Lecture 25: Caches - Direct Mapped II
Direct-Mapped Cache
在直接映射缓存中,每个内存地址与缓存中的一个可能的块相关联。
- 因此,如果数据存在于缓存中,我们只需要在缓存的单一位置查找数据。
- 块是缓存和内存之间传输的单位。
工作原理
- 每个内存地址都映射到一个特定的缓存位置。
- 该位置可以存放来自不同内存地址的数据,但每次只能存放一个数据块。
-
例如,内存地址0、4、8、12等都映射到缓存位置0,内存地址1、5、9、13等都映射到缓存位置1,以此类推。
- 直接映射缓存的映射方式使得查找数据非常快速,但也容易导致缓存冲突。
- 缓存冲突发生在两个不同的内存地址映射到同一个缓存位置时,最新的地址数据会覆盖旧数据。
4 Byte Direct-Mapped Cache
缓存位置0可以被以下数据占据:
- 内存位置0、4、8,等等。
- 4个块,即任何内存位置是4的倍数。
- 块大小为1字节。
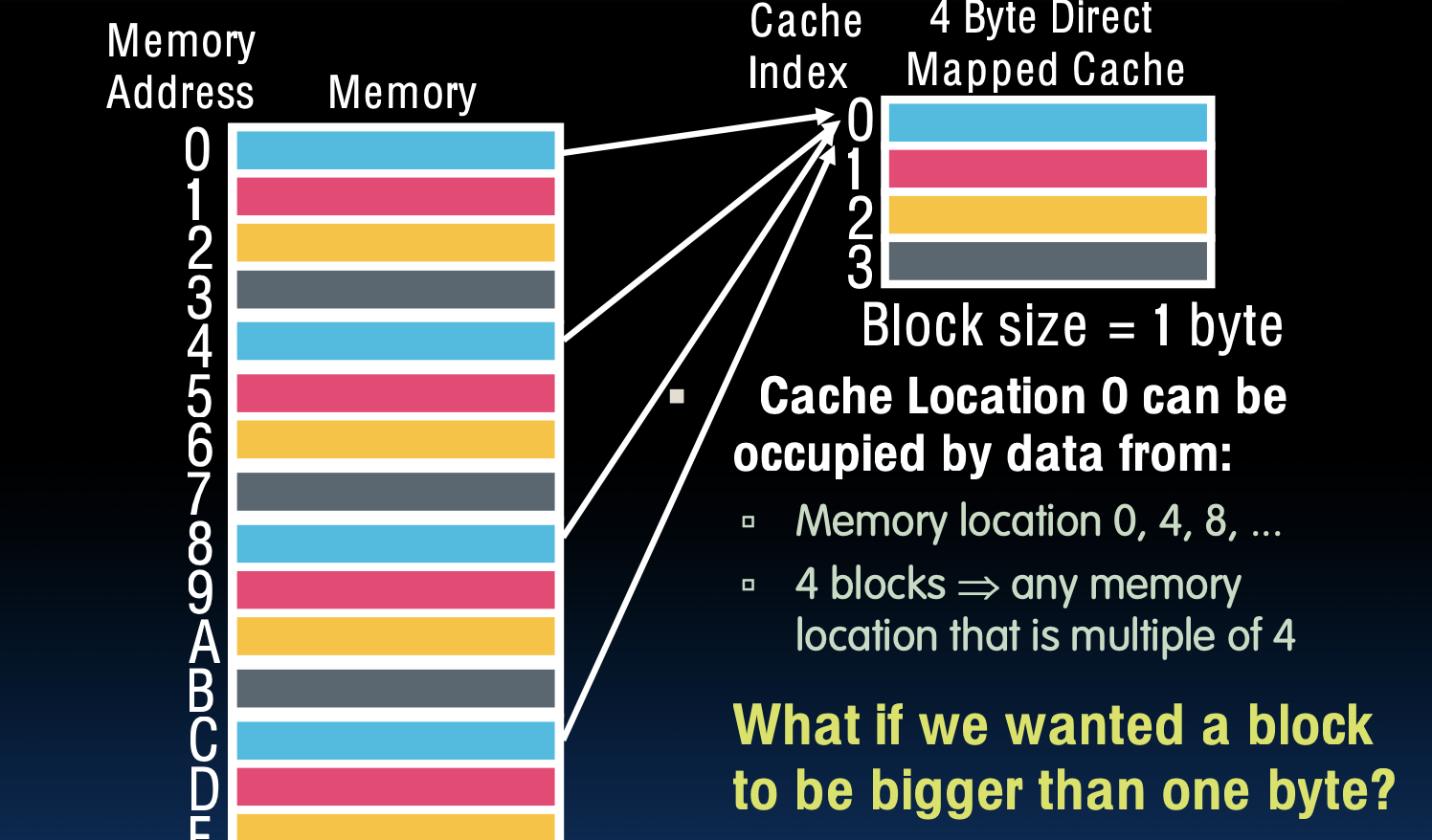
- 在图中,内存地址从0到F,代表16个不同的内存地址。
- 4字节直接映射缓存意味着缓存有4个位置,每个位置可以存放一个字节的数据。
- 当我们访问内存时,特定地址的数据会被映射到特定的缓存位置。例如,内存位置0的数据会被映射到缓存索引0。
如果我们希望块大于一个字节怎么办?
- 假设我们希望每个块包含更多的数据,例如4个字节,这将意味着我们需要调整缓存结构以适应更大的数据块。这样的调整会影响数据的传输效率和缓存命中率,需要在设计时仔细权衡各种因素。
8-Byte Direct-Mapped Cache
- 当我们请求一个字节时,控制器会找到正确的块并加载所有数据。
- 如何知道正确的块?
- 我们如何选择字节?
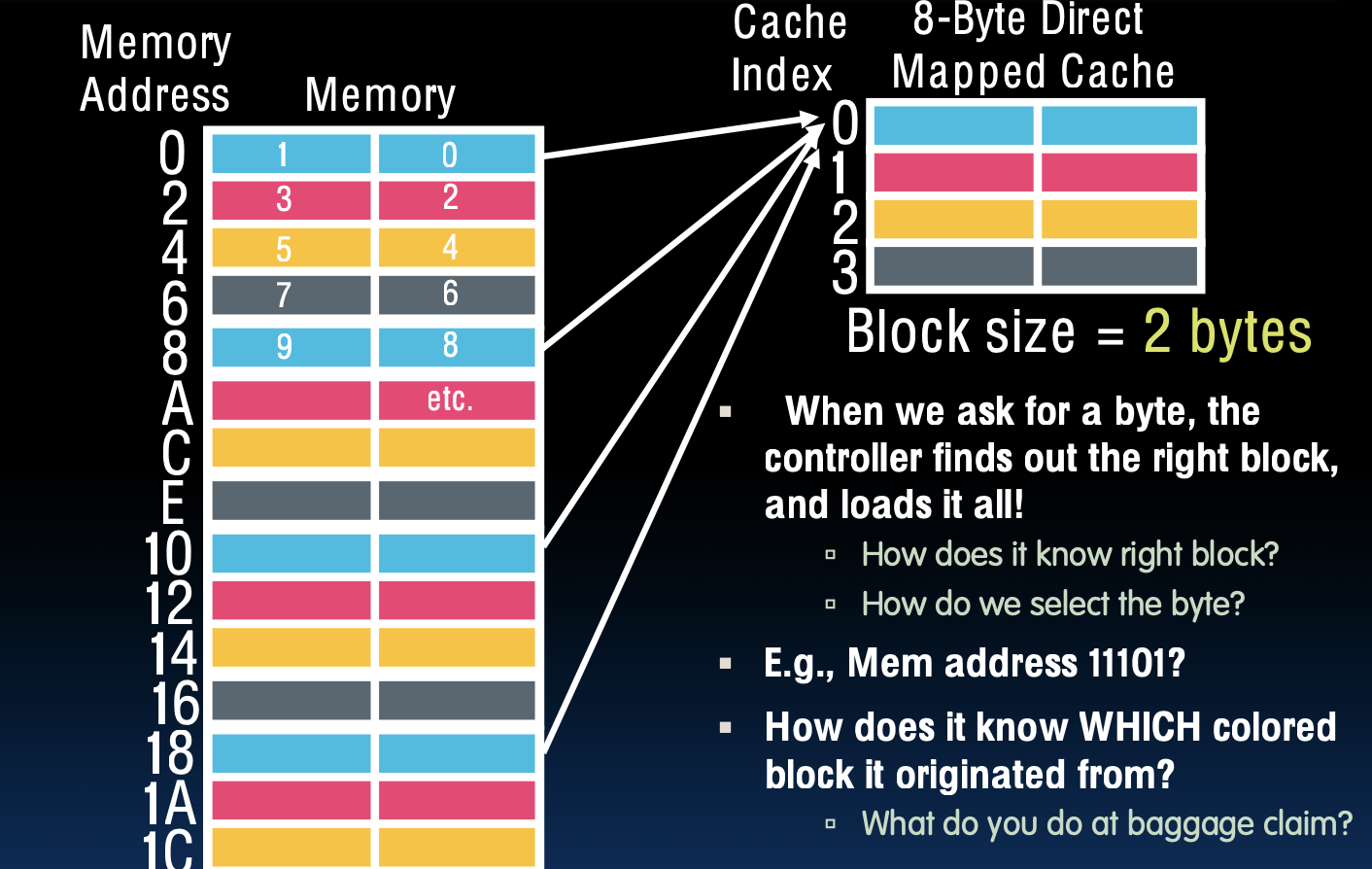
例如,内存地址1110属于哪个块?
- 块大小为2字节,这意味着每个缓存索引可以存储两个字节的数据。
- 内存地址1110的内容会映射到缓存中的某个特定位置。
如何知道数据来自哪个颜色的块?
- 为了区分不同的内存块,通常会在缓存中附加标签(tag)。标签帮助缓存控制器识别内存数据的来源,类似于行李标签帮助你在机场认领行李。
在直接映射缓存中,内存地址的某些位决定了缓存索引,而剩余的位则作为标签。例如,地址的低两位可以用来选择缓存索引,而高位则作为标签存储在缓存中。当访问缓存时,系统会检查标签是否匹配,如果匹配则命中,否则未命中。
8-Byte Direct-Mapped Cache
- 块大小 = 2字节。
- 什么应该放在标签中?
- 我们需要整个地址吗?
- 这些标签有什么共同点?
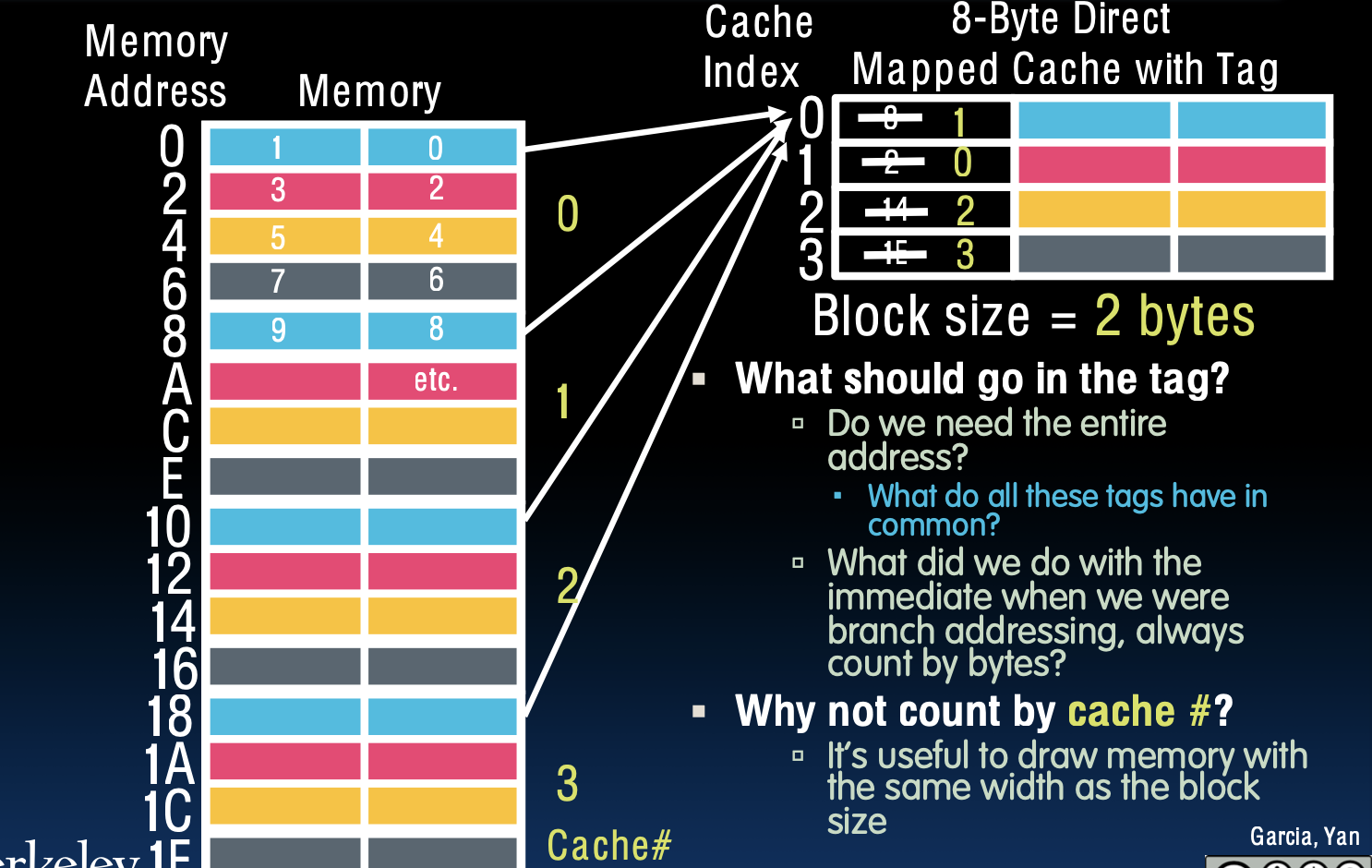
- 在图中,每个内存地址映射到特定的缓存索引,并带有一个标签。
- 标签用于区分不同内存地址的数据,以确保缓存命中时能正确识别数据来源。
Issues with Direct-Mapped
直接映射缓存的问题
由于多个内存地址映射到相同的缓存索引,我们如何区分哪个地址在缓存中?
- 当我们有一个大于1字节的块大小时,该如何处理?
- 解决方案是将内存地址分成三个字段:标签(tag)、索引(index)和字节偏移量(byte offset)。
内存地址字段划分:
- 标签(tag):用于检查缓存中是否有正确的块。
- 索引(index):用于选择缓存中的块。
- 字节偏移量(byte offset):用于选择块内的具体字节。

直接映射缓存术语
- 所有字段均读取为无符号整数。
- 索引(Index):指定缓存索引(缓存中应查找的“行”或块)。
- 偏移量(Offset):找到正确的块后,指定我们想要的块内字节。
- 标签(Tag):偏移量和索引确定后的剩余位,这些用于区分映射到相同位置的所有内存地址。
TIQ Cache Mnemonic (Thanks Uncle Dan!)
TIQ缓存助记法(感谢Uncle Dan)
- 缓存的面积(AREA)表示为缓存大小(B)。
- 面积等于高度(块数)乘以宽度(每个块的大小)。
公式: \[ \text{AREA (cache size, B)} = \text{HEIGHT (# of blocks)} \times \text{WIDTH (size of one block, B/block)} \]
字段分配:
- 标签(Tag)
- 索引(Index)
- 偏移量(Offset)
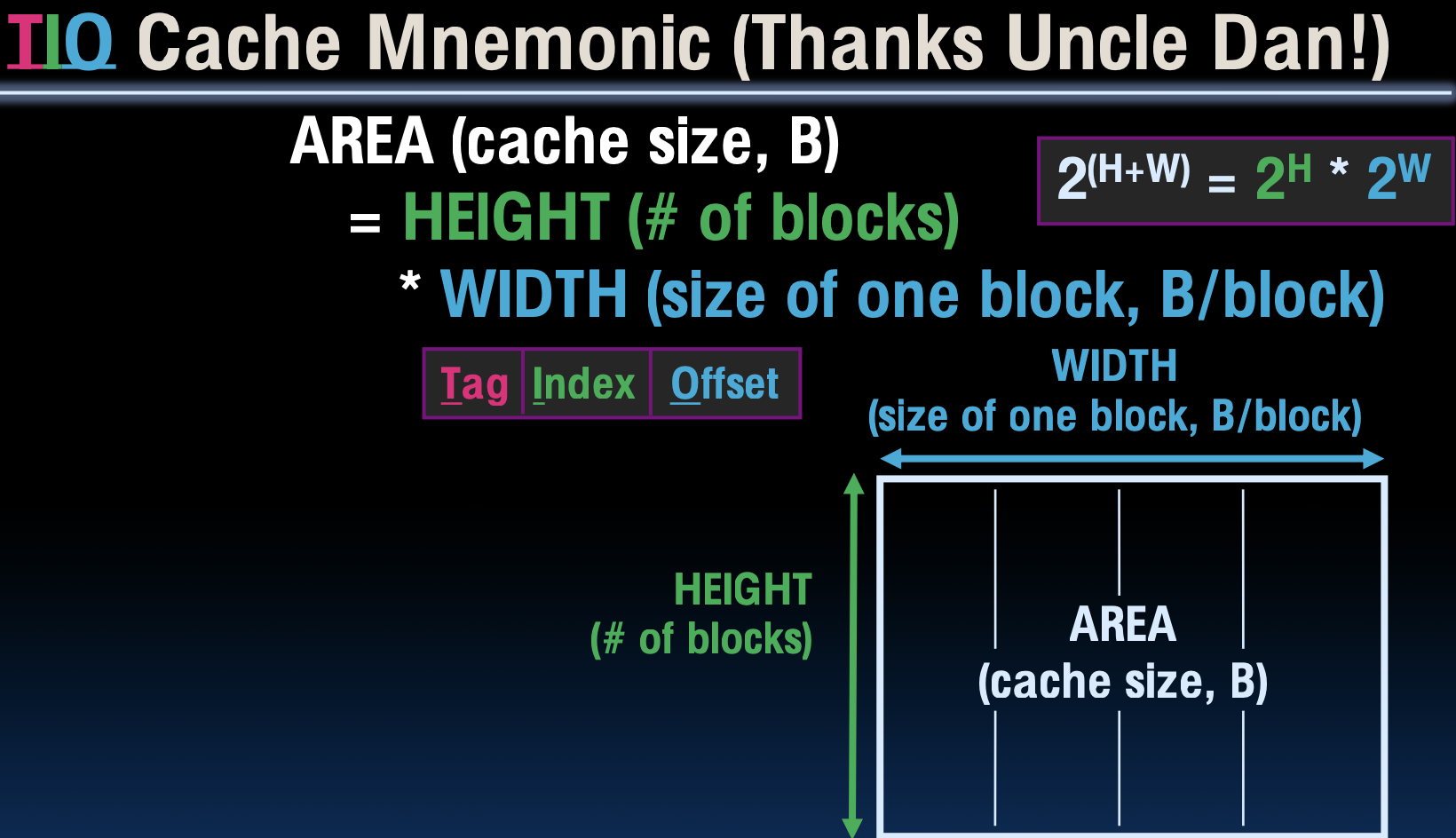
在设计缓存时,我们需要考虑缓存的大小、块的数量以及每个块的大小。通过这个公式,我们可以更直观地理解缓存的结构和布局。标签用于区分不同的块,索引用于定位块的位置,而偏移量则用于访问块内的具体数据。
Direct-Mapped Cache Example
直接映射缓存示例 (1/3)
假设我们有8B的数据,使用具有2字节块的直接映射缓存。
我们需要确定在一个8字节的数据缓存中,确定标签、索引和偏移字段各占多少位(在使用32位架构RV32的情况下)。
偏移:
- 需要指定块内正确的字节。由于每个块包含2字节,因此我们需要1位来表示偏移量。
索引:
- 需要指定缓存中的正确块。
- 缓存包含8B(即2^3字节)。
- 块包含2B(即2^1字节)。
- 块数/缓存大小=(字节数/缓存大小)/(字节数/块)= 2^3 / 2^1 = 2^2(即4块)。
- 需要2位来指定这些块。
标签:
- 使用剩余的位作为标签。
- 标签长度=地址长度-偏移-索引=32-1-2=29位。
- 所以标签是内存地址的最左边29位。
- 标签可以被认为是“缓存编号”。
为什么不用完整的32位地址作为标签?
- 块内的所有字节需要相同的地址。
- 索引对块内的每个地址都是相同的,因此在标签检查中是冗余的,从而可以节省内存。
- 标签字段用来区分不同的块。由于每个块内的地址是相同的,所以我们只需要用29位来表示标签,从而节省了存储空间。
Memory Access without Cache
没有缓存的内存访问
加载字指令:lw t0, 0(t1)
- t1 包含 1022\(_{10}\),
Memory[1022] = 99
- 处理器向内存发出地址 1022\(_{10}\)。
- 内存读取地址 1022\(_{10}\) 处的字(99)。
- 内存将99发送给处理器。
- 处理器将99加载到寄存器 t0 中。
在没有缓存的情况下,每次加载指令都需要直接从内存中读取数据,这会导致访问延迟增加,因为每次访问都需要通过较慢的内存路径。
Memory Access with Cache
有缓存的内存访问
加载字指令:lw t0, 0(t1)
- t1 包含 1022\(_{10}\),
Memory[1022] = 99
- 处理器向缓存发出地址 1022\(_{10}\)。
- 缓存检查是否在地址 1022\(_{10}\) 处有数据的副本。
- 2a. 如果找到匹配(命中):缓存读取99,发送给处理器。
- 2b. 如果没有匹配(未命中):缓存将地址 1022 发送给内存。
- I. 内存读取地址 1022\(_{10}\) 处的99。
- II. 内存将99发送给缓存。
- III. 缓存用新的99替换字。
- IV. 缓存将99发送给处理器。
- 处理器将99加载到寄存器 t0 中。
在有缓存的情况下,处理器首先检查缓存是否包含所需的数据。如果命中,数据可以快速从缓存中获取;如果未命中,则数据从内存中读取并加载到缓存,以便下次访问更快。
Solving Cache Problems
绘制具有T I O位的内存块:
解释:给定T(Tag位),I(Index位),O(Offset位),绘制内存块的宽度。虚线表示字边界。
标记(Tag),索引(Index),偏移量(Offset):
- Tag:标记位,用于区分缓存中的不同块。
- Index:索引位,用于在缓存中找到特定的缓存行。
- Offset:偏移量位,用于在缓存行中找到具体的数据。
缓存的结构和地址映射:
- 缓存由多个缓存行组成,每行包含一个块的数据。
- 地址分为Tag,Index和Offset,用于在内存和缓存之间映射。
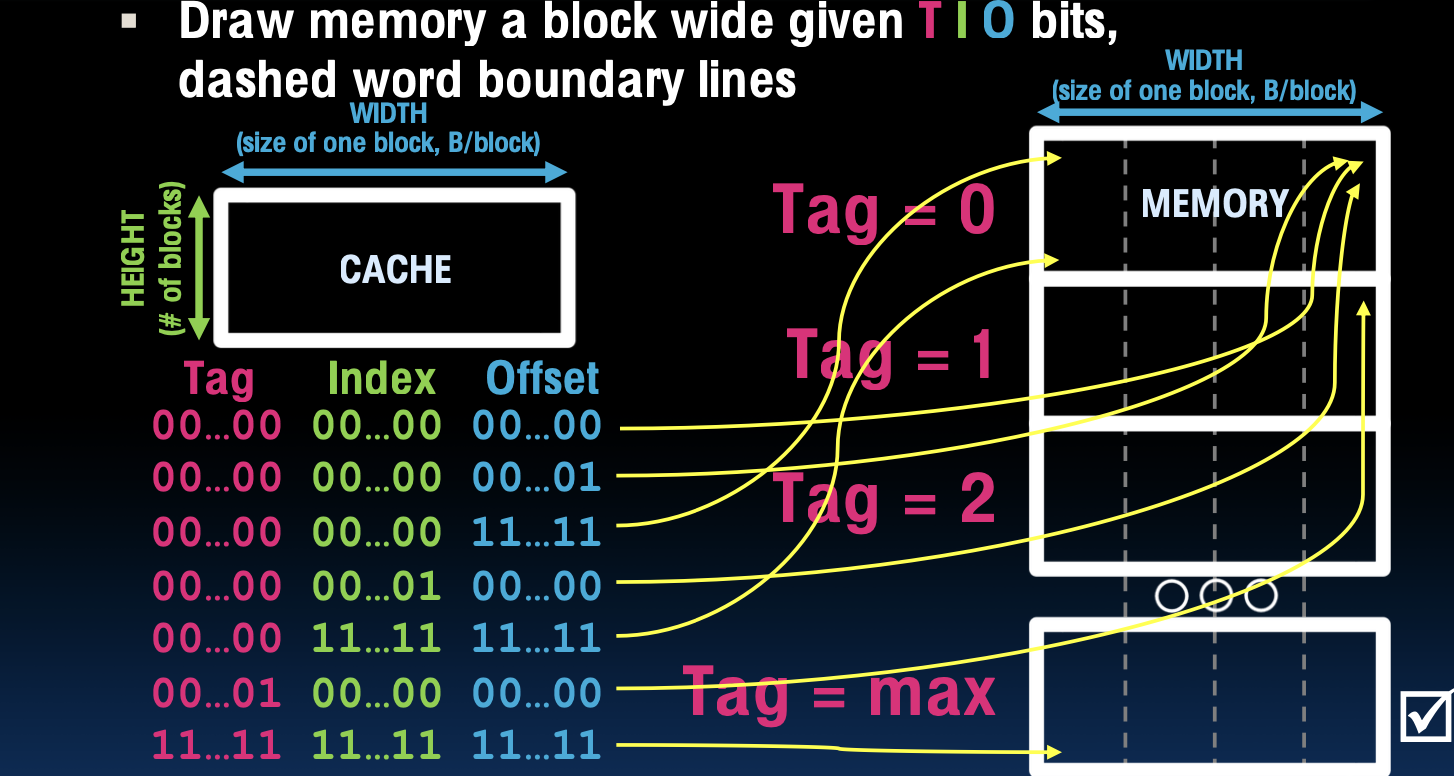
示例:
- Tag = 0, Index = 00…00, Offset = 00…00:
- 表示内存中第一个块的第一个字。
- Tag = 1, Index = 00…00, Offset = 00…00:
- 表示内存中第二个块的第一个字。
- Tag = max, Index = 11…11, Offset = 11…11:
- 表示内存中最后一个块的最后一个字。
高度和宽度:
- 高度(HEIGHT):块的数量(number of blocks)。
- 宽度(WIDTH):一个块的大小(size of one block, B/block)。
通过这些字段,缓存能够有效地组织和管理内存数据,提高内存访问的速度和效率。这种设计利用了局部性原理,确保了常用数据能够快速被处理器访问。
Caching Terminology
缓存术语
当读取内存时,可能发生三种情况:
- 缓存命中(cache hit):缓存块是有效的并且包含正确的地址,因此可以读取所需的数据。
- 解释:当处理器需要访问的数据在缓存中找到时,就称为缓存命中。这时,处理器可以快速从缓存中获取数据,而不需要访问较慢的主存。
- 缓存未命中(cache miss):缓存中适当的块没有任何数据,因此需要从内存中获取。
- 解释:当处理器需要的数据不在缓存中时,就会发生缓存未命中。这时,处理器必须从主存中读取数据,这会增加访问延迟。
- 缓存未命中,块替换(cache miss, block replacement):缓存中适当的块包含错误的数据,因此需要丢弃它并从内存中获取所需的数据(缓存总是副本)。
- 解释:当缓存中已有的数据块不再需要时,会被新的数据块替换。这种情况下,如果处理器需要的数据不在缓存中,且缓存已满,需要选择一个块进行替换。
缓存的工作机制主要是为了提高数据访问速度。通过缓存命中,可以减少访问主存的频率,从而提高系统性能。而缓存未命中和块替换则是缓存管理中的挑战,需要通过合理的替换策略来提高缓存的命中率。
Cache Temperatures
缓存温度
- 冷(Cold):缓存为空。
- 解释:此时缓存中没有存储任何数据,当处理器需要访问数据时,必须从主存中读取,导致较高的延迟。
- 变暖(Warming):缓存正在填充将来可能会再次访问的数据。
- 解释:随着程序运行,缓存开始存储一些数据,这些数据在短期内可能会被再次访问,逐渐减少主存访问的频率,提高访问速度。
- 温暖(Warm):缓存正在发挥作用,有一定比例的命中率。
- 解释:此时缓存已经存储了大量的数据,大部分访问都可以直接从缓存中获取,显著提升系统性能。
- 热(Hot):缓存效果非常好,高比例的命中率。
- 解释:缓存中的大部分数据都是频繁访问的,几乎所有访问请求都能在缓存中找到对应的数据,系统性能达到最佳状态。
Cache Terms
缓存术语
- 命中率(Hit rate):缓存访问中命中的比例。
- 解释:命中率越高,表示处理器从缓存中成功获取数据的次数越多,系统性能越好。
- 未命中率(Miss rate):1 - 命中率。
- 解释:未命中率越低,表示处理器需要从主存中读取数据的次数越少,系统性能越好。
- 未命中惩罚(Miss penalty):从内存层级的较低层次替换块到缓存所需的时间。
- 解释:未命中惩罚越小,系统性能越好,因为处理器可以更快地从主存获取数据。
- 命中时间(Hit time):访问缓存内存所需的时间(包括标签比较)。
- 解释:命中时间越短,缓存访问速度越快,系统性能越好。
- 缩写:$:表示缓存。
- 解释:这是伯克利大学的一项创新,用于简化表示缓存。
One More Detail: Valid Bit
再详述一点:有效位
- 当启动新程序时,缓存中没有该程序的有效信息。
- 解释:因为缓存中的数据是前一个程序运行时留下的,对新程序来说,这些数据可能是无效的。
- 需要一个指示器来判断该标签条目对该程序是否有效。
- 解释:通过判断标签条目是否有效,可以避免读取无效的数据,提高系统效率。
- 向缓存标签条目添加一个“有效位”。
- 0 -> 缓存未命中,即使碰巧地址=标签。
- 解释:当有效位为0时,即使地址和标签匹配,处理器也不会使用缓存中的数据,而是从主存读取。
- 1 -> 缓存命中,如果处理器地址=标签。
- 解释:当有效位为1时,表示缓存中的数据是有效的,可以直接使用,避免了从主存读取数据的延迟。
- 0 -> 缓存未命中,即使碰巧地址=标签。
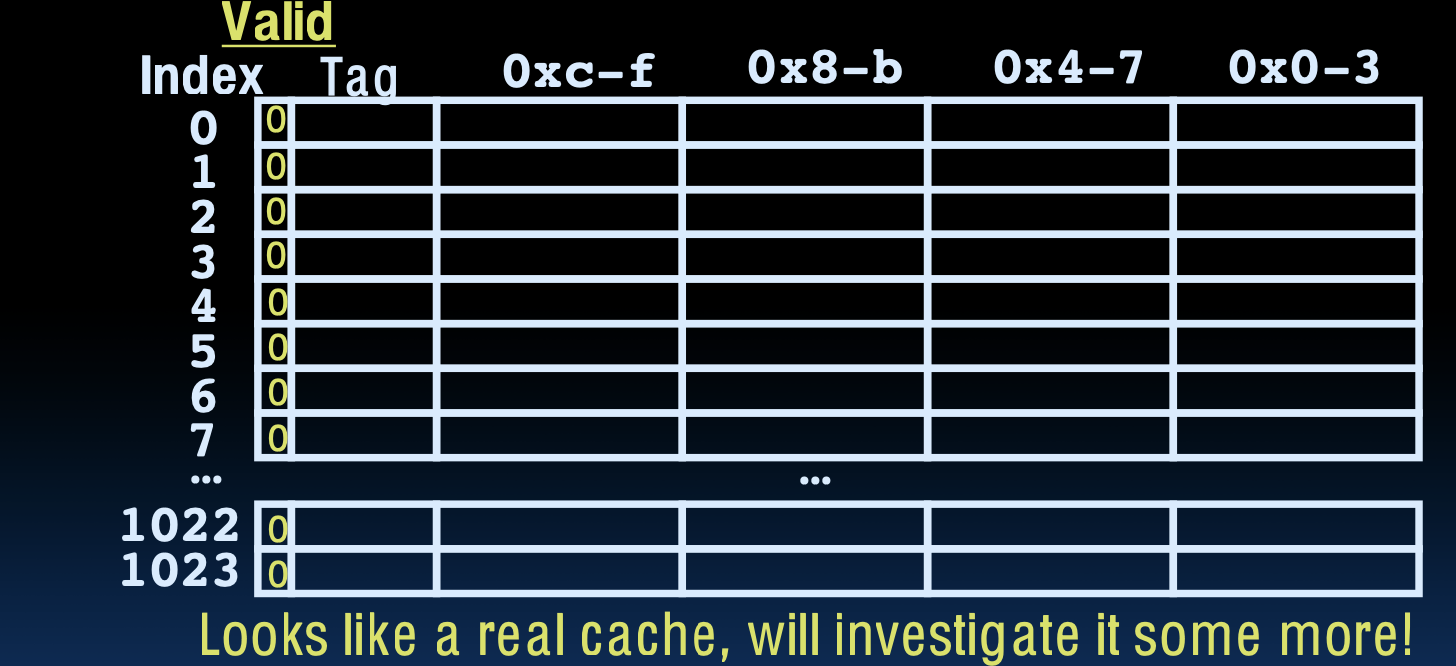
Example: 16 KB Direct-Mapped Cache, 16B blocks
示例:16KB直接映射缓存,16B块
- 有效位(Valid bit):确定在计算机初始启动时是否有任何信息存储在该行(初次启动时所有条目无效)。
- 解释:有效位用于指示缓存中的数据是否有效,当计算机刚启动时,缓存中的所有有效位均为0,表示缓存中没有有效数据。
Conclusion
总结
- 我们已经学习了直接映射缓存的操作
- 解释:直接映射缓存将每个内存地址映射到缓存中的一个唯一位置,这样可以快速确定数据是否在缓存中。
- 数据在不同层次的内存层级中透明移动的机制
- 地址/值绑定集合
- 解释:缓存中存储了内存地址和对应数据的绑定集合,通过地址可以快速找到数据。
- 地址 -> 索引到候选集
- 解释:通过内存地址计算出在缓存中的索引位置,找到可能存储该地址数据的缓存行。
- 将期望地址与标签进行比较
- 解释:检查计算出的索引位置的缓存行中的标签是否与期望地址匹配,以确定数据是否命中。
- 服务命中或未命中
- 解释:如果地址命中,则直接从缓存读取数据;如果未命中,则从主存中读取数据,并将数据加载到缓存中。
- 解释:在未命中的情况下,新的数据块将被加载到缓存中,同时更新地址和标签信息。
- 解释:如果地址命中,则直接从缓存读取数据;如果未命中,则从主存中读取数据,并将数据加载到缓存中。
- 地址/值绑定集合
Additional Notes
其他笔记
- 对于给定的缓存大小:较大的块大小可能导致较低的命中率
- 解释:较大的块大小意味着每个块中包含更多的数据,但每次只能访问其中的一部分,这可能导致更多的未命中情况。
- 如果知道计算机的缓存大小,通常可以使代码运行更快
- 解释:了解缓存大小和特性可以优化数据访问模式,减少缓存未命中的情况,提高程序性能。
- 空间局部性意味着将最近的数据保留在靠近处理器的位置
- 解释:利用空间局部性原则,将相邻数据块保存在缓存中,可以减少访问主存的次数,提高访问效率。