语法:
jalr rd, (imm[11:0])rs- 描述:
rd寄存器存储当前 PC 加 4 的值,为返回时提供跳转目标。- PC 跳转到
rs + imm所计算的目标地址,rs是寄存器,imm是 12 位的立即数(范围 ±2 KiB)。- 主要特点:
- 用于间接跳转的情况,目标地址基于
rs寄存器和偏移量计算。- 可以用于返回或跳转到非固定的目标地址,比如函数指针。
总结比较
地址计算:
jal:目标地址直接基于当前 PC 和立即数偏移计算。jalr:目标地址基于寄存器rs和立即数偏移计算。使用场景:
jal:适用于直接调用具有固定偏移的子程序。jalr:用于返回函数或跳转到动态计算的地址。
插入补充:x86 与 RISC-V 中
ret指令的区别
x86 的
ret指令
- x86 的
ret(Return)指令从栈中弹出返回地址,并将其加载到程序计数器(PC)中。- 栈指针
ESP(32 位)或RSP(64 位)管理函数调用栈的顶部,指向下一个返回地址。ret执行时,还可能接收一个立即数参数,用于从栈中移除函数调用的参数。RISC-V 的
ret指令
- RISC-V 并没有直接的
ret指令,而是通过JALR(Jump and Link Register)来实现返回功能。- 返回地址在 RISC-V 中存储于特定的寄存器
RA(Return Address),通常是X1。JALR指令使用RA寄存器中的地址来跳转回调用点。序言与尾声(Prologue 与 Epilogue)的差异
x86 序言与尾声
- 序言与尾声是函数调用过程中在函数入口和出口执行的指令集,用于设置与清理函数调用栈。
- x86 使用
PUSH指令保存寄存器值,MOV指令调整栈指针以分配局部变量空间。- 尾声部分使用
POP指令恢复寄存器值,并调整栈指针回到函数入口状态,最后用ret指令返回。RISC-V 序言与尾声
- RISC-V 通常使用
ADDI(Add Immediate)指令调整栈指针,为局部变量分配空间。- 参数传递使用寄存器完成,超出寄存器数量的参数会存入栈中。
- 在尾声部分,通过
ADDI恢复栈指针状态,并使用JALR指令返回。关键区别
返回地址存储方式
- x86:返回地址存储在栈中,
ret直接从栈中弹出并返回。- RISC-V:返回地址存储在
RA寄存器中,JALR从寄存器中取回地址。
RISC-V 汇编与机器码
- 快速入门
- RISC-V 汇编文档提供了基本指令的详细说明,包括
AUIPC和JALR。 快速入门RISC-V汇编的文档 - 理解这些指令有助于编写操作系统代码以及调试和优化程序。
- RISC-V 汇编文档提供了基本指令的详细说明,包括
函数调用约定的共识
-
参数传递与函数结构
- 参数传递和函数结构的设计是函数调用约定的核心部分。
- 函数的上下文包括输入参数、返回值、寄存器和内存状态。
- 编译器从不同层次生成函数的结构,但机器级别的上下文包括寄存器和内存,更底层和详细。
-
调用者与被调用者保存的寄存器
- 在函数调用中,一些寄存器由调用者(caller)保存,另一些由被调用者(callee)保存。
- 这种分工确保符合规范的程序能够正确运行。
-
返回值寄存器
- 返回值存储在寄存器
A0,具体名称取决于不同平台的约定。- RISC-V32:如果返回值 64bit,则用 a0~a1 来放置。
- RISC-V64:如果返回值 64bit,则用 a0 来放置。
- 返回值存储在寄存器

栈帧的结构
-
栈帧组成
- 栈帧由调用返回地址、栈帧链、保存的寄存器和局部变量组成。
- 每次函数调用都创建一个新的栈帧,以便跟踪函数调用关系。
-
返回地址
Return Address保存当前函数返回调用者的地址,确保函数调用结束后能正确跳转。
-
栈帧链
- 栈帧链通过
Frame Pointer建立联系,将各栈帧串联起来。 - 动态链可通过 GDB(或其他调试工具)展示完整的函数调用关系。
- 栈帧链通过
-
保存的寄存器
- 调用者或被调用者需要保存的寄存器值,确保在函数调用期间或返回后数据不被破坏。
-
局部变量
- 栈帧的顶部通常存储函数的局部变量。

工业级编译器的作用
-
编译器构造栈帧
- 工业级编译器如 GCC 或 Rustc 会自动生成栈帧结构。
- 这使得开发者可以将主要精力放在业务逻辑上,而不必关心栈帧的细节。
-
理解栈帧结构
- 需要了解栈帧的详细结构,因为在操作系统级别进行优化或调整时,必须正确管理栈帧。
栈帧的结构与回收
-
栈帧的头和尾
- 栈帧由栈指针(SP)和帧指针(FP)标识其顶部和底部。
- 栈指针通常指向栈帧的顶部,而帧指针指向底部。
-
回收栈帧
- 当
return(或对应的汇编指令)执行时,栈帧会被回收。 - 通过
SP = FP + FRAME_SIZE调整栈帧,回到之前的栈帧状态。 - 返回地址(RA)存储在特定寄存器中,通过将其赋值给程序计数器(PC)跳转回调用者。
pc = return address sp = sp + ENTRY_SIZE fp = previous fp - 当

Stack
.
.
+-> .
| +-----------------+ |
| | return address | |
| | previous fp ------+
| | saved registers |
| | local variables |
| | ... | <-+
| +-----------------+ |
| | return address | |
+------ previous fp | |
| saved registers | |
| local variables | |
+-> | ... | |
| +-----------------+ |
| | return address | |
| | previous fp ------+
| | saved registers |
| | local variables |
| | ... | <-+
| +-----------------+ |
| | return address | |
+------ previous fp | |
| saved registers | |
| local variables | |
$fp --> | ... | |
+-----------------+ |
| return address | |
| previous fp ------+
| saved registers |
$sp --> | local variables |
+-----------------+
在程序执行过程中,栈用于存储局部变量、函数返回地址以及其他调用上下文。以下是对此栈帧结构的解释:
- 栈的方向
- 栈从高地址向低地址增长。
- 这是函数调用过程中栈指针(
$sp)的移动方向。- 栈帧(Stack Frame)
- 每个栈帧代表一个函数调用,包括其局部变量、返回地址和保存的寄存器等信息。
- 栈帧在函数调用期间分配,调用结束时释放。
- 返回地址(Return Address)
- 每个栈帧的顶部保存了返回地址,当函数结束后需要跳回调用者的执行位置。
- 该地址用于
ret或类似指令返回到调用函数的下一条指令。- 先前的帧指针(Previous Frame Pointer)
- 指向调用者的栈帧,以便函数能够找到前一个栈帧的结构。
- 有助于调试或在堆栈中遍历整个调用链。
- 保存的寄存器(Saved Registers)
- 一些寄存器需要在调用期间保存,防止数据被覆盖。
- 保存的寄存器包括调用者或被调用者负责的寄存器。
- 局部变量(Local Variables)
- 局部变量在栈帧的底部分配,分配空间大小根据函数的需要而变化。
- 栈指针与帧指针(Stack Pointer 和 Frame Pointer)
$sp:栈指针,指向当前栈帧的底部位置。函数返回时,栈指针恢复到之前的值。$fp:帧指针,通常指向当前栈帧的顶部或一个固定位置。某些架构使用$fp来指向调用者的帧。
更多内容参见,MIT6.004notebook RISC-V栈
序言与尾声
-
序言与尾声
- 函数的序言(Prologue)与尾声(Epilogue)由编译器生成,确保函数调用的上下文保存与恢复。
- 序言部分负责保存返回地址与设置局部变量空间。
- 尾声部分恢复返回地址并调整栈帧,为返回调用者做好准备。
-
函数调用规范的执行
- 序言和尾声确保函数调用规范被正确执行,使函数调用者和被调用者保持一致。
-
函数内的嵌套调用
- 当一个函数在自身内部嵌套调用其他函数时,需确保返回地址不被覆盖。
- 返回地址(RA)应该存储在固定位置,供嵌套调用使用。
.global sum_then_double
sum_then_double:
addi sp, sp, -16 # prologue
sd ra, 0(sp)
call sum_to # body part
li t0, 2
mul a0, a0, t0
ld ra, 0(sp) # epilogue
addi sp, sp, 16
ret
.global sum_then_double
sum_then_double:
call sum_to # body part
li t0, 2
mul a0, a0, t0
ret
Q: 此代码的执行与前面的代码执行相比有何不同?
RISC-V 中没有序言和尾声导致死循环的原因
-
函数调用的返回地址问题
- 在 RISC-V 中,
call指令(由JALR实现)将当前 PC 存储在RA寄存器(X1)中,并跳转到目标函数的地址。 - 如果函数调用缺乏序言和尾声,返回地址将不会被保存到栈中。因此,在嵌套或递归调用时,
RA寄存器的值会被新调用的函数覆盖。 - 当没有尾声恢复
RA寄存器的值时,返回指令ret将会尝试跳转到错误的地址(上一个调用的函数操作赋予RA的地址),导致死循环或程序崩溃。
- 在 RISC-V 中,
-
栈帧的作用
- 序言和尾声负责在栈中设置和恢复栈帧,包括保存与恢复
RA寄存器的值。 - 缺乏序言和尾声会导致无法正确保存返回地址,并且新调用的函数会覆盖
RA中的值。
- 序言和尾声负责在栈中设置和恢复栈帧,包括保存与恢复
x86 中类似情况的对比
x86 中的
call与ret
- 在 x86 架构中,
call指令会将返回地址直接推入栈中,并跳转到目标函数。ret指令则从栈中弹出返回地址,并将其赋值给 PC,从而实现返回。序言与尾声在 x86 中的作用
- x86 序言与尾声负责设置与恢复栈帧,包括保存与恢复调用者的返回地址。
- 如果没有序言和尾声,返回地址将无法正确保存或恢复,这会导致
ret从错误位置读取返回地址,进而跳转到不正确的内存地址。相同的风险
- RISC-V 和 x86 都需要通过序言和尾声来正确保存返回地址。
- 如果在这两个架构中都缺少这两个部分的保护机制,都会导致程序陷入死循环或崩溃,因为返回地址无法准确恢复。
x86 与 RISC-V 的区别
x86 的函数调用机制与问题
函数调用与返回机制
- 在 x86 架构中,
call指令会将当前程序计数器(PC)的值(即下一条指令的地址)推入栈中。- 函数返回时,
ret指令从栈中弹出先前保存的返回地址,并跳转到这个地址,继续执行调用者的代码。错误的读取和死循环问题
- 如果缺少序言与尾声,将不会正确保存或恢复栈帧,这会导致返回地址无法正确处理。
ret指令会从错误位置的栈中读取错误的地址。- 如果这个地址指向调用函数自身或已经跳转的指令,将导致程序反复在错误的指令位置循环,形成死循环。
- 另外,错误的返回地址可能指向无效或非法的内存区域,导致程序崩溃或触发安全漏洞。
RISC-V 的函数调用机制与问题
函数调用与返回机制
- 在 RISC-V 中,
call指令由JALR指令实现,将当前 PC 存储在RA(X1)寄存器中。- 返回时,
ret也由JALR指令实现,通过读取RA寄存器中的地址进行跳转。错误的读取和死循环问题
- 缺少序言与尾声导致
RA寄存器的值没有正确保存,并可能被其他函数调用覆盖。- 返回指令使用
JALR读取RA的地址,并跳转到这个错误的地址。- 如果该地址是先前的函数调用点,程序将陷入无尽的循环。如果是无效地址,程序会崩溃。
主要差异
返回地址的存储位置
- x86:返回地址始终存储在栈中。
- RISC-V:返回地址存储在
RA寄存器中,只有在必要时才存储到栈中。错误的地址来源
- x86:错误的返回地址可能来自栈指针的错误位置。
- RISC-V:错误的返回地址来自
RA寄存器中被覆盖的地址。
ⅧLibOS 初始化
-
目标与重要性
- LibOS 初始化的目标是确保操作系统的基础组件能够顺利运行,包括设置栈空间、执行环境以及初始化
print功能。 - 初始化过程对于确保应用程序和操作系统稳定执行至关重要。
- LibOS 初始化的目标是确保操作系统的基础组件能够顺利运行,包括设置栈空间、执行环境以及初始化
-
汇编与 Entry 点
- 初始化的起点是汇编代码的入口点(Entry),它是链接脚本中定义的符号,通常是
.text段中的entry函数。 - 该入口点地址由链接脚本确定,例如
0x80200000。
- 初始化的起点是汇编代码的入口点(Entry),它是链接脚本中定义的符号,通常是
-
设置栈指针
- 在
entry函数执行时,首先需要设置栈指针SP,指向操作系统为其准备的栈空间。 - 栈空间大小需预先分配,例如 64KB,超出栈空间则可能导致覆盖代码或其他栈区域,引发严重错误。
- 在
-
栈帧与安全
- 使用
SP指针设置栈空间,通常从高地址向低地址增长。 - 如果调用嵌套层数过多或递归次数过多,可能导致栈帧溢出,覆盖其他代码区域,进而产生难以调试的内存错误。
- 使用
-
内存错误与并发错误
- 内存相关的错误(如栈溢出、堆内存错误)与并发错误是操作系统编程中难以调试的两类问题。
- 应仔细规划栈与堆空间,并确保并发环境中的锁定与同步。
-
全局变量与链接
- 链接脚本负责在编译时将全局变量的地址分配到适当的内存区域。
- 初始化过程中需将这些全局变量的起始地址与运行时的物理地址对齐,以确保正确加载并执行。
通过合理的 LibOS 初始化流程,能够确保栈、全局变量等资源正常分配,构建稳定的执行环境。
- 分配并使用启动栈 快速入门RISC-V汇编的文档
# os/src/entry.asm
.section .text.entry
.globl _start
_start:
la sp, boot_stack_top
call rust_main
.section .bss.stack
.globl boot_stack
boot_stack:
.space 4096 * 16
.globl boot_stack_top
boot_stack_top:
# os/src/linker-qemu.ld
.bss : {
*(.bss.stack)
sbss = .;
*(.bss .bss.*)
*(.sbss .sbss.*)
}
ebss = .;
在链接脚本 linker.ld 中 .bss.stack 段最终会被汇集到 .bss 段中 .bss 段一般放置需要被初始化为零的数据
参见,entry.asm
LibOS 初始化的后续步骤
-
栈设置完成后
-
在设置好栈指针并为栈空间分配内存后,下一步就是执行
call rust_main,这意味着从汇编代码跳转到 Rust 或 C 的主函数。-
将控制权转交给 Rust 代码,该入口点在 main.rs 中的
rust_main函数。#![allow(unused)] fn main() { // os/src/main.rs pub fn rust_main() -> ! { loop {} } }
-
-
这是混合编程的一个实例,其中汇编负责初始环境的配置,而高级语言则承担应用程序逻辑。
-
-
调用约定的简化
- 初始阶段的调用者(caller)函数并不完全遵循标准的函数调用约定,因为无需保存调用者的寄存器状态。
- 初始化程序直接跳转到
rust_main,并在该函数中执行操作系统的主循环。
-
函数注释与解释
- 在
rust_main中进行死循环是为了保持操作系统的运行状态,防止程序意外退出。 - 函数注释可以帮助理解代码的意图和执行逻辑。
- 在
-
未定义变量的清理
- 对于未初始化的全局变量,需要确保它们的值为零。
- 在应用程序中,编译器通常负责初始化这些变量,但在操作系统编写中,需要手动清理 BSS 段。
-
清理 BSS 段
clear_bss函数负责将 BSS 段的内存区域清零。- 使用链接脚本中定义的
bss_start和bss_end确定内存区域的起点和终点,然后在该范围内填充零值。
-
全局变量的地址
- BSS 段的起始和结束位置通过链接脚本中的全局变量提供,编译器在链接时将这些变量的地址传递给程序。
- 通过这些全局变量,能够确保 BSS 段的初始化和全局变量的正确使用。
-
总结初始化过程
- 初始化完成后,LibOS 已具备执行环境,能够支持函数调用和全局变量的正常使用。
print等应用程序功能在此基础上正常工作,确保操作系统与应用程序能够顺利交互。
参见main.rs
ⅨSBI调用
SBI 服务与 OS 关系

-
SBI 的定位
- 在 RISC-V 中,操作系统不一定是最底层的软件组件,SBI(Supervisor Binary Interface)通常位于操作系统之下。
- SBI 作为一个中间层,为操作系统提供底层服务,如虚拟化和 Bootloader。
-
设计思路与目的
- SBI 的设计目的是提供底层服务,使操作系统无需直接管理硬件。
- 通过 SBI 提供的功能,操作系统可以减少硬件驱动的复杂性,直接调用已实现的接口。
-
调用机制
- SBI 服务接口类似于系统调用(syscall),但是为操作系统层提供服务。
- 调用由操作系统通过编号发起,编号对应具体的服务功能。
-
输出字符服务
- SBI 中提供了
putchar服务,用于输出字符。 - 传递字符参数和编号,供底层服务函数解析与执行,返回值表明成功或失败。
- SBI 中提供了
-
SBI 内嵌汇编
- SBI 调用需要内嵌汇编来实现。
- 使用高级语言直接嵌入汇编代码,在 Rust 或 C 代码中执行汇编指令。
- 汇编指令通过寄存器传递参数,模拟
call指令的参数传递逻辑。
-
封装与抽象
- 为了简化上层调用,SBI 调用通常被封装成更易用的函数,例如
console_putchar。 - 封装后的函数隐藏底层汇编细节,方便操作系统开发者使用。
- 为了简化上层调用,SBI 调用通常被封装成更易用的函数,例如
-
高级宏与
println!- Rust 提供了高级宏,如
println!,可以进一步简化输出字符的逻辑。 - 宏用于生成一系列相关代码,将输入参数展开成完整的汇编调用,并确保语法和语义的一致性。
- Rust 提供了高级宏,如
重要的 SBI 服务
-
Print 服务
- 提供输出字符的
putchar服务,让操作系统能够将字符信息打印到控制台或日志。
- 提供输出字符的
-
Shutdown 服务
shutdown服务用于关闭虚拟机,模拟机器关机操作。- 在 QEMU 中,
shutdown会使模拟器优雅退出。 - 此服务用于:
- 程序正常执行完毕时关机。
- 当程序遇到致命错误时,以
panic的方式触发shutdown服务。
-
Panic 机制
- Rust 提供
panic机制,在程序出错时打印错误信息并调用shutdown服务优雅退出。 panic会触发专门的panic handler,输出详细的错误日志,供开发者调试和排查。
- Rust 提供
第二讲总结
-
掌握 OS 的知识点
- 本课程提供了对操作系统设计与实践的简要概述,涵盖了理论和实践中需要掌握的核心知识点。
- 理论包括系统调用、内存管理等方面,实践则侧重设计与实现 OS 结构。
-
计算机系统的全面理解
- 通过学习 OS,不仅要掌握操作系统本身,还需要理解与编译器、CPU、内存和 I/O 的交互。
- 综合理解计算机系统的结构和功能是更好掌握操作系统的基础。
-
从启动到应用程序的执行流程
- 学习并理解从机器启动到应用程序打印字符串的完整流程。
- 理解汇编入口、栈设置、SBI 调用等机制,深入掌握计算机的运行原理。
-
开发三层 OS 的能力
- 课程结束时,学生应具备开发简单三层 OS 的能力。
- 理解裸机程序的编写和执行,使学生能够应对更复杂的 OS 开发和应用。
Lab1
1. 设置环境
- 参考lab0,确保你已安装 Rust 、Qemu以及相关工具。
2. 创建项目结构/试运行
-
创建一个新的 Cargo 项目:
cargo new os-
这将创建一个名为
os的新项目,文件结构如下:os ├── Cargo.toml └── src └── main.rs
-
-
在项目目录下创建
bootloader文件夹,并将rustsbi-qemu.bin放入其中。- rustsbi-qemu.bin:这是内核依赖的运行在 M 特权级的 SBI(Supervisor Binary Interface)实现。本项目中使用 RustSBI,通常用于在 QEMU 虚拟机中启动内核。
-
尝试运行项目,使用命令
cargo run-
这将编译并运行项目,输出如下:
Compiling os v0.1.0 (/path/to/os) Finished dev [unoptimized + debuginfo] target(s) in 1.15s Running `target/debug/os` Hello, world! -
确保项目目录结构如下:
os/ ├── Cargo.toml ├── bootloader/ │ └── rustsbi-qemu.bin └── src/ └── main.rs
-
- 在
src/main.rs文件中,cargo已经为我们准备了最简单的 Rust 应用程序:fn main() { println!("Hello, world!"); }
尽管这个 Rust 代码中只有几行代码来实现
Hello, world!的输出,但实际上,背后涉及许多复杂的底层支持才能实现这一功能。这包括:
- Rust 标准库
std提供的println!宏。std库依赖的底层实现,如 GNU Libc 库提供的标准输入输出函数。- 操作系统(如 Linux)提供的系统调用接口,用于实现底层的输入输出操作。
- 硬件驱动程序和设备管理程序,这些由操作系统管理,以支持屏幕显示等硬件操作。
因此,看似简单的几行代码实际上依赖于多层次的软件和硬件支持,才能最终在屏幕上打印出 "Hello, world!"。
3. 理解执行环境与平台支持
3.1 理解应用程序执行环境
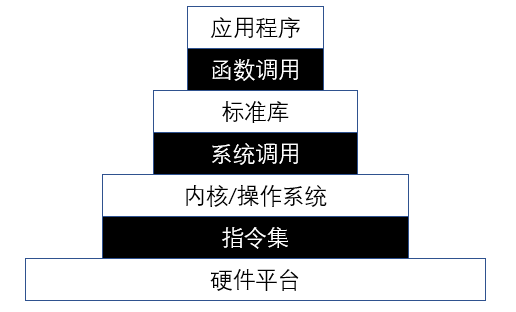
该图片展示了一个典型的应用程序执行环境栈,从底层硬件到最顶层的应用程序。每一层都为上层提供支持,并且各层之间通过接口进行交互。
-
硬件平台:
- 底层的物理硬件,包括 CPU、内存和输入输出设备。
- 所有软件层次最终都要与硬件平台交互来执行实际的操作。
-
指令集:
- 硬件平台支持的 CPU 指令集架构(ISA),如 x86_64、ARM 或 RISC-V。
- 指令集定义了 CPU 可以执行的指令集合,是硬件与软件之间的接口。
-
内核/操作系统:
- 操作系统内核管理硬件资源,并提供基本的系统功能,如进程调度、内存管理、文件系统和设备驱动程序。
- 操作系统通过系统调用接口(System Call Interface)与用户空间程序交互。
-
系统调用:
- 系统调用是应用程序与操作系统交互的接口。
- 通过系统调用,应用程序可以请求操作系统执行特权操作,如文件操作、进程管理和网络通信。
-
标准库:
- 标准库(如 Rust 的
std库或 C 的glibc)为应用程序提供了高层次的功能抽象,封装了系统调用,简化了编程。 - 标准库通过系统调用与操作系统交互,从而实现其功能。
- 标准库(如 Rust 的
-
函数调用:
- 函数调用是应用程序内部或者不同库之间的调用。
- 这是应用程序逻辑的具体实现部分,通过调用库函数实现各种功能。
-
应用程序:
- 顶层是最终运行的应用程序。
- 应用程序使用标准库和第三方库提供的功能,通过函数调用实现其特定的业务逻辑。
例子:Hello, world! 程序
让我们用 Hello, world! 程序来具体说明这一执行环境栈:
fn main() { println!("Hello, world!"); }
-
应用程序:
main函数调用了println!宏,这就是我们的应用程序层。
-
函数调用:
println!宏展开后会调用标准库中的 I/O 函数,这属于函数调用层。
-
标准库:
println!宏是由 Rust 标准库std提供的。std库内部实现了调用系统调用的逻辑。
-
系统调用:
std库中的 I/O 函数最终通过系统调用接口请求操作系统将字符串输出到标准输出(屏幕)。
-
内核/操作系统:
- 操作系统内核管理和调度硬件资源,执行系统调用,将字符串数据传递给适当的设备驱动程序。
-
指令集:
- 操作系统内核和驱动程序通过 CPU 指令集与硬件进行交互,执行相应的操作指令。
-
硬件平台:
- 最终,物理硬件(如显示器)在屏幕上显示 "Hello, world!" 字符串。
执行环境 (Execution Environment) 是指应用程序在运行时所依赖的各种软件和硬件组件的集合。这个环境为应用程序提供了必需的基础设施和支持,以便其能够正常运行并执行预期的功能。执行环境通常包括以下几个层次:
- 硬件平台:物理设备,包括 CPU、内存、存储、网络和输入输出设备。
- 操作系统:管理硬件资源,提供基本服务,如文件系统、网络通信和进程调度。
- 系统调用接口:应用程序与操作系统之间的接口,通过它们可以访问操作系统提供的服务。
- 标准库和第三方库:提供高层次的功能抽象,简化应用程序的开发。标准库通常由编程语言的运行时提供,如 Rust 的
std库。- 应用程序代码:实际运行的业务逻辑,通过调用标准库和系统调用来完成具体的功能。
3.2 平台与目标三元组
平台 (Platform) 和 目标三元组 (Target Triplet) 是编译器在编译和链接时需要了解的,以便生成在特定环境中运行的可执行文件。
目标三元组
目标三元组是一个由三部分组成的字符串,用来描述目标平台的信息:
- CPU 指令集:例如 x86_64 或 riscv64。
- 操作系统类型:例如 linux 或 none(裸机平台)。
- 标准运行时库:例如 gnu(使用 GNU C 库)或 elf(没有标准库,仅生成 ELF 格式的可执行文件)。
示例分析
让我们分析当前的 Hello, world! 程序的目标三元组:
$ rustc --version --verbose
rustc 1.61.0-nightly (68369a041 2022-02-22)
binary: rustc
commit-hash: 68369a041cea809a87e5bd80701da90e0e0a4799
commit-date: 2022-02-22
host: x86_64-unknown-linux-gnu
release: 1.61.0-nightly
LLVM version: 14.0.0
输出中 host 一项表明默认目标平台是 x86_64-unknown-linux-gnu,具体解释如下:
- CPU 架构:
x86_64 - CPU 厂商:
unknown - 操作系统:
linux - 运行时库:
gnu libc
移植到 RISC-V 平台
我们希望将 Hello, world! 程序移植到 RISC-V 目标平台 riscv64gc-unknown-none-elf 上运行。
- riscv64gc:CPU 架构是 RISC-V 64 位,支持压缩指令和浮点指令集扩展。
- unknown:CPU 厂商是未知。
- none:操作系统是无操作系统(裸机平台)。
- elf:没有标准运行时库,但可以生成 ELF 格式的可执行文件。
我们选择 riscv64gc-unknown-none-elf 而不是 riscv64gc-unknown-linux-gnu,因为我们的目标是开发操作系统内核,而不是在 Linux 系统上运行的应用程序。
修改目标平台
为了将程序的目标平台换成 riscv64gc-unknown-none-elf,可以按照以下步骤进行。让我们试试看会发生什么:
$ cargo run --target riscv64gc-unknown-none-elf
Compiling os v0.1.0 (/home/shinbokuow/workspace/v3/rCore-Tutorial-v3/os)
error[E0463]: can't find crate for `std`
|
= note: the `riscv64gc-unknown-none-elf` target may not be installed
报错的原因是目标平台上确实没有 Rust 标准库 std,也不存在任何受 OS 支持的系统调用。这样的平台被我们称为 裸机平台 (bare-metal)。
裸机平台 (Bare-metal)
在裸机平台上,程序直接运行在硬件上,没有操作系统的支持。因此,许多高级功能(如文件系统、网络堆栈等)无法使用。裸机平台通常用于嵌入式系统、微控制器和自定义操作系统的开发。
幸运的是,除了标准库 std 之外,Rust 还有一个不需要任何操作系统支持的核心库 core,它包含了 Rust 语言的大部分核心机制,可以满足我们在裸机平台上的需求。有许多第三方库也不依赖于标准库 std,而仅仅依赖于核心库 core。
使用核心库 core
为了以裸机平台为目标编译程序,我们需要将对标准库 std 的引用换成核心库 core。
ELF 文件
ELF(Executable and Linkable Format,可执行与可链接格式)是 Unix 系统中常用的一种文件格式,主要用于可执行文件、目标代码、共享库和核心转储。以下是对 ELF 文件的一些详细解释:
ELF 文件的基本结构
ELF 文件由以下几部分组成:
- ELF 头部(ELF Header):
- 包含文件的总体信息,如文件类型(可执行文件、共享库、目标文件等)、架构类型、入口点地址、程序头部表和节头部表的位置和大小等。
- 程序头部表(Program Header Table):
- 描述了程序在内存中的布局。每个条目描述一个段(segment),包括段的类型、虚拟地址、文件偏移、内存大小、文件大小、权限等。用于程序加载器将文件加载到内存中。
- 节头部表(Section Header Table):
- 描述了文件中的各个节(section)。每个条目包含节的名称、类型、地址、偏移、大小、属性等。节用于连接和调试等用途。例如,
.text节通常包含代码,.data节通常包含已初始化的数据。- 各个节(Sections):
- 文件的实际内容分布在各个节中,如代码节(.text)、数据节(.data)、只读数据节(.rodata)、符号表(.symtab)、字符串表(.strtab)等。
ELF 文件的类型
- 可执行文件(Executable):包含可以直接运行的程序代码。
- 目标文件(Relocatable):包含链接器使用的代码和数据片段,用于生成可执行文件或共享库。
- 共享库(Shared Object):动态链接库,可以在运行时被其他程序加载和使用。
- 核心转储(Core Dump):程序异常终止时的内存映像,用于调试。
ELF 文件的优点
- 可扩展性:结构清晰,易于扩展。
- 可移植性:支持不同的处理器架构。
- 兼容性:广泛应用于各类 Unix 系统,包括 Linux 和 BSD 系统。
4. 移除标准库依赖
4.1 安装目标平台工具链
$ rustup target add riscv64gc-unknown-none-elf
作用:
- 这一步安装了目标平台工具链,使你的 Rust 编译器能够生成
riscv64gc-unknown-none-elf目标平台的二进制文件。 - 这是为交叉编译准备的基础步骤,因为没有安装目标平台工具链,就无法生成该平台的可执行文件。
4.2 设置默认目标平台
首先在 os 目录下新建 .cargo 目录,并在这个目录下创建 config 文件,输入如下内容:
# os/.cargo/config
[build]
target = "riscv64gc-unknown-none-elf"
.cargo/config 的作用和效果
- 作用:通过在
.cargo/config文件中指定目标平台,可以让 Cargo 在编译和运行项目时默认使用riscv64gc-unknown-none-elf作为目标平台。 - 效果:配置
.cargo/config文件后,开发人员不再需要每次编译或运行项目时手动指定目标平台,简化了命令行操作。
交叉编译 (Cross Compile)
这种编译器运行的平台(如 x86_64)与可执行文件运行的目标平台(如 riscv64gc-unknown-none-elf)不同的情况,称为 交叉编译 (Cross Compile)。交叉编译允许在开发机上生成适用于其他架构或操作系统的可执行文件。
配置 .cargo/config 文件的具体效果是:当运行 Cargo 命令(如 cargo build 或 cargo run)时,Cargo 工具会自动使用 riscv64gc-unknown-none-elf 作为目标平台,而不需要每次手动指定 --target 参数。例如:
-
未配置
.cargo/config文件时:$ cargo build --target riscv64gc-unknown-none-elf $ cargo run --target riscv64gc-unknown-none-elf -
配置
.cargo/config文件后:$ cargo build $ cargo run
这样不仅简化了操作,还确保了项目的一致性,特别是在团队协作时,每个开发者都可以使用相同的目标平台配置。
交叉编译(Cross Compile)
交叉编译 是指在一个平台上生成在另一个平台上运行的可执行文件。即编译器运行的平台(host)与可执行文件运行的目标平台(target)不同的情况。
举例说明
在本项目中,我们的开发环境可能是基于 x86_64 架构的 Linux 系统(如个人电脑),而目标平台是
riscv64gc-unknown-none-elf,这是一个基于 RISC-V 架构的裸机平台。
- 编译器平台(Host Platform):
x86_64-unknown-linux-gnu- 目标平台(Target Platform):
riscv64gc-unknown-none-elf交叉编译就是在
x86_64-unknown-linux-gnu平台上编译生成riscv64gc-unknown-none-elf平台上的可执行文件。为什么需要交叉编译?
交叉编译在多种场景下非常有用,尤其是在嵌入式开发、操作系统开发以及跨平台软件开发中。以下是一些原因:
- 目标平台资源受限:
- 许多嵌入式设备和裸机平台资源有限,无法直接进行编译操作。交叉编译允许在功能更强大的开发机上编译代码,然后将生成的可执行文件部署到目标设备上。
- 提高开发效率:
- 交叉编译可以利用功能强大的开发机进行编译,提高编译速度和效率。
- 多平台支持:
- 通过交叉编译,开发者可以在一个平台上编写代码并生成多个平台的可执行文件,支持不同的架构和操作系统。
.cargo/config的作用
.cargo/config文件用于为 Cargo 项目提供自定义配置选项,以便控制项目的构建和编译行为。在这个文件中,可以指定诸如默认目标平台、编译选项、链接器配置等。
指定默认目标平台:
- 通过在
.cargo/config文件中设置目标平台,可以让 Cargo 在编译和运行项目时自动使用该目标平台,而不需要每次手动指定。- 配置示例:
# os/.cargo/config [build] target = "riscv64gc-unknown-none-elf"简化命令行操作:
- 配置了
.cargo/config文件后,所有与构建相关的命令都会默认使用该文件中指定的配置,从而简化了命令行操作。- 减少了开发人员在每次构建或运行项目时重复输入目标平台的麻烦。
项目一致性:
- 在团队协作中,确保所有开发人员使用相同的构建配置,从而避免由于不同开发环境导致的构建不一致问题。
- 提高了项目的可维护性和一致性。
4.3 移除 println! 宏
回到我们的程序,为了以裸机平台为目标编译程序,我们需要将对标准库 std 的引用换成核心库 core。
在 main.rs 的开头加上一行 #![no_std],告诉 Rust 编译器不使用标准库 std 而转向核心库 core。由于 println! 宏是由标准库 std 提供的,所以这一步会导致编译错误。
步骤
-
在
main.rs中添加#![no_std]:#![no_std] fn main() { println!("Hello, world!"); } -
重新编译:
$ cargo build -
错误信息:
error: cannot find macro `println` in this scope --> src/main.rs:4:5 | 4 | println!("Hello, world!"); | ^^^^^^^
解释
println!宏是由标准库std提供的,依赖于write系统调用。- 在没有标准库的情况下,无法使用
println!宏,因此会报错。 - 为了继续编译,我们需要移除或注释掉这行代码。我们先直接把
main函数注释掉。
4.4 提供语义项 panic_handler
在移除 println! 宏后,我们还需要处理另一个错误:缺少 #[panic_handler] 函数。
步骤
- 编译后遇到的错误信息:
$ cargo builderror: `#[panic_handler]` function required, but not found
解释
- 标准库
std提供了 Rust 错误处理函数#[panic_handler],其功能是打印出错位置和原因并终止当前应用。 - 核心库
core并没有提供这种功能,所以我们需要自己实现一个panic_handler。
实现 panic_handler
-
创建子模块
lang_items.rs:- 在
src目录下创建一个新的文件lang_items.rs。
- 在
-
在
lang_items.rs中编写panic_handler函数:#![allow(unused)] fn main() { // os/src/lang_items.rs use core::panic::PanicInfo; #[panic_handler] fn panic(_info: &PanicInfo) -> ! { loop {} } }#[panic_handler]标记告诉编译器这个函数是我们的 panic 处理函数。- 当程序发生 panic 时,这个函数会被调用。当前实现只是进入一个无限循环。
-
在
main.rs中引入lang_items模块:- 修改
main.rs,引入我们定义的panic_handler:
#![no_std] mod lang_items; fn main() { // println!("Hello, world!"); // 注释掉这一行 } - 修改
-
重新编译:
$ cargo build又有了新错误:
$ cargo build Compiling os v0.1.0 (/home/shinbokuow/workspace/v3/rCore-Tutorial-v3/os) error: requires `start` lang_item
4.5 移除 main 函数
编译器提醒我们缺少一个名为 start 的语义项。 start 语义项代表了标准库 std 在执行应用程序之前需要进行的一些初始化工作。由于我们禁用了标准库,编译器也就找不到这项功能的实现了。
在 main.rs 的开头加入设置 #![no_main] 告诉编译器我们没有一般意义上的 main 函数, 并将原来的 main 函数删除。这样编译器也就不需要考虑初始化工作了。
步骤
-
在
main.rs的开头加入#![no_main]:- 这行代码告诉编译器我们没有通常意义上的
main函数。 - 然后删除原来的
main函数。 - 修改后的
main.rs文件内容如下:#![allow(unused)] #![no_std] #![no_main] fn main() { mod lang_items; }
- 这行代码告诉编译器我们没有通常意义上的
-
重新编译:
$ cargo build执行
cargo build,编译成功:
$ cargo build
Compiling os v0.1.0 (/home/shinbokuow/workspace/v3/rCore-Tutorial-v3/os)
Finished dev [unoptimized + debuginfo] target(s) in 0.06s
至此,我们终于移除了所有标准库依赖,目前的代码如下:
#![allow(unused)] fn main() { // os/src/main.rs #![no_std] #![no_main] mod lang_items; // os/src/lang_items.rs use core::panic::PanicInfo; #[panic_handler] fn panic(_info: &PanicInfo) -> ! { loop {} } }
分析被移除标准库的程序
我们可以通过一些工具来分析目前的程序:
-
文件格式:
$ file target/riscv64gc-unknown-none-elf/debug/os target/riscv64gc-unknown-none-elf/debug/os: ELF 64-bit LSB executable, UCB RISC-V, ...... -
文件头信息:
$ rust-readobj -h target/riscv64gc-unknown-none-elf/debug/os File: target/riscv64gc-unknown-none-elf/debug/os Format: elf64-littleriscv Arch: riscv64 AddressSize: 64bit ...... Type: Executable (0x2) Machine: EM_RISCV (0xF3) Version: 1 Entry: 0x0 ...... } -
反汇编导出汇编程序:
$ rust-objdump -S target/riscv64gc-unknown-none-elf/debug/os target/riscv64gc-unknown-none-elf/debug/os: file format elf64-littleriscv
通过 file 工具对二进制程序 os 的分析可以看到,它好像是一个合法的 RV64 执行程序,但 rust-readobj 工具告诉我们它的入口地址 Entry 是 0。再通过 rust-objdump 工具把它反汇编,没有生成任何汇编代码。可见,这个二进制程序虽然合法,但它是一个空程序,原因是缺少了编译器规定的入口函数 _start。
下面我们将着手实现本节移除的、由用户态执行环境提供的功能。
在构建和分析一个移除标准库的程序时,使用了一些常用的命令行工具来检查生成的二进制文件。这些工具帮助我们理解生成的程序是否正确以及是否包含了预期的内容。以下是对这些命令和它们的作用的详细解释:
1. 文件格式
$ file target/riscv64gc-unknown-none-elf/debug/os target/riscv64gc-unknown-none-elf/debug/os: ELF 64-bit LSB executable, UCB RISC-V, ......
file命令:这个命令用于确定文件的类型。它通过检查文件的头部信息,推断文件的格式和内容。- 输出说明:输出结果表明
os文件是一个 ELF 64-bit LSB(Little-Endian)可执行文件,适用于 UCB RISC-V 架构。其他细节省略表示更多的文件头信息。2. 文件头信息
$ rust-readobj -h target/riscv64gc-unknown-none-elf/debug/os File: target/riscv64gc-unknown-none-elf/debug/os Format: elf64-littleriscv Arch: riscv64 AddressSize: 64bit ...... Type: Executable (0x2) Machine: EM_RISCV (0xF3) Version: 1 Entry: 0x0 ...... }
rust-readobj命令:这是一个 Rust 工具,类似于readelf,用于读取和显示 ELF 格式文件的内容。-h选项表示显示文件头信息。- 输出说明:
- Format: 文件格式是 ELF 64-bit 小端(littleriscv)。
- Arch: 架构是 riscv64。
- AddressSize: 地址大小是 64 位。
- Type: 文件类型是可执行文件(0x2)。
- Machine: 机器类型是 RISC-V(EM_RISCV)。
- Entry: 程序入口地址是 0x0(这意味着程序没有正确设置入口点)。
3. 反汇编导出汇编程序
$ rust-objdump -S target/riscv64gc-unknown-none-elf/debug/os target/riscv64gc-unknown-none-elf/debug/os: file format elf64-littleriscv
rust-objdump命令:这是一个 Rust 工具,用于反汇编 ELF 文件。-S选项表示显示反汇编后的代码。- 输出说明:输出结果显示文件格式为 elf64-littleriscv。由于没有进一步的输出,意味着该文件没有包含任何有效的汇编指令。
总结
通过上述工具的输出,我们得出以下结论:
- 文件格式:
file命令确认生成的os文件是一个合法的 RISC-V 架构的 ELF 可执行文件。- 文件头信息:
rust-readobj显示文件的入口地址为 0,这表明程序缺少有效的入口点_start。其他头部信息如架构和类型都是正确的。- 反汇编结果:
rust-objdump没有生成任何有效的汇编代码,这表明程序是一个空程序,因为缺少有效的入口函数_start。这些工具帮助我们确认了生成的二进制文件是一个合法的 ELF 文件,但由于缺少有效的入口点
_start,程序实际上是空的,无法执行。因此,必须在程序中定义一个入口函数_start,以确保生成的程序可以正确运行。
5. 构建用户态执行环境
5.1 用户态最小化执行环境
为了运行用户态程序,我们需要构建一个最小化的执行环境,并提供必要的初始化代码。以下是具体步骤和相关解释。
5.1.1 执行环境初始化
首先,我们需要为 Rust 编译器提供一个入口函数 _start。这是程序执行的起点,类似于标准库程序中的 main 函数。在 main.rs 文件中添加如下内容:
#![allow(unused)] fn main() { // os/src/main.rs #[no_mangle] extern "C" fn _start() { loop {} } }
代码解析
#[no_mangle]:这是一个属性宏,告诉编译器不要对函数名进行修改(即不进行名称重整),确保生成的符号名与定义的一致。extern "C":这表明函数采用 C 语言的调用约定,使其与其他语言(如汇编、C)的代码兼容。_start函数:这是程序的入口点。该函数进入一个无限循环,表示程序已开始执行。
重新编译与分析
我们重新编译上述代码,并用工具分析生成的二进制文件:
$ cargo build
Compiling os v0.1.0 (/home/user/workspace/os)
Finished dev [unoptimized + debuginfo] target(s) in 0.06s
使用 rust-objdump 反汇编导出汇编程序:
$ rust-objdump -S target/riscv64gc-unknown-none-elf/debug/os
target/riscv64gc-unknown-none-elf/debug/os: file format elf64-littleriscv
Disassembly of section .text:
0000000000011120 <_start>:
; loop {}
11120: 09 a0 j 2 <_start+0x2>
11122: 01 a0 j 0 <_start+0x2>
反汇编出的两条指令表示一个死循环,说明编译器生成了一个合理的程序。我们可以使用 QEMU 执行该程序:
$ qemu-riscv64 target/riscv64gc-unknown-none-elf/debug/os
5.1.2 程序正常退出
为了进一步验证,我们可以将 _start 函数中的循环语句注释掉,重新编译并分析其汇编代码:
#![allow(unused)] fn main() { // os/src/main.rs #[no_mangle] extern "C" fn _start() { // loop {} } }
重新编译后,用 rust-objdump 反汇编:
$ rust-objdump -S target/riscv64gc-unknown-none-elf/debug/os
target/riscv64gc-unknown-none-elf/debug/os: file format elf64-littleriscv
Disassembly of section .text:
0000000000011120 <_start>:
; }
11120: 82 80 ret
虽然这看起来是合法的执行程序,但如果我们执行它,会引发问题:
$ qemu-riscv64 target/riscv64gc-unknown-none-elf/debug/os
段错误 (核心已转储)
这个简单的程序导致 QEMU 崩溃了。这是因为程序试图从 _start 函数返回,而没有设置正确的返回地址,导致非法操作。
QEMU的运行模式
QEMU 有两种运行模式:
- User mode(用户态模式):如
qemu-riscv64,模拟不同处理器的用户态指令的执行,并可以直接解析 ELF 可执行文件,加载运行为不同处理器编译的用户级 Linux 应用程序。- System mode(系统态模式):如
qemu-system-riscv64,模拟一个完整的基于不同 CPU 的硬件系统,包括处理器、内存及其他外部设备,支持运行完整的操作系统。在用户态模式下,QEMU 可以直接执行 ELF 可执行文件,但该文件必须符合特定的用户态执行环境要求。例如,需要有正确的入口点和合适的返回地址。而在系统态模式下,QEMU 会模拟完整的硬件环境,执行更复杂的操作系统和应用程序。
用户态模式(User Mode)
在用户态模式下,QEMU 可以运行特定架构的用户态程序。对于 RISC-V 架构,命令通常为:
qemu-riscv64 target/riscv64gc-unknown-none-elf/debug/os此命令将运行编译后的 RISC-V 用户态程序
os。在这种模式下,QEMU 仅仿真用户态指令,不涉及整个系统的模拟。系统态模式(System Mode)
在系统态模式下,QEMU 可以仿真完整的系统,包括 CPU、内存和其他外设。命令通常为:
qemu-system-riscv64 target/riscv64gc-unknown-none-elf/debug/os这种模式可以启动一个完整的操作系统或仿真裸机环境。对于系统态模式,需要提供更多的参数来指定内存大小、硬件设备、内核映像等。例如:
qemu-system-riscv64 -machine virt -kernel target/riscv64gc-unknown-none-elf/debug/os -nographic
-machine virt:指定虚拟机硬件类型。-kernel:指定要加载的内核映像。-nographic:不使用图形输出,使用控制台输出。所以。。。
深入解释代码和退出机制
为了完成一个简陋的用户态最小化执行环境,我们需要提供程序退出的机制。在 RISC-V 架构下,通过使用 ecall 指令来发出系统调用,下面是具体实现:
代码解析
main.rs 文件
#![allow(unused)] fn main() { // os/src/main.rs const SYSCALL_EXIT: usize = 93; fn syscall(id: usize, args: [usize; 3]) -> isize { let mut ret; unsafe { core::arch::asm!( "ecall", inlateout("x10") args[0] => ret, in("x11") args[1], in("x12") args[2], in("x17") id, ); } ret } pub fn sys_exit(xstate: i32) -> isize { syscall(SYSCALL_EXIT, [xstate as usize, 0, 0]) } #[no_mangle] extern "C" fn _start() { sys_exit(9); } }
代码解析
-
定义系统调用号:
const SYSCALL_EXIT: usize = 93;:定义exit系统调用的编号为 93,这是 RISC-V 的约定。
-
实现系统调用函数:
fn syscall(id: usize, args: [usize; 3]) -> isize:这是一个通用的系统调用函数。它使用内联汇编ecall指令来执行系统调用。core::arch::asm!:这是 Rust 中用于编写内联汇编的宏。"ecall":执行 RISC-V 的ecall指令,发出系统调用。inlateout("x10") args[0] => ret:输入输出操作数。将args[0]的值传入寄存器x10,并将x10的结果值赋给ret。in("x11") args[1]和in("x12") args[2]:将args[1]和args[2]分别传入寄存器x11和x12。in("x17") id:将系统调用号传入寄存器x17。
-
实现
sys_exit函数:pub fn sys_exit(xstate: i32) -> isize:这是一个特定的系统调用函数,用于调用exit系统调用。syscall(SYSCALL_EXIT, [xstate as usize, 0, 0]):调用通用的syscall函数,传入exit系统调用号和退出状态。
-
定义程序入口点
_start:#[no_mangle] extern "C" fn _start():定义程序的入口点_start,使用no_mangle防止函数名被修改,并指定使用 C 语言调用约定。sys_exit(9):调用sys_exit函数,退出状态为 9。
编译和运行
编译程序:
$ cargo build --target riscv64gc-unknown-none-elf
运行程序并打印返回值:
$ qemu-riscv64 target/riscv64gc-unknown-none-elf/debug/os; echo $?
9
上述步骤展示了如何在一个简陋的用户态最小化执行环境中实现程序的退出机制。通过定义系统调用和使用内联汇编,我们能够发出 exit 系统调用,使程序正确退出,并返回指定的退出状态码。这样,我们就完成了一个基本的用户态执行环境的构建。
相关寄存器
在 RISC-V 架构中,寄存器是处理器内的一种快速存储器,用于存放数据和指令。以下是代码中涉及的几个关键寄存器:
x10(a0):第一个参数寄存器,用于传递系统调用的第一个参数,并存储返回值。x11(a1):第二个参数寄存器,用于传递系统调用的第二个参数。x12(a2):第三个参数寄存器,用于传递系统调用的第三个参数。x17(a7):系统调用号寄存器,用于传递系统调用的编号。RISC-V 寄存器的命名有两种表示方式:物理编号(x0-x31)和功能名称(如 a0-a7 表示函数调用的参数和返回值)。在内联汇编中,我们通常使用物理编号进行操作。
系统调用号和
syscall函数的参数系统调用号
系统调用号是操作系统用来标识不同系统调用的唯一编号。在 RISC-V 架构下,系统调用号被传递给
x17(a7) 寄存器。例如:
SYSCALL_EXIT:编号为 93,用于标识exit系统调用。每个系统调用号对应一个特定的操作,例如创建进程、读写文件或退出程序。操作系统根据系统调用号执行相应的内核函数。
syscall函数的参数#![allow(unused)] fn main() { fn syscall(id: usize, args: [usize; 3]) -> isize { let mut ret; unsafe { core::arch::asm!( "ecall", inlateout("x10") args[0] => ret, in("x11") args[1], in("x12") args[2], in("x17") id, ); } ret } }
syscall函数是一个通用的系统调用封装器,用于发出各种系统调用。它接受以下参数:
id: usize:系统调用号,指定要执行的系统调用类型。args: [usize; 3]:系统调用的参数数组,包含三个参数。参数解释
inlateout("x10") args[0] => ret:将args[0]的值传入寄存器x10,并将x10的返回值存储到变量ret中。ret存储系统调用的返回值。in("x11") args[1]:将args[1]的值传入寄存器x11。in("x12") args[2]:将args[2]的值传入寄存器x12。in("x17") id:将系统调用号id传入寄存器x17。
sys_exit函数#![allow(unused)] fn main() { pub fn sys_exit(xstate: i32) -> isize { syscall(SYSCALL_EXIT, [xstate as usize, 0, 0]) } }
sys_exit函数是一个特定的系统调用函数,用于执行exit系统调用。它接受一个参数xstate,表示退出状态,并调用syscall函数:
SYSCALL_EXIT:系统调用号 93,用于退出程序。[xstate as usize, 0, 0]:传递退出状态和两个未使用的参数(设置为 0)。在后续章节中,我们将更深入地探讨系统调用相关内容。
5.2 有显示支持的用户态执行环境
为了让用户态执行环境支持字符串输出,我们需要实现类似 println! 的功能。虽然标准库 std 的 println! 宏无法使用,但我们可以通过扩展 core 库中的特性和数据结构,来定制一个类似的功能。
实现输出字符串的相关函数
我们需要以下几个步骤:
- 封装对
SYSCALL_WRITE系统调用的封装 - 实现基于
WriteTrait 的数据结构 - 实现 Rust 格式化宏
5.2.1 封装 SYSCALL_WRITE 系统调用
#![allow(unused)] fn main() { const SYSCALL_WRITE: usize = 64; pub fn sys_write(fd: usize, buffer: &[u8]) -> isize { syscall(SYSCALL_WRITE, [fd, buffer.as_ptr() as usize, buffer.len()]) } }
解释:
-
SYSCALL_WRITE:这是一个常量,表示写操作的系统调用号。在 RISC-V 架构中,写操作的系统调用号是 64。 -
sys_write函数:该函数封装了SYSCALL_WRITE系统调用,参数包括文件描述符fd和待写入的字节数组buffer。fd:文件描述符,1表示标准输出(stdout)。buffer:待写入的数据,以字节数组形式传递。
函数内部调用了
syscall函数,并传递SYSCALL_WRITE、文件描述符和数据指针及长度。
5.2.2 实现基于 Write Trait 的数据结构
#![allow(unused)] fn main() { struct Stdout; impl core::fmt::Write for Stdout { fn write_str(&mut self, s: &str) -> core::fmt::Result { sys_write(1, s.as_bytes()); Ok(()) } } pub fn print(args: core::fmt::Arguments) { Stdout.write_fmt(args).unwrap(); } }
解释:
-
struct Stdout:定义一个名为Stdout的空结构体,用于表示标准输出设备。 -
实现
WriteTrait:impl core::fmt::Write for Stdout:为Stdout实现core::fmt::WriteTrait。这使得Stdout可以使用write_fmt方法来格式化输出。write_str函数:实现WriteTrait 所需的write_str方法。该方法将字符串转换为字节数组,并调用sys_write函数,将数据写入标准输出。
-
print函数:- 参数:接受一个
fmt::Arguments类型的参数,这是格式化后的输出内容。 - 实现:调用
Stdout.write_fmt(args).unwrap(),将格式化后的内容输出到标准输。
- 参数:接受一个
5.2.3 实现 Rust 格式化宏
最后,我们实现 print 和 println 宏。
宏定义
#![allow(unused)] fn main() { #[macro_export] macro_rules! print { ($fmt: literal $(, $($arg: tt)+)?) => { $crate::console::print(format_args!($fmt $(, $($arg)+)?)); } } #[macro_export] macro_rules! println { ($fmt: literal $(, $($arg: tt)+)?) => { print(format_args!(concat!($fmt, "\n") $(, $($arg)+)?)); } } }
print! 宏
print! 宏用于格式化输出,不带换行符。以下是详细解释:
-
#[macro_export]:标记宏可以在模块外部使用。这个属性告诉编译器将该宏导出,使其可以在包的任何地方使用。 -
macro_rules! print:定义宏print。macro_rules!是 Rust 用来定义宏的关键字。 -
模式匹配:
#![allow(unused)] fn main() { ($fmt: literal $(, $($arg: tt)+)?) => { $crate::console::print(format_args!($fmt $(, $($arg)+)?)); } }$fmt: literal:匹配一个字面量格式字符串。$(, $($arg: tt)+)?:匹配可选的一个或多个参数。$(...)?表示可选模式,$(...)+表示至少一个,$arg: tt表示捕获任意 Token Tree。
-
宏体:
#![allow(unused)] fn main() { $crate::console::print(format_args!($fmt $(, $($arg)+)?)); }$crate:表示当前包的根模块。$crate::console::print:调用当前包中定义的print函数。format_args!($fmt $(, $($arg)+)?):调用format_args!宏来生成格式化的参数,传递给print函数。
println! 宏
println! 宏用于格式化输出,并在末尾添加换行符。以下是详细解释:
-
#[macro_export]:同样标记宏可以在模块外部使用。 -
模式匹配:
#![allow(unused)] fn main() { ($fmt: literal $(, $($arg: tt)+)?) => { print(format_args!(concat!($fmt, "\n") $(, $($arg)+)?)); } }$fmt: literal:匹配一个字面量格式字符串。$(, $($arg: tt)+)?:匹配可选的一个或多个参数。
-
宏体:
#![allow(unused)] fn main() { print(format_args!(concat!($fmt, "\n") $(, $($arg)+)?)); }concat!($fmt, "\n"):使用concat!宏将格式字符串和换行符\n连接起来。format_args!(concat!($fmt, "\n") $(, $($arg)+)?):生成格式化的参数,包括换行符。- 调用
print宏:最终调用print宏进行输出。
5.2.4 应用示例编译和执行
应用示例
将定义好的宏应用到我们的用户态程序中:
#![allow(unused)] fn main() { #[no_mangle] extern "C" fn _start() { println!("Hello, world!"); sys_exit(9); } }
代码解析
#[no_mangle]:告诉编译器不要对函数名进行修饰,使得函数名保持为_start。extern "C":指定函数使用 C 语言的调用约定,使其可以被外部链接和调用。_start函数:程序的入口点。程序启动时,会首先执行这个函数。println!("Hello, world!");:调用我们定义的println!宏,输出 "Hello, world!" 字符串并换行。sys_exit(9);:调用sys_exit函数,发出退出系统调用,退出码为 9。
编译和执行
编译和执行修改后的程序:
$ cargo build --target riscv64gc-unknown-none-elf
Compiling os v0.1.0 (/path/to/project)
Finished dev [unoptimized + debuginfo] target(s) in 0.61s
$ qemu-riscv64 target/riscv64gc-unknown-none-elf/debug/os; echo $?
Hello, world!
9
-
编译:
cargo build --target riscv64gc-unknown-none-elf:使用 Cargo 构建目标为riscv64gc-unknown-none-elf的项目。成功后生成os可执行文件。
-
执行:
qemu-riscv64 target/riscv64gc-unknown-none-elf/debug/os:使用 QEMU 运行编译好的 RISC-V 可执行文件os。echo $?:打印上一条命令的退出状态码,显示为 9,表示程序正确退出。
结果
运行程序后,我们可以看到输出 "Hello, world!",并且程序以退出码 9 正确退出。通过这个过程,我们实现了一个支持 println! 输出和正确退出的简陋用户态执行环境。后续章节将详细介绍更多系统调用和复杂功能的实现。
6 构建裸机执行环境
6.1 裸机启动过程
讲解裸机上的最小执行环境
我们将在本节中将之前实现的用户态的最小执行环境改造为裸机上的最小执行环境,并模拟 RISC-V 64 计算机的启动过程。通过 QEMU 模拟器,我们可以加载并运行内核程序。
裸机启动过程
用 QEMU 软件 qemu-system-riscv64 来模拟 RISC-V 64 计算机,并加载内核程序的命令如下:
qemu-system-riscv64 \
-machine virt \
-nographic \
-bios $(BOOTLOADER) \
-device loader,file=$(KERNEL_BIN),addr=$(KERNEL_ENTRY_PA)
参数详解
-
qemu-system-riscv64:- 这是 QEMU 的一个实例,用于模拟 RISC-V 64 架构的计算机。
-
-machine virt:- 指定虚拟机的硬件类型为虚拟机类型(virt),这是一个适合于虚拟化的通用 RISC-V 机器模型。
-
-nographic:- 禁用图形输出,使用纯文本控制台。这对于没有显示设备的裸机环境非常有用。
-
-bios $(BOOTLOADER):- 指定 BIOS 文件路径。
$(BOOTLOADER)是一个环境变量,表示引导加载程序(BootLoader)的路径。 - 例如,RustSBI 是一个常见的 RISC-V BootLoader 实现。
- 指定 BIOS 文件路径。
-
-device loader,file=$(KERNEL_BIN),addr=$(KERNEL_ENTRY_PA):file=$(KERNEL_BIN):指定要加载的内核二进制文件路径,$(KERNEL_BIN)是一个环境变量,表示内核二进制文件的路径。addr=$(KERNEL_ENTRY_PA):指定内核加载的物理地址,$(KERNEL_ENTRY_PA)是一个环境变量,表示内核的入口地址,通常是0x80200000。
启动流程
-
虚拟机启动:
- 当执行
qemu-system-riscv64命令时,模拟器会启动虚拟的 RISC-V 64 计算机,这相当于给虚拟计算机加电。
- 当执行
-
CPU 初始化:
- CPU 的所有通用寄存器初始化为零,程序计数器(PC)指向地址
0x1000,这里存储着固化在硬件中的一小段引导代码。
- CPU 的所有通用寄存器初始化为零,程序计数器(PC)指向地址
-
引导代码执行:
- 引导代码从地址
0x1000开始执行,并很快跳转到地址0x80000000的 RustSBI 处。
- 引导代码从地址
-
RustSBI 初始化:
- RustSBI 是一个 RISC-V 的 SBI(Supervisor Binary Interface)实现。它负责完成硬件初始化,并提供基本的服务(如关机和输出字符等)。
- 初始化完成后,RustSBI 会跳转到操作系统内核的入口地址
0x80200000,开始执行内核的第一条指令。
RustSBI 介绍
RustSBI 是什么?
- SBI(Supervisor Binary Interface):RISC-V 的一种底层规范,用于在不同特权级之间提供标准化的接口。它类似于 x86 架构中的 BIOS 或者 ARM 架构中的 SMC(Secure Monitor Call)。
- RustSBI:是 SBI 的一个实现,用 Rust 编写。它运行在最高特权级(Machine 模式),提供一些基本服务,如关机、字符输出等。
操作系统内核与 RustSBI 的关系:
- 操作系统内核运行在更低的特权级(Supervisor 模式),并依赖于 RustSBI 提供的一些基本服务。
- 这种关系类似于应用程序依赖操作系统内核提供服务的关系,只不过 RustSBI 提供的服务更少且更底层。
通过 QEMU 模拟器,我们可以模拟 RISC-V 64 架构的计算机,并加载和执行内核程序。使用 RustSBI 作为 BootLoader,完成硬件初始化后,跳转到内核入口地址执行内核代码。这种机制使得我们能够在虚拟环境中开发和测试裸机程序,了解和验证其启动过程和运行行为。
6.2 实现关机功能
实现关机功能
为了在裸机环境中实现关机功能,我们需要通过 ecall 调用 RustSBI 提供的关机服务。下面是具体的实现和详细的解释。
代码讲解
1. SBI 调用函数 sbi_call
首先,我们实现一个通用的 SBI 调用函数 sbi_call:
#![allow(unused)] fn main() { // os/src/sbi.rs fn sbi_call(which: usize, arg0: usize, arg1: usize, arg2: usize) -> usize { let mut ret; unsafe { core::arch::asm!( "ecall", // 发出系统调用 inlateout("a0") arg0 => ret, // 将 arg0 放入 a0 寄存器,返回值存入 ret in("a1") arg1, // 将 arg1 放入 a1 寄存器 in("a2") arg2, // 将 arg2 放入 a2 寄存器 in("a7") which, // 将调用号放入 a7 寄存器 ); } ret } }
-
sbi_call函数:用于发出 SBI 调用。- 参数:
which:SBI 调用号。arg0、arg1、arg2:传递给 SBI 调用的参数。
- 返回值:调用的返回值。
- 参数:
-
ecall指令:发出一个系统调用。这个指令用于从一个特权级切换到另一个特权级。 -
寄存器使用:
a0:第一个参数,同时也是返回值。a1、a2:第二个和第三个参数。a7:调用号。
2. 实现关机功能
我们定义一个常量 SBI_SHUTDOWN 表示关机的调用号,并实现 shutdown 函数:
#![allow(unused)] fn main() { const SBI_SHUTDOWN: usize = 8; pub fn shutdown() -> ! { sbi_call(SBI_SHUTDOWN, 0, 0, 0); panic!("It should shutdown!"); } }
SBI_SHUTDOWN:关机调用号,为 8。shutdown函数:- 调用
sbi_call(SBI_SHUTDOWN, 0, 0, 0)发出关机请求。- RustSBI 在 Machine Mode 运行,负责处理系统调用。它识别到调用号为
SBI_SHUTDOWN后,会执行关机操作。
- RustSBI 在 Machine Mode 运行,负责处理系统调用。它识别到调用号为
- 如果关机失败,程序会继续执行并触发
panic!,表示关机应该成功。
- 调用
3. 程序入口 _start
在 main.rs 中调用 shutdown 函数:
#![allow(unused)] fn main() { // os/src/main.rs #[no_mangle] extern "C" fn _start() { shutdown(); } }
#[no_mangle]:防止编译器对函数名进行重整,使得函数名保持为_start。extern "C":指定函数使用 C 语言调用约定。_start函数:程序入口,调用shutdown函数以执行关机操作。
应用程序访问系统调用
ecall指令:- 应用程序通过
ecall指令访问操作系统提供的系统调用。 - 操作系统通过
ecall指令访问 RustSBI 提供的 SBI 调用。 - 虽然指令相同,但它们所在的特权级不同:应用程序在用户特权级(User Mode),操作系统在内核特权级(Supervisor Mode),RustSBI 在机器特权级(Machine Mode)。
- 应用程序通过
编译和执行
编译生成 ELF 格式的执行文件
$ cargo build --release
Compiling os v0.1.0 (/path/to/os)
Finished release [optimized] target(s) in 0.15s
转换 ELF 执行文件为二进制文件
$ rust-objcopy --binary-architecture=riscv64 target/riscv64gc-unknown-none-elf/release/os --strip-all -O binary target/riscv64gc-unknown-none-elf/release/os.bin
rust-objcopy:用于处理对象文件的工具。--binary-architecture=riscv64:指定目标架构为 RISC-V 64。--strip-all:移除所有符号表信息。-O binary:输出格式为纯二进制。
加载并运行内核
$ qemu-system-riscv64 -machine virt -nographic -bios ../bootloader/rustsbi-qemu.bin -device loader,file=target/riscv64gc-unknown-none-elf/release/os.bin,addr=0x80200000
-bios ../bootloader/rustsbi-qemu.bin:指定 RustSBI 引导加载程序。-device loader,file=target/riscv64gc-unknown-none-elf/release/os.bin,addr=0x80200000:将内核二进制文件加载到地址0x80200000。
问题:程序入口地址设置
在尝试运行程序时,程序陷入死循环,可能是由于程序入口地址设置不正确导致的。通过 rust-readobj 分析可执行程序,可以发现其入口地址不是 RustSBI 约定的 0x80200000 。我们需要修改程序的内存布局并设置好栈空间。
6.3 设置正确的程序内存布局
为了使生成的可执行文件符合我们的预期内存布局,我们需要通过链接脚本(Linker Script)调整链接器的行为。我们可以通过修改 Cargo 配置文件来使用我们自定义的链接脚本 os/src/linker.ld。
修改 Cargo 配置文件
首先,编辑 os/.cargo/config 文件,指向我们的链接脚本:
# os/.cargo/config
[build]
target = "riscv64gc-unknown-none-elf"
[target.riscv64gc-unknown-none-elf]
rustflags = [
"-Clink-arg=-Tsrc/linker.ld", "-Cforce-frame-pointers=yes"
]
-Clink-arg=-Tsrc/linker.ld:指定链接器使用src/linker.ld链接脚本。-Cforce-frame-pointers=yes:强制生成帧指针,便于调试。
链接脚本 os/src/linker.ld
下面是我们的链接脚本,它定义了程序的内存布局:
/* os/src/linker.ld */
OUTPUT_ARCH(riscv)
ENTRY(_start)
BASE_ADDRESS = 0x80200000;
SECTIONS
{
. = BASE_ADDRESS;
skernel = .;
stext = .;
.text : {
*(.text.entry)
*(.text .text.*)
}
. = ALIGN(4K);
etext = .;
srodata = .;
.rodata : {
*(.rodata .rodata.*)
}
. = ALIGN(4K);
erodata = .;
sdata = .;
.data : {
*(.data .data.*)
}
. = ALIGN(4K);
edata = .;
.bss : {
*(.bss.stack)
sbss = .;
*(.bss .bss.*)
}
. = ALIGN(4K);
ebss = .;
ekernel = .;
/DISCARD/ : {
*(.eh_frame)
}
}
关键内容解释
-
OUTPUT_ARCH(riscv):- 设置目标架构为 RISC-V。
-
ENTRY(_start):- 定义程序的入口点为
_start。
- 定义程序的入口点为
-
BASE_ADDRESS = 0x80200000;:- 定义一个常量
BASE_ADDRESS,其值为0x80200000。这是 RustSBI 期望的操作系统起始地址。
- 定义一个常量
-
段定义:
. = BASE_ADDRESS;:设置程序的起始地址。skernel = .;:定义一个标记skernel,表示内核的起始地址。.text段:包含代码段,所有代码(包括入口代码)都放在这里。.rodata段:只读数据段,包含只读数据。.data段:数据段,包含已初始化的数据。.bss段:未初始化的数据段,包含所有未初始化的数据。
-
对齐和段结束地址:
. = ALIGN(4K);:将段地址对齐到 4KB 边界。etext、erodata、edata、ebss:这些符号表示各段的结束地址。
-
丢弃段:
/DISCARD/ : { *(.eh_frame) }:丢弃.eh_frame段,避免不必要的信息占用空间。
编译并使用新链接脚本
执行以下命令进行编译和转换:
$ cargo build --release
$ rust-objcopy --binary-architecture=riscv64 target/riscv64gc-unknown-none-elf/release/os --strip-all -O binary target/riscv64gc-unknown-none-elf/release/os.bin
$ qemu-system-riscv64 -machine virt -nographic -bios ../bootloader/rustsbi-qemu.bin -device loader,file=target/riscv64gc-unknown-none-elf/release/os.bin,addr=0x80200000
通过以上步骤,我们确保程序的内存布局符合预期,并设置了正确的入口地址和栈空间,使程序能够正常启动和运行。
6.4 正确配置栈空间布局
在裸机环境中运行操作系统时,必须正确配置栈空间以确保程序正常执行。我们通过汇编代码初始化栈空间,并在 Rust 代码中引用这段汇编代码来实现。
汇编代码初始化栈空间
首先,我们在 os/src/entry.asm 文件中编写汇编代码,用于初始化栈空间:
// os/src/entry.asm
.section .text.entry
.globl _start
_start:
la sp, boot_stack_top
call rust_main
.section .bss.stack
.globl boot_stack
boot_stack:
.space 4096 * 16
.globl boot_stack_top
boot_stack_top:
代码详解
-
定义代码段和入口点
.section .text.entry .globl _start _start: la sp, boot_stack_top call rust_main.section .text.entry:定义代码段.text.entry,用于放置入口代码。.globl _start:声明_start为全局符号,即程序的入口点。_start标签:入口点标签,程序从这里开始执行。la sp, boot_stack_top:将栈指针sp设置为栈顶boot_stack_top。call rust_main:调用rust_main函数。
-
定义栈空间段
.section .bss.stack .globl boot_stack boot_stack: .space 4096 * 16 .globl boot_stack_top boot_stack_top:.section .bss.stack:定义栈空间段.bss.stack。.globl boot_stack:声明boot_stack为全局符号,即栈底。boot_stack:标签:栈底标签。.space 4096 * 16:预留 64KB 的栈空间。.globl boot_stack_top:声明boot_stack_top为全局符号,即栈顶。
嵌入汇编代码并声明应用入口
接下来,在 os/src/main.rs 文件中嵌入汇编代码,并声明应用入口 rust_main:
#![allow(unused)] fn main() { // os/src/main.rs #![no_std] #![no_main] mod lang_items; core::arch::global_asm!(include_str!("entry.asm")); #[no_mangle] pub fn rust_main() -> ! { shutdown(); } }
代码详解
-
禁用标准库和入口点
#![allow(unused)] #![no_std] #![no_main] fn main() { }#![no_std]:禁用标准库,因为我们在裸机环境中运行。#![no_main]:禁用默认入口点main,我们将使用自定义入口_start。
-
导入必要的模块
#![allow(unused)] fn main() { mod lang_items; } -
嵌入汇编代码
#![allow(unused)] fn main() { core::arch::global_asm!(include_str!("entry.asm")); }- 使用
global_asm!宏,将同目录下的entry.asm文件中的汇编代码嵌入到 Rust 代码中。
- 使用
-
声明应用入口
rust_main#![allow(unused)] fn main() { #[no_mangle] pub fn rust_main() -> ! { shutdown(); } }#[no_mangle]:防止编译器对函数名进行重整,使函数名保持为rust_main。rust_main函数:应用入口,调用shutdown函数执行关机操作。
编译、生成和运行
通过以下命令进行编译、生成和运行,我们可以看到 QEMU 模拟的 RISC-V 64 计算机优雅地退出:
$ cargo build --release
$ rust-objcopy --binary-architecture=riscv64 target/riscv64gc-unknown-none-elf/release/os --strip-all -O binary target/riscv64gc-unknown-none-elf/release/os.bin
$ qemu-system-riscv64 -machine virt -nographic -bios ../bootloader/rustsbi-qemu.bin -device loader,file=target/riscv64gc-unknown-none-elf/release/os.bin,addr=0x80200000
结果分析
运行结果如下:
[rustsbi] Version 0.1.0
.______ __ __ _______.___________. _______..______ __
| _ \ | | | | / | | / || _ \ | |
| |_) | | | | | | (----`---| |----`| (----`| |_) || |
| / | | | | \ \ | | \ \ | _ < | |
| |\ \----.| `--' |.----) | | | .----) | | |_) || |
| _| `._____| \______/ |_______/ |__| |_______/ |______/ |__|
[rustsbi] Platform: QEMU
[rustsbi] misa: RV64ACDFIMSU
[rustsbi] mideleg: 0x222
[rustsbi] medeleg: 0xb1ab
[rustsbi] Kernel entry: 0x80200000
- QEMU 输出:显示了 RustSBI 的版本和平台信息,表明模拟器成功加载并运行了我们的操作系统二进制文件。
- 优雅退出:调用
shutdown函数后,QEMU 模拟的计算机优雅地退出,表示我们的配置和程序运行成功。
通过上述步骤,我们成功配置了栈空间布局,并确保程序正确运行和关机。具体来说,我们通过编写汇编代码初始化栈空间,并在 Rust 代码中嵌入这段汇编代码,最终实现了在裸机环境中运行并优雅退出的功能。这种方法不仅确保了程序的正确执行,还为后续更复杂的系统功能实现打下了基础。
6.5 清空 .bss 段
清空 .bss 段
在裸机编程中,.bss 段用于存储未初始化的全局变量和静态变量。在程序启动时,通常需要将 .bss 段清零,以确保这些变量初始为零。我们将在 rust_main 函数中添加清零 .bss 段的功能。
代码实现
首先,在 os/src/main.rs 文件中添加清零 .bss 段的函数 clear_bss:
#![allow(unused)] fn main() { // os/src/main.rs fn clear_bss() { extern "C" { fn sbss(); fn ebss(); } (sbss as usize..ebss as usize).for_each(|a| { unsafe { (a as *mut u8).write_volatile(0) } }); } #[no_mangle] pub fn rust_main() -> ! { clear_bss(); shutdown(); } }
代码详解
-
定义
clear_bss函数:#![allow(unused)] fn main() { fn clear_bss() { extern "C" { fn sbss(); fn ebss(); } (sbss as usize..ebss as usize).for_each(|a| { unsafe { (a as *mut u8).write_volatile(0) } }); } }extern "C"块:声明外部符号sbss和ebss,它们由链接脚本定义,表示.bss段的起始和结束地址。- 遍历
.bss段:使用 Rust 的范围语法(sbss as usize..ebss as usize)遍历.bss段的每个地址。 - 清零
.bss段:对每个地址,使用write_volatile(0)将其写为零。write_volatile确保编译器不会优化掉这段代码。
-
修改
rust_main函数:#![allow(unused)] fn main() { #[no_mangle] pub fn rust_main() -> ! { clear_bss(); shutdown(); } }- 调用
clear_bss:在执行关机前调用clear_bss函数,以清零.bss段。 - 调用
shutdown:执行关机操作。
- 调用
链接脚本中的全局符号
在 linker.ld 文件中,我们需要确保定义了 sbss 和 ebss 符号,表示 .bss 段的起始和结束地址。
从 BASE_ADDRESS 开始,代码段 .text, 只读数据段 .rodata,数据段 .data, bss 段 .bss 由低到高依次放置, 且每个段都有两个全局变量给出其起始和结束地址(比如 .text 段的开始和结束地址分别是 stext 和 etext )。
参见上面的 linker.ld
6.6 添加裸机打印相关函数
6.6.1 os/src/console.rs
在上一节中我们为用户态程序实现的 println 宏,略作修改即可用于本节的内核态操作系统。 详见 os/src/console.rs。
讲解参见 1. console.rs补充讲解 , 2. 有显示支持的用户态执行环境
6.6.2 panic | os/src/lang_items.rs
利用 println 宏,我们重写异常处理函数 panic,使其在 panic 时能打印错误发生的位置。 相关代码位于 os/src/lang_items.rs 中。
讲解参见 lang_items.rs补充讲解
6.6.3 os/src/logging.rs
我们还使用第三方库 log 为你实现了日志模块,相关代码位于 os/src/logging.rs 中。
在 cargo 项目中引入外部库 log,需要修改 Cargo.toml 加入相应的依赖信息。
#![allow(unused)] fn main() { [dependencies] log = "0.4" }
讲解参见 logging.rs补充讲解
现在,让我们重复一遍本章开头的试验,make run LOG=TRACE!
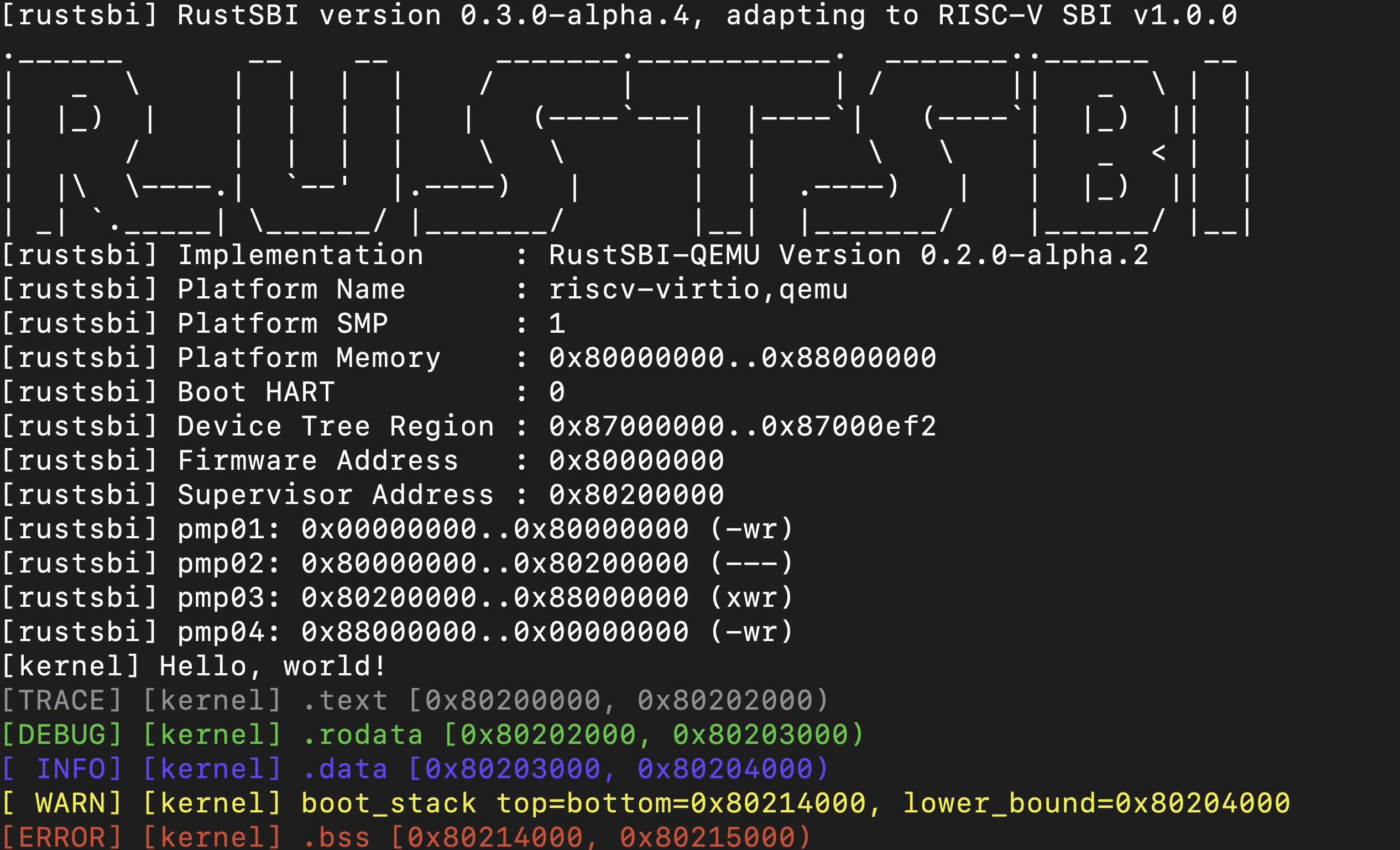
第三讲 基于特权级的隔离与批处理
第一节 从OS角度看计算机系统
一 OS与硬件的关系
特权级隔离与批处理的基本概念
-
硬件与软件的隔离
- 计算机系统由硬件和软件共同构成。
- 操作系统(OS)位于硬件与应用之间,为应用程序提供访问硬件资源的抽象接口。
- 特权级的隔离确保用户应用与系统内核的安全界限,防止应用直接操作硬件或关键资源。
-
隔离的重要性
- 隔离是确保计算机系统安全性和稳定性的重要机制。
- 确保用户应用不能直接访问硬件设备或其他应用的数据,避免潜在的恶意或错误行为。
- 通过特权级别的划分和系统调用机制,提供安全的硬件访问和数据共享方式。
计算机系统与 RISC-V 指令集
-
计算机系统结构层次
- 从下到上,包括物理层设备、电路设计、门级/寄存器传输级、微架构、指令集架构、操作系统、编译器、程序设计和应用。
- 微架构实现指令集架构,为操作系统和应用程序提供硬件抽象接口。
-
RISC-V 指令集架构
- RISC-V 提供多级特权机制,允许操作系统和用户程序之间实现严格的隔离。
CSR(Control and Status Register)寄存器用于管理特权级和控制硬件资源。
| Level | 层次 |
|---|---|
| Application | 应用 |
| Algorithm | 算法 |
| Programming Language | 编程语言 |
| Operating System/Virtual Machines | 操作系统/虚拟机 |
| Instruction Set Architecture (ISA) | 指令集架构 |
| Microarchitecture | 微架构 |
| Gates/Register-Transfer Level (RTL) | 门级/寄存器传输级 (RTL) |
| Circuits | 电路 |
| Devices | 设备 |
| Physics | 物理 |
| 计算机系统抽象层次 |
|---|
| 1. Physics(物理): 这是基础层,涉及物理学原理,如量子力学和电磁学,它们是构造计算设备物理组件的基础。 |
| 2. Devices(设备): 在物理层之上是设备层,这里的设备指的是实际构成计算机的物理组件,例如晶体管、二极管和电容器等。 |
| 3. Circuits(电路): 设备层的上一层是电路层,这里设计将电子设备(例如晶体管)连接在一起形成电路,以实现特定的功能,如逻辑门电路。 |
| 4. Gates/Register-Transfer Level (RTL): 在电路层之上是门级/寄存器传输级别,这里涉及逻辑门(如与门、或门和非门)的设计,以及如何将这些门组合成更复杂的电路来执行寄存器之间的数据传输和操作。 |
| 5. Microarchitecture(微架构): 微架构层是在逻辑门和电路的基础上构建具体的处理器架构。它定义了处理器内部的数据路径、流水线结构、缓存和执行单元等。 |
| 6. Instruction Set Architecture (ISA): 指令集架构是硬件(微架构)和软件之间的接口。它定义了处理器可以识别和执行的指令集合,包括数据类型、寄存器、指令格式、寻址模式等。 |
| 7. Operating System/Virtual Machines(操作系统/虚拟机): 操作系统是管理计算机硬件资源和提供用户与应用程序接口的软件层。虚拟机为运行在物理硬件之上的软件提供了一个虚拟的平台。 |
| 8. Programming Language(编程语言): 编程语言层提供了开发者用来编写软件的高级语言,这些语言通常更接近人类语言和抽象概念,使得软件开发更加高效。 |
| 9. Algorithm(算法): 算法层指的是解决特定问题和执行任务的方法和流程。算法是在编程语言中实现的,但在概念上独立于具体的实现。 |
| 10. Application(应用程序): 最顶层是应用程序层,它指的是最终用户直接使用的软件,例如文本编辑器、游戏或者企业软件等。这些应用程序使用底层所有层级提供的功能来执行用户需要的任务。 |
| 总的来说,这些层次从物理硬件到用户界面提供了一种分层的方式来理解和构建复杂的计算系统。每个层级抽象了底层的复杂性,提供了建立在其上的下一个层级所需的接口和功能。 |
特权级隔离与批处理系统
-
特权级隔离
- 操作系统在最高特权级别(通常称为内核模式)下运行,控制硬件资源。
- 用户应用程序在较低的特权级别(用户模式)运行,通过系统调用访问操作系统提供的服务。
-
批处理系统的实现
- 批处理操作系统在任务调度和隔离方面有独特要求。
- 每个批处理任务被隔离在独立的进程或容器中,以防止跨任务的数据泄露和干扰。
硬件与软件的边界
-
指令集与寄存器
- 硬件与软件之间的接口主要由指令集和寄存器构成。
- 指令集提供应用程序访问硬件的控制指令,寄存器保存数据和控制状态。
-
边界的重要性
- 明确的硬件与软件边界确保两者各自负责的职责范围,避免越界引起的问题。
- 软件负责高层逻辑控制,硬件实现底层指令执行与数据管理。
指令集与寄存器的隔离
-
指令集与寄存器
- 硬件与软件之间的接口不仅定义了硬件与操作系统的边界,同时也是硬件与编译器的边界。
- 编译器只能生成符合指令集的指令,不能直接控制硬件的内部设计,如流水线或中间寄存器等细节。
- 指令集提供了明确的硬件和软件分界线,有助于维护系统的稳定性和安全性。
-
硬件抽象与应用隔离
- 操作系统为应用程序提供抽象接口,如进程内存(地址空间)和文件系统。
- 这些抽象帮助隔离不同的应用程序,使其无法直接操作硬件或其他进程的数据。
- 操作系统通过指令和寄存器专门为系统调用(如文件操作)提供接口。
RISC-V 架构与操作系统
-
架构图与操作系统交互
- RISC-V 架构的硬件设计包括 CPU 内核、寄存器和 I/O 设备等。
- 操作系统的职责是利用这些硬件组件,提供一套标准的抽象接口,供上层应用程序调用。
- 这些接口通常以系统调用的方式提供,包括进程管理、内存分配和设备访问等。
-
硬件抽象层
- 操作系统在硬件和应用程序之间提供硬件抽象层,封装并虚拟化底层硬件。
- 这一层帮助操作系统屏蔽不同硬件架构的差异,为应用提供一致的接口。
u/rCore 的框架结构 
二 OS 与应用程序的关系
-
服务与隔离
- 操作系统的主要职责之一是为应用程序提供服务,确保应用能够正常运行。
- 但同时操作系统必须保持自身的安全和稳定,防止应用程序通过系统调用或直接内存访问破坏系统。
-
系统调用机制
- 系统调用(syscall)是应用程序访问操作系统服务的主要接口。
- 系统调用提供内核与用户空间的隔离,通过硬件特权级的支持,确保应用程序无法直接访问内核态资源。
-
特权级与内核态
- 操作系统利用硬件提供的特权级机制,将应用程序置于较低特权级的用户态。
- 系统调用提供安全的切换方式,使应用程序能够以安全的方式访问内核态资源。
- 内核态和用户态之间的转换在硬件支持下变得更为安全和有效。
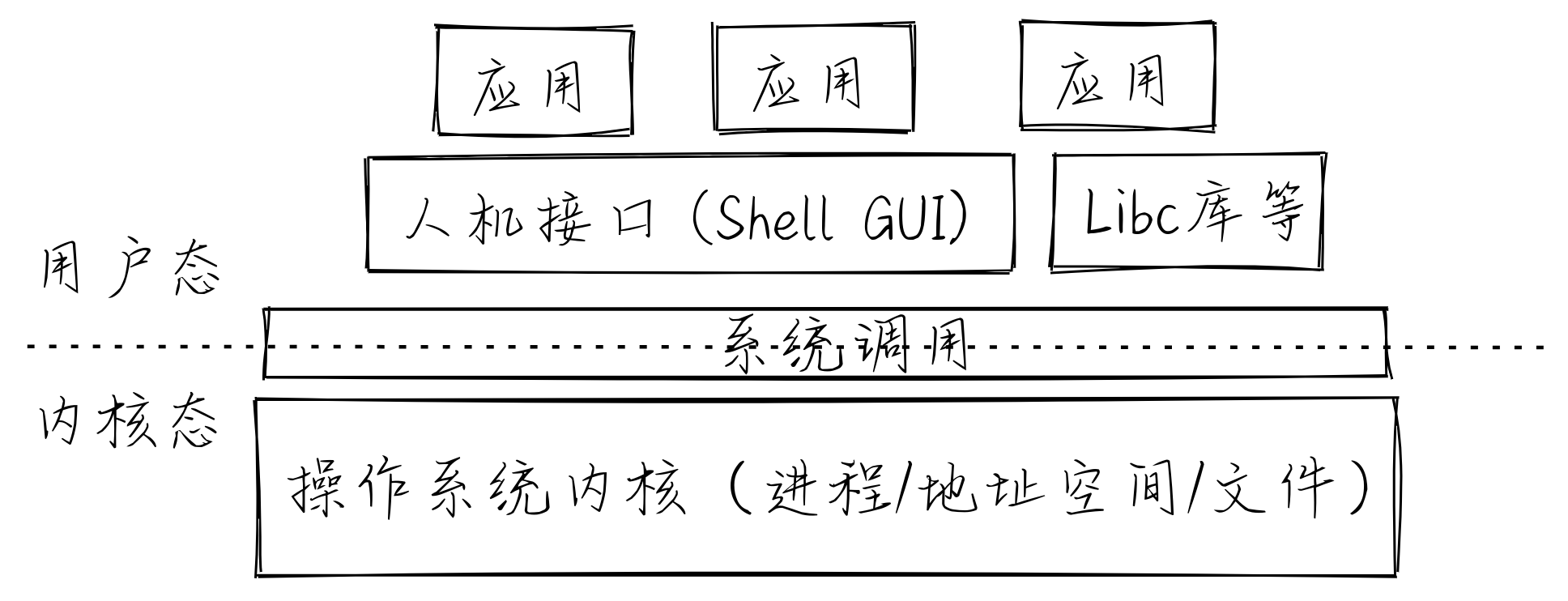
系统调用举例:read 函数
read 系统调用示例
read系统调用用于从文件中读取数据。- 调用
ssize_t read(int fd, void *buf, size_t count);会发生什么? - 调用流程大致如下:
- 应用程序调用
read函数。 - 通过系统调用的上下文切换机制,从用户态切换到内核态。
- 内核执行文件描述符检查、权限验证和读取数据操作。
- 将读取到的数据复制到应用程序的缓冲区。
- 切换回用户态,将读取到的字节数返回给应用程序。
- 应用程序调用
操作系统与应用程序间的关系
-
两个问题的回答
- 可以在应用程序中直接调用内核的函数吗?
- 可以在内核中使用应用程序普通的函数调用吗?
在某些操作系统或特殊情况下,确实可以在应用程序和内核之间直接调用函数,但这通常带来一些特殊的问题。
-
在应用程序中直接调用内核函数
-
常规情况:
- 在大多数现代操作系统中,直接调用内核函数是不允许的。
- 这是因为内核和应用程序在不同的特权级别运行,需要系统调用或其他安全机制来确保隔离。
-
特殊情况:LibOS
- 在特定的轻量级操作系统(如 LibOS)或嵌入式系统中,应用程序与操作系统可能没有明确的隔离。
- 这种情况下,应用程序可以直接调用系统提供的库函数,如
printf等,因为这些库和操作系统是捆绑在一起的。
-
问题与风险:
- 这种直接调用会导致安全问题或内核崩溃,缺乏隔离可能让恶意或错误的应用程序影响整个系统。
-
-
在内核中调用应用程序的函数
-
常规情况:
- 在现代操作系统中,内核通常不直接使用应用程序的代码。
- 内核无法信任用户级函数,因为它们可能导致内核不稳定或带来安全隐患。
-
特殊情况:LibOS
- 在轻量级的 LibOS 中,内核与应用程序共享部分代码或函数库。
- 在这种情况下,内核可以使用共享库中的一些函数,因为它们被认为是受信任的。
-
问题与风险:
- 共享代码可能带来安全问题。
- 需要谨慎设计,确保共享部分的完整性和隔离性。
-
-
系统调用与函数调用的对比
-
函数调用的优点与缺点:
- 优点:函数调用速度快,因为没有额外的检查和上下文切换。
- 缺点:没有安全检查,应用程序调用内核函数时可能破坏系统稳定性。
-
系统调用的好处:
- 提供额外的检查和隔离,防止应用程序直接访问系统资源或破坏内核。
-
-
内存隔离的必要性
-
内存布局与隔离机制:
- 在现代操作系统中,内存布局的隔离不仅由编译器控制,还需要操作系统的内存管理机制。
- 内核通过虚拟内存机制和页表实现内核态与用户态的隔离,确保用户程序无法访问内核空间。
-
多层特权级与内存隔离:
- 使用硬件特权级(如内核态和用户态)与虚拟内存机制确保系统的安全性。
- 当用户程序越权访问内核区域时,系统会触发异常终止该程序,避免影响内核。
-
三 隔离机制
为什么需要隔离
-
隔离的目的
- 防止应用程序破坏操作系统。
- 避免应用程序之间相互干扰或破坏。
- 提高系统的安全性,防止恶意程序和病毒的传播。
-
常见问题
- 不隔离的情况下,程序可能意外或故意地破坏系统或其他程序。
- 安全漏洞、恶意程序和程序漏洞会使系统不稳定或瘫痪。
隔离的定义与本质
-
定义
- 在操作系统中,隔离指的是确保应用程序不会影响或破坏其他应用程序或操作系统的正常运行与信息安全。
-
本质
- 隔离的关键在于既要提供数据共享和资源共享的能力,同时要确保操作系统的稳定和安全。
-
隔离的边界
- 边界决定了各自的权限和范围,超出边界的行为可能带来风险。
- 共享资源需要严格的权限控制和访问管理。
隔离的主要方法
-
控制隔离
- 使用特权级机制(用户态与内核态)限制应用程序执行的指令类型。
- 用户态应用程序无法直接执行与系统相关的特权指令。
-
数据隔离
- 使用地址空间将应用程序和操作系统的数据分开,确保应用程序无法直接访问内核数据。
- 使用页表机制划分用户地址空间和内核地址空间,一旦越界访问,则会触发异常处理。
-
时间隔离
- 使用时间片和中断机制限制每个应用程序的执行时间,防止单个应用程序无限制地占用 CPU。
- 中断可随时打断当前应用程序的执行,确保调度机制合理地分配 CPU 资源。
异常处理与隔离维持
-
异常与中断处理
- 操作系统可以通过异常与中断机制,在应用程序破坏隔离时及时处理。
- 一旦发生越权访问、无效操作或其他异常行为,操作系统可以立即终止相关进程,确保系统的稳定性。
-
维持隔离
- 硬件特权机制、虚拟内存管理和中断处理共同确保隔离的实现。
- 操作系统通过特权级划分、地址空间和调度机制实现对控制、数据和时间的隔离管理。
虚拟内存与特权级
数据隔离:虚拟内存机制
-
虚拟地址与物理地址映射
- 虚拟内存通过页表将虚拟地址映射到物理地址,帮助操作系统隔离应用程序的内存空间。
- 应用程序无法直接访问其他程序或操作系统的地址空间。
-
地址空间的安全性
- 如果访问的虚拟地址未在映射表中,则操作系统会报告访问异常。
- 这种机制确保了不同程序之间的内存隔离,提升了系统的安全性。
-
典型内存布局
- 内存中的不同区域由操作系统分配给不同应用程序和系统组件。
- 每个应用程序有其专属的虚拟内存空间,不允许越界访问。
特权级与隔离
-
特权级的定义
- 特权级决定了程序或进程可以执行的操作权限,能否控制和管理计算机系统。
- 常见的特权操作包括关机、修改进程的地址空间等。
-
特权级划分
- 现代操作系统通常有两种特权级别:内核态和用户态。
- 内核态执行操作系统代码,用户态执行应用程序代码。
-
特权级与异常处理
- 硬件应至少支持这两种特权级,以区分操作系统与应用程序的权限。
- CPU 还需要能够及时响应中断和异常,将控制权交还给操作系统。
- 操作系统的中断处理程序或异常处理程序会解决相关问题。
-
中断与异常的区别
- 中断:来自外部设备或硬件计时器的异步信号,通常用于外设请求或时间片到期。
- 异常:同步事件,如非法操作、无效地址访问,通常由 CPU 或软件错误引发。
操作系统与硬件的关系
-
不可信应用程序
- 应用程序是不可信的,可能通过错误或恶意操作试图破坏系统。
- 操作系统必须建立硬件、操作系统和应用程序之间的边界,以确保各自的稳定性。
-
边界的重要性
- 边界不仅用于隔离应用程序,还用于在操作系统和应用程序之间实现协作与共享。
- 接口边界既要确保安全,也要提供高效的协同机制。
中断
- 异步性: 中断是异步发生的,来自处理器外部 I/O 设备的信号
- 中断处理例程:
- I/O 设备向处理器芯片的一个引脚发信号并将异常号放到系统总线上,触发中断
- 在当前指令执行完后,处理器读取异常号,保存现场,切换到内核态
- 调用中断处理例程,完成后返回给下一条要执行的指令
时钟中断
- Timer: 定时产生中断,防止应用程序死占 CPU
- 中断处理例程:
- 触发中断,保存现场,切换到内核态运行
- 完成后返回并恢复中断前的下一条指令
异常处理例程
- 异常处理:
- 根据异常编号查询处理程序,保存现场
- 可能的操作:
- 杀死产生异常的程序
- 重新执行异常指令
- 恢复现场
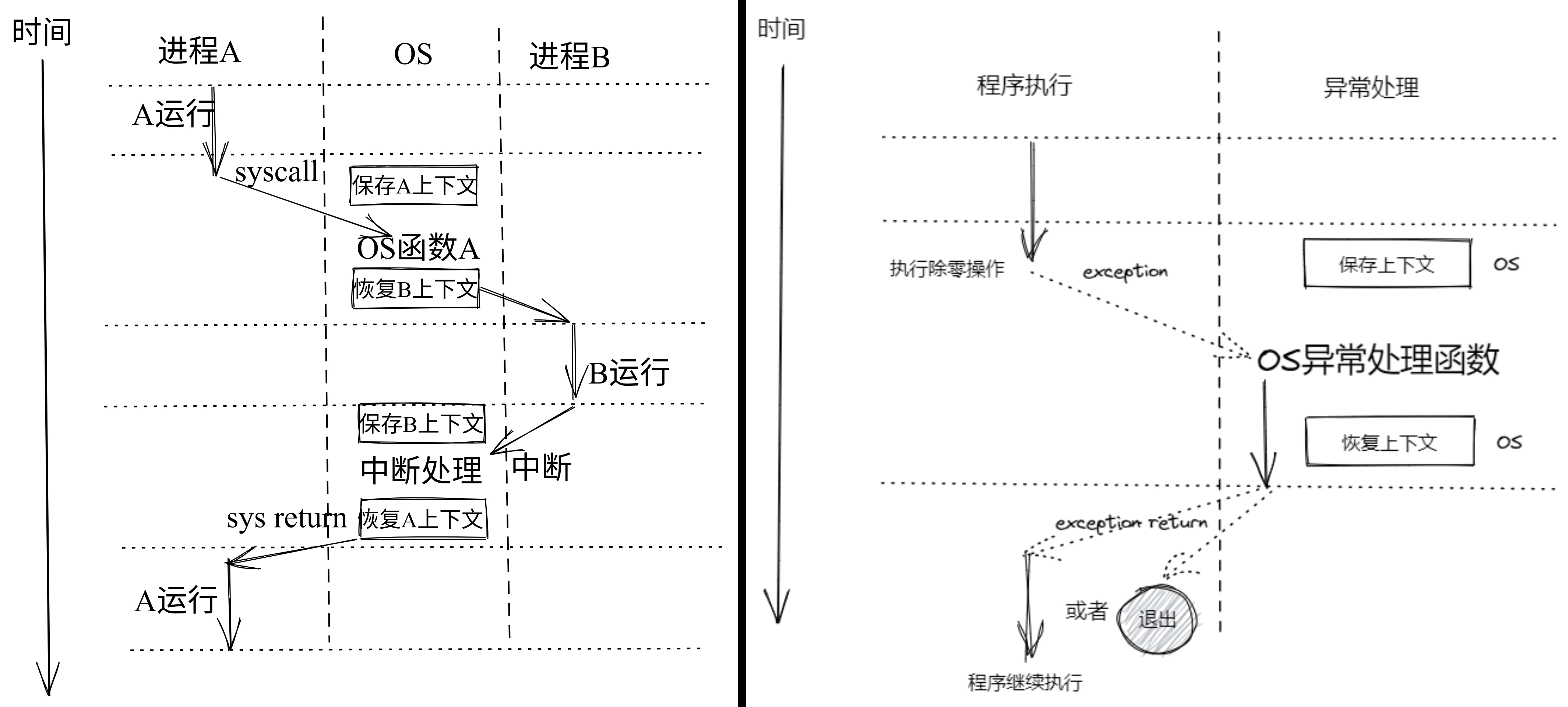
系统调用处理例程
- 系统调用处理:
- 查找系统调用程序
- 切换用户态至内核态
- 栈切换与上下文保存
- 执行内核态操作后返回用户态
中断 vs 异常 vs 系统调用
| 中断 | 异常 | 系统调用 | |
|---|---|---|---|
| 发起者 | 外设、定时器 | 应用程序 | 应用程序 |
| 响应方式 | 异步 | 同步 | 同步、异步 |
| 触发机制 | 被动触发 | 内部异常、故障 | 自愿请求 |
| 处理机制 | 持续,用户透明 | 杀死或重新执行 | 等待和持续 |
进程切换 vs 函数切换
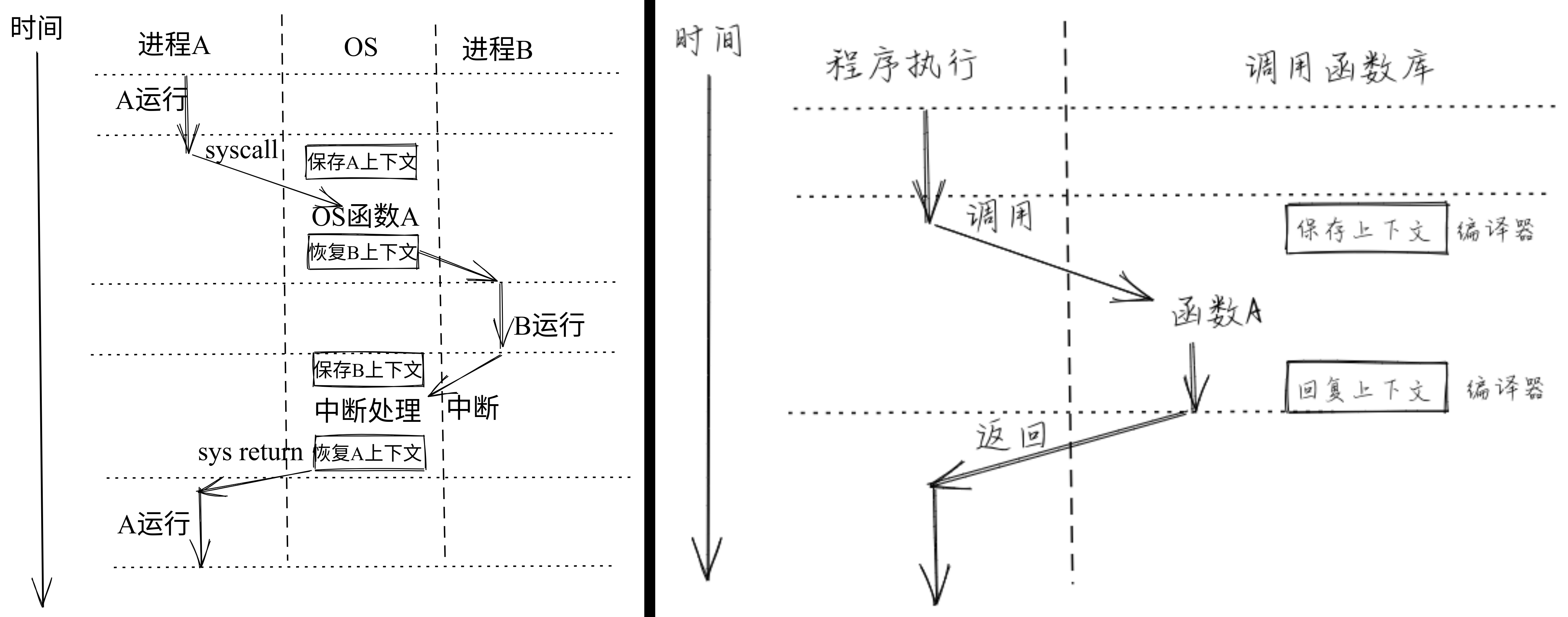
小结
- 了解计算机硬件与操作系统的关系:接口/边界
- 了解操作系统与应用程序的关系:接口/边界
- 了解操作系统如何隔离与限制应用程序
第三讲 基于特权级的隔离与批处理
第一节 从OS角度看计算机系统
一 OS与硬件的关系
特权级隔离与批处理的基本概念
-
硬件与软件的隔离
- 计算机系统由硬件和软件共同构成。
- 操作系统(OS)位于硬件与应用之间,为应用程序提供访问硬件资源的抽象接口。
- 特权级的隔离确保用户应用与系统内核的安全界限,防止应用直接操作硬件或关键资源。
-
隔离的重要性
- 隔离是确保计算机系统安全性和稳定性的重要机制。
- 确保用户应用不能直接访问硬件设备或其他应用的数据,避免潜在的恶意或错误行为。
- 通过特权级别的划分和系统调用机制,提供安全的硬件访问和数据共享方式。
计算机系统与 RISC-V 指令集
-
计算机系统结构层次
- 从下到上,包括物理层设备、电路设计、门级/寄存器传输级、微架构、指令集架构、操作系统、编译器、程序设计和应用。
- 微架构实现指令集架构,为操作系统和应用程序提供硬件抽象接口。
-
RISC-V 指令集架构
- RISC-V 提供多级特权机制,允许操作系统和用户程序之间实现严格的隔离。
CSR(Control and Status Register)寄存器用于管理特权级和控制硬件资源。
| Level | 层次 |
|---|---|
| Application | 应用 |
| Algorithm | 算法 |
| Programming Language | 编程语言 |
| Operating System/Virtual Machines | 操作系统/虚拟机 |
| Instruction Set Architecture (ISA) | 指令集架构 |
| Microarchitecture | 微架构 |
| Gates/Register-Transfer Level (RTL) | 门级/寄存器传输级 (RTL) |
| Circuits | 电路 |
| Devices | 设备 |
| Physics | 物理 |
| 计算机系统抽象层次 |
|---|
| 1. Physics(物理): 这是基础层,涉及物理学原理,如量子力学和电磁学,它们是构造计算设备物理组件的基础。 |
| 2. Devices(设备): 在物理层之上是设备层,这里的设备指的是实际构成计算机的物理组件,例如晶体管、二极管和电容器等。 |
| 3. Circuits(电路): 设备层的上一层是电路层,这里设计将电子设备(例如晶体管)连接在一起形成电路,以实现特定的功能,如逻辑门电路。 |
| 4. Gates/Register-Transfer Level (RTL): 在电路层之上是门级/寄存器传输级别,这里涉及逻辑门(如与门、或门和非门)的设计,以及如何将这些门组合成更复杂的电路来执行寄存器之间的数据传输和操作。 |
| 5. Microarchitecture(微架构): 微架构层是在逻辑门和电路的基础上构建具体的处理器架构。它定义了处理器内部的数据路径、流水线结构、缓存和执行单元等。 |
| 6. Instruction Set Architecture (ISA): 指令集架构是硬件(微架构)和软件之间的接口。它定义了处理器可以识别和执行的指令集合,包括数据类型、寄存器、指令格式、寻址模式等。 |
| 7. Operating System/Virtual Machines(操作系统/虚拟机): 操作系统是管理计算机硬件资源和提供用户与应用程序接口的软件层。虚拟机为运行在物理硬件之上的软件提供了一个虚拟的平台。 |
| 8. Programming Language(编程语言): 编程语言层提供了开发者用来编写软件的高级语言,这些语言通常更接近人类语言和抽象概念,使得软件开发更加高效。 |
| 9. Algorithm(算法): 算法层指的是解决特定问题和执行任务的方法和流程。算法是在编程语言中实现的,但在概念上独立于具体的实现。 |
| 10. Application(应用程序): 最顶层是应用程序层,它指的是最终用户直接使用的软件,例如文本编辑器、游戏或者企业软件等。这些应用程序使用底层所有层级提供的功能来执行用户需要的任务。 |
| 总的来说,这些层次从物理硬件到用户界面提供了一种分层的方式来理解和构建复杂的计算系统。每个层级抽象了底层的复杂性,提供了建立在其上的下一个层级所需的接口和功能。 |
特权级隔离与批处理系统
-
特权级隔离
- 操作系统在最高特权级别(通常称为内核模式)下运行,控制硬件资源。
- 用户应用程序在较低的特权级别(用户模式)运行,通过系统调用访问操作系统提供的服务。
-
批处理系统的实现
- 批处理操作系统在任务调度和隔离方面有独特要求。
- 每个批处理任务被隔离在独立的进程或容器中,以防止跨任务的数据泄露和干扰。
硬件与软件的边界
-
指令集与寄存器
- 硬件与软件之间的接口主要由指令集和寄存器构成。
- 指令集提供应用程序访问硬件的控制指令,寄存器保存数据和控制状态。
-
边界的重要性
- 明确的硬件与软件边界确保两者各自负责的职责范围,避免越界引起的问题。
- 软件负责高层逻辑控制,硬件实现底层指令执行与数据管理。
指令集与寄存器的隔离
-
指令集与寄存器
- 硬件与软件之间的接口不仅定义了硬件与操作系统的边界,同时也是硬件与编译器的边界。
- 编译器只能生成符合指令集的指令,不能直接控制硬件的内部设计,如流水线或中间寄存器等细节。
- 指令集提供了明确的硬件和软件分界线,有助于维护系统的稳定性和安全性。
-
硬件抽象与应用隔离
- 操作系统为应用程序提供抽象接口,如进程内存(地址空间)和文件系统。
- 这些抽象帮助隔离不同的应用程序,使其无法直接操作硬件或其他进程的数据。
- 操作系统通过指令和寄存器专门为系统调用(如文件操作)提供接口。
RISC-V 架构与操作系统
-
架构图与操作系统交互
- RISC-V 架构的硬件设计包括 CPU 内核、寄存器和 I/O 设备等。
- 操作系统的职责是利用这些硬件组件,提供一套标准的抽象接口,供上层应用程序调用。
- 这些接口通常以系统调用的方式提供,包括进程管理、内存分配和设备访问等。
-
硬件抽象层
- 操作系统在硬件和应用程序之间提供硬件抽象层,封装并虚拟化底层硬件。
- 这一层帮助操作系统屏蔽不同硬件架构的差异,为应用提供一致的接口。
u/rCore 的框架结构
二 OS 与应用程序的关系
-
服务与隔离
- 操作系统的主要职责之一是为应用程序提供服务,确保应用能够正常运行。
- 但同时操作系统必须保持自身的安全和稳定,防止应用程序通过系统调用或直接内存访问破坏系统。
-
系统调用机制
- 系统调用(syscall)是应用程序访问操作系统服务的主要接口。
- 系统调用提供内核与用户空间的隔离,通过硬件特权级的支持,确保应用程序无法直接访问内核态资源。
-
特权级与内核态
- 操作系统利用硬件提供的特权级机制,将应用程序置于较低特权级的用户态。
- 系统调用提供安全的切换方式,使应用程序能够以安全的方式访问内核态资源。
- 内核态和用户态之间的转换在硬件支持下变得更为安全和有效。
系统调用举例:read 函数
read 系统调用示例
read系统调用用于从文件中读取数据。- 调用
ssize_t read(int fd, void *buf, size_t count);会发生什么? - 调用流程大致如下:
- 应用程序调用
read函数。 - 通过系统调用的上下文切换机制,从用户态切换到内核态。
- 内核执行文件描述符检查、权限验证和读取数据操作。
- 将读取到的数据复制到应用程序的缓冲区。
- 切换回用户态,将读取到的字节数返回给应用程序。
- 应用程序调用
操作系统与应用程序间的关系
-
两个问题的回答
- 可以在应用程序中直接调用内核的函数吗?
- 可以在内核中使用应用程序普通的函数调用吗?
在某些操作系统或特殊情况下,确实可以在应用程序和内核之间直接调用函数,但这通常带来一些特殊的问题。
-
在应用程序中直接调用内核函数
-
常规情况:
- 在大多数现代操作系统中,直接调用内核函数是不允许的。
- 这是因为内核和应用程序在不同的特权级别运行,需要系统调用或其他安全机制来确保隔离。
-
特殊情况:LibOS
- 在特定的轻量级操作系统(如 LibOS)或嵌入式系统中,应用程序与操作系统可能没有明确的隔离。
- 这种情况下,应用程序可以直接调用系统提供的库函数,如
printf等,因为这些库和操作系统是捆绑在一起的。
-
问题与风险:
- 这种直接调用会导致安全问题或内核崩溃,缺乏隔离可能让恶意或错误的应用程序影响整个系统。
-
-
在内核中调用应用程序的函数
-
常规情况:
- 在现代操作系统中,内核通常不直接使用应用程序的代码。
- 内核无法信任用户级函数,因为它们可能导致内核不稳定或带来安全隐患。
-
特殊情况:LibOS
- 在轻量级的 LibOS 中,内核与应用程序共享部分代码或函数库。
- 在这种情况下,内核可以使用共享库中的一些函数,因为它们被认为是受信任的。
-
问题与风险:
- 共享代码可能带来安全问题。
- 需要谨慎设计,确保共享部分的完整性和隔离性。
-
-
系统调用与函数调用的对比
-
函数调用的优点与缺点:
- 优点:函数调用速度快,因为没有额外的检查和上下文切换。
- 缺点:没有安全检查,应用程序调用内核函数时可能破坏系统稳定性。
-
系统调用的好处:
- 提供额外的检查和隔离,防止应用程序直接访问系统资源或破坏内核。
-
-
内存隔离的必要性
-
内存布局与隔离机制:
- 在现代操作系统中,内存布局的隔离不仅由编译器控制,还需要操作系统的内存管理机制。
- 内核通过虚拟内存机制和页表实现内核态与用户态的隔离,确保用户程序无法访问内核空间。
-
多层特权级与内存隔离:
- 使用硬件特权级(如内核态和用户态)与虚拟内存机制确保系统的安全性。
- 当用户程序越权访问内核区域时,系统会触发异常终止该程序,避免影响内核。
-
三 隔离机制
为什么需要隔离
-
隔离的目的
- 防止应用程序破坏操作系统。
- 避免应用程序之间相互干扰或破坏。
- 提高系统的安全性,防止恶意程序和病毒的传播。
-
常见问题
- 不隔离的情况下,程序可能意外或故意地破坏系统或其他程序。
- 安全漏洞、恶意程序和程序漏洞会使系统不稳定或瘫痪。
隔离的定义与本质
-
定义
- 在操作系统中,隔离指的是确保应用程序不会影响或破坏其他应用程序或操作系统的正常运行与信息安全。
-
本质
- 隔离的关键在于既要提供数据共享和资源共享的能力,同时要确保操作系统的稳定和安全。
-
隔离的边界
- 边界决定了各自的权限和范围,超出边界的行为可能带来风险。
- 共享资源需要严格的权限控制和访问管理。
隔离的主要方法
-
控制隔离
- 使用特权级机制(用户态与内核态)限制应用程序执行的指令类型。
- 用户态应用程序无法直接执行与系统相关的特权指令。
-
数据隔离
- 使用地址空间将应用程序和操作系统的数据分开,确保应用程序无法直接访问内核数据。
- 使用页表机制划分用户地址空间和内核地址空间,一旦越界访问,则会触发异常处理。
-
时间隔离
- 使用时间片和中断机制限制每个应用程序的执行时间,防止单个应用程序无限制地占用 CPU。
- 中断可随时打断当前应用程序的执行,确保调度机制合理地分配 CPU 资源。
异常处理与隔离维持
-
异常与中断处理
- 操作系统可以通过异常与中断机制,在应用程序破坏隔离时及时处理。
- 一旦发生越权访问、无效操作或其他异常行为,操作系统可以立即终止相关进程,确保系统的稳定性。
-
维持隔离
- 硬件特权机制、虚拟内存管理和中断处理共同确保隔离的实现。
- 操作系统通过特权级划分、地址空间和调度机制实现对控制、数据和时间的隔离管理。
虚拟内存与特权级
数据隔离:虚拟内存机制
-
虚拟地址与物理地址映射
- 虚拟内存通过页表将虚拟地址映射到物理地址,帮助操作系统隔离应用程序的内存空间。
- 应用程序无法直接访问其他程序或操作系统的地址空间。
-
地址空间的安全性
- 如果访问的虚拟地址未在映射表中,则操作系统会报告访问异常。
- 这种机制确保了不同程序之间的内存隔离,提升了系统的安全性。
-
典型内存布局
- 内存中的不同区域由操作系统分配给不同应用程序和系统组件。
- 每个应用程序有其专属的虚拟内存空间,不允许越界访问。
特权级与隔离
-
特权级的定义
- 特权级决定了程序或进程可以执行的操作权限,能否控制和管理计算机系统。
- 常见的特权操作包括关机、修改进程的地址空间等。
-
特权级划分
- 现代操作系统通常有两种特权级别:内核态和用户态。
- 内核态执行操作系统代码,用户态执行应用程序代码。
-
特权级与异常处理
- 硬件应至少支持这两种特权级,以区分操作系统与应用程序的权限。
- CPU 还需要能够及时响应中断和异常,将控制权交还给操作系统。
- 操作系统的中断处理程序或异常处理程序会解决相关问题。
-
中断与异常的区别
- 中断:来自外部设备或硬件计时器的异步信号,通常用于外设请求或时间片到期。
- 异常:同步事件,如非法操作、无效地址访问,通常由 CPU 或软件错误引发。
操作系统与硬件的关系
-
不可信应用程序
- 应用程序是不可信的,可能通过错误或恶意操作试图破坏系统。
- 操作系统必须建立硬件、操作系统和应用程序之间的边界,以确保各自的稳定性。
-
边界的重要性
- 边界不仅用于隔离应用程序,还用于在操作系统和应用程序之间实现协作与共享。
- 接口边界既要确保安全,也要提供高效的协同机制。
中断
- 异步性: 中断是异步发生的,来自处理器外部 I/O 设备的信号
- 中断处理例程:
- I/O 设备向处理器芯片的一个引脚发信号并将异常号放到系统总线上,触发中断
- 在当前指令执行完后,处理器读取异常号,保存现场,切换到内核态
- 调用中断处理例程,完成后返回给下一条要执行的指令
时钟中断
- Timer: 定时产生中断,防止应用程序死占 CPU
- 中断处理例程:
- 触发中断,保存现场,切换到内核态运行
- 完成后返回并恢复中断前的下一条指令
异常处理例程
- 异常处理:
- 根据异常编号查询处理程序,保存现场
- 可能的操作:
- 杀死产生异常的程序
- 重新执行异常指令
- 恢复现场
系统调用处理例程
- 系统调用处理:
- 查找系统调用程序
- 切换用户态至内核态
- 栈切换与上下文保存
- 执行内核态操作后返回用户态
中断 vs 异常 vs 系统调用
| 中断 | 异常 | 系统调用 | |
|---|---|---|---|
| 发起者 | 外设、定时器 | 应用程序 | 应用程序 |
| 响应方式 | 异步 | 同步 | 同步、异步 |
| 触发机制 | 被动触发 | 内部异常、故障 | 自愿请求 |
| 处理机制 | 持续,用户透明 | 杀死或重新执行 | 等待和持续 |
进程切换 vs 函数切换
小结
- 了解计算机硬件与操作系统的关系:接口/边界
- 了解操作系统与应用程序的关系:接口/边界
- 了解操作系统如何隔离与限制应用程序
第三讲 基于特权级的隔离与批处理
第二节 从OS角度看RISC-V
一 主流 CPU 架构的比较
-
复杂指令集(CISC) vs. 精简指令集(RISC)
-
x86 架构(CISC)
- 优点:具有强大的兼容性,广泛应用于各种计算领域。
- 缺点:体系结构复杂,指令集庞大,具有大量历史包袱。
-
ARM 架构(RISC)
- 优点:能效比高,指令集较为简洁,广泛用于移动设备。
- 缺点:商业授权较复杂,体系结构同样具有复杂性。
-
RISC-V 架构(RISC)
- 优点:开放的指令集,结构简洁,适合教学与研究。
- 缺点:尚未广泛普及,与 x86 和 ARM 生态系统相比较新。
-
-
RISC-V 的教学价值
- RISC-V 的架构精简明确,适合教学和理解系统编程的基本概念。
- 虽然 MIPS 也具备类似特点,但 RISC-V 具备更现代化的设计。
常见术语
-
ABI(Application Binary Interface):应用程序二进制接口,应用程序与操作系统之间的接口,允许应用程序以与平台无关的方式运行。
-
AEE(Application Execution Environment):应用执行环境,提供一个可以在其上运行应用程序的抽象层。
-
SBI(Supervisor Binary Interface):管理员二进制接口,操作系统与硬件抽象层之间的接口。
-
SEE(Supervisor Execution Environment):管理员执行环境,提供硬件资源和操作系统服务的抽象层。
-
HAL(Hardware Abstraction Layer):硬件抽象层,在硬件与操作系统之间创建一层抽象,使得软件能够以硬件无关的方式运行。
-
Hypervisor(虚拟机监视器或 VMM):虚拟化软件,允许多个操作系统在同一硬件上并行运行。
-
HBI(Hypervisor Binary Interface):虚拟机监视器二进制接口,虚拟机监视器与硬件抽象层之间的接口。
-
HEE(Hypervisor Execution Environment):虚拟机监视器执行环境,虚拟机监视器运行的抽象层。
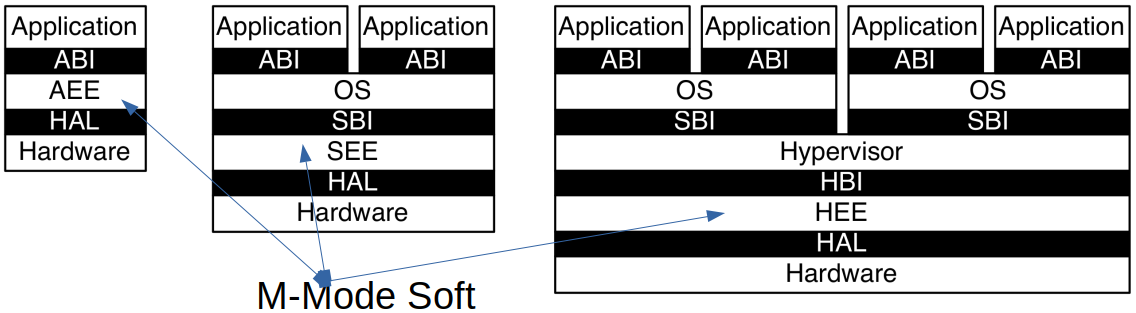
二 RISC-V系统模式
2.1 RISC-V 模式概述
-
四种模式
RISC-V 定义了四种特权模式,支持不同类型的应用与系统需求:-
M 模式(Machine Mode):
- 最高权限:负责底层硬件控制和配置。
- 固件功能:包括启动、硬件初始化等,直接管理硬件资源。
-
S 模式(Supervisor Mode):
- 操作系统运行模式:运行现代操作系统,提供资源隔离和内存管理功能。
- 直接访问硬件:具备访问硬件资源和设置页表的能力。
-
U 模式(User Mode):
- 用户程序运行模式:受 S 模式的操作系统管理。
- 安全隔离:无法直接访问硬件资源,确保系统安全。
-
H 模式(Hypervisor Mode):
- 虚拟化管理程序:用于虚拟化管理,隔离多个虚拟机操作系统。
- 硬件支持虚拟化:目前该模式还未在硬件上完全实现。
-
-
各模式的区别与联系
-
灵活设计:RISC-V 允许根据实际需求自由组合不同模式。
- 例如,仅设计 M 和 U 模式的嵌入式处理器,适合简单应用。
- 或者采用 M、S 和 U 模式的复杂系统,支持多进程、多任务应用。
-
组合方式
- M 模式:提供最基础的硬件管理功能,是其他模式的基础。
- S 模式:在 M 模式之上增加现代操作系统的内存管理和隔离。
- H 模式:为虚拟机提供专属管理功能。
-
-
模式转换与隔离
-
特权模式转换
- 操作系统通过上下文切换与模式转换,在不同特权级别之间切换。
- 例如从 U 模式切换到 S 模式进行系统调用,再返回到 U 模式。
-
隔离机制
- 控制隔离:使用特权指令和系统调用,防止非特权模式直接访问硬件。
- 内存隔离:通过页表等机制划分不同模式的内存区域,防止越权访问。
- 时间隔离:使用定时器和中断,实现多任务调度,防止单个应用程序独占 CPU。
-
系统编程与硬件隔离
-
M 模式的作用
- 硬件初始化:在系统启动时初始化硬件资源,启动操作系统或应用程序。
- 硬件配置:管理所有硬件配置,包括外设、时钟、内存等。
-
S 模式的作用
- 操作系统管理:控制应用程序的执行、隔离和内存管理。
- 硬件资源访问:通过页表等机制将硬件资源分配给应用程序。
-
U 模式的作用
- 应用程序执行:在受限环境中执行应用程序。
- 系统调用接口:通过系统调用与 S 模式的操作系统交互。
系统编程概述
-
系统编程定义
系统编程涉及操作系统以及与硬件交互的底层软件开发。它不仅包括操作系统开发,还涵盖系统库、驱动程序、引导加载程序等。 -
系统编程与用户编程的区别
- 系统编程:
- 与硬件直接交互。
- 需要特殊的权限或特权指令。
- 负责管理资源和提供服务。
- 用户编程:
- 使用系统库和 API 完成应用开发。
- 无需直接访问硬件或底层功能。
- 系统编程:
RISC-V 系统模式不同场景下的应用:
1. 单应用场景
在单个应用场景中,只有一个应用程序运行在整个系统上。其设计特征如下:
- ABI:应用程序二进制接口(ABI)作为应用程序与用户级指令集架构(ISA)以及应用执行环境(AEE)之间的桥梁。
- AEE:为应用程序提供执行环境,使得 ABI 隐藏底层硬件的复杂性,并为应用程序的执行提供更大的灵活性。
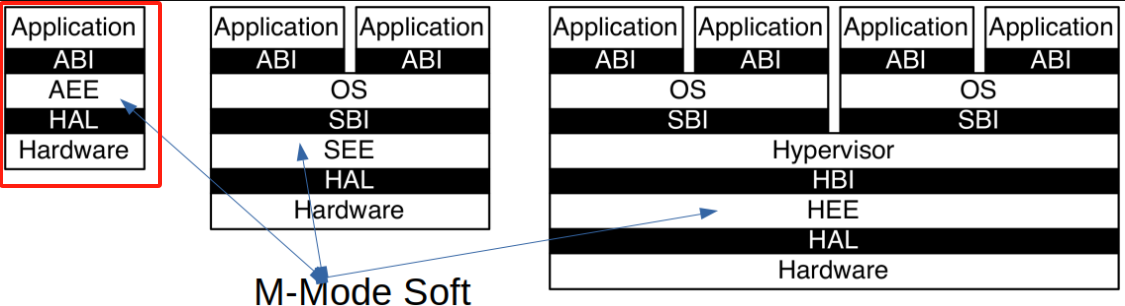
2. 操作系统场景
在操作系统场景中,有一个操作系统负责管理多个应用程序的执行:
- ABI:每个应用程序通过 ABI 与操作系统(OS)通信。
- OS:操作系统负责协调多个应用程序的执行。
- SBI:操作系统通过 SBI(管理员二进制接口)与管理员执行环境(SEE)进行通信,为操作系统提供硬件支持。
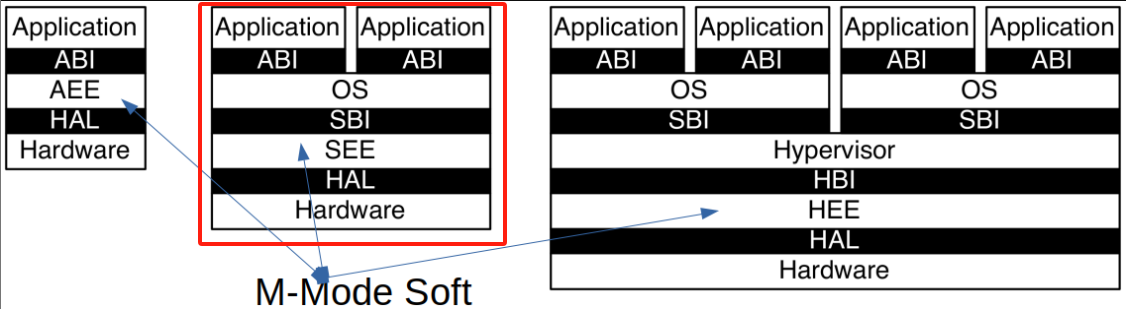
3. 虚拟机场景
在虚拟机(Hypervisor)场景中,可以在一个硬件平台上运行多个操作系统:
- Hypervisor:虚拟机监视器(Hypervisor)管理操作系统的执行,提供虚拟化能力。
- HBI:Hypervisor 通过 HBI(虚拟机二进制接口)与 Hypervisor 执行环境(HEE)进行通信,为虚拟化操作系统提供硬件支持。
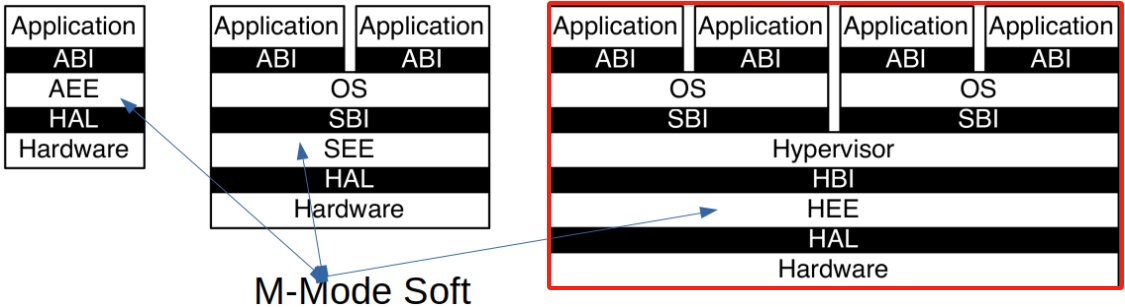
4. 应用场景
根据硬件平台的规模和需求,RISC-V 系统模式可以在不同的设备中找到合适的应用:
- M Mode(机器模式):用于小型设备,例如蓝牙耳机。
- U + M Mode:用于嵌入式设备,例如电视遥控器或刷卡机。
- U + S + M Mode:用于手机或其他复杂设备。
- U + S + H + M Mode:用于数据中心服务器,提供更高级的虚拟化功能。
5. 硬件线程(Hart)与特权级
- Hart:硬件线程是 CPU 内的执行单元,负责在不同的特权级上运行。
- 特权级:每个特权级提供不同的软件栈保护机制。当应用程序试图执行当前特权级不允许的操作时,将触发异常并进行自陷(trap)操作,切换到下层执行环境接管控制权。
2.2 RISC-V 特权级别与跨级别操作
特权级别和 CSR 寄存器
-
特权级别
- 用户模式(U Mode):应用程序的执行环境,无法访问特权寄存器。
- 监视器模式(S Mode):操作系统执行环境,可以管理内存、设备等。
- 机器模式(M Mode):最高特权级别,直接控制硬件。
- 虚拟机模式(H Mode):尚未完全实现,为虚拟机管理程序提供支持。
-
CSR 寄存器
- 定义:控制状态寄存器,管理和配置系统状态。
- 权限:仅在高级别模式下可访问,大部分对 U 模式应用程序不可用。
- 功能:提供特权级别信息、异常处理、设备状态等。
特权级别之间的隔离和跨越
-
隔离
- 硬件级隔离:硬件直接阻止低级别模式访问高级别特权指令。
- CSR 寄存器保护:防止用户模式访问重要的控制寄存器。
- 系统调用:通过 ecall 指令,从用户模式请求高级别模式服务。
-
跨越特权级别
-
ecall 指令
- 用户模式到 S 模式:用户程序请求操作系统服务时使用 ecall 指令。
- 用户模式到 M 模式:在仅有 U 和 M 模式的处理器中,ecall 会直接进入 M 模式。
- S 模式到 M 模式:操作系统需要访问更高级别的硬件特性时,使用 ecall 指令。
-
跨越的限制
- ecall 指令确保调用权限,但只能跨越到预定的更高特权级别。
- 在有 U、S 和 M 模式的情况下,ecall 从用户模式只能进入 S 模式,无法直接进入 M 模式。
-
| 执行环境 | 编码 | 含义 | 跨越特权级 |
|---|---|---|---|
| APP | 00 | User/Application | ecall |
| OS | 01 | Supervisor | ecall sret |
| VMM | 10 | Hypervisor | --- |
| BIOS | 11 | Machine | ecall mret |
2.3 特权模式与 CSR 寄存器
控制状态寄存器(CSR)
- 定义
CSR 是控制状态寄存器,用于管理和配置系统的状态。 - 数量
RISC-V 定义了最多 4096 个 CSR 寄存器。由于 RISC-V 指令集中 CSR 的编码为 12 位,所以最多可以表示 4096 个寄存器。 - 访问权限
- 用户模式:只能读取某些只读的 CSR,如时间信息等。
- 内核态:可以访问大部分 CSR,特别是与系统控制相关的寄存器。
- 用途
CSR 主要用于管理以下方面:- 特权级别隔离:设定不同特权级别的操作权限,防止应用访问系统管控相关寄存器。
- 地址空间配置寄存器:mstatus/sstatus CSR(中断及状态)
- 时间隔离:通过定时器中断,实现时间隔离,防止应用长期使用 100%的 CPU。
- 中断配置寄存器:sstatus/stvec CSR(中断跳转地址)
- 地址空间隔离:通过页表管理实现地址空间隔离,防止应用破坏窃取数据。
- 地址空间相关寄存器:sstatus/stvec/satp CSR (分页系统)
- 特权级别隔离:设定不同特权级别的操作权限,防止应用访问系统管控相关寄存器。
- 功能
- 信息类:主要用于获取当前芯片id和cpu核id等信息。
- Trap设置:用于设置中断和异常相关寄存器。
- Trap处理:用于处理中断和异常相关寄存器。
- Risc-V中异常和中断统称Trap
- 内存保护:有效保护内存资源
三 RISC-V系统编程:用户态编程
3.1 系统模式下的编程概述
-
特权级别的编程
- 用户模式(U Mode):编写应用程序,不能直接访问特权操作。
- 内核态(S Mode):操作系统使用,需通过 CSR 管理进程调度、异常处理、内存管理等。
-
系统调用机制
- 用户态到内核态:RISC-V 使用 ecall 指令让用户程序请求内核态的系统服务。
- 系统调用流程
- 用户态:应用程序通过 ecall 指令发出请求。
- 内核态:操作系统捕获 ecall 异常,进入系统调用处理例程,对请求参数和权限进行检查。
CSR 寄存器与系统编程
- 系统编程中的 CSR 角色
- 控制与配置:通过 CSR 寄存器控制特权指令的执行、配置中断和内存管理等功能。
- 特权指令:某些特权指令只能在内核态或更高的特权模式下执行。
- 硬件和软件的交互
- 硬件:提供必要的 CSR 寄存器和特权模式切换机制。
- 软件:通过系统编程,操作系统借助 CSR 实现特权级别切换、异常处理、资源分配等功能。
理解计算机系统的深度
在操作系统课程中,目标不仅是简单地构建一个小型操作系统 (比如 libOS),更重要的是深入理解计算机系统的整体结构与软件硬件之间的协同工作。以下通过打印字符串的过程来解释整个调用路径和涉及的模式转换。
3.2 U-Mode编程示例:”hello world”
打印过程的路径
-
应用程序层
- 应用程序中的打印函数,如
printf或print,通常调用一个库函数,这个库函数是系统调用的入口点。
- 应用程序中的打印函数,如
-
系统调用
- 库函数将生成一个系统调用 (syscall) 指令,通常在 RISC-V 上使用
ecall指令,它触发用户态到内核态的切换。 ecall会将控制权从用户态交给操作系统内核中的sys_write函数。
- 库函数将生成一个系统调用 (syscall) 指令,通常在 RISC-V 上使用
-
内核态处理
- 内核态的
sys_write函数将处理实际的输出操作。 - 它可能需要访问外部硬件设备(如显示器、串口等),这时会通过 SBI(Supervisor Binary Interface)向更底层的引导程序发出请求。
- 内核态的
-
底层引导程序 (SBI)
- SBI 是操作系统与底层硬件之间的接口。
- 通过 SBI,操作系统可以让硬件执行实际的 I/O 操作。
第一个例子的启动执行
在用户态打印”hello world”的小例子 启动执行流
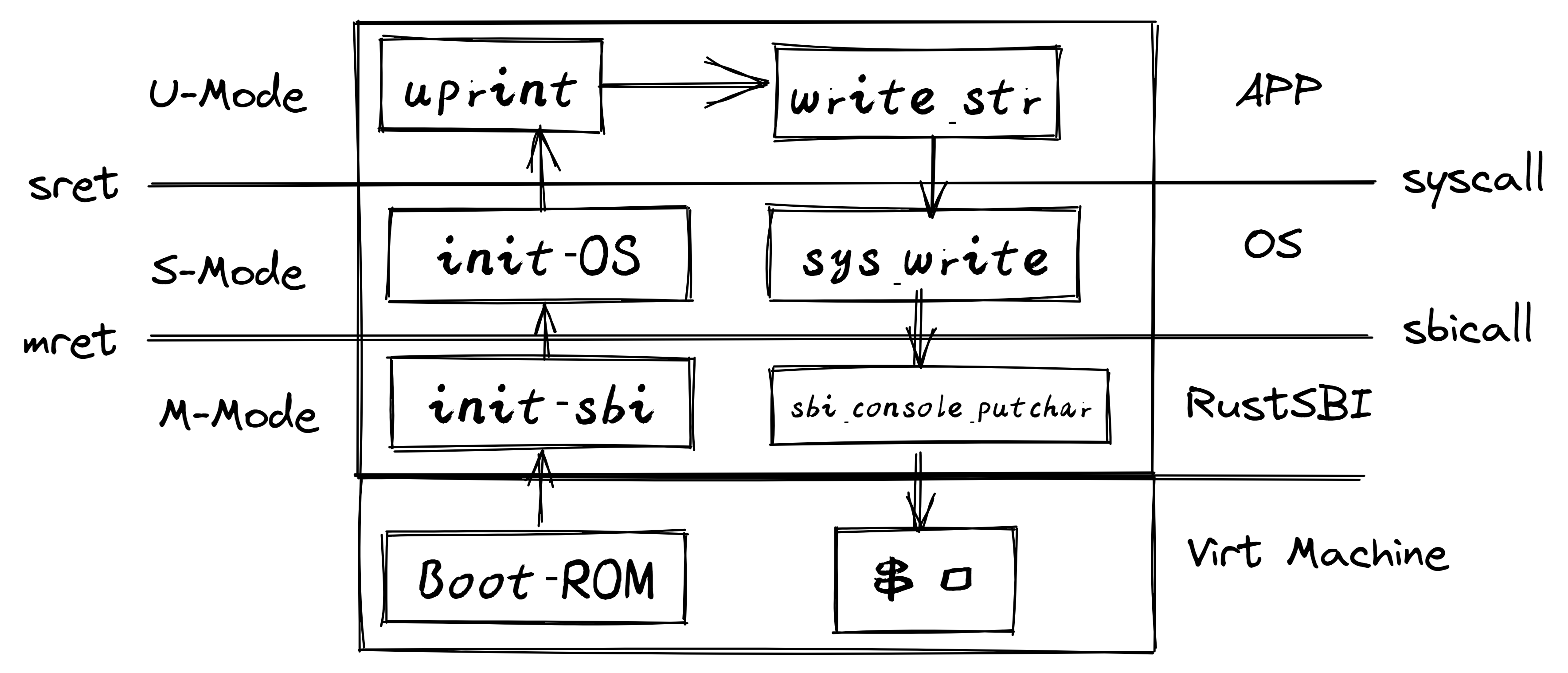
第二个例子:在用户态执行特权指令
在用户态执行特权指令的小例子 启动与执行流程
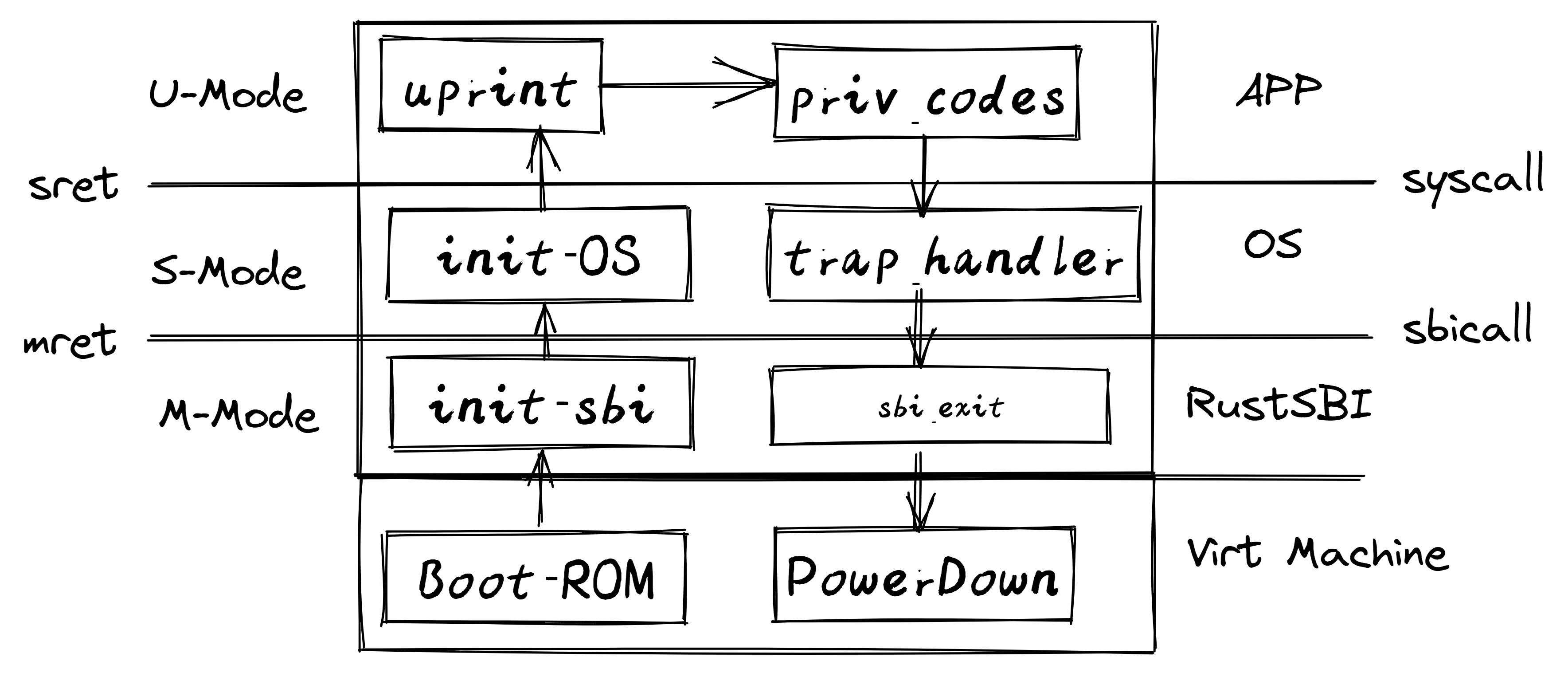
内核态与用户态的指令集差异
-
特权指令
- 用户态不能执行特权指令。
- 某些与硬件直接交互的指令只能在内核态执行,如内存管理、外设 I/O。
-
模式切换指令
- 指令
ecall能让用户态请求内核服务。 - 指令
sret让内核返回到用户态。
- 指令
安全性与隔离
-
特权检查
ecall指令触发了硬件的特权检查,确保只有合法的系统调用能被执行,防止应用程序直接访问底层硬件。
-
隔离机制
- 操作系统通过系统调用的方式确保了用户程序和内核程序之间的隔离,避免用户程序直接访问内核的敏感区域。
通过库函数、系统调用、内核处理和底层接口,字符串输出体现了操作系统对硬件资源的管理和访问控制。理解这种分层和特权级别的切换有助于深入掌握计算机系统的整体架构和设计原则。
系统特权保护与页表机制
-
系统调用与特权级别
- 系统调用保护:应用程序可以直接调用系统函数,前提是这些函数不包含特权指令。然而,真正的保护来自于特权指令集的隔离。
- 页表机制:即使没有特权指令集,用户态还是不能访问操作系统的内核数据或代码。页表机制通过内存隔离将应用程序和操作系统的数据区域严格分离,一旦越界访问就会触发异常。
-
判断当前特权级别
- 在操作系统编程中,我们通常假定当前代码处于某一特权模式。
- RISC-V 模式判断:在 RISC-V 架构中,没有直接的寄存器来检查当前的执行模式。通常,我们在操作系统编程中无需直接知道当前模式,因为假设内核已经运行在
S-mode或者M-mode。 - 灵活性与虚拟化:
- 这种设计的一个好处是,赋予了底层软件更大的灵活性。例如,可以让操作系统在用户态运行,从而模拟更高级别的模式(如在虚拟机中运行)。
- 如果某个特权指令在用户态执行,会触发异常,然后通过异常处理机制交由更高级别的权限进行处理。
- 这种灵活性在虚拟化场景中更有用,通过特权级别的陷阱机制,可以实现应用在虚拟机内运行时的平滑切换。
特权保护不仅仅依靠特权指令集,还依靠页表等硬件机制,进一步确保应用程序不能直接访问到操作系统的敏感区域。理解这些保护机制,能帮助开发者设计更可靠的系统和更安全的特权分离策略。
3.3 RISC-V 特权指令与系统控制寄存器 (CSR)
控制状态寄存器 (CSR)
- 用途与功能:CSR用于系统配置和状态管理,不同的CSR负责不同的系统功能,如中断管理、性能监控、系统配置等。
- 访问限制:用户模式 (U-mode) 通常不能访问大多数CSR,以防止非授权访问影响系统稳定性。内核模式 (S-mode 或 M-mode) 可以访问这些寄存器来执行系统级操作。
指令种类与功能
-
mret(机器模式返回):
- 从机器模式返回到上一个特权级别,并恢复执行。
- 通常用于恢复陷入机器模式的操作,返回到之前的应用执行状态。
-
sret(监管者模式返回):
- 从监管者(Supervisory)模式返回到上一个特权级别并恢复执行。
- 类似于 mret,但用于监管者模式(S-mode)。
-
wfi(等待中断):
- 用于使处理器在没有工作时进入等待中断状态,降低功耗。
- 处理器将暂停执行,直到下一个中断或事件到来。
-
sfence.vma(虚拟地址屏障):
- 用于同步和无效化虚拟内存页表缓存。
- 当页表发生更改时,确保虚拟内存的映射被及时更新。
CSR 读写操作:
特权操作还涉及对控制状态寄存器(CSR)的读写,以执行系统管理功能。例如:
- 读取 CSR:获取 CPU 当前特权级别或状态寄存器中的信息。
- 写入 CSR:配置寄存器的值以改变系统行为,如启用或禁用中断、设置页表基址、修改特权级别等。
注:fence.i
- 用于 i-cache 和 d-cache 一致性。
- 它是一个非特权指令,属于 "Zifencei" 扩展规范,用于清空或同步指令缓存,以确保缓存内容与内存保持一致。
系统编程与中断处理
-
系统模式编程
- M-Mode (Machine Mode):处理器的最高权限模式,负责处理中断和异常,是处理器的核心控制层。
- M-Mode 功能:主要处理中断和异常,控制低层硬件和系统初始化等。
-
系统中断和异常管理
- mstatus 和 mcause 寄存器:用于追踪和响应系统状态和事件。
mstatus寄存器反映当前模式下的系统状态,如中断使能状态;mcause寄存器记录异常或中断的原因。 - 中断处理机制:处理器使用定时器中断来防止单一程序长时间占用CPU,确保系统的公平性和响应性。这是多任务操作系统中的关键机制。
- mstatus 和 mcause 寄存器:用于追踪和响应系统状态和事件。
系统编程的实践
- 从用户模式到系统模式的转换:使用
ecall指令从用户态跳转到系统态,这允许应用程序请求操作系统服务而不破坏系统的保护边界。 - 系统调用的处理:操作系统在响应系统调用时进行安全检查和资源调度,保证系统的稳定性和安全性。
系统编程涉及深入理解和操作处理器的底层功能,特别是在处理中断、异常和系统调用时。RISC-V的设计通过提供清晰的特权级别和功能分离,使得系统编程既灵活又具有可控性。这些特点允许开发者根据应用需求调整硬件配置,优化系统性能和响应能力。
四 RISC-V系统编程:M-Mode编程
4.1 中断机制和异常机制
-
同步的异常:
- 在指令执行期间产生。
- 例如,访问无效的寄存器地址或执行无效操作码的指令。
-
异步的中断:
- 异步发生于指令流之外的外部事件。
- 例如,时钟中断。
-
精确异常:
- RISC-V 要求实现精确异常。
- 确保异常之前的所有指令均完整执行,异常后的指令未开始执行。
M-Mode编程
-
最高权限模式:
-
M-Mode 是 RISC-V 中 hart(hardware thread)的最高权限模式。
-
在此模式下,hart 对计算机系统的底层功能具有完全的使用权。
-
M-Mode 最重要的特性是拦截和处理中断/异常。
-
mstatus CSR寄存器
- mstatus(Machine Status):
- 保存全局中断以及其他状态信息。
- SIE 控制 S-Mode 下的全局中断。
- MIE 控制 M-Mode 下的全局中断。
- SPIE、MPIE 记录发生中断前的 SIE 和 MIE 值。
- SPP 表示变化之前的特权级别(S-Mode 或 U-Mode)。
- MPP 表示变化前的特权级别(M-Mode、S-Mode、U-Mode)。
- PP:Previous Privilege

mcause CSR寄存器
- mcause(Machine Cause):
- 当发生异常时,mcause CSR 中会写入指示异常事件的代码。
- 若事件由中断引起,则置上 Interrupt 位。
- Exception Code 字段包含指示最后一个异常的编码。
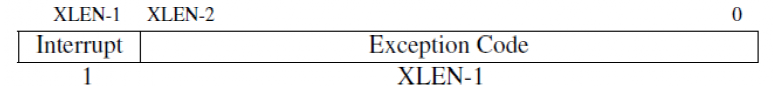
M-Mode时钟中断Timer
-
中断:
- 是异步发生的。
- 由来自处理器外部的 I/O 设备信号触发。
-
Timer:
- 可以稳定地产生中断。
- 防止应用程序长时间独占 CPU,确保 OS Kernel 有执行权。
- 允许高特权模式的软件获得 CPU 控制权。
- 高特权模式的软件可授权低特权模式的软件处理中断。
RISC-V处理器FU540模块图
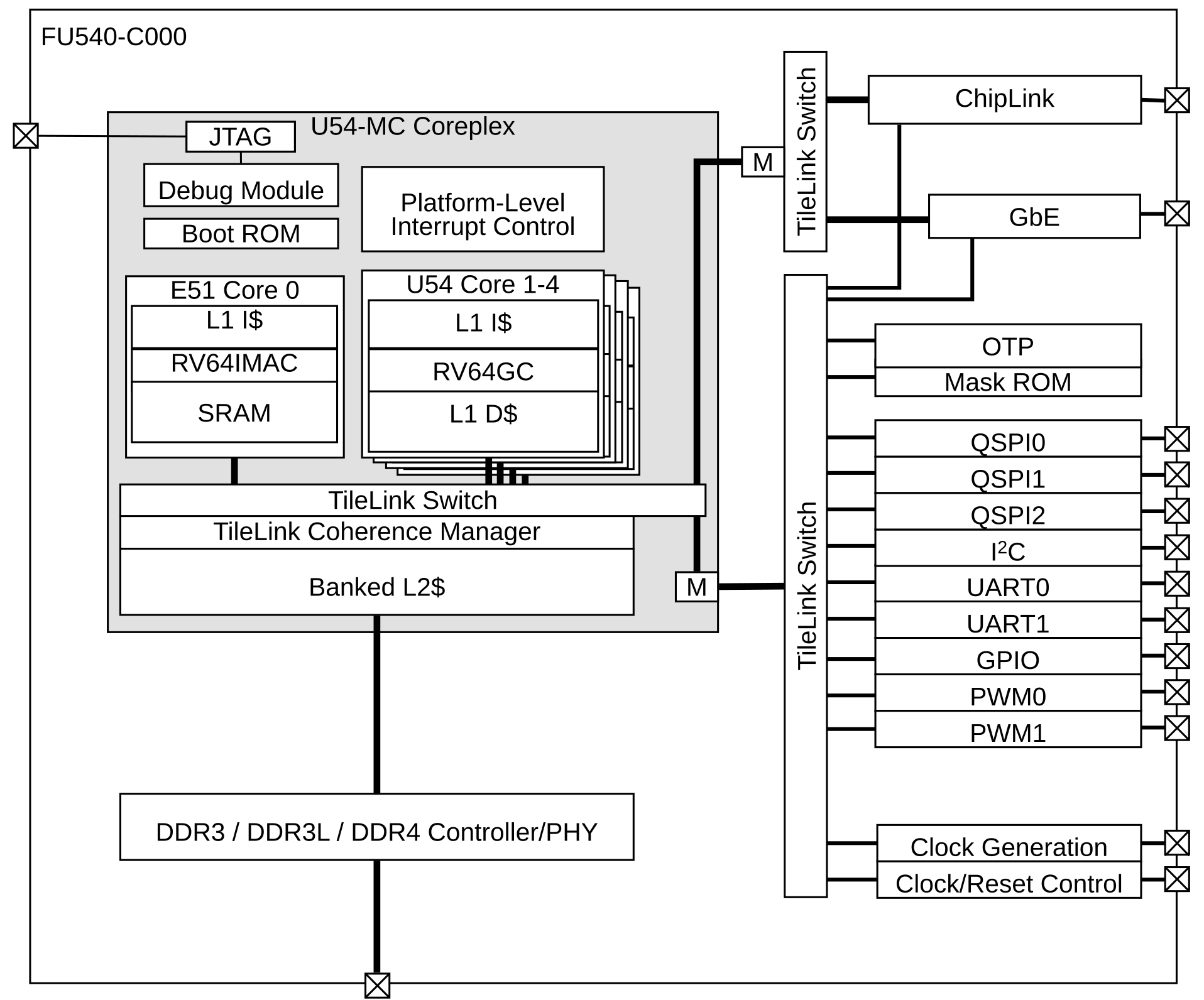
4.2 中断/异常的硬件响应
-
Mcause (中断与异常原因)
- 在 RISC-V 架构中,
mcause寄存器保存了当前异常或中断的原因。 - 中断的种类有限,通过
mcause可以知道中断类型及编号。 mcause寄存器的最高位为1表示中断,0表示异常。- 将
mtval设置为出错的地址或者其它适用于特定异常的信息字
- 在 RISC-V 架构中,
-
Mepc (异常程序计数器)
mepc用于存储被中断或发生异常时的程序计数器 (PC) 地址,以便中断或异常处理完毕后恢复正常执行。
-
Mtvec (陷阱向量)
mtvec是一个陷阱处理器寄存器,保存了异常或中断发生时处理函数的入口地址。- 处理器在发生中断或异常时会跳转到该寄存器中指定的处理函数执行。
-
Mstatus (状态寄存器)
mstatus记录处理器当前的全局状态,包括中断允许 (IE) 位。- 当处理器接收到中断或异常时,硬件会自动将中断使能位 (IE) 清除,禁用后续中断,以防止当前处理中断时被新的中断打断。
- 软件可以根据需要启用或禁用中断。
M-Mode中断的硬件响应过程
硬件响应:
-
保存和设置程序计数器(PC):
- 异常或中断发生时,指令的 PC 被保存在 mepc 寄存器中。
- PC 接着设置为 mtvec(trap vector base address)的值。
- 对于同步异常:mepc 指向导致异常的指令。
- 对于中断:mepc 指向中断处理完成后应继续执行的位置。
-
设置mcause和mtval:
- mcause 寄存器设置为标识异常或中断源的编码。
- 如果是中断,mcause 的最高位被置为1。
- Exception Code 字段包含异常或中断的具体原因。
- mtval 寄存器设置为出错的地址或其他与特定异常相关的信息字。
- mcause 寄存器设置为标识异常或中断源的编码。
-
禁用和保存中断使能:
- mstatus 寄存器的 MIE 位被置零,禁用进一步中断。
- 先前的 MIE 值保存到 MPIE 中。
- SIE 控制 S-Mode 下的全局中断,而 MIE 控制 M-Mode 下的全局中断。
-
权限模式的保存和更改:
- 发生异常之前的权限模式被保存在 mstatus 的 MPP 域中。
- 更改当前权限模式为 M-Mode。MPP 字段记录之前是 S-Mode、M-Mode 或 U-Mode。
软件响应:
- 软件读取
mcause和mtval,获取中断或异常的详细信息。 - 根据异常类型和中断原因,软件调用适当的中断处理程序或异常处理程序。
- 处理完成后,软件通过修改
mstatus中的 IE 位,恢复中断使能状态,并使用mepc返回中断或异常发生时的地址继续执行。
通过这种硬件与软件协作的方式,RISC-V 架构能够有效管理中断和异常,确保操作系统和应用程序在受到外部干扰时能够安全、稳定地恢复执行。
M-Mode中断分类
中断类型通过 mcause 寄存器的不同位来区分:
-
软件中断:
- 通过写入特定内存映射寄存器来触发。
- 用于处理器间通信(hart间中断)。
-
时钟中断:
- 当 hart 的时间计数器寄存器 mtime 大于时间比较寄存器 mtimecmp 时发生。
- 用于定时任务和防止某个程序过度占用 CPU。
-
外部中断:
- 由外部中断控制器触发。
- 大多数外设(如网络接口、磁盘控制器等)连接至中断控制器,并通过此控制器向 CPU 发送中断信号。
通过 mcause 寄存器的不同位来获取中断源的信息。 第一列1代表中断,第2列代表中断ID,第3列中断含义 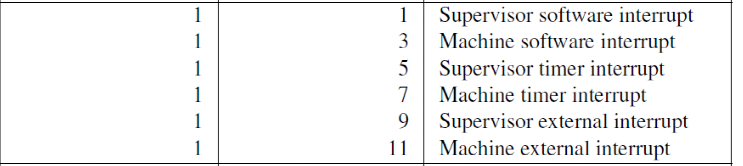
异常种类
-
常见异常
- RISC-V 异常的种类较多,如地址错位、非法指令、系统调用 (
ecall)、页面缺失等。 mcause中最高位为0时表示当前为异常。
- RISC-V 异常的种类较多,如地址错位、非法指令、系统调用 (
-
系统调用异常
ecall指令通常由用户模式下的应用程序发出,以请求操作系统的服务。- 系统调用是应用程序和操作系统之间的重要接口,在 RISC-V 中被视作异常进行处理。
通过 mcause 寄存器的不同位来获取导致异常的信息。 第一列0代表异常,第2列代表异常ID,第3列异常含义 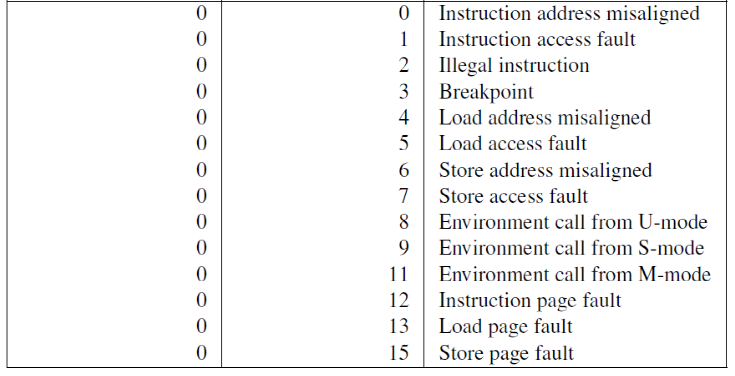
4.3 中断/异常处理的控制权移交
1. 中断/异常委托机制概述
-
M-Mode 默认处理所有中断/异常:默认情况下,所有中断和异常事件都交由 M-Mode 处理。M-Mode 的处理例程可以根据具体情况将某些中断或异常重新导向 S-Mode。
-
通过 mideleg 和 medeleg CSR (Machine Interrupt/Exception Delegation):
mideleg和medeleg是两个控制状态寄存器(CSR),用于指定哪些中断和异常可以直接交由 S-Mode 处理,而无需经过 M-Mode。- 中断委托寄存器
mideleg中的每一位代表某个中断类型,如果相应位被置位,该类型的中断事件将直接交由 S-Mode 处理。- mideleg (Machine Interrupt Delegation)控制将哪些中断委托给 S 模式处理
- mideleg 中的每个为对应一个中断/异常
- mideleg[1]用于控制是否将核间中断交给s模式处理
- mideleg[5]用于控制是否将定时中断交给s模式处理
- mideleg[9]用于控制是否将外部中断交给s模式处理
- 异常委托寄存器
medeleg的每一位代表某种异常类型,如果相应位被置位,则该类型的异常事件将直接交由 S-Mode 处理。- medeleg (Machine Exception Delegation)控制将哪些异常委托给 S 模式处理
- medeleg 中的每个为对应一个中断/异常
- medeleg[1]用于控制是否将指令获取错误异常交给s模式处理
- medeleg[12]用于控制是否将指令页异常交给s模式处理
- medeleg[9]用于控制是否将数据页异常交给s模式处理
- 中断委托寄存器
-
提高效率,减少开销:此种设计允许操作系统根据需要调整中断/异常的处理流程,避免每次中断或异常都经过 M-Mode,从而减少开销,提高中断和异常处理的效率。
2. 各种模式的中断/异常处理
-
M-Mode:机器模式拥有最高权限,负责全局的中断管理和系统配置。因此,M-Mode 中断/异常处理器能够在 S-Mode 和 U-Mode 中发生严重问题时处理系统恢复、初始化或关闭。
-
S-Mode:监督模式通常用于操作系统内核,负责管理硬件资源并控制用户进程。因此,直接将某些中断和异常交给 S-Mode 处理可以提高系统性能和效率,减少不必要的上下文切换。
-
U-Mode:用户模式权限最低,不具备直接处理硬件中断和异常的能力。U-Mode 下的应用程序依赖操作系统来管理和处理所有的硬件异常和中断。
3. 为什么 U-Mode 不处理中断/异常
-
安全性:用户程序处理硬件中断/异常可能会带来重大安全隐患。允许普通用户程序直接处理硬件资源,可能导致权限滥用和恶意行为。
-
复杂性:硬件中断和异常处理非常复杂,需要充分了解底层硬件和系统状态。普通用户程序一般不具备这样的知识与权限,因此将中断/异常处理集中在更高权限的模式下可以确保系统的可靠性。
-
资源管理:M-Mode 和 S-Mode 的处理程序可以通过内核全面管理系统资源。直接在 U-Mode 下处理中断/异常会破坏操作系统对资源的控制。
总之,RISC-V 中断/异常处理的控制权移交机制旨在确保系统的安全性、可靠性和效率。通过 mideleg 和 medeleg 的灵活配置,操作系统可以优化处理过程,以适应不同系统和应用的需求。
4.4 调试功能
-
断点调试
- 在调试器设置断点时,会在目标代码中插入
ebreak指令。 - 当处理器执行到
ebreak指令时,会产生一个断点异常,硬件将跳转到异常处理例程。 - 操作系统捕获这个异常后可以调用调试器,使其控制执行流。
- 在调试器设置断点时,会在目标代码中插入
-
单步调试
- 单步调试是一种让处理器逐条执行代码的调试模式。
- 通过软件设置特定的中断或异常(如时钟中断),使得每条指令执行后都会产生一个中断。
- 操作系统捕获到中断并移交给调试器,从而实现逐条执行的效果。
五 RISC-V系统编程:内核编程
5.1 中断/异常机制
编程概述
目标与角色: S-mode(supervisor mode)是 RISC-V 架构中操作系统运行的权限模式,它的主要目标是:
- 保护 U-mode(用户模式)应用程序免于越权操作。
- 防止非法访问内存地址。
- 防止 U-mode 应用长期占用处理器资源。
- 提供系统服务给 U-mode 应用程序,实现交互。
S-mode 必须依靠软硬件协同来完成以上目标。具体功能包括处理中断和异常、特权级别的切换等。
S-Mode 寄存器概述
1. stvec (Supervisor Trap Vector)
- 功能:
stvec寄存器保存了当 S-Mode 发生中断或异常时需要跳转的地址,即陷入(trap)处理程序的基地址。 - 结构:
BASE域:表示中断/异常处理程序的基地址,应按 4 字节对齐。MODE域:定义陷入处理的模式:0:直接模式,将所有中断/异常都引导至基地址指向的一个处理程序。1:向量模式,每个中断或异常都有单独的处理程序,基地址指向一个表格,包含所有中断或异常的处理程序地址。
2. sepc (Supervisor Exception PC)
- 功能:
sepc寄存器存储了触发中断或异常的指令地址。它记录了当前 PC,当中断或异常处理完成后恢复执行时会使用此值继续执行。
3. scause (Supervisor Exception Cause)
- 功能:
scause寄存器保存了导致当前中断或异常的事件编号,并指示其来源是中断还是异常。 - 结构:
Exception Code域:存储中断或异常的具体编号,用于识别事件类型。Interrupt位:如果事件是中断而非异常,该位设置为 1,否则设置为 0。
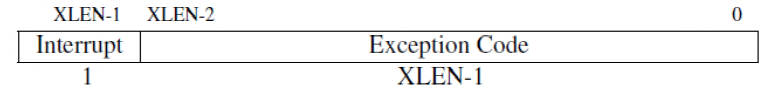
4. sie (Supervisor Interrupt Enable) 和 sip (Supervisor Interrupt Pending)
- 功能:
sie:该寄存器控制 S-Mode 中的各个中断源是否启用。通过设置或清除其中的位,可以使能或禁用某个中断。sip:该寄存器指示当前等待处理的中断。中断硬件可以直接将中断请求置入该寄存器,以便中断处理例程进行相应的响应。

5. stval (Supervisor Trap Value)
- 功能:
stval寄存器记录了与中断或异常相关的附加信息。在地址相关的异常(如页面错误)中,它保存相关地址。对其他类型的异常,该寄存器的值可能没有特殊意义。
6. sscratch (Supervisor Scratch)
- 功能:
sscratch寄存器提供了一个数据交换的中转站,通常用于在中断或异常处理期间存储临时信息或切换上下文。它在不同模式间提供数据交换的便利。
7. sstatus (Supervisor Status)
- 功能:
sstatus寄存器保存了 S-Mode 中全局中断和其他状态信息。 - 结构:
SIE:当前中断使能状态,如果设置为 1,允许处理器处理中断。SPIE:记录中断发生前的中断使能状态,用于恢复到中断发生前的状态。

8. mtvec & stvec 寄存器
- 功能:
mtvec和stvec分别用于 M-Mode 和 S-Mode 中配置陷入处理程序的基地址和模式。它们的功能和结构类似:BASE域:基地址,表示陷入处理程序的地址基准。MODE域:决定陷入的处理模式,和stvec相同。

通过这些寄存器,S-Mode 能够有效地控制、管理和响应各类中断和异常事件,确保系统资源得以充分利用,并保持系统的稳定性和安全性。
5.2 中断/异常的处理
在 RISC-V S-Mode 中,硬件和软件协作处理中断和异常时的关键步骤如下:
硬件行为:
-
保存被中断指令的地址:异常或中断发生时,当前的程序计数器(PC)被保存在
sepc寄存器,以便稍后恢复到这个位置继续执行。 -
设置陷阱处理程序地址:处理器根据
stvec寄存器中的值,将 PC 设置为陷阱处理程序的入口地址。 -
记录原因:
scause寄存器记录异常或中断的原因编号,方便陷阱处理程序根据具体原因采取相应的操作。stval被设置为出错的地址/异常相关信息。 -
禁用中断:为了防止陷阱处理程序处理过程中被打断,把 sstatus中的 SIE 位置零, SIE位之前的值被保存在 SPIE 位中。
-
发生例外前的特权模式被保存在 sstatus 的 SPP(previous privilege) 域,然后设置当前特权模式为S-Mode
-
跳转到stvec CSR设置的地址继续执行
软件行为:
硬件所记录的状态信息是不完整的,软件必须进一步保存状态,以确保陷阱处理程序可以正确恢复上下文。典型的陷阱处理程序包括以下流程:
-
初始化陷阱处理程序:
- 为所有中断和异常设置统一或分离的入口地址,通常在操作系统启动时完成。
- 编写中断/异常的处理例程(如trap_handler)
- 将
stvec配置为合适的陷阱处理程序(如trap_handler)的入口地址。
-
保存通用寄存器:
- 陷阱处理程序开始时,保存当前状态,包括通用寄存器和栈帧,以便在陷阱处理完毕后能正确恢复执行。
-
分析中断或异常的原因:
- 处理器跳转到trap_handler。检查
scause和相关寄存器,以确定发生的异常类型或中断编号。
- 处理器跳转到trap_handler。检查
-
处理特定中断或异常:
- trap_handler 处理中断/异常/系统调用等
- 对于中断,通常根据中断类型或编号采取特定的动作。
- 对于异常,可能需要检查内存权限、地址有效性等,并采取适当措施,如终止出错的进程或处理页面错误。
-
恢复上下文:
- 陷阱处理完毕后,将先前保存的寄存器和状态恢复,以确保程序能够继续从被中断的地方执行。
硬件和软件的设计理念:
RISC-V 的设计理念是让硬件只执行最小限度的工作,将更多的灵活性留给软件去实现。与 X86 不同,RISC-V 更注重软件和硬件的协作。
5.3 虚存机制(Virtual Memory Mechanism)
在 RISC-V 中,S-Mode 使用虚拟内存系统管理进程的内存资源,并提供内存保护与地址转换功能。它使用页表将虚拟地址映射到物理地址,从而实现了虚拟内存。以下是对 S-Mode 虚拟内存系统及其工作原理的深入解释:
1. 虚拟地址划分与页表概念
-
虚拟地址的页划分:虚拟地址空间划分为固定大小的页。每个页的大小通常为 4 KB,但可以根据系统配置不同有所变化。页表负责管理这些页的映射关系,将虚拟地址映射到实际的物理地址。
-
页表的层级结构:在 RISC-V 中,页表通常分为多级结构。每一级页表负责解析虚拟地址的一部分,最终找到指向物理地址的页表项。每个页表项保存指向下一页表的地址,或者是实际数据页的地址。
2. satp(Supervisor Address Translation and Protection)
-
功能:
satp寄存器是 S-Mode 中控制地址转换和保护的关键寄存器。 -
结构:
MODE:确定分页机制的类型。常见的值为:0:关闭分页机制。8:使用 Sv39(39 位虚拟地址)。9:使用 Sv48(48 位虚拟地址)。
ASID:地址空间标识符。它是一个可选字段,用于标识不同进程的地址空间。通过在页表查询时匹配ASID,可以减少 TLB 缓存刷新操作,提高上下文切换的效率。PPN:物理页号。它保存了根页表的基地址,通过将其乘以页大小(通常为 4 KB)可以得到根页表的起始物理地址。

3. 页表建立与 OS/APP 页表管理
-
OS 页表:操作系统负责创建、维护和管理页表。根页表通常由操作系统在初始化阶段或加载新程序时创建,并由
satp寄存器指向根页表的物理地址。 -
APP 页表:每个应用程序在运行时,都会使用其专属的页表。操作系统需要在应用程序上下文切换时切换到应用程序对应的页表,同时通过
satp的ASID来标识不同应用程序的地址空间。
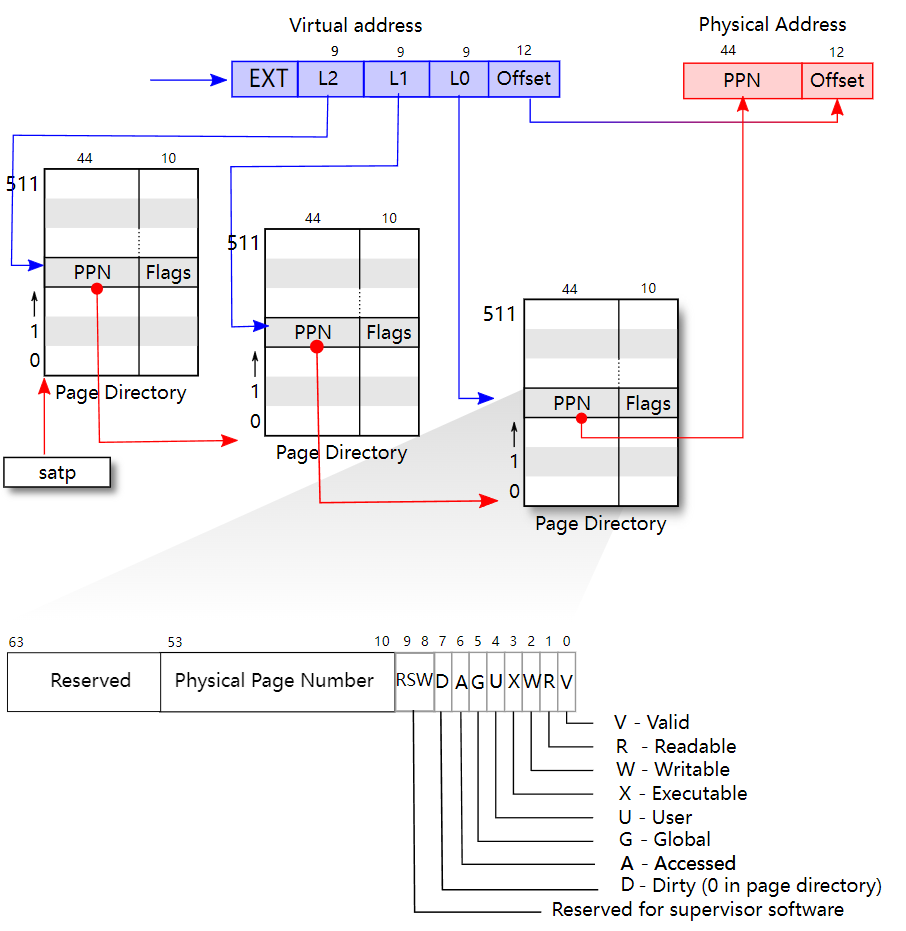
4. 虚拟地址到物理地址的转换
在 S-Mode 或 U-Mode 中,虚拟地址通过遍历页表转换为物理地址,以下是 Sv39 模式下的详细步骤:
-
一级页表:
- 根页表的基地址由
satp.PPN指定。 - 虚拟地址的高 10 位(
VA[31:22])用于索引一级页表项。 - CPU 读取一级页表项的地址是
(satp.PPN * 4096 + VA[31:22] * 8)。
- 根页表的基地址由
-
二级页表:
- 一级页表项(PTE)包含了二级页表的基地址。
- 虚拟地址的中间 10 位(
VA[21:12])用于索引二级页表项。 - CPU 读取二级页表项的地址是
(PTE.PPN * 4096 + VA[21:12] * 8)。
-
叶节点页表:
- 二级页表项包含了实际数据页的基地址(叶节点页表)。
- 虚拟地址的低 12 位(
VA[11:0])表示页内偏移。 - 物理地址由叶节点页表项(
LeafPTE.PPN)和页内偏移组合而成,即(LeafPTE.PPN * 4096 + VA[11:0])。
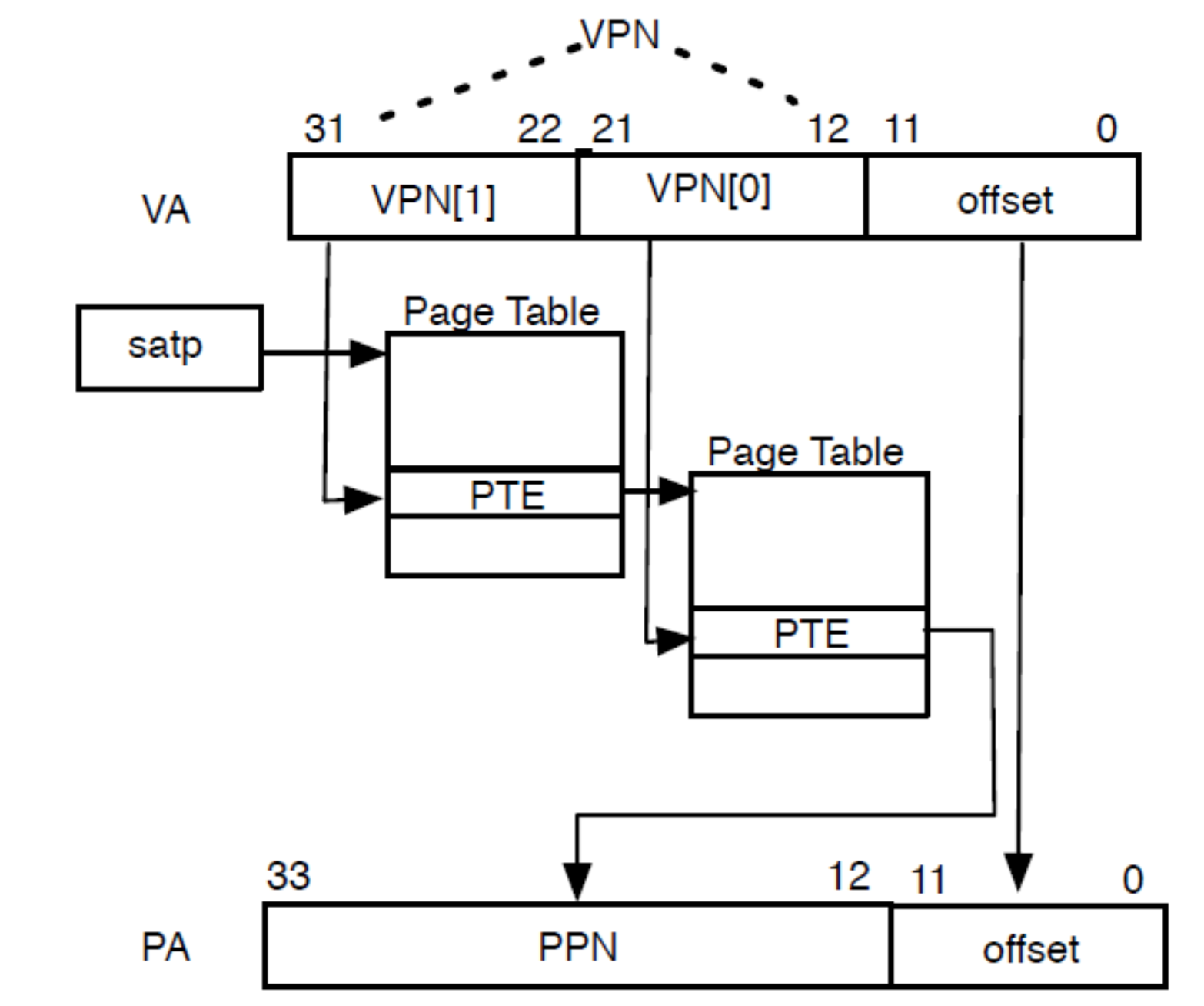
5. 内存访问异常处理
- 内存访问异常:如果在遍历页表的过程中未找到合适的页表项,或者找到的页表项表明当前访问不被允许,则会触发异常。操作系统可以通过中断处理程序来处理这些异常,如页面错误或访问权限错误。
通过这种分级页表结构和地址转换机制,S-Mode 实现了虚拟内存,确保操作系统和应用程序可以灵活、安全地使用内存资源。
总结
在这部分内容中,我们重点讨论了 RISC-V 架构中不同特权级别的机制和它们与虚存、异常、系统调用之间的相互作用,进一步了解了操作系统与硬件之间的协作关系。
特权级别与隔离机制
-
M 模式(Machine Mode):
- 最高权限级别,直接控制硬件。
- 负责初始化系统、设置中断和异常处理程序,并将部分任务委托给 S 模式(Supervisor Mode)。
- 具备控制 CSR(控制状态寄存器)和 TLB(地址转换缓存)的能力。
-
S 模式(Supervisor Mode):
- 作为操作系统的主要工作模式,管理虚拟内存、进程间隔离和系统调用。
- 通过页表机制,实现用户进程与操作系统之间的隔离,并控制硬件资源的分配。
- 配置中断和异常处理程序,以确保在应用程序引发系统调用或异常时进行有效的响应。
-
U 模式(User Mode):
- 用于运行用户应用程序,权限最小。
- 无法直接访问系统级别资源,必须通过系统调用与操作系统通信。
- 借助 ECall 指令,将控制权转交给 S 模式。
中断与异常处理
-
硬件响应:
- RISC-V 硬件在检测到中断或异常时,会保存当前指令状态(如 PC 寄存器)至对应的 CSR,更新状态信息,并跳转到特定的中断或异常处理程序入口。
-
软件响应:
- 操作系统中的异常处理程序读取相关寄存器,确定异常或中断的原因,执行相应的处理逻辑。
- 中断处理程序负责恢复上下文,确保程序正常继续执行。
虚拟内存与页表
-
多级页表结构:
- RISC-V 使用三级页表,将虚拟地址分为多个部分,通过逐级查询页表进行地址转换。
- 页表中的映射项由操作系统设置,确保各应用程序仅访问分配给它们的物理内存。
-
虚实地址转换:
- TLB 缓存最近的地址映射,提升内存访问性能。
- 操作系统通过设置页表基址寄存器(
satp)和页表内容,为应用程序提供隔离的地址空间。
补充总结
以下是一些简单的补充和总结
可能有不准确的地方
使用场景和比喻来加深理解
理解RISC-V的中断、异常处理和虚存机制需要把握很多概念和细节。让我们尝试通过一些具体的场景和比喻来加深理解。
中断/异常处理
想象你在一个大型公司工作,每个员工(程序)都在各自的办公室(内存空间)里忙碌。突然,火警(中断)响起,大家需要按照既定的紧急疏散程序(中断服务例程)迅速撤离。这个疏散计划就像是mtvec或stvec寄存器,它告诉大家在紧急情况下应该去哪里集合。
- M-Mode中断处理:想象公司的保安部门(M-Mode)负责处理所有紧急情况。他们有权利决定是自己处理还是指派给各楼层的安全代表(S-Mode)。
- S-Mode中断处理:楼层的安全代表只负责自己楼层的紧急情况。如果有更大的紧急情况,他们会联系保安部门。
中断/异常的控制权移交
当保安部门决定让楼层的安全代表处理某些类型的紧急情况时,这就像是通过mideleg和medeleg寄存器将中断和异常处理的控制权委托给S-Mode。
虚拟内存系统
虚拟内存系统可以比作一家大型图书馆,每本书(数据/指令)都有一个特定的位置(物理地址)。但是,图书馆为了方便访问和管理,使用了一个索引系统(页表),让读者(程序)通过索引号(虚拟地址)就能找到书籍的实际位置。satp寄存器就是这个索引系统的入口,告诉你如何通过虚拟地址找到数据的物理地址。
- 地址转换:当你查找一本书时,你只需知道它的索引号。图书馆的管理系统(MMU)会自动通过索引号查找到书的实际位置,这个过程就像虚拟地址被转换为物理地址。
实际应用
- 开发调试:使用断点和单步执行来调试程序,就像是在图书馆里找书时偶尔需要停下来检查你是否走在正确的路径上。
- 操作系统设计:操作系统的设计者就像图书馆的管理员,需要规划索引系统,决定哪些书籍(数据/程序)应该放在哪里,以及如何高效地管理这些资源。
通过这些场景和比喻,希望能帮你更直观地理解RISC-V的这些概念。在实践中,通过编写和运行一些简单的RISC-V程序,尤其是那些涉及中断处理和内存管理的程序,将进一步加深你对这些概念的理解。
中断/异常处理寄存器
- PC (Program Counter): 程序计数器,保存着处理器当前执行指令的地址。
- mepc (Machine Exception Program Counter): 机器异常程序计数器,保存发生异常时指令的地址。在M-Mode中用于记录中断或异常发生前的PC值。
- sepc (Supervisor Exception Program Counter): 监管者异常程序计数器,与mepc相似,但用于S-Mode。记录发生异常或中断时的PC值。
- mtvec (Machine Trap-Vector Base-Address Register): 机器陷阱向量基址寄存器,存储M-Mode中断处理程序的入口地址。
- stvec (Supervisor Trap-Vector Base-Address Register): 监管者陷阱向量基址寄存器,存储S-Mode中断处理程序的入口地址。
- mcause (Machine Cause Register): 机器原因寄存器,记录最近一次异常或中断的原因。
- scause (Supervisor Cause Register): 监管者原因寄存器,与mcause类似,但用于S-Mode。
- mie (Machine Interrupt Enable): 机器中断使能寄存器,M-Mode中断使能寄存器,用于控制是否允许中断发生。
- sie (Supervisor Interrupt Enable): 监管者中断使能寄存器,S-Mode中断使能寄存器,与mie相似,但用于S-Mode。
- mideleg (Machine Interrupt Delegation Register): 机器中断委托寄存器,控制哪些中断可以被委托给S-Mode处理的M-Mode寄存器。
- medeleg (Machine Exception Delegation Register): 机器异常委托寄存器,控制哪些异常可以被委托给S-Mode处理的M-Mode寄存器。
虚拟内存系统寄存器
- satp (Supervisor Address Translation and Protection): S-Mode下控制页表的寄存器,包括启用分页机制、页表的物理地址和地址空间标识符。
| 寄存器缩写 | 英文全称 | 中文全称 | 功能描述 |
|---|---|---|---|
| PC | Program Counter | 程序计数器 | 保存着处理器当前执行指令的地址。 |
| mepc | Machine Exception Program Counter | 机器异常程序计数器 | 保存发生异常时指令的地址,在M-Mode中用于记录中断或异常发生前的PC值。 |
| sepc | Supervisor Exception Program Counter | 监管者异常程序计数器 | 与mepc相似,但用于S-Mode,记录发生异常或中断时的PC值。 |
| mtvec | Machine Trap-Vector Base-Address Register | 机器陷阱向量基址寄存器 | 存储M-Mode中断处理程序的入口地址。 |
| stvec | Supervisor Trap-Vector Base-Address Register | 监管者陷阱向量基址寄存器 | 存储S-Mode中断处理程序的入口地址。 |
| mcause | Machine Cause Register | 机器原因寄存器 | 记录最近一次异常或中断的原因。 |
| scause | Supervisor Cause Register | 监管者原因寄存器 | 与mcause类似,但用于S-Mode。 |
| mie | Machine Interrupt Enable | 机器中断使能寄存器 | M-Mode中断使能寄存器,用于控制是否允许中断发生。 |
| sie | Supervisor Interrupt Enable | 监管者中断使能寄存器 | S-Mode中断使能寄存器,与mie相似,但用于S-Mode。 |
| mideleg | Machine Interrupt Delegation Register | 机器中断委托寄存器 | 控制哪些中断可以被委托给S-Mode处理的M-Mode寄存器。 |
| medeleg | Machine Exception Delegation Register | 机器异常委托寄存器 | 控制哪些异常可以被委托给S-Mode处理的M-Mode寄存器。 |
工作流程示例
以下是一个简化的中断处理流程:
- 中断触发:首先,中断信号由硬件(如定时器、I/O设备)发出。
- 中断识别:处理器检测到中断信号,并根据当前的中断使能状态(通过
mie或sie寄存器控制)和优先级决定是否接受中断。 - 保存当前状态:
- 保存PC:处理器自动将当前的程序计数器(PC)保存到
mepc(如果在M-Mode)或sepc(如果中断被委托给S-Mode)寄存器中。 - 设置
mcause/scause:mcause(在M-Mode)或scause(在S-Mode)寄存器被设置为描述中断原因的值。
- 保存PC:处理器自动将当前的程序计数器(PC)保存到
- 中断处理程序入口:
- 跳转执行:处理器读取
mtvec(在M-Mode)或stvec(在S-Mode)寄存器的值,并跳转到相应的中断处理程序入口地址执行。
- 跳转执行:处理器读取
- 执行中断处理程序:执行中断服务例程(ISR),完成必要的处理任务,如读取数据、更新状态、清除中断标志等。
- 恢复现场并返回:
- 通过执行
mret(在M-Mode)或sret(在S-Mode)指令,处理器从mepc/sepc寄存器恢复之前保存的PC值,返回到中断发生前的执行点继续执行。
- 通过执行
在虚拟内存系统中的地址转换过程:
- 程序访问虚拟地址:用户程序试图访问一个虚拟地址。
- 地址转换:
- CPU使用
satp寄存器中的信息找到根页表。 - 根据虚拟地址中的页号和偏移量,通过一系列页表项遍历找到最终的物理地址。
- CPU使用
- 访问物理内存:CPU根据转换后的物理地址访问实际的内存数据或指令。
通过这些寄存器和工作流程,RISC-V能够有效地处理中断和异常,同时提供灵活的内存管理机制。
RISC-V的启动流程中,不同的模式(U-Mode、S-Mode、M-Mode)以及它们之间的交互反映了一个层级结构和控制流程。这个流程确保了系统在启动和运行时的安全和稳定性。
从下到上(启动和初始化流程)
- 启动(Boot-ROM):
- 系统电源开启或重置后,首先执行的是ROM中的启动代码,它初始化硬件,并跳转到更高级别的程序或者引导加载器。
- 机器模式(M-Mode):
- 接下来,控制权传递到机器模式,这是最低级别的权限模式。在这里,通常执行的是固件代码,如RustSBI(Supervisor Binary Interface的一个实现),负责初始化系统的基础设施,包括设置中断和异常处理程序。
- 监管模式(S-Mode):
- 一旦机器模式的初始化完成,通过
mret指令将控制权交给监管模式。监管模式负责启动操作系统,设置虚拟内存、进程和用户模式的隔离。
- 一旦机器模式的初始化完成,通过
- 用户模式(U-Mode):
- 操作系统创建用户空间环境,并通过
sret指令跳转到用户模式运行用户程序。用户模式程序可以通过系统调用与操作系统交互,请求服务。
- 操作系统创建用户空间环境,并通过
从上到下(系统调用和响应流程)
- 用户模式(U-Mode):
- 当用户程序需要操作系统服务时(比如写文件、网络通信等),它会通过系统调用(syscall)请求操作系统介入。
- 监管模式(S-Mode):
- 系统调用触发中断,将控制权从用户模式转交给监管模式。操作系统在监管模式中响应系统调用,执行必要的服务。
- 机器模式(M-Mode):
- 若需要执行更低级别的操作,如控制台输入输出,操作系统可能会通过SBI调用(sbicall),请求机器模式下的SBI固件提供支持。
从下到上(执行SBI调用并从M-Mode返回到U-Mode)
- M-Mode执行SBI调用:
- 在机器模式下,RustSBI等固件执行一个特权级操作,如
sbicall进行系统级别的服务请求。
- 在机器模式下,RustSBI等固件执行一个特权级操作,如
- M-Mode完成操作:
- SBI服务完成后,例如完成了控制台字符输出或硬件设备的控制。
- 返回到S-Mode:
- 使用
mret指令,RustSBI将控制权从M-Mode返回到S-Mode。此时,处理器状态恢复到S-Mode执行sbicall之前的状态。
- 使用
- S-Mode处理结果:
- 操作系统在S-Mode处理
sbicall的结果,可能是更新操作系统状态、记录日志或者准备返回到用户模式。
- 操作系统在S-Mode处理
- 准备返回到U-Mode:
- 操作系统完成所有必要的处理后,准备将控制权返回给用户程序。
- 返回到U-Mode:
- 操作系统使用
sret指令,将控制权返回到用户模式,继续用户程序的执行。
- 操作系统使用
- U-Mode继续执行:
- 用户程序继续执行,可能是处理SBI调用的结果,或者执行下一步操作。
- 用户程序运行结束:
- 用户程序完成其任务后,可能是自然结束,或者因为需要再次服务而触发另一次系统调用。
在整个流程中,mret和sret指令用于返回到之前的权限模式,它们分别用在机器模式和监管模式的退出操作。这样的层级结构和控制流程允许RISC-V系统在保证安全性的同时,实现复杂的操作系统功能,包括用户与硬件之间的交互。
从上到下(关机流程)
- 用户模式(U-Mode):
- 用户程序决定关机,发起系统调用(syscall)通知操作系统进行关机。
- 监管模式(S-Mode):
- 操作系统接收到来自用户程序的关机系统调用,并开始执行关机准备工作,如关闭文件、通知其他进程等。
- 机器模式(M-Mode):
- 操作系统执行完所有准备工作后,通过SBI调用(sbicall)请求M-Mode的固件执行关机操作。
- 执行SBI关机调用:
- 固件(如RustSBI)接收到关机请求,执行必要的硬件关闭程序,包括停止时钟、关闭I/O设备等。
- 电源关闭(Power Down):
- 完成所有硬件关闭程序后,固件执行最终的电源关闭操作。
用户程序执行“Hello World”
- 执行用户程序:
- 用户程序(在U-Mode中)开始执行,当需要打印输出时,会执行如
uprint这样的打印函数。
- 用户程序(在U-Mode中)开始执行,当需要打印输出时,会执行如
- 系统调用:
- 执行
uprint函数时,用户程序会进行系统调用(通过ecall指令),请求操作系统提供打印服务。
- 执行
- S-Mode响应系统调用:
- 系统调用将控制权从U-Mode转交给S-Mode,操作系统的
sys_write函数响应系统调用,处理打印请求。
- 系统调用将控制权从U-Mode转交给S-Mode,操作系统的
- 调用SBI服务:
- 如果打印需要低级访问,如向控制台输出字符,操作系统可能会调用SBI服务(通过SBI调用)。
- M-Mode SBI执行打印:
- SBI的
sbi.console_putchar函数在M-Mode中被调用,将字符输出到控制台。
- SBI的
返回监管模式(S-Mode)
- SBI to OS:
- 打印操作完成后,SBI固件通过
mret指令返回到监管模式,准备返回控制权给操作系统。
- 打印操作完成后,SBI固件通过
- OS处理完成:
- 操作系统接收来自SBI的返回,并完成任何后续的清理或状态更新操作。
返回用户模式(U-Mode)
- 返回到系统调用点:
- 操作系统通过
sret指令将控制权返回到发起系统调用的用户程序的位置。
- 操作系统通过
- 用户程序继续执行:
- 用户程序继续执行打印“Hello World”后的下一条指令。
- 程序执行完毕:
- “Hello World”打印请求执行完毕后,用户程序可能会继续执行其他任务或者终止。
系统返回到正常状态
-
任务调度(可选):
- 如果有多任务调度,操作系统可能在此时进行上下文切换,调度另一个进程或线程运行。
-
系统空闲或等待:
- 如果用户程序是最后一个任务或系统处于空闲状态,操作系统可能会进入等待状态,等待下一个中断或系统调用。
在RISC-V架构中,用户态(U-Mode)是不允许直接执行特权指令的。如果用户程序尝试执行特权指令,这将触发一个异常,进而由更高权限模式的异常处理程序来响应。以下是在用户态执行特权指令时的流程:
- 用户模式(U-Mode)执行特权指令:
- 用户程序试图执行特权指令(例如:
uprint内部尝试直接执行硬件操作)。
- 用户程序试图执行特权指令(例如:
- 异常被触发:
- 由于用户程序无权执行特权指令,处理器将触发异常。
- 转到监管模式(S-Mode):
- 异常使处理器从U-Mode跳转到S-Mode,控制权转交给操作系统的异常处理程序(trap handler)。
- 操作系统处理异常:
- 操作系统的异常处理程序确定异常原因(通过
scause寄存器)并决定如何处理(比如记录错误、终止程序等)。
- 操作系统的异常处理程序确定异常原因(通过
- 可选的SBI调用:
- 如果需要,操作系统可以选择调用SBI接口(例如:
sbi_exit),请求M-Mode下的SBI来执行某些操作(比如关闭硬件设备或重启)。
- 如果需要,操作系统可以选择调用SBI接口(例如:
- 恢复或终止:
- 根据异常的性质和严重性,操作系统可能会决定继续执行应用程序、重新启动应用程序或完全终止应用程序。
- 返回用户模式(U-Mode):
- 如果操作系统决定让应用程序继续运行,它将通过执行
sret指令返回到用户模式。
- 如果操作系统决定让应用程序继续运行,它将通过执行
- 处理完成:
- 用户程序根据操作系统的处理结果决定下一步操作,可能是继续执行、尝试其他操作或正常退出。
在这个流程中,异常处理程序为系统的稳定性提供了关键保障,确保即使在不当操作尝试时,系统也能保持响应性和可靠性。这也显示了RISC-V架构对权限控制的严格性,防止了非授权的特权操作。
RISC-V架构中的中断处理和权限模式为系统设计提供了一系列的优点,这些优点在上述的“Hello World”程序执行流程和关机流程中表现得尤为明显:
- 层级安全性:通过层级化的权限模式(U-Mode, S-Mode, M-Mode),RISC-V确保了每个层级只能执行它被授权的操作。这防止了低权限代码对系统的潜在破坏,提高了系统的整体安全性。
- 细粒度控制:通过各种模式特定的寄存器和指令(如
mepc,sepc,mcause,scause,mret,sret),系统可以精确控制执行流程和资源管理,从而在需要时提供灵活性。 - 异常处理:当用户态程序尝试执行非法操作时(如特权指令),RISC-V能够优雅地捕获并处理异常,而不是让整个系统崩溃。
- 中断效率:通过委托机制(
mideleg和medeleg),RISC-V允许中断直接被S-Mode处理,而无需每次都经过M-Mode,这减少了中断响应时间,提高了效率。 - 模块化设计:RISC-V的设计鼓励模块化,这意味着不同的组件(比如SBI)可以独立于处理器核心进行开发和优化。
- 简化的上下文切换:在中断处理和系统调用过程中,通过寄存器保存和恢复现场,RISC-V简化了上下文切换,减少了切换开销。
- 可预测的行为:每个级别的行为都是可预测的,这对于系统的可靠性和可维护性至关重要。在关机流程中,这一点尤其显著,因为系统需要按照严格的顺序逐步关闭资源。
- 支持虚拟化:通过
satp寄存器和虚存机制的支持,RISC-V允许操作系统实现强大的内存管理策略,为虚拟化和容器化技术提供了基础。 - 底层支持:底层的SBI提供了一个通用的接口,让上层操作系统能够与硬件进行互动,而不需要关心硬件的具体实现细节,促进了软硬件之间的解耦。
总的来说,通过这些设计,RISC-V架构提供了一个强大、安全和高效的平台,适用于从简单的嵌入式系统到复杂的操作系统和应用程序。它的设计允许系统开发者在确保核心功能安全性的同时,为最终用户提供灵活、快速响应的体验。
第三讲 基于特权级的隔离与批处理
第三节 实践:批处理操作系统
一 实验目标/历史背景
批处理操作系统是一种能够在隔离环境下运行多个应用程序的系统,其目的是确保安全与资源的高效利用。
批处理OS目标
-
隔离与安全:
- 应用与操作系统之间的隔离确保了系统的完整性和安全性,防止恶意或有缺陷的应用破坏系统。
- 通过特权级别和虚存机制限制应用程序对硬件资源的直接访问。
-
批处理:
- 系统自动加载并逐个执行多个应用程序,每次内存中只存在一个应用程序。
- 在应用程序之间保持明确的状态切换,确保不会出现资源冲突和数据泄漏。
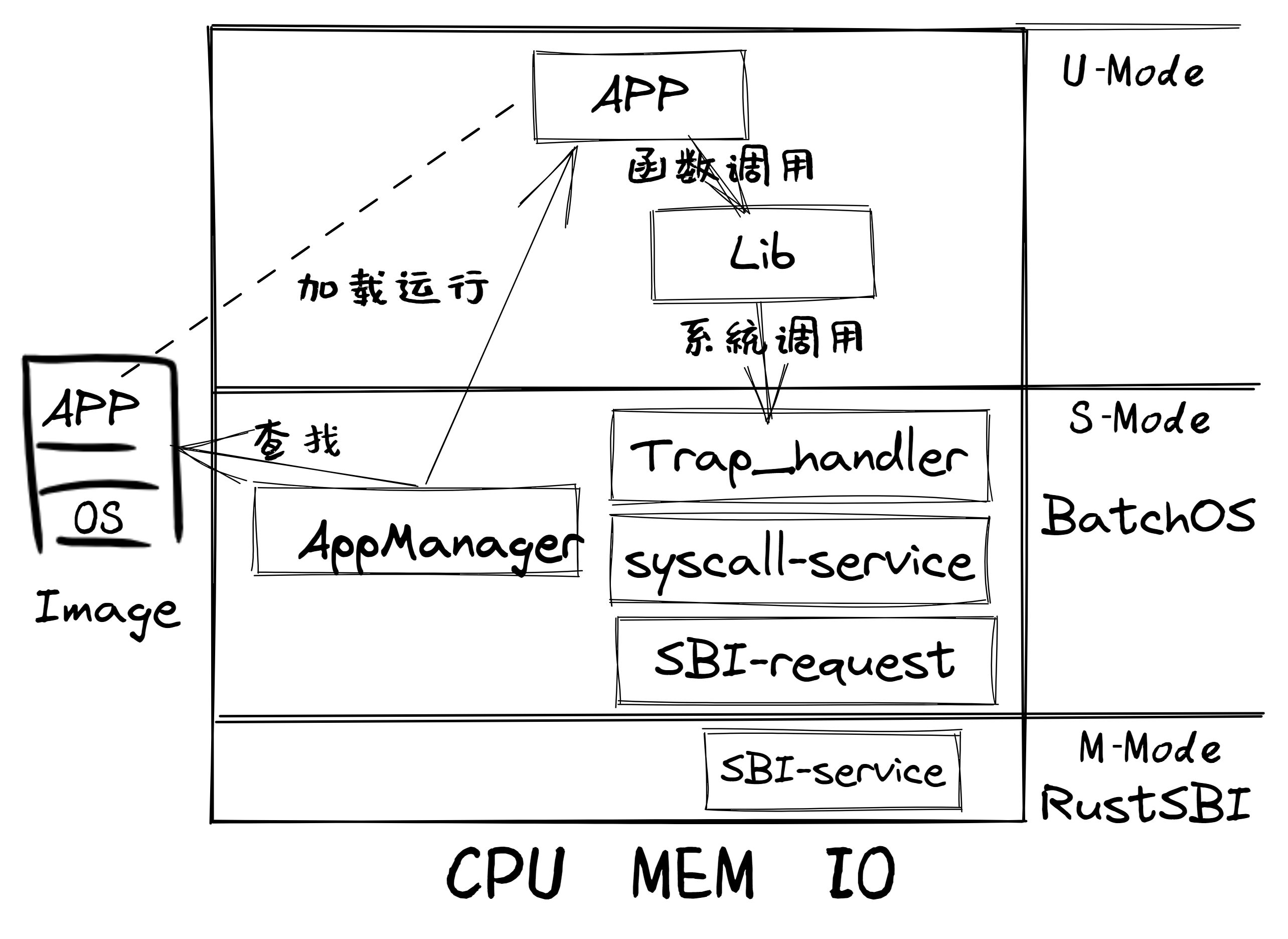
软件设计目标
-
软件层次结构:
- 将应用程序与操作系统分别编译并最终合成一个镜像,减少了耦合性,便于调试与更新。
- 操作系统负责应用程序的加载、管理和调度。
-
系统调用接口:
- 使用系统调用机制(如 ECall)替代函数调用,实现应用程序与操作系统的安全通信。
- 构建支持用户程序的库函数,简化应用程序的开发与调试。
-
操作系统管理与调度:
- 操作系统应具备管理应用程序和初始化的能力。
- 利用特权级别、虚拟内存和系统调用机制,实现批处理环境下应用程序之间的状态切换和资源分配。
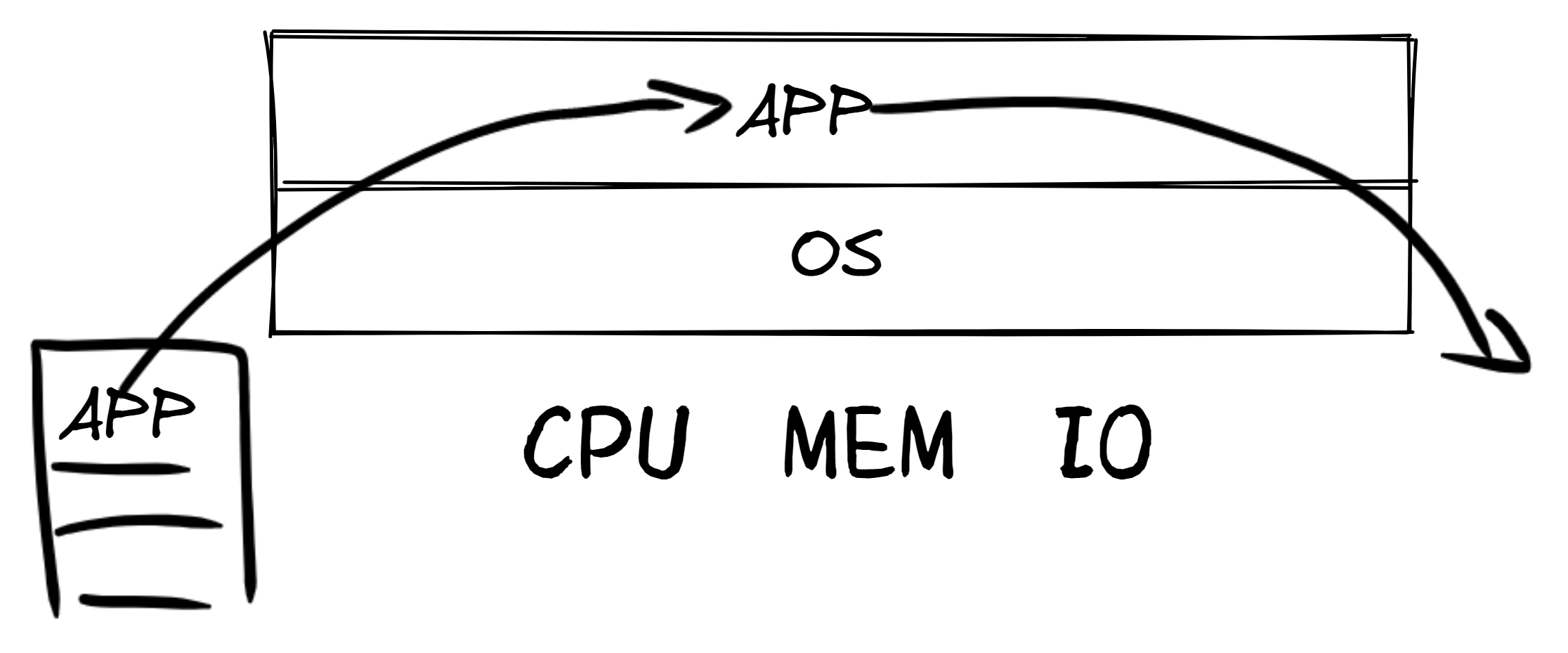
状态切换
-
状态保存与恢复:
- 应用程序在系统调用或中断时,会触发状态保存操作,以保护当前执行的上下文信息。
- 在返回到应用程序或进入其他程序时,系统应确保上下文信息能够完整恢复,以保持程序的连续性。
-
切换机制:
- 使用特定的硬件寄存器(如 CSR)存储和恢复状态信息。
- 系统调用和中断处理程序需要结合硬件机制以确保切换过程的安全性和完整性。
实验要求
- 理解运行其他软件的软件
- 理解特权级和特权级切换
- 理解系统调用
- 会写批处理操作系统
历史背景
-
GM-NAA I/O System (1956):
- 1956年首次出现的一款早期操作系统,具有批处理特性。它的名字中,
GM代表通用汽车公司 (General Motors)。 - 这种批处理系统从当时汽车流水线的管理模式中获得灵感,旨在最大限度地提高计算资源的利用率。
- 1956年首次出现的一款早期操作系统,具有批处理特性。它的名字中,
-
MULTICS OS:
- MULTICS(Multiplexed Information and Computing Service)在1960年代末作为一种先进的多用户操作系统出现,使用 GE 645 大型机的八级硬件保护机制,实现了安全的多用户批处理环境。
- 保护环 (Protection Ring) 机制在现代 X86 架构中以
Ring 0-3的形式继续存在,但在 RISC-V 架构中,这种特权级别称为 模式 (Mode)。
二 实现步骤
- 构建镜像:
- 将操作系统和应用程序编译成独立的二进制文件,然后合并成一个完整的镜像文件,供批处理系统加载并执行。
- 通过批处理支持多个APP的自动加载和运行
- 跨特权级切换:
- 支持应用程序与操作系统间的特权级别切换。应用程序通过系统调用请求服务,操作系统根据请求提供适当的功能。
- 应用程序和操作系统之间的通信可以通过
ECall指令来实现。 - 利用硬件特权级机制实现对操作系统自身的保护
- 支持跨特权级的系统调用
- 执行与处理:
- 系统按顺序加载并执行批处理镜像中的各个应用程序。
- 执行过程中,系统需要管理好每个应用的状态和资源,确保它们在各自的地址空间内独立运行。
- 实现特权级的切换
- 实验和调试:
- 建议下载代码,运行并修改,以便更好地理解批处理操作系统的内部结构和运行机制。
- 运行时可以观察到操作系统如何逐个加载并执行应用程序,执行完毕后进行适当的清理工作。
编译步骤
git clone https://github.com/rcore-os/rCore-Tutorial-v3.git
cd rCore-Tutorial-v3
git checkout ch2
cd os
make run
参考运行结果
...
[kernel] num_app = 5
[kernel] app_0 [0x8020a038, 0x8020af90)
...
[kernel] Loading app_0
Hello, world!
[kernel] Application exited with code 0
[kernel] Loading app_1
...
[kernel] Panicked at src/batch.rs:58 All applications completed!
三 软件架构
批处理操作系统的架构主要由两个主要部分构成:
-
用户态应用层(User Mode Applications):
- 用户态程序可以是任何简单的程序,例如打印输出或求和计算程序。
- 通过用户态库的封装,用户程序可以直接调用库函数,如
u_print,来发送系统调用指令 ECall。 - 用户库通过封装系统调用指令,为用户程序提供易用的接口,将复杂的系统操作隐藏在后台。
-
操作系统内核层(Kernel Layer):
-
应用管理器(App Manager):负责从镜像中检索并加载每个应用程序到内存执行。
-
中断处理与系统调用服务(Trap Handler & System Services):
- 处理与应用程序相关的中断和系统调用。
- 管理特权级别的状态保存与恢复,确保从用户态到内核态的切换顺利。
- 最底层的
trap.S汇编程序负责保存与恢复特权状态。
-
硬件抽象与外设交互:
- 使用 RISC-V 的 SBI(Supervisor Binary Interface)调用,简化对实际外设的操作。
- 通过 Rust SBI 接口,OS 负责字符串显示,外设驱动设计被隐藏。
-
构建应用
- 使用
link_app.S作为应用程序的链接脚本,将多个用户程序的二进制镜像与操作系统内核一起打包成单一的镜像。- 把多个应用合在一起与OS形成一个二进制镜像
├── os
│ ├── build.rs(新增:生成 link_app.S 将应用作为一个数据段链接到内核)
│ ├── Cargo.toml
│ ├── Makefile(修改:构建内核之前先构建应用)
│ └── src
│ ├── link_app.S(构建产物,由 os/build.rs 输出)
-
Python 或 Rust 脚本会自动生成此汇编脚本,确保最终生成镜像的一致性。
-
多应用程序支持:系统允许同时存在多个用户程序,通过批处理模式依次执行每个程序。
改进OS
- 特权级别切换:通过
trap.S等程序实现用户态与内核态之间的切换,保障程序隔离与特权级别的正确性。- 加载和执行程序、特权级上下文切换
├── os
│ └── src
│ ├── batch.rs(新增:实现了一个简单的批处理系统)
│ ├── main.rs(修改:主函数中需要初始化 Trap 处理并加载和执行应用)
│ └── trap(新增:Trap 相关子模块 trap)
│ ├── context.rs(包含 Trap 上下文 TrapContext)
│ ├── mod.rs(包含 Trap 处理入口 trap_handler)
│ └── trap.S(包含 Trap 上下文保存与恢复的汇编代码)
- 中断与异常处理:确保所有应用程序运行时的异常被有效捕获与处理。
- 应用加载与管理:内核层负责检索和加载每个用户程序,确保其执行环境的完整性。
系统调用
系统调用机制是用户程序和内核交互的重要桥梁。其主要目标是确保用户程序可以借助内核的功能完成所需的任务,同时保持不同特权级别间的隔离。
├── os
│ └── src
│ ├── syscall(新增:系统调用子模块 syscall)
│ │ ├── fs.rs(包含文件 I/O 相关的 syscall)
│ │ ├── mod.rs(提供 syscall 方法根据 syscall ID 进行分发处理)
│ │ └── process.rs(包含任务处理相关的 syscall)
- 字符串显示:
- 用户程序需要显示字符串时,会逐字符地将内容通过系统调用交给内核。
- 内核利用 RISC-V 的 SBI(Supervisor Binary Interface)调用来最终处理显示任务。
RustSBI负责与底层硬件交互,使得内核层无需直接处理硬件操作。
添加应用
系统中包含五个简单的应用程序,每个程序都旨在测试和展示不同的操作系统功能。批处理OS会按照文件名开头的数字顺序依次加载并运行它们
└── user(新增:应用测例保存在 user 目录下)
└── src
├── bin(基于用户库 user_lib 开发的应用,每个应用放在一个源文件中)
│ ├── 00hello_world.rs # 显示字符串的应用
│ ├── 01store_fault.rs # 非法写操作的应用
│ ├── 02power.rs # 计算与I/O频繁交替的应用
│ ├── 03priv_inst.rs # 执行特权指令的应用
│ └── 04priv_csr.rs # 执行CSR操作指令的应用
下面逐一进行描述:
-
00_hello_world.rs:
- 显示字符串 "Hello, World!"。
- 用于验证基本的系统调用输出功能。
-
01_store_fault.rs:
- 执行非法写操作,触发内存存取错误。
- 用于测试操作系统异常处理功能,确保在越权或非法操作时产生适当的错误反馈。
-
02_power.rs:
- 不断交替读取和写入 I/O 设备。
- 用于测试 I/O 频繁交替的能力以及资源调度的健壮性。
-
03_priv_inst.rs:
- 尝试执行特权指令。
- 用于验证系统对特权指令的正确隔离和处理。
-
04_priv_csr.rs:
- 尝试对 CSR(控制状态寄存器)进行读写操作。
- 用于测试系统对 CSR 操作的隔离和异常处理能力。
这些应用程序通过编号的方式方便查找和执行,同时它们的多样性确保了操作系统各项功能的正确性。
应用库和编译应用支持
-
用户态系统库:
- 为用户态程序提供简单的函数接口,如
u_print,封装了系统调用逻辑。 - 用户库中包含了特权级别转换的汇编指令,使用户程序可以轻松调用内核功能。
- 为用户态程序提供简单的函数接口,如
-
汇编层的
ecall封装:- 以汇编形式实现系统调用的具体细节。
└── user(新增:应用测例保存在 user 目录下)
└── src
├── console.rs # 支持println!的相关函数与宏
├── lang_items.rs # 实现panic_handler函数
├── lib.rs(用户库 user_lib) # 应用调用函数的底层支撑库
├── linker.ld # 应用的链接脚本
└── syscall.rs(包含 syscall 方法生成实际用于系统调用的汇编指令,
各个具体的 syscall 都是通过 syscall 来实现的)
四 相关硬件
相关硬件与异常处理
在设计批处理操作系统的过程中,硬件的支持和特定指令的使用至关重要,尤其是 RISC-V 架构的特权指令。以下是这些关键指令及其在异常处理中的角色:
关键指令与异常处理
-
ecall指令:ecall是特权指令,允许用户态程序通过系统调用进入内核态(或从更低特权级进入更高特权级)。- 在批处理操作系统中,
ecall用于从用户态 (u-mode) 切换至内核态 (s-mode) 以执行系统调用,如显示字符串、读写 I/O 等操作。 - 在 RISC-V 架构中,
ecall产生Environment Call from U-Mode异常,进入内核并执行系统调用处理程序。
-
sret指令:sret是返回指令,用于从内核态返回用户态,恢复执行用户态程序。- 系统调用处理程序执行完毕后,通过
sret恢复特权级的上下文信息,使得控制权交还给先前的用户程序。
-
e-break指令:e-break是调试相关的特权指令,触发断点异常,使程序进入调试状态。- 用于开发和调试时,捕获并显示程序中的断点,以便系统开发者分析和修改。
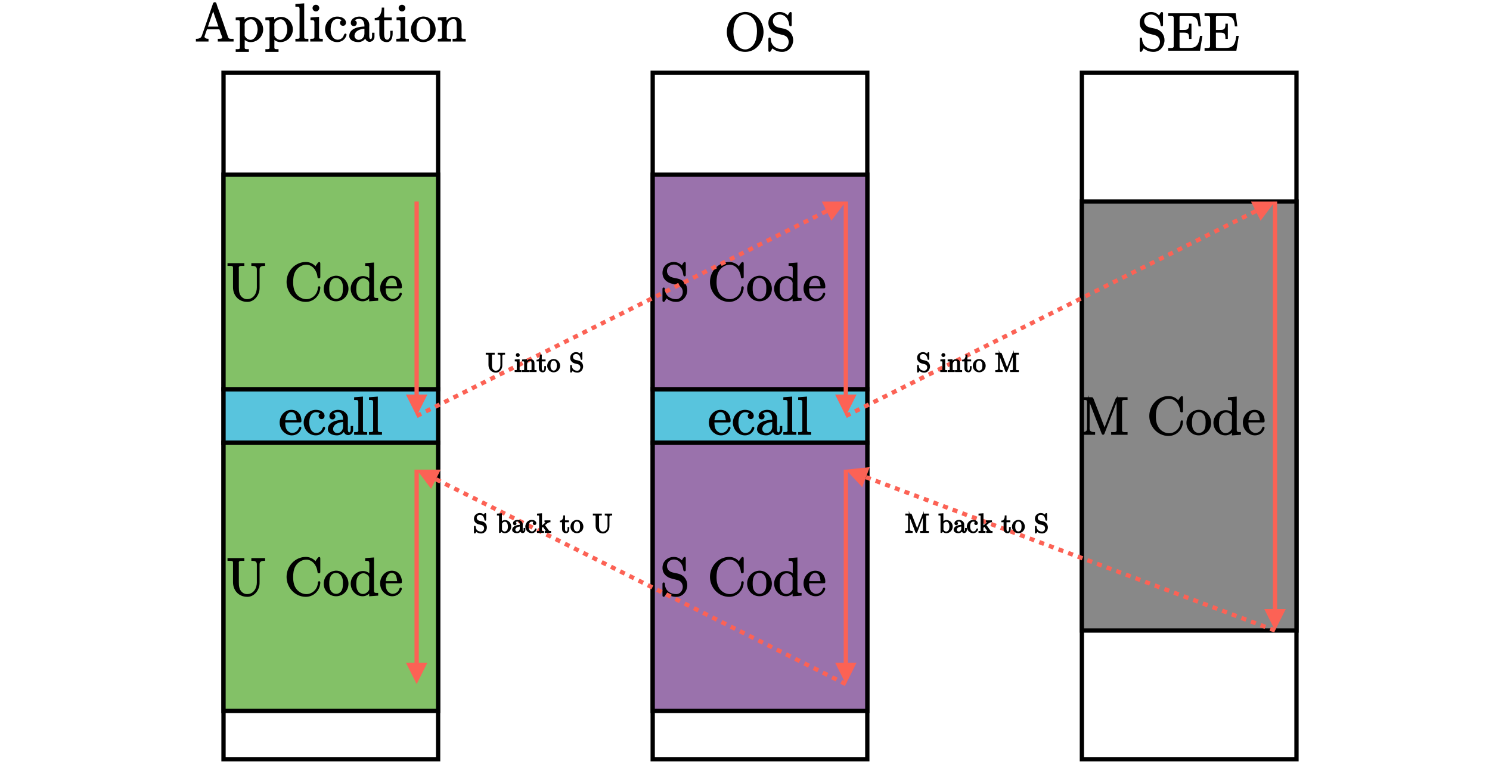
特权级转换流程
- 用户程序通过
ecall进入内核态后:- 内核保存当前的程序计数器 (
sepc) 和特权级别信息。 - 根据系统调用编号跳转至相应的系统调用处理程序。
- 处理程序执行完毕后,通过
sret恢复用户态,并继续执行程序。
- 内核保存当前的程序计数器 (
外设支持
- Supervisor Binary Interface (SBI):
- RISC-V 的 SBI 提供对外设的统一接口。
- 内核通过 SBI 完成与硬件串口、计时器等设备的交互,使其可以专注于高层的系统管理。
硬件异常处理流程
硬件异常处理流程如下:
- 异常或中断发生,硬件保存程序计数器和特权级别信息。
- 将异常或中断原因(如
ecall from U-Mode、e-break等)存储在指定寄存器中。 - 跳转至异常处理程序,由操作系统处理和解决。
- 处理完毕后,通过特权返回指令恢复特权级别和继续执行。
这些机制确保在用户态和内核态之间切换时,有一个稳定、安全且高效的上下文保存和恢复流程。
RISC-V异常向量
| Interrupt | Exception Code | Description | |
|---|---|---|---|
| 0 | 0 | Instruction address misaligned | 指令地址未对齐 |
| 0 | 1 | Instruction access fault | 指令访问错误 |
| 0 | 2 | Illegal instruction | 非法指令 |
| 0 | 3 | Breakpoint | 断点 |
| 0 | 4 | Load address misaligned | 加载地址未对齐 |
| 0 | 5 | Load access fault | 加载访问错误 |
| 0 | 6 | Store/AMO address misaligned | 存储/AMO 地址未对齐 |
| 0 | 7 | Store/AMO access fault | 存储/AMO 访问错误 |
| 0 | 8 | Environment call from U-mode | U 模式环境调用 |
| 0 | 9 | Environment call from S-mode | S 模式环境调用 |
| 0 | 11 | Environment call from M-mode | M 模式环境调用 |
| 0 | 12 | Instruction page fault | 指令页错误 |
| 0 | 13 | Load page fault | 加载页错误 |
| 0 | 15 | Store/AMO page fault | 存储/AMO 页错误 |
- AMO: atomic memory operation 原子内存操作
五 应用程序设计
5.1 项目结构
在程序设计中,用户态程序与操作系统之间的交互需要依赖于底层硬件和库的支持。特权级别的管理、系统调用的封装以及程序初始化都对实现批处理操作系统至关重要。
用户态程序结构
-
应用程序与库的分离:
- 应用程序应专注于业务逻辑,使用库中的共性代码进行系统调用和底层支持。
- 库封装了应用程序常用的功能,如打印、I/O、错误处理等。
-
库的组织结构:
user/src/目录包含应用程序和其所需的库文件。bin/放置基于用户库 user_lib 开发的应用。
-
库的引用方式:
- C 语言通过
#include引用库的头文件。 - Rust 语言通过
crate或者extern crate指令加载库。
- C 语言通过
-
应用与底层支撑库分离
└── user(应用程序和底层支撑库)
└── src
├── bin(该目录放置基于用户库 user_lib 开发的应用)
├── lib.rs(用户库 user_lib) # 库函数的底层支撑库
├── ...... # 支撑库相关文件
└── linker.ld # 应用的链接脚本
- 引入外部库
#![allow(unused)] fn main() { #[macro_use] extern crate user_lib; }
程序初始化流程/设计支撑库
-
启动逻辑 (
start):- 在执行应用程序的
main函数之前,启动逻辑会初始化程序的执行环境。 - 初始化包括清零未初始化的全局变量所在的
.bss段,确保所有变量初始值正确。
- 在执行应用程序的
-
主逻辑 (
main):- 应用程序的主要功能和逻辑在
main函数中实现。 - 在初始化完成后,
start函数将调用main开始执行程序。
- 应用程序的主要功能和逻辑在
在 lib.rs 中我们定义了用户库的入口点 _start :
#![allow(unused)] fn main() { #[no_mangle] #[link_section = ".text.entry"] pub extern "C" fn _start() -> ! { clear_bss(); exit(main()); panic!("unreachable after sys_exit!"); } }
异常与退出处理
-
异常处理:
- 在程序执行过程中,如果发生异常(如未处理的系统调用、内存访问违规等),库会触发
panic,以便操作系统进行相应处理。
- 在程序执行过程中,如果发生异常(如未处理的系统调用、内存访问违规等),库会触发
-
正常退出:
- 当程序正常结束时,将通过系统调用通知操作系统退出。
- 退出时,系统调用确保上下文和资源的清理,并返回操作系统供后续程序执行。
5.2 内存布局
编译器生成的程序结构
- 代码与数据段: 应用程序在内存中的布局分为代码段和数据段两大部分。每个部分进一步细分,包括已初始化数据、未初始化数据、只读数据等。
- 链接器脚本 (
.ld文件): 链接器使用脚本确定最终执行程序的内存布局。脚本指定代码段、数据段的起始地址和各自的大小。我们可以修改.ld文件调整内存布局,但需要确保操作系统也了解这些更改。
系统调用的参数传递
-
寄存器传递方式:
- 为提高系统调用的效率,使用寄存器传递参数与返回值。
- 特定的寄存器约定:A7 寄存器用于指定系统调用号,A0-A2 等用于传递参数或接收返回值。
-
硬件约定与软件协议:
- 这类参数传递约定是一种软件协议,由应用程序和操作系统共同遵循。
- 硬件本身不干预参数传递的约定,所以只要软件双方遵守这个约定,系统调用就能顺利进行。
设计支撑库
user/src/linker.ld
- 将程序的起始物理地址调整为 0x80400000 ,应用程序都会被加载到这个物理地址上运行;
- 将 _start 所在的 .text.entry 放在整个程序的开头,也就是说批处理系统只要在加载之后跳转到 0x80400000 就已经进入了 用户库的入口点,并会在初始化之后跳转到应用程序主逻辑;
- 提供了最终生成可执行文件的 .bss 段的起始和终止地址,方便 clear_bss 函数使用。
- 其余的部分与之前相同
5.3 系统调用
在批处理操作系统中,系统调用(syscall)是一种机制,让应用程序可以请求操作系统的服务或完成特定任务。下面是实现系统调用的关键点:
-
Sys Write 与 Sys Exit
- Sys Write: 负责将字符串写入输出设备,需要提供缓冲区地址和缓冲区大小等参数。
- 调用结束后,操作系统会返回实际写入的字节数。
- Sys Exit: 负责退出程序,并带有退出码参数,调用后应用程序将不再继续执行。
- 以感叹号
!标识的系统调用是不会返回的。
- Sys Write: 负责将字符串写入输出设备,需要提供缓冲区地址和缓冲区大小等参数。
-
内联汇编实现
- 使用嵌入式的内联汇编来实现系统调用,可以确保性能和效率。
- 汇编代码包括:
- 设置系统调用 ID 和参数到指定寄存器(A0, A1, A2 等)。
- 通过
ecall指令触发系统调用。 - 从寄存器中获取返回值并传递给程序。
- 示例内联汇编代码(Rust 风格):
- 系统调用 ID 被存储在 X17 寄存器(A7)。
- 参数 被存储在 X10, X11, 和 X12(A0, A1, A2)等寄存器。
- 返回值 被存储在 X10(A0)。
-
流程
- 汇编代码将传入的参数存储到特定寄存器。
- 发出
ecall指令,触发 名为 Environment call from U-mode 的异常 - Trap 进入 S 模式执行批处理系统针对这个异常特别提供的服务代码
- 操作系统处理后,将结果保存在寄存器中并返回应用程序。
- a0~a6 保存系统调用的参数, a0 保存返回值, a7 用来传递 syscall ID
通过这种内联汇编机制,系统调用可在应用程序和操作系统之间保持良好连接,使用户程序能够充分利用操作系统提供的服务。
| Register | ABI Name | Description | 描述 | Saver |
|---|---|---|---|---|
| x0 | zero | Hard-wired zero | 硬连线零值 | —— |
| x1 | ra | Return address | 返回地址 | Caller |
| x2 | sp | Stack pointer | 栈指针 | Callee |
| x3 | gp | Global pointer | 全局指针 | —— |
| x4 | tp | Thread pointer | 线程指针 | —— |
| x5 | t0 | Temporary/alternate link register | 临时寄存器/备用链接寄存器 | Caller |
| x6–7 | t1–2 | Temporaries | 临时寄存器 | Caller |
| x8 | s0/fp | Saved register/frame pointer | 保存的寄存器/帧指针 | Callee |
| x9 | s1 | Saved register | 保存的寄存器 | Callee |
| x10–11 | a0–1 | Function arguments/return values | 函数参数/返回值 | Caller |
| x12–17 | a2–7 | Function arguments | 函数参数 | Caller |
| x18–27 | s2–11 | Saved registers | 保存的寄存器 | Callee |
| x28–31 | t3–6 | Temporaries | 临时寄存器 | Caller |
| f0–7 | ft0–7 | FP temporaries | 浮点临时寄存器 | Caller |
| f8–9 | fs0–1 | FP saved registers | 浮点保存寄存器 | Callee |
| f10–11 | fa0–1 | FP arguments/return values | 浮点参数/返回值 | Caller |
| f12–17 | fa2–7 | FP arguments | 浮点参数 | Caller |
| f18–27 | fs2–11 | FP saved registers | 浮点保存寄存器 | Callee |
| f28–31 | ft8–11 | FP temporaries | 浮点临时寄存器 | Caller |
Caller表示寄存器在调用者保存策略中由调用方负责保存。Callee表示寄存器在调用者保存策略中由被调用方负责保存。
应用程序设计
-
系统调用的实现
- 状态保存与恢复:
- 应用程序无需手动管理状态保存与恢复,OS 会自动处理。
- 汇编代码的重要性:
- 系统调用需要特定的汇编代码(如
ecall)来触发,而这在高级语言中无法直接实现。 - 高级语言(如 Rust 和 C)无法直接翻译成
ecall指令。
- 系统调用需要特定的汇编代码(如
- 状态保存与恢复:
-
实现库支持
- Sys Write 和 Sys Exit:
- 这些函数封装了系统调用,实现应用程序与操作系统的接口。
- 使用系统调用函数
syscall来触发具体的ecall指令。
- 嵌入汇编的作用:
- 汇编代码提供了一种直接与操作系统交互的方法,将调用 ID 和参数加载到特定寄存器中。
ecall发出后,操作系统执行对应的功能并返回结果。
- Sys Write 和 Sys Exit:
-
应用程序与库的关系
- 库设计的目标:
- 确保应用程序通过高级语言函数(如
println!或printf)调用底层的系统服务。 - 将复杂的系统调用细节隐藏在库中,以便应用程序更容易实现。
- 确保应用程序通过高级语言函数(如
- 库设计的目标:
-
应用程序开发的要点
- 管控地址空间:
- 应用程序不需过多关注底层地址空间的管理,由操作系统来提供保护。
- 拓展系统调用:
- 当需要新功能时,可以在库中添加新的系统调用,并扩展
syscall实现。
- 当需要新功能时,可以在库中添加新的系统调用,并扩展
- 管控地址空间:
通过这种设计方式,应用程序可以更专注于业务逻辑,而操作系统与库的封装确保了应用程序的安全性和稳定性。
系统调用支撑库
#![allow(unused)] fn main() { /// 功能:将内存中缓冲区中的数据写入文件。 /// 参数:`fd` 表示待写入文件的文件描述符; /// `buf` 表示内存中缓冲区的起始地址; /// `len` 表示内存中缓冲区的长度。 /// 返回值:返回成功写入的长度。 /// syscall ID:64 fn sys_write(fd: usize, buf: *const u8, len: usize) -> isize; /// 功能:退出应用程序并将返回值告知批处理系统。 /// 参数:`xstate` 表示应用程序的返回值。 /// 返回值:该系统调用不应该返回。 /// syscall ID:93 fn sys_exit(xstate: usize) -> !; }
系统调用参数传递
#![allow(unused)] fn main() { fn syscall(id: usize, args: [usize; 3]) -> isize { let mut ret: isize; unsafe { asm!( "ecall", inlateout("x10") args[0] => ret, //第一个参数&返回值 in("x11") args[1], //第二个参数 in("x12") args[2], //第三个参数 in("x17") id //syscall编号 ); } ret //返回值 } }
参考文档:Rust by Example - Inline assembly
系统调用封装
#![allow(unused)] fn main() { const SYSCALL_WRITE: usize = 64; const SYSCALL_EXIT: usize = 93; //对系统调用的封装 pub fn sys_write(fd: usize, buffer: &[u8]) -> isize { syscall(SYSCALL_WRITE, [fd, buffer.as_ptr() as usize, buffer.len()]) } pub fn sys_exit(xstate: i32) -> isize { syscall(SYSCALL_EXIT, [xstate as usize, 0, 0]) } }
系统调用封装
#![allow(unused)] fn main() { pub fn write(fd: usize, buf: &[u8]) -> isize { sys_write(fd, buf) } const STDOUT: usize = 1; impl Write for Stdout { fn write_str(&mut self, s: &str) -> fmt::Result { write(STDOUT, s.as_bytes()); Ok(()) } } }
六 内核程序设计
6.1 应用管理和加载
-
形成单一镜像
- 构建脚本:
- 使用
builder.rs或者 Python 脚本将应用程序和内核代码合并为一个完整的镜像。 - 使用汇编指令
incbin将应用程序的二进制文件纳入最终镜像中。
- 使用
- 构建脚本:
-
将应用程序链接到内核
- 查找与加载:
- 自动生成的汇编程序包含应用程序的位置信息(如
app0_start和app0_end),这些变量用于标识应用程序的起始和结束位置。 app_manager负责查找这些位置信息,并将应用程序二进制代码拷贝到预定的内存地址。
- 自动生成的汇编程序包含应用程序的位置信息(如
- 固定的执行地址:
- 应用程序应加载到预设的固定地址,以符合链接器脚本
link.ld中的指定位置。
- 应用程序应加载到预设的固定地址,以符合链接器脚本
- 查找与加载:
-
处理特权级切换
- ecall 指令的处理:
- 应用程序通过
ecall指令请求系统调用,此时特权级从用户态切换到内核态。 - 内核需要响应这些系统调用,确保在执行前对相关资源进行初始化并保持状态一致。
- 应用程序通过
- 状态管理与切换:
- 内核需负责保存当前用户态的状态,以便系统调用完成后能正确恢复并返回到用户态。
- ecall 指令的处理:
-
进一步的初始化与执行
- 初始化工作:
- 在执行应用程序前,需要完成必要的内存管理与系统调用机制初始化。
- 特权级的切换和状态的管理需要在内核设计中重点考虑。
- 初始化工作:
通过以上流程,内核可以有效链接和执行应用程序,管理系统调用和切换不同的特权级。
应用程序管理与加载
-
应用程序管理(
app_manager.rs)- 初始化过程:
- 在初始化过程中,
app_manager会识别应用程序的起始和结束地址,并将其保存在全局变量中,方便后续访问和管理。
- 在初始化过程中,
- 全局变量:
- 这些全局变量会存储当前加载的应用程序数量以及每个程序的起始和结束位置。
- 初始化过程:
-
加载应用程序
- 从预定地址加载:
- 应用程序会从指定的内存地址加载到另一个固定的内存区域,以确保它能在合适的地址范围内执行。
- 内嵌汇编指令
fence.i:- 为确保指令缓存(I-Cache)内容的正确性,在应用程序加载完成后会执行
fence.i指令。 - 这条指令并非特权指令,而是扩展指令,用于清空 I-Cache。
- 原因:不清空 I-Cache 可能导致指令缓存中仍保存上一个应用程序的指令。
fence.i确保新程序的代码能够正确执行。 - CPU 对物理内存所做的缓存又分成d-cache和i-cache
- OS将修改会被 CPU 取指的内存区域,这会使得 i-cache 中含有与内存中不一致的内容
- OS在这里必须使用 fence.i 指令手动清空 i-cache ,让里面所有的内容全部失效,才能够保证CPU访问内存数据和代码的正确性。
- 为确保指令缓存(I-Cache)内容的正确性,在应用程序加载完成后会执行
- 从预定地址加载:
通过以上管理与加载机制,系统能够正确识别、加载和运行不同的应用程序,并确保各程序之间的缓存数据不会混淆。
将应用程序映像链接到内核
# os/src/link_app.S 由脚本 os/build.rs 生成
.section .data
.global _num_app
_num_app:
.quad 5
.quad app_0_start
...
.quad app_4_end
.section .data
.global app_0_start
.global app_0_end
app_0_start:
.incbin "../user/target/riscv64gc-unknown-none-elf/release/00hello_world.bin"
app_0_end:
应用程序管理数据结构
#![allow(unused)] fn main() { // os/src/batch.rs struct AppManager { num_app: usize, current_app: usize, app_start: [usize; MAX_APP_NUM + 1], } }
找到应用程序二进制码
- 找到 link_app.S 中提供的符号 _num_app
#![allow(unused)] fn main() { lazy_static! { static ref APP_MANAGER: UPSafeCell<AppManager> = unsafe { UPSafeCell::new({ extern "C" { fn _num_app(); } let num_app_ptr = _num_app as usize as *const usize; ... app_start[..=num_app].copy_from_slice(app_start_raw); AppManager { num_app, current_app: 0, app_start, } }
加载应用程序二进制码
#![allow(unused)] fn main() { unsafe fn load_app(&self, app_id: usize) { // clear icache asm!("fence.i"); // clear app area ... let app_src = core::slice::from_raw_parts( self.app_start[app_id] as *const u8, self.app_start[app_id + 1] - self.app_start[app_id] ); let app_dst = core::slice::from_raw_parts_mut( APP_BASE_ADDRESS as *mut u8, app_src.len() ); app_dst.copy_from_slice(app_src); } }
6.2 特权级切换
在特权级切换中,硬件需要处理以下四个关键步骤,以确保正确切换到内核模式并记录相关状态。
-
保存前一个特权级状态(sstatus 寄存器):
SPP(Supervisor Previous Privilege)记录了执行ecall指令时的特权级,以便恢复时知道应该返回哪个特权级。SPP等字段给出 Trap 发生之前 CPU 的特权级(S/U)等
- 主要用于在返回用户态或更低的特权级时,确保返回正确的上下文。
-
保存异常指令地址(SEPC 寄存器):
SEPC(Supervisor Exception Program Counter)保存了发生异常或ecall指令的确切地址。- 记录 Trap 发生之前执行的最后一条指令的地址
- 这使得操作系统能够识别并确定应该恢复到哪个指令继续执行。
- 在异常处理完毕后,软件通常需要将该地址加4,以跳过已执行的
ecall指令,继续执行后续的正常指令。
-
保存异常原因/附加信息(SCAUSE/stval 寄存器):
SCAUSE(Supervisor Cause)记录了ecall或其他异常的具体原因。- 描述 Trap 的原因
- 操作系统通过读取
SCAUSE,可以识别异常的类型,以便进行适当的处理。 stval给出 Trap 附加信息
-
切换到内核特权级并跳转到异常处理入口(STVEC):
- 硬件将特权级设为 S 模式,并将程序计数器跳转到内核设置的异常处理入口。
STVEC寄存器保存了异常处理程序的入口地址,硬件会根据它跳转到相应的处理函数执行。- 控制 Trap 处理代码的入口地址
通过这四个关键步骤,硬件确保了从用户模式到内核模式的平稳切换,并使内核有足够信息来准确处理异常和 ecall 指令。
| CSR 名 | 该 CSR 与 Trap 相关的功能 |
|---|---|
| sstatus | SPP 等字段给出 Trap 发生之前 CPU 的特权级(S/U)等 |
| sepc | 记录 Trap 发生之前执行的最后一条指令的地址 |
| scause | 描述 Trap 的原因 |
| stval | 给出 Trap 附加信息 |
| stvec | 控制 Trap 处理代码的入口地址 |
特权级切换与用户栈和内核栈
在操作系统中,用户栈和内核栈分别用于处理用户态和内核态的任务。它们的分离设计旨在提高系统的安全性和稳定性。以下是一些设计与实现的原因:
-
安全性:
- 用户程序的栈不受信任,可能包含恶意数据或受损。让内核直接使用用户栈可能导致安全漏洞,例如被用户代码利用进行攻击。
- 使用单独的内核栈确保内核在处理异常和系统调用时能够在受控且可信的内存区域操作,避免受到用户程序的影响。
-
隔离与稳定性:
- 用户程序的栈内存空间可能不稳定或不一致,在内核处理复杂任务或大量数据时,可能会出现栈溢出、非法访问等问题。
- 内核栈在内核管理的独立区域中,确保操作系统在处理系统调用、异常和中断时,有足够的栈空间和稳定的内存布局。
-
状态管理:
- 系统调用和中断处理可能需要保存和恢复大量的寄存器和状态信息。
- 内核栈能够专门用于保存内核态的状态信息,确保系统能够正确地从异常或中断中恢复。
-
性能优化:
- 内核栈可以通过特定的硬件机制或结构进行优化,使其在系统调用和异常处理中更加高效。
- 这有助于在性能敏感的系统调用和中断处理中保持高效响应。
综上所述,分离用户栈和内核栈是确保系统安全、稳定和高效运行的重要设计原则。它使得操作系统在面对不受信任的用户程序时,仍能保持其完整性和可靠性。
#![allow(unused)] fn main() { const USER_STACK_SIZE: usize = 4096 * 2; const KERNEL_STACK_SIZE: usize = 4096 * 2; static KERNEL_STACK: KernelStack = KernelStack { data: [0; KERNEL_STACK_SIZE] }; static USER_STACK: UserStack = UserStack { data: [0; USER_STACK_SIZE] }; }
特权级切换中的换栈
#![allow(unused)] fn main() { impl UserStack { fn get_sp(&self) -> usize { self.data.as_ptr() as usize + USER_STACK_SIZE } } RegSP = USER_STACK.get_sp(); RegSP = KERNEL_STACK.get_sp(); }
6.3 Trap上下文
用户和内核栈的初始化与异常上下文
用户栈和内核栈的初始化:
- 在系统初始化时,操作系统将为应用程序分配独立的用户栈,并为内核程序分配独立的内核栈。
- 在执行应用程序之前,需要将应用程序的执行环境设置好,包括用户栈。
- 在响应系统调用时,操作系统将准备内核栈,以处理接下来的任务。
异常上下文:
- 为了让内核在处理完系统调用后能够正确恢复应用程序状态,需要保存异常上下文(Trap Context)。
- 异常上下文保存的信息包括:
- 通用寄存器的值(可能包含32个寄存器的内容)。
- 特权级状态(
sstatus)和异常返回地址(sepc)。
状态保存的重要性:
-
通用寄存器:
- 通用寄存器包含应用程序当前的操作数据和状态。
- 如果不保存这些寄存器的数据,内核在执行过程中会覆盖它们,导致应用程序的状态丢失或异常。
-
sstatus和sepc:sstatus:指示特权级状态,确保返回到用户态时,系统能恢复正确的特权级设置。sepc:记录异常发生的指令地址,用于系统调用处理完毕后,准确返回用户代码。
额外保存的原因:
- 如果在处理系统调用或异常期间再次发生异常或中断,特权级状态和异常返回地址可能会被覆盖。
- 保存这些状态有助于操作系统在复杂的多重异常情况下,确保正确恢复到用户代码的执行状态。
通过在异常上下文中保存所有必要的寄存器和状态信息,操作系统能够确保在从内核返回用户态时恢复应用程序的执行环境。
Trap 上下文数据结构
#![allow(unused)] fn main() { #[repr(C)] pub struct TrapContext { pub x: [usize; 32], pub sstatus: Sstatus, pub sepc: usize, } }
- 对于通用寄存器而言,应用程序/内核控制流运行在不同的特权级
- 进入 Trap 的时候,硬件会立即覆盖掉 scause/stval/sstatus/sepc
sscratch CSR 重要的中转寄存器
- 暂时保存内核栈的地址
- 作为一个中转站让 sp (目前指向的用户栈的地址)的值可以暂时保存在 sscratch
- 仅需一条
csrrw sp, sscratch, sp // 交换对 sp 和 sscratch 两个寄存器内容 - 完成用户栈-->内核栈的切换
保存通用寄存器的宏
# os/src/trap/trap.S
.macro SAVE_GP n
sd x\n, \n*8(sp)
.endm
6.4 Trap处理流程
特权级切换与异常处理入口点初始化
- 设置特权级切换的入口点是重要的准备工作,确保当发生系统调用或异常时,操作系统能够正确处理。
- 通过设置
STVEC寄存器,将异常处理程序的入口点指向trap.S中的汇编函数__alltraps,使得所有的异常处理都进入这个函数。
Trap 入口点
#![allow(unused)] fn main() { pub fn init() { extern "C" { fn __alltraps(); } unsafe { stvec::write(__alltraps as usize, TrapMode::Direct); } } }
系统调用过程中的Trap上下文处理
- 应用程序通过
ecall进入到内核状态时,操作系统保存被打断的应用程序的 Trap 上下文; - 操作系统根据 Trap 相关的 CSR 寄存器内容,完成系统调用服务的分发与处理;
- 操作系统完成系统调用服务后,需要恢复被打断的应用程序的 Trap 上下文,并通
sret指令让应用程序继续执行。
or 异常处理流程
- 识别异常:通过读取
scause和mtval等寄存器获取异常类型和相关地址信息。- 保存状态:保存寄存器和栈信息以便恢复。
- 采取措施:根据异常类型选择合适的响应,比如页面错误处理、访问权限检查、系统调用等。
- 恢复状态:在处理完成后,恢复状态并返回继续执行。
异常发生后的具体处理步骤
-
保存上下文:
- 在异常发生后,操作系统会进入异常处理程序,并首先将应用程序的上下文信息(寄存器、状态)保存到内存中的一个特定区域(通常是内核栈)。
- 上下文信息保存在一个
trap context结构中,确保操作系统能够恢复被中断的应用程序状态。
-
特权级切换与异常信息:
- 确保
trap context完整保存后,操作系统将开始处理异常或系统调用。 - 通过检查相关寄存器,确定是哪种异常或系统调用触发了特权级切换。例如,系统调用会通过特定寄存器(如
A7)传递调用编号。 - 根据系统调用编号或异常类型,操作系统会调用相应的服务例程或异常处理程序。
- 确保
-
系统调用处理:
- 在这个操作系统实现中,主要处理两个基本系统调用:
sys_write:将应用程序请求的字符串输出到终端。sys_exit:退出应用程序并返回控制权给操作系统。
- 在处理系统调用时,操作系统会从寄存器中读取传递的参数,执行对应的功能。
- 在这个操作系统实现中,主要处理两个基本系统调用:
注意事项
- 完整的寄存器保存:为了在从内核返回到用户态时正确恢复状态,需要确保所有寄存器都被完整保存。
- 控制跳转:根据异常或系统调用的类型,操作系统必须确保跳转到适当的处理例程,才能提供正确的服务或处理异常。
Trap处理流程代码
- 首先通过 __alltraps 将 Trap 上下文保存在内核栈上;
- 然后跳转到 trap_handler 函数完成 Trap 分发及处理。
__alltraps:
csrrw sp, sscratch, sp
# now sp->kernel stack, sscratch->user stack
# allocate a TrapContext on kernel stack
addi sp, sp, -34*8
保存Trap上下文
保存通用寄存器
# save general-purpose registers
sd x1, 1*8(sp)
# skip sp(x2), we will save it later
sd x3, 3*8(sp)
# skip tp(x4), application does not use it
# save x5~x31
.set n, 5
.rept 27
SAVE_GP %n
.set n, n+1
.endr
保存 sstatus 和 sepc
# we can use t0/t1/t2 freely, because they were saved on kernel stack
csrr t0, sstatus
csrr t1, sepc
sd t0, 32*8(sp)
sd t1, 33*8(sp)
保存 user SP
# read user stack from sscratch and save it on the kernel stack
csrr t2, sscratch
sd t2, 2*8(sp)
#![allow(unused)] fn main() { pub struct TrapContext { pub x: [usize; 32], pub sstatus: Sstatus, pub sepc: usize, } }
调用trap_handler
# set input argument of trap_handler(cx: &mut TrapContext)
mv a0, sp
call trap_handler
让寄存器 a0 指向内核栈的栈指针也就是我们刚刚保存的 Trap 上下文的地址,这是由于我们接下来要调用 trap_handler 进行 Trap 处理,它的第一个参数 cx 由调用规范要从 a0 中获取。
恢复Trap上下文
- 大部分是保存寄存器的反向操作;
- 最后一步是
sret指令 //从内核态返回到用户态
注:后面讲解“执行程序”时会比较详细的讲解"恢复Trap上下文"
trap_handler处理syscall
#![allow(unused)] fn main() { #[no_mangle] pub fn trap_handler(cx: &mut TrapContext) -> &mut TrapContext { let scause = scause::read(); let stval = stval::read(); match scause.cause() { Trap::Exception(Exception::UserEnvCall) => { cx.sepc += 4; cx.x[10] = syscall(cx.x[17], [cx.x[10], cx.x[11], cx.x[12]]) as usize; } ... } cx } }
#![allow(unused)] fn main() { pub fn sys_exit(xstate: i32) -> ! { println!("[kernel] Application exited with code {}", xstate); run_next_app() } }
6.5 执行应用程序
应用程序的执行时机
- 当批处理操作系统初始化完成
- 某个应用程序运行结束或出错
从内核态切换到用户态
- 准备好应用的上下文
Trap上下文 - 恢复应用的相关寄存器
- 特别是应用用户栈指针和执行地址
- 返回用户态让应用执行
特权级切换与恢复
返回用户态:执行 sret
- 当操作系统完成了系统调用或异常处理后,需要通过
sret指令从内核态返回用户态。 sret指令确保操作系统能正确跳回到应用程序中断的位置,继续执行。sret指令的硬件逻辑:- 恢复响应中断/异常
- CPU Mode从S-Mode 回到U-Mode
pc<--specCSR- 继续运行
恢复上下文
-
在执行
sret之前,需要从内核栈恢复寄存器的上下文信息,包括通用寄存器、状态寄存器等,确保返回时能够恢复用户程序的执行状态。 -
切换到下一个应用程序
调用 run_next_app 函数切换到下一个应用程序:
- 构造应用程序开始执行所需的 Trap 上下文;
- 通过
__restore函数,从刚构造的 Trap 上下文中,恢复应用程序执行的部分寄存器; - 设置
sepcCSR的内容为应用程序入口点0x80400000; - 切换
scratch和sp寄存器,设置sp指向应用程序用户栈; - 执行
sret从 S 特权级切换到 U 特权级。
sscratch 寄存器与栈切换
- 为了在执行上下文保存与恢复时避免破坏寄存器,需要一个中转寄存器来存储关键数据。
sscratch寄存器用于保存当前用户态栈顶地址,以便在切换到内核栈时可以恢复回来。- 通过指令
csrrw SP, sscratch, SP,将当前栈顶地址与sscratch中的数据进行交换:- 先将用户态栈顶地址保存到
sscratch。 - 再将
sscratch中保存的内核栈地址赋值给当前栈顶寄存器SP。 - 这一步使得当前执行环境切换到内核栈,为接下来的异常处理提供独立的空间。
- 先将用户态栈顶地址保存到
相关代码:
构造Trap上下文
#![allow(unused)] fn main() { impl TrapContext { pub fn set_sp(&mut self, sp: usize) { self.x[2] = sp; } pub fn app_init_context(entry: usize, sp: usize) -> Self { let mut sstatus = sstatus::read(); sstatus.set_spp(SPP::User); let mut cx = Self { x: [0; 32], sstatus, sepc: entry, }; cx.set_sp(sp); cx }
运行下一程序
#![allow(unused)] fn main() { ub fn run_next_app() -> ! { ... unsafe { app_manager.load_app(current_app); } ... unsafe { __restore(KERNEL_STACK.push_context( TrapContext::app_init_context(APP_BASE_ADDRESS, USER_STACK.get_sp()) ) as *const _ as usize); } panic!("Unreachable in batch::run_current_app!"); } }
__restore:
# case1: start running app by __restore
# case2: back to U after handling trap
mv sp, a0
# now sp->kernel stack(after allocated), sscratch->user stack
# restore sstatus/sepc
ld t0, 32*8(sp)
ld t1, 33*8(sp)
ld t2, 2*8(sp)
csrw sstatus, t0
csrw sepc, t1
csrw sscratch, t2
# restore general-purpuse registers except sp/tp
ld x1, 1*8(sp)
ld x3, 3*8(sp)
.set n, 5
.rept 27
LOAD_GP %n
.set n, n+1
.endr
# release TrapContext on kernel stack
addi sp, sp, 34*8
# now sp->kernel stack, sscratch->user stack
csrrw sp, sscratch, sp
sret
创建第一个应用程序的 Trap Context
- Trap Context 初始化:尽管第一个应用程序还未开始执行,系统仍需为它构建一个完整的 Trap Context。
- 寄存器设置:
X0到X31除SP之外的寄存器通常初始化为零。 - 栈指针 (SP):指向预分配的用户态栈的起始地址,确保程序执行时能够正确使用栈。
- SEPC:设置为该应用程序的入口地址,以便系统在 SRET 指令执行后跳转到正确的入口。
- 寄存器设置:
内核态返回用户态的机制
- SRET 指令:SRET(Supervisor Return)通过以下方式实现从内核态到用户态的切换:
- 前一个状态:根据
sstatus中的前一个状态位,切换至u mode或其他模式。 - 恢复 PC:从
sepc恢复 PC 寄存器的值,确保从指定的应用程序入口地址开始执行。
- 前一个状态:根据
管理特权指令的安全性
- PC 寄存器的访问限制:由于
PC寄存器管理当前执行的指令位置,它并不直接对用户应用程序开放,只能由 CPU 和内核进行读取和设置。这样设计的原因在于保护系统的安全,防止恶意程序干扰执行流或读取系统敏感信息。
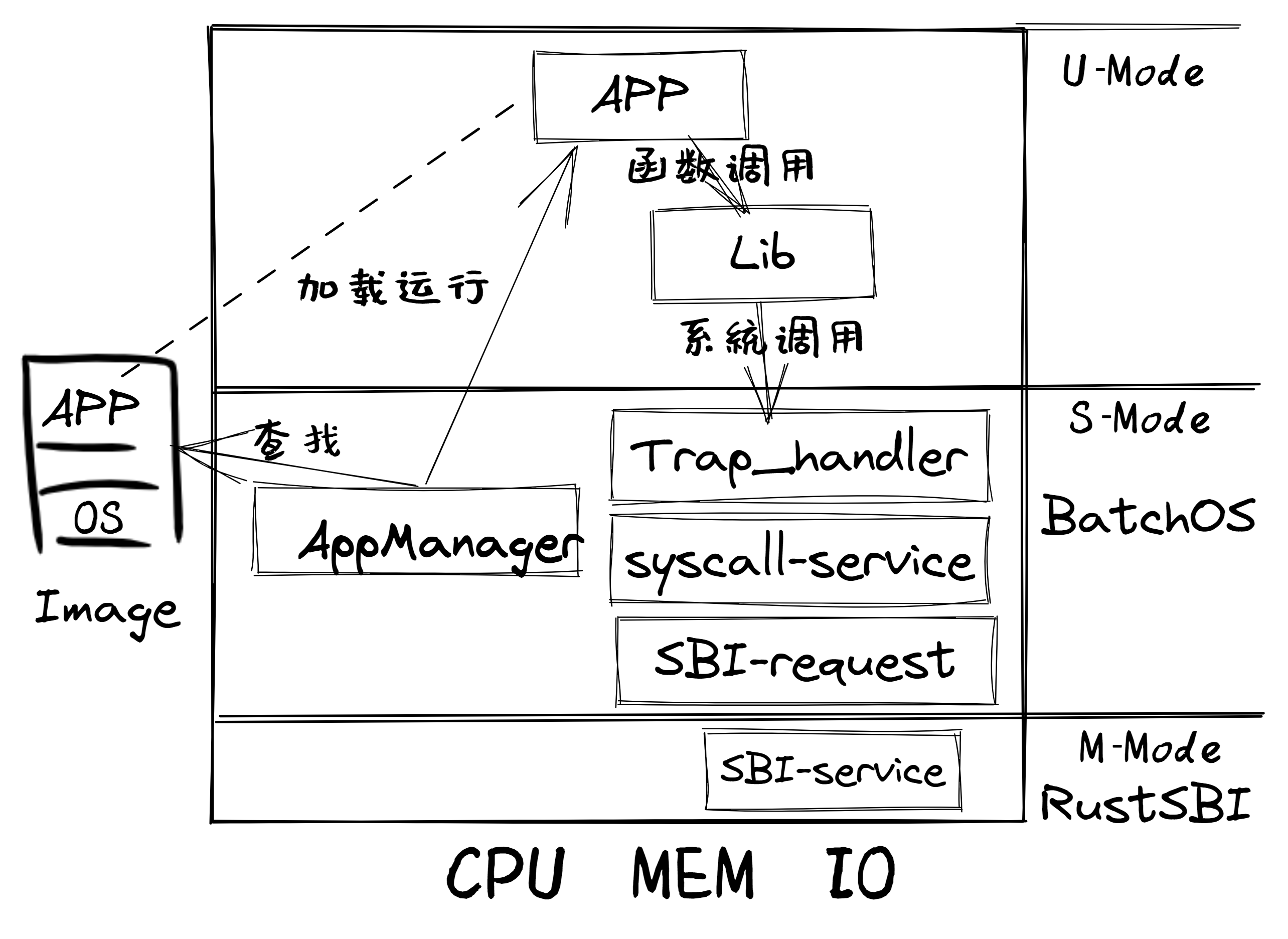
小结
内核态上下文管理
保存 trap 上下文
trap上下文的保存过程旨在确保内核可以在处理完系统调用或异常后,正确恢复到用户态继续执行。- 在保存过程中:
- 首先将所有通用寄存器的内容(包括
sstatus和sepc)保存到内核栈顶。 - 使用
sscratch寄存器作为临时存储用户态栈顶的中间值。 - 在
trap上下文保存的过程中,确保最终sp寄存器内容正确地存储到trap上下文中。
- 首先将所有通用寄存器的内容(包括
trap_handler 的处理
- 当进入
trap_handler时,处理的主要任务是:- 确保内核栈在处理中保持正确的栈顶。
- 完成函数调用前所需的准备工作,使得接下来的处理过程可以正常进行。
- 使用编译器生成的高级代码执行剩下的
syscall或异常处理逻辑。
利用内核栈与编译器生成代码
- 内核栈在系统调用和异常处理中是独立的栈空间,用于确保内核逻辑与用户程序逻辑分离。
- 编译器生成的代码可以高效管理函数调用过程中的栈数据,确保上下文完整保存与恢复。
trap 上下文保存:通过保存寄存器和相关状态信息,确保特权级之间能够正确切换与恢复。
trap_handler:提供了函数调用的栈管理,并与编译器生成代码紧密协作,确保操作系统能够正确完成系统调用与异常处理。
内核与应用程序的交互
系统调用的处理与恢复
-
系统调用处理
- 当用户程序发出
ecall指令时,硬件触发特权级切换并跳入操作系统。 - 通过读取
scause和stval寄存器,操作系统能够识别ecall的原因。 - 如果
ecall源自用户态系统调用,将根据相应的调用 ID 来调用操作系统的服务。 - 执行
sys_write系统调用时,操作系统会调用 SBI (Supervisor Binary Interface) 服务来输出字符。 sys_exit系统调用用于用户程序主动退出,此时操作系统会标记当前任务结束,准备加载并运行下一个程序。
- 当用户程序发出
-
系统调用的限制
- 当前批处理操作系统仅支持主动退出的程序和被异常终止的程序两种情况的切换。
- 如果用户程序进入无限循环而不发出
exit,则操作系统无法中断并切换任务,因为缺乏时钟中断机制。
应用程序的执行与初始化
-
应用程序初始化
- 应用程序的执行需要预先设置好执行环境,尤其是用户栈的内存空间和相关寄存器。
- 操作系统需确保栈空间足够,并通过初始化来确保执行环境的完整性。
-
执行控制
- 应用程序执行完或主动退出时,操作系统才会加载并切换到下一个应用程序。
下一步工作
- 中断机制的引入
- 现有的批处理操作系统仅能处理主动退出和异常终止的程序。为了实现更复杂的任务管理,应引入时钟中断机制来主动打断执行中的程序,实现更全面的多任务管理。
初始化用户程序的执行环境
在批处理操作系统中,必须提前为第一个用户程序创建一个完整的执行环境,以便从内核态切换到用户态并开始运行该程序。
要点
在设计批处理操作系统与应用程序之间的交互时,需要关注以下核心概念和机制:
1. 应用程序的初始化与系统调用
- 库函数支持:应用程序通过库函数发起系统调用,如
sys_write和sys_exit。库函数封装ecall指令,将请求传递到内核。 - 应用程序环境:应用程序的栈和寄存器初始化确保程序的正确运行。
2. 内核对系统调用的响应
- Trap Context 保存与恢复:在执行
ecall时,系统必须保存当前状态,以便稍后恢复。Trap Context 包含所有重要的寄存器和状态信息。 - 系统调用处理:在内核中,根据系统调用的编号执行相应的逻辑,比如字符串输出或进程退出。
- 特权级切换:特权级切换的关键在于保存和恢复正确的状态,以确保应用程序的连续执行。
3. 特殊寄存器和特权指令的作用
- sscratch 寄存器:用于缓存用户态的栈顶指针,以便在特权级切换时安全地管理内核栈与用户栈。
- SRET 指令:根据
sstatus和sepc的值,将控制权从内核返回用户态。
总结
- OS 与应用程序分工明确:应用程序通过系统调用请求内核的服务,内核通过 Trap Handler 安全地响应请求。
- 特权级隔离:通过分开管理内核和用户栈,并使用特定的特权指令,确保特权级之间的安全切换。
- 硬件与软件协同:特定的硬件寄存器与软件逻辑紧密配合,共同完成状态保存与恢复。
Lab2
第四讲 多道程序与分时多任务
第一节 进程和进程模型
一 多道程序与协作式调度
背景
-
硬件发展:随着硬件技术的发展,内存容量不断增大,CPU的速度不断提升。此时,软件应尽可能让CPU保持忙碌,以充分利用其性能。一个重要的转变在于大型机OS/360中引入的多道批处理模式。随着内存容量的提升,系统可以同时在内存中容纳多个程序,从而提高CPU的利用率。
-
计算机类型变化:大型机逐渐向小型机过渡,计算机应用的范围越来越广泛。用户希望与计算机实现更好的交互,批处理模式难以满足这种需求,因此分时系统逐渐普及,使用户能够更好地进行程序调试和开发。
-
术语的多样性:多道程序分时多任务系统的讨论中会出现大量术语,如“job”、“task”、“process”等。这些词汇在不同阶段和场景中有细微的差异,但总体上都描述了应用程序的执行过程。IBM的调度算法中明确提到“job”一词,而没有直接提到“process”。这些术语的细微差异无需纠结,但需要理解其背后的概念。
多道程序带来的问题
-
CPU调度:在多道程序中,如何分配CPU资源成为一个关键问题。最初,系统采取非抢占式的方式,由应用程序自行决定何时放弃CPU。然而,为防止程序陷入死循环导致资源浪费,现代操作系统普遍使用抢占式调度,使操作系统能够控制CPU的分配。
-
分时系统的实现:MIT研发的多种计算机系统中都具备抢占机制,以实现分时任务的处理,保障多用户和多任务的需求。
Task与Process
在多道程序分时多任务系统中,我们常提到“task”和“process”两个概念。它们都描述了应用程序的执行过程,任务被分割成多个时间片。每个时间片在不同任务间切换,形成完整的任务执行过程。
二 分时多任务与抢占式调度
在操作系统的发展过程中,任务和进程的定义和使用逐渐清晰化。以下是对任务和进程概念以及相关机制的深入总结。
任务的定义
任务被定义为具有独立功能的程序在一个数据集合上动态执行的过程,它是进程的前身。任务不管理太多资源,而进程则更加复杂,负责管理资源。任务的执行过程由时间片组成,在每个时间片中执行任务或保持空闲状态。
- 计算任务片:在时间片上执行某一计算任务的时间段。
- 空闲任务片:时间片处于空闲状态,不执行计算任务。
时间片用于分配CPU的执行时间,在不同任务之间切换。任务切换的频率过高会影响系统效率,但为了充分利用CPU资源,操作系统必须定期在任务之间切换。
抢占式调度
抢占式调度机制由操作系统控制,应用程序无需自行管理CPU的释放。操作系统通过时间片机制确保在某个时间片执行任务,在下一个时间片暂停执行。应用程序对这一切换过程完全透明,并未感知到任务切换。
- 操作系统的假象:应用程序会误认为自己占用整个处理器,尽管其他程序正在“偷偷”使用时间片。由于切换速度极快,应用程序难以察觉。
任务与进程的概念
术语“任务”和“进程”在不同环境下的使用可能会引起争议。虽然“进程”更常见,但历史上“任务”先出现,其合理性也受到操作系统实际应用的支持。
- Windows任务管理器:在Windows系统中,任务管理器用于查看和管理任务,而非称为“进程管理器”。
- Linux Top命令:在Linux系统中,Top命令显示系统任务的数量与状态,同样称为任务而非进程。
虽然操作系统教材多使用“进程”一词,但在实践中“任务”仍有广泛使用。历史上,任务管理是先于进程概念而存在的,体现出操作系统发展中的合理性与连续性。
22年的视频里主要使用“任务”,新的(2024年)幻灯片里还是改成主要使用“进程”了,当成一个东西吧。
另外下面是一些参考的解释:
在 Windows 操作系统中,任务管理器是一种监控和管理计算机上运行的任务、进程和资源的工具。以下是一些常用概念的解释,以及“任务”和“进程”的区别:
任务(Task):
- 任务通常指的是计算机执行的某个特定操作或活动,比如打开某个应用程序、处理一个文件等。
- 任务可以包含多个子任务,这些子任务可能由一个或多个进程来执行。
进程(Process):
- 进程是系统中运行的一个程序的实例。它代表程序代码和相关的资源(如内存、文件句柄、设备)在系统中的执行状态。
- 一个进程通常包含一个或多个线程,线程是一个进程内部的执行路径。
- 每个进程在 Windows 中都有一个唯一的标识符(PID),任务管理器可以显示每个进程的 PID、使用的资源和运行状态。
进程树(Process Tree):
- 进程树展示了某个进程及其所有子进程的层次结构。
- 可以帮助你理解哪些进程是由其他进程启动的,从而跟踪进程的父子关系。
运行新任务(Run New Task):
- 允许你启动一个新的程序或任务,可以输入可执行文件名称或者选择文件以启动。
结束任务(End Task):
- 可以终止一个正在运行的任务或进程。
- 注意,强行结束某个任务或进程可能会导致数据丢失或文件损坏,尤其是如果程序正处于写入数据的过程中。
结束进程树(End Process Tree):
- 结束整个进程树,意味着将会终止某个进程及其所有子进程。
在 Windows 操作系统中,任务往往表示用户在界面上看到的活动(如应用程序窗口),而进程则是操作系统管理的一个执行实体。在 Windows 中,将任务与进程相比,可以理解为:
任务(Task):
- 更像一个抽象概念,通常表示一个用户从界面或系统角度所感知的活动,例如一个应用程序的运行状态。
- 从任务管理器的角度,任务可能显示为活动窗口或应用程序。
进程(Process):
- 是系统中实际运行的对象。它由操作系统进行管理,包含了可执行文件、内存空间、文件句柄和其他资源。
- 进程是系统内的执行单位,每个进程都有一个唯一的进程 ID(PID)和一组资源。
- 一个进程通常可以包含多个线程,这些线程共同完成该进程的工作。
所以,任务与进程的关系可以比作用户感知的活动(抽象概念)与系统中实际存在的对象(具体实例)。从技术角度看,任务通常依赖于一个或多个进程来执行实际的工作。
在一些系统中,“任务”和“进程”可以在某些上下文中被认为是相互替换的。但需要注意具体的概念定义:
Linux:
- 在 Linux 和其他类 Unix 系统中,进程(process)和任务(task)有更明确的含义。
- 进程通常指一个正在运行的程序实例,它有自己的地址空间、系统资源、文件描述符等。
- 在 Linux 内核中,术语 “task” 通常用来指代内核中的一个进程结构(
task_struct)。因此,“task” 和“process” 在技术上可以互换使用。- 线程也可以被视为进程的一部分,但线程共享父进程的地址空间。
嵌入式系统:
- 在嵌入式系统中,任务通常表示的是独立的执行单元,通常使用实时操作系统(RTOS)调度和管理。
- 进程概念在某些较小的嵌入式系统中并不常用,因为这些系统往往不提供进程隔离或多任务能力,或者它们直接使用任务的概念来描述调度的执行单元。
总的来说,在无图形界面的系统或嵌入式系统中,“任务”和“进程”有时是可以互换的,但在技术和上下文上仍可能存在细微的差异,具体取决于操作系统和开发人员的定义。
下面的内容我们还是也改成进程吧,因为:
使用“任务”会同时使用“任务控制块(TCB,Task Control Block)”,而 TCB 也代表 Thread Control Block,线程控制块,可能造成混淆。
- TCB(Thread Control Block,线程控制块):
- TCB 是一个数据结构,存储了线程的相关信息,比如线程 ID、寄存器状态、优先级和栈指针等。
- 它用于保存和恢复线程的状态,以支持线程的调度和管理。
- TCB 通常作为线程管理的主要结构,在多线程系统中,线程是调度的最小单位。
同样对于抽象和使用场景还有:
在操作系统教学中,“进程”比“任务”作为抽象概念更加明确和合适。原因包括:
- 明确的定义:
- “进程”在计算机科学中有一个明确的定义,表示一个程序的执行实例。
- 进程包括程序代码、数据、内存空间、文件句柄等资源,由操作系统管理。
- 实例化的抽象:
- 进程是一个实例化的概念,作为操作系统管理和调度的独立实体存在。
- 操作系统中的进程控制块(PCB)表示了每个进程的状态和相关资源,具象地体现了进程的抽象。
- 调度与资源分配:
- 进程是调度的独立单位,操作系统可以根据优先级、调度算法等对其进行管理。
- 进程抽象涵盖了资源分配和进程切换的机制。
- 多任务环境:
- 在多任务操作系统中,进程的概念与调度策略和资源分配密切相关。
相对而言,“任务”则更多是用户或开发者角度的术语,指代一种活动或需要完成的目标,在某些情况下没有明确的定义。操作系统中直接使用“进程”更能帮助理解和区分相关概念。
Task Control Block(TCB) 和 Process Control Block(PCB) 都是操作系统中的关键数据结构,但它们常在不同的场景下使用:
- Task Control Block(TCB):
- TCB 用于实时操作系统(RTOS)或嵌入式系统中,表示任务的信息。
- 它记录任务的状态、堆栈指针、优先级、时间片、调度状态等信息。
- TCB 通常用于较小规模的系统,帮助实时操作系统管理任务和进行任务调度。
- Process Control Block(PCB):
- PCB 是操作系统中代表进程状态和信息的结构体。
- 它包含进程的 PID(进程 ID)、内存分配、文件句柄、寄存器内容、调度信息等。
- PCB 适用于多任务和多用户的复杂操作系统,确保进程管理和调度。
TCB 在 RTOS 中常用于描述“任务”,这在实时系统和嵌入式环境中很常见。
PCB 在通用操作系统中描述“进程”,更适用于复杂的计算机系统。
| 如果我没仔细看后面可能出现进程和任务混用或用混的情况。
从用户的视角看分时多任务
分时多任务(Time sharing multitask):从用户的视角看
- 在内存中存在多个可执行程序
- 各个可执行程序分时共享处理器
- 操作系统按时间片来给各个可执行程序分配CPU使用时间
- 进程(Process) :应用的一次执行过程
从OS的视角看分时多任务(Time sharing multitask)
- 进程(Process) :一个具有一定独立功能的程序在一个数据集合上的一次动态执行过程。也称为任务(Task)。
- 从一个应用程序对应的进程切换到另外一个应用程序对应的进程,称为进程切换。
作业(Job)、任务(Task)和进程(Process)
历史上出现过的术语:Job、Task、Process
- Task、Process是Multics和UNIX等用于分时多任务提出的概念
- 进程是一个应用程序的一次执行过程。在操作系统语境下,任务和进程是同义词。
- 作业(目标)是围绕一个共同目标由一组相互关联的程序执行过程(进程、任务)形成的一个整体
参考:Difference between Job, Task and Process
抢占式调度(Preemptive scheduling)
- 进程被动地放弃处理器使用
- 进程按时间片轮流使用处理器,是一种“暂停-继续”组合的执行过程
- 基于时钟硬件中断机制,操作系统可随时打断正在执行的程序
- 操作系统选择下一个执行程序使用处理器
三 进程的概念
进程的特点与进程和程序的关系
进程的特点
-
切换性:进程能够在不同进程之间切换,每个进程拥有自己独立的执行控制流。
-
动态性:进程的执行过程是动态的,在执行时可能会中断或暂停。
-
并发性:在一段时间内,多个进程可以同时运行,形成并发的执行环境。
-
有限度的独立性:进程之间并不感知彼此的存在,而操作系统需要管理和感知所有进程的状态。
进程与程序的关系
-
程序的定义:程序是静态的代码,无论是源代码还是可执行文件,都是一种静态的文件。
-
进程的定义:进程是程序在内存中的动态执行过程,操作系统会将程序加载到内存中,并执行其中的代码。
-
执行状态:执行状态指的是进程在执行过程中对内存、寄存器等资源的修改。由于进程的执行状态不断变化,因此同一个程序的不同执行过程可能呈现出不同的进程执行状态。
-
资源需求:进程的执行主要需要两种资源:CPU和内存。
-
程序与进程的区别:
- 程序是静态的,而进程是动态的。
- 程序是永久的文件,而进程是暂时的执行过程。
- 程序和进程的组成不同,进程在执行过程中具有自己的内存空间和控制流。
总之,进程是程序的执行过程,在执行中具有动态性、并发性和独立性。程序作为静态文件提供了执行的基础,而进程通过加载程序代码并运行在内存中,将程序的静态代码转化为动态的执行状态。尽管进程是暂时的,但它体现了程序的真正功能,进一步明确了进程与程序的区别与联系。
进程与程序的组成
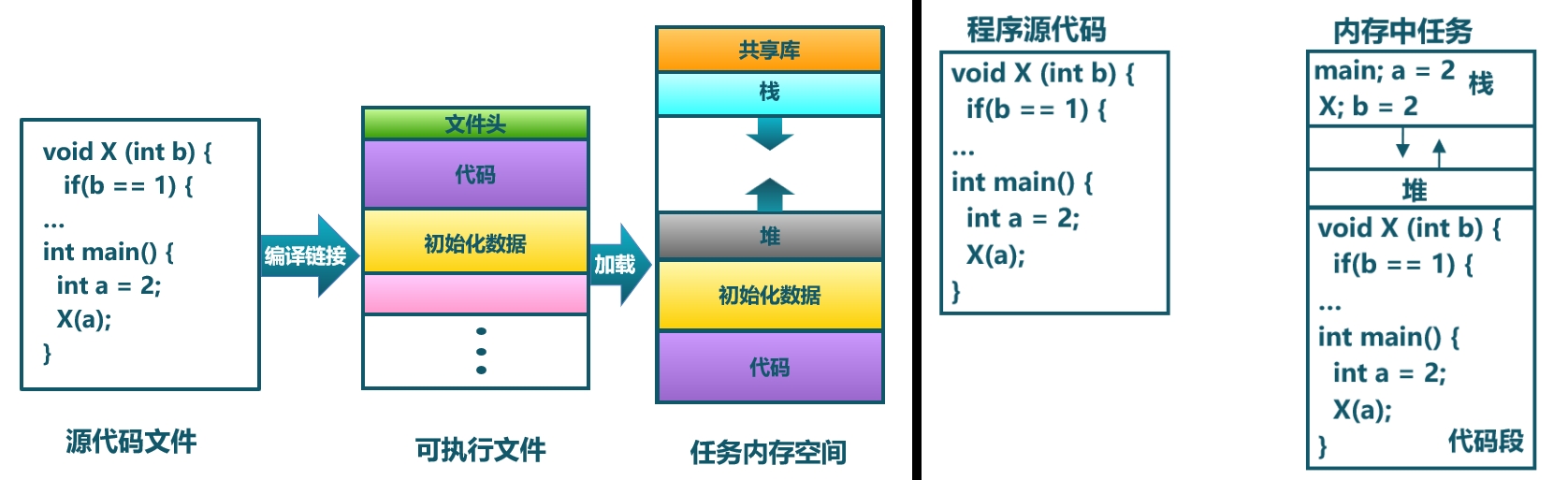
在操作系统中,进程的管理需要确保系统能够在执行过程中有效切换进程,并保持执行的一致性。为此,进程的组成和状态信息管理显得尤为重要。
进程状态
进程在执行过程中包含一些状态信息,这些信息在特定时刻被系统记录下来,以实现进程切换。具体而言,进程状态包括:
-
控制流:控制流指示进程当前执行的具体位置。通过程序计数器(PC),系统能够跟踪进程代码执行的具体位置,以便在恢复进程时继续从中断点执行。
-
数据状态:进程访问的数据包括内存和寄存器。其中,内存可进一步划分为堆、栈、数据段等部分。寄存器则保存了进程执行的各种临时数据。
在进程被中断或暂停时,操作系统需要保存进程的上下文,包括控制流、寄存器状态等,以便在进程切换时正确恢复。这种上下文保存被称为进程上下文切换,需包括:
- 程序计数器:记录进程执行的具体代码位置。
- 栈地址:保存进程当前的栈指针位置。
- 通用寄存器:保存进程执行中需要恢复的各种寄存器数据。
- 其他资源:......
进程控制块(PCB)
操作系统需要有效管理每个进程的状态和信息,这依赖于一种数据结构,称为进程控制块(Process Control Block,PCB)。PCB用于记录进程的状态和其他管理信息,并在进程切换时提供完整的进程上下文。
- 进程标识信息:为每个进程分配唯一的标识符(如PID,进程ID)。
- 处理器现场信息:保存进程执行状态的寄存器、程序计数器等信息。
- 进程控制信息:管理进程状态,如正在运行(running)、就绪(ready)或休眠(sleep)等。
通过PCB,操作系统能够在进程间进行有效的上下文切换,确保不同进程在各自的状态下继续执行。
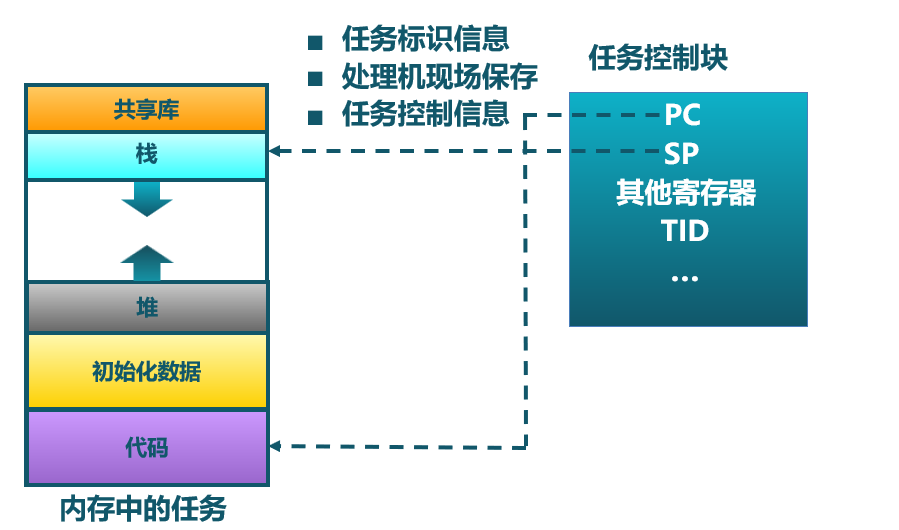
进程的组成和管理需要依赖于状态信息的保存和切换。通过进程控制块,操作系统能够跟踪和管理进程的执行状态,实现有效的进程上下文切换,并在进程执行时保持执行过程的一致性。
四 进程模型
进程状态与切换过程
进程在执行过程中会经历不同的状态,这些状态与进程的执行相关,并在操作系统中被清晰地管理。以下是进程状态及其切换过程的简要总结:
进程状态
-
创建状态:进程在被创建时,进程控制块(PCB)和相关资源尚未准备好。操作系统为进程创建初始的栈、寄存器和代码空间,设置初始状态,使其具备执行条件。此时,进程处于“创建状态”。
-
就绪状态:创建完成后,进程进入就绪状态(Ready),意味着它已准备好执行。就绪进程在等待操作系统的调度,直到系统选择该进程执行时,它才会从就绪状态进入运行状态。
-
运行状态:就绪进程被操作系统调度后,将从就绪状态切换到运行状态(Running)。操作系统通过上下文切换,让当前运行的进程让出CPU,并将其分配给新调度的进程。操作系统需要将状态从内核态切换到用户态,使进程代码能够执行。
-
等待状态:运行中的进程可能会进入等待状态(Waiting),例如当进程需要等待外部资源时。常见的等待场景包括:
- Sleep:进程主动请求休眠,例如调用“sleep 5秒”。
- I/O等待:等待文件读写或其他外部设备操作完成。由于I/O速度较慢,进程会主动放弃CPU,进入等待状态,使其他进程可以使用CPU。
-
终止状态:进程完成其功能或因某种原因被终止,将进入终止状态(Terminated)。此时,进程的资源将被操作系统回收,以供其他进程使用。
状态切换过程
进程状态及状态转换详解
-
创建(Creation)到就绪(Ready):
- 何时创建:进程在系统启动、用户请求或其他进程的要求下被创建。
- 如何创建:操作系统通过进程创建机制,为新进程分配唯一的进程 ID(PID)、内存空间、文件描述符及其他资源,并在进程控制块(PCB)中存储其状态信息。
- 转换到就绪:创建完成的进程具备执行条件,并进入就绪队列,等待 CPU 调度。
-
就绪(Ready)到运行(Running):
- 内核选择任务:调度程序从就绪队列中选择一个合适的进程,将其分配到 CPU 上执行,进程状态从就绪切换为运行。
- 如何执行:执行开始时,操作系统恢复进程的寄存器状态,并开始执行该进程的指令。
-
运行(Running)到等待(Waiting/Blocked):
- 任务进入等待的原因:
- 自身:进程主动等待某个事件(例如 I/O 操作或休眠)并主动让出 CPU。
- 外界:其他事件导致进程暂停执行(例如系统调用或同步操作)。
- 状态切换:进程让出 CPU 后,其状态切换为等待,并等待事件的完成或被唤醒。
- 任务进入等待的原因:
-
等待(Waiting/Blocked)到就绪(Ready):
- 被唤醒的原因:
- 自身:进程设置的等待时间结束,自行唤醒进入就绪状态。
- 外界:等待的事件完成,或进程被操作系统或其他进程唤醒,恢复到就绪状态。
- 被唤醒的原因:
-
运行(Running)到抢占(Preempted):
- 任务被抢占的原因:
- 系统调度器基于优先级、时间片等策略,从 CPU 上中断当前执行的进程,将其状态切换为就绪,并调度另一个进程执行。
- 任务被抢占的原因:
-
运行(Running)到退出(Terminated/Exited):
- 任务退出的原因:
- 自愿:进程正常执行完成,或通过特定系统调用(如
exit)自愿退出。 - 被迫:由于外部因素导致进程终止,如错误、异常或被其他进程强制结束。
- 自愿:进程正常执行完成,或通过特定系统调用(如
- 任务退出的原因:
在进程的生命周期中,不同状态的转换由调度程序根据系统需求和任务特性控制,确保多任务系统在有限的资源下高效运作。通过这种状态切换机制,操作系统能够有效管理和调度进程,使其在合适的时机获取资源并执行其功能。
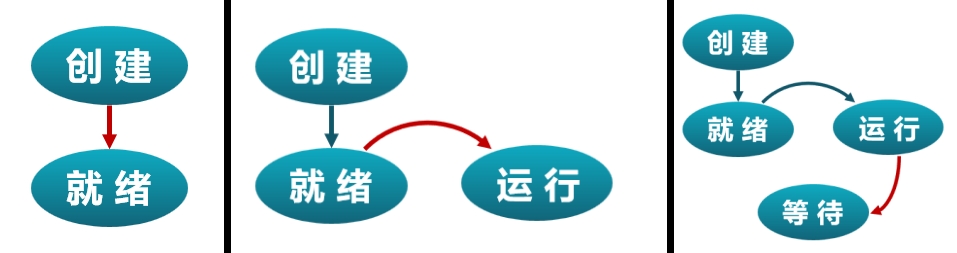
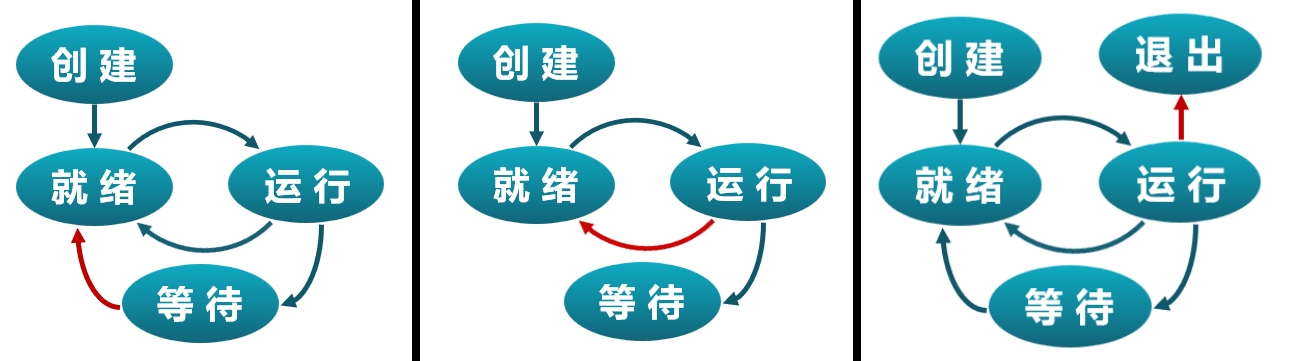
在多任务操作系统中,进程的状态会不断变化,有时可能会被抢占。以下是进程的抢占、状态转换以及系统调用之间的关系。
抢占
抢占是指操作系统强制停止当前正在运行的进程,让它从运行状态转换到就绪状态,以便给其他进程提供运行的机会。抢占通常由时钟中断触发,操作系统在中断发生时将当前进程置于就绪状态,为其他进程的调度和执行腾出资源。
- 时钟中断:时钟中断是一种周期性中断,用于触发抢占。在时钟中断发生时,操作系统暂停当前进程的执行,将其从运行状态置为就绪状态,然后选择其他进程执行。
进程退出
进程退出可以是自愿的或被迫的:
-
自愿退出:进程主动调用退出指令(如
exit系统调用),结束自身的执行。这通常发生在进程完成预定工作后主动请求退出。 -
被迫退出:
- 非法操作:进程尝试执行非法操作或触发严重错误,操作系统会终止该进程的执行。
- 外部强制:更高级别的管理程序或系统管理员可能会强制终止进程的执行。
进程模型
进程在执行过程中主要存在以下三种状态:
- 就绪:进程已具备执行条件,等待操作系统的调度以获得CPU时间。
- 运行:进程正在CPU上执行。
- 等待:进程由于需要等待资源(如I/O操作)或休眠等原因而暂停执行。
此外,还有两个额外的过程:
- 创建:创建进程时,操作系统分配并初始化进程控制块(PCB)等资源。
- 退出:进程结束执行后,操作系统回收资源,将进程控制块和其他资源释放。
这形成了进程状态的五个基本过程:创建、就绪、运行、等待和退出。
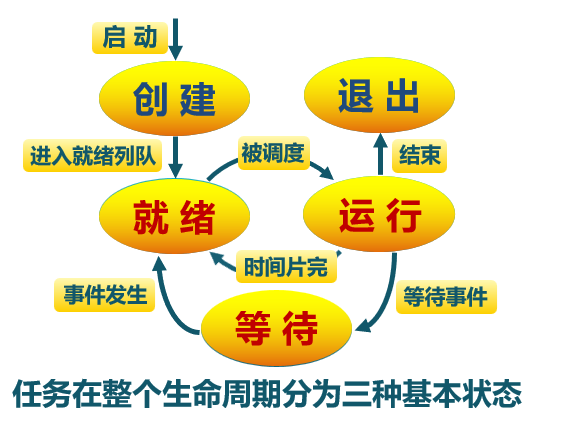
系统调用与状态转换
系统调用是用户程序与操作系统交互的主要方式,会导致进程状态发生变化:
- 运行到退出:进程主动调用
exit系统调用,退出并释放资源。 - 运行到等待:进程可能通过系统调用进入等待状态,如调用
sleep使进程休眠一段时间。 - 运行到就绪:通常由中断触发的抢占或高优先级进程到来,使当前进程暂停并进入就绪状态。
进程在操作系统中会经历多种状态转换,包括抢占、系统调用或异常等原因导致的状态变化。了解进程状态及转换的原因,有助于掌握操作系统中进程管理的核心逻辑和实现机制。
进程切换的时机与过程
进程在操作系统中进行切换是不可避免的,确保了多进程的并发执行和资源的合理分配。以下是进程何时会进行切换的时机及其过程。
进程切换的时机
进程切换是指操作系统暂停当前运行的进程,并在合适的时机切换到其他进程继续执行。主要有以下几个时机:
-
主动进入等待状态:当进程调用
sleep或其他系统调用以进入等待状态(如等待I/O操作),操作系统将进程状态置为等待,进而切换到下一个就绪进程执行。 -
时间片用尽:在多任务操作系统中,每个进程被分配一个固定时间片(time slice)。当进程用完时间片,时钟中断触发抢占,操作系统将当前进程置为就绪状态,然后切换到下一个就绪进程执行。
-
进程退出:进程执行完毕或被迫退出后,操作系统将当前进程状态置为终止,并切换到下一个就绪进程执行。
进程切换的过程
进程切换涉及暂停当前进程并恢复新进程的执行环境,确保进程状态的一致性。进程切换的步骤如下:
-
保存当前进程的现场:操作系统在中断或系统调用发生时将当前进程的上下文(context)信息保存至进程控制块(PCB),包括程序计数器、通用寄存器、栈指针等。
-
选择下一个进程:操作系统根据调度算法选择下一个就绪进程进行执行。
-
恢复新进程的现场:从新进程的进程控制块中恢复其上下文信息,包括程序计数器、寄存器、栈等。
-
切换到新进程:操作系统将控制权交给新进程,恢复用户态并开始执行进程的代码。
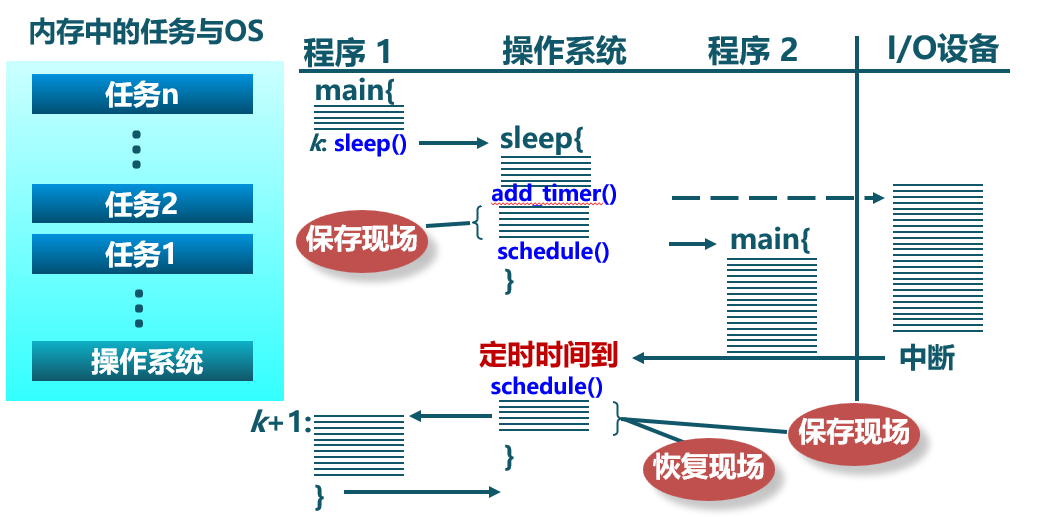
进程切换的简单结构
可以将进程切换的过程形象化为一个结构图:
-
程序A与程序B:假设有两个程序在执行进程。进程A主动调用
sleep系统调用进入等待状态,触发进程切换过程。 -
进入内核态:操作系统将通过中断或系统调用进入内核态,保存进程A的上下文信息。
-
选择下一个进程:操作系统根据调度算法选择进程B执行,并恢复其上下文。
-
返回用户态:操作系统将控制权交给进程B,使其从用户态开始执行。
这种进程切换的结构图展示了进程的上下文保存和恢复过程,以及多进程之间的交替执行机制。
下一节
实践:多道程序与分时多任务操作系统
分时多任务操作系统通过多阶段的改进,实现了更高效的进程切换和资源利用。以下是各个阶段的变化与进程切换的实践方法。
第一阶段:引入进程管理
-
应用程序管理模块的拆分:内核中的应用程序管理模块被拆分为不同的子模块,其中引入了程序加载器(loader),负责查找和加载程序。进程切换模块(task manager)则用于管理进程控制块(PCB),独立处理进程切换逻辑。
-
多进程支持:引入进程管理后,操作系统可以同时在内存中运行多个应用程序,并实现进程间的切换。这是最早期的多进程系统设计,其中引入了基本的进程结构和管理概念。
第二阶段:主动进程切换
-
系统调用支持主动切换:在这个阶段,系统调用被扩展,增加了进程放弃与切换的功能。进程可以通过系统调用主动放弃对CPU的占用,切换到其他进程执行。
-
上下文保存与恢复:在进程主动放弃CPU时,操作系统保存当前进程的上下文信息(包括寄存器、栈、程序计数器等),并恢复下一个被调度的进程的上下文。
-
进程调度:此阶段的操作系统在系统调用中主动管理进程的上下文,并通过进程管理模块实现多进程的调度与切换。
第三阶段:中断与时间片管理
-
引入时钟中断:操作系统在此阶段引入了时钟中断机制。通过时钟中断,系统可以准确追踪进程的执行时间,为进程分配固定的时间片(time slice)。
-
时间片切换:一旦时钟中断指示某个进程的时间片已用尽,操作系统将保存当前进程的上下文,并切换到下一个就绪进程。
-
统一异常、系统调用与中断处理:系统调用、中断和异常在本质上都是从用户态切换到内核态的过程。在这个阶段,操作系统统一了它们的处理流程,使它们共用相同的机制来保存和恢复上下文信息。
-
进程执行时间追踪:操作系统通过时钟中断追踪每个进程的执行时间,确保进程不会长期独占CPU,保证进程之间的公平调度。
通过这三个阶段的逐步改进,操作系统在管理进程时具备更强的灵活性和效率,实现了真正意义上的多道程序与分时多任务操作系统。
第四讲 多道程序与分时多任务
第一节 进程和进程模型
一 多道程序与协作式调度
背景
-
硬件发展:随着硬件技术的发展,内存容量不断增大,CPU的速度不断提升。此时,软件应尽可能让CPU保持忙碌,以充分利用其性能。一个重要的转变在于大型机OS/360中引入的多道批处理模式。随着内存容量的提升,系统可以同时在内存中容纳多个程序,从而提高CPU的利用率。
-
计算机类型变化:大型机逐渐向小型机过渡,计算机应用的范围越来越广泛。用户希望与计算机实现更好的交互,批处理模式难以满足这种需求,因此分时系统逐渐普及,使用户能够更好地进行程序调试和开发。
-
术语的多样性:多道程序分时多任务系统的讨论中会出现大量术语,如“job”、“task”、“process”等。这些词汇在不同阶段和场景中有细微的差异,但总体上都描述了应用程序的执行过程。IBM的调度算法中明确提到“job”一词,而没有直接提到“process”。这些术语的细微差异无需纠结,但需要理解其背后的概念。
多道程序带来的问题
-
CPU调度:在多道程序中,如何分配CPU资源成为一个关键问题。最初,系统采取非抢占式的方式,由应用程序自行决定何时放弃CPU。然而,为防止程序陷入死循环导致资源浪费,现代操作系统普遍使用抢占式调度,使操作系统能够控制CPU的分配。
-
分时系统的实现:MIT研发的多种计算机系统中都具备抢占机制,以实现分时任务的处理,保障多用户和多任务的需求。
Task与Process
在多道程序分时多任务系统中,我们常提到“task”和“process”两个概念。它们都描述了应用程序的执行过程,任务被分割成多个时间片。每个时间片在不同任务间切换,形成完整的任务执行过程。
二 分时多任务与抢占式调度
在操作系统的发展过程中,任务和进程的定义和使用逐渐清晰化。以下是对任务和进程概念以及相关机制的深入总结。
任务的定义
任务被定义为具有独立功能的程序在一个数据集合上动态执行的过程,它是进程的前身。任务不管理太多资源,而进程则更加复杂,负责管理资源。任务的执行过程由时间片组成,在每个时间片中执行任务或保持空闲状态。
- 计算任务片:在时间片上执行某一计算任务的时间段。
- 空闲任务片:时间片处于空闲状态,不执行计算任务。
时间片用于分配CPU的执行时间,在不同任务之间切换。任务切换的频率过高会影响系统效率,但为了充分利用CPU资源,操作系统必须定期在任务之间切换。
抢占式调度
抢占式调度机制由操作系统控制,应用程序无需自行管理CPU的释放。操作系统通过时间片机制确保在某个时间片执行任务,在下一个时间片暂停执行。应用程序对这一切换过程完全透明,并未感知到任务切换。
- 操作系统的假象:应用程序会误认为自己占用整个处理器,尽管其他程序正在“偷偷”使用时间片。由于切换速度极快,应用程序难以察觉。
任务与进程的概念
术语“任务”和“进程”在不同环境下的使用可能会引起争议。虽然“进程”更常见,但历史上“任务”先出现,其合理性也受到操作系统实际应用的支持。
- Windows任务管理器:在Windows系统中,任务管理器用于查看和管理任务,而非称为“进程管理器”。
- Linux Top命令:在Linux系统中,Top命令显示系统任务的数量与状态,同样称为任务而非进程。
虽然操作系统教材多使用“进程”一词,但在实践中“任务”仍有广泛使用。历史上,任务管理是先于进程概念而存在的,体现出操作系统发展中的合理性与连续性。
22年的视频里主要使用“任务”,新的(2024年)幻灯片里还是改成主要使用“进程”了,当成一个东西吧。
另外下面是一些参考的解释:
在 Windows 操作系统中,任务管理器是一种监控和管理计算机上运行的任务、进程和资源的工具。以下是一些常用概念的解释,以及“任务”和“进程”的区别:
任务(Task):
- 任务通常指的是计算机执行的某个特定操作或活动,比如打开某个应用程序、处理一个文件等。
- 任务可以包含多个子任务,这些子任务可能由一个或多个进程来执行。
进程(Process):
- 进程是系统中运行的一个程序的实例。它代表程序代码和相关的资源(如内存、文件句柄、设备)在系统中的执行状态。
- 一个进程通常包含一个或多个线程,线程是一个进程内部的执行路径。
- 每个进程在 Windows 中都有一个唯一的标识符(PID),任务管理器可以显示每个进程的 PID、使用的资源和运行状态。
进程树(Process Tree):
- 进程树展示了某个进程及其所有子进程的层次结构。
- 可以帮助你理解哪些进程是由其他进程启动的,从而跟踪进程的父子关系。
运行新任务(Run New Task):
- 允许你启动一个新的程序或任务,可以输入可执行文件名称或者选择文件以启动。
结束任务(End Task):
- 可以终止一个正在运行的任务或进程。
- 注意,强行结束某个任务或进程可能会导致数据丢失或文件损坏,尤其是如果程序正处于写入数据的过程中。
结束进程树(End Process Tree):
- 结束整个进程树,意味着将会终止某个进程及其所有子进程。
在 Windows 操作系统中,任务往往表示用户在界面上看到的活动(如应用程序窗口),而进程则是操作系统管理的一个执行实体。在 Windows 中,将任务与进程相比,可以理解为:
任务(Task):
- 更像一个抽象概念,通常表示一个用户从界面或系统角度所感知的活动,例如一个应用程序的运行状态。
- 从任务管理器的角度,任务可能显示为活动窗口或应用程序。
进程(Process):
- 是系统中实际运行的对象。它由操作系统进行管理,包含了可执行文件、内存空间、文件句柄和其他资源。
- 进程是系统内的执行单位,每个进程都有一个唯一的进程 ID(PID)和一组资源。
- 一个进程通常可以包含多个线程,这些线程共同完成该进程的工作。
所以,任务与进程的关系可以比作用户感知的活动(抽象概念)与系统中实际存在的对象(具体实例)。从技术角度看,任务通常依赖于一个或多个进程来执行实际的工作。
在一些系统中,“任务”和“进程”可以在某些上下文中被认为是相互替换的。但需要注意具体的概念定义:
Linux:
- 在 Linux 和其他类 Unix 系统中,进程(process)和任务(task)有更明确的含义。
- 进程通常指一个正在运行的程序实例,它有自己的地址空间、系统资源、文件描述符等。
- 在 Linux 内核中,术语 “task” 通常用来指代内核中的一个进程结构(
task_struct)。因此,“task” 和“process” 在技术上可以互换使用。- 线程也可以被视为进程的一部分,但线程共享父进程的地址空间。
嵌入式系统:
- 在嵌入式系统中,任务通常表示的是独立的执行单元,通常使用实时操作系统(RTOS)调度和管理。
- 进程概念在某些较小的嵌入式系统中并不常用,因为这些系统往往不提供进程隔离或多任务能力,或者它们直接使用任务的概念来描述调度的执行单元。
总的来说,在无图形界面的系统或嵌入式系统中,“任务”和“进程”有时是可以互换的,但在技术和上下文上仍可能存在细微的差异,具体取决于操作系统和开发人员的定义。
下面的内容我们还是也改成进程吧,因为:
使用“任务”会同时使用“任务控制块(TCB,Task Control Block)”,而 TCB 也代表 Thread Control Block,线程控制块,可能造成混淆。
- TCB(Thread Control Block,线程控制块):
- TCB 是一个数据结构,存储了线程的相关信息,比如线程 ID、寄存器状态、优先级和栈指针等。
- 它用于保存和恢复线程的状态,以支持线程的调度和管理。
- TCB 通常作为线程管理的主要结构,在多线程系统中,线程是调度的最小单位。
同样对于抽象和使用场景还有:
在操作系统教学中,“进程”比“任务”作为抽象概念更加明确和合适。原因包括:
- 明确的定义:
- “进程”在计算机科学中有一个明确的定义,表示一个程序的执行实例。
- 进程包括程序代码、数据、内存空间、文件句柄等资源,由操作系统管理。
- 实例化的抽象:
- 进程是一个实例化的概念,作为操作系统管理和调度的独立实体存在。
- 操作系统中的进程控制块(PCB)表示了每个进程的状态和相关资源,具象地体现了进程的抽象。
- 调度与资源分配:
- 进程是调度的独立单位,操作系统可以根据优先级、调度算法等对其进行管理。
- 进程抽象涵盖了资源分配和进程切换的机制。
- 多任务环境:
- 在多任务操作系统中,进程的概念与调度策略和资源分配密切相关。
相对而言,“任务”则更多是用户或开发者角度的术语,指代一种活动或需要完成的目标,在某些情况下没有明确的定义。操作系统中直接使用“进程”更能帮助理解和区分相关概念。
Task Control Block(TCB) 和 Process Control Block(PCB) 都是操作系统中的关键数据结构,但它们常在不同的场景下使用:
- Task Control Block(TCB):
- TCB 用于实时操作系统(RTOS)或嵌入式系统中,表示任务的信息。
- 它记录任务的状态、堆栈指针、优先级、时间片、调度状态等信息。
- TCB 通常用于较小规模的系统,帮助实时操作系统管理任务和进行任务调度。
- Process Control Block(PCB):
- PCB 是操作系统中代表进程状态和信息的结构体。
- 它包含进程的 PID(进程 ID)、内存分配、文件句柄、寄存器内容、调度信息等。
- PCB 适用于多任务和多用户的复杂操作系统,确保进程管理和调度。
TCB 在 RTOS 中常用于描述“任务”,这在实时系统和嵌入式环境中很常见。
PCB 在通用操作系统中描述“进程”,更适用于复杂的计算机系统。
| 如果我没仔细看后面可能出现进程和任务混用或用混的情况。
从用户的视角看分时多任务
分时多任务(Time sharing multitask):从用户的视角看
- 在内存中存在多个可执行程序
- 各个可执行程序分时共享处理器
- 操作系统按时间片来给各个可执行程序分配CPU使用时间
- 进程(Process) :应用的一次执行过程
从OS的视角看分时多任务(Time sharing multitask)
- 进程(Process) :一个具有一定独立功能的程序在一个数据集合上的一次动态执行过程。也称为任务(Task)。
- 从一个应用程序对应的进程切换到另外一个应用程序对应的进程,称为进程切换。
作业(Job)、任务(Task)和进程(Process)
历史上出现过的术语:Job、Task、Process
- Task、Process是Multics和UNIX等用于分时多任务提出的概念
- 进程是一个应用程序的一次执行过程。在操作系统语境下,任务和进程是同义词。
- 作业(目标)是围绕一个共同目标由一组相互关联的程序执行过程(进程、任务)形成的一个整体
参考:Difference between Job, Task and Process
抢占式调度(Preemptive scheduling)
- 进程被动地放弃处理器使用
- 进程按时间片轮流使用处理器,是一种“暂停-继续”组合的执行过程
- 基于时钟硬件中断机制,操作系统可随时打断正在执行的程序
- 操作系统选择下一个执行程序使用处理器
三 进程的概念
进程的特点与进程和程序的关系
进程的特点
-
切换性:进程能够在不同进程之间切换,每个进程拥有自己独立的执行控制流。
-
动态性:进程的执行过程是动态的,在执行时可能会中断或暂停。
-
并发性:在一段时间内,多个进程可以同时运行,形成并发的执行环境。
-
有限度的独立性:进程之间并不感知彼此的存在,而操作系统需要管理和感知所有进程的状态。
进程与程序的关系
-
程序的定义:程序是静态的代码,无论是源代码还是可执行文件,都是一种静态的文件。
-
进程的定义:进程是程序在内存中的动态执行过程,操作系统会将程序加载到内存中,并执行其中的代码。
-
执行状态:执行状态指的是进程在执行过程中对内存、寄存器等资源的修改。由于进程的执行状态不断变化,因此同一个程序的不同执行过程可能呈现出不同的进程执行状态。
-
资源需求:进程的执行主要需要两种资源:CPU和内存。
-
程序与进程的区别:
- 程序是静态的,而进程是动态的。
- 程序是永久的文件,而进程是暂时的执行过程。
- 程序和进程的组成不同,进程在执行过程中具有自己的内存空间和控制流。
总之,进程是程序的执行过程,在执行中具有动态性、并发性和独立性。程序作为静态文件提供了执行的基础,而进程通过加载程序代码并运行在内存中,将程序的静态代码转化为动态的执行状态。尽管进程是暂时的,但它体现了程序的真正功能,进一步明确了进程与程序的区别与联系。
进程与程序的组成
在操作系统中,进程的管理需要确保系统能够在执行过程中有效切换进程,并保持执行的一致性。为此,进程的组成和状态信息管理显得尤为重要。
进程状态
进程在执行过程中包含一些状态信息,这些信息在特定时刻被系统记录下来,以实现进程切换。具体而言,进程状态包括:
-
控制流:控制流指示进程当前执行的具体位置。通过程序计数器(PC),系统能够跟踪进程代码执行的具体位置,以便在恢复进程时继续从中断点执行。
-
数据状态:进程访问的数据包括内存和寄存器。其中,内存可进一步划分为堆、栈、数据段等部分。寄存器则保存了进程执行的各种临时数据。
在进程被中断或暂停时,操作系统需要保存进程的上下文,包括控制流、寄存器状态等,以便在进程切换时正确恢复。这种上下文保存被称为进程上下文切换,需包括:
- 程序计数器:记录进程执行的具体代码位置。
- 栈地址:保存进程当前的栈指针位置。
- 通用寄存器:保存进程执行中需要恢复的各种寄存器数据。
- 其他资源:......
进程控制块(PCB)
操作系统需要有效管理每个进程的状态和信息,这依赖于一种数据结构,称为进程控制块(Process Control Block,PCB)。PCB用于记录进程的状态和其他管理信息,并在进程切换时提供完整的进程上下文。
- 进程标识信息:为每个进程分配唯一的标识符(如PID,进程ID)。
- 处理器现场信息:保存进程执行状态的寄存器、程序计数器等信息。
- 进程控制信息:管理进程状态,如正在运行(running)、就绪(ready)或休眠(sleep)等。
通过PCB,操作系统能够在进程间进行有效的上下文切换,确保不同进程在各自的状态下继续执行。
进程的组成和管理需要依赖于状态信息的保存和切换。通过进程控制块,操作系统能够跟踪和管理进程的执行状态,实现有效的进程上下文切换,并在进程执行时保持执行过程的一致性。
四 进程模型
进程状态与切换过程
进程在执行过程中会经历不同的状态,这些状态与进程的执行相关,并在操作系统中被清晰地管理。以下是进程状态及其切换过程的简要总结:
进程状态
-
创建状态:进程在被创建时,进程控制块(PCB)和相关资源尚未准备好。操作系统为进程创建初始的栈、寄存器和代码空间,设置初始状态,使其具备执行条件。此时,进程处于“创建状态”。
-
就绪状态:创建完成后,进程进入就绪状态(Ready),意味着它已准备好执行。就绪进程在等待操作系统的调度,直到系统选择该进程执行时,它才会从就绪状态进入运行状态。
-
运行状态:就绪进程被操作系统调度后,将从就绪状态切换到运行状态(Running)。操作系统通过上下文切换,让当前运行的进程让出CPU,并将其分配给新调度的进程。操作系统需要将状态从内核态切换到用户态,使进程代码能够执行。
-
等待状态:运行中的进程可能会进入等待状态(Waiting),例如当进程需要等待外部资源时。常见的等待场景包括:
- Sleep:进程主动请求休眠,例如调用“sleep 5秒”。
- I/O等待:等待文件读写或其他外部设备操作完成。由于I/O速度较慢,进程会主动放弃CPU,进入等待状态,使其他进程可以使用CPU。
-
终止状态:进程完成其功能或因某种原因被终止,将进入终止状态(Terminated)。此时,进程的资源将被操作系统回收,以供其他进程使用。
状态切换过程
进程状态及状态转换详解
-
创建(Creation)到就绪(Ready):
- 何时创建:进程在系统启动、用户请求或其他进程的要求下被创建。
- 如何创建:操作系统通过进程创建机制,为新进程分配唯一的进程 ID(PID)、内存空间、文件描述符及其他资源,并在进程控制块(PCB)中存储其状态信息。
- 转换到就绪:创建完成的进程具备执行条件,并进入就绪队列,等待 CPU 调度。
-
就绪(Ready)到运行(Running):
- 内核选择任务:调度程序从就绪队列中选择一个合适的进程,将其分配到 CPU 上执行,进程状态从就绪切换为运行。
- 如何执行:执行开始时,操作系统恢复进程的寄存器状态,并开始执行该进程的指令。
-
运行(Running)到等待(Waiting/Blocked):
- 任务进入等待的原因:
- 自身:进程主动等待某个事件(例如 I/O 操作或休眠)并主动让出 CPU。
- 外界:其他事件导致进程暂停执行(例如系统调用或同步操作)。
- 状态切换:进程让出 CPU 后,其状态切换为等待,并等待事件的完成或被唤醒。
- 任务进入等待的原因:
-
等待(Waiting/Blocked)到就绪(Ready):
- 被唤醒的原因:
- 自身:进程设置的等待时间结束,自行唤醒进入就绪状态。
- 外界:等待的事件完成,或进程被操作系统或其他进程唤醒,恢复到就绪状态。
- 被唤醒的原因:
-
运行(Running)到抢占(Preempted):
- 任务被抢占的原因:
- 系统调度器基于优先级、时间片等策略,从 CPU 上中断当前执行的进程,将其状态切换为就绪,并调度另一个进程执行。
- 任务被抢占的原因:
-
运行(Running)到退出(Terminated/Exited):
- 任务退出的原因:
- 自愿:进程正常执行完成,或通过特定系统调用(如
exit)自愿退出。 - 被迫:由于外部因素导致进程终止,如错误、异常或被其他进程强制结束。
- 自愿:进程正常执行完成,或通过特定系统调用(如
- 任务退出的原因:
在进程的生命周期中,不同状态的转换由调度程序根据系统需求和任务特性控制,确保多任务系统在有限的资源下高效运作。通过这种状态切换机制,操作系统能够有效管理和调度进程,使其在合适的时机获取资源并执行其功能。
在多任务操作系统中,进程的状态会不断变化,有时可能会被抢占。以下是进程的抢占、状态转换以及系统调用之间的关系。
抢占
抢占是指操作系统强制停止当前正在运行的进程,让它从运行状态转换到就绪状态,以便给其他进程提供运行的机会。抢占通常由时钟中断触发,操作系统在中断发生时将当前进程置于就绪状态,为其他进程的调度和执行腾出资源。
- 时钟中断:时钟中断是一种周期性中断,用于触发抢占。在时钟中断发生时,操作系统暂停当前进程的执行,将其从运行状态置为就绪状态,然后选择其他进程执行。
进程退出
进程退出可以是自愿的或被迫的:
-
自愿退出:进程主动调用退出指令(如
exit系统调用),结束自身的执行。这通常发生在进程完成预定工作后主动请求退出。 -
被迫退出:
- 非法操作:进程尝试执行非法操作或触发严重错误,操作系统会终止该进程的执行。
- 外部强制:更高级别的管理程序或系统管理员可能会强制终止进程的执行。
进程模型
进程在执行过程中主要存在以下三种状态:
- 就绪:进程已具备执行条件,等待操作系统的调度以获得CPU时间。
- 运行:进程正在CPU上执行。
- 等待:进程由于需要等待资源(如I/O操作)或休眠等原因而暂停执行。
此外,还有两个额外的过程:
- 创建:创建进程时,操作系统分配并初始化进程控制块(PCB)等资源。
- 退出:进程结束执行后,操作系统回收资源,将进程控制块和其他资源释放。
这形成了进程状态的五个基本过程:创建、就绪、运行、等待和退出。
系统调用与状态转换
系统调用是用户程序与操作系统交互的主要方式,会导致进程状态发生变化:
- 运行到退出:进程主动调用
exit系统调用,退出并释放资源。 - 运行到等待:进程可能通过系统调用进入等待状态,如调用
sleep使进程休眠一段时间。 - 运行到就绪:通常由中断触发的抢占或高优先级进程到来,使当前进程暂停并进入就绪状态。
进程在操作系统中会经历多种状态转换,包括抢占、系统调用或异常等原因导致的状态变化。了解进程状态及转换的原因,有助于掌握操作系统中进程管理的核心逻辑和实现机制。
进程切换的时机与过程
进程在操作系统中进行切换是不可避免的,确保了多进程的并发执行和资源的合理分配。以下是进程何时会进行切换的时机及其过程。
进程切换的时机
进程切换是指操作系统暂停当前运行的进程,并在合适的时机切换到其他进程继续执行。主要有以下几个时机:
-
主动进入等待状态:当进程调用
sleep或其他系统调用以进入等待状态(如等待I/O操作),操作系统将进程状态置为等待,进而切换到下一个就绪进程执行。 -
时间片用尽:在多任务操作系统中,每个进程被分配一个固定时间片(time slice)。当进程用完时间片,时钟中断触发抢占,操作系统将当前进程置为就绪状态,然后切换到下一个就绪进程执行。
-
进程退出:进程执行完毕或被迫退出后,操作系统将当前进程状态置为终止,并切换到下一个就绪进程执行。
进程切换的过程
进程切换涉及暂停当前进程并恢复新进程的执行环境,确保进程状态的一致性。进程切换的步骤如下:
-
保存当前进程的现场:操作系统在中断或系统调用发生时将当前进程的上下文(context)信息保存至进程控制块(PCB),包括程序计数器、通用寄存器、栈指针等。
-
选择下一个进程:操作系统根据调度算法选择下一个就绪进程进行执行。
-
恢复新进程的现场:从新进程的进程控制块中恢复其上下文信息,包括程序计数器、寄存器、栈等。
-
切换到新进程:操作系统将控制权交给新进程,恢复用户态并开始执行进程的代码。
进程切换的简单结构
可以将进程切换的过程形象化为一个结构图:
-
程序A与程序B:假设有两个程序在执行进程。进程A主动调用
sleep系统调用进入等待状态,触发进程切换过程。 -
进入内核态:操作系统将通过中断或系统调用进入内核态,保存进程A的上下文信息。
-
选择下一个进程:操作系统根据调度算法选择进程B执行,并恢复其上下文。
-
返回用户态:操作系统将控制权交给进程B,使其从用户态开始执行。
这种进程切换的结构图展示了进程的上下文保存和恢复过程,以及多进程之间的交替执行机制。
下一节
实践:多道程序与分时多任务操作系统
分时多任务操作系统通过多阶段的改进,实现了更高效的进程切换和资源利用。以下是各个阶段的变化与进程切换的实践方法。
第一阶段:引入进程管理
-
应用程序管理模块的拆分:内核中的应用程序管理模块被拆分为不同的子模块,其中引入了程序加载器(loader),负责查找和加载程序。进程切换模块(task manager)则用于管理进程控制块(PCB),独立处理进程切换逻辑。
-
多进程支持:引入进程管理后,操作系统可以同时在内存中运行多个应用程序,并实现进程间的切换。这是最早期的多进程系统设计,其中引入了基本的进程结构和管理概念。
第二阶段:主动进程切换
-
系统调用支持主动切换:在这个阶段,系统调用被扩展,增加了进程放弃与切换的功能。进程可以通过系统调用主动放弃对CPU的占用,切换到其他进程执行。
-
上下文保存与恢复:在进程主动放弃CPU时,操作系统保存当前进程的上下文信息(包括寄存器、栈、程序计数器等),并恢复下一个被调度的进程的上下文。
-
进程调度:此阶段的操作系统在系统调用中主动管理进程的上下文,并通过进程管理模块实现多进程的调度与切换。
第三阶段:中断与时间片管理
-
引入时钟中断:操作系统在此阶段引入了时钟中断机制。通过时钟中断,系统可以准确追踪进程的执行时间,为进程分配固定的时间片(time slice)。
-
时间片切换:一旦时钟中断指示某个进程的时间片已用尽,操作系统将保存当前进程的上下文,并切换到下一个就绪进程。
-
统一异常、系统调用与中断处理:系统调用、中断和异常在本质上都是从用户态切换到内核态的过程。在这个阶段,操作系统统一了它们的处理流程,使它们共用相同的机制来保存和恢复上下文信息。
-
进程执行时间追踪:操作系统通过时钟中断追踪每个进程的执行时间,确保进程不会长期独占CPU,保证进程之间的公平调度。
通过这三个阶段的逐步改进,操作系统在管理进程时具备更强的灵活性和效率,实现了真正意义上的多道程序与分时多任务操作系统。
第四讲 多道程序与分时多任务
第二节 实践:多道程序与分时多任务操作系统
〇 回顾
系统调用与应用程序的交互
从课程的起始,我们便重点讨论了系统调用的重要性。系统调用是应用程序获取操作系统服务的桥梁。通过介绍如读写文件等基本系统调用,帮助大家理解这一机制。对于开发者来说,这些内容相对容易从用户和应用程序的角度理解。
裸机编程与操作系统的基础
进入到课程的第二阶段,我们的学习内容开始与常规的应用开发有所不同。这时,你需要了解如何进行裸机编程,也就是直接与硬件交互的开发方式。我们关注了三个主要的知识点:
- 硬件与软件的启动过程:理解计算机系统是如何从硬件电源开启到加载操作系统的。
- 函数调用的底层实现:虽然这与编译原理课程中的内容略有不同,但同样重要,需要深入理解。
- 操作系统与更底层软件的关系:介绍了SBI(Supervisor Binary Interface)等软件,它们为操作系统提供服务,形成一个层次更深的软件架构。
多应用支持与特权模式
第三次课程中,我们讨论了操作系统如何支持多个应用程序同时运行。引入了特权级的概念,区分了用户态和内核态,这两者虽然相互隔离,但并非完全独立,它们之间需要通过系统调用进行通信。这种通信实现了特权级的切换,不同于常规的函数调用切换,这种特权集切换涉及到更为复杂的上下文保存与恢复操作。
应用程序的加载与执行环境构建
我们还需要掌握的是,在支持多应用的环境下,操作系统如何管理、加载并执行这些应用程序。这包括了如何在内存中构建应用的映像(image),并在需要时将它们加载至运行状态。这不仅涉及内存拷贝,还包括从特权态到用户态的状态切换。此外,操作系统还需要为每个应用程序构建和准备其执行环境,确保它们可以从初始指令开始正确执行。
一 实验目标和步骤
1.1 实验目标
- MultiprogOS目标
- 进一步提高系统中多个应用的总体性能和效率
- BatchOS目标
- 让APP与OS隔离,提高系统的安全性和效率
- LibOS目标
- 让应用与硬件隔离,简化应用访问硬件的难度和复杂性
多应用内存管理与调度策略
为了提高应用的资源效率,操作系统在内存中同时运行多个应用程序。关键在于确保这些应用程序能够公平且有效地共享处理器资源。我们讨论了两种基本的调度方法:
-
协作调度:在这种模式下,每个应用程序在执行完必要的任务后,会主动释放CPU,通过特定的系统调用让操作系统切换到另一个程序。这要求应用程序通过合作的方式,主动告诉操作系统它们已经完成了当前的任务,并准备好让出处理器。
-
任务上下文与线程上下文:任务切换是多任务操作系统中的一个核心功能,它涉及到任务上下文的保存与恢复。任务上下文包括了程序的所有状态信息,如寄存器、内存状态等,以保证程序可以在之后的某个时刻从同一点继续执行。这与线程上下文不同,后者更多关注于线程的执行状态。
系统级特性的实现复杂性
操作系统的设计复杂性主要体现在处理多个应用程序和任务的能力上,尤其是在它们的上下文切换处理。这包括特权级切换、任务切换和内存地址空间的管理。这些底层和复杂的处理确保了系统能够高效地在多个应用间切换,维护稳定性和安全性。
多道程序与分时多任务操作系统
-
多道程序操作系统:在这类系统中,应用程序需要主动放弃CPU,以便操作系统可以调度其他程序执行。这种方式依赖于程序的协作性,是一种较为简单的调度策略。
-
分时操作系统:分时系统通过时间片来实现多任务处理,自动按时间间隔切换正在执行的程序,不依赖程序的自主协作。这提高了CPU的使用效率,允许多个用户或多个程序看似同时运行。
总体思路
- 编译:应用程序和内核独立编译,合并为一个镜像
- 编译:应用程序需要各自的起始地址
- 构造:系统调用服务请求接口,进程的管理与初始化
- 构造:进程控制块,进程上下文/状态管理
- 运行:特权级切换,进程与OS相互切换
- 运行:进程通过系统调用/中断实现主动/被动切换
多应用性能提升策略
在操作系统的设计中,我们的目标不是提升单个应用的性能,而是提升多个应用共同执行时的整体性能。一种基本的方法是将多个应用加载到内存中,以支持它们的并发执行。这种方法相较于早期只支持单个应用的操作系统,表现在能够同时处理多个应用的能力上。
任务抽象与调度
为了便于管理不同应用的分时执行,我们引入了“任务”这一抽象概念。任务抽象允许操作系统将应用的执行过程切分为不同的段,便于按时间片分配处理器资源。这有助于形成如多道程序操作系统和分时多任务操作系统这样的两种不同类型的系统模型。
多应用内存管理与地址空间
在多应用并发的环境下,每个应用都必须在内存中有独立的地址空间。这要求操作系统在编译时将多个应用及内核编译成一个统一的镜像,并在物理地址上进行适当的管理和隔离。由于现在我们处理的是多个应用,不同应用的起始地址必须不同,以确保它们能够在物理地址空间中正确执行,这与早期单应用的操作系统有显著不同。
系统调用与任务控制
为了支持应用的主动放弃处理器资源,我们需要设计新的系统调用接口来管理这一行为。这些系统调用通过进程控制块(Process Control Block, PCB)来实现,PCB负责管理程序执行的特定阶段和状态,包括保存和恢复任务上下文。任务上下文的切换通常在内核态中完成,这涉及到在内核态完成特权级切换后,进一步进行任务级切换,以允许其他程序执行。
任务的主动与被动切换
除了通过系统调用实现的主动任务切换外,操作系统还可以通过中断方式强制打断当前处理器的执行,实现任务的被动切换。这意味着无论应用是否愿意,都可能被操作系统强制切换,以响应可能的高优先级任务或处理突发事件。
通过上述探讨,我们了解到操作系统如何通过精细的内存管理、任务调度和系统调用设计,支持高效的多应用执行。这些系统级的设计不仅仅是理论上的讨论,它们是构建强大、灵活的现代操作系统所必需的实际技术实现。
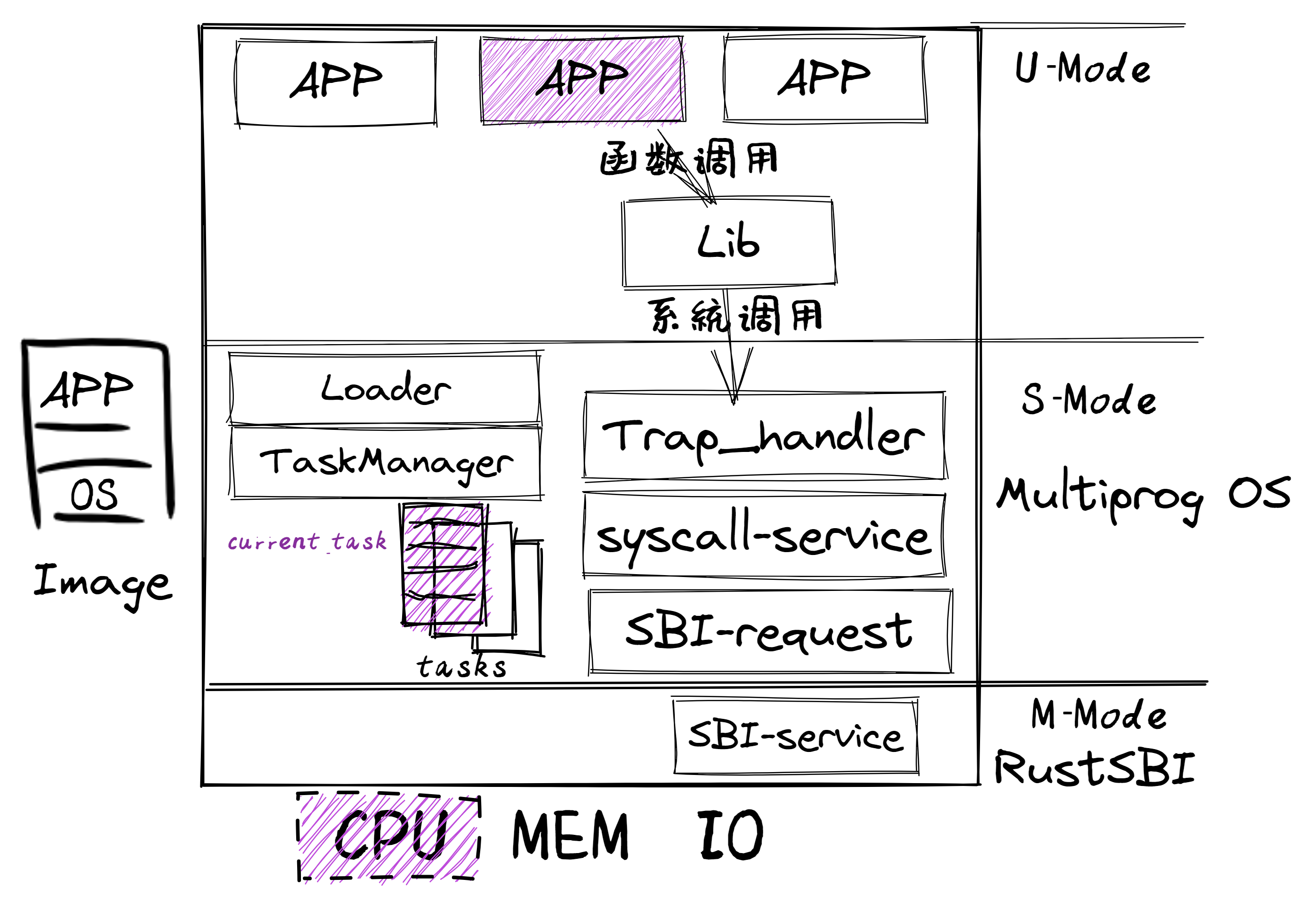
历史背景
尽管我们今天讨论的操作系统的设计思想起源于20世纪60年代,这些理念仍然具有现实意义和应用价值。例如,早期的计算机如Libra 3已经实现了支持多个程序顺序执行的批处理系统。这些历史上的设计不仅没有过时,反而在某些特定的应用场景中依然适用。
1.2 实践步骤
在现代操作系统教学与实践中,第一步通常是重构应用程序,确保其可以在多任务环境下正确执行。具体步骤包括:
-
修改应用的链接脚本:这是为了使应用能在内存中被正确地定位和执行。链接脚本(LD脚本)指定了应用程序在内存中的加载地址,是由连接器在编译过程中处理的。
-
加载与执行多个任务:这是操作系统的基本职责,要确保多个程序可以被有效地加载和执行。在教学中,通常会提供代码的分支供学生下载和实践。
-
使用系统调用进行任务切换:在没有分时系统的环境下,操作系统依靠
yield这类系统调用来实现任务之间的切换。每个程序执行一定的计算后,会主动通过系统调用放弃CPU,从而允许其他程序执行。这种方式要求程序是“友好”的,即能主动分享处理器资源。
实践步骤(基于BatchOS)
- 修改APP的链接脚本(定制起始地址)
- 加载&执行应用
- 切换任务
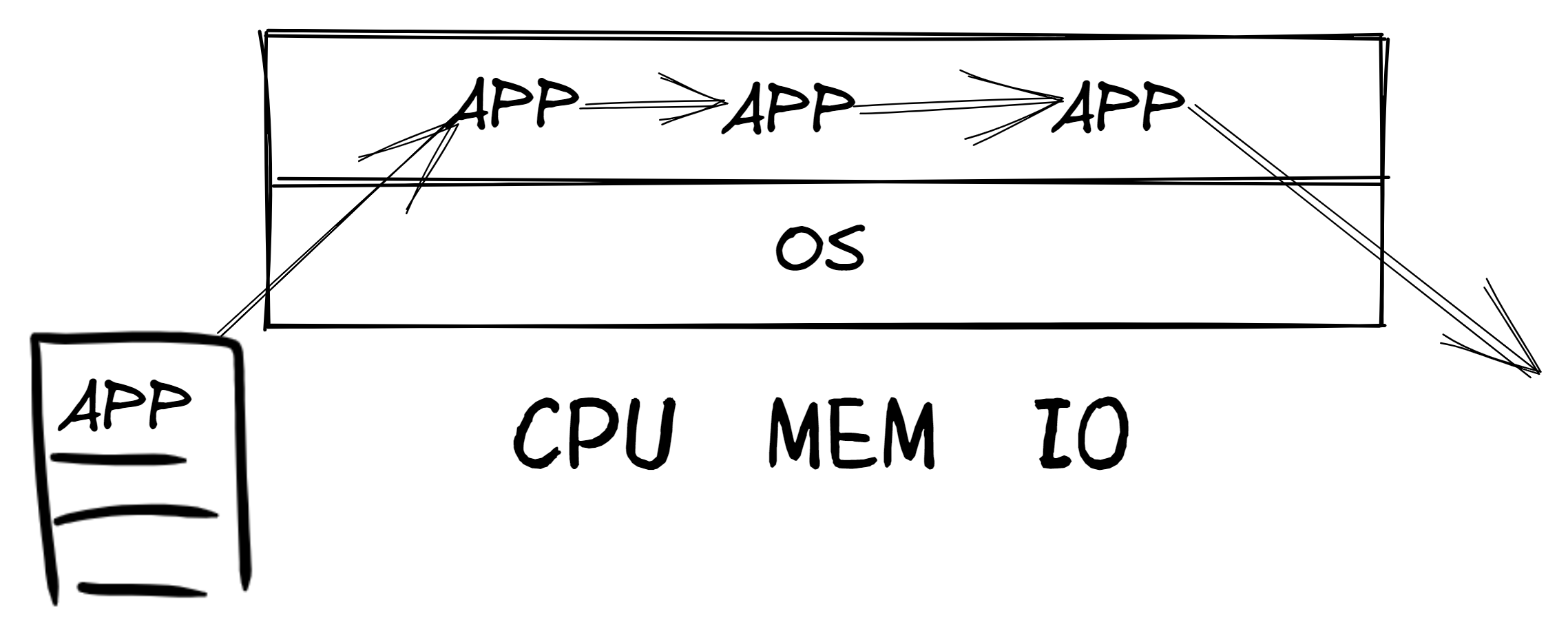
三个应用程序交替执行
git clone https://github.com/rcore-os/rCore-Tutorial-v3.git
cd rCore-Tutorial-v3
git checkout ch3-coop
包含三个应用程序,大家谦让着交替执行
user/src/bin/
├── 00write_a.rs # 5次显示 AAAAAAAAAA 字符串
├── 01write_b.rs # 2次显示 BBBBBBBBBB 字符串
└── 02write_c.rs # 3次显示 CCCCCCCCCC 字符串
运行结果
#![allow(unused)] fn main() { [RustSBI output] [kernel] Hello, world! AAAAAAAAAA [1/5] BBBBBBBBBB [1/2] .... CCCCCCCCCC [2/3] AAAAAAAAAA [3/5] Test write_b OK! [kernel] Application exited with code 0 CCCCCCCCCC [3/3] ... [kernel] Application exited with code 0 [kernel] Panicked at src/task/mod.rs:106 All applications completed! }
二 多道批处理操作系统设计
应用程序的构建与链接
在多任务操作系统的环境下,为了确保每个应用程序能在其专有的地址空间运行而不互相干扰,必须对应用程序的构建过程进行特定的修改。具体操作包括:
- 定制链接脚本的生成:通过工具如
builder.py为每个应用程序生成定制的链接脚本,确保每个程序的起始地址不同。 - 修改构建系统:调整
Makefile,以支持自动生成的链接脚本,确保在链接阶段各应用程序正确地被定位。
这些改动不仅涉及到应用程序的编译过程,还涉及到整个构建环境的调整,从而为多任务操作系统的运行打下基础。
操作系统结构的调整
对操作系统自身的改动更为复杂,主要集中在任务的加载和管理上:
- 模块分离:将任务加载(Loader)和任务管理(Task Manager)分为两个子模块,使得功能更加分明且易于管理。
- 系统调用的增加和支持:引入新的系统调用如
yield,来支持任务的主动放弃CPU,需要在操作系统中增加相应的处理逻辑,以支持状态的保存、恢复和任务切换。
汇编程序与任务切换
在实现任务切换的过程中,由于涉及到底层的寄存器操作,通常需要通过汇编语言来实现:
- 任务切换的汇编实现:
switch.S是一个关键的汇编程序,用于实现任务上下文的保存与恢复。这是因为高级语言难以直接操作寄存器等硬件资源。 - 核心数据结构:任务控制块(Task Control Block, TCB)作为核心的数据结构,存储在
task.s中,是任务管理的基础。
硬件需求与操作系统升级
关于硬件需求,实现一个多程序操作系统并不需要对现有硬件进行功能上的增加:
- 利用现有硬件特性:通过充分利用现有硬件的特权级等特性,可以在不增加新硬件的前提下升级和优化操作系统,使其支持多任务处理。
这些改动说明了现代操作系统如何通过软件架构的优化和底层编程来支持更高级的多任务功能,而无需依赖于硬件的改进。
代码结构:应用程序
构建应用
└── user
├── build.py(新增:使用 build.py 构建应用使得它们占用的物理地址区间不相交)
├── Makefile(修改:使用 build.py 构建应用)
└── src (各种应用程序)
代码结构:完善任务管理功能
改进OS:Loader模块加载和执行程序
├── os
│ └── src
│ ├── batch.rs(移除:功能分别拆分到 loader 和 task 两个子模块)
│ ├── config.rs(新增:保存内核的一些配置)
│ ├── loader.rs(新增:将应用加载到内存并进行管理)
│ ├── main.rs(修改:主函数进行了修改)
│ ├── syscall(修改:新增若干 syscall)
代码结构:进程切换
改进OS:TaskManager模块管理/切换程序的执行
├── os
│ └── src
│ ├── task(新增:task 子模块,主要负责任务管理)
│ │ ├── context.rs(引入 Task 上下文 TaskContext)
│ │ ├── mod.rs(全局任务管理器和提供给其他模块的接口)
│ │ ├── switch.rs(将任务切换的汇编代码解释为 Rust 接口 __switch)
│ │ ├── switch.S(任务切换的汇编代码)
│ │ └── task.rs(任务控制块 TaskControlBlock 和任务状态 TaskStatus 的定义)
三 应用程序设计
任务抽象和进程概念的引入
在现代操作系统中,引入了任务抽象概念,这是后来进程概念的前身。任务代表了一个程序的执行过程,包括其运行时的各种状态,这些都需要操作系统进行管理。从操作系统的角度来看,任务是一个动态的实体,其状态随着程序的执行而变化。
应用程序的地址空间管理
对于应用程序而言,它们看起来与常规应用程序相似,但实际上它们的起始地址在系统中是动态分配的。为了确保每个应用有其独立的物理空间,操作系统通过设定不同的起始地址来隔离各个程序。这通常通过在程序地址中加入特定的前缀(如0x0102等)来实现,确保每个应用在内存中占据的空间不会相互冲突。这种设计限制了应用程序的最大大小,通常为2MB,超出这个范围可能会导致内存覆盖问题。
系统调用的封装与使用
系统调用是操作系统提供给应用程序的接口,如 yield 调用,它允许应用程序主动放弃CPU,以让其他程序得以执行。这种系统调用通常被封装在用户级库中,如 lib 库,以简化应用程序的编码工作。例如,yield 函数是对底层 syscall 的封装,使得开发者无需直接编写汇编代码,而可以通过高级语言直接调用。
应用程序与内核的集成
在操作系统的设计中,一个重要的方面是如何将应用程序与内核集成成一个单一的镜像,这简化了系统的加载和执行过程。在编写应用程序时,开发者需要了解如何通过系统调用与内核交互,以及如何在编码中利用操作系统提供的各种服务。
这部分内容主要从应用程序的角度探讨了如何利用操作系统的服务,特别是通过系统调用来实现任务管理和CPU资源的共享。同时,也解释了操作系统如何管理各个应用程序的地址空间,确保它们在独立的空间内安全运行,以及如何通过封装系统调用来简化应用程序的开发过程。这些都是构建高效且安全操作系统的关键技术。
应用程序项目结构
没有更新 应用名称有数字编号
user/src/bin/
├── 00write_a.rs # 5次显示 AAAAAAAAAA 字符串
├── 01write_b.rs # 2次显示 BBBBBBBBBB 字符串
└── 02write_c.rs # 3次显示 CCCCCCCCCC 字符串
应用程序的内存布局
-
由于每个应用被加载到的位置都不同,也就导致它们的链接脚本 linker.ld 中的
BASE_ADDRESS都是不同的。 -
写一个脚本定制工具
build.py,为每个应用定制了各自的链接脚本应用起始地址 = 基址 + 数字编号 \* 0x20000
yield系统调用
//00write_a.rs fn main() -> i32 { for i in 0..HEIGHT { for _ in 0..WIDTH { print!("A"); } println!(" [{}/{}]", i + 1, HEIGHT); yield_(); //放弃处理器 } println!("Test write_a OK!"); 0 }
-
应用之间是相互不知道的
-
应用需要主动让出处理器
-
需要通过
新的系统调用
实现
const SYSCALL_YIELD: usize = 124;
const SYSCALL_YIELD: usize = 124;
pub fn sys_yield() -> isize {
syscall(SYSCALL_YIELD, [0, 0, 0])
}
pub fn yield_() -> isize {
sys_yield()
}
四 LibOS:支持应用程序加载
应用程序加载过程
在操作系统的工作流程中,加载应用程序是一个核心任务,特别是在系统初始启动时或当操作系统需要运行新程序时。这一过程主要由操作系统的加载器(loader)完成,其基本步骤包括:
- 识别镜像位置:确定操作系统镜像已经加载到模拟器或真实硬件的内存中。
- 从镜像中提取应用:加载器负责从内存中的镜像定位并提取各个应用程序。
- 计算应用大小:通过比较连续两个应用的起始地址,使用地址差计算出每个应用程序的大小。
- 内存拷贝:将应用程序从镜像位置拷贝到指定的物理地址。这通常涉及到基于应用程序标识符(APPID)计算出的地址,每个应用有固定大小(如2MB)的空间。
这个过程确保了每个应用都被正确地加载到其预定的内存区域,为接下来的执行做好准备。
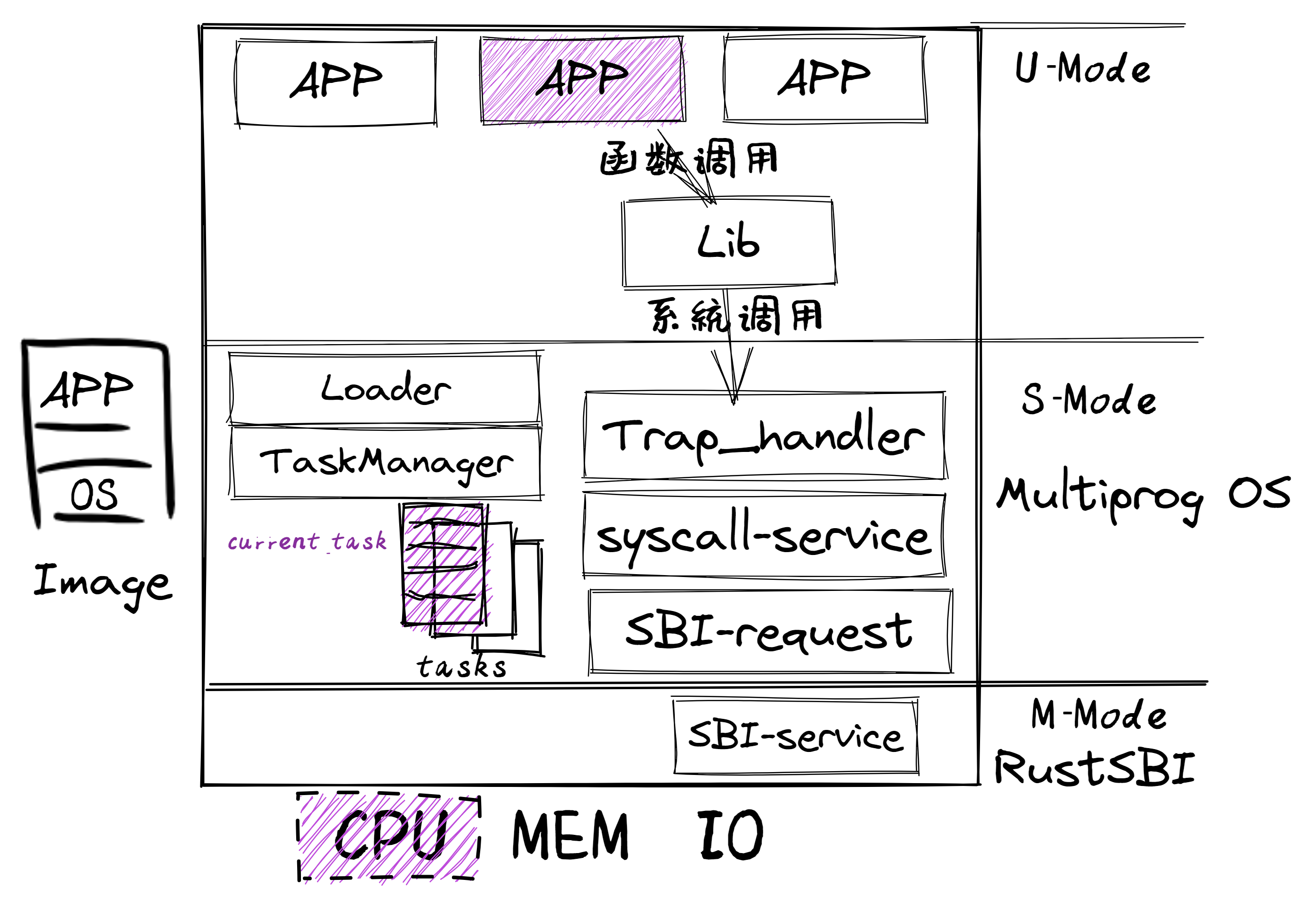
应用程序的执行
一旦应用程序被加载到内存中,操作系统接下来的任务是执行这些程序。执行应用程序的关键在于确定何时以及如何启动这些程序:
- 初始化时执行第一个程序:操作系统在启动后首先运行第一个加载的应用程序。
- 运行下一个应用程序:在当前运行的应用程序执行完毕或需要进行任务切换时,操作系统会选择并运行下一个程序。
- 调用 run_next_app 函数切换到第一个/下一个应用程序
- 跳转到编号i的应用程序编号i的入口点
entry(i) - 将使用的栈切换到用户栈stack(i)
- 跳转到编号i的应用程序编号i的入口点
- 调用 run_next_app 函数切换到第一个/下一个应用程序
- 执行函数:操作系统通过专门的函数来管理应用程序的运行,这些函数负责初始化程序执行的环境,并触发程序的开始。
这个执行机制不仅涉及到程序的启动,还包括在多任务环境中管理程序间切换的逻辑,确保系统资源被高效利用,同时保持系统的响应性和稳定性。
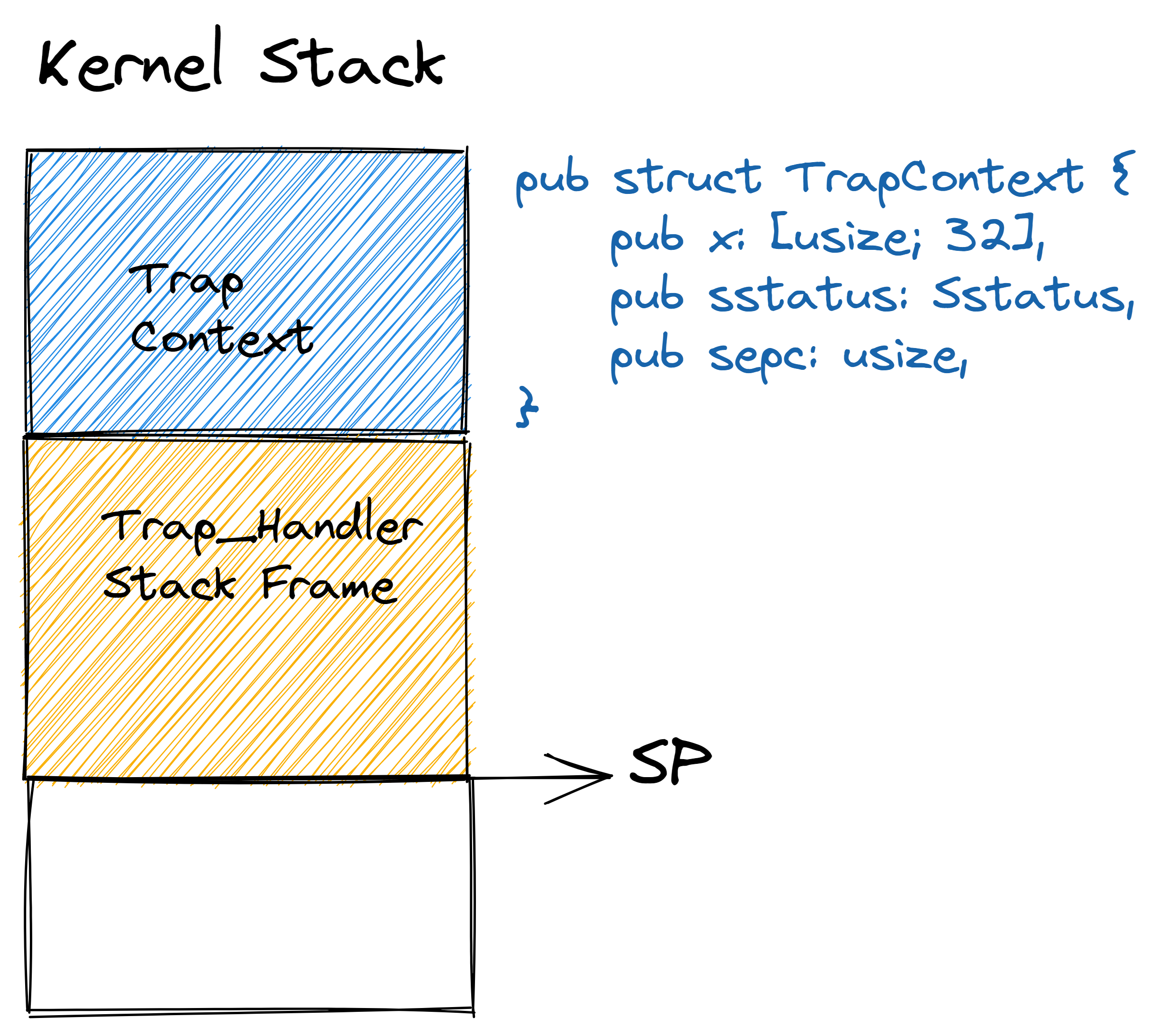
上下文切换和状态恢复
操作系统的上下文切换是一个关键过程,它涉及到从内核态到用户态以及从用户态到内核态的转换。这种转换通常涉及到所谓的“陷阱上下文”(trap context),其中包括保存和恢复程序状态的重要步骤。
初始化陷阱上下文
对于系统中的第一个程序,其陷阱上下文在初始时并不存在,因此需要特别构造一个。这一步骤是确保应用程序能够从正确的位置开始执行至关重要的。
-
入口点确定(SEPC):在构造陷阱上下文时,一个关键的步骤是设置程序的入口点。这通常通过设置
SEPC寄存器来实现,该寄存器存储了应用程序由用户态切换到内核态时的异常地址。在操作系统重新将控制权交给应用程序时,它通过特权指令SRET读取SEPC,从而跳转到程序的正确执行点。 -
构造堆栈(Stack):编译器通常不会预先设置应用程序的堆栈,因此操作系统必须在陷阱上下文的创建过程中手动构造堆栈。这包括为应用程序分配一个堆栈空间,并设置堆栈指针(SP)到一个通用寄存器。当程序控制权通过
SRET跳转到入口点时,堆栈指针已经就位,确保了程序的正常运行。
应用程序的执行环境
操作系统不仅需要处理程序的代码和数据段的加载到适当的内存位置,还需要确保环境完整,以便程序可以无误执行。
-
代码段和数据段的加载:这些通常在应用程序加载过程中已完成。操作系统将应用程序的代码和数据从镜像复制到分配的物理地址空间。
-
堆栈的设置:堆栈的正确设置对于应用程序的稳定运行至关重要。操作系统需要确保每个应用程序都有足够的堆栈空间,并且堆栈指针正确指向这个空间的起始位置。
通过上述步骤,操作系统确保在执行任何应用程序之前,其执行环境是完备的。这包括程序的入口点、代码、数据、以及堆栈的准备,这些都是通过系统的陷阱上下文管理和恢复过程完成的。这样的机制使得多任务操作系统能够高效而安全地管理多个应用程序的执行。
五 BatchOS:支持多道程序协作调度
5.1 任务切换
任务管理与上下文切换
为了有效支持操作系统中的yield操作,需要进一步完善任务管理和上下文切换的机制。在简单的OS中,已经实现了应用程序的加载和执行,但缺乏对任务状态的保存和恢复,这对于支持yield操作是不够的。
任务上下文和保存
-
任务上下文:任务上下文是指任务在执行过程中的状态信息,包括通用寄存器等。在操作系统中,任务上下文的保存和恢复是非常重要的,特别是在任务切换时。
-
任务控制块(TCB):TCB是管理任务的关键数据结构,其中包括了任务的状态信息、寄存器值、堆栈指针等。通过保存和恢复TCB,操作系统可以实现任务的切换和状态的管理。
-
任务切换时的保存和恢复:当一个任务被打断时,需要保存其当前的上下文信息。这包括将当前的通用寄存器值保存到该任务的TCB中,以便之后恢复。当任务重新被调度执行时,需要从其TCB中恢复先前保存的上下文信息,以确保任务能够从被打断的地方继续执行。
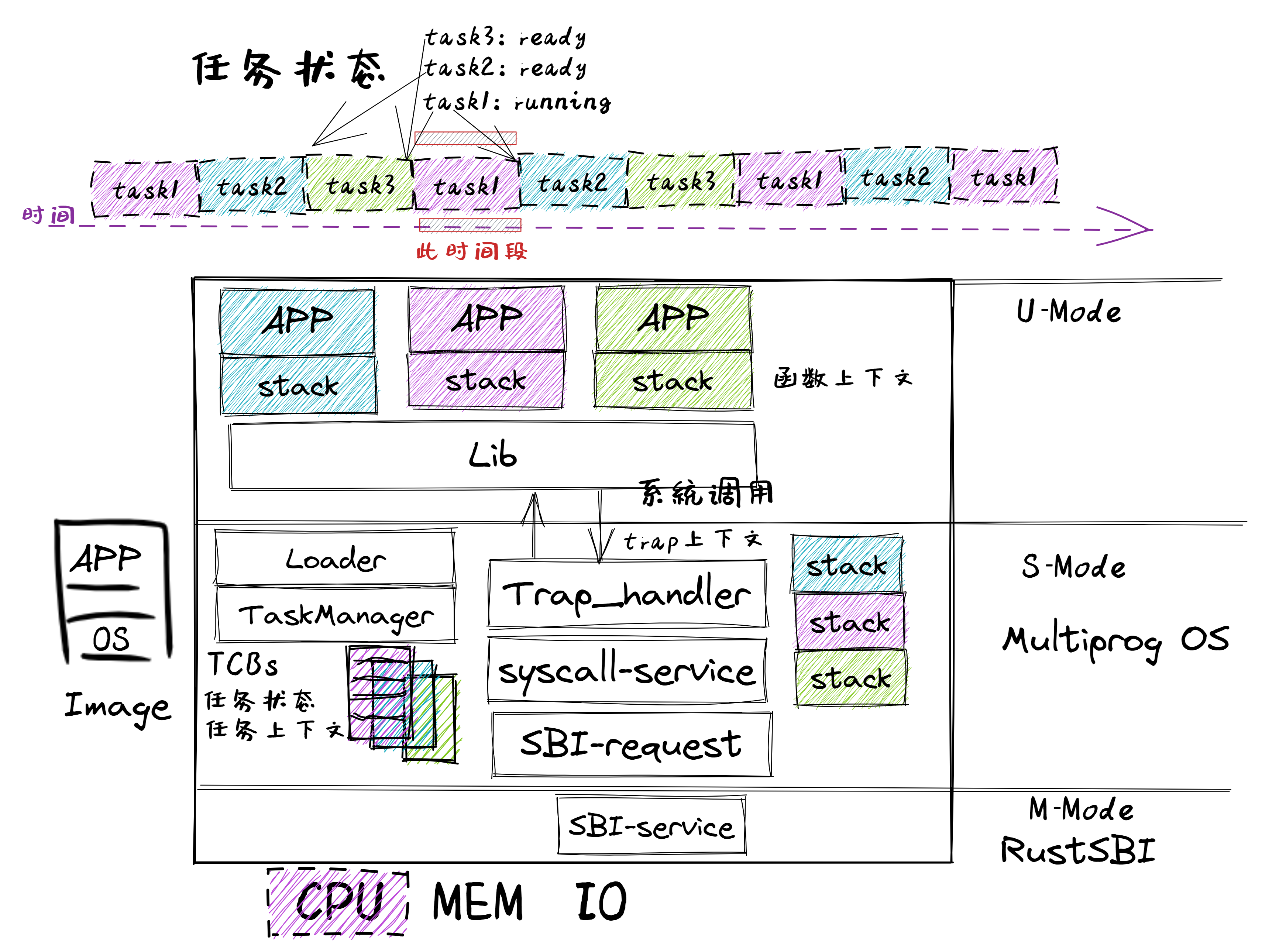
任务切换过程
-
任务打断:任务可能因为系统调用或时钟中断而被打断,此时需要保存当前任务的上下文并选择下一个要执行的任务。
-
保存当前任务的上下文:将当前任务的通用寄存器值等保存到其TCB中。
-
选择下一个任务:根据调度算法选择下一个要执行的任务。
-
恢复下一个任务的上下文:从下一个任务的TCB中恢复其上下文信息。
-
任务恢复执行:恢复的任务将从之前打断的地方继续执行。
通过这样的任务管理和上下文切换机制,操作系统能够实现多任务的管理和调度,支持任务的切换和yield操作,从而更有效地利用系统资源。
任务状态与调度
操作系统中任务的管理涉及到对任务运行状态的精细控制,以及在不同状态之间进行切换的能力。这对于实现有效的多任务处理至关重要。
任务状态的定义
任务在操作系统中可以处于多种状态,其中最核心的包括:
- Running(运行状态):当任务正在CPU上执行时,它处于此状态。这是任务实际占用处理器资源进行操作的时段。
- Ready(就绪状态):当任务准备好执行但因为CPU被其他任务占用而不能执行时,它处于此状态。就绪状态的任务在等待CPU变得可用,以便可以切换到运行状态。
- Blocked(阻塞状态) 或 Sleep(睡眠状态):任务因等待某些事件(如输入/输出操作完成、接收到特定信号等)而不能执行时,会被置于阻塞状态。在事件完成后,任务可以转回就绪状态,等待重新获得CPU时间。
在一个时间片内的应用执行情况
- running
- ready
#![allow(unused)] fn main() { pub enum TaskStatus { UnInit, Ready, Running, Exited, } }
状态转换与任务调度
从一个应用的执行过程切换到另外一个应用的执行过程
- 暂停一个应用的执行过程(当前任务)
- 继续另一应用的执行过程(下一任务)
操作系统的任务调度器负责管理这些状态的转换,以及决定哪个任务应该获得CPU资源。关键的状态转换包括:
-
从Running到Ready:当一个正在运行的任务执行完毕其时间片或主动释放CPU(如执行
yield系统调用)时,它应从运行状态转为就绪状态,等待下一次获得处理器时间。 -
从Running到Blocked:当任务等待外部事件(如I/O操作)时,会从运行状态转为阻塞状态。一旦外部事件处理完成,任务可以被唤醒并转移到就绪状态。
-
从Blocked到Ready:当阻塞的条件被满足(如读取操作完成),任务状态应从阻塞转为就绪,等待重新调度。
-
从Ready到Running:调度器选择一个就绪状态的任务并分配CPU资源给它,使其从就绪状态转为运行状态。
这些状态及其转换是操作系统设计的核心部分,确保了任务公平且有效地共享处理器资源,同时响应系统和用户的需求。通过管理任务的运行状态,操作系统能够提供强大的多任务处理能力,优化系统性能和响应性。
不同类型上下文
上下文的分类和重要性
在操作系统中,主要有两种上下文:陷阱上下文(Trap Context)和任务上下文(Task Context)。这两种上下文的管理对于任务切换至关重要。
-
陷阱上下文(Trap Context):
- 保存涉及从用户态到内核态的切换所必需的信息。
- 包含返回地址(Return Address,即
RA)、栈指针(SP),以及其他关键寄存器。 SP在陷阱上下文中通常指向内核栈,因为当异常发生时,处理器已经在内核模式下运行。
-
任务上下文(Task Context):
- 专门用于任务之间切换时保存任务的状态。
- 包含一组重要的寄存器,这些寄存器在函数调用中由调用者(caller)和被调用者(callee)共同管理。例如,
S0到S11寄存器在callee保存和恢复。 - 当任务恢复执行时,操作系统从任务上下文中恢复这些寄存器的值。
-
任务上下文和trap上下文数据结构
#![allow(unused)] fn main() { // os/src/task/context.rs pub struct TaskContext { ra: usize, sp: usize, s: [usize; 12], } }
#![allow(unused)] fn main() { // os/src/trap/context.rs pub struct TrapContext { pub x: [usize; 32], pub sstatus: Sstatus, pub sepc: usize, } }
切换过程的详细说明
任务切换过程不仅涉及保存当前运行任务的状态,还包括准备下一个任务的执行环境:
-
保存当前任务的状态:当任务执行
yield或由于时间片结束等原因需要被暂停时,当前任务的状态(如寄存器内容)被保存到其任务上下文中。 -
选择下一个任务:调度器根据特定的策略(如轮转、优先级调度等)选择下一个要执行的任务。
-
恢复下一个任务的状态:从选定任务的任务上下文中恢复寄存器等状态信息,准备该任务的执行。
-
切换栈指针:如果任务切换涉及从一个任务的内核栈切换到另一个任务的内核栈,操作系统需要调整栈指针(
SP)指向正确的内核栈。 -
执行任务恢复:通过执行如
SRET指令来从内核态恢复到用户态,继续执行新任务。
通过这一复杂的保存和恢复过程,操作系统确保每个任务能够在适当的时候接续其执行,而不会互相干扰,从而维护系统的稳定性和响应性。
理解不同上下文
在操作系统中,理解上下文切换是关键。我们通常会遇到三种类型的上下文:
- 函数上下文:函数调用的上下文涉及函数所需的状态和寄存器。
- Trap上下文:在操作系统内核中,当发生系统调用或中断时,执行系统级别的上下文切换。
- 任务上下文:任务上下文切换涉及不同的进程或线程之间的切换。
函数上下文
- 函数上下文是控制流的最小单位。当一个函数调用另一个函数时,会产生一个新的函数上下文,保存当前函数的状态。
- 函数A调用B时,A的上下文被保存并切换到B的上下文;当B调用C时,切换到C的上下文。这样每个函数上下文保持独立,形成嵌套。
- 所有这些嵌套的函数调用上下文都属于同一个应用程序,是编译器生成的控制流。在这个层面上,程序执行是一个完整的控制流。
Trap上下文
- Trap上下文在系统调用或中断时出现。
- 当用户态的应用程序执行系统调用指令(如
ecall),会发生从用户态到内核态的切换。 - 用户应用程序和操作系统内核有各自独立的控制流,因此系统调用是一次不同控制流间的切换。
- 用户应用程序的控制流切换到内核的控制流,内核完成相关的系统服务后,再切换回用户态。
任务上下文
- 任务上下文涉及不同任务的切换,例如不同的进程或线程。
- 操作系统通过调度器,利用某种方式切换两个任务,使它们能够交替占用处理器执行。
- 调度器在任务间切换时,会保存当前任务的上下文,包括寄存器、内存映射等信息,并切换到下一个任务的上下文。
- 这种切换允许多个应用程序各自运行在独立的任务上下文中,共享处理器资源。
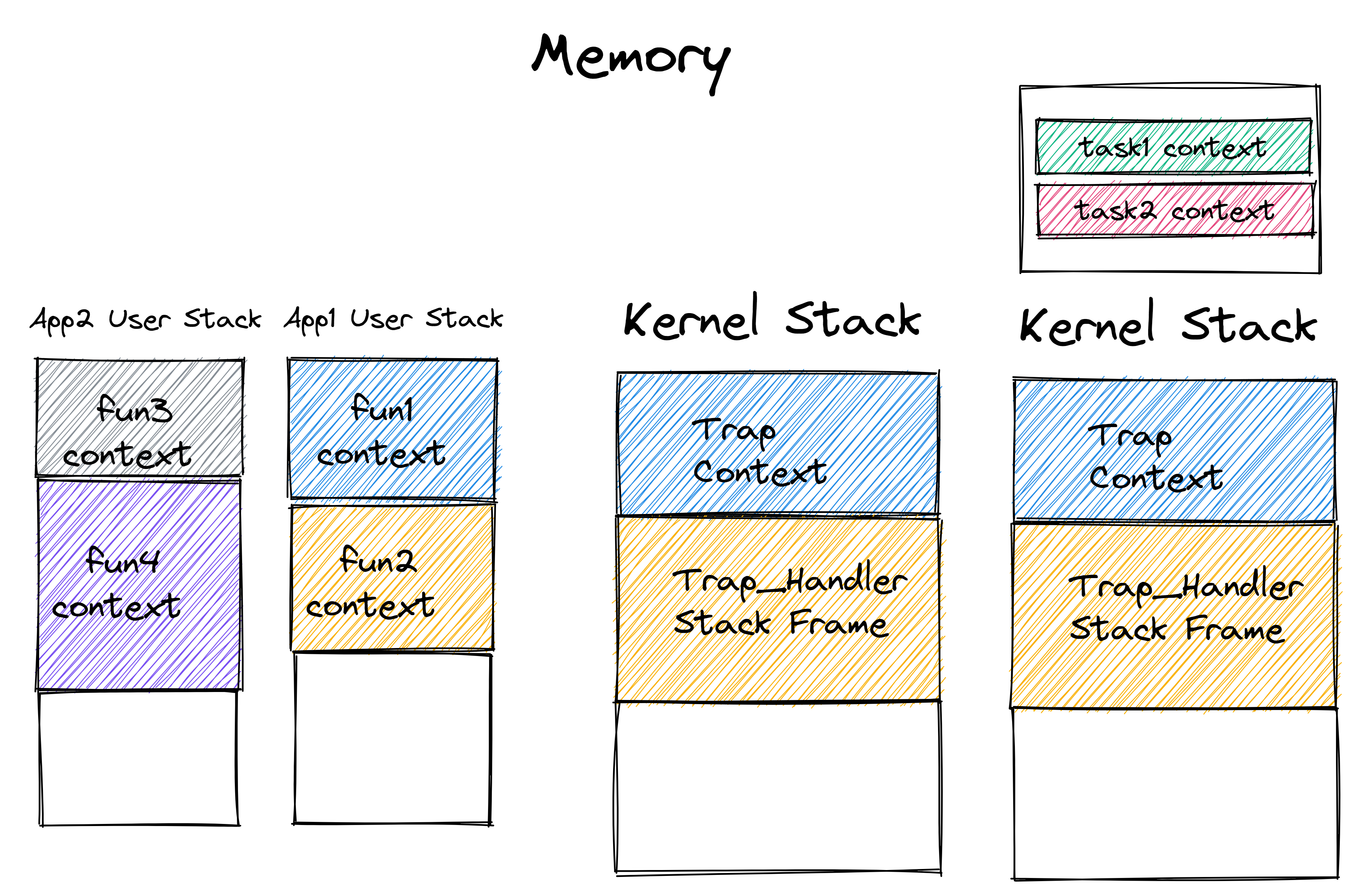
OS 中的任务上下文和内核上下文
操作系统涉及到两种关键的上下文类型:任务上下文和内核上下文。让我们深入探讨它们的区别和运作原理。
任务上下文
- 任务上下文与特权级切换无关。它只保存12个通用寄存器,因为编译器规定了这些寄存器需要在函数调用时被保存和恢复。
- 当函数
switch用于上下文切换时,它负责保存和恢复这12个寄存器的值,但我们希望它以一种“巧妙”的方式操作,使函数返回时切换到另一个任务的上下文。 - 除通用寄存器外,还涉及两个特殊寄存器:
- RA(返回地址寄存器):指向函数的返回地址。
- SP(栈指针寄存器):指向栈的位置。
- 这两个寄存器标记了两个任务的返回地址和栈空间。因为内核有其专属的栈,所以切换到另一个任务的栈空间时,需要保存并恢复更多内容。应用程序的栈通常不会与其他任务共享栈空间。
内核上下文
- 内核上下文切换涉及到操作系统特权级别的改变,例如在执行系统调用或中断时。
- 用户应用程序无法直接察觉到内核上下文的变化,因为它是对用户透明的,所有相关的操作都是在内核中执行的。
- 内核上下文切换通常用于处理系统调用的服务或中断处理,以确保用户任务继续以受控且安全的方式运行。
控制流
任务切换本质上是两个不同应用程序在操作系统内核的Trap控制流之间进行的切换。为了更好地理解任务切换的概念,我们需要先了解什么是控制流。
控制流的定义
-
编译中的控制流:
- 编译器处理的对象是程序本身,不论是高级语言代码还是汇编语言代码,编译器都是针对程序的。
- 程序的控制流指的是一组程序指令、语句或基本块按顺序执行,形成的执行序列即称为控制流。
-
计算机组成中的控制流:
- 在计算机组成原理中,关注的对象是CPU(中央处理器)。
- 处理器的控制流是指程序计数器(PC,Program Counter)的指令转移序列,或每条机器指令的执行流。
-
操作系统中的控制流:
- 操作系统把应用程序和内核的控制流统筹考虑。
- 在《计算机系统概论》(CS:APP)一书中,从程序员的角度看,应用程序员所看到的控制流只是应用程序自身的控制流,并不涉及不同应用或应用与OS之间的切换。
- 对于操作系统而言,控制流不仅仅是单个应用的执行流,还包括多个应用的流,以及操作系统自身的控制流。操作系统还需要负责管理各个应用的控制流。
普通控制流:从应用程序员的角度来看控制流
- 普通控制流 (CCF,Common Control Flow) 是指程序中的常规控制流程,比如顺序执行、条件判断、循环等基本结构。是程序员编写的程序的执行序列,这些序列是程序员预设好的。
- 普通控制流是可预测的。
- 普通控制流是程序正常运行所遵循的流。
异常控制流:从操作系统程序员的角度来看控制流
- 在OS中,从应用程序切换到内核,通过中断或系统调用、CPU 异常等情况发生的控制流被称为异常控制流(ECF, Exception Control Flow)。
- 从应用程序的角度来看,这种切换是异常的,因为它脱离了应用程序本身的执行控制。
- 这种异常控制流的机制允许操作系统管理和控制应用程序,实现任务间的切换与资源管理。
- 这种“突变”的控制流称为异常控制流。
- 在RISC-V场景中,异常控制流 == Trap控制流
不同类型的控制流与上下文
普通控制流的上下文
- 普通控制流上下文就是函数上下文。
- 在函数调用过程中,程序控制流在不同函数之间切换,保存和恢复相应的函数上下文。
Trap和任务控制流的上下文
-
Trap控制流上下文:
- Trap控制流上下文属于异常控制流上下文,保存了被打断的应用程序的状态。
- 当系统调用或中断发生时,应用程序的普通控制流被打断,系统进入异常控制流,并且上下文由内核的Trap机制管理。
-
任务控制流上下文:
- 任务上下文的控制流在内核中运行,是内核的普通控制流上下文,而不是异常控制流。
- 任务上下文属于内核中的函数上下文,通常是某个特殊函数(如
switch)用于在不同任务之间进行切换。 switch是一个用汇编语言实现的特殊函数,在执行时会切换两个不同任务的上下文,因此它是一个特殊的内核函数上下文。
区别与总结
-
普通函数上下文:
- 包含应用程序的普通函数调用和返回。
- 应用程序通过高级语言进行开发并生成相应的函数。
-
内核函数上下文:
- 包含内核中的函数,上下文之间可能涉及不同任务的切换。
- 内核函数通常是高级语言或汇编语言编写的。
-
Trap上下文:
- 属于异常控制流,保存被打断应用的状态。
- 系统调用和中断是异常控制流的主要来源。
理解这些不同的上下文类型,有助于深入掌握操作系统的任务切换和控制流管理。
5.2 Trap控制流切换
任务切换的设计与实现
任务切换涉及多个数据结构和关键点,理解它们的工作原理对于设计操作系统至关重要。
关键点
-
数据结构的位置:
- Trap上下文:保存被打断应用的状态。通常,Trap上下文会被放置在每个应用的内核栈(kernel stack)顶部。
- 任务上下文:不同于Trap上下文,它可以放置在栈中或全局数据结构中。具体位置取决于实现方式。
-
切换的方式:
- 任务切换通过
__switch()函数完成,用于在任务间保存和恢复状态。 - 任务切换的逻辑可能发生在不同情况下,包括中断、系统调用或内核调度。
- 任务切换通过
-
何时切换:
- 调度器决定何时发生任务切换,例如时间片耗尽、I/O完成或外部事件发生等。
- 切换的触发条件决定了调度器的调度策略。
-
切换的可逆性:
- 任务切换需要支持切换回原任务,以保证应用程序的状态可以恢复。
内核栈和数据结构
- 每个应用程序都有其专属的内核栈。例如,应用1的内核栈存放应用1的Trap上下文和函数调用信息。
__switch()函数执行任务切换,确保在函数返回时切换到另一个任务。- Trap上下文通常保存在内核栈顶部,但任务上下文可能保存在全局数据结构中,以确保独立管理。
多种实现方式
- 操作系统的设计并非只有一种实现方式,有许多实现方法可以选择。
- 概念和实现之间存在联系,但操作系统中的概念不像数学那么精确,通常可以通过多种途径实现。
- 理解概念与实现的关系是关键,设计能够自圆其说的实现方案才是最重要的。
学习建议
- 理解操作系统的设计需要找到概念和实现之间的联系,确保它们相互对应。
- 学习过程中,保持开放的心态接受多样化的实现方式,理解操作系统的灵活性。
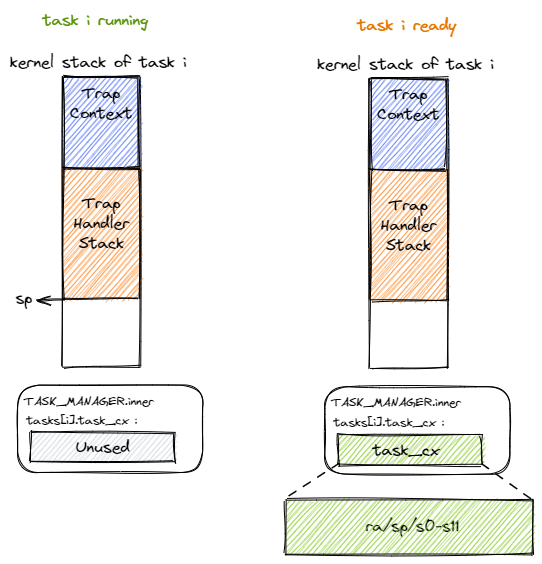
Trap 和 Task 上下文的切换
为了实现多任务操作系统的切换,需要掌握 trap 和 task 上下文的结构和切换方法。
数据结构位置
- Trap 上下文:保存在每个应用的内核栈底部,包含系统调用或中断的上下文。
- Task 上下文:保存于全局变量中,用于在不同任务之间切换时恢复任务状态。
系统调用 yield 和上下文切换
yield系统调用是多道程序 OS 切换任务的入口,触发调度器切换到另一个任务。- 内核检测到
yield请求后,会调用特殊的__switch()函数,完成任务切换。
__switch() 函数的作用
switch是用汇编语言编写的特殊函数,执行任务切换的核心逻辑。- 它将当前任务的上下文状态保存到 Task 上下文结构中,并从下一个任务的 Task 上下文结构中恢复新的状态。
- 关键是改变内核栈,使得控制流返回到下一个任务。
__switch() 函数的参数
__switch()函数通常接收两个参数:- Current:当前正在执行的任务的 Task 上下文指针,表示当前状态。
- Next:下一个任务的 Task 上下文指针,表示需要切换到的任务。
切换过程
Current指针指向当前任务的 Task 上下文,Next指针指向下一个任务的 Task 上下文。__switch()函数保存当前任务的上下文,包括返回地址(RA)、栈指针(SP)和通用寄存器到当前 Task 上下文结构中。__switch()函数加载Next中的上下文,将新的返回地址、栈指针和寄存器加载到 CPU 中。- 改变内核栈,使得控制流返回到
Next任务的内核栈,并继续执行下一个任务的代码。
结论
__switch()函数的关键工作是更改内核栈,并确保当前 CPU 状态与要切换的任务保持一致。- 切换的过程需要确保当前任务的上下文被妥善保存,以便在将来可以无缝恢复。
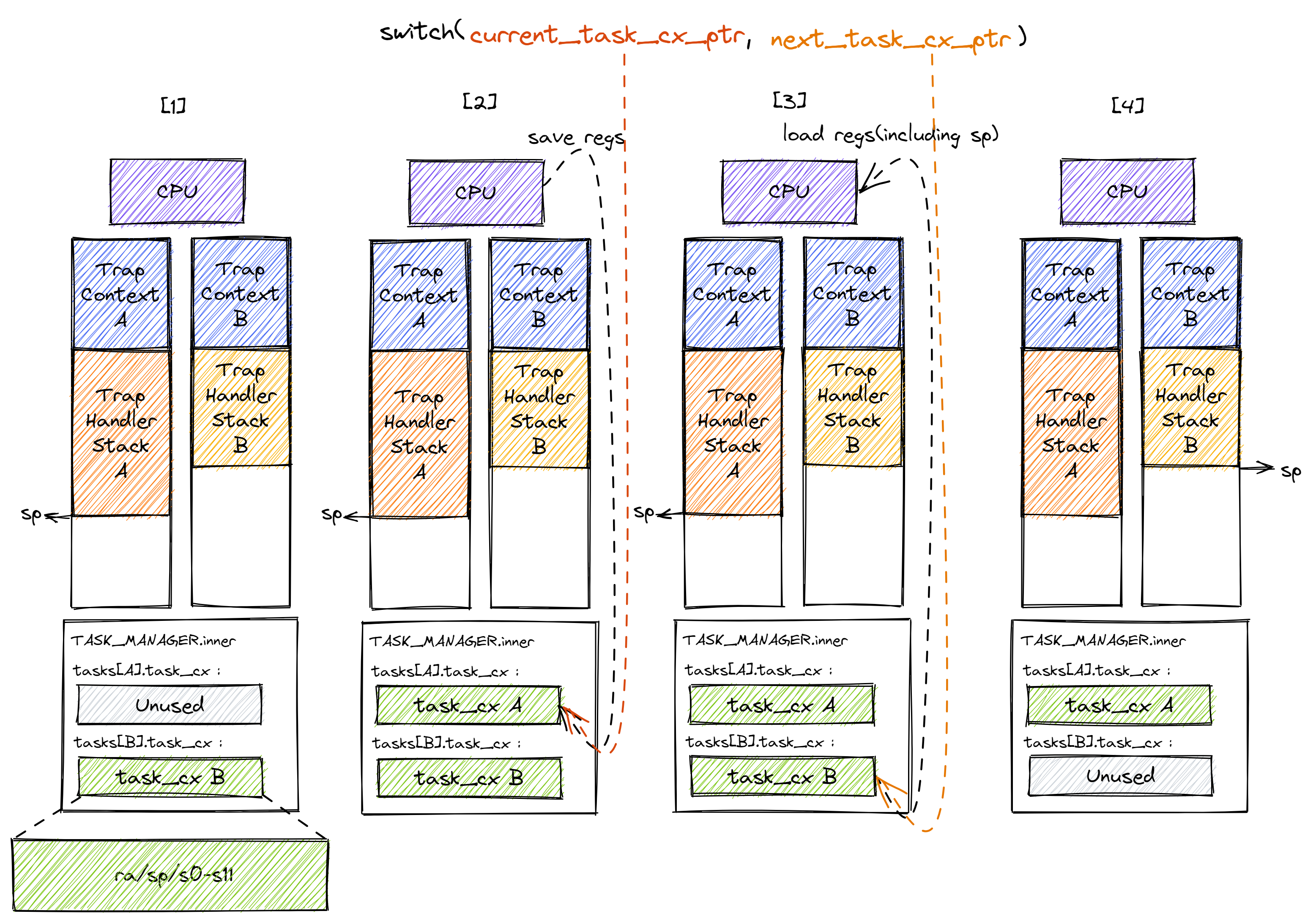
__switch() 函数的四个步骤
__switch() 函数用于在任务之间切换,操作复杂且涉及多个关键步骤。以下是任务切换的四个主要步骤:
第一步:初始状态
- 在进入内核并执行内核代码之前,当前任务 A 的内核栈上只包含其 Trap 上下文和相关的 Trap 处理器函数信息。
- 被切换出的任务 B 的上下文在全局变量中独立存储,暂未使用。
第二步:保存当前任务 A 的上下文
__switch()函数在任务 A 的上下文结构中保存当前 CPU 的寄存器状态,包括返回地址(RA)、栈指针(SP)和其他通用寄存器。- 当前任务 A 的内核栈仍在使用,而任务 B 的内核栈暂时没有用到。
第三步:恢复任务 B 的上下文
__switch()函数读取next_task_cx_ptr指向的 B 任务上下文,将下一个任务 B 的上下文指针作为参数传递,以便找到任务 B 的寄存器快照,恢复 ra 寄存器、s0~s11 寄存器以及 sp 寄存器。- 函数将任务 B 上下文中的寄存器值(包括 RA 和 SP)复制到 CPU 中,准备恢复任务 B 的执行状态。
- 此时,CPU 寄存器已经更换为任务 B 的上下文内容,但尚未执行
return。 - 这一步做完后,
__switch()才能做到一个函数跨两条控制流执行,即 通过换栈也就实现了控制流的切换 。
第四步:执行 return 并切换到任务 B
__switch()函数执行return指令,使得 CPU 根据新的返回地址(RA)跳转到任务 B 的代码位置。- 同时,栈指针(SP)已经更改为任务 B 的栈指针。
- 一旦
ret执行,CPU 将完全切换到任务 B,并开始在任务 B 的内核栈上执行代码,任务 B 可以从调用__switch()的位置继续向下执行。 - 原任务 A 的上下文已被保存并将暂停执行,直到被再次调度。
__switch()通过恢复 sp 寄存器换到了任务 B 的内核栈上,实现了控制流的切换,从而做到一个函数跨两条控制流执行。
结论
__switch()函数是任务切换的核心,它通过保存和恢复上下文确保任务之间的无缝切换。- 任务 A 的上下文被妥善保存,以备后续恢复,而任务 B 的上下文被正确恢复,以开始其执行流程。
任务切换与用户态的可行性
- 任务切换通常在内核完成,因为它涉及到特权操作和对系统资源的管理。
- 理论上,用户程序可以使用特定的编译器和汇编技巧模拟任务切换,但这通常是有限制的,因为用户态缺乏直接操作系统资源的权限。
- 多数情况下,用户态的任务切换不如内核态切换有效,因为内核拥有对资源的完全控制权。
__switch() 函数的实现难点
__switch()函数有两个参数:当前任务和下一个任务的 Task 上下文。- 汇编代码中划分为四个阶段,依次保存和恢复相关寄存器状态,并通过
return指令切换任务。 - 学生在课后应仔细查看代码,理解每个阶段的功能。实现这种代码可能需要指导,因为它对寄存器和内核栈的操作较复杂。
__switch()的接口
#![allow(unused)] fn main() { // os/src/task/switch.rs global_asm!(include_str!("switch.S")); use super::TaskContext; extern "C" { pub fn __switch( current_task_cx_ptr: *mut TaskContext, next_task_cx_ptr: *const TaskContext ); } }
__switch()的实现
__switch:
# 阶段 [1]
# __switch(
# current_task_cx_ptr: *mut TaskContext,
# next_task_cx_ptr: *const TaskContext
# )
# 阶段 [2]
# save kernel stack of current task
sd sp, 8(a0)
# save ra & s0~s11 of current execution
sd ra, 0(a0)
.set n, 0
.rept 12
SAVE_SN %n
.set n, n + 1
.endr
# 阶段 [3]
# restore ra & s0~s11 of next execution
ld ra, 0(a1)
.set n, 0
.rept 12
LOAD_SN %n
.set n, n + 1
.endr
# restore kernel stack of next task
ld sp, 8(a1)
# 阶段 [4]
ret
5.3 协作式调度
任务控制块
操作系统管理控制进程运行所用的信息集合
pub struct TaskControlBlock {
pub task_status: TaskStatus,
pub task_cx: TaskContext,
}
- 任务管理模块
struct TaskManagerInner {
tasks: [TaskControlBlock; MAX_APP_NUM],
current_task: usize,
}
任务调度
- 任务调度 是一种策略,决定何时切换任务,以充分利用 CPU 资源。
- 任务切换 则是具体的实现方法,用于在不同任务之间切换状态。
协作式调度
- 协作式调度依赖应用程序主动触发,例如通过
yield或exit系统调用。 - 这种调度方式较为简单,被动等待应用程序请求,不主动进行调度策略的选择。
- 在这种模式下,操作系统只是根据用户请求执行相应操作。
任务切换步骤
- Suspend 当前任务:调用
__switch()函数,将当前任务的上下文保存,标记其为暂停。 - Run Next:通过
context switch切换到下一个任务的上下文,恢复其 Trap 上下文和 Task 上下文。
任务的上下文
- 每个任务在内核中拥有独立的上下文,包括:
- Trap 上下文:保存被打断的用户态程序状态。
- Task 上下文:保存任务本身的状态,用于在任务间切换。
协作式调度实现
sys_yield和sys_exit系统调用
#![allow(unused)] fn main() { pub fn sys_yield() -> isize { suspend_current_and_run_next(); 0 } pub fn sys_exit(exit_code: i32) -> ! { println!("[kernel] Application exited with code {}", exit_code); exit_current_and_run_next(); panic!("Unreachable in sys_exit!"); } }
#![allow(unused)] fn main() { // os/src/task/mod.rs pub fn suspend_current_and_run_next() { mark_current_suspended(); run_next_task(); } pub fn exit_current_and_run_next() { mark_current_exited(); run_next_task(); } }
fn run_next_task(&self) {
......
unsafe {
__switch(
current_task_cx_ptr, //当前任务上下文
next_task_cx_ptr, //下个任务上下文
);
}
内核程序设计与进入用户态
内核态到用户态的第一次切换
- 初始状态:操作系统在启动时一直在内核态运行,需要进行初始化工作。
- 用户任务的准备:
- Task 上下文:准备任务的 Task 上下文,以便在任务切换时恢复。
- 内核栈:为任务分配独立的内核栈,用于处理 Trap 和系统调用。
- 用户栈:为任务分配用户栈,用于应用程序的普通执行。
- Trap 上下文:保存系统调用或中断发生时的应用程序状态。
- 程序加载:
- 使用 loader 将应用程序代码和数据加载到合适的内存区域。
- 完成内存、栈和上下文的初始化,为任务配置正确的入口地址。
- 进入用户态:
- 在上述准备完成后,通过特定的汇编指令(如
SRET)切换到用户态并执行用户任务。
- 在上述准备完成后,通过特定的汇编指令(如
六 MultiprogOS:分时多任务OS
MultiprogOS的基本思路
- 设置时钟中断
- 在收到时钟中断后统计任务的使用时间片
- 在时间片用完后,切换任务
时钟中断与任务切换
- 时钟中断:是一种硬件中断,用于周期性打断当前执行的任务。
- 中断处理:
- 时钟中断产生时,系统会从用户态或内核态切换到内核态的中断处理程序。
- 中断处理程序会统计当前任务的执行时间,判断时间片是否已耗尽。
- 任务切换:
- 如果时间片耗尽,则需要切换任务,暂停当前任务并调度下一个任务。
- 调用任务切换函数
switch或调度器函数进行任务切换。
- 简单策略:这种切换策略是固定的,只要时钟中断触发,便立即进行任务切换。这种策略简单明了,方便理解和实现。
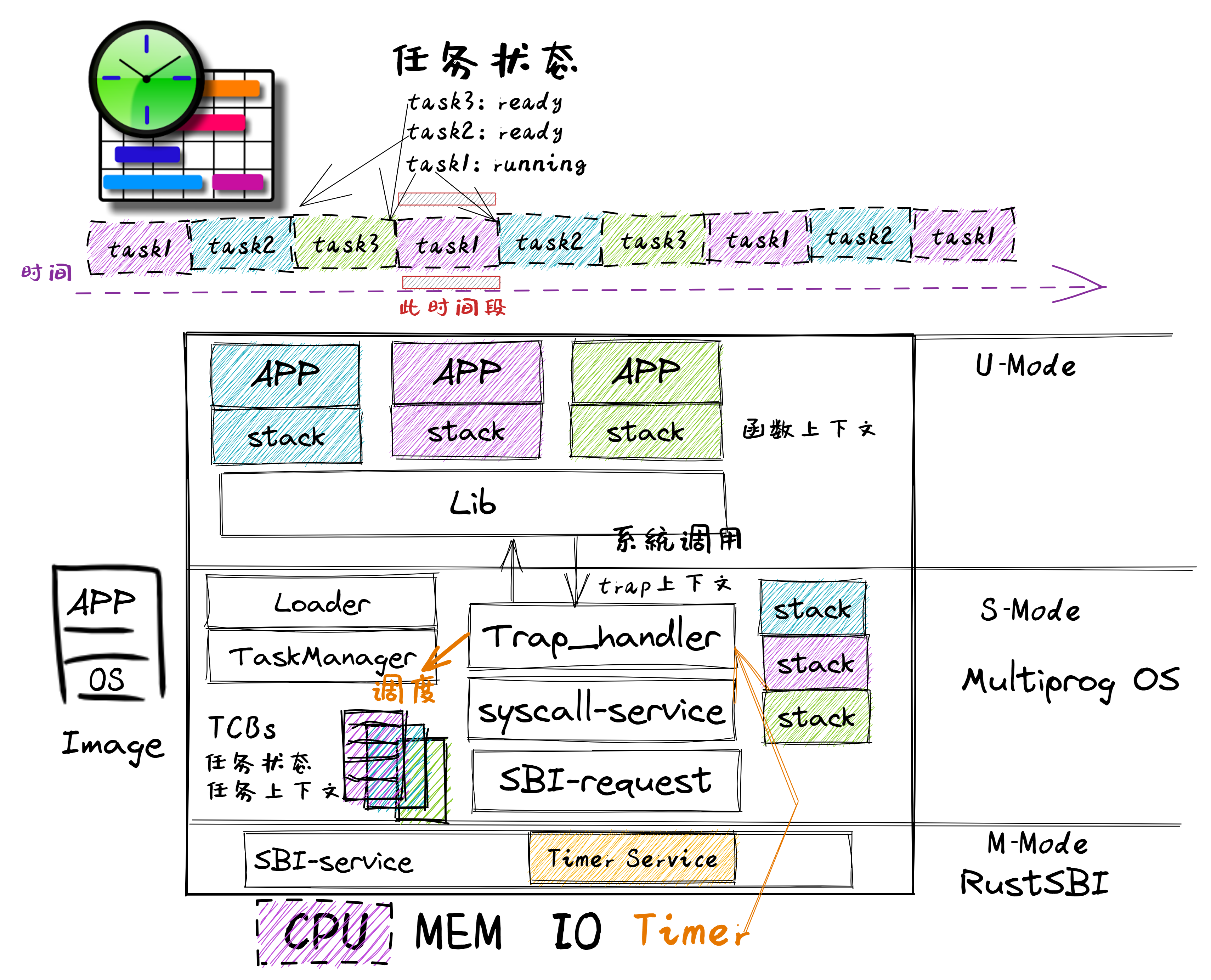
多任务操作系统的定时器和中断
设置定时器
-
定时器设置:
- 为了实现任务的时间片调度,必须设置定时器。
- 使用 SBI(Supervisor Binary Interface)接口中的
set_timer函数,设置下一个中断触发的时间点。 - 设置完成后,还需要启用时钟中断。
-
启用时钟中断:
- 在系统初始化时,时钟中断通常是被禁用的。
- 启用时钟中断后,可以确保系统定期收到中断信号并触发调度。
时钟中断的处理
- 中断处理:
- 当时钟中断触发时,系统会立即进入内核的中断处理程序。
- 在中断处理程序中,重新设置下一个中断触发时间,确保定时器定期触发。
- 处理任务切换逻辑,根据调度策略选择下一个任务执行。
时钟中断与计时器实现
- 设置时钟中断
#![allow(unused)] fn main() { // os/src/sbi.rs pub fn set_timer(timer: usize) { sbi_call(SBI_SET_TIMER, timer, 0, 0); } // os/src/timer.rs pub fn set_next_trigger() { set_timer(get_time() + CLOCK_FREQ / TICKS_PER_SEC); } pub fn rust_main() -> ! { trap::enable_timer_interrupt(); timer::set_next_trigger(); } }
抢占式调度
#![allow(unused)] fn main() { // os/src/trap/mod.rs trap_handler函数 ...... match scause.cause() { Trap::Interrupt(Interrupt::SupervisorTimer) => { set_next_trigger(); suspend_current_and_run_next(); } } }
多任务 OS 的要点
-
多道程序设计:
- 多个程序同时驻留在内存中,通过主动或被动方式共享处理器资源。
- 这种多任务设计使得系统能够分时共享 CPU,有效提高资源利用率。
-
协作式与抢占式调度:
- 协作式调度需要应用程序主动放弃 CPU,而抢占式调度通过时钟中断进行任务切换。
-
任务切换的概念与实现:
- 任务切换涉及任务的上下文、内核栈、Trap 上下文等多个部分。
- 实验中,任务切换需要综合考虑内核和用户态的设计。
-
中断机制:
- 中断机制在调度中扮演重要角色,通过设置定时器和启用中断实现定期的任务切换。
- 中断使得系统能够主动调度任务,实现抢占式的多任务操作。
课程实验一
-
实验任务:增加一个系统调用
sys_task_info() -
实验提交要求
- 在自己的已创建实验仓库中提交完整的代码和文档;
- 提交实验一报告链接和commit ID;
- 实验截止时间:布置实验任务后的第13天;
Lab3
待整理
第四讲 多道程序与分时多任务
代码树解释
── os
├── build.rs
├── Cargo.toml
├── Makefile
└── src
├── batch.rs (移除:功能分别拆分到 loader 和 task 两个子模块)
├── config.rs (新增:保存内核的一些配置)
├── console.rs
├── logging.rs
├── sync
├── entry.asm
├── lang_items.rs
├── link_app.S
├── linker.ld
├── loader.rs (新增:将应用加载到内存并进行管理)
├── main.rs (修改:主函数进行了修改)
├── sbi.rs (修改:引入新的 sbi call set_timer)
├── syscall (修改:新增若干 syscall)
│ ├── fs.rs
│ ├── mod.rs
│ └── process.rs
├── task (新增:task 子模块,主要负责任务管理)
│ ├── context.rs (引入 Task 上下文 TaskContext)
│ ├── mod.rs (全局任务管理器和提供给其他模块的接口)
│ ├── switch.rs (将任务切换的汇编代码解释为 Rust 接口 __switch)
│ ├── switch.S (任务切换的汇编代码)
│ └── task.rs (任务控制块 TaskControlBlock 和任务状态 TaskStatus 的定义)
├── timer.rs (新增:计时器相关)
└── trap
├── context.rs
├── mod.rs (修改:时钟中断相应处理)
└── trap.S
详细解释
顶层结构
build.rs: 编译脚本,用于编译期间的自定义构建步骤。Cargo.toml: Rust 项目的配置文件,定义了项目的依赖和元数据。Makefile: 使用make构建项目的配置文件。
src 目录
batch.rs: 原来负责批处理功能的模块,现已移除,其功能被拆分到loader和task两个子模块中。config.rs: 新增的模块,用于保存内核的一些配置。console.rs: 控制台相关功能。logging.rs: 日志记录相关功能。sync: 同步相关功能。entry.asm: 程序入口的汇编代码。lang_items.rs: 定义了一些语言项目(如 panic 处理)。link_app.S: 用于链接用户应用程序的汇编代码。linker.ld: 链接脚本,用于定义内存布局。loader.rs: 新增的模块,负责将应用加载到内存并进行管理。main.rs: 主函数,进行了修改以适应新增和修改的功能。sbi.rs: 修改后的模块,引入了新的 SBI 调用set_timer。syscall: 系统调用相关功能,新增了若干系统调用。fs.rs: 文件系统相关系统调用。mod.rs: 系统调用模块入口。process.rs: 进程相关系统调用。
task: 新增的任务管理子模块。context.rs: 引入了任务上下文TaskContext。mod.rs: 定义了全局任务管理器并提供接口给其他模块。switch.rs: 将任务切换的汇编代码解释为 Rust 接口__switch。switch.S: 任务切换的汇编代码。task.rs: 定义了任务控制块TaskControlBlock和任务状态TaskStatus。
timer.rs: 新增的计时器相关模块。trap: 中断和异常处理相关功能。context.rs: 中断和异常处理上下文。mod.rs: 修改了时钟中断的相应处理。trap.S: 中断和异常处理的汇编代码。
通过这些模块的拆分和新增,内核实现了多道程序与分时多任务的功能,提高了系统的并发能力和响应速度。
我们将详细深入讲解 loader.rs 文件中的 load_apps 函数每个细节。
loader.rs 文件
#![allow(unused)] fn main() { // os/src/loader.rs pub fn load_apps() { extern "C" { fn _num_app(); } let num_app_ptr = _num_app as usize as *const usize; let num_app = unsafe { num_app_ptr.read() }; let app_start = unsafe { core::slice::from_raw_parts(num_app_ptr.add(1), num_app + 1) }; // clear i-cache first unsafe { core::arch::asm!("fence.i"); } // load apps for i in 0..num_app { let base_i = get_base_i(i); // clear region (base_i..base_i + APP_SIZE_LIMIT) .for_each(|addr| unsafe { (addr as *mut u8).write_volatile(0) }); // load app from data section to memory let src = unsafe { core::slice::from_raw_parts(app_start[i] as *const u8, app_start[i + 1] - app_start[i]) }; let dst = unsafe { core::slice::from_raw_parts_mut(base_i as *mut u8, src.len()) }; dst.copy_from_slice(src); } } }
详细解释
1. 获取应用程序数量
#![allow(unused)] fn main() { extern "C" { fn _num_app(); } let num_app_ptr = _num_app as usize as *const usize; let num_app = unsafe { num_app_ptr.read() }; }
extern "C": 这里声明了一个外部函数_num_app,它的定义在其他地方(通常是汇编代码中)。_num_app as usize as *const usize: 将_num_app的函数指针转换为usize类型,再转换为指向usize的指针。num_app_ptr.read(): 读取指针指向的值,即应用程序的数量。由于这个操作涉及到裸指针,需要使用unsafe块来保证内存安全。
2. 获取应用程序起始地址数组
#![allow(unused)] fn main() { let app_start = unsafe { core::slice::from_raw_parts(num_app_ptr.add(1), num_app + 1) }; }
core::slice::from_raw_parts: 将一个原始指针和长度转换为一个切片。num_app_ptr.add(1): 指针向后移动一位,跳过应用程序数量的存储位置,指向应用程序起始地址数组的开始。num_app + 1: 切片的长度为num_app + 1,包括所有应用程序的起始地址和结束位置。
3. 清除指令缓存
#![allow(unused)] fn main() { unsafe { core::arch::asm!("fence.i"); } }
core::arch::asm!("fence.i"): 使用内联汇编清除指令缓存(I-cache),确保后续加载的指令能够被正确执行。fence.i是 RISC-V 指令,用于指令序列之间的隔离。
4. 加载应用程序
#![allow(unused)] fn main() { for i in 0..num_app { let base_i = get_base_i(i); // clear region (base_i..base_i + APP_SIZE_LIMIT) .for_each(|addr| unsafe { (addr as *mut u8).write_volatile(0) }); // load app from data section to memory let src = unsafe { core::slice::from_raw_parts(app_start[i] as *const u8, app_start[i + 1] - app_start[i]) }; let dst = unsafe { core::slice::from_raw_parts_mut(base_i as *mut u8, src.len()) }; dst.copy_from_slice(src); } }
for i in 0..num_app: 遍历每个应用程序。get_base_i(i): 计算每个应用程序的起始地址base_i。
清除目标内存区域
#![allow(unused)] fn main() { (base_i..base_i + APP_SIZE_LIMIT) .for_each(|addr| unsafe { (addr as *mut u8).write_volatile(0) }); }
(base_i..base_i + APP_SIZE_LIMIT): 创建从base_i到base_i + APP_SIZE_LIMIT的地址范围。for_each: 对该范围内的每个地址执行操作。(addr as *mut u8).write_volatile(0): 将地址addr转换为可变指针,并写入0。使用write_volatile确保编译器不会优化掉这段代码,确保每个字节都被清零。
加载应用程序数据
#![allow(unused)] fn main() { let src = unsafe { core::slice::from_raw_parts(app_start[i] as *const u8, app_start[i + 1] - app_start[i]) }; let dst = unsafe { core::slice::from_raw_parts_mut(base_i as *mut u8, src.len()) }; dst.copy_from_slice(src); }
core::slice::from_raw_parts: 将应用程序在数据段中的起始地址转换为切片。src: 来源数据切片,表示应用程序的二进制数据。core::slice::from_raw_parts_mut: 将目标地址转换为可变切片。dst: 目标数据切片,表示应用程序在内存中的位置。copy_from_slice(src): 将src中的数据复制到dst。
get_base_i 函数
每个应用程序被加载到以物理地址 base_i 开头的一段物理内存上,而 base_i 的计算方式如下:
#![allow(unused)] fn main() { fn get_base_i(app_id: usize) -> usize { APP_BASE_ADDRESS + app_id * APP_SIZE_LIMIT } }
APP_BASE_ADDRESS: 应用程序的基地址,通常在config模块中定义。这里设置为0x80400000。APP_SIZE_LIMIT: 每个应用程序的内存大小限制。这里设置为0x20000。APP_BASE_ADDRESS + app_id * APP_SIZE_LIMIT: 计算第app_id个应用程序的起始地址,确保每个应用程序都有一个独立的内存区域。
config.rs 文件中的常数定义
#![allow(unused)] fn main() { // os/src/config.rs pub const APP_BASE_ADDRESS: usize = 0x80400000; pub const APP_SIZE_LIMIT: usize = 0x20000; }
APP_BASE_ADDRESS: 基地址,设置为0x80400000。APP_SIZE_LIMIT: 每个应用程序的大小限制,设置为0x20000。
通过这些步骤,内核实现了多道程序的加载和执行,为系统带来了并发处理能力。每个应用程序都有独立的内存区域,确保了它们可以同时驻留在内存中并被正确执行。
多道程序放置与加载中的硬件和操作系统流程
1. 获取应用程序数量
- 代码位置:
loader.rs - 函数名:
load_apps
#![allow(unused)] fn main() { extern "C" { fn _num_app(); } let num_app_ptr = _num_app as usize as *const usize; let num_app = unsafe { num_app_ptr.read() }; }
硬件状态:
- 内存读取: CPU 从固定的内存位置读取应用程序数量。
- 内存位置: 该位置由
_num_app函数指向,可能是由汇编代码或链接器设置的一个标记位置。
操作系统状态:
- 内核数据准备: 内核通过读取
num_app_ptr获取应用程序数量并存储在num_app变量中。 - 内核流程: 准备遍历和加载多个应用程序。
2. 获取应用程序起始地址数组
- 代码位置:
loader.rs - 函数名:
load_apps
#![allow(unused)] fn main() { let app_start = unsafe { core::slice::from_raw_parts(num_app_ptr.add(1), num_app + 1) }; }
硬件状态:
- 内存读取: CPU 访问内存中存储的应用程序起始地址数组。
- 内存位置: 起始地址数组从
num_app_ptr开始的下一个位置开始。
操作系统状态:
- 内核数据准备: 内核通过
core::slice::from_raw_parts获取应用程序起始地址和结束地址,存储在app_start切片中。 - 内核流程: 准备按照这些地址加载应用程序。
3. 清除指令缓存
- 代码位置:
loader.rs - 函数名:
load_apps
#![allow(unused)] fn main() { unsafe { core::arch::asm!("fence.i"); } }
硬件状态:
- CPU 操作: 执行
fence.i指令,清除指令缓存(I-cache)。 - 指令缓存: 确保指令缓存中的旧指令不会影响新加载的应用程序。
操作系统状态:
- 内核初始化: 确保内存中的新指令可以被正确执行,准备加载应用程序。
4. 加载应用程序
- 代码位置:
loader.rs - 函数名:
load_apps
#![allow(unused)] fn main() { for i in 0..num_app { let base_i = get_base_i(i); // clear region (base_i..base_i + APP_SIZE_LIMIT) .for_each(|addr| unsafe { (addr as *mut u8).write_volatile(0) }); // load app from data section to memory let src = unsafe { core::slice::from_raw_parts(app_start[i] as *const u8, app_start[i + 1] - app_start[i]) }; let dst = unsafe { core::slice::from_raw_parts_mut(base_i as *mut u8, src.len()) }; dst.copy_from_slice(src); } }
硬件状态:
- 内存操作: CPU 清除目标内存区域 (
base_i..base_i + APP_SIZE_LIMIT) 并写入应用程序数据。 - 内存读取和写入: CPU 从
app_start读取应用程序数据,并写入base_i开始的内存区域。
操作系统状态:
- 内核数据准备: 内核计算每个应用程序的基地址 (
get_base_i)。 - 内核初始化: 清除目标内存区域,确保没有残留数据。
- 内核加载: 复制应用程序数据到目标内存区域,确保每个应用程序都在独立的内存区域中正确加载。
5. 计算应用程序的基地址
- 代码位置:
loader.rs - 函数名:
get_base_i
#![allow(unused)] fn main() { fn get_base_i(app_id: usize) -> usize { APP_BASE_ADDRESS + app_id * APP_SIZE_LIMIT } }
- 代码位置:
config.rs - 常量定义:
APP_BASE_ADDRESS和APP_SIZE_LIMIT
#![allow(unused)] fn main() { pub const APP_BASE_ADDRESS: usize = 0x80400000; pub const APP_SIZE_LIMIT: usize = 0x20000; }
硬件状态:
- 内存布局: 计算每个应用程序在物理内存中的起始地址。
操作系统状态:
- 内核地址计算: 使用
APP_BASE_ADDRESS和APP_SIZE_LIMIT,通过应用程序编号app_id计算每个应用程序的基地址base_i。 - 内存管理: 确保每个应用程序都有独立的内存区域,防止地址冲突。
流程总结
-
获取应用程序数量:
- 硬件: 从固定内存位置读取数量。
- 操作系统: 读取并存储在
num_app变量中。
-
获取应用程序起始地址数组:
- 硬件: 读取内存中的地址数组。
- 操作系统: 存储在
app_start切片中。
-
清除指令缓存:
- 硬件: 执行
fence.i指令,清除 I-cache。 - 操作系统: 确保新指令可以正确执行。
- 硬件: 执行
-
加载应用程序:
- 硬件: 清除目标内存区域并写入应用程序数据。
- 操作系统: 计算基地址,初始化内存,复制数据。
-
计算应用程序基地址:
- 硬件: 基于常量计算地址。
- 操作系统: 确保内存布局合理,防止地址冲突。
通过这些步骤,操作系统成功实现了多道程序的加载和运行,为系统提供了多任务并发处理的能力。每个应用程序都有独立的内存区域,确保它们可以同时驻留在内存中并被正确执行。
任务切换
任务切换是操作系统的核心机制之一,使得应用可以在运行中主动或被动地交出 CPU 的使用权,内核可以选择另一个程序继续执行。任务切换的关键在于保证用户程序在两次运行期间,任务上下文(如寄存器、栈等)保持一致。
任务切换的设计与实现
任务切换与 Trap 控制流切换相比,有如下异同:
- 不同点:
- 不涉及特权级切换,部分由编译器完成。
- 相同点:
- 对应用是透明的。
任务切换实质上是来自两个不同应用在内核中的 Trap 控制流之间的切换。当一个应用 Trap 到 S 态 OS 内核中进行进一步处理时,其 Trap 控制流可以调用一个特殊的 __switch 函数。在 __switch 返回之后,Trap 控制流将继续从调用该函数的位置继续向下执行。
__switch 函数
任务切换通过 __switch 函数实现。在 __switch 函数中,保存 CPU 的某些寄存器,它们就是任务上下文 (Task Context)。
下面是 __switch 的实现:
# os/src/task/switch.S
.altmacro
.macro SAVE_SN n
sd s\n, (\n+2)*8(a0)
.endm
.macro LOAD_SN n
ld s\n, (\n+2)*8(a1)
.endm
.section .text
.globl __switch
__switch:
# __switch(
# current_task_cx_ptr: *mut TaskContext,
# next_task_cx_ptr: *const TaskContext
# )
# save kernel stack of current task
sd sp, 8(a0)
# save ra & s0~s11 of current execution
sd ra, 0(a0)
.set n, 0
.rept 12
SAVE_SN %n
.set n, n + 1
.endr
# restore ra & s0~s11 of next execution
ld ra, 0(a1)
.set n, 0
.rept 12
LOAD_SN %n
.set n, n + 1
.endr
# restore kernel stack of next task
ld sp, 8(a1)
ret
流程细节
-
函数调用:
- 函数名:
__switch - 参数:
current_task_cx_ptr(当前任务的上下文指针,通过寄存器a0传入)next_task_cx_ptr(下一个任务的上下文指针,通过寄存器a1传入)
- 函数名:
-
保存当前任务上下文:
-
保存栈指针(sp):
sd sp, 8(a0)- 硬件状态: 将当前任务的栈指针
sp保存到current_task_cx_ptr指向的内存位置。 - 操作系统状态: 当前任务的栈状态被保存。
- 硬件状态: 将当前任务的栈指针
-
保存返回地址(ra)和保存寄存器(s0~s11):
sd ra, 0(a0) .set n, 0 .rept 12 SAVE_SN %n .set n, n + 1 .endr- 硬件状态: 将返回地址
ra和保存寄存器s0~s11保存到current_task_cx_ptr指向的内存位置。 - 操作系统状态: 当前任务的寄存器状态被保存。
- 硬件状态: 将返回地址
-
-
恢复下一个任务上下文:
-
恢复返回地址(ra)和保存寄存器(s0~s11):
ld ra, 0(a1) .set n, 0 .rept 12 LOAD_SN %n .set n, n + 1 .endr- 硬件状态: 从
next_task_cx_ptr指向的内存位置恢复返回地址ra和保存寄存器s0~s11。 - 操作系统状态: 下一个任务的寄存器状态被恢复。
- 硬件状态: 从
-
恢复栈指针(sp):
ld sp, 8(a1)- 硬件状态: 从
next_task_cx_ptr指向的内存位置恢复栈指针sp。 - 操作系统状态: 下一个任务的栈状态被恢复。
- 硬件状态: 从
-
-
返回(ret):
- 硬件状态: 返回到下一个任务的执行点。
- 操作系统状态: CPU 开始执行下一个任务。
总结
任务切换的关键步骤:
- 保存当前任务的上下文:
- 保存当前任务的栈指针
sp和寄存器ra,s0~s11到current_task_cx_ptr。
- 保存当前任务的栈指针
- 恢复下一个任务的上下文:
- 从
next_task_cx_ptr恢复下一个任务的栈指针sp和寄存器ra,s0~s11。
- 从
硬件状态变化:
- 内存操作: 多次读写内存,用于保存和恢复任务上下文。
- 寄存器操作: 读写多个寄存器值,包括
sp,ra,s0~s11。
操作系统状态变化:
- 上下文切换: 当前任务的上下文被保存,下一个任务的上下文被恢复。
- 任务执行: 切换到下一个任务的执行点,继续执行下一个任务的代码。
通过 __switch 函数,内核能够有效地在不同的任务之间切换,确保每个任务在两次运行之间保持上下文一致。这是实现多任务并发运行的基础。
任务切换中的硬件和操作系统流程细节
任务切换是操作系统中的核心机制,它使得应用可以在运行中主动或被动地交出 CPU 的使用权,从而允许另一个程序继续执行。在这一过程中,操作系统需要确保用户程序两次运行期间,任务上下文(如寄存器、栈等)保持一致。
代码位置和函数名
- 代码位置:
os/src/task/switch.Sos/src/task/switch.rs - 函数名:
__switch - 相关变量:
current_task_cx_ptr,next_task_cx_ptr
详细流程
1. 获取当前任务和下一个任务的上下文指针
- 操作系统状态:
- 函数调用:
__switch(current_task_cx_ptr: *mut TaskContext, next_task_cx_ptr: *const TaskContext) - 变量传递:
current_task_cx_ptr和next_task_cx_ptr分别通过寄存器a0和a1传入。
- 函数调用:
2. 保存当前任务的上下文
- 函数名:
__switch
-
保存栈指针(sp):
- 硬件状态: CPU 将当前任务的栈指针
sp保存到current_task_cx_ptr指向的内存位置(通过sd sp, 8(a0))。 - 操作系统状态: 当前任务的栈状态被保存。
- 硬件状态: CPU 将当前任务的栈指针
-
保存返回地址(ra)和保存寄存器(s0~s11):
- 硬件状态: CPU 将返回地址
ra和保存寄存器s0~s11保存到current_task_cx_ptr指向的内存位置(通过sd ra, 0(a0)和SAVE_SN宏)。 - 操作系统状态: 当前任务的寄存器状态被保存。
- 硬件状态: CPU 将返回地址
3. 恢复下一个任务的上下文
- 函数名:
__switch
-
恢复返回地址(ra)和保存寄存器(s0~s11):
- 硬件状态: CPU 从
next_task_cx_ptr指向的内存位置恢复返回地址ra和保存寄存器s0~s11(通过ld ra, 0(a1)和LOAD_SN宏)。 - 操作系统状态: 下一个任务的寄存器状态被恢复。
- 硬件状态: CPU 从
-
恢复栈指针(sp):
- 硬件状态: CPU 从
next_task_cx_ptr指向的内存位置恢复栈指针sp(通过ld sp, 8(a1))。 - 操作系统状态: 下一个任务的栈状态被恢复。
- 硬件状态: CPU 从
4. 返回到下一个任务的执行点
-
函数名:
__switch -
指令:
ret -
硬件状态: CPU 执行
ret指令,跳转到恢复的返回地址ra,开始执行下一个任务。 -
操作系统状态: CPU 切换到下一个任务的执行点,继续执行下一个任务的代码。
总结
硬件状态变化
- 内存读写: 多次读写内存,用于保存和恢复任务上下文(寄存器和栈指针)。
- 寄存器操作: 读写多个寄存器值,包括
sp,ra,s0~s11。 - 指令执行: 执行
ret指令,切换到下一个任务的执行点。
操作系统状态变化
- 上下文切换: 当前任务的上下文被保存,下一个任务的上下文被恢复。
- 任务执行: 切换到下一个任务的执行点,继续执行下一个任务的代码。
通过 __switch 函数,操作系统实现了不同任务之间的切换,确保每个任务在两次运行之间保持上下文一致。这是实现多任务并发运行的基础。
任务上下文(TaskContext)和任务切换(__switch)的实现
任务上下文(TaskContext)
在任务切换中,保存和恢复任务的上下文是关键。上下文保存了任务在切换前的状态,以便在切换回来时能从中断点继续执行。具体来说,上下文包括返回地址(ra)、栈指针(sp)、以及保存寄存器(s0~s11)。
TaskContext 结构体
#![allow(unused)] fn main() { // os/src/task/context.rs #[repr(C)] pub struct TaskContext { ra: usize, sp: usize, s: [usize; 12], } }
详细解释
- #[repr(C)]: 这个属性保证结构体的内存布局与 C 语言兼容,以确保在汇编代码中能正确访问这些字段。
- ra: usize: 保存返回地址寄存器(Return Address)。
ra寄存器记录了函数返回后应该跳转到的地址。 - sp: usize: 保存栈指针寄存器(Stack Pointer)。
sp寄存器指向当前栈顶位置。 - s: [usize; 12]: 保存被调用者保存寄存器(Saved Registers)。
s0~s11是被调用者保存寄存器,在函数调用过程中需要保持它们的值。
__switch 的 Rust 封装
#![allow(unused)] fn main() { // os/src/task/switch.rs core::arch::global_asm!(include_str!("switch.S")); extern "C" { pub fn __switch( current_task_cx_ptr: *mut TaskContext, next_task_cx_ptr: *const TaskContext); } }
详细解释
-
core::arch::global_asm!(include_str!("switch.S")):
- 将
switch.S中的汇编代码包含进来,确保汇编函数__switch可被 Rust 代码调用。
- 将
-
extern "C":
- 声明外部函数
__switch,表示该函数是用 C ABI 调用的汇编函数。
- 声明外部函数
-
pub fn __switch(current_task_cx_ptr: *mut TaskContext, next_task_cx_ptr: *const TaskContext):
- 该函数接受两个参数:
current_task_cx_ptr和next_task_cx_ptr,分别是当前任务和下一个任务的上下文指针。 current_task_cx_ptr是一个可变指针,指向当前任务的上下文,表示需要保存的当前任务的寄存器状态。next_task_cx_ptr是一个不可变指针,指向下一个任务的上下文,表示需要恢复的下一个任务的寄存器状态。
- 该函数接受两个参数:
通过 TaskContext 结构体和 __switch 汇编函数的实现,操作系统能够在不同任务之间进行切换,确保每个任务在切换过程中保持上下文一致。这是实现多任务并发运行的关键机制。
管理多道程序
内核需要管理多个任务以实现多道程序的并发执行。管理任务的关键在于维护任务信息,包括任务运行状态、任务控制块、以及任务相关的系统调用。
任务运行状态
任务运行状态包括:
- 未初始化: 任务尚未准备好执行。
- 准备执行: 任务已经准备好,可以执行。
- 正在执行: 任务当前正在 CPU 上执行。
- 已退出: 任务已经完成,不再需要执行。
这些状态帮助内核跟踪每个任务的执行进度和调度需求。
任务控制块(Task Control Block)
任务控制块 (TCB) 是用于维护每个任务的状态和上下文的结构体。TCB 包含了任务的上下文(如寄存器、栈指针等)以及任务的运行状态。
任务相关系统调用
系统调用是用户程序与内核交互的接口,任务相关的系统调用包括:
- 主动暂停(sys_yield): 任务主动交出 CPU 使用权,让其他任务执行。
- 主动退出(sys_exit): 任务主动退出,表示任务已完成。
yield 系统调用
sys_yield 系统调用允许任务主动交出 CPU 使用权,让内核调度其他任务执行。这在多道程序中尤为重要,可以避免 CPU 资源的浪费。
#![allow(unused)] fn main() { // user/src/syscall.rs pub fn sys_yield() -> isize { syscall(SYSCALL_YIELD, [0, 0, 0]) } // user/src/lib.rs // yield 是 Rust 的关键字 pub fn yield_() -> isize { sys_yield() } }
sys_yield 系统调用流程
-
调用
sys_yield函数:- 函数名:
sys_yield - 定义位置:
user/src/syscall.rs - 功能: 应用主动交出 CPU 使用权,并切换到其他应用。
- 返回值: 总是返回 0。
- syscall ID: 124
- 函数名:
-
用户库封装
sys_yield:- 函数名:
yield_ - 定义位置:
user/src/lib.rs - 功能: 用户调用
yield_函数,内部调用sys_yield实现。
- 函数名:
硬件和操作系统流程细节
-
应用调用
yield_函数:- 操作系统状态: 应用调用
yield_,实际上调用了sys_yield系统调用。
- 操作系统状态: 应用调用
-
sys_yield系统调用实现:- 操作系统状态: 内核处理
sys_yield系统调用,将当前任务的上下文保存到 TCB 中,并选择下一个任务执行。 - 硬件状态:
- 上下文切换: 内核保存当前任务的寄存器和栈指针。
- CPU 调度: 内核调度器选择下一个任务,将其上下文恢复到寄存器和栈指针。
- 操作系统状态: 内核处理
-
内核调度下一个任务:
- 操作系统状态: 内核根据调度策略选择下一个任务,将其状态从 "准备执行" 切换为 "正在执行"。
- 硬件状态:
- 恢复上下文: 内核恢复下一个任务的寄存器和栈指针。
- CPU 执行: CPU 开始执行下一个任务。
多道程序的典型执行情况
通过 sys_yield 系统调用,任务可以在需要等待外设返回结果时主动交出 CPU 使用权,让其他任务执行。以下是一个典型的多道程序执行过程:
-
蓝色应用请求外设:
- 操作系统状态: 蓝色应用向外设提交请求,外设开始工作,需要一段时间才能返回结果。
- 硬件状态: 外设开始处理请求。
-
蓝色应用调用
sys_yield:- 操作系统状态: 蓝色应用调用
sys_yield系统调用,主动交出 CPU 使用权。 - 硬件状态: 内核保存蓝色应用的上下文,调度绿色应用执行。
- 操作系统状态: 蓝色应用调用
-
绿色应用执行:
- 操作系统状态: 内核将绿色应用的上下文恢复到寄存器,调度绿色应用执行。
- 硬件状态: CPU 开始执行绿色应用的代码。
-
外设返回结果前的多次
sys_yield:- 操作系统状态: 蓝色应用在外设返回结果前多次调用
sys_yield,内核多次在蓝色应用和其他任务之间进行调度。 - 硬件状态: CPU 多次在不同任务之间切换。
- 操作系统状态: 蓝色应用在外设返回结果前多次调用
-
外设返回结果:
- 操作系统状态: 蓝色应用最终等待到外设返回结果,可以继续执行。
- 硬件状态: CPU 继续执行蓝色应用的代码。
通过上述流程,操作系统实现了多道程序的并发执行,充分利用了 CPU 资源,提高了系统的响应速度和效率。
任务控制块与任务运行状态
任务控制块(Task Control Block,TCB)和任务运行状态是操作系统管理任务的核心组件。下面我们深入讲解它们的实现和作用。
任务运行状态
任务运行状态用于描述任务在生命周期中的不同阶段。定义在 os/src/task/task.rs 中:
#![allow(unused)] fn main() { // os/src/task/task.rs #[derive(Copy, Clone, PartialEq)] pub enum TaskStatus { UnInit, // 未初始化 Ready, // 准备运行 Running, // 正在运行 Exited, // 已退出 } }
详细解释
- UnInit: 任务未初始化,尚未准备好执行。
- Ready: 任务已准备好,可以运行,但尚未开始执行。
- Running: 任务当前正在 CPU 上执行。
- Exited: 任务已经完成执行并退出。
这些状态帮助内核跟踪每个任务的执行进度和调度需求。
任务控制块(Task Control Block)
任务控制块是用于维护每个任务状态和上下文的数据结构。定义在 os/src/task/task.rs 中:
#![allow(unused)] fn main() { // os/src/task/task.rs #[derive(Copy, Clone)] pub struct TaskControlBlock { pub task_status: TaskStatus, pub task_cx: TaskContext, } }
详细解释
- task_status: 任务状态(TaskStatus),表示任务当前的运行状态。
- task_cx: 任务上下文(TaskContext),包含任务的寄存器和栈指针等信息。
任务管理器
任务管理器是内核中用于管理多个任务控制块的全局结构。定义在 os/src/task/mod.rs 中:
#![allow(unused)] fn main() { // os/src/task/mod.rs pub struct TaskManager { num_app: usize, inner: UPSafeCell<TaskManagerInner>, } struct TaskManagerInner { tasks: [TaskControlBlock; MAX_APP_NUM], current_task: usize, } }
详细解释
-
TaskManager
- num_app: 应用程序数量,在
TaskManager初始化后保持不变。 - inner: 包含实际任务管理数据的结构体,用
UPSafeCell包装以保证线程安全。
- num_app: 应用程序数量,在
-
TaskManagerInner
- tasks: 任务控制块数组,包含所有任务的状态和上下文。
- current_task: 当前正在执行的任务编号。
这种设计将不变的字段(如 num_app)和变化的字段(如 tasks 和 current_task)分离,保证了代码的可读性和维护性。
硬件和操作系统流程细节
任务状态管理
-
任务初始化:
- 操作系统状态: 将任务状态设置为
TaskStatus::UnInit,准备初始化任务。
- 操作系统状态: 将任务状态设置为
-
任务准备运行:
- 操作系统状态: 将任务状态设置为
TaskStatus::Ready,表示任务已准备好,可以调度执行。
- 操作系统状态: 将任务状态设置为
-
任务开始运行:
- 操作系统状态: 将任务状态设置为
TaskStatus::Running,表示任务正在 CPU 上执行。 - 硬件状态: CPU 开始执行任务的代码。
- 操作系统状态: 将任务状态设置为
-
任务退出:
- 操作系统状态: 将任务状态设置为
TaskStatus::Exited,表示任务已完成执行并退出。 - 硬件状态: CPU 结束任务的执行。
- 操作系统状态: 将任务状态设置为
任务控制块管理
-
保存任务上下文:
- 操作系统状态: 在任务切换时,内核将当前任务的上下文保存到对应的
TaskControlBlock中。 - 硬件状态: CPU 将寄存器值写入内存中的
TaskContext结构体。
- 操作系统状态: 在任务切换时,内核将当前任务的上下文保存到对应的
-
恢复任务上下文:
- 操作系统状态: 在任务切换时,内核将下一个任务的上下文从对应的
TaskControlBlock中恢复。 - 硬件状态: CPU 从内存中的
TaskContext结构体读取寄存器值,并恢复到寄存器中。
- 操作系统状态: 在任务切换时,内核将下一个任务的上下文从对应的
任务管理器
-
初始化任务管理器:
- 操作系统状态: 在内核启动时,初始化
TaskManager和TaskManagerInner,并设置应用程序数量num_app。
- 操作系统状态: 在内核启动时,初始化
-
管理任务控制块数组:
- 操作系统状态: 任务管理器维护一个包含所有任务控制块的数组
tasks,并跟踪当前正在执行的任务编号current_task。
- 操作系统状态: 任务管理器维护一个包含所有任务控制块的数组
-
调度任务:
- 操作系统状态: 调度器选择下一个任务,将其状态从 "准备运行" 切换为 "正在运行",并通过任务控制块恢复其上下文。
- 硬件状态: CPU 切换到下一个任务的上下文,继续执行任务代码。
初始化 TaskManager 的全局实例 TASK_MANAGER
为了管理所有任务,操作系统需要一个全局的任务管理器实例 TASK_MANAGER。我们使用 lazy_static 宏来实现这个全局实例的懒加载初始化。
代码位置
#![allow(unused)] fn main() { // os/src/task/mod.rs }
代码详解
#![allow(unused)] fn main() { lazy_static! { pub static ref TASK_MANAGER: TaskManager = { let num_app = get_num_app(); let mut tasks = [TaskControlBlock { task_cx: TaskContext::zero_init(), task_status: TaskStatus::UnInit, }; MAX_APP_NUM]; for (i, t) in tasks.iter_mut().enumerate().take(num_app) { t.task_cx = TaskContext::goto_restore(init_app_cx(i)); t.task_status = TaskStatus::Ready; } TaskManager { num_app, inner: unsafe { UPSafeCell::new(TaskManagerInner { tasks, current_task: 0, }) }, } }; } }
详细解释
-
使用
lazy_static!宏:- 宏名:
lazy_static! - 作用: 实现全局静态变量的懒初始化,即在第一次使用时进行初始化。
- 宏名:
-
获取应用总数:
- 函数名:
get_num_app - 作用: 获取链接到内核的应用程序总数。
- 位置: 调用
loader子模块提供的接口。
#![allow(unused)] fn main() { let num_app = get_num_app(); } - 函数名:
-
初始化任务控制块数组:
- 结构体:
TaskControlBlock - 数组大小:
MAX_APP_NUM - 初始状态:
task_cx: 使用TaskContext::zero_init()初始化。task_status: 设置为TaskStatus::UnInit。
#![allow(unused)] fn main() { let mut tasks = [TaskControlBlock { task_cx: TaskContext::zero_init(), task_status: TaskStatus::UnInit, }; MAX_APP_NUM]; } - 结构体:
-
遍历并初始化每个任务控制块:
- 迭代器:
tasks.iter_mut().enumerate().take(num_app) - 初始化任务上下文: 使用
TaskContext::goto_restore(init_app_cx(i))。 - 设置任务状态: 将任务状态设置为
TaskStatus::Ready。
#![allow(unused)] fn main() { for (i, t) in tasks.iter_mut().enumerate().take(num_app) { t.task_cx = TaskContext::goto_restore(init_app_cx(i)); t.task_status = TaskStatus::Ready; } }- 函数:
init_app_cx(i)- 作用: 初始化每个应用程序的上下文。
- 函数:
TaskContext::goto_restore- 作用: 设置任务上下文的初始值,确保任务能够从正确的位置恢复执行。
- 迭代器:
-
创建并返回
TaskManager实例:- 结构体:
TaskManager - 字段:
num_app: 应用程序总数。inner: 包含实际任务管理数据的结构体,用UPSafeCell包装以保证线程安全。
- 内部结构体:
TaskManagerInner- 字段:
tasks: 任务控制块数组。current_task: 当前正在执行的任务编号。
- 字段:
#![allow(unused)] fn main() { TaskManager { num_app, inner: unsafe { UPSafeCell::new(TaskManagerInner { tasks, current_task: 0, }) }, } } - 结构体:
任务管理器的初始化流程
-
获取应用总数:
- 操作系统状态: 调用
get_num_app获取链接到内核的应用程序总数。 - 位置:
loader子模块提供的接口。
- 操作系统状态: 调用
-
初始化任务控制块数组:
- 操作系统状态: 创建并初始化一个大小为
MAX_APP_NUM的任务控制块数组。 - 初始状态: 每个任务控制块的
task_cx初始化为零,task_status设置为TaskStatus::UnInit。
- 操作系统状态: 创建并初始化一个大小为
-
遍历并初始化每个任务控制块:
- 操作系统状态: 使用迭代器遍历任务控制块数组的前
num_app个元素。 - 任务上下文初始化:
- 函数:
init_app_cx(i)- 作用: 初始化应用程序上下文。
- 函数:
TaskContext::goto_restore- 作用: 设置任务上下文的初始值,确保任务能够从正确的位置恢复执行。
- 函数:
- 设置任务状态: 将任务状态设置为
TaskStatus::Ready。
- 操作系统状态: 使用迭代器遍历任务控制块数组的前
-
创建
TaskManager实例:- 操作系统状态: 创建并初始化
TaskManager实例。 - 字段:
num_app: 应用程序总数。inner: 包含实际任务管理数据的结构体,用UPSafeCell包装以保证线程安全。
- 操作系统状态: 创建并初始化
-
返回
TaskManager实例:- 操作系统状态: 返回初始化后的
TaskManager实例,赋值给全局变量TASK_MANAGER。
- 操作系统状态: 返回初始化后的
总结
通过以上步骤,操作系统完成了 TaskManager 全局实例 TASK_MANAGER 的初始化。TASK_MANAGER 负责管理所有任务控制块,并通过其内部结构体 TaskManagerInner 来维护任务状态和上下文。这个设计确保了任务的正确初始化和调度,为多任务并发执行提供了基础。
ASK_MANAGER, TaskControlBlock 和 TaskContext 的对比
-
TASK_MANAGER:
- 位置:
os/src/task/mod.rs - 类型: 全局静态实例,使用
lazy_static!宏初始化。 - 功能: 管理所有任务控制块(TCB),负责任务调度和切换。
- 结构:
num_app: 应用程序数量。inner: 包含实际任务管理数据的结构体TaskManagerInner。
- 位置:
-
TaskControlBlock:
- 位置:
os/src/task/task.rs - 类型: 结构体。
- 功能: 维护单个任务的状态和上下文。
- 结构:
task_status: 任务状态(TaskStatus)。task_cx: 任务上下文(TaskContext)。
- 位置:
-
TaskContext:
- 位置:
os/src/task/context.rs - 类型: 结构体。
- 功能: 保存任务的寄存器和栈指针等上下文信息。
- 结构:
ra: 返回地址寄存器(Return Address)。sp: 栈指针寄存器(Stack Pointer)。s: 被调用者保存寄存器(Saved Registers),包含s0~s11。
- 位置:
实现 sys_yield 和 sys_exit
sys_yield 和 sys_exit 是两个重要的系统调用,分别用于让任务主动放弃 CPU 使用权和退出任务。它们依赖于任务管理器提供的接口来实现任务的调度和状态管理。
sys_yield 的实现
sys_yield 通过 suspend_current_and_run_next 接口实现,这个接口的作用是暂停当前的任务并切换到下一个任务。
代码位置和实现
#![allow(unused)] fn main() { // os/src/syscall/process.rs use crate::task::suspend_current_and_run_next; pub fn sys_yield() -> isize { suspend_current_and_run_next(); 0 } }
-
函数名:
sys_yield- 作用: 应用主动交出 CPU 使用权,让内核调度其他任务执行。
- 返回值: 总是返回 0。
-
调用
suspend_current_and_run_next接口- 位置:
os/src/task/mod.rs - 作用: 暂停当前任务并切换到下一个任务。
- 位置:
sys_exit 的实现
sys_exit 通过 exit_current_and_run_next 接口实现,这个接口的作用是退出当前的任务并切换到下一个任务。
代码位置和实现
#![allow(unused)] fn main() { // os/src/syscall/process.rs use crate::task::exit_current_and_run_next; pub fn sys_exit(exit_code: i32) -> ! { println!("[kernel] Application exited with code {}", exit_code); exit_current_and_run_next(); panic!("Unreachable in sys_exit!"); } }
-
函数名:
sys_exit- 参数:
exit_code(i32),表示任务退出时的状态码。 - 作用: 应用主动退出,并让内核调度其他任务执行。
- 返回值: 永远不返回(
!表示返回类型为 Never)。
- 参数:
-
调用
exit_current_and_run_next接口- 位置:
os/src/task/mod.rs - 作用: 退出当前任务并切换到下一个任务。
- 位置:
-
打印退出信息:
- 输出:
"[kernel] Application exited with code {}"。 - 作用: 在任务退出时打印退出状态码。
- 输出:
-
触发 panic:
- 作用: 理论上不应到达此处,触发 panic 以捕获错误。
suspend_current_and_run_next 和 exit_current_and_run_next 的实现
这两个函数都是先修改当前任务的运行状态,然后尝试切换到下一个任务。
代码位置和实现
#![allow(unused)] fn main() { // os/src/task/mod.rs pub fn suspend_current_and_run_next() { TASK_MANAGER.mark_current_suspended(); TASK_MANAGER.run_next_task(); } pub fn exit_current_and_run_next() { TASK_MANAGER.mark_current_exited(); TASK_MANAGER.run_next_task(); } }
-
函数名:
suspend_current_and_run_next- 作用: 暂停当前任务并切换到下一个任务。
- 步骤:
- 调用
TASK_MANAGER.mark_current_suspended()将当前任务状态标记为暂停。 - 调用
TASK_MANAGER.run_next_task()切换到下一个任务。
- 调用
-
函数名:
exit_current_and_run_next- 作用: 退出当前任务并切换到下一个任务。
- 步骤:
- 调用
TASK_MANAGER.mark_current_exited()将当前任务状态标记为退出。 - 调用
TASK_MANAGER.run_next_task()切换到下一个任务。
- 调用
修改任务运行状态和任务切换
修改运行状态:mark_current_suspended
修改运行状态主要涉及到任务控制块数组中的当前任务状态。在任务管理器 TaskManager 中实现一个方法来修改当前任务的状态,例如 mark_current_suspended。
代码位置和实现
#![allow(unused)] fn main() { // os/src/task/mod.rs impl TaskManager { fn mark_current_suspended(&self) { let mut inner = self.inner.exclusive_access(); let current = inner.current_task; inner.tasks[current].task_status = TaskStatus::Ready; } } }
详细解释
-
获取内部任务管理器的可变引用:
- 方法:
self.inner.exclusive_access() - 作用: 获取
TaskManagerInner的可变引用,以便修改内部状态。
- 方法:
-
获取当前任务的索引:
- 变量:
current - 作用: 从
TaskManagerInner中获取当前任务的索引。
- 变量:
-
修改当前任务的状态:
- 变量:
inner.tasks[current].task_status - 作用: 将当前任务的状态修改为
TaskStatus::Ready,表示任务暂停,准备再次运行。
- 变量:
切换到下一个任务:run_next_task
run_next_task 方法负责切换到下一个准备运行的任务。
代码位置和实现
#![allow(unused)] fn main() { // os/src/task/mod.rs impl TaskManager { fn run_next_task(&self) { if let Some(next) = self.find_next_task() { let mut inner = self.inner.exclusive_access(); let current = inner.current_task; inner.tasks[next].task_status = TaskStatus::Running; inner.current_task = next; let current_task_cx_ptr = &mut inner.tasks[current].task_cx as *mut TaskContext; let next_task_cx_ptr = &inner.tasks[next].task_cx as *const TaskContext; drop(inner); // before this, we should drop local variables that must be dropped manually unsafe { __switch(current_task_cx_ptr, next_task_cx_ptr); } // go back to user mode } else { panic!("All applications completed!"); } } } }
详细解释
-
寻找下一个准备运行的任务:
- 方法:
self.find_next_task() - 作用: 寻找一个状态为
TaskStatus::Ready的任务,并返回其 ID。
- 方法:
-
获取内部任务管理器的可变引用:
- 方法:
self.inner.exclusive_access() - 作用: 获取
TaskManagerInner的可变引用,以便修改内部状态。
- 方法:
-
设置下一个任务的状态:
- 变量:
inner.tasks[next].task_status - 作用: 将下一个任务的状态设置为
TaskStatus::Running,表示任务正在运行。
- 变量:
-
更新当前任务索引:
- 变量:
inner.current_task - 作用: 更新当前任务的索引为下一个任务的索引。
- 变量:
-
获取当前和下一个任务的上下文指针:
- 变量:
current_task_cx_ptr和next_task_cx_ptr - 作用: 分别获取当前任务和下一个任务的上下文指针,以便在任务切换时使用。
- 变量:
-
手动 drop 内部任务管理器的可变引用:
- 方法:
drop(inner) - 作用: 手动释放
inner的可变引用,以确保TASK_MANAGER的inner字段回到未被借用的状态。
- 方法:
-
任务切换:
- 函数:
__switch - 作用: 使用汇编代码实现的任务切换函数,切换当前任务的上下文到下一个任务的上下文。
- 函数:
-
处理所有任务完成的情况:
- 作用: 如果没有找到准备运行的任务,
find_next_task返回None,内核会触发panic,表示所有任务都已经完成。
- 作用: 如果没有找到准备运行的任务,
寻找下一个任务:find_next_task
find_next_task 方法用于寻找下一个准备运行的任务,并返回其 ID。
代码位置和实现
#![allow(unused)] fn main() { // os/src/task/mod.rs impl TaskManager { fn find_next_task(&self) -> Option<usize> { let inner = self.inner.exclusive_access(); let current = inner.current_task; (current + 1..current + self.num_app + 1) .map(|id| id % self.num_app) .find(|id| inner.tasks[*id].task_status == TaskStatus::Ready) } } }
详细解释
-
获取内部任务管理器的可变引用:
- 方法:
self.inner.exclusive_access() - 作用: 获取
TaskManagerInner的可变引用,以便读取内部状态。
- 方法:
-
获取当前任务的索引:
- 变量:
current - 作用: 从
TaskManagerInner中获取当前任务的索引。
- 变量:
-
遍历任务数组寻找准备运行的任务:
- 方法:
current + 1..current + self.num_app + 1: 从当前任务的下一个任务开始遍历,循环遍历任务数组。.map(|id| id % self.num_app): 确保任务索引在任务数组范围内循环。.find(|id| inner.tasks[*id].task_status == TaskStatus::Ready): 找到第一个状态为TaskStatus::Ready的任务,并返回其 ID。
- 方法:
总结
通过 mark_current_suspended 方法,我们可以将当前任务的状态修改为 Ready,表示任务暂停,准备再次运行。run_next_task 方法负责切换到下一个准备运行的任务,并调用 __switch 进行上下文切换。find_next_task 方法用于寻找下一个准备运行的任务,确保任务切换的正确进行。
修改运行状态和任务切换的关键步骤
-
修改当前任务的状态:
- 获取
TaskManagerInner的可变引用。 - 修改当前任务的状态为
Ready或其他状态。
- 获取
-
任务切换:
- 寻找下一个准备运行的任务。
- 更新任务状态和当前任务索引。
- 获取上下文指针。
- 调用汇编实现的
__switch进行上下文切换。
通过这些步骤,操作系统实现了多任务的调度和切换,确保任务能够有效地并发执行。
第一次进入用户态
背景
在第二章中,CPU 第一次从内核态进入用户态的方法是通过在内核栈上压入构造好的 Trap 上下文,并通过调用 __restore 函数恢复上下文。本章在此基础上进行扩展,详细解释任务上下文的初始化和任务切换的实现。
初始化任务控制块
在任务管理器中初始化任务控制块时,我们使用 init_app_cx 函数向内核栈压入一个 Trap 上下文,并返回压入 Trap 上下文后栈指针(sp)的值。goto_restore 函数保存传入的 sp,并将返回地址(ra)设置为 __restore 的入口地址。
代码位置和实现
#![allow(unused)] fn main() { // os/src/task/mod.rs for (i, t) in tasks.iter_mut().enumerate().take(num_app) { t.task_cx = TaskContext::goto_restore(init_app_cx(i)); t.task_status = TaskStatus::Ready; } }
-
初始化任务上下文:
- 函数名:
init_app_cx - 作用: 向内核栈压入一个 Trap 上下文,并返回压入 Trap 上下文后栈指针的值。
- 函数名:
-
设置任务上下文:
- 函数名:
TaskContext::goto_restore - 作用: 保存传入的栈指针,并将返回地址设置为
__restore的入口地址。
- 函数名:
TaskContext 实现
TaskContext 结构体用于保存任务上下文,包括返回地址(ra)、栈指针(sp)和保存寄存器(s0~s11)。
代码位置和实现
#![allow(unused)] fn main() { // os/src/task/context.rs impl TaskContext { pub fn goto_restore(kstack_ptr: usize) -> Self { extern "C" { fn __restore(); } Self { ra: __restore as usize, sp: kstack_ptr, s: [0; 12], } } } }
-
返回地址(ra):
- 设置为
__restore的入口地址:- 函数名:
__restore - 作用: 恢复 Trap 上下文并进入用户态。
- 函数名:
- 设置为
-
栈指针(sp):
- 设置为
init_app_cx返回的值:- 作用: 指向内核栈上的 Trap 上下文。
- 设置为
-
保存寄存器(s0~s11):
- 初始化为 0:
- 作用: 在任务初始化时,保存寄存器的值为 0。
- 初始化为 0:
运行第一个任务
在 rust_main 函数中,我们调用 task::run_first_task 来执行第一个应用。该函数切换到第一个任务并进入用户态。
代码位置和实现
#![allow(unused)] fn main() { // os/src/task/mod.rs fn run_first_task(&self) -> ! { let mut inner = self.inner.exclusive_access(); let task0 = &mut inner.tasks[0]; task0.task_status = TaskStatus::Running; let next_task_cx_ptr = &task0.task_cx as *const TaskContext; drop(inner); let mut _unused = TaskContext::zero_init(); // before this, we should drop local variables that must be dropped manually unsafe { __switch(&mut _unused as *mut TaskContext, next_task_cx_ptr); } panic!("unreachable in run_first_task!"); } }
-
获取第一个任务的上下文指针:
- 变量:
next_task_cx_ptr - 作用: 获取第一个任务的上下文指针。
- 变量:
-
设置任务状态:
- 变量:
task0.task_status - 作用: 将第一个任务的状态设置为
TaskStatus::Running。
- 变量:
-
获取任务上下文指针
- 获取任务上下文引用:
- 代码:
&task0.task_cx - 作用: 获取第一个任务的任务上下文
task_cx的引用。
- 代码:
- 转换为指针:
- 代码:
as *const TaskContext - 作用: 将任务上下文的引用转换为原生指针(const pointer),指向
TaskContext结构体。 - 原因:
__switch函数接受指向TaskContext的原生指针。
- 代码:
- 变量:
next_task_cx_ptr- 类型:
*const TaskContext - 作用: 保存指向第一个任务的任务上下文的指针。
- 类型:
- 获取任务上下文引用:
-
手动释放
TaskManagerInner的可变引用:- 方法:
drop(inner) - 作用: 手动释放
inner的可变引用,以确保TASK_MANAGER的inner字段回到未被借用的状态。
- 方法:
-
任务切换:
- 函数名:
__switch - 参数:
_unused和next_task_cx_ptr - 作用: 切换到第一个任务的上下文,进入用户态。
- 声明未使用的任务上下文:
- 代码:
let mut _unused = TaskContext::zero_init(); - 作用: 创建一个未使用的任务上下文
_unused,用作__switch的第一个参数。 - 原因: 在第一次任务切换时,没有真正的上一个任务上下文,所以使用一个占位符
_unused。
- 代码:
- 转换为指针:
- 代码:
&mut _unused as *mut TaskContext - 作用: 将未使用的任务上下文的引用转换为原生指针(mut pointer),指向
TaskContext结构体。 - 原因:
__switch函数接受指向TaskContext的原生指针。
- 代码:
- 调用
__switch:- 代码:
__switch(&mut _unused as *mut TaskContext, next_task_cx_ptr); - 作用: 调用
__switch函数进行任务切换。 - 参数:
&mut _unused as *mut TaskContext: 指向未使用的任务上下文的指针,作为当前任务的上下文指针。next_task_cx_ptr: 指向第一个任务的任务上下文的指针,作为下一个任务的上下文指针。
- 代码:
- 使用
unsafe块:- 原因: 调用
__switch函数涉及到直接操作原生指针,这在 Rust 中是unsafe的,需要用unsafe块包裹。
- 原因: 调用
- 声明未使用的任务上下文:
- 函数名:
__restore 函数的实现
在 __switch 中恢复 sp 后,sp 将指向 init_app_cx 构造的 Trap 上下文,后面就回到第二章的情况了。此外,__restore 的实现需要做出变化:它不再需要在开头 mv sp, a0,因为在 __switch 之后,sp 就已经正确指向了我们需要的 Trap 上下文地址。
总结
通过初始化任务控制块和任务上下文,我们能够将 CPU 从内核态切换到用户态。具体步骤包括:
-
初始化任务控制块:
- 使用
init_app_cx向内核栈压入 Trap 上下文,并返回栈指针。 - 使用
TaskContext::goto_restore设置任务上下文,包括返回地址和栈指针。
- 使用
-
运行第一个任务:
- 调用
task::run_first_task切换到第一个任务的上下文,并进入用户态。
- 调用
-
任务切换:
- 在
__switch中切换任务上下文,恢复 sp 后进入用户态。
- 在
通过这些步骤,操作系统能够正确地初始化任务并在首次运行时切换到用户态,确保任务能够正确执行。
分时多任务系统
分时多任务系统通过时间片轮转算法 (Round-Robin, RR) 来实现任务调度。在这种系统中,每个任务只能连续执行一个时间片(可能在毫秒量级),然后内核强制性切换到下一个任务。
关键概念
-
时间片 (Time Slice):
- 是任务连续执行的时间度量单位。
- 一般在毫秒量级。
-
时间片轮转算法 (Round-Robin, RR):
- 每个任务按顺序轮流执行一个时间片。
-
时钟中断:
- 计时器到达设定时间时触发,用于实现时间片轮转调度。
时钟中断与计时器
RISC-V 架构要求处理器维护时钟计数器 mtime 和比较寄存器 mtimecmp。当 mtime 的值超过 mtimecmp 时,会触发时钟中断。
获取当前时间
get_time 函数用于获取当前的 mtime 计数器值。
代码位置和实现
#![allow(unused)] fn main() { // os/src/timer.rs use riscv::register::time; pub fn get_time() -> usize { time::read() } }
详细解释
-
导入
riscv::register::time模块:- 模块:
riscv::register::time - 作用: 提供读取 RISC-V 时钟计数器
mtime的功能。
- 模块:
-
定义
get_time函数:- 返回类型:
usize - 作用: 返回当前的
mtime计数器值。
- 返回类型:
-
读取当前时间:
- 方法:
time::read() - 作用: 读取
mtime计数器的当前值并返回。
- 方法:
设置时钟中断
set_timer 函数用于设置 mtimecmp 的值,从而在指定时间后触发时钟中断。
代码位置和实现
#![allow(unused)] fn main() { // os/src/sbi.rs const SBI_SET_TIMER: usize = 0; pub fn set_timer(timer: usize) { sbi_call(SBI_SET_TIMER, timer, 0, 0); } }
详细解释
-
定义常量
SBI_SET_TIMER:- 类型:
usize - 值: 0
- 作用: SBI 调用
set_timer的函数编号。
- 类型:
-
定义
set_timer函数:- 参数:
timer(类型usize),表示设置的mtimecmp的值。 - 作用: 调用 SBI 接口设置
mtimecmp的值。
- 参数:
-
调用
sbi_call函数:- 参数:
SBI_SET_TIMER: SBI 调用编号。timer: 设置的mtimecmp的值。- 其他两个参数为 0。
- 作用: 通过 SBI 接口调用设置
mtimecmp的值。
- 参数:
定时触发
set_next_trigger 函数用于计算下一个时钟中断的触发时间,并设置 mtimecmp 的值。
代码位置和实现
#![allow(unused)] fn main() { // os/src/timer.rs use crate::config::CLOCK_FREQ; const TICKS_PER_SEC: usize = 100; pub fn set_next_trigger() { set_timer(get_time() + CLOCK_FREQ / TICKS_PER_SEC); } }
详细解释
-
导入
CLOCK_FREQ常量:- 模块:
config - 作用: 表示平台的时钟频率,单位为赫兹。
- 模块:
-
定义常量
TICKS_PER_SEC:- 类型:
usize - 值: 100
- 作用: 表示每秒的时钟中断次数(即每 10ms 一次)。
- 类型:
-
定义
set_next_trigger函数:- 作用: 设置下一个时钟中断的触发时间。
-
计算下一个时钟中断时间:
- 方法:
get_time() + CLOCK_FREQ / TICKS_PER_SEC - 作用: 获取当前时间
get_time(),加上CLOCK_FREQ / TICKS_PER_SEC的增量,计算出 10ms 后的时间。
- 方法:
-
设置时钟中断:
- 函数:
set_timer - 参数: 计算出的下一个时钟中断时间。
- 作用: 设置
mtimecmp的值,使得 10ms 后触发时钟中断。
- 函数:
时钟中断处理
当 mtime 超过 mtimecmp 的值时,会触发时钟中断。时钟中断处理程序需要执行以下步骤:
- 保存当前任务的上下文。
- 调度下一个任务。
- 恢复下一个任务的上下文。
时钟中断处理流程
-
触发时钟中断:
- 硬件: 当
mtime超过mtimecmp的值时,硬件触发时钟中断。 - 作用: 通知内核需要进行任务调度。
- 硬件: 当
-
保存当前任务的上下文:
- 内核: 保存当前任务的寄存器、栈指针等上下文信息。
- 作用: 保持当前任务的状态,以便以后恢复。
-
调度下一个任务:
- 内核: 调用任务调度算法(如 RR 算法)选择下一个任务。
- 作用: 确定下一个任务,并准备切换上下文。
-
恢复下一个任务的上下文:
- 内核: 恢复下一个任务的寄存器、栈指针等上下文信息。
- 作用: 切换到下一个任务,开始执行。
-
重新设置时钟中断:
- 内核: 调用
set_next_trigger函数,设置下一个时钟中断时间。 - 作用: 确保下一个时钟中断能够正确触发,实现持续的任务调度。
- 内核: 调用
总结
通过上述步骤和代码实现,我们构建了一个分时多任务系统。该系统利用时钟中断和时间片轮转算法,实现任务的定时调度和上下文切换,确保每个任务能够公平地获得 CPU 使用权,并在特定时间片后强制切换任务,提高系统的响应速度和资源利用率。
计时需求和新系统调用
为了满足后续的计时需求,我们需要设计一个能够以微秒为单位返回当前计时器值的函数,并新增一个系统调用,使应用能够获取当前时间。
以微秒为单位返回当前计时器值
在 timer 子模块中,我们设计了 get_time_us 函数,用于以微秒为单位返回当前计时器的值。
代码位置和实现
#![allow(unused)] fn main() { // os/src/timer.rs use riscv::register::time; use crate::config::CLOCK_FREQ; const MICRO_PER_SEC: usize = 1_000_000; pub fn get_time_us() -> usize { time::read() / (CLOCK_FREQ / MICRO_PER_SEC) } }
详细解释
-
常量定义:
- 常量:
MICRO_PER_SEC - 类型:
usize - 值: 1_000_000(表示一秒中的微秒数)
- 常量:
-
函数定义:
get_time_us- 返回类型:
usize - 作用: 以微秒为单位返回当前计时器的值
- 返回类型:
-
读取当前时间:
- 函数:
time::read() - 作用: 读取 RISC-V 时钟计数器
mtime的当前值
- 函数:
-
计算当前时间(微秒):
- 公式:
time::read() / (CLOCK_FREQ / MICRO_PER_SEC) - 作用: 将
mtime值转换为微秒数
- 公式:
新增系统调用:获取当前时间
为了使应用能够获取当前时间,我们设计了一个新的系统调用 sys_get_time,并定义了 TimeVal 结构体来存储时间值。
系统调用定义
#![allow(unused)] fn main() { /// 功能:获取当前的时间,保存在 TimeVal 结构体 ts 中,_tz 在我们的实现中忽略 /// 返回值:返回是否执行成功,成功则返回 0 /// syscall ID:169 fn sys_get_time(ts: *mut TimeVal, _tz: usize) -> isize; }
结构体 TimeVal 的定义
#![allow(unused)] fn main() { // os/src/syscall/process.rs #[repr(C)] pub struct TimeVal { pub sec: usize, pub usec: usize, } }
系统调用实现
#![allow(unused)] fn main() { // os/src/syscall/process.rs use crate::timer::get_time_us; pub fn sys_get_time(ts: *mut TimeVal, _tz: usize) -> isize { if ts.is_null() { return -1; } let us = get_time_us(); let time_val = TimeVal { sec: us / 1_000_000, usec: us % 1_000_000, }; unsafe { *ts = time_val; } 0 } }
详细解释
-
引入
get_time_us函数:- 模块:
timer - 作用: 获取当前时间(微秒)
- 模块:
-
函数定义:
sys_get_time- 参数:
ts: 指向TimeVal结构体的指针,用于存储当前时间_tz: 时区参数,在我们的实现中被忽略
- 返回值:
isize,表示执行结果,成功返回 0
- 参数:
-
检查指针是否为空:
- 判断:
ts.is_null() - 作用: 检查传入的指针是否为
null,如果是则返回错误码-1
- 判断:
-
获取当前时间(微秒):
- 函数:
get_time_us() - 作用: 获取当前时间,单位为微秒
- 函数:
-
计算时间值:
- 变量:
us - 公式:
sec: us / 1_000_000:将微秒转换为秒usec: us % 1_000_000:取余数,得到剩余的微秒数
- 变量:
-
创建
TimeVal结构体:- 结构体:
TimeVal - 字段:
sec: 秒数usec: 微秒数
- 结构体:
-
写入时间值到指针:
- 代码:
*ts = time_val; - 作用: 使用
unsafe块将计算的时间值写入传入的指针所指向的内存位置
- 代码:
-
返回成功码:
- 返回值:
0 - 作用: 表示系统调用成功执行
- 返回值:
总结
通过上述步骤和代码实现,我们完成了以微秒为单位返回当前计时器值的函数 get_time_us,以及一个新的系统调用 sys_get_time,使应用能够获取当前时间。
关键步骤
-
定义
get_time_us函数:- 获取当前
mtime计数器值并转换为微秒数。
- 获取当前
-
定义
TimeVal结构体:- 用于存储秒和微秒两个时间字段。
-
实现
sys_get_time系统调用:- 检查指针合法性。
- 获取当前时间并计算秒和微秒。
- 将时间值写入传入的
TimeVal结构体指针。
通过这些步骤,我们能够实现一个分时多任务系统中的计时功能,并通过系统调用使用户应用能够获取当前时间。
解释涉及的公式及其原因
1. 设置下一个时钟中断触发时间
#![allow(unused)] fn main() { pub fn set_next_trigger() { set_timer(get_time() + CLOCK_FREQ / TICKS_PER_SEC); } }
详细解释
-
get_time():- 作用: 获取当前的
mtime计数器值。mtime是 RISC-V 架构中的一个硬件计数器,用于计时。
- 作用: 获取当前的
-
CLOCK_FREQ / TICKS_PER_SEC:- 公式:
CLOCK_FREQ表示时钟频率(每秒的计数值),TICKS_PER_SEC表示每秒的时钟中断次数。 - 作用: 计算每个时间片的时钟计数器增量。
CLOCK_FREQ是一秒内的时钟计数器增量,TICKS_PER_SEC是每秒的时间片数,CLOCK_FREQ / TICKS_PER_SEC就是每个时间片对应的时钟计数器增量。
- 公式:
-
get_time() + CLOCK_FREQ / TICKS_PER_SEC:- 作用: 计算下一个时钟中断触发的时间点。当前时间加上一个时间片的增量就是下一个时钟中断触发的时间点。
-
set_timer():- 作用: 将计算出的下一个触发时间点设置到
mtimecmp中,以便触发时钟中断。
- 作用: 将计算出的下一个触发时间点设置到
原因
- 这个公式确保每个时间片后触发一次时钟中断,以实现时间片轮转调度。
CLOCK_FREQ / TICKS_PER_SEC确保时间片的长度固定,从而实现公平的任务调度。
2. 获取当前时间(微秒)
#![allow(unused)] fn main() { pub fn get_time_us() -> usize { time::read() / (CLOCK_FREQ / MICRO_PER_SEC) } }
详细解释
-
time::read():- 作用: 读取当前的
mtime计数器值。
- 作用: 读取当前的
-
CLOCK_FREQ / MICRO_PER_SEC:- 公式:
CLOCK_FREQ表示时钟频率,MICRO_PER_SEC表示一秒内的微秒数(1,000,000)。 - 作用: 计算每微秒对应的时钟计数器增量。
CLOCK_FREQ是一秒内的时钟计数器增量,MICRO_PER_SEC是一秒内的微秒数,CLOCK_FREQ / MICRO_PER_SEC就是每微秒对应的时钟计数器增量。
- 公式:
-
time::read() / (CLOCK_FREQ / MICRO_PER_SEC):- 作用: 将当前的
mtime计数器值转换为微秒数。通过除以每微秒的计数器增量,可以得到当前的时间(单位为微秒)。
- 作用: 将当前的
原因
- 这个公式确保
mtime计数器值可以被转换为更精细的时间单位(微秒),从而实现高精度的计时功能。
3. 定义 TimeVal 结构体及其初始化
#![allow(unused)] fn main() { pub struct TimeVal { pub sec: usize, pub usec: usize, } let time_val = TimeVal { sec: us / 1_000_000, usec: us % 1_000_000, }; }
详细解释
-
结构体
TimeVal:- 字段:
sec: 秒数usec: 微秒数
- 字段:
-
初始化
TimeVal结构体:- 变量:
us - 类型:
usize - 作用: 表示当前时间(单位为微秒)
- 变量:
-
sec: us / 1_000_000:- 公式:
us / 1_000_000 - 作用: 将微秒数转换为秒数。通过将微秒数除以 1,000,000(每秒的微秒数),得到当前的秒数。
- 公式:
-
usec: us % 1_000_000:- 公式:
us % 1_000_000 - 作用: 获取当前秒数之外的剩余微秒数。通过取余操作,得到当前秒数之外的微秒数。
- 公式:
原因
- 这个公式将微秒数分解为秒数和微秒数,使得时间表示更加精确和易于理解。
TimeVal结构体将时间分为两个部分,便于系统调用返回更高精度的时间值。
总结
这些公式和计算方法确保了系统能够以高精度计时,并实现时间片轮转调度。通过这些机制,操作系统可以准确地管理任务执行时间和调度,确保系统的公平性和响应速度。
- 时间片轮转调度:
set_next_trigger计算下一个时钟中断触发时间,以实现时间片轮转调度。
- 高精度计时:
get_time_us将mtime计数器值转换为微秒,以实现高精度计时。
- 时间表示:
TimeVal结构体将时间分为秒和微秒,提供更高精度的时间表示。
这些机制和计算方法共同构成了一个高效的分时多任务操作系统。
RISC-V 架构中的嵌套中断问题
在 RISC-V 架构中,嵌套中断(Nested Interrupt)指在处理一个中断的过程中,又被同特权级或高特权级的中断打断。默认情况下,RISC-V 硬件会屏蔽同特权级的中断,以避免嵌套中断。
1. Trap 和中断处理
在 RISC-V 中,当 Trap(包括中断、异常和系统调用)发生时,系统进入某个特权级(如 S 特权级),并进行相应的处理。在这个过程中,默认情况下,当前特权级的中断会被屏蔽。
2. S 特权级的中断屏蔽机制
sstatus 寄存器
sstatus 是一个控制和状态寄存器,包含多个字段,其中 sie 和 spie 与中断屏蔽相关:
- sstatus.sie: S 特权级中断使能位。若为 1,表示使能 S 特权级的中断;若为 0,表示屏蔽 S 特权级的中断。
- sstatus.spie: 保存先前的 S 特权级中断使能状态。
Trap 处理流程
-
Trap 发生:
- 动作:
sstatus.sie被保存在sstatus.spie中,同时sstatus.sie被置零。 - 结果: 屏蔽所有 S 特权级的中断,确保当前 Trap 处理过程中不会被其他 S 特权级中断打断。
- 动作:
-
Trap 处理完毕:
- 动作:
sret指令执行时,将sstatus.sie恢复为sstatus.spie的值。 - 结果: 恢复 S 特权级中断使能状态。
- 动作:
3. 嵌套中断与嵌套 Trap
嵌套中断
嵌套中断指在处理一个中断的过程中,又被同特权级或高特权级的中断打断。
- 默认情况:
- 硬件会避免同特权级中断的嵌套,因为
sstatus.sie在 Trap 处理过程中被置零。
- 硬件会避免同特权级中断的嵌套,因为
- 手动设置:
- 可以通过手动设置
sstatus寄存器来允许同特权级中断的嵌套。
- 可以通过手动设置
- 高特权级中断:
- 高特权级的中断仍可以打断低特权级的中断处理,这种情况是无法避免的。
嵌套 Trap
嵌套 Trap 指在处理一个 Trap 的过程中,再次发生 Trap。嵌套中断是嵌套 Trap 的一种情况。
- 例子:
- 在处理系统调用时发生页面缺失异常。
- 在处理中断时发生另一种类型的 Trap(如非法指令异常)。
处理嵌套中断的机制
RISC-V 硬件和操作系统提供机制来处理嵌套中断,以确保系统的稳定性和响应性。
1. sstatus CSR 的设置
操作系统可以通过手动设置 sstatus 寄存器来控制中断的屏蔽和使能。
代码示例
#![allow(unused)] fn main() { use riscv::register::sstatus; fn enable_nested_interrupts() { unsafe { sstatus::set_sie(); } } fn disable_nested_interrupts() { unsafe { sstatus::clear_sie(); } } }
2. Trap 和中断处理流程
操作系统在处理 Trap 和中断时,可以根据需要选择是否允许嵌套中断。
示例流程
-
进入 Trap 处理程序:
- 屏蔽同特权级中断:
sstatus.sie被置零。 - 根据需要决定是否启用嵌套中断:调用
enable_nested_interrupts。
- 屏蔽同特权级中断:
-
处理 Trap:
- 处理异常、系统调用或中断。
- 可能发生新的 Trap(如嵌套中断或异常)。
-
退出 Trap 处理程序:
- 恢复中断使能状态:
sret指令将sstatus.sie恢复为sstatus.spie的值。
- 恢复中断使能状态:
3. 操作系统中的嵌套中断处理
操作系统可以在设计中考虑嵌套中断的处理,以提高系统的响应性和鲁棒性。
设计策略
-
确定哪些中断可以嵌套:
- 某些高优先级中断可以嵌套,例如时钟中断或紧急系统事件。
- 低优先级中断可能不允许嵌套。
-
实现嵌套中断处理:
- 在中断处理程序中,根据中断优先级决定是否允许嵌套。
- 保存和恢复上下文时,确保不会影响正在处理的中断或 Trap。
总结
在 RISC-V 架构中,默认情况下同特权级的中断在 Trap 处理过程中会被屏蔽,以避免嵌套中断。通过手动设置 sstatus CSR,可以允许嵌套中断的发生。而高特权级的中断可以打断低特权级的中断处理,这是无法避免的。
嵌套中断与嵌套 Trap 是操作系统设计中需要处理的复杂问题。通过合理设计中断处理机制和使用适当的硬件控制寄存器,操作系统可以有效管理和处理嵌套中断,确保系统的稳定性和响应速度。
抢占式调度
抢占式调度是一种调度算法,通过时钟中断和计时器强制任务切换。利用 RISC-V 架构中的时钟中断机制,我们可以实现时间片轮转调度算法(Round-Robin, RR),确保每个任务都能公平地获得 CPU 资源。
实现抢占式调度的步骤
-
时钟中断处理:
- 当触发 S 特权级时钟中断时,重新设置计时器,暂停当前任务,并切换到下一个任务。
-
启用时钟中断:
- 在执行第一个应用前,启用 S 特权级时钟中断,并设置第一个 10ms 的计时器。
时钟中断处理
在 trap_handler 函数中新增一个分支,用于处理 S 特权级时钟中断。
代码位置和实现
#![allow(unused)] fn main() { // os/src/trap/mod.rs match scause.cause() { Trap::Interrupt(Interrupt::SupervisorTimer) => { set_next_trigger(); suspend_current_and_run_next(); } } }
详细解释
-
识别时钟中断:
- 方法:
scause.cause() - 枚举:
Trap::Interrupt(Interrupt::SupervisorTimer) - 作用: 识别 S 特权级时钟中断。
- 方法:
-
重新设置计时器:
- 函数:
set_next_trigger() - 作用: 设置下一个时钟中断触发时间,以便在 10ms 后再次触发中断。
- 函数:
-
暂停当前任务并切换到下一个任务:
- 函数:
suspend_current_and_run_next() - 作用: 暂停当前任务的执行,并切换到下一个任务。
- 函数:
启用时钟中断
在执行第一个应用前,启用 S 特权级时钟中断,并设置第一个 10ms 的计时器。
代码位置和实现
#![allow(unused)] fn main() { // os/src/main.rs #[no_mangle] pub fn rust_main() -> ! { // ... trap::enable_timer_interrupt(); timer::set_next_trigger(); // ... } }
详细解释
-
启用 S 特权级时钟中断:
- 函数:
trap::enable_timer_interrupt() - 作用: 设置 S 特权级时钟中断使能位,使得时钟中断不会被屏蔽。
- 函数:
-
设置第一个 10ms 的计时器:
- 函数:
timer::set_next_trigger() - 作用: 设置下一个时钟中断触发时间,为 10ms 后。
- 函数:
启用时钟中断的具体实现
在 trap 模块中,实现 enable_timer_interrupt 函数。
#![allow(unused)] fn main() { // os/src/trap/mod.rs use riscv::register::sie; pub fn enable_timer_interrupt() { unsafe { sie::set_stimer(); } } }
详细解释
-
导入
sie模块:- 模块:
riscv::register::sie - 作用: 提供设置和清除 S 特权级中断使能位的功能。
- 模块:
-
启用 S 特权级时钟中断:
- 函数:
sie::set_stimer() - 作用: 设置 S 特权级时钟中断使能位,使得时钟中断不会被屏蔽。
- 函数:
核心函数和机制
suspend_current_and_run_next
暂停当前任务并切换到下一个任务。
代码位置和实现
#![allow(unused)] fn main() { // os/src/task/mod.rs pub fn suspend_current_and_run_next() { TASK_MANAGER.mark_current_suspended(); TASK_MANAGER.run_next_task(); } }
详细解释
-
标记当前任务为暂停:
- 函数:
TASK_MANAGER.mark_current_suspended() - 作用: 将当前任务的状态设置为
TaskStatus::Ready。
- 函数:
-
运行下一个任务:
- 函数:
TASK_MANAGER.run_next_task() - 作用: 调度并运行下一个准备好的任务。
- 函数:
set_next_trigger
设置下一个时钟中断触发时间。
代码位置和实现
#![allow(unused)] fn main() { // os/src/timer.rs use crate::config::CLOCK_FREQ; const TICKS_PER_SEC: usize = 100; pub fn set_next_trigger() { set_timer(get_time() + CLOCK_FREQ / TICKS_PER_SEC); } }
详细解释
-
获取当前时间:
- 函数:
get_time() - 作用: 获取当前的
mtime计数器值。
- 函数:
-
计算下一个时钟中断触发时间:
- 公式:
CLOCK_FREQ / TICKS_PER_SEC - 作用: 计算 10ms 的计时器增量。
- 公式:
-
设置下一个时钟中断触发时间:
- 函数:
set_timer(get_time() + CLOCK_FREQ / TICKS_PER_SEC) - 作用: 设置
mtimecmp的值,使得 10ms 后触发时钟中断。
- 函数:
总结
通过利用 RISC-V 架构中的时钟中断机制,我们实现了抢占式调度。这一调度算法通过时钟中断定期强制任务切换,确保每个任务都能公平地获得 CPU 资源,实现了时间片轮转调度算法。
关键步骤
-
时钟中断处理:
- 在
trap_handler中新增分支,处理 S 特权级时钟中断。 - 重新设置计时器,暂停当前任务并切换到下一个任务。
- 在
-
启用时钟中断:
- 在执行第一个应用前,启用 S 特权级时钟中断。
- 设置第一个 10ms 的计时器。
-
核心函数:
suspend_current_and_run_next: 暂停当前任务并切换到下一个任务。set_next_trigger: 设置下一个时钟中断触发时间。
通过这些机制,我们实现了一个高效的抢占式调度系统,确保多任务操作系统中的任务能够公平地竞争 CPU 资源。
多道程序与分时多任务操作系统的全流程描述
1. 系统初始化
文件: src/main.rs
主要步骤:
rust_main函数初始化系统,包括启用时钟中断和设置第一个 10ms 的计时器。
关键函数和变量:
trap::enable_timer_interrupt()timer::set_next_trigger()task::run_first_task()
2. 启用 S 特权级时钟中断
文件: src/trap/mod.rs
主要步骤:
enable_timer_interrupt函数设置 S 特权级时钟中断使能位,确保时钟中断不会被屏蔽。
关键函数和变量:
sie::set_stimer()
3. 设置计时器
文件: src/timer.rs
主要步骤:
set_next_trigger函数设置下一个时钟中断触发时间。get_time函数获取当前的mtime计数器值。set_timer函数设置mtimecmp的值。
关键函数和变量:
CLOCK_FREQTICKS_PER_SECset_timer(get_time() + CLOCK_FREQ / TICKS_PER_SEC)
4. 加载应用程序
文件: src/loader.rs
主要步骤:
load_apps函数将应用程序加载到内存。init_app_cx函数初始化任务控制块,构造 Trap 上下文,并返回应用程序的初始栈指针。
关键函数和变量:
get_num_app()TaskContext::goto_restore()
5. 任务上下文和任务控制块
文件: src/task/context.rs
主要步骤:
TaskContext结构体定义任务上下文,包括返回地址(ra)、栈指针(sp)和保存寄存器(s0~s11)。TaskControlBlock结构体定义任务控制块,包括任务状态和上下文。
关键函数和变量:
TaskContext::goto_restore()
6. 任务管理器
文件: src/task/mod.rs
主要步骤:
TASK_MANAGER全局实例初始化任务管理器。suspend_current_and_run_next函数暂停当前任务并切换到下一个任务。run_next_task函数调度并运行下一个任务。find_next_task函数查找下一个准备运行的任务。
关键函数和变量:
TaskManagerTaskManagerInnermark_current_suspended()mark_current_exited()
7. 任务切换
文件: src/task/switch.S 和 src/task/switch.rs
主要步骤:
__switch函数使用汇编实现任务上下文的保存和恢复,进行任务切换。
关键函数和变量:
__switch
8. 时钟中断处理
文件: src/trap/mod.rs
主要步骤:
trap_handler函数处理 S 特权级时钟中断,重新设置计时器,并进行任务切换。
关键函数和变量:
scause.cause()Trap::Interrupt(Interrupt::SupervisorTimer)set_next_trigger()suspend_current_and_run_next()
总结
通过以上步骤,我们实现了一个多道程序与分时多任务的操作系统。关键步骤包括系统初始化、启用时钟中断、设置计时器、加载应用程序、管理任务上下文和任务控制块、实现任务切换以及处理时钟中断。这些步骤确保了操作系统能够高效地调度任务,实现公平的时间片轮转调度。
第五讲 物理内存管理
第一节 地址空间
0 地址空间简介
地址空间是操作系统中的一个重要概念,它指的是一个进程可以使用的所有内存地址的集合。地址空间分为物理地址空间和虚拟地址空间:
-
物理地址空间:直接对应计算机硬件的物理内存(RAM)。物理地址空间的大小受到物理内存容量的限制。
-
虚拟地址空间:由操作系统提供给进程使用的地址空间。每个进程都有自己的虚拟地址空间,可以认为是一个抽象层,帮助简化内存管理。虚拟地址空间可以大于物理内存,通过分页(paging)或分段(segmentation)技术来管理。
物理内存管理
物理内存管理是操作系统内核的重要功能之一,它负责管理计算机的物理内存。常见的物理内存管理方法包括:
-
分页(Paging):
- 将物理内存划分为固定大小的块,称为“页框”(page frames)。
- 将虚拟内存划分为相同大小的块,称为“页”(pages)。
- 使用页表(page table)将虚拟页映射到物理页框。
- 当进程需要访问某个虚拟地址时,操作系统通过页表找到对应的物理地址。
- 页表通常存放在内存中,使用硬件支持的TLB(Translation Lookaside Buffer)进行加速。
-
分段(Segmentation):
- 将内存划分为不同大小的块,称为“段”(segments),每个段可以代表代码段、数据段、堆栈段等。
- 使用段表(segment table)将虚拟段映射到物理内存区域。
- 段表记录了每个段的起始地址和长度。
地址转换
地址转换是从虚拟地址到物理地址的映射过程。主要分为以下几个步骤:
-
段式转换:如果使用分段机制,首先通过段表查找段基址(base address)和段偏移量(offset),将虚拟地址转换为线性地址。
-
分页转换:线性地址通过页表转换为物理地址。虚拟地址分为页号(page number)和页内偏移量(offset within page)。页号通过页表查找页框号(frame number),页框号加上页内偏移量得到物理地址。
内存分配
内存分配策略主要包括:
-
固定分区分配:
- 将内存划分为若干固定大小的分区,每个分区只能分配给一个进程。
- 优点是管理简单,但容易造成内存碎片和资源浪费。
-
动态分区分配:
- 根据进程需要动态分配内存块。
- 常用方法包括首次适配(First Fit)、最佳适配(Best Fit)和最差适配(Worst Fit)。
- 动态分区分配易于灵活使用内存,但也会产生外部碎片。
-
伙伴系统(Buddy System):
- 将内存划分为大小为2的幂的块,块可以合并和分割。
- 伙伴系统易于管理和合并碎片,但可能导致内部碎片。
内存保护
操作系统通过以下技术保护内存不被非法访问:
-
基址寄存器(Base Register)和界限寄存器(Limit Register):
- 设置进程可以访问的内存范围,防止越界访问。
-
页表和段表:
- 控制进程访问特定的页或段,通过页表和段表实现内存保护。
-
硬件支持:
- 现代处理器提供内存管理单元(MMU)和TLB支持高效的地址转换和内存保护。
地址空间和物理内存管理是操作系统中至关重要的部分,通过虚拟内存技术实现进程隔离和内存保护。理解这些概念有助于更好地掌握操作系统的运行机制,设计高效的内存管理方案。
1. 计算机的存储层次
我们前面讨论了物理地址空间,接下来我们要深入探讨一种更高级的技术——虚拟地址空间。这涉及到地址空间管理的重要概念,有助于我们更深入地理解计算机内存管理的工作原理。
1.1 什么是地址空间
在讨论地址空间之前,我们需要重新理解和回顾与内存相关的一些概念,包括物理地址、逻辑地址、线性地址和虚拟地址。
物理地址
物理地址是指直接对应于内存芯片的地址,是硬件层面上实际存在的地址。当我们访问内存时,读取的地址就是物理地址。
逻辑地址
逻辑地址是程序在编写和编译时使用的地址。程序员在写程序时并不直接操作物理地址,而是操作逻辑地址。编译器将这些逻辑地址转换成具体的地址。在Intel的x86处理器中,逻辑地址是指编程时看到的地址。
线性地址
线性地址是经过段机制转换后的地址。对于x86架构,逻辑地址通过段机制转换成线性地址,线性地址再通过页机制转换成物理地址。
虚拟地址
虚拟地址是操作系统提供给进程的地址空间,进程使用虚拟地址进行内存访问。操作系统和硬件通过映射机制将虚拟地址转换成物理地址。对于RISC-V架构,没有段机制,虚拟地址等同于线性地址。
1.2 地址转换过程
在x86架构中,地址转换分为以下几个步骤:
- 逻辑地址到线性地址:逻辑地址通过段机制转换成线性地址。
- 线性地址到物理地址:线性地址通过页机制转换成物理地址。
由于RISC-V架构没有段机制,逻辑地址直接等于虚拟地址,通过页机制转换成物理地址。逻辑地址 -> 线性地址(虚拟地址) -> 物理地址
1.3 存储层次结构
计算机的存储层次结构从快到慢依次为:
- 寄存器:速度最快,但数量有限。
- 高速缓存(Cache):稍慢于寄存器,但比内存快。
- 内存(RAM):主要存储运行时的数据。
- I/O设备(例如磁盘):速度最慢,但容量大。
操作系统需要屏蔽这些存储细节,给应用程序提供统一的内存视图。应用程序看到的是一块大的虚拟内存空间,不需要关心底层是磁盘、内存还是缓存。
操作系统的作用
操作系统的一个重要职责是管理地址空间和物理内存,为应用程序提供一个统一的虚拟内存环境。这个虚拟内存环境通过地址映射技术,将应用程序的逻辑地址映射到物理地址,使应用程序可以在不关心底层存储细节的情况下运行。
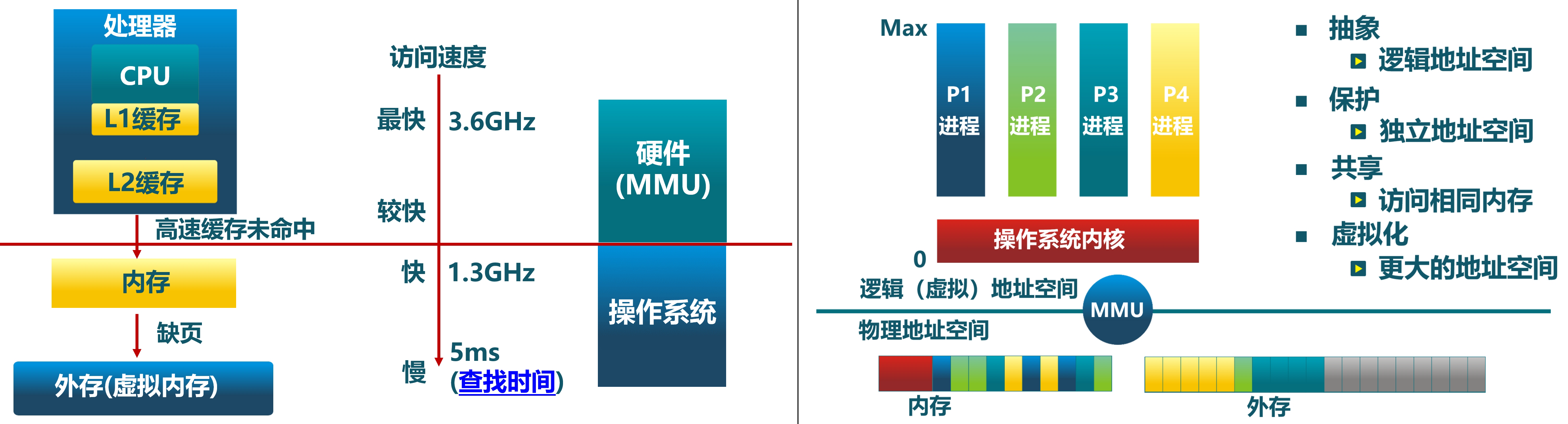
1.4 虚拟内存关键概念和技术
在深入探讨操作系统中的虚拟内存时,我们需要了解一些关键概念和技术,包括虚拟地址空间的连续性、地址空间的保护、数据共享和隔离、以及虚拟存储技术。以下是对这些内容的详细总结:
虚拟地址空间的连续性
虚拟内存的一个重要特点是逻辑地址空间是连续的。这意味着每个运行的程序(即进程或任务)在其视角下有一个连续的地址空间,便于编程和管理。然而,物理上,这些地址可能是离散分布的。
虚拟地址与物理地址的映射
- 逻辑地址空间的连续性:每个程序在运行时认为其地址空间是连续的,简化了编程和内存管理。
- 物理地址的离散性:实际的物理内存分布是离散的。操作系统通过页表或段表将虚拟地址映射到物理地址,从而提供一个连续的虚拟地址空间。
1.5 地址空间的保护
虚拟内存不仅提供了更大的地址空间,还实现了内存保护,确保进程之间互不干扰。
地址空间保护机制
- 边界保护:每个地址空间有边界,超出边界会产生异常,从而防止进程越界访问。
- 异常处理:当进程尝试访问越界地址时,操作系统会触发异常处理机制,并可能终止该进程。
数据共享与隔离
虚拟内存允许多个进程共享相同的物理内存区域,同时保证各自的独立性和数据隔离。
共享内存
- 共享机制:操作系统可以让多个进程映射到同一块物理内存,从而实现数据共享。每个进程看到的地址空间虽然不同,但实际上访问的是相同的数据。
- 隔离机制:尽管进程可以共享内存,但它们的地址空间是隔离的,防止彼此干扰。
1.6 虚拟存储技术
实现虚拟内存需要多种技术的支持,包括重定位、分段、分页以及硬件支持。
关键技术
- 重定位:动态调整进程的地址空间,使其适应物理内存的分布。
- 分段:将内存划分为大小不等的段,每个段代表不同类型的数据或代码。
- 分页:将内存划分为固定大小的页,通过页表管理虚拟地址和物理地址的映射。
- 虚拟存储技术:综合运用重定位、分段和分页技术,提供一个统一的虚拟内存空间。
1.7 硬件支持
实现虚拟内存需要硬件的支持,主要包括异常中断处理、优先级管理以及分页机制。
硬件特性
- 异常中断:处理越界访问、缺页等异常情况,保证系统稳定运行。
- 优先级管理:确保重要进程优先得到处理资源。
- 分页机制:通过页表和TLB(Translation Lookaside Buffer)实现高效的地址转换和内存管理。
虚拟内存是操作系统的一个重要功能,它通过提供连续的逻辑地址空间、内存保护、数据共享与隔离,以及虚拟存储技术,为应用程序提供了一个统一且高效的内存管理环境。这些技术的综合应用,使得操作系统能够抽象出一个大而快的虚拟内存空间,极大地提高了系统的灵活性和性能。
2. 地址和地址空间
在操作系统中,地址空间的生成和管理是一个复杂而重要的过程。物理地址、逻辑地址和虚拟地址的生成和使用各不相同,它们由硬件、操作系统(OS)和编译器共同决定。
物理地址与逻辑地址的区别
物理地址和逻辑地址是两个不同的概念,出发点和使用场景也不同。
物理地址
- 定义:物理地址是直接对应于内存芯片的地址,是硬件层面上实际存在的地址。
- 生成:物理地址由硬件(内存管理单元MMU)生成,受硬件设计和配置的限制。
逻辑地址
- 定义:逻辑地址是程序在编写和编译时使用的地址。
- 生成:逻辑地址由编译器生成,取决于编译器的设定和操作系统提供的地址范围。
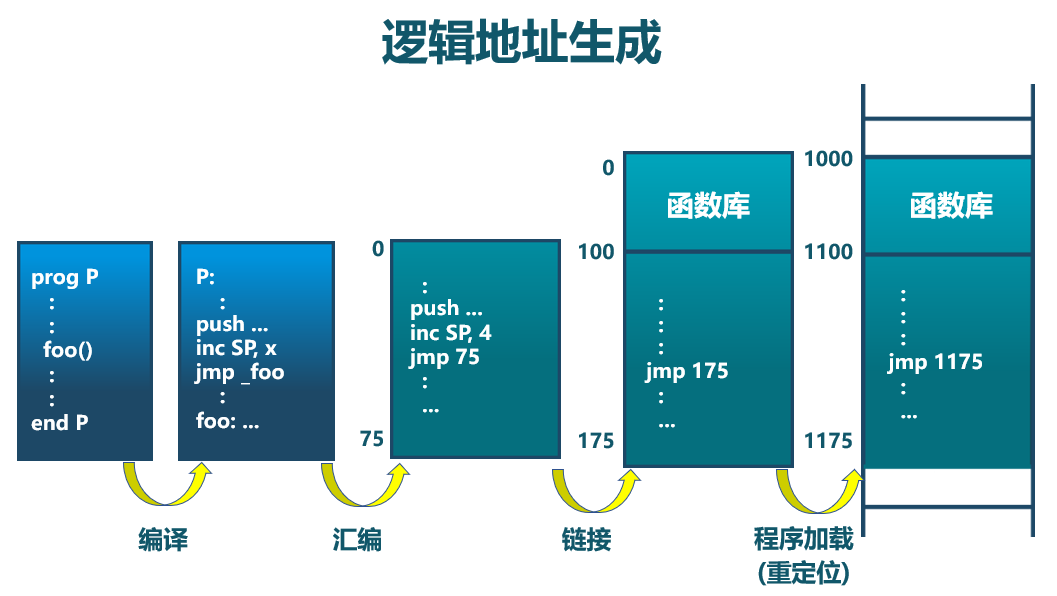
虚拟地址空间
虚拟地址空间是操作系统提供给应用程序使用的地址范围。虚拟地址空间的大小和范围由操作系统和硬件共同决定。
虚拟地址的范围
- OS决定:操作系统决定虚拟地址空间的范围,并为每个进程分配独立的虚拟地址空间。
- 编译器决定:编译器根据操作系统提供的虚拟地址范围生成逻辑地址。
- 硬件决定:硬件(如CPU和MMU)通过页表等机制将虚拟地址转换为物理地址。
地址空间的紧耦合
操作系统、编译器和硬件之间需要紧密合作,才能有效管理地址空间并确保应用程序的正确运行。
紧耦合的实现
- 操作系统与硬件:操作系统利用硬件提供的地址转换和内存管理功能(如页表和TLB)来实现虚拟内存。
- 操作系统与编译器:操作系统向编译器提供虚拟地址范围,编译器生成相应的逻辑地址。
- 硬件与编译器:编译器生成的逻辑地址通过硬件转换为物理地址。
地址生成的过程
地址生成过程包括编译时、加载时和执行时三个阶段,每个阶段生成的地址形式不同。
编译时
- 逻辑地址生成:编译器将高级语言代码转换为逻辑地址,生成目标文件和可执行文件。
加载时
- 重定位:加载器将逻辑地址转换为内存中的实际地址(重定位),确保程序正确运行。
- 动态链接库:动态链接库在加载时也需要进行重定位,以适应内存中的实际地址。
执行时
- 地址转换:操作系统和硬件共同管理虚拟地址到物理地址的转换,确保程序的正确执行。
- 安全检查:在执行过程中,硬件通过MMU和页表机制进行地址转换和安全检查,确保不同类型的内存区域具有正确的访问权限。
内存区域的特征与保护
不同类型的内存区域(如代码段和数据段)具有不同的访问权限和特征。
代码段
- 特征:只读、可执行。
- 保护:防止修改和非法访问。
数据段
- 特征:可读、可写、不可执行。
- 保护:防止代码注入和非法执行。
地址空间管理的硬件支持
地址空间管理依赖于硬件的支持,特别是内存管理单元(MMU)和页表机制。
内存管理单元(MMU)
- 作用:负责地址转换和内存保护,确保虚拟地址正确映射到物理地址。
- 功能:通过页表和TLB实现高效的地址转换和内存保护。
页表机制
- 作用:存储虚拟地址到物理地址的映射关系。
- 功能:页表项包含物理地址和访问权限信息,硬件通过页表进行地址转换和安全检查。
操作系统中的地址转换与管理
在操作系统中,地址转换与管理是一个复杂且至关重要的任务。这个过程涉及硬件组件如内存管理单元(MMU)和中央处理单元(CPU)的协作,以及操作系统的有效管理。
地址转换过程
地址转换是从逻辑地址(虚拟地址)到物理地址的映射过程,这个过程主要依赖于MMU和页表机制。
0. 逻辑地址和虚拟地址
- 逻辑地址:由编译器生成,是程序中使用的地址。
- 虚拟地址:由操作系统提供给进程使用的地址空间,可以看作是逻辑地址的一种。
1. 地址转换的过程
- 第一步:当CPU需要访问内存时,它首先产生一个虚拟地址。
- CPU将这个虚拟地址发送给MMU进行转换。
MMU和地址转换缓存(TLB)
MMU是处理器中的一个组件,负责将虚拟地址转换为物理地址。TLB(Translation Lookaside Buffer)是MMU中的一个高速缓存,用于加速地址转换。
2. TLB查找
- 步骤2.1:MMU首先在TLB中查找虚拟地址的映射。如果命中,直接得到对应的物理地址。
- 步骤2.2:如果TLB未命中,MMU将查找页表。
3. 页表查找
- 步骤3.1:如果TLB未命中,MMU会查找页表。页表由操作系统维护,记录了虚拟地址到物理地址的映射关系。
- 步骤3.2:如果页表中存在对应的映射关系,MMU得到物理地址并返回给CPU。
4. 异常处理
- 步骤4:如果页表中没有对应的映射关系,MMU将触发一个页表异常(page fault)。此时操作系统介入处理。
页表异常处理
页表异常是指在页表中找不到对应的虚拟地址到物理地址的映射关系,操作系统需要进行异常处理。
5. 异常处理的步骤/读取到数据
- 步骤5.1:操作系统检查虚拟地址是否有效。如果虚拟地址有效,操作系统将为其分配物理内存,并更新页表。
- 步骤5.2:如果虚拟地址无效,操作系统将终止相应的进程。
- 步骤5.3:如果虚拟地址对应的页面在硬盘上,操作系统将从硬盘读取页面到内存中,更新页表,然后重新执行导致异常的指令。
地址转换与管理是操作系统、硬件和编译器之间复杂且紧密合作的结果。通过虚拟地址空间、页表和异常处理机制,操作系统能够提供一个安全、高效、统一的内存管理环境,确保应用程序的正确运行。理解这些机制有助于深入掌握操作系统的工作原理和内存管理技术。
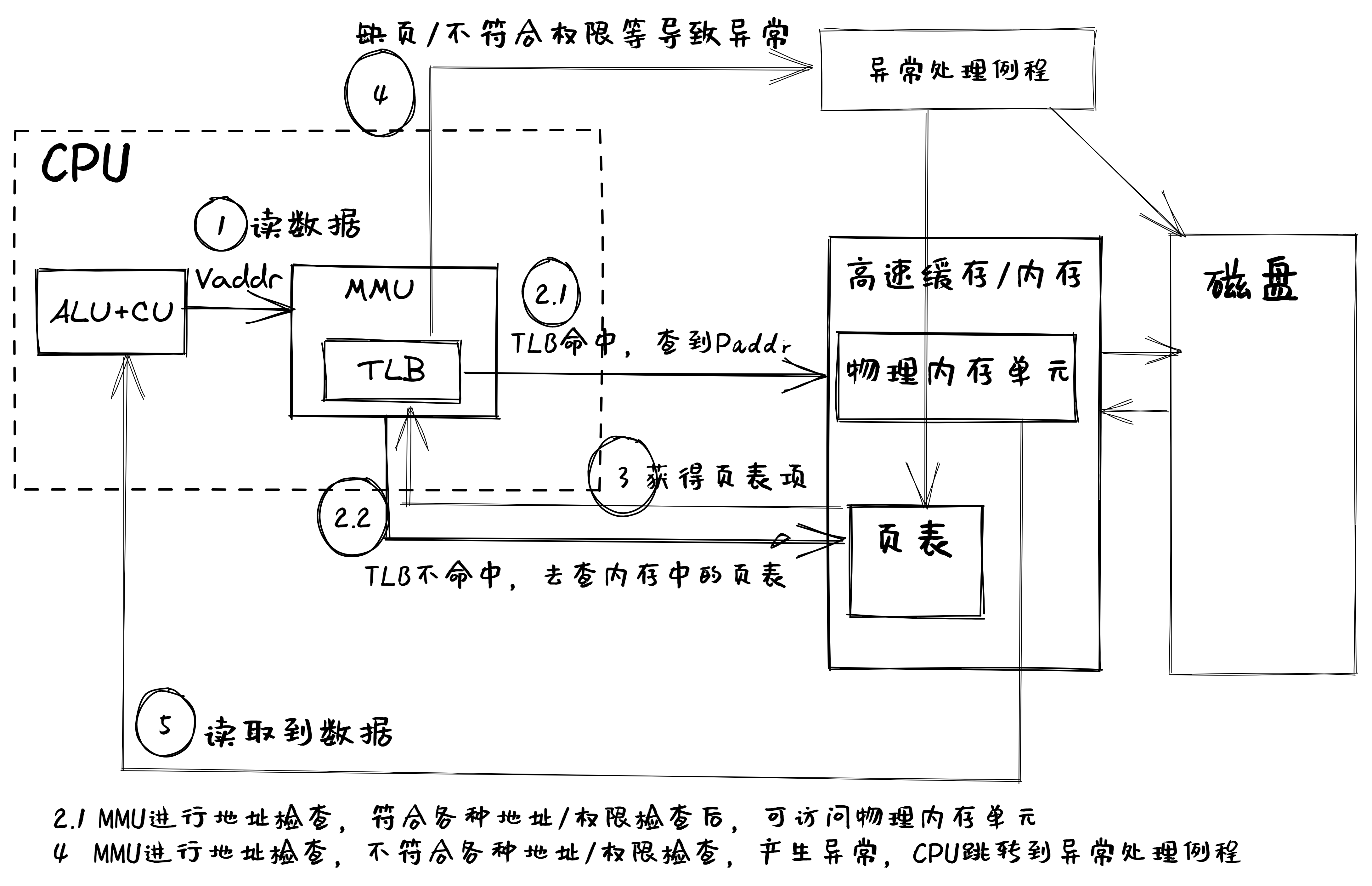
3. 虚拟存储的作用
虚拟内存是操作系统中的一项关键技术,它通过将内存和外存结合在一起,提供了一个更大的地址空间,并提高了内存管理的效率。
虚拟内存的好处
虚拟内存带来了多个好处,包括扩展地址空间、简化编程和执行、提高安全性和共享数据的方便性。
扩展内存空间
- 扩展地址空间:通过将物理内存和外存结合,虚拟内存提供了一个更大的可用地址空间。
- 提高性能:常用数据保存在内存中,不常用数据保存在外存中,提高了内存使用效率和系统性能。
简化编程和执行
- 独立地址空间:每个应用程序拥有独立的地址空间,简化了编程过程,避免了地址冲突。
- 简化编译和链接过程:编译器可以为每个程序分配相同的逻辑地址,而操作系统负责将这些逻辑地址映射到不同的物理地址。
- 简化加载过程:程序在加载时基于虚拟地址进行,而不需要考虑具体的物理地址位置。
数据共享与内存分配
- 简化数据共享:通过虚拟内存,不同进程可以方便地共享数据,同时保持各自的独立性。
- 简化内存分配:虚拟内存管理简化了内存分配的过程,操作系统可以更灵活地分配和回收内存。
虚拟内存的安全性
虚拟内存提供了多种内存保护机制,确保程序的安全性和稳定性。
内存隔离与保护
- 内存隔离:虚拟内存为每个进程提供独立的地址空间,防止进程间的内存干扰。
- 访问权限控制:操作系统可以设置内存区域的访问权限,如代码段只可执行不可写、数据段可读可写不可执行等。
- 内核与用户空间的隔离:操作系统可以将内核空间与用户空间隔离,防止用户程序访问内核数据。
虚拟内存的实现
实现虚拟内存需要多种技术和硬件支持,包括页表、TLB、页面置换算法等。
页表与TLB
- 页表:存储虚拟地址到物理地址的映射关系。
- TLB:加速地址转换的缓存,通过快速查找虚拟地址到物理地址的映射,提高系统性能。
页面置换算法
- 页面置换:当内存不足时,操作系统需要将一些页面交换到外存中,以腾出内存空间。
- 置换算法:常用的页面置换算法包括FIFO(先进先出)、LRU(最近最少使用)等,用于决定哪些页面需要被交换出去。
虚拟内存的应用
虚拟内存在现代操作系统中广泛应用,为各种应用程序提供高效、灵活、安全的内存管理。
应用程序的独立性
- 独立地址空间:每个应用程序拥有独立的虚拟地址空间,简化了开发和调试过程。
- 动态内存分配:虚拟内存支持动态内存分配,允许程序在运行时分配和释放内存。
系统资源管理
- 资源隔离:虚拟内存实现了系统资源的隔离,防止进程间的资源争用和冲突。
- 高效利用内存:通过页面置换和内存管理算法,操作系统可以高效利用物理内存和外存资源。
虚拟内存是操作系统中的一项重要技术,通过扩展地址空间、简化编程和执行、提高安全性和共享数据的方便性,为应用程序提供了一个高效、灵活、安全的内存管理环境。理解虚拟内存的工作原理和实现技术,有助于深入掌握操作系统的核心概念和内存管理方法。
第五讲 物理内存管理
第一节 地址空间
0 地址空间简介
地址空间是操作系统中的一个重要概念,它指的是一个进程可以使用的所有内存地址的集合。地址空间分为物理地址空间和虚拟地址空间:
-
物理地址空间:直接对应计算机硬件的物理内存(RAM)。物理地址空间的大小受到物理内存容量的限制。
-
虚拟地址空间:由操作系统提供给进程使用的地址空间。每个进程都有自己的虚拟地址空间,可以认为是一个抽象层,帮助简化内存管理。虚拟地址空间可以大于物理内存,通过分页(paging)或分段(segmentation)技术来管理。
物理内存管理
物理内存管理是操作系统内核的重要功能之一,它负责管理计算机的物理内存。常见的物理内存管理方法包括:
-
分页(Paging):
- 将物理内存划分为固定大小的块,称为“页框”(page frames)。
- 将虚拟内存划分为相同大小的块,称为“页”(pages)。
- 使用页表(page table)将虚拟页映射到物理页框。
- 当进程需要访问某个虚拟地址时,操作系统通过页表找到对应的物理地址。
- 页表通常存放在内存中,使用硬件支持的TLB(Translation Lookaside Buffer)进行加速。
-
分段(Segmentation):
- 将内存划分为不同大小的块,称为“段”(segments),每个段可以代表代码段、数据段、堆栈段等。
- 使用段表(segment table)将虚拟段映射到物理内存区域。
- 段表记录了每个段的起始地址和长度。
地址转换
地址转换是从虚拟地址到物理地址的映射过程。主要分为以下几个步骤:
-
段式转换:如果使用分段机制,首先通过段表查找段基址(base address)和段偏移量(offset),将虚拟地址转换为线性地址。
-
分页转换:线性地址通过页表转换为物理地址。虚拟地址分为页号(page number)和页内偏移量(offset within page)。页号通过页表查找页框号(frame number),页框号加上页内偏移量得到物理地址。
内存分配
内存分配策略主要包括:
-
固定分区分配:
- 将内存划分为若干固定大小的分区,每个分区只能分配给一个进程。
- 优点是管理简单,但容易造成内存碎片和资源浪费。
-
动态分区分配:
- 根据进程需要动态分配内存块。
- 常用方法包括首次适配(First Fit)、最佳适配(Best Fit)和最差适配(Worst Fit)。
- 动态分区分配易于灵活使用内存,但也会产生外部碎片。
-
伙伴系统(Buddy System):
- 将内存划分为大小为2的幂的块,块可以合并和分割。
- 伙伴系统易于管理和合并碎片,但可能导致内部碎片。
内存保护
操作系统通过以下技术保护内存不被非法访问:
-
基址寄存器(Base Register)和界限寄存器(Limit Register):
- 设置进程可以访问的内存范围,防止越界访问。
-
页表和段表:
- 控制进程访问特定的页或段,通过页表和段表实现内存保护。
-
硬件支持:
- 现代处理器提供内存管理单元(MMU)和TLB支持高效的地址转换和内存保护。
地址空间和物理内存管理是操作系统中至关重要的部分,通过虚拟内存技术实现进程隔离和内存保护。理解这些概念有助于更好地掌握操作系统的运行机制,设计高效的内存管理方案。
1. 计算机的存储层次
我们前面讨论了物理地址空间,接下来我们要深入探讨一种更高级的技术——虚拟地址空间。这涉及到地址空间管理的重要概念,有助于我们更深入地理解计算机内存管理的工作原理。
1.1 什么是地址空间
在讨论地址空间之前,我们需要重新理解和回顾与内存相关的一些概念,包括物理地址、逻辑地址、线性地址和虚拟地址。
物理地址
物理地址是指直接对应于内存芯片的地址,是硬件层面上实际存在的地址。当我们访问内存时,读取的地址就是物理地址。
逻辑地址
逻辑地址是程序在编写和编译时使用的地址。程序员在写程序时并不直接操作物理地址,而是操作逻辑地址。编译器将这些逻辑地址转换成具体的地址。在Intel的x86处理器中,逻辑地址是指编程时看到的地址。
线性地址
线性地址是经过段机制转换后的地址。对于x86架构,逻辑地址通过段机制转换成线性地址,线性地址再通过页机制转换成物理地址。
虚拟地址
虚拟地址是操作系统提供给进程的地址空间,进程使用虚拟地址进行内存访问。操作系统和硬件通过映射机制将虚拟地址转换成物理地址。对于RISC-V架构,没有段机制,虚拟地址等同于线性地址。
1.2 地址转换过程
在x86架构中,地址转换分为以下几个步骤:
- 逻辑地址到线性地址:逻辑地址通过段机制转换成线性地址。
- 线性地址到物理地址:线性地址通过页机制转换成物理地址。
由于RISC-V架构没有段机制,逻辑地址直接等于虚拟地址,通过页机制转换成物理地址。逻辑地址 -> 线性地址(虚拟地址) -> 物理地址
1.3 存储层次结构
计算机的存储层次结构从快到慢依次为:
- 寄存器:速度最快,但数量有限。
- 高速缓存(Cache):稍慢于寄存器,但比内存快。
- 内存(RAM):主要存储运行时的数据。
- I/O设备(例如磁盘):速度最慢,但容量大。
操作系统需要屏蔽这些存储细节,给应用程序提供统一的内存视图。应用程序看到的是一块大的虚拟内存空间,不需要关心底层是磁盘、内存还是缓存。
操作系统的作用
操作系统的一个重要职责是管理地址空间和物理内存,为应用程序提供一个统一的虚拟内存环境。这个虚拟内存环境通过地址映射技术,将应用程序的逻辑地址映射到物理地址,使应用程序可以在不关心底层存储细节的情况下运行。
1.4 虚拟内存关键概念和技术
在深入探讨操作系统中的虚拟内存时,我们需要了解一些关键概念和技术,包括虚拟地址空间的连续性、地址空间的保护、数据共享和隔离、以及虚拟存储技术。以下是对这些内容的详细总结:
虚拟地址空间的连续性
虚拟内存的一个重要特点是逻辑地址空间是连续的。这意味着每个运行的程序(即进程或任务)在其视角下有一个连续的地址空间,便于编程和管理。然而,物理上,这些地址可能是离散分布的。
虚拟地址与物理地址的映射
- 逻辑地址空间的连续性:每个程序在运行时认为其地址空间是连续的,简化了编程和内存管理。
- 物理地址的离散性:实际的物理内存分布是离散的。操作系统通过页表或段表将虚拟地址映射到物理地址,从而提供一个连续的虚拟地址空间。
1.5 地址空间的保护
虚拟内存不仅提供了更大的地址空间,还实现了内存保护,确保进程之间互不干扰。
地址空间保护机制
- 边界保护:每个地址空间有边界,超出边界会产生异常,从而防止进程越界访问。
- 异常处理:当进程尝试访问越界地址时,操作系统会触发异常处理机制,并可能终止该进程。
数据共享与隔离
虚拟内存允许多个进程共享相同的物理内存区域,同时保证各自的独立性和数据隔离。
共享内存
- 共享机制:操作系统可以让多个进程映射到同一块物理内存,从而实现数据共享。每个进程看到的地址空间虽然不同,但实际上访问的是相同的数据。
- 隔离机制:尽管进程可以共享内存,但它们的地址空间是隔离的,防止彼此干扰。
1.6 虚拟存储技术
实现虚拟内存需要多种技术的支持,包括重定位、分段、分页以及硬件支持。
关键技术
- 重定位:动态调整进程的地址空间,使其适应物理内存的分布。
- 分段:将内存划分为大小不等的段,每个段代表不同类型的数据或代码。
- 分页:将内存划分为固定大小的页,通过页表管理虚拟地址和物理地址的映射。
- 虚拟存储技术:综合运用重定位、分段和分页技术,提供一个统一的虚拟内存空间。
1.7 硬件支持
实现虚拟内存需要硬件的支持,主要包括异常中断处理、优先级管理以及分页机制。
硬件特性
- 异常中断:处理越界访问、缺页等异常情况,保证系统稳定运行。
- 优先级管理:确保重要进程优先得到处理资源。
- 分页机制:通过页表和TLB(Translation Lookaside Buffer)实现高效的地址转换和内存管理。
虚拟内存是操作系统的一个重要功能,它通过提供连续的逻辑地址空间、内存保护、数据共享与隔离,以及虚拟存储技术,为应用程序提供了一个统一且高效的内存管理环境。这些技术的综合应用,使得操作系统能够抽象出一个大而快的虚拟内存空间,极大地提高了系统的灵活性和性能。
2. 地址和地址空间
在操作系统中,地址空间的生成和管理是一个复杂而重要的过程。物理地址、逻辑地址和虚拟地址的生成和使用各不相同,它们由硬件、操作系统(OS)和编译器共同决定。
物理地址与逻辑地址的区别
物理地址和逻辑地址是两个不同的概念,出发点和使用场景也不同。
物理地址
- 定义:物理地址是直接对应于内存芯片的地址,是硬件层面上实际存在的地址。
- 生成:物理地址由硬件(内存管理单元MMU)生成,受硬件设计和配置的限制。
逻辑地址
- 定义:逻辑地址是程序在编写和编译时使用的地址。
- 生成:逻辑地址由编译器生成,取决于编译器的设定和操作系统提供的地址范围。
虚拟地址空间
虚拟地址空间是操作系统提供给应用程序使用的地址范围。虚拟地址空间的大小和范围由操作系统和硬件共同决定。
虚拟地址的范围
- OS决定:操作系统决定虚拟地址空间的范围,并为每个进程分配独立的虚拟地址空间。
- 编译器决定:编译器根据操作系统提供的虚拟地址范围生成逻辑地址。
- 硬件决定:硬件(如CPU和MMU)通过页表等机制将虚拟地址转换为物理地址。
地址空间的紧耦合
操作系统、编译器和硬件之间需要紧密合作,才能有效管理地址空间并确保应用程序的正确运行。
紧耦合的实现
- 操作系统与硬件:操作系统利用硬件提供的地址转换和内存管理功能(如页表和TLB)来实现虚拟内存。
- 操作系统与编译器:操作系统向编译器提供虚拟地址范围,编译器生成相应的逻辑地址。
- 硬件与编译器:编译器生成的逻辑地址通过硬件转换为物理地址。
地址生成的过程
地址生成过程包括编译时、加载时和执行时三个阶段,每个阶段生成的地址形式不同。
编译时
- 逻辑地址生成:编译器将高级语言代码转换为逻辑地址,生成目标文件和可执行文件。
加载时
- 重定位:加载器将逻辑地址转换为内存中的实际地址(重定位),确保程序正确运行。
- 动态链接库:动态链接库在加载时也需要进行重定位,以适应内存中的实际地址。
执行时
- 地址转换:操作系统和硬件共同管理虚拟地址到物理地址的转换,确保程序的正确执行。
- 安全检查:在执行过程中,硬件通过MMU和页表机制进行地址转换和安全检查,确保不同类型的内存区域具有正确的访问权限。
内存区域的特征与保护
不同类型的内存区域(如代码段和数据段)具有不同的访问权限和特征。
代码段
- 特征:只读、可执行。
- 保护:防止修改和非法访问。
数据段
- 特征:可读、可写、不可执行。
- 保护:防止代码注入和非法执行。
地址空间管理的硬件支持
地址空间管理依赖于硬件的支持,特别是内存管理单元(MMU)和页表机制。
内存管理单元(MMU)
- 作用:负责地址转换和内存保护,确保虚拟地址正确映射到物理地址。
- 功能:通过页表和TLB实现高效的地址转换和内存保护。
页表机制
- 作用:存储虚拟地址到物理地址的映射关系。
- 功能:页表项包含物理地址和访问权限信息,硬件通过页表进行地址转换和安全检查。
操作系统中的地址转换与管理
在操作系统中,地址转换与管理是一个复杂且至关重要的任务。这个过程涉及硬件组件如内存管理单元(MMU)和中央处理单元(CPU)的协作,以及操作系统的有效管理。
地址转换过程
地址转换是从逻辑地址(虚拟地址)到物理地址的映射过程,这个过程主要依赖于MMU和页表机制。
0. 逻辑地址和虚拟地址
- 逻辑地址:由编译器生成,是程序中使用的地址。
- 虚拟地址:由操作系统提供给进程使用的地址空间,可以看作是逻辑地址的一种。
1. 地址转换的过程
- 第一步:当CPU需要访问内存时,它首先产生一个虚拟地址。
- CPU将这个虚拟地址发送给MMU进行转换。
MMU和地址转换缓存(TLB)
MMU是处理器中的一个组件,负责将虚拟地址转换为物理地址。TLB(Translation Lookaside Buffer)是MMU中的一个高速缓存,用于加速地址转换。
2. TLB查找
- 步骤2.1:MMU首先在TLB中查找虚拟地址的映射。如果命中,直接得到对应的物理地址。
- 步骤2.2:如果TLB未命中,MMU将查找页表。
3. 页表查找
- 步骤3.1:如果TLB未命中,MMU会查找页表。页表由操作系统维护,记录了虚拟地址到物理地址的映射关系。
- 步骤3.2:如果页表中存在对应的映射关系,MMU得到物理地址并返回给CPU。
4. 异常处理
- 步骤4:如果页表中没有对应的映射关系,MMU将触发一个页表异常(page fault)。此时操作系统介入处理。
页表异常处理
页表异常是指在页表中找不到对应的虚拟地址到物理地址的映射关系,操作系统需要进行异常处理。
5. 异常处理的步骤/读取到数据
- 步骤5.1:操作系统检查虚拟地址是否有效。如果虚拟地址有效,操作系统将为其分配物理内存,并更新页表。
- 步骤5.2:如果虚拟地址无效,操作系统将终止相应的进程。
- 步骤5.3:如果虚拟地址对应的页面在硬盘上,操作系统将从硬盘读取页面到内存中,更新页表,然后重新执行导致异常的指令。
地址转换与管理是操作系统、硬件和编译器之间复杂且紧密合作的结果。通过虚拟地址空间、页表和异常处理机制,操作系统能够提供一个安全、高效、统一的内存管理环境,确保应用程序的正确运行。理解这些机制有助于深入掌握操作系统的工作原理和内存管理技术。
3. 虚拟存储的作用
虚拟内存是操作系统中的一项关键技术,它通过将内存和外存结合在一起,提供了一个更大的地址空间,并提高了内存管理的效率。
虚拟内存的好处
虚拟内存带来了多个好处,包括扩展地址空间、简化编程和执行、提高安全性和共享数据的方便性。
扩展内存空间
- 扩展地址空间:通过将物理内存和外存结合,虚拟内存提供了一个更大的可用地址空间。
- 提高性能:常用数据保存在内存中,不常用数据保存在外存中,提高了内存使用效率和系统性能。
简化编程和执行
- 独立地址空间:每个应用程序拥有独立的地址空间,简化了编程过程,避免了地址冲突。
- 简化编译和链接过程:编译器可以为每个程序分配相同的逻辑地址,而操作系统负责将这些逻辑地址映射到不同的物理地址。
- 简化加载过程:程序在加载时基于虚拟地址进行,而不需要考虑具体的物理地址位置。
数据共享与内存分配
- 简化数据共享:通过虚拟内存,不同进程可以方便地共享数据,同时保持各自的独立性。
- 简化内存分配:虚拟内存管理简化了内存分配的过程,操作系统可以更灵活地分配和回收内存。
虚拟内存的安全性
虚拟内存提供了多种内存保护机制,确保程序的安全性和稳定性。
内存隔离与保护
- 内存隔离:虚拟内存为每个进程提供独立的地址空间,防止进程间的内存干扰。
- 访问权限控制:操作系统可以设置内存区域的访问权限,如代码段只可执行不可写、数据段可读可写不可执行等。
- 内核与用户空间的隔离:操作系统可以将内核空间与用户空间隔离,防止用户程序访问内核数据。
虚拟内存的实现
实现虚拟内存需要多种技术和硬件支持,包括页表、TLB、页面置换算法等。
页表与TLB
- 页表:存储虚拟地址到物理地址的映射关系。
- TLB:加速地址转换的缓存,通过快速查找虚拟地址到物理地址的映射,提高系统性能。
页面置换算法
- 页面置换:当内存不足时,操作系统需要将一些页面交换到外存中,以腾出内存空间。
- 置换算法:常用的页面置换算法包括FIFO(先进先出)、LRU(最近最少使用)等,用于决定哪些页面需要被交换出去。
虚拟内存的应用
虚拟内存在现代操作系统中广泛应用,为各种应用程序提供高效、灵活、安全的内存管理。
应用程序的独立性
- 独立地址空间:每个应用程序拥有独立的虚拟地址空间,简化了开发和调试过程。
- 动态内存分配:虚拟内存支持动态内存分配,允许程序在运行时分配和释放内存。
系统资源管理
- 资源隔离:虚拟内存实现了系统资源的隔离,防止进程间的资源争用和冲突。
- 高效利用内存:通过页面置换和内存管理算法,操作系统可以高效利用物理内存和外存资源。
虚拟内存是操作系统中的一项重要技术,通过扩展地址空间、简化编程和执行、提高安全性和共享数据的方便性,为应用程序提供了一个高效、灵活、安全的内存管理环境。理解虚拟内存的工作原理和实现技术,有助于深入掌握操作系统的核心概念和内存管理方法。
第五讲 物理内存管理
第二节 内存分配
1. 内存分配
内存分配是操作系统管理内存资源的重要环节,涉及多个技术和方法,以确保系统运行高效且稳定。
内存分配的基本概念
内存分配可以分为针对操作系统自身的分配和针对应用程序的分配。主要关注的是面向应用程序的内存分配。
静态内存分配
- 定义:静态内存分配在编译时完成,分配的内存大小和位置在程序运行期间不会改变。
- 特点:分配过程简单,效率高,适用于全局变量和静态变量。
动态内存分配
- 定义:动态内存分配在程序运行时进行,内存的分配和释放由程序员控制。
- 特点:灵活性高,适用于需要在运行时确定大小的数据结构,如堆(heap)。
连续内存分配与非连续内存分配
内存分配还可以根据分配方式的不同分为连续内存分配和非连续内存分配。
连续内存分配
- 定义:内存分配在连续的地址空间中进行。
- 特点:分配简单,内存地址连续,但容易产生内存碎片,且难以高效利用大块内存。
非连续内存分配
- 定义:内存分配在不连续的地址空间中进行,通过页表等机制管理。
- 特点:可以有效利用零散的内存块,减少内存碎片,但管理复杂度较高。
动态内存分配的技术
动态内存分配主要涉及栈(stack)和堆(heap)的管理。
栈的管理
- 特点:栈的内存分配和释放由编译器自动管理,适用于局部变量和函数调用。
- 优点:管理简单,效率高。
- 限制:栈的大小在程序启动时固定,不能动态调整。
堆的管理
- 特点:堆的内存分配和释放由程序员通过系统调用(如
malloc和free)管理。 - 优点:灵活性高,适用于需要动态调整大小的数据结构。
- 挑战:需要程序员手动管理内存,容易产生内存泄漏和碎片。
内存分配的优化策略
为了提高内存使用效率和系统性能,操作系统采用多种优化策略进行内存分配。
内存分配算法
- 首次适配(First Fit):从头开始查找第一个足够大的空闲块进行分配。
- 最佳适配(Best Fit):查找所有空闲块中最小的一个足够大的块进行分配。
- 最差适配(Worst Fit):查找所有空闲块中最大的一个块进行分配,以保留大块空闲内存。
分区分配
- 固定分区:将内存划分为若干固定大小的分区,每个分区只能分配给一个进程。
- 动态分区:根据进程需要动态分配内存块,可以使用首次适配、最佳适配等算法。
内存回收
- 垃圾回收(Garbage Collection):自动回收不再使用的内存,减少内存泄漏,常用于高级语言的运行时环境。
- 引用计数(Reference Counting):通过计数来管理内存,当引用计数为零时释放内存。
内存分配的安全性与隔离
操作系统通过多种机制确保内存分配的安全性和进程间的隔离。
内存保护机制
- 页表:记录虚拟地址到物理地址的映射关系,并包含访问权限信息。
- 访问权限控制:根据内存区域的类型(如代码段、数据段)设置不同的访问权限,防止非法访问。
进程隔离
- 独立地址空间:每个进程拥有独立的虚拟地址空间,防止进程间的内存干扰。
- 内核与用户空间隔离:内核空间与用户空间隔离,防止用户程序访问内核数据。
动态内存分配的类型
在操作系统中,动态内存分配是一项重要的功能,分为显式内存分配和隐式内存分配。不同的编程语言和环境对内存分配的管理方式有所不同。
显式内存分配
显式内存分配由程序员控制内存的申请和释放,常见的函数如malloc和free。
典型例子
- C语言:使用
malloc申请内存,使用free释放内存。 - 内存管理:程序员负责管理内存的生命周期,手动释放不再使用的内存。
优缺点
- 优点:高效,内存管理灵活,适用于性能要求高的应用。
- 缺点:容易产生内存泄漏和内存释放错误,需要程序员小心管理。
隐式内存分配
隐式内存分配由运行时环境自动管理内存的申请和释放,不需要程序员显式地释放内存。
典型例子
- Java、Python、Go:这些语言有垃圾回收机制(Garbage Collection),自动管理内存。
- Rust:Rust通过编译器在编译时确定内存的释放,不依赖运行时垃圾回收。
优缺点
- 优点:降低内存管理的复杂性,减少内存泄漏和释放错误的可能性。
- 缺点:垃圾回收可能带来性能开销,Rust的编译器管理内存增加了编程复杂性。
动态内存分配的实现
动态内存分配可以是连续的或非连续的,操作系统通过系统调用支持这些分配方式。
栈和堆的增长方向
- 栈:由高地址向低地址增长,自动管理,不需要程序员干预。
- 堆:由低地址向高地址增长,由程序员控制,通过系统调用进行管理。
系统调用
sbrk:一个简单的系统调用,用于调整数据段的大小,从而增加或减少堆空间。mmap:用于在堆空间中分配不连续的内存块,可以指定内存地址和大小。
内存分配函数的使用
动态内存分配函数如malloc和free是C语言中的标准函数,用于申请和释放内存。
malloc函数
- 功能:申请指定大小的内存块,并返回指向该内存块的指针。
- 使用方法:
void* ptr = malloc(size_t size); - 优点:简单易用,适用于大多数动态内存分配需求。
free函数
- 功能:释放由
malloc申请的内存块,防止内存泄漏。 - 使用方法:
free(void* ptr); - 注意事项:必须保证每个
malloc对应一个free,否则会导致内存泄漏或重复释放错误。
动态内存管理中的常见问题
动态内存管理需要仔细处理,否则容易出现内存泄漏、重复释放和内存碎片等问题。
内存泄漏
- 定义:程序在运行过程中未释放已分配的内存,导致内存使用量逐渐增加。
- 原因:未正确调用
free函数释放内存。
重复释放
- 定义:同一块内存被多次释放,可能导致程序崩溃。
- 原因:逻辑错误或内存管理不当。
内存碎片
- 定义:由于频繁的内存分配和释放,导致内存中出现许多小的未使用块,影响内存利用率。
- 解决方法:使用内存池或内存整理技术减少碎片。
动态内存分配在大规模程序中的应用
在大规模程序中,动态内存管理的复杂性和重要性显著增加,需要更多的策略和工具支持。
静态分析工具
- 功能:检查代码中的内存管理问题,如内存泄漏和未初始化内存使用。
- 工具:Valgrind、AddressSanitizer等。
自动化测试
- 功能:通过自动化测试检测动态内存分配和释放中的问题。
- 工具:单元测试框架(如JUnit、pytest)和内存测试工具。
动态内存分配是操作系统和编程语言中的重要功能,通过显式和隐式内存管理方法,为程序提供灵活高效的内存使用方式。理解和正确应用这些技术,有助于提高程序的性能和稳定性,特别是在大规模复杂应用中。
2. 连续内存分配
2.1 动态分区分配
连续内存分配
在操作系统中,连续内存分配是一种常见的内存管理方式,旨在为应用程序提供一块连续的内存区域。以下是对连续内存分配的详细总结和扩展:
连续内存分配的概念
连续内存分配指的是从一块连续的内存区域中为应用程序分配指定大小的内存。这种分配方式可以由操作系统内核管理,也可以由库(如C标准库)来管理。
分配过程
malloc与free:使用malloc函数为应用程序分配一块连续的内存,使用free函数释放这块内存。- 管理方式:可以由内核直接管理,或者通过库(如
glibc)进行管理,以提高效率。
内碎片与外碎片
内存碎片是内存管理中的一个重要问题,主要分为内碎片和外碎片。
内碎片
- 定义:当分配的内存块比实际需要的大时,未使用的部分就成为内碎片。
- 例子:如果申请了一块较大的内存区域,但只使用了其中的一小部分,未使用的部分就是内碎片。
外碎片
- 定义:内存中存在许多小的空闲块,但这些块由于不连续,无法满足较大内存块的分配需求。
- 例子:多次分配和释放内存后,内存中可能会出现许多小的空闲块,这些空闲块虽然总量上足够大,但由于不连续,无法分配给需要大块内存的程序。
提高内存分配效率
为了提高内存分配的效率,需要解决以下几个关键问题:
空闲块的组织
- 链表:使用链表将空闲块组织起来,方便快速查找和分配。
- 位图:使用位图表示内存块的使用情况,每个位代表一个固定大小的内存块,0表示空闲,1表示已使用。
空闲块的选择
- 首次适配(First Fit):从头开始查找第一个足够大的空闲块进行分配。
- 最佳适配(Best Fit):查找所有空闲块中最小的一个足够大的块进行分配。
- 最差适配(Worst Fit):查找所有空闲块中最大的一个块进行分配,以保留大块空闲内存。
内存块的分割
- 分割策略:当一个空闲块比实际需要的内存块大时,将其分割为两个部分,一部分分配给应用程序,另一部分作为新的空闲块。
- 碎片管理:尽量减少分割后产生的碎片,提高内存利用率。
内存块的合并
- 合并策略:当释放一个内存块时,如果其相邻的内存块也是空闲的,则将这些空闲块合并为一个更大的空闲块。
- 防止碎片:通过合并相邻的空闲块,减少内存碎片,提高内存分配效率。
内存分配算法与策略
为了实现高效的内存分配,需要设计合理的内存分配算法和策略。
内存分配算法
- 首次适配算法(First Fit):从链表头开始查找第一个足够大的空闲块。
- 最佳适配算法(Best Fit):遍历所有空闲块,查找最小的一个足够大的块。
- 最差适配算法(Worst Fit):遍历所有空闲块,查找最大的一个块。
内存分配策略
- 空闲块管理:使用链表或位图管理空闲块,方便快速查找和分配。
- 合并和分割:在分配和释放内存时,合理进行内存块的合并和分割,提高内存利用率。
- 动态调整:根据实际内存使用情况,动态调整内存分配策略,优化性能。
连续内存分配是操作系统内存管理中的一项重要技术,通过合理的分配和管理策略,可以提高内存利用率,减少内存碎片。理解和应用这些技术,有助于设计高效的内存管理方案,确保系统的稳定性和性能。
内存分配算法总结
内存分配算法在操作系统中起着至关重要的作用,它们决定了内存分配的效率和内存碎片的管理。常见的内存分配算法包括首次适配(First Fit)、最佳适配(Best Fit)和最差适配(Worst Fit)。这些算法各有优缺点,需要根据具体应用场景选择合适的算法。
首次适配(First Fit)
概念
- 定义:从链表头开始查找第一个足够大的空闲块进行分配。
- 过程:依次检查空闲块列表,找到第一个能满足分配请求的块,然后进行分割和分配。
优点
- 效率高:查找过程简单,速度快。
- 实现容易:算法逻辑简单,易于实现。
缺点
- 外碎片多:随着内存的分配和释放,空闲块会变得越来越小,导致外碎片问题严重。
- 内存利用率低:容易产生大量无法利用的小碎片。
最佳适配(Best Fit)
概念
- 定义:查找所有空闲块中最小的一个足够大的块进行分配。
- 过程:遍历所有空闲块,找到最接近需求大小的块,然后进行分割和分配。
优点
- 减少内碎片:通过选择最接近需求大小的块,减少了内存块内部的浪费。
缺点
- 查找耗时:需要遍历所有空闲块,查找过程较慢。
- 外碎片多:虽然减少了内碎片,但可能产生更多的小块空闲块,增加了外碎片。
最差适配(Worst Fit)
概念
- 定义:查找所有空闲块中最大的块进行分配。
- 过程:遍历所有空闲块,找到最大的块进行分割和分配。
优点
- 减少外碎片:通过优先使用大块内存,保留更多的中小块内存,减少了外碎片的产生。
缺点
- 大块内存用完快:大块内存优先被分配,可能导致大块内存很快被用完。
- 查找耗时:需要遍历所有空闲块,查找过程较慢。
内存释放(Free)操作
内存释放操作是内存管理的重要环节,需要考虑释放后的内存合并问题,以提高内存利用率。
内存合并
- 概念:当释放一个内存块时,如果其相邻的内存块也是空闲的,则将这些空闲块合并为一个更大的空闲块。
- 优点:通过合并相邻的空闲块,减少内存碎片,提高内存分配效率。
- 实现:检查释放块的上下相邻块,如果它们也是空闲块,则合并这些块。
内存分配中的碎片问题
内存分配中的碎片问题是影响内存利用率的重要因素,主要分为内碎片和外碎片。
内碎片
- 定义:当分配的内存块比实际需要的大时,未使用的部分就成为内碎片。
- 解决方法:通过最佳适配算法减少内碎片的产生。
外碎片
- 定义:内存中存在许多小的空闲块,但这些块由于不连续,无法满足较大内存块的分配需求。
- 解决方法:通过最差适配算法和内存合并技术减少外碎片。
内存分配策略的选择
内存分配策略的选择需要综合考虑系统性能、内存利用率和应用需求。
应用场景
- 首次适配:适用于查找效率要求高的场景。
- 最佳适配:适用于对内碎片敏感的场景。
- 最差适配:适用于希望减少外碎片的场景。
综合策略
- 混合使用:在实际应用中,可以根据具体情况混合使用多种内存分配算法,以达到最佳的内存管理效果。
2.2 伙伴系统(Buddy System)
内存分配策略:减少外碎片
为了减少外碎片并提高内存利用率,操作系统和编程语言采取了一些限制和策略。例如,Java通过对内存分配的大小进行限制,以减少外碎片的产生。
固定大小的内存分配
通过限制内存分配的大小,使其符合特定的大小(例如2的幂次方),可以有效减少外碎片。
固定大小块的好处
- 减少外碎片:通过统一的分配大小,消除了许多不连续的小块空闲内存,从而减少外碎片。
- 快速分配和释放:固定大小的块便于快速查找、分配和释放内存,提高了内存管理效率。
- 便于合并:固定大小的块在释放时更容易合并,进一步减少碎片。
内存分配示例
假设内存块的最小单位是4KB,内存分配按照4KB、8KB、16KB等大小进行分配。
内存分配过程
- 申请内存:当程序申请内存时,内存管理系统会根据申请大小选择合适的内存块。例如,申请大小为4KB,则分配一个4KB的内存块。
- 释放内存:当程序释放内存时,内存管理系统会将内存块标记为可用,并尝试合并相邻的空闲块。
分配算法:伙伴系统(Buddy System)
伙伴系统是一种常用的内存分配算法,通过将内存块划分为固定大小的块,实现快速分配和合并。
伙伴系统的结构
- 内存块的划分:将内存块划分为固定大小的块,例如4KB、8KB、16KB等。
- 块的组织:使用二叉树或链表结构组织这些块,每个块都可以进一步划分或合并。
分配和释放过程
- 分配内存:从最小的空闲块开始查找,直到找到合适大小的块。如果当前块太大,则将其拆分为两个伙伴块,继续查找。
- 释放内存:将内存块标记为空闲,并尝试合并相邻的伙伴块,直到无法合并为止。
内存分配的效率
固定大小块和伙伴系统通过限制内存分配的大小,提高了内存分配的效率。
快速查找
- 固定大小块:由于内存块大小固定,可以通过索引或二叉树快速查找合适的块。
- 伙伴系统:通过二叉树结构,可以快速找到合适的块,并进行分割或合并。
减少碎片
- 外碎片减少:固定大小块和伙伴系统有效减少了外碎片,提高了内存利用率。
- 内碎片:虽然固定大小块可能会产生内碎片,但整体效率较高,适用于大多数应用场景。
示例:伙伴系统
假设内存总大小为16KB,最小块大小为4KB。以下是内存分配和释放的示例:
初始状态
- 内存划分为16KB的一个大块。
分配过程
- 申请4KB内存:将16KB块分为两个8KB块,继续分割其中一个8KB块为两个4KB块,分配一个4KB块。
- 申请8KB内存:分配剩下的一个8KB块。
释放过程
- 释放4KB内存:将4KB块标记为空闲,尝试合并相邻的伙伴块。
- 释放8KB内存:将8KB块标记为空闲,继续尝试合并相邻的伙伴块。
通过固定大小块和伙伴系统等策略,内存分配算法可以有效减少外碎片,提高内存利用率和分配效率。这些技术在实际操作系统和编程语言中得到广泛应用,确保内存管理的高效性和稳定性。理解这些算法的工作原理和应用场景,有助于设计和实现高效的内存管理方案。
+连续内存分配中的伙伴系统
连续内存分配中的伙伴系统(Buddy System)是一种常用的内存分配算法,通过将内存块划分为固定大小的块,实现快速分配和合并,减少内存碎片。以下是对伙伴系统的详细总结和扩展:
伙伴系统的数据结构
伙伴系统利用数组和链表结构来组织空闲内存块,实现高效的内存分配和释放。
数据结构
- 二维数组或链表:用于组织空闲块,不同大小的块分别存储在不同的链表中。
- 空闲块列表:每个链表存储相同大小的空闲块,通过链表可以快速查找和分配。
伙伴系统的分配过程
伙伴系统按照从小到大的顺序查找最小的可用块,如果空闲块过大,则进行切分,将其分割成更小的块。
分配示例
- 初始化:假设初始内存大小为1MB。
- 分配请求:如果请求分配100KB(或128KB),系统将1MB块分为两个512KB块,再将512KB块分为两个256KB块,最终将256KB块分为两个128KB块,分配其中一个128KB块。
- 进一步分配:如果再请求分配240KB,系统将查找满足240KB的块,如果没有合适的块,则继续分割更大的块,直到找到合适的块。
内存释放与合并
释放内存块时,需要检查相邻的块是否也是空闲的,如果是,则将它们合并为更大的块。
合并示例
- 释放128KB块:释放时,检查相邻的128KB块是否也是空闲的,如果是,则将两个128KB块合并为一个256KB块。
- 进一步合并:如果再释放一个256KB块,则检查相邻的256KB块是否也是空闲的,如果是,则将它们合并为一个512KB块。
伙伴系统的优势
伙伴系统通过固定大小块和高效的分配与合并策略,减少了内存碎片,提高了内存利用率。
优势
- 减少外碎片:通过固定大小块,减少了不连续的小块空闲内存,从而减少外碎片。
- 快速分配和释放:利用链表和数组结构,可以快速查找、分配和释放内存块。
- 便于合并:固定大小块在释放时更容易合并,进一步减少碎片。
伙伴系统的缺点
尽管伙伴系统有许多优点,但也存在一些缺点,特别是内碎片问题。
缺点
- 内碎片:由于固定大小块的限制,分配的块可能比实际需要的大,导致内碎片。
- 合并复杂性:合并过程需要检查相邻块是否也是空闲的,增加了复杂性。
伙伴系统在操作系统中的应用
伙伴系统广泛应用于实际操作系统,如Linux和Windows,以实现高效的内存管理。
Linux内核中的伙伴系统
- 内存管理:Linux内核利用伙伴系统管理内存块,实现快速的内存分配和释放。
- 灵活性:Linux内核的伙伴系统支持多种内存块大小,满足不同应用的需求。
高效内存分配算法:Slab分配器
除了伙伴系统,另一个常用的高效内存分配算法是Slab分配器,特别适用于小块内存的分配。
Slab分配器
- 定义:Slab分配器是一种针对小块内存的高效分配算法,广泛应用于操作系统和应用程序中。
- 优点:减少内碎片,提高内存利用率,特别适用于频繁分配和释放的小块内存。
3. 非连续内存分配
3.1 非连续内存分配的概念
?
?
?
段式和页式内存管理
在操作系统中,内存管理的策略有多种,其中段式(Segmentation)和页式(Paging)内存管理是两种常见的方式。以下是对这两种内存管理方式的详细总结和扩展。
段式内存管理
段式内存管理是一种将内存划分为不同段的方式,每个段对应程序中的不同部分,如代码段、数据段等。
段式内存管理的基本概念
- 段:内存分为多个段,每个段包含一类数据,如代码段、数据段、堆栈段等。
- 段表:操作系统使用段表(Segment Table)来记录每个段的基址和长度信息。
段表结构
- 基址(Base Address):段的起始地址。
- 长度(Limit):段的长度。
- 访问控制信息:权限检查,用于判断访问是否合法。
段式内存管理的工作流程
- 地址转换:逻辑地址由段号和段内偏移组成。通过段号在段表中查找段的基址,再加上段内偏移得到物理地址。
- 权限检查:在访问内存时,硬件检查访问是否超出段的长度,并进行相应的权限检查。
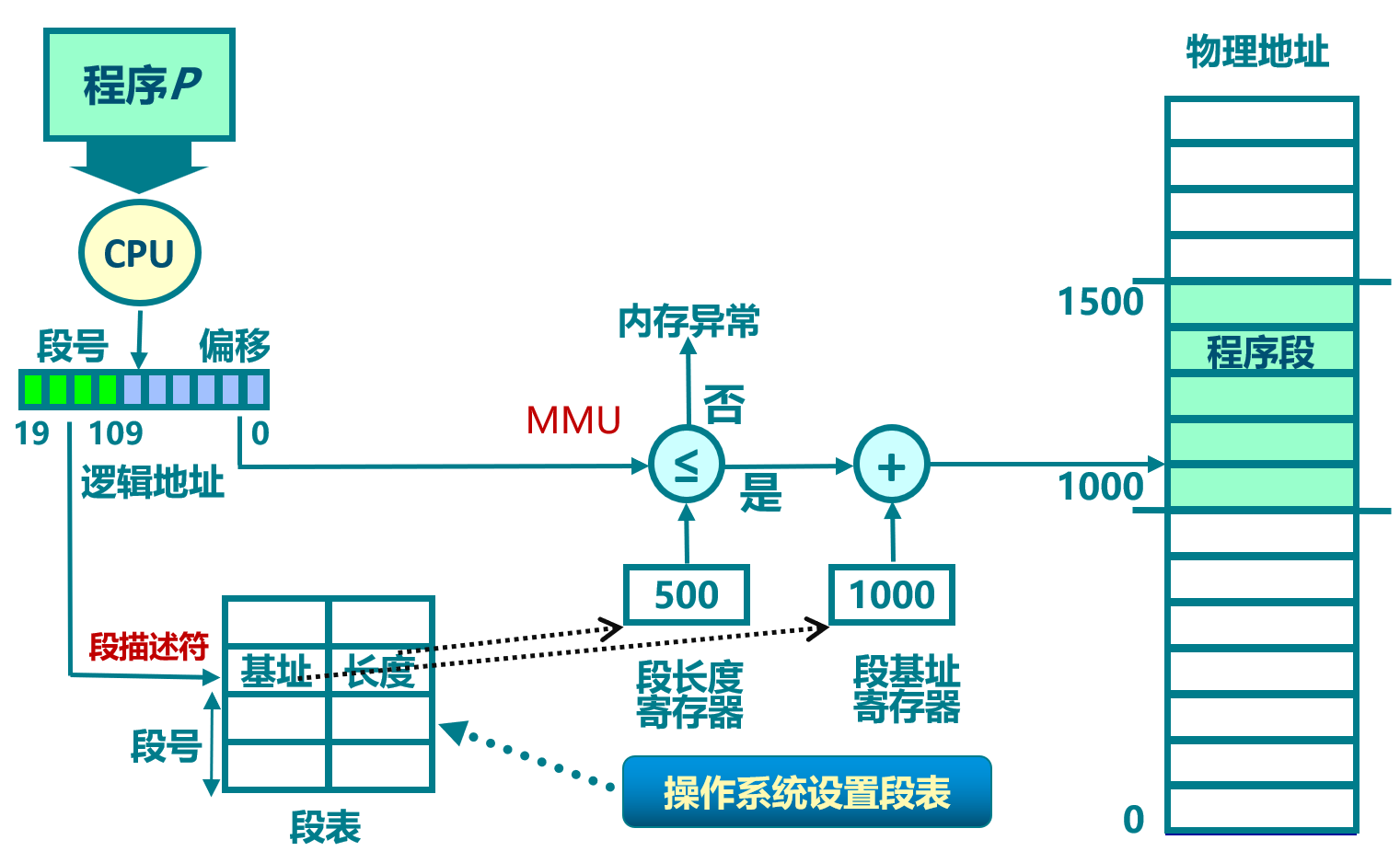
操作系统的职责
- 段表管理:操作系统负责创建和维护段表,并在任务切换时加载正确的段表。
- 内存分配:操作系统根据程序的需求分配段,并在段表中记录段的信息。
优缺点
- 优点:段式管理可以实现内存的逻辑分段,便于程序的模块化和保护。
- 缺点:可能会导致外部碎片问题,内存分配和管理复杂。
页式内存管理
页式内存管理是一种将内存划分为固定大小的页的方式,每个页独立管理。
页式内存管理的基本概念
- 页框(Page Frame):物理内存划分为固定大小的块,称为页框。
- 页(Page):虚拟内存也划分为相同大小的块,称为页。
- 页表(Page Table):操作系统使用页表记录每个虚拟页到物理页框的映射关系。
页表结构
- 页号(Page Number):虚拟地址的高位部分,作为页表的索引。
- 页内偏移(Page Offset):虚拟地址的低位部分,表示页内的具体地址。
页式内存管理的工作流程
- 地址转换:虚拟地址由页号和页内偏移组成。通过页号在页表中查找对应的页框号,再加上页内偏移得到物理地址。
- 权限检查:页表中包含访问权限信息,硬件在地址转换时进行权限检查。
操作系统的职责
- 页表管理:操作系统负责创建和维护页表,并在任务切换时加载正确的页表。
- 内存分配:操作系统根据程序的需求分配页,并在页表中记录页的映射关系。
优缺点
- 优点:页式管理可以有效解决外部碎片问题,内存分配灵活。
- 缺点:页表较大,可能导致页表管理的开销。
页表查找与内存管理单元(MMU)
页表查找
- 页表查找过程:通过页号在页表中查找对应的页框号,将虚拟地址转换为物理地址。
- 硬件支持:内存管理单元(MMU)负责实现页表查找和地址转换,操作系统提供页表内容。
快表(TLB)
- 快表:为了加速页表查找,使用转换后备缓冲(TLB)缓存最近的页表项。
- TLB命中:如果TLB中有对应的页表项,直接使用,减少查找时间。
- TLB未命中:如果TLB中没有对应的页表项,查找页表并更新TLB。
段页式内存管理
段页式内存管理结合了段式和页式管理的优点,将内存划分为段,每个段再划分为页。
段页式管理的结构
- 段表:记录每个段的基址和长度。
- 页表:每个段有一个页表,记录该段内每个页的映射关系。
段页式管理的优缺点
- 优点:结合了段式和页式管理的优点,实现内存的逻辑分段和灵活分配。
- 缺点:管理复杂度较高,页表和段表的维护开销大。
段式和页式内存管理是操作系统中两种重要的内存管理方式,各有优缺点。段页式管理结合了两者的优点,实现了更加灵活和高效的内存管理。理解这些内存管理方式的工作原理和应用场景,有助于深入掌握操作系统的内存管理机制。
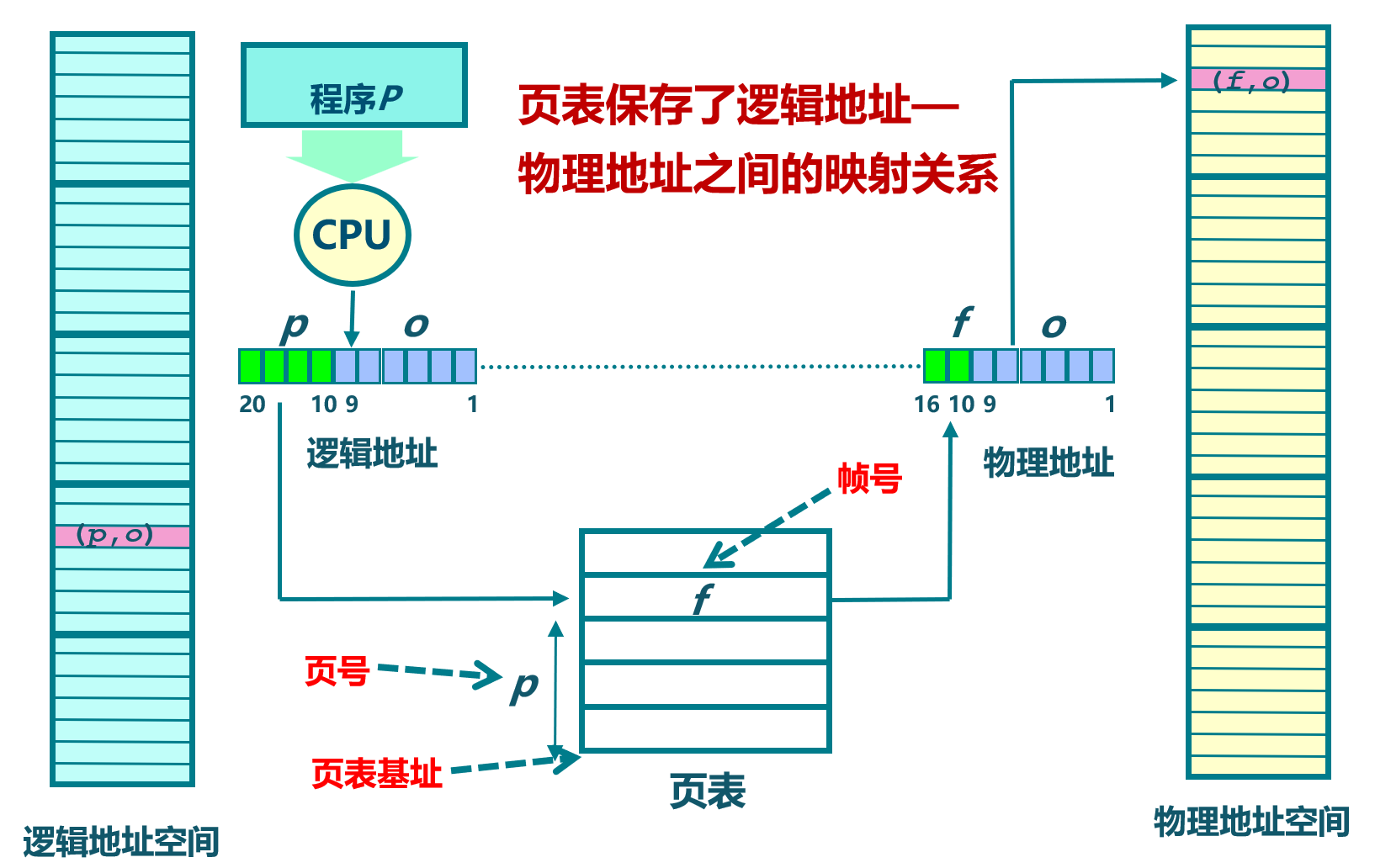
页表性能问题与解决方案
页表(Page Table)是操作系统中管理虚拟内存的重要数据结构,它的性能和容量对系统性能有直接影响。以下是对页表性能问题及其解决方案的详细总结和扩展。
页表性能问题
性能瓶颈
- 内存访问延迟:由于页表位于内存中,访问页表需要额外的内存读取操作,这会导致性能下降。
- 页表容量大:在64位机器上,如果每页大小为4KB,单级页表的容量会非常大,存储所有的页表项需要大量内存空间。
容量计算示例
- 64位地址空间:假设每页大小为4KB(2^12字节),页表项大小为8字节(64位)。
- 单级页表:需要2^52个页表项(2^64 / 2^12),即需要2^52 * 8字节 ≈ 36PB的内存来存储单级页表。
性能提升方法
多级页表
为了减少单级页表的巨大内存需求,多级页表通过分级存储页表项,有效地减少了内存开销。
- 多级页表结构:通过分级存储页表项,每一级页表指向下一层的页表,从而减少了不必要的页表项存储。
- 示例:
- 二级页表:使用两级页表,第一级页表指向第二级页表。
- 三级页表:进一步分级,第一级页表指向第二级页表,第二级页表指向第三级页表。
多级页表的优缺点
- 优点:通过按需创建页表,减少了不必要的内存消耗,支持更大的虚拟地址空间。
- 缺点:多级页表增加了地址转换的复杂度,每次地址转换需要多次内存访问,导致性能下降。
TLB(Translation Lookaside Buffer)
为了缓解多级页表带来的性能问题,使用TLB(转换后备缓冲)来缓存最近使用的页表项。
- TLB的作用:TLB是一个小型的、高速缓存,用于存储最近使用的页表项,减少频繁的内存访问。
- TLB命中和未命中:
- 命中:如果TLB中存在所需的页表项,则直接使用,无需访问内存。
- 未命中:如果TLB中不存在所需的页表项,则需要访问内存中的页表,更新TLB。
数据缓存(Cache)
除了TLB,数据缓存(Cache)用于缓存最近访问的数据,进一步提高内存访问的效率。
- 数据缓存的作用:缓存最近访问的数据,减少对内存的直接访问。
- 层级缓存:
- 一级缓存(L1 Cache):速度最快,容量最小。
- 二级缓存(L2 Cache):速度和容量介于一级缓存和内存之间。
- 三级缓存(L3 Cache):速度较慢,容量较大。
操作系统的职责
操作系统需要负责页表和TLB之间的数据一致性,以及多级页表的管理。
数据一致性
- 一致性维护:确保页表和TLB中的数据一致,如果页表更新,需要同步更新TLB。
- 页表更新:操作系统在页表更新时,必须使相关的TLB条目失效,确保数据一致性。
多级页表管理
- 页表初始化:操作系统在进程创建时初始化页表,并在任务切换时加载正确的页表。
- 页表分配和回收:根据进程的内存需求,动态分配和回收页表项,优化内存使用。
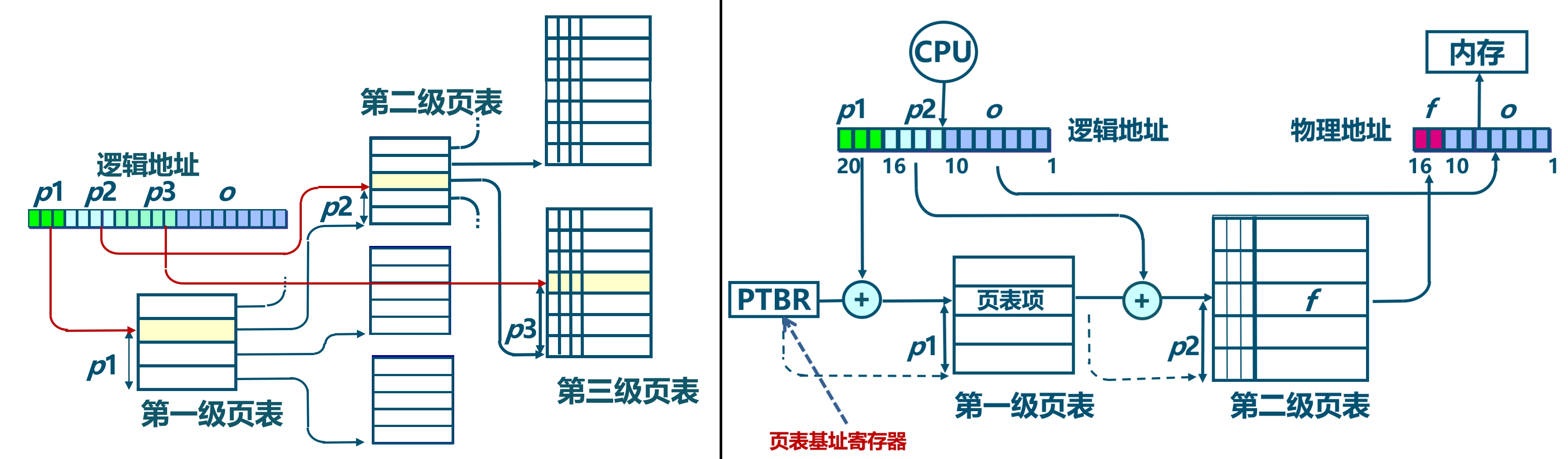
解决方案总结
为了提升页表的性能和减少内存开销,操作系统采用多级页表和TLB缓存等技术。
- 多级页表:通过分级存储页表项,减少了不必要的内存消耗,但增加了地址转换的复杂度。
- TLB缓存:通过缓存最近使用的页表项,减少了内存访问,提高了地址转换的速度。
- 数据缓存:通过层级缓存结构,进一步提升内存访问效率,减少了CPU对内存的直接访问。
页表性能问题是操作系统内存管理中的重要挑战,通过多级页表和TLB缓存等技术,可以有效提升页表性能和内存利用率。理解这些技术的工作原理和应用场景,有助于设计和实现高效的内存管理方案。
反置页表(Inverted Page Table)
反置页表是一种解决页表容量问题的少见方式,它通过反转查找顺序来减少页表的大小。以下是对反置页表的详细总结和扩展:
反置页表的基本概念
传统页表使用虚拟页号作为索引,查找物理地址。然而,反置页表则是使用物理页号作为索引,查找虚拟地址。
反置页表的工作原理
- 物理页号作为索引:反置页表将物理页号作为索引,查找虚拟页号及相关信息。
- 哈希机制:通过哈希机制将虚拟地址和进程ID映射到物理地址。
反置页表的查找过程
地址转换
- 虚拟地址和进程ID哈希:将虚拟地址和进程ID进行哈希计算,得到一个哈希值。
- 查找反置页表:使用哈希值作为索引,查找反置页表中的条目。
- 验证虚拟地址:如果找到的条目中的虚拟地址和进程ID与原始请求一致,则查找成功。
- 组合物理地址:将物理页号与页内偏移组合,得到物理地址。
反置页表的优势
反置页表相对于传统页表有一些明显的优势:
- 减少页表大小:反置页表的大小与物理内存大小相关,而不是虚拟地址空间的大小。
- 提高内存利用率:通过哈希机制和链表解决冲突,可以高效地管理内存。
反置页表的挑战
尽管反置页表有其优势,但也面临一些挑战:
- 哈希冲突:由于哈希函数的限制,不同的虚拟地址可能映射到相同的哈希值,需要处理冲突。
- 查找复杂性:反置页表查找涉及哈希计算和冲突处理,增加了查找的复杂性。
反置页表的查找与冲突处理
查找过程示例
- 初始查找:将虚拟地址和进程ID进行哈希计算,得到索引。
- 索引查找:使用哈希值作为索引,查找反置页表条目。
- 条目验证:检查条目中的虚拟地址和进程ID是否匹配,如果匹配,则查找成功。
- 物理地址生成:将物理页号与页内偏移组合,生成物理地址。
冲突处理
- 链表解决冲突:如果哈希冲突(多个虚拟地址映射到相同哈希值),使用链表存储冲突条目。
- 链表查找:在冲突链表中查找匹配的虚拟地址和进程ID,找到后生成物理地址。
实例:PowerPC中的反置页表
反置页表在一些特定的架构中得到了应用,例如IBM的PowerPC 64位处理器。
PowerPC中的实现
- 反置页表结构:PowerPC使用反置页表来管理虚拟到物理地址的映射。
- 性能优化:通过硬件支持和优化的哈希函数,提高查找和冲突处理的效率。
性能优化
为了提高反置页表的性能,通常会采用一些优化技术:
- 硬件哈希支持:利用硬件加速哈希计算,提高查找速度。
- 缓存机制:使用TLB(转换后备缓冲)缓存最近使用的页表项,减少内存访问。
- 优化哈希函数:选择高效的哈希函数,减少冲突,提高查找效率。
反置页表是一种通过反转页表查找顺序来减少页表大小的技术,具有减少页表容量、提高内存利用率的优点,但也面临哈希冲突和查找复杂性的挑战。理解反置页表的工作原理和应用场景,有助于掌握操作系统中不同内存管理策略的优缺点和实现方法。
段式和页式内存管理的总结
在操作系统中,段式(Segmentation)和页式(Paging)内存管理各有特点和应用场景。以下是对段式和页式内存管理的总结及其在实际操作系统中的应用。
段式内存管理
段式内存管理将内存划分为逻辑上的段,每个段表示程序中的不同部分,如代码段、数据段等。
特点
- 逻辑分段:内存根据程序逻辑分为多个段,如代码段、数据段、堆栈段等。
- 段表管理:段表记录每个段的基址和长度信息,用于地址转换和权限检查。
优点
- 模块化:段式管理便于程序的模块化和数据保护。
- 灵活性:不同段可以有不同的权限和属性。
缺点
- 外部碎片:内存分配容易产生外部碎片,影响内存利用率。
- 复杂性:段表的管理和维护较为复杂。
页式内存管理
页式内存管理将内存划分为固定大小的页,所有页大小相同,便于管理。
特点
- 固定大小页:内存和虚拟地址空间都划分为固定大小的页(Page)。
- 页表管理:页表记录虚拟页到物理页的映射关系,用于地址转换。
优点
- 减少外部碎片:固定大小的页减少了内存中的外部碎片。
- 简单管理:页表管理相对简单,适用于大多数操作系统。
缺点
- 页表大小:对于大地址空间,页表可能非常大,占用大量内存。
- 内存访问延迟:页表查找需要多次内存访问,增加了内存访问延迟。
段页式内存管理
段页式内存管理结合了段式和页式的优点,内存划分为段,每个段再划分为页。
特点
- 段页结合:内存先划分为段,每个段再划分为页,段表和页表共同管理内存。
- 灵活管理:既有段的逻辑分段优点,又有页的固定大小管理优势。
优点
- 灵活性:段页式管理结合了段式和页式的优点,提供更灵活的内存管理。
- 模块化和减少碎片:既能实现模块化管理,又能减少外部碎片。
缺点
- 复杂性:管理和维护段表和页表的复杂性较高。
例子:malloc函数的内存分配过程
以C语言中的malloc函数为例,解释内存分配过程。
内存分配过程
- 程序加载:操作系统将程序加载到内存中,分配堆区域用于动态内存分配。
- 调用malloc:程序调用
malloc函数请求分配内存。 - libc库处理:
malloc函数由C标准库(libc)实现,libc库管理堆内存的分配和释放。 - 堆内存管理:libc库在堆区域中查找空闲块,如果找到合适的块,则直接分配。
- 系统调用:如果堆中没有足够的空闲块,libc库通过系统调用(如
sbrk)请求操作系统分配新的内存区域。 - 内存分配完成:操作系统分配新的内存区域后,libc库将新的内存块合并到堆中,满足
malloc请求。
代码示例
#include <stdlib.h>
int main() {
// 调用malloc函数请求分配内存
int* ptr = (int*)malloc(10 * sizeof(int));
// 检查内存分配是否成功
if (ptr == NULL) {
// 内存分配失败,处理错误
return -1;
}
// 使用分配的内存
for (int i = 0; i < 10; i++) {
ptr[i] = i;
}
// 释放分配的内存
free(ptr);
return 0;
}
段式和页式内存管理各有优缺点,页式管理由于减少外部碎片和管理简单性,在现代操作系统中应用广泛。然而,段页式管理结合了两者的优点,提供了更加灵活和高效的内存管理方式。理解这些内存管理技术和实际应用,有助于深入掌握操作系统的内存管理机制和提高程序设计的效率和性能。