Lecture 9. Tree Recursion
Announcements
期中考试成绩已发布,如果对评分有异议,可以通过 GradeScope 提交重新评分申请,截止日期为周一。可以在 Piazza 上提问,但如果要正式修改成绩,必须通过 GradeScope 提交申请。整体来看,大家在这次具有挑战性的期中考试中表现得非常出色,我为大家的进步感到高兴。
即使有些同学没有解决所有问题,这也是正常的。关键是学习,如果还有一些内容尚未掌握,不用担心,在期中考试二和期末考试中仍有大量机会来提升。继续努力,专注于尚未完全理解的部分,坚持下去。
我们还监测了考试中的各种合作行为,结果显示作弊行为的发生率非常低。大多数同学都按规定独立完成了考试,这很重要,因为课程是不曲线评分的,因此他人的分数对你没有影响。专注于自己的进步才是关键。
如果你在 Google Drive 上存有考试视频,请保留这些视频到周一,以便我们完成检查。
Homework 2 将在今天发布,截止日期为下周四。本周没有考试准备环节,取而代之的是明天下午2:10的问答环节,不会录制,如果有问题可以来参加。
此外,还有一个完全可选的 Hog 策略比赛。提交表单已经发布,现在没有时间限制,只要策略在比赛结束前提交即可。你可以提前提交,查看自己在排行榜上的位置。目前,”Blockchain” 策略击败了所有对手,位列第一。
递归的回顾与新内容
今天的课程内容与以往不同,教授 Fried 录制了一些视频,回顾了上节课的内容。他的讲解方式有些不同,这很有帮助,能让你从多角度复习递归的基础。
接下来的课程将是新内容,这些内容非常重要,通常需要实践才能完全掌握。因此,下周我们会有实验和作业,帮助你巩固这些概念。
Python 核心内容的总结
到目前为止,我们已经覆盖了成为Python 程序员所需的核心计算概念,包括:
- 函数
- 变量
- 循环结构(
while和for) - 条件语句(
if、elif和else)
尽管还有很多数据结构和算法需要学习,但这些构成了你编写通用 Python 程序的基础。接下来的课程将进入更复杂的主题,比如面向对象编程。
递归的美
递归是一种非常优美的计算结构,它与之前所学的内容(例如循环和条件判断)不同。递归允许我们通过自我调用的方式解决问题,改变了我们对计算过程的思考方式。
在介绍递归之前,先讨论一下阶乘(Factorial)运算的定义以及如何用迭代实现它。
阶乘的数学定义
阶乘的符号是感叹号(!),定义如下:
- 对于非负整数
n,n!表示从n到 1 的所有正整数的乘积。 - 特殊情况:
0! = 1。
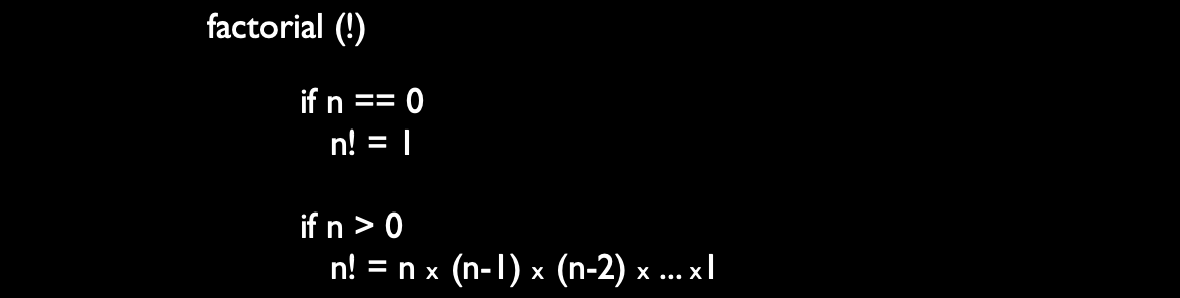
迭代实现阶乘
在写递归版本之前,我们可以用迭代的方法来实现阶乘。通过 while 循环逐步计算从 1 到 n 的乘积。以下是迭代的 Python 实现:
迭代版阶乘代码:
def factorial(n):
fact = 1 # 初始化结果
i = 1 # 计数器,从 1 开始
while i <= n:
fact *= i # 计算累积乘积
i += 1 # 计数器递增
return fact # 返回最终结果
解释:
fact:用于存储当前的乘积结果,初始值为1。i:计数器,初始值为1,每次循环递增。- 在每次循环中,
fact被更新为fact * i,计算从 1 到n的乘积。
特殊情况处理:n = 0
在上面的实现中,虽然没有特别处理 n = 0 的情况,但代码可以正确处理这一情况。当 n = 0 时,循环条件 i <= 0 为假,因此直接返回 fact = 1。这与 0! = 1 的定义一致。
递归与迭代的对比
迭代方案通过显式地维护一个变量 fact 来计算阶乘。接下来,我们将讨论如何使用递归实现相同的功能,并解释为什么递归在某些情况下是一种更优雅的解决方案。
阶乘与递归的定义
在前面,我们使用了迭代的方法来计算阶乘。接下来,我们将讨论如何通过递归实现相同的功能,并且解释为什么递归虽然看似“自我引用”,但它实际上是有效且逻辑严谨的。
阶乘的递归定义
递归是一种通过自我调用来解决问题的计算方法。递归定义通常有两个部分:
- 基准情况:最简单的情况,它不需要进一步的递归调用。例如,
0! = 1。 - 递归情况:通过对较小问题的递归调用来解决当前问题。例如,
n! = n * (n-1)!。

阶乘递归实现的代码
def factorial(n):
if n == 0:
return 1 # 基准情况:0! = 1
else:
return n * factorial(n - 1) # 递归调用:n! = n * (n-1)!
递归的解释
让我们逐步解释为什么递归定义有效,并且与迭代等效。假设我们想计算 5!,递归过程如下:
factorial(5):这一步计算5 * factorial(4),但factorial(4)还未计算出结果,因此继续递归。factorial(4):计算4 * factorial(3),继续递归。factorial(3):计算3 * factorial(2)。factorial(2):计算2 * factorial(1)。factorial(1):计算1 * factorial(0)。factorial(0):基准情况返回1。
然后,递归开始“回溯”,将计算结果逐级返回:
factorial(1) = 1 * 1 = 1factorial(2) = 2 * 1 = 2factorial(3) = 3 * 2 = 6factorial(4) = 4 * 6 = 24factorial(5) = 5 * 24 = 120
最终,factorial(5) 返回 120。
递归与迭代的比较
- 递归简洁性:递归直接反映了阶乘的数学定义,代码简洁、清晰。相较于迭代,递归更易于理解其本质。
- 状态管理:递归通过调用栈隐式管理状态,每一次递归调用都会将当前的状态(即
n的值)存储在栈帧中。而迭代通过显式的变量更新来管理状态。 - 效率与空间开销:递归虽然在概念上简洁,但它会占用更多的栈空间,尤其当
n较大时,递归深度过大可能导致栈溢出。因此,迭代在处理大规模问题时往往更高效。
递归定义的有效性
递归定义并不是“自我循环”或“无解的”。递归的关键在于,每一次递归调用都会将问题规模缩小,直到遇到基准情况为止。例如,在计算 n! 时,我们通过每次递减 n,最终递减到 0,这时递归停止并返回已知结果。
通过这种方式,递归逐步“解开”问题,最终返回正确结果。递归的强大之处在于它能够通过分解问题,简洁地解决复杂的计算问题。
递归提供了一种优雅的方式来解决问题。通过递归,我们可以将复杂问题逐步分解,直到遇到基准情况。递归的核心是它允许我们用简单的方式定义和求解看似复杂的问题,如阶乘。这种方式不仅在计算上有效,而且在概念上更接近问题的数学定义。
递归调用的顺序
递归调用中的记忆与返回
递归中的每个函数调用都会保留之前的计算上下文,直到基准情况返回结果后才开始进行计算。正如我们在 factorial(3) 中所看到的:
factorial(3)保持对3 * factorial(2)的记忆。factorial(2)保持对2 * factorial(1)的记忆。- 直到
factorial(0)返回1,我们才开始逐步计算并返回结果。
这种递归堆栈的机制使得每一层递归能够在正确的上下文中进行计算。
递归中的函数调用顺序与等待
递归的关键在于函数调用的顺序和等待返回值。在一个递归函数中,每次递归调用都必须等待下一个递归调用完成并返回结果,才能继续进行计算。因此,递归的计算过程是一个逐层深入,层层回溯的过程。
例如,在 factorial(3) 的调用中:
factorial(3)调用了factorial(2),并等待其返回。factorial(2)又调用了factorial(1),继续等待。- 直到
factorial(0)返回1后,递归才开始逐步回溯并完成所有计算。
cascade 函数的例子
为了更好地理解递归调用的顺序和回溯,让我们来看一个新的例子:cascade 函数。这个函数以一种嵌套的方式递归打印出数字。
def cascade(n):
if n < 10:
print(n) # 基准情况:直接打印 n
else:
print(n) # 先打印 n
cascade(n // 10) # 递归调用,去掉最后一位
print(n) # 再次打印 n
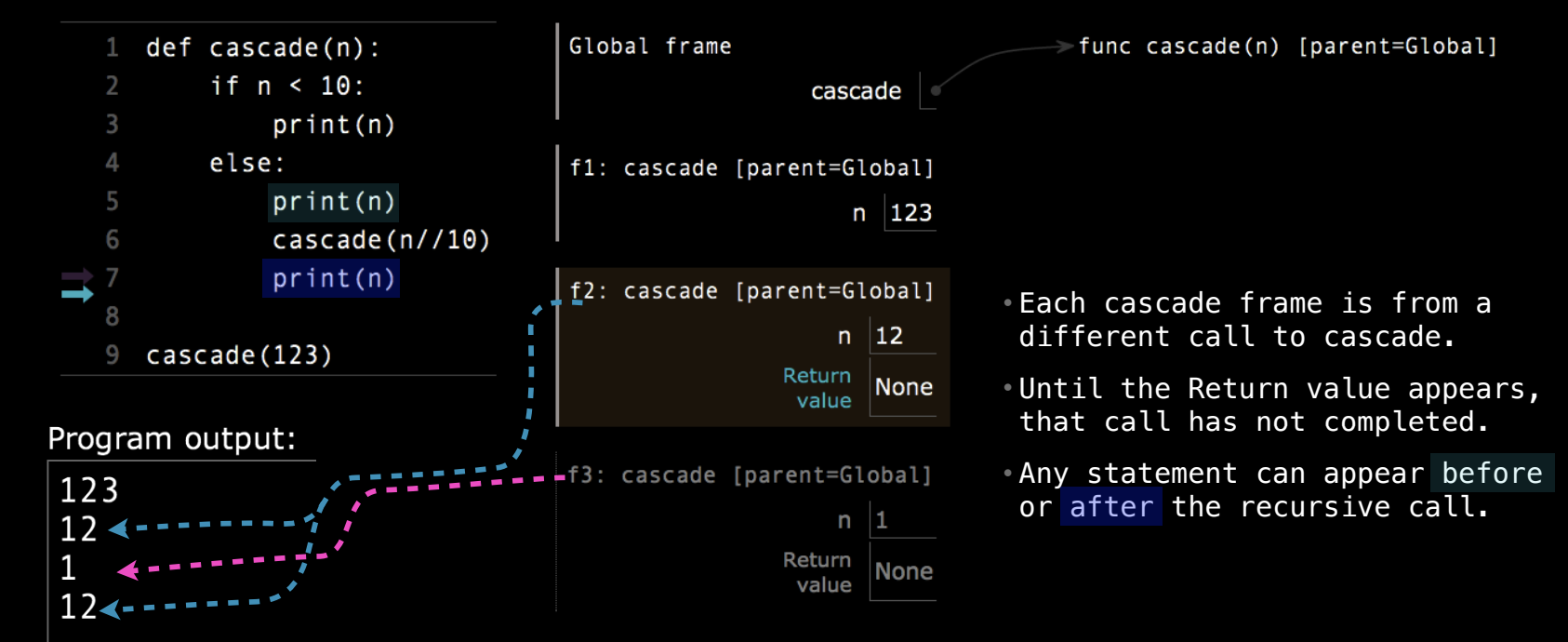
当我们调用 cascade(123) 时,递归的过程如下:
cascade(123):首先打印123,然后递归调用cascade(12)。cascade(12):打印12,再递归调用cascade(1)。cascade(1):基准情况,直接打印1。
之后,递归开始回溯,逐步完成剩下的打印操作:
cascade(12)再次打印12。cascade(123)最后打印123。
输出结果为:
123
12
1
12
123
递归返回 None 的问题
在递归调用中,如果没有显式的 return 语句,函数会自动返回 None。例如,当 cascade(12) 完成对 cascade(1) 的调用后,cascade(1) 返回 None,这意味着递归已经完成,可以继续执行 cascade(12) 剩下的部分。同样,当 cascade(123) 完成对 cascade(12) 的调用后,cascade(12) 返回 None,并继续执行 cascade(123) 的最后一步。
递归与不同的实现方式
我们还可以通过另一种更简洁的方式实现 cascade 函数:
def cascade(n):
print(n)
if n >= 10:
cascade(n // 10)
print(n)
这个版本将递归的打印操作集中在一起,减少了冗余代码。在逻辑上,与前一个版本等价,但更加简洁。

简洁与可读性
虽然简洁的代码通常更好,因为它更容易理解和维护,但在学习递归时,较长且分离基准情况和递归情况的实现可能更清晰。因此,初学者在编写递归函数时,建议明确分离基准情况和递归情况,这有助于理解递归的执行流程。
逆向级联问题
现在我们要实现一个逆向级联的函数,给定一个数字 n,依次打印出从最小到最大的递增数字,然后再递减回去。目标是打印以下格式的数字:
1
12
123
1234
123
12
1
实现思路
我们可以使用 grow 和 shrink 函数来分别实现递增和递减的打印操作,通过递归实现逆向级联。
def inverse_cascade(n):
grow(n)
print(n)
shrink(n)
def grow(n):
if n >= 10:
grow(n // 10)
print(n)
def shrink(n):
print(n)
if n >= 10:
shrink(n // 10)
grow(n):递归地从小到大打印数字。通过grow(n // 10)逐步缩小数字,直到基准情况,然后开始回溯打印。shrink(n):递归地从大到小打印数字。先打印当前数字,再调用shrink(n // 10)。
通过这种方式,我们得到了逆向级联的效果。
Inverse Cascade 函数 高阶函数
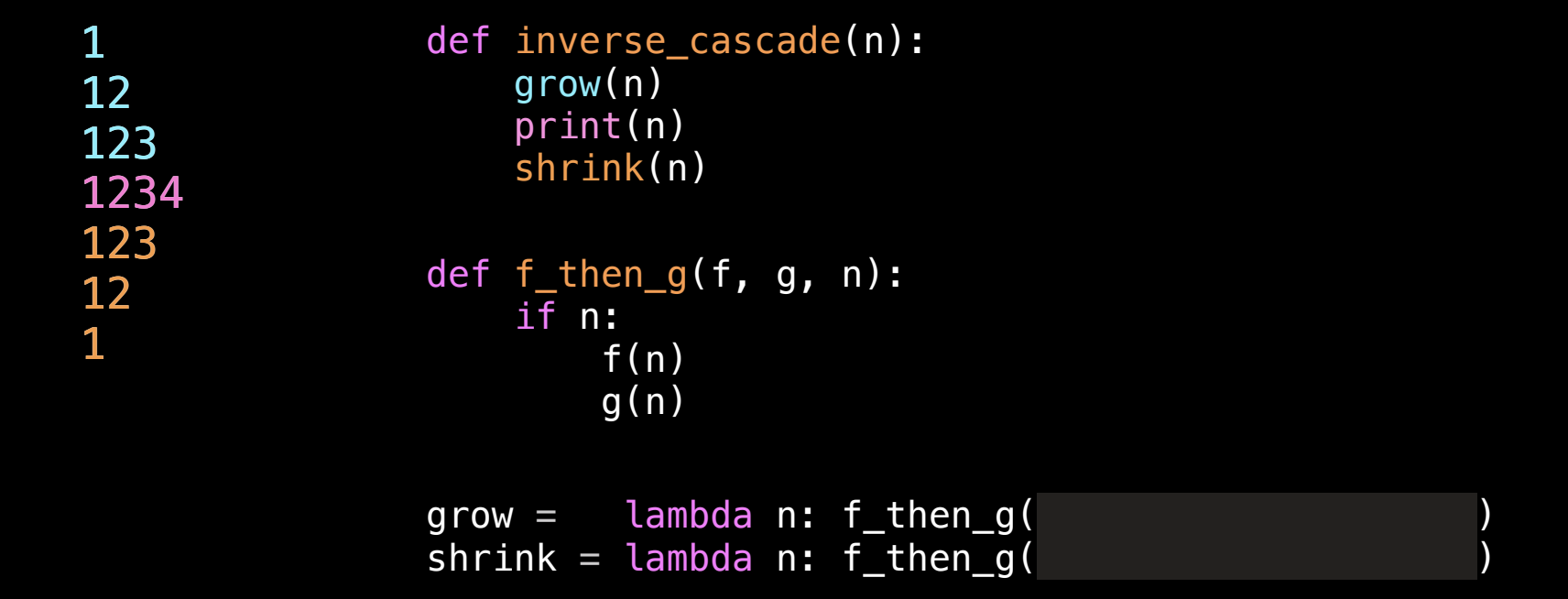
1. 主函数 inverse_cascade(n)
该函数的核心是通过递归的方式,逐步“增长”(grow)数字,然后打印出完整的数字 n,最后递归地“减少”(shrink)数字。
def inverse_cascade(n):
grow(n)
print(n) # 打印完整的数字 n
shrink(n)
在 inverse_cascade 中:
grow(n):负责递增打印数字。shrink(n):负责递减打印数字。- 中间的
print(n):用于打印当前的数字n。
2. 辅助函数 f_then_g(f, g, n)
这是一个高阶函数,它接受两个函数 f 和 g,以及一个数字 n。其作用是:如果 n 不为零,先调用函数 f(n),再调用函数 g(n)。
def f_then_g(f, g, n):
if n:
f(n)
g(n)
f_then_g 是通过递归调用 f 和 g 来实现数字的递增和递减。
3. 递增和递减函数的定义
通过 lambda 表达式,我们定义了 grow 和 shrink 函数,这两个函数都是基于 f_then_g 实现的。
grow = lambda n: f_then_g(grow, print, n//10)
shrink = lambda n: f_then_g(print, shrink, n//10)
grow 函数
- 作用:逐步递增打印数字,直至
n。 n//10:表示将数字逐步“缩小”一位,例如,1234变为123,依此类推。- 逻辑:
f_then_g(grow, print, n//10)表示递归调用grow(n//10)直到最小数字,然后打印数字n。
shrink 函数
- 作用:在打印了
n后,逐步递减打印,返回到最小值。 - 逻辑:
f_then_g(print, shrink, n//10)先打印n,然后递归调用shrink(n//10),从而实现递减效果。
代码执行流程
以 n = 1234 为例,函数的执行顺序如下:
grow(1234):递增到最小值,打印如下:1 12 123print(1234):打印中间的最大值1234。shrink(1234):递减返回最小值,打印如下:123 12 1
最终输出结果为:
1
12
123
1234
123
12
1
树形递归
递归函数不仅可以进行一次递归调用,还可以进行多次递归调用。这就引出了树形递归的概念。在树形递归中,一个函数的执行会产生多个递归调用,生成一个树状的递归结构。
树形递归的例子
例如,计算斐波那契数列的递归函数:
def fib(n):
if n == 0 or n == 1:
return n
else:
return fib(n - 1) + fib(n - 2)
在这个函数中,fib(n) 同时调用 fib(n-1) 和 fib(n-2),形成了树形递归结构。随着 n 的增加,递归调用次数成倍增长,因此树形递归的效率较低。
斐波那契数列
斐波那契数列的定义如下:
- 第 0 个斐波那契数是 0,记为 F(0) = 0。
- 第 1 个斐波那契数是 1,记为 F(1) = 1。
- 对于 n ≥ 2,F(n) = F(n-1) + F(n-2)。
所以,斐波那契数列从零开始:
F(0) = 0, F(1) = 1, F(2) = 1, F(3) = 2, F(4) = 3, F(5) = 5,
F(6) = 8, F(7) = 13, F(8) = 21, F(9) = 34, F(10) = 55, ...
树形递归计算斐波那契数
斐波那契数列的计算可以用树形递归实现。代码如下:
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n - 1) + fib(n - 2)
在这个实现中:
- 当
n = 0或n = 1时,直接返回已知的结果(基准情况)。 - 当
n > 1时,通过递归调用fib(n-1)和fib(n-2),计算前两个斐波那契数之和。
这是树形递归,因为每次递归调用 fib(n) 都会进一步调用 fib(n-1) 和 fib(n-2),形成树状的递归调用结构。
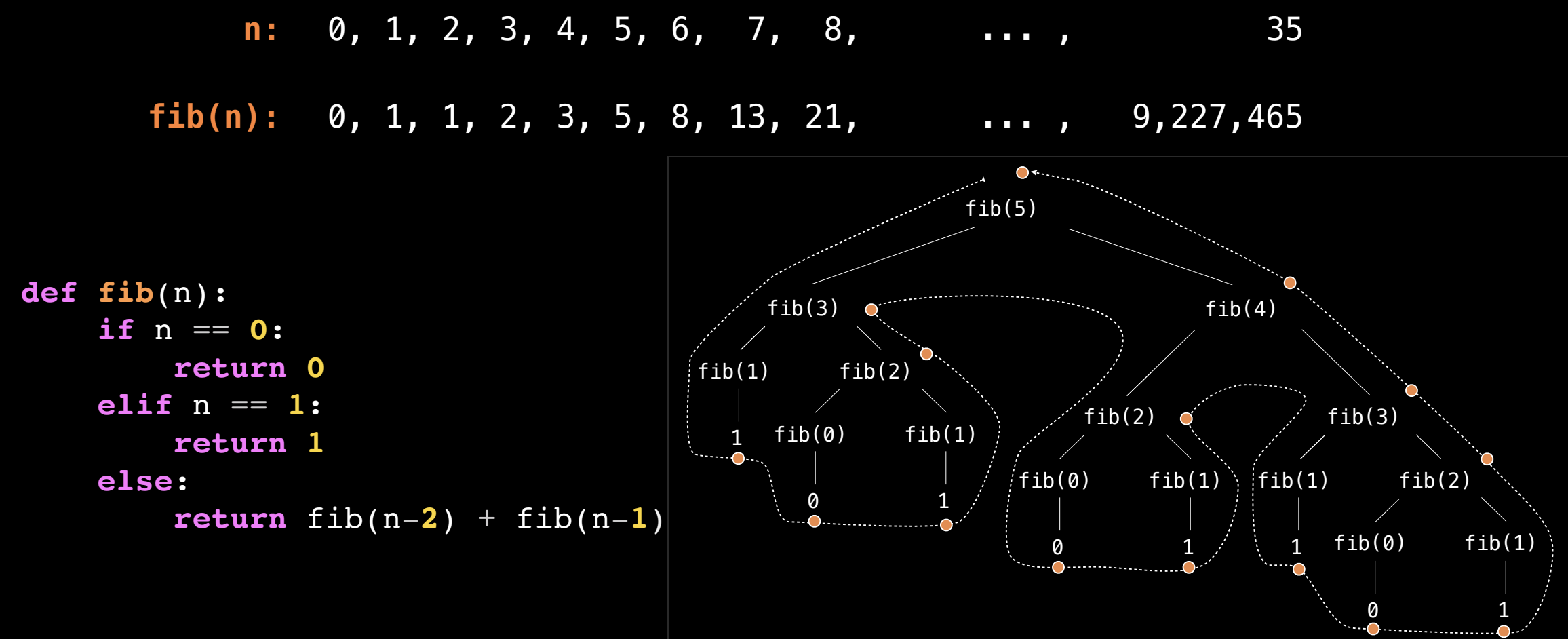
计算过程
例如,计算 fib(5) 时,调用过程如下:
fib(5)
│
├─ fib(4)
│ ├─ fib(3)
│ │ ├─ fib(2)
│ │ │ ├─ fib(1) = 1
│ │ │ └─ fib(0) = 0
│ │ ├─ fib(2) 返回 1
│ │ └─ fib(1) = 1
│ └─ fib(3) 返回 2
│ ├─ fib(2)
│ │ ├─ fib(1) = 1
│ │ └─ fib(0) = 0
│ └─ fib(2) 返回 1
├─ fib(4) 返回 3
├─ fib(3)
│ ├─ fib(2)
│ │ ├─ fib(1) = 1
│ │ └─ fib(0) = 0
│ ├─ fib(2) 返回 1
│ └─ fib(1) = 1
├─ fib(3) 返回 2
│
fib(5) 返回 5
fib(5)调用fib(4)和fib(3)。fib(4)再调用fib(3)和fib(2),依次递归下去,直到基准情况。
整个计算过程构成一棵递归调用的树,根节点是 fib(5),每个节点依次展开调用前两个斐波那契数。
树形递归的效率问题
虽然树形递归可以正确计算斐波那契数,但它的效率非常低。原因在于,树形递归中许多计算是重复的。例如,在计算 fib(5) 时,fib(3) 被计算了两次,fib(2) 也被计算了多次。
由于递归调用次数随着 n 的增加呈指数增长,所以当 n 较大时,这种实现方式会非常慢。例如,计算 fib(35) 时,尽管斐波那契数列的增长相对较快,但计算耗时较长。对每一个 n,函数会重复计算很多次之前已经计算过的斐波那契数。
优化树形递归:记忆化 (Memoization)
为了解决这个效率问题,可以通过记忆化(Memoization)来优化。记忆化是一种缓存技术,用于存储已经计算过的结果,避免重复计算。
实现记忆化的递归斐波那契函数如下:
def fib_memo(n, memo={}):
if n in memo:
return memo[n]
if n == 0:
result = 0
elif n == 1:
result = 1
else:
result = fib_memo(n - 1, memo) + fib_memo(n - 2, memo)
memo[n] = result
return result
memo是一个字典,用于存储已经计算过的斐波那契数。- 每次递归调用前,检查
n是否已经在memo中,如果在,直接返回结果;否则,继续递归计算并将结果存入memo。
这样一来,每个斐波那契数只会计算一次,极大提高了效率。
树形递归是递归的一种形式,它通过多次递归调用形成树状结构。斐波那契数列的递归计算是树形递归的经典例子,但由于大量的重复计算,效率较低。通过记忆化等技术可以优化递归函数,使其性能显著提升。在实际编程中,根据问题的特点选择合适的递归实现方式和优化技术至关重要。
Example: Towers of Hanoi 汉诺塔问题
我们在前面介绍了递归的概念,并通过 Fibonacci 数列和其他例子展示了树形递归的执行过程。接下来,我们将讨论另一个经典的递归问题:汉诺塔问题(Towers of Hanoi)。
汉诺塔问题简介
汉诺塔问题是一个非常著名的递归问题。游戏的规则很简单:
- 你有三个柱子和若干个大小不一的圆盘,这些圆盘最初按照从大到小的顺序堆叠在第一个柱子上,形成一个塔状结构。
- 你的目标是将整个塔从第一个柱子移动到第三个柱子。
- 每次只能移动一个圆盘,并且在任何时候都不能将较大的圆盘放在较小的圆盘上。
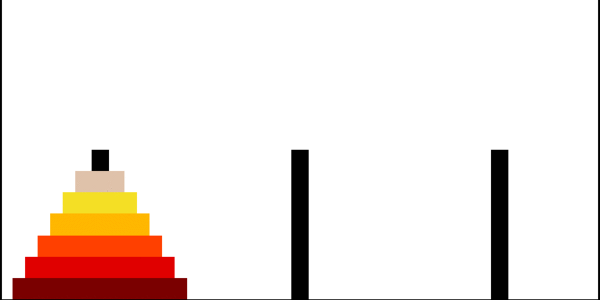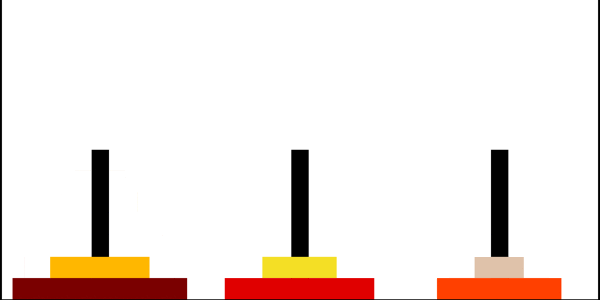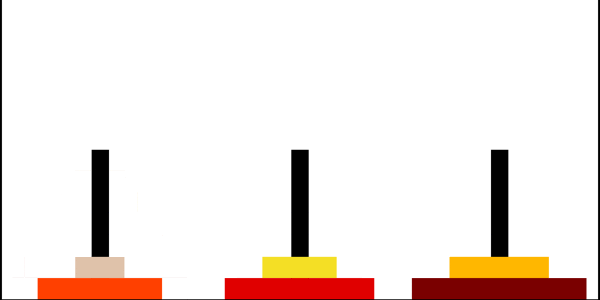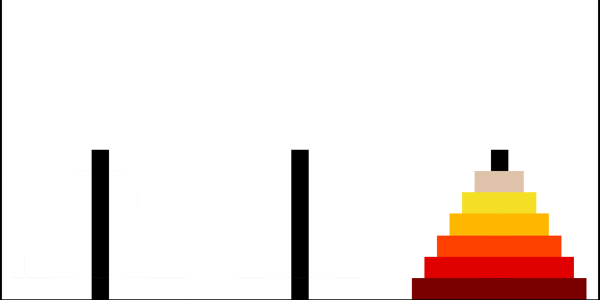
汉诺塔问题的递归解法
递归解决汉诺塔问题非常自然,以下是解决步骤:
- 将
n-1个圆盘从第一个柱子移动到第二个柱子。 - 将第
n个(即最大的)圆盘从第一个柱子移动到第三个柱子。 - 最后,将之前的
n-1个圆盘从第二个柱子移动到第三个柱子。
通过这种递归分解,我们可以将一个复杂的问题分解为多个相对简单的子问题。对于基本情况,当只有一个圆盘时,直接将圆盘从起始柱子移动到目标柱子即可。
汉诺塔问题的递归 Python 实现
在递归调用中,每个调用都是对更简单问题的求解。具体地说,若我们要移动 n 个盘子从起始柱子到目标柱子,我们需要做三件事:
- 递归地将
n-1个盘子从起始柱子移动到辅助柱子。 - 将第
n个盘子从起始柱子移动到目标柱子。 - 递归地将
n-1个盘子从辅助柱子移动到目标柱子。
代码实现:
def hanoi(n, source, target, auxiliary):
if n == 1:
print(f"Move disk 1 from {source} to {target}")
else:
hanoi(n - 1, source, auxiliary, target) # 第一步:将 n-1 个盘子移动到辅助柱子
print(f"Move disk {n} from {source} to {target}") # 第二步:移动第 n 个盘子到目标柱子
hanoi(n - 1, auxiliary, target, source) # 第三步:将 n-1 个盘子从辅助柱子移动到目标柱子
案例分析:三层汉诺塔
假设我们有 3 个盘子,起始柱子是 1,目标柱子是 3,辅助柱子是 2。我们希望将 3 个盘子从柱子 1 移动到柱子 3:
-
首先,我们递归调用
hanoi(2, 1, 2, 3),这是将前两个盘子从 1 移动到辅助柱子 2。- 再次递归调用
hanoi(1, 1, 3, 2),将盘子 1 从 1 移动到 3(这是基础情况,直接打印)。 - 然后移动盘子 2 从 1 到 2。
- 之后,递归调用
hanoi(1, 3, 2, 1),将盘子 1 从 3 移动到 2。
此时,前两个盘子已经从起始柱子 1 移动到了辅助柱子 2。
- 再次递归调用
-
现在,我们移动盘子 3(最大的盘子)从 1 到目标柱子 3。
-
接着,递归调用
hanoi(2, 2, 3, 1),将两个盘子从辅助柱子 2 移动到目标柱子 3。- 递归调用
hanoi(1, 2, 1, 3),将盘子 1 从 2 移动到 1。 - 然后移动盘子 2 从 2 到 3。
- 最后,递归调用
hanoi(1, 1, 3, 2),将盘子 1 从 1 移动到 3。
- 递归调用
整个过程完成。
核心思想是递归切换柱子,或者说函数参数的位置。具体来说,汉诺塔问题的核心在于如何通过不断递归,将盘子从一个柱子有序地移动到另一个柱子,且在移动过程中始终满足以下两个规则:
- 每次只能移动一个盘子。
- 在任何时刻,较大的盘子不能放在较小的盘子上。
函数参数的位置决定了每次递归调用中的盘子从哪儿移动到哪儿,以及使用哪个柱子作为辅助柱子。
切换柱子的核心步骤
第一步:将 n-1 个盘子从起始柱子 source 移动到辅助柱子 auxiliary,此时目标柱子 target 作为辅助柱子使用。
递归调用:hanoi(n-1, source, auxiliary, target)
在这一步,起始柱子 source 保持不变,目标柱子 target 被当作辅助柱子,而辅助柱子 auxiliary 变成新的目标柱子。
第二步:将第 n 个盘子从 source 移动到 target,这是一个直接的移动操作。
打印输出:Move disk {n} from {source} to {target}
第三步:将 n-1 个盘子从辅助柱子 auxiliary 移动到目标柱子 target,此时起始柱子 source 作为辅助柱子。
递归调用:hanoi(n-1, auxiliary, target, source)
在这一步,辅助柱子 auxiliary 变成了新的起始柱子,目标柱子 target 保持不变,而原先的起始柱子 source 被当作新的辅助柱子。
起始柱子和目标柱子之间不断切换,同时每次都利用辅助柱子来过渡。每个递归调用本质上都是在不同的柱子之间切换,按照规则有序地移动盘子,直到所有盘子都成功移动到目标柱子。
换句话说,汉诺塔的解决方案就是利用递归的分解与切换,逐步将问题简化为可以处理的子问题,从而完成复杂的整体任务。
递归调用的效率分析
递归带来的问题之一是计算量的指数增长。每次添加一个盘子,所需的步骤数量几乎翻倍,这是因为:
- 每增加一个盘子,涉及到的递归调用数量也随之增加。
- 为了移动
n个盘子,递归调用必须两次处理n-1个盘子的移动。
这种递归模式的复杂度是 指数级的。通过观察:
- 移动 1 个盘子只需 1 步;
- 移动 2 个盘子需要 3 步;
- 移动 3 个盘子需要 7 步;
- 移动 4 个盘子需要 15 步;
- 移动 5 个盘子需要 31 步; 可以看出步骤数每次大约翻倍。这种指数增长在数学上可以表示为:移动
n个盘子的最小步骤数是2^n - 1。
指数增长的影响
这种指数增长在计算中非常昂贵,尤其当盘子的数量增加时。比如,对于 64 个盘子的汉诺塔问题,所需的移动次数是 2^64 - 1,这显然是一个巨大的数字,几乎不可能在现实中处理。因此,递归虽然能够提供一个简单优雅的解法,但在这种场景下,其效率并不理想。
指数增长 是计算中一个非常重要的概念,它告诉我们算法的增长速度以及其可扩展性。在某些安全应用场景下,比如密码学中,指数增长是我们所期望的,因为它能提供足够的计算难度来保护系统不被暴力破解。然而,在实际问题求解中,指数增长往往是我们需要避免的,因为它会导致计算时间和资源的急剧增加。
递归与迭代的权衡
递归并不是解决所有问题的唯一方式。在设计算法时,我们应该权衡递归与迭代的使用。递归能够简化问题的分解,并提供优雅的解法,但它的效率有时会受到限制。在有些情况下,迭代方法可能更高效,尤其当问题规模较大时。
在汉诺塔问题中,递归展示了其优雅之处,我们通过简单的递归调用解决了一个复杂的多步问题。然而,伴随递归的还有性能上的代价。这提醒我们在设计和选择算法时,既要考虑解法的简洁性,也要考虑算法的效率和适用场景。
递归的启示
- 递归的威力:递归能够通过分解问题,逐步解决复杂问题。汉诺塔问题展示了递归的强大和优雅。
- 计算复杂度:递归往往伴随复杂度的增长。在汉诺塔问题中,递归的计算复杂度呈现指数级增长。
- 设计决策:递归并非适用于所有场景。设计解决方案时,应根据具体问题选择合适的方法。
通过汉诺塔问题,我们不仅看到了递归的强大,还引出了算法复杂度的重要性。在实际编程中,递归和迭代各有优劣,如何选择取决于具体问题。未来,在学习更复杂的算法和数据结构时,递归和复杂度分析将更加频繁地出现,帮助我们设计出更高效的解决方案。
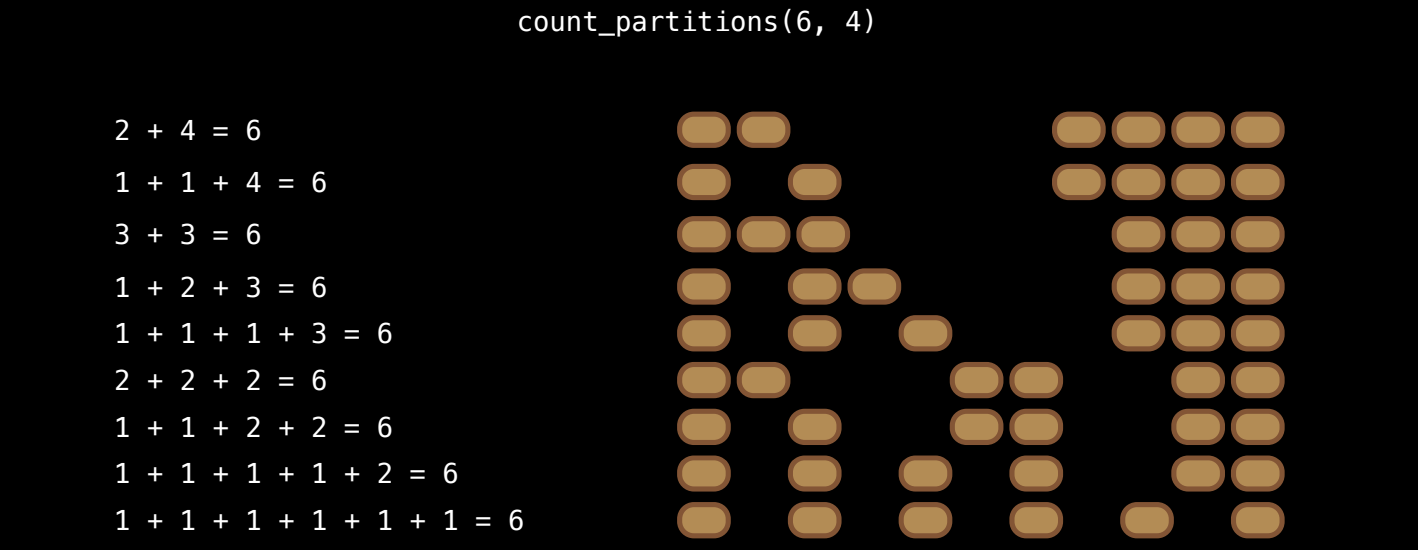
Example: Counting Partitions 分区计数问题
在递归概念的延续下,我们引入了 分区计数问题(Counting Partitions)。这个问题展示了递归如何帮助解决复杂的组合问题,并且是递归在某些情况下比迭代更优雅和有效的一个具体例子。
分区计数问题的定义
对于一个正整数 n 和一个最大部分 m,问题要求计算所有可能的方式将 n 分解为多个部分,并且每个部分的大小不能超过 m,且分解后的部分要按非递减顺序排列。
例如:
- 对于
n = 6和m = 4,分区的方式有:2 + 41 + 1 + 41 + 2 + 33 + 3- 等等……
这样一共有 9 种不同的分区方式。
递归解法的思想
为了计算 count_partitions(n, m),可以通过递归将问题简化。核心是将问题分解为两个互斥的子问题:
- 包含至少一个
m的分区:这种情况下,我们可以将问题转化为计算count_partitions(n - m, m),即计算n - m的分区数量,使用的最大部分仍为m。 - 不包含
m的分区:这种情况下,我们计算的是count_partitions(n, m - 1),即不使用m,只使用最大为m - 1的部分。
递归的思路
递归的核心在于:
- 如果我们使用了一个
m,那么问题就变成了如何将剩下的n - m进行分区。 - 如果我们不使用
m,问题就变成如何将n仅用最大部分为m - 1的数字进行分区。
通过这两种递归调用,最终我们会得到问题的解。这个递归解法是树形递归的一个典型例子,其中每个递归调用会引发两个进一步的递归调用,类似于一棵二叉树逐层展开。
代码实现
我们可以使用 Python 实现这个递归的分区计数算法:
def count_partitions(n, m):
# 基本情况
if n == 0:
return 1 # 找到一个有效分区
elif n < 0 or m == 0:
return 0 # 无效分区
# 递归调用:包含 m 或不包含 m
return count_partitions(n - m, m) + count_partitions(n, m - 1)
代码解析
- 当
n == 0时,表示我们已经找到了一种有效的分区方式,因此返回1。 - 如果
n < 0或者m == 0,表示当前分区不可能,因此返回0。 - 递归的核心是分别处理“包含
m”和“不包含m”的两种情况,最终将这两部分的结果相加,得到总的分区数量。
分区计数的计算流程
假设我们需要计算 count_partitions(n, m),即将数字 n 使用不大于 m 的部分进行分区。我们将问题分解为两个互斥的子问题:
- 包含至少一个大小为
m的部分:这意味着我们将问题简化为count_partitions(n - m, m),即计算剩余部分n - m的分区,允许使用的部分仍为大小不超过m。 - 不包含大小为
m的部分:我们将问题转化为count_partitions(n, m - 1),即不使用大小为m的部分,仅使用大小不超过m - 1的部分进行分区。
这两个子问题涵盖了所有可能的分区情况,因此可以通过将它们的结果相加,得到最终的答案。
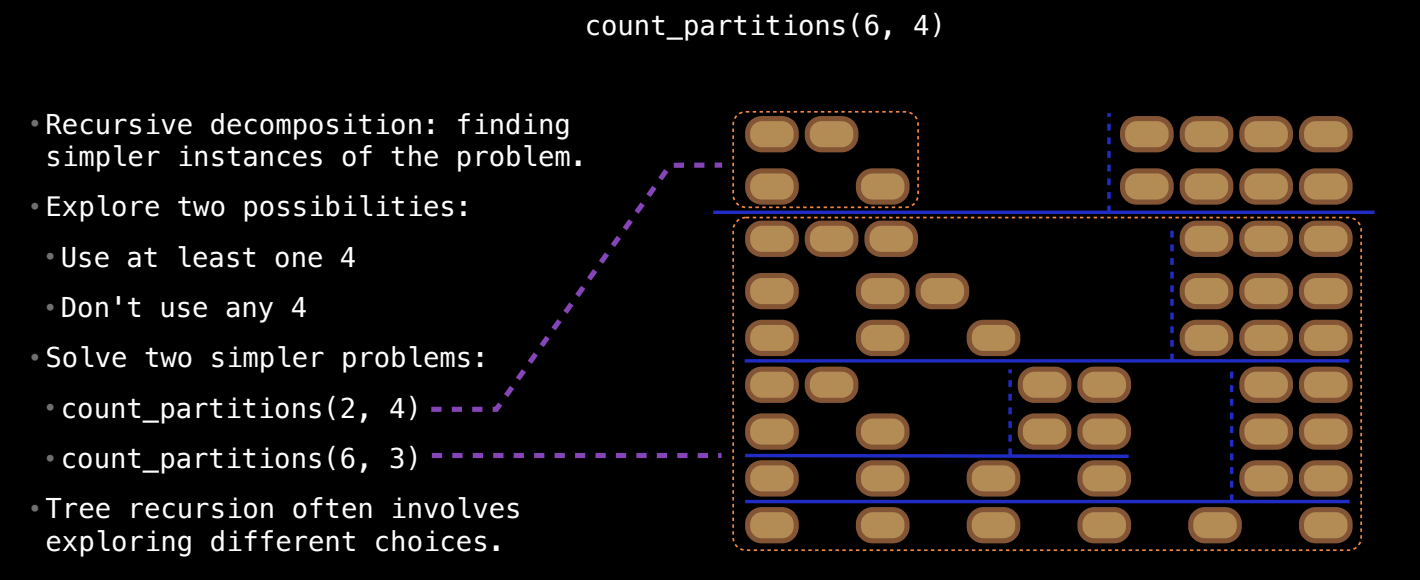
递归的分解过程
例如,计算 count_partitions(6, 4):
- 包含至少一个
4的分区,问题转化为count_partitions(2, 4)。 - 不包含
4的分区,问题转化为count_partitions(6, 3)。
然后递归地解决这些子问题,直到达到基本情况。
代码实现
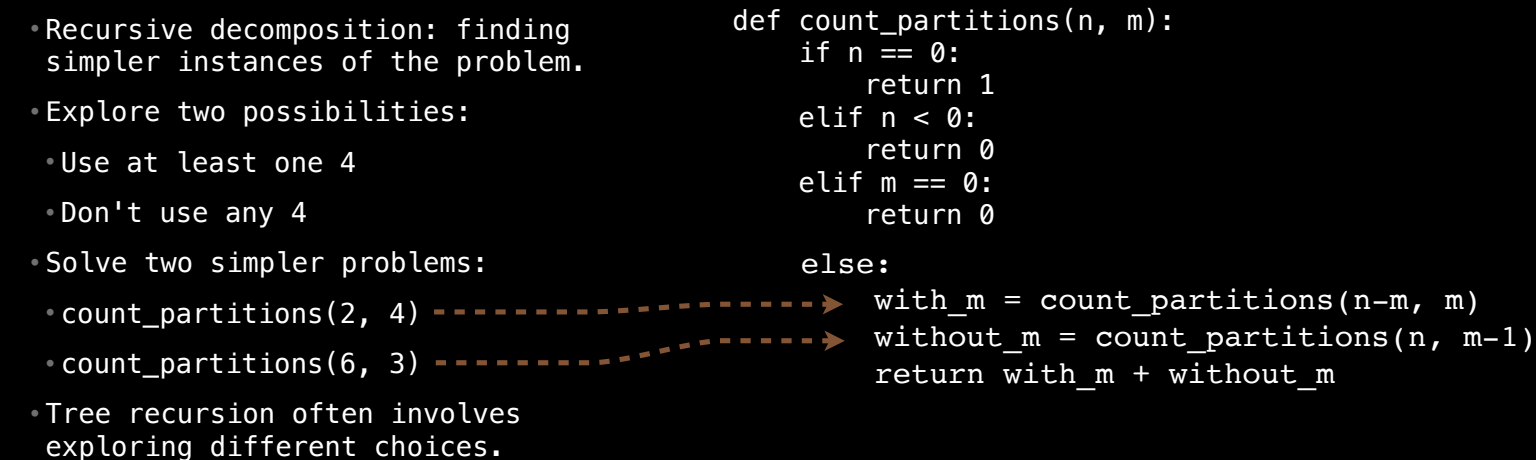
以下是 Python 中的递归实现:
def count_partitions(n, m):
# 基本情况:n 为 0 时,只有一种方式,即不添加任何部分
if n == 0:
return 1
# 基本情况:n 小于 0 或 m 为 0 时,没有有效的分区方式
elif n < 0 or m == 0:
return 0
else:
# 递归调用:包含 m 和 不包含 m 的两种情况
return count_partitions(n - m, m) + count_partitions(n, m - 1)
n == 0:表示我们找到了一个有效的分区方式,即不再添加部分。n < 0或m == 0:表示无效分区,例如,无法将负数进行分区,或者没有可用的部分时无法分区。
测试代码
让我们通过一些实例来测试这个递归函数:
print(count_partitions(6, 4)) # 输出 9
print(count_partitions(5, 3)) # 输出 5
在 count_partitions(5, 3) 中,递归过程如下:
- 包含
3的分区:问题转化为count_partitions(2, 3)。- 计算
count_partitions(2, 3):- 包含
3的情况:count_partitions(-1, 3),无效,返回0。 - 不包含
3的情况:count_partitions(2, 2),返回2(1+1和2)。
- 包含
- 计算
- 不包含
3的分区:问题转化为count_partitions(5, 2)。- 计算
count_partitions(5, 2):- 包含
2的情况:count_partitions(3, 2),返回2(1+1+1和1+2)。 - 不包含
2的情况:count_partitions(5, 1),返回1(1+1+1+1+1)。
- 包含
- 计算
最终结果为 2 + 3 = 5。
递归的优势与总结
- 递归是一种强大的技术,尤其在解决组合问题时,它可以帮助系统地探索所有可能的选择。
- 分区计数问题展示了递归如何简化复杂问题,通过递归地将问题分解为更小的子问题来找到最终解。
- 尽管递归有时效率较低,但它提供了一种简洁优雅的解法,尤其适用于处理像分区计数这样的组合问题。
通过这个问题,我们能够更深入地理解树形递归的工作原理,并且学会如何通过递归来解决复杂的分区问题。