Lecture 15. Mutable Values
Announcements
- 项目截止日期:猫科项目(Cats Project)将在星期五截止,今天(星期四)提交整个项目可以获得额外的加分。
- 作业发布:第三次作业将在星期五发布,截止日期是下周四。
- 学术指导预约:可以在星期五、星期六和星期一预约学术指导,这些预约只提供学术咨询,不包括作业或项目帮助。
- 办公室时间排队问题:近期,办公室时间的排队时间较长。可以通过 Piazza 私密帖子提问,虽然不会立即得到回复,但我们会尽快解答。此外,学生之间也可以通过讨论组讨论代码和问题,但请注意不能与尚未完成问题的同学分享完整代码。
对象与可变性
今天,我们将介绍一个非常重要的编程概念——可变性(Mutation)。这是课程中首次涉及值的变化。可变性是面向对象编程(Object-Oriented Programming,OOP)的核心之一。
对象 Objects
对象的基本概念
在软件工程中,对象(Object)是一个行为像其所表示值的实体。对象可以通过其属性(Attribute)和方法(Method)来表现行为。
示例:在 Python 中,我们可以使用 datetime 模块来处理日期和时间。
from datetime import date
today = date(2024, 9, 14) # 创建一个日期对象
freedom = date(2025, 6, 15) # 创建另一个日期对象
在这里,date 是一个类,我们通过调用类创建了具体的实例(对象)。
对象的行为
对象通过其属性和方法来表现行为。例如,我们可以通过点表达式(dot expression)访问日期对象的属性,例如年、月和日。
today.year # 获取年份
today.month # 获取月份
这些属性告诉我们这个日期的年份和月份,且点表达式也可以用来访问对象的方法。
方法示例
对象的方法是绑定到对象的函数。我们可以调用日期对象的 strftime 方法来将日期格式化为字符串。
today.strftime('%A %B %d')
# 输出: 'Saturday September 14'
这里,%A 对应星期几,%B 对应月份名称,%d 对应日期数字。通过这种方式,我们可以灵活地将日期对象转换为所需的字符串格式。
对象和类的概念
在面向对象编程中,对象 是用于组织和管理复杂程序的一种重要抽象。对象不仅可以表示事物,还可以表示事物的属性、交互或过程。每个对象都具有属性 和方法,可以对其进行操作。
- 类(Class):对象的类型称为类。类是 Python 中的一等公民,可以作为参数传递给函数。
- 对象与方法:每个对象都可以通过点表达式访问其属性或方法。例如,日期对象
today可以通过today.year访问其年份,today.strftime()格式化日期为字符串。
在面向对象编程中,大型程序可以被认为是多个对象的集合,这些对象通过消息传递相互通信。Python 中的每个值都是对象,包括数字和字符串。
函数与对象的区别
- 函数:通常用于执行单一任务。函数接受参数,返回值,专注于特定的操作。
- 对象:表示一个实体或概念,包含多个相关行为(方法)。例如,
date对象不仅可以代表日期,还能执行与日期相关的操作,如格式化、计算时间差等。
Example: Strings
字符串对象的示例
字符串是 Python 中的对象,因此也有自己的方法。例如:
s = "hello"
s.upper() # 返回 'HELLO'
s.lower() # 返回 'hello'
s.swapcase() # 返回 'HELLO'
这些方法都不会改变原始字符串,而是返回一个新的字符串。
ASCII 和 Unicode
在表示字符串时,Python 使用 ASCII 和 Unicode 编码。了解这两种编码对于理解字符处理非常重要。
ASCII 编码
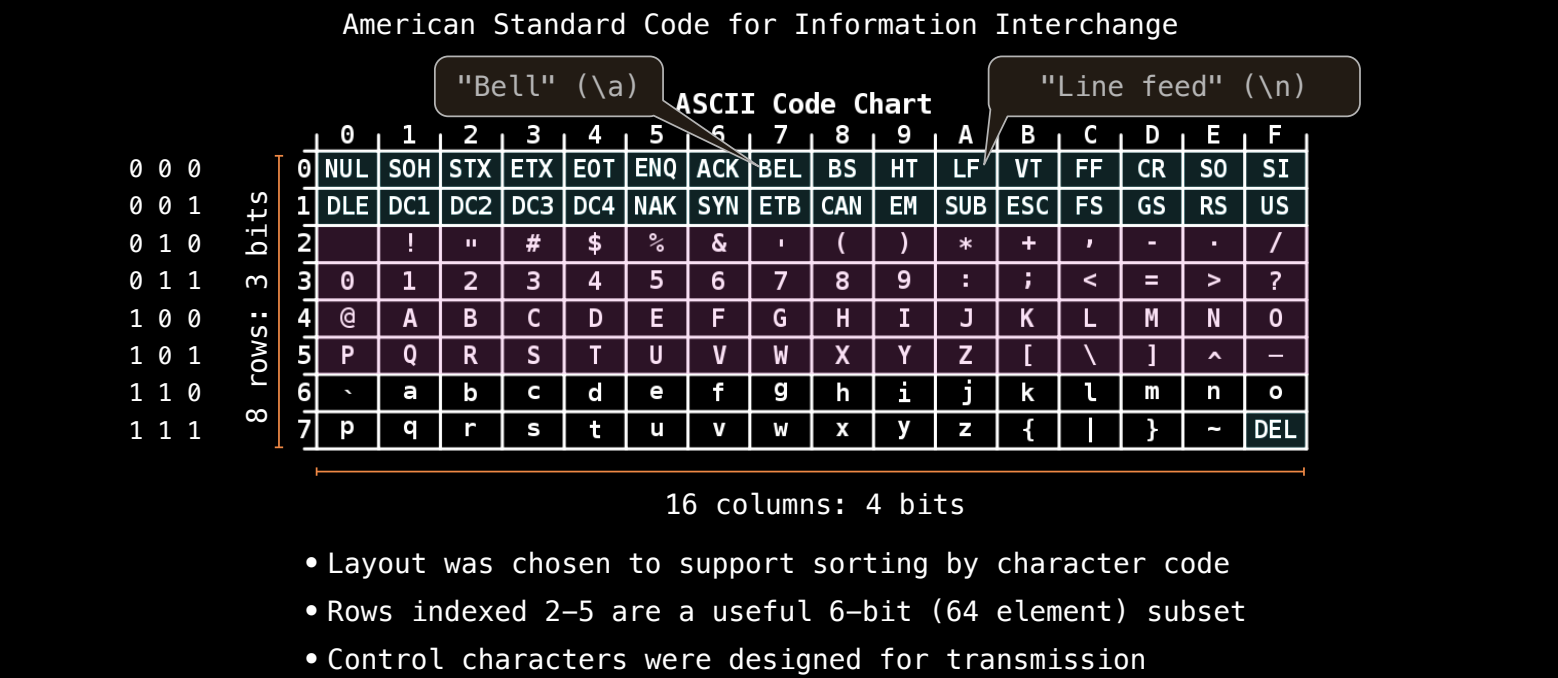
ASCII 是美国信息交换标准代码,最早用于计算机字符编码。它将字符映射为数字,分为8行和16列。每个字符都可以用数字表示。
- 示例:字母
A的 ASCII 编码是 65(十六进制是 41),可以在 ASCII 表中找到它在第4行第1列的位置。
ASCII 编码的一些控制字符在早期计算机通信中有特殊作用,例如 LF(换行)和 BEL(响铃)。
Unicode 编码
Unicode 设计用于支持全球所有语言的字符编码。Unicode 为每个字符分配一个码点(code point),以便在不同的计算机系统和编程语言中统一处理字符。
- Unicode 目前包含超过 14.9 万个字符,覆盖 159 种不同的书写系统。它不仅包括字符的编码,还支持双向显示(如英语从左到右、阿拉伯语从右到左)等特性。
你可以使用 Python 的 unicode-data 模块来查看 Unicode 字符的名称:
from unicodedata import name, lookup
name('A') # 输出 'LATIN CAPITAL LETTER A'
lookup('LATIN CAPITAL LETTER A') # 返回 'A'
Unicode 字符的多样性
在 Unicode 编码中,字符不仅包括字母和数字,还包括许多不同的图形符号,比如笑脸、雪人、足球等。这些字符在不同的操作系统和字体下可能显示不同,但它们的编码是统一的。例如:
- 笑脸😊
- 雪人☃
- 足球⚽
- 婴儿👶
不同平台上显示的符号可能会有所不同,但这些字符背后的编码和概念在不同编程语言中是一致的。通过 unicodedata 模块,可以查看字符的名称:
from unicodedata import name, lookup
name('😊') # 输出 'SMILING FACE WITH SMILING EYES'
lookup('SMILING FACE WITH SMILING EYES') # 返回 '😊'
即使符号的显示效果因平台或字体不同而变化,但它们的编码表示在计算机间是通用的。例如,字符“婴儿👶”可以被编码为一组字节。
对象的可变性(Mutation)
Python 中的对象可以变异,即对象的值可以随着时间发生变化。尤其是列表(lists)和字典(dictionaries)等可变类型,允许修改其内容,而不可变对象(如字符串、元组)一旦创建则无法更改。
列表的可变性
例如,以下操作演示了如何修改列表内容:
suits = ['coin', 'string', 'myriad']
suits.pop() # 移除并返回列表的最后一个元素,返回 'myriad'
suits.append('club') # 在列表末尾添加一个元素
suits.extend(['sword', 'cup']) # 扩展列表,添加多个元素
当你对 suits 进行修改时,绑定到同一个对象的其他变量也会反映出这些变化。这说明了对象的可变性。
字典的可变性
类似地,字典也可以修改其键值对:
numerals = {'I': 1, 'V': 5, 'X': 10}
numerals['X'] = 11 # 修改字典中键 'X' 的值
numerals['L'] = 50 # 添加新的键值对 'L': 50
numerals.pop('X') # 移除键 'X',返回 11
修改字典后,访问相同键时返回的值会发生变化,这就是字典的可变性。
共享引用与对象变异
多个变量可以指向同一个对象,当该对象发生变化时,所有变量都能反映这些变化:
list1 = [1, 2, 3]
list2 = list1
list1.append(4)
print(list2) # 输出 [1, 2, 3, 4]
lst.pop() # 移除最后一个元素,返回 4
lst.append(5) # 在列表末尾添加元素 5
在这个例子中,list1 和 list2 指向同一个列表对象,因此对 list1 的修改也会影响 list2。
如果你传递一个列表给函数,函数可以直接修改该列表的内容,因为列表是可变的。
def mystery(s):
s.pop()
s.pop()
lst = [1, 2, 3, 4]
mystery(lst)
print(lst) # 输出 [1, 2]
在这个例子中,函数 mystery 修改了传入的列表对象 lst。由于列表是可变的,函数对 s 的修改会影响到外部的 lst。
函数中的变异
函数可以改变其作用域内的任何可变对象。如果对象在全局作用域中,函数也可以直接访问并修改它。例如:
lst = [1, 2, 3, 4]
def change_global_list():
lst.pop()
lst.pop()
change_global_list()
print(lst) # 输出 [1, 2]
在这个例子中,lst 是一个全局变量,函数 change_global_list 可以直接访问和修改它。通过 pop() 函数移除了列表的最后两个元素。
Tuples
元组的不可变性
与列表和字典不同,元组(tuple)是不可变的。一旦创建,元组中的值就不能被改变:
tup = (1, 2, 3)
# tup[0] = 5 # 错误,不能修改元组中的值
元组中的值是固定的,不能被修改。这意味着你可以将元组作为字典的键,而列表不能作为字典的键,因为列表是可变的。
# 可以使用元组作为字典的键
coordinates = {(1, 2): "Point A", (3, 4): "Point B"}
虽然元组本身是不可变的,但如果元组包含可变对象(如列表),则这些可变对象仍然可以改变:
tup = (1, 2, [3, 4])
tup[2].append(5) # 可以修改元组中的列表
print(tup) # 输出 (1, 2, [3, 4, 5])
总结
- 可变对象(如列表和字典)可以在函数内被修改。
- 不可变对象(如元组和字符串)不能修改其内容,但如果元组包含可变对象,这些对象仍然可以被修改。
- 函数可以通过引用修改全局作用域中的可变对象。
对象的可变性为我们在编程中管理复杂数据结构提供了灵活性,同时也要求我们在修改对象时小心处理,以避免意外的副作用。
Python中的对象身份与变异
在编程中,理解对象的身份和变异性是至关重要的。对象不仅有值,还拥有身份,即使其值发生了改变,它仍然是同一个对象。本节课详细讨论了对象的身份与值的区别,以及变异(Mutation)如何影响对象。
对象的身份与相等性
对象可以有相同的值,但不一定具有相同的身份。理解相等性(equality)和身份(identity)的区别十分重要:
- 相等性:两个对象的值相等时,它们被认为是相等的。
- 身份:如果两个对象是同一个对象,即它们在内存中占用相同的位置,那么它们具有相同的身份。
例如:
a = [10]
b = a # a 和 b 指向同一个列表
a.append(20)
print(a) # 输出 [10, 20]
print(b) # 输出 [10, 20],b 也会发生变化,因为它与 a 是同一个对象
在这个例子中,a 和 b 都指向相同的列表对象,改变 a 也会反映在 b 上,因为它们拥有相同的身份。
相反,如果它们只是具有相同的值但不是同一个对象:
a = [10]
b = [10] # a 和 b 是不同的对象,尽管它们有相同的值
print(a == b) # True,值相等
print(a is b) # False,它们不是同一个对象
使用 is 和 == 进行身份比较

在Python中,可以使用 is 运算符来检查两个对象是否具有相同的身份,而 == 运算符用于比较两个对象的值是否相等:
x is y:如果x和y是同一个对象,则返回True。x == y:如果x和y的值相等,则返回True。
例如:
a = [10]
b = [10]
print(a is b) # False,a 和 b 是不同的对象
print(a == b) # True,a 和 b 的值相等
变异中的危险:默认参数
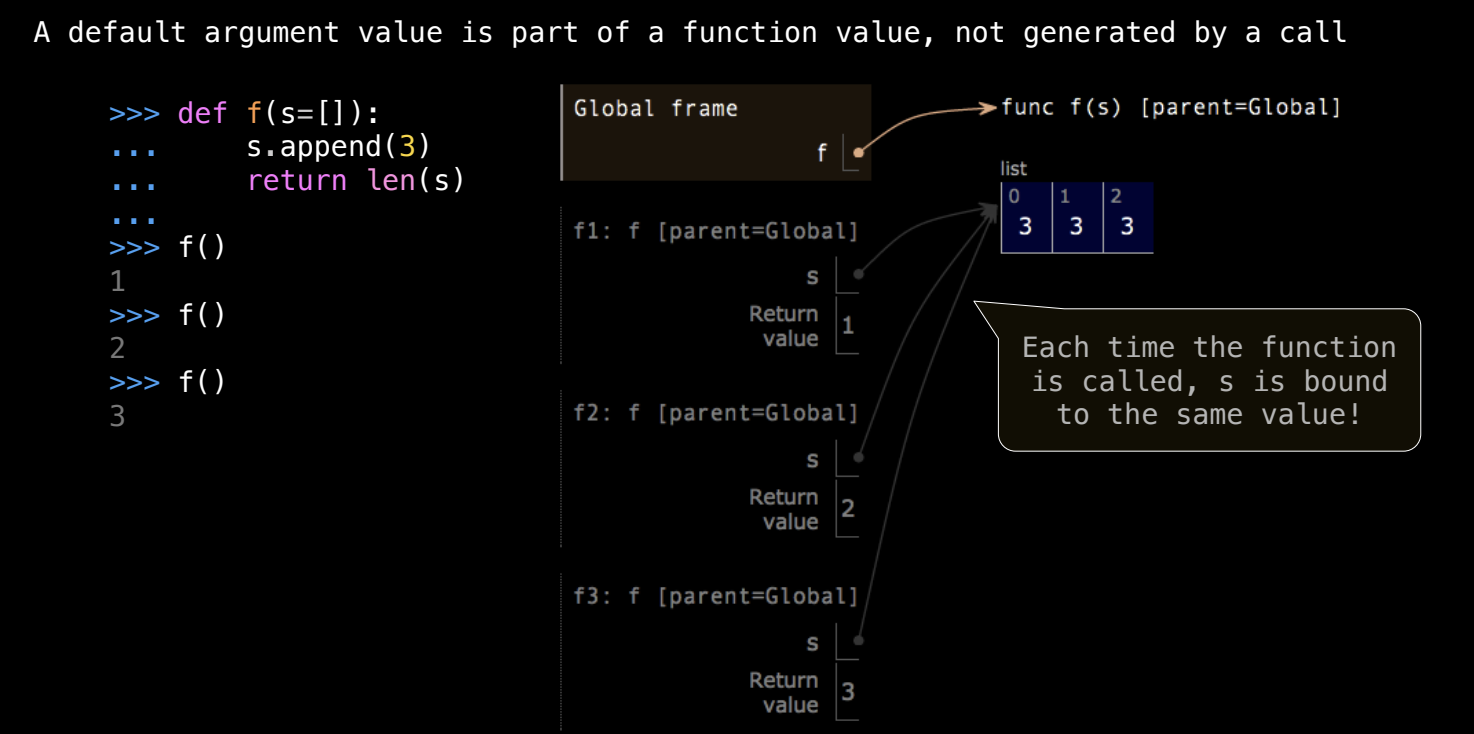
默认参数在函数定义时只被计算一次,后续函数调用如果对默认参数进行变异操作,这些变动会影响后续调用。来看一个例子:
def append_five(s=[]):
s.append(5)
return len(s)
print(append_five()) # 输出 1
print(append_five()) # 输出 2,列表 `s` 是在上次调用时修改过的同一个列表
这里,默认参数 s 是一个可变的列表对象,调用函数时对其进行了修改,修改后的列表在下次调用时依然存在。因此,避免使用可变对象作为默认参数的一种方式是使用 None 作为默认值:
def append_five(s=None):
if s is None:
s = []
s.append(5)
return len(s)
print(append_five()) # 输出 1
print(append_five()) # 输出 1
####
Lists 列表的变异操作及其效果
对象的变异可以通过环境图来跟踪。环境图帮助我们理解变量在内存中的引用关系,尤其在涉及多个变量绑定到同一对象时尤为重要。
1. append() 操作:
append() 向列表的末尾添加一个元素。
s = [2, 3]
t = [5, 6]
s.append(t)
# s = [2, 3, [5, 6]]
- 这里
append操作将整个列表t作为一个元素添加到s中。此时,s变为一个包含三个元素的列表:2,3和[5, 6]。需要注意的是,s中的最后一个元素是指向[5, 6]的引用,而不是将t本身复制进去。
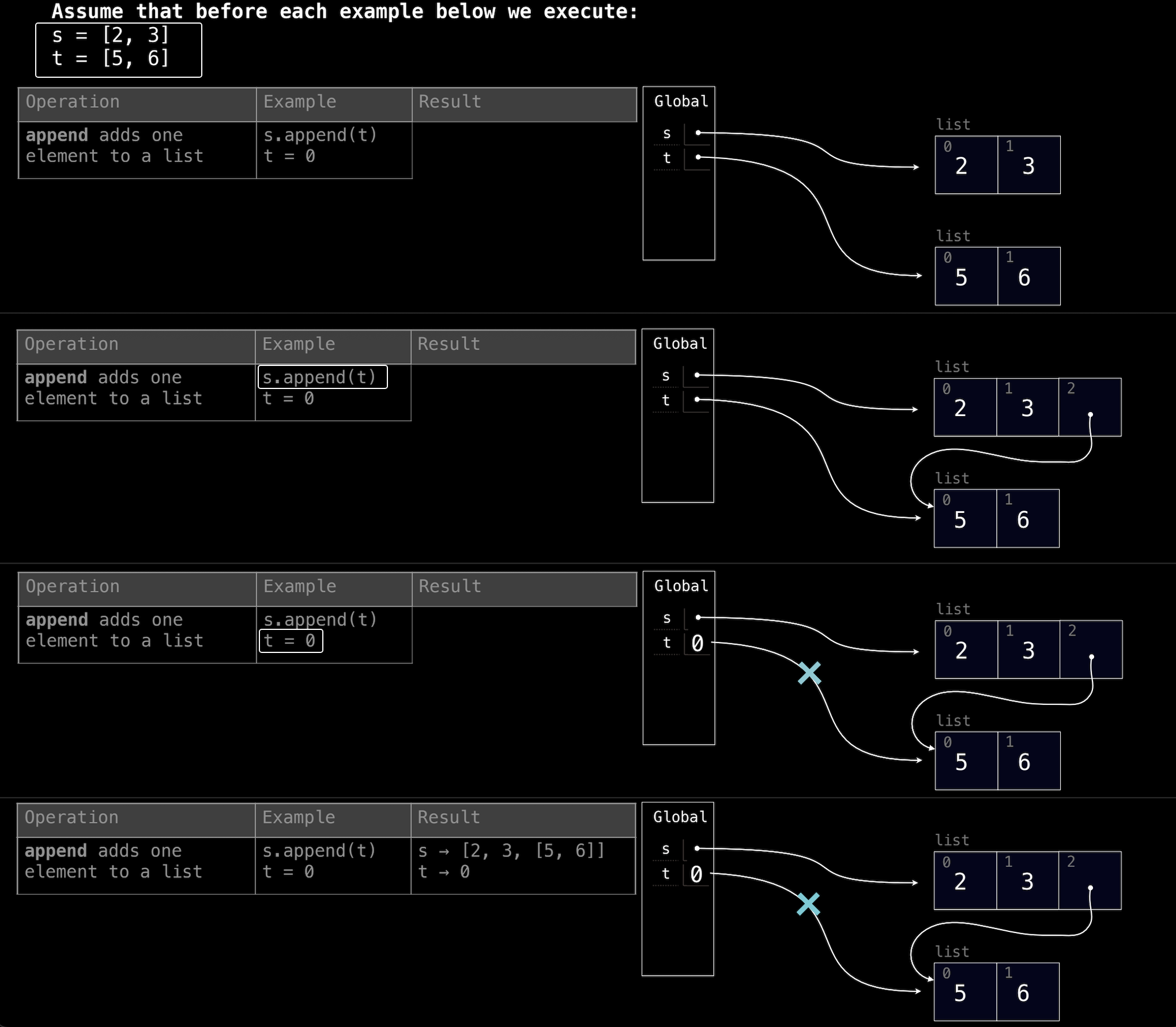
s.append(t)
t = 0
1. 初始化
最开始,代码执行前,变量 s 和 t 被赋值为两个独立的列表:
s = [2, 3]t = [5, 6]
在内存中,s 和 t 分别指向不同的列表:
s指向的列表[2, 3]有两个元素,分别在索引0和1位置。t指向的列表[5, 6]同样有两个元素,分别在索引0和1位置。
这是整个流程的初始状态,两个列表完全独立,互不影响。
2. 执行 s.append(t)
接下来执行 s.append(t) 操作。这一步将 t 作为一个整体追加到 s 中,注意这里是将 t 列表本身作为一个对象加入到 s,而不是将 t 的元素一一加入。append 操作不会复制 t,而是将其作为引用添加到 s 中,因此 s 的第三个元素是 t 的引用。
此时 s 的结构变为:
s = [2, 3, [5, 6]]
在内存中,s 的第三个元素是对 t 的引用。因此,s 现在包含了三个元素:2、3,以及一个引用列表 t 的 [5, 6]。此时 t 没有变化,仍然是 [5, 6]。
3. 执行 t = 0
现在执行 t = 0。这一步将 t 从指向列表 [5, 6] 变为指向整数 0。也就是说,t 不再引用原来的列表,而是变成了一个整数变量。
需要特别注意的是,虽然 t 的值被改变了,但由于之前 s.append(t) 是通过引用将 t 添加到 s 中的,因此 s 依然保持着对原始列表 [5, 6] 的引用。换句话说,s 的第三个元素仍然是 [5, 6],不会因为 t 的改变而发生变化。
4. 最终状态
在所有操作结束后,s 和 t 的最终状态如下:
s=[2, 3, [5, 6]]:s包含了两个整数2和3,以及t原本指向的[5, 6]列表。t=0:t已经被赋值为0,不再指向原来的列表。
这个流程展示了列表在 Python 中的引用特性:即使变量 t 的值发生变化,s 中对 t 的引用依然指向 t 原本的列表。
2. extend() 操作:
extend() 将一个列表的所有元素逐个添加到另一个列表中。
s = [2, 3]
t = [5, 6]
s.extend(t)
# s = [2, 3, 5, 6]
extend()不会像append()那样添加一个嵌套的列表,而是将t中的所有元素平铺到s的末尾。
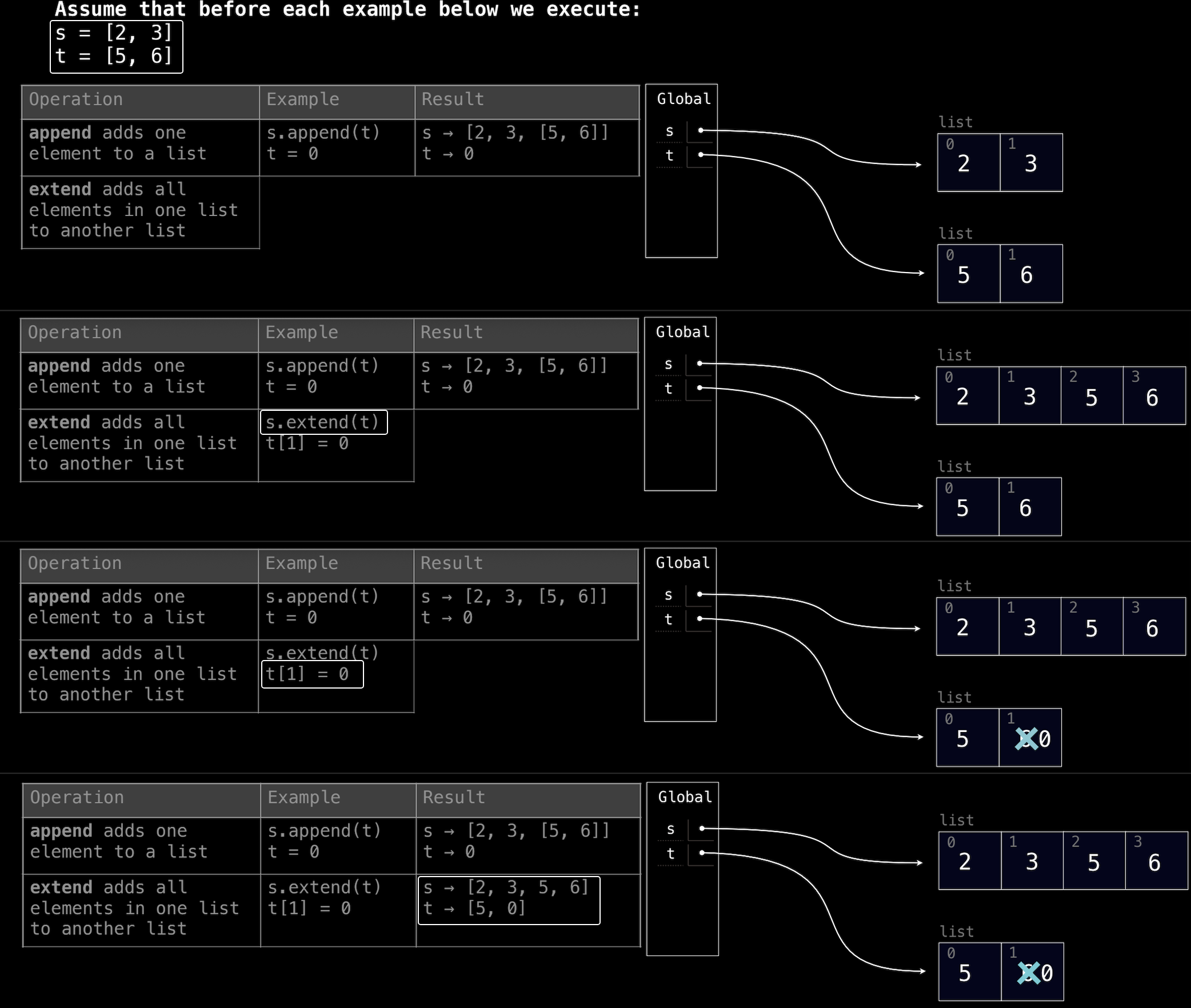
s.extend(t)
t[1] = 0
1. 初始化
在所有操作执行之前,变量 s 和 t 的初始值为:
s = [2, 3]t = [5, 6]
内存中的状态是:
s指向一个包含2和3的列表。t指向一个包含5和6的列表。
这时,s 和 t 是完全独立的两个列表。
2. 执行 s.extend(t)
接下来执行 s.extend(t) 操作。不同于 append,extend 不会将 t 作为一个整体追加到 s,而是将 t 中的每个元素逐个添加到 s 的末尾。
在这一步之后:
s的内容变为[2, 3, 5, 6]。s列表的末尾增加了t列表的两个元素5和6。t保持不变,依然是[5, 6]。
因此,s.extend(t) 操作只是将 t 中的元素展开放入 s,不会创建嵌套列表,也不会改变 t。
3. 执行 t[1] = 0
接下来,执行 t[1] = 0 操作。这一步将 t 中索引 1 的元素 6 修改为 0。
这一步的影响是:
t变为[5, 0],其中原本的6被修改为0。s不受影响,仍然是[2, 3, 5, 6]。这是因为s.extend(t)时,t的元素已经被复制到s,此后修改t不会影响s。
4. 最终状态
在所有操作结束后,s 和 t 的最终状态如下:
s = [2, 3, 5, 6]:s包含了t中的原始元素5和6,但t的后续修改不会影响到s。t = [5, 0]:t的第二个元素被修改为0。
关键点:
extend操作是将另一个列表的所有元素依次追加到目标列表中。- 在
extend之后,两个列表是完全独立的,修改t不会影响s,因为s已经复制了t的元素,而不是引用。
3. 列表相加与切片:
列表相加 (+) 会创建一个新列表,并且切片操作也会创建新列表。
s = [2, 3]
t = [5, 6]
a = s + [t]
# a = [2, 3, [5, 6]]
- 这段代码将
s和[t]相加,生成一个新列表a,其中包含s的元素以及t作为一个嵌套列表。
b = a[1:] # 切片操作
# b = [3, [5, 6]]
- 切片操作生成一个新的列表
b,它包含a从索引 1 开始的元素。b中的[5, 6]依然是对原始列表的引用。
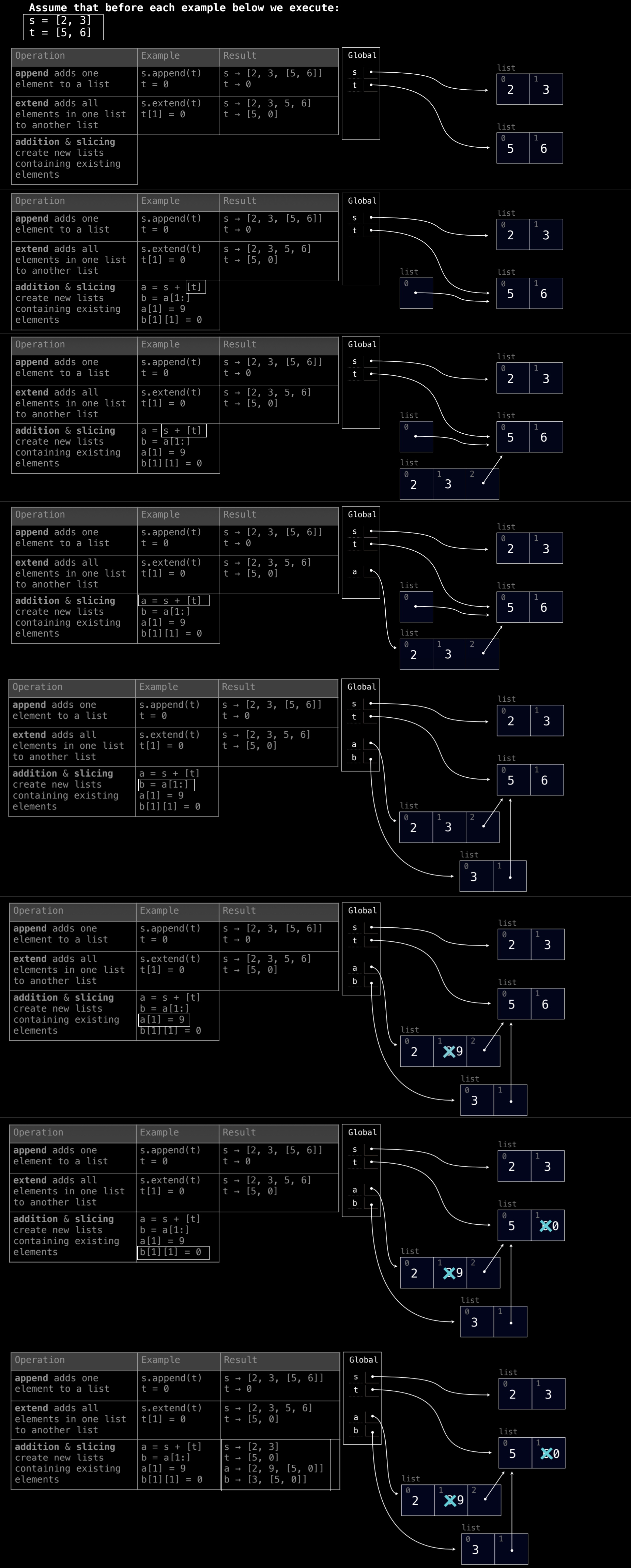
a = s + [t]
b = a[1:]
a[1] = 9
b[1][1] = 0
1. 初始化
首先,变量 s 和 t 初始化为两个独立的列表:
s = [2, 3]t = [5, 6]
此时:
s指向[2, 3],t指向[5, 6]。- 这两个列表在内存中是独立的。
2. [t]
接下来,我们对 t 进行了包裹,形成一个新的列表 [t]:
[t] = [[5, 6]]
此时,内存中 t 仍然指向 [5, 6],而新的列表 [t] 中包含了对 t 的引用。这意味着 [[5, 6]] 实际上是包含 t 的列表的一个引用。
3. s + [t]
执行 s + [t] 操作时,将 s 和 [t] 两个列表拼接在一起,形成一个新的列表:
s + [t] = [2, 3, [5, 6]]
这里的加法操作不会改变原来的 s 或 t,而是创建了一个新的列表。[t] 中包含的是对 t 的引用,因此新的列表中实际上包含了 t 的引用。
4. a = s + [t]
这一步将 s + [t] 的结果赋值给 a:
a = [2, 3, [5, 6]]
此时,a 成为一个新的列表,其中前两个元素是 s 中的值 2 和 3,而第三个元素是对 t(即 [5, 6])的引用。因此,a[2] 指向的是与 t 相同的列表。
5. b = a[1:]
接下来,执行切片操作 a[1:],得到从 a 的索引 1 开始到结尾的子列表,并将其赋值给 b:
b = [3, [5, 6]]
这里 b 是一个新的列表,其第一个元素是 a 中的值 3,第二个元素是 a[2],也就是对 t 的引用 [5, 6]。因此,b[1] 仍然指向 t,与 a[2] 引用了同一个对象。
6. a[1] = 9
现在我们修改 a 中索引 1 处的值,将其赋值为 9:
a = [2, 9, [5, 6]]
这一步将 a 的第二个元素从 3 改为 9,但对 b 没有直接影响。b 中的 3 依然保持原样,因为 b 是在 a[1:] 的切片基础上创建的,b[0] 仍然是 3。
7. b[1][1] = 0
最后,执行 b[1][1] = 0。b[1] 是对 t 的引用(也就是 [5, 6]),因此修改 b[1][1] 相当于修改 t[1]:
b = [3, [5, 0]]t = [5, 0]
这一步修改了 t 的第二个元素,将 6 改为 0。由于 a[2] 也是对 t 的引用,因此 a[2] 中的值也被同步修改为 [5, 0]。
最终状态
a:a = [2, 9, [5, 0]],其中a[1]已经被改为9,而a[2]仍然引用了t(修改后的[5, 0])。b:b = [3, [5, 0]],其中b[1]仍然是t的引用,因此t的修改反映在b[1]上。t:t = [5, 0],被修改为[5, 0]。
关键点
- 列表相加(
+)操作会创建一个新列表,但引用不会被复制,仍然指向原始对象。 - 切片(
a[1:])操作创建一个新列表,引用的对象依然与原列表中的对象共享相同的内存地址。 - 修改嵌套列表中的元素(如
b[1][1])会同时影响所有引用该列表的变量。
4. list() 函数:
list() 函数创建一个新的列表:使用 list(s) 创建的新列表 t 是 s 的浅拷贝。虽然它们最初的元素相同,但 s 和 t 是完全独立的,修改其中一个不会影响另一个。
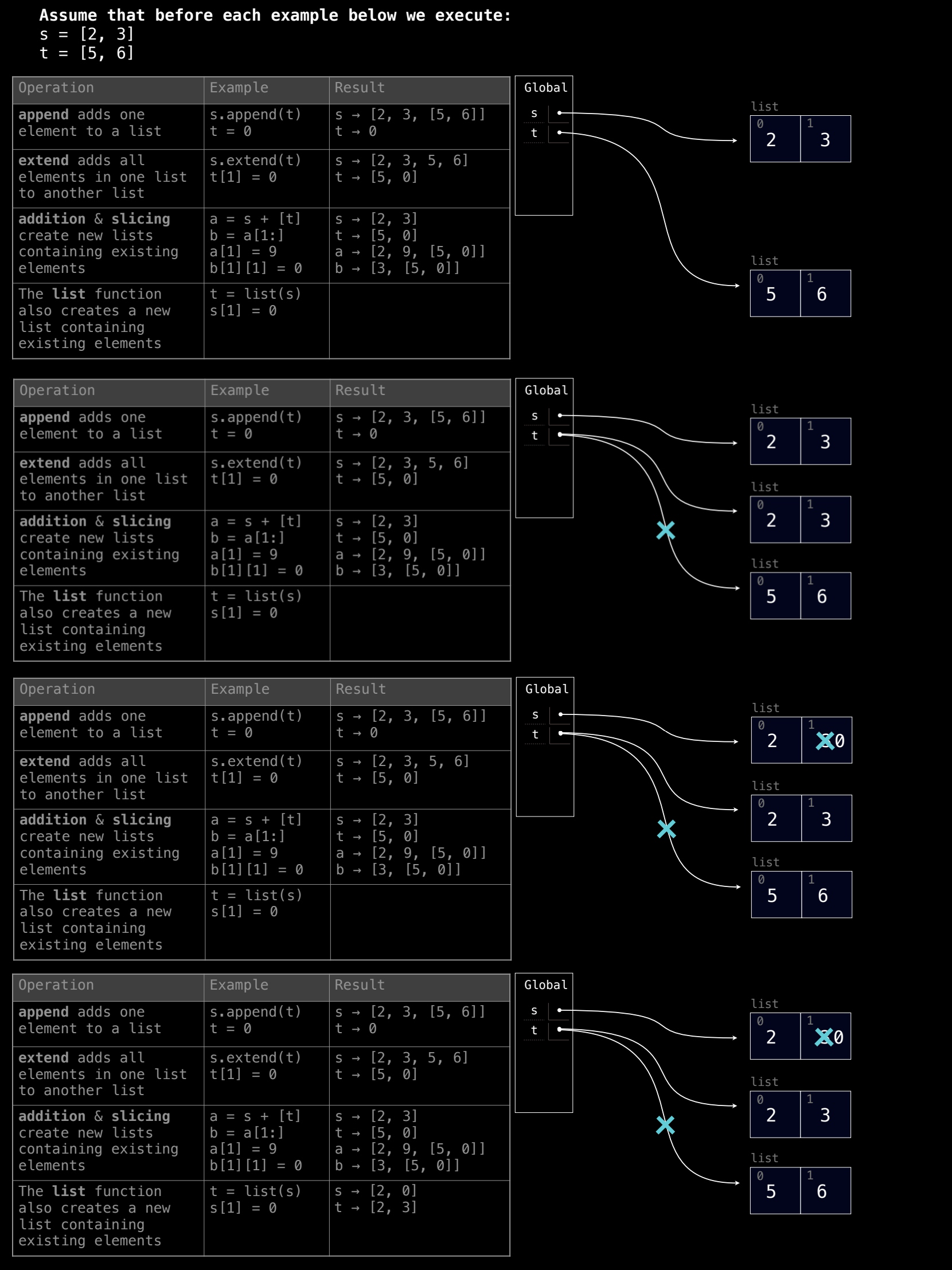
t = list(s)
s[1] = 0
1. 初始化
最初,s 和 t 被初始化为:
s = [2, 3]t = [5, 6]
在内存中:
s指向一个包含元素2和3的列表。t指向一个包含元素5和6的列表。
此时 s 和 t 是完全独立的两个列表,彼此没有任何引用关系。
2. 执行 t = list(s)
接下来,执行 t = list(s) 操作。这一步使用 list() 函数将 s 的内容复制到一个新列表 t 中:
t = list(s)生成了一个新的列表,它包含与s相同的元素,但t和s是两个独立的列表,不再共享引用。- 因此,
t现在是一个新的列表,内容与s相同,即t = [2, 3]。
此时:
s和t都是[2, 3],但它们指向不同的内存位置,修改其中一个不会影响另一个。
3. 执行 s[1] = 0
在 t 创建后,修改 s 中索引 1 的值,将其赋值为 0:
s[1] = 0将s的第二个元素从3修改为0,因此s变为[2, 0]。- 由于
t是通过list()函数创建的一个新列表,t中的值不会因为s的改变而发生变化。
因此,此时:
s = [2, 0]t = [2, 3]
两者已经完全独立,修改 s 对 t 没有任何影响。
4. 最终状态
在所有操作完成后,s 和 t 的最终状态如下:
s = [2, 0]:s的第二个元素被修改为0。t = [2, 3]:t保持不变,仍然是创建时的[2, 3],因为list(s)创建了一个新的独立列表。
关键点
list()函数创建一个新的列表:使用list(s)创建的新列表t是s的浅拷贝。虽然它们最初的元素相同,但s和t是完全独立的,修改其中一个不会影响另一个。- 独立修改:对
s的修改不会传播到t,因为t是s的拷贝,而不是引用。
5. 切片赋值:
通过切片赋值可以替换列表中的部分内容。
s = [2, 3]
t = [5, 6]
s[0:0] = t
# s = [5, 6, 2, 3]
s[0:0] = t将t的元素插入s的起始位置,s的其余部分右移。
s[1:] = [7]
# s = [5, 7]
- 切片赋值
s[1:] = [7]将s的索引 1 及以后的元素替换为[7],缩减了列表的长度。
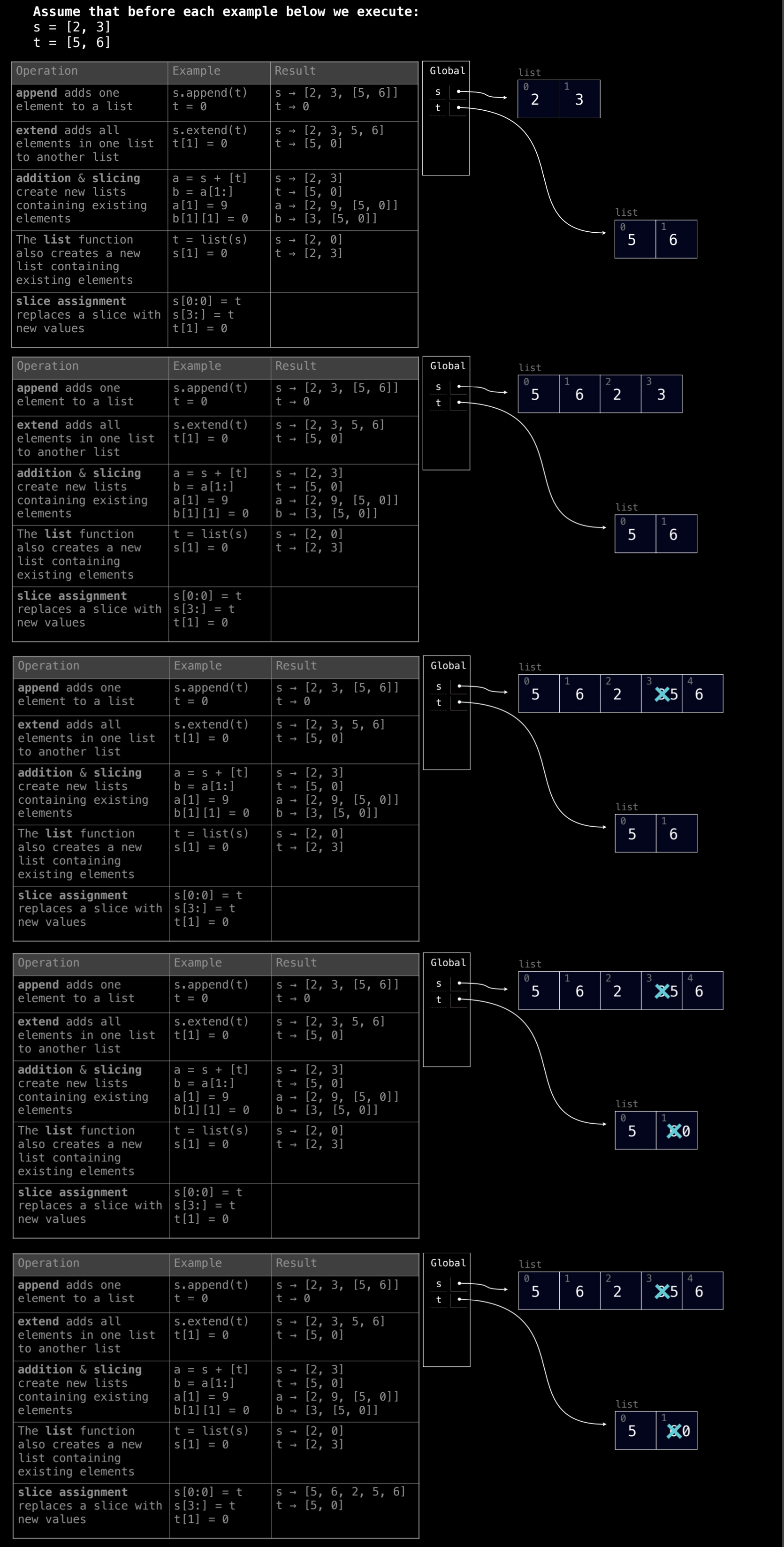
s[0:0] = t
s[3:] = t
t[1] = 0
1. 初始化
最初,s 和 t 被初始化为两个独立的列表:
s = [2, 3]t = [5, 6]
在内存中:
s指向一个包含元素2和3的列表。t指向一个包含元素5和6的列表。
这时,s 和 t 之间没有引用关系。
2. 执行 s[0:0] = t
这一步执行切片赋值 s[0:0] = t,意味着将 t 的所有元素插入到 s 的起始位置:
s[0:0] = t将t列表的所有元素5, 6插入到s的索引0处。- 结果是
s变为[5, 6, 2, 3],其中t的元素5和6被添加到s的最前面,而s原来的元素2和3向后移动。
此时:
s = [5, 6, 2, 3]t仍然是[5, 6]。
3. 执行 s[3:] = t
接下来执行 s[3:] = t,这一步将 t 列表的所有元素从 s 的索引 3 处开始替换原来的元素:
s[3:] = t将s从索引3开始的所有元素替换为t中的元素。- 结果是
s变为[5, 6, 2, 5, 6]。这意味着s原本的3被替换成了t中的元素5和6。
此时:
s = [5, 6, 2, 5, 6]t依然保持[5, 6],没有变化。
4. 执行 t[1] = 0
接下来执行 t[1] = 0,这一步将 t 中索引 1 处的元素(即 6)修改为 0:
t[1] = 0将t列表中的第二个元素从6改为0,因此t变为[5, 0]。- 由于之前
s[3:] = t是通过将t的值复制到s,而不是引用,因此这一步对s没有影响。
此时:
s = [5, 6, 2, 5, 6]保持不变。t = [5, 0],t的第二个元素被修改为0。
5. 最终状态
在所有操作完成后,s 和 t 的最终状态如下:
s = [5, 6, 2, 5, 6]:s中的内容是[5, 6]插入到了开头,并且用t的值[5, 6]替换了索引3开始的部分。尽管t后来被修改,但s已经独立于t,没有受影响。t = [5, 0]:t的第二个元素被修改为0,但这不会影响到s,因为s只是复制了t的值而不是引用。
6. pop() 和 remove():
-
pop()删除并返回列表的最后一个元素。s = [2, 3] x = s.pop() # s = [2], x = 3pop()操作将列表s的最后一个元素3删除,并返回这个值。 -
remove()删除列表中首次出现的指定元素。s = [5, 6, 5, 6] s.remove(5) # s = [6, 5, 6]remove(5)删除列表中第一个5。

1. pop 操作
操作:t = s.pop()
pop 操作从列表 s 中移除最后一个元素,并将其返回赋值给 t。
- 原本的
s = [2, 3]。 s.pop()将移除s的最后一个元素3,并将它赋值给t。
结果:
s变为[2],因为3已被移除。t的值变为3。
最终状态:
s = [2]t = 3
2. remove 操作
操作:t.extend(t); t.remove(5)
首先执行 t.extend(t),这一步将 t 自身的元素扩展两倍,将列表 t 的元素追加到自身的末尾:
- 原本的
t = [5, 6]。 t.extend(t)会把t变成[5, 6, 5, 6],即t的元素被复制并添加到自身的末尾。
接着执行 t.remove(5),这一步从 t 中删除第一个等于 5 的元素:
t.remove(5)会删除t中第一个出现的5,使t变为[6, 5, 6]。
结果:
s保持不变,仍然是[2, 3]。t经过扩展和删除操作后变为[6, 5, 6]。
最终状态:
s = [2, 3]t = [6, 5, 6]
3. 切片赋值(slice assignment)
操作:s[:1] = []; t[0:2] = []
首先执行 s[:1] = [],这一步将 s 列表中从索引 0 开始到 1 结束的切片替换为空列表,即删除该范围内的元素:
- 原本
s = [2, 3]。 s[:1] = []会删除s中索引0处的元素2,使s变为[3]。
接着执行 t[0:2] = [],这一步将 t 列表中从索引 0 开始到 2 结束的切片替换为空列表,删除该范围内的元素:
- 原本
t = [5, 6]。 t[0:2] = []会删除t中的所有元素,使t变为空列表[]。
结果:
s变为[3],因为2被删除。t变为空列表[],因为所有元素都被删除。
最终状态:
s = [3]t = []
7. Lists in Lists in Lists
循环引用与递归列表
在列表中可以创建自引用结构,使得列表包含自身的引用:
t = [1, 2, 3]
t[1:3] = [t]
# t = [1, [1, 2, 3]]
- 这段代码通过切片赋值让
t的部分元素变成其自身的引用,从而创建了一个递归列表结构。
t.extend(t)
# t = [1, [1, 2, 3], 1, [1, 2, 3]]
extend()操作会将t的所有元素,包括自身的引用,追加到列表末尾,导致列表递归地包含自身。
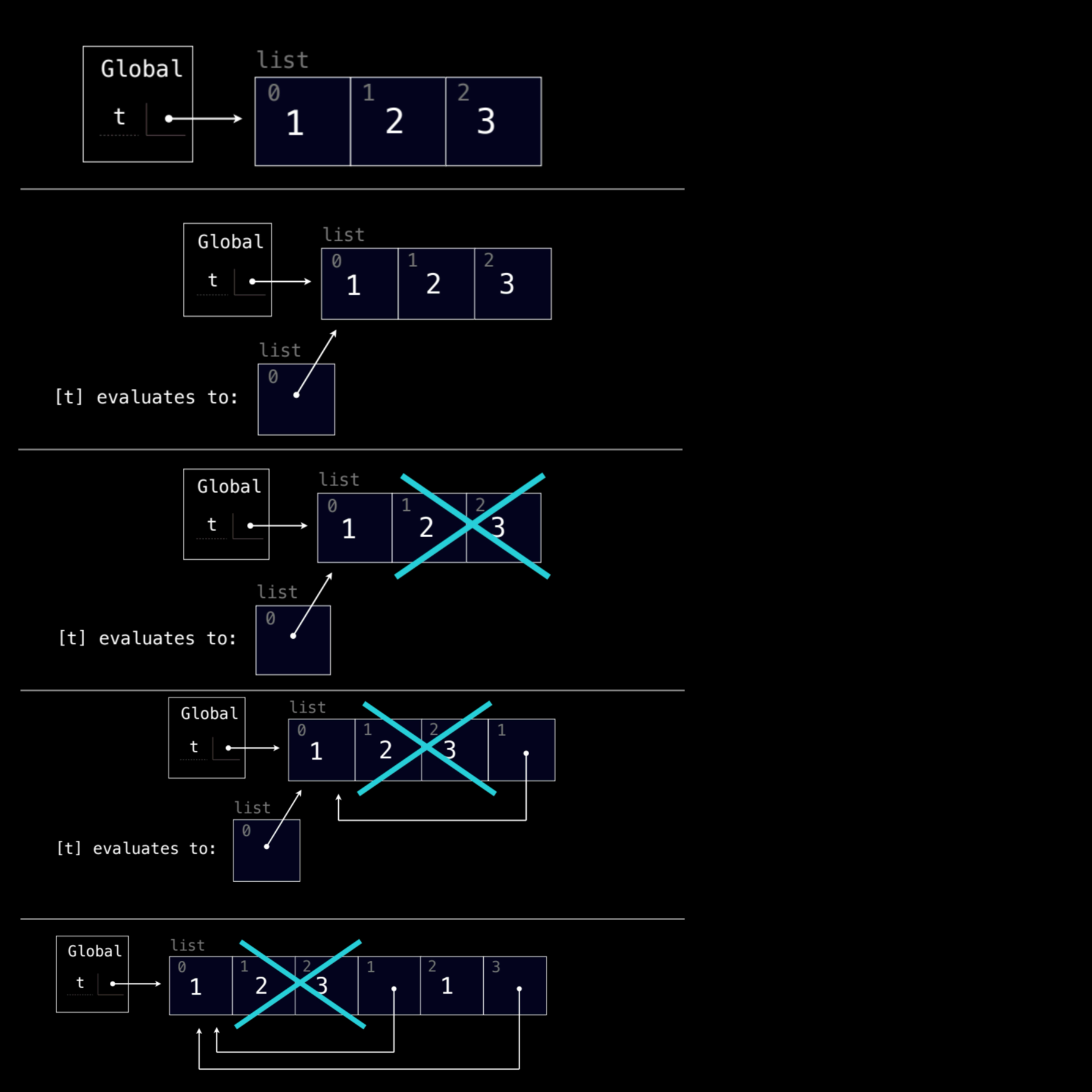
t = [1, 2, 3]
t[1:3] = [t]
t.extend(t)
1. 初始化
首先,列表 t 被初始化为 [1, 2, 3]。
t = [1, 2, 3]:这是一个简单的列表,包含三个整数:1、2和3。- 环境图中显示,变量
t指向了这个列表,它在内存中占据了一个位置,其中索引0、1和2分别存储了1、2和3。
此时,列表 t 的状态为:
t = [1, 2, 3]
2. 操作 [t]
接下来,我们执行 [t]。这一步的意思是将 t 列表放在另一个列表中,生成一个新的嵌套列表 [t]。
[t]:这会创建一个包含列表t的新列表,即[[1, 2, 3]]。该新列表包含了对原始t的引用,而不是复制。- 环境图中可以看到,新的列表
[[1, 2, 3]]指向的是原来的t,所以[t]中的内容实际上是引用了t的位置。
此时,[t] 评估为:
[[1, 2, 3]],并且这个列表中的元素是对t的引用。
3. 操作 t[1:3] = t
这一操作是将 t[1:3] 的切片替换为 t 本身。它将 t 的索引 1 到 2(即 2 和 3)替换为 t 列表本身。
t[1:3] = t:这里,t[1:3]是指[2, 3]。我们用t代替了该切片,所以列表t变为[1, [1, 2, 3], 1]。此时,t在索引1处引用了自身,形成了自引用的结构。- 环境图显示了这一变化,
t的索引1处现在是对t自身的引用。
此时,t 的状态是:
t = [1, [1, 2, 3], 1]
4. 操作 t.extend(t)
接下来,执行 t.extend(t),将列表 t 的所有元素扩展并添加到 t 的末尾。
t.extend(t):这一操作将列表t的元素依次添加到t的末尾。由于t当前的元素是[1, [1, 2, 3], 1],extend操作会将1、[1, 2, 3]和1依次追加到t中。所以t变为[1, [1, 2, 3], 1, 1, [1, 2, 3], 1],其中包含多个对自身的引用。- 环境图中,列表的最后部分是对
t中已有元素的复制。
此时,t 的状态是:
t = [1, [1, 2, 3], 1, 1, [1, 2, 3], 1]
5. 最终状态
在所有操作执行完毕后,列表 t 的最终结构如下:
- 递归的自引用:
t包含两个对自身的引用。在索引1和4处,都包含了对t的引用,即[1, 2, 3]。 - 重复的元素:
t通过extend操作将原始的1、[1, 2, 3]和1依次追加到了自身的末尾。
最终的 t 结构是:
t = [1, [...], 1, 1, [...], 1]
在环境图中,这种递归引用表现为列表中的箭头指向自身,形成了自引用的结构。
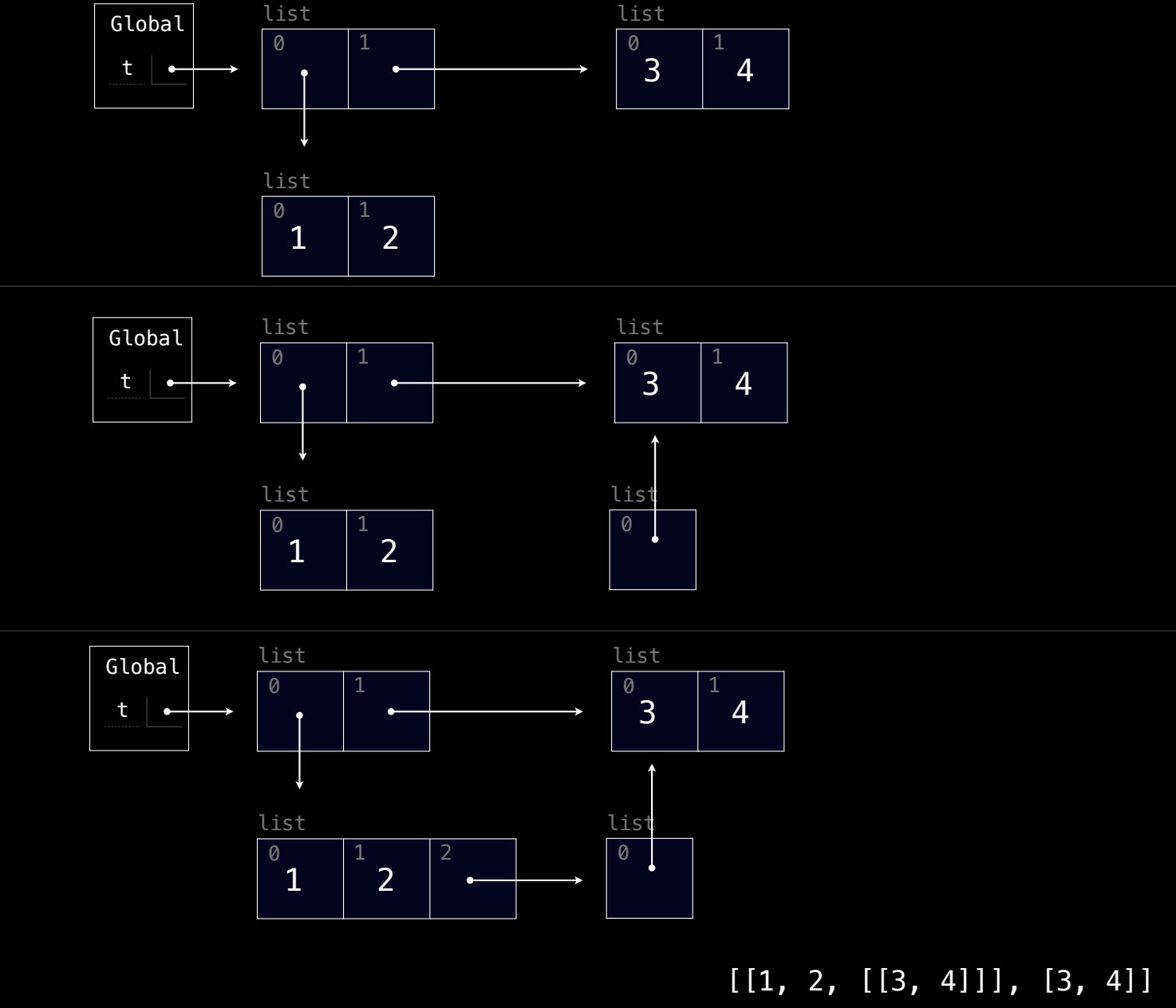
t = [[1, 2], [3, 4]]
t[0].append(t[1:2])
1. 初始化
首先,列表 t 被初始化为一个包含两个子列表的列表:
t = [[1, 2], [3, 4]]:这是一个二维列表,t[0]是列表[1, 2],t[1]是列表[3, 4]。- 在环境图中,
t指向一个包含两个列表的列表,索引0指向[1, 2],索引1指向[3, 4]。
此时,t 的状态为:
t = [[1, 2], [3, 4]]
2. 操作 t[1:2]
执行 t[1:2],这一步是一个切片操作,它从 t 中获取索引 1 处的元素,并将其放在一个新列表中。
t[1:2]:切片操作t[1:2]返回的是一个新列表,它包含t中索引1处的元素,即[[3, 4]]。这个新列表只包含一个元素[3, 4],是对t[1]的引用。
环境图中,这一步操作生成了一个新列表 [[3, 4]],它指向 t[1] 中的 [3, 4]。
此时,t[1:2] 评估为:
[[3, 4]],这是一个包含对t[1]的引用的新列表。
3. 操作 t[0].append(t[1:2])
接下来,执行 t[0].append(t[1:2]),将切片 t[1:2] 作为一个新元素添加到 t[0] 的末尾。
t[0].append(t[1:2]):这一操作在t[0](即[1, 2])的末尾追加了t[1:2],也就是一个包含[3, 4]的列表[[3, 4]]。因此,t[0]变为[1, 2, [[3, 4]]],其中t[0]的第三个元素是一个嵌套列表。- 环境图中显示,
t[0]现在有三个元素:1、2和对新列表[[3, 4]]的引用。这个新列表引用了t[1]的内容[3, 4]。
此时,t 的状态是:
t = [[1, 2, [[3, 4]]], [3, 4]]
4. 最终状态
在所有操作执行完毕后,t 的最终结构如下:
- 嵌套列表结构:
t[0]的第三个元素是一个列表[[3, 4]],这个列表包含了对t[1]的引用。因此,t[0]的末尾元素是嵌套的列表[[3, 4]]。 - 原列表保持不变:
t[1]依然保持[3, 4]不变,且在t[0]中有一个嵌套的引用。
最终,t 的结构为:
t = [[1, 2, [[3, 4]]], [3, 4]]
环境图展示了这一嵌套结构,其中 t[0] 包含对 [[3, 4]] 的引用,而 t[1] 仍然是单独的 [3, 4]。
总结
通过本节的学习,我们深入了解了列表的各种变异操作及其在 Python 环境中的效果。这些操作展示了列表在 Python 中的强大灵活性以及操作时的注意事项,比如如何管理列表中的嵌套引用,以及理解变量如何绑定到相同的对象上。