Lecture 29: Parallelism I: Thread-level Parallelism
Parallel Computer Architectures
并行计算机体系结构
软件层次的并行
- 软件层面的并行请求:多个请求同时发送给计算机处理,例如搜索“Cats”。
- 在大规模数据处理或搜索引擎中,多个用户请求可以同时处理,以提高响应速度和系统吞吐量。
- 并行线程(本节内容):多个线程同时分配给计算机核心进行处理,例如查找、广告。
- 多线程技术可以充分利用多核处理器的资源,提高计算效率。例如,现代浏览器通过多线程加载页面元素,实现快速渲染。
- 并行指令:每个时刻处理多条指令,例如,流水线处理的5条指令。
- 流水线技术通过将指令分解成多个阶段,并行处理不同阶段的指令,从而提高处理器的整体执行效率。典型应用包括指令级并行(ILP)和超标量处理器。
- 并行数据:每个时刻处理多条数据,例如同时处理4对字的加法。
- 向量处理器和SIMD(单指令多数据)架构利用并行数据处理技术,在图像处理、科学计算和机器学习等领域大大提升性能。
- 硬件描述的并行:所有逻辑门同时工作。
- 在硬件层面,电路设计中各个逻辑门并行工作,从而实现快速的信号传播和处理。这是硬件并行处理的基础。
并行处理的硬件结构
- 大型仓库级计算机(Warehouse Scale Computer):用于处理大规模并行任务,通常包含多个计算节点。
- 这种架构常用于云计算和数据中心,能够处理大规模数据和复杂计算任务,提供高可用性和可扩展性。
- 计算机核心和内存(Core, Memory):包括多个处理核心和层次化的内存结构。
- 现代处理器通过多核设计和层次化的缓存结构,优化数据访问速度和计算效率。
- 执行单元(Exec. Units)和功能块(Functional Blocks):执行具体的运算任务,如加法、乘法等。
- 在处理器内部,执行单元负责具体的计算操作,各种功能块根据需要调度和执行特定的指令。
- 主存储器和逻辑门(Main Memory, Logic Gates):负责数据存储和基本逻辑运算。
- 主存储器用于存储正在处理的数据和程序,逻辑门实现基本的逻辑运算和控制信号的生成。
并行计算机架构
独立计算机集群
多台独立的计算机通过网络(如以太网)连接在一起,形成一个计算集群。这种架构通常用于构建大型计算集群,如超级计算机或数据中心。这些计算机可以协同工作,处理大规模并行任务,通常通过消息传递接口(MPI)或其他并行计算框架进行通信与协调。
- 优点:具有高扩展性,适用于处理需要大量计算资源的问题。
- 缺点:通信开销较大,延迟较高,尤其是在处理需要频繁数据交换的任务时。
GPU (图形处理单元)
GPU是一种专门用于图形计算的处理器,设计之初主要用于处理图形渲染任务。由于其多数据路径设计,GPU非常适合执行大量的并行任务,如矩阵计算、图像处理和深度学习。
- 结构:GPU拥有数百到上千个计算核心,每个核心可以独立执行简单的计算任务。其架构通常采用SIMD(单指令多数据)或SIMT(单指令多线程)模型,能够在短时间内处理大量数据。
- 应用:除了图形处理,GPU现已广泛应用于科学计算、机器学习和人工智能领域,因其高并行处理能力而备受青睐。
多核CPU
多核CPU是在单个芯片上集成多个独立处理器核心的设计。每个核心可以独立执行指令,并有自己的寄存器、算术逻辑单元(ALU)、一级缓存(L1缓存)和二级缓存(L2缓存)。
- 结构:除了独立资源外,多核CPU通常还拥有共享资源,如三级缓存(L3缓存)和内存控制器。通过共享三级缓存,多个核心可以更高效地交换数据。
- 优势:多核CPU可以在并行处理任务时显著提高系统的性能,特别是在多任务环境或多线程应用中。
- 挑战:设计和管理多个核心的协作,特别是在内存一致性和缓存一致性方面,是多核架构的一大挑战。
示例:具有两个核心的CPU
处理器“核心”1和“核心”2
在一个双核处理器中,每个核心都是一个独立的处理单元,具备自己的控制单元、数据通路、寄存器和算术逻辑单元(ALU)。这些资源是核心独立拥有的,称为独立资源。每个核心可以独立执行自己的指令集,并与内存进行读写操作。
- 独立资源(不共享):
- 程序计数器(PC):每个核心有自己的PC,用于跟踪其执行的指令。
- 寄存器:每个核心有一组独立的寄存器,存储临时数据和计算结果。
- 算术逻辑单元(ALU):每个核心有自己的ALU,用于执行算术和逻辑运算。
- 一级缓存(L1缓存):高速缓存,仅供核心本身使用。
共享资源
尽管每个核心有自己的独立资源,但它们也共享一些系统资源,以提高整体系统效率。
- 三级缓存(L3缓存):通常在同一芯片上实现,供多个核心共享,用于存储常用数据,减少访问主内存的频率。
- 内存(DRAM):所有核心共享系统主内存。访问内存时,核心之间需要协调,以确保数据一致性和有效性。
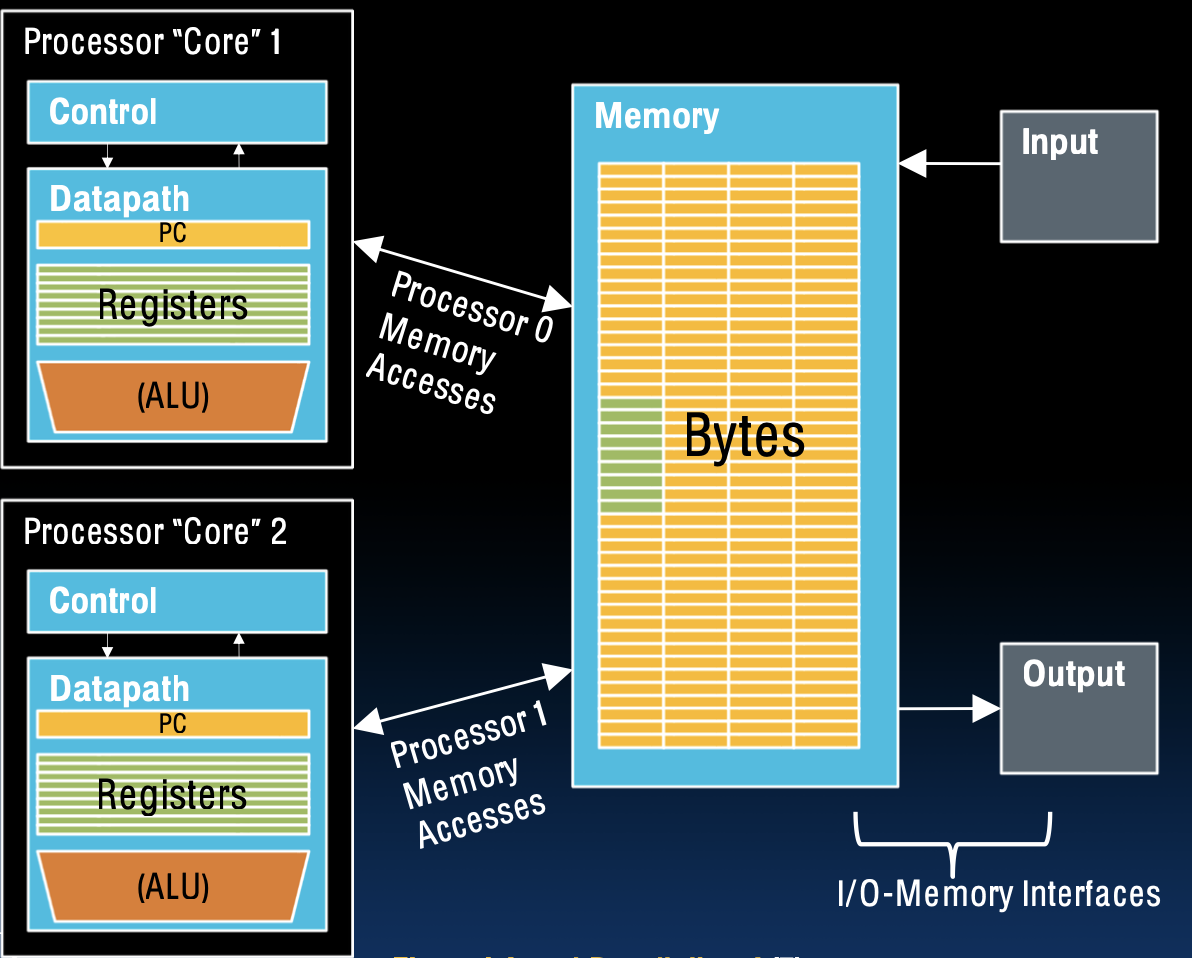
多处理器执行模型
在多处理器系统中,每个处理器(核心)执行自己的指令集,拥有独立的资源,同时共享部分资源(如L3缓存和主内存)。这种架构允许多个核心同时执行任务,实现并行计算,从而显著提高系统性能。
- 优点:多核处理器能够并行处理多个任务,提高系统的吞吐量和响应速度。
- 挑战:管理共享资源,确保缓存一致性和内存一致性,以避免竞争条件和数据冲突。
名称术语
多处理器微处理器和多核处理器描述了具有多个计算核心的处理器。
- 多处理器微处理器:通常指单个芯片上集成了多个完全独立的处理器。
- 多核处理器:指单个芯片上集成了多个处理器核心,每个核心可以独立执行任务。
例如,一个四核CPU能够同时执行四条不同的指令流,每个核心独立工作,但共享部分资源(如内存和三级缓存)。这种架构广泛应用于现代计算机和服务器中,能够有效提高系统的并行处理能力。
Multicore
过渡到多核
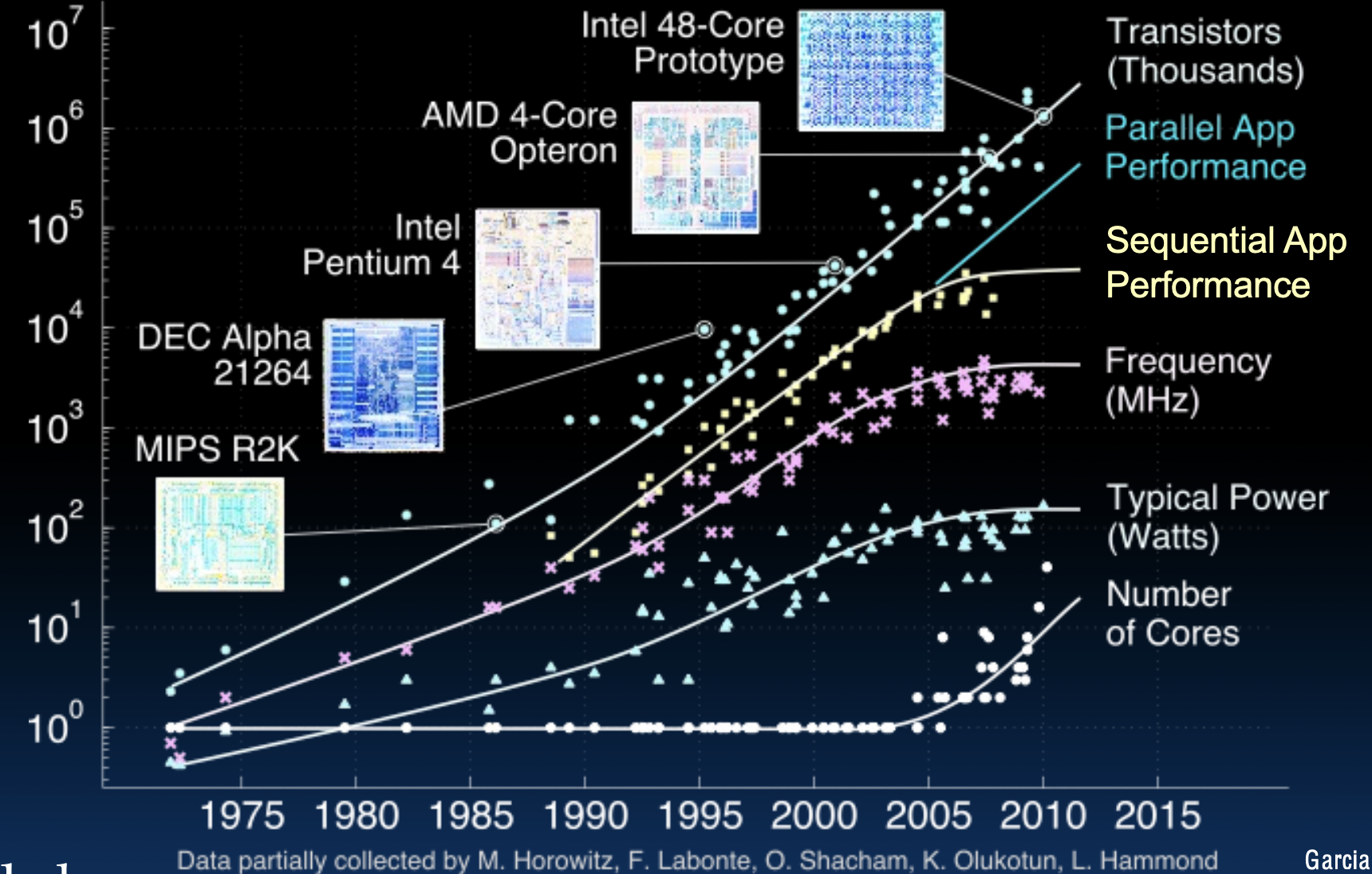
图表解释
这张图表展示了从1975年到2015年间处理器发展的一些重要趋势,主要包括以下几个方面:
-
晶体管数量:随着摩尔定律的推动,晶体管数量显著增加。每隔约两年,晶体管数量翻一番,这使得处理器可以拥有更多的功能和更强的计算能力。
-
并行应用性能:随着核心数量的增加,并行应用的性能大幅提升。这是因为多核处理器能够同时处理多个任务,从而加快并行计算的速度。
-
顺序应用性能:相比并行应用性能,顺序应用性能的提升速度较慢。这是因为单线程性能的提升越来越接近物理极限,难以进一步突破。
-
处理器频率:在早期,处理器频率的提高是提升性能的主要途径。然而,由于功耗和散热问题,频率的提升在2000年代中期逐渐放缓。
-
典型功耗:随着频率提升的放缓,功耗问题成为主要瓶颈。现代处理器在设计时必须考虑到功耗和散热,以避免过热和能效低下。
-
核心数量:多核处理器的引入是应对频率提升瓶颈的一种策略。通过增加核心数量,可以在不显著增加频率的情况下提升处理器性能。
这些趋势表明,现代处理器的发展已经从依赖于单核性能转向依赖于多核和并行计算能力。
Apple A14 芯片

Apple A14芯片是苹果在移动设备处理器领域的一项重大创新。以下是A14芯片的一些关键特性:
-
5纳米工艺:A14是全球首款采用5纳米工艺制造的芯片。这种先进的制造工艺使得芯片能够容纳更多的晶体管,从而提升性能和能效。
-
118亿个晶体管:A14芯片拥有118亿个晶体管,相比其前代产品显著增加。这使得芯片具备更强的处理能力和更丰富的功能。
-
6核CPU:A14配备了6个CPU核心,能够高效地处理多任务。它的设计包括两个高性能核心和四个高效能核心,能够在性能和能效之间取得平衡。
-
16核神经引擎:用于机器学习任务,每秒可执行11万亿次操作。神经引擎在A14中扮演了关键角色,尤其是在图像处理、语音识别和其他AI任务中。
-
4核GPU:A14还集成了一个4核图形处理单元,专为图形密集型任务设计,如游戏和高分辨率视频处理。
-
机器学习控制器和安全隔区:这些组件提高了芯片的安全性和专用任务处理能力,使得A14在复杂任务处理时表现出色。
A14芯片展示了多核架构和专用处理单元的结合如何推动现代移动设备在性能和功能上的持续进步。
多处理器执行模型
共享内存
在多核处理器中,每个核心都可以访问系统中的整个内存空间。这种共享内存架构由特殊硬件保持缓存一致性,从而简化了程序中的通信。共享内存架构的优势在于,它使得通过共享变量进行通信变得相对简单。然而,其主要缺点在于扩展性不佳,因为多个核心同时访问共享内存时,内存带宽可能成为性能瓶颈,这种瓶颈的严重性可以通过阿姆达尔定律来解释。
使用多处理器的两种方式
-
作业级并行:在这种模式下,每个核心处理完全独立的任务,任务之间没有通信。例如,在服务器环境中,不同的用户请求可以由不同的核心独立处理。
-
任务分割:将一个大任务分解成多个子任务,每个核心负责执行其中的一部分。例如,在矩阵乘法中,每个核心可以独立计算矩阵的一部分,最终结果由各核心的计算结果组合而成。
这种多处理器执行模型允许同时处理多个任务,大幅提升了计算效率和系统性能。
并行处理
并行处理的重要性
- 并行处理非常困难:并行计算的设计、编程和调试都充满挑战,尤其是在确保正确性和高效性方面。
- 并行处理不可避免:随着单核性能提升空间的减小,提升系统性能的唯一有效途径是通过并行计算。此外,并行处理能够显著降低功耗,这对于延长移动设备的电池寿命至关重要。
在移动系统中的应用(如智能手机、平板电脑)
现代移动设备普遍配备多个核心和专用处理器,以提高设备的性能和能效。
-
多个核心:允许设备同时处理多任务,从而提高响应速度和整体性能。
-
专用处理器:
- 运动处理器:专门处理设备中的传感器数据,如加速度计和陀螺仪的信号处理。
- 图像处理器(ISP):优化照片和视频质量,支持高分辨率拍摄和实时图像处理。
- 神经处理器:用于执行机器学习任务,如图像识别、自然语言处理和增强现实。
- GPU:专为图形渲染和并行计算设计,支持复杂的图形和视觉效果。
这些专用处理器使得现代移动设备能够以更高的效率处理特定任务,同时减少主处理器的负担,提高整体能效。
仓库规模的计算机(将在61C课程中详细讨论)
在大规模计算环境中,计算能力通过多个节点进行扩展,每个节点包含多个CPU和其他计算资源。
- 多个“节点”:
- 每个“节点”通常包含多核处理器、存储设备和网络接口,以便在分布式系统中协同工作。
- 这些节点内部可能包括多种并行处理架构,如MIMD(多指令多数据)和SIMD(单指令多数据,例如AVX指令集)。
这种架构广泛应用于数据中心、超级计算机和大型分布式系统中,支持高效的数据处理和复杂的计算任务。
潜在的并行性能(假设软件可以利用它)
处理器核心和SIMD位宽的演变
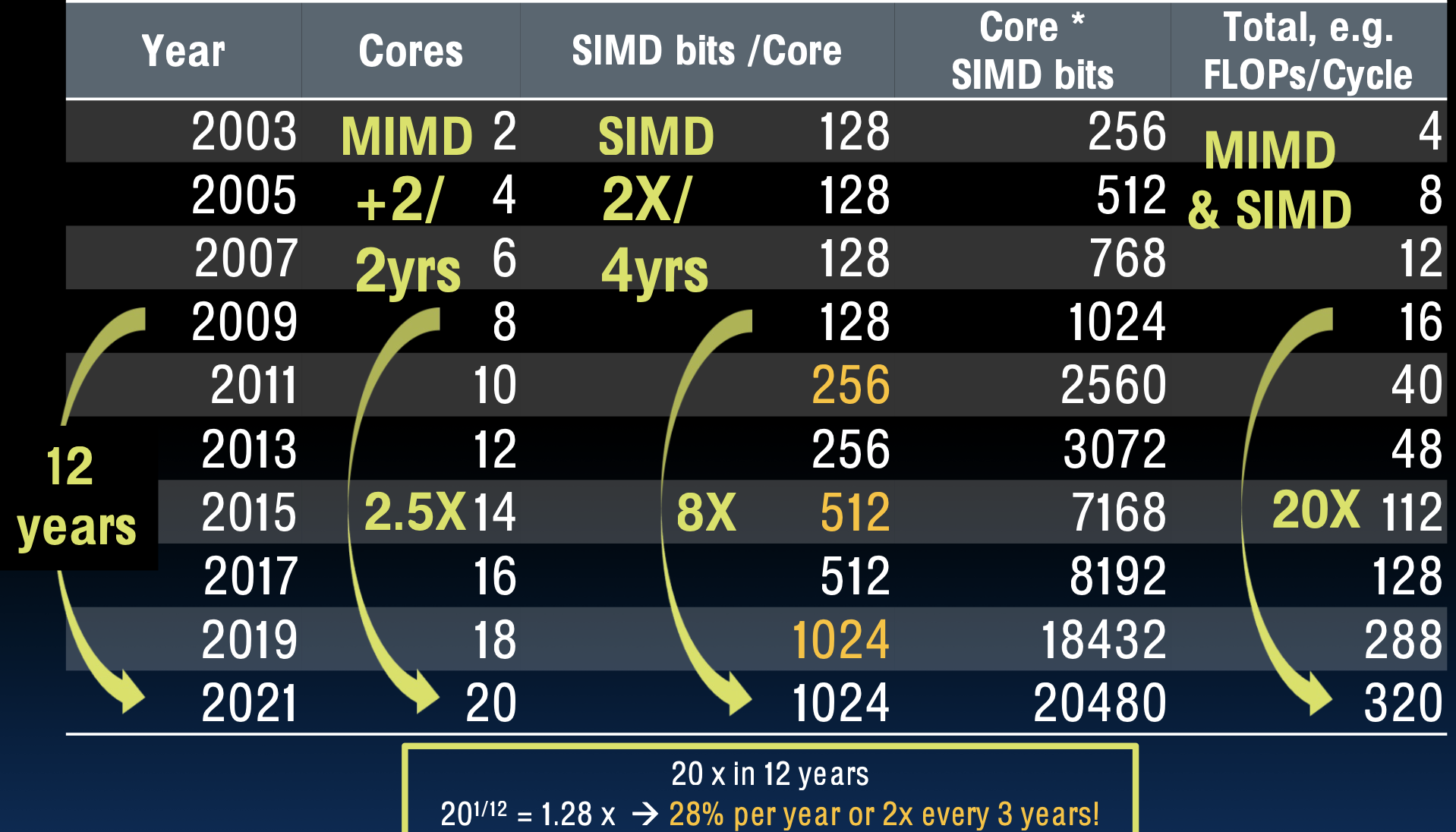
在12年内,核心数量和SIMD位宽的增长带来了20倍的性能提升。这相当于每年性能提高28%,或每三年性能翻倍(假设软件能够充分利用这些硬件性能)。
这种并行处理能力的增长使得现代计算机能够处理更复杂、更大规模的任务,如大数据处理、深度学习和科学计算等。
Threads
典型计算机上运行的程序
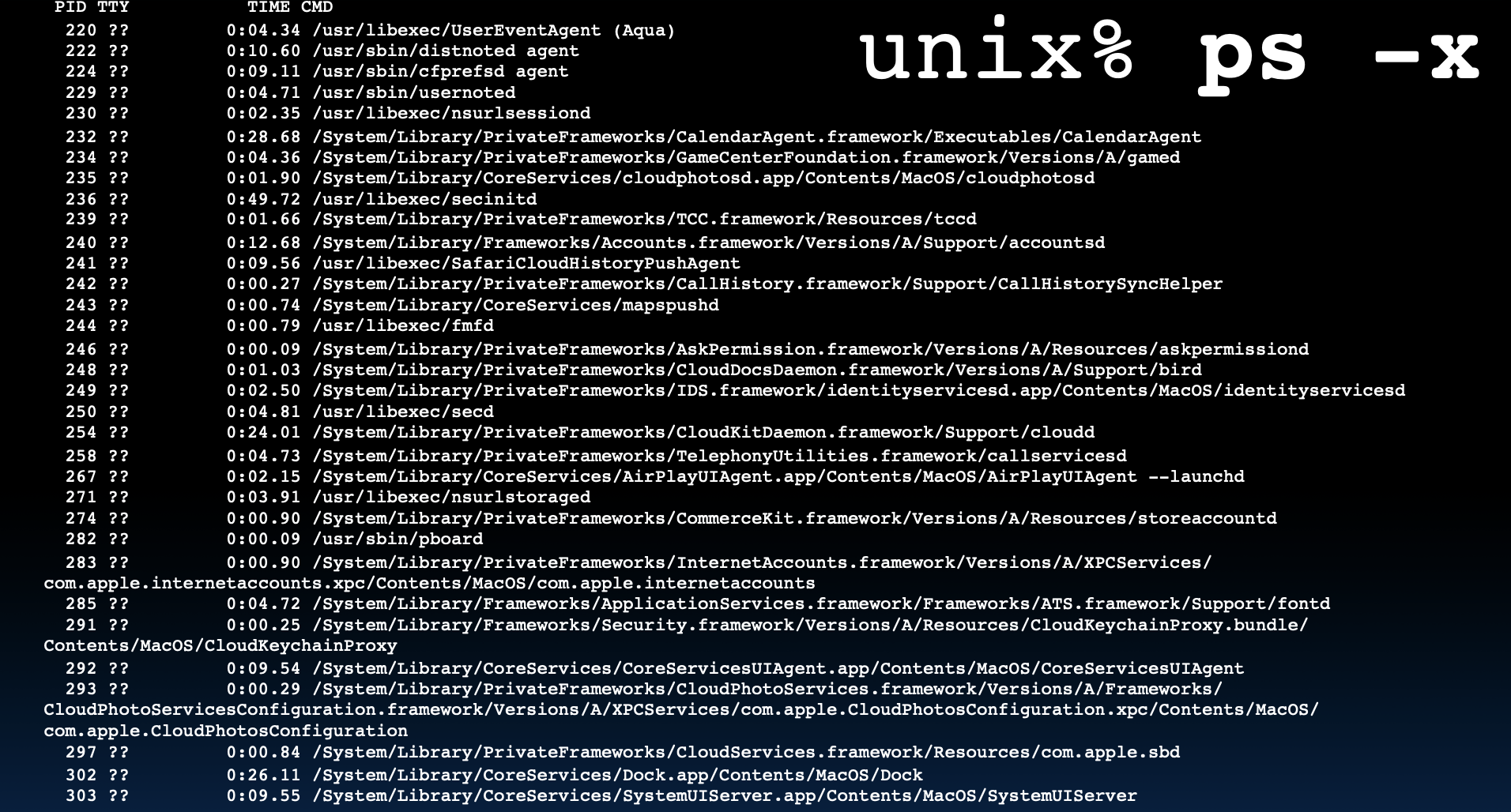
在典型的计算机上,可以同时运行多个程序。通过使用UNIX命令ps -x可以查看当前正在运行的进程列表。这些进程可能包括系统服务、用户应用程序以及后台任务。例如,在一个示例中,计算机正在运行156个进程。这种多任务处理的能力展示了现代计算机在不影响用户体验的情况下,同时处理多个任务的能力。这种并行性是通过操作系统的调度和管理来实现的,允许多个进程在计算资源之间共享执行时间。
线程(1)
- 线程:线程(Thread)是一个程序中独立的指令执行路径,可以认为是程序内的一个“执行线程”。每个线程都能独立执行,但与同一进程内的其他线程共享相同的内存空间。
- 一个程序或进程可以分裂或分叉成多个独立的线程,这些线程理论上可以同时执行。这种机制为并行计算提供了基础,允许程序更高效地利用多核处理器。
- 线程提供了一种更细粒度的并行性描述和实现方法,使得程序能够在多个任务之间并行工作。

- 时间共享:在单核心情况下,CPU通过时间共享技术来执行多个线程。这意味着CPU会在不同线程之间快速切换,以便让每个线程都能得到执行的机会,从而模拟并行处理的效果。
- 时间共享的实现依赖于操作系统的调度算法,通过分配时间片给每个线程,来管理多个线程的执行。
- 这种方法虽然在物理上并非真正的并行处理,但通过高速切换,用户感受到的是多线程的并行执行。
线程(2)
- 顺序指令流:每个线程可以看作是一个顺序指令流,用于执行特定的任务。传统上我们会将一个这样的指令流视为一个“程序”。
- 线程的执行是顺序的,意味着每个指令都会按顺序执行,但多个线程之间的执行顺序可能会交错,这导致了并发执行的复杂性。
- 每个线程具备:
- 独立的程序计数器(PC):每个线程有自己的程序计数器,用于跟踪它当前正在执行的指令。
- 独立的寄存器:每个线程有自己的一组寄存器,用于保存临时数据和状态。
- 共享内存的访问权限:尽管每个线程有独立的寄存器,但它们共享相同的内存地址空间,这意味着它们可以相互访问和修改相同的数据。
- 每个物理核心提供一个或多个:
- 硬件线程:硬件线程是由物理核心提供的实际执行单元,负责执行指令。
- 软件线程:软件线程是由操作系统管理的,硬件线程实际执行这些软件线程中的指令。
- 操作系统的作用:
- 操作系统通过调度技术将多个软件线程映射到可用的硬件线程上。这个过程称为多路复用。
- 操作系统的调度算法决定了哪个线程在任何时刻被分配到硬件线程上执行,未分配到硬件线程的线程会处于等待状态。
这些内容强调了线程在现代计算机系统中的重要性,特别是在多任务处理和并行计算中的作用。操作系统通过线程管理和时间共享技术,确保多个任务可以高效并行执行,提高了计算机的整体性能和响应能力。
对线程的思考
“虽然线程看起来只是从顺序计算迈出的一个小步骤,但实际上它们代表了一个巨大的飞跃。它们舍弃了顺序计算最本质和最具吸引力的特性:可理解性、可预测性和确定性。线程作为一种计算模型,是高度不确定的,程序员的工作变成了修剪这种不确定性。”——Edward A. Lee,UC Berkeley,2006
Edward A. Lee的这段话强调了线程引入了计算模型中的非确定性。在线程并行执行的环境下,线程间的执行顺序并不是固定的,这使得程序的行为难以预测。线程之间的竞争条件、死锁和资源争夺等问题给编程带来了挑战。为了解决这些问题,程序员需要设计并发算法,使用同步原语(如锁、信号量)来控制线程的执行顺序,以减少竞争条件和不确定性,确保程序的正确性和稳定性。
这种非确定性使得线程编程变得复杂和难以调试,因为程序可能在每次运行时表现出不同的行为。因此,掌握并发编程的技术对于现代程序员来说尤为重要,以确保在并行环境下能够编写高效且可靠的程序。
操作系统线程
操作系统通过多路复用软件线程到硬件线程来创造出多个“同时”活动线程的假象。以下是操作系统管理线程的主要步骤和方法:
- 多路复用软件线程到硬件线程:
- 当某个线程被阻塞(如遇到缓存未命中、等待用户输入或网络访问)时,操作系统会将其从硬件线程中切换出来。
- 使用计时器(例如,每1毫秒)切换活跃线程,确保每个线程都能获得执行时间,从而实现多任务处理。
- 从硬件线程中移除软件线程:
- 当操作系统决定暂停某个线程的执行时,它会中断该线程的执行,将当前线程的寄存器状态和程序计数器(PC)保存到内存中。
- 开始执行不同的软件线程:
- 操作系统从内存中加载之前保存的寄存器状态和PC到硬件线程中,然后继续执行新的线程。
这些操作使操作系统能够高效地管理多个线程,实现并行处理,提高系统的资源利用率和整体性能。
示例:四核心处理器
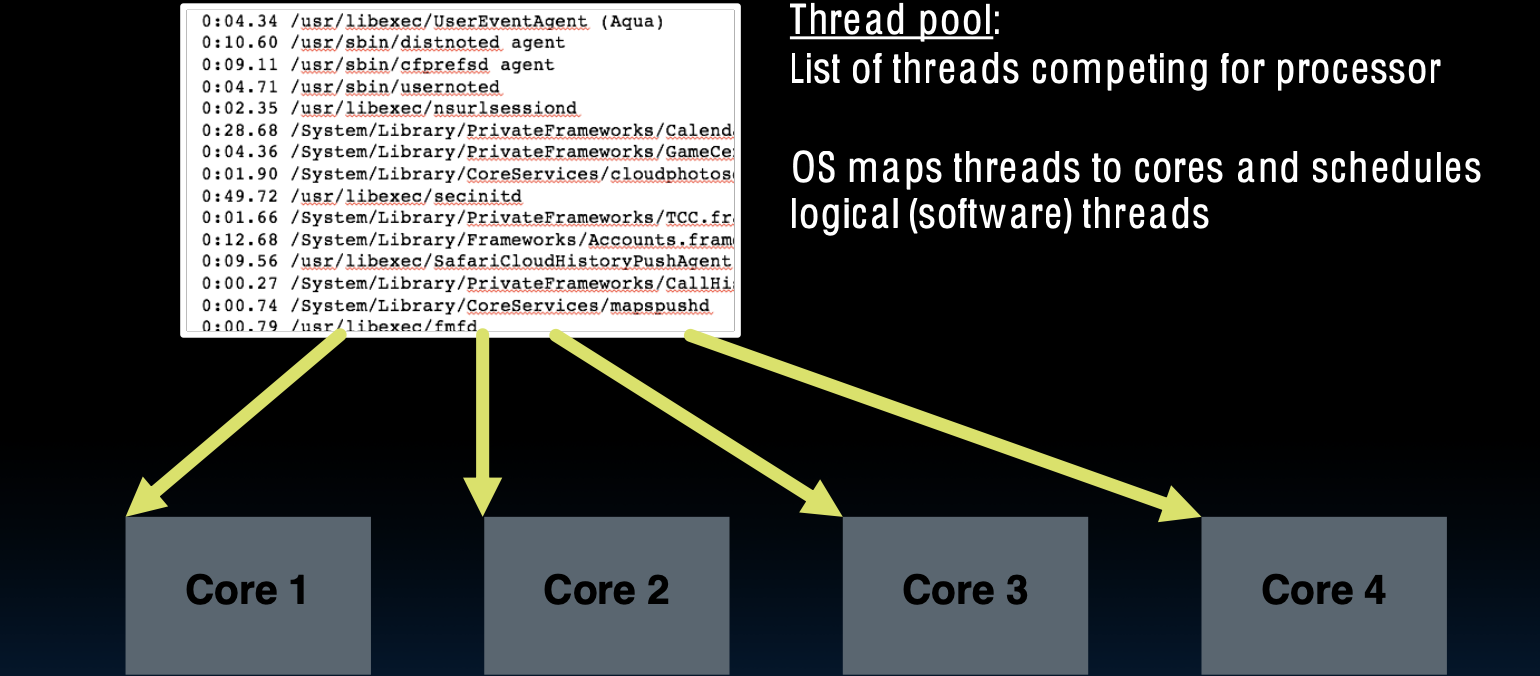
在一个四核心处理器中,操作系统管理着一个包含多个线程的线程池。每个核心可以同时积极运行一个指令流,操作系统根据每个线程的优先级和资源需求,将线程分配到不同的核心上执行。
- 每个核心可以独立处理一个线程,因此在四核心处理器上,最多可以同时并行运行四个线程。
- 操作系统负责调度线程,确保所有核心都能被充分利用,最大化系统的并行处理能力和性能。
- 这种多线程、多核心的架构使得计算机能够高效地处理多个任务,提升了整体的计算能力和响应速度。
Multithreading
多线程
典型场景:
- 缓存未命中:当活动线程访问缓存失败,必须等待约1000个周期从DRAM获取数据。
- 线程切换:为了避免处理器闲置,系统切换出当前线程,执行其他线程直到数据可用。
面临的问题:
- 状态保存和恢复:每次切换线程时,必须保存当前线程的状态(包括程序计数器和所有寄存器),并加载新线程的状态。这一操作必须在远少于1000个周期内完成,以确保效率。
硬件能否帮助?
- 摩尔定律:随着晶体管数量的增加,处理器中可以集成更多的硬件资源,这为硬件支持多线程提供了可能性。
在这种情况下,硬件支持的多线程技术(如超线程技术)通过在硬件中同时保存多个线程的状态来减少线程切换的开销。当一个线程被阻塞时,处理器可以快速切换到另一个线程,而不需要频繁地保存和恢复状态,这显著提高了处理器的利用率和整体性能。
硬件辅助的软件多线程
描述
- 处理器架构:
- 在一个核心中,硬件可以包含两个独立的程序计数器(PC)和寄存器文件,使其能够同时处理两个线程。
- 对于操作系统和应用程序,这样的处理器看起来像两个独立的处理单元(即硬件线程0和硬件线程1)。
- 超线程技术(Hyper-Threading):
- 通过在硬件中支持多个线程的并行执行(例如,Intel的超线程技术),可以使得两个线程在一个物理核心上同时处于活动状态。
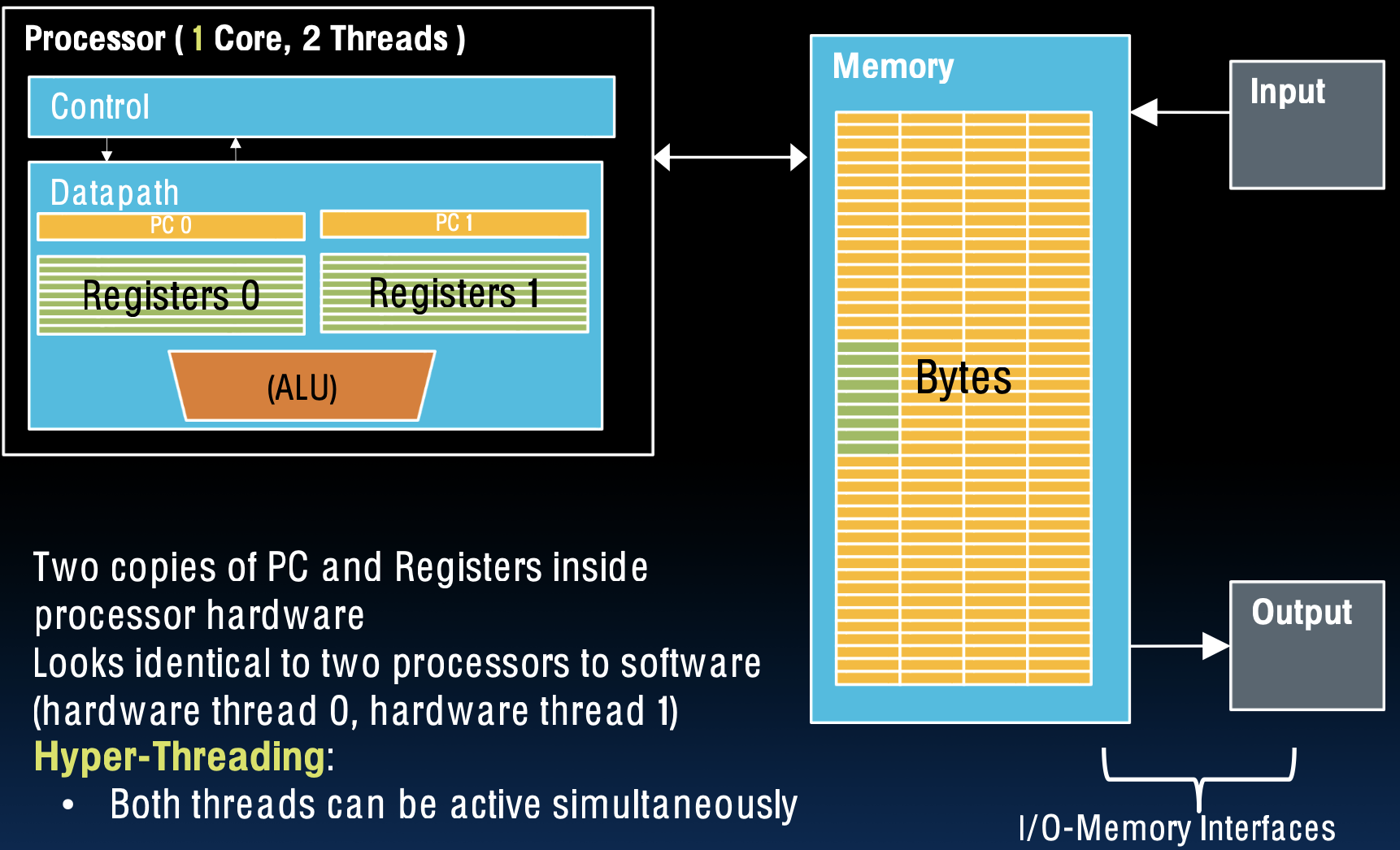
通过这种硬件辅助的多线程技术,单个处理器核心可以并行执行多个线程。这不仅提高了处理器的资源利用率,还减少了因缓存未命中等长延迟操作导致的等待时间。结果是整体系统性能和响应能力得到了显著提升,尤其是在处理多任务或并行计算时。
超线程技术
超线程技术(Hyper-Threading Technology,HT)是一种用于提高处理器效率的技术,它允许每个物理核心同时运行多个线程。在操作系统看来,逻辑CPU的数量多于实际的物理CPU数量,这使得系统能够更高效地利用处理器资源。
同时多线程(HT)的工作方式
-
每个核心同时运行多个线程:在有超线程技术的处理器中,每个物理核心能够同时处理多个线程,这些线程共享核心中的执行资源。
-
每个线程有自己独立的架构状态:每个线程拥有自己的程序计数器(PC)、寄存器文件等独立的架构状态。即使多个线程共享同一个物理核心,它们仍然保持彼此独立的执行状态。
-
共享资源:多个线程共享核心中的某些资源,如缓存、指令单元和执行单元。这种共享可以在不显著增加硬件成本的情况下提高处理器的资源利用率。
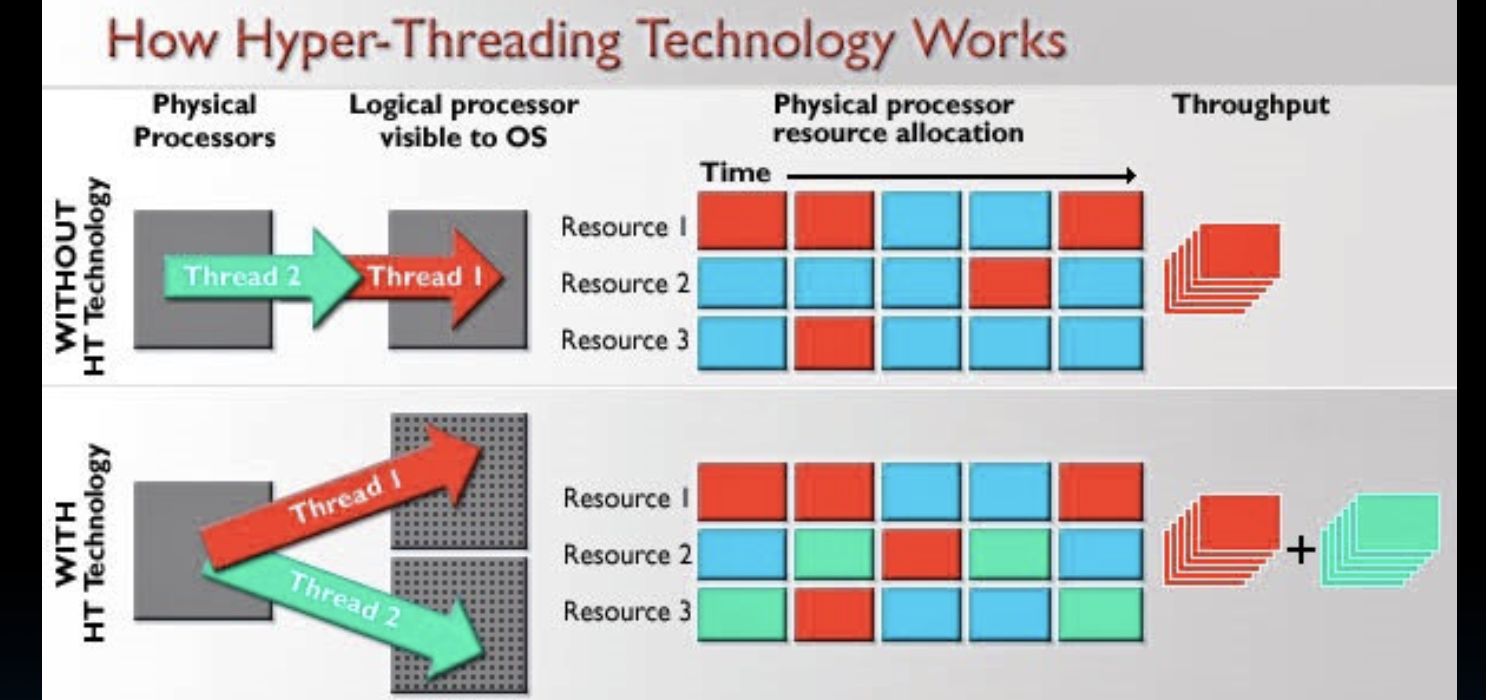
-
没有HT技术时:在没有超线程技术的处理器中,每个核心只能运行一个线程。在这种情况下,核心的资源利用率可能较低,尤其是在单个线程无法充分利用所有资源的情况下。
-
使用HT技术时:当启用超线程技术时,每个核心可以同时运行两个或更多线程。这种并行处理增加了资源利用率,减少了处理器的闲置时间,并提高了整体吞吐量和性能。
多线程
逻辑线程
-
硬件需求:增加一个逻辑线程通常只需要大约1%的额外硬件支持,因为多个逻辑线程共享核心中的大部分资源。
-
性能提升:尽管硬件增加有限,但启用多线程通常可以带来大约10%的性能提升。这主要得益于更高的资源利用率,特别是在处理器等待内存或执行其他长延时操作时,另一个线程可以继续执行,避免核心闲置。
-
独立的寄存器:每个逻辑线程拥有独立的寄存器文件,这使得它们可以独立执行任务而不会互相干扰。
-
共享的资源:如数据通路、算术逻辑单元(ALU)和缓存等资源在逻辑线程之间共享,最大化了硬件的使用效率。
多核心
-
实际的处理器复制:与逻辑线程不同,多核心架构实际上是在单个处理器芯片上集成多个独立的处理核心,每个核心可以独立运行。
-
硬件需求:多核心通常需要大约50%的额外硬件,因为每个核心都包含完整的计算资源。
-
性能提升:多核心架构通常可以提供接近两倍的性能提升,因为多个核心可以完全并行地执行不同的任务。
现代机器的做法
现代计算机通常结合使用多核心和多线程技术。每个物理核心支持多个逻辑线程,从而在同一个处理器中实现更高的并行度和资源利用率。这种设计极大地提高了计算性能,特别是在处理多任务或并行计算时效果显著。
Dan的笔记本电脑(参见活动监视器)
通过命令sysctl hw可以查看系统的硬件信息,例如:
-
物理CPU核心数:4:表示该处理器有四个物理核心。
-
逻辑CPU核心数:8:通过启用超线程技术,每个物理核心能够同时运行两个线程,因此总共有8个逻辑核心。
解释
这台笔记本电脑的配置显示出现代处理器架构的典型特征——结合了多核心和超线程技术。四个物理核心通过超线程技术变为八个逻辑核心,使得系统在多任务处理能力和整体计算性能上大大提升。这种架构能够有效处理复杂的计算任务,同时保持较高的能效。
Intel® Xeon® W-3275M处理器
技术规格
- 核心数量:28个
- 线程数量:56个
- 基础频率:2.50 GHz
- 最大睿频:4.40 GHz
- 缓存:38.5 MB
- 总线速度:8 GT/s
- 热设计功耗(TDP):205W
- 上市日期:2019年第二季度
- 制程工艺:14纳米
这款处理器是专为工作站设计的高性能处理器,具有28个物理核心,通过超线程技术可以支持56个逻辑线程。高缓存容量和高总线速度使其能够在高负载情况下保持出色的性能表现。TDP表示处理器在高复杂度工作负载下运行时的平均功耗,为205W。
示例:6核,24逻辑线程
线程池
- 列出竞争处理器的线程列表
- 操作系统将线程映射到核心,并调度逻辑(软件)线程

- 每个核心有4个逻辑线程(硬件线程)
在这个示例中,每个物理核心可以支持4个逻辑线程,使得总共有24个逻辑线程。这种多线程技术提高了处理器的利用率,使其在处理并发任务时表现更为出色。
复习:定义
线程级并行(Thread Level Parallelism, TLP)
- 线程(Thread):线程是一系列指令的顺序执行单元,每个线程有自己的程序计数器(PC)和处理器状态(如寄存器文件)。线程级并行是通过同时执行多个线程来提高处理器性能的一种方法。
多核处理器(Multicore)
-
物理CPU(Physical CPU):每个物理CPU核心一次只能执行一个线程。当线程因I/O事件(如磁盘读/写)阻塞时,操作系统会在多个线程之间切换。
-
逻辑CPU(Logical CPU):在多核处理器中,每个物理核心可以通过超线程技术(Hyper-Threading, HT)支持多个逻辑线程。硬件可以在细粒度级别上进行线程切换,例如,当线程因缓存未命中或内存访问而阻塞时,硬件会切换到另一个可运行的线程。
-
超线程技术(Hyper-Threading, HT):超线程技术允许在同一个物理核心上同时执行来自不同线程的指令流。这利用了处理器的超标量架构,通过同时发射多个指令,提高资源利用率和并行处理能力。
线程级并行的核心思想是通过并行执行多个独立线程来加速处理器的工作。在现代多核处理器中,每个物理核心不仅可以独立处理任务,还可以通过超线程技术进一步分解成多个逻辑线程,从而增强并行处理的效果。
多核计算对软件和硬件设计师的挑战
随着多核处理器的普及,设计高效的并行程序和优化硬件架构成为主要挑战。这些挑战包括:
-
控制(Control):管理多个线程或进程的执行顺序和同步,确保并行任务之间的正确协调。
-
数据路径(Datapath):设计有效的数据路径以支持并行操作,确保多个核心能够高效访问和处理数据。
-
内存(Memory):处理器核之间需要高效共享和访问内存资源,避免内存瓶颈对性能的影响。
-
输入/输出(Input/Output):优化I/O操作,使得多核系统能够高效处理并发I/O请求,减少等待时间。
总结
顺序软件执行速度的限制
- 时钟速率的平稳或下降:过去,单核处理器的性能提升主要依赖于时钟速度的增加。然而,随着技术进步的放缓和功耗限制的影响,时钟速率的增长已经趋缓甚至停滞。单纯依靠提升时钟速率来提高处理器性能的时代已经结束。
并行化是提高性能的唯一途径
SIMD:数据级并行(Single Instruction, Multiple Data)
-
应用:SIMD技术通过在单条指令下并行处理多个数据,实现高效的向量计算。这种技术已被广泛应用于现代高性能CPU(如x86和ARM架构)中。
-
编译器支持:部分SIMD操作可以通过编译器优化实现,但仍然需要程序员的优化以充分利用硬件能力。
-
性能提升:SIMD技术的引入和改进通常每2-3年带来性能的翻倍,使其成为现代处理器性能提升的关键因素之一。
MIMD:线程级并行(Multiple Instruction, Multiple Data)
-
多核处理器:MIMD架构依赖于多核处理器的能力,通过让每个核心执行独立的指令流,实现真正的并行计算。
-
操作系统支持:操作系统负责将任务分配到多个核心,并管理线程之间的调度和同步。
-
程序员干预:虽然硬件和操作系统支持MIMD架构,但程序员仍需要编写并行程序或使用并行编程模型,以充分利用多核处理器的潜力。
SIMD和MIMD组合实现最大性能
- 示例:像Intel Xeon W-3275这样的处理器结合了SIMD和MIMD技术,拥有28个物理核心和56个线程,通过同时执行大量并行任务,实现了极高的计算性能。
关键挑战:编写高性能的并行程序
随着处理器核心数量的增加,编写能够在多处理器上高效运行的并行程序成为主要挑战。需要解决的问题包括:
-
调度:如何有效地分配任务到不同核心,以避免资源争夺和性能下降。
-
负载平衡:确保每个核心承担合理的工作量,避免某些核心过载而其他核心空闲。
-
同步时间:减少线程间同步的开销,避免在等待和通信上浪费大量时间。
-
通信开销:优化数据在核心之间的传递,减少由于通信导致的延迟。
通过解决这些挑战,程序员和硬件设计师可以更好地利用多核处理器的优势,显著提高应用程序的性能。
最后的趣味示例
四种逻辑门(OR、AND、XOR、NAND、NOR、XNOR)的“万圣节要糖”示例展示了不同逻辑操作的视觉化表达方式,这些图示幽默地展示了逻辑门的基本功能。
最近的内容开始接近操作系统的领域,特别是在讨论线程管理、超线程技术、多核处理器的调度和并行计算时。这些主题涉及到操作系统如何与硬件协同工作,以优化系统性能和资源利用。这些内容包括:
线程管理与多任务处理:操作系统如何调度和管理多个线程以实现并行处理,这涉及到时间共享、多路复用等操作系统技术。
硬件辅助的多线程:超线程技术、逻辑CPU和物理CPU的概念,这些是硬件提供的功能,但如何高效利用这些功能则是操作系统的责任。
多核处理器的调度:操作系统如何在多核处理器上分配任务,以实现高效的并行计算和资源管理。
早期的内容更侧重于硬件层面,讨论了处理器结构、内存层次结构、缓存管理等。这些涉及计算机系统的硬件设计和优化策略,属于计算机体系结构的范畴。
随着话题的深入,自然地过渡到了操作系统的角色,因为操作系统是连接硬件与应用软件的重要桥梁。它负责管理硬件资源,并向软件提供抽象,以简化编程并优化系统性能。因此,硬件与操作系统的内容经常是密切相关的,在讨论如何提升计算性能时,两者的界限也会变得模糊。
总结来说,硬件和操作系统的关系是紧密相连的,特别是在高性能计算、并行处理等领域,理解操作系统如何利用硬件特性来提升性能是非常重要的。