Lecture 24. Data Example
Announcements
作业提交与加分机会
- Homework 5 需要在周一前提交,但如果在周四之前提前提交,可以获得额外的加分。
- Lab 9 的唯一必做内容是完成 Homework 5,因此可以用平时完成实验的时间来完成该作业。实验 9 也包含一些可选问题,会作为期中考试的良好练习。实验 9 将附带解决方案,更多是作为学习辅助工具。
期中考试准备
- 期中考试二 临近,有多种备考方式可供选择。
- 可以回看课程讲座视频,或者做过去实验中的可选题目。
- 学生小组 CS Mentors 和 HKN 将分别在周六和周日举行复习讲座,CS Mentors 的复习时间为周六中午和下午 6 点,HKN 的复习时间为周日下午 4 点,所有讲座均会录制。
- 教师团队将在周一上午 11 点开始提供一份模拟考试,考试内容来自 2020 年春季的期中考试二,题目格式与实际考试一致。模拟考试可以在任何时间完成,用于熟悉考试环境和软件。
- Piazza 上发布了一些与课堂讨论相关的往期考试题目及其讲解视频的链接,供复习参考。
- 期中考试二的复习指南和备考文档已准备好,可以在复习时参考。
期中考试规则与安排
- 考试将于 下周三晚 7 点 开始,监考方式将通过视频进行,视频中需要包含考生的头部和屏幕。若希望申请监考豁免,需在周日前提交表格申请。
- 如果有需要在不同时间参加考试的需求,请提交替代时间申请表。
课程日程与内容调整
学生反馈与内容调整
- 由于不少学生反馈在远程学习环境中感到压力过大,课程团队对内容进行了调整。课程的某些内容,例如二进制数和电路,不会在考试中涉及,仅作为拓展内容,旨在提供一些有趣的学习材料,而不增加学习负担。
- 未来两周将有两次可选讲座,分别在周一和周五,主要任务是完成 Homework 5 和期中考试。期中考试结束后将不会再引入新的必修内容。
可选讲座与减少的学习压力
- 未来某些讲座内容将变为可选,并且不会出现在期末考试或作业中。这些可选内容包括宏与尾调用的讲座以及数据库的讲座。学生可以选择学习这些内容,但不会对最终成绩产生影响。
Examples: Objects
面向对象系统的示例
属性查找规则
- 当通过实例名称查找属性时,首先查找的是实例属性,其次是类属性。如果实例中未找到,则会查找类中的属性,如果类中也没有找到,则继续在父类中查找。这种机制使得类属性可以被继承。
示例:Worker 类
class Worker:
greeting = "Sir"
def __init__(self, elf):
self.elf = elf
def work(self):
return self.greeting + ", I work"
def __repr__(self):
return Bourgeoisie.greeting
- 属性解释:
greeting: 这是类属性,所有Worker实例都共享这个属性,默认为 “sir”。-
__init__: 构造函数,__init__方法中将一个名为elf的属性赋值为Worker类的引用。这意味着,每个创建的Worker实例都拥有一个指向Worker类的elf属性。 work()方法:返回对象的greeting属性值加上字符串" I work"。__repr__()方法:在交互式会话中,输出类实例的字符串表示。
示例:Worker 与 Bourgeoisie 类
定义 Worker 类后,我们还创建了一个继承自 Worker 的 Bourgeoisie 类。该类覆盖了 greeting 属性,将其值设为 "Peon"。这意味着 Bourgeoisie 类的实例在调用 work() 方法时,会显示与 Worker 类不同的 greeting 值。
class Bourgeoisie(Worker):
greeting = 'Peon'
def work(self):
print(Worker.work(self))
return 'I gather wealth'
创建了两个实例:
jack = Worker():jack是Worker类的实例,其greeting属性默认为"Sir"。john = Bourgeoisie():john是Bourgeoisie类的实例,继承了Worker类的__init__方法,但其greeting属性为"Peon"。
属性查找规则
- 当访问
jack.greeting时,系统会先检查jack实例自身是否有greeting属性。如果没有,则会查找Worker类的greeting,该值为"Sir"。 - 属性赋值规则:当对
jack.greeting进行赋值时,例如jack.greeting = "Ma'am",该操作会直接在jack实例中创建一个新的greeting属性,而不会修改Worker类中的greeting属性。因此,此时jack.greeting为"Ma'am",而其他Worker实例的greeting仍然是"Sir"。
代码结构回顾与属性查找
class Worker:
greeting = 'Sir'
def __init__(self):
self.elf = Worker
def work(self):
return self.greeting + ', I work'
def __repr__(self):
return Bourgeoisie.greeting
class Bourgeoisie(Worker):
greeting = 'Peon'
def work(self):
print(Worker.work(self)) # 调用父类的 work 方法
return 'I gather wealth'
jack = Worker()
john = Bourgeoisie()
jack.greeting = 'Maam'

1. jack.work()的执行流程
-
jack = Worker():- 创建
Worker类的一个实例jack。由于类Worker有greeting = 'Sir'作为类属性,jack会继承该属性。
- 创建
-
jack.greeting = 'Maam':- 给
jack这个实例添加一个实例属性greeting,值为'Maam'。这会覆盖Worker类中的greeting类属性,但只对jack有效。
- 给
-
jack.work():-
调用
jack.work()时,Python首先查找实例jack的work()方法。由于jack是Worker类的实例,Worker类中的work()方法被找到并调用。 -
在
work()方法内部,self.greeting用于获取greeting的值。Python首先在实例jack中查找greeting属性,发现jack的实例属性greeting = 'Maam',因此返回这个值。 -
然后,
self.greeting + ', I work'会使用实例属性greeting的值,拼接并返回字符串'Maam, I work'。
最终输出:
'Maam, I work' -
2. john.work()的执行流程
john = Bourgeoisie():- 创建
Bourgeoisie类的一个实例john。Bourgeoisie类继承了Worker类,因此john会继承Worker类的所有方法和属性。 - 由于
Bourgeoisie类定义了自己的类属性greeting = 'Peon',所以john会使用Bourgeoisie类的greeting属性,覆盖掉Worker类的greeting = 'Sir'。
- 创建
john.work():-
调用
john.work()时,Python首先查找john的work()方法。由于Bourgeoisie类重写了Worker的work()方法,Bourgeoisie的work()方法被调用。 -
在
Bourgeoisie类的work()方法中,首先执行了Worker.work(self),这是一次父类方法调用,传递了self为john。- Python会调用
Worker类的work()方法。 - 在
Worker.work(self)中,self.greeting的查找顺序是:首先查找实例john的greeting属性,未找到实例属性,接着查找Bourgeoisie类的类属性,发现greeting = 'Peon',因此返回'Peon'。 Worker.work(self)返回'Peon, I work',并在Bourgeoisie.work()中打印出来。
- Python会调用
-
然后,
Bourgeoisie.work()方法的返回值是'I gather wealth'。
最终输出:
- 打印:
'Peon, I work' - 返回:
'I gather wealth'
-
3. john.elf.work(john)的执行流程
john.elf:john是Bourgeoisie类的实例。在Worker类的构造函数(__init__())中,self.elf被设置为类Worker。因此,john.elf实际上是Worker类本身。
john.elf.work(john):-
john.elf指向Worker类,因此调用的是Worker.work()方法,且self参数被传递为john实例。 - 在
Worker.work(john)中,self.greeting的查找过程如下:- 首先查找实例
john的greeting属性,没有找到实例属性。 - 然后查找
Bourgeoisie类的类属性,发现greeting = 'Peon',因此使用该值。
- 首先查找实例
Worker.work(john)返回字符串'Peon, I work'。
最终输出:
'Peon, I work'-
属性查找总结:
- 实例属性优先于类属性:当
jack.greeting = 'Maam'时,调用jack.work()时,Python会优先使用jack实例上的greeting = 'Maam',而不是Worker类的greeting = 'Sir'。 - 类属性的继承和覆盖:
Bourgeoisie类继承了Worker类的属性和方法,但通过设置自己的类属性greeting = 'Peon',覆盖了父类的greeting = 'Sir'。 - 父类方法调用:
john.work()中调用了父类Worker的work()方法,返回'Peon, I work',并且在调用结束后返回'I gather wealth'。 - 类引用:
john.elf引用了Worker类本身,允许通过john.elf.work(john)来调用Worker类的方法。
Examples: Iterables & Iterators
示例:可迭代对象和迭代器
接下来,我们来看几个通过列表解析、字典解析和内置函数实现的复杂数据操作示例。
1. 找到列表中绝对值最小的元素的索引

给定一个列表 s,我们要找到所有具有最小绝对值的元素的索引。例如,列表 s = [3, -2, 5, 7, 2] 中,绝对值最小的元素是 -2 和 2,它们的索引分别为 1 和 4。
解决思路:
- 首先,计算列表中每个元素的绝对值,并找到最小的绝对值。
- 然后,通过列表解析,找到与该最小绝对值相等的元素的索引。
代码实现:
s = [3, -2, 5, 7, 2]
min_abs_value = min(map(abs, s)) # 计算最小绝对值
indices = [i for i in range(len(s)) if abs(s[i]) == min_abs_value] # 找到对应索引
print(indices) # 输出:[1, 4]
解释:
-
min(map(abs, s))计算列表s中元素的最小绝对值。 -
使用列表解析
[i for i in range(len(s)) if abs(s[i]) == min_abs_value]找到绝对值等于最小值的索引。1.
x for x in s if abs(x) == min_abs_value这个列表推导式返回的是符合条件的元素。也就是说,它会返回
s中那些绝对值等于min_abs_value的实际值。s = [3, -2, 5, 7, 2] min_abs_value = min(map(abs, s)) # 计算最小绝对值 result = [x for x in s if abs(x) == min_abs_value] print(result) # 输出:[-2, 2]- 它会从列表
s中筛选出元素本身,比如-2和2,因为它们的绝对值等于min_abs_value。 - 结果:
[-2, 2]是符合条件的元素。
2.
i for i in range(len(s)) if abs(s[i]) == min_abs_value这个列表推导式返回的是符合条件的索引,即
s列表中符合条件的元素的位置(索引)。s = [3, -2, 5, 7, 2] min_abs_value = min(map(abs, s)) # 计算最小绝对值 indices = [i for i in range(len(s)) if abs(s[i]) == min_abs_value] print(indices) # 输出:[1, 4]- 它会返回满足条件的元素在
s列表中的索引。例如,-2和2的绝对值为2,它们在s中的索引分别是1和4。 - 结果:
[1, 4]是符合条件的元素的索引。
关键区别:
x for x in s if abs(x) == min_abs_value:返回的是元素本身,如[-2, 2]。i for i in range(len(s)) if abs(s[i]) == min_abs_value:返回的是元素的索引,如[1, 4]。
选择使用哪种方式:
- 如果你关心的是哪些元素符合条件,使用
x for x in s的形式。 - 如果你关心的是这些元素在列表中的索引,使用
i for i in range(len(s))的形式。
- 它会从列表
2. 计算列表中相邻两个元素的最大和

给定一个列表 s,找到其中相邻两个元素的最大和。例如,s = [1, -3, 4, -2, 5],相邻元素最大和是 4 + (-2) = 6。
方法1:通过索引遍历
- 我们可以通过索引遍历
s,计算相邻元素的和,排除最后一个元素以避免越界错误。 - 使用
max()函数找到所有相邻元素和中的最大值。
代码实现:
s = [1, -3, 4, -2, 5]
max_sum = max(s[i] + s[i+1] for i in range(len(s)-1)) # 遍历相邻元素对并求和
print(max_sum) # 输出:6
解释:
range(len(s)-1)生成从0到列表倒数第二个元素的索引,确保我们计算s[i] + s[i+1]不会越界。max()函数返回所有相邻元素和中的最大值。
方法2:使用 zip() 函数
- 我们可以使用
zip()将列表s的元素与其偏移一个位置的元素配对,从而获得相邻元素对。 - 然后我们可以对这些配对的元素求和,最终使用
max()找到最大值。
代码实现:
s = [1, -3, 4, -2, 5]
max_sum = max(a + b for a, b in zip(s, s[1:])) # 使用 zip 将相邻元素配对
print(max_sum) # 输出:6
解释:
zip(s, s[1:])将s列表与它的偏移版本s[1:]配对,生成所有相邻元素对。max(a + b for a, b in zip(s, s[1:]))计算相邻元素的和,并返回其中的最大值。
###
3. 创建一个字典,映射每个数字 d 到列表中以 d 结尾的元素

给定一个整数列表 s,创建一个字典,键为 0-9 的数字,值为以该数字结尾的元素列表。例如,s = [15, 25, 33, 42, 55, 68, 99],输出的字典为:
{1: [], 2: [42], 3: [33], 5: [15, 25, 55], 8: [68], 9: [99]}
解决思路:
- 遍历列表中的每个元素,获取其最后一位数字,按照该数字将元素分类存储在字典中。
代码实现:
s = [15, 25, 33, 42, 55, 68, 99]
digit_map = {d: [x for x in s if x % 10 == d] for d in range(10)} # 创建字典映射
print(digit_map)
解释:
- 使用字典解析
{d: [x for x in s if x % 10 == d] for d in range(10)}将每个元素按照其末尾数字进行分类,x % 10用来获取元素的最后一位数字。
思路解析
这个问题的目标是:给定一个整数列表
s,将其按照每个数的最后一位数字进行分类,生成一个字典,键为0-9之间的数字,值为以该数字结尾的元素组成的列表。例如,对于
s = [15, 25, 33, 42, 55, 68, 99],字典的输出是:{0: [], 1: [], 2: [42], 3: [33], 4: [], 5: [15, 25, 55], 6: [], 7: [], 8: [68], 9: [99]}这里的字典构建过程,是通过嵌套的字典解析和列表推导式完成的。
代码实现:
s = [15, 25, 33, 42, 55, 68, 99] digit_map = {d: [x for x in s if x % 10 == d] for d in range(10)} # 创建字典映射 print(digit_map)代码分解与思路:
获取每个数的最后一位数字:
x % 10:这是核心操作,通过对 10 取模,能得到数字的最后一位。例如:
15 % 10 = 542 % 10 = 299 % 10 = 9字典解析:
字典解析使用的是
for d in range(10),也就是说,字典的键是 0 到 9 的每一个数字。字典的值则是一个列表,包含以该数字结尾的s中的元素。{d: [x for x in s if x % 10 == d] for d in range(10)}
- 键:
d表示 0 到 9 这十个数字。- 值:
[x for x in s if x % 10 == d]是一个列表推导式,筛选出s中以d为末尾数字的元素。嵌套列表推导式:
列表推导式
[x for x in s if x % 10 == d]遍历列表s,对于每个元素x,计算其x % 10的结果,并判断是否等于当前的字典键d。如果等于,则将该元素加入到列表中。例如,当
d = 5时,列表推导式会将所有以5结尾的数字(即15, 25, 55)放入列表中。示例运行:
对于
s = [15, 25, 33, 42, 55, 68, 99]:
- 当
d = 5时,[x for x in s if x % 10 == 5]返回[15, 25, 55],这些都是以5结尾的数字。- 当
d = 2时,[x for x in s if x % 10 == 2]返回[42],因为只有42以2结尾。- 当
d = 9时,[x for x in s if x % 10 == 9]返回[99]。最终的字典为:
{ 0: [], 1: [], 2: [42], 3: [33], 4: [], 5: [15, 25, 55], 6: [], 7: [], 8: [68], 9: [99] }适用场景:
这种嵌套思路非常适合以下场景:
- 分类问题:当你需要根据某个条件对一组数据进行分类时,这种嵌套的字典解析和列表推导式可以简洁高效地实现分类。
- 简单映射:当映射的条件非常明确且易于计算(例如取模操作)时,使用这种方式可以避免手动写复杂的循环逻辑。
- 数据聚合:如果你需要按某种规则聚合数据(例如按某个属性的取值范围),这种嵌套方式也非常有用。
优点:
- 简洁明了:字典解析和列表推导式让代码短小精悍,逻辑非常直观。
- 高效:相比手动循环、判断,列表推导式和字典解析往往在性能上也更具优势。
- 这种嵌套结构适合处理类似的分类或分组问题,当数据量较小时,它既高效又简洁。
下面举一个更复杂的使用嵌套字典解析和列表推导式的例子。假设我们要根据多个条件对数据进行分组,并构建一个嵌套的字典结构。
例子背景:
假设我们有一个包含很多学生成绩的列表,每个学生的成绩信息包括姓名、科目和分数。我们希望:
- 将所有学生按科目分类。
- 在每个科目下,再将学生按分数段分类(例如,80-89,90-100等)。
这个需求可以通过嵌套字典解析和列表推导式来完成。
数据结构:
假设学生数据如下:
students = [ {'name': 'Alice', 'subject': 'Math', 'score': 85}, {'name': 'Bob', 'subject': 'Math', 'score': 92}, {'name': 'Charlie', 'subject': 'History', 'score': 78}, {'name': 'David', 'subject': 'History', 'score': 88}, {'name': 'Eve', 'subject': 'Math', 'score': 75}, {'name': 'Frank', 'subject': 'History', 'score': 93}, {'name': 'Grace', 'subject': 'Math', 'score': 60}, {'name': 'Heidi', 'subject': 'History', 'score': 82} ]要求:
- 将学生按
subject(科目)分类。- 每个科目下,将学生按
score分数段分类:
- 60-69 分:
'D'- 70-79 分:
'C'- 80-89 分:
'B'- 90-100 分:
'A'实现代码:
# 学生数据 students = [ {'name': 'Alice', 'subject': 'Math', 'score': 85}, {'name': 'Bob', 'subject': 'Math', 'score': 92}, {'name': 'Charlie', 'subject': 'History', 'score': 78}, {'name': 'David', 'subject': 'History', 'score': 88}, {'name': 'Eve', 'subject': 'Math', 'score': 75}, {'name': 'Frank', 'subject': 'History', 'score': 93}, {'name': 'Grace', 'subject': 'Math', 'score': 60}, {'name': 'Heidi', 'subject': 'History', 'score': 82} ] # 根据分数获得等级 def get_grade(score): if 90 <= score <= 100: return 'A' elif 80 <= score < 90: return 'B' elif 70 <= score < 80: return 'C' elif 60 <= score < 70: return 'D' else: return 'F' # 嵌套字典解析和列表推导式 subject_score_map = { subject: {grade: [student['name'] for student in students if student['subject'] == subject and get_grade(student['score']) == grade] for grade in ['A', 'B', 'C', 'D']} # 分类到不同的成绩段 for subject in set(student['subject'] for student in students) # 按科目分类 } # 输出结果 from pprint import pprint pprint(subject_score_map)代码详解:
- 分数分级函数
get_grade(score):
- 根据分数的范围返回相应的成绩等级:
'A','B','C','D','F'。- 每个分数段的定义为:
- 90-100:
'A'- 80-89:
'B'- 70-79:
'C'- 60-69:
'D'- 外层字典解析:
for subject in set(student['subject'] for student in students):这部分是外层的字典解析,用于创建以科目为键的字典。- 使用
set()来获取不重复的科目名,例如:{'Math', 'History'}。- 内层字典解析:
{grade: [student['name'] for student in students if student['subject'] == subject and get_grade(student['score']) == grade] for grade in ['A', 'B', 'C', 'D']}:这是内层字典解析,用来将学生按分数段分类。- 对每个分数段
'A','B','C','D',我们筛选出符合条件的学生并创建一个以分数段为键的字典。- 通过列表推导式
[student['name'] for student in students if student['subject'] == subject and get_grade(student['score']) == grade]找到符合当前科目subject和成绩等级grade的所有学生姓名。运行结果:
{ 'History': { 'A': ['Frank'], 'B': ['David', 'Heidi'], 'C': ['Charlie'], 'D': [] }, 'Math': { 'A': ['Bob'], 'B': ['Alice'], 'C': ['Eve'], 'D': ['Grace'] } }结果解释:
- 科目
History:
- 成绩为
A的学生是Frank。- 成绩为
B的学生是David和Heidi。- 成绩为
C的学生是Charlie。- 没有成绩为
D的学生。- 科目
Math:
- 成绩为
A的学生是Bob。- 成绩为
B的学生是Alice。- 成绩为
C的学生是Eve。- 成绩为
D的学生是Grace。适用场景:
- 嵌套数据分类:当你需要基于多个维度(如科目、分数段)对数据进行分类和聚合时,这种嵌套结构非常有用。
- 数据分层处理:这种代码结构特别适合数据层次分明、需要按多个标准进行归类和处理的情况。
通过这种嵌套字典和列表推导式的组合,可以高效地对数据进行多层次的分组和分类,适合处理复杂的逻辑需求。
下面仔细梳理一下
subject_score_map这部分的嵌套结构,逐层解析每个部分的逻辑和它们是如何协同工作的。代码片段(左右滚动查看):
subject_score_map = { subject: {grade: [student['name'] for student in students if student['subject'] == subject and get_grade(student['score']) == grade] for grade in ['A', 'B', 'C', 'D']} # 分类到不同的成绩段 for subject in set(student['subject'] for student in students) # 按科目分类 }1. 外层字典解析(按科目分类):
for subject in set(student['subject'] for student in students)
- 目的:对所有学生的科目进行分类。
- 解释:
student['subject']:从学生数据中提取每个学生的科目信息。set(...):使用set()函数是为了去重。因为可能有多个学生属于同一个科目,因此使用set可以确保科目唯一。- 结果:生成一个唯一的科目集合,如
{'Math', 'History'}。- 作用:外层字典解析遍历这个集合,为每个科目生成一个键,字典的键就是科目名。
例如:
for subject in {'Math', 'History'}这部分的作用是给字典的每个键赋值为科目,比如
'Math'和'History'。2. 内层字典解析(按分数段分类):
{grade: [student['name'] for student in students if student['subject'] == subject and get_grade(student['score']) == grade] for grade in ['A', 'B', 'C', 'D']}
- 目的:对于每个科目,按分数段(’A’、’B’、’C’、’D’)分类存储学生姓名。
- 分解:
- 字典键
grade:for grade in ['A', 'B', 'C', 'D']
- 解释:内层字典的键是成绩段
'A'、'B'、'C'和'D',这些分数段会被逐个作为键创建。- 结果:对于每个
grade,我们要构建一个列表,这个列表包含所有符合条件的学生姓名。- 列表推导式:
[student['name'] for student in students if student['subject'] == subject and get_grade(student['score']) == grade]
- 解释:遍历
students列表,筛选出符合条件的学生(即科目等于当前的subject,成绩段等于当前的grade),并提取出他们的姓名。- 筛选条件:
student['subject'] == subject:确保学生的科目和外层循环的subject一致。get_grade(student['score']) == grade:根据学生的分数通过get_grade()函数确定成绩段,并与当前内层字典的grade进行比较。- 作用:每次循环将生成一个分数段下的学生列表。
3. 总结:嵌套结构解读
这个嵌套字典的生成过程实际上是两层嵌套:
- 外层字典:按科目分类生成字典的键值对,键是科目名(例如
'Math'或'History'),值是内层字典。- 内层字典:按分数段分类生成字典的键值对,键是成绩段(例如
'A'、'B'、'C'和'D'),值是符合该成绩段的学生姓名列表。完整执行流程:
- 外层字典首先根据科目生成键:
'Math'和'History'。- 对于每个科目,进入内层字典解析。
- 内层字典按分数段遍历:首先按
grade = 'A'进行过滤,找到符合subject且score对应grade == 'A'的学生,存入列表;然后按grade = 'B'、'C'、'D'依次处理。- 最后,每个分数段下生成对应的学生姓名列表。
执行实例:
当我们遍历
Math科目时:
- 内层字典首先检查成绩段
'A'的学生,结果是['Bob'](因为Bob的分数是 92,属于’A’)。- 接着检查成绩段
'B'的学生,结果是['Alice'](因为Alice的分数是 85,属于’B’)。- 同理,
'C'段得到['Eve'],'D'段得到['Grace']。最终生成的字典是:
{ 'Math': {'A': ['Bob'], 'B': ['Alice'], 'C': ['Eve'], 'D': ['Grace']}, 'History': {'A': ['Frank'], 'B': ['David', 'Heidi'], 'C': ['Charlie'], 'D': []} }
嵌套结构中的逻辑关系:
- 外层字典:
- 生成条件:遍历每个科目,确保每个科目成为字典的键。
- 值的类型:每个科目的值是一个字典,表示该科目中学生按成绩段分类后的结果。
- 内层字典:
- 生成条件:在当前科目下,按分数段(
grade)分类。- 值的类型:每个成绩段的值是符合条件的学生姓名列表。
适用场景:
这种嵌套结构适合在数据维度较多的场景中使用,例如:
- 分类统计:当数据需要按多个维度分类时,嵌套字典是一种简洁而高效的结构。
- 复杂数据聚合:当你需要对数据进行多层次的分组、聚合并筛选时,嵌套字典解析非常有用。
C语言实现 (如果会C语言)
将Python的嵌套字典和列表推导式转换为C语言时,C语言没有内置的字典结构或高级数据处理功能(如列表推导式),因此我们需要使用结构体、数组和函数来实现相似的功能。
我们将用结构体表示学生和字典,将二维数组或链表作为存储学生数据的容器。对于映射关系,我们将使用结构体数组来模拟字典的行为。
Python代码的C语言转换思路:
- 学生数据:使用结构体来存储每个学生的信息,包括姓名、科目和分数。
- 字典:我们使用二维数组(或链表)存储学生按科目和分数段分类后的结果。
- 嵌套逻辑:用循环和条件语句代替Python中的字典解析和列表推导式。
C语言实现:
1. 定义结构体来存储学生信息:
#include <stdio.h> #include <string.h> #define MAX_STUDENTS 100 // 假设最多有100个学生 #define MAX_NAME_LENGTH 50 // 定义学生结构体 typedef struct { char name[MAX_NAME_LENGTH]; char subject[MAX_NAME_LENGTH]; int score; } Student; // 定义用于存储按成绩分类的学生组 typedef struct { char grade; // 'A', 'B', 'C', 'D' char names[MAX_STUDENTS][MAX_NAME_LENGTH]; // 存储学生姓名 int count; // 学生人数 } GradeGroup; // 每个科目下按成绩分段的学生分类 typedef struct { char subject[MAX_NAME_LENGTH]; GradeGroup grades[4]; // 'A', 'B', 'C', 'D' } SubjectGroup;2. 实现分数段判断函数:
// 根据分数返回成绩段 'A', 'B', 'C', 'D' char get_grade(int score) { if (score >= 90) { return 'A'; } else if (score >= 80) { return 'B'; } else if (score >= 70) { return 'C'; } else if (score >= 60) { return 'D'; } else { return 'F'; } }3. 初始化科目分组结构体:
// 初始化SubjectGroup,指定科目名 void init_subject_group(SubjectGroup *subjectGroup, const char *subject) { strcpy(subjectGroup->subject, subject); // 设置科目名 char grades[] = {'A', 'B', 'C', 'D'}; for (int i = 0; i < 4; i++) { subjectGroup->grades[i].grade = grades[i]; // 初始化成绩段 subjectGroup->grades[i].count = 0; // 初始学生人数为0 } }4. 将学生分类到对应的成绩段:
// 将学生添加到对应的成绩段 void add_student_to_grade(SubjectGroup *subjectGroup, Student student) { char grade = get_grade(student.score); for (int i = 0; i < 4; i++) { if (subjectGroup->grades[i].grade == grade) { int count = subjectGroup->grades[i].count; strcpy(subjectGroup->grades[i].names[count], student.name); // 添加学生姓名 subjectGroup->grades[i].count++; // 学生人数增加 break; } } }5. 按科目分类学生:
// 分类所有学生 void categorize_students_by_subject(Student students[], int num_students, SubjectGroup subjectGroups[], int *num_subjects) { *num_subjects = 0; for (int i = 0; i < num_students; i++) { Student student = students[i]; int found = 0; for (int j = 0; j < *num_subjects; j++) { if (strcmp(subjectGroups[j].subject, student.subject) == 0) { // 如果科目已存在,直接添加学生 add_student_to_grade(&subjectGroups[j], student); found = 1; break; } } if (!found) { // 如果科目不存在,初始化新科目 init_subject_group(&subjectGroups[*num_subjects], student.subject); add_student_to_grade(&subjectGroups[*num_subjects], student); (*num_subjects)++; } } }6. 输出分类结果:
// 输出分类后的结果 void print_subject_groups(SubjectGroup subjectGroups[], int num_subjects) { for (int i = 0; i < num_subjects; i++) { printf("Subject: %s\n", subjectGroups[i].subject); for (int j = 0; j < 4; j++) { GradeGroup gradeGroup = subjectGroups[i].grades[j]; printf(" Grade %c: ", gradeGroup.grade); for (int k = 0; k < gradeGroup.count; k++) { printf("%s ", gradeGroup.names[k]); } printf("\n"); } printf("\n"); } }7. 完整的主程序:
int main() { // 初始化学生数据 Student students[] = { {"Alice", "Math", 85}, {"Bob", "Math", 92}, {"Charlie", "History", 78}, {"David", "History", 88}, {"Eve", "Math", 75}, {"Frank", "History", 93}, {"Grace", "Math", 60}, {"Heidi", "History", 82} }; int num_students = 8; // 存储按科目分类后的学生组 SubjectGroup subjectGroups[10]; // 假设最多10个科目 int num_subjects; // 按科目和分数分类学生 categorize_students_by_subject(students, num_students, subjectGroups, &num_subjects); // 输出分类结果 print_subject_groups(subjectGroups, num_subjects); return 0; }输出结果:
Subject: Math Grade A: Bob Grade B: Alice Grade C: Eve Grade D: Grace Subject: History Grade A: Frank Grade B: David Heidi Grade C: Charlie Grade D:代码解读:
- 结构体定义:
- 使用
Student结构体来存储每个学生的姓名、科目和分数。- 使用
GradeGroup结构体来表示每个分数段(’A’, ‘B’, ‘C’, ‘D’)的学生列表。- 使用
SubjectGroup结构体来按科目存储学生,包含四个GradeGroup(即分数段)结构体。- 函数解释:
get_grade():根据分数返回学生的成绩段。init_subject_group():初始化每个科目的学生分数段。add_student_to_grade():将学生按其分数段分类到相应的GradeGroup。categorize_students_by_subject():遍历所有学生,根据科目和分数段分类。print_subject_groups():输出分类后的结果。整体逻辑总结
Python语法结构 C语言对应结构 外层字典解析:按科目分类 用 for循环遍历students,使用strcmp()判断是否为相同科目内层字典解析:按分数段分类 用 for循环遍历grades(即'A','B','C','D'),判断分数段列表推导式:按条件筛选学生姓名 用 if判断student.subject和get_grade(student.score)字典的键值对结构:科目和分数段为键,学生为值 用 SubjectGroup和GradeGroup结构体来模拟字典,学生姓名存储在二维数组中区别
- 字典结构:Python有内置的字典类型,支持动态键值对存储;C语言没有类似的结构,我们使用结构体数组来模拟这种关系。
- 推导式:Python的推导式非常简洁,可以直接用于筛选数据;在C语言中,我们需要用显式的
for循环和if判断来实现类似功能。- 字符串操作:Python处理字符串很简便,C语言中需要使用
strcpy()和strcmp()来处理字符串的复制和比较。
4. 检查列表中每个元素是否都有重复项

给定一个列表 s,检查是否每个元素都有重复项。例如,s = [-4, 4, 3, 2, 4, 3, 2],此时每个元素都有重复项,返回 True;如果 s = [-4, 4, 3, 2],由于 -4 没有重复,返回 False。
代码实现解析:
检查给定列表 s 中的每个元素是否都有重复项,即每个元素的出现次数是否大于 1。通过使用 Python 的内置函数 count() 和 all() 来实现这个逻辑。
s = [-4, 4, 3, 2, 4, 3, 2]
all_have_duplicates = all(s.count(x) > 1 for x in s) # 检查每个元素是否有重复
print(all_have_duplicates) # 输出:True
解决思路:
- 遍历列表中的每个元素:
- 通过列表推导式
s.count(x) > 1 for x in s,我们遍历s列表中的每个元素x,检查它的出现次数是否大于 1。 s.count(x)会计算元素x在列表中出现的次数。- 如果
x在列表中的出现次数大于 1,则说明它有重复项,表达式返回True。
- 通过列表推导式
all()函数:all()函数用于检查所有元素是否都为True。如果列表中每个元素的出现次数都大于 1,则返回True;只要有一个元素的出现次数不大于 1,则返回False。
代码执行流程:
- 对于列表
s = [-4, 4, 3, 2, 4, 3, 2]:-4的出现次数是 1。4的出现次数是 2。3的出现次数是 2。2的出现次数是 2。
虽然大多数元素都有重复,但
-4的出现次数是 1,表示它没有重复项。因此,all_have_duplicates的值将是False。 - 如果列表
s = [4, 3, 2, 4, 3, 2],每个元素至少出现了两次,all_have_duplicates将会返回True。
扩展思路与改进:
使用 count() 的方法在大数据集上可能效率不高,因为 count() 每次都会遍历整个列表进行计数。为了提高效率,可以先使用 collections.Counter 或者字典来对每个元素的出现次数进行预计算。这样只需要一次遍历即可得到每个元素的出现次数。
改进代码:
from collections import Counter
s = [-4, 4, 3, 2, 4, 3, 2]
element_counts = Counter(s) # 预计算每个元素的出现次数
all_have_duplicates = all(count > 1 for count in element_counts.values()) # 检查所有元素是否有重复
print(all_have_duplicates) # 输出:False
Counter(s):Counter是collections模块中的一个类,用于计算可迭代对象(如列表)中每个元素的出现次数。element_counts将会是一个字典,键为列表中的元素,值为它们的出现次数。
all(count > 1 for count in element_counts.values()):- 遍历每个元素的计数值,检查是否所有的计数值都大于 1。如果所有元素的出现次数都大于 1,则返回
True;否则返回False。
- 遍历每个元素的计数值,检查是否所有的计数值都大于 1。如果所有元素的出现次数都大于 1,则返回
改进后的优势:
- 效率更高:原始代码对于列表中的每个元素调用了
s.count(x),这需要 O(n) 的复杂度,总的时间复杂度为 O(n^2)。改进后的代码使用Counter只需一次遍历列表,因此时间复杂度降为 O(n)。
Linked List Exercises
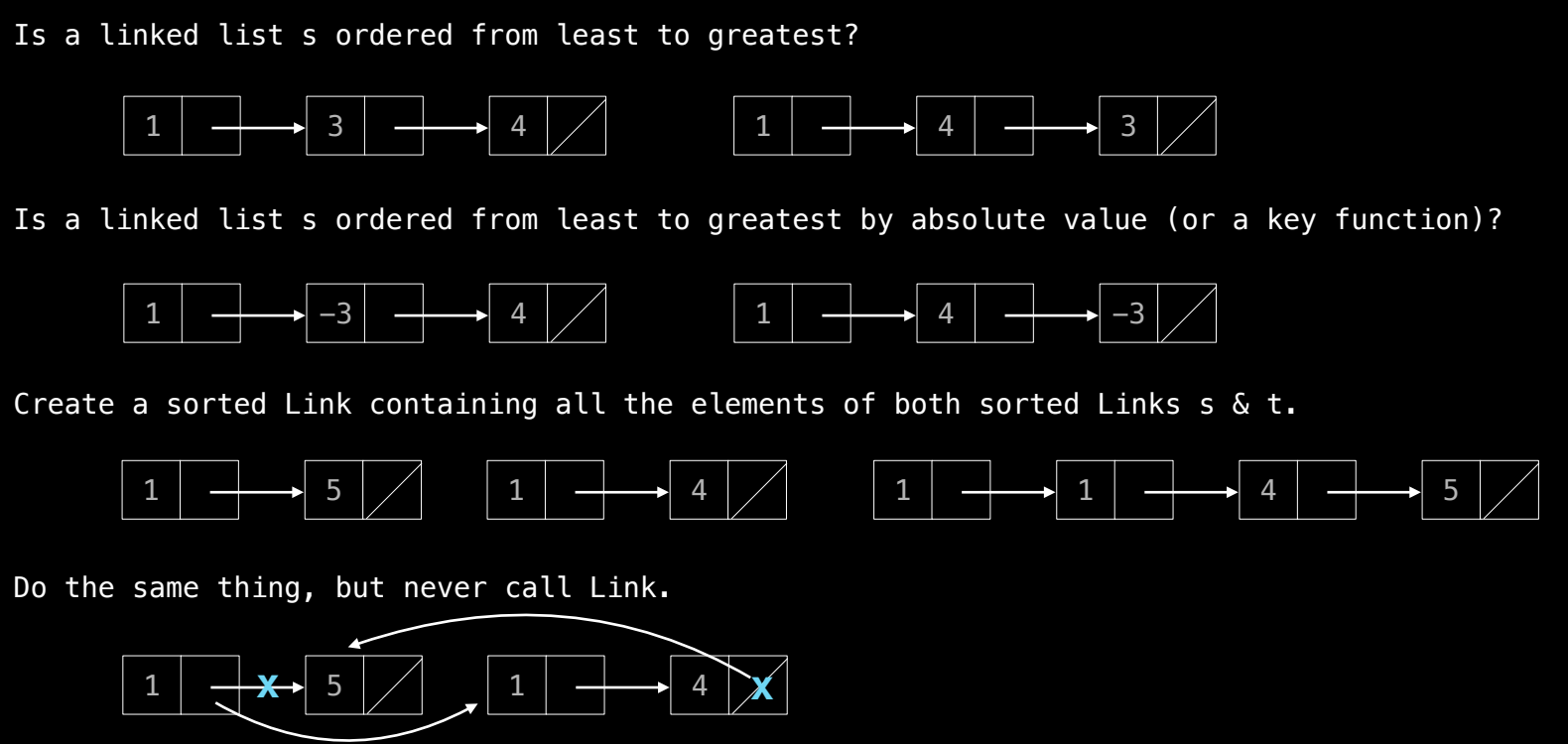
1. 检查链表是否按从小到大的顺序排列
- 问题:给定一个链表
s,你需要检查链表是否从小到大排序。 -
思路:遍历链表的每个节点,比较当前节点和下一个节点的值。如果任何一个节点的值大于下一个节点,则链表不是有序的。
class Link: def __init__(self, first, rest=None): self.first = first self.rest = rest def is_sorted(s): while s.rest is not None: if s.first > s.rest.first: return False s = s.rest return True # 示例链表 s = Link(1, Link(3, Link(4))) print(is_sorted(s)) # 输出:True
2. 按绝对值检查链表的顺序
- 问题:给定一个链表
s,你需要检查链表是否按绝对值从小到大排序。
3. 合并两个排序链表
- 问题:给定两个排序好的链表
s和t,创建一个新的链表,将两个链表中的所有元素按顺序合并。
4. 合并两个链表但不调用 Link 构造函数
- 问题:与上面的练习相同,但要求不直接调用
Link构造函数。
Click me after thinking
1. 检查链表是否按从小到大的顺序排列
- 问题:给定一个链表
s,你需要检查链表是否从小到大排序。 - 思路:遍历链表的每个节点,比较当前节点和下一个节点的值。如果任何一个节点的值大于下一个节点,则链表不是有序的。
class Link:
def __init__(self, first, rest=None):
self.first = first
self.rest = rest
def is_sorted(s):
while s.rest is not None:
if s.first > s.rest.first:
return False
s = s.rest
return True
# 示例链表
s = Link(1, Link(3, Link(4)))
print(is_sorted(s)) # 输出:True
2. 按绝对值检查链表的顺序
- 问题:给定一个链表
s,你需要检查链表是否按绝对值从小到大排序。 - 思路:与前一个问题类似,但这次需要比较每个节点的绝对值。
def is_sorted_by_absolute_value(s):
while s.rest is not None:
if abs(s.first) > abs(s.rest.first):
return False
s = s.rest
return True
# 示例链表
s = Link(1, Link(-3, Link(4)))
print(is_sorted_by_absolute_value(s)) # 输出:True
3. 合并两个排序链表
- 问题:给定两个排序好的链表
s和t,创建一个新的链表,将两个链表中的所有元素按顺序合并。 - 思路:使用递归或迭代方法,依次比较两个链表的头节点,取较小的节点值作为新链表的头节点,继续递归或迭代处理剩余的部分。
def merge_sorted(s, t):
if s is None:
return t
if t is None:
return s
if s.first < t.first:
return Link(s.first, merge_sorted(s.rest, t))
else:
return Link(t.first, merge_sorted(s, t.rest))
# 示例链表
s = Link(1, Link(5))
t = Link(1, Link(4))
merged = merge_sorted(s, t)
# 打印合并后的链表
def print_link(link):
while link is not None:
print(link.first, end=" -> ")
link = link.rest
print(None)
print_link(merged) # 输出:1 -> 1 -> 4 -> 5 -> None
4. 合并两个链表但不调用 Link 构造函数
- 问题:与上面的练习相同,但要求不直接调用
Link构造函数。 - 思路:我们需要通过修改现有的链表结构,而不是创建新的链表。直接操作链表节点的指针来完成合并。
def merge_sorted_no_new_links(s, t):
# 创建一个临时头节点,方便操作
dummy = Link(0)
current = dummy
while s is not None and t is not None:
if s.first < t.first:
current.rest = s
s = s.rest
else:
current.rest = t
t = t.rest
current = current.rest
# 处理剩余的节点
if s is not None:
current.rest = s
else:
current.rest = t
return dummy.rest
# 示例链表
s = Link(1, Link(5))
t = Link(1, Link(4))
merged = merge_sorted_no_new_links(s, t)
print_link(merged) # 输出:1 -> 1 -> 4 -> 5 -> None
总结:
- 排序检查:通过遍历链表,比较每个节点与下一个节点的值,可以检查链表是否按值或绝对值排序。
- 链表合并:通过递归或迭代的方式合并两个排序好的链表,合并过程需要比较两个链表的当前节点,将较小的节点插入到新链表中。
- 无新节点合并:通过操作现有链表节点的指针,可以在不创建新链表节点的情况下,合并两个链表。