Lecture 26: Caches - MultiLevel
Accessing Data in a Direct-Mapped Cache
访问直接映射缓存中的数据
示例:16KB的数据,直接映射,4字块
- 缓存高度:缓存的高度指的是缓存中存储的数据块数量。在这里,我们有16KB的缓存,每块4个字,这意味着缓存的总块数是:
- 高度 = 16KB / 4字 = 4096块。
- 缓存宽度:缓存的宽度指的是每个数据块的大小,这里每块是4个字,每个字是4字节,所以每块的宽度是:
- 宽度 = 4字 * 4字节/字 = 16字节。
- 缓存面积:缓存的面积是高度和宽度的乘积:
- 面积 = 高度 * 宽度 = 4096块 * 16字节/块 = 65536字节 = 64KB。
读取4个地址
- 地址:
- 0x00000014
- 0x0000001C
- 0x00000034
- 0x00008014
内存值
- 设内存地址和值的对应关系:
- 0x00000010 -> a
- 0x00000014 -> b
- 0x00000018 -> c
- 0x0000001C -> d
- …
- 0x00008010 -> i
- 0x00008014 -> j
- …

Example: 16 KB Direct-Mapped Cache, 16B blocks
有效位(Valid bit)
- 定义:有效位决定了在计算机初始启动时是否有信息存储在该行(启动时所有条目均为无效)。
- 示例解释:如图所示,当所有行的有效位为0时,表示缓存中没有有效数据。一旦有数据存入缓存,对应的有效位会被置为1,表示该行的数据是有效的。

分析4个地址


读取地址 0x00000014
步骤 1:读取地址 0x00000014
地址解析
- 二进制表示:00000000000000000000000000010100
- 标签 (Tag):000000000000000000
- 索引 (Index):00000001
- 偏移量 (Offset):0100
检查缓存
- 在缓存中找到对应的索引 1 位置,检查有效位和标签是否匹配。
- 由于是第一次访问,有效位为 0,表示该行没有有效数据。
步骤 2:从内存加载数据到缓存
内存加载
- 内存地址 0x00000014 对应的数据块被加载到缓存中。
- 数据块包含:a、b、c、d,分别对应内存地址 0x00000010、0x00000014、0x00000018、0x0000001C。
更新缓存
- 将数据块加载到索引 1 位置,并设置有效位为 1。
- 更新标签为 000000000000000000。
步骤 3:缓存数据结构更新
缓存状态
- 索引 (Index):00000001
- 标签 (Tag):000000000000000000
- 数据块:包含 d(地址 0x0000001C)、c(地址 0x00000018)、b(地址 0x00000014)、a(地址 0x00000010)
- 有效位 (Valid bit):1
此时,缓存中已经存储了从内存加载的数据,后续访问相同索引的数据时,只要标签匹配且有效位为 1,就可以直接从缓存中读取数据,而不需要再次访问内存。
步骤 4:从缓存中读取数据
从缓存中读取数据
- 在索引 1 的位置检查标签匹配且有效位为 1。
- 根据偏移量 0100,从数据块中选择相应的字(word)读取。
- 读取到的数据字(word)为 b,对应地址 0x00000014。
更新缓存数据结构
- 缓存结构不变,有效位仍为 1,标签仍为 000000000000000000。
- 数据块内容保持不变:d、c、b、a。
返回数据
- 将数据字(word)b返回给处理器。
- 处理器将读取的数据存储到目标寄存器中。
通过这个过程,我们展示了缓存命中和未命中的操作步骤,以及如何从内存加载数据到缓存,并更新缓存的有效位和标签。后续相同地址的访问将更加高效,因为可以直接从缓存中读取数据。
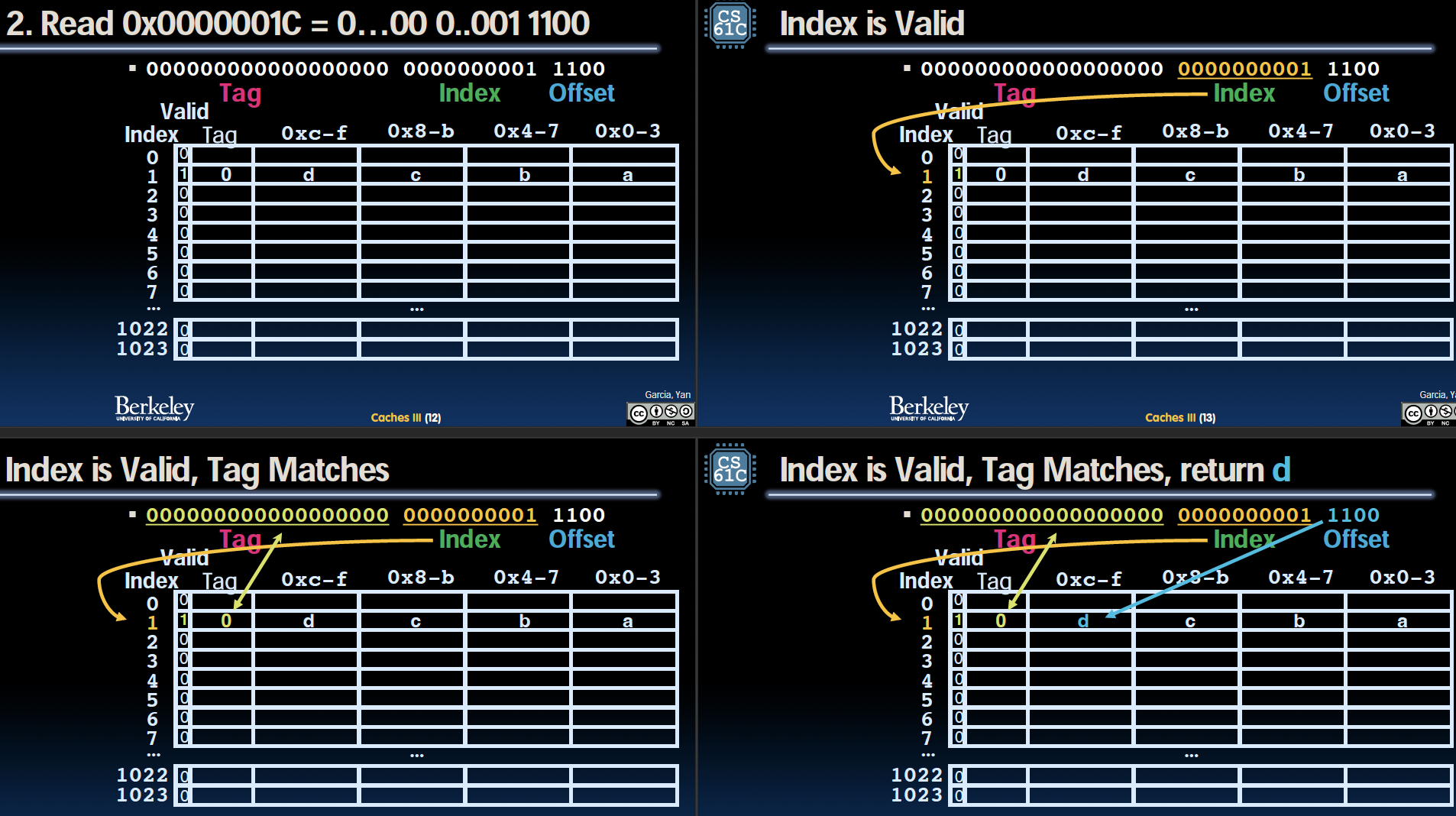
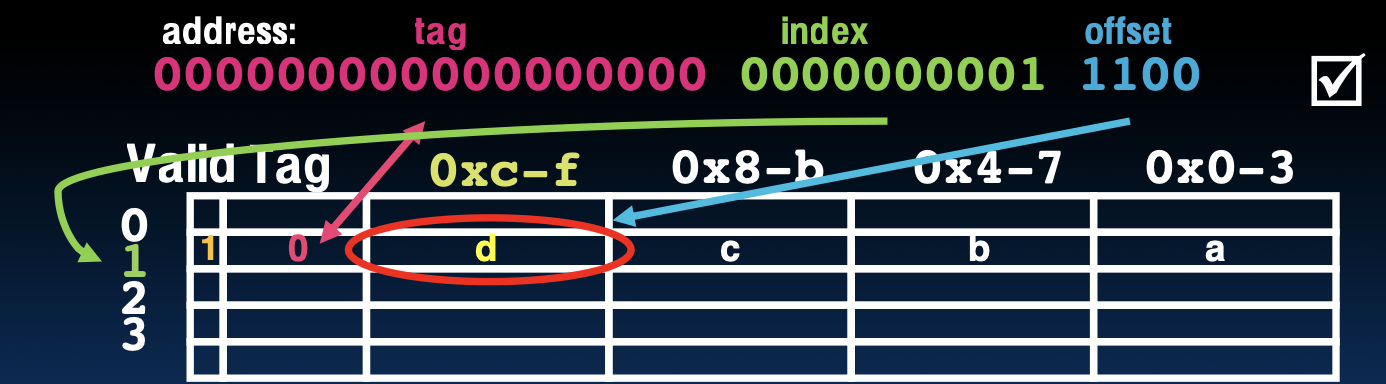
读取地址 0x0000001C
步骤 1:读取地址 0x0000001C
地址解析
- 二进制表示:00000000000000000000000000011100
- 标签 (Tag):000000000000000000
- 索引 (Index):00000001
- 偏移量 (Offset):1100
检查缓存
- 在缓存中找到对应的索引 1 位置,检查有效位和标签是否匹配。
步骤 2:索引有效
缓存状态
- 索引 (Index):00000001
- 标签 (Tag):000000000000000000
- 有效位 (Valid bit):1
标签匹配
- 检查索引 1 位置的标签是否与目标标签匹配。
- 当前标签为 000000000000000000,匹配目标标签。
步骤 3:从缓存中读取数据
根据偏移量读取数据
- 在索引 1 的位置,标签匹配且有效位为 1。
- 根据偏移量 1100,从数据块中选择相应的字(word)读取。
- 读取到的数据字(word)为 d,对应内存地址 0x0000001C。
步骤 4:返回数据
返回数据
- 将数据字(word)d返回给处理器。
- 处理器将读取的数据存储到目标寄存器中。
通过这个过程,我们展示了缓存命中时的操作步骤,以及如何根据偏移量从缓存中读取数据字。与之前的未命中情况不同,这里由于缓存中已经有了所需的数据,处理器可以直接从缓存中读取数据,从而提高了访问速度。
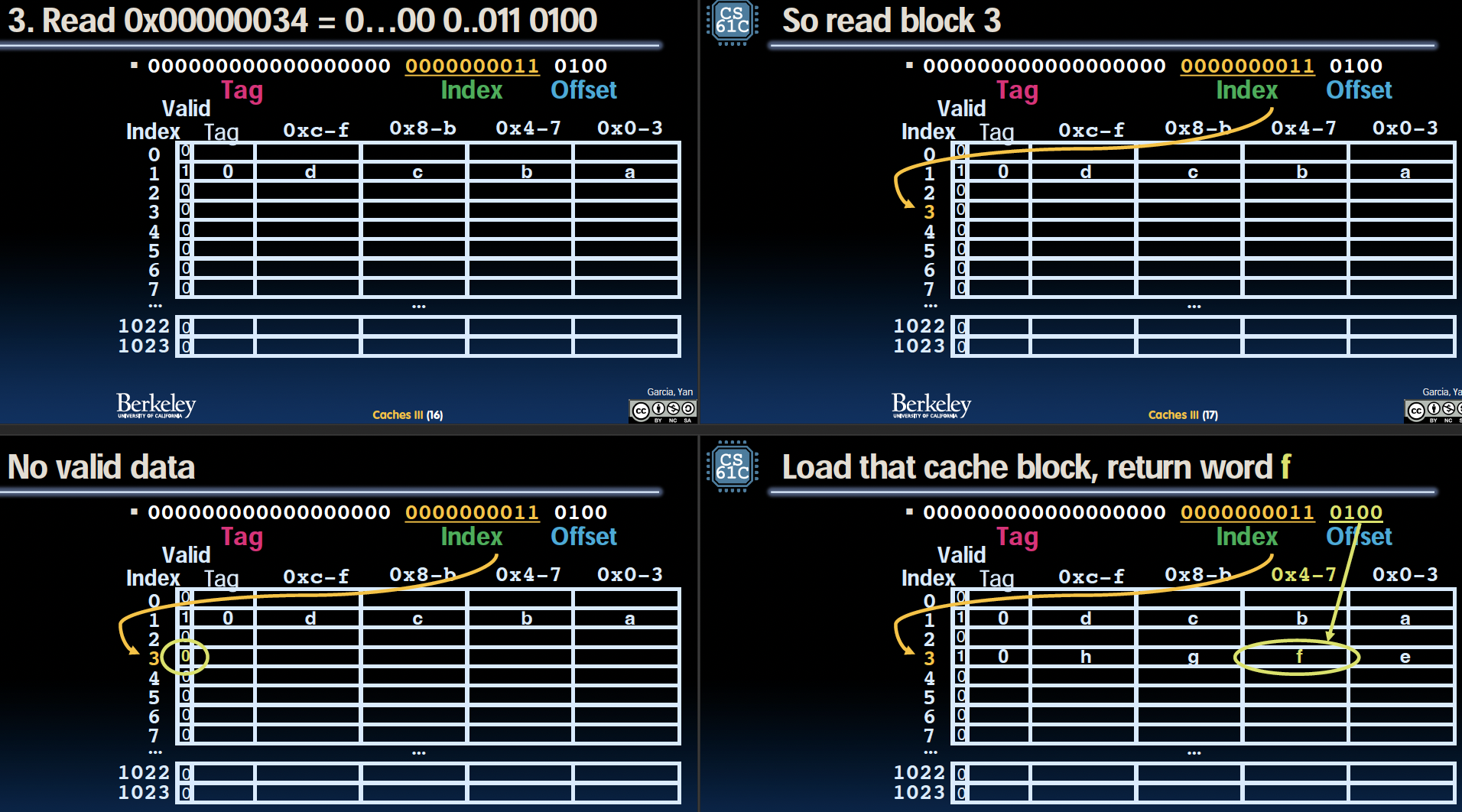
读取地址 0x00000034
步骤 1:读取地址 0x00000034
地址解析
- 二进制表示:00000000000000000000000000110100
- 标签 (Tag):000000000000000000
- 索引 (Index):00000011
- 偏移量 (Offset):0100
检查缓存
- 在缓存中找到对应的索引 3 位置,检查有效位和标签是否匹配。
步骤 2:索引有效
缓存状态
- 索引 (Index):00000011
- 标签 (Tag):000000000000000000
- 有效位 (Valid bit):0
无有效数据
- 当前索引 3 位置的有效位为 0,表示该行没有有效数据。
步骤 3:从内存加载数据到缓存
内存加载
- 内存地址 0x00000034 对应的数据块被加载到缓存中。
- 数据块包含:e、f、g、h,分别对应内存地址 0x00000030、0x00000034、0x00000038、0x0000003C。
更新缓存
- 将数据块加载到索引 3 位置,并设置有效位为 1。
- 更新标签为 000000000000000000。
步骤 4:从缓存中读取数据
根据偏移量读取数据
- 在索引 3 的位置,标签匹配且有效位为 1。
- 根据偏移量 0100,从数据块中选择相应的字(word)读取。
- 读取到的数据字(word)为 f,对应内存地址 0x00000034。
步骤 5:返回数据
返回数据
- 将数据字(word)f返回给处理器。
- 处理器将读取的数据存储到目标寄存器中。
通过这个过程,我们展示了缓存未命中时的操作步骤,以及如何从内存加载数据到缓存,并更新缓存的有效位和标签。后续相同地址的访问将更加高效,因为可以直接从缓存中读取数据。

读取地址 0x00008014
步骤 1:读取地址 0x00008014
地址解析
- 二进制表示:00000000000000001000000000010100
- 标签 (Tag):000000000000000010
- 索引 (Index):00000001
- 偏移量 (Offset):0100
检查缓存
- 在缓存中找到对应的索引 1 位置,检查有效位和标签是否匹配。
步骤 2:索引有效
缓存状态
- 索引 (Index):00000001
- 标签 (Tag):000000000000000010
- 有效位 (Valid bit):1
标签不匹配
- 当前索引 1 位置的标签为 000000000000000000,与目标标签 000000000000000010 不匹配。
步骤 3:从内存加载数据到缓存
内存加载
- 内存地址 0x00008014 对应的数据块被加载到缓存中。
- 数据块包含:i、j、k、l,分别对应内存地址 0x00008010、0x00008014、0x00008018、0x0000801C。
更新缓存
- 将数据块加载到索引 1 位置,并设置有效位为 1。
- 更新标签为 000000000000000010。
步骤 4:从缓存中读取数据
根据偏移量读取数据
- 在索引 1 的位置,标签匹配且有效位为 1。
- 根据偏移量 0100,从数据块中选择相应的字(word)读取。
- 读取到的数据字(word)为 j,对应内存地址 0x00008014。
步骤 5:返回数据
返回数据
- 将数据字(word)j返回给处理器。
- 处理器将读取的数据存储到目标寄存器中。
通过这个过程,我们展示了缓存未命中时的操作步骤,以及如何从内存加载数据到缓存,并更新缓存的有效位和标签。后续相同地址的访问将更加高效,因为可以直接从缓存中读取数据。
Do an example yourself. What happens?
从缓存中选择:命中,未命中,未命中且替换
返回的值:a, b, c, d, e, …, k, l
读取地址 0x00000030?
地址解析
- 二进制表示:00000000000000000000000000110000
- 标签 (Tag):000000000000000000
- 索引 (Index):00000011
- 偏移量 (Offset):0000
检查缓存
- 在缓存中找到对应的索引 3 位置,检查有效位和标签是否匹配。
- 当前缓存状态:
- 索引 3:有效位为 1,标签为 000000000000000000
- 数据块:包含 e、f、g、h,分别对应内存地址 0x00000030、0x00000034、0x00000038、0x0000003C
缓存命中
- 索引 3 的有效位为 1,且标签匹配。
- 根据偏移量 0000,读取数据 e 对应内存地址 0x00000030。
读取地址 0x0000001C?
地址解析
- 二进制表示:00000000000000000000000000011100
- 标签 (Tag):000000000000000000
- 索引 (Index):00000001
- 偏移量 (Offset):1100
检查缓存
- 在缓存中找到对应的索引 1 位置,检查有效位和标签是否匹配。
- 当前缓存状态:
- 索引 1:有效位为 1,标签为 000000000000000010
- 数据块:包含 i、j、k、l,分别对应内存地址 0x00008010、0x00008014、0x00008018、0x0000801C
缓存未命中
- 索引 1 的有效位为 1,但标签不匹配。
- 从内存中加载数据块包含 a、b、c、d,分别对应内存地址 0x00000010、0x00000014、0x00000018、0x0000001C。
- 更新缓存索引 1 的数据块,并设置有效位为 1,标签为 000000000000000000。
- 根据偏移量 1100,读取数据 d 对应内存地址 0x0000001C。
Answers
0x00000030 是一次命中
- 索引:3
- 标签匹配:是
- 偏移量:0,对应的值为 e
0x0000001C 是一次未命中
- 索引:1
- 标签不匹配:所以需要从内存替换
- 偏移量:0xC,对应的值为 d
因为是读取操作,无论是否缓存,值必须是内存值
- 0x00000030 = e
- 0x0000001C = d
内存数据
| 地址 (十六进制) | 单词值 |
|---|---|
| 00000010 | a |
| 00000014 | b |
| 00000018 | c |
| 0000001C | d |
| 00000030 | e |
| 00000034 | f |
| 00000038 | g |
| 0000003C | h |
| 00008010 | i |
| 00008014 | j |
| 00008018 | k |
| 0000801C | l |
通过这个过程,我们展示了缓存命中和未命中的操作步骤,以及如何从内存加载数据到缓存,并更新缓存的有效位和标签。后续相同地址的访问将更加高效,因为可以直接从缓存中读取数据。
Writes, Block Sizes, Misses
写入、块大小和未命中
多字块直接映射缓存
在这个图中,我们展示了一个具有多字块的直接映射缓存的结构。这里假设每个块包含四个字,并且缓存的总大小为 4K 字。
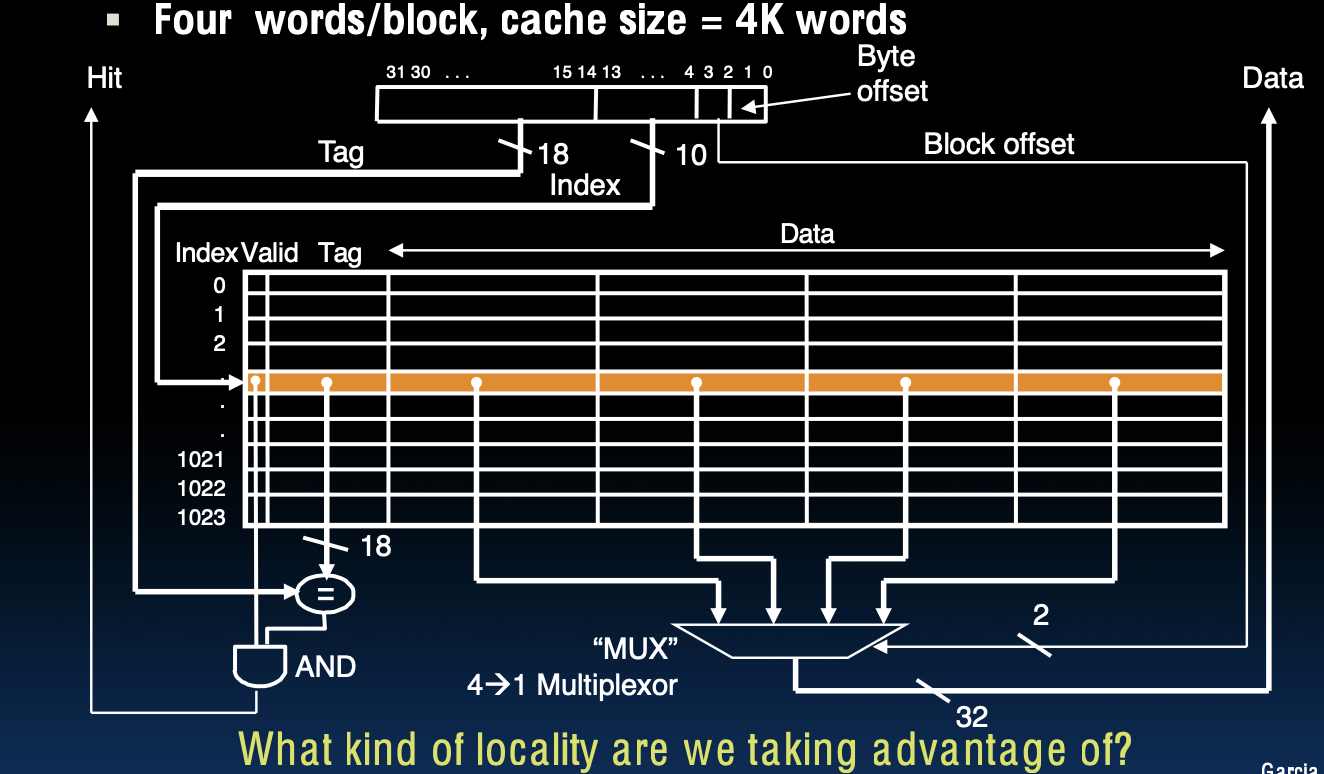
缓存结构解析
- 标签 (Tag):地址的高 18 位用于标签。
- 索引 (Index):地址的中间 10 位用于索引,确定数据在缓存中的具体位置。
- 块偏移 (Block Offset):地址的低 2 位用于块内偏移,确定具体字的位置。
操作过程
- 缓存命中 (Hit):
- 当访问某个地址时,首先通过地址的索引位找到缓存中的对应位置。
- 检查该位置的有效位 (Valid bit) 是否为 1,以确认该位置的数据是否有效。
- 如果有效,则比较标签,确定是否为所需的数据。
- 如果标签匹配,通过块偏移选择具体的字,并通过多路复用器 (MUX) 输出数据。
利用的局部性类型
这个缓存结构主要利用了 空间局部性 (Spatial Locality)。由于每个块包含多个字,当一个块被加载到缓存时,包含的多个连续地址的数据也被一起加载。因此,如果程序在短时间内访问了相邻的地址,则可以减少缓存未命中的次数,提高缓存命中率。
块大小的影响
增加块的大小可以进一步利用空间局部性,但也会带来一些问题:
- 优点:
- 更好地利用空间局部性。
- 减少缓存未命中时的内存访问次数,因为每次未命中会加载更多的数据。
- 缺点:
- 增加了每次缓存未命中时的开销,因为需要从内存中加载更多的数据。
- 如果程序的访问模式不具有空间局部性,则较大的块可能会浪费缓存空间。
写入策略
在多字块缓存中,写入操作也需要特殊处理:
- 写直达 (Write-through):每次写入缓存时,数据也会立即写入主存。
- 写回 (Write-back):数据仅写入缓存,当块被替换时,才会将数据写入主存。
写直达简单但可能导致较高的内存带宽消耗,写回则需要更多的控制逻辑以跟踪缓存块的修改状态。
通过这个多字块直接映射缓存的结构,我们可以更好地理解缓存如何利用局部性来提高访问速度,同时也要考虑块大小和写入策略对性能的影响。
What to do on a write hit?
写入命中时该做什么?
- Write-through (直写)
- 同时更新缓存和内存。
- Write-back (回写)
- 只更新缓存块中的字。
- 允许内存字变“陈旧”。
- 在块中添加“脏位”。
- 内存和缓存不一致。
- 当块被替换时需要更新内存。
- 操作系统在输入/输出前刷新缓存。
性能权衡?
- Write-through
- 优点:数据一致性好,易于实现。
- 缺点:每次写入都要访问内存,延迟较高。
- Write-back
- 优点:减少内存写入次数,提升性能。
- 缺点:复杂度增加,需要管理脏位,数据一致性稍差。
Block Size Tradeoff
块大小权衡
- 较大块大小的好处
- 空间局部性:如果我们访问一个字,很可能很快会访问到附近的其他字。
- 与存储程序概念非常适用。
- 对于顺序数组访问效果很好。
- 较大块大小的缺点
- 较大的块大小意味着较大的未命中惩罚。
- 在未命中时,从下一层加载新块所需的时间更长。
- 如果块大小相对于缓存大小过大,那么块太少。
- 结果:未命中率上升。
- 较大的块大小意味着较大的未命中惩罚。
Extreme Example: One Big Block
极端示例:一个大块
- 有效位 (Valid Bit):表示缓存块是否有效。
- 标签 (Tag):用于区分不同内存地址。
- 缓存数据 (Cache Data):存储实际的数据。

缓存大小 = 4 字节,块大小 = 4 字节
- 缓存中只有一个条目(行)。
- 如果访问了该条目,可能很快会再次访问。
- 但不太可能立即再次访问!
- 下次访问很可能又是未命中。
- 不断将数据加载到缓存中,但在再次使用前将其丢弃(强制退出)。
- 对缓存设计者来说是噩梦:乒乓效应。
Block Size Tradeoff Conclusions
块大小权衡结论
- 未命中惩罚 (Miss Penalty):随着块大小增加而增加。
- 未命中率 (Miss Rate):
- 利用空间局部性
- 块较少:损害时间局部性
- 平均访问时间 (Average Access Time):
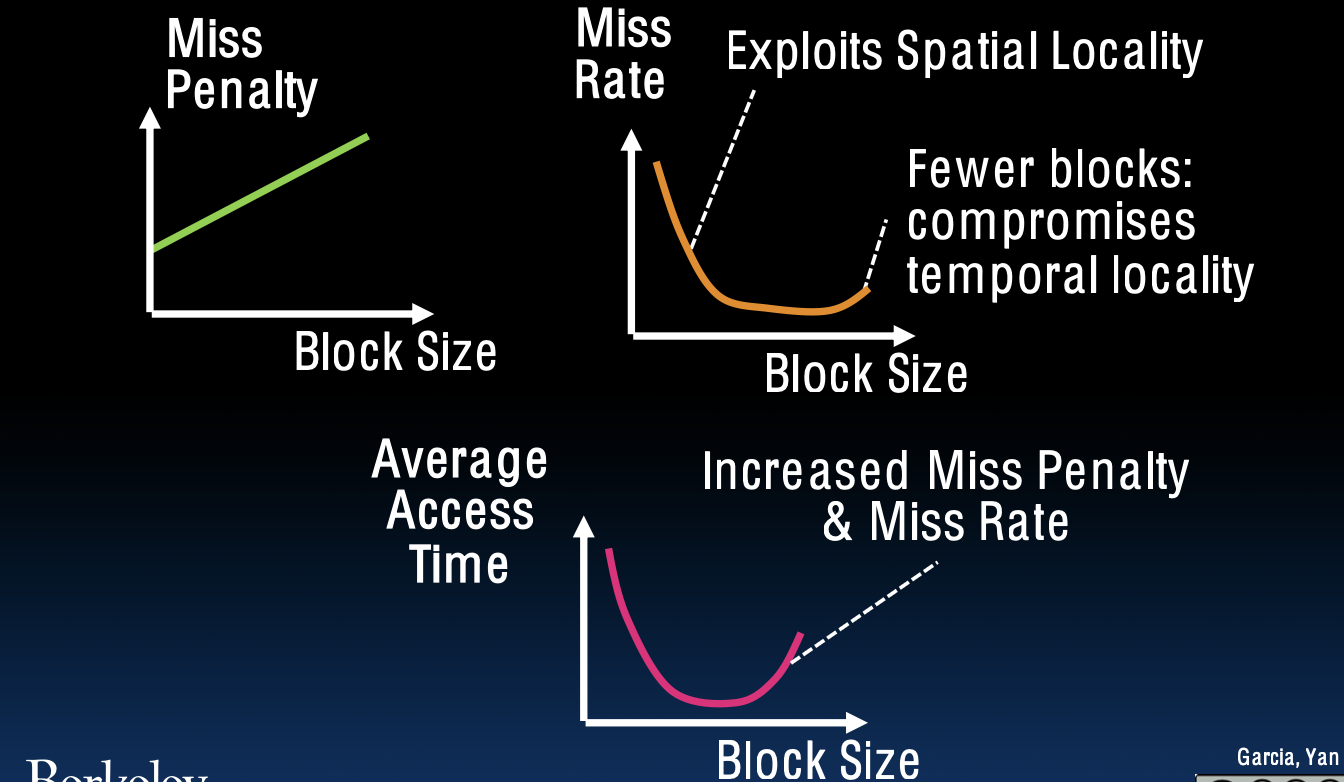
Types of Cache Misses (1/2)
缓存未命中的类型
- “Three Cs” Model of Misses
- 未命中模型的“三个C”
- 1st C: Compulsory Misses (第一类C:强制未命中)
- 描述:
- 发生在程序第一次启动时。
- 缓存不包含任何该程序的数据,因此未命中是必然的。
- 无法轻易避免,因此本课程不会专注于此类未命中。
- 重点:
- 每个内存块将有一次强制未命中(不仅仅是每个缓存块)。
- 描述:
强制未命中是由于数据第一次被访问时必然会发生的情况,因为缓存之前没有存储过这些数据。尽管这类未命中无法完全避免,但在实际应用中,通过优化数据访问模式和预取策略可以减少其影响。
Types of Cache Misses (2/2)
缓存未命中的类型
- 2nd C: Conflict Misses (第二类C:冲突未命中)
- 描述:
- 因为两个不同的内存地址映射到同一个缓存位置而发生的未命中。
- 两个映射到同一位置的块可能会不断地相互覆盖。
- 在直接映射缓存中是一个大问题。
- 问题:
- 如何减少这些未命中的影响?
- 描述:
- 处理冲突未命中
- 解决方案1:增大缓存大小
- 结果:
- 最终会失效。
- 结果:
- 解决方案2:多个不同的块可以适应同一个缓存索引?
- 解决方案1:增大缓存大小
冲突未命中发生在多个内存地址映射到同一个缓存位置的情况下,这会导致缓存频繁替换,降低命中率。解决冲突未命中的一个常用方法是使用组相联缓存(Set-Associative Cache),它允许多个块存储在同一组内,提高缓存利用率。另一个方法是增加缓存的大小,但这也会增加成本和能耗。
Fully Associative Caches
Fully Associative Cache (1/3)
全相联缓存
- 内存地址字段:
- 标签:与之前相同
- 偏移量:与之前相同
- 索引:不存在
- 这意味着什么?
- 没有“行”:任何块可以存储在缓存中的任何位置
- 必须与整个缓存中的所有标签进行比较,以查看数据是否存在
全相联缓存是一种缓存组织方式,其中每个内存块可以存储在缓存的任何位置。这种方式消除了冲突未命中,但需要将每个内存地址的标签与缓存中所有标签进行比较,增加了硬件复杂性和延迟。
Fully Associative Cache (2/3)
全相联缓存
- Fully Associative Cache (全相联缓存)
- 并行比较标签
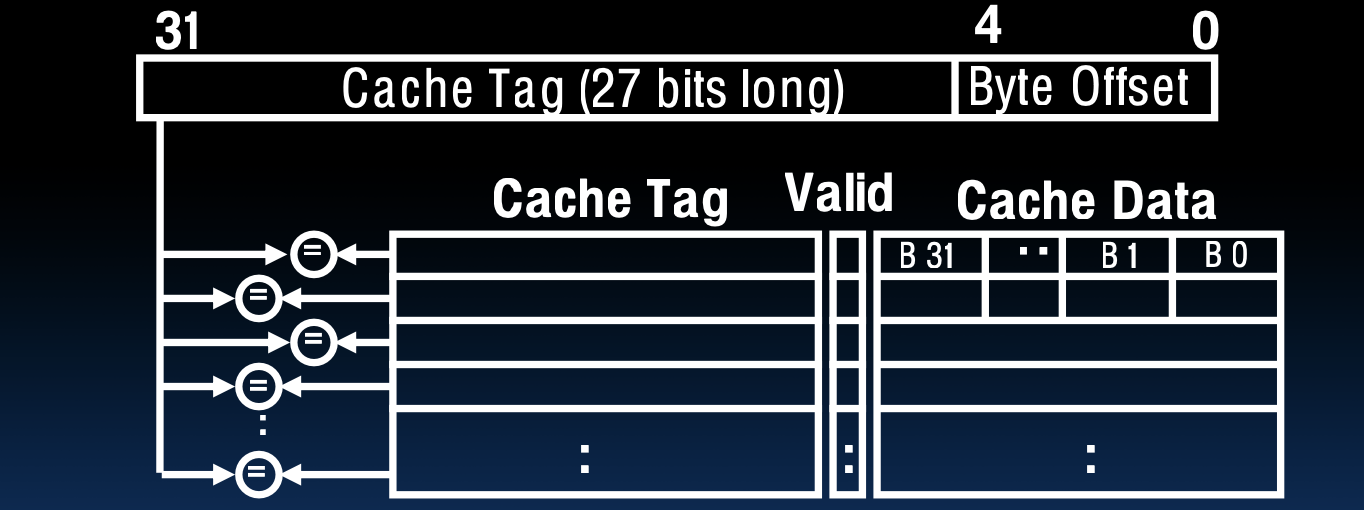
为了提高全相联缓存的性能,标签比较需要并行进行。这意味着每次访问缓存时,所有的标签比较操作同时进行,这样可以迅速确定是否命中。但是,这种并行比较需要复杂的硬件支持,并且随着缓存大小的增加,硬件需求也会急剧增加。
Fully Associative Cache (3/3)
全相联缓存
- 全相联缓存的优点
- 没有冲突未命中,因为数据可以存储在任何地方
- 全相联缓存的缺点
- 需要为每个条目提供硬件比较器
- 例如:如果我们有64KB的数据缓存,每个条目4B,我们需要16K个比较器;不可行
虽然全相联缓存消除了冲突未命中,但其硬件需求是一个巨大挑战。为了实现并行标签比较,每个缓存条目都需要一个独立的比较器,当缓存大小增加时,这种需求会迅速变得不可行。因此,全相联缓存一般只用于小型高速缓存,如一级缓存(L1 Cache)。
最后一类缓存未命中
3rd C: 容量未命中 (Capacity Misses)
- 定义:因为缓存大小有限而发生的未命中。
- 细节:如果我们增加缓存大小,这种未命中就不会发生。
- 描述:虽然定义有些模糊,但只需理解大概意思。
- 重要性:这是全相联缓存(Fully Associative caches)的主要未命中类型。
容量未命中是指由于缓存的容量有限,导致某些数据无法继续保存在缓存中,从而在需要访问这些数据时产生未命中。这在全相联缓存中尤其常见,因为虽然全相联缓存允许数据存储在缓存的任意位置,但一旦缓存被填满,新的数据将替换掉旧的数据,从而引发未命中。
如何分类未命中
分类方法
- 步骤:
- 无限大小的全相联缓存:首先,考虑一个无限大小的全相联缓存。对于现在发生的每个未命中,认为它是一个强制未命中 (compulsory miss)。
- 有限大小的全相联缓存:接下来,考虑一个你想检查的有限大小的缓存,仍然是全相联的。每个未命中不是强制未命中的就是容量未命中 (capacity miss)。
- 有限大小的有限相联缓存:最后,考虑一个有限大小的、具有有限相联度的缓存。剩下的未命中即是冲突未命中 (conflict miss)。
通过上述步骤,可以有效地分类不同类型的未命中。首先,通过一个假设无限大小的缓存,去除掉由于数据首次加载引起的强制未命中。然后,通过一个有限大小的全相联缓存,识别出由于缓存大小有限导致的容量未命中。最后,通过有限相联的缓存,确定由于地址冲突引起的冲突未命中。这种方法帮助我们更清晰地理解和分析不同类型的缓存未命中现象。
缓存大小与块大小的关系
- 缓存大小不变,块大小增大:块大小越大,命中率越低。因为较大的块可能导致缓存中较少的块数量,从而增加未命中率。
- 代码优化:了解计算机的缓存大小可以让你的代码运行更快。你可以通过优化代码,使得访问模式更好地利用缓存。
- 空间局部性:意味着最近使用的数据会被保存在离处理器更近的地方,这样可以更快地访问。
在编写代码时,如果了解缓存的大小和块大小,可以通过调整数据结构和访问模式来最大化缓存的使用效率。例如,数组的顺序访问可以更好地利用空间局部性,从而减少缓存未命中的次数。
总结
步骤:
- T I O 位划分,转到索引 = I,检查有效位
- 如果有效位为0,加载块,设置有效位和标记(强制未命中),并使用偏移量返回正确的数据块(1,2,4字节)。
- 如果有效位为1,检查标记。
- 如果标记匹配(命中),使用偏移量返回正确的数据块。
- 如果标记不匹配(冲突未命中),加载块,设置有效位和标记,并使用偏移量返回正确的数据块。
在缓存中,当需要访问某一数据时,首先根据地址将其划分为 T I O 三部分,其中 T 是标记(Tag),I 是索引(Index),O 是偏移量(Offset)。根据索引找到缓存中的对应行,然后检查有效位(Valid bit)和标记(Tag)。如果有效位为0,表示该行没有有效数据,需要从主存中加载数据;如果有效位为1,且标记匹配,则表示命中,可以直接返回数据;如果标记不匹配,则表示发生冲突未命中,需要替换缓存中的数据块。通过这种方式,缓存系统可以高效地管理和访问数据,提高整体系统的性能。