Lecture 23. Decomposition
Announcements
作业与项目截止时间提醒
- Lab 8:截止日期为今天。
- 蚂蚁项目:完整项目将于本周五截止,但今天需要提交第一和第二阶段的检查点。如果在周四之前提交整个项目,可获得提前提交的加分。
- 作业5:已发布,截止日期是下周一。它将为即将到来的期中考试提供很好的练习。
实验和期中考试准备
- Lab 9:唯一必做的部分是完成作业5,帮助复习期中考试。Lab 9 的其他问题是可选的,提供更多练习。
- 期中考试二:将在下周三举行,考试格式与期中考试一相似,但不会有“神秘函数”的问题。重点是实现描述的函数和环境图问题。
复习资料和考前准备
- 考试范围:包括教科书的第 2.9 节内容,排除一些未覆盖的或明确声明为可选的章节。讲座内容涵盖到上周五的讲座,排除九月底的“二进制数”和“马戏团”讲座。
- 监考要求:考试时需要录制屏幕和头部视频。建议使用 Zoom 进行网络或本地录制,避免像 Loom 那样的技术问题。如果需要考试时间调整,请在周日前填写申请表,即使之前已经申请过期中考试一的调整,这次也需要重新填写。
- 复习指南:可以使用期中考试一的复习指南和更新后的期中考试二的复习指南,后者包括一些新的例子。你可以使用你自己创建的不限页数的笔记,但不建议使用过多的笔记(两页可能是理想的量)。所有笔记必须由你自己创建,不能与他人共享。
考试规则
- 允许使用的资源:考试期间只能使用公开发布的课程材料和课内工具,如 CS61A 官网、Piazza 和 Python Tutor。你不能使用互联网搜索引擎、问答网站、Reddit 或与他人通信。作弊行为会导致课程不及格。
- 申请免除监考:如果你发现监考对你有问题,可以在周日前提交免除监考的申请。如果你在期中考试一时已经申请免除,就不需要再申请。
考试帮助
- 本周三和周四,课程助教将通过 Zoom 提供概念帮助时间,帮助解答概念问题。
Modular Design 模块化设计
今天的内容关于分解(Decomposition),介绍了如何将大程序拆解为更小、更独立的模块,以实现复杂程序的功能。模块化设计的目标是通过分离关注点(Separation of Concerns)来减少系统各部分的依赖性,从而简化复杂系统的管理和扩展。
模块化设计与分解原则
模块化设计的目标是将程序分解为相对独立的组件,每个组件负责不同的功能或关注点。通过分离关注点,可以减少复杂程序的耦合性,从而提高程序的可维护性和可扩展性。
模块化设计中的主要思想:
-
分离关注点(Separation of Concerns):程序的不同部分负责处理不同的逻辑或功能,避免需要同时考虑所有程序的需求。
-
模块独立性:模块应尽可能独立开发和测试,以确保其功能符合预期,而不必依赖程序的其他部分。每个模块关注的是其自身的功能,而不关心其他模块的实现细节。
-
抽象屏障:模块之间应该有明确的接口或抽象屏障,隐藏实现细节,模块只需通过接口进行交互。例如,游戏中的策略函数只需要通过接口调用,而不需要了解游戏内部如何运行。
案例:Hog 游戏的模块化设计
在 Hog 游戏项目中,代码被分为三个独立的模块:
- 游戏模拟器:处理游戏规则、事件顺序和状态跟踪(如谁获胜)。它不关心评论内容。
- 评论功能:描述游戏中发生的事件并生成评论内容。它只负责描述,而不关心游戏规则或玩家的策略。
- 玩家策略:负责决定玩家在每个回合中的决策规则,不关心其他游戏逻辑。
这些模块互相协作,但通过接口进行解耦。例如,play 函数调用了评论和策略函数,但它不需要了解它们的内部逻辑,只需要调用它们生成结果。
案例:蚂蚁项目的模块化设计
- 游戏模拟器:负责处理整体的游戏状态和食物资源的跟踪,决定游戏是否结束。它不需要知道蚂蚁或蜜蜂的具体动作。
- 动作函数:每个蚂蚁或蜜蜂的动作都是独立实现的,专注于描述它们的特殊行为。
- 隧道结构:负责设置隧道和跟踪所有蚂蚁和蜜蜂的位置,与其他模块协同工作以保持游戏的正常运行。
这些模块可以独立开发,并且通过模块化设计,程序的各部分互不依赖,便于维护和扩展。
模块化设计应用于餐厅搜索
Example: Restaurant Search
在这个餐厅搜索的例子中,我们需要管理复杂的数据集,其中包含 Yelp 上的餐厅信息和用户评论。
数据结构:
- 餐厅信息:包括餐厅的名称、星级、价格类别、商业 ID 等。
- 评论信息:包括用户的唯一标识、评论内容、评分以及与之相关的餐厅 ID。
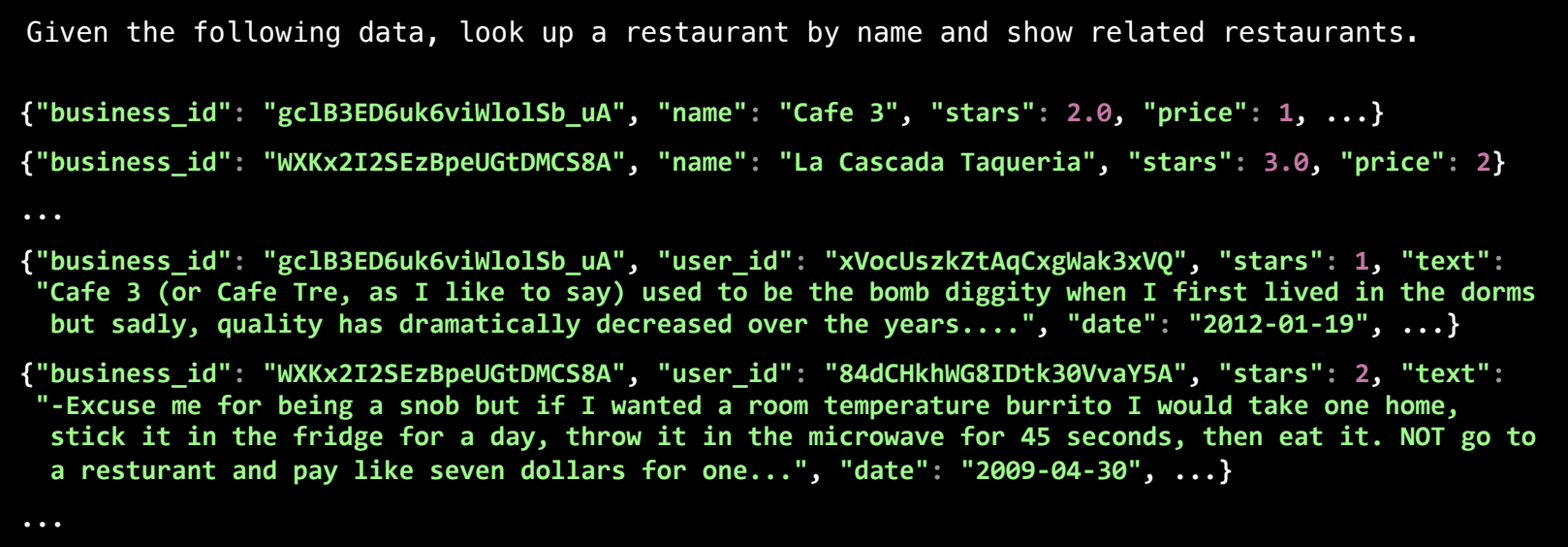
为了构建一个可以按名称搜索餐厅并显示相关餐厅的应用,我们需要考虑一些设计问题。通过模块化设计,我们可以将不同功能模块分离,使程序更易于维护和扩展。
问题与设计思路
- 按名称搜索餐厅:需要定义搜索功能,根据餐厅名称中的关键字查找匹配的餐厅。
- 餐厅的相似性:确定如何定义相似餐厅。相似性可以基于多种因素,例如地理位置、评分、价格或评论。
- 数据结构的表示:如何表示餐厅和评论。餐厅可以使用类来封装其属性,如名称、星级、价格等。
分解与实现细节
1. 数据结构的设计
我们需要两个主要的数据结构:
- 餐厅类:用于表示每个餐厅的信息,包括名称、星级、价格、位置等。
- 评论类(可选):存储每个餐厅的评论信息,包括用户的评分和评论文本。
class Restaurant:
all_restaurants = []
def __init__(self, name, stars, price, business_id):
self.name = name
self.stars = stars
self.price = price
self.business_id = business_id
Restaurant.all_restaurants.append(self)
def __repr__(self):
return f"<Restaurant {self.name}>"
def similar(self, k, similarity_fn):
"""
返回与当前餐厅最相似的 k 个餐厅。
"""
# 使用相似性函数来比较餐厅
similar_restaurants = sorted(
Restaurant.all_restaurants,
key=lambda r: similarity_fn(self, r)
)
return similar_restaurants[:k]
2. 搜索功能的实现
搜索功能允许用户根据餐厅名称进行搜索。通过使用 Python 的字符串匹配功能,可以很容易地实现这一点。
def search(query, ranking_fn=lambda r: -r.stars):
"""
搜索餐厅,并按指定的排名函数排序。
默认按星级从高到低排序。
"""
results = [r for r in Restaurant.all_restaurants if query.lower() in r.name.lower()]
return sorted(results, key=ranking_fn)
3. 定义相似性函数
相似性可以基于多种标准:地理位置、价格、星级等。这里我们可以定义多个不同的相似性函数,并将它们传递给 similar 方法。这样可以使代码更加模块化和灵活。
def similarity_by_price(r1, r2):
return abs(r1.price - r2.price)
def similarity_by_stars(r1, r2):
return abs(r1.stars - r2.stars)
4. 示例测试
接下来,我们可以创建一些餐厅实例并测试搜索和相似性功能。
# 创建一些餐厅
r1 = Restaurant("Thai Delight", 2, 2, "123")
r2 = Restaurant("Thai Basil", 3, 2, "456")
r3 = Restaurant("Top Dog", 5, 1, "789")
# 测试搜索功能
search_results = search("thai")
print(search_results) # 输出: [<Restaurant Thai Delight>, <Restaurant Thai Basil>]
# 测试相似性功能
similar_restaurants = r1.similar(2, similarity_by_stars)
print(similar_restaurants) # 输出: 根据星级相似度的餐厅列表
模块化设计的好处
- 分离关注点:搜索功能与餐厅的表示、相似性函数完全解耦。这使得我们可以独立修改搜索算法或相似性计算,而不影响其他模块。
- 灵活性:相似性计算通过传入不同的函数来实现,这使得程序可以很容易地扩展。例如,可以基于地理位置、价格等不同标准进行相似性比较。
- 可维护性:通过使用类和函数,代码结构清晰,容易维护和测试。每个模块都可以独立开发和调试,减少了复杂性。
下一步扩展
- 从文件读取数据:可以扩展程序,支持从文件中读取餐厅和评论数据,将餐厅和评论匹配起来。
- 进一步优化相似性计算:可以结合多个相似性函数,例如权重加权后的相似性评分。
实现餐厅搜索与相似性计算
我们现在已经了解了如何构建一个餐厅搜索应用,并通过相似性函数来计算相似餐厅。在这个实现中,我们将餐厅按名称进行搜索,并利用评论用户信息来确定哪些餐厅具有相似性。
1. 餐厅类的扩展
我们首先定义了餐厅类 Restaurant,并在其中实现了搜索和相似性计算功能。每个餐厅都有属性,例如名称、评分、价格、以及评论的用户列表。
class Restaurant:
all_restaurants = []
def __init__(self, name, stars, price, business_id, reviewers):
self.name = name
self.stars = stars
self.price = price
self.business_id = business_id
self.reviewers = reviewers
Restaurant.all_restaurants.append(self)
def __repr__(self):
return f"<Restaurant {self.name}>"
def similar(self, k, similarity_fn):
"""
返回与当前餐厅最相似的 k 个餐厅。
:param k: 返回最相似餐厅的数量
:param similarity_fn: 计算餐厅相似度的函数
"""
others = Restaurant.all_restaurants.copy()
others.remove(self) # 排除自己
# 根据相似度排序
sorted_restaurants = sorted(others, key=lambda r: -similarity_fn(self, r))
return sorted_restaurants[:k] # 返回前 k 个相似餐厅
2. 定义相似性函数
相似性函数用于比较两个餐厅的相似度。在这里,我们使用“共同评论用户”作为相似性的标准,即评论相同餐厅的用户越多,餐厅越相似。
def similarity_by_reviewers(r1, r2):
"""
通过共同评论的用户数量计算相似度。
:param r1: 餐厅 1
:param r2: 餐厅 2
:return: 相似度分数(共同评论用户的数量)
"""
common_reviewers = set(r1.reviewers).intersection(set(r2.reviewers))
return len(common_reviewers)
3. 搜索功能
我们实现了一个简单的搜索功能,按餐厅名称中的关键字进行搜索,并根据评分对结果进行排序。
def search(query, ranking_fn=lambda r: -r.stars):
"""
根据餐厅名称进行搜索,并按排名函数排序。
:param query: 搜索关键词
:param ranking_fn: 用于排序的函数(默认按评分降序)
:return: 搜索结果的餐厅列表
"""
results = [r for r in Restaurant.all_restaurants if query.lower() in r.name.lower()]
return sorted(results, key=ranking_fn)
4. 读取文件数据
为了从文件中读取餐厅和评论数据,我们需要使用 Python 的 json 模块读取 JSON 格式的数据,并建立餐厅和评论者的对应关系。
import json
def load_data():
# 构建餐厅的评论者字典
reviewers_for_restaurant = {}
# 读取评论数据
with open("reviews.json") as reviews_file:
for line in reviews_file:
review = json.loads(line)
business_id = review["business_id"]
user_id = review["user_id"]
if business_id not in reviewers_for_restaurant:
reviewers_for_restaurant[business_id] = []
reviewers_for_restaurant[business_id].append(user_id)
# 读取餐厅数据
with open("restaurants.json") as restaurants_file:
for line in restaurants_file:
restaurant_data = json.loads(line)
name = restaurant_data["name"]
stars = restaurant_data["stars"]
price = restaurant_data["price"]
business_id = restaurant_data["business_id"]
reviewers = reviewers_for_restaurant.get(business_id, [])
Restaurant(name, stars, price, business_id, reviewers)
5. 测试与运行
通过创建一些餐厅对象并调用 search 和 similar 函数,我们可以测试搜索和相似性计算功能。
# 加载餐厅和评论数据
load_data()
# 搜索关键字 "Thai"
search_results = search("Thai")
print("搜索结果:", search_results)
# 找到与 "Thai Basil" 最相似的 3 家餐厅
thai_basil = search("Thai Basil")[0]
similar_restaurants = thai_basil.similar(3, similarity_by_reviewers)
print(f"{thai_basil} 的相似餐厅:", similar_restaurants)
6. 输出结果
示例输出可能如下:
搜索结果: [<Restaurant Thai Delight>, <Restaurant Thai Basil>]
<Restaurant Thai Basil> 的相似餐厅: [<Restaurant La Cascada>, <Restaurant Gypsy's Trattoria Italiana>, <Restaurant Top Dog>]
在这个例子中,我们根据共同评论者的数量,找到与 “Thai Basil” 最相似的餐厅。
性能优化:使用排序与线性比较
在之前的实现中,我们遇到了性能问题:当查找餐厅及其相似餐厅时,运行时间过长。问题的根源在于相似度计算过程中比较每个餐厅的评论用户列表时,需要遍历每个用户,这导致了二次复杂度(O(n^2)),尤其是在处理用户数量庞大的情况下,效率较低。
我们可以通过以下方法优化性能:
- 使用排序列表:对于每个餐厅的评论用户列表,将其转换为有序列表。
- 线性合并算法:实现一个高效的算法,能够在两个有序列表中找到共同的元素,并且只需要线性时间(O(n))。
1. 线性合并算法实现
这个算法通过依次比较两个有序列表的元素,找到它们的交集。每次比较较小的元素,推进指针直到找到相同的元素或达到列表的末尾。
def fast_overlap(s, t):
"""
计算两个有序列表 s 和 t 的交集大小。
:param s: 有序列表 1
:param t: 有序列表 2
:return: 两个列表的交集大小
"""
i, j = 0, 0
overlap_count = 0
while i < len(s) and j < len(t):
if s[i] == t[j]:
overlap_count += 1
i += 1
j += 1
elif s[i] < t[j]:
i += 1
else:
j += 1
return overlap_count
2. 相似度函数的改进
之前我们使用了 O(n^2) 的算法来比较两个餐厅的评论者列表,现在可以使用 fast_overlap 函数来优化这一过程。
def similarity_by_reviewers_fast(r1, r2):
"""
通过使用排序的评论用户列表来计算两个餐厅的相似度。
:param r1: 餐厅 1
:param r2: 餐厅 2
:return: 相似度分数(共同评论用户的数量)
"""
return fast_overlap(sorted(r1.reviewers), sorted(r2.reviewers))
3. 测试性能优化
通过替换掉之前的 similarity_by_reviewers 函数为新的 similarity_by_reviewers_fast,可以测试性能提升效果。我们将使用一些餐厅和评论数据来验证优化的效果。
# 创建一些餐厅对象
r1 = Restaurant("Thai Delight", 2, 2, "123", ["user1", "user2", "user3"])
r2 = Restaurant("Thai Basil", 3, 2, "456", ["user2", "user3", "user4"])
r3 = Restaurant("Top Dog", 5, 1, "789", ["user5", "user6", "user1"])
# 测试优化后的相似度计算
similar_restaurants = r1.similar(2, similarity_by_reviewers_fast)
print(f"{r1} 的相似餐厅:", similar_restaurants)
4. 进一步优化:使用集合
Python 中的集合(set)能够快速进行交集操作,我们可以将餐厅的评论者列表转换为集合,然后直接利用集合的交集运算符来计算共同评论者的数量。使用集合的交集运算,时间复杂度可以降到 O(n)。
def similarity_by_reviewers_set(r1, r2):
"""
使用 Python 的集合计算评论者的交集大小来提高效率。
:param r1: 餐厅 1
:param r2: 餐厅 2
:return: 相似度分数(共同评论用户的数量)
"""
return len(set(r1.reviewers) & set(r2.reviewers))
5. 最终性能测试
替换了新的相似度计算后,我们再次测试搜索与相似度计算的效率。由于集合的交集操作非常高效,这将显著提升程序的性能,尤其是在处理大量评论用户时。
# 测试使用集合进行相似度计算
similar_restaurants = r1.similar(2, similarity_by_reviewers_set)
print(f"{r1} 的相似餐厅:", similar_restaurants)
6. 总结
通过以下几个步骤,我们成功优化了餐厅搜索与相似度计算的性能:
- 从 O(n^2) 到 O(n):通过将评论用户列表排序后进行线性比较,或者使用集合交集运算,我们将计算两个餐厅相似度的时间复杂度从 O(n^2) 降低到了 O(n)。
- 显著的性能提升:在处理大量餐厅和评论时,新的算法可以让搜索和相似度计算的响应时间大幅缩短,增强了系统的交互性。
通过这种优化,我们的餐厅搜索引擎不仅功能强大,而且在性能上也达到了较好的表现。
集合(set)
Python 中的集合(set)是一种非常常用的数据结构,提供了高效的元素存储和集合操作。以下是集合的几个关键特点及其操作方式:
1. 集合的基本特性
- 集合中的元素唯一:不能包含重复的元素。
- 无序:集合中的元素没有特定的顺序,当你迭代集合时,元素的顺序是随机的。
- 常量时间的查找:查找某个元素是否在集合中是 O(1) 的操作,而列表的查找是 O(n)。
例如:
s = {1, 2, 3, 4, 4}
print(s) # 输出: {1, 2, 3, 4}
尽管我们试图插入两个 4,集合中只保留了一个。
2. 常用集合操作
- 添加元素:使用
add()方法向集合中添加元素。 - 删除元素:使用
remove()或discard()方法删除元素。 - 检查元素:使用
in运算符判断元素是否在集合中。 - 集合大小:使用
len()方法获取集合的元素数量。
例如:
s = {1, 2, 3}
s.add(4)
print(s) # 输出: {1, 2, 3, 4}
s.remove(3)
print(s) # 输出: {1, 2, 4}
print(2 in s) # 输出: True
print(len(s)) # 输出: 3
3. 集合的运算
- 交集(
intersection):获取两个集合的共同元素。 - 并集(
union):获取两个集合的所有元素,不包含重复项。 - 差集(
difference):获取在一个集合中而不在另一个集合中的元素。
例如:
s1 = {1, 2, 3}
s2 = {3, 4, 5}
# 交集
intersection = s1.intersection(s2)
print(intersection) # 输出: {3}
# 并集
union = s1.union(s2)
print(union) # 输出: {1, 2, 3, 4, 5}
# 差集
difference = s1.difference(s2)
print(difference) # 输出: {1, 2}
4. 集合运算的效率
集合的主要优势之一是其操作的高效性:
- 元素查找:O(1)
- 交集、并集和差集:这些操作在 Python 中实现非常高效,时间复杂度通常为 O(min(len(s1), len(s2))),适合处理大量数据。
例如,通过集合的交集来计算两个集合的重叠元素,可以使用如下代码:
s1 = {1, 2, 3, 4}
s2 = {3, 4, 5, 6}
overlap = len(s1.intersection(s2))
print(overlap) # 输出: 2
5. 集合的不可变形式:frozenset
frozenset 是不可变的集合,它一旦创建就不能修改。适用于需要集合不可变的场景,比如将集合作为字典的键。
fs = frozenset([1, 2, 3])
print(fs) # 输出: frozenset({1, 2, 3})
总结
Python 集合是处理无序且唯一元素集合的理想工具,尤其在执行高效查找、交集、并集等集合运算时非常有用。通过使用集合操作,我们可以显著提高程序性能,特别是在需要频繁查找或比较元素的场景。