Lecture 5: C Memory (Mis)Management
What gets printed?
sizeof(): 编译时操作符,用于获取类型或变量的字节大小
// 对于本练习,假设
// short 类型为 16 位,指针为 32 位
void mystery(short arr[], int len) {
printf("%d ", len);
printf("%d\n", sizeof(arr)); // 数组在函数中退化为指针
}
int main() {
short nums[] = {1, 2, 3, 99, 100};
printf("%d ", sizeof(nums)); // 在数组的声明范围内,获取数组总大小
mystery(nums, sizeof(nums)/sizeof(short)); // 在数组的声明范围内,获取数组元素数量
return 0;
}
正确答案为
- 10:
sizeof(nums)返回数组总大小,5 个元素,每个元素 2 个字节,共 10 个字节。sizeof(nums)在main函数中是 10,因为nums是一个包含 5 个short元素的数组,每个short为 2 字节,5 * 2 = 10 字节。 - 5:
sizeof(nums) / sizeof(short)计算数组元素的数量,10 字节 / 2 字节 = 5。这是在main函数中计算的,通过数组的总大小除以每个元素的大小。 - 4:
sizeof(arr)在函数中退化为指针类型,指针为 4 个字节。当数组传递给函数时,它会退化为指针,因此sizeof(arr)在mystery函数中返回指针的大小,而不是数组的大小。对于 32 位系统,指针的大小是 4 字节。
Memory Locations
C Program Address Space
程序的地址空间包含 4 个区域
- 栈(Stack):函数内部的局部变量,向下增长。栈用于存储函数调用中的临时变量和返回地址。当函数被调用时,会在栈上分配空间,当函数返回时,这些空间会被释放。
- 堆(Heap):通过
malloc()请求的空间,动态增长,向上增长。堆用于动态分配内存,程序员需要显式地分配和释放这些内存。如果忘记释放,会导致内存泄漏。 - 静态数据(Static Data):在
main函数外部声明的变量,不会增长或缩小。这些变量在程序的整个生命周期内存在,并在程序开始时分配空间。 - 代码(也叫文本)(Code/Text):程序启动时加载,不会变化。代码段包含了程序的可执行指令,这部分内存通常是只读的,防止程序意外修改自己的指令。
- 0x00000000 部分是不可写/不可读的,因此在访问
NULL指针时会崩溃。这种保护机制帮助捕捉对无效指针的访问。

Where are variables allocated?
变量的分配位置
- 函数外部声明(全局变量),分配在静态存储中。全局变量在程序启动时分配,并在程序结束时释放。它们在程序的整个生命周期内都存在。
- 函数内部声明(局部变量),分配在栈中,函数返回时释放。局部变量的生命周期仅限于函数的执行期间,当函数结束时,栈上的空间会被释放。
main()也是一个函数,因此main中声明的变量也是局部变量,分配在栈上。
对于这两种存储类型,管理是自动的:
- 不需要担心手动释放不再使用的变量。静态存储和栈的内存管理由编译器和运行时环境自动处理。
- 但是,一旦函数结束,变量就不再存在。对于局部变量,函数结束后,它们所占用的栈空间会被释放。
int myGlobal; // 静态存储,全局变量
main() {
int myTemp; // 栈,局部变量
}
The Stack
栈
每当一个函数被调用时,就会在栈上分配一个新的“栈帧”。
- 栈帧包括:
- 返回“指令”地址(谁调用了我?)
- 参数
- 其他局部变量的空间
栈帧是连续的内存块;栈指针指示栈帧的起始位置。
- 当函数结束时,栈帧从栈上被移除;释放内存以供将来栈帧使用。栈帧的管理通过栈指针和基址指针(如在 x86 体系结构中)或仅通过栈指针(如在某些 RISC 体系结构中)进行。
以后,我们将介绍RISC-V处理器的细节。
The Stack is Last In, First Out (LIFO)
栈是后进先出(LIFO)
- 栈是一种后进先出(LIFO,Last In, First Out)数据结构,这意味着最后被压入栈的数据最先被弹出。这种特性使得栈非常适合函数调用的管理,因为最新的调用最先完成。
代码示例:
int main() {
a(0); // 调用函数a
}
void a (int m) {
b(1); // 调用函数b
}
void b (int n) {
c(2); // 调用函数c
}
void c (int o) {
d(3); // 调用函数d
}
void d (int p) {
// 函数d的内容
}
在这个例子中,当main()调用a()时,栈上会分配一个新的栈帧用于a()。然后a()调用b(),分配新的栈帧用于b()。依次类推,直到调用d()。在d()执行完后,d()的栈帧被移除,返回到c(),再依次回到b()、a()和main(),实现后进先出。
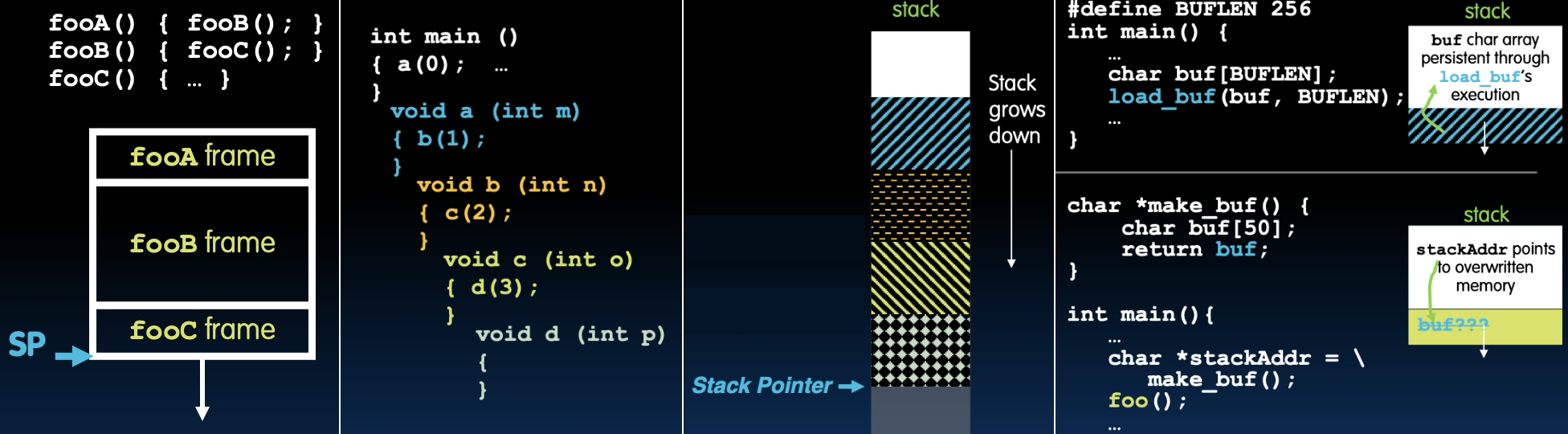
Passing Pointers into the Stack
将指针传递到栈中
将指针传递到更深的栈空间是可以的。
- 例如:
#define BUFLEN 256
int main() {
char buf[BUFLEN];
load_buf(buf, BUFLEN); // 将指针buf传递给函数load_buf
}
在这个例子中,buf是一个长度为256的字符数组,在main()函数中定义,并传递给load_buf()函数。这样做是安全的,因为buf在main()的栈帧中有效,直到main()函数返回。
但是,将指针返回到栈中的某个东西是灾难性的!
内存将在其他函数被调用时被覆盖!
- 例如:
char *make_buf() {
char buf[50];
return buf; // 返回局部变量buf的指针
}
int main() {
char *stackAddr = make_buf(); // stackAddr指向已被覆盖的内存
foo();
}
在这个例子中,buf在make_buf()函数结束时会被销毁,因此返回buf的指针是无效的,可能导致内存被其他函数调用时覆盖,导致程序崩溃。返回指向局部变量的指针会导致未定义行为,因为局部变量的生命周期在函数返回时结束。
The Heap
What is the Heap?
堆是什么?
- 堆是动态内存,即在程序运行期间可以分配、调整大小和释放的内存。
- 在Java中,
new命令用于分配内存。 - 堆内存用于函数调用之间的持久性存储。
- 但堆内存也是指针错误、内存泄漏等问题的主要来源。
- 在Java中,
- 堆由大量内存池组成,不以连续顺序分配。
- 对堆内存的连续请求可能导致内存块分散得非常远。
- 在C语言中,明确指定要分配的字节数:
malloc():从堆中分配原始、未初始化的内存。free():释放堆上的内存。realloc():将先前分配的堆块调整为新的大小。- 与栈不同,堆内存只有在程序员显式清理时才会重用。
void *malloc(size_t n)
- 分配一块未初始化的内存:
size_t是标准库定义的类型,通常为无符号整数类型,专门用于表示内存大小。它的大小与目标平台相关,确保能够表示任何可能的内存大小,保证了跨平台的兼容性。malloc返回一个指向分配内存块的void *指针。void *是一种通用指针,可以转换为任何其他类型的指针。- 返回NULL表示没有更多的内存(务必检查它!!!)。如果
malloc无法分配请求的内存,则返回NULL。因此,在使用malloc后应立即检查返回值是否为NULL,以防止后续操作中出现内存访问错误。
-
分配一个结构体:
typedef struct { ... } TreeNode; TreeNode *tp = (TreeNode *) malloc(sizeof(TreeNode));Typecast将返回值从(void *)转换为(TreeNode *)。因为malloc返回void *指针,而我们需要一个特定类型的指针,所以需要进行类型转换(Typecast)。在此示例中,将void *转换为TreeNode *。sizeof(type)以字节为单位给出大小。sizeof操作符返回指定类型或变量的大小(以字节为单位)。在此例中,sizeof(TreeNode)返回结构体TreeNode所需的字节数。- 假设对象大小可能导致误导和不便移植的代码。使用
sizeof()!- 假设固定的对象大小是错误的做法,因为不同平台的对象大小可能不同。使用
sizeof操作符可以确保代码的可移植性和正确性。
- 假设固定的对象大小是错误的做法,因为不同平台的对象大小可能不同。使用
-
分配一个包含20个整数的数组:
int *ptr = (int *) malloc(20 * sizeof(int));- 多年前,整数大小是16位。现在是32位或64位……
void free(void *ptr)
- 动态释放堆内存:
ptr是包含由malloc()或realloc()返回地址的指针。
int *ptr = (int *) malloc(sizeof(int) * 20); ... free(ptr); // 隐式类型转换为(void *) - 当你释放内存时,一定要传递
malloc()返回的原始地址。否则,程序可能崩溃或出现其他更严重的问题。
void realloc(voidptr, size_t size)
- 将先前在
ptr处分配的块调整为新的大小:- 返回内存块的新地址。
- 重新分配时,可能需要将所有数据复制到新位置。
realloc(NULL, size); // 行为类似malloc realloc(ptr, 0); // 行为类似free,释放堆块 -
记住:总是检查返回的
NULL,这意味着你已经用完了内存!int *ip; ip = (int *) malloc(10 * sizeof(int)); ... ip = (int *) realloc(ip, 20 * sizeof(int)); ... realloc(ip, 0); // 等效于free(ip);
Linked List Example
链表示例
#include <string.h>
int main() {
struct Node *head = NULL; // 初始化链表头指针为空
add_to_front(&head, "abc"); // 将字符串"abc"添加到链表前端
// ... // 在此处释放节点和字符串的内存
}
void add_to_front(struct Node **head_ptr, char *data) {
struct Node *node = (struct Node *) malloc(sizeof(struct Node)); // 为新节点分配内存
node->data = (char *) malloc(strlen(data) + 1); // 为数据分配内存,多分配一个字节用于'\0'
strcpy(node->data, data); // 将字符串复制到节点的数据中,strcpy也会复制'\0'
node->next = *head_ptr; // 将新节点的next指针指向当前头节点
*head_ptr = node; // 将头指针指向新节点
}
struct Node {
char *data; // 指向数据的指针
struct Node *next; // 指向下一个节点的指针
};
详细解释
- 初始化链表头指针
struct Node *head = NULL;:链表头指针head初始化为空。
- 将字符串添加到链表前端
add_to_front(&head, "abc");:调用add_to_front函数,将字符串"abc"添加到链表的前端。
- 在add_to_front函数中
struct Node *node = (struct Node *) malloc(sizeof(struct Node));:分配内存给新节点node,大小为struct Node的大小。node->data = (char *) malloc(strlen(data) + 1);:为新节点的数据字段分配内存,大小为字符串长度加1,用于存储字符串和终止符\0。strcpy(node->data, data);:将字符串data复制到新节点的data字段中,strcpy函数会复制字符串包括终止符\0。node->next = *head_ptr;:将新节点的next指针指向当前的头节点。*head_ptr = node;:更新头指针,使其指向新节点。
运行结果
- 在
add_to_front函数执行完毕后,链表结构如下:- 新节点
node的地址为0x300 node的data字段指向分配的内存,存储字符串"abc"和终止符\0node的next指针指向原来的头节点(此时为NULL)- 头指针
head_ptr指向新节点
- 新节点
通过这种方式,新的节点被成功添加到了链表的前端,链表的头指针更新为指向新节点。需要注意的是,在实际使用中,还需要在适当的位置释放分配的内存,以避免内存泄漏。
链表节点变化过程
初始状态
head -> NULL分配新节点并初始化
node +-------+-------+ | data | next | +-------+-------+分配数据内存并复制字符串
node +-------+-------+ | data | next | +-------+-------+ | v +---+---+---+---+ | a | b | c | \0| +---+---+---+---+更新新节点的
next指针node +-------+-------+ | data | next | +-------+-------+ | | | v | NULL v +---+---+---+---+ | a | b | c | \0| +---+---+---+---+更新
head指针head -> node +-------+-------+ | data | next | +-------+-------+ | | | v | NULL v +---+---+---+---+ | a | b | c | \0| +---+---+---+---+以下是逐步详细的链表节点添加过程:
- 初始状态:头指针
head指向NULL,表示链表为空。- 分配新节点并初始化:使用
malloc为新节点node分配内存,节点包含两个字段:data和next。- 分配数据内存并复制字符串:为
data字段分配内存,并将字符串"abc"复制到data字段中,包含终止符\0。- 更新新节点的
next指针:将新节点的next指针指向当前的头指针(此时为NULL)。- 更新头指针:将头指针
head更新为指向新节点node。
Working with Memory
内存管理
代码和静态存储(Code, Static storage)
- 代码和静态存储管理较为简单:
- 它们在程序的整个生命周期中不会增长或缩小,分配的内存大小在编译时已经确定。
- 代码段包含了程序的指令,而静态存储区包含了全局变量和静态局部变量。
栈空间(Stack space)
- 栈空间管理也相对简单:
- 栈帧按照后进先出的顺序创建和销毁,每次函数调用都会在栈上分配一个新的栈帧,函数返回时释放这个栈帧。
- 只需避免“悬挂引用”:指向已释放栈帧的指针(例如,来自旧的栈帧)。这种错误通常发生在函数返回后继续使用局部变量的指针。
堆管理(Heap management)
- 使用堆管理内存较为棘手:
- 堆内存可以随时分配和释放,灵活性增加了管理的复杂性。
- 内存泄漏(Memory leak):如果忘记释放内存,程序会不断消耗内存,最终耗尽可用内存。
- 释放后使用(Use after free):如果在调用
free后继续使用指针,可能会导致程序错误或崩溃。 - 双重释放(Double free):对同一块内存调用两次
free,可能导致程序崩溃或产生安全漏洞。
Failure to free()
未能释放内存
- 运行时不会自动检查程序员是否正确管理了内存:
- 由于内存性能非常重要,运行时检查会增加额外的开销。
- 结果是,如果程序员未能正确释放内存,内存分配器的内部结构可能会被破坏,并导致代码的其他部分出现问题。
内存泄漏:未能释放已分配的内存
- 初始症状:可能没有明显症状,直到程序达到临界点。
- 后期症状:性能急剧下降,程序可能会崩溃。
- 内存层次结构的行为通常是平稳的,直到内存泄漏变得严重。
- 操作系统在无法提供更多内存时,会终止程序。
Use after Free
释放后的使用
悬挂引用(Dangling reference)
- 当继续使用一个指针,即使它已经被释放时,就会发生悬挂引用。
- 在
free之后读取内存:- 如果其他数据接管了该内存,程序可能会读取到错误的数据。
- 写入已释放的内存:
- 写入操作会破坏其他数据,导致程序崩溃。
- 在
代码示例:
struct foo *f;
...
f = malloc(sizeof(struct foo));
...
free(f);
...
bar(f->a); // !!!
- 在调用
free之后,继续访问f指针指向的内存,会导致程序读取无效数据或崩溃。这种情况特别危险,因为错误通常在稍后的代码执行中才会表现出来,增加了调试的难度。
Double Free
双重释放
代码示例:
struct foo *f = (struct foo *) malloc(10 * sizeof(struct foo));
...
free(f);
...
free(f); // !!!
- 双重释放是指对同一块内存调用
free两次。第一次调用free会释放这块内存,但第二次调用free会试图再次释放已经被释放的内存,这可能导致严重的问题。- 后果之一是释放后使用的问题。其他地方的
malloc调用可能会分配相同的内存地址,此时再次free会导致释放不属于当前数据的内存。 - 另一个后果是堆数据的破坏。双重释放会破坏内存分配器的内部结构,导致程序崩溃或其他不可预测的行为。
- 后果之一是释放后使用的问题。其他地方的
Forgetting realloc() Can Move Data
忘记 realloc() 会移动数据
悬挂引用(Dangling reference)
- 记住,当你调用
realloc时,它可能会将数据复制到堆的不同部分。这意味着原指针可能不再指向同一个内存位置。
代码示例:
int *nums;
nums = malloc(10 * sizeof(int));
...
int *g = nums;
...
nums = realloc(nums, 20 * sizeof(int));
// g 现在可能指向无效内存
- 如果你忘记在调用
realloc时更新nums,可能会导致nums指向无效内存,并且可能丢失指向新块的指针。- 读取问题:如果
realloc移动了数据块,旧指针g将指向一个无效的内存地址,读取该地址会导致程序读取到无效或错误的数据。 - 写入问题:写入通过旧指针
g指向的内存地址会破坏其他内存块的数据,导致程序崩溃或出现难以调试的错误。
- 读取问题:如果
Faulty Heap Management
错误的堆管理
问题代码:
void free_mem_x() {
int fnh[3];
...
free(fnh);
}
void free_mem_y() {
int *fum = malloc(4 * sizeof(int));
free(fum + 1);
...
free(fum);
...
free(fum);
}
- 第一个函数(free_mem_x)中存在一个错误:
fnh是一个局部数组,不能使用free释放,因为它不是从堆中分配的。- 局部数组
fnh是在栈上分配的内存,不需要也不应该用free来释放。调用free来释放栈上分配的内存是非法的,会导致未定义行为。
- 局部数组
- 第二个函数(free_mem_y)中存在多个错误:
- 第一次
free时,尝试释放fum + 1,这是无效的,因为fum + 1不是原始分配的指针。free函数只能释放从malloc、calloc或realloc返回的指针,任何偏移量都会导致错误。
- 第二次
free时,重复释放了同一个指针fum,导致双重释放问题。- 双重释放会破坏内存管理器的内部数据结构,可能导致程序崩溃或出现安全漏洞。
- 第一次
Valgrind to the Rescue!!!
Valgrind 来拯救!!!
- Valgrind 是一个非常强大的内存调试工具,尽管它会使你的程序运行速度下降一个数量级,但其强大的功能可以极大地帮助捕捉内存错误:
- Valgrind 会添加大量检查,旨在捕捉大多数(但不是全部)内存错误:
- 内存泄漏:Valgrind 可以检测到程序在运行过程中分配的内存是否没有被正确释放。
- 不当使用
free:Valgrind 能够捕捉到多次释放同一块内存或释放未分配内存的错误。 - 数组越界写入:Valgrind 可以检测到数组操作中的越界错误,防止非法访问和潜在的程序崩溃。
- Valgrind 会添加大量检查,旨在捕捉大多数(但不是全部)内存错误:
- 使用 Valgrind 这样的工具对于调试 C 代码是绝对必要的。它能帮助你找到许多隐蔽的错误,使你的程序更加稳定和可靠。
Implementing Memory Management
实现内存管理
Heap Management Requirements
堆管理要求
- 希望
malloc()和free()快速运行:内存分配和释放操作应该尽量高效,以避免性能瓶颈。 - 希望内存开销最小:内存管理机制本身不应占用过多内存,以确保更多内存用于实际数据存储。
- 希望避免碎片化:碎片化是指空闲内存被分割成许多小块,无法满足大块内存请求:
- 当大部分空闲内存都以许多小块存在时,尽管有许多空闲字节,但由于它们在内存中不是连续的,可能无法满足大的内存请求。
- 内存碎片化会导致效率降低和内存浪费,特别是对于需要大量连续内存的大型应用程序。
Heap Management Example
堆管理示例
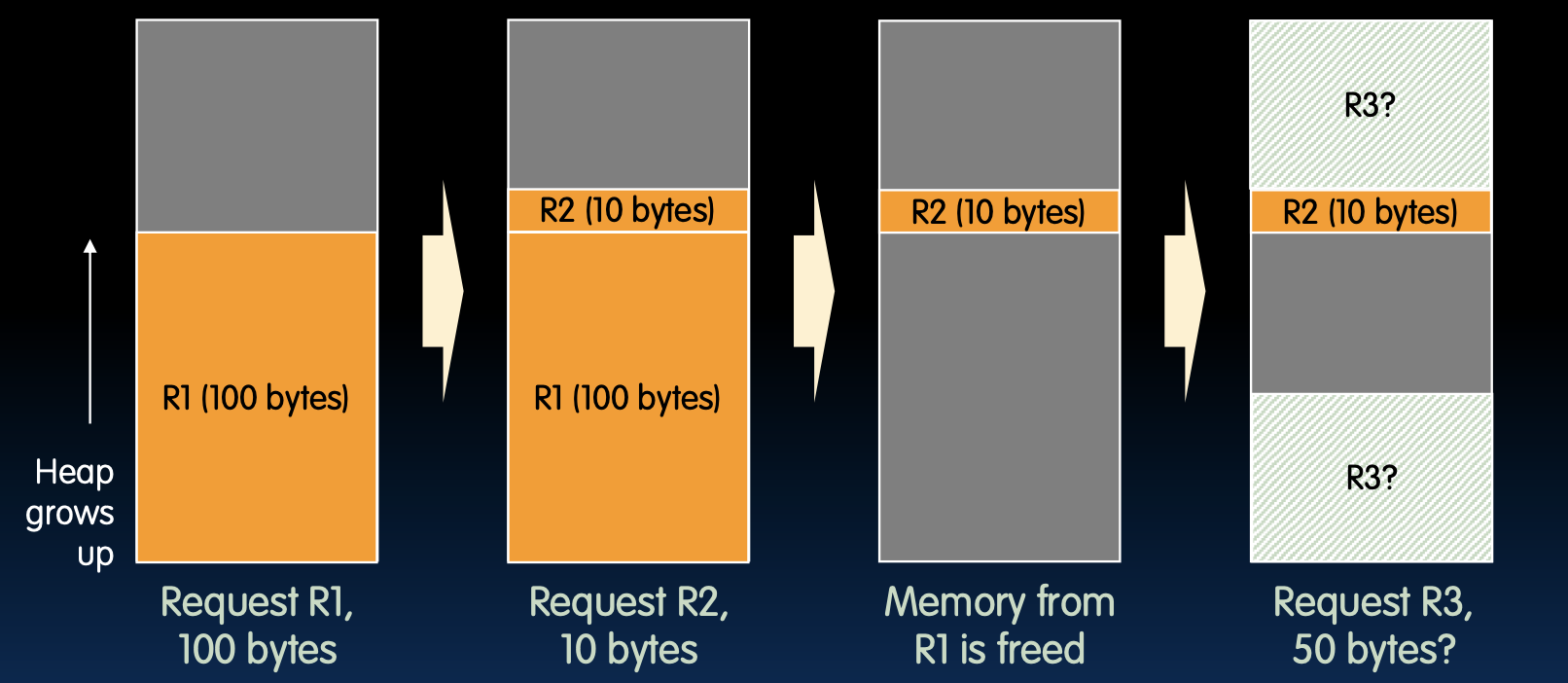
请求 R1,100 字节 -> 请求 R2,10 字节 -> 释放 R1 的内存 -> 请求 R3,50 字节
- 这是外部碎片化的技术示例。当大部分空闲内存都以许多小块存在时,很难满足大的内存请求。尽管有足够的空闲内存,但由于这些内存块不连续,无法满足较大内存块的分配需求。这会导致程序需要进行额外的内存管理操作,例如内存整理(memory compaction),以合并分散的空闲内存块,增加大块内存的可用性。
K&R Malloc/Free Implementation
K&R Malloc/Free 实现
来自 K&R 第8.7节
- 本书中的代码使用了一些未讨论的C语言特性,并以非常简洁的风格编写;如果你无法解读代码,不必担心。
每个内存块前都有一个包含两个字段的头部
- 块的大小:记录当前块的大小,以字节为单位。这使得
free函数能够识别和管理块的大小。 - 指向下一个块的指针:用于将空闲块链接成一个链表。这个链表可以循环,使得内存管理更高效。
所有空闲块都保存在循环链表中
- 在已分配的块中,头部的指针字段未使用。这个字段在内存块被分配时无效,仅在块被释放后才用于链接空闲链表。
malloc() 函数
malloc函数搜索空闲链表,找到足够大的块来满足内存分配请求。- 如果找到合适的块,则分配该块,并根据需要调整空闲链表。
- 如果没有找到足够大的块,
malloc函数会向操作系统请求更多内存,并将其添加到空闲链表中。 - 如果系统无法提供更多内存,则
malloc函数返回NULL,表示分配失败。
free() 函数
free函数将释放的内存块添加回空闲链表中。free函数会检查释放块的相邻块是否也是空闲的。- 如果相邻块也是空闲的,则将这些块合并成一个更大的块,以减少碎片化。
- 如果相邻块不是空闲的,则仅将释放的块添加到空闲链表中,不进行合并操作。
Choosing a block in malloc()
在 malloc() 中选择块
如果有多个足够大的空闲块来满足某个请求,如何选择使用哪一个?
- 最适合(best-fit):选择最小的、足够大的块来满足请求。这种方法可以最大限度地减少内存浪费,但可能会导致更多的碎片化。
- 首次适合(first-fit):选择第一个足够大的块。这种方法通常比最适合更快,因为它不需要遍历所有空闲块,但可能会留下较大的未使用空间。
- 下次适合(next-fit):类似于首次适合,但记住上次搜索结束的位置,并从那里继续搜索。这种方法试图平衡搜索速度和内存利用效率。
And in Conclusion…
结论
C语言有三种内存池
- 静态存储(Static storage):用于存储全局变量和静态局部变量。这些变量在程序的整个生命周期内存在,内存分配在编译时完成。
- 栈(The Stack):用于存储局部变量、函数参数和返回地址。栈内存是临时的,随着函数调用和返回自动分配和释放。
- 堆(The Heap):用于动态内存分配。程序在运行时通过
malloc和free函数管理堆内存,这提供了更大的灵活性,但也增加了内存管理的复杂性。
堆数据是C语言代码中错误的最大来源
malloc()和free()函数使用空闲链表来管理空闲堆空间。了解如何正确地使用这些函数以及如何避免常见的内存管理错误,对于编写健壮的C语言程序至关重要。要深入学习内存管理的原理和实践,可以参考更高级的课程和资料,如CS162。