Lecture 22: RISC-V 5-Stage Pipeline II, Hazards
Single-Cycle RV32I Datapath
指令获取阶段 (Instruction Fetch, IF)
在单周期数据通路中,指令获取阶段 (IF) 是流水线的第一个阶段。在这个阶段中,程序计数器 (PC) 的值被用来从指令存储器 (IMEM) 中读取指令。此时,PC 的值会被加上 4 (因为每条指令长度为 4 个字节),准备下一条指令的获取。
- PC的更新:PC 会在每个周期内加 4,这意味着每个时钟周期获取一条新指令。
- 指令存储器读取 (IMEM Read):当前指令被从 IMEM 中读取,并送往下一阶段。
- 这一过程需要 200 皮秒 (ps)。
指令解码阶段 (Instruction Decode, ID)
指令解码阶段 (ID) 是流水线的第二个阶段。在这个阶段中,读取到的指令会被解码,以确定要执行的操作类型及其操作数。指令解码器从指令中提取寄存器地址,并从寄存器文件 (RegFile) 中读取操作数。
- 操作数读取:两个源操作数 (rs1 和 rs2) 从寄存器文件中读取出来,准备送往执行阶段。
- 立即数生成 (Imm Gen):立即数生成器根据指令类型 (I, S, B, J, U) 提取并扩展指令中的立即数。
- 这个阶段需要 100 皮秒 (ps)。
执行阶段 (Execute, EX)
执行阶段 (EX) 是流水线的第三个阶段。在这个阶段中,ALU(算术逻辑单元)执行指定的运算。根据指令的不同,ALU 可以执行加法、减法、逻辑运算等。
- ALU 操作:根据解码阶段传递来的控制信号,ALU 执行指定操作,例如加法、减法、或与运算。
- 分支判断:对于分支指令,ALU 会进行条件判断(例如比较两个寄存器值),并决定是否跳转。
- 这个阶段需要 200 皮秒 (ps)。
存储器访问阶段 (Memory Access, MEM)
存储器访问阶段 (MEM) 是流水线的第四个阶段。在这个阶段中,指令可能会访问数据存储器 (DMEM),执行读取或写入操作。
- 数据读取:对于 load 指令,存储器读取数据,并将其送往写回阶段。
- 数据写入:对于 store 指令,ALU 计算得到的存储地址和寄存器中的数据会被写入到数据存储器中。
- 这一阶段也需要 200 皮秒 (ps)。
写回阶段 (Write Back, WB)
写回阶段 (WB) 是流水线的最后一个阶段。在这个阶段中,计算或读取到的结果会被写回寄存器文件 (RegFile),完成一次指令的执行。
- 寄存器写回:ALU 或 DMEM 的输出会被写回到指定的目标寄存器中。
- 流水线结束:该指令的执行结束,流水线准备处理下一条指令。
- 这个阶段需要 100 皮秒 (ps)。
- ID、WB 阶段分别读取和写入相同的硬件元件 Reg(RegFile)。
通过以上五个阶段,单周期 RV32I 数据通路实现了每个时钟周期执行一条指令的目标。虽然这种设计简单,但由于每条指令都需要占用整个周期,导致每条指令的执行时间较长,性能不高。因此,在实际应用中,往往采用多周期或流水线技术来提高性能。
Sequential RISC-V Datapath
在单周期处理器 (Single-Cycle CPU) 中,每个时钟周期只能执行一条指令,所有指令的执行过程是顺序的。在这个处理器模型中,所有资源 (例如寄存器文件、ALU、数据存储器) 只能被一个指令在一个时钟周期内访问。
顺序执行的例子:
add t0, t1, t2or t3, t4, t5lw t0, 8(t3)
每条指令依次经过五个阶段:
- IF (Instruction Fetch): 从指令存储器中取指令。
- ID (Instruction Decode): 解码指令并读取寄存器操作数。
- EX (Execute): 使用 ALU 执行算术或逻辑操作。
- MEM (Memory Access): 访问数据存储器(仅对 load/store 指令)。
- WB (Write Back): 将结果写回寄存器文件。
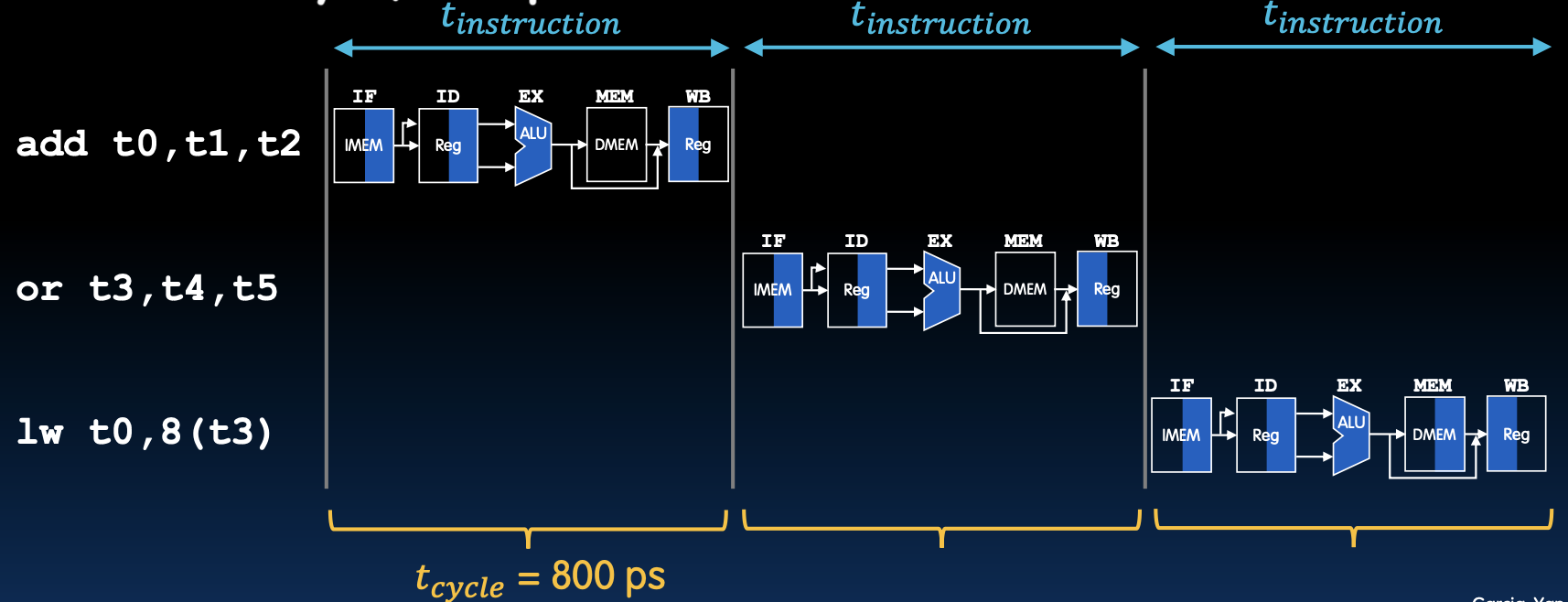
- 顺序执行:每条指令依次通过五个阶段,需要完整的一个时钟周期才能完成。
- t_cycle = 800 ps:每条指令的执行时间都是 800 皮秒,因此每个时钟周期都是 800 皮秒。
Pipelined RISC-V Datapath
在流水线处理器 (Pipelined CPU) 中,多个指令可以同时访问资源,在同一时钟周期内执行。这种并行执行方式大大提高了处理器的吞吐量。
流水线执行的例子:
add t0, t1, t2lw t0, 8(t3)or t3, t4, t5sw t0, 4(t3)sll t6, t0, t3
每条指令依次经过五个阶段,但由于流水线的存在,指令可以重叠执行。例如,在执行 add 指令的同时,可以开始执行 lw 指令的 IF 阶段。
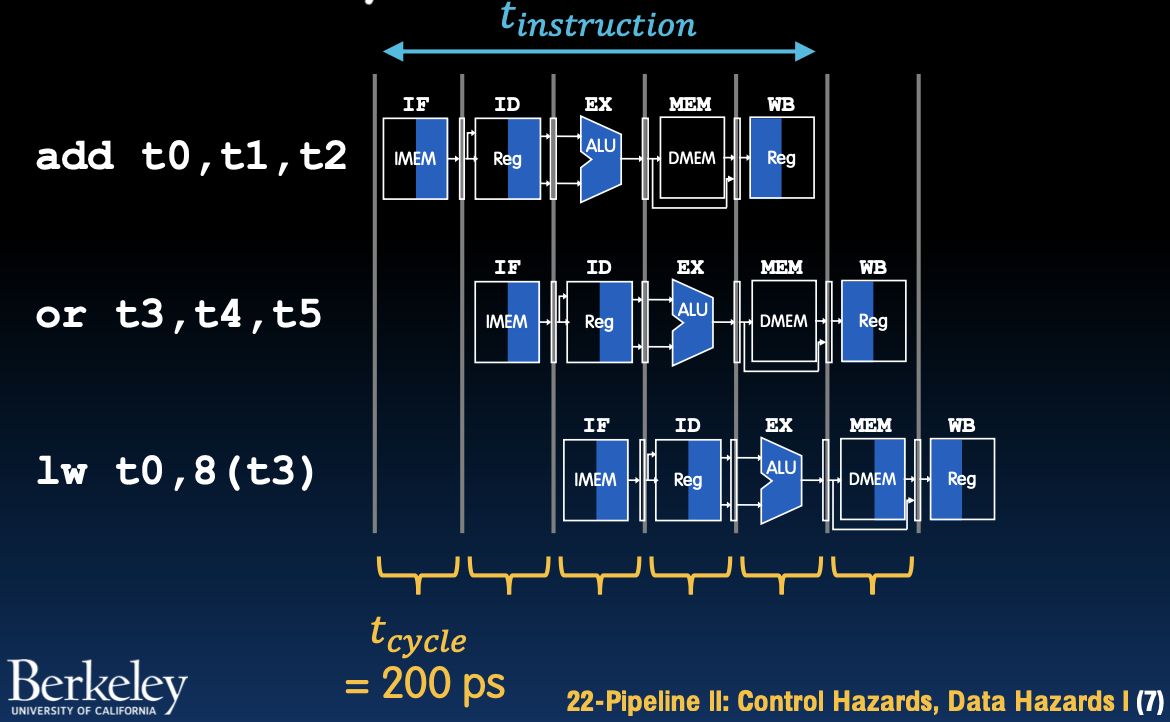
- 并行执行:流水线允许多个指令在不同阶段同时进行,这样在一个时钟周期内可以有多条指令处于执行状态。
- t_cycle = 200 ps:每个时钟周期只需 200 皮秒,因为流水线使得每个阶段的处理时间更短。
What Happens Sequentially? Simultaneously?
在这个图中展示了在流水线 CPU 中,资源的使用情况:
- 顺序使用:同一指令在多个时钟周期内使用资源。
- 同时使用:多条指令在同一时钟周期内使用资源。
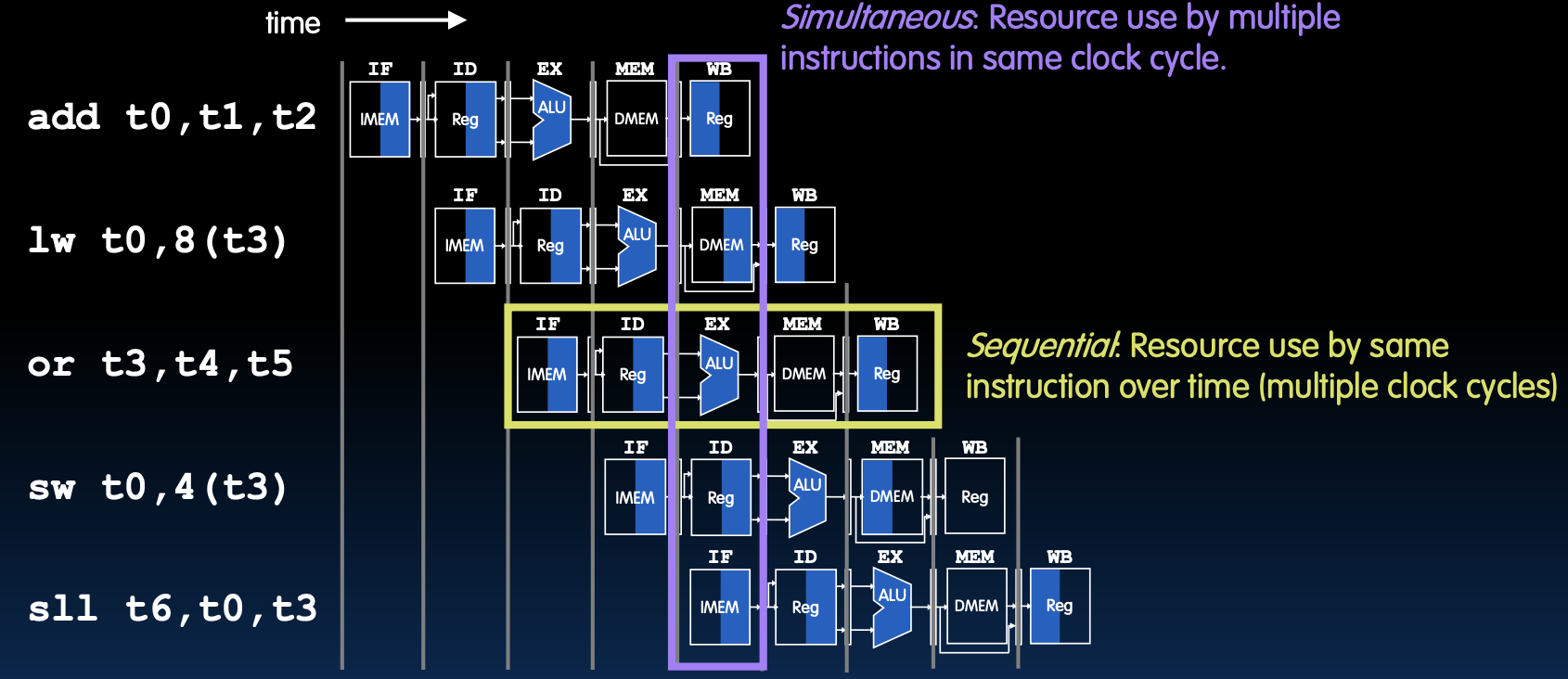
- 资源使用:同一资源可以在不同的时钟周期内被不同的指令使用,这就是流水线的本质,使得 CPU 的利用率更高。
- 吞吐量提升:流水线显著提高了指令的吞吐量,使得 CPU 在同一时间内可以处理更多的指令。
通过理解这些内容,可以看到流水线技术如何通过并行执行多条指令来提高处理器的效率和性能。
Performance (1/2): Latency 延迟
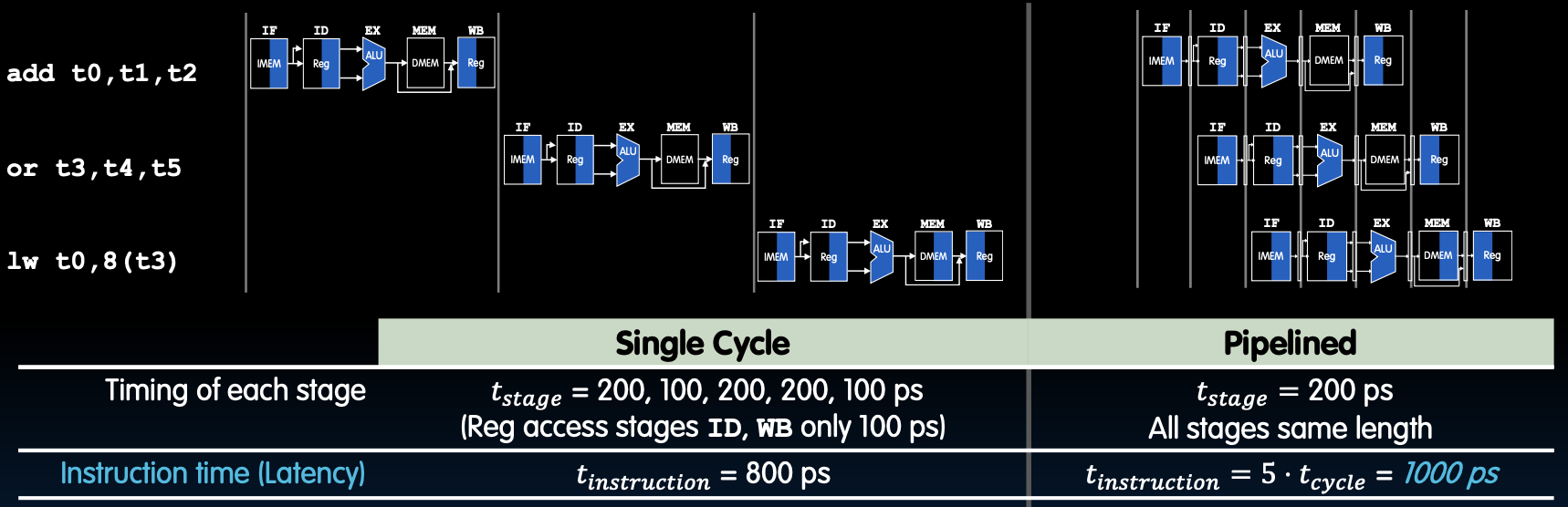
单周期处理器(Single Cycle CPU)
- 阶段时间 (Timing of each stage): t_stage = 200, 100, 200, 200, 100 ps(寄存器访问阶段 ID 和 WB 仅为 100 ps)
- 指令执行时间 (Instruction time, Latency): t_instruction = 800 ps
在单周期处理器中,每个指令依次通过所有五个阶段,所有阶段在一个时钟周期内完成。因此,每个时钟周期都需要 800 皮秒(ps)。
流水线处理器(Pipelined CPU)
- 阶段时间 (Timing of each stage): t_stage = 200 ps(所有阶段长度相同)
- 指令执行时间 (Instruction time, Latency): t_instruction = 5 * t_cycle = 1000 ps
在流水线处理器中,每个阶段在同一时钟周期内并行执行不同的指令部分,但总的指令延迟时间为五个阶段的总和,即 1000 皮秒(ps)。
流水线处理器使用一个时钟周期来控制所有阶段,时钟周期时间由最慢的阶段决定。在这种情况下,时钟周期时间为 200 皮秒。
Performance (2/2): Throughput 吞吐量
单周期处理器(Single Cycle CPU)
- 阶段时间 (Timing of each stage): t_stage = 200, 100, 200, 200, 100 ps(寄存器访问阶段 ID 和 WB 仅为 100 ps)
- 指令执行时间 (Instruction time, Latency): t_instruction = 800 ps
- 时钟周期时间 (Clock cycle time, t_cycle): t_cycle = t_instruction = 800 ps
- 时钟频率 (Clock rate, f_s): f_s = 1/t_cycle = 1/800 ps = 1.25 GHz
- 每指令时钟周期数 (CPI): ~1(理想情况下)

流水线处理器(Pipelined CPU)
- 阶段时间 (Timing of each stage): t_stage = 200 ps(所有阶段长度相同)
- 指令执行时间 (Instruction time, Latency): t_instruction = 5 * t_cycle = 1000 ps
- 时钟周期时间 (Clock cycle time, t_cycle): t_cycle = t_stage = 200 ps
- 时钟频率 (Clock rate, f_s): f_s = 1/t_cycle = 1/200 ps = 5 GHz
- 每指令时钟周期数 (CPI): ~1(理想情况下)
通过引入流水线技术,处理器的时钟周期时间显著减少,从而提高了时钟频率(f_s)。尽管每条指令的执行时间增加,但由于流水线的并行执行,整体吞吐量(每秒处理的指令数量)大幅提高。相比单周期处理器,流水线处理器的相对吞吐量增益达到 4 倍。
处理器性能铁律(Iron Law of Processor Performance)
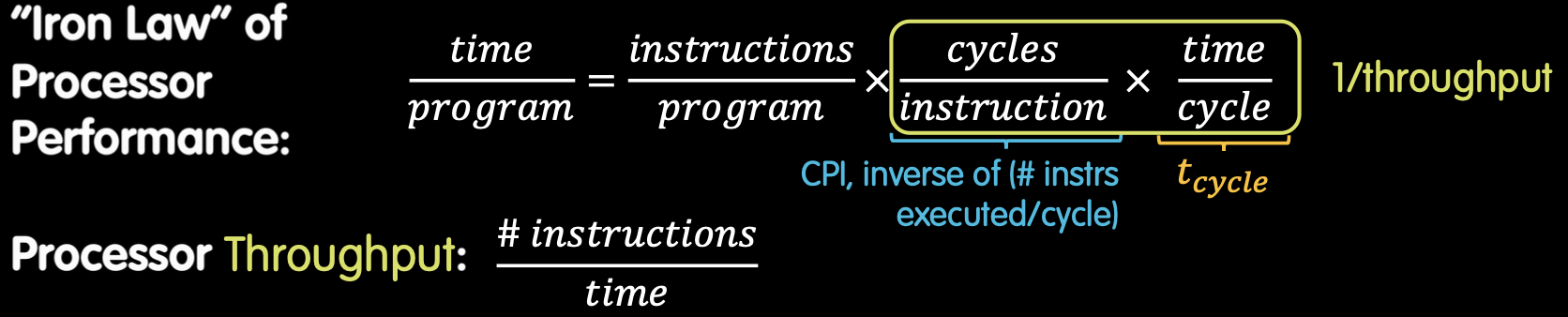
- (\text{CPI})(每指令周期数)是处理器执行一条指令所需的平均时钟周期数
- (\text{time}_{\text{cycle}}) 是一个时钟周期的时间
通过优化流水线阶段的长度和平衡,可以进一步减少时钟周期时间,从而提高处理器的时钟频率和整体性能。
Pipelined Datapath and Control
Constructing a Pipelined RV32I Datapath
在构建RV32I流水线数据通路时,需要将数据通路分为五个阶段,并通过流水线寄存器(pipeline registers)来分隔各个阶段。这样,每个阶段能够独立处理不同指令的数据,从而实现并行处理,提高处理器的整体性能。
使用流水线寄存器
- 作用:流水线寄存器用于在阶段之间传递指令数据,使得每个阶段能够并行处理不同指令。
- 结果:通过使用流水线寄存器,数据通路能够同时处理多个指令,提高了处理器的吞吐量(throughput)。
Pipelining to Improve Performance
单周期数据通路
- 特点:单周期数据通路意味着从输入到输出只有一个时钟周期。
- 限制:时钟周期时间由加法器和移位器的传播延迟决定。
插入流水线寄存器
- 优势:插入流水线寄存器允许更高的时钟频率。
- 时钟周期时间现在由加法器/移位器的最大传播延迟决定。
- 提高了输出速率(每秒输出数量)。
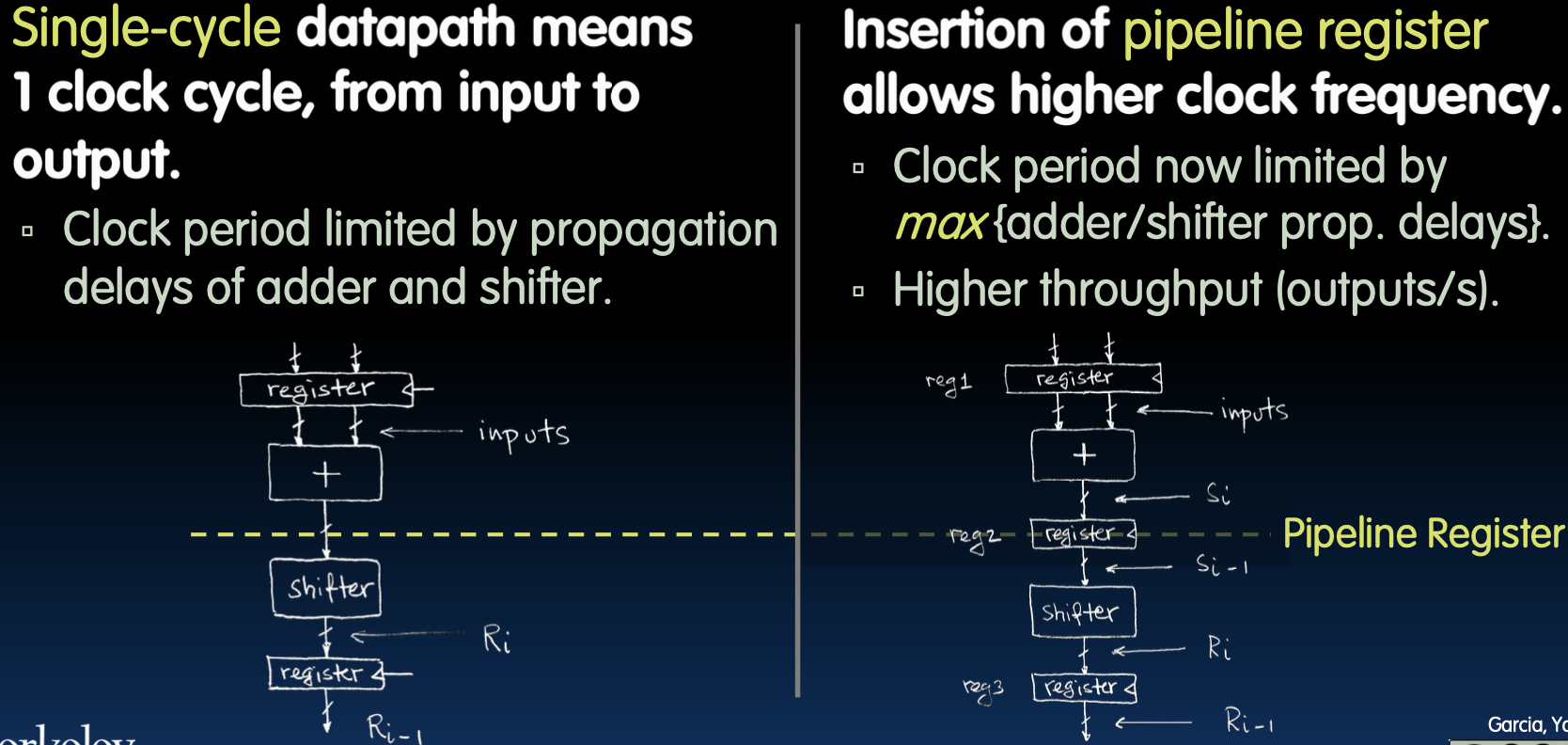
通过将单周期数据通路改为流水线数据通路,并在各个阶段之间插入流水线寄存器,能够显著提高处理器的时钟频率和吞吐量。每个阶段处理不同指令的一部分,同时不同指令在同一个时钟周期内并行处理。这种方式不仅提高了指令执行的效率,还使得处理器能够在单位时间内处理更多的指令,从而提升整体性能。
IF/ID Pipeline Registers
IF/ID流水线寄存器
- IF/ID阶段流水线寄存器:
- PC_ID
- inst_ID
- 功能:
- 将PC增加4以便下一周期的取指阶段(Instruction Fetch,IF)使用。
- 将指令寄存到inst_ID中,为下一阶段指令解码(Instruction Decode,ID)做准备。
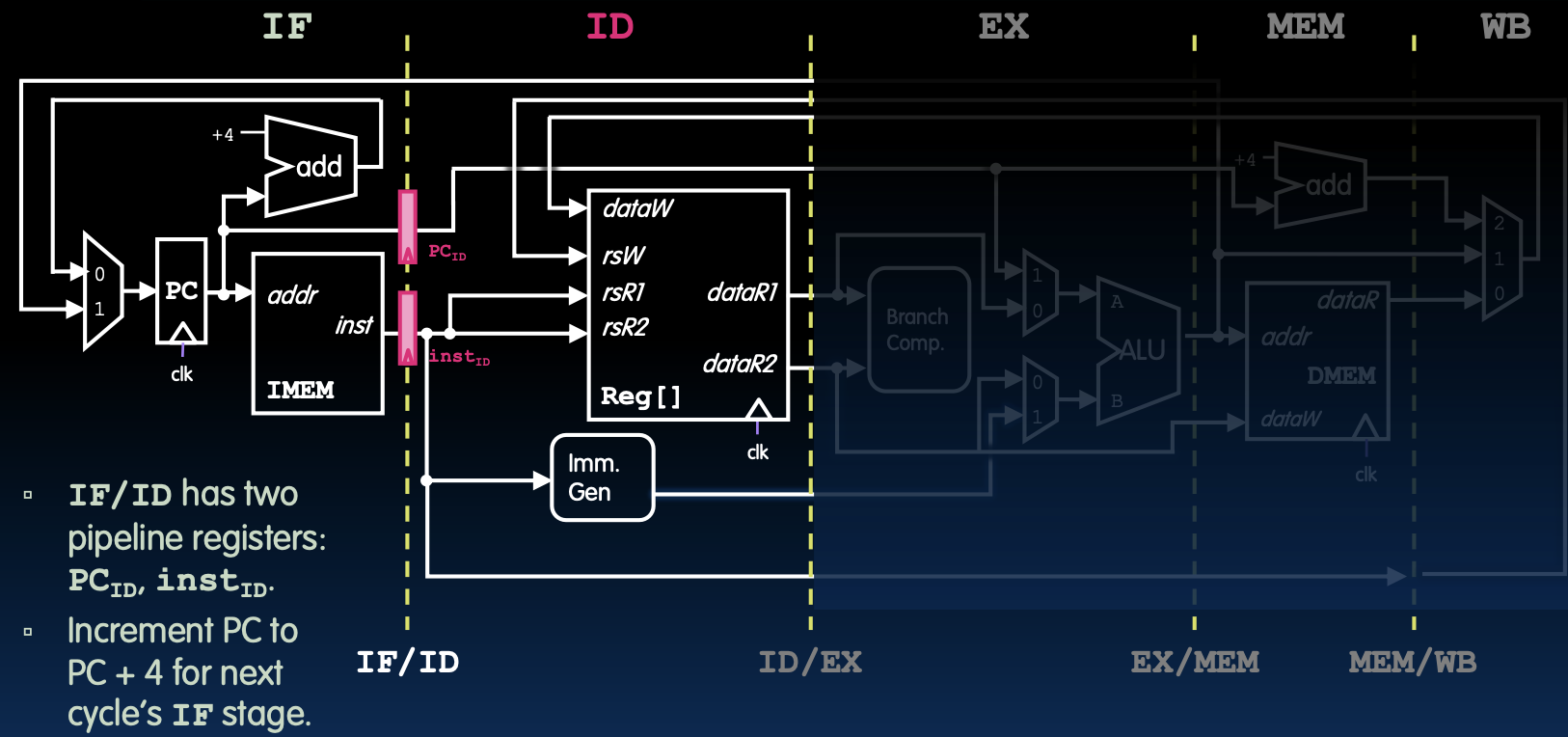
在指令从取指阶段进入指令解码阶段时,流水线寄存器起到了关键作用。PC_ID寄存器保存当前指令的地址,而inst_ID寄存器则保存实际的指令内容。通过将PC值增加4,可以确保下一条指令在下一个周期中被正确取出。
ID/EX Pipeline Registers
ID/EX流水线寄存器
- ID/EX阶段流水线寄存器:
- PC_EX
- inst_EX
- rs1_EX
- rs2_EX
- imm_EX
- 功能:
- 将指令和相关数据传送到执行阶段(Execution,EX)以正确操作每个阶段的控制。
- 确保指令在每个周期内正确传递,并使控制信号正确设置。
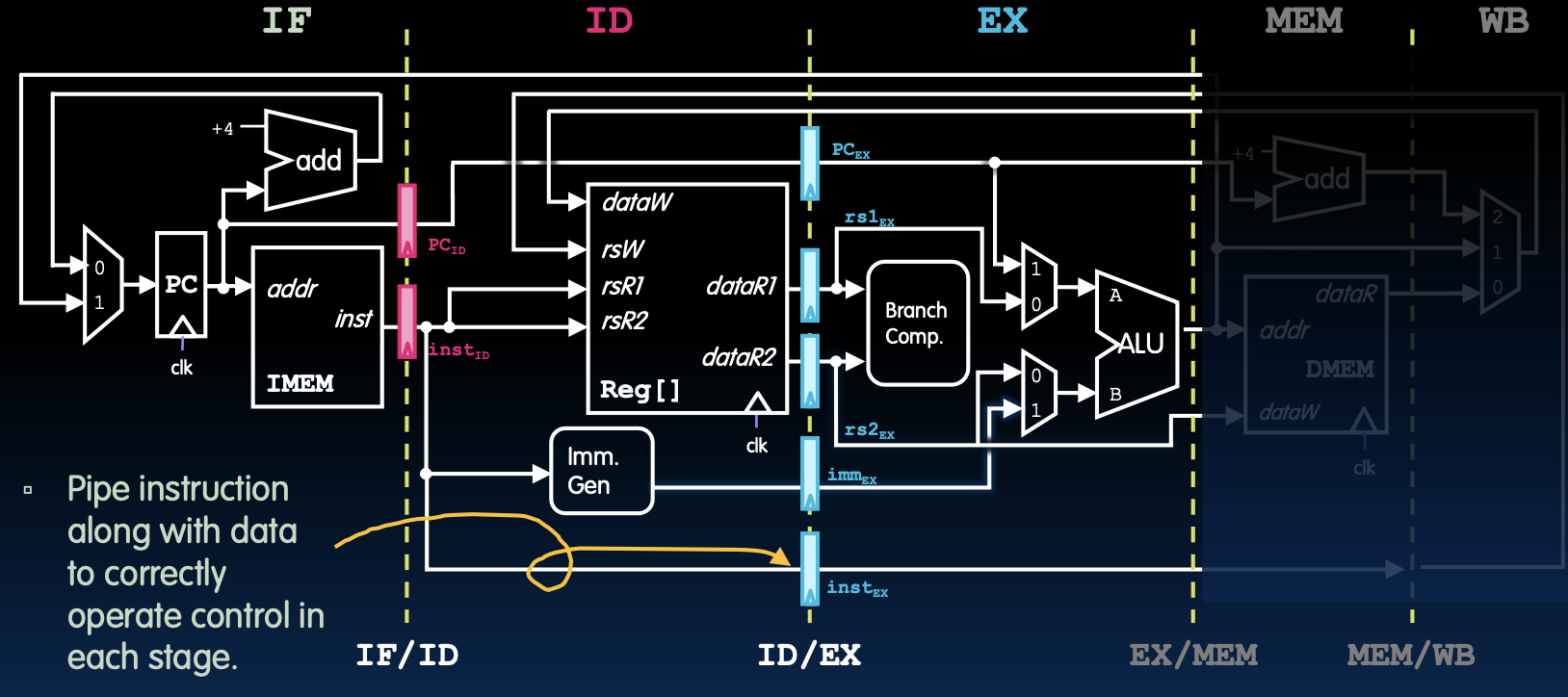
从指令解码阶段到执行阶段,ID/EX流水线寄存器起到了关键作用。这些寄存器负责传递当前指令的地址、内容以及相关的源寄存器和立即数数据。通过这些寄存器,指令可以在流水线的不同阶段被正确传递和处理,确保执行阶段能够获得所有必要的数据以完成操作。
EX/MEM Pipeline Registers
EX/MEM流水线寄存器
- EX/MEM阶段有多个流水线寄存器:
- PC_MEM
- ALU_out_MEM
- rs2_MEM
- inst_MEM
- 功能:
- 将执行阶段(EX)生成的ALU结果传递给内存访问阶段(MEM)。
- 将需要存储的数据(rs2_MEM)传递给内存访问阶段,以便进行存储操作。
- 将指令和相关数据传递给内存访问阶段,以确保正确的数据访问和写回操作。
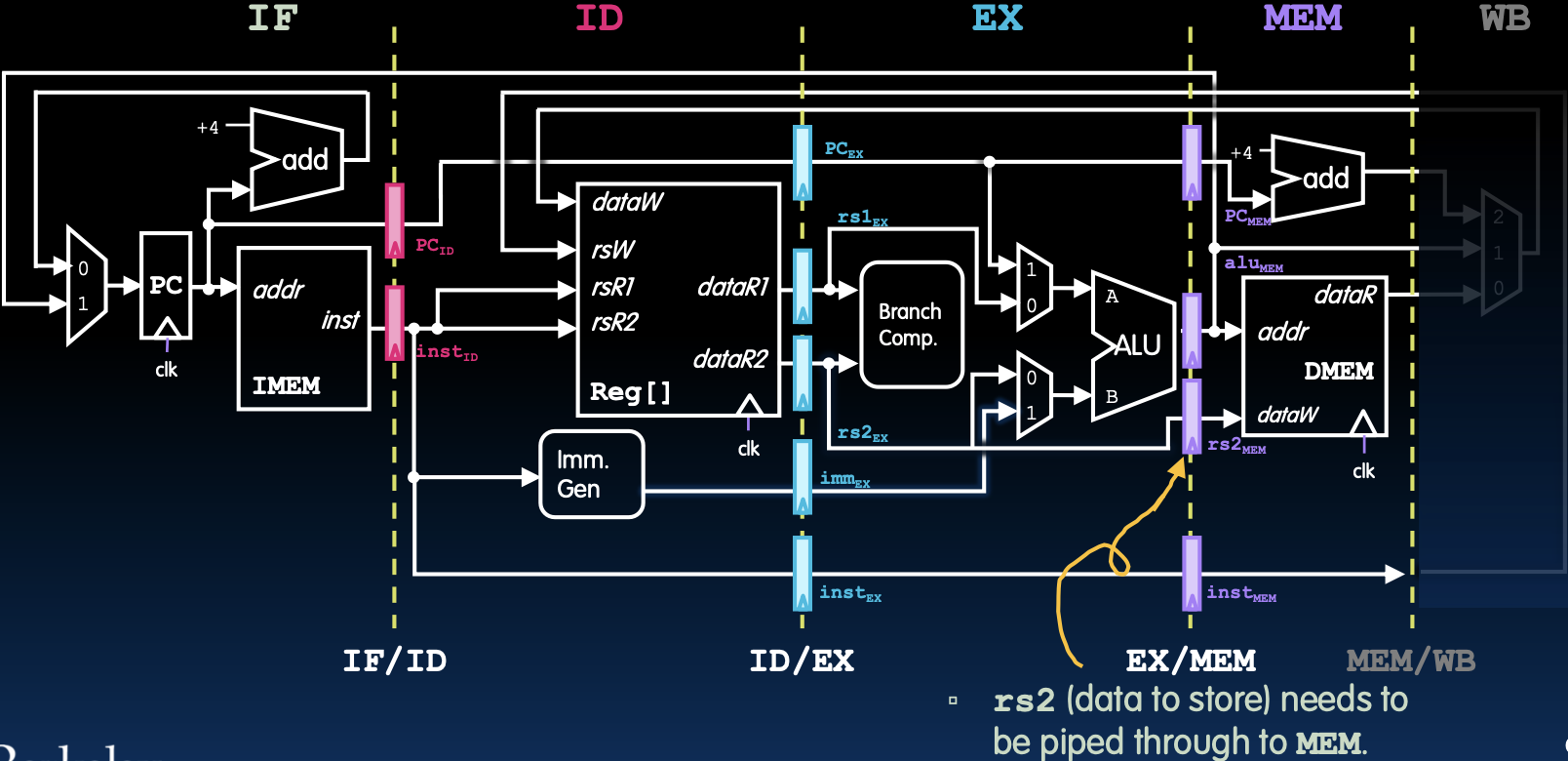
在从执行阶段到内存访问阶段的过程中,EX/MEM流水线寄存器起到了关键作用。它们负责传递ALU计算的结果和需要存储的数据,以便内存访问阶段能够正确执行读写操作。通过这些寄存器,指令在不同阶段间的传递得以实现,从而确保处理器能够高效地处理指令流水线。
MEM/WB Pipeline Registers
MEM/WB流水线寄存器
- MEM/WB阶段有多个流水线寄存器:
- PC_WB
- ALU_out_WB
- mem_data_WB
- inst_WB
- 功能:
- 将内存访问阶段(MEM)读取的数据和ALU结果传递给写回阶段(WB)。
- 确保写回阶段能够将正确的数据写回寄存器文件。
- 避免在流水线中同时传递PC和PC+4,确保控制信号的正确性。
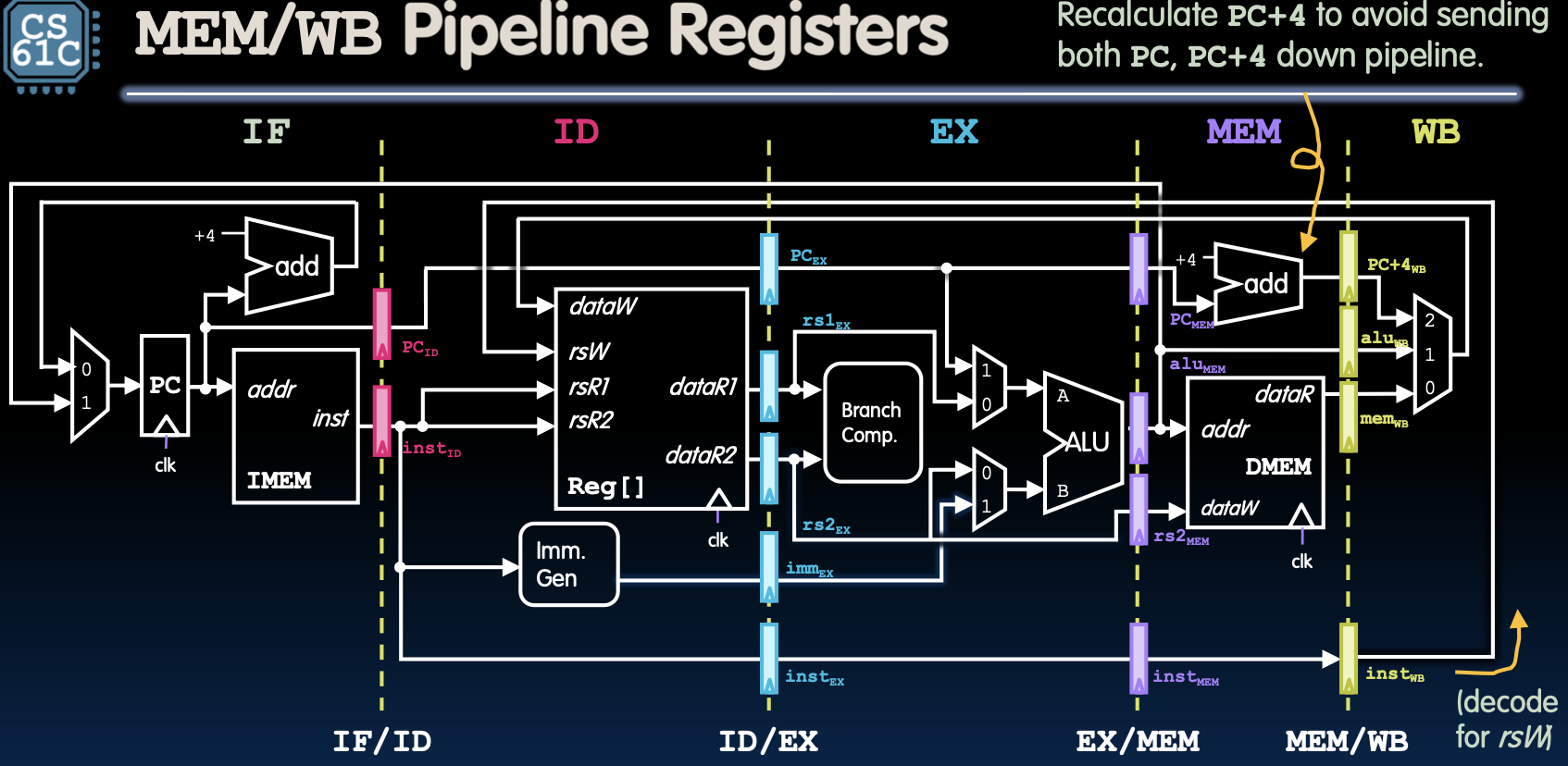
从内存访问阶段到写回阶段,MEM/WB流水线寄存器的作用是传递内存读取的数据和ALU计算的结果。这些寄存器确保了写回阶段能够将正确的数据写回寄存器文件,完成指令的最后一步。此外,为了避免同时传递PC和PC+4,需要在内存访问阶段重新计算PC+4,以确保流水线中的控制信号正确。
流水线寄存器的使用使得处理器能够在同一时间并行处理多条指令,从而提高处理器的整体性能和吞吐量。每个阶段独立处理不同指令的一部分,通过流水线寄存器传递数据,实现指令的高效执行。
匹配问题
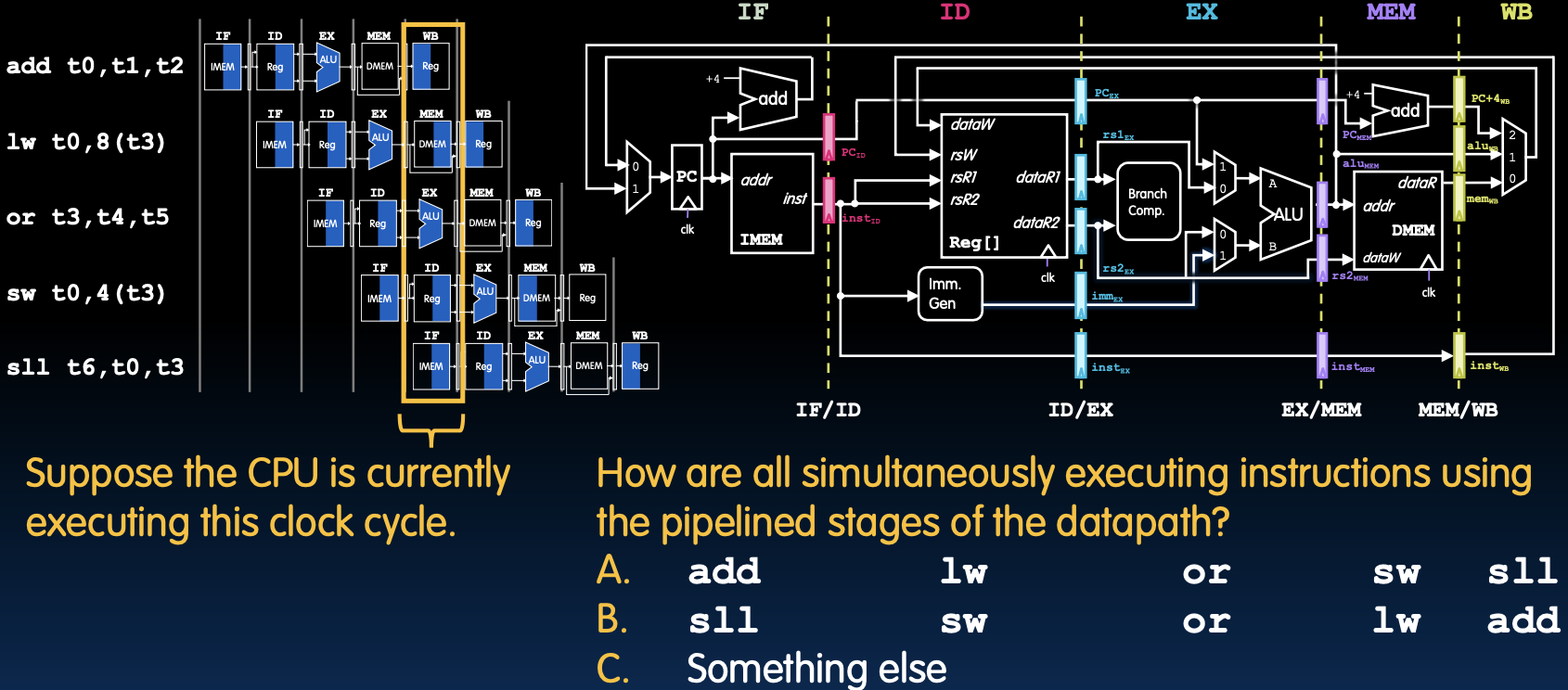
在这张图中,假设CPU当前正在执行橙色框时钟周期。在流水线的不同阶段,指令可以同时执行。图中的问题是如何使用流水线阶段同时执行指令。
图中指令示例
- add t0, t1, t2
- lw t0, 8(t3)
- or t3, t4, t5
- sw t0, 4(t3)
- sll t6, t0, t3
流水线阶段
- IF(取指阶段):指令从指令存储器(IMEM)中取出。
- ID(指令解码阶段):从寄存器文件(Reg)中读取操作数,进行指令解码。
- EX(执行阶段):在ALU中执行操作。
- MEM(内存访问阶段):访问数据存储器(DMEM),进行读或写操作。
- WB(写回阶段):将结果写回寄存器文件。
同时执行指令
在一个时钟周期内,不同指令可以位于流水线的不同阶段。例如:
- add t0, t1, t2 可能位于 WB(写回阶段)。
- lw t0, 8(t3) 可能位于 MEM(内存访问阶段)。
- or t3, t4, t5 可能位于 EX(执行阶段)。
- sw t0, 4(t3) 可能位于 ID(指令解码阶段)。
- sll t6, t0, t3 可能位于 IF(取指阶段)。
控制也在流水线中
控制信号的传递
在单周期CPU中,控制信号通常在指令解码阶段(ID)计算。在流水线CPU中,控制信息在流水线寄存器中传递给后续阶段。
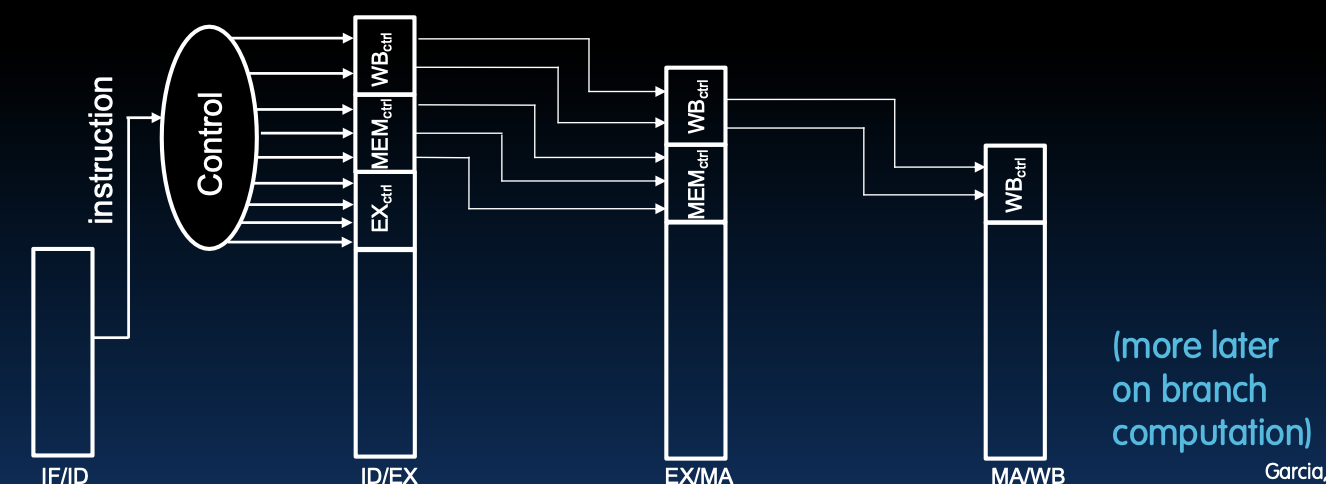
- 控制信号计算**:在指令解码阶段,从指令中提取控制信号。
- 控制信息传递:通过流水线寄存器将控制信号传递到相应的阶段。例如,EX控制信号传递到执行阶段(EX),MEM控制信号传递到内存访问阶段(MEM),WB控制信号传递到写回阶段(WB)。
示例
- IF/ID寄存器:包含PC和当前指令,传递给解码阶段。
- ID/EX寄存器:包含解码阶段的控制信号和数据,传递给执行阶段。
- EX/MEM寄存器:包含执行阶段的控制信号和数据,传递给内存访问阶段。
- MEM/WB寄存器:包含内存访问阶段的控制信号和数据,传递给写回阶段。
这种设计确保了每个阶段可以独立工作,并通过流水线寄存器进行协调和同步,实现高效的指令并行处理。