Lecture 31: Parallelism III: Cache Coherence, Performance
Hardware Synchronization
在并行计算中,硬件同步是一种通过硬件机制来确保多个线程或进程之间同步执行的重要手段。硬件同步的目标是避免竞争条件(Race Condition),从而保证数据的完整性和一致性。为了实现这一目标,硬件同步通常依赖于原子读/写操作,即在一个不可分割的单一指令中完成读写操作。在这种操作过程中,其他访问请求会被阻止,直到操作完成,确保数据在被访问和修改时的原子性。
这些操作必须在共享内存环境中进行,这意味着多个处理器需要访问同一个内存地址空间来进行协调和同步。
常见的硬件同步实现方式
-
原子交换(Atomic Swap):这是硬件同步中常用的一种方法,通过将寄存器中的值与内存中的值进行交换,确保某个线程可以安全地对内存数据进行操作。例如,使用
amoswap.w指令将寄存器中的值与指定内存位置的值进行交换,可以保证交换操作的原子性,避免多个线程同时修改数据引发的问题。 -
链接读写指令对(Load-Linked/Store-Conditional, LL/SC):这一方法通过一对链式的读取和写入指令来完成同步操作。它确保在执行链式写入之前,如果其他线程修改了内存位置,则写入操作将失败,从而避免竞争条件。
在RISC-V处理器架构中,这两种方法都得到支持。但在讨论中,我们将主要关注原子交换(Atomic Swap)的实现方式。
RISC-V架构中的原子内存操作(Atomic Memory Operations, AMOs)提供了一种强有力的方式来在并发编程中处理共享内存。通过这些操作,可以在不使用锁或其他同步原语的情况下,确保对内存的更新是原子性的。
AMO指令的基本原理
AMO操作的核心在于它们可以在单个原子操作中完成读取-修改-写入的过程。这些指令的作用是:从指定的内存地址读取值,与一个寄存器中的值进行某种运算,然后将运算结果存储在内存中,同时将最初从内存中读取的值保存在目标寄存器中。
AMO指令的格式
- funct5:定义操作的类型。可能的操作包括加法(add)、与(and)、或(or)、交换(swap)、异或(xor)、最大值(max)、最小值(min)等。
- aq 和 rl:控制指令的执行顺序。
- aq(Acquire):确保在当前指令之前的所有内存操作已经完成。
- rl(Release):确保当前指令完成后才能继续执行后续的内存操作。
- rs1 和 rs2:源寄存器。
- rs1:通常保存内存地址。
- rs2:保存用于计算的值。
- rd:目标寄存器,用于存储从内存中读取的原始值。

示例:amoadd.w rd, rs2, (rs1)
指令amoadd.w rd, rs2, (rs1)的作用如下:
- 读取:
- 从
rs1寄存器中读取一个内存地址,将该地址所指向的内存位置中的32位数据读入处理器,并保存这个值到rd寄存器。
- 从
- 计算:
- 将从内存中读取的值与
rs2寄存器中的值进行加法操作。
- 将从内存中读取的值与
- 写入:
- 将加法运算的结果写回到内存的同一个位置(
rs1指向的内存地址)。
- 将加法运算的结果写回到内存的同一个位置(
举例
假设内存地址0x1000处存储的值为10,rs2寄存器中的值为5,并且执行指令amoadd.w x1, x2, (x3),其中x3的值是0x1000。
- 步骤1:从内存地址
0x1000读取值10,并将该值保存到目标寄存器x1中。 - 步骤2:将读取的值
10与寄存器x2中的值5相加,得到结果15。 - 步骤3:将结果
15写回到内存地址0x1000。
执行完这个指令后,x1的值为10(内存中原始的值),而内存地址0x1000中的值更新为15。
我们可以通过对比使用普通的
add指令和amoadd.w指令在内存中进行加法操作的流程,来更清楚地理解两者的区别。使用普通的
add进行内存加法操作如果我们要用普通的
add指令对内存中的一个值进行加法操作,流程通常如下:流程:
- 从内存加载值到寄存器:
- 使用
lw(load word)指令从内存中加载数据到寄存器。- 示例:
lw x1, 0(x2)// 从x2指向的内存地址加载32位数据到寄存器x1。- 进行加法操作:
- 使用
add指令将寄存器x1中的值与另一个寄存器x3中的值相加。- 示例:
add x4, x1, x3// 将x1和x3中的值相加,结果存入x4。- 将结果写回内存:
- 使用
sw(store word)指令将结果存储回内存。- 示例:
sw x4, 0(x2)// 将寄存器x4的值存回到x2指向的内存地址。总结:
- 问题:在多线程或多处理器环境中,这个过程并不是原子的。其他线程或处理器可能会在读取和写回内存的过程中干扰操作,导致竞争条件。例如:
- 线程 A 读取了内存值
10。- 在线程 A 还未将结果写回内存之前,线程 B 也读取了同样的内存值
10。- 结果,两个线程分别将计算结果
15写回内存,而不是预期的20。使用
amoadd.w进行内存加法操作与上述普通的
add操作不同,amoadd.w指令可以在一个原子操作中完成内存加法。流程如下:流程:
- 从内存读取值并进行加法操作:
amoadd.w rd, rs2, (rs1)指令从rs1指向的内存地址读取一个32位的值,将其与寄存器rs2的值相加,并将结果写回rs1指向的内存地址。- 同时,将原始的内存值(修改前的值)存储在目标寄存器
rd中。总结:
- 优势:整个读取-加法-写回内存的过程是原子的,任何其他线程或处理器无法在这个操作中途插入或干扰。因此,
amoadd.w能够避免竞争条件,确保并发操作的正确性。对比总结
- 普通
add操作:
- 涉及多个指令:
lw(加载内存值)、add(寄存器加法)和sw(存储结果)。- 在多线程或多处理器环境中,每个步骤之间可能会被打断,导致数据竞态问题。
amoadd.w操作:
- 单条指令内完成所有操作:从内存读取值、执行加法并写回结果,同时保存原始值到寄存器。
- 保证了操作的原子性,不会被中断,从而避免竞态条件。
使用
amoadd.w指令的关键在于它能够以原子的方式处理内存操作,而普通的add需要通过多个指令来完成相同的任务,这在并发环境下可能导致数据不一致的问题。
RISC-V Critical Section

这部分展示了一个使用 RISC-V 的原子内存交换指令 (amoswap.w) 来实现“临界区”(Critical Section)的流程。这种操作通常用于多线程或多处理器系统中,以确保某些关键代码段在任意时刻只能由一个线程执行,避免并发问题。
背景介绍
在多线程编程中,临界区是一段代码,这段代码在同一时间只能被一个线程执行。通常通过“锁”机制来保护临界区。锁的状态可以是“已设置”(1)或“空闲”(0)。在这个流程中,锁的位置存储在寄存器 a0 所指向的内存位置。
流程解释
-
初始化锁值:
li t0, 1 # Get 1 to set lock- 这条指令将立即数
1加载到寄存器t0中,准备将锁设置为“已设置”状态(1)。
- 这条指令将立即数
-
尝试获取锁:
Try: amoswap.w.aq t1, t0, (a0) # t1 gets old lock value while we set it to 1amoswap.w.aq t1, t0, (a0)是一条原子指令,表示“交换”操作。这条指令会:- 从内存地址
a0读取当前的锁值,并将其存储在寄存器t1中。 - 将寄存器
t0中的值(即 1)写入内存地址a0,即设置锁为“已设置”状态。
- 从内存地址
aq标志表示“Acquire”,确保在指令之前的所有内存操作完成后再执行该指令。- 如果锁已经被其他线程设置为1,则
t1中会返回1,表明锁已被占用。
-
检查锁是否已被占用:
bnez t1, Try # if it was already 1, another thread has the lock, so we need to try againbnez t1, Try是一个条件跳转指令,如果t1不为零(表示锁已被占用),则跳转回标签Try重新尝试获取锁。- 这个循环会一直持续,直到锁的原始值为0(表示锁空闲),此时当前线程成功获取锁。
-
进入临界区:
- 一旦获取到锁,线程可以安全地进入临界区执行代码,因为它已经排除了其他线程同时进入临界区的可能性。
-
释放锁:
amoswap.w.rl x0, x0, (a0) # store 0 in lock to releaseamoswap.w.rl x0, x0, (a0)再次使用原子交换指令,这次将x0(即0)存入锁所对应的内存位置,以释放锁。rl标志表示“Release”,确保在这条指令执行后,其他的内存操作才能继续进行。- 由于
x0是零寄存器,所以这条指令相当于将锁值重置为0,使得其他线程可以获取锁。
原子指令 amoswap.w
amoswap.w:这是RISC-V中的一种原子内存操作指令,它在单个指令中完成以下操作:- 从内存中读取一个32位的值并将其存储在寄存器中。
- 将寄存器中的值写入相同的内存地址。
- 这个操作是原子的,意味着在这个指令执行过程中,其他处理器或线程无法介入,确保操作的完整性。
aq和rl标志:这些标志用于内存顺序控制。aq(Acquire):确保指令之前的所有内存操作都已完成,这样就可以防止在获取锁前出现内存操作乱序。rl(Release):确保指令后的所有内存操作只有在该指令完成后才能开始,从而防止锁释放前的操作乱序。
这个流程使用 amoswap.w 指令来实现锁的获取和释放,确保了在多线程环境下临界区的互斥性。amoswap.w 保证了操作的原子性,从而避免了多个线程同时修改锁的状态,确保只有一个线程可以进入临界区执行代码。
**第一次执行
Try: amoswap.w.aq t1, t0, (a0)**在第一次执行
Try: amoswap.w.aq t1, t0, (a0)时,指令是会立即执行的,并且会将寄存器t0中的值(1)写入到a0指向的内存位置,同时将原始的内存值(即锁的原始值)加载到寄存器t1中。这是一个原子操作,意味着这两个步骤在硬件层面上是不可分割的。流程细节
- 第一次执行
amoswap.w.aq t1, t0, (a0):
- 情况1:如果
a0指向的内存位置的值是0(表示锁当前是空闲的),那么t1将被设置为0,并且锁会被设置为1(表示锁已被占用)。- 情况2:如果
a0指向的内存位置的值是1(表示锁已经被其他线程占用),那么t1将被设置为1,但锁的值保持不变,仍然是1。- 执行
bnez t1, Try:
- 如果
t1的值是0(表示锁在原子操作之前是空闲的),则bnez t1, Try不会触发跳转,也就是说,代码继续执行并进入临界区。- 如果
t1的值是1(表示锁已经被其他线程占用),bnez t1, Try会触发跳转,跳回到Try标签处,重新尝试获取锁。第一次运行到
Try: amoswap.w.aq t1, t0, (a0),amoswap.w.aq立即执行,并将锁值设置为1,同时把锁的原始值存入t1。
bnez t1, Try是在amoswap.w.aq执行后进行判断的:
- 第一次执行
amoswap.w.aq t1, t0, (a0)时,如果t1中的值为0(表示之前锁是空闲的),bnez t1, Try不会触发跳转,锁被成功设置为1,当前线程进入临界区。- 如果
t1中的值为1(表示之前锁已经被占用),bnez t1, Try会触发跳转,程序回到Try处,重新尝试获取锁。关键点
amoswap.w.aq是原子操作,它在执行时确保同时完成读取和写入操作,没有其他线程能在这两个步骤之间插入操作。bnez t1, Try是在amoswap.w.aq执行后,根据t1的值决定是否需要重新尝试获取锁。- 如果锁是空闲的,
t1会是0,那么线程成功获取锁,进入临界区。如果锁已被占用,t1是1,线程将继续尝试获取锁。这个机制确保了在多线程环境下的安全性,只有在锁空闲时才能进入临界区,否则将继续尝试获取锁。
Lock Synchronization
在并行编程中,锁同步是确保多个线程不会同时访问共享资源的重要机制。然而,如果在实现锁同步时,仅使用简单的 while (lock != 0); 循环来等待锁的释放,而没有考虑到多个线程同时竞争锁的情况,可能会导致多个线程同时获取锁,从而进入临界区。这将破坏同步机制,导致数据竞争和结果错误。

问题描述
假设多个线程同时执行 while (lock != 0);,当锁被释放时,多个线程可能会同时检测到锁的状态为“未锁定”(即 lock == 0),然后同时尝试获取锁。如果没有进一步的同步措施,这些线程可能会同时进入临界区,导致数据竞争和不可预测的行为。
解决方法
为了确保只有一个线程能够成功获取锁,而其他线程必须等待锁的释放,可以使用原子操作指令,如 amoswap.w(原子交换指令)。这种指令能够在单一不可分割的操作中完成对锁的获取和设置,确保同步的正确性。
修正后的同步流程
-
尝试获取锁:使用
amoswap.w.aq指令,尝试将寄存器t0中的值与锁对应的内存位置进行交换。如果锁之前已经被其他线程占用(即lock != 0),交换操作将失败,并返回旧的锁值。 -
检查锁状态:如果
amoswap.w.aq指令返回的值为0,则说明当前线程成功获取了锁;否则,线程需要继续尝试获取锁。 -
进入临界区:一旦成功获取锁,线程即可进入临界区执行共享资源的操作。
-
释放锁:在退出临界区后,使用
amoswap.w.rl指令将锁的值重新设置为0,释放锁供其他线程使用。
示例代码
Try:
li t0, 1 // 将 1 赋值给 t0,表示准备设置锁
amoswap.w.aq t1, t0, (a0) // 尝试获取锁,将 t0 的值与 a0 指向的锁值交换
bnez t1, Try // 如果 t1 != 0,表示锁未成功获取,继续尝试
// 临界区代码
amoswap.w.rl zero, zero, (a0) // 释放锁,将锁值设置为 0
OpenMP Locks
在并行编程中,OpenMP提供了一套丰富的同步机制,其中包括锁(locks)。使用OpenMP的锁,可以有效地同步多线程对共享资源的访问,避免竞争条件。
使用OpenMP锁的步骤
-
初始化锁:在并行区域外使用
omp_init_lock(&lock);初始化锁变量。在所有线程尝试访问共享资源之前,必须首先初始化锁。 -
设置锁:在并行区域内,当一个线程想要访问临界区时,调用
omp_set_lock(&lock);来设置锁。这确保了只有该线程能够进入临界区,其他线程必须等待。 -
临界区:在成功设置锁后,线程可以进入临界区执行其任务。这些任务可能包括访问或修改共享资源。
-
释放锁:当线程完成了在临界区内的工作后,使用
omp_unset_lock(&lock);释放锁,以允许其他线程进入临界区。 -
销毁锁:在并行区域结束后,使用
omp_destroy_lock(&lock);销毁锁变量,释放资源。
示例代码
#include <stdio.h>
#include <omp.h>
int main() {
omp_lock_t lock;
omp_init_lock(&lock); // 初始化锁
#pragma omp parallel num_threads(4)
{
omp_set_lock(&lock); // 设置锁,进入临界区
printf("Thread %d is in the critical section\n", omp_get_thread_num());
omp_unset_lock(&lock); // 释放锁,退出临界区
}
omp_destroy_lock(&lock); // 销毁锁
return 0;
}
Synchronization in OpenMP
OpenMP 提供了多种同步机制,用于构建复杂的并行编程结构。以下是几种常见的同步指令:
-
critical:用来保护一段代码,确保每次只有一个线程可以执行这段代码,其它线程必须等待。这通常用于保护对共享资源的访问。
#pragma omp critical { // 这段代码块是临界区,只有一个线程可以执行 } -
atomic:确保对某些共享变量的操作是原子的,避免多个线程同时修改变量时引发的竞争条件。适用于简单的赋值或更新操作。
#pragma omp atomic sum += value; -
barrier:用于在程序的某个点上同步所有线程。只有当所有线程都到达这一点时,程序才能继续执行。这在需要确保所有线程完成某些工作后再继续执行时非常有用。
#pragma omp barrier -
ordered:确保在并行循环中,某些操作按顺序执行,避免在执行顺序上出现问题。
#pragma omp ordered { // 这段代码按顺序执行 }
OpenMP 的这些同步机制可以帮助开发者有效地管理并发任务,确保线程安全和数据一致性。通过正确使用这些同步指令,程序员可以避免常见的并行编程错误,如竞争条件和死锁,从而构建更高效、更可靠的并行程序。
OpenMP Critical Section
在并行编程中,临界区(Critical Section) 是一段代码,在多线程环境中,必须确保每次只有一个线程可以执行该段代码,以避免多个线程同时修改共享资源,从而导致数据不一致或竞争条件的发生。在 OpenMP 中,使用 #pragma omp critical 指令可以方便地实现临界区的功能。
示例代码解析
-
定义线程数和步长:首先,定义线程数量
NUM_THREADS和步长step,这些变量用于控制并行计算的粒度和范围。 -
并行区域:使用
#pragma omp parallel指令指定接下来的代码将在多个线程中并行执行。这意味着每个线程将独立执行同一段代码,但可能会访问和修改共享资源。 -
计算部分结果:在并行区域内,每个线程根据其线程ID (
omp_get_thread_num()) 执行一定数量的计算,并将部分结果存储在sum[id]数组中,其中id是线程的唯一标识符。 -
临界区:使用
#pragma omp critical指令定义临界区。在临界区内,每次只能有一个线程进行操作,其余线程需要等待。这一操作确保了每个线程安全地将自己的部分结果累加到总结果pi中,避免了竞争条件的出现。
代码示例
#include <stdio.h>
#include <omp.h>
int main() {
const int NUM_THREADS = 4;
const long num_steps = 1000000;
double step = 1.0/(double)num_steps;
double sum[NUM_THREADS], pi = 0.0;
for (int i=0; i<NUM_THREADS; i++) sum[i] = 0.0;
#pragma omp parallel num_threads(NUM_THREADS)
{
int id = omp_get_thread_num();
for (int i=id; i<num_steps; i+=NUM_THREADS) {
double x = (i + 0.5) * step;
sum[id] += 4.0 / (1.0 + x * x);
}
#pragma omp critical
pi += sum[id] * step;
}
printf("Calculated pi = %.12f\n", pi);
return 0;
}
在这个示例中,通过 #pragma omp critical 指令,保证了并行计算的正确性,并且避免了多线程对共享资源 pi 的同时访问。
Deadlock
死锁(Deadlock) 是并发编程中的一种常见问题,它指的是多个线程或进程因互相等待对方释放资源而陷入僵局,导致程序无法继续执行。
哲学家就餐问题

这是一个经典的死锁问题,用来形象地描述死锁的发生条件和如何避免死锁。
- 场景描述:
- 多个哲学家围坐在餐桌旁,每人面前有一只叉子。
- 每位哲学家在进餐前,必须先拿起左边的叉子,再拿起右边的叉子。
- 如果每位哲学家同时拿起左边的叉子并等待右边的叉子,这将导致死锁——所有哲学家都无法继续进餐,因为他们各自只拿到了一只叉子。
- 解决死锁的策略:
- 资源分配限制:引入一个管理员,控制每次最多只有四位哲学家可以拿起左边的叉子,确保至少有一位哲学家可以完成进餐,从而释放叉子,避免死锁。
- 顺序拿起叉子:规定哲学家拿起叉子的顺序,例如,总是先拿编号较小的叉子,再拿编号较大的叉子。这种策略可以避免循环等待的发生,从而防止死锁。
OpenMP Timing
在并行编程中,评估程序的性能是非常重要的,而 OpenMP 提供了 omp_get_wtime() 函数,用于获取当前线程的壁钟时间(Wall Clock Time)。
关键点解析
-
独立测量:
omp_get_wtime()返回的是从某个时间点到当前时间的秒数。因为每个线程独立测量时间,不同线程之间的测量结果可能会有所不同。 -
计算经过的时间:为了计算经过的时间(即运行时间),可以在开始和结束时分别调用
omp_get_wtime(),然后计算它们的差值。
代码示例
#include <stdio.h>
#include <omp.h>
int main() {
double start_time, end_time;
start_time = omp_get_wtime();
// 代码段:进行某些计算
#pragma omp parallel for
for (int i = 0; i < 1000000; i++) {
// 计算操作
}
end_time = omp_get_wtime();
printf("Elapsed time: %f seconds\n", end_time - start_time);
return 0;
}
通过这种方式,可以精确地测量并行计算的运行时间,从而进行性能调优和分析。这在优化并行程序时尤为重要,因为了解程序的瓶颈可以帮助开发者做出更好的优化决策。
Shared Memory and Caches
在多核处理器(Multicore Multiprocessor)架构中,共享内存和缓存是至关重要的组件。该架构通常被称为SMP(对称多处理器,Symmetric Multiprocessor),其设计和实现直接影响系统的并行计算能力和整体性能。以下是SMP架构的关键特点及其背后的工作原理:
SMP(对称多处理器)架构的关键特点
- 多个相同的处理器或核心:
- 在SMP系统中,存在两个或更多个相同的CPU或核心。这些核心之间通常是对称的,这意味着每个核心在功能和性能上是等价的,它们能够独立执行任务,但也能协同完成复杂的并行任务。
- 单一共享内存:
- SMP系统中的所有核心共享一个一致性内存(coherent memory)。一致性内存的含义是所有核心都能看到相同的内存视图,无论哪个核心对内存进行了修改,其他核心都能在一定的时间范围内看到最新的内存状态。这保证了多个核心在并行计算时数据的一致性,避免了由于数据不同步导致的错误。
- 缓存的一致性:
- 每个核心都有自己的私有缓存,通常包括一级缓存(L1 Cache)和二级缓存(L2 Cache)。缓存与共享内存之间通过互连网络(Interconnection Network)进行通信,以确保缓存数据的一致性(Cache Coherence)。缓存一致性是指所有核心对某一内存位置的访问顺序是一致的,即如果一个核心更新了某一内存位置的值,其他核心在读取该位置时能够看到最新的值。
这种SMP架构在并行计算中非常常见,它允许多个处理器同时访问和处理相同的数据,从而提高计算效率和性能。然而,在实际应用中,需要避免多个核心同时修改同一块数据而导致数据冲突或错误。这种情况通常会导致所谓的缓存一致性问题,如缓存同步困难、内存顺序不一致等,需要通过硬件协议(如MESI协议)来解决。
Multiprocessor Key Questions
在多处理器系统中,有几个关键问题需要解决,这些问题决定了系统的设计复杂度和最终性能:
- 它们如何共享数据?
- 多处理器如何共享数据是并行计算中首先需要解决的问题。共享内存提供了一个全局的地址空间,所有处理器可以在这个地址空间中访问和修改相同的数据。为了实现数据共享,处理器可以通过读取和写入共享变量来进行通信。然而,这种共享方式也引发了竞争条件(Race Condition)的问题,需要同步机制来保证数据一致性。
- 它们如何协调?
- 协调是指处理器之间如何管理共享资源的访问,以避免数据冲突和同步问题。这通常通过同步机制如锁(Locks)、信号量(Semaphores)或屏障(Barriers)来实现。这些机制可以确保在多个处理器同时访问共享数据时,不会发生数据竞争,并且所有处理器能够有序地完成各自的任务。
- 能支持多少个处理器?
- 系统的可扩展性是一个重要的考虑因素。支持更多的处理器通常意味着更高的并行处理能力,但也增加了系统复杂性,尤其是在缓存一致性和内存访问延迟方面。SMP系统的设计必须在处理器数量和系统性能之间找到平衡,以确保系统能够高效地扩展而不会显著降低性能。
Shared Memory Multiprocessor (SMP)
- 单一地址空间共享:
- 在共享内存的多处理器系统(SMP)中,所有处理器或核心共享一个地址空间。这意味着所有核心可以访问相同的内存区域,能够直接读取和写入相同的数据。这种共享的内存模型使得编程更加直观,因为开发者可以直接利用内存中的共享变量进行通信和数据交换。
- 通过共享变量进行协调:
- 处理器之间的协调是通过内存中的共享变量实现的。通常,处理器通过加载(Load)和存储(Store)操作对这些变量进行读写操作。为了防止多个处理器同时访问和修改相同的数据,通常使用同步原语(如锁)来管理访问。锁机制能够确保在一个处理器访问共享变量时,其他处理器被阻止进入临界区,直到锁被释放。
- 所有多核计算机都是SMP:
- 现代的多核计算机几乎都是共享内存多处理器系统(SMP)。这种架构能够有效地支持并行计算,并简化处理器之间的数据共享和协调。SMP架构的广泛应用使得并行计算变得更加普遍,并且得益于共享内存模型,开发者可以更容易地编写并行程序。
SMP架构中的共享内存和缓存一致性是并行计算系统设计中的核心问题。通过合理的内存模型和缓存管理,SMP系统能够在保证数据一致性的前提下,实现高效的并行处理能力。这种架构在现代计算机系统中广泛应用,尤其是在多核处理器环境下,成为提升计算性能的关键技术。然而,随着处理器数量的增加,如何高效地管理和协调多个处理器之间的共享数据,以及如何解决缓存一致性问题,依然是并行计算中面临的主要挑战。
Multiprocessor Caches
在多处理器系统中,缓存的使用和管理是影响系统性能的关键因素。以下是多处理器缓存架构中的一些重要概念和挑战,以及如何通过缓存机制来优化性能。
1. 内存是瓶颈
即使在单处理器系统中,内存访问速度往往成为系统性能的瓶颈。这是因为现代处理器的速度远远高于内存的访问速度,处理器执行指令的速度通常能够达到数十亿次每秒,而内存的访问延迟可能达到数百个处理器时钟周期。因此,处理器在执行计算任务时,往往需要等待内存数据的到达,从而降低了整体性能。
2. 使用缓存减少内存带宽需求
为了缓解这一问题,每个处理器通常配备有一个本地私有缓存,用于存储最近访问的数据。缓存的存在显著减少了处理器对主存的依赖,因为在大多数情况下,处理器可以直接从缓存中读取所需的数据,而无需访问速度较慢的主存。这种缓存机制尤其在多处理器系统中至关重要,因为它不仅减少了对主存的访问需求,还减少了处理器之间对共享内存的竞争,从而提高了系统的整体性能。
3. 缓存未命中才访问共享内存
在多处理器系统中,只有当处理器缓存中找不到所需的数据(即缓存未命中)时,处理器才需要访问共享的主存。这样的机制进一步减少了对共享内存带宽的需求,因为多数情况下处理器能够直接从缓存中获得所需的数据,只有在缓存无法提供数据时才会访问共享内存。这种策略极大地提升了多处理器系统的并行处理能力和数据访问速度。
Shared Memory and Caches
问题设想
考虑一个有三个处理器的多处理器系统:Processor 0, Processor 1 和 Processor 2。假设它们同时尝试读取内存地址 1000 处的数据,该内存地址的初始值为 20。
-
情景 1:Processor 1 和 Processor 2 分别读取了 Memory[1000],并将该值(20)存储到它们各自的缓存中。因此,此时 Processor 1 和 Processor 2 的缓存中都保存了内存地址 1000 的值,即 1000 -> 20。
-
情景 2:接下来,Processor 0 对 Memory[1000] 进行了写操作,将其值修改为 40。Processor 0 的缓存中存储了更新后的值(即缓存值为 1000 -> 40)。然而,此时 Processor 1 和 Processor 2 的缓存中仍然保存着旧值(1000 -> 20),而共享内存的值是否同步更新到了 40 取决于系统的缓存一致性协议。
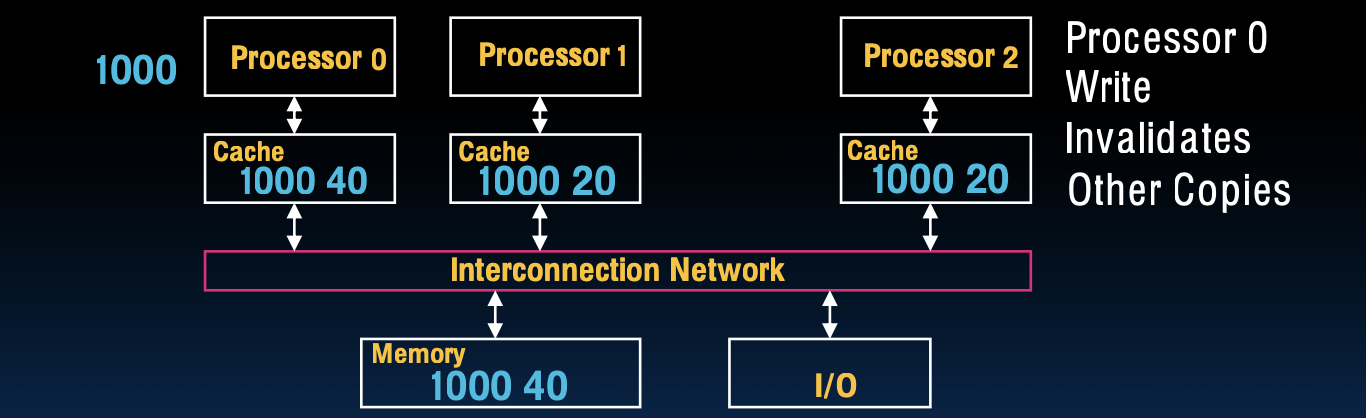
可能的问题
当多个处理器在各自的缓存中存储了同一内存地址的不同值时,系统可能会遇到缓存一致性问题(Cache Coherence Problem)。这种情况会导致处理器在并行计算中基于不同的缓存数据进行操作,从而产生不一致的计算结果。例如,Processor 1 和 Processor 2 可能继续使用旧的值(20)进行计算,而 Processor 0 使用新的值(40),这显然会导致错误的计算结果。
缓存一致性问题
缓存一致性问题是多处理器系统中一个关键的挑战,特别是在共享内存系统中。如果多个处理器的缓存中存在同一内存地址的不同版本数据,则可能会导致数据的不一致性和计算错误。为了解决这一问题,通常采用缓存一致性协议(Cache Coherence Protocols)来确保各处理器缓存中的数据保持一致。
Cache Coherency
Keeping Multiple Caches Coherent
保持多个缓存一致性
在多处理器系统中,缓存一致性是一个关键问题。缓存一致性确保多个处理器在并行访问共享内存时,所有缓存中的数据保持一致。缓存一致性主要涉及以下两个操作:
-
读取操作:在读取操作中,多个处理器可以持有相同内存地址的副本,因为读取操作不会改变数据的内容。因此,多个处理器可以同时读取相同的数据,而无需担心数据不一致的问题。
-
写入操作:在写入操作中,如果一个处理器修改了某个内存地址的数据,其他处理器缓存中的对应数据必须失效。这是因为修改后的数据需要被传播到所有处理器,以确保数据一致性。这个过程通常通过硬件机制来实现,当一个处理器执行写操作时,其他处理器的缓存会通过互连网络接收到通知,并使得缓存中对应的数据失效。
缓存一致性机制
当一个处理器对共享内存地址进行写操作时,其他处理器的缓存会监听(snoop)公共互连网络,以检查是否有需要更新的部分。如果检测到其他缓存持有相同的内存地址,它们会自动使相关缓存行失效,确保所有处理器访问的一致数据。
How Does HW Keep Cache Coherent?
硬件如何保持缓存一致性?
硬件通过特定的缓存一致性协议来确保缓存的一致性。每当一个处理器对内存进行写操作时,硬件会自动触发一致性协议,更新或失效其他处理器的缓存数据。这些协议定义了缓存行在不同处理器之间的状态转换规则,确保每个处理器在访问数据时得到的是最新、最正确的版本。
Common Cache Coherency Protocol: MOESI
常见的缓存一致性协议:MOESI
MOESI协议是多处理器系统中广泛应用的一种缓存一致性协议,它通过定义五种缓存状态,确保处理器之间缓存数据的一致性。每个状态都描述了缓存行在多处理器环境中的特定情境下如何处理数据。以下是每个状态的详细说明,以及处理器在每种状态下可以执行的操作:
- Modified(修改状态):
- 数据处理:在“修改”状态下,缓存行的数据已被当前处理器修改,并且此修改尚未写回主存。这意味着,当前缓存中的数据是最新的,其他处理器的缓存中不包含该数据的副本,主存中的数据已过时。
- 处理器操作:处理器可以对该缓存行进行读写操作,所有更改仅影响本地缓存。由于数据是最新的且未同步到主存,因此在此状态下,如果其他处理器请求访问该数据,当前处理器必须首先将数据写回主存(回写),然后将其状态更改为“共享”或“无效”。
- 状态转换:在处理器写回数据到主存后,缓存行状态可能转换为“共享”或“无效”,取决于其他处理器是否请求访问该数据。
- Owned(拥有状态):
- 数据处理:在“拥有”状态下,缓存行的数据可能已被修改,并且可能存在多个副本。在此状态下,当前缓存行持有的数据是最新的,并且此缓存行负责将数据的最新副本写回主存。其他处理器的缓存中可能持有过时的数据副本。
- 处理器操作:处理器可以读取和写入此缓存行,但当其他处理器请求访问时,当前处理器必须提供最新数据。此状态通常发生在处理器需要共享更新后的数据,并允许其他处理器读取该数据。
- 状态转换:当数据被写回主存或其他处理器获取了该数据的最新副本后,缓存行状态可能转换为“共享”或“无效”。
- Exclusive(独占状态):
- 数据处理:在“独占”状态下,缓存行中的数据是最新的,并且该数据的副本仅存在于当前处理器的缓存中,其他处理器的缓存和主存中没有此数据的副本。
- 处理器操作:处理器可以自由地读取或修改此缓存行的数据,而不需要立即将更改写回主存。如果处理器对数据进行写操作,则状态转换为“修改”;如果其他处理器请求访问该数据,则状态转换为“共享”或“无效”。
- 状态转换:当处理器写入数据时,状态转换为“修改”;如果其他处理器请求读取该数据,状态转换为“共享”。
- Shared(共享状态):
- 数据处理:在“共享”状态下,缓存行中的数据可以存在于多个处理器的缓存中,并且数据与主存中的副本一致。这意味着多个处理器可以同时读取该数据,而无需担心数据不一致。
- 处理器操作:处理器可以读取缓存行的数据,但不能修改。如果需要修改数据,处理器必须首先获得独占访问权(通常通过无效其他处理器的缓存副本),然后状态转换为“独占”或“修改”。
- 状态转换:如果处理器请求写入,状态将转换为“独占”或“修改”;如果缓存行被其他处理器修改,当前处理器的缓存行状态将转换为“无效”。
- Invalid(无效状态):
- 数据处理:在“无效”状态下,缓存行中的数据是无效的,不再可用。这通常发生在其他处理器修改了共享的数据后,通知当前处理器将其缓存行置为无效。
- 处理器操作:处理器不能读取或写入无效状态下的缓存行。如果需要访问此数据,处理器必须从主存或其他处理器的缓存中重新获取最新数据,并将缓存行状态更新为“共享”或“独占”。
- 状态转换:如果处理器重新加载数据,状态将转换为“共享”或“独占”;如果处理器放弃对该缓存行的控制,状态保持“无效”。
处理器的角色与数据处理
在MOESI协议下,处理器在每种状态中都有特定的操作和数据处理方式:
- 读操作:处理器可以在“共享”、“独占”和“修改”状态下自由读取数据。在“无效”状态下,处理器必须从主存或其他缓存重新加载数据。
- 写操作:写操作只能在“独占”和“修改”状态下进行。如果数据在其他处理器的缓存中存在副本,处理器必须首先获取独占访问权,将其他副本置为无效。
- 状态管理:处理器通过监听其他处理器的内存操作(如总线监听)来管理其缓存行的状态,并根据操作类型动态调整缓存行的状态,确保数据一致性。
MOESI协议的工作原理
当处理器对缓存行执行操作时,MOESI协议根据当前状态和操作类型决定如何处理缓存行。例如,当一个处理器对缓存行进行写操作时,如果缓存行处于“Shared”状态,则该处理器需要获取数据的所有权,并通知其他处理器使相关缓存行无效或更新,从而转移到“Owned”或“Modified”状态。
Shared Memory and Caches
在具有缓存一致性机制的多处理器系统中,处理器可以正确地共享和访问内存数据。例如:
-
假设处理器1和处理器2从内存地址
Memory[1000]中读取数据,初始值为20。两个处理器分别在各自的缓存中存储了该数据的副本,缓存中的值均为20。 -
随后,处理器0对
Memory[1000]执行写操作,将值修改为40。
在处理器0执行写操作后,MOESI协议会触发缓存一致性机制,使处理器1和处理器2缓存中与Memory[1000]对应的数据行失效。这迫使处理器1和处理器2在下一次访问Memory[1000]时,从主存中重新加载更新后的值,即40。
缓存一致性的重要性
缓存一致性机制确保了多处理器系统中的数据一致性,避免了因多个处理器缓存数据不同步而引起的计算错误。通过硬件支持的缓存一致性协议,如MOESI协议,系统能够有效管理多个缓存之间的数据同步,确保并行计算的正确性和效率。
Poll Answer
-
使用写通缓存并不能消除缓存一致性的需求
写通缓存(write-through cache)意味着每次写操作都会立即更新主存。尽管这确保了主存中的数据总是最新的,但它并不能解决多处理器系统中不同处理器缓存中可能存在的副本问题。即使主存已更新,如果其他处理器的缓存中仍然保留了旧数据副本,它们读取的仍然是过时的信息。因此,写通缓存无法完全消除缓存一致性问题,这表明即便使用写通缓存,也必须依赖缓存一致性协议来协调处理器之间的缓存内容一致性。 -
每个处理器的存储指令都必须检查其他缓存的内容
这个观点是错误的。缓存一致性协议(如MESI、MOESI协议)的存在就是为了确保当处理器执行写操作时,能够知道是否有其他处理器缓存了相同的数据块。如果存在这样的缓存副本,协议会通过广播机制或总线监听来通知其他处理器,使得相应的缓存数据无效或更新,而不是要求每个存储指令都主动检查其他处理器的缓存。 -
一次只能有一个处理器缓存任何内存位置
这个说法也是错误的。在多处理器系统中,多个处理器可以同时缓存同一个内存位置,尤其是在读取操作的情况下。多个处理器可以共享缓存相同的数据副本,而不需要相互间干扰。然而,在写操作涉及的情况下,缓存一致性协议会协调处理器之间的缓存更新,以确保所有处理器最终看到的数据是一致的。
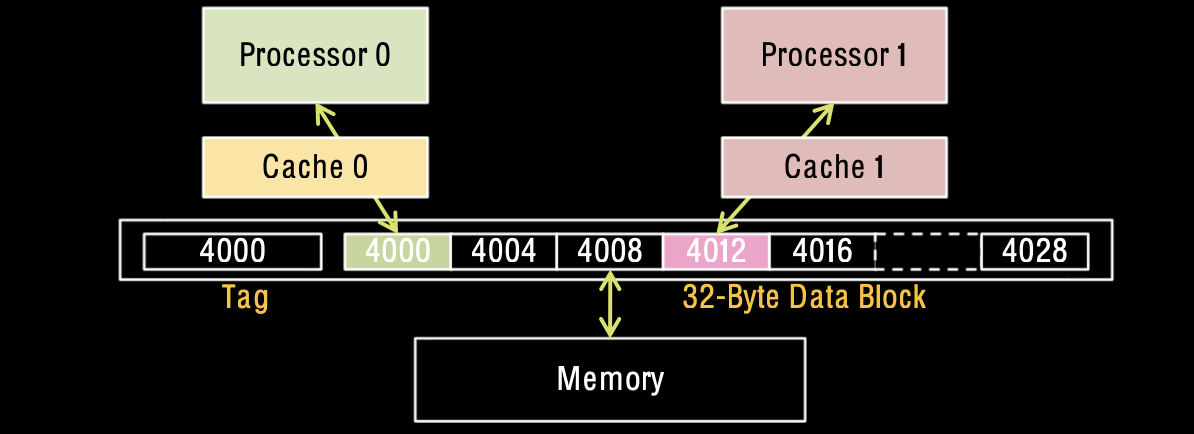
Cache Coherency Tracked by Block
当缓存一致性通过缓存块跟踪时,每个缓存块的状态都在处理器之间进行协调。例如,假设缓存块的大小为32字节,处理器0正在读取和写入变量X,处理器1正在读取和写入变量Y。如果X存储在内存地址4000,Y存储在内存地址4012,这两个变量可能会落在同一个缓存块内。
即使处理器0和处理器1分别在访问不同的变量X和Y,由于它们位于同一缓存块内,当一个处理器修改缓存块中的数据时,另一个处理器也会因为缓存一致性协议而被迫重新加载该缓存块。这种现象称为伪共享(False Sharing)。伪共享会导致缓存块在处理器之间频繁切换,使得系统在执行时需要进行大量的缓存一致性维护操作,从而影响整体性能。
Remember The 3Cs?
缓存未命中的三种常见原因,即3Cs:
-
Compulsory Misses(必然未命中)
这是指冷启动时或进程迁移后的首次访问,由于这是对某一数据块的第一次访问,因此缓存中还没有该块的数据。尽管其影响通常较小,但它是无法完全避免的。增大缓存块的大小可以减少这种未命中类型的发生,但可能会带来其他问题,如增加冲突未命中或更高的缓存未命中惩罚。 -
Capacity Misses(容量未命中)
当程序所需的数据块总量超过了缓存的容量,即使使用最优的替换策略,也无法将所有数据块保留在缓存中,从而导致容量未命中。通过增加缓存的总容量可以缓解这种未命中,但这通常会提高缓存的访问时间。 -
Conflict Misses(冲突未命中)
当多个内存地址映射到相同的缓存位置时,发生冲突未命中。增加缓存的关联度(如从直接映射缓存升级到组相联缓存)或采用更好的替换策略(如LRU,最近最少使用)可以减少冲突未命中的发生。
Fourth “C” of Cache Misses: Coherence Misses
Coherence Misses(一致性未命中)
一致性未命中是由于处理器之间缓存一致性协议所引发的未命中。这种未命中通常发生在处理器之间需要通过缓存一致性机制同步数据时,被称为通信未命中。在并行程序中,特别是共享数据频繁更新的情况下,一致性未命中可能成为影响系统性能的主要因素之一。
总结
-
OpenMP:OpenMP 是一种用于C语言的并行编程扩展,它通过简化的指令集(如
parallel for、private变量和reductions)实现线程级并行编程。 -
线程级并行性(TLP):缓存一致性机制确保了在共享内存环境中,即使在多个缓存中存在同一数据的多个副本时,数据的一致性也能得到维护。然而,伪共享问题需要特别注意,开发者需要合理地选择缓存块大小并优化数据布局,以减少不必要的缓存一致性流量,从而提升系统性能。