C 简介 - 基础知识
本节是 CS 61C L03 C Intro - Basics
首先探讨了如何利用硬件的底层特性,通过编程语言C来实现更接近硅片(silicon)的操作。C语言因其能够直接管理内存而受到推崇,尽管这在Java或Python中是不常见的。此外,本讲座也涉及了特殊的硬件指令,如并行化指令,以及C语言的流行度和其历史演变。
C语言的特性与风险
C语言的一个核心特性是它允许程序员直接与硬件对话,并进行细粒度的内存管理。这个特性使得C语言在编写高性能和系统级程序时非常强大。然而,这也带来了许多安全风险。C语言中的指针和数组可以导致程序错误,这些错误可能不会立即导致程序崩溃,而是让程序处于不一致或易被利用的状态。例如,缓冲区溢出和空指针引用是常见的安全问题,这些问题可能导致程序崩溃,甚至被恶意利用。
现代编程语言的选择
尽管C语言功能强大,但在启动新项目时,开发者可能会选择其他现代语言如Rust和Go。这些语言继承了C语言的许多特性,同时在一些方面进行了优化:
- Rust:Rust语言引入了所有权和借用机制,极大地提高了内存安全性,避免了C语言中常见的内存泄漏和数据竞争问题。Rust的编译器可以在编译时捕获很多错误,提供了更高的安全性。
- Go:Go语言则关注并行和并发编程,内置了简化多核处理和并行计算的工具。Go的垃圾收集机制自动管理内存,降低了手动内存管理的复杂性。
编译与解释
编译语言和解释语言之间存在显著差异。C语言是一种完全编译型语言,这意味着在运行程序之前,源代码必须被编译成机器码。相较之下,Python是一种解释型语言,源代码在运行时被逐行解释执行。Java则介于两者之间,先编译成字节码,再由虚拟机(JVM)解释或即时编译(JIT)执行。选择编译型语言的主要原因之一是为了性能优化,因为编译生成的机器码可以针对特定硬件进行优化,从而提供更高的执行效率。
编译过程的深入理解
编译过程通常分为三个主要步骤:编译(Compilation)、汇编(Assembly)和链接(Linking),简称CAL。这些步骤是生成可执行程序的关键过程:
- 编译:将源代码转换为汇编代码。
- 汇编:将汇编代码转换为机器码(目标文件)。
- 链接:将多个目标文件和库文件链接在一起,生成最终的可执行文件。
虽然使用GCC等编译工具时,这些步骤通常被隐藏在后台,但了解这些过程对于理解程序是如何构建的至关重要。理解这些步骤不仅能帮助调试和优化程序,还能提供更深层次的编程知识。
编译概述
- C 编译器将 C 程序直接映射到特定架构的机器码(1 和 0 的字符串)
- 与 Java 不同:Java 转换为与架构无关的字节码,然后可能通过即时编译器(JIT)编译。
- 与 Python 环境不同:Python 转换为在运行时解释的字节码。
- 主要区别:这些区别主要在于程序何时转换为低级机器指令(“解释层次”)。
- 对于 C,一般是一个两步过程:先将 .c 文件编译为 .o 文件,再将 .o 文件链接为可执行文件
- 汇编也会进行:但汇编是隐藏的,即自动完成的;稍后会详细讨论。
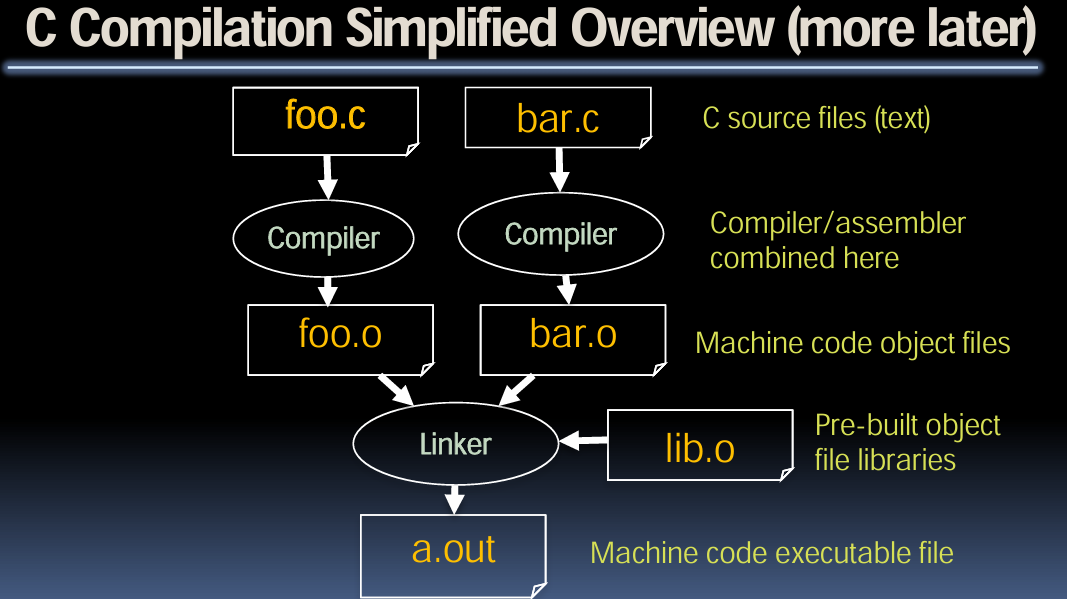
C 编译简化概述
- 源文件(foo.c 和 bar.c)
- 这些是用 C 编写的源代码文件(文本文件)。
- 编译器
- 编译器(以及汇编器)在此阶段一起工作,将源代码文件(.c)编译为目标文件(.o),即机器码目标文件。
- 目标文件(foo.o 和 bar.o)
- 编译后的目标文件,包含了特定架构的机器码。
- 链接器
- 链接器将多个目标文件(.o 文件)和预构建的目标文件库(如 lib.o)链接起来,生成最终的机器码可执行文件(a.out)。
进一步解释
- 汇编:虽然在这张图中未详细说明,但在编译过程中,汇编是一个必要的步骤。源代码首先会被编译器转换为汇编代码,然后汇编器将汇编代码转换为机器码。
- 链接器的作用:链接器的作用是将多个目标文件(可能是程序的不同模块)以及必要的库文件组合在一起,生成最终的可执行文件。这一步骤是必要的,因为程序通常分为多个模块,编译生成多个目标文件后,需要通过链接器将它们结合起来,形成一个完整的可执行程序。
文件协作与编译过程
在这段内容中,描述了一个团队协作的编程场景,其中两个程序员分别独立工作在不同的C文件上(例如food.c和bar.c)。每个程序员都有自己的编译器,最终产生机器代码文件(.o文件)。这种方法允许每个成员在不影响其他人的情况下独立工作,同时编译结果可以通过链接库等方式组合成一个完整的可执行文件(.out文件)。此外,讲述了使用GCC的-o标志来为输出文件命名的重要性,避免使用默认的a.out文件名,这被认为是新手的表现。
优化编译时间与Make文件的作用
这部分讲解了通过适当的文件管理和使用Make文件来优化编译过程的方法。Make文件可以识别不同文件间的依赖关系,当某个文件被修改时,只重新编译依赖该文件的部分,而不是整个项目。这样做不仅减少了等待编译的时间,也提高了开发效率。例如,如果只修改了food.c文件,而bar.c文件没有变动,那么在编译时只需重新编译food.c相关的部分。
运行性能与编程语言的选择
讨论了为何在需要高运行性能的场景下,编译语言通常比解释语言更有优势。编译语言如C可以直接编译成针对特定硬件优化的机器代码,从而提供更高的执行效率。同时,也提到了Python在数据科学和大规模数据处理(如使用Spark)中的应用优势,因为它可以方便地调用分布式计算资源,并且能够通过Cython等工具调用C语言编写的底层库,这样结合了Python的易用性和C的性能优势。
编译的优点
- 合理的编译时间:由于编译过程中的增强功能(如 Makefiles),只需重新编译修改过的文件。
- Makefiles:Makefiles 是一个自动化工具,可以根据文件的变化情况只重新编译那些发生改变的文件,而不是重新编译整个程序。这种方式不仅提高了编译效率,还节省了时间和计算资源。
- 出色的运行时性能:对于相同的代码,一般来说,C 的运行时性能比 Scheme 或 Java 更快,因为它针对给定的架构进行了优化。
- 优化优势:C 编译器在生成机器代码时,会针对具体的硬件架构进行优化,使得生成的代码能更高效地运行。这种优化是 Scheme 和 Java 这样的解释型或半编译型语言所无法比拟的。
- 库的性能:现代计算中,许多性能提升依赖于高效的库。虽然 Python 等动态语言在某些方面较慢,但它们通过调用高效的 C 库(例如 NumPy、SciPy)来弥补性能不足。
- 科学计算:许多科学计算使用 Python,是因为它有强大的库来处理 GPU 资源,以及简化并行计算和分布式计算的库(例如 TensorFlow 和 PyTorch)。
- 调用低级 C 代码:Python 可以通过 Cython 或直接调用 C 库来执行低级别的高效操作,从而提升性能。
编译的缺点
- 编译后的文件(包括可执行文件)是架构特定的:依赖于处理器类型(如 MIPS vs. x86 vs. RISC-V)和操作系统(如 Windows vs. Linux vs. MacOS)。
- 这意味着,编译生成的可执行文件只能在特定的硬件和操作系统上运行,如果更换了硬件或操作系统,就需要重新编译代码以适应新的环境。
- 可执行文件需要在每个新系统上重建:
- 移植代码:当需要在不同的硬件或操作系统上运行程序时,必须重新编译代码,这被称为“移植代码”。这可能需要对代码进行修改以适应新的编译器或系统库。
- “更改 → 编译 → 运行 [重复]”迭代周期在开发过程中可能很慢:
-
在开发过程中,每次代码的修改都需要重新编译和运行,这个过程可能会比较耗时,尤其是对于大型项目。
-
Make 工具:Make 工具可以通过只编译发生变化的部分来加快编译过程,并且可以通过
make -j选项并行编译多个文件。然而,链接器通常是顺序执行的,这意味着最终的链接过程仍然可能会比较慢。这受到阿姆达尔定律的限制,即在并行处理中的加速受限于必须串行执行的部分。阿姆达尔定律
阿姆达尔定律(Amdahl’s Law)是由计算机科学家吉恩·阿姆达尔(Gene Amdahl)提出的,它描述了并行计算中加速效果的极限。阿姆达尔定律指出,当我们试图通过增加处理器数量来提高程序性能时,程序中的串行部分将限制整体性能的提升。具体来说,假设程序的某部分可以并行化,而另一部分必须串行执行,那么即使无限增加并行处理器的数量,程序的加速比也是有限的。阿姆达尔定律的公式如下:
\[ \text{加速比} = \frac{1}{(1 - P) + \frac{P}{N}} \]
其中:
- ( P ) 是可以并行化的程序部分的比例,
- ( N ) 是并行处理器的数量。
这意味着,即使并行化的部分很大,如果串行部分的时间占比很小,整体加速效果仍然会受到限制。
-

C 预处理器(CPP)
- C 源文件首先通过宏处理器 CPP,然后编译器才会看到代码:
- CPP 的功能:CPP(C Pre-Processor)是一个文本替换工具,它会在编译之前处理源文件中的宏定义和其他预处理指令。
- 注释替换:CPP 会用一个空格替换掉代码中的注释,以确保注释不会影响编译过程。
- 预处理指令:CPP 命令以
#开头,这些命令包括文件包含(#include)、宏定义(#define)、条件编译(#if/#endif)等。#include "file.h":将 file.h 文件的内容插入到当前文件中。#include <stdio.h>:在标准位置查找并插入 stdio.h 文件。#define PI (3.14159):定义常量 PI,其值为 3.14159。#if/#endif:有条件地包含或排除代码段。
- 查看预处理结果:使用
--save-temps选项给 gcc 可以查看预处理的结果,这有助于调试和理解预处理过程。
CPP 宏:警告
- 你经常会看到 C 预处理器宏被定义为创建小“函数”:
- 但它们并不是真正的函数,而只是改变了程序的文本。
- 字符串替换:
#define指令只是进行简单的字符串替换,不进行任何类型检查或语法检查。例如:#define min(X,Y) ((X)<(Y)?(X):(Y)):定义一个宏 min,用来求两个值中的较小值。
- 这可能会产生有趣的错误,例如如果
foo(z)有副作用:- 如果宏中包含的表达式具有副作用,例如
foo(z)可能修改某些全局状态,那么使用宏可能会导致意想不到的行为。 - 例如:
next = min(w, foo(z));- 展开后可能会变成:
next = ((w)<(foo(z))?(w):(foo(z))); - 如果
foo(z)有副作用,那么它可能会被执行多次,导致错误的结果或不可预测的行为。
- 如果宏中包含的表达式具有副作用,例如
C语言与Java语言的比较
这部分内容对C语言和Java语言进行了比较。Java是一种面向对象的编程语言,强调封装和对象的管理,而C语言则是以函数为中心的,更注重具体函数的操作而不是对象。这两种语言在内存管理上有本质的差异:Java具有自动垃圾收集机制,可以自动管理内存,而C语言需要程序员显式地使用malloc和free等函数来管理内存。这种差异使得Java在编写代码时可能更为简便,但C语言在性能和底层操作上提供了更大的灵活性和控制力。
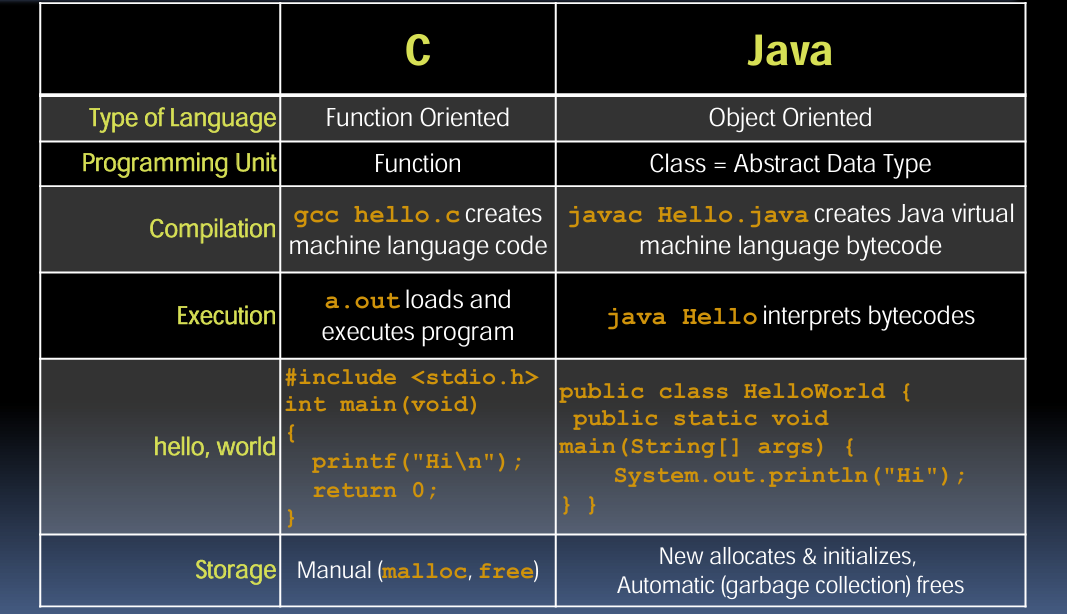
1. 语言类型与编程单元
| 特性 | C | Java |
|---|---|---|
| 语言类型 | 面向过程 | 面向对象 |
| 编程单元 | 函数 | 类(抽象数据类型) |
解释:C语言是面向过程的,程序结构基于函数。而Java是面向对象的,程序结构基于类和对象,强调封装和继承。
2. 编译与执行
| 特性 | C | Java |
|---|---|---|
| 编译 | gcc hello.c 生成机器语言代码 | javac Hello.java 生成Java虚拟机字节码 |
| 执行 | a.out 加载并执行程序 | java Hello 解释字节码 |
解释:C语言通过编译器生成特定机器的机器码,直接运行。而Java通过编译器生成字节码,由Java虚拟机(JVM)解释或即时编译执行,具有跨平台能力。
3. 示例代码
#include <stdio.h>
int main(void) {
printf("Hi\n");
return 0;
}
public class HelloWorld {
public static void main(String[] args) {
System.out.println("Hi");
}
}
解释:C程序通过printf函数输出文本,Java程序通过System.out.println方法输出文本。
4. 存储管理
| 特性 | C | Java |
|---|---|---|
| 存储管理 | 手动 (malloc, free) | 自动 (new 分配并初始化,垃圾回收释放) |
解释:C语言的内存管理需要程序员手动管理,可能导致内存泄漏或非法内存访问。Java通过自动垃圾回收机制,减轻了程序员的负担。
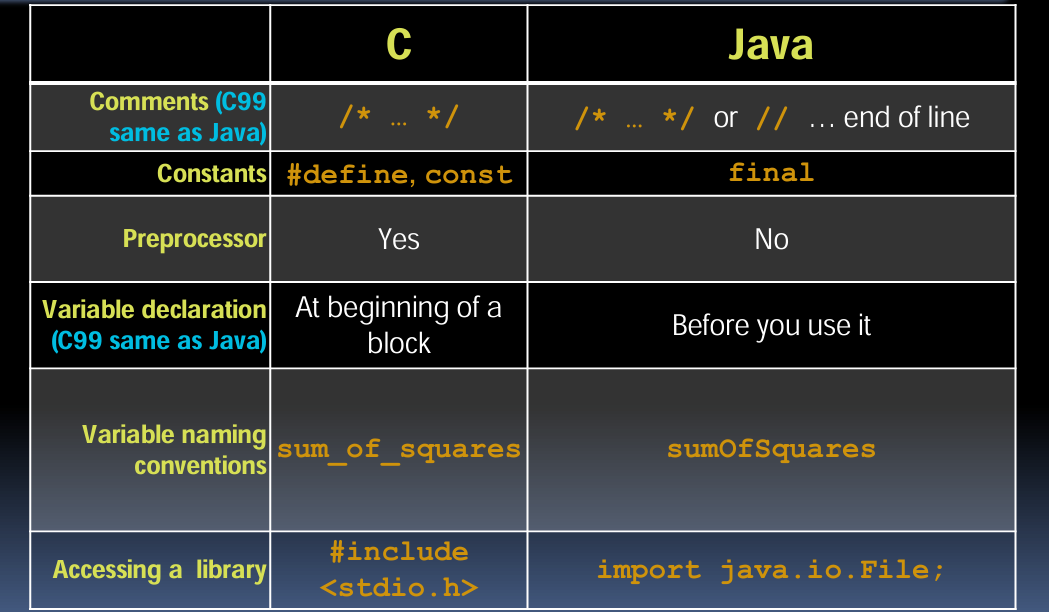
5. 注释与常量
| 特性 | C | Java |
|---|---|---|
| 注释 | /* ... */ | /* ... */ 或 // ... 行尾注释 |
| 常量 | #define, const | final |
解释:两种语言在注释方式上相似,但Java增加了单行注释。C语言使用#define和const定义常量,而Java使用final关键字。
6. 预处理器与变量声明
| 特性 | C | Java |
|---|---|---|
| 预处理器 | 有 | 无 |
| 变量声明 | 块的开始 | 使用前声明 |
解释:C语言有预处理器,用于宏定义、文件包含等。Java没有预处理器,所有代码直接由编译器处理。C语言要求变量在块的开头声明,而Java允许在任何地方声明变量,只要在使用前声明即可。
7. 变量命名约定与库访问
| 特性 | C | Java |
|---|---|---|
| 变量命名约定 | sum_of_squares | sumOfSquares |
| 访问库 | #include <stdio.h> | import java.io.File; |
解释:C语言通常使用下划线分隔单词,而Java使用驼峰命名法。C语言通过#include包含头文件,而Java通过import导入包和类。
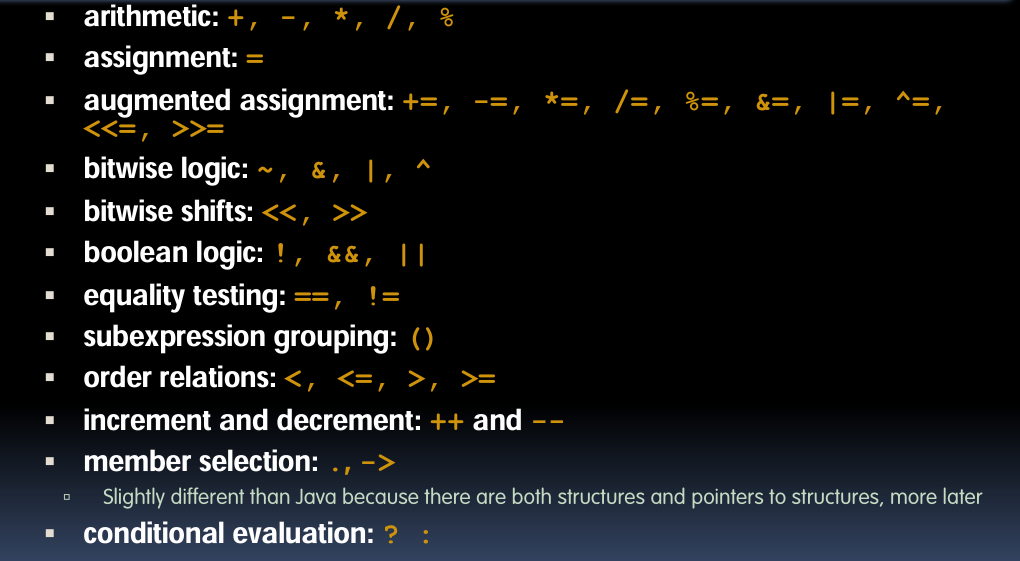
8. 操作符几乎相同
| 操作符类型 | 操作符 |
|---|---|
| 算术运算符 | +, -, *, /, % |
| 赋值运算符 | = |
| 复合赋值运算符 | +=, -=, *=, /=, %=, &=, |=, ^=, <<=, >>= |
| 位逻辑运算符 | ~, &, |, ^ |
| 位移运算符 | <<, >> |
| 布尔逻辑运算符 | !, &&, || |
| 相等性测试运算符 | ==, != |
| 子表达式分组 | () |
| 顺序关系运算符 | <, <=, >, >= |
| 增量和减量运算符 | ++ 和 -- |
| 成员选择 | . 和 -> |
| 条件评估 | ? : |
解释:C和Java的操作符基本一致,确保了两者在数学计算、逻辑判断等方面的兼容性。C语言在结构体和指针成员选择上有所不同,但整体操作符保持相似。
通过以上比较和解释,可以清晰地了解C和Java语言在编程单元、编译与执行、代码示例、存储管理、注释与常量、预处理器与变量声明、变量命名约定与库访问以及操作符方面的异同点。这些信息有助于理解两种语言的特点,尤其是从一个语言过渡到另一个语言时。
ANSI C的更新
C语言虽然是一种较老的编程语言,但通过不断的更新和改进,它仍然保持着与现代编程需求相符合的能力。与Java的比较显示了两种语言各有优势,但都在不断进化中寻求改善和优化。
1. C99 标准
- 使用方式
- 为了确保使用C99标准进行编译,可以使用以下命令:
gcc -std=c99 - 检查C标准版本,可以使用以下代码:
printf("%ld\n", __STDC_VERSION__);输出
199901表示C99标准。
- 为了确保使用C99标准进行编译,可以使用以下命令:
- 参考资料
- 可以在 维基百科C99 上找到更多关于C99标准的信息。
- C99 标准的亮点
- for 循环中的声明:C99允许在for循环中声明变量,这与Java类似,增加了代码的可读性和简洁性。例如:
for (int i = 0; i < 10; i++) { // 代码 } - Java样式的注释:支持
//注释直到行尾,提供了更方便的注释方式。 - 可变长度非全局数组:C99引入了可变长度数组(VLA),允许在局部范围内声明长度可变的数组。
- **
**:引入了显式整数类型,例如 `int32_t`, `uint64_t`,这使得代码在不同平台上更具可移植性。 - **
**:增加了对布尔类型的支持,定义了 `bool` 类型和 `true`,`false` 值,使得代码更具可读性。
- for 循环中的声明:C99允许在for循环中声明变量,这与Java类似,增加了代码的可读性和简洁性。例如:
2. C11 标准
- 使用方式
- 使用C11标准进行编译,可以使用以下命令:
gcc -std=c11 - 检查C标准版本,可以使用以下代码:
printf("%ld\n", __STDC_VERSION__);输出
201112L表示C11标准,201710L表示C18标准(修复了一些C11的问题)。
- 使用C11标准进行编译,可以使用以下命令:
- 参考资料
- 可以在 维基百科C11 上找到更多关于C11标准的信息。
- C11 标准的亮点
- 多线程支持:C11标准引入了多线程支持,增加了线程操作的标准库函数,例如
thrd_create、mtx_lock等。 - Unicode 字符串和常量:C11支持Unicode字符串和常量,增强了对国际化的支持。
- 移除
gets()函数:由于gets()函数存在严重的安全问题,C11标准中移除了这个函数,推荐使用更安全的fgets()函数。 - 类型泛型宏:C11引入了类型泛型宏,根据类型进行分派的宏,例如:
#define max(a, b) _Generic((a), \ int: max_int, \ float: max_float)(a, b) - 复数支持:C11增加了对复数类型的支持,可以直接进行复数运算。
- 静态断言:引入静态断言功能,可以在编译时进行条件检查,提高代码的可靠性。
- 独占创建和打开:支持独占的文件创建和打开操作,增强了文件操作的安全性和原子性。
- 多线程支持:C11标准引入了多线程支持,增加了线程操作的标准库函数,例如
C 语法
C 语法:main 函数
- 接受参数的
main函数- 要使
main函数能够接受命令行参数,可以使用以下定义方式:int main(int argc, char *argv[])
- 要使
- 参数解释
- argc:
argc表示命令行参数的数量,包括程序本身的名称。例如,对于命令unix% sort myFile,argc的值为2。 - argv:
argv是一个指向字符串数组的指针,每个元素都是一个命令行参数。程序名称通常是argv[0],后续的参数依次存储在argv[1],argv[2]等位置。以下示例演示了如何处理命令行参数:int main(int argc, char *argv[]) { for (int i = 0; i < argc; i++) { printf("Argument %d: %s\n", i, argv[i]); } return 0; }
- argc:
通过这些内容和扩展讲解,可以深入理解C语言ANSI标准的更新,以及如何使用C99和C11标准的新特性。这些新特性不仅提高了C语言的安全性和效率,还增强了其在多线程和国际化等方面的能力。同时,了解 main 函数的参数传递方式,可以帮助处理命令行参数,增强程序的灵活性和功能性。
C 语法:True 或 False?
- 什么在 C 中被评估为 FALSE?
- 整数0:在C语言中,整数0被认为是false。
- NULL:空指针NULL被认为是false。稍后会详细讨论指针。
- C99 的布尔类型:通过引入
<stdbool.h>提供了布尔类型,定义了true和false值,使代码更加清晰和直观。
- 什么在 C 中被评估为 TRUE?
- 所有其他值:除了0和NULL之外的所有值都被认为是true。这与Scheme语言类似,在Scheme中,只有
#f被认为是false,其余一切都被认为是true。
- 所有其他值:除了0和NULL之外的所有值都被认为是true。这与Scheme语言类似,在Scheme中,只有
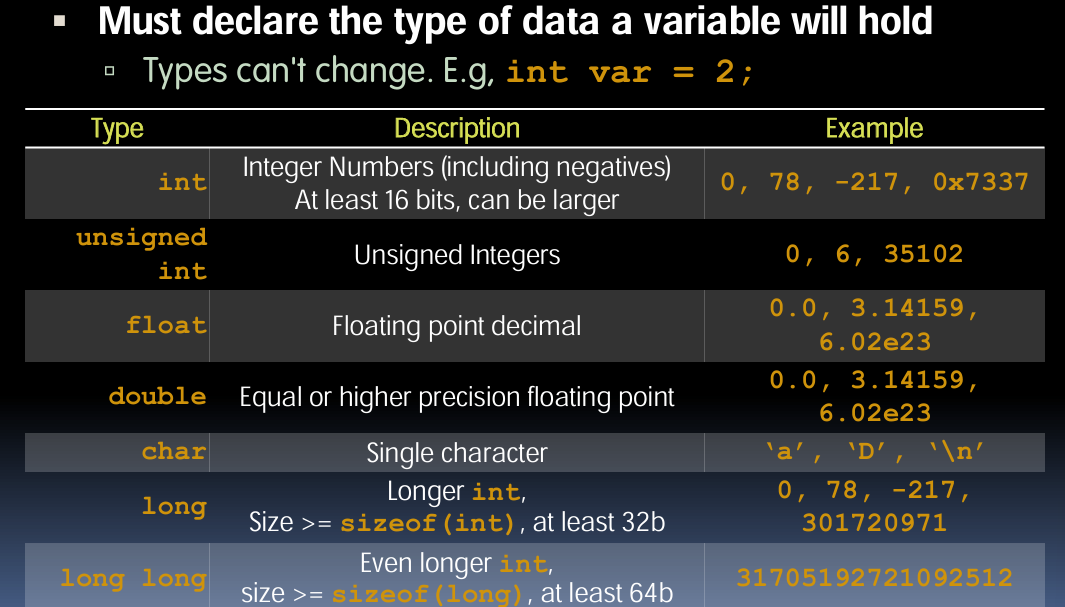
C 中的类型变量
- 声明变量类型
- 在C语言中,必须声明变量将要持有的数据类型。一旦声明,类型就不能更改。例如:
int var = 2;
- 在C语言中,必须声明变量将要持有的数据类型。一旦声明,类型就不能更改。例如:
- 类型和示例
| 类型 | 描述 | 示例 |
|---|---|---|
| int | 整数,包括负数 | 0, 78, -217, 0x7337 |
| unsigned int | 无符号整数 | 0, 6, 35102 |
| float | 浮点小数 | 0.0, 3.14159, 6.02e23 |
| double | 等于或高于 float 精度的浮点数 | 0.0, 3.14159, 6.02e23 |
| char | 单个字符 | ‘a’, ‘D’, ‘\n’ |
| long | 较长的整数,至少32位 | 0, 78, -217, 301720971 |
| long long | 更长的整数,至少64位 | 31705192721092512 |
整数:Python vs. Java vs. C
- C 语言中的 int
- 在C语言中,
int类型应该是目标处理器最有效处理的整数类型。
- 在C语言中,
- 唯一保证
- 大小比较:
sizeof(long long) >= sizeof(long) >= sizeof(int) >= sizeof(short) - short 至少16位,long 至少32位,但所有这些类型可能在不同平台上都是64位。
- 大小比较:
- 标准库建议
- 为了便于跨平台开发,推荐使用标准库提供的定长整数类型,如
int32_t,uint64_t等。这些类型在<stdint.h>中定义,确保了在不同平台上的一致性。
- 为了便于跨平台开发,推荐使用标准库提供的定长整数类型,如
- 不同语言的 int 类型大小
| 语言 | sizeof(int) |
|---|---|
| Python | >=32 位(普通 int),无限制(长 int) |
| Java | 32 位 |
| C | 依赖于具体计算机,可以是16、32或64位 |
- Python:在Python中,
int类型没有固定大小,普通的int至少32位,而长int大小是无限制的,取决于可用内存。 - Java:在Java中,
int类型固定为32位,这确保了代码在不同平台上的一致性。 - C:在C语言中,
int类型的大小依赖于具体平台,通常是16、32或64位。为了避免平台相关问题,使用定长整数类型(如int32_t)是一个好习惯。
C语言中的常量和枚举
- 常量(Consts)
- 常量在声明时被赋予类型和值,并且在整个程序执行过程中不会改变。例如:
const float golden_ratio = 1.618; const int days_in_week = 7; const double the_law = 2.99792458e8; - 你可以为任何标准C变量类型创建常量版本,例如
const int,const float等。
- 常量在声明时被赋予类型和值,并且在整个程序执行过程中不会改变。例如:
- 枚举(Enums)
- 枚举是一组相关的整数常量,用于表示一组命名的整数。例如:
enum cardsuit {CLUBS, DIAMONDS, HEARTS, SPADES}; enum color {RED, GREEN, BLUE}; - 枚举的好处在于增加了代码的可读性和可维护性,因为使用枚举比使用直接的整数更具意义。
- 枚举是一组相关的整数常量,用于表示一组命名的整数。例如:
C语言中的类型化函数
- 函数的返回类型
- 必须声明函数返回的数据类型,返回类型可以是任何C变量类型,并且放在函数名的左侧。例如:
int number_of_people() { return 3; } float dollars_and_cents() { return 10.33; } - 如果函数不返回任何值,可以使用
void作为返回类型。例如:void print_message() { printf("Hello, World!\n"); }
- 必须声明函数返回的数据类型,返回类型可以是任何C变量类型,并且放在函数名的左侧。例如:
- 传入函数的参数类型
- 传入函数的参数也需要声明类型。例如:
int add(int a, int b) { return a + b; } - 在C语言中,变量和函数必须在使用之前声明。
- 传入函数的参数也需要声明类型。例如:
C语言中的结构体(Structs)
- Typedef
typedef允许你定义新的类型名称,增加代码的可读性。例如:typedef uint8_t BYTE; BYTE b1, b2;
- 结构体
- 结构体是一组结构化的变量组,用于表示复杂的数据类型。例如:
typedef struct { int length_in_seconds; int year_recorded; } SONG; - 结构体变量可以使用点符号进行访问和赋值。例如:
SONG song1; song1.length_in_seconds = 213; song1.year_recorded = 1994; SONG song2; song2.length_in_seconds = 248; song2.year_recorded = 1988;
- 结构体是一组结构化的变量组,用于表示复杂的数据类型。例如:
常量和枚举
常量:常量是不可改变的变量,在声明时初始化。常量的使用可以提高代码的安全性和可维护性,避免在程序中意外修改重要值。例如,
const int days_in_week = 7;定义了一周的天数为7,这个值在程序中不会改变。枚举:枚举为一组相关的常量提供了一个有意义的名字集合。例如,
enum color {RED, GREEN, BLUE};定义了颜色枚举,使得代码中使用颜色常量更具可读性。枚举值默认从0开始递增,但也可以手动赋值。类型化函数
函数返回类型:C语言函数必须明确返回类型,这有助于编译器进行类型检查和内存管理。例如,
int number_of_people() { return 3; }声明了一个返回整数的函数。参数类型:函数参数的类型必须在函数声明时指定。这确保了传递给函数的数据类型正确,避免了类型错误。例如,
int add(int a, int b) { return a + b; }声明了两个整数参数的相加函数。结构体
Typedef:
typedef允许你为现有类型定义新的名称,增加代码的可读性。例如,typedef uint8_t BYTE;定义了一个新类型BYTE,它是uint8_t的别名。结构体:结构体是一种用户定义的复合数据类型,包含多个不同类型的变量。使用结构体可以更好地组织和管理相关的数据。例如,定义一个歌曲结构体
SONG,包含长度和录制年份两个属性。使用点符号可以方便地访问和操作结构体的成员变量。
C语言提供了强大的语法和结构来支持高级编程需求,如数据抽象、类型安全和模块化设计。通过枚举、常量定义、函数类型声明和结构体等特性,C语言允许开发者编写清晰、可维护和效率高的低级代码。虽然这些特性增加了语言的复杂性,但也提供了更大的控制力和灵活性,使得C语言成为系统编程和性能敏感型应用的首选语言。
C 语法:控制流 (1/2)
- 控制流与 Java 的相似性
- 在函数内,C 语言的控制流结构与 Java 非常相似。这显示了 Java 从 C 语言继承的语法结构。
- 语句可以是由大括号
{}包围的一组代码块,或者只是一个独立的语句。
- if-else 结构
- 基本形式:
if (expression) statement - 示例:
if (x == 0) y++; if (x == 0) {y++;} if (x == 0) {y++; j = j + y;} - 复杂形式:
if (expression) statement1 else statement2 - 注意:在一系列的 if/else if/else 语句中,如果不使用
{}包围代码块,可能会导致歧义。因此,最好养成将语句放在{}中的习惯,以避免意外错误。
- 基本形式:
- while 循环
- 基本形式:
while (expression) statement do statement while (expression); - 示例:
while (x > 0) { // code } do { // code } while (x > 0);
- 基本形式:
C 语法:控制流 (2/2)
- for 循环
- 基本形式:
for (initialize; check; update) statement - 示例:
for (int i = 0; i < 10; i++) { // code }
- 基本形式:
- switch 语句
- 基本形式:
switch (expression) { case const1: statements case const2: statements default: statements } break; - 注意:在 switch 语句中,除非遇到
break语句,否则执行会继续下一个 case 分支。
- 基本形式:
- goto 语句
- 虽然 C 语言中有
goto语句,但强烈不推荐使用,因为它会导致代码的可读性和可维护性极差。 - 示例:
goto label; // code label: // code
- 虽然 C 语言中有
第一个大点的程序:计算正弦表
计算正弦函数值的表格,并输出角度和对应的正弦值。
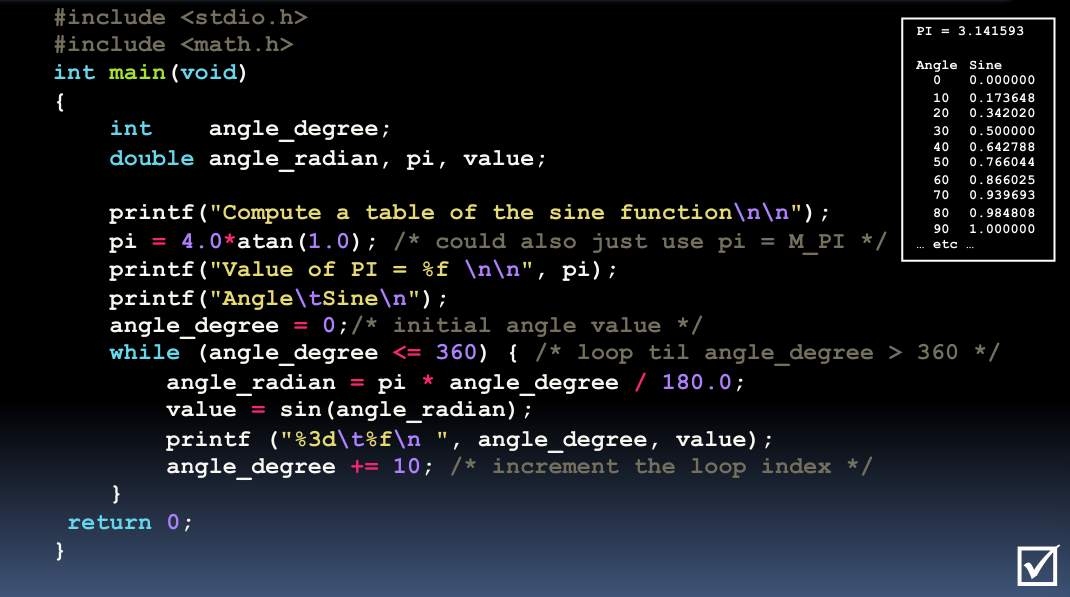
这段C程序的主要功能是计算并打印从0度到360度的正弦值(Sine values)。代码分析如下:
#include <stdio.h>
#include <math.h>
int main(void)
{
int angle_degree; // 定义角度变量(以度为单位)
double angle_radian, pi, value; // 定义弧度变量、π值和正弦值变量
printf("Compute a table of the sine function\n\n"); // 打印程序功能描述
pi = 4.0 * atan(1.0); // 计算π的值,atan(1.0)返回π/4
printf("Value of PI = %f\n\n", pi); // 显示计算得到的π值
printf("Angle\tSine\n"); // 打印表头
angle_degree = 0; // 初始化角度为0
while (angle_degree <= 360) { // 循环从0度到360度
angle_radian = pi * angle_degree / 180.0; // 将角度转换为弧度
value = sin(angle_radian); // 计算当前弧度的正弦值
printf("%3d\t%f\n", angle_degree, value); // 打印当前角度和对应的正弦值
angle_degree += 10; // 角度增加10度,准备下一次循环
}
return 0; // 程序结束
}
程序解释:
- 头文件包含:
<stdio.h>:用于输入输出函数如printf。<math.h>:包含数学函数如sin和atan。
- 变量声明:
angle_degree:整型变量,用于存储角度,以度为单位。angle_radian:浮点型变量,存储将角度转换为弧度后的值。pi:浮点型变量,存储π的值。value:浮点型变量,存储计算出的正弦值。
-
计算π值:使用
4.0 * atan(1.0)计算π的值。因为atan(1.0)返回的是π/4,所以乘以4得到π。 -
输出表头:打印”Angle”和”Sine”,准备输出正弦值表。
- 循环计算正弦值:
- 使用
while循环从0度循环到360度。 - 在每次循环中,首先将角度从度转换为弧度(角度*π/180)。
- 使用
sin函数计算出弧度的正弦值。 - 使用
printf打印当前的角度和对应的正弦值。 - 角度每次增加10度。
- 使用
C 语法:变量声明
- 变量声明的基本规则
- 类似于Java,但有一些重要的不同之处:
- 所有变量声明必须在使用之前出现。
- 所有变量声明必须位于块的开头。
- 变量可以在声明时初始化;如果没有初始化,它们会包含垃圾值,即未定义的内容。这意味着未初始化的变量会持有内存中的随机数据,可能导致不可预测的行为。
- 类似于Java,但有一些重要的不同之处:
- 变量声明的示例
- 正确的声明:
{ int a = 0, b = 10; // 其他代码 } - 在ANSI C中不正确的声明:
for (int i = 0; i < 10; i++) { // 代码 } - 在C99及更高版本中正确的声明:
for (int i = 0; i < 10; i++) { // 代码 } - 解释:在C99之前,变量声明必须在块的开头,而不能在for循环的初始化部分中。C99及更高版本允许在for循环的初始化部分中声明变量,使得代码更加简洁和现代化。
- 正确的声明:
重要提示:未定义行为
- 未定义行为的含义
- C语言中存在很多“未定义行为”:
- 这意味着行为通常是不可预测的。
- 它可能在一台计算机上以一种方式运行…
- 在另一台计算机上以另一种方式运行…
- 甚至每次执行程序时表现不同!
- 这意味着行为通常是不可预测的。
- C语言中存在很多“未定义行为”:
- 海森堡错误(Heisenbugs)
- 这些错误看起来是随机的/难以重现的,并且在调试时似乎会消失或改变。
- 相对于可以重复的“波尔虫(Bohrbugs)”:
- Heisenbugs 是指那些在调试过程中表现出不同行为的错误,而 Bohrbugs 则是那些始终表现一致的可重复错误。
- 解释:未定义行为会导致程序在不同环境下表现不一致,调试这些问题通常非常困难,因为它们没有固定的触发条件。
总结
- 选择 C 语言以利用硬件底层特性
- 解释:C语言允许程序员直接与硬件交互,通过指针和低级内存管理实现高效的性能。这使得C语言在系统编程、嵌入式系统和高性能计算领域非常流行。
- 关键的 C 概念
- 指针:指针是C语言中的一种变量类型,它存储了另一个变量的内存地址。指针使得函数可以直接操作内存,提高了程序的灵活性和效率。
- 示例:
int x = 10; int *p = &x; // p是一个指针,存储x的地址
- 示例:
- 数组:数组是C语言中另一种重要的结构,它允许存储一组相同类型的变量。数组和指针关系密切,数组名实际上是一个指向数组第一个元素的指针。
- 示例:
int arr[5] = {1, 2, 3, 4, 5}; int *p = arr; // p指向数组的第一个元素
- 示例:
- 内存管理:C语言提供了手动管理内存的能力,通过
malloc和free函数分配和释放内存。这使得程序员可以精确控制内存使用,但也增加了内存泄漏和指针错误的风险。
- 指针:指针是C语言中的一种变量类型,它存储了另一个变量的内存地址。指针使得函数可以直接操作内存,提高了程序的灵活性和效率。
- C 语言的编译和链接
- 优点(速度):编译后的C程序直接运行在机器上,无需解释,执行速度快。
- 缺点(编辑-编译周期缓慢):每次修改代码后都需要重新编译,这会增加开发时间,特别是在大型项目中。
- C语言看起来大部分像Java,但有以下不同
- 没有面向对象编程(OOP):C语言不支持面向对象编程,数据抽象类型(ADT)通过结构体定义。
- 示例:
typedef struct { int length; int width; } Rectangle;
- 示例:
- 布尔值:在C语言中,0(和NULL)被视为FALSE,其他所有值被视为TRUE。C99标准引入了
<stdbool.h>提供了bool类型。- 示例:
#include <stdbool.h> bool flag = true;
- 示例:
- 便携代码的定长整数类型:为了编写便携代码,推荐使用
intN_t和uintN_t类型,这些类型在不同平台上具有相同的大小。- 示例:
#include <stdint.h> int32_t a = 100; uint64_t b = 1000;
- 示例:
- 未初始化的变量包含垃圾值:未初始化的变量会包含随机的内存数据,这可能导致不可预测的行为。
- 示例:
int a; printf("%d\n", a); // a的值未定义,可能是任何值
- 示例:
- 没有面向对象编程(OOP):C语言不支持面向对象编程,数据抽象类型(ADT)通过结构体定义。
- Bohrbugs(可重复)与 Heisenbugs(随机)
- Bohrbugs:这些错误是可重复的,每次执行时表现一致,通常比较容易调试和修复。
- Heisenbugs:这些错误是随机的,难以重现,在调试过程中可能消失或改变行为,非常难以调试。
- 解释:Heisenbugs 是指那些在调试过程中表现出不同行为的错误,而 Bohrbugs 则是那些始终表现一致的可重复错误。
通过这些深入讲解,我们可以更好地理解C语言的优势和局限性,以及关键概念在实际编程中的应用。这些知识对于编写高效、健壮的C程序非常重要。