Lecture 17. Attributes/Iterations
Announcements
作业与项目修改
- 作业三:截止日期为周四。
-
Hog 项目修改:可以在周五之前修改你的项目,找回因组合评分丢失的分数。具体操作详见 Piazza 帖子,重点是你需要在
hog目录下执行以下命令:python3 --revise
讨论与教程安排
- 在参加教程之前,请确保参加了讨论方向会。很多同学在没有参加讨论的情况下直接进入教程,这会影响学习效果。教程是基于讨论会内容进行的,如果缺席讨论方向会,你将无法充分参与教程的互动学习。
期中考试与学习指南
- 期中考试二:定于三周后的周三(28日)进行。为了帮助学生准备考试,课程组提供了学习指南,建议在考试前几周就开始准备,而不是临时抱佛脚。学习指南主要围绕掌握课程内容展开,其中一个重要的建议是观看课程讲座。
办公时间
- 周五将有额外的咨询办公时间,除了正常的办公时间外,课程组还安排了更多的机会来帮助学生处理实验室和作业问题。即使没有作业截止,你也可以与课程组成员探讨课程或伯克利的相关问题。
Inheritance
迭代器与 Python 容器
-
顺序数据可以通过迭代器(iterator)进行隐式表示,迭代器是许多编程语言中的常见接口,尤其在 Python 中。它为我们提供了一种访问不同容器中元素的方式。
-
容器与迭代器:
- 容器可以提供一个迭代器,这个迭代器允许按照一定顺序访问容器的元素。
- Python 中的内建函数
iter和next分别用于创建和推进迭代器。iter:接受任何可迭代对象(iterable)作为参数,并返回该对象的迭代器。next:用于获取迭代器的下一个元素。
示例:
lst = [3, 4, 5]
t = iter(lst) # 创建一个迭代器 t
next(t) # 返回 3
next(t) # 返回 4
- 调用
next(t)会推进迭代器,使下次调用next(t)时返回下一个元素。可以为同一个容器创建多个迭代器,它们会独立记录各自的进度。
嵌套列表示例:
nested_lst = [[1, 2], 3, 4, 5]
t = iter(nested_lst)
next(t) # 返回 [1, 2]
- 如果调用
next(t)超过列表中的元素数量,Python 会抛出StopIteration异常,表示迭代结束。
字典的顺序
自 Python 3.6 起,字典中的元素顺序是按照插入顺序排列的,因此字典被称为有序的键值对集合。然而,在更早的 Python 版本中,字典中的项是以任意顺序排列的,字典当时被称为无序的键值对集合。虽然现在字典是有序的,但在编写代码时,仍然需要考虑运行程序的 Python 版本,因为对于较旧的版本,字典的顺序仍然是不可靠的。
在我们假设使用的是较新的 Python 版本时,字典的顺序会按照插入顺序排列。例如,假设我有一个字典 d,初始包含三个键值对 1:1、2:2 和 3:3,然后我添加了一个新的键值对 0:0。此时,遍历字典键时的顺序将是 1, 2, 3, 0,因为键 0 是最后加入的。
迭代字典的键、值和键值对
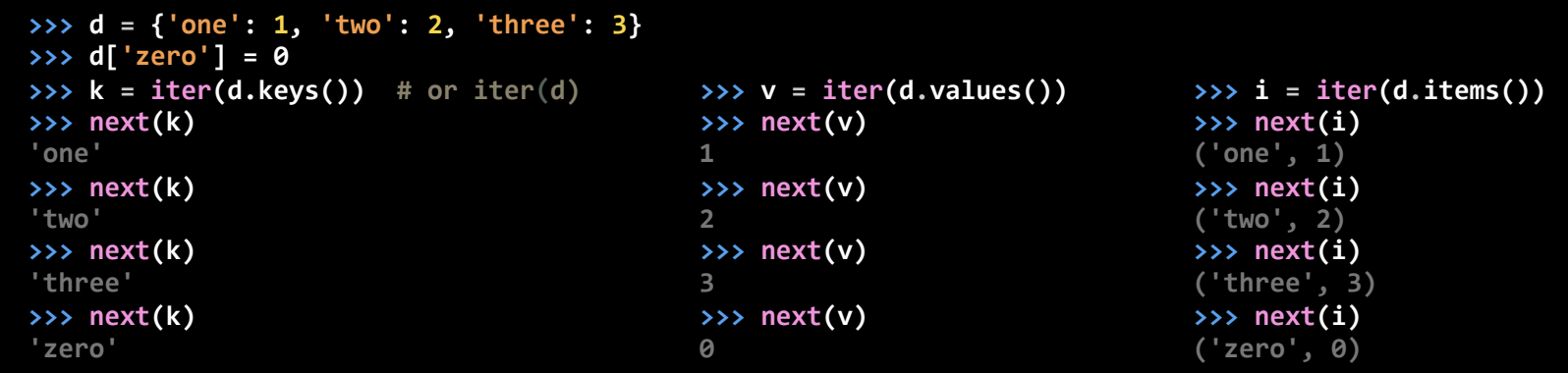
- 迭代字典的键:
d = {1: 1, 2: 2, 3: 3, 0: 0} k = iter(d) # 等同于 iter(d.keys()) next(k) # 返回 1 next(k) # 返回 2 - 迭代字典的值:
v = iter(d.values()) next(v) # 返回 1 next(v) # 返回 2 - 迭代字典的键值对(以元组形式返回键和值):
items = iter(d.items()) next(items) # 返回 (1, 1) next(items) # 返回 (2, 2)
字典的视图对象
在 Python 中,可以通过 keys()、values() 和 items() 分别获取字典的键、值和键值对的视图对象。这些视图对象都是可迭代对象,可以传递给 iter 函数并生成对应的迭代器。如果字典在迭代过程中发生了结构性变化(如增加或删除键值对),原有的迭代器将失效,并抛出 RuntimeError 错误。
例如:
k = iter(d.keys())
next(k) # 返回 1
d[4] = 4 # 字典增加新元素
next(k) # 抛出 RuntimeError: dictionary changed size during iteration
但是,如果只改变了字典中某个键的值,迭代器仍然可以正常工作,因为这不影响字典的结构。
使用 for 循环迭代可迭代对象
for 循环不仅可以遍历列表、字典等可迭代对象,还可以直接作用于迭代器。每次循环都会推进迭代器的标记到下一个位置。例如:
r = range(3, 6) # 生成范围为 3 到 5 的可迭代对象
for i in r:
print(i) # 输出 3, 4, 5
与可迭代对象不同的是,迭代器在使用 for 循环遍历完一次后,将无法再次遍历,因为迭代器的位置已经到达末尾。
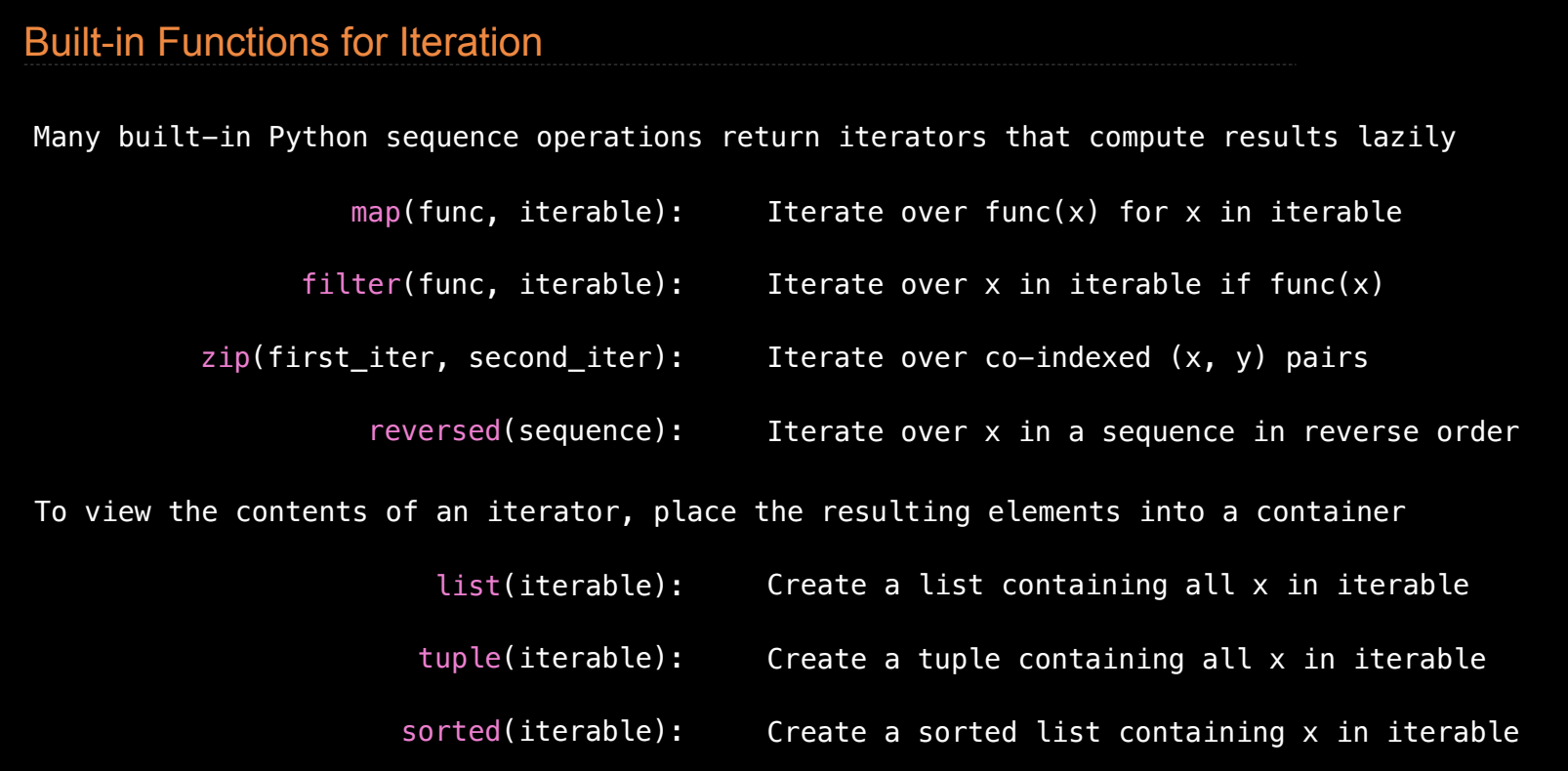
惰性计算
Python 中许多内建函数返回的是惰性计算的迭代器。惰性计算的特点是,结果只有在需要时才会计算出来,而不是立即计算。这种特性允许我们在处理大规模数据时节省内存。例如:
map函数:接受一个函数和一个可迭代对象,返回一个迭代器,只有当调用next时,才会对每个元素应用该函数。result = map(lambda x: x * 2, [1, 2, 3]) # 返回迭代器 list(result) # 输出 [2, 4, 6]filter函数:接受一个谓词函数和一个可迭代对象,返回一个迭代器,只有当元素满足谓词条件时,才会包含在结果中。result = filter(lambda x: x % 2 == 0, [1, 2, 3, 4]) # 返回迭代器 list(result) # 输出 [2, 4]zip函数:将两个或多个可迭代对象进行配对,返回一个迭代器,迭代时每次返回一对元素。result = zip([1, 2, 3], ['a', 'b', 'c']) # 返回迭代器 list(result) # 输出 [(1, 'a'), (2, 'b'), (3, 'c')]
通过惰性计算,Python 提供了一种高效处理大数据的方法。
示例:map 函数与惰性计算
假设有一个列表 ['b', 'c', 'd'],可以通过 upper 方法将其全部转换为大写字母。以下是两种实现方式:
- 使用列表推导式:
[x.upper() for x in ['b', 'c', 'd']] # 输出 ['B', 'C', 'D'] - 使用
map函数:m = map(lambda x: x.upper(), ['b', 'c', 'd']) next(m) # 输出 'B' next(m) # 输出 'C' next(m) # 输出 'D'注意,
map返回的是一个迭代器对象,它不会立即计算出所有结果,而是每次调用next时才会计算下一个值。
惰性计算与 map 示例2
定义一个函数 double,用于将输入的数字加倍并打印处理过程:
def double(x):
print(f"Doubling {x}")
return 2 * x
当我们将 double 函数应用于 [3, 5, 7] 的列表时,map 返回一个迭代器:
m = map(double, [3, 5, 7])
# 此时还没有任何计算发生
next(m) # 输出 "Doubling 3" 并返回 6
next(m) # 输出 "Doubling 5" 并返回 10
next(m) # 输出 "Doubling 7" 并返回 14
在调用 next 前,double 函数不会被应用到任何元素上,只有当请求下一个值时,才会懒惰地进行计算。
组合 map 和 filter 示例
可以将 map 返回的迭代器传递给另一个函数,如 filter,来进一步处理结果。例如:
- 将
double函数映射到range(3, 7),并使用filter过滤掉小于 10 的结果:m = map(double, range(3, 7)) f = filter(lambda y: y >= 10, m) next(f) # 输出 10 next(f) # 输出 12 - 如果将所有结果放入一个列表中,Python 会耗尽整个迭代器:
list(f) # 输出 [10, 12]
迭代器和列表的比较
迭代器与可迭代对象(如列表)有一个重要区别。迭代器的状态会随调用 next 发生变化,直到元素耗尽,而列表可以反复遍历。例如,假设我们有一个回文列表 t = [1, 2, 3, 2, 1],通过 reversed 获取其反向迭代器:
r = reversed(t) # 返回一个迭代器对象
list(r) == t # 输出 True
r == t # 输出 False,因为 r 是一个迭代器,而 t 是一个列表
这里,如果直接比较一个列表和一个迭代器,结果将是 False。要进行正确的比较,必须将两者都转为列表。
字典与迭代
当你迭代一个字典时,字典的元素顺序是固定的。可以通过 zip 函数将字典的键和值压缩在一起,形成一个新的迭代器,返回键值对。例如:
d = {'b': 2, 'a': 1}
z = zip(d.keys(), d.values())
list(z) # 输出 [('b', 2), ('a', 1)]
生成器函数
生成器(generator) 是一种特殊的迭代器,由生成器函数生成。生成器函数与普通函数的区别在于,它使用 yield 关键字返回值,而不是 return。每次调用 yield,生成器都会暂停执行并返回值,直到再次调用 next 时恢复执行。示例:
def plus_minus(x):
yield x
yield -x
t = plus_minus(3)
next(t) # 输出 3
next(t) # 输出 -3
在这个例子中,plus_minus 函数返回一个生成器 t。当调用 next(t) 时,第一次返回 3,第二次返回 -3。生成器函数在每次遇到 yield 时暂停执行,并保存当前的函数状态,直到下一次调用 next 时继续执行。
生成偶数的生成器函数
以下是一个生成偶数的生成器函数:
def evens(start, end):
even = start if start % 2 == 0 else start + 1
while even < end:
yield even
even += 2
调用该生成器函数时,会返回一个生成器对象。例如,生成从 2 到 10 的偶数:
e = evens(2, 10)
list(e) # 返回 [2, 4, 6, 8]
每次调用 next 时,生成器会返回当前的偶数,并在 yield 处暂停,直到生成出下一个偶数。生成器的执行是惰性的,也就是说,只有在需要时才会执行计算。
yield from 语句
Python 3.3 引入了 yield from 语法,用于简化多个迭代器的嵌套生成。yield from 可以将所有元素从一个可迭代对象中依次 yield 出来,避免手动写 for 循环。例如,下面的函数返回两个迭代器的所有元素:
def a_then_b(a, b):
yield from a
yield from b
这与以下代码等效:
def a_then_b(a, b):
for x in a:
yield x
for x in b:
yield x
通过 yield from,可以简化代码,并避免为每个元素命名。
示例:递归计数生成器
定义一个递归生成器 countdown 来从某个数字递减:
def countdown(k):
if k > 0:
yield k
yield from countdown(k - 1)
else:
yield "Blast off!"
调用 countdown(3) 将会返回一个生成器,通过 next 可以依次得到 3, 2, 1, "Blast off!":
for i in countdown(3):
print(i)
# 输出 3, 2, 1, "Blast off!"
生成字符串的前缀与子串
通过生成器函数,我们可以生成字符串的所有前缀或子串。下面的例子生成一个字符串的前缀:
def prefixes(s):
# 定义函数 prefixes,接受一个字符串 s 作为参数
if s:
# 如果字符串 s 不是空的(非空字符串在 Python 中会被视为 True)
yield from prefixes(s[:-1])
# 递归调用 prefixes 函数,传入字符串 s 去掉最后一个字符的部分(s[:-1]),
# 并且使用 yield from 来直接生成这个递归调用的结果
yield s
# 最后生成当前字符串 s 作为一个结果
调用 prefixes("both") 会返回一个生成器,列出字符串 “both” 的所有前缀:
list(prefixes("both")) # 输出 ['b', 'bo', 'bot', 'both']
类似地,可以生成字符串的所有子串:
def substrings(s):
if s:
yield from prefixes(s)
yield from substrings(s[1:])
调用 substrings("tops") 将返回所有的前缀及其后续的子串:
list(substrings("tops"))
# 输出 ['t', 'to', 'top', 'tops', 'o', 'op', 'ops', 'p', 'ps', 's']