Lecture 27: Caches - Set-associative, Performance with Caches
Set-Associative Caches
N-Way 组相联缓存(1/3)
内存地址字段:
- 标记(Tag):用于识别缓存行中的唯一数据,确保数据的唯一性。
- 偏移量(Offset):用于确定缓存行内的具体字节位置。
- 索引(Index):用于指向正确的“行”(在N-Way组相联缓存中称为“集合”)。
那有什么不同?
-
每个集合包含多个块
-
一旦找到正确的集合,必须与该集合中的所有标记进行比较以找到数据
-
总大小 = 缓存中集合的数量 x 每集合的块数 x 块大小
-
每集合的块数:每个集合中包含的缓存块(cache block)的数量,即N-Way中的N。
块大小:每个缓存块的大小,通常以字节为单位。
-
在N-Way组相联缓存中,内存地址被分成三部分:标记、索引和偏移量。索引用于找到缓存中的一个集合,每个集合包含多个块。在集合中查找时,需要比较该集合中所有块的标记以确定数据是否存在。这种方式相比直接映射缓存可以减少冲突未命中的发生,因为一个集合中可以存储多个块。
在N-Way组相联缓存中,内存地址被分成三部分:标记、索引和偏移量。
索引:用于找到缓存中的一个集合(Set)。每个集合包含多个块(Block)。
集合中的块:一旦找到正确的集合,必须与该集合中的所有块的标记进行比较以找到数据。也就是说,在一个集合中,可以有多个缓存块来存储数据,从而减少冲突未命中的发生。
标记比较:在找到集合后,需要逐一比较集合中所有块的标记,以确定是否存在所需的数据。
这种缓存组织方式相比直接映射缓存(Direct Mapped Cache)可以显著减少冲突未命中的发生,因为一个集合中可以存储多个块,这样在不同的数据块映射到相同索引时,可以存储在同一个集合的不同块中,而不会覆盖之前的数据。
举例说明
假设有一个缓存:
- 总大小为32KB。
- 块大小为64字节。
- 4-Way组相联(即每个集合有4个块)。
计算缓存参数:
- 缓存块数:总块数 = 总大小 / 块大小 = 32KB / 64B = 512块。
- 集合数:集合数 = 总块数 / 每集合的块数 = 512块 / 4块 = 128集合。
因此,缓存的大小可以表示为: \[ 32KB = 128 \text{集合} \times 4 \text{块/集合} \times 64 \text{字节/块} \]
在这种情况下,内存地址分为:
- 标记:用于唯一识别一个数据块。
- 索引:用于找到128个集合中的一个。
- 偏移量:用于找到每个块内的具体位置(64字节内的具体字节)。
通过这种方式,N-Way组相联缓存提高了缓存的利用率和命中率,减少了冲突未命中的发生,使缓存性能更加高效。
关联缓存示例
示例说明:
- 内存地址映射到缓存索引
- 这里是一个简单的2路组相联缓存
- 2个集合,每个集合有2个块
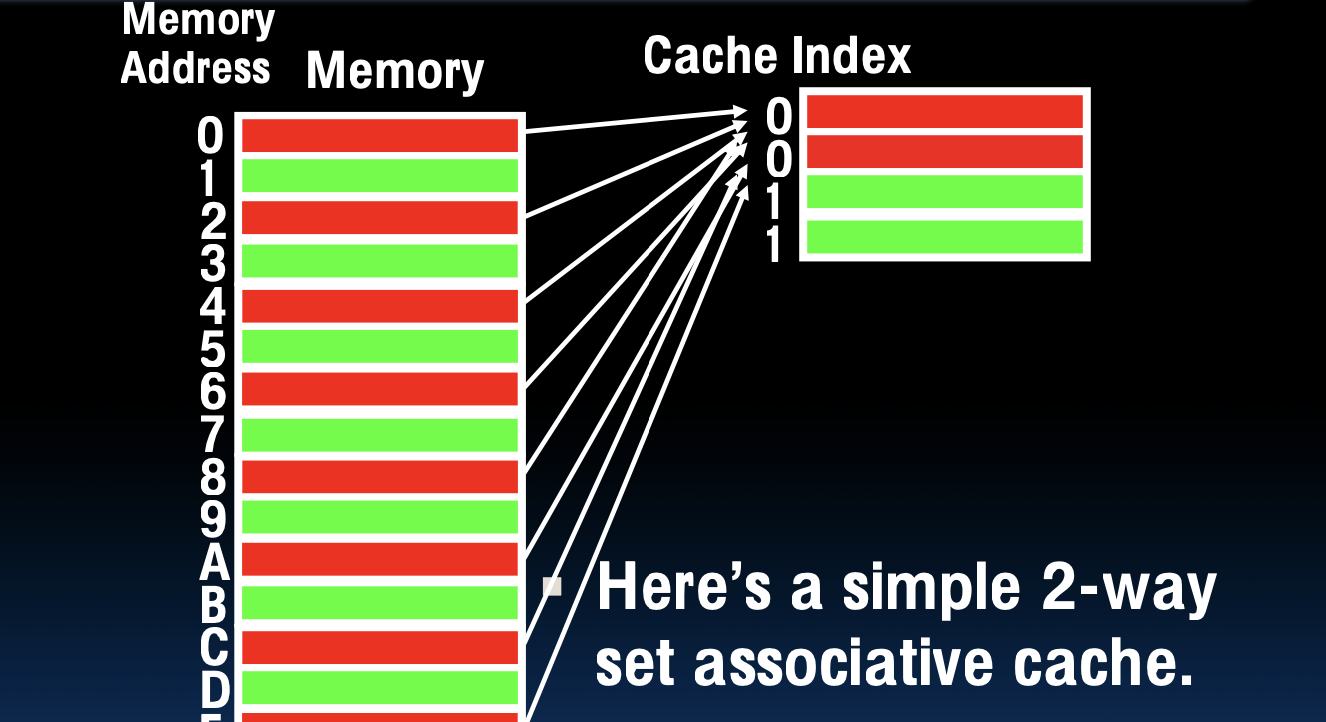
在这个示例中,内存地址通过索引值被映射到缓存中的某个集合。每个集合包含多个块,因此在一个集合内可以有多个可能的块存储数据。这种结构比直接映射缓存更灵活,可以有效减少由于地址冲突导致的缓存未命中。
N-Way 组相联缓存(2/3)
基本概念
- 缓存在集合方面是直接映射的
- 每个集合在其内部是完全相联的,有N个块
给定内存地址的操作步骤:
- 使用索引值找到正确的集合
- 将标记与该集合中所有标记值进行比较
- 如果匹配,命中;否则,未命中
- 最后,使用偏移字段找到块内所需的数据
在N-Way组相联缓存中,首先通过索引值定位到缓存中的一个集合。然后在该集合中,遍历所有块的标记进行比较。如果找到匹配的标记,则表示命中,直接返回数据;如果没有匹配,则表示未命中,需要从主存中加载数据并更新缓存。通过这种方式,N-Way组相联缓存可以有效减少未命中率,提高缓存的效率。
N-Way 组相联缓存(3/3)
这种设计有何优越之处?
- 即使是2路组相联缓存也能避免很多冲突未命中
- 硬件成本并不高:只需要N个比较器
实际上,对于有M个块的缓存
- 如果是1路组相联缓存,则是直接映射
- 如果是M路组相联缓存,则是全相联缓存
- 因此,这两种只是更一般的组相联设计的特例
比较三种缓存设计方式
1. 直接映射缓存(Direct Mapped Cache)
特点:
- 每个内存地址只能映射到缓存中的一个固定位置。
- 缓存块的索引直接由地址中的索引位决定。
优点:
- 硬件实现简单,成本低。
- 每个内存地址只有一个缓存块位置,无需复杂的替换策略。
缺点:
- 容易发生冲突未命中(Conflict Misses),因为多个内存地址可能映射到同一个缓存块位置。
2. 全相联缓存(Fully Associative Cache)
特点:
- 内存地址可以映射到缓存中的任何位置。
- 所有缓存块都必须检查以确定是否存在所需的数据。
优点:
- 减少冲突未命中,因为任何内存地址都可以存储在缓存的任何位置。
- 最大限度地利用缓存空间。
缺点:
- 硬件实现复杂,需要大量的比较器。
- 替换策略复杂,需要有效管理所有缓存块的位置和使用情况。
3. 组相联缓存(Set Associative Cache)
特点:
- 结合了直接映射和全相联缓存的特点。
- 内存地址首先映射到一个集合,然后在该集合内的多个块中存储数据。
优点:
- 有效减少冲突未命中,因为每个集合内有多个块可供选择。
- 硬件成本适中,只需N个比较器(N-Way)。
缺点:
- 比直接映射复杂,需要管理集合和块的替换策略。
- 硬件实现比直接映射稍微复杂,但远比全相联简单。
优越之处
- 减少冲突未命中:即使是简单的2路组相联设计,也能有效避免很多冲突未命中。
- 硬件成本低:只需要N个比较器,硬件开销相对较低。
- 平衡设计:组相联缓存提供了一种在硬件成本和性能之间的平衡,是直接映射和全相联缓存之间的一种折中设计。
特例分析
- 1路组相联缓存:等同于直接映射缓存,每个集合内只有一个块。
- M路组相联缓存:等同于全相联缓存,每个集合内包含所有缓存块。
组相联缓存的优点在于可以显著减少冲突未命中。即使是简单的2路组相联设计,也可以有效避免很多冲突未命中情况,而硬件成本只增加了少量比较器。组相联缓存可以视为介于直接映射和全相联缓存之间的一种折中设计:1路组相联相当于直接映射缓存,而M路组相联则等同于全相联缓存。因此,组相联缓存提供了一种在硬件成本和性能之间的平衡。
通过这种设计,组相联缓存在实际应用中广泛使用,因为它能够提供更高的缓存命中率,同时保持硬件实现的可行性和成本效益。在现代处理器中,通常使用2路、4路或8路组相联缓存,以在性能和成本之间找到最佳平衡点。
解释 N-Way 组相联缓存的流程和各个部分(以四路为例)
地址结构
- 地址字段:
- Tag(标记):用于识别缓存行中的唯一数据,地址的高位部分。
- Index(索引):用于找到缓存中的一个集合,地址的中间部分。
- Offset(偏移量):用于找到缓存行内的具体字节位置,地址的低位部分。
缓存结构
- 有效位(V):表示缓存行中的数据是否有效。
- 标记(Tag):存储该缓存行对应的内存地址的标签部分。
- 数据(Data):存储实际的数据。
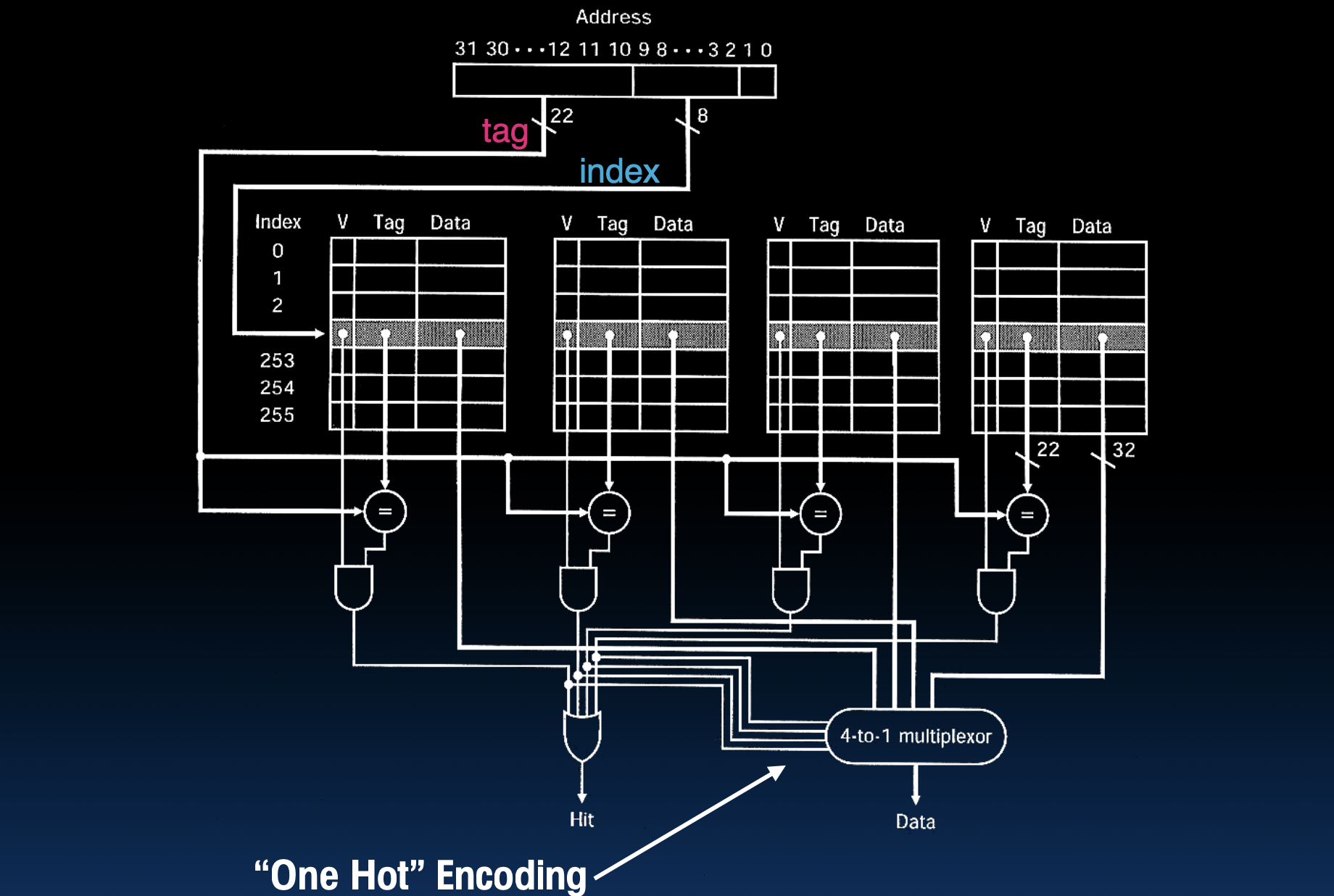
缓存工作流程(以四路组相联为例)
- 地址解析:
- 从内存地址中提取 Tag、Index 和 Offset。
- 图中,Tag 使用地址的高位部分,Index 使用中间部分,Offset 使用低位部分。
- 找到对应的集合:
- 根据 Index 找到对应的缓存集合。图中,每个集合有 4 个块(4-Way 组相联)。
- Tag 比较:
- 在集合中,对每个块的 Tag 进行比较,同时检查有效位。
- 如果有效位为 1 且 Tag 匹配,则表示缓存命中(Hit)。
- 数据选择:
- 使用多路复用器(Multiplexer)选择正确的数据块。
- 图中使用 4-to-1 多路复用器,从四个块中选择匹配的那个。
- 输出数据:
- 如果缓存命中,从选择的缓存块中输出数据。
- 如果缓存未命中,缓存会从主存中加载数据,并可能替换集合中的某个块。
详细部件说明
- 比较器:
- 每个块都有一个比较器,用于比较输入地址的 Tag 和缓存块的 Tag。
- 同时检查有效位(V)。
- 与门(AND Gate):
- 用于结合比较器的输出和有效位,生成命中信号。
- 多路复用器(Multiplexer):
- 4-to-1 多路复用器根据命中信号选择正确的数据块。
- One Hot Encoding:
- 用于表示某个特定块被选择。
- 在图中,通过比较器和与门组合,生成一个“一热编码”信号,用于选择正确的数据块。
- 数据输出:
- 最终数据通过多路复用器输出,如果命中,则从缓存读取数据,如果未命中,则从内存加载数据。
图中具体流程
- 地址分解:
- 地址被分成 Tag、Index 和 Offset 三部分。
- Tag 用于与缓存块的 Tag 比较,Index 用于选择集合,Offset 用于确定块内的字节偏移。
- 索引选择集合:
- 根据 Index 选择一个集合。图中示例有 256 个集合(图中显示为 256 行,每行表示一个集合),每个集合有 4 个块。
- 标签比较和有效性检查:
- 对于选定集合中的每个块,比较地址的 Tag 和缓存块的 Tag,同时检查有效位。
- 如果找到匹配的 Tag 且有效位为 1,则命中(Hit)。
- 选择数据块:
- 如果命中,使用多路复用器选择正确的块。
- 多路复用器的输入是集合中所有块的输出,选择由比较结果和有效位决定。
- 数据输出:
- 通过多路复用器,输出命中的数据块中的数据。
- 如果未命中,则从内存加载数据并更新缓存。
偏移量(Offset)
- 作用:偏移量用于确定在缓存块内的具体字节位置。
- 详细流程:
- 假设块大小为 32 字节,偏移量字段为 5 位(因为 (2^5 = 32))。
- 在命中时,偏移量字段用于在缓存块中选择具体的字节位置。
- 例如,偏移量为 0100 表示选择缓存块内第 4 个字节(从 0 开始计数)。
通过这种设计,四路组相联缓存(4-Way Set Associative Cache)有效地平衡了缓存的命中率和硬件实现的复杂度,提高了缓存的性能和利用率。这样可以减少缓存的冲突未命中,同时避免全相联缓存带来的高硬件复杂度。
在图中,可以看到每个集合包含 4 个块(从 V、Tag、Data 字段组成),这些块通过比较器和与门进行比较,并通过多路复用器选择正确的数据输出。偏移量字段用于最终从选定的缓存块中提取具体的数据字节。
Block Replacement with Example
块替换策略
直接映射缓存
- 索引完全指定了块在未命中时可以进入的位置
N路组相联缓存
- 索引指定了一个集合,但块可以在未命中时占据集合内的任何位置
全相联缓存
- 块可以写入任何位置
问题:如果有选择,应该将新的块写入哪里?
- 如果有一个无效位被关闭,新的块写入第一个无效位置
- 如果所有位置都是有效的,则选择替换策略
- 规则:在未命中时,决定哪个块被“替换”出去
块替换策略决定了在缓存已满时,新的数据块应该替换哪个旧的数据块。对于不同类型的缓存,这些策略可能会有所不同。在直接映射缓存中,由于每个地址只有一个对应的缓存位置,因此没有选择的余地。对于N路组相联和全相联缓存,可以选择写入的位置,这时需要一种替换策略来优化缓存性能。
块替换策略
LRU(最近最少使用)
- 思想:替换掉最近没有被访问(读或写)的块
- 优点:符合时间局部性原则,即最近使用过的数据块很可能会再次使用,因此这是一个非常有效的策略
- 缺点:在2路组相联缓存中,容易跟踪(只需一个LRU位);在4路或更高的组相联缓存中,需要复杂的硬件和大量时间来跟踪这一策略
FIFO(先进先出)
- 思想:忽略访问,只跟踪初始顺序
随机替换
- 如果工作负载的时间局部性较低,该策略效果尚可
不同的替换策略有不同的应用场景。LRU替换策略利用了时间局部性,适用于大多数情况下的数据访问模式。然而,在高路组相联缓存中实现LRU策略会增加硬件复杂度和成本。FIFO策略相对简单,只需跟踪数据块的加载顺序。随机替换策略则在工作负载的时间局部性较低时表现良好,因为它不会增加额外的硬件复杂度。选择合适的替换策略对于提高缓存的性能和效率至关重要。
块替换示例
块替换示例:LRU
- 我们的2路组相联缓存具有4字节的总容量和1字节的块。我们执行以下字节访问: 0, 2, 0, 1, 4, 0…
- 对于LRU替换策略,会有多少次命中和未命中?


对于每个访问地址:
- 访问地址0:未命中,将其带入集合0(位置0)
- 访问地址2:未命中,将其带入集合0(位置1)
- 再次访问地址0:命中
- 访问地址1:未命中,将其带入集合1(位置0)
- 访问地址4:未命中,将其带入集合0(位置0),替换掉地址2
- 再次访问地址0:命中
LRU替换策略确保最近最少使用的块会被替换,优化了缓存的命中率。
缓存模拟器!
在这个示例中,通过缓存模拟器来验证上述访问序列的命中和未命中情况。通过输入访问序列,模拟器显示了每次访问是命中还是未命中,以及具体的替换过程。

通过使用缓存模拟器,可以直观地理解不同缓存替换策略的效果。例如,LRU替换策略会记录每个块的最近使用情况,从而在需要替换时选择最久未使用的块。模拟器还提供了其他替换策略,如FIFO和随机替换,以便进行比较和分析。使用模拟器可以帮助我们深入理解缓存替换策略的工作原理和性能影响。
Average Memory Access Time(AMAT)
平均内存访问时间(AMAT)
如何在关联度、块大小、替换和写入策略之间做出选择?
- 根据性能模型进行设计:
- 最小化:平均内存访问时间
- 平均内存访问时间 = 命中时间 + 未命中惩罚 × 未命中率
- 受到技术和程序行为的影响
- 最小化:平均内存访问时间
- 创建一种既大又便宜且快速的内存幻觉——平均而言
选择缓存参数时,需要权衡多个因素,如关联度、块大小、替换策略和写入策略。为了优化性能,设计者通常会根据平均内存访问时间进行调整。该公式考虑了命中时间、未命中惩罚和未命中率等因素。通过降低未命中率和未命中惩罚,可以显著提升系统性能。
改善未命中惩罚
当缓存首次流行时,未命中惩罚约为10个处理器时钟周期
- 今天的3 GHz处理器(每时钟周期1/3纳秒),访问DRAM大约需要80纳秒
- 大约200个处理器时钟周期!
- 解决方案:在内存和处理器缓存之间再加一个缓存:二级(L2)缓存
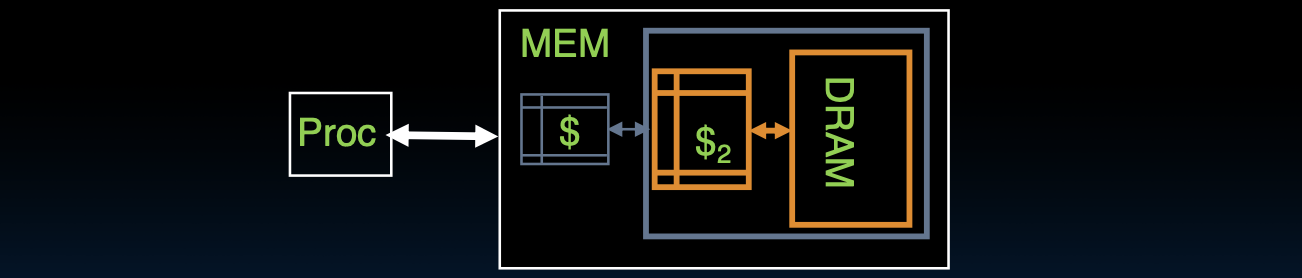
随着处理器速度的提升,未命中惩罚变得越来越显著。在过去,未命中惩罚仅为几个时钟周期,而如今由于DRAM访问延迟的增加,未命中惩罚已经大幅增加。为了解决这一问题,可以在处理器缓存和内存之间添加二级缓存,从而减少未命中时的延迟,提高整体系统性能。
伟大的想法#3:局部性原理/存储层次结构
- 存储层次结构由多个级别组成,每一级别都有不同的速度、成本和容量。
- 顶层是寄存器,速度最快但容量最小且成本最高。
- 随着级别的增加,速度降低但容量增大且成本下降。
- 通过利用局部性原理,可以将常用的数据保存在较高层次的缓存中,从而提高访问速度。
分析多级缓存层次结构
平均内存访问时间计算
多级缓存的平均内存访问时间(AMAT)计算如下:
- 平均内存访问时间 = 一级缓存命中时间 + 一级缓存未命中率 × 一级缓存未命中惩罚
- 一级缓存未命中惩罚 = 二级缓存命中时间 + 二级缓存未命中率 × 二级缓存未命中惩罚
- 总的平均内存访问时间 = 一级缓存命中时间 + 一级缓存未命中率 × (二级缓存命中时间 + 二级缓存未命中率 × 二级缓存未命中惩罚)
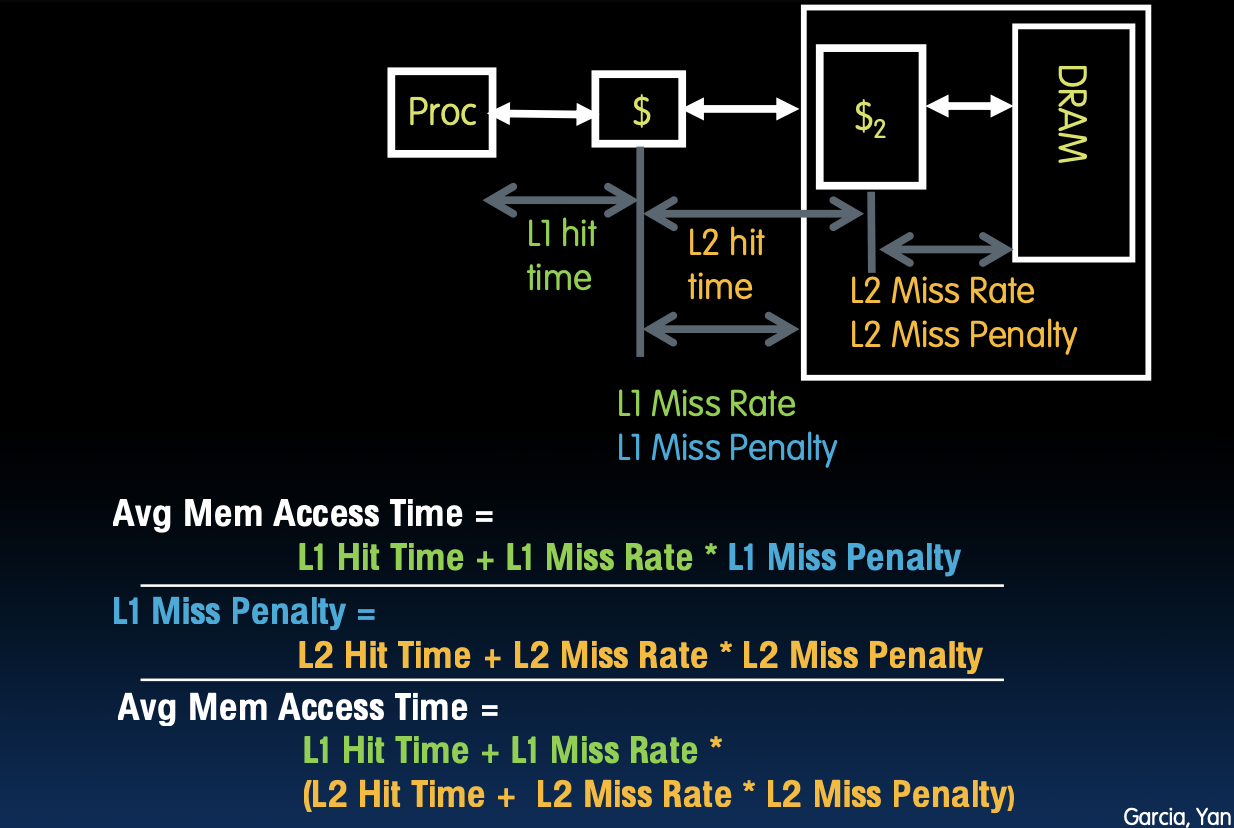
多级缓存的设计通过引入多个缓存层次来减少未命中惩罚。例如,如果一级缓存未命中,那么系统会检查二级缓存,这样可以显著减少访问主内存的次数,从而提高性能。
示例
假设
- 命中时间 = 1个周期
- 未命中率 = 5%
- 未命中惩罚 = 20个周期
计算平均内存访问时间
- 平均内存访问时间 = 1 + 0.05 × 20 = 1 + 1 = 2个周期
在这个例子中,通过计算可以看到,尽管未命中惩罚很高,但由于未命中率较低,整体的平均内存访问时间依然较低。这说明了优化未命中率和惩罚的重要性。
减少未命中率的方法
更大的缓存
- 受限于成本和技术
- 一级缓存命中时间 < 时钟周期时间(更大的缓存通常较慢)
增加缓存的大小可以显著减少未命中率,因为更多的数据可以保存在缓存中,减少对主内存的访问。然而,缓存的大小受限于硬件成本和技术限制,过大的缓存可能导致访问速度变慢。
缓存中的更多位置存放每个内存块——关联度
- 全关联:任何块可以在任何行
- N路集合关联:每个块有N个位置
- 直接映射:N=1
通过提高缓存的关联度,可以减少冲突未命中。例如,全关联缓存可以将任何内存块存放在缓存中的任何位置,从而完全避免冲突未命中。然而,全关联缓存的硬件实现复杂且成本高,因此通常采用N路集合关联缓存作为折中方案。
典型规模
L1缓存
- 大小:几十KB
- 命中时间:一个时钟周期内完成
- 未命中率:1-5%
L1缓存是最靠近处理器的缓存,具有最快的访问速度,因此其命中时间通常非常短,仅为一个时钟周期。未命中率较低,通常在1%到5%之间。
L2缓存
- 大小:几百KB
- 命中时间:几个时钟周期
- 未命中率:10-20%
L2缓存比L1缓存更大,但其访问速度稍慢,通常需要几个时钟周期。未命中率相对较高,介于10%到20%之间。
L2未命中率是L1未命中的一部分
L2未命中率是L1未命中的一部分,为什么这么高呢?
示例:使用L2缓存
假设
- L1命中时间 = 1周期
- L1未命中率 = 5%
- L2命中时间 = 5周期
- L2未命中率 = 15% (L1未命中的未命中率)
- L2未命中惩罚 = 200周期
计算L1未命中惩罚
- L1未命中惩罚 = 5 + 0.15 * 200 = 35
平均内存访问时间
- 平均内存访问时间 = 1 + 0.05 * 35 = 2.75周期
L1未命中后,处理器会访问L2缓存。如果L2缓存命中,则总的未命中惩罚仅为L2的命中时间。如果L2也未命中,则会产生更高的未命中惩罚。
示例:没有L2缓存
假设
- L1命中时间 = 1周期
- L1未命中率 = 5%
- L1未命中惩罚 = 200周期
平均内存访问时间
- 平均内存访问时间 = 1 + 0.05 * 200 = 11周期
如果没有L2缓存,那么每次L1未命中都会直接访问主内存,导致较高的未命中惩罚,从而显著增加平均内存访问时间。
比较
- 使用L2缓存的情况下,平均内存访问时间为2.75周期
- 没有L2缓存的情况下,平均内存访问时间为11周期
使用L2缓存使系统性能提高了4倍(2.75 vs. 11),显著减少了平均内存访问时间。通过引入L2缓存,可以有效减少未命中的惩罚,从而提高系统的整体性能。
一个实际的CPU——早期的PowerPC
缓存
- 32 KiB 指令缓存和 32 KiB 数据缓存的L1缓存
- 外部L2缓存接口,带有集成控制器和缓存标签,支持最多1 MiB的外部L2缓存
- 双内存管理单元(MMU),带有转换后备缓冲区(TLB)

早期的PowerPC处理器具有独立的指令和数据缓存,L1缓存的大小为32 KiB。它还支持外部L2缓存接口,最多可以扩展到1 MiB。双内存管理单元(MMU)使得地址转换更加高效。
流水线
- 超标量(每周期3条指令)
- 6个执行单元(2个整数单元和1个双精度IEEE浮点单元)
该处理器采用超标量架构,每个时钟周期可以执行三条指令。它拥有六个执行单元,包括两个整数单元和一个双精度浮点单元,从而提高了处理器的并行处理能力。
一个实际的CPU——Pentium M
Pentium M处理器具有全新的微架构,包含7700万个晶体管。它采用了Micro-Ops Fusion技术,将操作融合以实现更快的指令执行和更低的功耗。此外,它还具有先进的分支预测功能,以减少指令重做,提高性能。
缓存
- 32 KiB 指令缓存
- 32 KiB 数据缓存
- 1 MiB 功耗优化的L2缓存
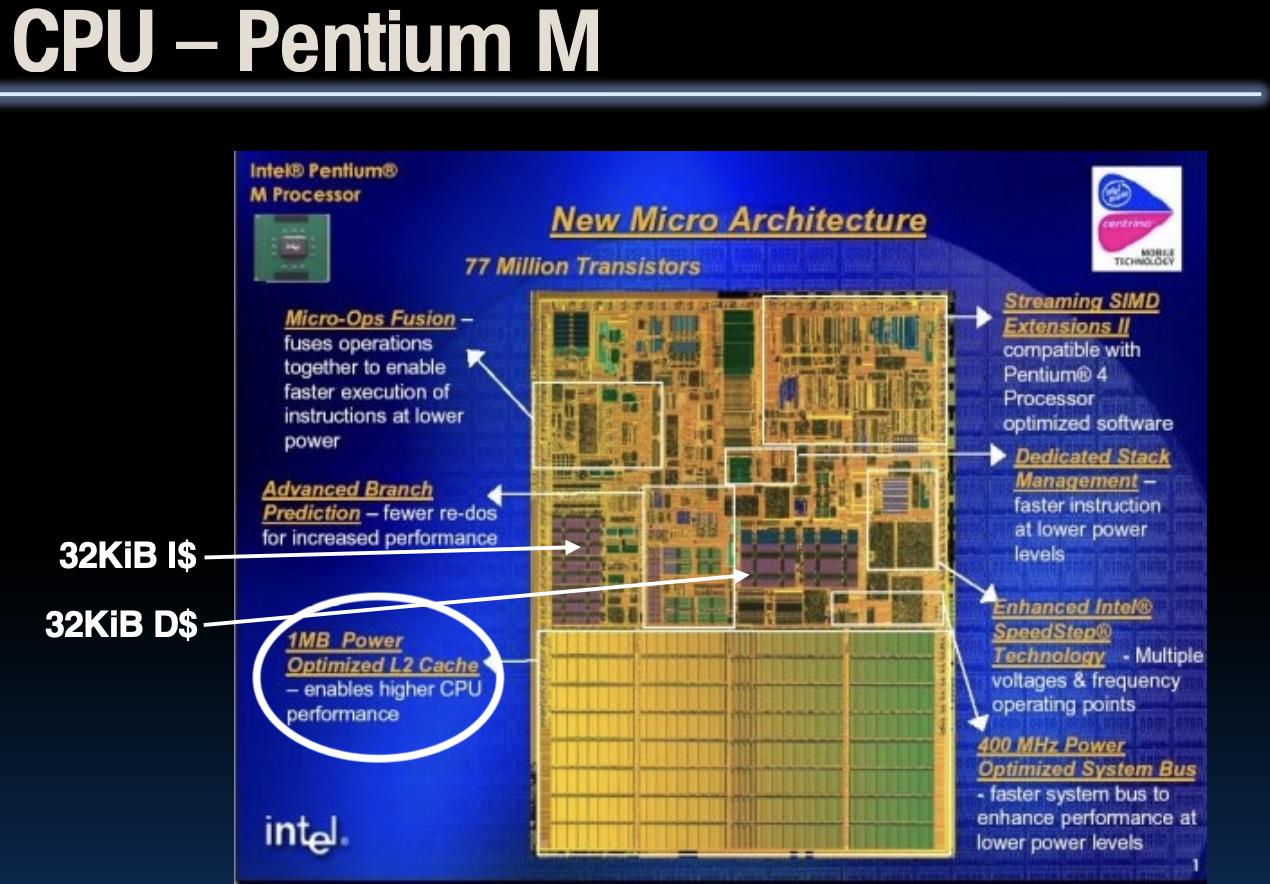
Pentium M处理器的L1缓存包括32 KiB的指令缓存和32 KiB的数据缓存。它还配备了1 MiB的L2缓存,这大大提高了处理器的性能和功效。
一个实际的CPU——Intel Core i7
Intel Core i7处理器采用多核架构,每个核心都有自己的缓存和执行单元,同时共享一个大的L3缓存。该设计使得处理器可以更有效地管理和处理多任务,提高整体性能。
共享L3缓存
多个核心共享一个大的L3缓存,可以减少数据的重复存储,提高缓存的命中率,从而提高处理器的整体效率。
内存控制器
集成的内存控制器使得处理器可以直接与内存进行通信,减少了数据传输的延迟,提高了数据访问的速度。

Core i7处理器代表了现代高性能处理器的发展方向,通过多核设计和大容量的共享缓存,提供了强大的计算能力和高效的资源管理。
两路组相联缓存无法被直接映射缓存超越
两路组相联缓存在最坏的情况下,会出现N个地址重复映射到同一个组的情况。这种情况下,N路组相联缓存的性能会显著下降。此外,最新的芯片上通常包含了L4缓存,这进一步提高了缓存的效率。
如何让直接映射缓存击败两路组相联缓存?
假设我们有前几页提到的缓存配置(总容量为4字节、块大小为1字节的两路组相联缓存),并且给出了以下工作负载: 0, 2, 0, 4, 2
对于两路组相联缓存,结果是: 0m, 2m, 0h, 4m, 2m;
对于直接映射缓存,结果是: 0m, 2m, 0h, 4m, 2h;
可以看到,在这种特定情况下,直接映射缓存由于减少了冲突缺失,从而表现优于两路组相联缓存。
结论
我们详细讨论了内存缓存,缓存在计算机系统中反复出现,如文件系统缓存、网页缓存、游戏数据库/表格缓存、软件记忆化等。
大想法
如果某些操作很昂贵但我们想重复执行,那么可以执行一次并缓存结果。
缓存设计选择
- 缓存大小:速度与容量
- 块大小(即缓存的宽高比)
- 写入策略(直写与回写)
- 关联度选择(直接映射、组相联与完全相联)
- 块替换策略
- 二级缓存?
- 三级缓存?
使用性能模型选择
根据程序、技术、预算等使用性能模型进行选择。