Lecture 21: RISC-V 5-Stage Pipeline I
并行处理概述
- 软件层面的并行请求:多个请求同时发送给计算机处理,例如搜索“Cats”。
- 在大规模数据处理或搜索引擎中,多个用户请求可以同时处理,以提高响应速度和系统吞吐量。
- 并行线程:多个线程同时分配给计算机核心进行处理,例如查找、广告。
- 多线程技术可以充分利用多核处理器的资源,提高计算效率。例如,现代浏览器通过多线程加载页面元素,实现快速渲染。
- 并行指令:每个时刻处理多条指令,例如,流水线处理的5条指令。
- 流水线技术通过将指令分解成多个阶段,并行处理不同阶段的指令,从而提高处理器的整体执行效率。典型应用包括指令级并行(ILP)和超标量处理器。
- 并行数据:每个时刻处理多条数据,例如同时处理4对字的加法。
- 向量处理器和SIMD(单指令多数据)架构利用并行数据处理技术,在图像处理、科学计算和机器学习等领域大大提升性能。
- 硬件描述的并行:所有逻辑门同时工作。
- 在硬件层面,电路设计中各个逻辑门并行工作,从而实现快速的信号传播和处理。这是硬件并行处理的基础。
并行处理的硬件结构
- 大型仓库级计算机(Warehouse Scale Computer):用于处理大规模并行任务,通常包含多个计算节点。
- 这种架构常用于云计算和数据中心,能够处理大规模数据和复杂计算任务,提供高可用性和可扩展性。
- 计算机核心和内存(Core, Memory):包括多个处理核心和层次化的内存结构。
- 现代处理器通过多核设计和层次化的缓存结构,优化数据访问速度和计算效率。
- 执行单元(Exec. Units)和功能块(Functional Blocks):执行具体的运算任务,如加法、乘法等。
- 在处理器内部,执行单元负责具体的计算操作,各种功能块根据需要调度和执行特定的指令。
- 主存储器和逻辑门(Main Memory, Logic Gates):负责数据存储和基本逻辑运算。
- 主存储器用于存储正在处理的数据和程序,逻辑门实现基本的逻辑运算和控制信号的生成。
计算机体系结构中的六大重要思想
-
抽象(Abstraction):分层表示和解释。
- 通过抽象,各层次的硬件和软件可以独立设计和优化,从而提高系统的可维护性和可扩展性。
-
摩尔定律(Moore’s Law):每隔大约18个月,集成电路上的晶体管数量会翻一番。
- 摩尔定律驱动了计算机硬件的快速发展,使得计算能力和存储容量不断提升。
-
局部性原理/内存层次结构(Principle of Locality/Memory Hierarchy):利用数据的时间局部性和空间局部性,优化内存访问效率。
- 通过缓存机制和分层内存结构,系统能够高效地管理和访问数据。
-
并行性(Parallelism):通过并行处理提高系统性能。
- 并行性是现代计算机体系结构的重要特征,通过多核处理、向量处理等技术,实现高性能计算。
-
性能测量与改进(Performance Measurement & Improvement):通过性能测量和分析,不断优化和改进系统性能。
- 系统性能的不断优化依赖于精确的测量和分析,帮助识别瓶颈并提出改进方案。
-
通过冗余实现可靠性(Dependability via Redundancy):通过冗余设计提高系统的可靠性和容错能力。
- 冗余设计如RAID存储、多重电源和备份系统,确保系统在发生故障时依然能够可靠运行。
指令时序
时序图解析
下图展示了单周期处理器中指令的执行时序图,以及各个阶段所需的时间。
- 时钟周期(Clock):
- 每个时钟周期由上升沿和下降沿组成。
- 程序计数器(PC):
PC的值在每个周期都会更新。PC指向当前指令,新的PC值(pc+4)指向下一条指令。
- 指令获取(IF):
- 从内存中取指令,并将其加载到指令寄存器中。
- 指令译码(ID):
- 解析指令,确定操作码和操作数。
- 从寄存器文件中读取操作数。
- 执行(EX):
- 在ALU中执行操作,计算结果。
- 内存访问(MEM):
- 访问数据内存(如果是
lw或sw指令)。
- 访问数据内存(如果是
- 写回(WB):
- 将结果写回寄存器文件。

各阶段所需时间
- 指令获取(IF):200 ps
- 指令译码(ID):100 ps
- 执行(EX):200 ps
- 内存访问(MEM):200 ps
- 写回(WB):100 ps
不同指令的执行时间
add指令:- IF + ID + EX + WB = 200 + 100 + 200 + 100 = 600 ps
beq指令:- IF + ID + EX = 200 + 100 + 200 = 500 ps
jal指令:- IF + ID + EX = 200 + 100 + 200 = 500 ps
lw指令:- IF + ID + EX + MEM + WB = 200 + 100 + 200 + 200 + 100 = 800 ps
sw指令:- IF + ID + EX + MEM = 200 + 100 + 200 + 200 = 700 ps
时钟频率计算
- 最大时钟频率:\( f_{\text{max}} = \frac{1}{800 \text{ ps}} = 1.25 \text{ GHz} \)
- ALU最大频率:\( f_{\text{max, ALU}} = \frac{1}{200 \text{ ps}} = 5 \text{ GHz} \)

- 单周期处理器的时钟周期由最长的指令决定,即
lw指令,需800 ps。 - 大多数硬件单元在大部分时间都是空闲的。
- 了解指令的执行时间对于优化处理器性能和设计具有重要意义。这有助于识别瓶颈和潜在的改进点,尤其是考虑如何提高并行度或引入流水线来提升整体效率。
Performance Measures
RISC-V CPU的性能评估
- 执行速度:我们的单周期RISC-V CPU在1.25 GHz的频率下执行指令,每800皮秒(ps)执行一条指令。
- 这个频率表示每秒可以执行12.5亿条指令,这是处理器性能的一个基本衡量标准。
提高性能的途径
- 响应时间:更快的响应时间意味着单个任务可以更快完成,提高用户体验。
- 例如,减少网页加载时间或语音识别响应时间。
- 单位时间内的任务数量:在一定时间内完成更多任务,例如网络服务器每小时返回的页面数量或识别的语音词数。
- 提高吞吐量有助于服务器处理更多请求,提高系统整体效率。
- 电池寿命:通过优化能耗,使设备在不增加功耗的情况下完成更多任务,从而延长电池寿命。
- 对于移动设备和电池供电设备,能效优化是性能提升的一个关键方面。
交通类比
- 跑车 vs 公共汽车:比较跑车和公共汽车在运送乘客时的效率。
- 跑车速度快,但载客量小,燃油效率低。50英里行程需要15分钟,每次只能运送2人,100名乘客需要750分钟,总燃油消耗为5加仑/人。
- 公共汽车速度慢,但载客量大,燃油效率高。50英里行程需要60分钟,每次可以运送50人,100名乘客只需120分钟,总燃油消耗为0.5加仑/人。
计算机类比
- 行程时间 vs 程序执行时间:行程时间类似于程序的执行时间,例如更新显示器的时间。
- 提高程序执行时间可以减少等待时间,提高用户体验。
- 100名乘客的时间 vs 吞吐量:处理100名乘客的时间类似于计算机的吞吐量,例如每小时处理的服务器请求数量。
- 增加吞吐量可以提高系统的效率和处理能力。
- 每名乘客的加仑数 vs 每任务的能耗:每名乘客的加仑数类似于每任务的能耗,例如每电池充电可以观看多少部电影,或数据中心的能耗账单。
- 优化能耗可以减少能源消耗,延长设备使用时间,并降低运营成本。
能耗说明
- 功率并非良好衡量标准:低功率CPU可能运行时间较长以完成单个任务,反而消耗更多能源,而高功率CPU以更高的功率运行,但时间较短,总能耗可能更低。
- 这说明在性能评估中,必须综合考虑功率和执行时间,以找到最佳的能效平衡点。
Processor Performance Iron Law
处理器性能铁律
- 时间 = 指令数 * 每条指令的时钟周期数 * 每个时钟周期的时间
- 处理器的性能可以通过这条铁律来表示,即程序执行的总时间等于程序中的指令数乘以每条指令所需的时钟周期数,再乘以每个时钟周期的时间。
- 公式:
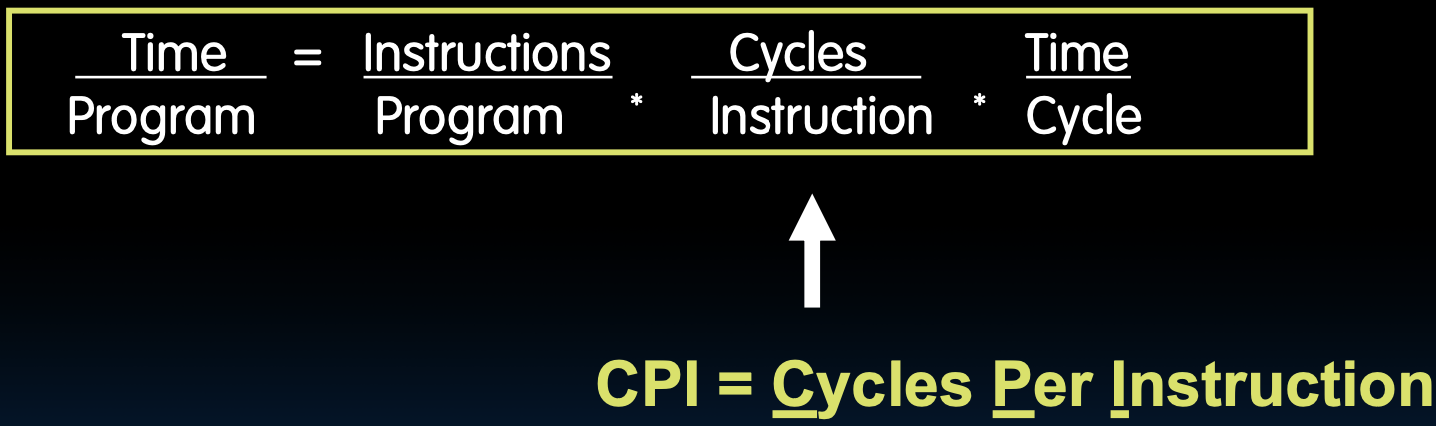
每条指令的周期数 (CPI)
- 每条指令的周期数:CPI(Cycles Per Instruction)是衡量处理器效率的重要指标。
- 它表示执行一条指令所需的平均时钟周期数。
- 较低的CPI值意味着处理器可以在更少的周期内完成指令,提高了执行效率。
程序中的指令数 Instructions per Program
- 任务:不同的任务需要不同数量的指令。
- 简单任务可能只需要少量指令,而复杂任务可能需要大量指令来完成。
- 算法:算法的复杂度对指令数有直接影响。
- 例如,O(N²)算法与O(N)算法相比,前者在处理相同数量的输入时需要更多的指令数。
- 优化算法可以显著减少指令数,从而提高程序执行效率。
- 编程语言:编程语言的抽象级别影响生成的指令数。
- 高级语言通常需要更多的指令来实现相同的功能,因为它们提供了更多的抽象和方便性。
- 编译器:编译器的优化水平对指令数有重要影响。
- 优化的编译器可以生成更高效的机器代码,减少指令数,提高执行效率。
- 指令集架构 (ISA):不同的指令集架构对指令数有直接影响。
- 精简指令集计算机(RISC)通常需要更多的指令来完成任务,但每条指令的执行速度更快。
- 复杂指令集计算机(CISC)通常每条指令更复杂,但需要的指令数较少。
(Average) Clock Cycles per Instruction (CPI)
平均每条指令的时钟周期数 (CPI)
CPI由以下因素决定:
- ISA(指令集架构):
- 不同的ISA会影响每条指令所需的时钟周期数。例如,RISC-V设计中的单周期实现,CPI为1。
- 处理器实现(或微架构):
- 处理器的具体实现方式影响CPI值。复杂指令如
strcpy的CPI会显著大于1。
- 处理器的具体实现方式影响CPI值。复杂指令如
- 复杂指令:
- 复杂指令会增加CPI值,例如字符串复制指令(
strcpy)。
- 复杂指令会增加CPI值,例如字符串复制指令(
- 超标量处理器:
- 超标量处理器通过并行执行多条指令,可以使CPI小于1。
Time per Cycle (1/Frequency)
每个周期的时间
每个时钟周期的时间由以下因素决定:
- 处理器微架构:
- 微架构决定了通过逻辑门的关键路径,从而影响每个周期的时间。
- 技术工艺:
- 例如,5纳米技术与28纳米技术相比,可以实现更快的时钟速度。
- 功耗预算:
- 较低的电压会降低晶体管的速度,从而影响每个周期的时间。
Speed Tradeoff Example
速度权衡示例
对于某些任务(例如图像压缩):
| 参数 | 处理器A | 处理器B |
|---|---|---|
| 指令数 | 100万 | 150万 |
| 平均CPI | 2.5 | 1 |
| 时钟频率 (f) | 2.5 GHz | 2 GHz |
| 执行时间 | 1 ms | 0.75 ms |
- 解释:
- 尽管处理器B执行的指令数更多,并且时钟频率较低,但它的CPI更小,因此总体执行时间更短。
- 处理器B在此任务中表现更快,即使执行更多指令且时钟频率较低。
Energy Efficiency
Where Does Energy Go in CMOS?
CMOS中能量的去向
在CMOS(互补金属氧化物半导体)中,能量主要消耗在以下两个方面:
- 泄漏电流(Leakage):
- 约占总能量消耗的30%。这是由于在晶体管未完全关闭时,仍然存在微小电流通过,从而导致能量损失。
- 充电电容(Charging Capacitors,CV²):
- 约占总能量消耗的70%。这是在电路切换时充放电容器所需的能量,这部分能量与电压平方成正比。
能量每任务
公式表示为: \[ \frac{\text{Energy}}{\text{Program}} = \frac{\text{Instructions}}{\text{Program}} \times \frac{\text{Energy}}{\text{Instruction}} \] 即: \[ \frac{\text{Energy}}{\text{Program}} \propto \frac{\text{Instructions}}{\text{Program}} \times \text{C} \times \text{V}^2 \]
- 电容(Capacitance,C):取决于技术和处理器特性(例如核心数量)。
- 供电电压(Supply Voltage,V):例如1V。
要降低任务能耗,可以减少电容和电压。
Energy Tradeoff Example
能量权衡示例
“下一代”处理器通过以下方式实现显著的能量效率提升:
- 电容(C)减少15%:遵循摩尔定律(Moore’s Law)。
- 供电电压(Vsup)减少15%。
- 能量消耗减少39%: \[ 0 - (1 - 0.853) = -39\% \]
这显著提高了能量效率,得益于摩尔定律和降低供电电压。
Performance/Power Trends
性能/功率趋势
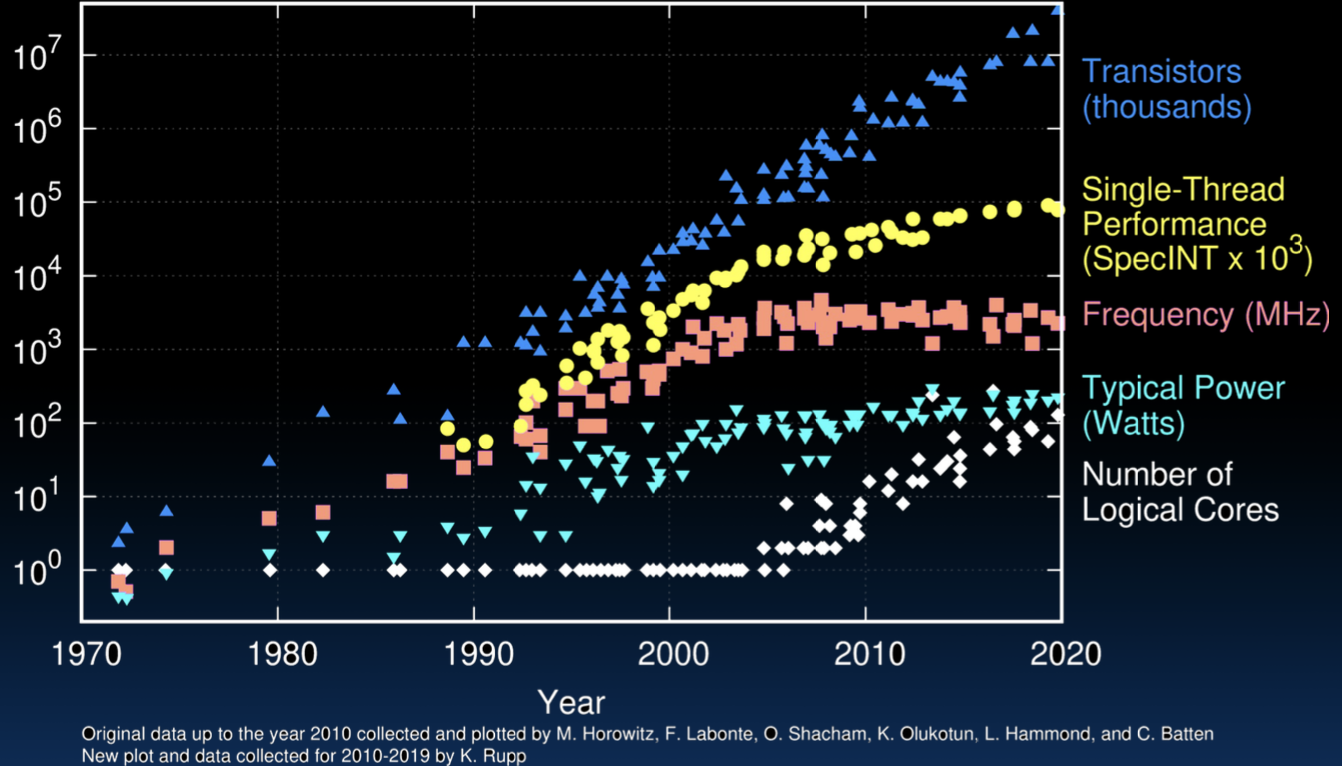
图中展示了过去48年微处理器的趋势数据,包括:
- 晶体管数量(Transistors):不断增加,从最初的数千个增加到数十亿个。
- 单线程性能(Single-Thread Performance):性能显著提高。
- 频率(Frequency):处理器时钟频率在不断提高。
- 典型功率(Typical Power):功耗也在上升。
- 逻辑核心数量(Number of Logical Cores):多核处理器的普及。
这些趋势反映了微处理器技术的发展,同时也揭示了随着技术进步,功率和能效的挑战。
End of Scaling
缩放的终结
近年来,行业在以下几个方面遇到了挑战:
- 降低供电电压的困难:进一步降低电压会导致“漏电功率”增加,因为晶体管开关无法完全关闭(类似于调光开关,而不是简单的开关)。
- 晶体管尺寸和电容的缩小速度放缓:下一代晶体管之间的尺寸变化不像以前那样显著,需要转向3D设计。
- 功耗问题:功耗成为一个日益严重的问题,被称为“功率墙(power wall)”。
Energy “Iron Law”
能量“铁律”
性能公式表示为: \[ \text{Performance} = \text{Power} \times \text{Energy Efficiency} \] 即: \[ \text{Performance} = \frac{\text{Tasks}}{\text{Second}} = \frac{\text{Joules}}{\text{Second}} \times \frac{\text{Tasks}}{\text{Joule}} \]
- 能效(Energy Efficiency):如每焦耳指令数(instructions/Joule),是所有计算设备的重要指标。
- 对于功耗受限系统(例如20MW数据中心),需要更好的能效以在相同功率下获得更高性能。
- 对于能量受限系统(例如1W手机),需要更好的能效以延长电池寿命。
通过提高能效,可以在功率限制内提升性能,满足不同计算设备的需求。
Introduction t o Pipelining
Introduction to Pipelining
流水线处理简介
在本页中,我们通过一个洗衣的例子来介绍流水线处理的概念。
Gotta Do Laundry
每个人(Avi, Bora, Caroline, Dan)都有一堆衣物需要洗、烘干、折叠和放入抽屉。具体的时间安排如下:
- 洗衣机(Washer):30分钟
- 烘干机(Dryer):30分钟
- 折叠(Folder):30分钟
- 放入抽屉(Stasher):30分钟
Sequential Laundry
在顺序处理的情况下,每个人依次完成所有步骤。具体时间安排如下:
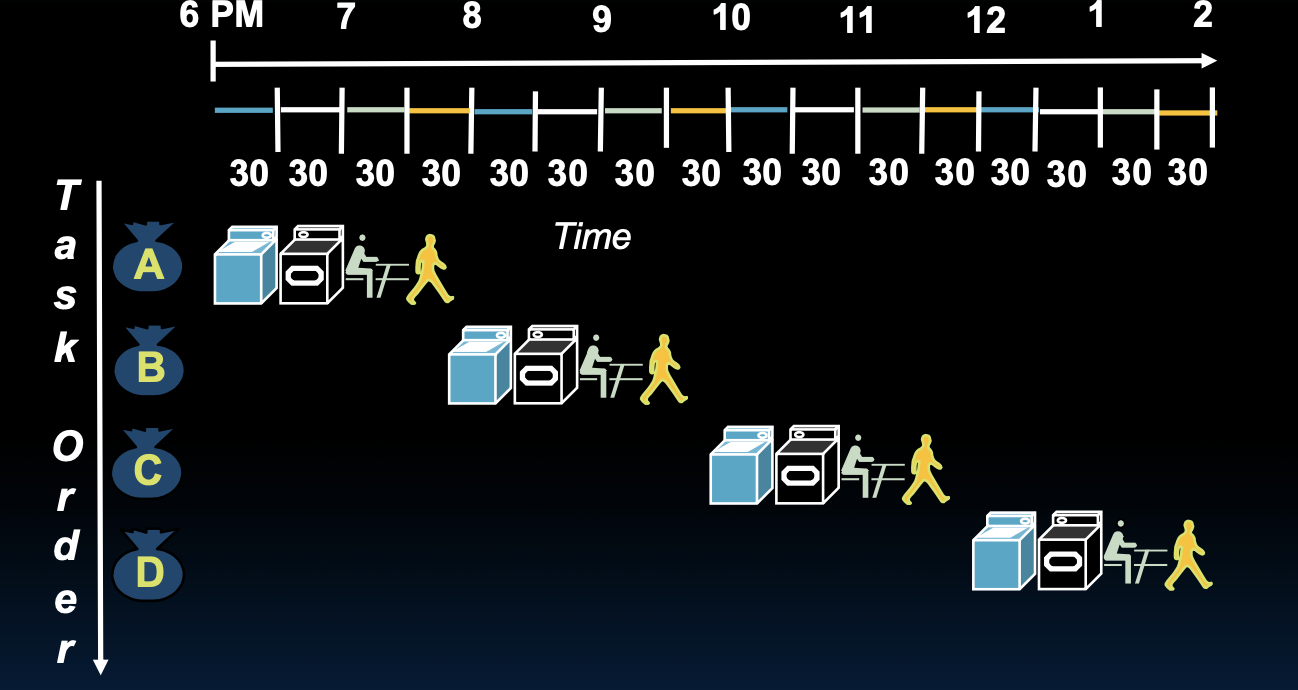
- 6 PM:Avi开始洗衣(30分钟)
- 6:30 PM:Avi的衣物完成洗涤,开始烘干(30分钟)
- 7 PM:Avi的衣物完成烘干,开始折叠(30分钟)
- 7:30 PM:Avi的衣物完成折叠,开始放入抽屉(30分钟)
- 8 PM:Bora开始洗衣(30分钟)
- 8:30 PM:Bora的衣物完成洗涤,开始烘干(30分钟)
- 9 PM:Bora的衣物完成烘干,开始折叠(30分钟)
- 9:30 PM:Bora的衣物完成折叠,开始放入抽屉(30分钟)
- 10 PM:Caroline开始洗衣(30分钟)
- 10:30 PM:Caroline的衣物完成洗涤,开始烘干(30分钟)
- 11 PM:Caroline的衣物完成烘干,开始折叠(30分钟)
- 11:30 PM:Caroline的衣物完成折叠,开始放入抽屉(30分钟)
- 12 AM:Dan开始洗衣(30分钟)
- 12:30 AM:Dan的衣物完成洗涤,开始烘干(30分钟)
- 1 AM:Dan的衣物完成烘干,开始折叠(30分钟)
- 1:30 AM:Dan的衣物完成折叠,开始放入抽屉(30分钟)
总时间:8小时
这个例子展示了顺序处理的缺点:每个步骤必须等待前一个步骤完成后才能开始,导致整体时间较长。通过引入流水线处理,可以同时进行多个步骤,提高效率。
Pipelined Laundry
流水线处理洗衣
在流水线处理的洗衣过程中,我们可以同时进行多个步骤,从而显著减少总的处理时间。
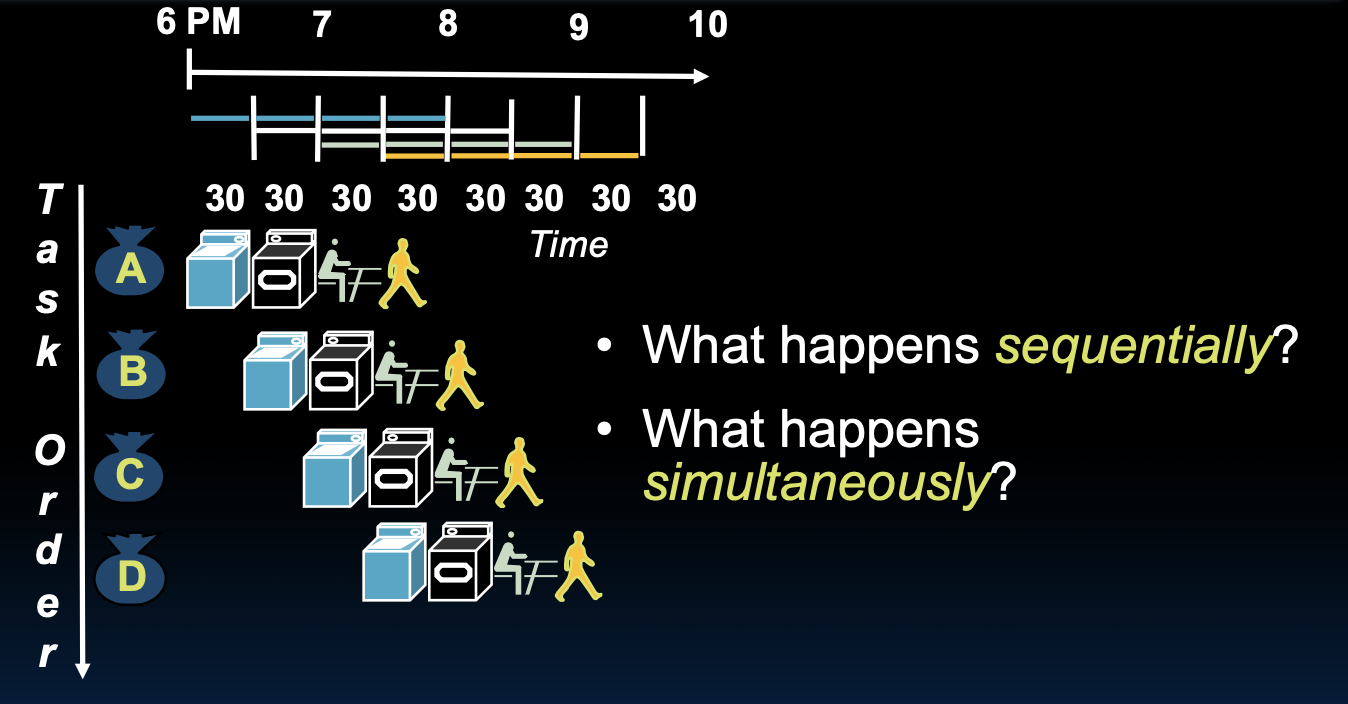
同时处理的情况如下:
- 每个步骤可以并行进行,不需要等待前一个步骤完成。
- 通过流水线处理,多个任务可以同时操作使用不同的资源。
- 总时间:3.5小时。
流水线的优势
- 延迟(Latency):流水线处理不会减少单个任务的延迟,但能显著提高整体工作量的吞吐量。
- 吞吐量(Throughput):通过并行处理多个任务,流水线处理能显著提高整体工作量的处理速度。
- 潜在加速比:加速比取决于流水线阶段的数量。在这个例子中,加速比为2.3X到4X。
在顺序洗衣的过程中,每个任务依次完成所有的步骤。这种方法的缺点如下:
- 时间延迟:每个步骤必须等待前一个步骤完成,导致整体时间较长。
- 速度限制:顺序处理的速度受限于每个步骤的最长时间。
改进洗衣设备
假设新的洗衣机和放入抽屉的设备每步只需20分钟,那么流水线的速度如何变化?
- 速度限制:流水线的速率受限于最慢的流水线阶段。
- 不平衡阶段的影响:不平衡的流水线阶段会降低加速比。
通过这些改进,流水线处理可以显著提高整体效率,减少处理时间。
流水线的优势:通过将任务分解为多个阶段并行处理,流水线技术显著减少了每个任务的处理时间。就像在洗衣过程中,通过并行处理多个洗衣步骤,可以更快地完成所有衣物的清洗。
长流水线的优势:更长的流水线意味着每个阶段需要处理的工作量更少,这允许时钟频率更高,从而提高整体处理速度。然而,必须注意的是,流水线的过长也可能导致其他问题,如流水线气泡和数据冒险(data hazards)。
CPI的稳定性:在不同的基准测试中,处理器的每条指令周期数(CPI)通常保持相对稳定。即使在不同的工作负载和应用程序下,CPI的波动也通常在一个可接受的范围内(例如±25%)。这表明流水线技术对不同类型的任务具有良好的适应性。
流水线气泡和数据冒险(Data Hazards)
流水线气泡(Pipeline Bubbles)
- 定义:流水线气泡是指在流水线中出现的空闲周期,即在某个时钟周期内,没有指令能够继续向下一个阶段推进,导致流水线中有一个或多个阶段处于空闲状态。
- 原因:流水线气泡通常是由于以下原因引起的:
- 分支预测失败:当分支预测器错误预测了跳转指令的方向时,需要清空流水线中错误预测的指令,填入正确的指令。这会导致多个周期的流水线气泡。
- 数据冒险:当某条指令需要前一条指令的结果作为输入,但结果还未计算出来时,就需要暂停流水线的进展,等待数据的准备。这段等待时间会导致流水线气泡。
- 结构冒险:当流水线中的多个指令需要使用相同的硬件资源(如同一个内存端口)时,可能需要等待资源的空闲,从而产生气泡。
数据冒险(Data Hazards)
- 定义:数据冒险是指在流水线中,由于指令间的数据依赖关系而引起的问题。这些问题可能导致指令的执行顺序被改变,影响指令的正确性或性能。
- 类型:数据冒险主要分为以下几种:
- 读后写冒险(RAW,Read After Write):又称为“真实依赖性”。指令B需要使用指令A写入的结果,但指令A的结果还未计算出来。这是最常见的数据冒险。
- 解决方法:可以通过数据前推(Forwarding)或插入气泡的方式来解决。数据前推是将尚未写回寄存器的数据直接传给需要它的指令。
- 写后读冒险(WAR,Write After Read):又称为“反依赖性”。指令B要写入的数据寄存器被指令A提前读取。这种冒险在顺序流水线中较少见,但在乱序执行中可能出现。
- 解决方法:通常通过重新排序指令来避免这种冒险。
- 写后写冒险(WAW,Write After Write):又称为“输出依赖性”。两条指令写入同一个寄存器,但顺序不同,可能导致后写入的指令覆盖先写入的指令。
- 解决方法:通过适当的指令调度或增加寄存器的使用来避免这种冒险。
解决数据冒险的方法
- 数据前推(Data Forwarding):又称为数据旁路(Data Bypassing)。将计算结果在寄存器写回之前直接传递给需要使用该结果的指令。
- 插入流水线气泡(Stalling):在数据准备好之前暂停流水线的某些阶段,等待数据准备完毕后再继续执行。
- 分支预测(Branch Prediction):提前猜测跳转指令的结果,并根据预测进行流水线填充,尽可能减少分支指令带来的气泡。
- 重新排序(Reordering):调整指令的执行顺序,以避免数据冒险的发生。
And in Conclusion, …
Instruction timing
- 指令定时:指令执行的时间由指令的复杂性、体系结构和技术决定。
- 流水线与时钟频率:流水线技术通过增加时钟频率来提高每秒执行的指令数。然而,这并不减少完成单条指令所需的时间,只是提高了整体的处理效率。
Performance measures
- 性能测量:性能测量取决于目标,可以有不同的指标:
- 响应时间:单个任务完成的时间。
- 每秒完成的任务数(Jobs/Second):例如,服务器每秒返回的网页数,或每秒识别的语音单词数。
- 每任务的能量消耗(Energy per task):例如,每个任务所消耗的电量,这对于电池寿命至关重要。