Lecture 13: Compiler, Assembler, Linker, Loader
Running a Program – CALL (Compiling, Assembling, Linking, and Loading)
Pseudoinstructions
伪指令(Pseudoinstructions)
伪指令是由汇编器(assembler)理解的便捷指令变体,但机器无法直接执行。汇编器会将这些伪指令转换为真实的机器指令。以下是一些常见的伪指令及其对应的实际指令:
| Pseudoinstruction | Real instruction(s) |
|---|---|
mv rd, rs1 | addi rd, rs1, 0 |
not rd, rs | xori rd, rs, -1 |
li rd, imm | 小于等于 12 位的有符号立即数addi rd, x0, imm大于 12 位的立即数 lui rd, imm[31:12]addi rd, rd, imm[11:0] |
j Label | jal x0, label |
jr rs1 | jalr x0, rs1 |
la rd, label | 绝对地址lui rd, label[31:12]addi rd, rd, label[11:0]相对地址 auipc rd, label[31:12]addi rd, rd, label[11:0] |
call label | 调用远处的子程序auipc ra, label[31:12]jalr ra, addr[11:0] |
详细解释
mv rd, rs1
- 功能:将源寄存器
rs1的值复制到目标寄存器rd。 - 实际指令:
addi rd, rs1, 0- 使用
addi指令将rs1的值加上 0 并存储到rd中。
- 使用
not rd, rs
- 功能:将源寄存器
rs的值按位取反后存储到目标寄存器rd中。 - 实际指令:
xori rd, rs, -1- 使用
xori指令将rs与-1进行异或操作(相当于按位取反)。
- 使用
li rd, imm
- 功能:将立即数
imm加载到目标寄存器rd中。 - 实际指令:
- 对于小于等于 12 位的有符号立即数:
addi rd, x0, imm - 对于大于 12 位的立即数:
lui rd, imm[31:12]:加载高 20 位。addi rd, rd, imm[11:0]:添加低 12 位。
- 对于小于等于 12 位的有符号立即数:
j Label
- 功能:无条件跳转到标签
Label。 - 实际指令:
jal x0, label- 使用
jal指令跳转并将返回地址存储到x0(表示不存储返回地址)。
- 使用
jr rs1
- 功能:无条件跳转到寄存器
rs1指定的地址。 - 实际指令:
jalr x0, rs1- 使用
jalr指令跳转并将返回地址存储到x0(表示不存储返回地址)。
- 使用
la rd, label
- 功能:将标签
label的地址加载到目标寄存器rd中。 - 实际指令:
- 绝对地址:
lui rd, label[31:12]:加载高 20 位。addi rd, rd, label[11:0]:添加低 12 位。
- 相对地址:
auipc rd, label[31:12]:将 PC 和标签高 20 位相加。addi rd, rd, label[11:0]:添加低 12 位。
- 绝对地址:
call label
- 功能:调用远处的子程序。
- 实际指令:
auipc ra, label[31:12]:将 PC 和标签高 20 位相加并存储到ra中。jalr ra, label[11:0]:跳转到标签低 12 位地址处,并将返回地址存储到ra中。
伪指令为汇编语言程序员提供了简洁方便的表达方式,而汇编器会将这些伪指令转换为等效的机器指令。

CALL (Compiling, Assembling, Linking, and Loading) 涉及程序从高级语言到机器语言的转换过程,以及进一步的硬件实现部分:
编译(Compiling)
- 高级语言程序(High Level Language Program):这是用高级编程语言(例如 C)编写的程序。它位于图的最顶部。
- 编译器(Compiler):编译器将高级语言程序转换为汇编语言程序。在图中,这一过程连接了高级语言程序和汇编语言程序。
汇编(Assembling)
- 汇编语言程序(Assembly Language Program):这是汇编器生成的汇编代码,例如 RISC-V 汇编代码。
- 汇编器(Assembler):汇编器将汇编语言程序转换为机器语言程序。在图中,这一过程连接了汇编语言程序和机器语言程序。
链接(Linking)
- 机器语言程序(Machine Language Program):这是最终生成的机器代码,用于硬件执行。在图中,它位于机器语言部分。
- 链接器(Linker):链接器将多个目标文件和库文件链接成一个可执行文件。这部分在图中没有单独显示,但它是 CALL 过程中的重要步骤。
加载(Loading)
- 加载器(Loader):加载器将可执行文件加载到内存中,以便处理器执行。这部分在图中也没有单独显示,但它也是 CALL 过程中的关键步骤。
How Do We Run a C Program?
Translator
翻译器:将源语言的程序转换为另一种语言的等效程序。将程序翻译/编译为更低级别的语言通常意味着更高的效率和更高的性能。
对比解释器:直接在源语言中执行程序。
- 注意:C程序/RISC-V也可以被解释执行。
- 例子:Venus RISC-V模拟器对于学习/调试非常有用。
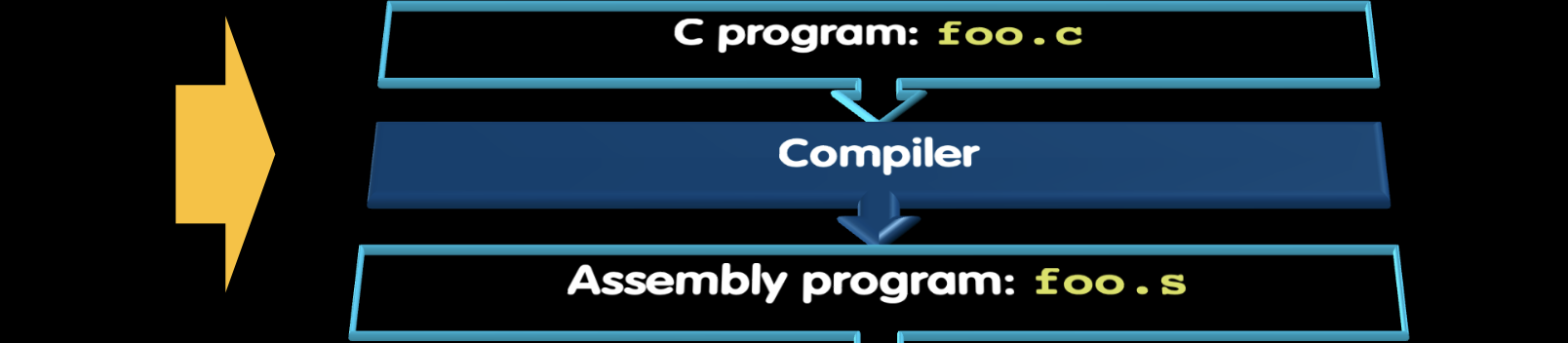
Steps in Compiling and Running a C Program
编译和运行C程序的步骤如下:
- C程序:foo.c
- 编译器(Compiler):将C程序转换为汇编程序。
- 命令:
gcc -S -O2 foo.c(-O2 表示优化编译;关闭优化使用 -O0)
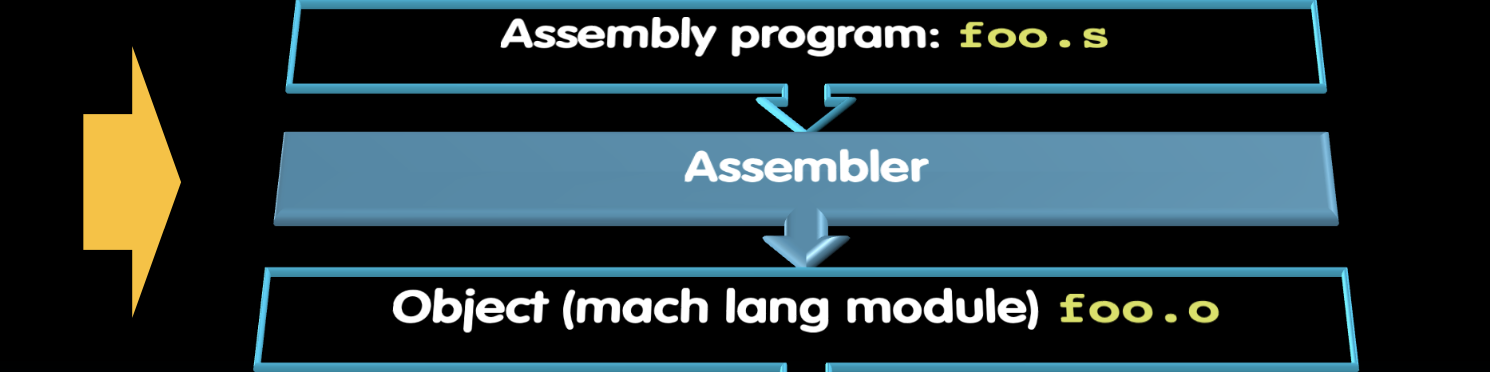
- 汇编程序:foo.s
- 汇编器(Assembler):将汇编程序转换为目标文件(机器语言模块)。
- 命令:
gcc -c foo.s
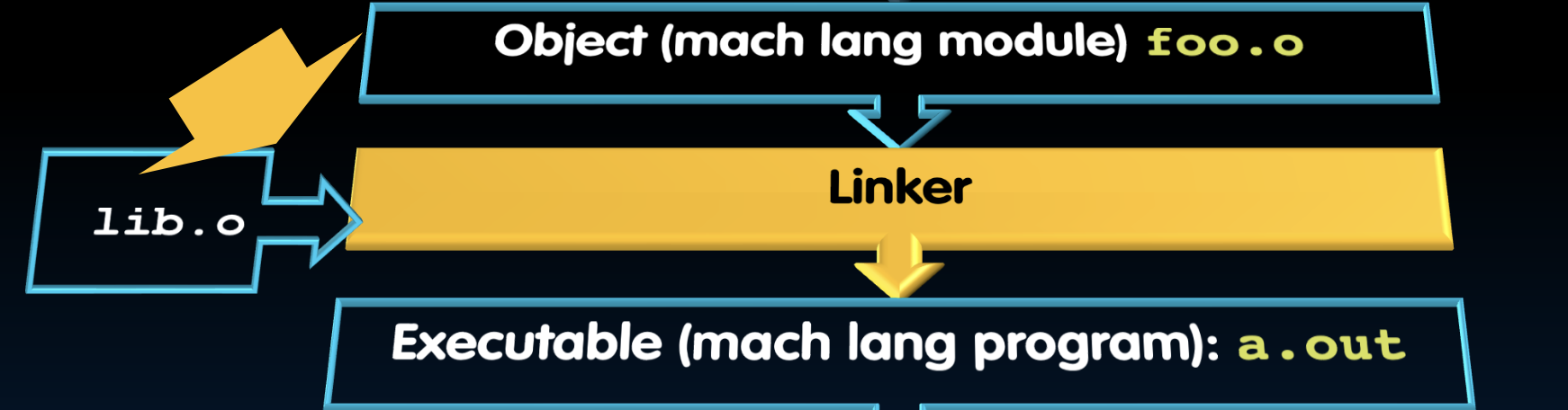
- 目标文件(机器语言模块):foo.o
- 链接器(Linker):将多个目标文件和库文件链接成一个可执行文件。
- 命令:
gcc foo.o
- 可执行文件(机器语言程序):a.out
- 加载器(Loader):将可执行文件加载到内存中。
- 命令:
./a.out
- 内存(Memory)
- 可执行文件在内存中运行。
总结:将C代码编译为二进制通常指的是步骤1-3,即将C程序转换为可执行文件。

Compiler
编译器
编译器的功能是将高级语言代码转换为汇编语言代码。
- 输入:高级语言代码(例如,
foo.c)。 - 输出:汇编语言代码(例如,
foo.s,适用于RISC-V)。 - 注意:输出中可能包含伪指令(pseudoinstructions),例如,
mv,li,call,j等。
Assembler
汇编器
汇编器的功能是将汇编语言代码转换为机器语言模块,即目标文件。
- 输入:汇编语言代码(例如,
foo.s,适用于RISC-V),包括伪指令。 - 输出:机器语言模块,目标文件(例如,
foo.o,适用于RISC-V)。- 目标代码(机器语言)。
- 用于链接和调试的信息,例如,符号表,重定位信息,数据段等。
汇编器读取和使用指令(directives),并用真实的汇编代码替换伪指令,然后生成机器语言代码。
Directives
指令向汇编器提供指示,通常由编译器生成(上一阶段)。指令不生成机器指令,而是提供如何构建目标文件的不同部分的信息。
常见指令包括:
.text:将后续项目放入用户文本段(机器代码)。.data:将后续项目放入用户数据段(源文件数据的二进制形式)。.globl sym:声明符号为全局变量,并且可以从其他文件中引用。.string str:在内存中存储字符串str并以空字符终止。.word w1 ... wn:将n个32位数量依次存储在连续的内存字中。
通过这些步骤和指令,汇编器能够有效地将高级语言代码转换为机器语言代码,并生成可执行文件。
Object File Format
目标文件格式
生成机器代码
简单情况:
- 算术、逻辑、移位等操作。
- 所有必要的信息都已经在指令中包含了。
例如:
add x18, x18, x10
addi x19, x19, -1
基于PC的相对分支和跳转:
例如:
j Label
jal x0, Label
- 位置无关代码 (PIC):
- 一旦伪指令被替换为实际指令,所有基于PC的相对寻址都可以计算出来。
- 通过计算当前指令和目标指令之间的指令数,确定要编码的偏移量(以半字(half-word)为单位)。
计算基于PC的相对地址:两次遍历
我们不能在一次遍历中计算所有偏移量,因为存在“前向引用”问题:
- 分支和基于PC的相对跳转可以引用程序中“向前”的标签。
- 在第一次遍历中,精确的正偏移量是未知的。
例如:
addi t2, zero, 9 # t2 = 9;
Loop: slt t1, zero, t2 # t1 = (0 < t2)?;
beq t1, zero, Exit # t2 <= 0; goto Exit
addi t2, t2, -1 # t2--;
j Loop # go back to Loop
Exit: ...
我们需要两次遍历程序:
- 第一次遍历:记住标签的位置(存储在符号表中)。
- 第二次遍历:使用标签位置生成机器代码。
其他引用怎么办?
- 对其他文件的引用?
- 例如,从C字符串库调用
strlen。
- 例如,从C字符串库调用
- 对静态数据的引用?
- 例如,
la指令被分解为lui和addi。 - 这些需要知道数据的完整32位地址。
- 例如,
- 这些引用在此阶段无法确定,所以汇编器会将它们记录在两个表中:重定位信息和符号表。
Symbol Table
符号表
- Instruction Labels: 指令标签,用于PC相对寻址、函数调用等。
- 使用
.global指令,可以让标签被其他文件引用。
- 使用
- Data:
.data段中的任何内容。- 全局变量可以被其他文件访问/使用。
Relocation Information
重定位信息
- 列出了这个文件需要的所有“项目”的地址。
- 任何跳转到的外部标签:
- 例如,外部标签(包括库文件):
jal ext_label
- 例如,外部标签(包括库文件):
- 静态段中的任何数据:
- 例如,
la指令(用于lw/sw基寄存器)。
- 例如,
Object File Format
目标文件格式
- Object File Header: 目标文件头,记录了目标文件中其他部分的大小和位置。
- Text Segment: 文本段,包含机器代码。
- Data Segment: 数据段,包含源文件中静态数据的二进制表示。
- Symbol Table: 符号表,列出文件中的标签和静态数据,供其他程序引用。
- Relocation Information: 重定位信息,包含需要后续修正的代码行(由链接器进行修正)。
- Debugging Information: 调试信息,帮助开发人员在调试过程中更好地理解和分析程序。
每个部分在目标文件中都有其特定的作用,确保程序在执行时能够正确运行。
目标文件格式
目标文件是一种中间文件格式,用于存储编译器生成的机器代码和相关信息。目标文件通常包括以下部分:
- Object File Header:
- 目标文件头包含了整个目标文件的元数据。它记录了目标文件中各个部分的大小和位置,以便于操作系统或链接器快速访问和处理这些部分。
- 例如,它会包含文本段和数据段的偏移量、大小,以及符号表的偏移量等信息。
- Text Segment:
- 文本段包含了实际的机器代码,也就是编译后的可执行指令。这是程序执行时需要加载到内存中的部分。
- 每个指令都被编码为二进制格式,链接器会将这些指令整合到最终的可执行文件中。
- Data Segment:
- 数据段包含了程序中定义的静态数据。这些数据在程序运行时通常会加载到特定的内存区域。
- 数据段中包括全局变量、静态变量及其初始值。这些变量在程序的生命周期内保持不变。
- Symbol Table:
- 符号表记录了文件中所有的符号(变量和函数的名称)及其地址。符号表用于链接过程中的符号解析。
- 符号表使得链接器可以将目标文件中的符号引用与实际定义的符号匹配起来,以便生成最终的可执行文件。
- Relocation Information:
- 重定位信息包含了需要在链接阶段进行修正的地址和符号引用。由于编译器在生成目标文件时并不知道程序最终在内存中的位置,所以需要重定位信息来调整地址。
- 例如,如果函数调用的目标地址在链接时尚未确定,重定位信息就会记录这些需要修正的地址和相关信息。
- Debugging Information:
- 调试信息包含了源代码和生成的机器代码之间的映射关系,这对调试工具非常重要。
- 调试信息包括源代码行号与对应的机器代码地址,变量和函数的作用域、类型信息等。这些信息使得调试工具可以在调试过程中展示源代码和变量的状态,帮助开发人员分析和排查问题。
目标文件详细解析
1. Object File Header
目标文件头通常包括以下信息:
- 文件魔数(Magic Number):用于标识文件格式。
- 目标文件格式版本:标识文件格式的版本。
- 入口点地址:程序开始执行的地址。
- 文本段偏移量和大小:文本段在目标文件中的位置和大小。
- 数据段偏移量和大小:数据段在目标文件中的位置和大小。
- 符号表偏移量和大小:符号表在目标文件中的位置和大小。
- 重定位信息偏移量和大小:重定位信息在目标文件中的位置和大小。
- 调试信息偏移量和大小:调试信息在目标文件中的位置和大小。
2. Text Segment
文本段存储了编译后的机器指令,是程序的核心执行部分。每个指令都以二进制形式存储在这个段中。例如,在一个简单的汇编程序中:
start: mov eax, 1 add eax, 2 ret这些指令会被翻译成相应的机器码并存储在文本段中。
3. Data Segment
数据段存储了程序中使用的静态数据。例如,全局变量、静态变量及其初始值。在C语言程序中,以下代码:
int global_var = 10; static int static_var = 20;对应的数据将被存储在数据段中。数据段确保这些变量在程序的生命周期内保持不变。
4. Symbol Table
符号表记录了程序中所有符号的名称、类型和地址。例如,在以下C语言代码中:
int global_var = 10; void func() { ... }符号表会包含
global_var和func的条目,记录它们在程序中的地址和类型。5. Relocation Information
重定位信息用于在链接阶段调整地址。例如,如果目标文件中的函数调用指令在编译时地址未知,重定位信息会记录需要调整的地址。链接器在链接时使用这些信息修正指令中的地址,使得函数调用指向正确的位置。
6. Debugging Information
调试信息帮助开发人员在调试过程中理解程序的执行情况。例如,它包括源代码行号与机器码地址的对应关系,使得调试器可以在程序崩溃时显示源代码中的对应位置。此外,它还包括变量和函数的类型信息,使得调试器可以显示变量的值和函数调用栈信息。
通过这些详细的信息,目标文件提供了程序从源代码到可执行文件的重要桥梁,确保程序可以正确地链接、加载和执行。
Linker
链接器
链接器负责将编译器生成的多个目标文件组合成一个单独的可执行文件。
- 输入:目标文件(例如,foo.o,lib.o,适用于RISC-V)
- 包含文本段和数据段,以及每个文件的信息表。
- 输出:可执行机器代码(例如,适用于RISC-V的a.out)
链接器的作用
链接器使得文件可以单独编译,修改单个文件时无需重新编译整个程序。这对于大型项目尤为重要,例如,Linux源代码超过2000万行代码。
- 旧称:”Link Editor”,源自编辑跳转和链接指令中的“链接”。
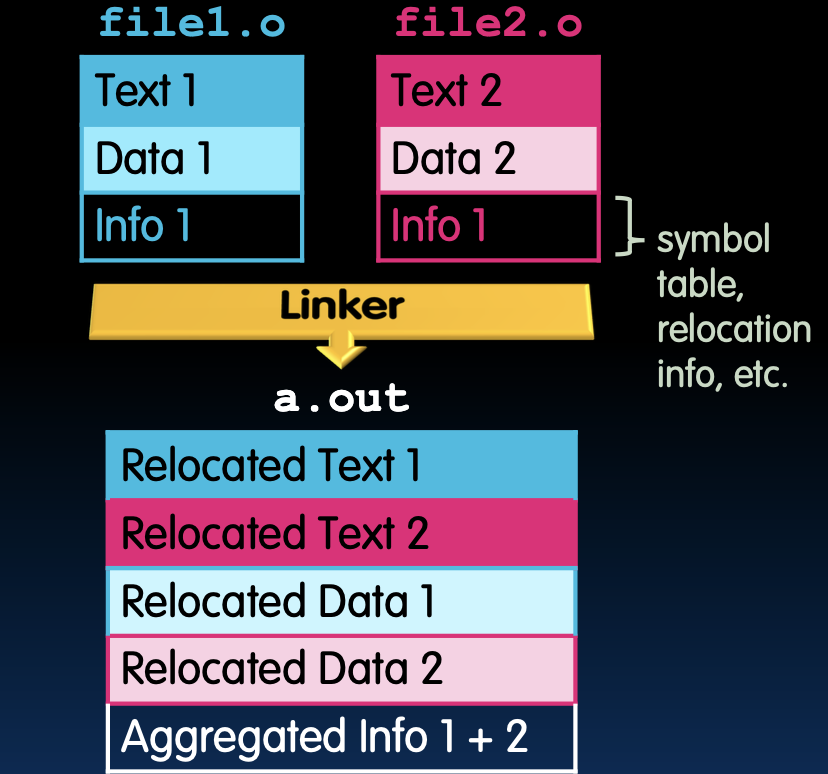
链接器将多个目标模块组合在一起
- 将每个.o文件的文本段组合在一起。
- 将每个.o文件的数据段组合在一起,并连接到文本段的末尾。
- 解析引用:
- 遍历重定位表并处理每个条目,填写所有绝对地址。
哪些地址需要重定位?
PC相对寻址 ❌
- beq、bne、jal、auipc/addi等:
- 这些指令使用PC相对地址,不需要重定位。
- 位置独立代码(PIC)。
外部函数引用
- 通常是jal或auipc/jalr:
- 这些指令引用外部函数,需要重定位。
- 在汇编时地址未知,需要在链接时解决。
静态数据引用
- lw、sw、lui/addi:
- 这些指令引用数据段中的静态数据,需要重定位。
- 数据段在链接时会被重定位。
哪些指令需要重定位编辑?
J-格式
- 仅当外部跳转时:
- 包含jal指令的情况需要重定位,因为外部跳转在汇编时地址未知。
使用gp访问数据变量的加载和存储
- 全局指针(gp) 是指向数据段或静态段的指针,用于访问全局变量。
I-格式和S-格式
- lui、addi;auipc/jalr(如果外部跳转):
- 这些指令总是需要重定位,因为它们涉及加载和存储的地址。
B-类型
- 条件分支(B-类型)不需要编辑:
- 即使文本段被重定位,条件分支指令仍然使用PC相对寻址,因此无需重定位。
进一步的细节
在处理目标文件时,链接器不仅仅是简单地拼接各个段,还需要解决各个段之间的地址引用问题。链接器会使用符号表和重定位表来确保所有的符号引用都能正确解析到对应的地址。这个过程包括以下步骤:
- 符号解析:链接器会遍历所有输入目标文件的符号表,确保所有的全局符号都有唯一的定义。
- 地址分配:为每个段分配内存地址,并确定每个符号的最终地址。
- 重定位处理:根据重定位表中的信息,调整代码中的地址引用,使其指向正确的内存地址。
通过这些步骤,链接器能够将多个独立编译的模块整合成一个完整的可执行程序,使程序可以正确运行。
Resolving References (1/2)
解析引用(1/2)
在解析引用过程中,链接器的主要任务是计算并解决程序中所有符号的实际地址。
- 对于RV32,链接器假设第一个文本段从地址0x10000开始(稍后会讨论虚拟内存)。
- 链接器知道:
- 每个文本段和数据段的长度
- 文本段和数据段的顺序
- 链接器计算:
- 每个要跳转的标签的绝对地址
- 每个引用的数据的绝对地址
Resolving References (2/2)
解析引用(2/2)
链接器通过以下步骤解析引用:
- 链接器解析引用:
- 在所有“用户”符号表中搜索引用(数据或标签)
- 如果未找到,则搜索库文件(例如,printf)。
- 一旦确定绝对地址,就相应地填写机器代码。
- 链接器输出:
- 包含文本段和数据段的可执行文件(以及头部和调试信息)
Static vs. Dynamic Linking
静态链接与动态链接
静态链接和动态链接是两种链接库的方法。
- 静态链接:
- 库在编译时被包含到可执行文件中。
- 优点:可执行文件是自包含的,便于分发和部署。
- 缺点:库更新后,需要重新编译用户程序,否则不会获得修复;可执行文件可能包含未使用的库部分,导致文件较大。
- 动态链接:
- 动态链接库(DLL)在程序运行时加载。常见于Windows和UNIX平台。
- 优点:
- 存储和传输程序所需的磁盘空间较小。
- 不同程序可以共享库,减少内存使用。
- 程序更新时,只需替换DLL即可升级所有使用该库的程序。
- 缺点:
- 运行时开销增加,需要额外的链接时间。
- 程序依赖外部库,必须确保所需的DLL存在并兼容。
- 方法:
- 使用机器代码作为“最低公分母”在机器代码级别进行链接,这样链接器不需要知道用什么编译器或语言编译的。
尽管动态链接增加了系统的复杂性,但其带来的灵活性和资源优化通常超过其复杂性。
Loader
加载器
加载器负责将可执行文件从磁盘加载到内存,并准备执行。
- 输入:可执行代码(例如,RISC-V的a.out)
- 输出:程序运行
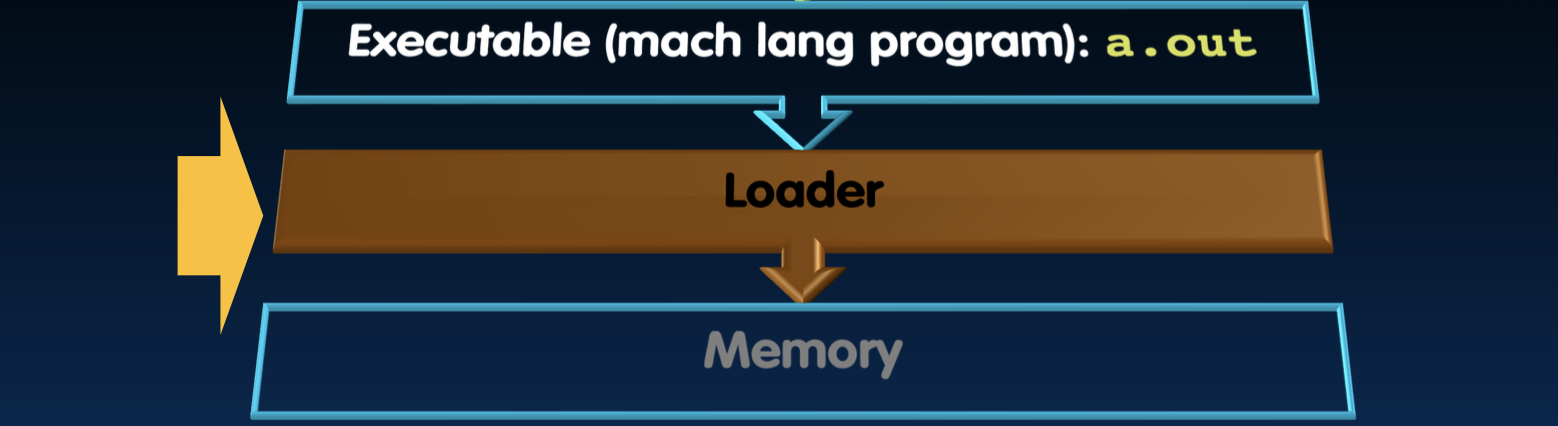
加载器的工作原理
加载器执行以下任务:
- 将程序加载到新创建的地址空间:
- 读取可执行文件头,获取文本段和数据段的大小。
- 为程序创建新的地址空间,足够容纳文本段、数据段和堆栈段。
- 将指令和数据从可执行文件复制到新地址空间。
- 将传递给程序的参数复制到堆栈上。
- 初始化机器寄存器:
- 大多数寄存器被清除;堆栈指针(sp)被赋予第一个空闲堆栈位置的地址。
- 跳转到启动例程,该例程执行以下操作:
- 将程序参数从堆栈复制到寄存器,设置程序计数器(PC)。
- 如果主例程返回,则终止程序并调用退出系统调用。
Peer Instruction
在处理的哪个阶段,以下汇编指令的所有机器代码位都已确定?
add x6, x7, x8jal x1, fprintf
A. 编译后
B. 汇编后
C. 链接后
D. 加载后
答案:add x6, x7, x8 在汇编后确定(答案 B),jal x1, fprintf 在链接后确定(答案 C)。
Example C Program: hello.c
示例C程序:hello.c
这个简单的C程序包含一个main函数,使用printf函数打印”Hello, world!”到控制台,然后返回0。
#include <stdio.h>
int main() {
printf("Hello, %s\n", "world");
return 0;
}
Compile: hello.c 到 hello.s
编译:hello.c 到 hello.s
编译器将C代码转换为汇编代码。以下是生成的汇编代码示例:
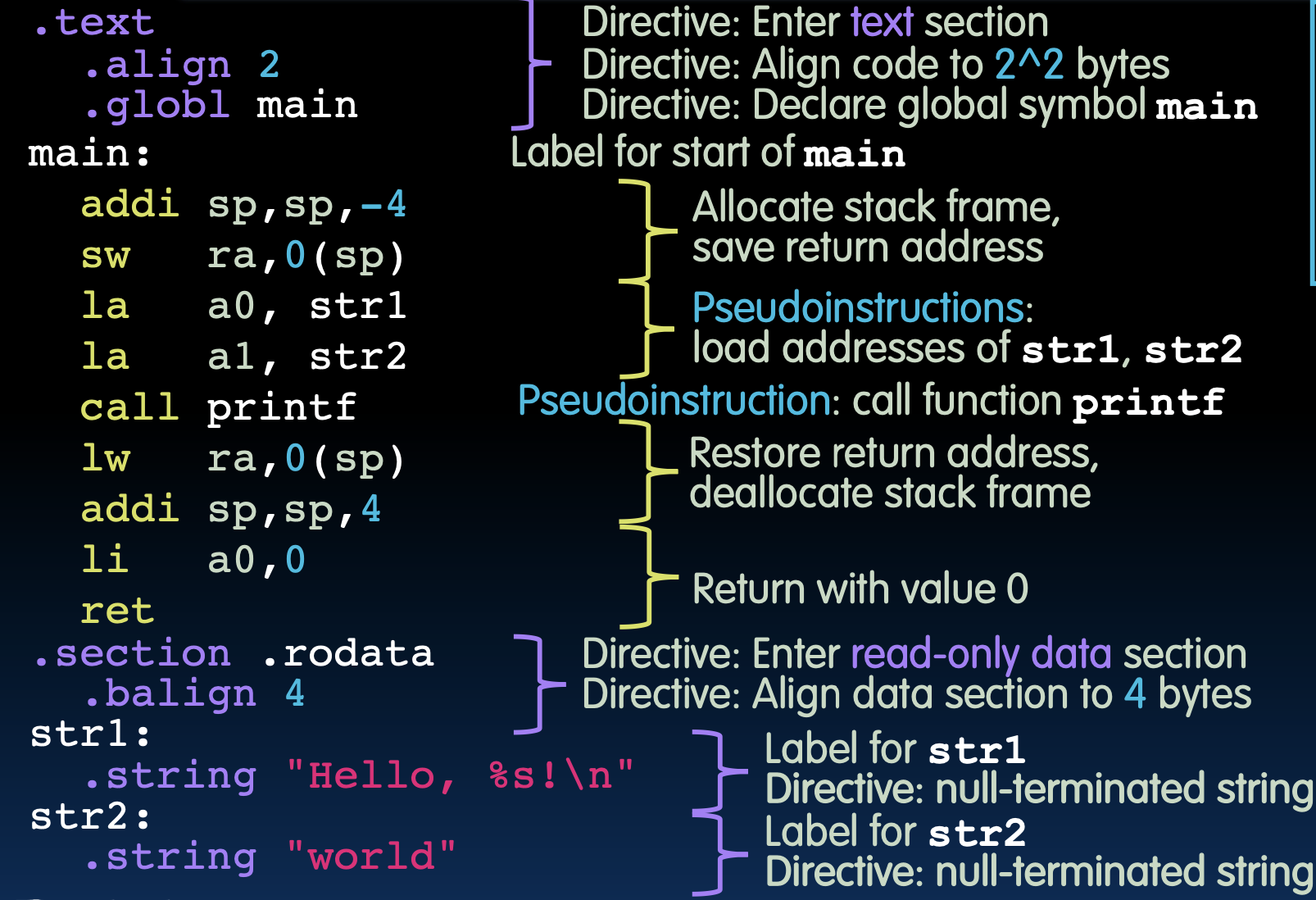
.text:代码段.align 2:将代码对齐到2^2字节边界。.globl main:声明main为全局符号。main::main函数的标签。addi sp, sp, -16:分配栈帧,保存返回地址。sw ra, 0(sp):将返回地址保存到栈上。la a0, str1:加载str1的地址到寄存器a0。la a1, str2:加载str2的地址到寄存器a1。call printf:调用printf函数。lw ra, 0(sp):从栈上恢复返回地址。addi sp, sp, 16:释放栈帧。li a0, 0:将返回值0加载到寄存器a0。ret:返回调用者。
.section .rodata:只读数据段.align 4:将数据对齐到4字节边界。str1::str1的标签。.string "Hello, %s\n":空终止字符串。str2::str2的标签。.string "world":空终止字符串。
Assemble: hello.s 到 hello.o
汇编:hello.s 到 hello.o
汇编器将汇编代码转换为目标文件。以下是一些关键步骤:

- Text segment:文本段
- 汇编器输出显示了每条指令的机器码。例如:
addi sp, sp, -16:ff010113sw ra, 12(sp):00112623
- 伪指令如
la和call被替换为实际指令,地址占位符将被填充。
- 汇编器输出显示了每条指令的机器码。例如:
- Object file (Assembler output):目标文件(汇编器输出)
- 包含指令的机器码,以及用于链接和重定位的信息。
- Symbol Table:符号表
- 包含每个标签在模块中的地址和类型。例如:
main:全局文本str1:本地数据str2:本地数据
- 包含每个标签在模块中的地址和类型。例如:
- Relocation Information:重定位信息
- 包含需要重定位的地址及其依赖关系。例如:
0x00000008:依赖于str1的高位部分0x0000000c:依赖于str1的低位部分0x00000010:依赖于str2的高位部分
- 包含需要重定位的地址及其依赖关系。例如:
Link: hello.o 到 a.out
链接:hello.o 到 a.out
在这一阶段,链接器会将多个目标文件(如hello.o)链接成一个可执行文件(如a.out)。链接器通过计算每个符号的最终地址来填充占位符。
101b0 <main>:
101b0: ff010113 addi sp, sp, -16
101b4: 00112623 sw ra, 12(sp)
101b8: 00021537 lui a0, 0x21
101bc: a0500513 addi a0, a0, -1520 # 20a10 <str1>
101c0: 000215b7 lui a1, 0x21
101c4: a0c58593 addi a1, a1, -1508 # 20a1c <str2>
101c8: 288000ef jal ra, 10450 # <printf>
101cc: 00012083 lw ra, 12(sp)
101d0: 01010113 addi sp, sp, 16
101d4: 00000513 li a0, 0
101d8: 00008067 jalr ra
以下是链接器如何计算这些立即数:
lui/addi 地址计算,再论
回顾addi指令如何扩展符号位。为了创建32位立即数0x20A10(str1的地址):
- 下12位的
addi立即数的符号位是负的。 - 需要在上20位的
lui立即数上加1。
00021537 lui a0, 0x21
a0500513 addi a0, a0, -1520
下12位立即数-1520:
- 0xFFFFFA10 的补码是0x000005F0 + 1 = 0x5F0,即1520。
- 所以0xFFFFFA10 = -1520。
总结
- 编译器将单个高级语言文件转换为单个汇编语言文件。
- 汇编器去除伪指令,将能转换的部分转换为机器语言,并为链接器创建重定位表。
- 汇编器通过两次遍历解决地址问题,处理内部前向引用。
- 链接器将多个目标文件组合在一起并解决绝对地址。
- 启用单独编译,库不需要重新编译,解决剩余地址问题。
- 加载器将可执行文件加载到内存中并开始执行。
通过这一系列的步骤,最终实现了从高级语言到可执行程序的完整转换过程。
Program Translation vs. Interpretation (recorded)
Language Execution Continuum
语言执行连续性

解释器是一种直接执行其他程序的程序。
- Python、Java、C++等语言容易编程,但解释执行效率较低。
- 汇编语言和机器码虽然难以编程,但执行效率高。
语言翻译提供了另一种选择
翻译是一种将程序从一种语言转换为另一种语言的过程。我们通常在以下情况下选择翻译或解释:
- 解释:当效率不是关键时,解释高级语言。
- 翻译:为了提高性能,将程序翻译为低级语言。
Interpretation
解释
以Python程序foo.py为例:
- Python解释器:解释器读取Python程序并执行该程序的功能。
Python解释器本身也是一个程序,它读取Python代码并逐行解释执行,从而实现程序的功能。
解释型语言和编译型语言各有优缺点,适用于不同的应用场景。解释型语言通常开发效率更高,适合快速开发和调试,而编译型语言则提供更高的运行时性能。
为什么在软件中解释机器语言?
- VENUS RISC-V模拟器:用于学习和调试,非常有用。
- 苹果Macintosh转换:从Motorola 680x0 ISA转换到PowerPC(在x86之前)。
- 可能需要将所有程序从高级语言重新翻译。
- 让可执行文件包含旧的和/或新的机器代码,必要时在软件中解释旧代码(仿真)。
解释机器语言在某些情况下非常有用。例如,模拟器可以帮助学习和调试新指令集架构,而在硬件转型期间,解释器可以使旧软件在新硬件上继续运行。
解释与翻译对比
- 编写解释器通常更容易。你在CS61A课程中已经做过了!
- 解释器更接近高级语言,可以提供更好的错误信息(例如,VENUS)。
- 翻译器反应:添加额外的信息以帮助调试(行号、名称)。
- 解释器较慢(可能慢10倍?),代码较小(可能小2倍?)。
- 解释器提供指令集独立性:可以在任何机器上运行。
解释器的灵活性使其成为跨平台开发的理想选择,因为同一个解释器可以在不同的硬件平台上运行相同的代码。
翻译/编译的代码几乎总是更高效,性能更高:
- 对许多应用程序尤其是操作系统非常重要。
翻译/编译有助于“隐藏”用户的程序“源代码”:
- 在市场中创造价值的一种模型(例如,微软保持所有源代码的秘密)。
- 另一种模型是“开源”,通过发布源代码并促进开发者社区来创造价值。
编译器将源代码翻译为目标机器的机器码,使程序的执行效率更高。对于需要高性能和安全性的应用,编译器是不可或缺的工具。而解释器则提供了更好的可移植性和调试能力。