Lecture 23: RISC-V 5-Stage Pipeline III, Hazards
Data Hazards II: Forwarding
MEM/WB流水线寄存器回顾
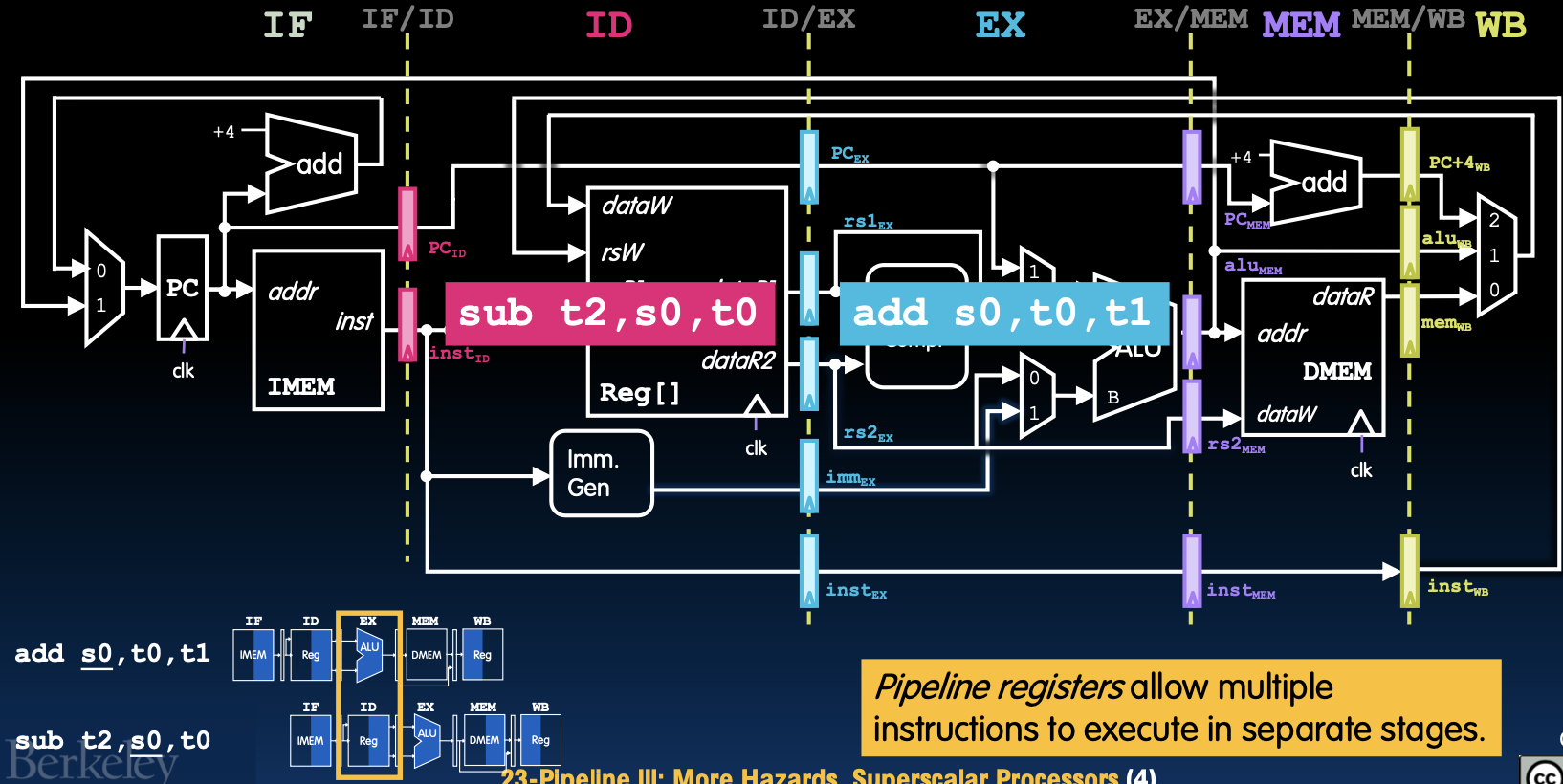
在这张图中展示了MEM/WB流水线寄存器的作用,它们用于在流水线的各个独立阶段之间传递指令和数据。图中显示了指令add s0, t0, t1和sub t2, s0, t0如何在不同的阶段进行处理。
数据流程
- 取指阶段(IF):取指指令
add s0, t0, t1。 - 指令解码阶段(ID):解码指令并读取寄存器文件中的操作数。
- 执行阶段(EX):在ALU中进行加法运算。
- 内存访问阶段(MEM):对于
add指令,此阶段不涉及内存访问。 - 写回阶段(WB):将结果写回寄存器文件。
控制信号
每个阶段都会生成相应的控制信号,通过流水线寄存器传递给下一个阶段,以确保指令能够正确执行。
数据冒险,解决方案1:停顿
数据冒险问题说明
当指令依赖于前一指令写入的寄存器值时,会出现数据冒险问题。例如,在执行add s0, t0, t1后立即执行sub t2, s0, t0时,sub指令将读取旧的s0值,而不是add指令计算的新值。
解决方案1:停顿流水线
- 问题:指令依赖于上一指令的寄存器写入。
- 解决方法:停顿流水线,使正确的指令在两次时钟周期后执行。
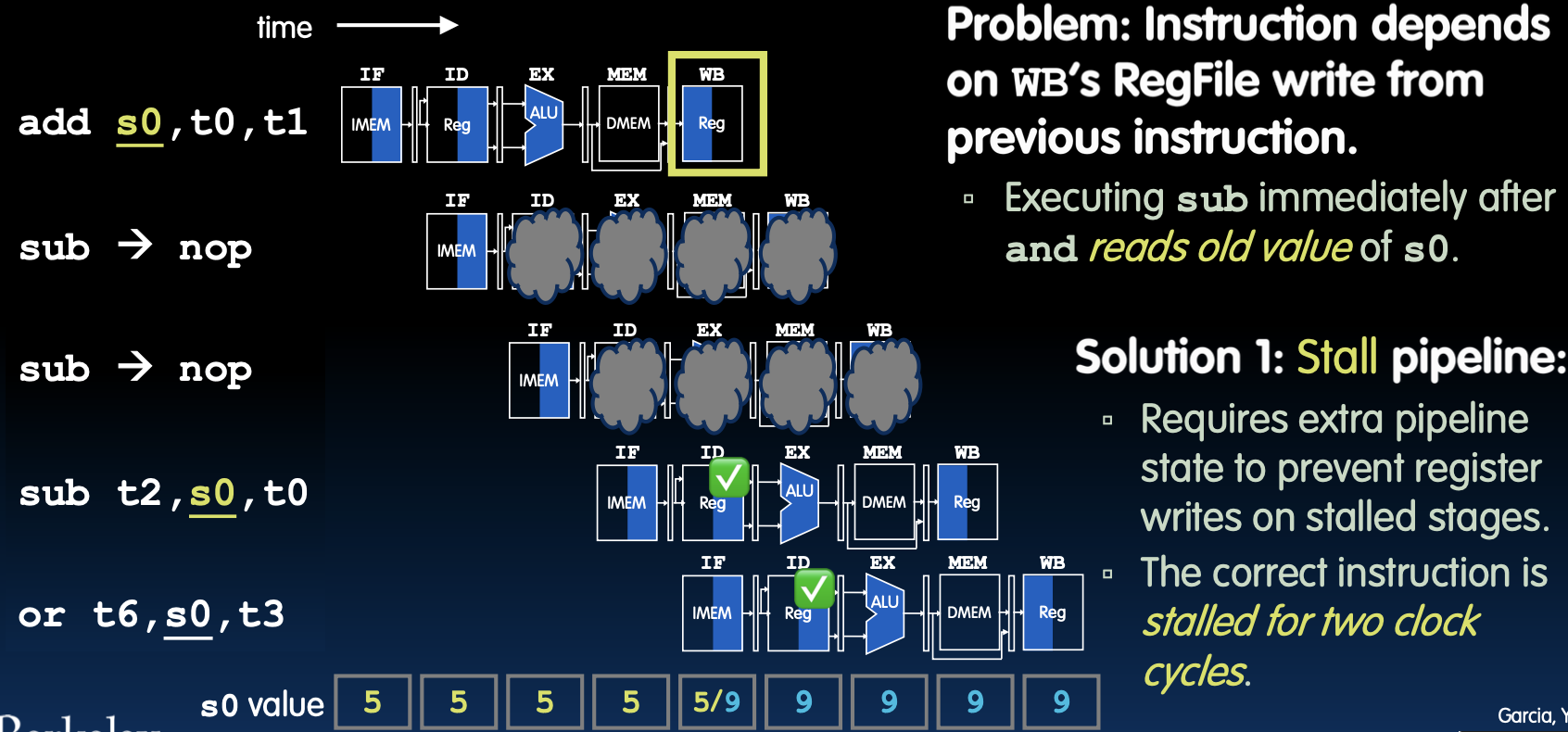
停顿机制
- 增加停顿阶段:在流水线中插入停顿阶段,防止数据冒险。例如,
add指令在写回阶段时,sub指令将在解码阶段停顿两次时钟周期,确保s0已经被正确写入。 - 寄存器更新:通过停顿机制,确保寄存器文件中的值在下一条指令执行前已更新。
数据流示例
- 初始状态:
add s0, t0, t1计算并更新s0值。 - 停顿周期:在执行
sub t2, s0, t0前,流水线停顿两个时钟周期,等待s0更新。 - 执行
sub指令:在s0更新后,sub指令读取正确的s0值,完成运算。
停顿效果
- 指令停顿:插入两次NOP(No Operation)指令,使流水线停顿,避免数据冒险。
- 正确执行:确保后续指令读取到正确的寄存器值,保证程序正确执行。
通过上述机制,流水线能够有效解决数据冒险问题,确保指令正确执行并保持流水线的高效性。
解决方案2:转发
转发(Forwarding)
转发,又称为旁路(bypassing),在结果计算出来时就直接使用它,而不是等待该值写入寄存器文件。通过这种方法,可以避免不必要的等待,从而提高流水线的效率。
- 实现:在数据路径中增加额外的连接,并添加转发控制逻辑。
- 好处:能够减少停顿周期,直接从流水线阶段抓取操作数。
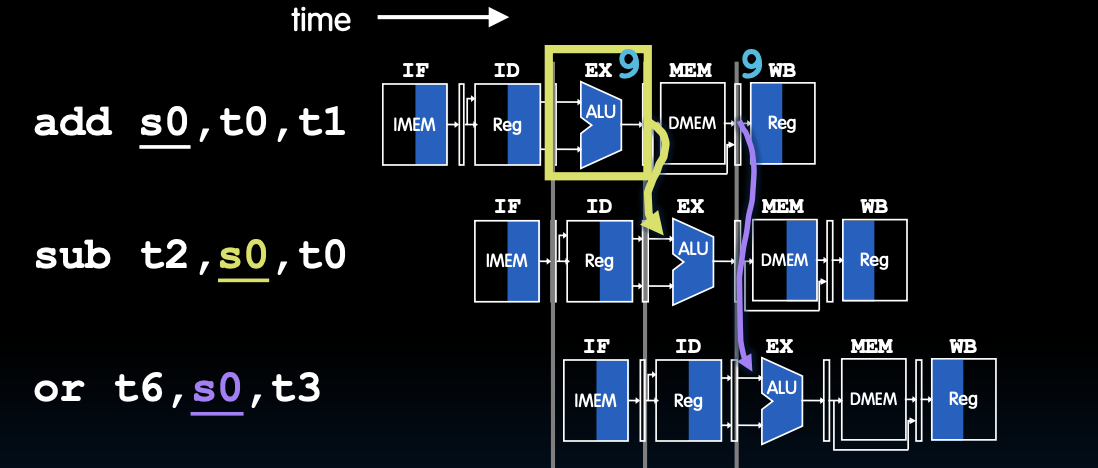
转发机制
- 指令
add s0, t0, t1:在执行阶段计算出s0的值并传递到下一阶段。 - 指令
sub t2, s0, t0:在指令解码阶段,通过转发机制直接获取s0的值,而无需等待s0写回到寄存器文件。 - 指令
or t6, s0, t3:同样通过转发机制直接获取s0的值进行操作。
数据流示例
- 数据路径:在ALU阶段计算出的结果可以直接转发到需要该结果的下一指令的ALU输入端。
- 控制信号:转发控制逻辑确保正确的操作数被传递到相应的执行单元。
转发EX结果
转发EX结果说明
图中展示了如何通过转发机制在执行阶段将计算结果直接转发给下一指令。在这个例子中,add s0, t0, t1的结果被直接转发给sub t2, s0, t0使用。
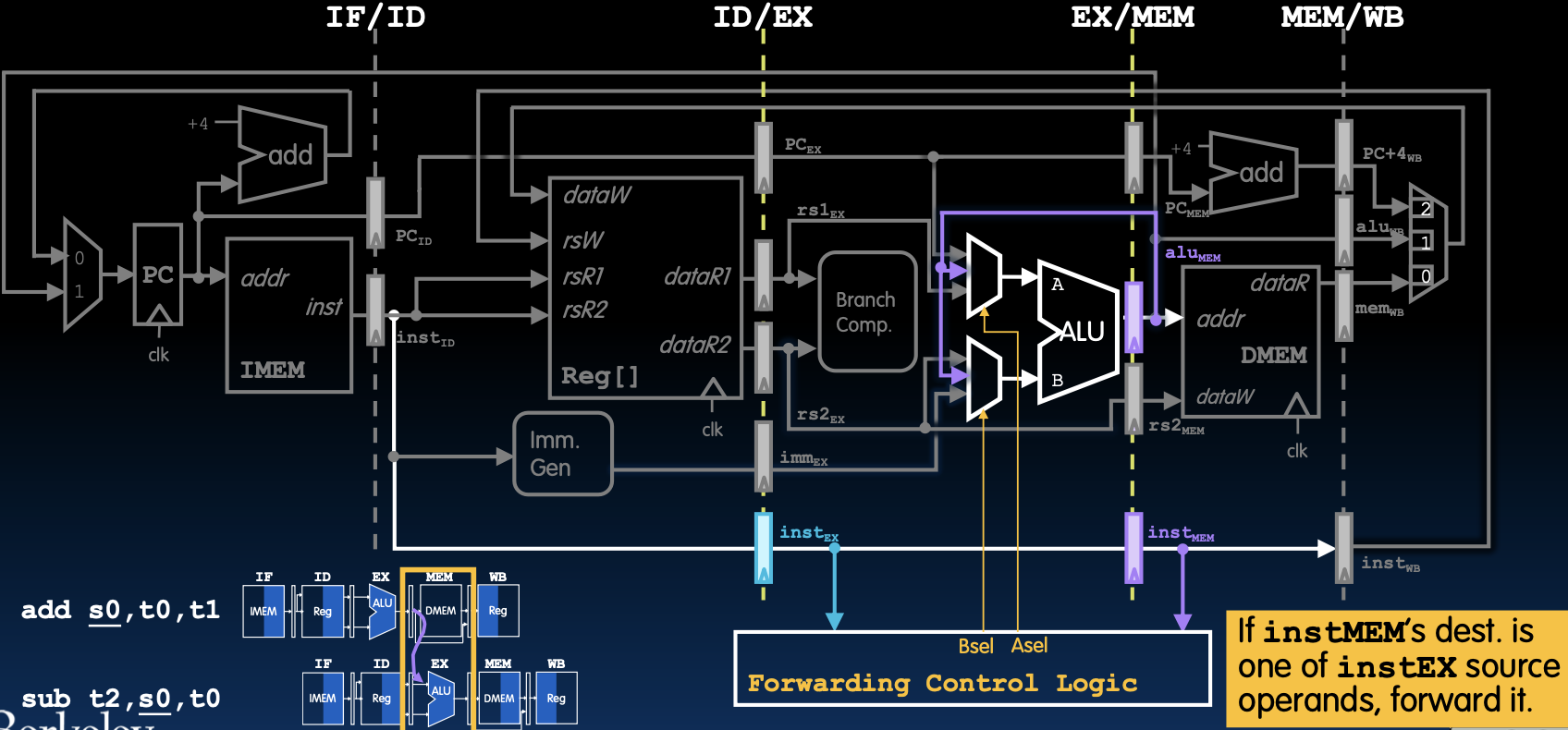
数据路径调整
- 增加连接:在数据路径中增加直接从EX阶段的ALU输出到ID/EX阶段的ALU输入的连接。
- 控制逻辑:通过控制信号来决定是否启用转发路径。
控制信号
- 转发控制逻辑:如果当前执行阶段的指令目标寄存器是下一指令所需的源操作数,则启用转发路径。
- 实现方式:在流水线寄存器中增加控制字段,用于指示是否需要进行数据转发。
数据冒险的解决
通过转发机制,可以有效地解决数据冒险问题,使流水线能够在不增加停顿周期的情况下继续高效运行。这种方法在硬件设计中非常常见,能够显著提高指令执行的效率。
Data Hazards III: Load
转发不能解决所有的数据冒险问题(1/2)
数据冒险解决方法
转发EX阶段的输出
- 解释:在下一个时钟周期,将EX阶段的输出转发到EX阶段的输入。
- 示例:
add s0, t1, t2的结果可以直接在EX阶段传递给下一条指令使用。
转发MEM阶段的输出
- 解释:在下一个时钟周期,将MEM阶段的输出转发到EX阶段的输入。
- 示例:
lw s1, 8(s0)的结果可以直接在MEM阶段传递给下一条指令使用。
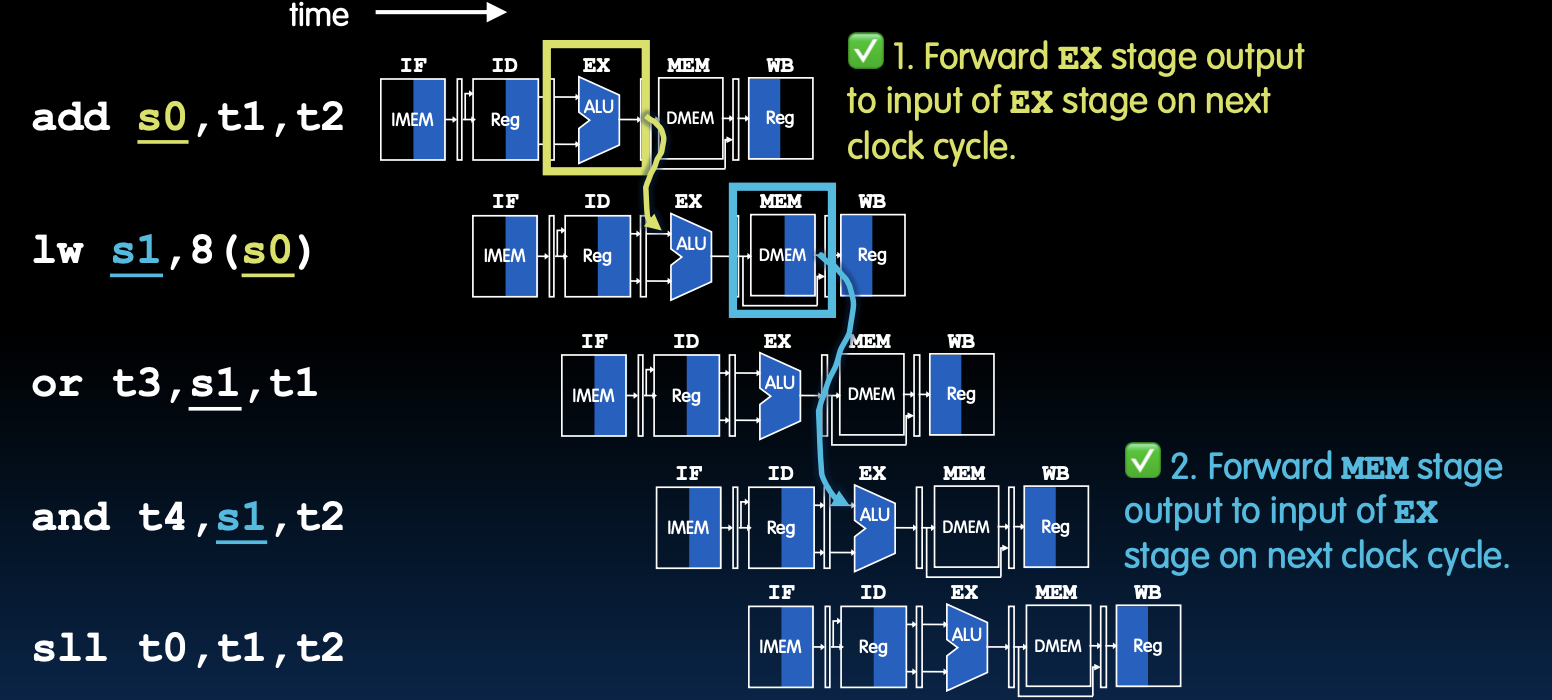
尽管通过转发可以解决大部分的数据冒险问题,但在某些情况下,转发也不能完全解决所有的数据冒险。例如,当指令lw从内存加载数据时,数据还没有准备好就被下一条指令所需,这时需要增加气泡(pipeline stall)来解决问题。
转发不能解决所有的数据冒险问题(2/2)
具体数据冒险案例
MEM阶段的输出需要作为EX阶段的输入
- 问题:如果
lw s1, 8(s0)指令的输出在MEM阶段,而下一条指令or t3, s1, t1在EX阶段需要这个数据,那么由于时钟周期的限制,这种情况下无法通过转发机制解决问题。 - 解决方案:需要插入气泡,确保
lw指令的输出在MEM阶段完成后,才能被or指令在EX阶段使用。
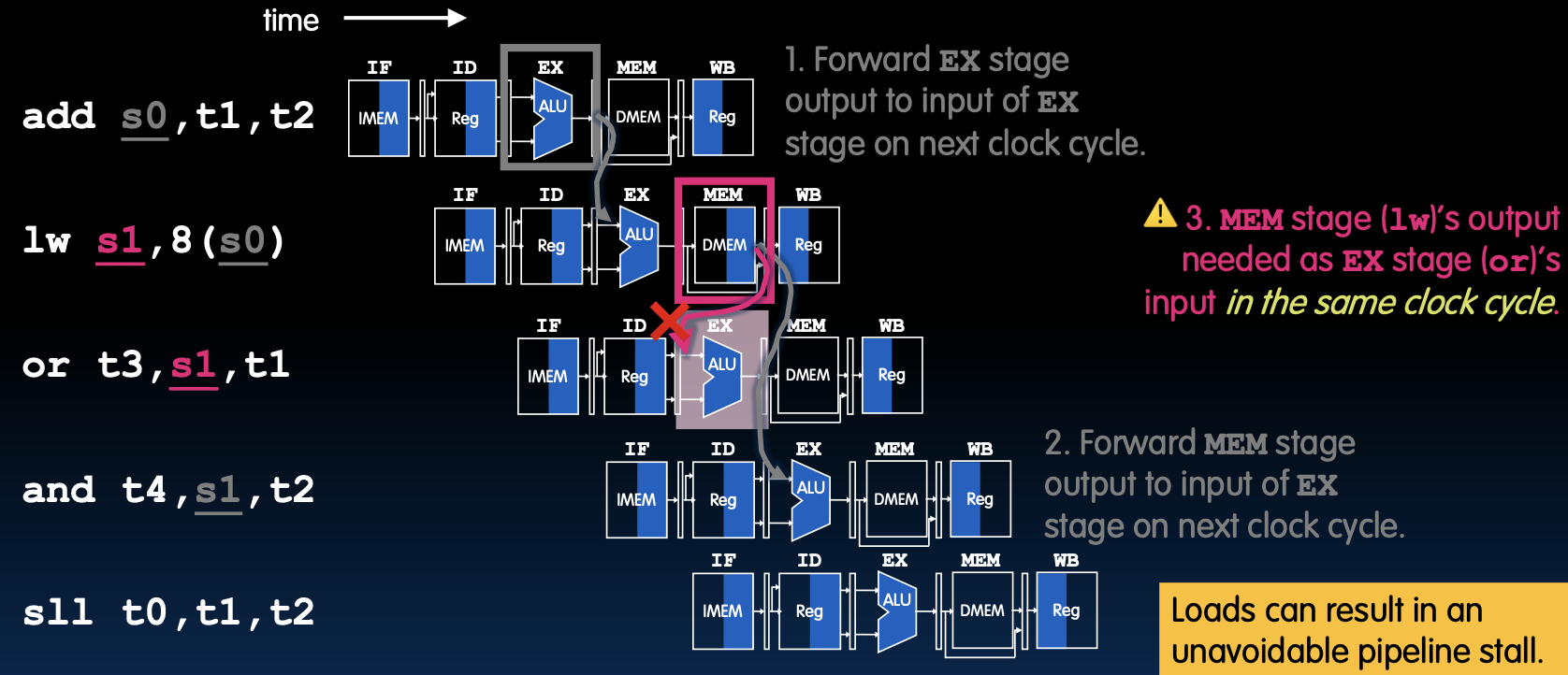
加载指令的影响
加载指令(lw)在流水线中会引起无法避免的停顿。由于加载操作需要从内存中获取数据,这个数据在MEM阶段才会准备好,而下一条指令在EX阶段就需要使用这些数据。这时,插入气泡是确保数据一致性和正确性的唯一方法。
气泡的插入
气泡(pipeline bubble)会暂停流水线的执行,直到数据准备好。例如,当lw指令在MEM阶段加载数据时,下一条依赖该数据的指令会在流水线中暂停,直到数据可用为止。这种方法虽然会降低流水线的效率,但可以确保程序的正确执行。
数据冒险 3:加载(Data Hazard 3: Loads)
加载延迟槽(Load Delay Slot)
- 定义:加载指令后的指令槽被称为加载延迟槽。
- 问题:如果该指令使用加载结果,则硬件必须停顿一个周期(加上转发时间)。
- 结果:导致性能损失。
示例
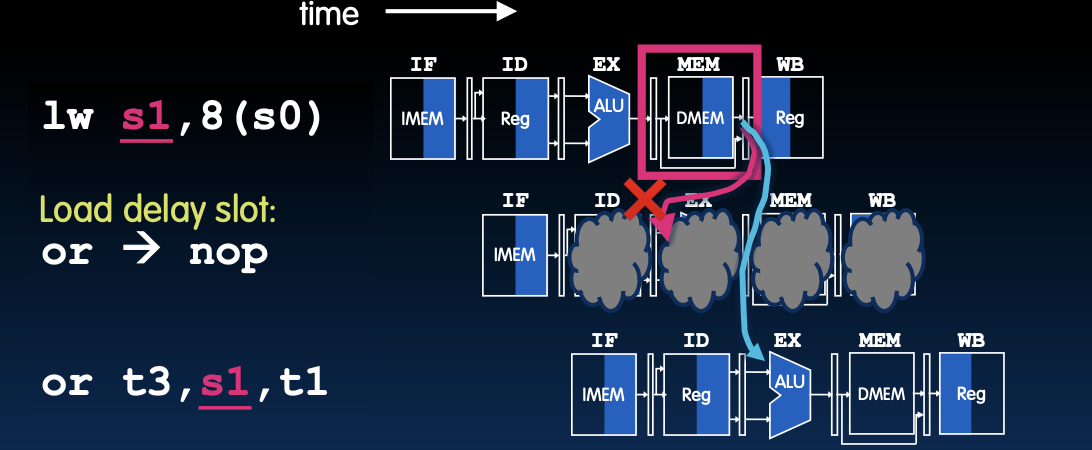
在此情况下,lw指令从内存中加载数据,下一条or指令需要该数据,但由于时钟周期限制,该数据在当前周期内不可用。因此,需要停顿一个周期来确保数据正确传递。
加载指令常常会导致流水线中的数据冒险问题,这是因为内存访问需要时间,而依赖该数据的后续指令需要等待数据准备好。这种等待会导致流水线停顿,降低整体处理器的性能。
解决方案:代码调度(Solution: Code Scheduling)
概念
- 目标:在代码编译阶段解决该冒险问题。
- 方法:在延迟槽中放置与加载结果无关的指令。
- 优势:无性能损失!
示例代码调度

代码调度是一种通过重新排列指令顺序来避免流水线停顿的技术。编译器在编译过程中,通过分析流水线结构和指令依赖关系,将不依赖于加载结果的指令插入加载延迟槽,从而避免停顿,提升处理器性能。
例如,在上述代码调度示例中,通过将add t3, t1, t2指令和lw t4, 8(t0)指令的位置互换,成功地避免了停顿,减少了执行周期。这样做不仅提高了指令执行的并行度,还显著提升了整体系统的性能。
Control Hazards
三种类型的流水线冒险(Three Types of Pipeline Hazards)
冒险(Hazard)定义
冒险是一种情况,即计划中的指令无法在“适当”的时钟周期内执行。
结构冒险(Structural Hazard)
- 定义:硬件不支持在同一周期内跨多条指令访问。
- 原因:当多个指令需要同时访问同一硬件资源时,可能会出现结构冒险。例如,当多个指令同时需要访问内存或寄存器文件时,就会发生结构冒险。
数据冒险(Data Hazard)
- 定义:指令之间存在数据依赖性。
- 需要等待:需要等待前一条指令完成其数据读取/写入操作。
- 扩展:数据冒险通常分为三种类型:RAW(Read After Write),WAR(Write After Read),和WAW(Write After Write)。在流水线处理器中,RAW冒险最常见,即后一条指令需要前一条指令写入的数据作为操作数。
控制冒险(Control Hazard)
- 定义:执行流程依赖于前一条指令的结果。
- 原因:控制冒险通常发生在分支指令或跳转指令之后,处理器在确定跳转目标之前已经取指了后续的指令,因此可能需要丢弃错误取指的指令。
分支结果在MEM阶段计算(Branch Results Computed During MEM)
分支处理
- 在MEM阶段:EX/MEM流水线寄存器将分支比较结果传递到IF阶段的多路复用器(MUX),并设置PC选择控制信号。
- 下一时钟周期:在IF阶段,程序计数器(PC)更新,并取出正确的下一条指令。
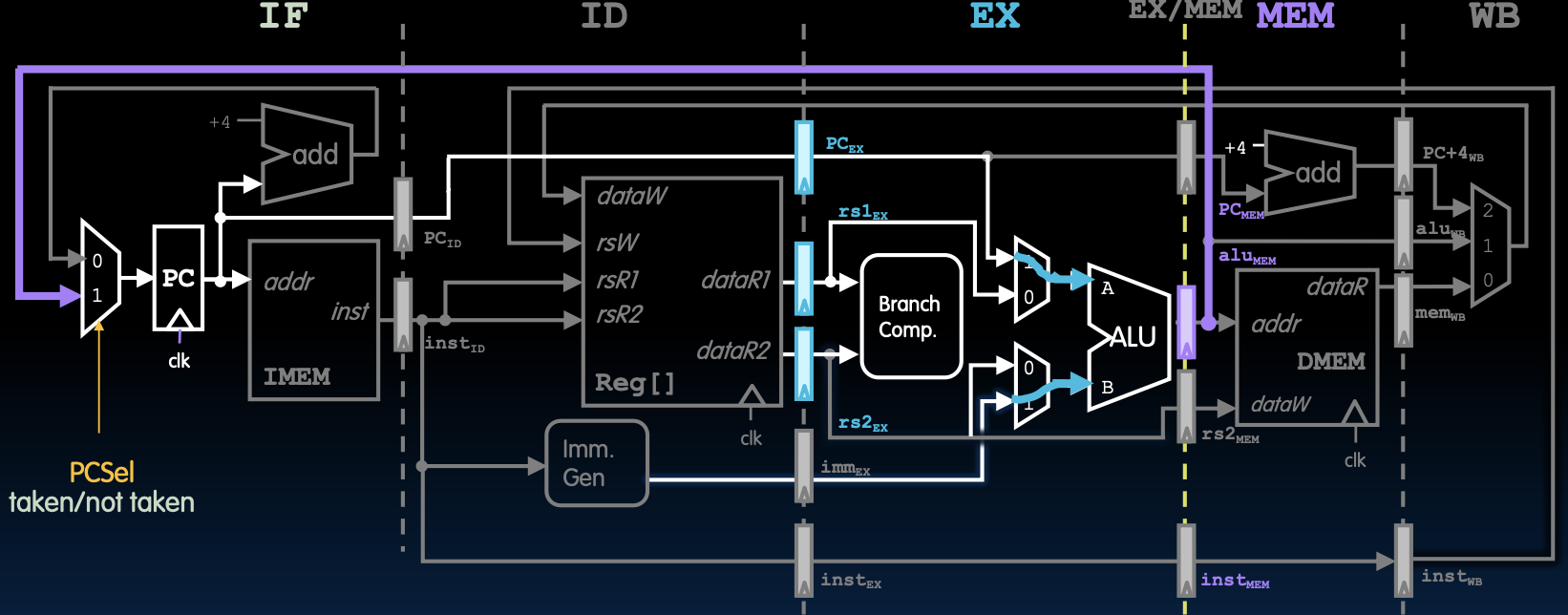
在控制冒险中,分支指令的处理尤为重要。为减少分支指令导致的流水线停顿,现代处理器通常采用分支预测技术,并在分支结果确定后修正错误的取指。将分支结果的计算提前到MEM阶段,可以减少分支误预测的影响,从而提高处理器的整体性能。
控制冒险:条件分支(Control Hazard: Conditional Branches)
什么是控制冒险
控制冒险发生在取指令时,取到的指令可能不是需要的指令。例如,在以下情况下,如果beq分支被执行:
代码示例
0x40 beq t0, t1, Label
0x44 sub t2, s0, t0
0x48 or t6, s0, t3
0x4c xor t5, t1, s0
0x70 sw s0, 8(t3) # Label
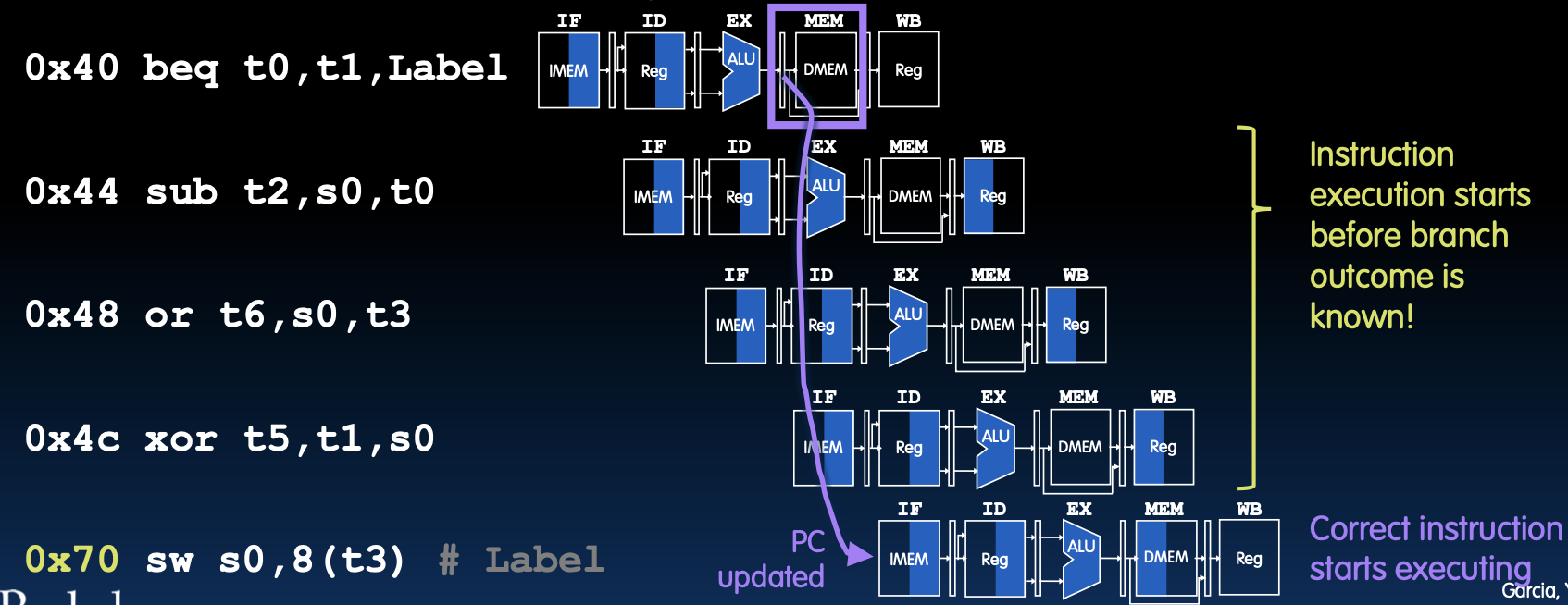
冒险解释
- 指令执行开始于分支结果未知时:在流水线处理器中,指令提取、译码和执行是并行进行的,因此在确定分支是否会跳转之前,后续指令已经进入流水线。
- 图示讲解:
- 分支预测错误:如果预测分支没有发生,但实际上分支发生了,需要更新PC并重新取指。
- 正确指令执行开始:在更新PC后,正确的指令才会被取指并执行。
分支后的指令清除(Kill Instructions after Branch (If Taken))
如何处理错误指令
- 刷新流水线:通过将错误的指令转换为nop指令(空操作),清除流水线中的错误指令。
代码示例
0x40 beq t0, t1, Label
0x44 sub t2, s0, t0
0x48 or t6, s0, t3
0x4c xor t5, t1, s0
0x70 sw s0, 8(t3)
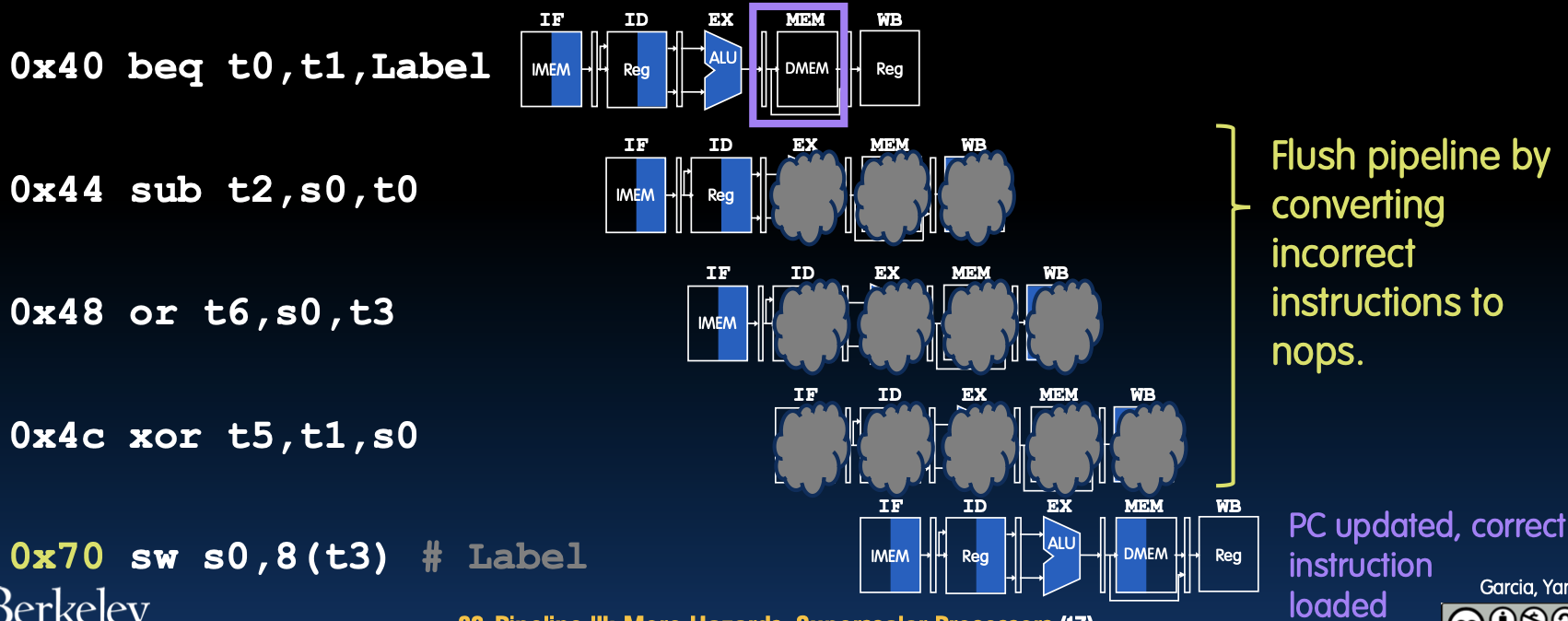
详细解释
- 分支预测错误处理:当分支指令实际跳转时,之前取指的指令需要被丢弃,这些指令在流水线中已经开始执行。
- PC更新和正确指令加载:在检测到分支跳转后,处理器需要更新程序计数器(PC),并从新的地址取指,重新填充流水线。
通过分支预测和流水线清除,处理器能够在分支指令发生时,迅速调整执行流程,避免错误指令的执行,从而提高处理器的执行效率。这些技术是现代高性能处理器中常见的优化手段,旨在最大限度地减少分支指令对流水线性能的影响。
分支预测以减少处罚(Branch Prediction to Reduce Penalties)
分支预测的重要性
在简单的RV32I流水线中,每次执行分支指令都会花费3个时钟周期。如果分支没有被执行,那么流水线不会停顿,正确的指令会按顺序取回并执行。因此,通过分支预测可以在平均情况下提高CPU性能。
提高CPU性能的途径
- 早期预测:在流水线早期阶段,猜测分支的方向。
- 错误预测处理:如果分支预测错误,则刷新流水线。
简单预测器:不执行分支(Naïve Predictor: Don’t Take Branch)
预测方法
简单的RV32I流水线总是预测分支不被执行,因此在预测过程中,将下一个PC设置为PC+4。
代码执行流程
- 取指和预测:假设分支不执行,PC设置为PC+4。
- 评估预测:当到达执行阶段,如果预测正确,则正确指令已经执行。如果预测错误,则需要刷新流水线。
图示讲解
- 预测正确:在分支未执行的情况下,指令按顺序执行,没有额外开销。
- 预测错误:如果预测错误,需要花费3个时钟周期来纠正错误。
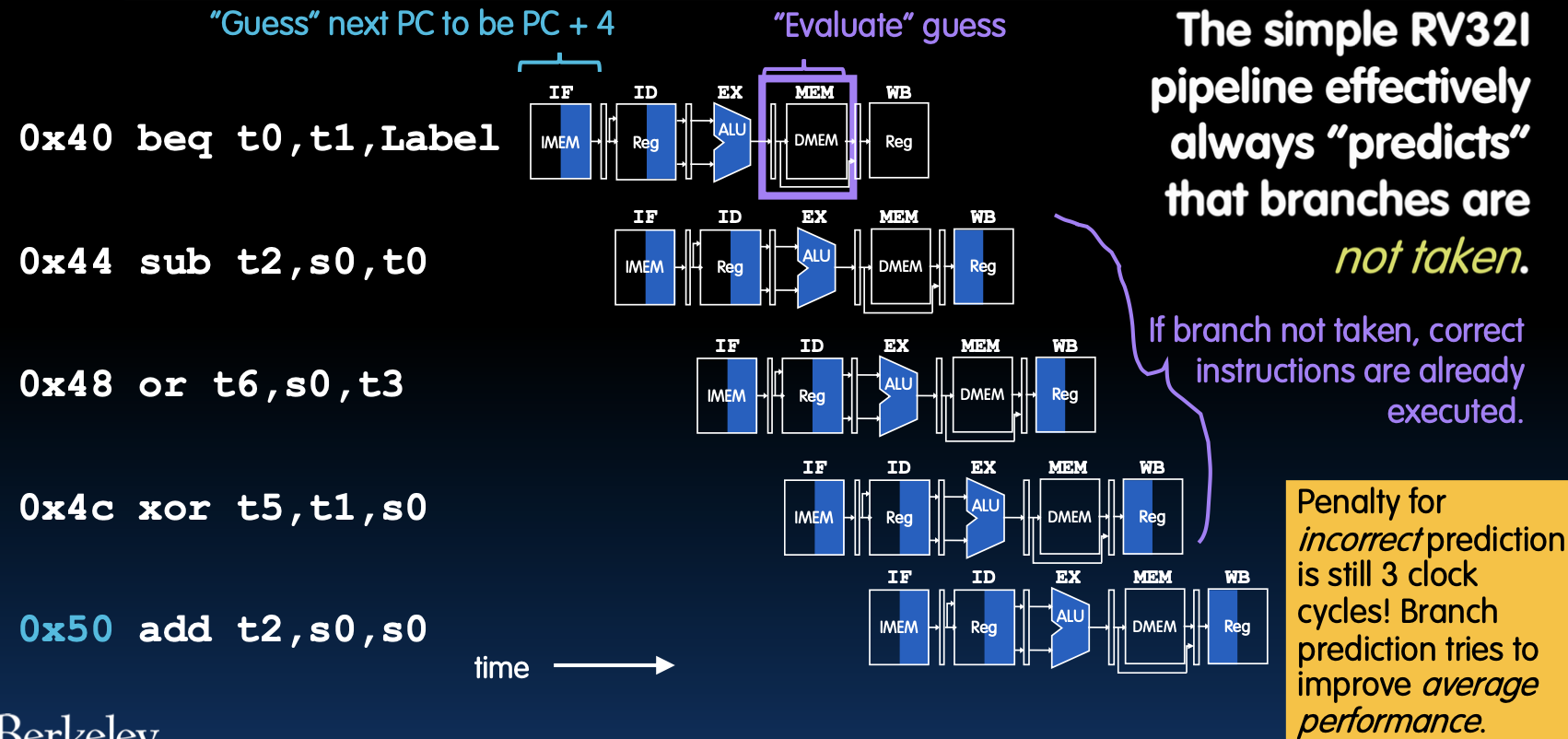
通过简单的“分支不执行”预测方法,可以在一定程度上减少分支指令带来的性能损失。然而,当预测错误时,仍然需要花费时间来纠正错误。因此,为了进一步提高处理器性能,可以采用更复杂的分支预测算法。
Superscalar Processors and Measuring CPI
超标量处理器和 CPI 测量
流水线和指令集设计(Pipelining and ISA Design)
RISC-V 指令集架构的设计目标
RISC-V 指令集架构(ISA)专为流水线设计:
- 所有指令都是32位宽:
- 易于在一个时钟周期内获取和解码。
- 与复杂指令集计算(CISC)x86对比,后者指令宽度从1字节到15字节不等。
- 一小组标准指令格式:
- 可以在一个阶段内解码/读取寄存器。
- 加载/存储寻址:
- 在第三阶段计算地址(使用ALU);
- 在第四阶段访问内存。
- 内存操作数全部对齐:
- 内存访问只需一个周期。
这种设计使得RISC-V的流水线实现更加高效,适用于各种设备,如汽车、家电等。
进一步提高处理器性能的方法
- 增加时钟频率:
- 受限于技术和功耗。
- 增加流水线深度:
- 通过更深的流水线(例如10或15个阶段)“重叠”指令执行。
- 每阶段工作量减少 -> 更短的时钟周期/更低的功耗。
- 但也增加了所有三种类型的风险!(更多停顿 -> CPI > 1)。
- 设计“超标量”处理器:
- 桌面电脑、笔记本电脑、手机等通常结合多个这样的处理器,配合更简单的5阶段流水线处理器。
通过这些方法,可以显著提升处理器的整体性能,但也需要平衡复杂性和能耗。
超标量处理器(Superscalar Processors)
多发射(Multiple-issue)
超标量处理器能够在每个时钟周期内启动多条指令:
- 多个执行单元并行执行指令。
- 每个执行单元都有自己的流水线。
- CPI < 1:每个时钟周期可以完成多条指令。
动态乱序执行(Dynamic “out-of-order” execution)
动态乱序执行能够在硬件中动态重新排序指令,以减少风险的影响:
- 通过乱序执行,可以避免等待上一个指令完成,提升处理器性能。
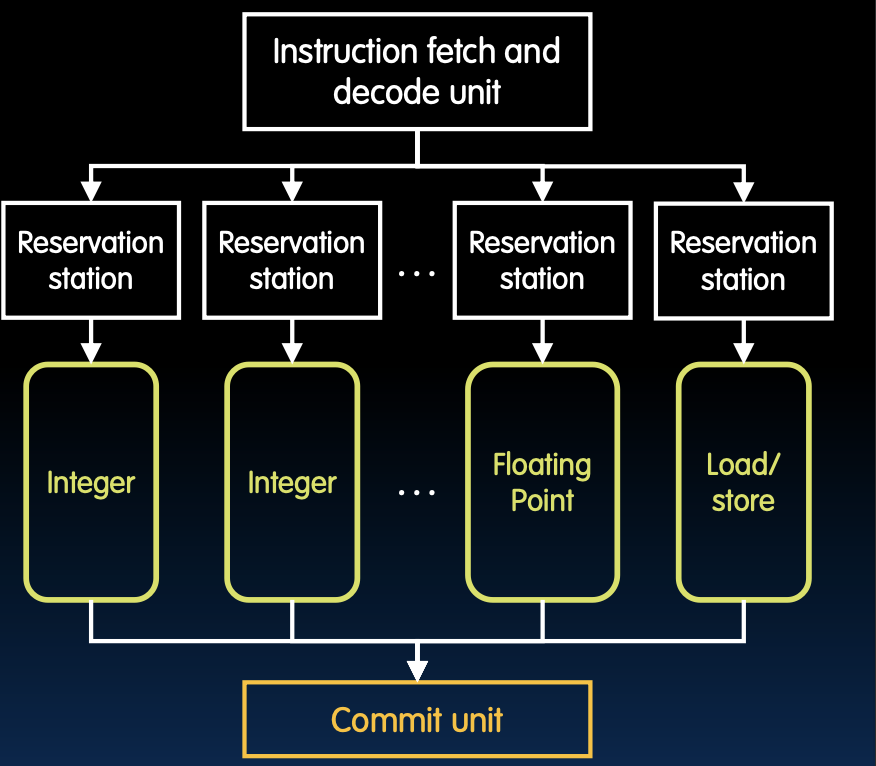
图示展示了指令获取和解码单元如何将指令分配到不同的保留站(Reservation Station),这些保留站对应不同的执行单元(整数、浮点、加载/存储等),最后通过提交单元(Commit Unit)完成指令的提交。
计算每条指令的周期数(Computing Cycles Per Instruction,CPI)
理论CPI和实际CPI
ARM Cortex-A53内核:2 GHz,双发射处理器:
- 峰值CPI为0.5(每秒执行40亿条指令)。
- 但是,指令/流水线的依赖性降低了实际性能。
实际测量CPI的方法
在实际应用中,通过各种基准测试程序来测量CPI:
- 使用已知的基准测试程序(数据压缩、代码编译、视频解码、网络仿真等)。
公式:
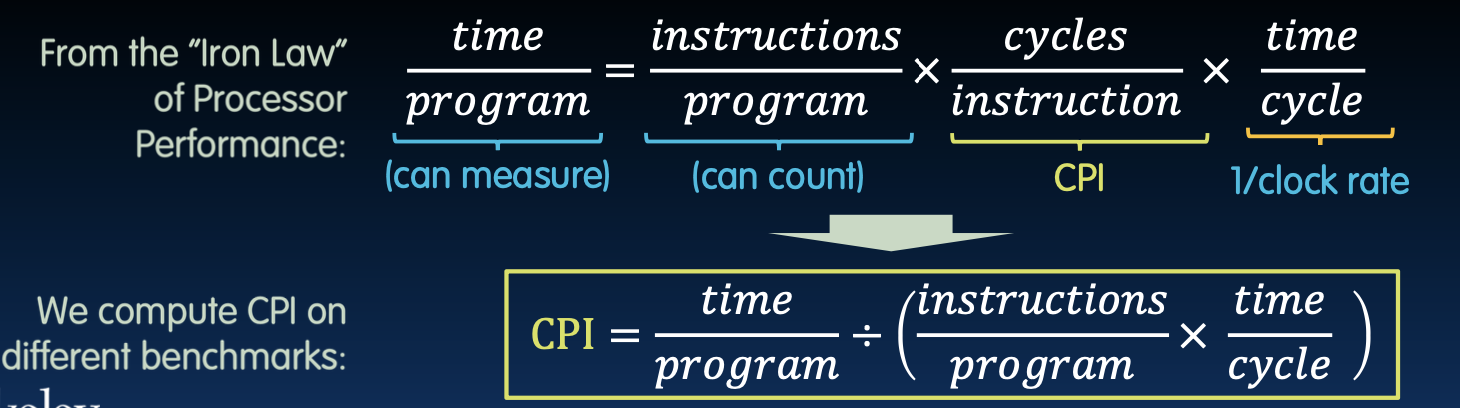
通过计算不同基准测试下的CPI,可以评估处理器的实际性能。
ARM A53 基准测试
ARM Cortex-A53内核:2 GHz,双发射处理器:
- 峰值CPI为0.5(每秒执行40亿条指令)。
- 但是,指令/流水线的依赖性降低了实际性能。
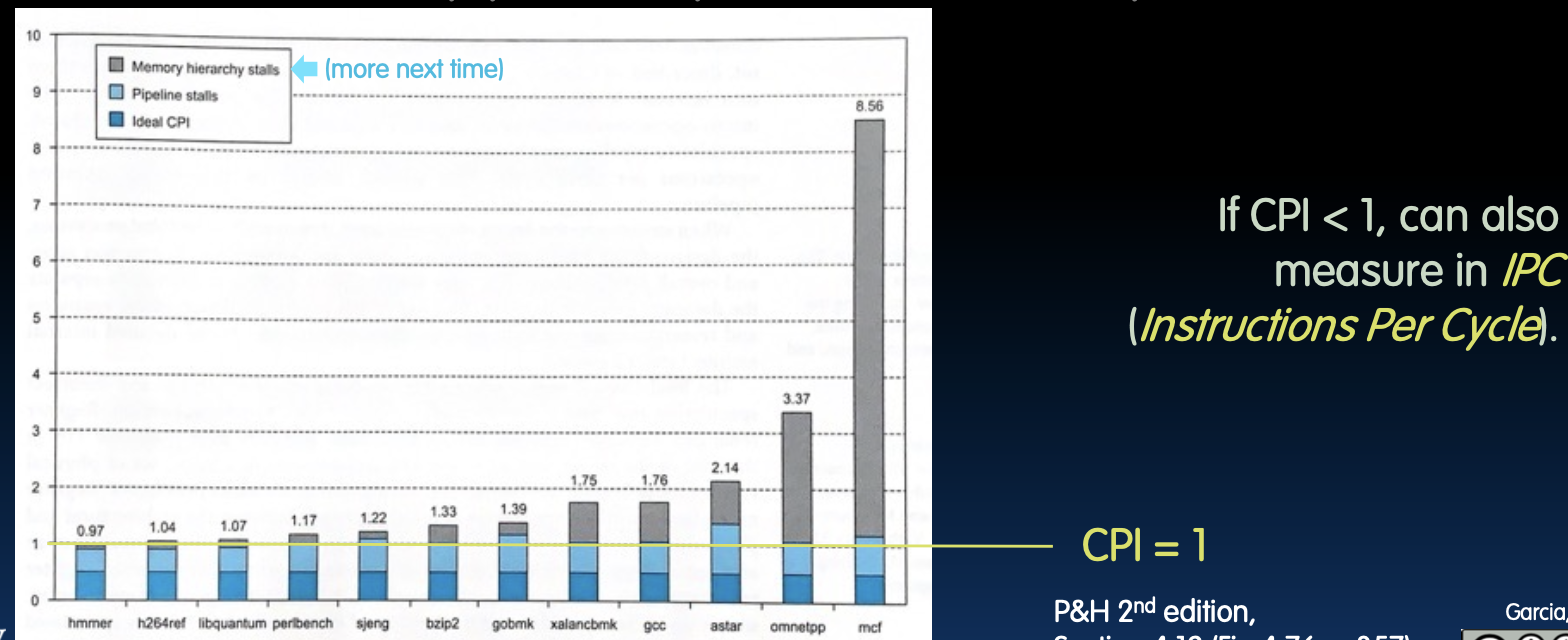
图表展示了在不同基准测试下的实际CPI值,其中包括内存层次结构停顿(Memory hierarchy stalls)和流水线停顿(Pipeline stalls)的影响。结果显示,即使理想CPI为1,由于各种依赖性和停顿,实际CPI往往大于1。